【深度学习】详解矩阵乘法、点积,内积,外积、哈达玛积极其应用|tensor系列02

- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @Yaoyao2024
- 往期回顾:【深度学习】你真的理解张量了吗?|标量、向量、矩阵、张量的秩|01
- 每日一言🌼: “脑袋想不明白的,就用脚想”——《走吧,张小砚》🌺
0、前言
在张量的操作的时候,有下面几个概念总容易弄混:
- 点积
- 内积
- 外积
- 哈达玛积(Hadamard Product
- 矩阵乘法
这篇博客,我将结合这三种操作在深度学习中的运用,来讲解一下这三种操作的区别。
1、点积(Dot Product)
点积定义和计算:
点积是两个向量的之间的二元运算,结果为标量。数学意义上:取两个相等长度的数字序列(通常是坐标向量,也就是坐标点),并返回一个数字。
对于向量(一阶张量) u = [ u 1 , u 2 , ⋯ , u n ] \mathbf{u} = [u_1, u_2, \cdots, u_n] u=[u1,u2,⋯,un] 和 v = [ v 1 , v 2 , ⋯ , v n ] \mathbf{v} = [v_1, v_2, \cdots, v_n] v=[v1,v2,⋯,vn] , u , v ∈ R n \mathbf{u},\mathbf{v}\in\mathbb{R}^n u,v∈Rn,点积的定义为: 逐元素相乘,再相加
u ⋅ v = ∑ i = 1 n u i v i \mathbf{u}\cdot\mathbf{v}=\sum_{i=1}^nu_iv_i u⋅v=i=1∑nuivi
在欧几里得空间中,点积也可表示为:
u ⋅ v = ∥ u ∥ ∥ v ∥ cos θ ( θ 为夹角) \mathbf{u}\cdot\mathbf{v}=\|\mathbf{u}\|\|\mathbf{v}\|\cos\theta\text{ (}\theta\text{ 为夹角) } u⋅v=∥u∥∥v∥cosθ (θ 为夹角)
示例:
[ 1 2 ] ⋅ [ 3 4 ] = 1 × 3 + 2 × 4 = 11 \begin{bmatrix}1\\2\end{bmatrix}\cdot\begin{bmatrix}3\\4\end{bmatrix}=1\times3+2\times4=11 [12]⋅[34]=1×3+2×4=11
特点:
- 仅适用于向量(一阶张量)。
- 满足交换律 u ⋅ v = v ⋅ u \mathbf{u}\cdot\mathbf{v}=\mathbf{v}\cdot\mathbf{u} u⋅v=v⋅u
- 是内积在欧几里得空间中的特例(当内积空间为 R n \mathbb{R}^n Rn且权重矩阵为单位矩阵时)
在深度学习中的应用
首先代码是:
# 点积(向量)
u = torch.tensor([1, 2, 3])
v = torch.tensor([4, 5, 6])
# NumPy
dot_product = np.dot(u, v) # 或 u @ v,一维矩阵相乘=向量点乘# PyTorch
dot_product = torch.dot(u, v) # 一维张量
-
余弦相似度(Cosine Similarity):
归一化点积用于衡量向量相似性:
cos ( θ ) = u ⋅ v ∥ u ∥ ∥ v ∥ = ∑ i = 1 n u i v i ∑ i = 1 n u i 2 ∑ i = 1 n v i 2 \cos(\theta)=\frac{\mathbf{u} \cdot \mathbf{v}}{\|\mathbf{u}\| \|\mathbf{v}\|} = \frac{\sum_{i=1}^{n} u_i v_i}{\sqrt{\sum_{i=1}^{n} u_i^2} \sqrt{\sum_{i=1}^{n} v_i^2}} cos(θ)=∥u∥∥v∥u⋅v=∑i=1nui2∑i=1nvi2∑i=1nuivi其中:
-
u ⋅ v \mathbf{u} \cdot \mathbf{v} u⋅v 表示向量 u \mathbf{u} u 和 v \mathbf{v} v 的点积,即 ∑ i = 1 n u i v i \sum_{i=1}^{n} u_i v_i ∑i=1nuivi。
-
∥ u ∥ \|\mathbf{u}\| ∥u∥ 和 ∥ v ∥ \|\mathbf{v}\| ∥v∥ 分别表示向量 u \mathbf{u} u 和 v \mathbf{v} v 的 L 2 L_2 L2 范数(也称为欧几里得范数),计算公式分别为 ∑ i = 1 n u i 2 \sqrt{\sum_{i=1}^{n} u_i^2} ∑i=1nui2 和 ∑ i = 1 n v i 2 \sqrt{\sum_{i=1}^{n} v_i^2} ∑i=1nvi2。
-
余弦相似度常用于对比学习(Contrastive Learning)或推荐系统。
# 计算两个特征向量的余弦相似度 def cosine_similarity(u, v, eps=1e-8):dot_product = torch.dot(u, v)norm_u = torch.norm(u)norm_v = torch.norm(v)return dot_product / (norm_u * norm_v + eps) # 用于对比损失(如InfoNCE Loss) positive_sim = cosine_similarity(anchor, positive) # 增大 negative_sim = cosine_similarity(anchor, negative) # 减小 -
2、内积(Inner Product)——点积的推广
