深度学习-torch,全连接神经网路
3. 数据集加载案例
通过一些数据集的加载案例,真正了解数据类及数据加载器。
3.1 加载csv数据集
代码参考如下
import torch from torch.utils.data import Dataset, DataLoader import pandas as pd class MyCsvDataset(Dataset):def __init__(self, filename):df = pd.read_csv(filename)# 删除文字列df = df.drop(["学号", "姓名"], axis=1)# 转换为tensordata = torch.tensor(df.values)# 最后一列以前的为data,最后一列为labelself.data = data[:, :-1]self.label = data[:, -1]self.len = len(self.data) def __len__(self):return self.len def __getitem__(self, index):idx = min(max(index, 0), self.len - 1)return self.data[idx], self.label[idx] def test001():excel_path = r"./大数据答辩成绩表.csv"dataset = MyCsvDataset(excel_path)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)for i, (data, label) in enumerate(dataloader):print(i, data, label) if __name__ == "__main__":test001()
练习:上述示例数据构建器改成TensorDataset
def build_dataset(filepath):df = pd.read_csv(filepath)df.drop(columns=['学号', '姓名'], inplace=True)data = df.iloc[..., :-1]labels = df.iloc[..., -1] x = torch.tensor(data.values, dtype=torch.float)y = torch.tensor(labels.values) dataset = TensorDataset(x, y) return dataset def test001():filepath = r"./大数据答辩成绩表.csv"dataset = build_dataset(filepath)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)for i, (data, label) in enumerate(dataloader):print(i, data, label)
3.2 加载图片数据集
参考代码如下:只是用于文件读取测试
import torch from torch.utils.data import Dataset, DataLoader import os # 导入opencv import cv2 class MyImageDataset(Dataset):def __init__(self, folder):# 文件存储路径列表self.filepaths = []# 文件对应的目录序号列表self.labels = []# 指定图片大小self.imgsize = (112, 112)# 临时存储文件所在目录名dirnames = [] # 递归遍历目录,root:根目录路径,dirs:子目录名称,files:子文件名称for root, dirs, files in os.walk(folder):# 如果dirs和files不同时有值,先遍历dirs,然后再以dirs的目录为路径遍历该dirs下的files# 这里需要在dirs不为空时保存目录名称列表if len(dirs) > 0:dirnames = dirs for file in files:# 文件路径filepath = os.path.join(root, file)self.filepaths.append(filepath)# 分割root中的dir目录名classname = os.path.split(root)[-1]# 根据目录名到临时目录列表中获取下标self.labels.append(dirnames.index(classname))self.len = len(self.filepaths) def __len__(self):return self.len def __getitem__(self, index):# 获取下标idx = min(max(index, 0), self.len - 1)# 根据下标获取文件路径filepath = self.filepaths[idx]# opencv读取图片img = cv2.imread(filepath)# 图片缩放,图片加载器要求同一批次的图片大小一致img = cv2.resize(img, self.imgsize)# 转换为tensorimg_tensor = torch.tensor(img)# 将图片HWC调整为CHWimg_tensor = torch.permute(img_tensor, (2, 0, 1))# 获取目录标签label = self.labels[idx] return img_tensor, label def test02():path = os.path.join(os.path.dirname(__file__), 'dataset')# 转换为相对路径path = os.path.relpath(path)dataset = MyImageDataset(path) dataloader = DataLoader(dataset, batch_size=8, shuffle=True) for img, label in dataloader:print(img.shape)print(label) if __name__ == "__main__":test02()
练习:1.重写上述代码,如果不对图片进行缩放会产生什么结果?2.在遍历图片的代码中打印图片查看图片效果(打印一批次即可)
# 导入opencv
import cv2
