深入理解卷积神经网络(CNN):从原理到实践
引言
卷积神经网络(Convolutional Neural Networks, CNN)是深度学习领域最具影响力的架构之一,尤其在计算机视觉任务中表现出色。自2012年AlexNet在ImageNet竞赛中一战成名以来,CNN不断演进,推动着图像识别、医疗影像分析、自动驾驶等领域的快速发展。本文将系统介绍CNN的核心原理、关键组件和实际应用,并通过PyTorch代码示例展示如何构建一个CNN模型。
一、CNN的基本原理
1.1 传统神经网络的问题
在处理图像数据时,传统全连接神经网络(FCN)存在明显缺陷:
- 参数爆炸:一张28×28的灰度图像展开后就有784个输入节点,若第一隐藏层有1000个神经元, 仅这一层就需要784,000个参数!
- 忽略局部相关性:图像中相邻像素间存在强相关性,但全连接网络无法有效利用这种空间信息
- 缺乏平移不变性:物体在图像中的位置变化会导致网络需要重新学习
1.2 CNN的三大核心思想
CNN通过以下设计巧妙解决了上述问题:
1. 局部感受野(Local Receptive Fields)
每个神经元只连接输入区域的局部区域,而非全部输入
2. 权值共享(Shared Weights)
同一特征图使用相同的卷积核,大幅减少参数数量
3. 空间下采样(Spatial Subsampling)
通过池化层逐步降低空间分辨率,增加高层特征的感受野
> 参数数量对比:
> 对于28×28图像,全连接层(隐藏层1000神经元)需要784,000参数
> 而5×5卷积核(32个通道)仅需5×5×32=800参数
二、CNN的核心组件详解
2.1 卷积层(Convolutional Layer)
import torch.nn as nn# 定义一个卷积层
conv_layer = nn.Conv2d(in_channels=3, # 输入通道数(RGB图像为3)out_channels=16, # 输出通道数/卷积核数量kernel_size=3, # 卷积核尺寸stride=1, # 步长padding=1 # 边缘填充
)

