静态链接part2
编译
语义分析
由语义分析器完成,这个步骤只是完成了对表达式的语法层面的分析,它并不了解这个语句是否真的有意义(例如在C语言中两个指针做乘法运算,这个语句在语法上是合法的,但是没有什么意义;还有同样一个指针和一个浮点数做乘法运算是否合法等),这里就要知道编译器所能分析的语义是静态语义(在编译期就可以确定的语义)反之则是动态语义(只有在运行期才能确定的语义)
补充:
静态语义通常包括声明和类型的匹配,类型的转换(例如当一个浮点型的表达式赋值给一个整型的表达式时,其中隐含了一个浮点数到整型的转换过程,在语义分析过程中需要完成这个步骤),比如将一个浮点型赋值给一个指针时,语义分析程序会发现类型不匹配,然后编译器就会报错
动态语义指的是在运行期出现的语义相关的问题,比如将0作为除数就是一个运行期的语义错误
语义分析阶段过后,之前的那个语法树的表达式就都被表示了类型,如果有些类型需要做隐式转换,语义分析程序会在语法树中插入相应转换节点
补充:
隐式类型转换,也叫做自动类型转换,是编译器根据表达式的上下文自动将某种类型的值转换为另一种类型的过程,隐式转换通常发生在类型不完全一致时,编译器会根据规则自动进行转换(例如上文提到的整型和浮点数),下面举个例子
int a = 5;
float b = a; // 这个就是隐式转换:a 从 int 类型转换为 float 类型
在编译过程中,转换节点是编译器在语法树中插入的节点,用来表示隐式类型转换的过程,通常,编译器会根据类型系统的规则自动插入这样的转换节点,照上文来说,在语法树中,有一个表达式需要将int转换为float,那么在构建语法树时,编译器会插入一个转换节点,表示这个类型的自动转换,这个节点会把 int 类型的值转换为 float 类型,然后继续执行后续的计算或操作,举个例子
int a = 5;
float b = 10.5;
float result = a + b;
上面这段代码中,在语法树里:a 是 int 类型,b 是 float 类型,编译器会检查 a + b 的类型,发现 a 和 b 类型不同,编译器会隐式将 a(int 类型)转换为 float 类型(因为 float 类型能够容纳 int 的值),然后,编译器执行 float + float 的操作,在这个过程中,语法树会被修改,插入一个转换节点,表示a需要被转换成float类型,并在计算之前完成这个过程
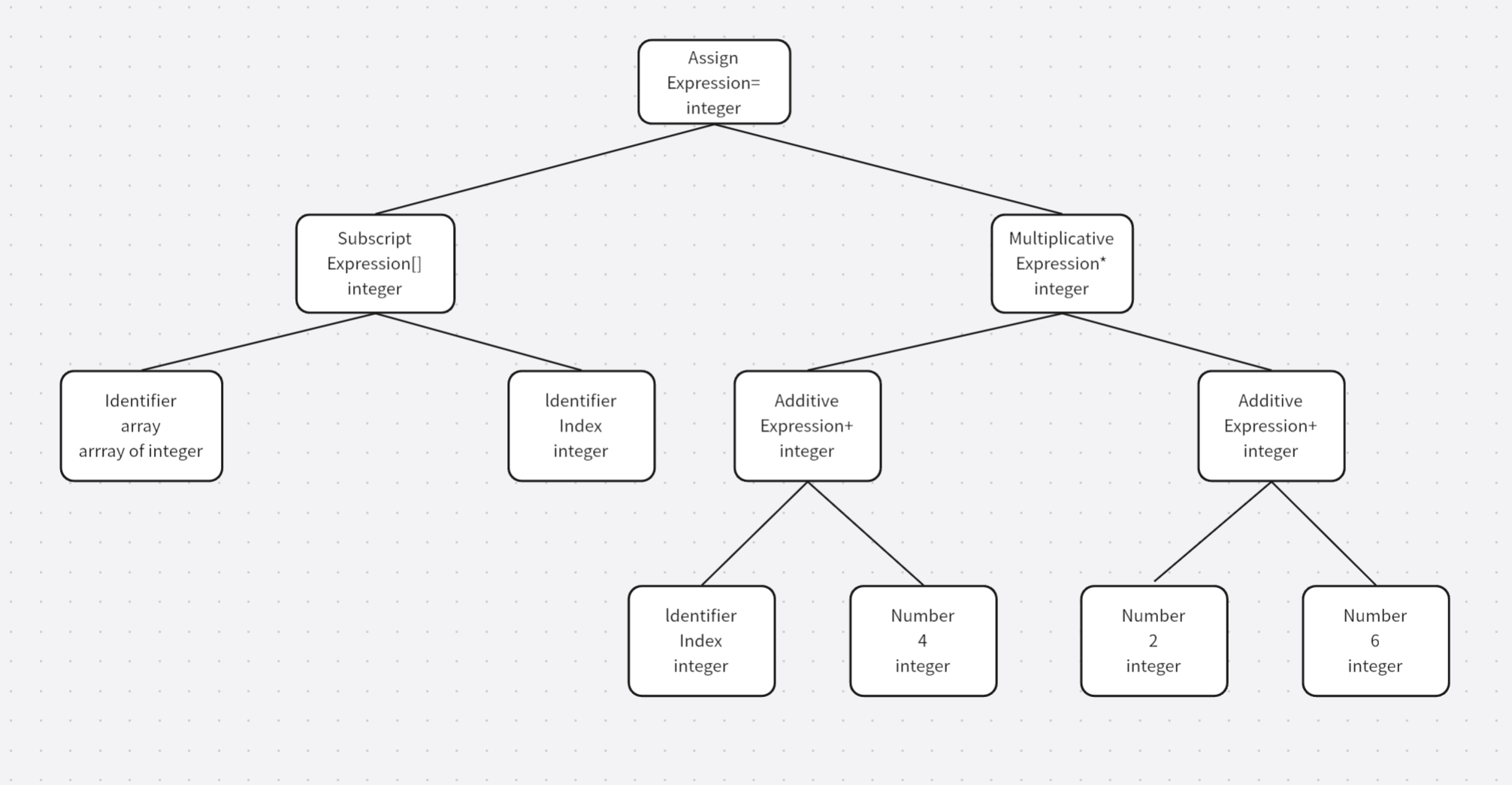
在这个语法树中可以看到每个表达式(包括符号和数字)都被标识了类型,另外符号分析器还对符号表中的符号类型进行了更新