class MyDataset(Dataset):def __init__(self, folder):
dirnames = []self.filepaths = []self.labels = []
for root, dirs, files in os.walk(folder):if len(dirs) > 0:dirnames = dirs
for file in files:filepath = os.path.join(root, file)self.filepaths.append(filepath)classname = os.path.split(root)[-1]if classname in dirnames:self.labels.append(dirnames.index(classname))else:print(f'{classname} not in {dirnames}')
self.len = len(self.filepaths)
def __len__(self):return self.len
def __getitem__(self, index):idx = min(max(index, 0), self.len - 1)filepath = self.filepaths[idx]img = cv2.imread(filepath)print(img.shape)# 不做图片缩放,报:RuntimeError: stack expects each tensor to be equal size, but got [3, 1333, 2000] at entry 0 and [3, 335, 600] at entry 1img = cv2.resize(img, (112, 112))t_img = torch.tensor(img)t_img = torch.permute(t_img, (2, 0, 1))
label = self.labels[idx]return t_img, label
def test02():path = os.path.join(os.path.dirname(__file__), 'dataset')dataset = MyDataset(path)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
for img, label in dataloader:
print(img.shape, label)for i in range(img.shape[0]):im = torch.permute(img[i], (1, 2, 0))plt.imshow(im)plt.show()
break
if __name__ == "__main__":test02()
优化:使用ImageFolder加载图片集
ImageFolder 会根据文件夹的结构来加载图像数据。它假设每个子文件夹对应一个类别,文件夹名称即为类别名称。例如,一个典型的文件夹结构如下:
root/class1/img1.jpgimg2.jpg...class2/img1.jpgimg2.jpg......
在这个结构中:
-
root是根目录。 -
class1、class2等是类别名称。 -
每个类别文件夹中的图像文件会被加载为一个样本。
ImageFolder构造函数如下:
torchvision.datasets.ImageFolder(root, transform=None, target_transform=None, is_valid_file=None)
参数解释
-
root:字符串,指定图像数据集的根目录。 -
transform:可选参数,用于对图像进行预处理。通常是一个torchvision.transforms的组合。 -
target_transform:可选参数,用于对目标(标签)进行转换。 -
is_valid_file:可选参数,用于过滤无效文件。如果提供,只有返回True的文件才会被加载。
import torch from torchvision import datasets, transforms import os from torch.utils.data import DataLoader from matplotlib import pyplot as plt torch.manual_seed(42) def load():path = os.path.join(os.path.dirname(__file__), 'dataset')print(path) transform = transforms.Compose([transforms.Resize((112, 112)),transforms.ToTensor()]) dataset = datasets.ImageFolder(path, transform=transform)dataloader = DataLoader(dataset, batch_size=1, shuffle=True) for x,y in dataloader:x = x.squeeze(0).permute(1, 2, 0).numpy()plt.imshow(x)plt.show()print(y[0])break if __name__ == '__main__':load()
3.3 加载官方数据集
在 PyTorch 中官方提供了一些经典的数据集,如 CIFAR-10、MNIST、ImageNet 等,可以直接使用这些数据集进行训练和测试。
数据集:Datasets — Torchvision 0.21 documentation
常见数据集:
-
MNIST: 手写数字数据集,包含 60,000 张训练图像和 10,000 张测试图像。
-
CIFAR10: 包含 10 个类别的 60,000 张 32x32 彩色图像,每个类别 6,000 张图像。
-
CIFAR100: 包含 100 个类别的 60,000 张 32x32 彩色图像,每个类别 600 张图像。
-
COCO: 通用对象识别数据集,包含超过 330,000 张图像,涵盖 80 个对象类别。
torchvision.transforms 和 torchvision.datasets 是 PyTorch 中处理计算机视觉任务的两个核心模块,它们为图像数据的预处理和标准数据集的加载提供了强大支持。
transforms 模块提供了一系列用于图像预处理的工具,可以将多个变换组合成处理流水线。
