为您的照片提供本地 AI 视觉:使用 Llama Vision 和 ChromaDB 构建 AI 图像标记器
有没有花 20 分钟浏览您的文件夹以找到心中的特定图像或屏幕截图?您并不孤单。
作为工作中的产品经理,我总是淹没在竞争对手产品的屏幕截图、UI 灵感以及白板会议或草图的照片的海洋中。在我的个人生活中,我总是捕捉我在生活中遇到的事物,比如我的晚餐、我可爱的猫,或者秋天随机的美丽树叶。我太了解这种挣扎了。有时很难找到一张你知道自己保存在某个地方的特定图像。
随着开源视觉语言模型 Llama 3.2 Vision 的发布,我想出了一个解决这个问题的方法:一个在本地运行的 AI 工具,它可以自动描述和标记图像,以便于语义搜索,同时保持照片和标签完全在本地(并且 API 费用为零)
在本文中,我将介绍如何构建 AI 图像标记器/管理器,包括设置和运行本地视觉语言模型和矢量数据库以进行语义搜索。无论您是对运行本地视觉语言模型感到好奇的 AI 爱好者,还是只是厌倦了在图像文件夹中痛苦搜索的人,这对您来说都是一个有趣且有用的项目。让我们开始吧!
(此项目在 https://github.com/Troyanovsky/llama-vision-image-tagger 上开源。随意克隆并试用!
查看实际作
前端对于管理图像集合相对简单。它使用 Vue3 构建以实现交互性,并使用 TailwindCSS 构建用于样式。它通过 FastAPI 服务器与后端通信,该服务器在视觉模型、矢量数据库和文件系统之间进行协调。让我们看看它是如何工作的。
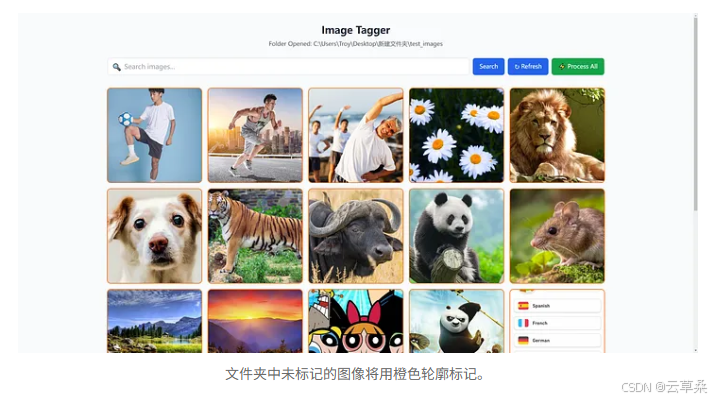
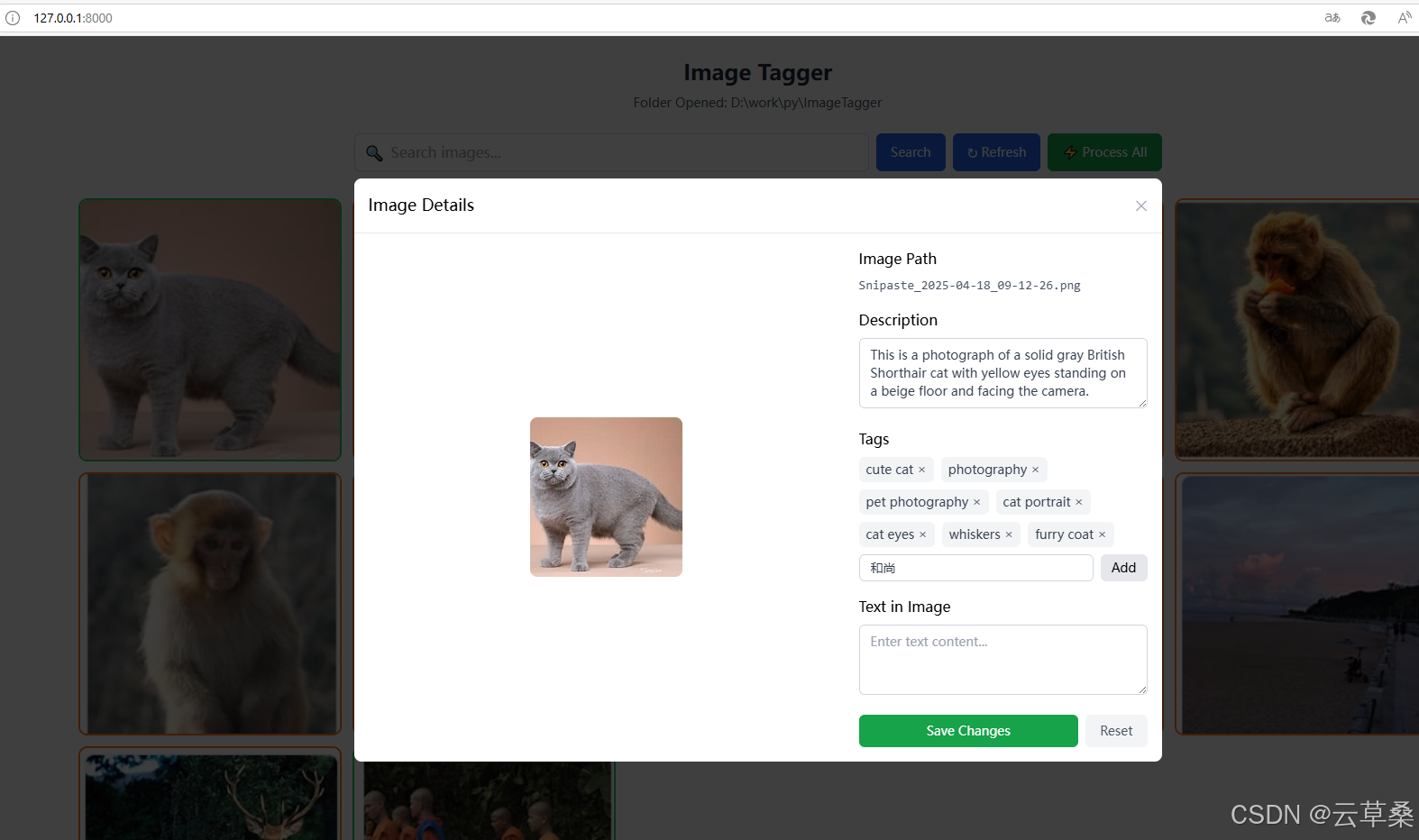
文件夹中未标记的图像将用橙色轮廓标记。
当它启动时,它会要求您提供一个包含您的图像的文件夹。只需复制并粘贴文件夹路径,它就会开始扫描文件夹和子文件夹中的图像。第一次打开文件夹时,它还会初始化一个 vector database 来存储数据,这可能需要一段时间。
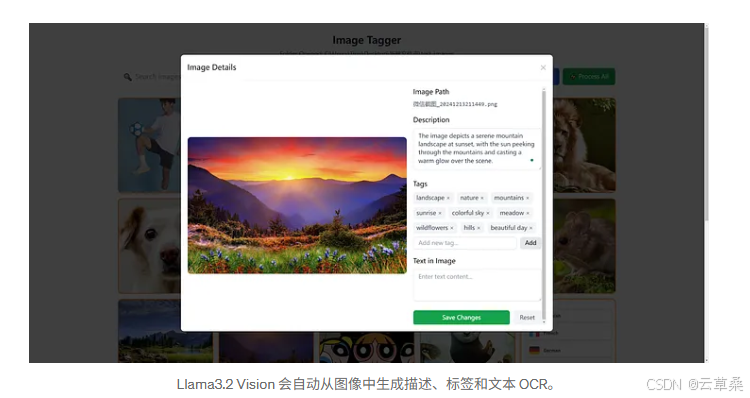
Llama3.2 Vision 会自动从图像中生成描述、标签和文本 OCR。
加载图像后,您可以单击单个图像以开始标记。它将向本地后端服务器发送请求并为映像生成标签。如果您对结果不满意,还可以手动编辑结果。所有生成/编辑的标签都将同步到矢量数据库
对于批处理,您只需按此 全部处理 按钮,它将发送所有图像进行处理。速度取决于您的计算机。如果您的 GPU 具有足够的 VRAM 来运行模型,则比在具有 RAM 的 CPU 上运行要快得多。已处理的图像将具有绿色轮廓,而尚未处理的图像将以橙色显示。
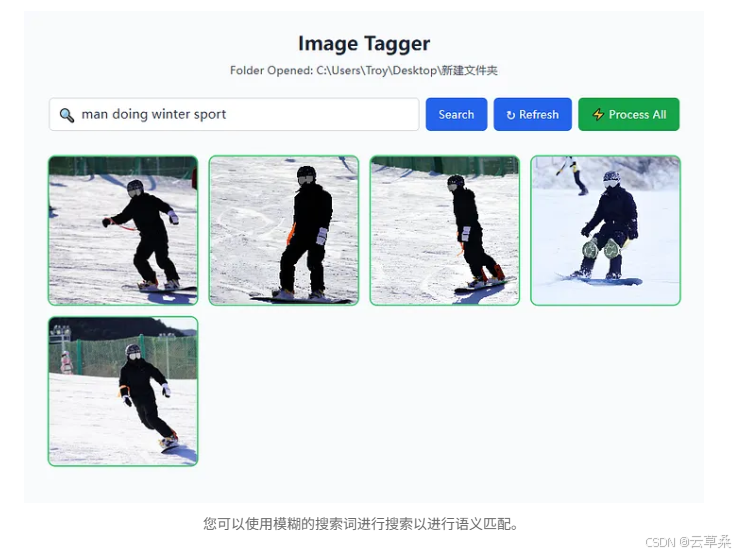
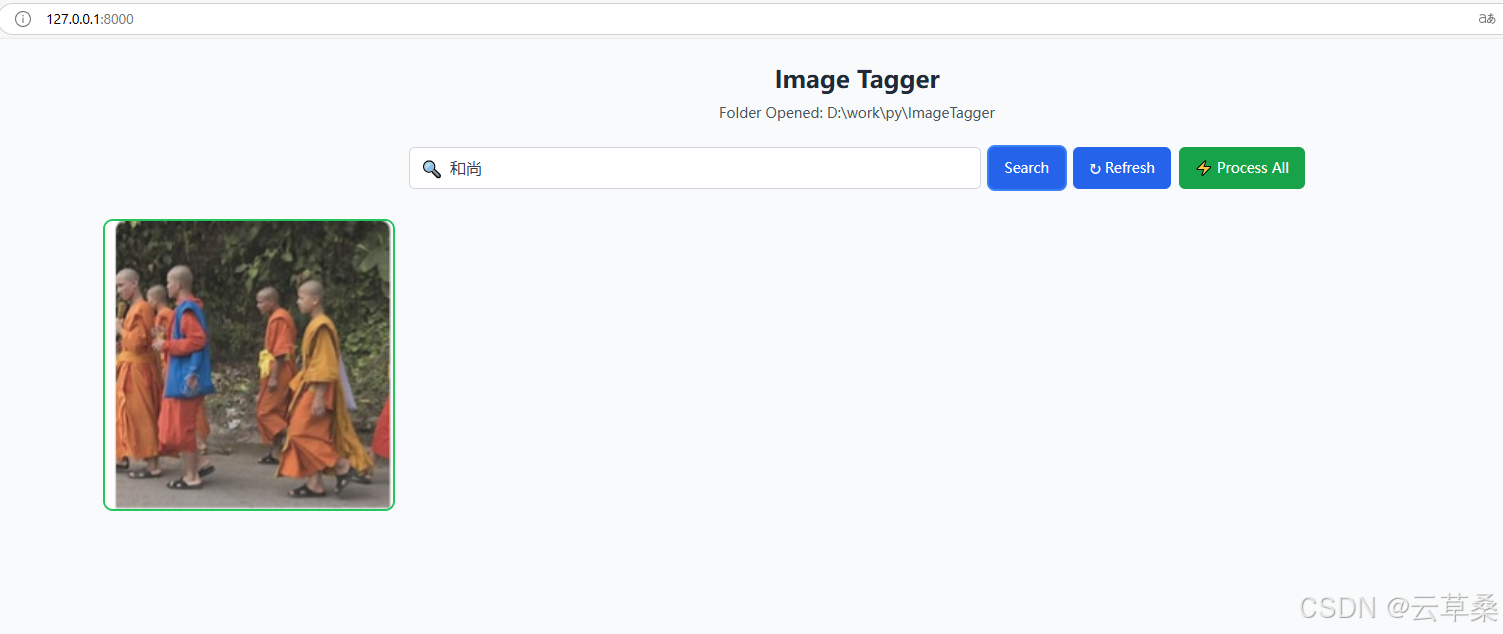
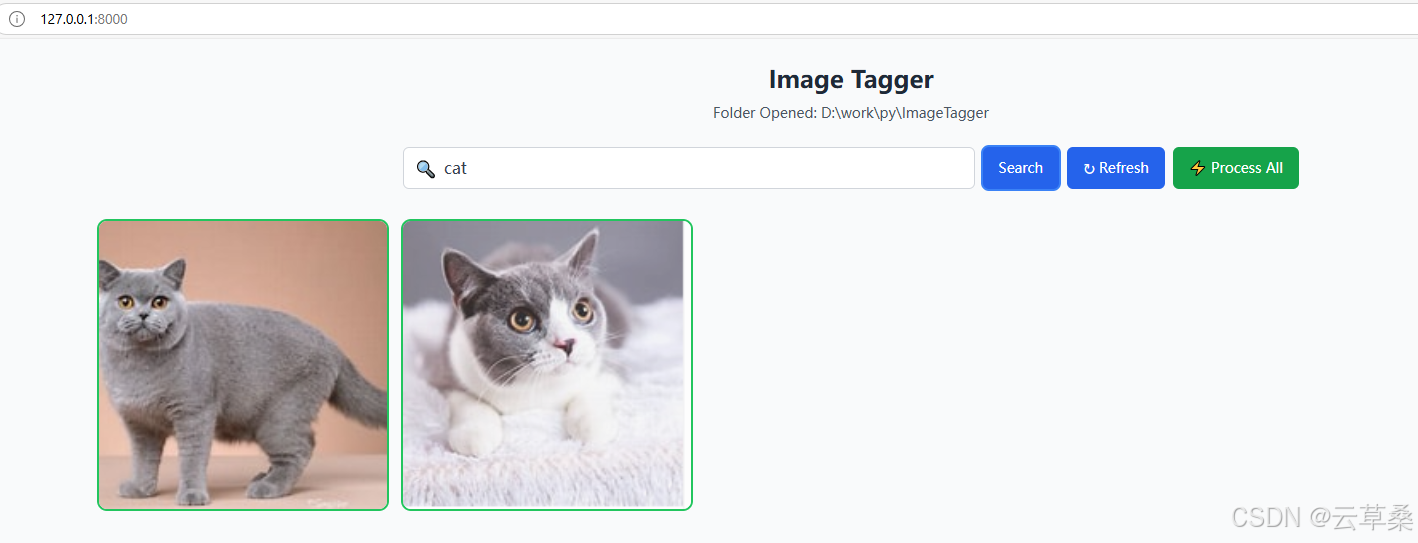
您可以使用模糊的搜索词进行搜索以进行语义匹配。
处理和标记图像后,您只需在搜索栏中键入要搜索的内容即可。它将执行包含全文搜索和向量相似性搜索的混合搜索。在这里,我们可以搜索带有模糊描述“man doing winter sport”的单板滑雪图片。
了解堆栈
在这个项目中,我们使用了 Llama 3.2 Vision、Ollama 和 ChromaDB。对于那些还不熟悉它们的人,让我快速概述一下。
Llama 3.2 Vision 是 Meta 几个月前于 2024 年 9 月发布的视觉语言模型 (VLM)。它有两种不同的尺寸,11B 和 90B。11B 版本可以在消费级计算机上本地运行。作为 VLM,它不仅可以像大型语言模型 (LLM) 一样理解文本,还可以理解上下文中的图像。它可以描述场景,理解对象之间的关系,并根据您的指示根据图像生成文本。在这个模型的帮助下,我们可以生成丰富的语义标签,而不仅仅是简单的对象检测。
Ollama 是一个开源项目,它使我们能够在本地计算机上轻松运行语言模型。它可在 Windows、MacOS 和 Linux 上使用,并支持几乎所有 GGUF 格式的本地语言模型,这使其成为在您自己的计算机上运行本地模型的最方便的选择。它还提供 Python 和 JavaScript 中的绑定,以便您可以在代码中以编程方式调用模型。更棒的是,它最近增加了对生成结构化输出(如 JSON)的支持,从而可以更轻松地处理文本生成。
(如果您对运行本地 LLM 感兴趣,可以阅读本文或访问此 GitHub 存储库,其中提供了有关如何运行本地 LLM 的资源,并为许多 LLM 提供了易于尝试的 Web UI。
至于我们的语义搜索,我们将使用 ChromaDB。这是一个开源矢量数据库,允许您保存文本嵌入数据,并使用自然语言以闪电般的速度查询它们。例如,您可以使用 “water sport”、“aquatics” 或 “snorkeling” ,而不必使用 “swimming” 等确切的关键字进行搜索。像 ChromaDB 这样的向量数据库通过将我们的图像描述转换为捕获语义含义并计算嵌入之间的相似性的高维向量来实现这一点。
现在您已经了解了此项目的组件,在下一节中,我们将深入探讨这些组件如何协同工作以创建我们的图像标记和搜索系统。
深入研究代码
让我们分解一下这些组件如何协同工作来创建我们的图像管理系统。由于在浏览器中访问文件系统的限制,我将应用程序分为前端和后端。前端用于查看和管理图片,后端主要包含两个流水线:图片标注流水线和图片查询流水线。
使用 Ollama 和 Llama3.2 Vision 的图像标记管道
选择文件夹后,我们将在该文件夹中扫描该文件夹中的所有图像。然后用户可以选择一个图像进行标记或标记所有图像。它本质上是具有结构化输出的简单提示工程。让我们引导您了解如何在您自己的本地计算机上使用 Ollama 运行 Llama 3.2 Vision 模型。
首先,您需要在您的机器上安装 Ollama。感谢出色的 Ollama 团队,他们为 Windows、MacOS 和 Linux 提供轻松下载 (https://ollama.com/download)。只需下载并安装可执行文件,您就可以使用 Ollama 命令行。然后,您可以使用以下命令下载 Llama3.2 Vision:
OLLAMA Run LLAMA3.2-vision如果你有一台非常强大的机器,你可以使用 OLLAMA Run LLAMA3.2-vision:90B 来获得更大的版本拉取模型后,您可以通过命令行或 Python 库使用它。在我们的项目中,我们将使用 ollama-python 库,您可以使用以下方法安装该库:
pip install ollama安装后,我们可以使用 Python 与模型进行交互。Ollama 最近增加了对结构化输出 (JSON) 的支持,因此我们可以使用 Pydantic 定义一个 JSON 模式,以传递给模型以进行类型安全和验证。
import ollama
from pydantic import BaseModel
from pathlib import 路径
from typing import List, Dictclass ImageTags(BaseModel):tags: List[str]def process_image(image_path: Path) -> Dict:try:# 如果不存在,请确保图像路径存在image_path exists():raise FileNotFoundError(f“Image not found: {image_path}”)# 将图像路径转换为 Ollama的字符串 image_path_str = str(image_path)# 获取标签tags_response = get_tags(image_path_str)return {“tags”: tags_response.tags}except Exception as e:raisedef get_tags(image_path: str) -> ImageTags:“”“获取图像的结构化标签。response = query_ollama(“列出此图像的 5-10 个相关标签。包括两个对象、艺术风格、图像类型、颜色等“,
image_path,ImageTags.model_json_schema
())返回 ImageTags.model_validate_json(响应)在这里,我只展示了get_tags函数来获取标签列表,但也可以添加其他数据,如描述、图像中的对象、图像上的 OCR 文本等。您只需为每个提示编写不同的提示,然后调用 Ollama,类似于调用 OpenAI 的 API 的方式。
def query_ollama(prompt: str, image_path: str, format_schema: dict) -> str:“”“向 Ollama 发送带有结构化输出图像的查询。try:response = ollama.chat(model='llama3.2-vision',messages=[{'角色': '用户','内容': 提示符,'images': [image_path],'options': {'num_gpu': 41}}],format=format_schema)return response['message']['content']except Exception as e:raise通过类似的设置,您可以在自己的计算机上使用 Ollama 轻松运行其他 LLM 或视觉语言模型。您可以在 Ollama 模型库 (library) 中找到可用模型的列表。
具有向量数据库的语义查询管道
标记所有图像后,我们可以保存它以便于查询。对于全文搜索,我们可以简单地将数据保存到 JSON 或关系数据库。但是,如果只有全文搜索,仍然很难找到相关的图像——有时您可能只是对您想要的图像有一个模糊的概念,而不是确切的标签,例如,您可能记得您有一张吃一顿丰盛晚餐的照片,但您不记得确切的菜肴。因此,我们将标签和描述保存到向量数据库中,并通过可以捕获语义含义的嵌入的相似性搜索来检索它们。
ChromaDB 易于设置,您可以完全离线运行。我们的向量存储实现的核心是 VectorStore 类。它处理与 ChromaDB 的所有交互,包括添加新图像、更新现有图像和执行语义搜索。
设置数据并将其保存到 ChromaDB 非常简单:
def add_or_update_image(self, image_path: str, metadata: Dict) -> None:# 合并所有文本字段进行嵌入text_to_embed = f“{metadata.get('description', '')} {' '.join(metadata.get('tags', []))} {metadata.get('text_content', '')}”# 准备元数据字典 - ChromaDB 需要字符串值meta_dict = {“description”: metadata.get(“description”, “”),“tags”: “,”.join(metadata.get(“tags”, [])),“text_content”: metadata.get(“text_content”, “”),“is_processed”: str(metadata.get(“is_processed“, False))}# 检查文档是否存在并相应地更新或添加results = self.collection.get(ids=[image_path])if results and results['ids']:self.collection.update(ids=[image_path],documents=[text_to_embed],metadatas=[meta_dict])否则:self.collection.add(ids=[image_path],documents=[text_to_embed],metadatas=[meta_dict])在这个函数中,我们做了一些重要的事情:
- 将所有文本字段(描述、标记、文本内容)合并为一个字符串以进行嵌入
- 将元数据转换为 ChromaDB 可以存储的格式(所有值都必须是字符串)
- 如果不在数据库中,则添加图像数据,如果图像数据已存在,则更新图像数据
现在我们已经存储了数据,让我们看看我们如何搜索它。ChromaDB 提供了简单的方法来查询数据库:
def search_images(self, query: str, limit: int = 5) -> List[str]:results = self.collection.query(query_texts=[query],n_results=limit,include=['documents', 'metadatas', 'distances'])filtered_results = []for image_id, distance in zip(results['ids'][0], results['distances'][0]):如果距离< 1.1: # 仅包含高置信度匹配项filtered_results.append(image_id)return filtered_results[:limit]ChromaDB 在后台使用相同的嵌入模型将您的搜索查询和存储的图像描述转换为高维向量。然后,它会根据相似性查找最接近的匹配项。这意味着搜索“beach vacation”可能会匹配带有“tropical paradise”或“seaside resort”标签的图片,即使您的查询中没有这些确切的字词。我还添加了对最大距离的检查,以便过滤掉不真正相关的结果。