总结来说就是在编译器的语义分析阶段,主要的任务是检查程序的语义正确性,并为表达式、变量、函数等绑定相关类型信息,确保类型之间的匹配符合语言的语法规则
中间语言生成
现代的编译器具备很多层次的优化,往往在源码级别会有一个优化过程,这里说到的源码级优化器在不同编译器中会有不同的定义或其他差异,比如说在上面的那个例子中(2+6)这个表达式是可以被优化掉的(值在编译期已确定),下面是优化后的语法树
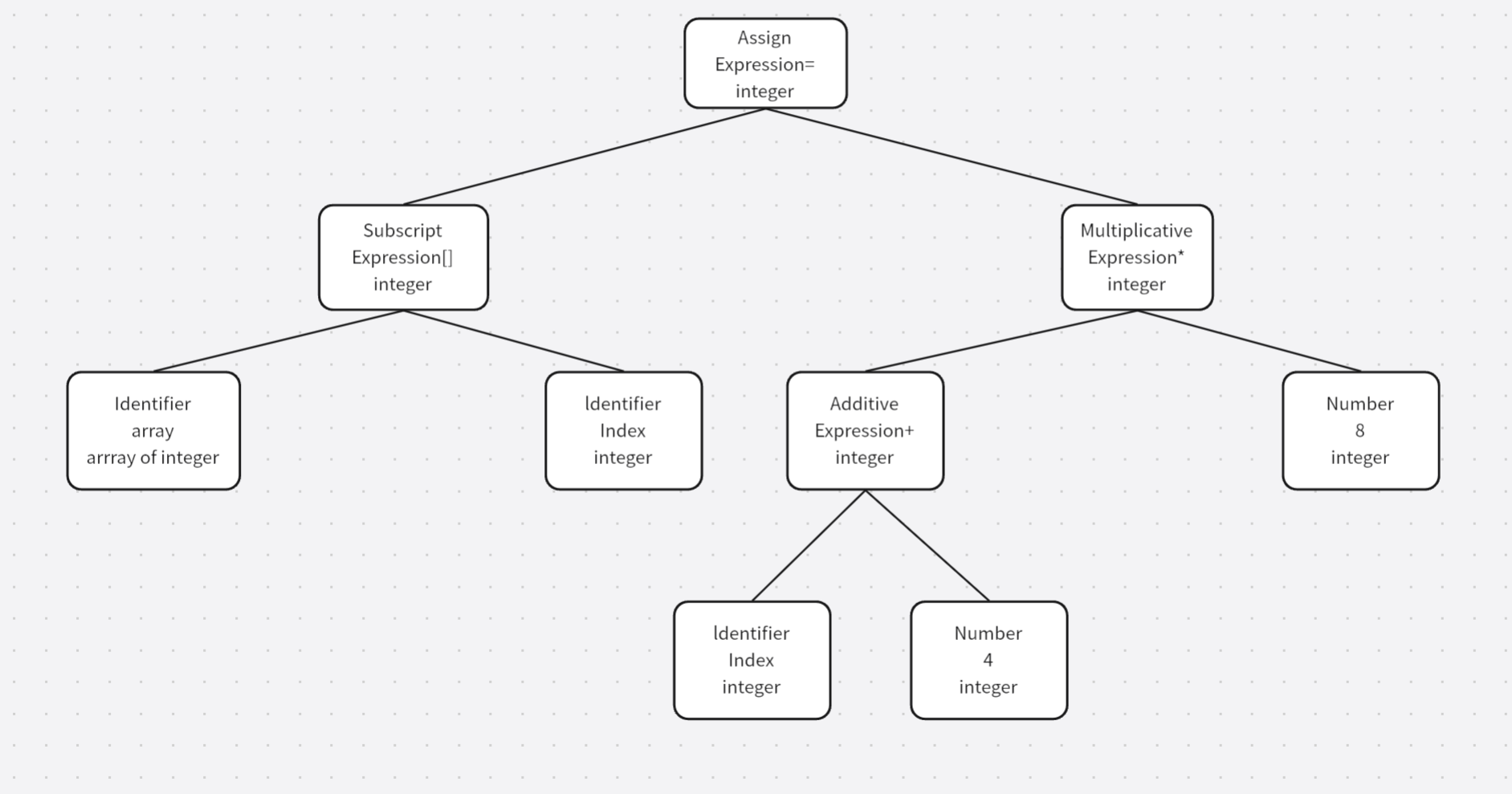
可以看到相较上面的语法树优化后直接变成8了,这里要注意直接在语法树上作优化比较困难,那么这里就引出了中间语言这一说法,源代码优化器往往会将整个语法树转换成中间代码(语法树的顺序表示),在编译过程中,中间代码是源代码和目标代码之间的桥梁,其实已经非常接近目标代码了,但是一般与目标机器和运行环境是无关的(比如不包含数据的尺寸、变量地址和寄存器的名字等),中间代码比较常见的类型有三地址和P-代码,除此之外还有很多不同的类型,在不同的编码器中有不同的形式
补充:
三地址码:一个三地址码语句中有三个变量地址,因此得名,每条指令最多包含三个操作数(通常是两个源操作数和一个目标操作数),每条指令执行一个基本操作(如算术运算、赋值、跳转等),使用临时变量存储中间结果,便于优化
常见指令形式
x = y op z # 二元运算(如加法、乘法)
x = op y # 一元运算(如取负)
x = y # 直接赋值
goto L # 无条件跳转
if x relop y goto L # 条件跳转(relop 为比较运算符)
例如
a = b + c * d;
这是源码
t1 = c * d
t2 = b + t1
a = t2
这是三地址码
可以看到结构更为简单,更易于理解和优化,而且更接近实际机器的指令格式,便于转换为目标代码。为了使所有操作符合三地址码形式,利用到了t1、t2、t3三个临时变量(由编译器自动生成的、用于存储中间计算结果的变量,没有对应的源代码变量名,仅在编译阶段或中间代码执行过程中临时存在)
P-代码:一种面向虚拟机的栈式中间代码,常用于解释型语言或早期编译器(如Pascal的编译器),指令通过操作栈完成计算,无需显式临时变量
常见指令形式
LOD x # 将变量x压栈
LIT 5 # 将常量5压栈
ADD # 弹出栈顶两个值相加,结果压栈
STO y # 弹出栈顶值并存储到变量y
例如
a = b + c * d;
这是源代码
LOD c
LOD d
MUL # 计算 c * d,结果压栈
LOD b
ADD # 计算 b + (c*d),结果压栈
STO a # 存储到a