datasets 模块提供了多种常用计算机视觉数据集的接口,可以方便地下载和加载。
参考如下:
import torch from torch.utils.data import Dataset, DataLoader import torchvision from torchvision import transforms, datasets def test():transform = transforms.Compose([transforms.ToTensor(),])# 训练数据集data_train = datasets.MNIST(root="./data",train=True,download=True,transform=transform,)trainloader = DataLoader(data_train, batch_size=8, shuffle=True)for x, y in trainloader:print(x.shape)print(y)break # 测试数据集data_test = datasets.MNIST(root="./data",train=False,download=True,transform=transform,)testloader = DataLoader(data_test, batch_size=8, shuffle=True)for x, y in testloader:print(x.shape)print(y)break def test006():transform = transforms.Compose([transforms.ToTensor(),])# 训练数据集data_train = datasets.CIFAR10(root="./data",train=True,download=True,transform=transform,)trainloader = DataLoader(data_train, batch_size=4, shuffle=True, num_workers=2)for x, y in trainloader:print(x.shape)print(y)break# 测试数据集data_test = datasets.CIFAR10(root="./data",train=False,download=True,transform=transform,)testloader = DataLoader(data_test, batch_size=4, shuffle=False, num_workers=2)for x, y in testloader:print(x.shape)print(y)break if __name__ == "__main__":test()test006()
1. 神经网络基础
1.1 生物神经元与人工神经元
神经网络的设计灵感来源于生物神经元。生物神经元通过树突接收信号,细胞核处理信号,轴突传递信号,突触连接不同的神经元。人工神经元模仿了这一过程,接收多个输入信号,经过加权求和和非线性激活函数处理后,输出结果。
1.2 人工神经元的组成
人工神经元由以下几个部分组成:
- 输入(Inputs):代表输入数据,通常用向量表示。
- 权重(Weights):每个输入数据都有一个权重,表示该输入对最终结果的重要性。
- 偏置(Bias):一个额外的可调参数,用于调整模型的输出。
- 加权求和:将输入乘以对应的权重后求和,再加上偏置。
- 激活函数(Activation Function):将加权求和后的结果转换为输出结果,引入非线性特性。
数学表示如下:
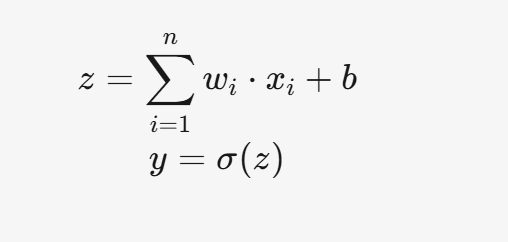
其中,σ(z) 是激活函数。
2. 神经网络结构
2.1 基本结构
神经网络由以下三层构成:
- 输入层(Input Layer):接收外部数据,不进行计算。
- 隐藏层(Hidden Layer):位于输入层和输出层之间,进行特征提取和转换。隐藏层可以有多层,每层包含多个神经元。
- 输出层(Output Layer):产生最终的预测结果或分类结果。
2.2 全连接神经网络
全连接神经网络(Fully Connected Neural Network,FCNN)是前馈神经网络的一种,每一层的神经元与上一层的所有神经元全连接。全连接神经网络常用于图像分类、文本分类等任务。
2.2.1 特点
- 权重数量大:由于全连接的特点,权重数量较大,计算量大。
- 学习能力强:能够学习输入数据的全局特征,但对高维数据的局部特征捕捉能力较弱。
2.2.2 计算步骤
- 数据传递:输入数据逐层传递到输出层。
- 激活函数:每一层的输出通过激活函数处理。
- 损失计算:计算预测值与真实值之间的差距。
- 反向传播:通过反向传播算法更新权重以最小化损失。
3. 激活函数
激活函数在神经网络中引入非线性,使网络能够处理复杂的任务。以下是几种常见的激活函数及其特点。
3.1 Sigmoid
3.1.1 公式
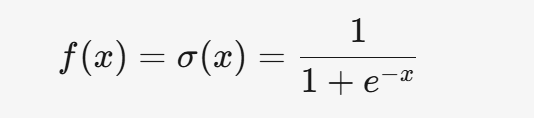
3.1.2 特点
- 将输入映射到 (0, 1) 之间,适合处理概率问题。
- 梯度消失问题严重,容易导致训练速度变慢。
- 计算成本较高。
3.1.3 应用场景
- 一般用于二分类问题的输出层。
3.2 Tanh
3.2.1 公式
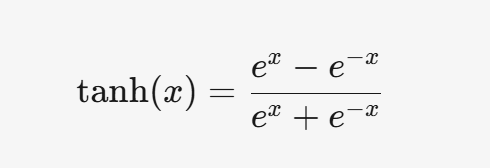
3.2.2 特点
- 输出范围为 (-1, 1),是零中心的,有助于加速收敛。
- 对称性较好,适合隐藏层。
- 仍然存在梯度消失问题。
3.2.3 应用场景
- 适用于隐藏层,但不如 ReLU 常用。
3.3 ReLU
3.3.1 公式
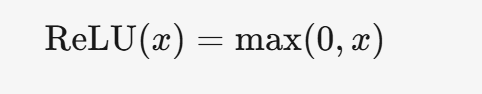
3.3.2 特点
- 计算简单,适合大规模数据训练。
- 缓解梯度消失问题,适合深层网络。
- 存在神经元死亡问题,即某些神经元可能永远不被激活。
3.3.3 应用场景
- 深度学习中最常用的激活函数,适用于隐藏层。
3.4 Leaky ReLU
3.4.1 公式
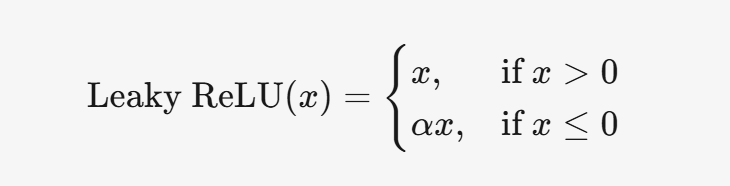
3.4.2 特点
- 解决了 ReLU 的神经元死亡问题。
- 计算简单,但需要调整超参数 α。
3.4.3 应用场景
- 适用于隐藏层,尤其是 ReLU 效果不佳时。
3.5 Softmax
3.5.1 公式
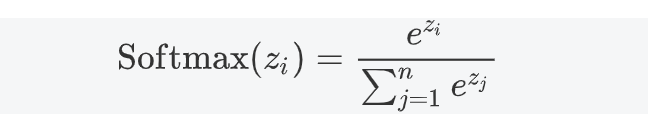