通过结合全文搜索和矢量搜索的混合搜索方法,如果我们对全文搜索有把握,我们可以确保准确找到我们想要的内容,并在不太确定时找到相关图像。
这是后端的两个主要组件,用于处理图像标记和语义查询。通过了解它们的工作原理,您还将学习如何使用 Ollama 在本地计算机上运行多模态视觉语言模型(或任何 LLM),以及如何设置向量数据库并使用 ChromaDB 等向量数据库对文本进行语义查询。这些对于许多其他基于 LLM 的本地项目非常有用。
一些进一步的改进
当前版本只是初始版本,非常适合我个人用于查找屏幕截图和个人照片。有很多方法可以改进它:
- 图像相似性搜索:用户不仅可以按文本搜索,还可以选择图像并找到视觉上相似的图像。但遗憾的是,Ollama 目前不支持多模态嵌入。我们可以使用其他嵌入模型(如 CLIP)并将嵌入保存到 ChromaDB。
- 可自定义的标记:目前,标记提示在代码中是硬编码的,但我们可以允许更灵活的方法来定义提示,以便不同的用户可以拥有符合他们需求的不同标签。例如,UI 设计人员可能希望专门标记界面元素,而摄影师可能更关心构图和光照。
- 更强大的视觉模型:我发现较小的 11B 版本的 llama 3.2 视觉有时会误解图像。幸运的是,模型公司不断推出新的开源模型,例如 Qwen 最近发布的 QvQ 模型。我们可以允许交换视觉模型,以便对图像进行更准确和详细的标记。
- 允许 Vision Model API。对于那些不太关心将图像发送到模型提供商的人,我们可以允许他们使用视觉语言模型的 API,以便更快地进行标记过程(Gemini、Qwen、OpenAI 等)。
结论:释放局部视觉模型的潜力
这个项目最让我兴奋的不仅仅是为自己解决了图像搜索问题,还在于开源多模态 AI 模型的可访问性。就像本地大型语言模型允许我们创建完全在本地机器上运行的基于文本的有趣应用程序一样,视觉语言模型开辟了更多的可能性。
这只是本地视觉语言模型可能性的一个示例。相同的基本组件:使用 Ollama + 向量数据库运行本地模型可以适应更多用例。
如果你一直对构建 AI 驱动的应用程序感到好奇,但担心复杂性、隐私或 API 成本,我希望这个项目向你展示它比你想象的要平易近人得多。请随意提取代码来试用它,或者更好的是,为这个项目做出贡献。您还可以对其进行修改,让它成为您自己项目的起点。
命令备注
Uvicorn 使用方法
bash
pip install uvicorn
在开始之前,你需要确保你的开发环境中安装了 Python 3.7 或更高版本。你还需要安装 FastAPI 和 Uvicorn。可以通过以下命令安装:
bash
pip install fastapi uvicorn安装ChromaDB
要安装ChromaDB,你需要先安装Python 3.6或更高版本,然后用pip命令安装chromadb包:
pip install chromadbChromaDB python 使用教程及记录 - 知乎
mark bei
小编实测 基本上是英文 对中文不友好
这是AI自己加的tag
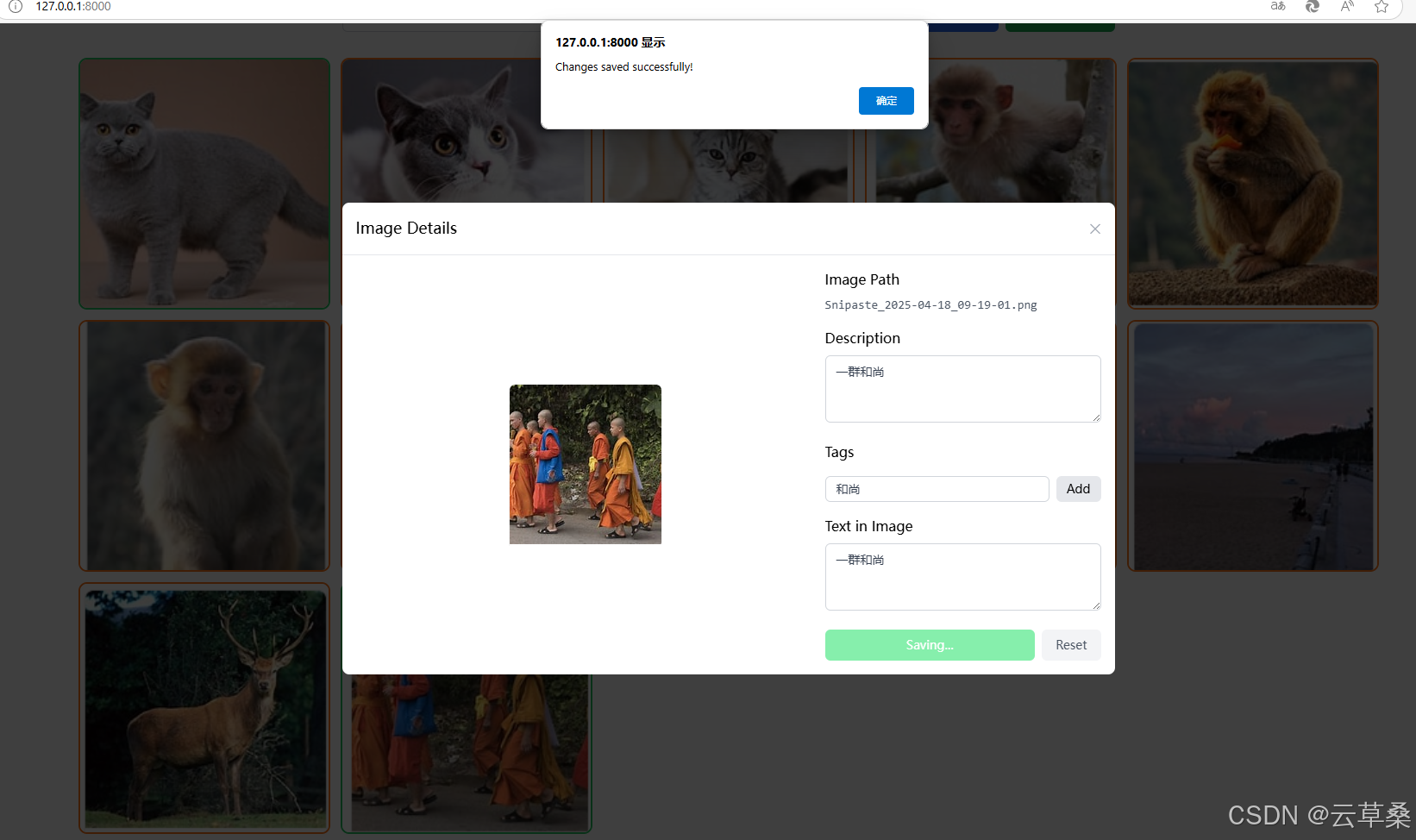
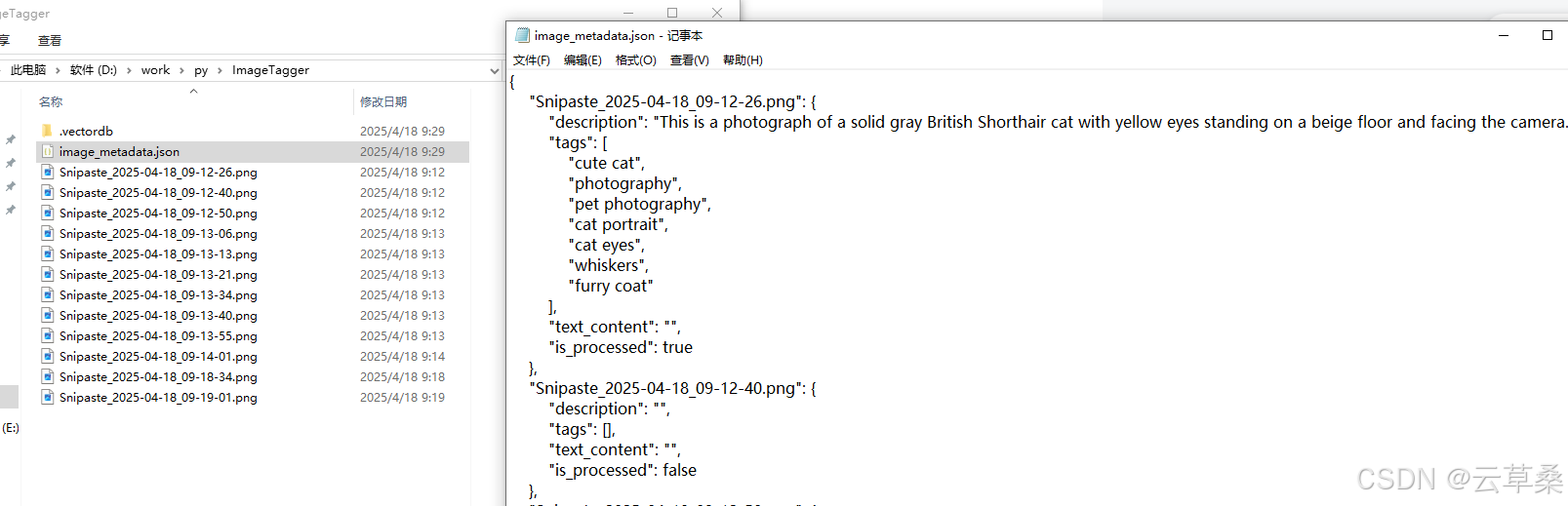
{"Snipaste_2025-04-18_09-12-26.png": {"description": "This is a photograph of a solid gray British Shorthair cat with yellow eyes standing on a beige floor and facing the camera.","tags": ["cute cat","photography","pet photography","cat portrait","cat eyes","whiskers","furry coat"],"text_content": "","is_processed": true},"Snipaste_2025-04-18_09-12-40.png": {"description": "The image shows a close-up of the head and upper body of what appears to be a British Shorthair cat lying down on a white fur blanket. The cat has orange eyes, a gray face with white markings around its nose and mouth, and a white body.","tags": ["cat","animal","fur","white","gray","close-up","portrait","pet","feline","photography","indoor","studio","lighting"],"text_content": "","is_processed": true},"Snipaste_2025-04-18_09-12-50.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-13-06.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-13-13.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-13-21.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-13-34.