这是P-代码
可以看到换为P-代码后指令变得紧凑,无需临时变量名,更适合解释执行
这里举例用的是最常见的三地址码
x = y op z
也就是上面补充中提到的二元运算的三地址码,表示的是将变量y和z进行op(二元运算符,可以是几件乘除,也可以是任何可以应用到y和z的操作)后赋值给x,那么上面那个语法树就可以被翻译为下面这样
t1 = 2+6
t2 = index + 4
t3 = t2 * t1
array[index] = t3
这里使用了几个临时变量:t1、t2、t3,接下来进行优化时,优化程序会计算2+6,也就是将t1的结果计算出来,得到8,然后后面的t1就会全部替换成8,那么t3也就不需要了,因为t2可以重复利用(t3现在只是t2 * 8的结果,而t2仍然有效,也就是说在t3 = t2 * 8时,t2的值没有被其他计算覆盖,所以可以直接复用t2),那么优化后代码就长这样
t2 = index + 4
t2 = t2 * 8
array[index] = t2
中间代码使得编译器可以被分为前端和后端(前端负责产生机器无关的中间代码,后端用来将中间代码转换成目标机器代码),那么对于一些可跨平台的编译器而言可以针对不同的平台使用同一个前端和针对不同机器平台的无数个后端
目标代码生成与优化
源代码级优化器产生中间代码标志着下面的过程都属于编译器后端,主要包括代码生成器和目标代码优化器
接下来详细讲一下代码生成器和目标代码优化器
代码生成器:
将编译器前端生成的中间代码,如三地址码、抽象语法树等,转换为目标机器的低级代码,通常是汇编代码或机器码,整个过程依赖于目标机器,因为不同的机器有着不同的字长、寄存器、整数数据类型和浮点数数据类型等,上面的例子中的中间代码代码生成器可能会生成下面这个代码序列(这里用的是x86汇编表示,假设index类型是int,array类型是int型数组),可以看到确实有冗余加载等问题
movl index,%ecx ; value of index to ecx
addl $4,%ecx ; ecx = ecx + 4
mull $8,%ecx ; ecx = ecx * 8
movl index,%eax ; value of index to eax
movl %ecx,array(,eax,4) ; array[index] = ecx
接下来讲的是目标代码优化器
目标代码优化器:
对代码生成器输出的目标代码进行窥孔优化(扫描短指令序列,替换为更高效的指令(如用 INC eax 代替 ADD eax, 1))、分支优化(调整跳转指令布局以减少流水线冲刷(如将高频分支放在前面))、机器特有的优化(利用特定CPU的指令集(如SIMD指令)或硬件特性(如多发射流水线))、冗余指令删除(消除不必要的加载/存储操作)等优化,现在对上述代码进行优化,惩罚由一条相对复杂的基址比例变址寻址的lea指令完成,随后由一条mov指令完成最后的赋值操作,这条mov指令的寻址方式与lea一致
movl index,%edx
leal 32(,%edx,8),%eax
movl %eax,array(,%edx,4)
补充:
基址比例变址寻址:
变址寻址指的是基址寄存器 + 变址寄存器 * 比例因子,例如
movl array(,%ecx,4), %eax ;
访问array + ecx*4地址处的值,适用于数组遍历(如 array[i],其中 i 是变量),比例因子(1, 2, 4, 8)用于支持不同数据类型(如 int 是 4 字节)
基址比例变址寻址:
基址比例变址寻址(也称为带比例的变址寻址)是一种 高级内存寻址模式,常用于访问数组、结构体等数据结构,结合了 基址寄存器、变址寄存器和比例因子来计算最终的内存地址,基本语法如下
displacement(base_reg, index_reg, scale_factor)
displacement:常量偏移量(可选,通常用于结构体成员访问)
base_reg:基址寄存器(如 %ebx),存放数组的起始地址
index_reg:变址寄存器(如 %ecx),存放数组下标
scale_factor:比例因子(1, 2, 4, 8),用于调整数据类型大小(如 int 是 4 字节)
计算最终内存地址:
address = base_reg + index_reg * scale_factor + displacement基址比例变址寻址 = 基址寄存器 + 变址寄存器 × 比例因子 + 偏移量
可以更高效的访问数组,并且支持不同的数据类型,还能减少指令数量
总结
经过上述扫描、语法分析、语义分析等过程后源代码就会被编译为目标代码,但是可以发现index和array的地址还未确定,如果二者定义在跟上面源代码同一个编译单元里面,那么编译器可为index和array分配空间从而确定地址,但是分配到其他模块就不知道了,也就是说目标代码中有变量定义在其他模块时该怎么办?
那么可以知道定义其他模块的全局变量和函数在最终运行时的绝对地址都要在最终链接时才能确定,所以现代编译器可以将一个源代码文件编译成一个未链接的目标文件,然后由链接器最终将这些目标文件链接起来形成一个可执行文件
链接
这个比较费解,关键点在于汇编器为什么不直接输出可执行文件,反而是生成一个目标文件,链接有什么用?过程包含了什么内容?为什么要链接?