3.5.2 特点
- 将输出转化为概率分布,适合多分类问题。
- 放大差异,使概率最大的类别更突出。
- 存在数值不稳定性问题,需进行数值调整。
3.5.3 应用场景
- 用于多分类问题的输出层。
4. 激活函数的选择
4.1 隐藏层
- 优先选择 ReLU。
- 如果 ReLU 效果不佳,尝试 Leaky ReLU 或其他激活函数。
- 避免使用 Sigmoid,可以尝试 Tanh。
4.2 输出层
- 二分类问题选择 Sigmoid。
- 多分类问题选择 Softmax。
5. 总结
神经网络是深度学习的核心,理解其结构和激活函数的作用至关重要。人工神经元是神经网络的基本单元,通过加权求和和激活函数实现非线性变换。全连接神经网络是最基本的神经网络结构,广泛应用于各类任务。激活函数在神经网络中引入非线性,增强了网络的表达能力。不同激活函数适用于不同的场景,合理选择激活函数可以显著提升模型性能。
相关文章:

深度学习-torch,全连接神经网路
3. 数据集加载案例 通过一些数据集的加载案例,真正了解数据类及数据加载器。 3.1 加载csv数据集 代码参考如下 import torch from torch.utils.data import Dataset, DataLoader import pandas as pd class MyCsvDataset(Dataset):def __init__(self, fil…...