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-13-40.png": {"description": "The image depicts a partially sliced cucumber on a light-colored cutting board. A basket of additional cucumbers sits above it to the left, while a partial view of another cucumber is visible behind the cutting board.","tags": ["food","cucumber","cutting board","kitchen","photography","still life","vegetable","slicing","raw food","healthy eating","cooking","ingredients"],"text_content": "","is_processed": true},"Snipaste_2025-04-18_09-13-55.png": {"description": "The photo is a low-resolution image of a sandy beach and body of water, with white clouds on the horizon.","tags": ["beach","ocean","clouds","sky","water","sand","people","blue"],"text_content": "","is_processed": true},"Snipaste_2025-04-18_09-14-01.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-18-34.png": {"description": "","tags": [],"text_content": "","is_processed": false},"Snipaste_2025-04-18_09-19-01.png": {"description": "\u4e00\u7fa4\u548c\u5c1a","tags": [],"text_content": "\u4e00\u7fa4\u548c\u5c1a","is_processed": true}
}缺点 识别处理的很慢 很容易卡死有可能是慢 不能识别为中文的
不支持高版本的Python
------------
C# WPF 图像处理 使用
LabelSharp: 深度学习计算机视觉标注工具/PascalVOC/YOLO
GPL-2.0
YOLO11 旋转目标检测 | OBB定向检测 | ONNX模型推理 | 旋转NMS_yolo11 obb-CSDN博客
yolo11n.onnx模型
YOLO(You Only Look Once)系列模型是目标检测领域的经典算法,由 Joseph Redmon 等人首次提出,后续经过多次迭代,目前官方最新版本为 YOLOv8(2023 年发布,由 Ultralytics 公司维护)。以下是 YOLO 系列的核心版本梳理及最新进展:
一、YOLO 系列核心版本回顾
1. YOLOv1(2016)
- 特点:首次提出端到端单阶段目标检测框架,将目标检测视为回归问题,直接输出目标的位置和类别,速度极快(45 FPS),但精度较低,小目标检测效果差。
- 缺点:定位误差大,召回率低,依赖手工特征提取。
2. YOLOv2(2017)
- 改进:引入 锚框(Anchor Boxes)、批归一化(Batch Normalization)、高分辨率训练(HRNet),使用 Darknet-19 作为骨干网络,精度和速度均有提升(mAP 28.2,67 FPS)。
- 创新:提出 K-means 锚框聚类 和 跨阶段特征融合(Feature Fusion)。
3. YOLOv3(2018)
- 核心升级:采用 多尺度检测(3 种尺度特征图),支持不同大小目标检测;使用 Darknet-53 骨干网络,结合残差连接(Residual Connections),平衡速度和精度(mAP 33,32 FPS)。
- 优势:在保持实时性的同时,显著提升小目标检测能力。
4. YOLOv4(2020)
- 优化:由 Alexey Bochkovskiy 团队开发,引入大量优化技巧,如 Mish 激活函数、马赛克数据增强(Mosaic Augmentation)、路径聚合网络(PAN) 等,精度大幅提升(mAP 43.5,65 FPS)。
- 特点:更适合工业级应用,对 GPU 算力要求较高。
5. YOLOv5(2020 至今)
- 商业化:Ultralytics 公司推出,非官方但广泛流行,基于 PyTorch 重构,代码更简洁灵活。
- 特性:支持 模型缩放(N/S/M/L/X 不同尺寸),适应不同算力设备;引入 Focus 结构、CSPNet(跨阶段局部网络),速度更快(YOLOv5s 在 COCO 上 26.2 mAP,140 FPS)。
- 生态:支持数据增强、模型导出(ONNX/TensorRT)、自定义训练,社区活跃。
6. YOLOv8(2023)
- 官方最新版本:Ultralytics 正式推出的首个官方 YOLO 版本(此前 v5 为非官方),支持 目标检测、实例分割、分类、姿态估计 四大任务。
- 关键改进:
- 骨干网络:使用 YOLO-NAS(基于神经架构搜索) 改进的骨干,引入 深度聚合网络(Deep Aggregation Network, PAN++)。
- 损失函数:优化 CIoU Loss 和 分类损失,提升边界框回归精度。
- 效率:比 v5 更快更强,YOLOv8n 在 COCO 上实现 50.1 mAP(640×640),推理速度 170 FPS(RTX 3090)。
- 部署:支持多平台(CPU/GPU/Edge),导出格式丰富(ONNX/TensorRT/OpenVINO 等)。
三、YOLO 系列核心优势与应用场景
-
优势:
- 速度快:单阶段检测框架,适合实时应用(如视频监控、自动驾驶)。
- 易用性:端到端训练,支持自定义数据集,部署流程成熟。
- 多任务支持:v8 版本扩展到实例分割和姿态估计,适用场景更广泛。
-
典型应用:
- 安防领域:实时目标检测与跟踪。
- 智能交通:车辆、行人检测与违章识别。
- 工业质检:产品缺陷检测与分拣。
- 无人机 / 机器人:环境感知与避障。
-----------
阿里云通用图像打标
通用图像打标常用语言和示例有哪些_视觉智能开放平台(VIAPI)-阿里云帮助中心
如何创建AccessKey_视觉智能开放平台(VIAPI)-阿里云帮助中心
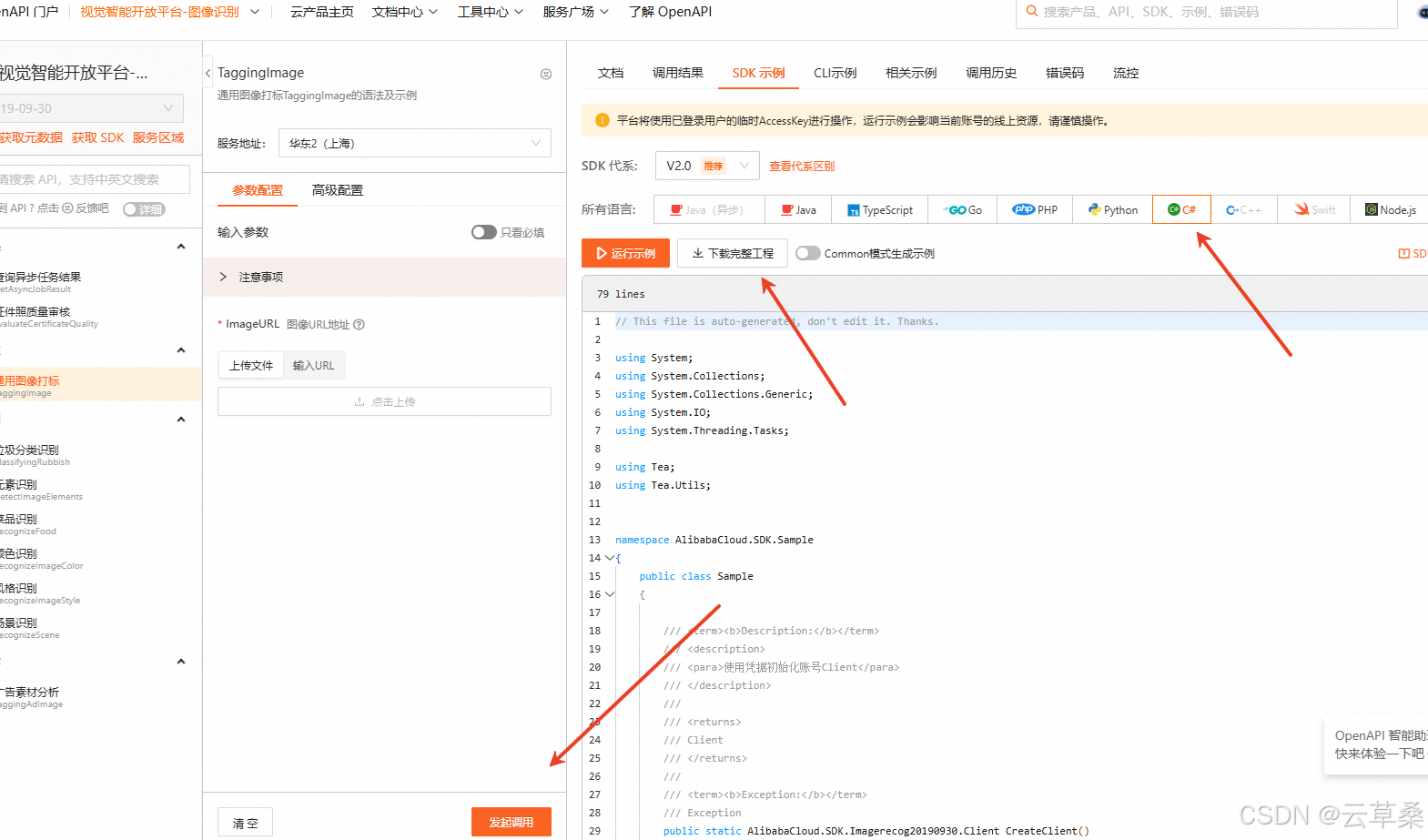
TaggingImage_视觉智能开放平台-图像识别_API调试-阿里云OpenAPI开发者门户
通用图像打标常用语言和示例有哪些_视觉智能开放平台(VIAPI)-阿里云帮助中心
这个SKD 文档找了好久 丢如何下载安装、使用视觉智能开放平台C#SDK及代码示例_视觉智能开放平台(VIAPI)-阿里云帮助中心
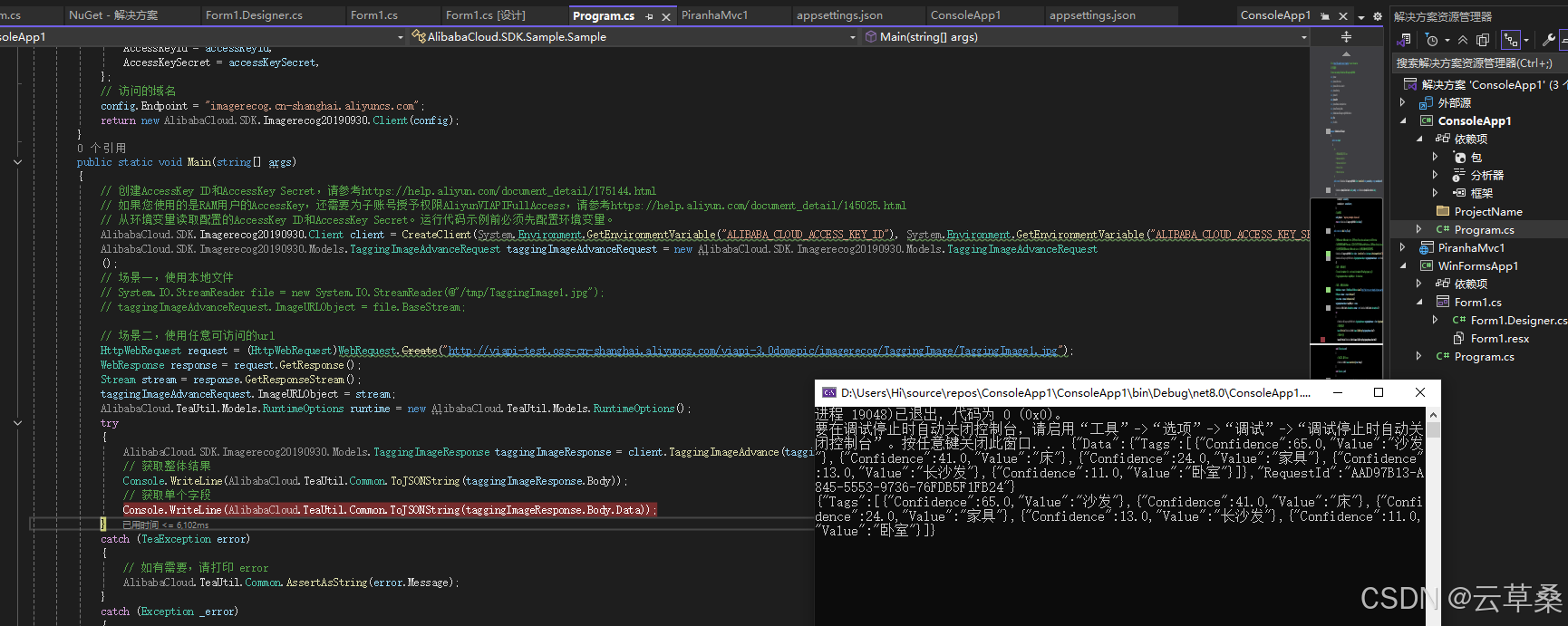
代码和图像打标结果
相关文章:

为您的照片提供本地 AI 视觉:使用 Llama Vision 和 ChromaDB 构建 AI 图像标记器
有没有花 20 分钟浏览您的文件夹以找到心中的特定图像或屏幕截图?您并不孤单。 作为工作中的产品经理,我总是淹没在竞争对手产品的屏幕截图、UI 灵感以及白板会议或草图的照片的海洋中。在我的个人生活中,我总是捕捉我在生活中遇到的事物&am…...

OpenAI 34页最佳构建Agent实践
penAI发布O4,也发布34页最佳构建Agent实践,值得阅读。 什么是Agent? 传统软件使用户能够简化和自动化工作流程,而代理能够以高度独立的方式代表用户执行相同的工作流程。 代理是能够独立地代表您完成任务的系统。 工作流程是必…...
:训练第一个 DDPM 模型(使用 CIFAR-10 数据集))
第 5 期(进阶版):训练第一个 DDPM 模型(使用 CIFAR-10 数据集)
—— 用 DDPM 模型生成彩色图像,感受扩散魔法在 CIFAR-10 上的威力! 本期目标 将 MNIST 替换为 CIFAR-10; 模型结构适配 RGB 三通道输入; 保持原始扩散与采样流程; 增加图像可视化对比! 数据准备&…...
----共享内存)
进程间通信(IPC)----共享内存
进程间通信(IPC)的共享内存机制允许不同进程直接访问同一块物理内存区域,是速度最快的IPC方式(无需数据拷贝)。 一、共享内存核心概念 1. 基本原理 共享内存区域:由内核管理的特殊内存段,可被…...

