# 使用 PyTorch 构建并训练一个简单的 CNN 模型进行图像分类
使用 PyTorch 构建并训练一个简单的 CNN 模型进行图像分类
在深度学习领域,卷积神经网络(CNN)是处理图像分类任务的强大工具。本文将通过一个简单的示例,展示如何使用 PyTorch 构建、训练和测试一个 CNN 模型,用于对食品图像进行分类。

1. 数据准备
在开始之前,我们需要准备数据集。假设我们有一个食品图像数据集,分为训练集和测试集,分别存储在 train 和 test 文件夹中。每个文件夹中包含多个子文件夹,每个子文件夹代表一个类别,其中包含该类别的图像。
为了方便模型训练和测试,我们需要生成两个文本文件(train.txt 和 test.txt),分别记录训练集和测试集中每个图像的路径及其对应的类别标签。以下是生成这些文件的代码:
import osdef train_test_file(root, dir):file_txt = open(dir + '.txt', 'w')path = os.path.join(root, dir)for roots, directories, files in os.walk(path):if len(directories) != 0:dirs = directorieselse:now_dir = roots.split('\\')for file in files:path_1 = os.path.join(roots, file)print(path_1)file_txt.write(path_1 + ' ' + str(dirs.index(now_dir[-1])) + '\n')file_txt.close()root = r'D:\Users\妄生\PycharmProjects\机器学习\深度学习\food_dataset2'
train_dir = 'train'
test_dir = 'test'
train_test_file(root, train_dir)
train_test_file(root, test_dir)
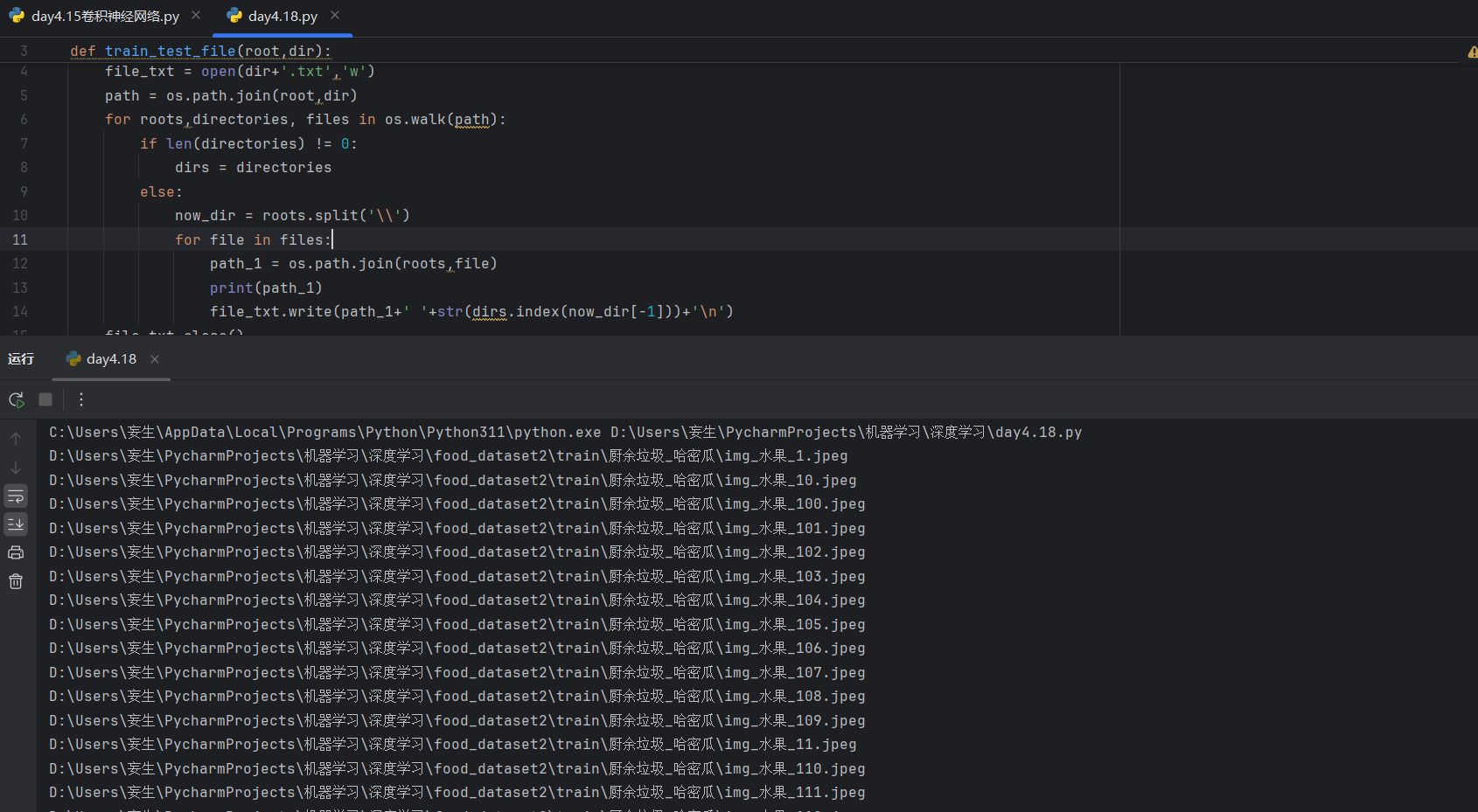
运行上述代码后,train.txt 和 test.txt 文件将被生成,每行包含一个图像路径和对应的类别标签,用空格分隔。
运行结果
2. 构建数据集类
接下来,我们需要构建一个自定义的数据集类,用于加载图像数据和标签。我们将使用 PyTorch 的 Dataset 类来实现这一点。以下是代码:
import numpy as np
from torch.utils.data import Dataset, DataLoader
import torch
from PIL import Image
from torchvision import transforms# 数据预处理转换
data_transforms = {'train': transforms.Compose([transforms.Resize([256, 256]), # 调整图像大小transforms.ToTensor(), # 将图像转换为Tensor]),'valid': transforms.Compose([transforms.Resize([256, 256]), # 调整图像大小transforms.ToTensor(), # 将图像转换为Tensor])
}# 自定义数据集类