其实了解完上面的编译过程至少能知道问题一链接有什么用:链接可以将各个模块连接到一起,变成一个可执行文件,问题三:因为定义的模块不相同,为了将代码中的各个模块连接起来,将各个模块互相引用的部分处理好才需要用到链接(这里是因为我看书的时候发现链接放到后面可能会比较容易理解一点,这些问题其实是在详细讲编译之前作者提出的,但很明显现在在了解了编译之后来看链接会更好)
先看看怎样调用链接器ld才可以产生一个能够正常运行的helloword:
ld -static crt1.o crti.o crtbeginT.o hello.o --start-group -lgcc -lgcc_eh -lc --end-group crtend.o crtn.o
ps:这里有一个问题啊,看书的时候发现的,长指令应该都是--,不知道为什么这里把路径省略了以后就成了-了,可能书印错了
接着上面讲,要得到可执行文件就需要把那么一大堆的文件链接起来,那么这些文件到底是什么呢
--start-group和--end-group
用于解决静态库之间的循环依赖问题,链接器默认按顺序扫描库,如果库A依赖库B,而库B又依赖库A,直接链接会报错(符号未找到),--start-group和--end-group之间的库会被反复扫描,直到所有符号解析完成。
这些文件是程序启动和退出时的关键代码,由编译器和操作系统提供:
1.crt1.o/crti.o/crtn.o
crt1.o(或crt0.o):程序的入口点(_start),负责初始化栈、加载argc/argv,最后调用main,如果没有的话程序就无法从main开始执行
2.crti.o和crtn.o:处理全局构造/析构(如 C++ 的全局对象构造函数、atexit 注册的函数),crti.o 包含.init和.fini段的开头,crtn.o包含结尾
3.crtbeginT.o和crtend.o
crtbeginT.o:用于静态链接的特殊版本,处理C++的全局构造函数和异常表初始化
crtend.o:与crtbeginT.o配对,清理全局对象和异常表
模块拼装——静态链接
当一个系统十分复杂时,为了达到各个突破的目的不得不将一个复杂的系统逐步分割成小的系统,一个复杂的软件也是一样的,所以会把每个源代码模块独立的编译,然后按需组装,也就是链接,链接的主要内容就是将各个模块建的相互引用部分处理好,使得各个模块间能够正确衔接,链接器所做的工作其实就是“程序员人工调整地址”(很久之前是用指代打孔操作的,打孔代表0,不打孔代表1,是机器语言,如果原先的指令中插入了新的指令就需要人工重新计算每个子程序或跳转的目标地址),区别就在于现代的高级语言有很多特性和功能,使得编译器、链接更加复杂,功能当然也更加强大,但是原理是一样的,都是把一些指令对其他符号地址的引用加以修正
链接的过程包括地址和空间分配、符号决议、重定位