定义和计算:
内积是点积的推广,适用于更一般的向量空间(如函数空间、矩阵空间)。对于向量或高阶张量,内积通常指在特定空间中的一种双线性运算,结果为标量。
在工科的讨论范围内,内积和点积会混在一起说。这是无可厚非的,毕竟点积是内积的一种特殊形式。
-
在 R n \mathbb{R}^n Rn空间中,内积与点积相同(一阶张量,n维向量,n个元素相乘再相加)。
-
在矩阵空间(二阶张量)中,Frobenius内积定义为:即两个形状相同的矩阵对应位置的元素相乘后求和,结果是一个标量。
⟨ A , B ⟩ F = ∑ i , j A i j B i j = t r ( A T B ) \langle\mathbf{A},\mathbf{B}\rangle_F=\sum_{i,j}A_{ij}B_{ij}=\mathrm{tr}(\mathbf{A}^T\mathbf{B}) ⟨A,B⟩F=i,j∑AijBij=tr(ATB)其中 tr ( ⋅ ) \operatorname{tr}(\cdot) tr(⋅)代表求矩阵的迹(trace): tr ( A T B ) = ∑ i = 1 n ( A T B ) i i = ∑ i = 1 n ∑ k = 1 m A k i B k i \operatorname{tr}(\mathbf{A}^T\mathbf{B})=\sum_{i=1}^n(\mathbf{A}^T\mathbf{B})_{ii}=\sum_{i=1}^n\sum_{k=1}^mA_{ki}B_{ki} tr(ATB)=∑i=1n(ATB)ii=∑i=1n∑k=1mAkiBki
特点:
- 广义性:内积可以定义在函数、矩阵等对象上(如 ⟨ f , g ⟩ = ∫ f ( x ) g ( x ) d x ) \langle f,g\rangle=\int f(x)g(x)dx) ⟨f,g⟩=∫f(x)g(x)dx)
- 需满足正定性、对称性和线性性(在复空间中为共轭对称性)。
- 点积是内积在有限维实数空间中的特例。
示例:
矩阵内积:
⟨ [ 1 2 3 4 ] , [ 5 6 7 8 ] ⟩ F = 1 × 5 + 2 × 6 + 3 × 7 + 4 × 8 = 70 。 \left\langle\begin{bmatrix}1&2\\3&4\end{bmatrix},\begin{bmatrix}5&6\\7&8\end{bmatrix}\right\rangle_F=1\times5+2\times6+3\times7+4\times8=70。 ⟨[1324],[5768]⟩F=1×5+2×6+3×7+4×8=70。
与内积的联系:内积 = 哈达玛积的所有元素之和。
内积的计算可以分解为两步:
- 先计算哈达玛积:对输入矩阵/向量逐元素相乘。
- 再求和:将哈达玛积的所有元素相加,得到标量。
| 运算 | 定义 | 输入要求 | 输出 |
|---|---|---|---|
| 哈达玛积 | A ∘ B ,逐元素相乘: C i j = A i j B i j \mathbf{A}\circ\mathbf{B}\text{,逐元素相乘:}C_{ij}=A_{ij}B_{ij} A∘B,逐元素相乘:Cij=AijBij | 同形状矩阵/张量 | 同形状矩阵 |
| 内积 | 向量: ⟨ u , v ⟩ = ∑ i u i v i 矩阵: ⟨ A , B ⟩ F = ∑ i , j A i j B i j \begin{aligned}&\text{向量:}\langle\mathbf{u},\mathbf{v}\rangle=\sum_iu_iv_i\\&\text{矩阵:}\langle\mathbf{A},\mathbf{B}\rangle_F=\sum_{i,j}A_{ij}B_{ij}\end{aligned} 向量:⟨u,v⟩=i∑uivi矩阵:⟨A,B⟩F=i,j∑AijBij | 向量同维或矩阵同形 | 标量 |
在深度学习中的应用(PyTorch代码实现
(1) 向量内积(就是点积,可以参考上面点积的应用)
import torchu = torch.tensor([1.0, 2.0, 3.0]) # [3]
v = torch.tensor([4.0, 5.0, 6.0]) # [3]# 方法1:直接点积
dot_product = torch.dot(u, v) # 输出: 1*4 + 2*5 + 3*6 = 32.0# 方法2:等价于求和逐元素乘积
dot_product_alt = torch.sum(u * v) # 同上
(2) 矩阵内积(Frobenius内积)
A = torch.tensor([[1.0, 2.0], [3.0, 4.0]]) # [2, 2]
B = torch.tensor([[5.0, 6.0], [7.0, 8.0]]) # [2, 2]# 方法1:逐元素乘后求和
frobenius_inner = torch.sum(A * B) # 1*5 + 2*6 + 3*7 + 4*8 = 70.0# 方法2:迹运算
frobenius_inner_alt = torch.trace(A.T @ B) # 同上
深度学习中的应用:
(1) 正则化(Regularization)
-
L2 正则化(权重衰减)可以看作权重矩阵与自身的内积
∥ W ∥ F 2 = ⟨ W , W ⟩ F \|\mathbf{W}\|_F^2=\langle\mathbf{W},\mathbf{W}\rangle_F ∥W∥F2=⟨W,W⟩F这样做是为了避免在求导时出现平方根运算,简化计算,避免过拟合。 -