Xcode16 调整 Provisioning Profiles 目录导致证书查不到
cronet demo 使用的 ninja 打包,查找 Provisioning Profiles 路径是 ~/Library/MobileDevice/Provisioning Profiles,但 Xcode16 把该路径改为了 ~/Library/Developer/Xcode/UserData/Provisioning Profiles,导致在编译 cronet 的demo 时找不…...

Debian服务器环境下env变量丢失怎么办
在 Debian服务器环境下,如果出现了 env 环境变量丢失的问题,比如常见的 PATH、JAVA_HOME、PYTHONPATH 等系统变量或自定义变量不起作用,可能会导致一些命令无法执行、服务无法启动、脚本报错等。 这个问题常见于: 使用 cron、sy…...

搜广推校招面经七十八
字节推荐算法 一、实习项目:多任务模型中的每个任务都是做什么?怎么确定每个loss的权重 这个根据实际情况来吧。如果实习时候用了moe,就可能被问到。 loss权重的话,直接根据任务的重要性吧。。。 二、特征重要性怎么判断的&…...
详细通关教程)
ctf.show—Web(1-10)详细通关教程
Web1-签到题 1、按F12查看元素,发现有一段被注释的字符串 2、看起来并不像flag,格式类似于Base64编码 扔到Base64在线编码平台:Base64 编码/解码 - 锤子在线工具此工具是一个 Base64 编码或解码在线工具,实现把字符串转成 Base6…...