2.2 池化层(Pooling Layer)
# 最大池化示例
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)# 平均池化示例
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
作用:
- 降低空间维度,减少计算量
- 增强平移不变性
- 扩大感受野
2.3 激活函数
# ReLU激活函数
activation = nn.ReLU()# LeakyReLU示例
leaky_relu = nn.LeakyReLU(negative_slope=0.01)
三、经典CNN架构演进
class CNN(nn.Module):def __init__(self): #python基础关于类,self类自已本身super(CNN,self).__init__() #继承的父类初始化self.conv1=nn.Sequential(nn.Conv2d(in_channels=1,out_channels=16,kernel_size=5,stride=1,padding=2,),nn.ReLU(),nn.MaxPool2d(kernel_size=2),)self.conv2=nn.Sequential(nn.Conv2d(16,32,5,1,2),nn.ReLU(),nn.Conv2d(32, 32, 5, 1, 2),nn.ReLU(),nn.MaxPool2d(2),)self.conv3=nn.Sequential(nn.Conv2d(32,64,5,1,2),nn.ReLU(),)self.out=nn.Linear(64*7*7,10)def forward(self,x):x=self.conv1(x)x=self.conv2(x)x=self.conv3(x)x=x.view(x.size(0),-1)output=self.out(x)return output四、PyTorch实现CNN实战
4.1手写数字识别:
import torchprint(torch.__version__)'''
MNIST包含70,000张手写数字图像:60,000张用于训练,10,000张用于测试。
图像是灰度的,28x28像素的,并且居中的,以减少预处理和加快运行。
'''
import torch
from torch import nn #导入神经网络模块,
from torch.utils.data import DataLoader #数据包管理工具,打包数据,
from torchvision import datasets #封装了很多与图像相关的模型,数据集
from torchvision.transforms import ToTensor #数据转换,张量,将其他类型的数据转换为tensor张量'''下载训练数据集(包含训练图片+标签)'''
training_data=datasets.MNIST(root='data', #表示下载的手写数字 到哪个路径。60000train=True, #读取下载后的数据 中的 训练集download=True, #如果你之前已经下载过了,就不用再下载transform=ToTensor(), #张量,图片是不能直接传入神经网络模型
) #对于pytorch库能够识别的数据一般是tensor张量。'''下载测试数据集(包含训练图片+标签)'''
test_data=datasets.MNIST(root='data', #表示下载的手写数字 到哪个路径。60000train=False, #读取下载后的数据 中的 训练集download=True, #如果你之前已经下载过了,就不用再下载transform=ToTensor(), #Tensor是在深度学习中提出并广泛应用的数据类型
) #NumPy数组只能在CPU上运行。Tensor可以在GPU上运行,这在深度学习应用中可以显著提高计算速度
print(len(training_data))'''展示手写字图片,把训练数据集中的前59000张图片展示一下'''
from matplotlib import pyplot as plt
figure = plt.figure()
for i in range(9):img,label=training_data[i+59000]#提取第59000张图片figure.add_subplot(3,3,i+1)#图像窗口中创建多个小窗口,小窗口用于显示图片plt.title(label)plt.axis("off") # plt.show(I)#是示矢量,plt.imshow(img.squeeze(),cmap="gray") #plt.imshow()将Numpy数组data中的数据显示为图像,并在图形窗口中显贡a = img.squeeze()# img.squeeze()从张量img中去掉维度为1的。如果该维度的大小不为1则张量不会改变。#cmap="gray
plt.show()# 创建数据DataLoader(数据加载器)
# batch_size:将数据集分成多份,每一份为batch_size个数据
# 优点:可以减少内存的使用,提高训练速度。train_dataloader=DataLoader(training_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)'''断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU。'''
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device") #字符串的格式化'''定义神经网络 类的继承'''