地址和空间分配
为程序中的各个段(如代码段 .text、数据段 .data、未初始化数据段 .bss)分配最终的内存布局(虚拟地址空间)
合并相同类型的段:将所有输入目标文件的 .text段合并到输出文件的 .text段,.data段同理,举个例子
目标文件1.o: .text (代码A) + .data (数据X)
目标文件2.o: .text (代码B) + .data (数据Y)
可执行文件: .text (代码A+代码B) + .data (数据X+数据Y) //合并后
分配虚拟地址:确定每个段在进程虚拟地址空间中的起始位置
地址和空间分配解决多个目标文件中段的冲突问题(避免地址重叠),为后续的符号决议和重定位提供基础
符号决议
有时也叫做符号绑定或名称绑定或名称决议,甚至还有叫地址绑定、指令绑定的,大致是一样的,但是也有细节上的区分,‘决议’倾向于静态链接,‘绑定’则是倾向于动态链接,也就是说适用范围不一样,在静态链接中统一称为符号决议
用于将符号(函数名、变量名)的引用与其定义关联起来,确保所有符号都能找到唯一实现
解析符号引用:例如,main.o调用了printf,链接器需要找到printf在libc.a或libc.so中的定义
处理重复符号:如果多个目标文件定义了同名符号(如全局变量int global),链接器会报错或按规则选择其一(如强符号优先)。
举个例子
// main.c
extern void foo(); // 声明(未定义)
int main() { foo(); return 0; }// utils.c
void foo() {} // 定义
链接时,main.o中对foo的引用会被绑定到utils.o中的定义
补充:
main.c文件编译成main.o时,编译器看到extern void foo(),知道foo不是当前文件定义的,就会生成一条未绑定的调用指令(如 call 0x00000000),地址暂时填0,在符号表中标记foo为未解决(UND)
utils.c文件编译成utils.o时,编译器生成foo函数的机器码,在符号表中标记foo为已定义(DEF),并记录它的段内偏移地址(如 0x100)
当运行链接器ld main.o utils.o时:扫描所有目标文件,发现main.o需要foo(UND状态),发现utils.o提供了foo(DEF状态),然后就会绑定关系,也就是将main.o中对foo的引用绑定到utils.o中foo的实际地址,接着重定位修正,将main.o中原本的call 0x00000000修正为call <foo的真实地址>
符号决议是为了避免运行时因未定义符号导致崩溃
重定位
简单来说就是将各个目标的地址重新计算
重定位是链接器和加载器在程序链接或加载时,调整代码和数据的内存地址的过程,核心目的是解决程序在不同内存位置正确运行的问题