应用场景:L2权重衰减(权重矩阵的Frobenius范数)。在 L2 权重衰减中,正则化项通常使用 L2 范数的平方
-
代码:
weight = torch.randn(100, 50, requires_grad=True) l2_reg = torch.sum(weight ** 2) # 等价于 Frobenius 内积 <weight, weight> loss = model_loss + 0.01 * l2_reg # 添加到总损失
(2) 核方法(Kernel Methods)
-
在支持向量机(SVM)或高斯过程中,内积用于计算数据在高维空间的相似性: K ( x , y ) = ⟨ ϕ ( x ) , ϕ ( y ) ⟩ K(\mathbf{x},\mathbf{y})=\langle\phi(\mathbf{x}),\phi(\mathbf{y})\rangle K(x,y)=⟨ϕ(x),ϕ(y)⟩其中 ϕ \phi ϕ 是特征映射。
-
核函数的核心思想是:直接计算高维空间中的内积 ⟨ ϕ ( x ) , ϕ ( y ) ⟩ \langle\phi(\mathbf{x}),\phi(\mathbf{y})\rangle ⟨ϕ(x),ϕ(y)⟩而无需显式构造到高维 ϕ ( x ) \phi(\mathbf{x}) ϕ(x)。对于高斯核,可以证明它对应一个无限维的特征映射(这里没有深究原理,但确实有数学公式可以证明)。
-
手动实现的高斯核
import numpy as npdef rbf_kernel(x, y, sigma=1.0):"""手动实现高斯核(内积形式)"""distance = np.linalg.norm(x - y) ** 2 # ||x - y||^2return np.exp(-distance / (2 * sigma ** 2)) # K(x,y) = <φ(x), φ(y)># 示例计算 x = np.array([1.0, 2.0]) y = np.array([3.0, 4.0]) print("手动计算高斯核:", rbf_kernel(x, y))
(3)自注意力机制中的Query-Key评分
-
虽然Transformer中的 Q K T QK^T QKT 是矩阵乘法,但每个评分 Q i ⋅ K j Q_i\cdot K_j Qi⋅Kj是向量点积(内积)
Q = torch.randn(10, 64) # [seq_len, d_k] K = torch.randn(10, 64) # [seq_len, d_k] scores = Q @ K.T # [10, 10], 每个元素是内积
3、外积(Outer Product)
定义和计算:
在线性代数中,两个坐标向量的外积(Outer product)是一个矩阵。如果这两个向量的维数分别为n和m,那么它们的外积是一个n×m矩阵。(相当于n×1的矩阵核1×m的矩阵相乘)
外积是两个向量的张量积,结果为高阶张量。对于向量 u ∈ R m \mathbf{u}\in\mathbb{R}^m u∈Rm和 v ∈ R n \mathbf{v}\in\mathbb{R}^n v∈Rn,外积生成一个矩阵(二阶张量):
u ⊗ v = u v T = [ u 1 v 1 ⋯ u 1 v n ⋮ ⋱ ⋮ u m v 1 ⋯ u m v n ] \mathbf{u}\otimes\mathbf{v}=\mathbf{u}\mathbf{v}^T=\begin{bmatrix}u_1v_1&\cdots&u_1v_n\\\vdots&\ddots&\vdots\\u_mv_1&\cdots&u_mv_n\end{bmatrix} u⊗v=uvT= u1v1⋮umv1⋯⋱⋯u1vn⋮umvn
对于高阶张量,外积将它们的阶数相加(如 m m m阶张量和 n n n阶张量,计算外积,结果是 m + n m+n m+n阶张量。
特点:
- 不满足交换律 ( u ⊗ v ≠ v ⊗ u (\mathbf{u}\otimes\mathbf{v}\neq\mathbf{v}\otimes\mathbf{u} (u⊗v=v⊗u
- 用于构造高阶张量(如矩阵、三阶张量等)。
- 与叉积(Cross Product)不同(叉积仅适用于三维向量,结果为向量)。
示例:
[ 1 2 ] ⊗ [ 3 4 ] = [ 1 × 3 1 × 4 2 × 3 2 × 4 ] = [ 3 4 6 8 ] \begin{bmatrix}1\\2\end{bmatrix}\otimes\begin{bmatrix}3&4\end{bmatrix}=\begin{bmatrix}1\times3&1\times4\\2\times3&2\times4\end{bmatrix}=\begin{bmatrix}3&4\\6&8\end{bmatrix} [12]⊗[34]=[1×32×31×42×4]=[3648]
在深度学习中的应用(PyTorch代码实现
import torch# 定义两个向量
u = torch.tensor([1, 2, 3])
v = torch.tensor([4, 5, 6])# 计算外积
outer_product = torch.outer(u, v)
print("外积结果:")
print(outer_product)# 等价的矩阵乘法matrix_m = u[:,None] @ v[None,:] assert torch.allclose(outer_product ,matrix_m )
4、哈达玛积(Hadamard Product)