class food_dataset(Dataset): #food_dataset是自己创建的类名称,可以改为你需要的名称def __init__(self, file_path, transform=None): #类的初始化,解析数据文件txtself.file_path = file_pathself.imgs = []self.labels = []self.transform = transformwith open(self.file_path) as f: #是把train.txt文件中图片的路径保存在 self.imgs,train.txt文件中标签保存在 sesamples = [x.strip().split(' ') for x in f.readlines()]for img_path, label in samples:self.imgs.append(img_path) #图像的路径self.labels.append(label) #标签,还不是tensor# 初始化:把图片目录加载到self,def __len__(self): #类实例化对象后,可以使用len函数测量对象的个数 ls=[12,3,4,4] len(training_data)return len(self.imgs)def __getitem__(self, idx): #关键,可通过索引的形式获取每一个图片数据及标签image = Image.open(self.imgs[idx]) #读取到图片数据,还不是tensor,BGRif self.transform: #将pil图像数据转换为tensorimage = self.transform(image) #图像处理为256*256,转换为tenorlabel = self.labels[idx] #label还不是tensorlabel = torch.from_numpy(np.array(label, dtype=np.int64)) #label也转换为tensor,return image, label# 实例化训练和测试数据集
training_data = food_dataset(file_path='./train.txt', transform=data_transforms['train'])
test_data = food_dataset(file_path='./test.txt', transform=data_transforms['valid'])# 创建数据加载器
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) #64张图片为一个包,
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)在上述代码中,我们定义了一个 FoodDataset 类,它读取 train.txt 和 test.txt 文件中的图像路径和标签,并对图像进行预处理。我们还定义了两个数据加载器(train_dataloader 和 test_dataloader),用于批量加载数据。
3. 构建 CNN 模型
接下来,我们将构建一个简单的卷积神经网络(CNN)模型。以下是代码:
# 选择设备
device = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f"{device}")# 定义CNN模型
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=16, kernel_size=5, stride=1, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=2),)self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 5, 1, 2),nn.ReLU(),nn.Conv2d(32, 32, 5, 1, 2),nn.ReLU(),nn.MaxPool2d(2),)self.conv3 = nn.Sequential(nn.Conv2d(32, 128, 5, 1, 2), nn.ReLU())self.out = nn.Linear(128 * 64 * 64, 20) # 这里的尺寸需要根据实际情况调整def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = x.view(x.size(0), -1)output = self.out(x)return output# 实例化模型并移动到选择的设备