程序在编译时,编译器生成的代码和数据地址通常是 基于假设的起始地址(如 0x00000000),但实际运行时,操作系统会将程序加载到 随机的内存位置(如 0x8048000),因此需要调整所有地址引用
要注意这里的是静态重定位发生在程序链接时(由链接器完成),直接修改目标文件中的地址,生成绝对地址的可执行文件,程序加载后地址固定,无法再改变
静态链接过程
最基本的静态链接过程如下所示
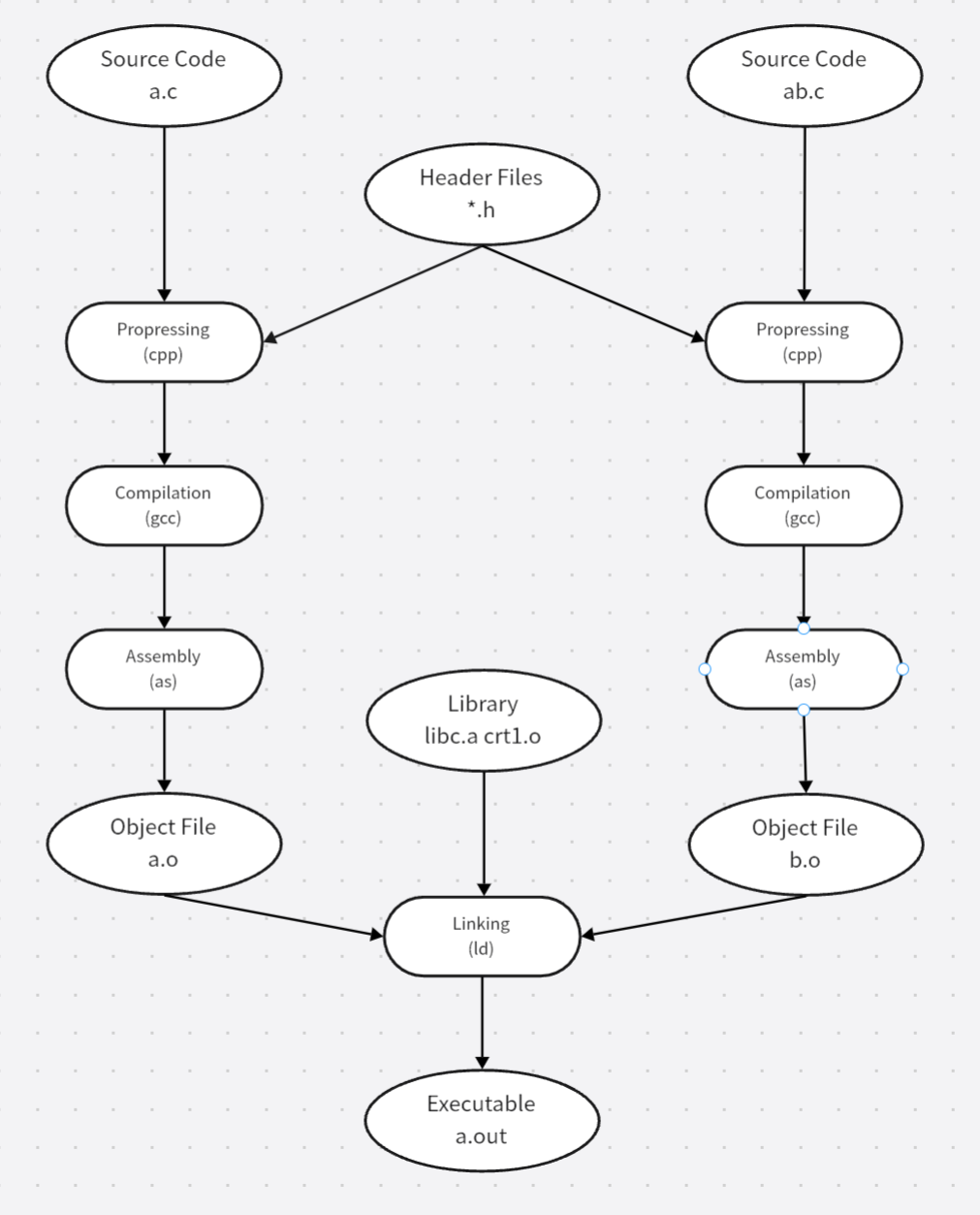
每个模块的源代码文件(如.c)文件经过编译器编译为目标文件(也就是Object File,一般为.o或.obj),目标文件和库一起链接形成可执行文件,而最常见的就是运行时库(支持程序运行的基本函数的合集),而库其实就是一组目标文件的包,也就是一些常用的代码编译成目标文件后打包存放
小结
对于Object文件没有适合的中文名称,叫做中间目标文件比较合适,简称目标文件,也会把目标文件称作模块
静态链接最基本的过程和作用:举个比较容易听懂的例子,加入现在在程序模块的main.c中使用另外一个模块func.c中的函数foo,在main.c中调用foo都必须知道确切的地址,但由于每个模块都是单独编译,所以main.c并不知道foo地址,然后就会暂时把调用了foo的指令目标地址搁置,等到最后链接时由链接器去修正地址,如果没有链接器就需要进行手动修正,填入正确的foo函数地址,当func.c模块重新编译时,foo地址就有可能改变,那么main.c中调用到foo的全部地方都要调整,很麻烦,使用链接器的话就会在引用其他模块的函数时自动去相应的模块查找地址,然后修正
在链接过程中,对其他定义在目标文件中的函数调用的指令须要重新调整,对使用其他定义在其他目标文件的变量来说,也是一样的接下来可以结合CPU指令了解一下过程,现在假设有一全局变量var在目标文件A中,在目标文件B中要访问这个全局变量,比如在目标文件B里有这样一条指令
movl $0x2a, var
给这个var变量赋值0x2a,相当于c语言中的语句var = 42,然后编译目标文件B,得到指令机器码
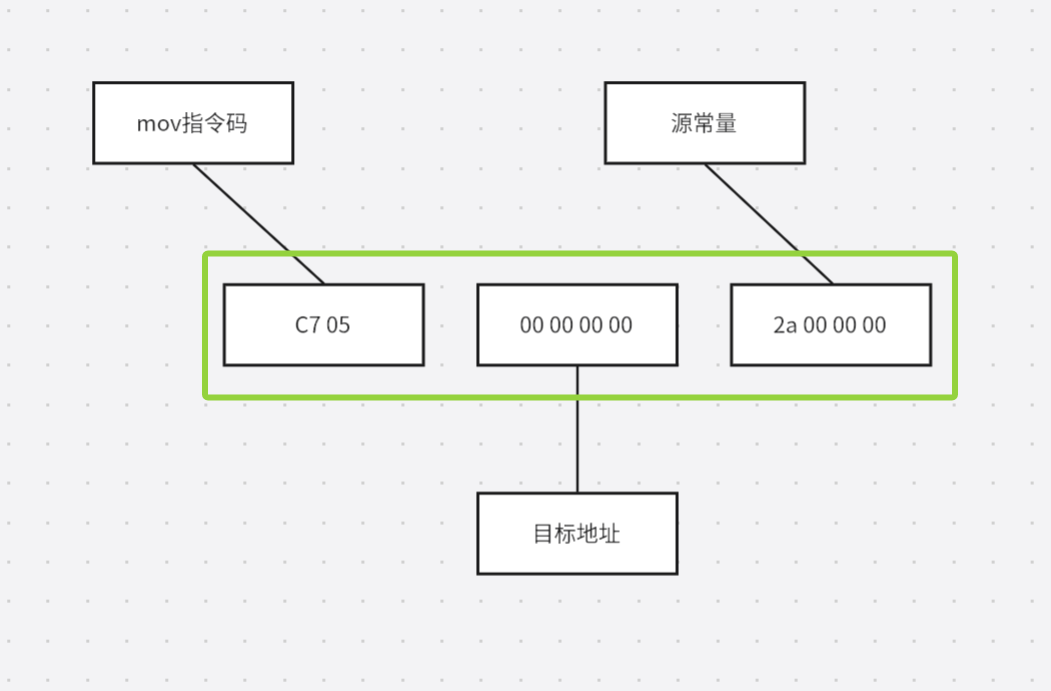
由于在编译目标文件B时,编译器不知道变量var的目标地址,所以编译器在无法确定地址的情况下将这条mov指令目标地址置为0,等待链接器在将目标文件A和B链接起来的时候会进行修正,假设链接后,变量var地址确定为0x10000,地址修正过程就叫做重定位,每一个要被修正的地方叫重定位入口
相关文章:

静态链接part2
编译 语义分析 由语义分析器完成,这个步骤只是完成了对表达式的语法层面的分析,它并不了解这个语句是否真的有意义(例如在C语言中两个指针做乘法运算,这个语句在语法上是合法的,但是没有什么意义;还有同样…...