是矩阵的逐元素乘积,与点积、外积无关。
哈达玛积(Hadamard Product),也称为 逐元素乘积(Element-wise Product),是一种基本的矩阵/张量运算,广泛应用于深度学习、信号处理和数值计算等领域。它与矩阵乘法完全不同,核心在于 对应位置的元素相乘,而非行列点积。
定义和计算:
对于两个形状相同的矩阵 A , B ∈ R m × n \mathbf{A},\mathbf{B}\in\mathbb{R}^{m\times n} A,B∈Rm×n,它们的哈达玛积 C = A ∘ B \mathbf{C}=\mathbf{A}\circ\mathbf{B} C=A∘B定义为:
C i j = A i j × B i j , ∀ i ∈ { 1 , … , m } , j ∈ { 1 , … , n } C_{ij}=A_{ij}\times B_{ij},\quad\forall i\in\{1,\ldots,m\},j\in\{1,\ldots,n\} Cij=Aij×Bij,∀i∈{1,…,m},j∈{1,…,n}
符号表示:
- 哈达玛积常用符号 ∘ \circ ∘ 或 ⊙ \odot ⊙
- 在代码中通常用
*或逐元素乘法函数(如np.multiply、torch.mul)
特点:
- 输入要求:两个矩阵/张量必须形状完全相同(广播机制除外)
- 对应位置相乘,输出维度不变
在深度学习中的应用:
首先哈达玛积在python中用*运算符来表示:
A = torch.randn(2, 3) # [2, 3]
B = torch.randn(2, 3) # [2, 3]
hadamard = A * B # 或 torch.mul(A, B)
- 门控机制(如LSTM/GRU)
# input_gate: [batch, hidden], candidate: [batch, hidden]
new_state = input_gate * candidate # 逐元素相乘
- 注意力掩码(Transformer)
# scores: [batch, seq_len, seq_len], mask: [seq_len, seq_len]
masked_scores = scores * mask.unsqueeze(0) # 应用掩码
5、矩阵乘法( matrix multiplication)
矩阵乘法(Matrix Multiplication)是线性代数中的核心运算,也是深度学习中最基本、最重要的操作之一。它用于将两个矩阵(或更高维张量)按照特定规则相乘,生成一个新的矩阵。
定义和计算:
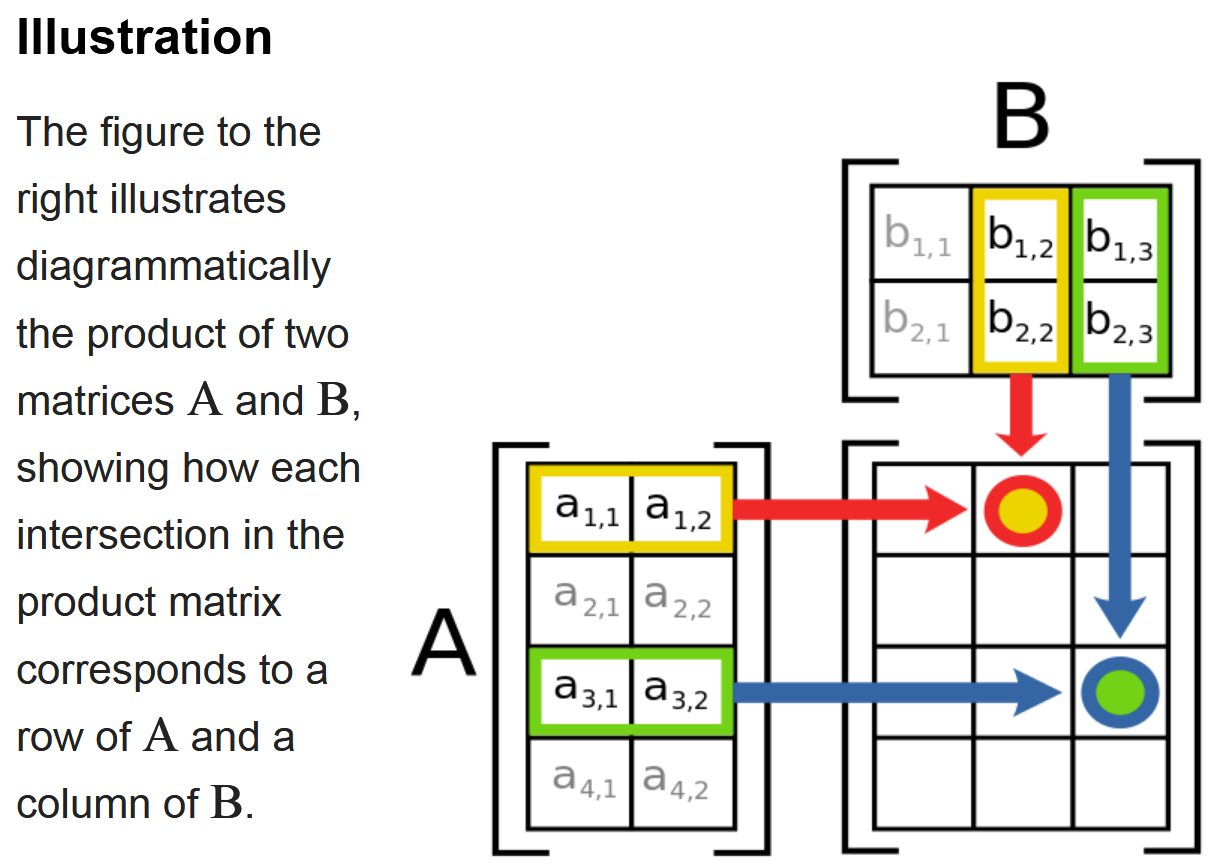
矩阵乘法定义为:对于矩阵 A ∈ R m × n \mathbf{A}\in\mathbb{R}^{m\times n} A∈Rm×n 和 B ∈ R n × p \mathbf{B}\in\mathbb{R}^{n\times p} B∈Rn×p ,它们的乘积 C = A B C = AB C=AB或写成 C = A × B C=A\times B C=A×B ,是一个 m × p m \times p m×p形状的矩阵。其中每个元素 C i j C_{ij} Cij的计算如下:也就是 A \mathbf{A} A 的第 i i i 行向量和 B \mathbf{B} B 的第 j j j 列向量做点积(对应元素相乘再求和)。
C i j = ∑ k = 1 n A i k B k j C_{ij}=\sum_{k=1}^nA_{ik}B_{kj} Cij=k=1∑nAikBkj
- 矩阵 A A A行和矩阵 B B B的列必须相同
- 结果矩阵的 C C C的行数 = A A A的行数,列数 = B B B的列数
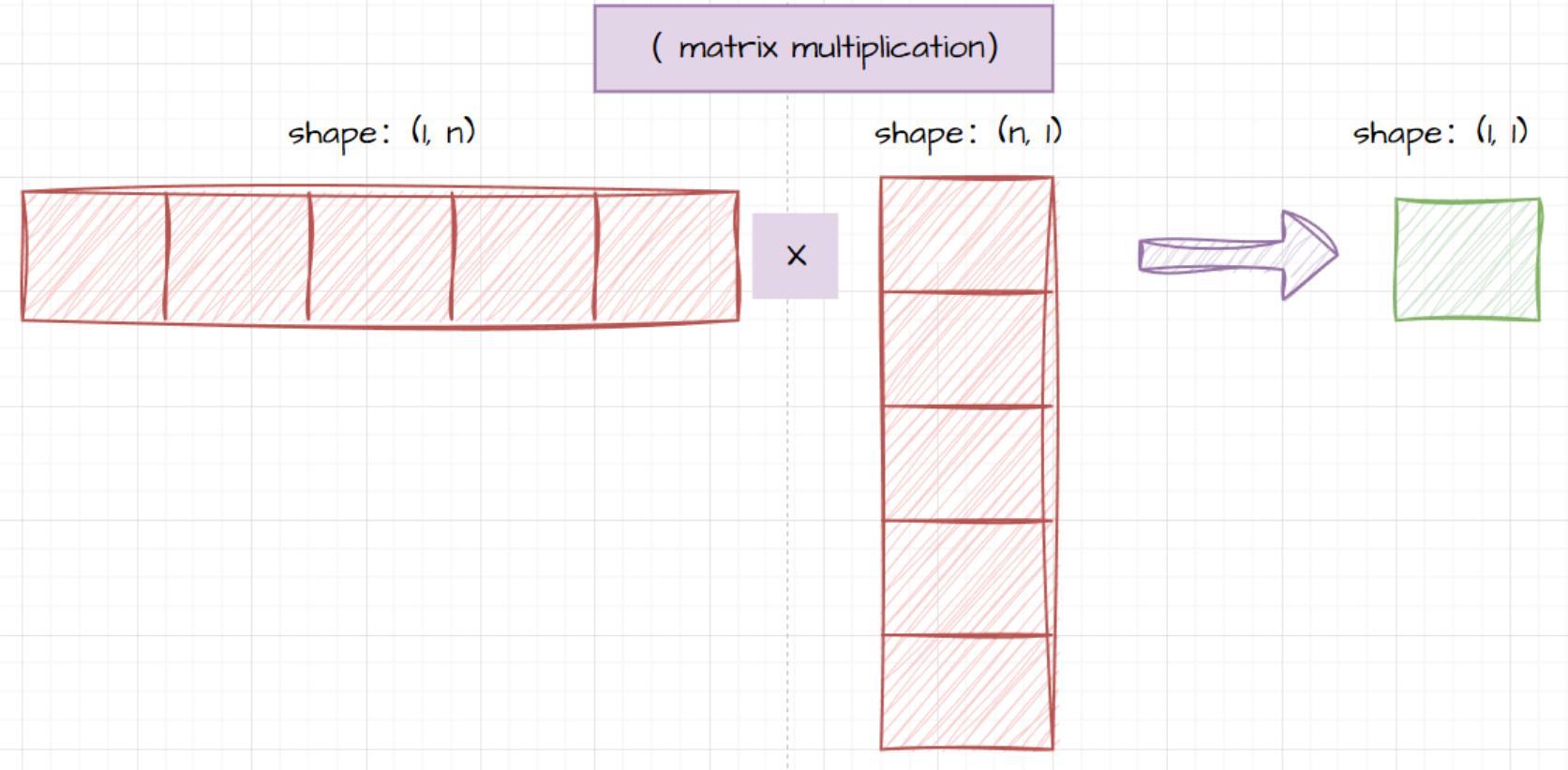
与内积的联系:
- 首先矩阵乘法的运算规则里面本来就包含了内积的概念,新矩阵的元素本来就由行向量和列向量最点积而来。
- 特殊情况:当矩阵退化为一维向量时,矩阵乘法就等同于内积。例如,对于两个一维向量 a = [ a 1 , a 2 , ⋯ , a n ] \mathbf{a}=[a_1,a_2,\cdots,a_n] a=[a1,a2,⋯,an] 和 b = [ b 1 , b 2 , ⋯ , b n ] \mathbf{b}=[b_1,b_2,\cdots,b_n] b=[b1,b2,⋯,bn],它们的内积 a ⋅ b = ∑ i = 1 n a i b i \mathbf{a}\cdot\mathbf{b}=\sum_{i = 1}^{n}a_ib_i a⋅b=∑i=1naibi,这可以看作是一个 1 × n 1\times n 1×n 的矩阵和一个 n × 1 n\times 1 n×1 的矩阵相乘。
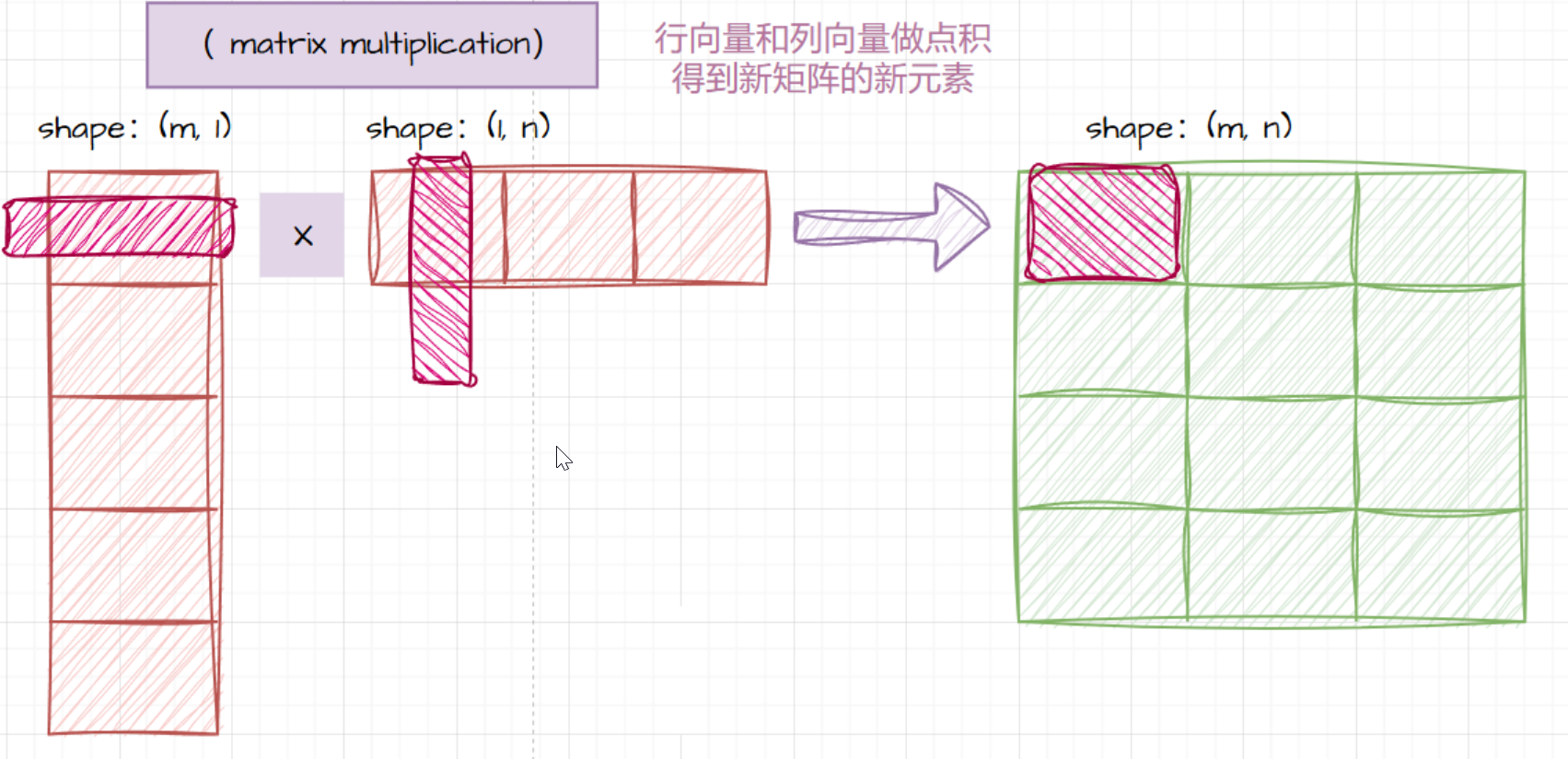
与外积的关联
- 矩阵乘法也能和外积联系起来。当一个列向量 a \mathbf{a} a(形状为 m × 1 m\times 1 m×1)和一个行向量 b \mathbf{b} b(形状为 1 × n 1\times n 1×n)相乘时,得到的结果是一个 m × n m\times n m×n 的矩阵,这个过程类似于外积的计算方式。
🙎🏻♀️几何意义
-
线性变换的组合:矩阵本身就可以代表一个线性的变换。在二维平面里,矩阵乘法可实现对二维向量的旋转、缩放、反射等几何变换。对于线性变换 A A A和 B B B, A B AB AB表示先应用 B B B的变换,再应用 A A A的变换


