Using the CubeMX code (一)(GPIO,PWM ,Cube AI,手写数字识别 MNIST,Demo)
该例程对使用CubeMX初始化GPIO做了示范,GPIO使用HAL库进行GPIO编程分为以下几个步骤:
一、例程简述
1. 包含必要的头文件和HAL库的相关头文件
CubeMX初始化会自动包含,对手敲HAL感兴趣的同学可以熟悉下生成的代码框架学习哦~
2. 初始化GPIO外设
`GPIO_InitTypeDef GPIO_InitStructure;`
3. 配置GPIO引脚的模式和参数
GPIO_InitStructure.Mode = GPIO_MODE_OUTPUT_PP; // 输出模式GPIO_InitStructure.Pull = GPIO_NOPULL; // 不使用内部上下拉电阻GPIO_InitStructure.Speed = GPIO_SPEED_FREQ_LOW; // 低速GPIO_InitStructure.Pin = GPIO_PIN_13; // 配置的引脚HAL_GPIO_Init(GPIOC, &GPIO_InitStructure); // 初始化GPIOC外设
4. 设置GPIO引脚的电平
HAL_GPIO_WritePin(GPIOC, GPIO_PIN_13, GPIO_PIN_SET); // 设置引脚为高电平
5. 读取GPIO引脚的电平
if (HAL_GPIO_ReadPin(GPIOC, GPIO_PIN_13) == GPIO_PIN_SET) // 判断引脚是否为高电平{// 做一些操作...}
6. GPIO应用示例代码
下面是一个简单的示例,说明如何使用HAL库配置一个GPIO引脚并控制其电平:
#include "stm32f4xx.h"#include "stm32f4xx_hal.h"void GPIO_Config(void){GPIO_InitTypeDef GPIO_InitStructure;// 初始化GPIOC外设__HAL_RCC_GPIOC_CLK_ENABLE();GPIO_InitStructure.Mode = GPIO_MODE_OUTPUT_PP;GPIO_InitStructure.Pull = GPIO_NOPULL;GPIO_InitStructure.Speed = GPIO_SPEED_FREQ_LOW;GPIO_InitStructure.Pin = GPIO_PIN_13;HAL_GPIO_Init(GPIOC, &GPIO_InitStructure);}int main(void){// 初始化HAL库HAL_Init();// 配置GPIO引脚GPIO_Config();// 此处范例为500ms翻转一次PC13,对应炸鸡板的用户灯引脚,效果为闪光灯。while (1){// 设置引脚为高电平HAL_GPIO_WritePin(GPIOC, GPIO_PIN_13, GPIO_PIN_SET);// 延时一段时间HAL_Delay(500);// 设置引脚为低电平HAL_GPIO_WritePin(GPIOC, GPIO_PIN_13, GPIO_PIN_RESET);// 延时一段时间HAL_Delay(500);}}
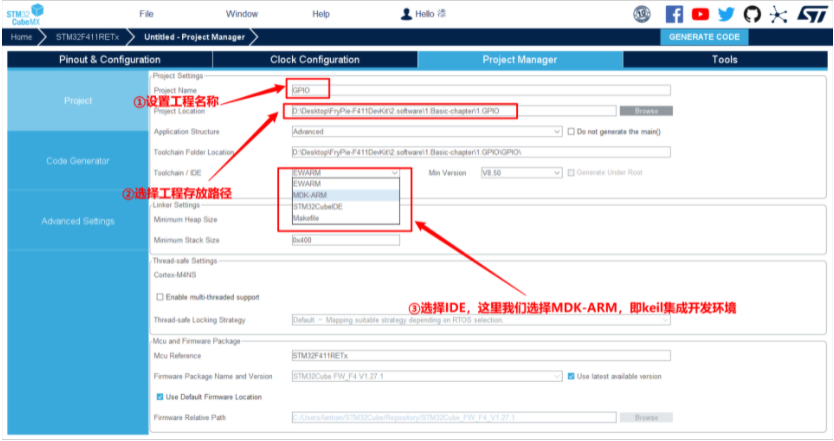
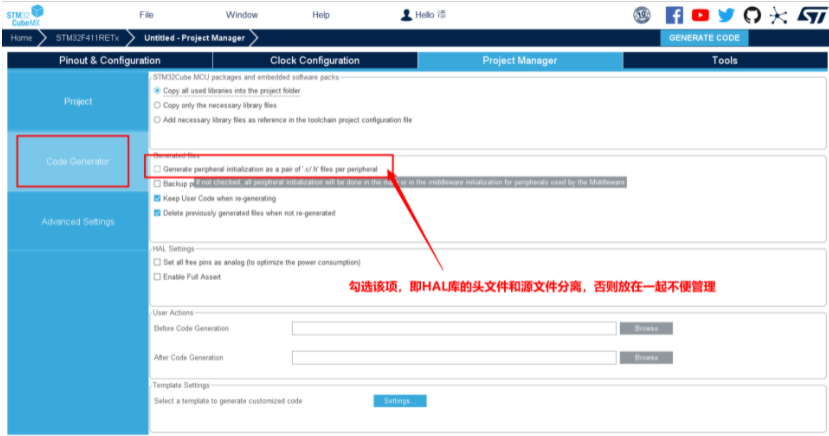
二、工程创建
(仅本次进行完全示范,之后例程README.md仅演示新内容)
1.打开CubeMX,选择ACCESS TO MCU SELECTOR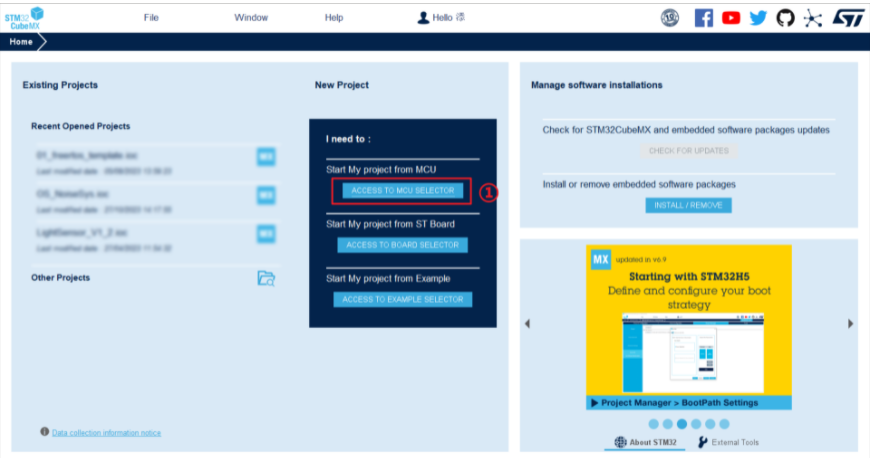
2.选择对应炸鸡板MCU--STM32F411RET6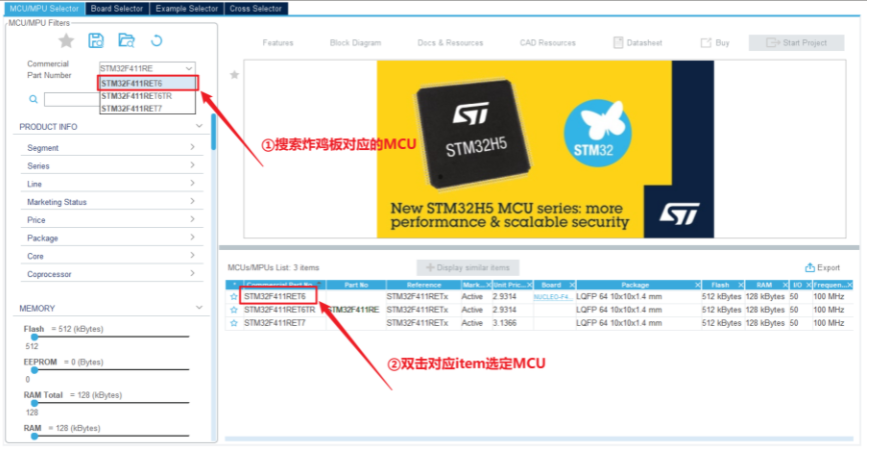
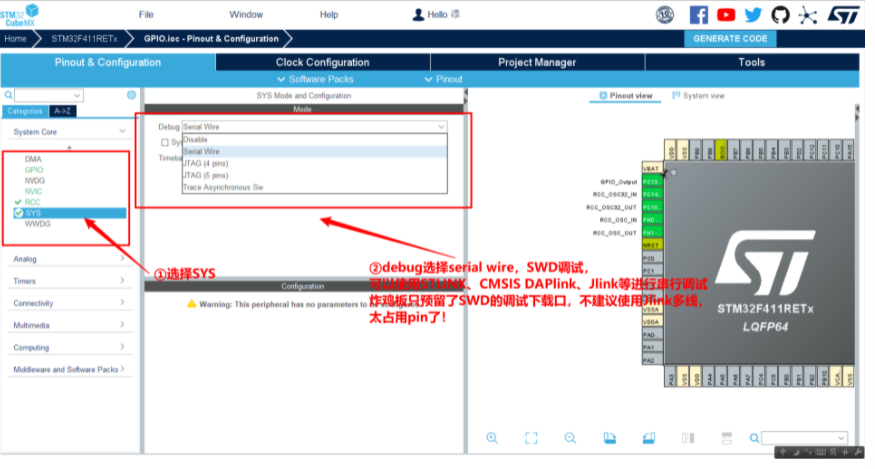
3.初始化时钟(配置时钟树)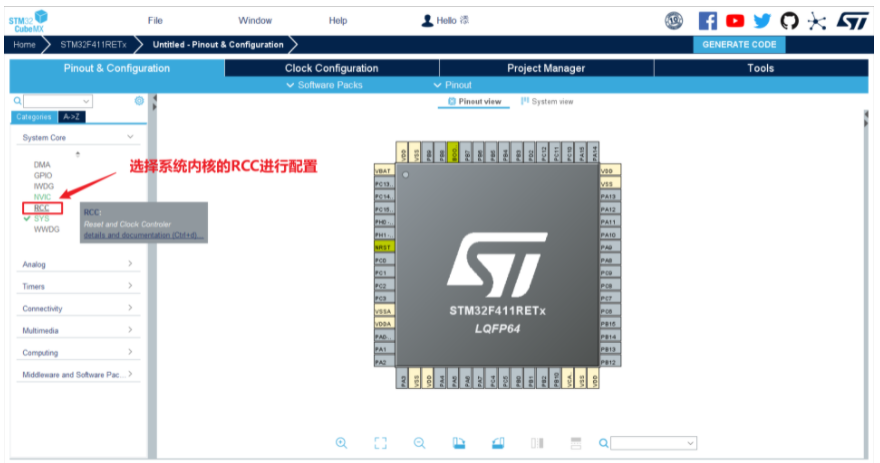
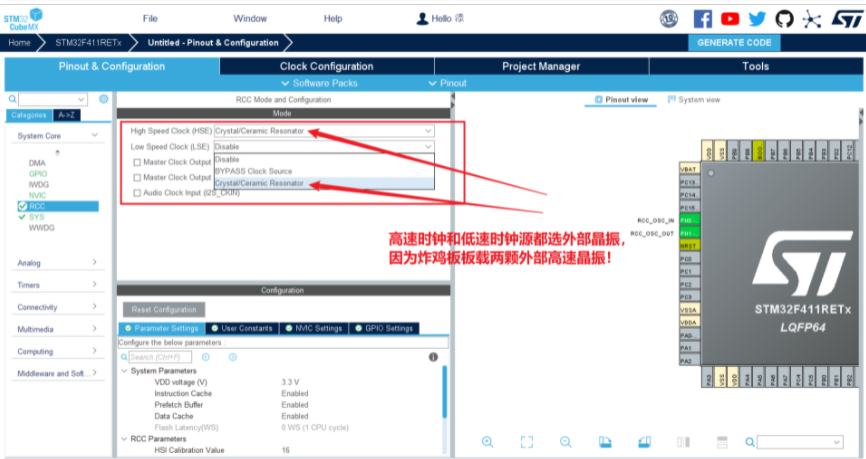
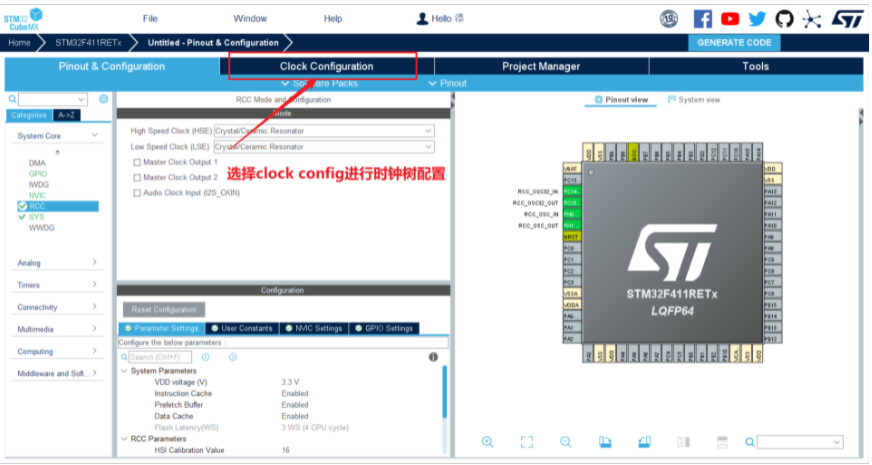
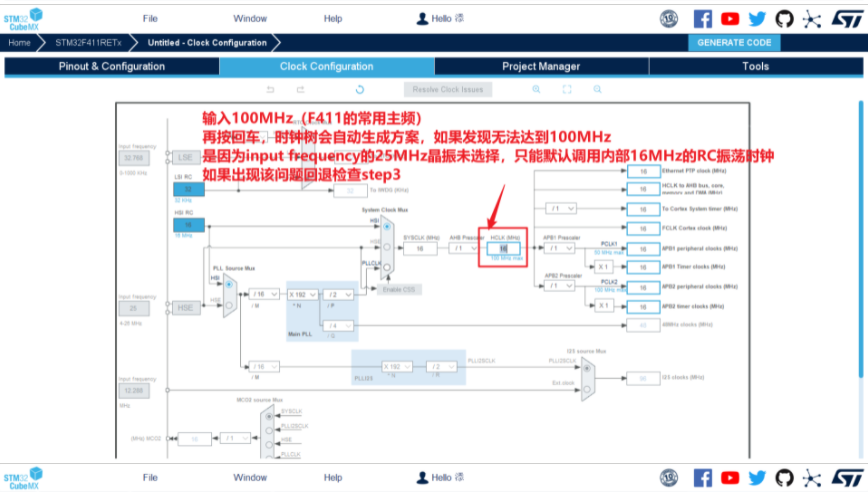
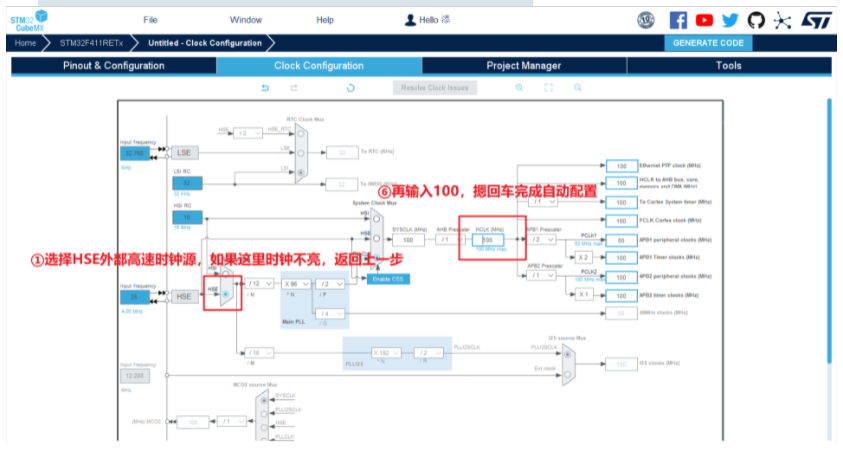
4.初始化GPIO(用于控制炸鸡板用户灯)
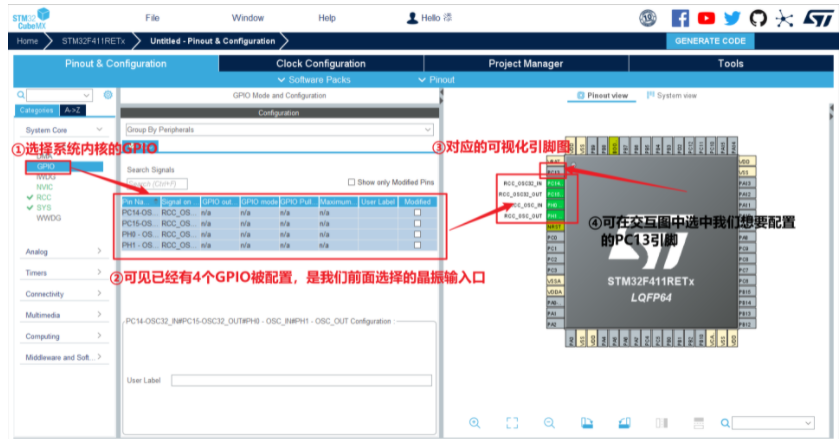
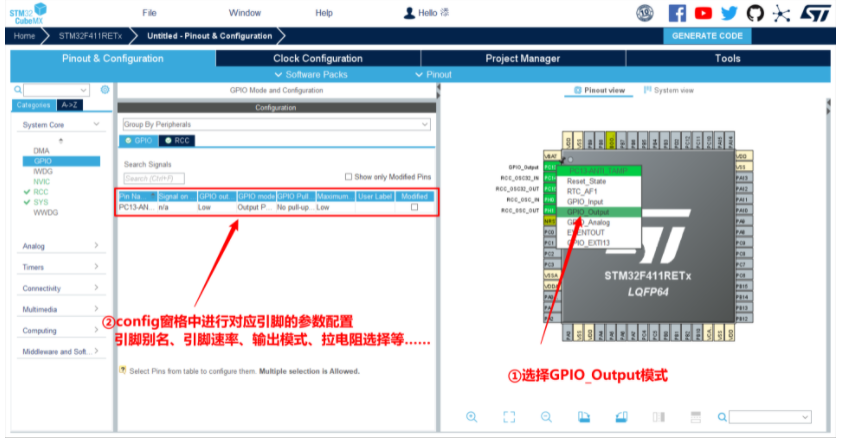
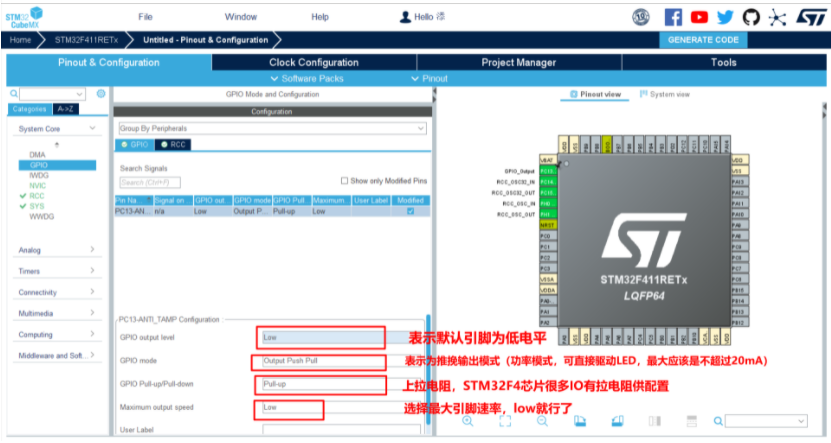
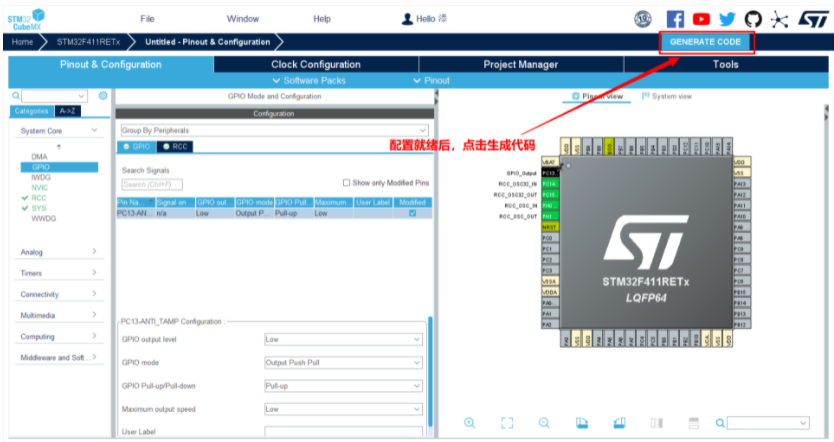
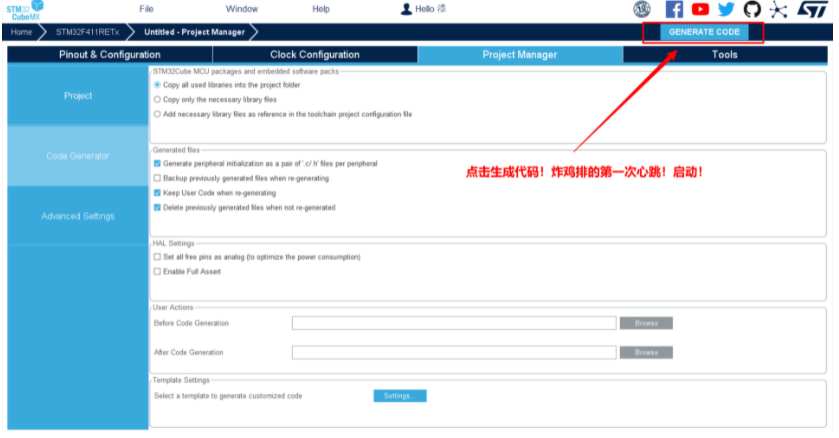
5.生成初始化工程
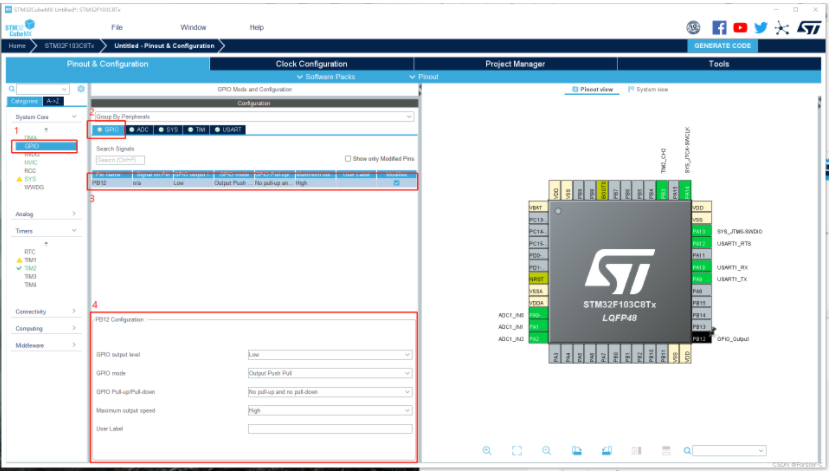
三、GPIO扩展知识(该部分摘自 尝试使用CubeMX做stm32开发之四:GPIO配置)
1)GPIO output level:只有当引脚设置为“GPIO output”时才需要设置
High:GPIO输出初始化为高电平Low:GPIO输出初始化为低电平
2)GPIO mode