echarts饼图中心呈现一张图片,并且能动态旋转的效果react组件
实现效果: 父组件: import React from react import styles from ./style.less import GaugeChart from ./GaugeChart;export default function index() {return (<div><div className{styles.bg} ></div><div style{{ width: 500…...

使用Docker搭建开源Email服务器
使用Docker搭建开源Email服务器 1 介绍 开源的Email服务器比较多,例如:poste.io、MailCatcher、Postal、mailcow等。由于poste.io支持docker安装,页面比较美观,使用简单,支持SMTP IMAP POP3等协议,安全…...

css图片设为灰色
使用filter方式将图片设置为灰色 普通图片使用:filter: saturate(0); 纯白图片使用: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"width…...

2025 年第十五届 MathorCup竞赛赛题浅析-助攻快速选题
本届妈杯竞赛各赛题难度均已经达到了国赛难度,也更好的回应了大家更为关心的,在当前AI环境下,似乎“数学建模变成了AI使用竞赛一样”。但是国委会一直以来都是一个态度:AI现在是无法直接解决任何一个国赛赛题的。对应的如今这句话…...

【android bluetooth 案例分析 03】【PTS 测试 1】【pts基本介绍】
Bluetooth SIG(Special Interest Group)提供的 PTS(Profile Tuning Suite)测试 是蓝牙认证过程中一项极为关键的步骤。它主要用于验证设备是否符合 Bluetooth SIG 制定的各项 蓝牙规范(Bluetooth Specification&#x…...

Java集合框架深度解析:HashMap、HashSet、TreeMap、TreeSet与哈希表原理详解
一、核心数据结构总览 1. 核心类继承体系 graph TDMap接口 --> HashMapMap接口 --> TreeMapSet接口 --> HashSetSet接口 --> TreeSetHashMap --> LinkedHashMapHashSet --> LinkedHashSetTreeMap --> NavigableMapTreeSet --> NavigableSet 2. 核心…...

【深度学习】张量计算:爱因斯坦求和约定|tensor系列03
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: Yaoyao2024往期回顾:【深度学习】详解矩阵乘法、点积,内积,外积、哈达玛积极其应用|tensor系列02每日一言🌼: “岱宗夫如何&…...

OpenHarmony-Risc-V上运行openBLAS中的benchmark
OpenHarmony-Risc-V上运行openBLAS中的benchmark 文章目录 OpenHarmony-Risc-V上运行openBLAS中的benchmark前言一、编译openBLAS1.源码下载2.工具链下载3.编译并安装openBLAS 二、编译open BLAS中的benchmark三、上设备运行总结 前言 参考https://zhuanlan.zhihu.com/p/18825…...
(2_梦境巡查_C++))
CCF CSP 第36次(2024.12)(2_梦境巡查_C++)
CCF CSP 第36次(2024.12)(2_梦境巡查_C) 解题思路:思路一: 代码实现代码实现(思路一): 时间限制: 1.0 秒 空间限制: 512 MiB 原题链接 解题思路…...

windows下安装mcp servers
以sequential-thinking为例 macos下安装就像github readme中那样安装即可: {"mcpServers": {"sequential-thinking": {"command": "npx","args": ["-y","modelcontextprotocol/server-sequenti…...

OpenGauss 数据库介绍
OpenGauss 数据库介绍 OpenGauss 是华为基于 PostgreSQL 开发的企业级开源关系型数据库,现已成为开放原子开源基金会的项目。以下是 OpenGauss 的详细介绍: 一 核心特性 1.1 架构设计亮点 特性说明优势多核并行NUMA感知架构充分利用现代CPU多核性能行…...

Web3区块链网络中数据隐私安全性探讨
在这个信息爆炸的时代,Web3 的概念如同一股清流,以其去中心化、透明性和安全性的特点,为数据隐私保护提供了新的解决方案。本文将探讨 Web3 区块链网络中数据隐私的安全性问题,并探索如何通过技术手段提高数据隐私的保护。 Web3 …...

linux驱动之poll
驱动中 poll 实现 在用户空间实现事件操作的一个主要实现是调用 select/poll/epoll 函数。那么在驱动中怎么来实现 poll 的底层呢? 其实在内核的 struct file_operations 结构体中有一个 poll 成员,其就是底层实现的接口函数。 驱动中 poll 函数实现原…...