图片来源于B站视频:【【从0开始学广义相对论02】嫌矩阵运算难写?看看爱因斯坦怎么做的:Einstein求和约定】 https://www.bilibili.com/video/BV1LF411s7MX/?share_source=copy_web&vd_source=f81ef849101bd49f5953b524b903fdfb
-
空间映射(空间变换)⭐:将输入空间( R p \mathbb{R}^p Rp)通过 B B B映射到中间空间 ( R n ) (\mathbb{R}^n) (Rn),再通过 A A A映射到输出空间 ( R m ) (\mathbb{R}^m) (Rm)。
示例代码
import torch# 创建两个矩阵
A = torch.tensor([[1, 2], [3, 4]])
B = torch.tensor([[5, 6], [7, 8]])# 进行矩阵乘法
C = torch.matmul(A, B)
C = torch.mm(A, B) # [3, 5] 或 A @ B
print(C)
在这个例子中,矩阵 C \mathbf{C} C 的每个元素都是通过 A \mathbf{A} A 的行向量和 B \mathbf{B} B 的列向量做点积得到的。
torch.matmul 和 torch.mm 都可用于执行张量乘法,但它们存在一些区别
torch.mm:仅适用于二维张量(即矩阵)。若输入不是二维张量,会抛出错误。torch.matmul:支持更灵活的输入维度,可处理多种维度组合的张量乘法。具体规则如下:- 若两个输入都是一维张量,计算的是它们的点积(内积),返回一个标量。
- 若两个输入都是二维张量,执行的是常规的矩阵乘法,与
torch.mm效果相同。 - 若一个输入是一维张量,另一个是二维张量,会自动对一维张量进行维度扩展以完成矩阵乘法,结果为一维张量。
- 若输入张量的维度超过二维,
torch.matmul会将最后两个维度视为矩阵维度进行乘法,其他维度作为批量维度处理。
总结
对比总结表
| 运算 | 数学符号 | 代码实现(PyTorch) | 输入要求 | 输出规则 |
|---|---|---|---|---|
| 矩阵乘法 | A B \mathbf{A} \mathbf{B} AB | A @ B 或 torch.mm(A, B) | 前列=后行 | 行列点积求和 |
| 点积(内积) | u ⋅ v \mathbf{u} \cdot \mathbf{v} u⋅v | torch.dot(u, v) | 同维向量 | 标量 |
| 外积 | u ⊗ v \mathbf{u} \otimes \mathbf{v} u⊗v | torch.outer(u, v) | 任意两向量 | 矩阵(( \mathbf{u} \mathbf{v}^T )) |
| 哈达玛积 | A ∘ B \mathbf{A} \circ \mathbf{B} A∘B | A * B 或 torch.mul(A, B) | 同形状矩阵/张量 | 逐元素相乘 |
| 克罗内克积 | A ⊗ B \mathbf{A} \otimes \mathbf{B} A⊗B | torch.kron(A, B) | 任意两矩阵 | 分块扩展矩阵 |
| 逐元素除法 | A ⊘ B \mathbf{A} \oslash \mathbf{B} A⊘B | A / B 或 torch.div(A, B) | 同形状矩阵/张量 | 逐元素相除 |
关键点
- 矩阵乘法是深度学习最核心的运算(如全连接层、注意力机制)。
- 哈达玛积用于逐元素操作(如激活函数、掩码)。
- 外积和克罗内克积在特定场景(如推荐系统、量子计算)中非常有用。
- 代码中注意区分
*(哈达玛积)和@(矩阵乘法),这是常见的错误来源!
参考
- 点积、内积、外积、叉积、张量积——概念区分
- 豆包、Deepseek(感谢)
相关文章:

【深度学习】详解矩阵乘法、点积,内积,外积、哈达玛积极其应用|tensor系列02
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: Yaoyao2024往期回顾:【深度学习】你真的理解张量了吗?|标量、向量、矩阵、张量的秩|01每日一言🌼: “脑袋想不明白的,就用脚想”…...

20.3 使用技巧3
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 20.3.5 禁止追加行与禁止删除行 通常情况下DataGridView最末一行是空白行,在此行单元格输入数据就可以追加新行。如果需要…...

使用代理IP提取数据的步骤是什么?代理IP如何提高爬虫采集效率?
在当今大数据时代,网络爬虫已成为获取互联网信息的重要手段。然而,许多网站为了防止数据被过度抓取,会设置反爬机制,如IP封禁、访问频率限制等。这时,使用代理IP就成为了一种有效的解决方案。本文将详细介绍使用代理IP…...

探索关系型数据库 MySQL
目录 引言 一.SQL的基本操作 1.数据库是什么? 什么是SQL? 1.1.OLTP 1.2.OLAP 1.3.SQL 1.4.DQL 1.5.DML 1.6.DDL 1.7.DCL 1.8.TCL 1.9.数据库术语 2.MySQL体系结构 2.1.连接者 2.2.MySQL 内部连接池 2.3.管理服务和工具组件 2.4.SQL接口 …...

Redis--事务
目录 一、事务介绍 二、事务操作 2.1 MULTI 2.2 EXEC 2.3 DISCARD 2.4 WATCH 2.5 UNWATCH 一、事务介绍 Redis 的事务和 MySQL 的事务概念上是类似的. 都是把一系列操作绑定成⼀组. 让这⼀组能够批量执行. 但是注意体会 Redis 的事务和 MySQL 事务的区别: 1.弱化的原子性…...

【Windows上配置Git环境】
在Windows上配置Git环境可以按照以下步骤进行: 1. 下载Git 打开浏览器,访问Git官方网站https://git-scm.com/downloads。在下载页面中,找到适用于Windows的下载链接,根据你的系统是32位还是64位选择相应的安装包进行下载 。 2.…...

揭秘大数据 | 23、软件定义网络
软件定义网络将网络的边缘从硬件交换机推进到了服务器里面,将服务器和虚拟机的所有部署、管理的职能从原来的系统管理员网络管理员的模式变成了纯系统管理员的模式,让服务器的业务部署变得简单,不再依赖于形态和功能各异的硬件交换机…...
简易template)
前端api(请求后端)简易template
微信小程序 API 模块模板 基本 API 模块结构 /*** 示例API模块*/ const api require(../api); const config require(../../config/index);// 示例API对象 const exampleApi {// API方法定义... };// 导出模块 module.exports exampleApi;标准 RESTful 请求方法 获取列表…...

【力扣】重排链表
重排链表 代码 class Solution { public:void reorderList(ListNode* head) {//当链表只有一个节点或两个节点时直接返回空,不用重排if (head->next NULL || head->next->next NULL) return;//1. 进行分割链表ListNode* fast head, *slow head;ListNode* end1 N…...

选 Hibernate 还是 MyBatis?全方位差异解读
Hibernate 和 MyBatis 都是 Java 开发中用于处理数据库操作的持久化框架,不过它们在实现技术上存在诸多差异,下面从多个方面进行对比: 1. 映射机制 Hibernate:采用全自动的对象关系映射(ORM)机制…...
—— 最佳实践之图片)
SvelteKit 最新中文文档教程(21)—— 最佳实践之图片
前言 Svelte,一个语法简洁、入门容易,面向未来的前端框架。 从 Svelte 诞生之初,就备受开发者的喜爱,根据统计,从 2019 年到 2024 年,连续 6 年一直是开发者最感兴趣的前端框架 No.1: Svelte …...
(详解))
类和对象(下篇)(详解)
【本节目标】 1. 再谈构造函数 2. Static成员 3. 友元 4. 内部类 5. 再次理解封装 1. 再谈构造函数 1.1 构造函数体赋值 在创建对象时,编译器通过调用构造函数,给对象中各个成员变量一个合适的初始值。 #include <iostream> using name…...

win10下github libiec61850库编译调试sntp_example
libiec61850 https://github.com/mz-automation/libiec61850 v1.6 简介 libiec61850 是一个开源(GPLv3)的 IEC 61850 客户端和服务器库实现,支持 MMS、GOOSE 和 SV 协议。它使用 C 语言(根据 C99 标准)实现…...