Output Push Pull:推挽输出,能输出高低电平,且高低电平都有驱动能力。以PB13引脚为例,若需要通过其控制LED灯,则该引脚应配置为“Output Push Pull”模式,对应标准库函数中的“GPIO_Mode_Out_PP”Output Open Drain:开漏输出,只能输出低电平,需要借助外部上拉电阻才能输出高电平,对应标准库函数中的“GPIO_Mode_Out_OD”Analog mode:模拟输入,ADC采样信号输入引脚的配置模式,对应标准库函数中的“GPIO_Mode_AIN”Alternate Function Push Pull:推挽式复用功能,对应标准库函数中的“GPIO_Mode_AF_PP”Input mode:输入模式,配合No pull-up/pull-down可形成GPIO_Mpde_IN_FLOATING、GPIO_Mode_IPD、GPIO_Mode_IPU等不同工作模式
3)GPIO Pull-up/Pul-down
No pull-up/pull-down:无内部上拉或下拉Pull-up:内部上拉Pull-down:内部下拉
4)Maximum output speed
Low:低速,对应标准库函数中的“GPIO_Speed_2MHz”Medium:中速,对应标准库函数中的“GPIO_Speed_10MHz”High:高速,对应标准库函数中的“GPIO_Speed_50MHz”
5)User Label:用户标签,可以按照需要给引脚命名
普通GPIO口配置(用于控制LED灯)
ADC引脚配置
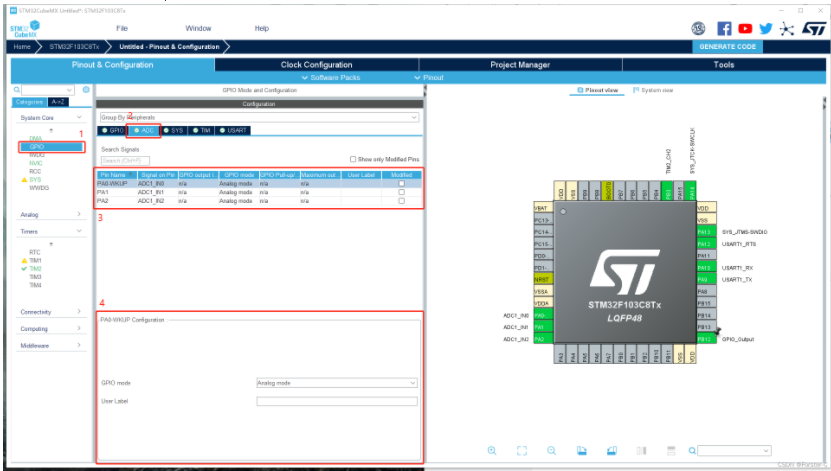
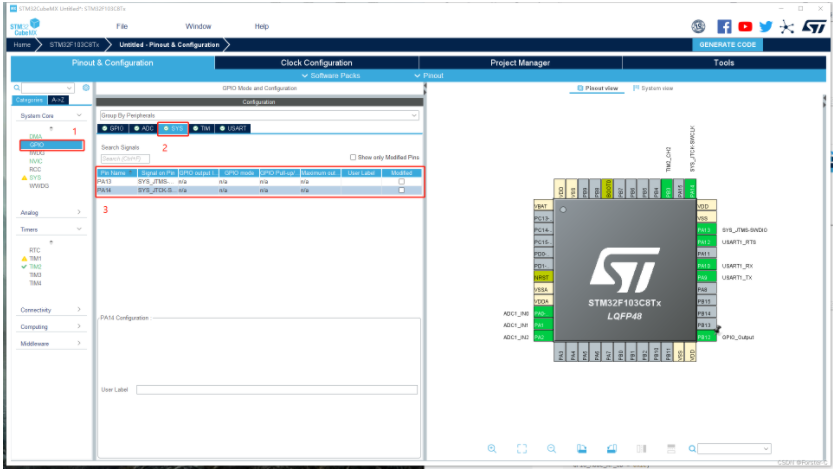
串行烧录引脚配置
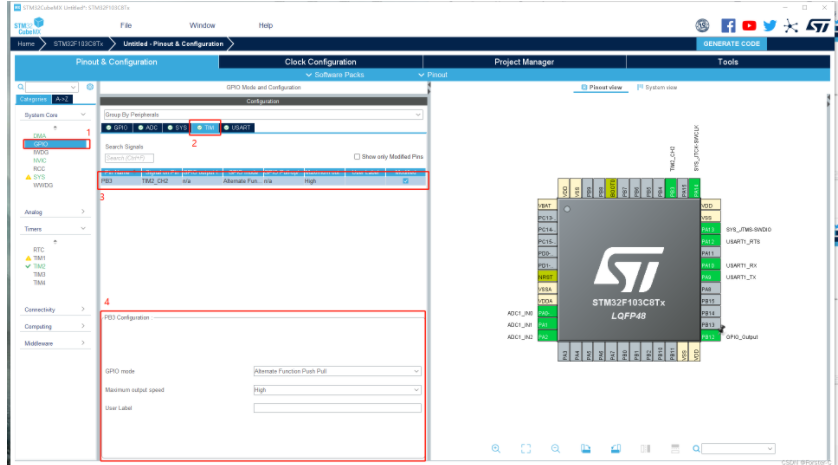
TIM比较输出引脚配置
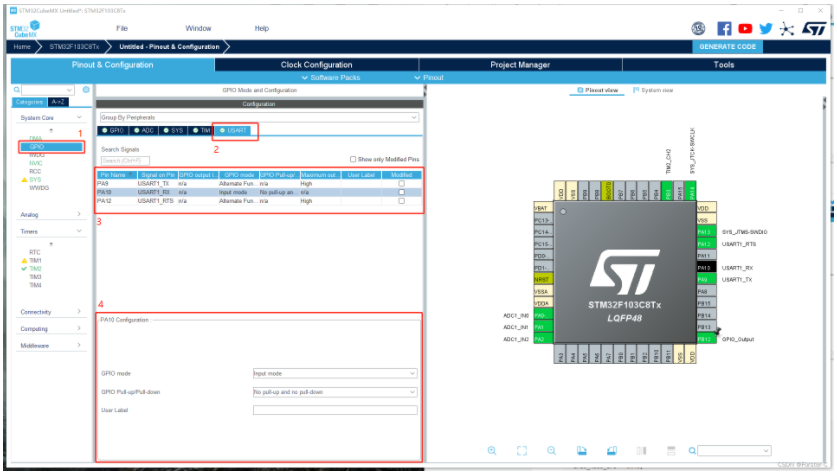
UART引脚配置
使用了如下函数进行了print重定向,记得勾选use Mirco LIB
int fputc(int ch, FILE *f)
{
HAL_UART_Transmit(&huart1, (uint8_t *)&ch, 1, 0xffff);
return ch;
}
如果需要不定长发送,可以看一下如何使用Idel空闲标志位如何使用,结合DMA一起使用
PWM Demo
1. 示例一:PWM_base例程
cubemx配置好后,在main函数中启动pwm。这里使用的是TIM2 channel3。
//Start the pwmHAL_TIM_PWM_Start(&htim2,TIM_CHANNEL_3);//PA2如果要更改占空比,更改MX_TIM2_Init()中的pulse即可,这里预分频设置为99,那么每加一个count则需要1÷(100÷(99+1))s,为1MHz,1us,这里再设置htim2.Init.Period为999,那么定时器的周期则为1ms了。
sConfigOC.Pulse = 300为设置载波的数值,调节此处可以调节占空比。原理详见手册。
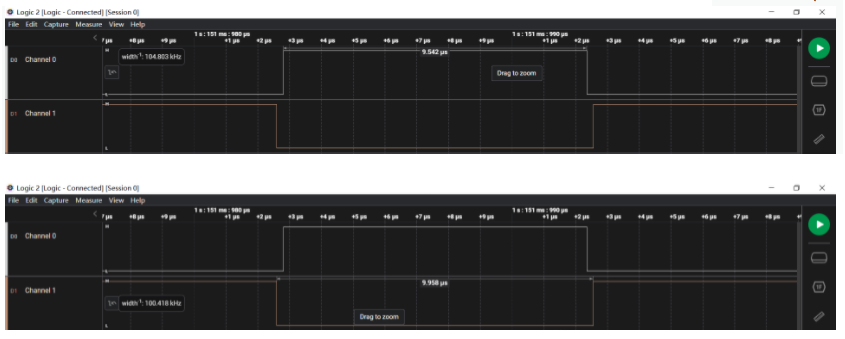
void MX_TIM2_Init(void){/* USER CODE BEGIN TIM2_Init 0 *//* USER CODE END TIM2_Init 0 */TIM_MasterConfigTypeDef sMasterConfig = {0};TIM_OC_InitTypeDef sConfigOC = {0};/* USER CODE BEGIN TIM2_Init 1 *//* USER CODE END TIM2_Init 1 */htim2.Instance = TIM2;htim2.Init.Prescaler = 99;htim2.Init.CounterMode = TIM_COUNTERMODE_UP;htim2.Init.Period = 999;htim2.Init.ClockDivision = TIM_CLOCKDIVISION_DIV1;htim2.Init.AutoReloadPreload = TIM_AUTORELOAD_PRELOAD_DISABLE;if (HAL_TIM_PWM_Init(&htim2) != HAL_OK){Error_Handler();}sMasterConfig.MasterOutputTrigger = TIM_TRGO_RESET;sMasterConfig.MasterSlaveMode = TIM_MASTERSLAVEMODE_DISABLE;if (HAL_TIMEx_MasterConfigSynchronization(&htim2, &sMasterConfig) != HAL_OK){Error_Handler();}sConfigOC.OCMode = TIM_OCMODE_PWM1;sConfigOC.Pulse = 300;sConfigOC.OCPolarity = TIM_OCPOLARITY_HIGH;sConfigOC.OCFastMode = TIM_OCFAST_DISABLE;if (HAL_TIM_PWM_ConfigChannel(&htim2, &sConfigOC, TIM_CHANNEL_3) != HAL_OK){Error_Handler();}/* USER CODE BEGIN TIM2_Init 2 *//* USER CODE END TIM2_Init 2 */HAL_TIM_MspPostInit(&htim2);}第一张图是pulse设置为300,第二张图是设置为800。