双层Key缓存
双层 Key 缓存是一种针对 缓存击穿 和 雪崩问题 的优化方案,其核心思想是通过 主备双缓存 的机制,确保在热点数据过期时仍能提供可用服务,同时降低对数据库的瞬时压力。以下是其核心原理、实现细节及适用场景的深度解析: 一、核心…...

android编译使用共享缓存
注意 服务器端与客户端系统的版本号需为Ubuntu20.04ccache版本不能低于4.4执行用户需要为sudo权限服务器端nfs目录权限必须为nobody:nogroup 一、服务端配置: 在服务器192.168.60.142上配置 NFS 共享 1.安装 NFS 服务器: 1 sudo apt-get install nfs…...

如何使用Labelimg查看已经标注好的YOLO数据集标注情况
文章目录 1、 安装并运行Labelimg1.1、安装Labelimg1.2、运行Labelimg 2、查看数据集标注情况2.1、创建类别名称文件classes.txt2.2、使用Labelimg打开查看标注文件2.3、正式标注 3、目标检测系列文章 本文主要介绍一下如何使用LabelImg查看已经标注好的YOLO数据集标注情况&…...

Web3架构下的数据隐私与保护
在这个信息爆炸的时代,Web3的概念如同一股清流,以其去中心化的特性,为数据隐私与保护带来了新的希望。Web3,也被称作下一代互联网,它通过区块链技术实现数据的去中心化存储和处理,旨在提高数据的安全性和隐…...

PCM 参数深度解析:采样率、帧、缓存大小与多通道关系
将下面的 PCM 配置作为例子: config.channels 2; // 立体声(2 个通道) config.rate 48000; // 采样率 48000 Hz,即每秒 48000 帧 config.period_size 1024; // 每个周…...

Kafka消费者端重平衡流程
重平衡的完整流程需要消费者 端和协调者组件共同参与才能完成。我们先从消费者的视角来审视一下重平衡的流程。在消费者端,重平衡分为两个步骤:分别是加入组和等待领导者消费者(Leader Consumer)分配方案。这两个步骤分别对应两类…...

【字节跳动AI论文】海姆达尔:生成验证的测试时间扩展
摘要:人工智能系统只能在能够验证知识本身的范围内创建和维护知识。 最近关于长链推理的研究表明,LLM在解决竞争问题方面具有巨大的潜力,但它们的验证能力仍然很弱,而且没有得到充分的研究。 在本文中,我们提出了Heimd…...
竞赛笔记)
【Datawhale Al春训营】气象预测(AI+航空安全)竞赛笔记
这里写自定义目录标题 欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants 创建一个自定义列表如何创建一个…...

大模型应用开发实战:AI Agent与智能体开发技术解析
更多AI大模型应用开发学习内容,尽在聚客AI学院 一、AI Agent的核心概念 AI Agent(智能体)是基于大模型构建的自主任务执行系统,能够根据用户指令拆解目标、调用工具、完成复杂任务(如数据分析、自动化办公)…...

《Learning Langchain》阅读笔记3-基于 Gemini 的 Langchain如何从LLMs中获取特定格式
纯文本输出是有用的,但在某些情况下,我们需要 LLM 生成结构化输出,即以机器可读格式(如 JSON、XML 或 CSV)或甚至以编程语言(如 Python 或 JavaScript)生成的输出。当我们打算将该输出传递给其他…...

Mac mini 安装mysql数据库以及出现的一些问题的解决方案
首先先去官网安装一下mysql数据库,基本上都是傻瓜式安装的流程,我也就不详细说了。 接下来就是最新版的mysql安装的时候,他就会直接让你设置一个新的密码。 打开设置,拉到最下面就会看到一个mysql的图标: 我设置的就是…...

智能体时代的产业范式确立,中国企业以探索者姿态走出自己的路
作者 | 曾响铃 文 | 响铃说 当前,一个新的20年的产业升级期已经开启,系统性的发展路径也正在形成。 前不久,以“共建智能体时代“为主题的超聚变探索者大会2025在河南郑州举办。超聚变变数字技术有限公司(以下简称:…...

电路安全智控系统与主机安全防护系统主要功能是什么
电路安全智控系统被称为电路安全用电控制系统。电路安全智控系统具备一系列强大且实用的功能。电路安全智控系统能够对总电压、总电流、总功率、总电能,以及各分路的电压、电流、功率、电能和功率因素等进行全方位的监控。在大型工厂的电力分配中,通过对…...

MCP Server驱动传统SaaS智能化转型:从工具堆叠到AI Agent生态重构,基于2025年技术演进与产业实践
MCP Server驱动传统SaaS智能化转型:从工具堆叠到AI Agent生态重构 (基于2025年技术演进与产业实践) MCP模型上下文协议 一、技术底座革新:MCP协议重构AI时代的"数字接口" 传统SaaS软件向大模型AI应用转型的核心矛盾…...
)
【工具变量】地市农业播种面积及粮食产量等21个相关指标(2013-2022年)
粮食产量、粮食播种面积及农作物播种面积等,是衡量农业发展水平和粮食安全的重要指标。随着全球粮食需求的持续增长,准确掌握这些数据对制定农业政策、优化生产结构和提高农业生产效率至关重要。因此,缤本次分享数据包括《中国统计NJ》、《中…...

使用 PySpark 批量清理 Hive 表历史分区
使用 PySpark 批量清理 Hive 表历史分区 在大数据平台中,Hive 表通常采用分区方式存储数据,以提升查询效率和数据管理的灵活性。随着数据的不断积累,历史分区会越来越多,既占用存储空间,也影响元数据管理性能。因此&a…...
)
A. k-th equality(1700)
Problem - 1835A - Codeforces Daily_CF_Problems/daily_problems/2025/04/0417/solution/cf1835a.md at main Yawn-Sean/Daily_CF_Problems 考虑所有形式为 abc 的等式,其中 a有 A 位数, b 有 B 位数, c 有 C 位数。所有数字都是正整数,求…...