model = CNN().to(device)在上述代码中,我们定义了一个包含三个卷积层和一个全连接层的 CNN 模型。模型的输入是 RGB 图像(3 个通道),输出是 20 个类别的预测结果。
4. 训练和测试模型
接下来,我们将定义训练和测试函数,并训练和测试我们的模型。以下是代码:
# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):model.train()batch_size_num = 1for x, y in dataloader:x, y = x.to(device), y.to(device)pred = model(x) # 使用model(x)而不是model.forward(x)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()loss_value = loss.item()print(f"{loss_value} {batch_size_num}")batch_size_num += 1# 定义测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for x, y in dataloader:x, y = x.to(device), y.to(device)pred = model(x) # 使用model(x)而不是model.forward(x)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()# 打印预测结果和真实结果predicted_labels = pred.argmax(1).cpu().numpy() # 获取预测的类别true_labels = y.cpu().numpy() # 获取真实的类别print(f"Predicted: {predicted_labels}")print(f"True: {true_labels}")test_loss /= num_batchescorrect /= sizeprint(f"Test result: \n Accuracy: {(100 * correct)}%, Avg loss: {test_loss}")# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 训练和测试模型
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)# 训练多个周期
epochs = 10
for t in range(epochs):print(f"epoch{t + 1}\n")train(train_dataloader, model, loss_fn, optimizer)
print("done")
test(test_dataloader, model, loss_fn)
在上述代码中,我们定义了训练函数 train 和测试函数 test。在训练函数中,我们对每个批次的数据进行前向传播、计算损失、反向传播和优化器更新。在测试函数中,我们对每个批次的数据进行前向传播,计算预测结果和真实结果,并打印出来。
我们还定义了损失函数(交叉熵损失)和优化器(Adam),并训练了 10 个周期。在训练完成后,我们测试了模型的性能。
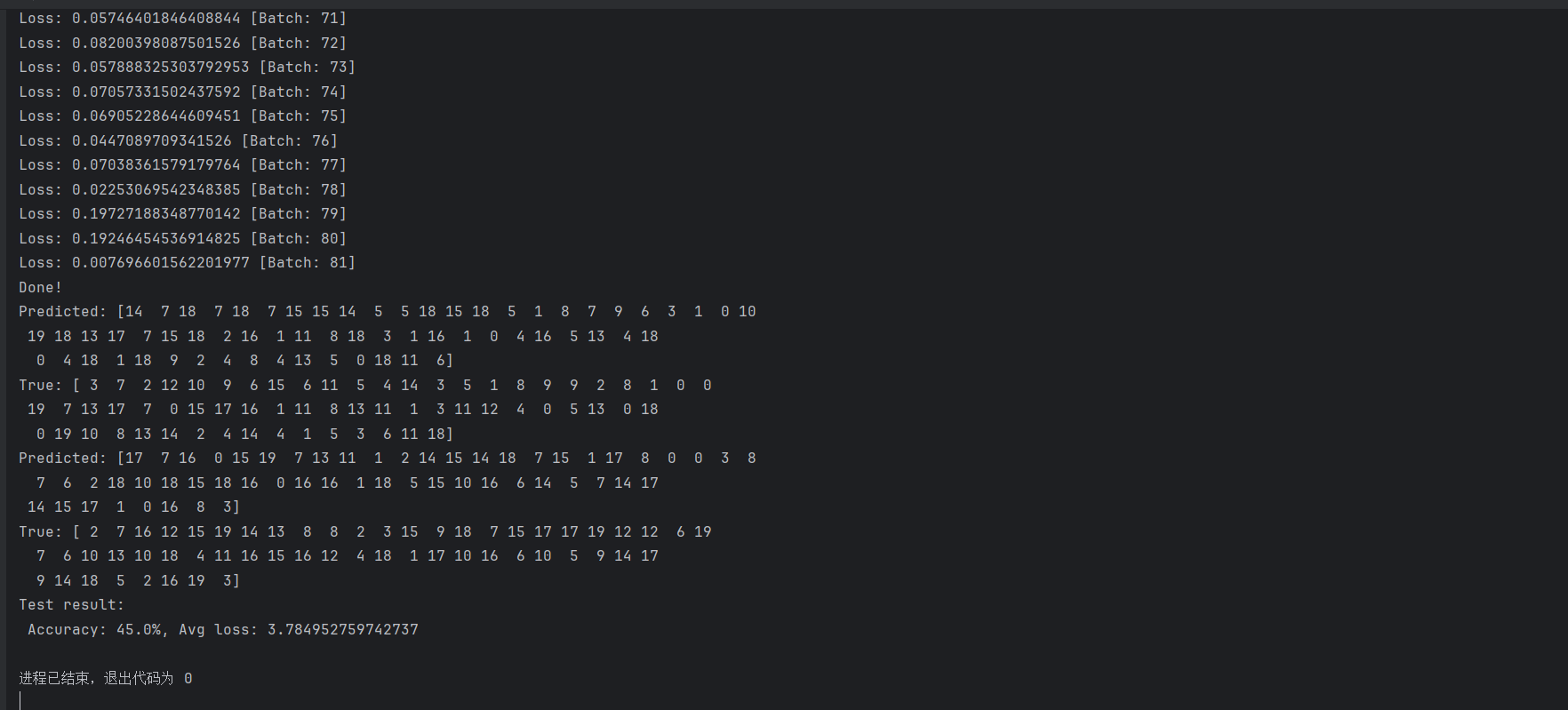
5. 结果分析
在测试阶段,模型的预测结果和真实结果将被打印出来:
`
相关文章:

# 使用 PyTorch 构建并训练一个简单的 CNN 模型进行图像分类
使用 PyTorch 构建并训练一个简单的 CNN 模型进行图像分类 在深度学习领域,卷积神经网络(CNN)是处理图像分类任务的强大工具。本文将通过一个简单的示例,展示如何使用 PyTorch 构建、训练和测试一个 CNN 模型,用于对食…...

Linux网络编程 深入解析TFTP协议:基于UDP的文件传输实战
知识点1【TFTP的概述】 学习通信的基本:通信协议(具体发送上面样的报文)、通信流程(按照什么步骤发送) 1、TFTP的概述 tftp:简单文件传输协议,**基于UDP,**不进行用户有效性验证 …...

汽车免拆诊断案例 | 2019款大众途观L车鼓风机偶尔不工作
故障现象 一辆2019款大众途观L车,搭载DKV发动机和0DE双离合变速器,累计行驶里程约为8万km。车主进厂反映,鼓风机偶尔不工作。 故障诊断 接车后试车,鼓风机各挡位均工作正常。用故障检测仪检测,空调控制单元&#x…...

编程常见错误归类
上一篇讲了调试,今天通过一个举例回忆一下上一篇内容吧! 1. 回顾:调试举例 在VS2022、X86、Debug的环境下,编译器不做任何优化的话,下⾯代码执⾏的结果是啥? #include <stdio.h> int main() {int …...