2.示例二: PWM互补输出,带死区
PWM互补输出带死区的通俗解释
一、PWM互补输出:一开一闭的“双人舞”
想象有两个开关(比如H桥的上下桥臂),它们的动作必须完全相反:当开关A打开时,开关B必须关闭,反之亦然。
PWM互补输出就是通过定时器生成两路完全反向的PWM信号,分别控制这两个开关。例如:
- 主信号高电平 → 上桥臂导通(电流流向负载)
- 互补信号低电平 → 下桥臂关闭(避免短路)
- 主信号低电平 → 下桥臂导通(电流反向流动)
这种互补关系就像两个人交替开合门,确保电流始终有正确的流动路径,常用于电机正反转、逆变器等场景。
二、死区时间:防止“打架”的安全间隔
虽然理论上互补信号应该无缝切换,但现实中开关元件(如MOSFET、IGBT)存在物理延迟:
- 关闭需要时间(比如0.1微秒)
- 开启也需要时间(比如0.05微秒)
问题:如果两路信号切换时没有间隔,可能出现短暂的上下桥同时导通 → 电源直接短路 → 烧毁元件!
解决:在两路信号切换时插入一段死区时间(Dead Time),让两个开关都短暂关闭,确保安全。
示例:
- 主信号从高变低 → 上桥开始关闭
- 死区时间开始(比如1微秒)→ 上下桥都强制关闭
- 死区结束后 → 互补信号变高,下桥才开启
三、死区的影响与设置要点
-
必要性:
- 避免短路和元件损坏(核心作用)
- 减少电流突变导致的电磁干扰
-
副作用:
- 实际输出波形会有微小中断 → 可能影响控制精度(占空比需补偿)
- 死区时间越长,系统效率越低(需平衡安全与性能)
-
设置规则:
- 根据元件开关延迟(参考元件手册)
- 高温环境需延长死区(元件关闭更慢)
- 典型值:IGBT常用3微秒以上,MOSFET约1微秒
四、实际应用场景
- 电机驱动:H桥电路控制电机正反转(互补信号驱动上下桥臂)
- 逆变器:将直流电转为交流电(互补PWM生成正弦波)
- 电源转换:防止开关电源中上下管直通短路
技术细节补充:
- STM32实现:高级定时器(如TIM1)可直接配置互补输出和死区时间,通过寄存器
TIMx_BDTR设置死区时钟周期数。 - 死区计算公式:
- 死区时间 = 关闭延迟时间 - 开启延迟时间 + 安全余量
1. H桥的基本工作逻辑
H桥由四个开关(如MOS管)组成,形状像字母H,中间的横杠是电机。
- 正转:左上和右下开关导通(Q1和Q4),电流从左上→电机→右下→地,电机正转。
- 反转:右上和左下开关导通(Q2和Q3),电流方向相反,电机反转。
问题根源:如果同一侧的两个开关(如左上和左下Q1和Q2)同时导通,电流会直接从电源正极→Q1→Q2→地,形成短路!这就像把电源正负极用导线直接连起来,瞬间电流极大,烧毁元件。
2. 为什么会发生上下桥短路?
原因①:开关的物理延迟
MOS管或三极管不是“瞬间开关”,关闭需要时间(比如0.1微秒)。例如:
- 切换方向时:假设正转切换为反转,Q1和Q4需要关闭,Q2和Q3需要开启。
- 实际场景:如果Q1还没完全关闭,Q2就已经开启,电流会从Q1→Q2→地,形成短路。
原因②:控制信号不同步
- 如果用普通PWM信号控制,可能因软件逻辑错误或信号干扰,导致同一侧的两个开关同时收到“开启”信号。
3. 如何避免短路?
方案①:死区时间(安全间隔)
在切换开关时,插入一段“双方都关闭”的时间(比如1微秒),确保上一个开关完全关闭后,再开启下一个开关。
- 类似场景:交通信号灯切换时,红灯和绿灯之间会有黄灯作为过渡,防止两方向车流相撞。
方案②:互锁电路(硬件保护)
用逻辑电路(如与非门)保证同一侧的开关信号永远互斥,一个开启时另一个强制关闭。
- 类似场景:电梯门的开关按钮,按“开”时“关”自动失效。
方案③:专用驱动芯片
例如L298N、HIP4081等芯片,内置死区时间和互锁逻辑,直接输出安全信号。
4. 实际应用中的典型错误
- 案例1:用分立元件搭建H桥,忘记设置死区时间,切换方向时烧毁MOS管。
- 案例2:使用低端MOS管驱动大电流电机,关断延迟过长,死区时间不足导致短路。
总结:H桥设计的核心安全法则
- 时序为王:死区时间必须覆盖开关元件的物理延迟。
- 硬件兜底:用互锁电路或专用芯片强制避免信号冲突。
- 测试验证:用示波器观察信号切换时的实际间隔,确保无重叠。
一句话记忆:H桥切换方向时,一定要“关完再开”,否则电流狂欢,元件火葬场!🔥
通过这种机制,系统既能高效控制功率,又能避免硬件损毁,是电力电子设计的核心保护措施。
详细设置见代码和cubemx工程,下图为带死区的PWM互补输出。
在MX_TIM1_Init()中设置如下代码,即可更改死区时间
sBreakDeadTimeConfig.DeadTime = 20;死区的计算方式如下图所示,详细见参考手册。