深度学习-torch,全连接神经网路
3. 数据集加载案例 通过一些数据集的加载案例,真正了解数据类及数据加载器。 3.1 加载csv数据集 代码参考如下 import torch from torch.utils.data import Dataset, DataLoader import pandas as pd class MyCsvDataset(Dataset):def __init__(self, fil…...

echarts饼图中心呈现一张图片,并且能动态旋转的效果react组件
实现效果: 父组件: import React from react import styles from ./style.less import GaugeChart from ./GaugeChart;export default function index() {return (<div><div className{styles.bg} ></div><div style{{ width: 500…...

使用Docker搭建开源Email服务器
使用Docker搭建开源Email服务器 1 介绍 开源的Email服务器比较多,例如:poste.io、MailCatcher、Postal、mailcow等。由于poste.io支持docker安装,页面比较美观,使用简单,支持SMTP IMAP POP3等协议,安全…...

css图片设为灰色
使用filter方式将图片设置为灰色 普通图片使用:filter: saturate(0); 纯白图片使用: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"width…...

2025 年第十五届 MathorCup竞赛赛题浅析-助攻快速选题
本届妈杯竞赛各赛题难度均已经达到了国赛难度,也更好的回应了大家更为关心的,在当前AI环境下,似乎“数学建模变成了AI使用竞赛一样”。但是国委会一直以来都是一个态度:AI现在是无法直接解决任何一个国赛赛题的。对应的如今这句话…...

【android bluetooth 案例分析 03】【PTS 测试 1】【pts基本介绍】
Bluetooth SIG(Special Interest Group)提供的 PTS(Profile Tuning Suite)测试 是蓝牙认证过程中一项极为关键的步骤。它主要用于验证设备是否符合 Bluetooth SIG 制定的各项 蓝牙规范(Bluetooth Specification&#x…...

Java集合框架深度解析:HashMap、HashSet、TreeMap、TreeSet与哈希表原理详解
一、核心数据结构总览 1. 核心类继承体系 graph TDMap接口 --> HashMapMap接口 --> TreeMapSet接口 --> HashSetSet接口 --> TreeSetHashMap --> LinkedHashMapHashSet --> LinkedHashSetTreeMap --> NavigableMapTreeSet --> NavigableSet 2. 核心…...

【深度学习】张量计算:爱因斯坦求和约定|tensor系列03
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: Yaoyao2024往期回顾:【深度学习】详解矩阵乘法、点积,内积,外积、哈达玛积极其应用|tensor系列02每日一言🌼: “岱宗夫如何&…...

OpenHarmony-Risc-V上运行openBLAS中的benchmark
OpenHarmony-Risc-V上运行openBLAS中的benchmark 文章目录 OpenHarmony-Risc-V上运行openBLAS中的benchmark前言一、编译openBLAS1.源码下载2.工具链下载3.编译并安装openBLAS 二、编译open BLAS中的benchmark三、上设备运行总结 前言 参考https://zhuanlan.zhihu.com/p/18825…...
(2_梦境巡查_C++))
CCF CSP 第36次(2024.12)(2_梦境巡查_C++)
CCF CSP 第36次(2024.12)(2_梦境巡查_C) 解题思路:思路一: 代码实现代码实现(思路一): 时间限制: 1.0 秒 空间限制: 512 MiB 原题链接 解题思路…...

windows下安装mcp servers
以sequential-thinking为例 macos下安装就像github readme中那样安装即可: {"mcpServers": {"sequential-thinking": {"command": "npx","args": ["-y","modelcontextprotocol/server-sequenti…...

OpenGauss 数据库介绍
OpenGauss 数据库介绍 OpenGauss 是华为基于 PostgreSQL 开发的企业级开源关系型数据库,现已成为开放原子开源基金会的项目。以下是 OpenGauss 的详细介绍: 一 核心特性 1.1 架构设计亮点 特性说明优势多核并行NUMA感知架构充分利用现代CPU多核性能行…...

Web3区块链网络中数据隐私安全性探讨
在这个信息爆炸的时代,Web3 的概念如同一股清流,以其去中心化、透明性和安全性的特点,为数据隐私保护提供了新的解决方案。本文将探讨 Web3 区块链网络中数据隐私的安全性问题,并探索如何通过技术手段提高数据隐私的保护。 Web3 …...

linux驱动之poll
驱动中 poll 实现 在用户空间实现事件操作的一个主要实现是调用 select/poll/epoll 函数。那么在驱动中怎么来实现 poll 的底层呢? 其实在内核的 struct file_operations 结构体中有一个 poll 成员,其就是底层实现的接口函数。 驱动中 poll 函数实现原…...

【最后203篇系列】028 FastAPI的后台任务处理
说明 今天偶然在别的文章里看到这个功能,突然觉得正好。 CeleryWorker已经搭好了,但是我一直想在用户请求时进行额外的处理会比较影响处理时间,用这个正好可以搭配上。 我设想的一个场景: 1 用户发起请求2 接口中进行关键信息…...
可以通过 自定义事件 或 页面引用 实现)
微信小程序中,将搜索组件获取的值传递给父页面(如 index 页面)可以通过 自定义事件 或 页面引用 实现
将搜索组件获取的值传递给父页面(如 index 页面)可以通过 自定义事件 或 页面引用 实现 方法 1:自定义事件(推荐) 步骤 1:搜索组件内触发事件 在搜索组件的 JS 中,当获取到搜索值时,…...

深入理解分布式缓存 以及Redis 实现缓存更新通知方案
一、分布式缓存简介 1. 什么是分布式缓存 分布式缓存:指将应用系统和缓存组件进行分离的缓存机制,这样多个应用系统就可以共享一套缓存数据了,它的特点是共享缓存服务和可集群部署,为缓存系统提供了高可用的运行环境,…...
框架基础)
C#核心笔记——(六)框架基础
我们在编程时所需的许多核心功能并不是由C#语言提供的,而是由.NET Framework中的类型提供的。本节我们将介绍Framework在基础编程任务(例如虚的等值比较、顺序比较以及类型转换)中的作用。我们还会介绍Framework中的基本类型,例如String、DateTime和Enum. 本章中的绝大部分…...

C# 点击导入,将需要的参数传递到弹窗的页面
点击导入按钮,获取本页面的datagridview标题的结构,并传递到导入界面。 新增一个datatable用于存储datagridview的caption和name,这里用的是devexpress组件中的gridview。 DataTable dt new DataTable(); DataColumn CAPTION …...

java面向对象编程【基础篇】之基础概念
目录 🚀前言🤔面向过程VS面向对象💯面向过程编程(POP)💯面向对象编程(OOP)💯两者对比 🌟三大特性💯封装性💯继承性💯多态性…...

Oceanbase单机版上手示例
本月初Oceanbase单机版发布,作为一个以分布式起家的数据库,原来一个集群动辄小十台机器,多着十几台几十台甚至更多,Oceanbase单机版的发布确实大大降低了硬件部署的门槛。 1.下载安装介质 https://www.oceanbase.com/softwarece…...
)
深度学习基础--CNN经典网络之InceptionV3详解与复现(pytorch)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 InceptionV3是InceptionV1的升级版,虽然加大了计算量,但是当时效果是比VGG效果要好的。本次任务是探究InceptionV3结构并进行复…...

VOIP通信中的错误码
cancle报文 Reason: SIP;cause200;text"Call completed elsewhere" Reason: Q.850;cause26表示取消的原因是呼叫在其他地方已经完成表示Q.850标准中的原因码26,通常对应于“呼叫被取消”(Call Cancelled)487 Request Terminated Re…...

C++ STL编程-vector概念、对象创建
vector 概念:是常见的一种容器,被称为“柔性数组”。 在vector中,front()是数组中的第一个元素,back()是数组的最后一个元素。begin()是是指向第一个元素,end()是指向back()的后一个元素 vector的对象创建࿰…...

easyexcel使用模板填充excel坑点总结
1.单层map设置值是{属性},那使用两层map进行设置值,是不是可以使用{属性.属性},以为取出map里字段只用{属性}就可以设置值,那再加个.就可以从里边map取出对应属性,没有两层map写法 填充得到的文件打开报错 was empty (…...