Python 3.13 support for PyTorch
Python 3.13 support for PyTorch Python 3.13 support for PyTorch 去官网可以查到具体信息:https://pytorch.org/get-started/locally/ 然后选择自己的CUDA版本,下面会显示下载网站,比如我选择12.4,则会出现:pip3 …...
)
中国联通:《DeepSeek洞察与大模型应用:人工智能技术发展与应用实践》(可下载)
近年来,人工智能(AI)技术迅猛发展,尤其是大模型技术的崛起,正在深刻改变各行各业的运营模式和创新路径。作为中国通信行业的领军企业之一,中国联通积极拥抱AI技术变革,结合自身在通信网络、大数…...

k8s 调整Node节点 Max_Pods
默认情况下,Kubernetes集群中一个Node最多能起110个Pod。 这是基于性能和资源管理的考虑,以确保Kubernetes集群的稳定性和可靠性。 查看kht125节点上支持的最大pod数量: kubectl describe node kht125 | grep -i “Capacity|Allocatable” -A 6 调整…...

VR拍摄要点与技巧有哪些?有哪些最佳实践?
VR拍摄要点与技巧:最佳实践 VR技术通过模拟环境,使用户能够沉浸在一个完全由计算机生成的虚拟世界中,进行互动体验。在VR拍摄领域,我们主要利用这一技术来创建360度全景视频或图片,让观众能够全方位、无死角地感受拍摄…...

使用 Docker 安装 Elastic Stack 并重置本地密码
Elastic Stack(也被称为 ELK Stack)是一个非常强大的工具套件,用于实时搜索、分析和可视化大量数据。Elastic Stack 包括 Elasticsearch、Logstash、Kibana 等组件。本文将展示如何使用 Docker 安装 Elasticsearch 并重置本地用户密码。 ###…...

安卓手机万能遥控器APP推荐
软件介绍 安卓手机也能当“家电总控台”?这款小米旗下的万能遥控器APP,直接把遥控器做成“傻瓜式操作”——不用配对,不连蓝牙,点开就能操控电视、空调、机顶盒,甚至其他品牌的电器!雷总这波操作直接封神&…...

PLOS ONE:VR 游戏扫描揭示了 ADHD 儿童独特的大脑活动
在孩子的成长过程中,总有那么一些“与众不同”的孩子。他们似乎总是坐不住,课堂上小动作不断,注意力难以集中,作业总是拖拖拉拉……这些行为常常被家长和老师简单地归结为“淘气”“不听话”。然而,他们可能并不只是“…...

Linux 系统编程 day4 进程管道
进程间通信(IPC) Linux环境下,进程地址空间相互独立,任何一个进程的全局变量在另一个进程中都看不到,所以进程和进程之间不能互相访问,要交换数据必须通过内核,在内核中开辟一块缓冲区…...

基于DeepSeek的考研暑假日志分析
注:我去年考研时写了日志,大致记录了我每天的主要活动。由于过于琐碎,一直没有翻看。突发奇想,现在利用deepseek总结其中规律。 从你的日志中可以总结出以下规律和活动兴衰起落: 一、学习活动规律与演变 …...
 网页 方便收集应用 ,局域网使用)
Python 写生成 应用商店(2025版) 网页 方便收集应用 ,局域网使用
工具【1】:nginx 配置 nginx.conf 文件 server { listen 8080; server_name example.com; location / { root E:/BIT_Soft_2025; index index.html index.htm; } # 定义错误页面 error_page 404 /4…...

LLaMA Factory多模态微调实践:微调Qwen2-VL构建文旅大模型
LLaMA Factory 是一款开源低代码大模型微调框架,集成了业界最广泛使用的微调技术,支持通过 Web UI 界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架之一,GitHub 星标超过 4.7 万。本教程将基于通义千问团队开源的…...

Ubuntu20.04 部署llama-factory问题集
llama3 微调教程之 llama factory 的 安装部署与模型微调过程,模型量化和gguf转换。_llamafactory 部署-CSDN博客 1.跟着教程 llama-factory下载不下来 来,试着换源,多试几次,就可以成功了。。。 2.跟着教程,发现无法…...