1. 死区时间的作用
死区时间就是防止H桥上下管同时导通的“安全间隔”,就像红绿灯切换时中间的黄灯时间,避免两方向的车(电流)相撞。
- 核心目标:确保上管完全关闭后,下管才开启,防止短路烧毁元件。
2. DTG[7:0]:调节死区时间的“档位旋钮”
- DTG[7:0] 是一个8位的二进制数值(范围0~255),用来控制死区时间的长短。
- 如何计算时间:根据DTG的最高3位(DTG[7:5])的不同值,选择不同的计算公式,类似“档位切换”:
- 档位1(DTG[7:5]=0xx):死区时间 = DTG[7:0] × 单个时间单位(如125ns)。
- 档位2(DTG[7:5]=10x):死区时间 = [64 + DTG[5:0]] × 2 × 时间单位。
- 档位3(DTG[7:5]=110):死区时间 = [32 + DTG[4:0]] × 时间单位。
- 档位4(DTG[7:5]=111):死区时间 = [32 + DTG[4:0]] × 2 × 时间单位。
示例(假设时间单位=125ns):
- 若DTG[7:0]=100(二进制),且档位1:
死区时间 = 100 × 125ns = 12.5微秒。 - 若DTG[7:0]=10100000(二进制,DTG[7:5]=101),则进入档位2:
死区时间 = [64 + 32] × 2 × 125ns = 24微秒。
1. DTG寄存器:死区时间的“多档调节器”
DTG寄存器就像一个多档位的旋钮开关,用8位二进制数(0~255)控制死区时间的长短。它的核心原理是:根据最高3位的值(DTG[7:5])选择不同计算公式,从而适配不同的时间范围和精度需求。
类比:就像汽车的档位(1档低速高精度,4档高速低精度),DTG的四个档位对应不同的时间范围和调节方式。
2. 四档位的具体规则
档位1(DTG[7:5]=0xx)
- 条件:最高3位是
0xx(例如000、001等)。 - 公式:死区时间 = DTG[7:0] × 时间单位(如125ns)。
- 特点:小范围高精度,适合精细调节。
示例:
若DTG=100(二进制),时间单位=125ns:
死区时间 = 100 × 125ns = 12.5微秒。
档位2(DTG[7:5]=10x)
- 条件:最高3位是
10x(例如100、101等)。 - 公式:死区时间 = [64 + DTG[5:0]] × 2 × 时间单位。
- 特点:中等范围中精度,适合常规需求。
示例:
若DTG=10100000(二进制),最高3位是101,时间单位=125ns:
DTG[5:0]=32(低6位),死区时间 = (64+32) × 2 × 125ns = 24微秒。
档位3(DTG[7:5]=110)
- 条件:最高3位是
110。 - 公式:死区时间 = [32 + DTG[4:0]] × 8 × 时间单位。
- 特点:大范围低精度,适合粗调。
示例:
若时间单位=13.89ns(72MHz时钟),DTG[4:0]=31:
死区时间 = (32+31) × 8 × 13.89ns ≈ 7微秒。
档位4(DTG[7:5]=111)
- 条件:最高3位是
111。 - 公式:死区时间 = [32 + DTG[4:0]] × 16 × 时间单位。
- 特点:超大范围粗糙调节,适合极端需求。
示例:
若时间单位=13.89ns,DTG[4:0]=31:
死区时间 = (32+31) × 16 × 13.89ns ≈ 14微秒。
3. 时间单位与时钟频率的关系
- 时间单位 = 1/系统时钟频率。例如:
- 72MHz时钟 → 时间单位=1/72MHz≈13.89ns。
- 若示例中使用125ns,可能是外部时钟或分频后的结果。
- 调节范围:从几纳秒到上百微秒,覆盖常见硬件需求。
4. 实际配置技巧
- 根据硬件需求选档位:
- 小死区时间(3微秒以内)→ 档位1或2。
- 大死区时间(7微秒以上)→ 档位3或4。
- 计算DTG值:
- 先确定所需死区时间,再反推DTG二进制值(如示例中的24微秒对应DTG=0xAC)。
- 验证:用示波器观察PWM信号,确保死区无重叠。
总结
DTG寄存器通过分档位+公式组合,灵活适配不同场景的死区时间需求。就像调节音量旋钮时选择“精细微调”或“快速粗调”,既能保护硬件安全,又能平衡控制精度和效率。
3. 时间范围和步长(类似“量程切换”)
当时间单位=125ns时,不同档位对应不同的时间范围和调节精度:
- 小范围高精度:0~15.875微秒,步长125ns(适合精细调节)。
- 中等范围中精度:16~31.75微秒,步长250ns。
- 大范围低精度:32~63微秒,步长1微秒。
- 超大范围粗糙调节:64~126微秒,步长2微秒。
类比:像手表调节时间的旋钮,有的档位适合调秒(精确),有的档位适合调小时(快速)。
4. LOCK位:死区时间的“防误触锁”
- LOCK位(在TIMx_BDTR寄存器中)是保护开关,设置为1、2或3时,禁止修改死区时间设置。
- 作用:防止程序跑飞或误操作意外修改死区时间,导致硬件损坏。
- 使用方法:先配置好死区时间,最后再设置LOCK位锁定。
5. 配置步骤总结
- 选档位:根据需要的死区时间范围,确定DTG[7:5]的取值(0xx/10x/110/111)。
- 算数值:用公式计算DTG[7:0]的二进制值。
- 写寄存器:将DTG值写入TIMx_BDTR寄存器的DTG[7:0]位。
- 上锁:设置LOCK位(如LOCK=1)保护配置。
避坑指南:
- 死区时间必须大于开关元件的关闭延迟(参考元件手册)。
- 测试时用示波器观察实际信号间隔,验证配置是否正确。
一句话总结
这段说明书教你如何用“档位+数值”精确调节H桥的安全间隔(死区时间),并提醒配置后要上锁,防止误改引发炸管!
3. 作业
这里仅展示了PWM的部分功能,更多详细的可以看官方的手册和官方的例程。
感兴趣可以尝试下如何生成SPWM,完成呼吸灯的效果。
Cube AI Demo
该例程使用Cube AI套件,在STM32上运行一个神经网络,功能实现分为以下几个步骤:
一、搭建一个神经网络
1. 模型搭建
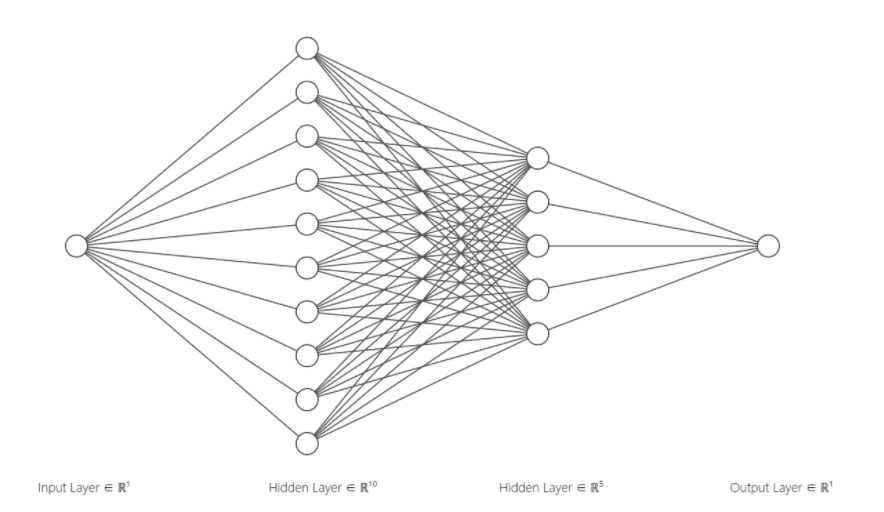
这里是我们的目标是预测正弦函数。给定一个输入,范围(0, 180),输出其对应的正弦值范围(0, 1)。搭建的网络结构如下图所示:
2. 生成sin(x)数据,进行模型的训练
在./python_code文件夹中已经给出所有的文件,请自行查看。在这里生成sin(x)的一系列数据后,使用keras框架搭建模型进行训练,激活函数使用tanh,没有使用sigmod是因为其不能表达负数的部分。学习率设置为0.001,epoch设置为2000。最后生成.h5和.tflite文件。
#导入工具包import tensorflow as tfimport pandas as pdimport numpy as np#读取数据data = pd.read_csv('./Embedded_things/sin_values.csv', sep=',', header=None)raw_x = data.iloc[:,0].astype(float)sinex = data.iloc[:,1].astype(float)print(sinex.shape)#建立模型model = tf.keras.Sequential()model.add(tf.keras.layers.Dense(units=10, activation='tanh', input_shape=(1,)))model.add(tf.keras.layers.Dense(units=5, activation='tanh'))model.add(tf.keras.layers.Dense(units=1))model.summary()model.compile(optimizer=tf.keras.optimizers.AdamW(0.001),loss=tf.keras.losses.mse, #loss使用均方差,刚才的分类用的交叉熵metrics=[tf.keras.metrics.mse])history = model.fit(x=raw_x, y=sinex, epochs=2000)print(model.evaluate(raw_x, sinex))#保存模型model.save('./Embedded_things/sine_calcu.h5')#转换模型为tf lite格式 不量化load_model = tf.keras.models.load_model('./Embedded_things/sine_calcu.h5')converter = tf.lite.TFLiteConverter.from_keras_model(load_model)tflite_model = converter.convert()open("./Embedded_things/sine_calcu.tflite", "wb").write(tflite_model)如果想测试一下模型,可以看一下test.py,这里就不过多进行阐述。以下是在./python_code中所有的文件,读者请自行查阅。
二、STM32工程创建
1.打开CubeMX,把常规的设置都设置好,打开串口等
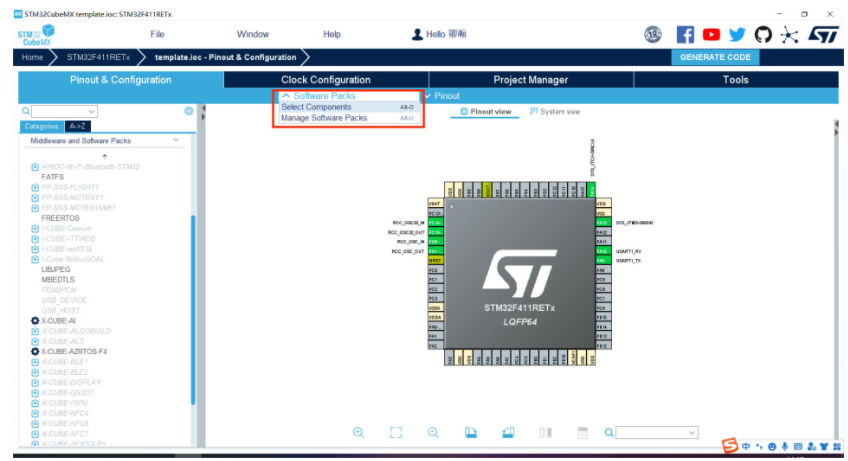
2.打开select components,选上X-CUBE-AI
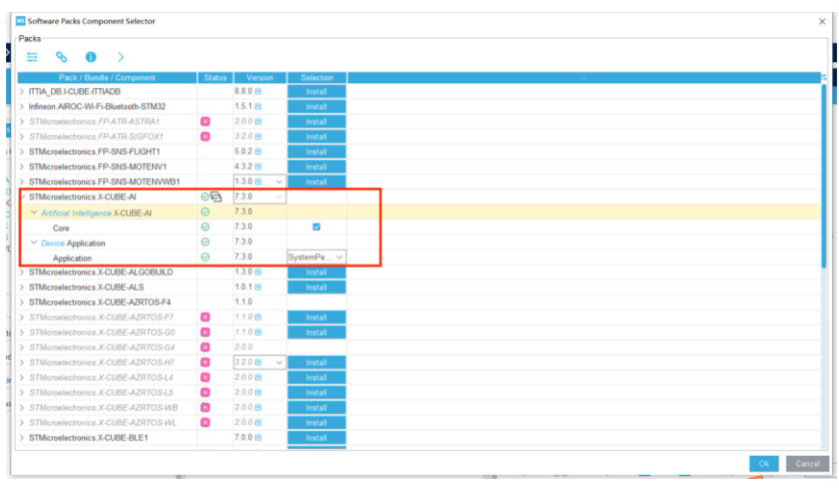
3.添加网络,选择你的模型(.h5或.tflite),再进行验证
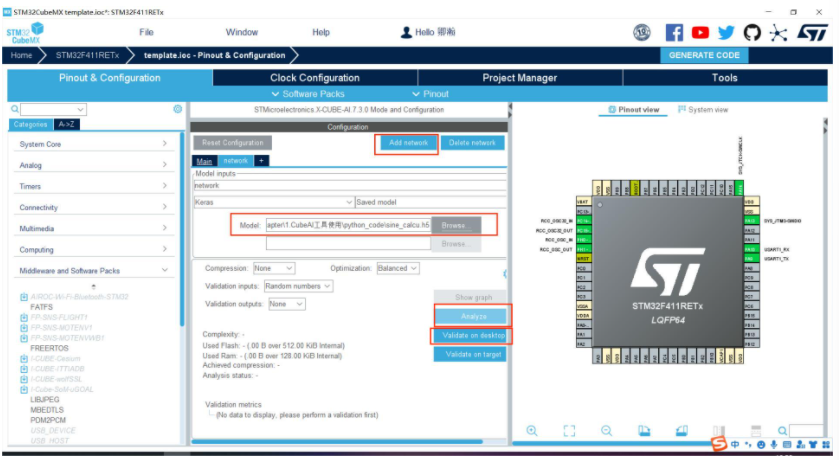
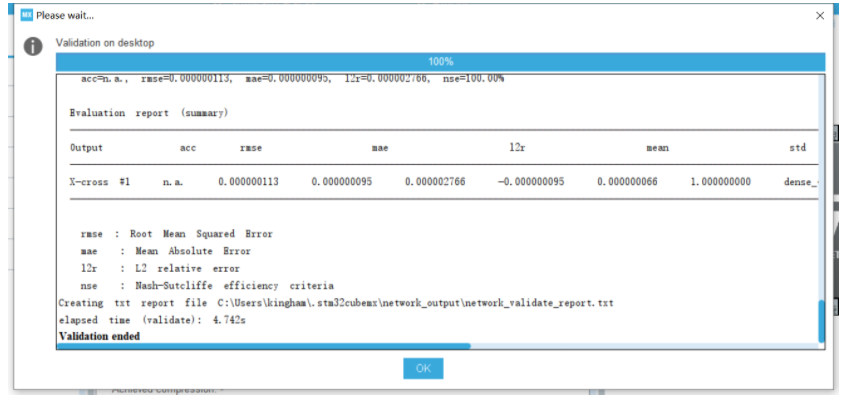
4.生成工程
5.更改代码
在main中,找到MX_X_CUBE_AI_Process()函数,然后更改其中的aiSystemPerformanceProcess()函数,更改为如下内容,其具体含义读者可以阅读手册或看API深入了解,这里不过多阐述。
int aiSystemPerformanceProcess(void){int idx = 0;int batch = 0;float y_pred;ai_buffer ai_input[AI_MNETWORK_IN_NUM];ai_buffer ai_output[AI_MNETWORK_OUT_NUM];ai_float input[1] = {0}; // initialai_float output[1] = {0};if (net_exec_ctx[idx].handle == AI_HANDLE_NULL){printf("E: network handle is NULL\r\n");return -1;}ai_input[0] = net_exec_ctx[idx].report.inputs[0];ai_output[0] = net_exec_ctx[idx].report.outputs[0];//ai_float test_data[] = {0, 1, 2, 3, 4, 5, 6, 7};uint16_t i=0;while(i<=180){i++;if(i == 180){i=0;}input[0] = i;output[0] = 0;ai_input[0].data = AI_HANDLE_PTR(input);ai_output[0].data = AI_HANDLE_PTR(output);batch = ai_mnetwork_run(net_exec_ctx[idx].handle, &ai_input[0], &ai_output[0]);if (batch != 1){aiLogErr(ai_mnetwork_get_error(net_exec_ctx[idx].handle),"ai_mnetwork_run");break;}y_pred = sin(input[0]*acos(-1)/180);printf("input, y_pre, y_ture: %.2f, %.2f, %.2f\r\n", input[0], output[0], y_pred);HAL_Delay(100);}}整个代码就像钟表齿轮生产线
int 智能校时系统(void)
{// 初始化生产线int 当前工位 = 0; // 只启用第一条生产线float 标准时间; // 瑞士天文台认证时间时间原料 待加工角度 = {0}; // 待组装的齿轮角度(0-180度)成品表针 预测结果 = {0}; // 组装完成的表针位置// 检查精密机床是否就绪if (校时机床.状态 == 未启动) {printf("精密校准仪故障!\n");return -1; // 紧急停止生产线}// 连接加工设备进料传送带 = 校时机床.原料入口;成品出口 = 校时机床.成品出口;// 启动永动流水线uint16_t 当前角度=0;while(持续运转){当前角度++; // 齿轮转动1度if(当前角度 == 180) 当前角度=0; // 完成半圈自动复位// 原料装载待加工角度 = 当前角度; // 装入待加工的齿轮角度成品表针 = 0; // 清空成品托盘// 精密加工(AI预测)加工状态 = 启动校时机床(进料传送带, 成品出口);if(加工异常){触发警报(校时机床.故障代码);break;}// 天文台认证标准时间 = 正弦函数(角度转弧度(当前角度)); // 获取瑞士标准printf("角度:%03d° | AI指针:%.2f | 天文台标准:%.2f\n", 当前角度, 成品表针, 标准时间);维持流水线节奏(100ms); // 控制每分钟60转}
}核心环节详解
-
设备检查:
- 如同钟表厂每日开机前的设备巡检,确保校时机床(神经网络)已正确加载
-
流水线运转:
- 齿轮持续转动0°→180°→0°,模拟钟表运作:
while(当前角度 <= 180) {当前角度++;if(当前角度 == 180) 复位归零; // 类似钟表走到6点位置后回弹 }
- 齿轮持续转动0°→180°→0°,模拟钟表运作:
-
AI校时机制:
- 进料:将当前齿轮角度送入传送带(
input[0] = i) - 加工:校时机床用神经网络"打磨"角度(
ai_mnetwork_run) - 出料:获得表针预测位置(
output[0])
- 进料:将当前齿轮角度送入传送带(
-
双重认证系统:
- 同时用数学公式计算标准值,如同:
- 普通手表 VS 瑞士天文台认证
- 预测结果 VS 真实正弦值
- 实时打印对比,像质检员在流水线终点比对:
角度:090° | AI指针:1.00 | 天文台标准:1.00 角度:123° | AI指针:0.84 | 天文台标准:0.83
- 同时用数学公式计算标准值,如同:
-
精密节奏控制:
HAL_Delay(100)如同瑞士钟表的摆轮擒纵机构,确保每100ms处理1度,维持精准节奏
这个比喻的巧妙之处
- 动态演示:像观赏透明机械表,直观看到齿轮联动过程
- 误差可视化:表针位置偏差类似机械表的日误差显示
- 嵌入式特性:
- 单一加工程序对应简单结构(0-180度循环)
- 异常处理如同防震装置,遇到剧烈震动自动停摆
- 内存管理像高效利用表壳内的有限空间
实际运行效果
当连接示波器时,会看到如同时光机般的场景:
角度:000° | AI指针:0.00 | 标准:0.00 ← 12点位置
角度:030° | AI指针:0.50 | 标准:0.50 ← 1点位置
角度:090° | AI指针:1.00 | 标准:1.00 ← 3点位置(顶端)
角度:150° | AI指针:0.50 | 标准:0.50 ← 5点位置
角度:180° | AI指针:0.00 | 标准:0.00 ← 6点位置就像有个隐形的瑞士制表师,在芯片内部持续校准着这个"AI机械表",既展示科技之美,又暗藏传统钟表匠的精密追求。
5.验证
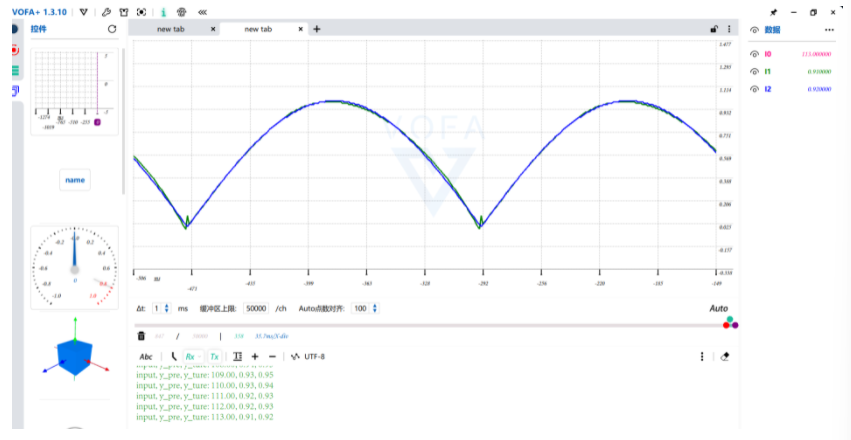
通过串口传数据到上位机VAFA,其中蓝色的线为准确的sin(x)的值,绿色的为模型输出的值,可以看到拟合的比较好,但是在接近sin(x)=0的附近,拟合的比较不好。
一、神经网络部分(相当于训练"计算器")
-
目标:输入一个角度(0-180度),输出对应的正弦值(0-1)
-
模型结构:
- 类似三层过滤网:
- 第一层:10个"计算单元"(神经元)
- 第二层:5个"计算单元"
- 第三层:输出结果
- 使用tanh激活函数(既能处理正数也能处理负数,比sigmoid更适合)
- 类似三层过滤网:
-
训练数据:
- 用0-180度的正弦值作为训练数据(类似给计算器输入标准答案)
- 训练2000遍(相当于反复做题直到学会)
-
输出结果:
- 生成两个文件:.h5(完整模型文件)和.tflite(精简版,专为嵌入式优化)
二、STM32运行部分(把"计算器"装进硬件)
-
硬件配置:
- 使用STM32CubeMX(图形化配置工具)设置芯片功能
- 添加X-CUBE-AI插件(相当于给STM32安装AI运行环境)
-
部署模型:
- 导入训练好的.tflite文件
- 自动生成可在STM32上运行的C代码(把数学计算转换成芯片能理解的指令)
-
核心代码逻辑:
循环0-180度 {输入当前角度 → 神经网络计算 → 输出预测值同时计算真实正弦值(用于对比)通过串口发送数据到电脑显示 }
三、实际效果
- 在电脑上看到两条曲线:
- 蓝色:真实的正弦曲线(数学计算)
- 绿色:神经网络预测的曲线
- 整体拟合良好,但在接近0度/180度时误差较大(可能因为数据分布不均匀或模型容量有限)
四、类比理解
想象训练一个"智能计算器":
- 先让它在电脑上学会计算正弦函数(训练模型)
- 然后把这个计算器的"大脑"移植到STM32芯片里
- 最后通过串口观察它的计算是否准确
整个过程展示了如何把人工智能算法落地到真实的硬件设备上,是嵌入式AI开发的典型流程。
手写数字识别 MNIST Demo
该例程使用触摸屏p169h002-ctp,在LCD上进行手写数字,再进行手写数字的识别。动态演示图如下所示:

MNIST是一个非常经典的机器学习的入门案例,本demo将会使用keras进行训练,导出模型部署到FryPie炸鸡派上。
一、文件夹组成
├─python_codes│ │ mnist.npz│ │ mnist.h5│ │ train.py│ └─stm32_codes├─MNIST文件夹大致如上,python_codes存放的是:train.py用于训练网络,mnist.npz为网上找的下载的MNIST数据集,用于网络的训练和测试,最后训练好的模型保存为mnist.h5。
二、触摸屏手写显示在LCD
屏幕的大小是240×280,使用上240×240部分作为绘制板,用于手写显示,下面240×40的部分用于显示识别的结果。读取点与绘制如下代码所示。由于CST816读取频率问题,绘制的触摸点与点的距离会有一定距离,同时1×1的点非常小,因此,需要对点进行膨胀,都变为8×8的黑点绘制到LCD上,其中SCALL_RATE为8。同时,这里也要完成originalImage数组的填充,作为原始的图片数据。
当然,还有一个问题,如果手写滑动速度太快,就算扩充成了8×8,点与点的距离远了看起来还是很明显,所以推荐再做处理,将没相连的黑点连接在一起。
时间采样率低(触摸点采集频率)和空间膨胀(8x8 方块)是两个维度的处理,但它们通过互补解决了同一个问题。我来拆解背后的原理:
1. 时间采样率低导致的问题
假设触摸屏每秒采样 10 次(实际可能更高,但原理相同):
- 快速滑动时:比如手指以 20像素/毫秒 的速度移动,两次采样间隔 100ms,手指移动了
20px/ms * 100ms = 2000px(远超屏幕宽度)。 - 实际场景:极端情况下,两次采样点可能相距很远(比如点 A 和点 B 相隔 100 像素),形成断裂的轨迹。
2. 空间膨胀如何弥补时间间隔
将每个采样点膨胀为 8x8 的方块,本质是 用空间覆盖时间不足:
- 假设两次采样点相距 15 像素(比如点 A 在 (10,10),点 B 在 (25,10)):
- 未膨胀时:两个点独立,中间有 15 像素的空白。
- 膨胀后:点 A 的 8x8 方块覆盖 (10±4, 10±4),点 B 的方块覆盖 (25±4,10±4)。
- 结果:两个方块在 X 轴上的覆盖范围是
6~14和21~29,中间仍有间隙(14~21 之间空白)。
- 但如果点间距 ≤ 膨胀尺寸:
- 比如点间距 8 像素,膨胀后的方块会边缘重叠,覆盖中间空白。
3. 为什么实际中能“看起来连续”
- 人类书写速度有限:正常手写数字时,手指移动速度不会极快(比如每秒滑动 1000 像素)。
- 膨胀尺寸的巧妙设计:
- 8x8 方块的尺寸(约屏幕的 3.3%)是根据典型书写速度和设备采样率平衡后的结果。
- 在大多数实际书写场景中,两次采样点的间距会被膨胀后的方块覆盖或部分重叠,视觉上形成连续线条。
4. 数学视角:覆盖间隙的条件
设:
- 采样时间间隔:
Δt秒 - 手指移动速度:
v像素/秒 - 膨胀方块边长:
s像素
两次采样点间距:d = v * Δt
覆盖间隙的条件:s ≥ d
如果满足此条件,膨胀后的方块会完全覆盖两次采样点之间的间隙。
实际设计:
- 假设
Δt = 0.01秒(100Hz 采样率),v = 500像素/秒(极快滑动),则d = 5像素。 - 若
s = 8像素,则8 ≥ 5,可以覆盖间隙。
5. 为什么不用插值算法?
插值算法(比如在两点间补全线段)是更精确的方案,但:
- 计算资源消耗大:嵌入式设备(如 STM32)的算力有限,插值需要实时计算线段上的所有点。
- 膨胀法简单粗暴:直接填充方块只需极低计算量,适合资源受限的设备。
总结:时空互补的工程思维
- 时间不足(低采样率) → 空间来补(膨胀覆盖)
- 用空间换时间:通过扩大每个点的空间影响范围,弥补时间采样间隔的不足。
- 平衡设计:膨胀尺寸 (
s=8) 是根据设备性能(采样率)和典型使用场景(手写速度)综合权衡的结果。
if(CST816_Get_FingerNum()!=0x00 && CST816_Get_FingerNum()!=0xFF){if(!reg_state){CST816_Get_XY_AXIS();if(CST816_Instance.X_Pos > SCALL_RATE/2 && CST816_Instance.Y_Pos > SCALL_RATE/2){for(uint8_t i=0; i<SCALL_RATE; i++){for(uint8_t j = 0; j < SCALL_RATE; j++){originalImage[(CST816_Instance.X_Pos - SCALL_RATE/2 + j) + (CST816_Instance.Y_Pos - SCALL_RATE/2 + i)*240] = 0xFF;}}LCD_Fill(CST816_Instance.X_Pos - SCALL_RATE/2, CST816_Instance.Y_Pos - SCALL_RATE/2,CST816_Instance.X_Pos + SCALL_RATE/2, CST816_Instance.Y_Pos + SCALL_RATE/2, BLACK);}} }
三、模型训练
搭建的模型如下所示,使用的手写数字MNIST数据集在网上很多,可以在kaggle上直接找数据集。训练完生成.h5模型最后需要部署到STM32上。