【最后203篇系列】028 FastAPI的后台任务处理
说明 今天偶然在别的文章里看到这个功能,突然觉得正好。 CeleryWorker已经搭好了,但是我一直想在用户请求时进行额外的处理会比较影响处理时间,用这个正好可以搭配上。 我设想的一个场景: 1 用户发起请求2 接口中进行关键信息…...
可以通过 自定义事件 或 页面引用 实现)
微信小程序中,将搜索组件获取的值传递给父页面(如 index 页面)可以通过 自定义事件 或 页面引用 实现
将搜索组件获取的值传递给父页面(如 index 页面)可以通过 自定义事件 或 页面引用 实现 方法 1:自定义事件(推荐) 步骤 1:搜索组件内触发事件 在搜索组件的 JS 中,当获取到搜索值时,…...

深入理解分布式缓存 以及Redis 实现缓存更新通知方案
一、分布式缓存简介 1. 什么是分布式缓存 分布式缓存:指将应用系统和缓存组件进行分离的缓存机制,这样多个应用系统就可以共享一套缓存数据了,它的特点是共享缓存服务和可集群部署,为缓存系统提供了高可用的运行环境,…...
框架基础)
C#核心笔记——(六)框架基础
我们在编程时所需的许多核心功能并不是由C#语言提供的,而是由.NET Framework中的类型提供的。本节我们将介绍Framework在基础编程任务(例如虚的等值比较、顺序比较以及类型转换)中的作用。我们还会介绍Framework中的基本类型,例如String、DateTime和Enum. 本章中的绝大部分…...

C# 点击导入,将需要的参数传递到弹窗的页面
点击导入按钮,获取本页面的datagridview标题的结构,并传递到导入界面。 新增一个datatable用于存储datagridview的caption和name,这里用的是devexpress组件中的gridview。 DataTable dt new DataTable(); DataColumn CAPTION …...

java面向对象编程【基础篇】之基础概念
目录 🚀前言🤔面向过程VS面向对象💯面向过程编程(POP)💯面向对象编程(OOP)💯两者对比 🌟三大特性💯封装性💯继承性💯多态性…...

Oceanbase单机版上手示例
本月初Oceanbase单机版发布,作为一个以分布式起家的数据库,原来一个集群动辄小十台机器,多着十几台几十台甚至更多,Oceanbase单机版的发布确实大大降低了硬件部署的门槛。 1.下载安装介质 https://www.oceanbase.com/softwarece…...
)
深度学习基础--CNN经典网络之InceptionV3详解与复现(pytorch)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 InceptionV3是InceptionV1的升级版,虽然加大了计算量,但是当时效果是比VGG效果要好的。本次任务是探究InceptionV3结构并进行复…...

VOIP通信中的错误码
cancle报文 Reason: SIP;cause200;text"Call completed elsewhere" Reason: Q.850;cause26表示取消的原因是呼叫在其他地方已经完成表示Q.850标准中的原因码26,通常对应于“呼叫被取消”(Call Cancelled)487 Request Terminated Re…...

C++ STL编程-vector概念、对象创建
vector 概念:是常见的一种容器,被称为“柔性数组”。 在vector中,front()是数组中的第一个元素,back()是数组的最后一个元素。begin()是是指向第一个元素,end()是指向back()的后一个元素 vector的对象创建࿰…...

easyexcel使用模板填充excel坑点总结
1.单层map设置值是{属性},那使用两层map进行设置值,是不是可以使用{属性.属性},以为取出map里字段只用{属性}就可以设置值,那再加个.就可以从里边map取出对应属性,没有两层map写法 填充得到的文件打开报错 was empty (…...

C#学习第16天:聊聊反射
什么是反射? 定义:反射是一种机制,允许程序在运行时获取关于自身的信息,并且可以动态调用方法、访问属性或创建实例。用途:常用于框架设计、工具开发、序列化、代码分析和测试等场景 反射的核心概念 1. 获取类型信息…...