鸿蒙语言基础
准备工作 去鸿蒙官网下载开发环境 点击右侧预浏览,刷新和插销按钮,插销表示热更新,常用按钮。 基础语法 string number boolean const常量 数组 let s : string "1111"; console.log("string", s);let n : number …...

每天一道C语言精选编程题之字符串拷贝
题目描述 写⼀个函数my_strcpy,实现拷⻉字符串的功能,假设给定⼀个字符数组a,再给定⼀个字符数组b,将字符串a中的内容拷⻉到字符串b中,拷⻉内容包含字符串末尾的 \0 字符。 解法思路 使⽤ while 循环通过指针的⽅式逐…...

C#中扩展方法和钩子机制使用
1.扩展方法: 扩展方法允许向现有类型 “添加” 方法,而无需创建新的派生类型、重新编译或以其他方式修改原始类型。扩展方法是一种特殊的静态方法,但可以像实例方法一样进行调用。 使用场景: 1.当无法修改某个类的源代码&#…...

基于CNN与VGG16的图像识别快速实现指南
基于CNN与VGG16的图像识别快速实现指南 以下是从零实现代码到原理剖析的完整流程,包含TensorFlow/Keras框架的代码示例与关键优化技巧,满足快速实验需求。 一、核心原理对比 特性CNN(基础模型)VGG16结构深度5-10层(如…...
)
中间件--ClickHouse-9--MPP架构(分布式计算架构)
1、MPP 架构基础概念 MPP(Massively Parallel Processing 大规模并行处理) 是一种分布式计算架构,专门设计用来高效处理大规模数据集。在这种架构下*,数据库被分割成多个部分,每个部分可以在不同的服务器节点上并行处理*。这意味着ÿ…...

如何在PDF.js中改造viewer.html以实现PDF的动态加载
在PDF.js中改造viewer.html实现PDF动态加载,需结合参数传递、文件流处理及跨域配置等技术。以下是综合多个技术方案的核心实现步骤: 一、基础参数传递法 1. URL参数动态加载 通过修改viewer.html的URL参数传递PDF路径,适用于静态文…...

Android——动画
帧动画 帧动画就是很多张图片,一帧一帧的播放,形成的一个动画效果。 frame.xml <?xml version"1.0" encoding"utf-8"?> <animation-list xmlns:android"http://schemas.android.com/apk/res/android">&l…...

基于linux 设置无线网卡Monitor模式 sniffer抓包
硬件 TP-WN722N 开源无线网卡 网卡设置成抓包模式,条件是什么? 硬件条件 网卡芯片支持监听模式,外置天线或高增益天线可提升抓包效果驱动与软件条件:正确的驱动程序系统与权限条件 Linux:原生支持(Kali …...

Ubuntu18.04安装Qt5.12
本文介绍了在Ubuntu18.04环境下安装QT QT5.12相关安装包下载地址 https://download.qt.io/archive/qt/5.12/ Linux系统下Qt的离线安装包以.run结尾 (sudo apt-get install open-vm-tools open-vm-tools-desktop解决无法paste的问题) 安装 1.cd命令 终端进入对应的文件夹下面 2.…...

克服储能领域的数据处理瓶颈及AI拓展
对于储能研究人员来说,日常工作中经常围绕着一项核心但有时令人沮丧的任务:处理实验数据。从电池循环仪的嗡嗡声到包含电压和电流读数的大量电子表格,研究人员的大量时间都花在了提取有意义的见解上。长期以来,该领域一直受到对专…...

PDF.js 生态中如何处理“添加注释\添加批注”以及 annotations.contents 属性
我们来详细解释一下在 PDF.js 生态中如何处理“添加注释”以及 annotations.contents 属性。 核心要点:PDF.js 本身主要是阅读器,不是编辑器 首先,最重要的一点是:PDF.js 的核心库 (pdfjs-dist) 主要设计用于解析和渲染…...
 从汇编角度分析报错原因)
L38.【LeetCode题解】四数之和(双指针思想) 从汇编角度分析报错原因
目录 1.题目 2.分析 去重的代码 错误代码 3.完整代码 提交结果 1.题目 四数之和 给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元…...