class CNN(nn.Module):def __init__(self): #python基础关于类,self类自已本身super(CNN,self).__init__() #继承的父类初始化self.conv1=nn.Sequential(nn.Conv2d(in_channels=1,out_channels=16,kernel_size=5,stride=1,padding=2,),nn.ReLU(),nn.MaxPool2d(kernel_size=2),)self.conv2=nn.Sequential(nn.Conv2d(16,32,5,1,2),nn.ReLU(),nn.Conv2d(32, 32, 5, 1, 2),nn.ReLU(),nn.MaxPool2d(2),)self.conv3=nn.Sequential(nn.Conv2d(32,64,5,1,2),nn.ReLU(),)self.out=nn.Linear(64*7*7,10)def forward(self,x):x=self.conv1(x)x=self.conv2(x)x=self.conv3(x)x=x.view(x.size(0),-1)output=self.out(x)return outputmodel = CNN().to(device)
print(model)def train(dataloader,model,loss_fn,optimizer):model.train() #告诉模型,我要开始训练,模型中w进行随机化操作,已经更新w。在训练过程中,w会被修改的
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train()和 model.eval()。
#一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval()batch_size_num=1for X,y in dataloader: #其中batch为每一个数据的编号X,y=X.to(device),y.to(device) #把训练数据集和标签传入cpu或GPUpred=model.forward(X) #.forward可以被省略,父类中已经对次功能进行了设置。自动初始化loss=loss_fn(pred,y) #通过交叉熵损失函数计算损失值loss# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() #梯度值清零loss.backward() #反向传播计算得到每个参数的梯度值woptimizer.step() #根据梯度更新网络w参数loss_value=loss.item() #从tensor数据中提取数据出来,tensor获取损失值if batch_size_num %100 ==0:print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')batch_size_num+=1def test(dataloader,model,loss_fn):size=len(dataloader.dataset)num_batches=len(dataloader) #打包的数量model.eval() #测试,w就不能再更新。test_loss,correct=0,0with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)test_loss+=loss_fn(pred,y).item() #test_loss是会自动累加每一个批次的损失值correct+=(pred.argmax(1)==y).type(torch.float).sum().item()a=(pred.argmax(1)==y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值b=(pred.argmax(1)==y).type(torch.float)test_loss /=num_batchescorrect /=sizeprint(f'Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}')loss_fn=nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别中一共有10个数字,输出会有10个结果
optimizer=torch.optim.Adam(model.parameters(),lr=0.01) #创建一个优化器,SGD为随机梯度下降算法
# #params:要训练的参数,一般我们传入的都是model.parameters()#
# lr:learning_rate学习率,也就是步长#loss表示模型训练后的输出结果与,样本标签的差距。如果差距越小,就表示模型训练越好,越逼近干真实的模型。# train(train_dataloader,model,loss_fn,optimizer)
# test(test_dataloader,model,loss_fn)epoch=9
for i in range(epoch):print(i+1)train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader,model,loss_fn)运行结果:
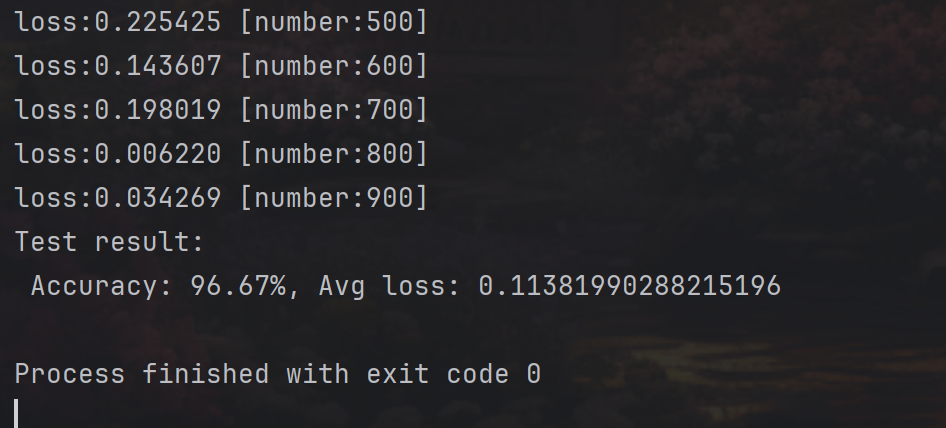
结语
CNN作为深度学习的基石架构,不仅在计算机视觉领域大放异彩,其核心思想也被广泛应用于语音识别、自然语言处理等领域。通过本文的系统介绍,希望读者能够建立起对CNN的全面认识,并能够动手实现自己的CNN模型。记住,理解原理只是第一步,持续的实践和创新才是掌握CNN的关键!
相关文章:
:从原理到实践)
深入理解卷积神经网络(CNN):从原理到实践
引言 卷积神经网络(Convolutional Neural Networks, CNN)是深度学习领域最具影响力的架构之一,尤其在计算机视觉任务中表现出色。自2012年AlexNet在ImageNet竞赛中一战成名以来,CNN不断演进,推动着图像识别、医疗影像分析、自动驾驶等领域的快…...