【Unity】使用Cinemachine+CharacterController实现第三人称视角下的角色视角、移动和跳跃控制
1.初始配置 安装Cinemachine插件给角色添加CharacterConroller创建Cinemachine-->Free Look Camera在Free Look Camera中调整参数,Y Axis勾选Inver,X Axis取消勾选InverFree Look Camera要看向角色 跟随角色(自行设置,我就不…...
如何通俗的理解transformer架构编码器和解码器干的活
我们可以用生活中的比喻来理解Transformer的编码器和解码器,以及解码器中两种注意力的作用: 一、编码器(Encoder):理解信息的「分析师团队」 想象你要翻译一句话,比如把中文“今天天气很好”翻译成英文。编…...

React 受控表单绑定基础
React 中最常见的几个需求是: 渲染一组列表绑定点击事件表单数据与组件状态之间的绑定 受控表单绑定是理解表单交互的关键之一。 📍什么是受控组件? 在 React 中,所谓“受控组件”,指的是表单元素(如 &l…...

UMG:ListView
1.创建WEB_ListView,添加Border和ListView。 2.创建Object,命名为Item(数据载体,可以是其他类型)。新增变量name。 3.创建User Widget,命名为Entry(循环使用的UI载体).添加Border和Text。 4.设置Entry继承UserObjectListEntry接口。 5.Entry中对象生成时…...

实验五 内存管理实验
实验五 内存管理实验 一、实验目的 1、了解操作系统动态分区存储管理过程和方法。 2、掌握动态分区存储管理的主要数据结构--空闲表区。 3、加深理解动态分区存储管理中内存的分配和回收。 4、掌握空闲区表中空闲区3种不同放置策略的基本思想和实现过程。 5、通过模拟程…...

初识 Firebase 与 FPM
Firebase 是什么 ? Firebase 是 Google 旗下面向 iOS、Android、Web 与多端框架(Flutter、Unity 等)的应用开发平台,提供从「构建 → 发布与运维 → 增长」全生命周期的一站式后端即服务(BaaS)。它把实时数据库、托管…...
的奥秘)
探索C++中的数据结构:栈(Stack)的奥秘
引言 栈是计算机科学中最基础且重要的数据结构之一,它像一摞盘子一样遵循"后进先出"(LIFO)的原则。无论是函数调用、表达式求值,还是浏览器前进后退功能,栈都扮演着关键角色。本文将深入解析栈的C实现及其应…...

vue3 nprogress 使用
nprogress 介绍与作用 1.nprogress 是一个轻量级的进度条组件,主要用于在页面加载或路由切换时显示一个进度条,提升用户体验。它的原理是通过在页面顶部创建一个 div,并使用 fixed 定位来实现进度条的效果 2.在 Vite Vue 3 项目中…...
科普)
MCP(Model Context Protocol 模型上下文协议)科普
MCP(Model Context Protocol,模型上下文协议)是由人工智能公司 Anthropic 于 2024年11月 推出的开放标准协议,旨在为大型语言模型(LLM)与外部数据源、工具及服务提供标准化连接,从而提升AI在实际…...

韩媒专访CertiK创始人顾荣辉:黑客攻击激增300%,安全优先的破局之路
4月17日,韩国知名科技媒体《韩国IT时报》(Korea IT Times)发布了对CertiK联合创始人兼CEO顾荣辉教授的专访。双方围绕CertiK一季度《HACK3D》安全报告,就黑客攻击手法的迭代和安全防御技术的创新路径等,展开深度对话。 顾荣辉认为࿰…...

华为openEuler操作系统全解析:起源、特性与生态对比
华为openEuler操作系统全解析:起源、特性与生态对比 一、起源与发展历程 openEuler(欧拉操作系统)是华为于2019年开源的Linux发行版,其前身为华为内部研发的服务器操作系统EulerOS。EulerOS自2010年起逐步发展,支持华…...

从零实现Git安装、使用
一、git安装 Git官方下载 1.下载exe程序 2.双击安装,一直点击next,默认安装 安装完成后,在任意文件夹右键,出现下图所示,即为安装成功。 3.【Git Bash Here】调出命令窗口,设置用户名和 email 地址。 gi…...

leetcode刷题日记——单词规律
[ 题目描述 ]: [ 思路 ]: 题目要求判断字符串 s 中的单词是否按照 pattern 这种模式排列具体思路和 205. 同构字符串基本一致,可以通过 hash 存储来实现思路二,通过字符串反推 pattern,如果一致,则遵循相…...