#------------------------------【搭模型】---------------------------------model = tf.keras.models.Sequential([tf.keras.layers.Conv2D(filters=3, kernel_size=(5, 5), padding='valid', activation=tf.nn.relu, input_shape=(30, 30, 1)),tf.keras.layers.MaxPool2D(pool_size=(2, 2), padding='same'),tf.keras.layers.Flatten(),tf.keras.layers.Dense(units=32, activation=tf.nn.relu),tf.keras.layers.Dense(units=16, activation=tf.nn.relu),tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)])model.summary()四、数据处理,模型部署
由于数据量的问题,需要吧240×240的数据压缩成30×30的数据,不然模型的参数量会非常的庞大,STM32上根本跑不了。下采样如下代码所示,这里是一个平均值池化,将240×240的图像数据压缩为30×30,原来的originalImage[]为uint8_t类型,压缩的compressedImage[]为float型。最后再将compressedImage[]输入到模型的API接口,得到输出找到最大值对应的index即为识别到的数字。
void downsample(uint8_t * originalImage, float * compressedImage) {for (int i = 0; i < COMPRESSED_SIZE; i++) {// 计算原始图片区域的左上角坐标int start_x = (i % 30) * (8); // 每行240个像素压缩成30个像素int start_y = (i / 30) * (8); // 每列240个像素压缩成30个像素// 计算原始图片区域的右下角坐标int end_x = start_x + 8; // 30 / 240 = 0.125,8 = 240 * 0.125int end_y = start_y + 8;// 计算原始图片区域内像素的平均值int sum = 0;for (int x = start_x; x < end_x; x++) {for (int y = start_y; y < end_y; y++) {sum += originalImage[x + y * 240];}}compressedImage[i] = sum / 64; // 8*8=64//normcompressedImage[i] /= 255;}}
场景设定
想象你有一幅巨大的 240x240像素 的壁画(originalImage),现在需要把它缩小成 30x30像素 的马赛克小画(compressedImage)。每个马赛克小块是原画的 8x8像素区域,颜色取这个小块的平均色。这段代码就是完成这个缩小的魔法咒语。
分步拆解:制作马赛克壁画
1. 划分马赛克格子
// 第i个马赛克块对应原画的位置
int start_x = (i % 30) * 8; // 马赛克列号 × 8 → 原画起始列
int start_y = (i / 30) * 8; // 马赛克行号 × 8 → 原画起始行- 比喻:把原画分成30行30列的格子(共900格),每格大小8x8像素。
- 比如第5行第3列的马赛克块,对应原画的位置是:
- 起始列:
3 * 8=24 - 起始行:
5 * 8=40 - 范围:原画的第40-47行,24-31列(共8x8=64像素)。
- 起始列:
- 比如第5行第3列的马赛克块,对应原画的位置是:
2. 计算小格子的平均颜色
int sum = 0;
for (int x = start_x; x < start_x+8; x++) {for (int y = start_y; y < start_y+8; y++) {sum += originalImage[x + y*240]; // 累加这64个像素的值}
}
compressedImage[i] = sum / 64; // 计算平均值- 比喻:
- 你带一群助手统计这个小块的颜色:
- 黑色像素(0xFF)算255分,白色(0x00)算0分,灰色按深浅打分。
- 所有人报数后,计算平均分 → 这就是马赛克块的颜色。
- 例如:64个像素中有32个全黑(255),32个全白(0),平均分是
(32×255 + 32×0)/64 = 127.5。
- 你带一群助手统计这个小块的颜色:
3. 归一化:把分数转换成标准比例
compressedImage[i] /= 255; // 0-255 → 0-1- 比喻:
- 原来分数是0-255分,现在统一除以255,变成0-1分。
- 比如127.5 →
127.5/255 = 0.5,表示中灰色。 - 为什么:AI模型习惯处理0-1的小数,就像人习惯用百分比(0%-100%)而不是具体数值。
动态示例:缩小数字“7”
- 原画:240x240的手写“7”,笔画粗细约8像素。
- 马赛克处理:
- 某马赛克块覆盖“7”的竖笔部分,其中50个像素是黑色(255),14个是灰色(127)。
- 平均分:
(50×255 + 14×127)/64 ≈ 209.3→ 归一化后209.3/255 ≈ 0.82。
- 结果:马赛克小画中这个块显示深灰色,代表这里原本是较黑的区域。
为什么是8x8?数学对应
- 原画240x240 → 压缩后30x30
- 每边缩小比例:
240/30 = 8 - 因此每个马赛克块对应原画的8x8区域。
- 每边缩小比例:
总结:三步完成“视觉压缩”
- 切块:把大画切成900个8x8的小豆腐块。
- 算平均:给每个豆腐块打平均分。
- 标准化:把分数压缩到0-1之间,方便AI处理。
就像把高清照片变成乐高积木拼图——保留轮廓,丢掉细节,但依然能认出图案! 🧩
场景设定
想象你有一块电子白板(LCD屏幕),和一个魔法印章(触摸屏传感器CST816)。当你用手指按印章时,它会在白板上盖一个 8x8的黑色方块(而不是只画一个点)。这段代码就是控制盖章过程的魔法咒语。
代码拆解:分步解释
1. 魔法印章检测手指
if(CST816_Get_FingerNum()!=0x00 && CST816_Get_FingerNum()!=0xFF)- 行为:检查魔法印章是否被按下。
- 比喻:
0x00:印章完全没被碰到(手指离开)。0xFF:印章坏了或数据错误(比如被猫踩了)。- 条件:只有当手指真实按压时(既不是未触碰,也不是错误状态),才执行盖章。
2. 防重复盖章(状态锁)
if(!reg_state)- 行为:检查是否已经处理过这次按压(防止一次按压重复盖章多次)。
- 比喻:
reg_state像一把锁:- 锁打开(
reg_state=0)→ 允许盖章。 - 锁关闭(
reg_state=1)→ 禁止重复操作。
- 锁打开(
3. 获取盖章位置
CST816_Get_XY_AXIS();- 行为:读取手指按压的坐标(
X_Pos和Y_Pos)。 - 比喻:魔法印章通过感应,告诉你手指按在白板的哪个位置(比如坐标(50,100))。
4. 检查边界(防止盖章出界)
if(CST816_Instance.X_Pos > 4 && CST816_Instance.Y_Pos > 4)- 假设
SCALL_RATE=8,则SCALL_RATE/2=4。 - 行为:确保盖章位置距离白板边缘至少4像素,避免8x8方块越界。
- 比喻:不让印章盖到白板的边框上(比如坐标(3,5)太靠左,8x8方块会超出左边界)。
5. 在白板上画8x8方块(盖章!)
// 循环画8x8的方块
for(uint8_t i=0; i<8; i++) {for(uint8_t j=0; j<8; j++) {// 计算方块中每个点的位置int x = 手指X坐标 - 4 + j; // j从0到7,覆盖X方向8个点int y = 手指Y坐标 - 4 + i; // i从0到7,覆盖Y方向8个点// 在内存中标记这些点为黑色(0xFF)originalImage[x + y*240] = 0xFF;}
}
// 在LCD上显示这个方块
LCD_Fill(手指X-4, 手指Y-4, 手指X+4, 手指Y+4, BLACK);- 关键点:
-
originalImage数组:相当于白板的“数字底稿”,记录哪里被涂黑(240x240像素)。 -
x + y*240:因为屏幕每行有240个像素,y*240跳到第y行,x是行内的横向位置。 - LCD_Fill:在屏幕上实际绘制黑色方块,让人眼能看到。
-
场景设定
想象你有一张巨大的方格纸(240行 x 240列),每个格子代表一个像素。当你用手指触碰某个位置时,你需要在纸上以这个位置为中心,用黑色蜡笔涂满 8x8的方格区域。这段代码就是实现这个填色规则的魔法咒语。
拆解代码:方格纸的坐标计算
originalImage[ (X中心 -4 + j) + (Y中心 -4 + i)*240 ] = 0xFF;假设:
- 手指触碰中心坐标为
(X_Pos=50, Y_Pos=100) SCALL_RATE=8(8x8区域),所以SCALL_RATE/2=4
1. 确定涂色区域的左上角起点
- X方向起点:
50 - 4 = 46 - Y方向起点:
100 - 4 = 96
这相当于在方格纸上,从第96行、第46列开始涂色。
2. 遍历8x8的每个小格子
i控制行(从0到7),j控制列(从0到7)- 对于每个小格子,计算它在方格纸上的坐标:
- X坐标:
46 + j(j从0到7 → 46到53列) - Y坐标:
96 + i(i从0到7 → 96到103行)
- X坐标:
3. 将二维坐标转换为一维索引
方格纸在内存中是一维数组originalImage,总共有 240x240=57,600 个格子。转换规则如下:
- 每行有240列:第
Y行的起始索引是Y*240 - 第
X列的偏移量:直接加上X - 最终索引:
X + Y*240
举例:涂第96行、第46列的格子:
- 索引 =
46 + 96 * 240 - 计算过程:
96行 x 每行240格 = 23,040→23,040 + 46 = 23,086 originalImage[23086] = 0xFF(涂黑这个格子)
动态演示:涂满8x8区域
- i=0, j=0 → 涂(46,96) → 索引=46+96 * 240
- i=0, j=1 → 涂(47,96) → 索引=47+96 * 240
- ...
- i=7, j=7 → 涂(53,103) → 索引=53+103 * 240
最终效果:以(50,100)为中心,涂满从(46,96)到(53,103)的8x8区域。
比喻:快递仓库的货架编号
- 仓库:一个超长货架(一维数组
originalImage),有57,600个位置。 - 货架规则:
- 每行有240个箱子(列),共240行(行)。
- 第
Y行的箱子从编号Y*240开始,比如第0行是0-239号,第1行是240-479号,依此类推。
- 涂色任务:找到第96行第46列的箱子,它的编号是
46 + 96 * 240 = 23,086,然后贴上黑色标签(0xFF)。
为什么这样设计?
- 一维数组更节省内存:计算机内存本质是一维的,二维数组需要转换。
- 快速计算:乘法和加法比二维数组的嵌套循环更快,适合嵌入式设备。
总结
这行代码就像在说:
“从(X-4, Y-4)开始,把接下来8行8列的所有格子,在内存的一维货架中找到对应编号,全部贴上黑色标签!”
完整流程比喻
- 检测按压:你用手指按了一下魔法印章。
- 检查状态:确认这是新的一次按压(而不是上次的残留信号)。
- 读取坐标:印章告诉你按在了(50,100)位置。
- 检查边界:发现50-4=46 >0,100-4=96 >0,位置合法。
- 盖章动作:
- 在内存的
originalImage数组中,把(46到53, 96到103)区域全部标记为黑色。 - 让白板立刻显示这个8x8的黑色方块。
- 在内存的
为什么用8x8?
- 防断线:如果只画1x1的点,快速移动时点之间会有空隙。8x8方块像“粗笔头”,即使两次盖章位置相隔几个像素,方块边缘也会重叠,看起来像连续线条。
- 简化计算:8x8的膨胀和下采样(后面压缩成30x30)配合,刚好能被模型处理。
终极总结
这段代码就是:当你触摸屏幕时,系统以触点为中心,盖一个8x8的“墨水章”,同时记录墨水位置到内存,并显示在屏幕上。就像用粗头印章在白板上连续盖章画线!
参考:
FryPi/2.software/1.Basic at master · No-Chicken/FryPi
相关文章:
(GPIO,PWM ,Cube AI,手写数字识别 MNIST,Demo))
Using the CubeMX code (一)(GPIO,PWM ,Cube AI,手写数字识别 MNIST,Demo)
该例程对使用CubeMX初始化GPIO做了示范,GPIO使用HAL库进行GPIO编程分为以下几个步骤: 一、例程简述 1. 包含必要的头文件和HAL库的相关头文件 CubeMX初始化会自动包含,对手敲HAL感兴趣的同学可以熟悉下生成的代码框架学习哦~ 2. 初始化GP…...