深度学习常见模块实现001
文章目录 1.学习目的2.常见模块使用与实现2.1 ResNet18实现2.2 SeNet模块2.3 CBAM模块 1.学习目的 深度学习在图像处理这块,很多模块已经成型,并没有很多新的东西,更多的是不同的模块堆叠,所以需要我们不断总结,动手实…...

Python实现贪吃蛇三
上篇文章Python实现贪吃蛇一,实现了一个贪吃蛇的基础版本。后面第二篇文章Python实现贪吃蛇二修改了一些不足,但最近发现还有两点需要优化: 1、生成食物的时候有概率和记分牌重合 2、游戏缺少暂停功能 先看生成食物的时候有概率和记分牌重合的…...

windows server C# IIS部署
1、添加IIS功能 windows server 2012、windows server 2016、windows server 2019 说明:自带的是.net 4.5 不需要安装.net 3.5 尽量使用 windows server 2019、2016高版本,低版本会出现需要打补丁的问题 2、打开IIS 3、打开iis应用池 .net 4.5 4、添…...

LLM小白自学笔记:1.两种指令微调
一、LoRA 简单来说,LoRA不直接调整个大模型的全部参数(那样太费资源),而是在模型的某些层(通常是注意力层)加个“旁路”——两个小的矩阵(低秩矩阵)。训练时只更新这俩小矩阵&#x…...

杰弗里·辛顿:深度学习教父
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 杰弗里辛顿:当坚持遇见突破,AI迎来新纪元 一、人物简介 杰弗…...

RHCE 第一次作业
一.定义延迟任务 1.安装邮件服务 [roothaiou ~]# yum install s-nail -y 2.配置邮件服务 [roothaiou ~]# vim /etc/mail.rc 3.测试邮件服务 [roothaiou ~]# echo 88888888 | mail -v -s Passion 13571532874163.com 4.设置定时任务 [roothaiou ~]# crontab -e 二.时间同步…...

库洛游戏一面+二面
目录 一面 1. ArrayList和LinkedList的区别,就是我在插入和删除的时候他们在时间复杂度上有什么区别 2. hashmap在java的底层是怎么实现的 3. 红黑树的实现原理 4. 红黑树的特点 5. 为什么红黑树比链表查询速度快 6. 在java中字符串的操作方式有几种 7. Stri…...

基于多模态深度学习的亚急性脊髓联合变性全流程预测与个性化管理技术方案
目录 技术方案文档1. 数据收集与预处理模块2. 多模态预测模型构建3. 术前风险评估系统4. 术中实时监测系统5. 术后并发症预测与护理6. 统计分析与验证模块7. 健康教育系统技术实现说明技术方案文档 1. 数据收集与预处理模块 功能:构建数据管道,清洗并整合多源数据 伪代码示…...

蓝桥杯日期的题型
做题思路 一般分为3个步骤,首先要定义一个结构体来存储月份的天数,第一循环日期,第二判断日期是否为闰年,第三就是题目求什么 结构体 static int[] ds{0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}; 判断是否闰年的函数 public static void f(int m,int d){//被4整…...

【树形dp题解】dfs的巧妙应用
【树形dp题解】dfs的巧妙应用 [P2986 USACO10MAR] Great Cow Gathering G - 洛谷 题目大意: Bessie 正在计划一年一度的奶牛大集会,来自全国各地的奶牛将来参加这一次集会。当然,她会选择最方便的地点来举办这次集会。 每个奶牛居住在 N N …...

《AI大模型应知应会100篇》第20篇:大模型伦理准则与监管趋势
第20篇:大模型伦理准则与监管趋势 摘要 随着人工智能(AI)技术的飞速发展,尤其是大模型(如GPT、PaLM等)在自然语言处理、图像生成等领域的广泛应用,AI伦理问题和监管挑战日益凸显。本文将梳理当…...
含文档+PPT)
线上教学平台(vue+springboot+ssm+mysql)含文档+PPT
线上教学平台(vuespringbootssmmysql)含文档PPT 该系统是一个在线教学平台,主要分为管理员和学员两个角色;管理员界面包含首页、交流中心、学员管理、资料类型管理、学习资料管理、交流论坛、我的收藏管理、留言板管理、考试管理…...

Being-0:具有视觉-语言模型和模块化技能的人形机器人智体
25年3月来自北大、北京智源和 BeingBeyond 的论文“Being-0: A Humanoid Robotic Agent with Vision-Language Models and Modular Skills”。 构建能够在现实世界具身任务中达到人类水平表现的自主机器人智体,是人形机器人研究的终极目标。近期,基于基…...

Fiddler 进行断点测试:调试网络请求
目录 一、什么是断点测试? 二、Fiddler 的断点功能 三、如何在 Fiddler 中设置断点? 步骤 1:启动 Fiddler 步骤 2:启用断点 步骤 3:捕获请求 步骤 4:修改请求或响应 四、案例:模拟登录失…...