【第48节】探究汇编使用特性:从基础到混合编程
目录 引言 一、调用约定的奥秘 1.1 . C调用约定(_cdecl) 1.2 stdcall调用约定(_stdcall) 1.3 fastcall快速调用约定(_fastcall) 1.4 thiscall调用约定(C类成员函数) 二、X64汇…...

【jenkins】首次配置jenkins
第一步,输入管理员密码 cat /var/jenkins_home/secrets/initialAdminPassword第二步,点击安装推荐的插件 第三步,创建管理员用户 第四步,返回实例 第五步, 升级jenkins 第六步, 修复提示 第七步,…...

Python 项目文档编写全攻略:从入门到自动化维护
引言 在软件开发领域,完善的文档可提升 40% 的团队协作效率(来源:IEEE 2022 年开发者调查报告 ^^1^^)。本文将深入探讨 Python 项目文档的最佳实践,涵盖文档生成工具、注释规范、自动化维护等关键环节。 一、Python 文…...

基于 React 和 CodeMirror 实现自定义占位符编辑器
npm git 在前端开发中,我们经常需要实现各种复杂的编辑器功能,比如代码编辑器、富文本编辑器等。本文将介绍如何基于 React 和 CodeMirror 实现一个带有自定义占位符功能的编辑器,这种编辑器在模板系统、表单设计器等场景中非常有用。 一…...

GitHub Copilot在产品/安全团队中的应用实践:处理Markdown、自动化报告与电子表格、使用CLI命令等
本文来源github.com,由GitHub中国授权合作伙伴-创实信息翻译整理。 在当今的快节奏时代,技术和非技术团队之间的协作至关重要,事实证明,GitHub Copilot等工具已成为不可或缺的助手。这些由AI驱动的工具已不只是开发者的“秘密武器…...

嵌入式系统中Flash操作全面解析与最佳实践
嵌入式系统中Flash操作全面解析与最佳实践 一、Flash存储器基础与分类 Flash存储器是嵌入式系统中最重要的非易失性存储介质,根据内部架构和工作原理主要分为两大类: 1.1 NOR Flash与NAND Flash对比 特性NOR FlashNAND Flash架构随机存取架构串行存取…...

tomcat 的安装与启动
文章目录 tomcat 服务器安装启动本地Tomcat服务器 tomcat 服务器安装 https://tomcat.apache.org/下载 Tomcat 10.0.X 启动本地Tomcat服务器 进入 Tomcat 的 bin...
:SPI NAND Flash与SPI NOR Flash)
Flash存储器(二):SPI NAND Flash与SPI NOR Flash
目录 一.存储架构 二.接口与封装 三.特性对比 四.典型应用场景 4.1 SPI NOR Flash 4.2 SPI NAND Flash 五.技术演进与市场趋势 六.选择建议 6.1 选择SPI NOR的场景 6.2 选择SPI NAND的场景 SPI NAND Flash和SPI NOR Flash是嵌入式设备中常用的存储器。下面通过全面对…...

第 7 期:DDPM 采样提速方案:从 DDPM 到 DDIM
本期关键词:采样加速、DDIM 推导、可控性提升、伪逆过程、代码实战 前情回顾:DDPM 的采样瓶颈 在前几期中,我们构建了一个完整的 DDPM 生成流程。但是你可能已经发现: 生成一张图像太慢了!!! 原因是: DDPM 要在 T 个时间步中一步步地去噪,从 x_T → x_0。而通常 T 至…...

axios 模拟实现
axios 模拟实现 包含[发送请求,拦截器,取消请求] 第一步 , axios模拟发送请求 //使用 xhr 发送请求function xhr_adpter(config){return new Promise(function handle(resolve,reject){let xhr new XMLHttpRequest();xhr.open(config.method, config.url,true);xhr.onreadys…...
:IM 消息收发逻辑)
架构师面试(三十一):IM 消息收发逻辑
问题 今天聊一下 IM 系统最核心的业务逻辑。 在上一篇短文《架构师面试(三十):IM 分层架构》中详细分析过,IM 水平分层架构包括:【入口网关层】、【业务逻辑层】、【路由层】和【数据访问层】;除此之外&a…...

hadoop三大组件的结构及各自的作用
1 HDFS 1.1功能 HDFS 是 Hadoop 的分布式文件系统,用于存储和管理海量数据。它具有高容错性、高吞吐量和可扩展性,能够在多个节点上存储和管理大规模数据 1.2架构:采用主从架构,由一个 NameNode 和多个 DataNode 组成。NameNode…...