【HDFS入门】HDFS高可用性与容错机制深度解析
目录 引言 1 HDFS高可用架构实现 1.1 基于QJM的NameNode HA架构 1.2 QJM vs NFS实现对比 2 故障切换流程与ZooKeeper作用 2.1 自动故障转移流程 2.2 状态转换机制 3 数据恢复与副本管理 3.1 DataNode故障处理流程 4 快照与数据保护机制 4.1 HDFS快照架构 4.2 快照使…...

Qt QML实现Windows桌面歌词动态播放效果
前言 使用Qt5.15.2,QML实现简单的歌词动态播放效果。 效果图如下: 注:这里只是为了演示播放效果,并未真正加载音频进行播放。可以在此基础上进行扩展。 正文 关键代码 QML部分 import QtQuick 2.15 import QtQuick.Window 2.…...

Qt GUI 库总结
Qt GUI 库总结 Qt GUI 库(QtGui)是 Qt 框架中负责图形用户界面(GUI)开发的核心模块。本文将一步步详解 QtGui,从基础入门到高级应用,帮助你全面掌握其功能。以下内容包括环境配置、基本功能、核心特性及进…...

[dp16_两个数组] 通配符匹配 | 交错字符串 | 两个字符串的最小ASCII删除和
目录 1.通配符匹配 题解 2.交错字符串 题解 3.两个字符串的最小ASCII删除和 1.通配符匹配 链接:44. 通配符匹配 给你一个输入字符串 (s) 和一个字符模式 (p) ,请你实现一个支持 ? 和 * 匹配规则的通配符匹配: ? 可以匹配任何单个字…...

记录一次生产中mysql主备延迟问题处理
登录库: mysql -uXXXX -pXXXX -P3306 -hXXXXXX -A 备库上执行:show slave status\G 查看 seconds_Behind_Master,延迟 2705s,而且还一直在增加。 SHOW CREATE TABLE proc_i_income_temp; -- 查看表的结构 show index from proc…...

【计算机视觉】OpenCV实战项目-AdvancedLaneDetection 车道检测
AdvancedLaneDetection 项目解析 项目概述项目结构功能和步骤依赖项使用方法项目特点改进建议结论运行项目1. 克隆项目仓库2. 安装依赖项创建虚拟环境(可选)激活虚拟环境安装依赖项 3. 准备数据4. 运行项目5. 调整配置(可选)6. 查…...

趣味编程之分布式系统:负载均衡的“雨露均沾“艺术
#此篇文章由Deepseek大力支持😋 凌晨三点,西二旗某火锅店后厨—— “羊肉卷走3号桌!” “肥牛卷去7号!” “虾滑优先给VIP区!” 我蹲在传菜口的监控屏幕前,看着机器人服务生们忙而不乱地穿梭。突然间&am…...

移植firefly core-1126-jd4官方sdk源码到其他rv1126板卡时 kernel启动中失去响应问题解决
问题背景 在项目中采用firefly core-1126-jd4的sdk适配其他rv1126板卡遇到kernel启动中无响应。串口能看到运行到usb、mmc等模块驱动流程,但之后就打印,通过追加打印确认usb、mmc模块的init已经执行完,怀疑是执行其他某个静态编译进kernel的…...

Oracle表的别名不能用as,列的别名可以用as
在 Oracle 数据库中,表的别名和列的别名在使用 AS 关键字时确实有不同规则,以下是详细说明: 1. 表的别名(Table Alias) 不支持 AS 关键字,直接跟在表名后即可。语法示例: S…...

对于“人工智能+教育”的一些思考
如果说人工智能当下最合适的落地场景,那么进入课堂这件事一定是排在靠前的位置。从当下的趋势来看,人工智能进入课堂已经不是设想,而是我们必须要去做的一件事了。 方向有了,但是问题是:人工智能进入中小学课堂到底应该…...

Android audio系统四 audiopolicy与audioflinger播放和录音
播放/录音在上层是通过AudioTrack与AudioRecord实现的。通过一张简单的流程图查看audiopolicy与audioflinger进行了哪些操作...

【Pandas】pandas DataFrame xs
Pandas2.2 DataFrame Indexing, iteration 方法描述DataFrame.head([n])用于返回 DataFrame 的前几行DataFrame.at快速访问和修改 DataFrame 中单个值的方法DataFrame.iat快速访问和修改 DataFrame 中单个值的方法DataFrame.loc用于基于标签(行标签和列标签&#…...

开源一体化白板工具Drawnix本地部署打造毫秒级响应的远程协作空间
文章目录 前言1、什么是Drawnix?2、部署Drawnix的环境和步骤3、Drawnix的简单使用方法4、安装cpolar内网穿透5、配置公网地址6、配置固定二级子域名公网地址总结 前言 想象一下,你是一个创意满满的设计师,脑海中涌现出无数灵感火花。你急忙打…...

UMAEA论文阅读
Preliminaries MMKG为一个五元组G{E, R, A, V, T},其中E、R、A和V分别表示实体集、关系集、属性集和图像集。 T⊆ERE是关系三元组集。 给定两个MMKG G1 {E1, R1, A1, V1, T1} 和 G2 {E2, R2, A2, V2, T2}, MMEA旨在识别每个实体对(e1…...

捕鱼船检测数据集VOC+YOLO格式2105张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2105 标注数量(xml文件个数):2105 标注数量(txt文件个数):2105 …...

R4打卡——pytorch实现LSTM预测火灾
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 1.检查GPU import torch.nn.functional as F import numpy as np import pandas as pd import torch from torch import nndata pd.read_csv("da…...

【数字图像处理】图像增强
图像增强——频率域分析 卷积定理 函数卷积的傅里叶变换是函数傅里叶变换的乘积,即:一个域中的卷积相当于另一个域中的乘积 F(x)为傅里叶变换 傅里叶 傅里叶级数:任何周期函数都可以用不同频率的正弦函数和余弦函数构成的无穷级数来表示。 正…...