决策树:ID3,C4.5,CART树总结
树模型总结 决策树部分重点关注分叉的指标,多叉还是单叉,处理离散还是连续值,剪枝方法,以及回归还是分类 一、决策树 ID3(Iterative Dichotomiser 3) 、C4.5、CART决策树 ID3:确定分类规则判别指标、寻找能够最快速降低信息熵的方…...

DDS信号发生器设计
一、基本概述 1.1 DDS简介 DDS信号发生器即直接数字频率合成(Direct Digital Frequency Synthesis,简称DDS)是一种利用数字技术生成信号的方法。它通过数字信号处理技术,将数字信号转换为模拟信号,从而生成高质量的正…...

23黑马产品经理Day01
今天过了一遍23黑马产品经理的基础视频 问题思考维度 抓住核心用户 为什么需要抓住核心用户? 主要原因:用户越来越细分,保持市场竞争力,产品开发推广更聚焦 做产品为什么要了解用户:了解用户的付费点,…...

18-21源码剖析——Mybatis整体架构设计、核心组件调用关系、源码环境搭建
学习视频资料来源:https://www.bilibili.com/video/BV1R14y1W7yS 文章目录 1. 架构设计2. 核心组件及调用关系3. 源码环境搭建3.1 测试类3.2 实体类3.3 核心配置文件3.4 映射配置文件3.5 遇到的问题 1. 架构设计 Mybatis整体架构分为4层: 接口层&#…...

东方潮流亮相广州益民艺术馆|朋克编码“艺术家潮玩”系列开幕引爆热潮
4月15日,由我的宇宙旗下公司朋克编码携“艺术家潮玩”系列亮相广州白云益民艺术馆,标志着其全国文化推广计划正式启航。本次展览围绕“潮玩艺术东方文化”展开,融合传统文化与当代潮流,以年轻化方式赋能中国文化出海。 展览现场潮…...

充电宝项目:规则引擎Drools学习
文章目录 规则引擎 Drools1 问题2 规则引擎概述2.1 规则引擎2.2 使用规则引擎的优势2.3 规则引擎应用场景2.4 Drools介绍 3 Drools入门案例3.1 创建springboot项目 引入依赖3.2 添加Drools配置类3.4 创建实体类Order3.5 orderScore.drl3.6 编写测试类 4 Drools基础语法4.1 规则…...

C++零基础实践教程 文件输入输出
模块八:文件输入输出 (数据持久化) 在之前的模块中,我们学习了如何使用程序处理数据。然而,当程序结束运行时,这些数据通常会丢失。数据持久化 (Data Persistence) 指的是将程序中的数据存储到非易失性存储介质(如硬盘…...

SpringAI+DeepSeek大模型应用开发——1 AI概述
AI领域常用词汇 LLM(LargeLanguage Model,大语言模型) 能理解和生成自然语言的巨型AI模型,通过海量文本训练。例子:GPT-4、Claude、DeepSeek、文心一言、通义干问。 G(Generative)生成式: 根据上…...

数据中台进化史:从概念萌芽到价值变现的蜕变之路
在数字化转型的浪潮中,数据中台已成为企业驾驭数据、驱动业务创新的关键力量。回顾数据中台的发展历程,犹如一场从混沌到有序、从萌芽到成熟的精彩蜕变,它由湖仓一体、数据治理平台、数据服务平台三大核心要素逐步构建而成,每一个…...

【Java学习笔记】运算符
运算符 运算符的类型 算数运算符 赋值运算符 关系运算符(比较哦啊运算符) 逻辑运算符 三元运算符 位运算符(需要二进制基础) 一、算数运算符 运算符计算范例结果正号77-负号b11; -b-11加法9918-减法10-82*乘法7*856/除法9…...
【python】OpenCV—Tracking(10.6)—People Counting
文章目录 1、功能描述2、代码实现3、效果展示4、完整代码5、涉及到的库函数6、参考来自 更多有趣的代码示例,可参考【Programming】 1、功能描述 借助 opencv-python,用 SSD 人形检测模型和质心跟踪方法实现对人群的计数 基于质心的跟踪可以参考 【pyt…...
)
JavaSE学习(前端初体验)
文章目录 前言一、准备环境二、创建站点(创建一个文件夹)三、将站点部署到编写器中四、VScode实用小设置五、案例展示 前言 首先了解前端三件套:HTML、CSS、JS HTML:超文本标记语言、框架层、描述数据的; CSS…...