【第46节】windows程序的其他反调试手段中篇
目录 引言 一、利用SetUnhandledExceptionFilter/Debugger Interrupts 二、Trap Flag 单步标志异常 三、利用SeDebugPrivilege 进程权限 四、利用DebugObject:NtQueryObject() 五、OllyDbg:Guard 六、Software Breakpoint Detection 引言 在程序反调试领域,存…...

【APM】How to enable Trace to Logs on Grafana?
系列文章目录 【APM】Observability Solution 【APM】Build an environment for Traces, Metrics and Logs of App by OpenTelemetry 【APM】NET Traces, Metrics and Logs to OLTP 【APM】How to enable Trace to Logs on Grafana? 前言 本文将介绍如何在Grafana上启用 …...

第十节:性能优化-如何排查组件不必要的重复渲染?
工具:React DevTools Profiler 方法:memo、shouldComponentUpdate深度对比 React 组件性能优化:排查与解决重复渲染问题指南 一、定位性能问题:React DevTools 高级用法 使用 React Developer Tools Profiler 精准定位问题组件&…...

Spring Boot 项目中发布流式接口支持实时数据向客户端推送
1、pom依赖添加 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId></dependency>2、事例代码 package com.pojo.prj.controller;import com.pojo.common.core.utils.String…...

SpringBoot整合Thymeleaf变量渲染全解析:从基础到高阶实践
Thymeleaf作为SpringBoot官方推荐的模板引擎,其核心价值在于将动态数据无缝注入静态HTML模板。本文将从基础语法到复杂场景,深入剖析Thymeleaf对各种类型变量的渲染机制。 一、环境搭建与基础配置 依赖注入 在pom.xml中引入核心依赖:<dependency><groupId>org.s…...

【verilog】Verilog 工程规范编码模板
这一套【Verilog 工程规范编码模板】,适合写清晰、可维护、可综合的 RTL 代码,适用于 FPGA/ASIC 开发: 📘 Verilog 工程级编码规范模板 1️⃣ 模块结构规范 module my_module #(parameter WIDTH 8 // 模块参数 )(input wire c…...

satoken的奇奇怪怪的错误
发了 /user/getBrowseDetail和/user/getResponDetail,但为什么进入handle里面有三次?且第一次的handle类型是AbstractHandleMapping$PreFlightHttpRequestHandlerxxx,这一次进来的时候flag为false,StpUtils.checkLogin抛出了异常 第二次进来的…...

使用prometheus-operator部署prometheus服务,并对外提供访问
先决条件: 已经部署好k8s #这里我使用的版本是1.28.12 [rootprometheus-operator /zpf/prometheus/kube-prometheus/manifests]$kubectl version Client Version: v1.28.12 Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3 Server Version: v1.28.12安装git服务 #安…...

FPGA阵列
FPGA(现场可编程门阵列)阵列是由多个 FPGA 芯片组成的集合,通过特定的架构和互联方式协同工作,以实现强大的计算和处理能力。以下是关于 FPGA 阵列的详细介绍: 基本原理 FPGA 是一种可重构的集成电路,内部…...

Oracle补丁安装工具opatch更新报错处理
今日,在进行Oracle补丁升级更新opatch工具包后,执行opatch命令出现了如下报错: [oracles203116 ~]$ opatch version /u01/product/oracle/12.1.0/db_1/OPatch/opatch: line 839: [: too many arguments /u01/product/oracle/12.1.0/db_1/O…...

前端笔记-html+css测试2
HTML & CSS 能力测试卷 选择题(每题2分,共20分) 下列哪个HTML5标签用于定义文档的导航链接? A) <nav> B) <navigate> C) <navbar> D) <navigation> CSS中哪个属性用于设置元素的透明度?…...

Visual Studio C++ 常用配置变量表
前言 visual studio中常用配置变量表 帮助你快速查阅,复制粘贴嘎嘎方便! 附上美图!! 一、解决方案 & 项目路径 变量含义示例(典型用法)$(SolutionDir)解决方案文件所在目录(末尾带\)$(S…...

论文阅读VACE: All-in-One Video Creation and Editing
code:https://github.com/ali-vilab/VACE 核心 单个模型同时处理多种视频生成和视频编辑任务通过VCU(视频条件单元)进行实现 方法 视频任务 所有的视频相关任务可以分为4类 文本生视频 参考图片生视频 视频生视频 视频mask生视频 VCU …...
)
【Python Cookbook】迭代器与生成器(一)
迭代器与生成器(一) 1.手动遍历迭代器2.代理迭代3.使用生成器创建新的迭代模式4.实现迭代器协议 1.手动遍历迭代器 你想遍历一个可迭代对象中的所有元素,但是却不想使用 for 循环。 为了手动的遍历可迭代对象,使用 next() 函数并…...