Windows平台用vistual studio 2017打包制作C++动态库
1. 创建库项目 打开 Visual Studio 2017,选择 文件 → 新建 → 项目。选择 Visual C → Windows 桌面 → 动态链接库 (DLL) 或 静态库 (LIB)。 动态库 (DLL):生成 .dll 和 .lib(导出符号表)。静态库 (LIB):生成 .lib&…...

QT日历控件重写美化
效果图 先放一个效果图以供大家参考,大家可以根据自己需要的效果来调整自己的控件,日历控件实现了自定义日历选择框,设置了表头颜色,设置日历当天重要事件提醒功能。 设置表头样式 setVerticalHeaderFormat(QCalendarWidget::NoV…...

单细胞分析读取处理大型数十万细胞的数据集的优化
单细胞分析读取处理大型数十万细胞的数据集的优化 背景简介 有朋友反映用自己的笔记本电脑在分析比较大的单细胞数据集的时候,比如细胞数量有十万个以上甚至几十万个的时候,可能自己的电脑的内存32G或64G都不够用,一般来说,做生…...

HTTP 3.0 协议的特点
HTTP/3 是互联网传输协议的一次重要升级,相较于 HTTP/2,它引入了多项显著改进和新特性。 基于 QUIC 协议: HTTP/3 采用了 QUIC(Quick UDP Internet Connections)作为底层传输协议,QUIC 基于 UDP࿰…...
架构)
电子电器架构 --- 下一代汽车电子/电气(E/E)架构
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁&am…...

08软件测试需求分析案例-删除用户
删除用户是后台管理菜单的一个功能模块,只有admin才有删除用户的权限。不可删除admin。 1.1 通读文档 通读需求规格说明书是提取信息,提出问题,输出具有逻辑、规则、流程的业务步骤。 信息:此功能应为用户提供确认删除的功能。…...

await 在多线程,子线程中的使用
await 在多线程,子线程中的使用 await self.send_reply(user, user, user, auto_content, reply) 这行代码是在一个异步函数里调用类的实例方法 send_reply 代码含义 1. await 关键字 在 Python 的异步编程里,await 关键字的作用是暂停当前异步函数的执行,直到 await 后…...
NLP高频面试题(四十六)——Transformer 架构中的位置编码及其演化详解
引言 Transformer 模型(Vaswani 等人,2017)在序列建模中取得了革命性突破,利用自注意力机制实现了并行的序列处理。然而,Transformer 本身对序列的顺序信息不敏感:输入序列元素在自注意力中是无排列的(Permutation-invariant)。换言之,Transformer 缺乏像 RNN 那样的…...

C++笔记-list
list即是我们之前学的链表,这篇主要还是讲解list的底层实现,前面会讲一些list区别于前面string和vector的一些接口以及它们的注意事项。 一.list的基本使用 和之前的string,vector一样,有很多之前见过的一些接口,经过…...
)
机器学习 | 细说Deep Q-Network(DQN)
文章目录 📚传统Q学习的局限性📚DQN介绍🐇核心思想🐇关键技术🐇DQN的工作流程⭐️流程分步讲解🔄 整体流程循环小结 🐇DQN的局限性及改进方向 👀参考视频&博客 什么是 DQN (Rein…...

【SpringBoot+Vue自学笔记】003 SpringBoot Controll
跟着这位老师学习的:https://www.bilibili.com/video/BV1nV4y1s7ZN?vd_sourceaf46ae3e8740f44ad87ced5536fc1a45 这段话的意思其实是:Spring Boot 简化了传统 Web 项目的搭建流程,让你少折腾配置,直接开搞业务逻辑。 ὒ…...

Sentinel源码—4.FlowSlot实现流控的原理一
大纲 1.FlowSlot根据流控规则对请求进行限流 2.FlowSlot实现流控规则的快速失败效果的原理 3.FlowSlot实现流控规则中排队等待效果的原理 4.FlowSlot实现流控规则中Warm Up效果的原理 1.FlowSlot根据流控规则对请求进行限流 (1)流控规则FlowRule的配置Demo (2)注册流控监…...

跟康师傅学Java-基础语法
跟康师傅学Java-基础SE 一、Java语言概述 1. 基本概念 什么是Java?干什么的? 前端是服务员,java做后台的,服务器,好比餐馆的厨师! Java之父:詹姆斯.高斯林(James Gosling) 软件:一系列按照特定顺序组织的计算机数据和指令的集合。分为系统软件和应用软件。 程序…...

Java语言实现递归调用算法
1. 递归调用原理 递归是一种编程技巧,其中函数直接或间接地调用自身。递归的核心思想是将一个复杂问题分解为更小的子问题,直到问题变得足够简单可以直接解决。递归通常包含两个部分: 1. 基础情况(Base Case)ÿ…...
)
【数据结构_10】二叉树(1)
一、树 树是一种非线性的数据结构,是由n个有限节点组成一个具有层次关系的集合。树的每个节点能够延伸出多个子节点,但每个子节点只能由一个父节点。 树形结构中,子树之间不能有交集,否则就不是树形结构。 二、树的表示形式 1…...

c++:智能指针
1.智能指针使用场景与优势 void Func() { int* array1 new int[10]; int* array2 new int[10]; try { int len, time; cin >> len >> time; cout << Divide(len, time) << endl; } catch (...) { cout << "delete []" << arr…...

RISC-V简介
RISC-V简介 1. RISC-V RISC-V(发音为“riskfive”)是一个基于精简指令集(RISC)原则的全新开源指令集架构(ISA)。其中的字母“V”包含两层意思,一是这是Berkeley从RISCI开始设计的第五代指令集…...

Google Test 与 Google Mock:C++ 测试与模拟的完美结合
Google Test 与 Google Mock:C 测试与模拟的完美结合 摘要 本文深入解析 Google Test(GTest)和 Google Mock(GMock)的核心功能与使用方法,探讨两者在 C 项目中的联合应用及集成策略。通过详细的功能介绍、…...

c语言数据结构----------二叉排序树
#include <stdio.h> #include <malloc.h>//定义二叉排序树 typedef struct BSTnode {int key; //节点值int keyNull; //便于地址传递struct BSTnode *lchild;struct BSTnode *rchild; } BSTnode;//往二叉排序树插入结点 int BSTInsert(BSTnode *T, int k) {if (…...

Sysstat学习
Sysstat(System Statistics)是一个功能强大的开源工具集,用于监控 Linux 系统的性能和资源使用情况,特别适用于 Ubuntu 系统。它包含多个工具,如 sar、iostat、mpstat 和 pidstat,帮助系统管理员实时或历史…...