智慧城市像一张无形大网,如何紧密连接你我他?
智慧城市作为复杂巨系统,其核心在于通过技术创新构建无缝连接的网络,使物理空间与数字空间深度融合。这张"无形大网"由物联网感知层、城市数据中台、人工智能中枢、数字服务入口和安全信任机制五大支柱编织而成,正在重塑城市运行规…...

Linux常用命令
一、history 用于显示历史命令。 history 10显示最近10条历史命令。!200使用第200行的指令。history -c清空历史记录。 二、pwd 用于显示当前绝对路径。 pwd显示当前绝对路径。 三、ls 用于以行的形式显示当前文件夹下所有内容。 ls -a显示所有内容,包括隐藏文…...

【AI】SpringAI 第二弹:接入 DeepSeek 官方服务
一、接入 DeepSeek 官方服务 通过一个简单的案例演示接入 DeepSeek 实现简单的问答功能 1.添加依赖 <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-openai</artifactId> </dependency> 2…...

QT的信号槽的直接触发,队列触发,自动触发
在Qt中,信号槽机制是一个非常强大的特性,它用于实现对象之间的通信。除了默认的直接触发方式之外,Qt还提供了队列触发等不同的触发方式。 1. 直接触发(Direct Connection) 直接触发是最常见的连接方式,信…...

typescript html input无法输入解决办法
input里加上这个: onkeydown:(e: KeyboardEvent) > {e.stopPropagation();...

工厂能耗系统智能化解决方案 —— 安科瑞企业能源管控平台
安科瑞顾强 政策背景与“双碳”战略驱动 2025年《政府工作报告》明确提出“单位国内生产总值能耗降低3%左右”的目标,要求通过产业结构升级(如高耗能行业技术革新或转型)、能源结构优化(提高非化石能源占比)及数字化…...

栅格数据处理
一、栅格数据的引入与基本操作 (一)加载栅格数据 在 ArcPy 中,栅格数据可以通过 arcpy.Raster 类来加载。例如,如果你有一个存储在本地路径下的栅格数据文件(如 GeoTIFF 格式),可以这样加载&a…...

C语言文件操作
本文重点: 什么是文件 文件名 文件类型 文件缓冲区 文件指针 文件的打开和关闭 文件的顺序读写 文件的随机读写 文件结束的判定 什么是文件 磁盘上的文件是文件。 但是在程序设计中,我们一般谈的文件有两种:程序文件、数据文件 程序文件 包括源程序文…...

毛笔书体检测-hog+svm python opencv源码
链接:https://pan.baidu.com/s/1l-bw8zR9psv1HycmMqQBqQ?pwd2ibp 提取码:2ibp --来自百度网盘超级会员V2的分享 1、毛笔字检测运行流程 如果解压文件发现乱码,可以下载Bandizip 解压文件 数据集在百度网盘里面 将文件名字改成images c…...

基于YOLOV11的道路坑洼分析系统
基于YOLOV11的道路坑洼分析系统 【包含内容】 【一】项目提供完整源代码及详细注释 【二】系统设计思路与实现说明 【三】图形化界面与实时检测统计可视化功能 【技术栈】 ①:系统环境:Windows/MacOS/Linux多平台支持,推荐NVIDIA GPU加速 ②…...

【系统搭建】DPDK安装配置与helloworld运行
一,安装相关依赖 1. 安装依赖 sudo apt update && sudo apt install -y \build-essential libnuma-dev meson ninja-build pciutils#安装Python3与PIP3 sudo apt install python3-pip2. 升级 pip 和 setuptools sudo apt install python3-pip python3-de…...