Qwen2.5-VL视觉大语言模型复现过程,没碰到什么坑
视频讲解:Qwen2.5-VL视觉大语言模型复现过程,没碰到什么坑_哔哩哔哩_bilibili Qwen2.5-VL视觉大语言模型复现过程,没碰到什么坑 今天复现下Qwen2.5-VL玩玩 https://github.com/QwenLM/Qwen2.5-VL 创建conda环境,实测22.04&#x…...

LVGL填充函数
lvgl填充函数的位置: static void disp_flush(lv_disp_drv_t * disp_drv, const lv_area_t * area, lv_color_t * color_p) {LCD_Color_Fill(area->x1,area->y1,area->x2,area->y2,(u16*)color_p);lv_disp_flush_ready(disp_drv); }填充函数的具体内容…...

关于 传感器 的详细解析,涵盖定义、分类、工作原理、常见类型、应用领域、技术挑战及未来趋势,结合实例帮助理解其核心概念
以下是关于 传感器 的详细解析,涵盖定义、分类、工作原理、常见类型、应用领域、技术挑战及未来趋势,结合实例帮助理解其核心概念: 一、传感器的定义与核心功能 1. 定义 传感器(Sensor)是一种能够将物理量ÿ…...

回归,git 分支开发操作命令
核心分支说明 主分支(master/production)存放随时可部署到生产环境的稳定代码,仅接受通过测试的合并请求。 开发分支(develop)集成所有功能开发的稳定版本,日常开发的基础分支,从该分支创建特性…...

指形铣刀的结构
指形铣刀,作为机械加工领域中一种至关重要的切削工具,其主要结构类型多样且各具特色,深入学习这些类型对于提升加工效率与精度至关重要。 首先,我们来看看最基本的直柄指形铣刀。这种铣刀的设计简洁明了,其柄部为直线…...
 是Verilog 中写组合逻辑)
【verilog】always @(*) 是Verilog 中写组合逻辑
always (*) 是 Verilog 中写组合逻辑(combinational logic) 的标准写法,下面讲解含义、作用、以及为什么这么写。 🌟 什么是 always (*)? always (*) begin// 组合逻辑 end它的意思是: “只要块中用到的任…...

【IC】STA计算
这张图很好,把STA的方法展示的很清楚! 时序分析在每个设计阶段都是必不可少的,以便在现代 IC 设计中实现时序收敛。除了准确性之外,全芯片分析的效率和可扩展性也尤为重要。因此,门级静态时序分析 (STA&am…...

Linux 常用命令总结
Linux 常用命令总结(全面版) Linux 命令行是系统管理和开发的核心工具,掌握常用命令可以极大提升效率。本文全面总结 Linux 常用命令,涵盖文件操作、进程管理、网络管理、系统监控、用户管理、软件安装等多个方面,适合…...

Muduo网络库实现 [十四] - HttpResponse模块
目录 设计思路 类的设计 模块的实现 公有接口 疑问点 设计思路 这个模块和HttpRequest一样,主要就是存储http响应的要素,但是其实真正需要设置存储的要素会比http请求少,首先,要存储http的版本号,我们最终使用的是…...

2025年CNG 汽车加气站操作工考试真题练习
CNG 汽车加气站操作工考试真题练习: 一、单选题 1、CNG 加气站的核心设备是( )。 A. 压缩机 B. 储气瓶组 C. 加气机 D. 脱水装置 答案:A 解析:压缩机是 CNG 加气站的核心设备,其作用是将天然气压缩…...

B端网站建设,怎样平衡功能与美观,满足企业多元需求?
在当今数字化时代,B端网站不仅是企业展示自身形象和产品的重要窗口,更是实现业务转化和客户关系维护的关键平台。然而,B端网站建设面临着功能需求复杂与美观设计之间的平衡问题。如何在满足企业多元需求的同时,打造一个既实用又美…...

PTA:模拟EXCEL排序
Excel可以对一组纪录按任意指定列排序。现请编写程序实现类似功能。 输入格式: 输入的第一行包含两个正整数 n (≤105) 和 c,其中 n 是纪录的条数,c 是指定排序的列号。之后有 n 行,每行包含一条学生纪录。每条学生纪录由学号(6…...

Edge浏览器安卓版流畅度与广告拦截功能评测【不卡还净】
安卓设备上使用浏览器的体验,很大程度取决于两个方面。一个是滑动和页面切换时的反应速度,另一个是广告干扰的多少。Edge浏览器的安卓版本在这两方面的表现比较稳定,适合日常使用和内容浏览。 先看流畅度。Edge在中端和高端机型上启动速度快&…...

Qt 核心库总结
Qt 核心库(QtCore) QtCore 是 Qt 框架的基础模块,提供非图形界面的核心功能,是所有 Qt 应用程序的基石。它包含事件循环、信号与槽、线程管理、文件操作、字符串处理等功能,适用于 GUI 和非 GUI 应用程序。本文将从入…...

四大wordpress模板站
WP汉主题 WP汉主题是一个专注于提供高质量WordPress中文主题的平台。它为中文用户提供了丰富的WordPress主题选择,包括但不限于企业网站模板、外贸建站模板等。WP汉主题致力于帮助用户轻松搭建专业的中文网站,无论是企业官网还是个人博客,都…...

Linux之 grep、find、ls、wc 命令
Linux之 grep、find、ls、wc 命令 “ 在 Linux 世界中,命令行是不可或缺的一部分,而掌握一些常用的命令可以帮助你更有效率地管理文件和系统。本文将为你介绍四個基礎而强大的 Linux 命令:grep、find、ls 和 wc,带你开启高效文件…...

SFC的含义
SFC 即 Single File Component,也就是单文件组件,在现代前端开发尤其是 Vue.js 框架中被广泛应用。下面将从概念、结构、优势、工作原理和应用场景几个方面详细介绍 SFC。 概念 单文件组件是一种将一个组件的模板(HTML)、逻辑&a…...

Qt 性能优化总结
Qt 性能优化总结 本文简单解析 Qt 应用程序的性能优化策略,涵盖 GUI 渲染、内存管理、信号与槽、QML 性能等核心领域,并通过具体示例展示优化效果。 1. Qt 性能优化简介 性能优化目标是减少资源消耗(如 CPU、内存、GPU)、提高响…...

亚马逊关键字搜索数据通过 Product Advertising API 来获取
亚马逊关键字搜索数据主要通过 Product Advertising API 来获取。 以下是使用该接口进行关键字搜索的一般步骤: (测试示例) 注册开发者账号:访问亚马逊开发者中心,完成三方供应商注册并同意相关开发者协议࿰…...
)
现代C++的范式演进与工程实践深度解析(本文序号不知道怎么整的,有点问题)
引言:C++的复兴时代 在经历了"已死语言"的质疑后,现代C++正迎来前所未有的复兴。据2024年TIOBE指数显示,C++以8.33%的占比稳居第三,较2020年上升2.1个百分点。这种复兴并非偶然——随着C++20标准的全面落地和C++23特性的逐步实现,这门已有40年历史的语言正在系…...

第二十五天 - Web安全防护 - WAF原理与实现 - 练习:请求过滤中间件
一、Celery核心机制解析 1.1 分布式架构四要素 # celery_config.py BROKER_URL redis://:passwordlocalhost:6379/0 # 消息中间件 RESULT_BACKEND redis://:passwordlocalhost:6379/1 # 结果存储 TASK_SERIALIZER json ACCEPT_CONTENT [json] TIMEZONE Asia/Shanghai核…...
)
springboot自定义starter(避坑教学)
在实际开发中,经常会定义一些公共组件,提供给各个项目团队使用。而在springboot的项目中,一般会将这些公共组件封装为springboot的starter。 1.命名规范 Spring官方Starter通常命名为 spring-boot-starter-{name} 如:spr…...

Python 实现日志备份守护进程
实训背景 假设你是一名运维工程师,需要为公司的监控系统开发一个简单的日志备份守护进程。该进程需满足以下需求: 后台运行:脱离终端,长期监控指定目录(如 /var/log/app/)中的日志文件。自动备份…...

详解JVM的底层原理
目录 1.JVM的内存区域划分 1)程序计数器(Program Counter Register) 2)元数据区(Metaspace) 3)虚拟机栈(Java Virtual Machine Stacks) 4)堆(…...

制表符是什么?与.txt文件的关系?
李升伟 整理 制表符(Tab)是一种控制字符(ASCII码为9,Unicode为\u0009),用于在文本中创建水平间距。它的作用类似于键盘上的 Tab 键,通常表现为光标跳转到下一个预设的“制表位”(一…...
:两数之和,三数之和,四数之和)
【专题刷题】双指针(三):两数之和,三数之和,四数之和
📝前言说明: 本专栏主要记录本人的基础算法学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码;ÿ…...

Java八种常见的设计模式
一、单例模式 单例模式是(Singleton Pattern)Java中最常用的设计模式之一,它保证一个类仅有一个实例,并提供一个全局访问点。 实现单例模式的核心是将类的构造方法私有化,以防止外部直接通过构造函数创建实例。同时&am…...

用Prompt 技术【提示词】打造自己的大语言智能体
机器如何按照人类的指令执行任务的探索 机器需具备理解任务叙述的能力,以便能够按照人类的指令执行任务,为机器提供一些范例作为参考,使其能够理解该执行的任务类型。这样的学习方式称为“Instruction learning”,透过精心设计的…...

灵鉴 AI五大核心能力洞穿 “数据黑箱”云取证深度支持8大核心应用
本文关键词:灵鉴AI 、电子数据取证分析AI助手、云取证、DeepSeek大模型 1.灵鉴AI ,V1.0深度融合DeepSeek大模型技术,破解行业痛点,5大核心能力,让大模型真正“懂”电子数据分析。 2.LX-A216云取证系统,V2.…...

了解高速设计的信号完整性仿真
高速设计需要精确的信号传输,以确保最佳性能。信号完整性差会导致关键应用中的误码、数据损坏甚至系统故障等问题。介电常数、损耗角正切和插入损耗等因素会显著影响信号质量。通过使用信号完整性仿真,您可以及早发现并解决这些挑战。这种主动方法有助于…...

用 Deepseek 写的html油耗计算器
在油价高企的今天,了解自己爱车的真实油耗情况对每位车主来说都至关重要。本文将介绍一个简单实用的油耗计算方法,并提供一个可以直接使用的HTML油耗计算器。 为什么要计算油耗? 计算油耗不仅能帮助我们: 了解车辆的真实燃油经济…...

SAP系统青果糖无法报工
问题:班长说工单号4100000101青果糖工单 无法报工 原因排查:工单4100000101的工艺路线版本错误,选了版本1的,版本1是委外的工艺,本厂生产应该选版本2. 解决: 1:重读主数据,更改工单4100000101的工艺路线版本. 2:工单成品已交库,不能直接更改工…...

GPU 招投标全流程分析与总结
GPU 招投标全流程分析与总结 招投标流程概述 以下是通过代理商采购Nvidia H20-GPU 141G的招投标全流程分析: #mermaid-svg-hMPPfkCpGj8GKXfV {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-hMPPfkCpGj8GKXfV .er…...

Centos7.6安装JDK 1.8教程
前提:先把jdk1.8文件上传到usr/local目录下,文件名如:jdk-8u151-linux-x64.tar.gz 1. 解压 JDK 压缩包 假设 jdk-8u151-linux-x64.tar.gz 文件位于 /usr/local 目录下。 进入 /usr/local 目录: cd /usr/local 解压文件&#…...

Golang errors 包快速上手
文章目录 1.变量2.类型3.函数3.1 New3.2 Is简介函数签名核心功能示例代码使用场景注意事项小结 3.3 As简介函数签名核心功能示例代码使用场景注意事项小结 3.4 Unwrap简介函数签名核心功能使用示例使用场景注意事项小结 3.5 Join简介函数签名核心功能使用场景注意事项小结 4.小…...