Ubuntu 修改语言报错Failed to download repository information
1.进入文件(ps:vim可能出现无法修改sources.list文件的问题) sudo gedit /etc/apt/sources.list2.修改(我是直接增添以下内容在其原始源前面,没有删原始内容)文件并保存,这里会替换原文件 deb http://mirrors.aliyun.com/ubuntu/ focal mai…...

烹饪与餐饮管理实训室数字课程开发方案
烹饪与餐饮管理专业需要具有餐饮产品设计、研发的能力; 具有饮食美学、科学配餐与高端宴席设计的能力; 具有餐饮企业、中央厨房运营管理的能力; 具有餐饮信息化系统应用、数字化运营的能力,这些能力的培养,需要烹饪与餐…...

关于模拟噪声分析的11个误区
目录 1. 降低电路中的电阻值总是能改善噪声性能 2. 所有噪声源的噪声频谱密度可以相加,带宽可以在最后计算时加以考虑 3. 手工计算时必须包括每一个噪声源 4. 应挑选噪声为ADC 1/10的ADC驱动器 5. 直流耦合电路中必须始终考虑1/f噪声 6. 因为1/f噪声随着频率降…...

基于 S2SH 架构的企业车辆管理系统:设计、实现与应用
在企业运营中,车辆管理是一项重要工作。随着企业规模的扩大,车辆数量增多,传统管理方式效率低下,难以满足企业需求。本文介绍的基于 S2SH 的企业车辆管理系统,借助现代化计算机技术,实现车辆、驾驶员和出车…...

51单片机实验七:EEPROM AT24C02 与单片机的通信实例
目录 一、实验环境与实验器材 二、实验内容及实验步骤 三、proteus复位电路 1.改电阻的阻值(方法一) 2.改电阻的属性(方法2) 一、实验环境与实验器材 环境:Keli,STC-ISP烧写软件,Proteus. …...

【TeamFlow】 1 TeamFlow 去中心化生产协同系统架构
总体架构设计 采用四层混合架构,结合分层设计与去中心化网络: #mermaid-svg-qBgw9wMd8Gi0gOci {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-qBgw9wMd8Gi0gOci .error-icon{fill:#552222;}…...

第 8 期:条件生成 DDPM:让模型“听话”地画图!
本期关键词:Conditional DDPM、Class Embedding、Label Control、CIFAR-10 条件生成 什么是条件生成(Conditional Generation)? 在标准的 DDPM 中,我们只是“随机生成”图像。 如果我想让模型生成「小狗」怎么办&…...
config.txt常用音频配置)
树莓派超全系列教程文档--(32)config.txt常用音频配置
config.txt常用音频配置 板载模拟音频(3.5mm耳机插孔)audio_pwm_modedisable_audio_ditherenable_audio_ditherpwm_sample_bits HDMI音频 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 板载模拟音频(3.5mm耳机…...

Perf学习
重要的能解决的问题是这些: perf_events is an event-oriented observability tool, which can help you solve advanced performance and troubleshooting functions. Questions that can be answered include: Why is the kernel on-CPU so much? What code-pa…...

量子神经网络编译器开发指南:从理论突破到产业落地全景解析
本文深度剖析IBM Qiskit 5.0量子经典混合编译器的技术架构,详解如何基于含噪量子处理器实现MNIST手写数字分类任务(准确率达89%)。结合本源量子云、百度量子等国内平台免费配额政策,系统性阐述量子神经网络开发的技术路线与资源获…...

守护者进程小练习
守护者进程含义 定义:守护进程(Daemon)是运行在后台的特殊进程,独立于控制终端,周期性执行任务或等待事件触发。它通常以 root 权限运行,名称常以 d 结尾(如 sshd, crond)。 特性&a…...