GEE学习笔记 29:基于GEE的多源Landsat合成与植被指数时序提取
基于GEE的多源Landsat合成与植被指数时序提取 🌿 1.写在前面 | 基于GEE的Landsat多尺度植被指数提取脚本📌 2.常用植被指数计算公式2.1. 🌿 NDVI(归一化植被指数)Normalized Difference Vegetation Index2.2. 🌱 EVI(增强型植被指数)Enhanced Vegetation Index2.3.…...

负载均衡的策略
目的:将请求均衡分发到后台的服务器 算法: 随机算法:随机数获取服务器加权随机算法:根据权重,增加某些服务器(性能比较好等)选择的随机比例轮询算法:轮流分发给服务器加权轮询算法…...
)
AWS Elastic Beanstalk的部署Python Flask后端服务(Hello,World)
问题 最近需要使用AWS Elastic Beanstalk来部署Python的Flask后端web接口。这里先做一个最简单的Flask Hello,World接口服务程序。 Flask工程与代码 创建本地虚拟环境 conda create -n flask python3.13 # 激活 conda activate flaskapp.py from flask import …...

Hadoop的三大结构及各自的作用?
1.HDFS 作用: 存储海量数据,支持高容错(数据自动备份)和高吞吐量(适合大文件读写)。 采用主从架构: NameNode:管理文件系统的元数据(如文件目录结构)。 Dat…...

在Ubuntu系统中安装和升级RabbitVCS
在Ubuntu系统中安装和升级RabbitVCS 目前在ubuntu中使用svn的GUI工具,已经安装了。想升级一下。 当前遇到的问题是,我想用它看看我当前的代码对应的版本号,然后再决定是否update。但是,好像我看不出来。根本不如在windows使用To…...

深入理解红黑树:原理、实现与应用
深入理解红黑树:原理、实现与应用 引言 红黑树(Red-Black Tree)是计算机科学中一种重要的自平衡二叉查找树。它通过简单的规则和高效的调整策略,保证了插入、删除、查找等操作的时间复杂度均为 O(log n)。红黑树广泛应用于实际开…...

Java学习手册:Java并发编程最佳实践
在Java并发编程中,遵循最佳实践可以显著提高程序的性能、可靠性和可维护性。本文将总结Java并发编程中的关键最佳实践,帮助开发者避免常见陷阱并编写高效的并发程序。 1. 选择合适的并发工具 Java提供了丰富的并发工具,选择合适的工具可以简…...
)
接口自动化测试(二)
一、接口测试流程:接口文档、用例编写 拿到接口文档——编写接口用例以及评审——进行接口测试——工具/自动化框架进行自动化用例覆盖(70%)——输出测试报告 自动化的目的一般是为了回归 第一件事情:理解需求,学会看接口文档 只需要找到我…...

C++类和对象上
1. 面向对象编程与面向过程编程的比较 我们一开始接触的C语言就是一门面向过程编程的语言,而C就是一门面向对象编程的语言。那么这两者有什么区别呢? 举个例子,就比如说点外卖,如果是C语言的话,那么在程序的编写过程…...

hadoop的三大结构及各自的作用
Hadoop 分布式文件系统(HDFS) 存储大量数据:HDFS 被设计用于在商品硬件上存储海量数据,它将大文件分割成多个数据块,并分布存储在集群中的不同节点上,支持数据的可靠存储和高效访问。提供数据冗余和容错机制…...