Distortion, Animation Raymarching
这节课的主要目的是对uv进行操作,实现一些动画的效果,实际就是采样的动画 struct texDistort {float2 texScale(float2 uv, float2 scale){float2 texScale (uv - 0.5) * scale 0.5;return texScale;}float2 texRotate(float2 uv, float angle){float…...
)
架构风格(高软59)
系列文章目录 架构风格 文章目录 系列文章目录前言一、架构风格定义?二、架构风格分类总结 前言 本节讲明架构风格知识点。 一、架构风格定义? 二、架构风格分类 总结 就是高软笔记,大佬请略过!...

免费使用RooCode + Boomerang AI + Gemini 2.5 Pro开发套件
若您正在寻找利用免费AI工具简化应用开发的方法,这份指南将为您揭开惊喜。 我们将详解如何免费整合RooCode、Boomerang AI智能代理与Google Gemini 2.5 Pro API,在Visual Studio Code中实现自动化编程加速。 这套方案能让您在几分钟内从创意跃迁至可运行原型。 套件构成与…...

《MAmmoTH2: Scaling Instructions from the Web》全文翻译
《MAmmoTH2: Scaling Instructions from the Web》 MAmmoTH2:从网络规模化采集指令数据 摘要 指令调优提升了大语言模型(LLM)的推理能力,其中数据质量和规模化是关键因素。大多数指令调优数据来源于人工众包或GPT-4蒸馏。我们提…...

解决Ubuntu终端命令不能补全的问题
使用命令: sudo vi /etc/bash.bashr 把框出的部分取消注释,取消后截图如下,保存退出: 使用命令env -i bash --noprofile --norc, 进行测试,查看tab自动补全是否可以使用。 tab键可正常使用, env -i bash …...

知识图谱与其它知识库的关系
知识图谱与其它知识库的关系 知识图谱与传统知识库:解构数据连接的哲学知识图谱的商业价值:连接带来的革命选择知识图谱还是传统数据库?一个实用指南 知识图谱的出现,正在改变了我们组织和理解信息的方式。 这种技术不仅仅是一种数…...

STM32基础教程——DMA+ADC多通道
目录 前言 编辑 技术实现 连线图 代码实现 技术要点 实验结果 问题记录 前言 DMA(Direct Memory Access)直接存储器存取,用来提供在外设和存储器 之间或者存储器和存储器之间的高速数据传输。无需CPU干预,数据可以通过DMA快速地移动࿰…...
从算法仿真到工程源码实现-第十一节-非线性波束形成算法工程化)
波束形成(BF)从算法仿真到工程源码实现-第十一节-非线性波束形成算法工程化
一、概述 本节我们对非线性波束形成算法进行工程化,运行在respeaker core v2平台上,算法实时率在0.046左右。更多资料和代码可以进入https://t.zsxq.com/qgmoN ,同时欢迎大家提出宝贵的建议,以共同探讨学习。 二、算法实现 2.1 …...

Windows安装Rust版本GDAL
前言 笔者想安装GDAL,这是一个开源的地理数据库, 笔者到处搜索,最后看到这位大佬写的这篇文章,终于成功了。 aliothor/Windows-Install-Rust-Gdal-Tutorial: Windows Install Rust Version Gdal Stepshttps://github.com/aliot…...
——图像的透视变换)
OpenCv高阶(六)——图像的透视变换
目录 一、透视变换的定义与作用 二、透视变换的过程 三、OpenCV 中的透视变换函数 1. cv2.getPerspectiveTransform(src, dst) 2. cv2.warpPerspective(src, H, dsize, dstNone, flagscv2.INTER_LINEAR, borderModecv2.BORDER_CONSTANT, borderValue0) 四、文档扫描校正&a…...

常用正则化技术dropout
在深度学习中,Dropout 是一种常用的正则化技术,用于防止神经网络过拟合。它的核心思想是随机丢弃(临时关闭)网络中的部分神经元,迫使模型不依赖单一神经元,从而提升泛化能力。 1. Dropout…...

66.加1
目录 一、问题描述 二、解题思路 三、代码 四、复杂度分析 一、问题描述 给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。 最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。 你可以假设除了整数 0 之外&#…...