)
在边缘端进行tensorflow模型的部署(小白初探)
1.配置tensorflow的环境 (我是安装GPU版本的) 建议参考这个博主的文章,确实非常快速! 十分钟安装Tensorflow-gpu2.6.0本机CUDA12 以及numpymatplotlib各包版本协调问题_tensorflow cuda12-CSDN博客 2.学习自制数据集 …...

合成数据如何赋能大模型预训练:效果与效率的双重加速器
目录 合成数据如何赋能大模型预训练:效果与效率的双重加速器 一、预训练模型为何需要合成数据? ✅ 克服真实数据的稀缺与偏倚 ✅ 控制训练内容结构与分布 ✅ 提升学习效率与训练稳定性 二、哪些预训练任务适合用合成数据? 三、如何构建…...

【n8n docker 部署的代理问题】解决n8n部署无法访问openai等外国大模型厂商的api
n8n docker 部署的代理问题:解决无法访问 OpenAI 等外国大模型厂商的 API 问题背景 在使用 n8n 进行自动化工作流开发时,经常需要调用 OpenAI 等外国大模型厂商的 API。然而,由于网络限制,直接部署的 n8n 容器无法访问这些 API …...

MongoDB 分账号限制数据访问
MongoDB 分账号限制数据访问 在 MongoDB 中,可以通过几种方式实现不同账号只能访问特定数据的需求,类似于你在 PostgreSQL 中实现的功能。 1. 基于角色的访问控制 (RBAC) 创建用户并分配角色 // 创建只能读取特定数据库的用户 use admin db.createUs…...

可控硅的工作原理和设计参考
可控硅物理结构如下图所示,P-N-P-N,就象两只背靠背的三极管。我们先来分析栅极不作电气联接的情况。当可控硅阴极电位大于阳极电位,J1和J3结反偏,器件截止。当可控硅阴极电位小于阳极电位,J1和J3正偏,但J2反…...

搭建axure cloud私有化平台
要求 https://blog.csdn.net/ss810540895/article/details/145833470 能不能找个空闲服务器,搭建一下 axure服务器,之前他们提供的免费服务终止了,我们需要尽快搭建一下服务。 步骤 mysql 数据库密码 Tbit36987. 分配权限 CREATE USER root…...

【无标题】spark SQL核心编程
MySQL Spark SQL 可以通过 JDBC 从关系型数据库中读取数据的方式创建 DataFrame,通过对 DataFrame 一系列的计算后,还可以将数据再写回关系型数据库中。 IDEA通过JDBC对MySQL进行操作: 1) 导入依赖 <dependency> &l…...

PostgreSql dump导入问题集合
PostgreSql dump导入问题集合 删除数据库无法删除问题 SELECT pg_terminate_backend(pg_stat_activity.pid) FROM pg_stat_activity WHERE datnametest AND pid<>pg_backend_pid();版本检查 pg_restore -l D:/suian/vrms2_backup.dump > D:/suian/vrms22list.txt…...

使用DeepSeek如何提升课题申报书中研究内容的专业性?25个进阶DeepSeek指令
家人们!搞课题申报的是不是都知道,课题申报书里的研究内容那可是重中之重,写得专业不专业直接影响申报能不能成功。今天咱就来唠唠怎么用DeepSeek提升课题申报书中研究内容的专业性,我还给大家准备了25个进阶使用小妙招哦…...
)
文章记单词 | 第33篇(六级)
一,单词释义 poison [ˈpɔɪzn] n. 毒药;毒物;有害的思想(或心情等);vt. 毒死;毒害;下毒;在… 中放毒;污染;adj. 有毒的justification [ˌdʒʌ…...

【LangChain核心组件】Memory:让大语言模型拥有持续对话记忆的工程实践
目录 一、Memory架构设计解析 1. 核心组件关系图 2. 代码中的关键实现 二、对话记忆的工程实现 1. 消息结构化存储 2. 动态提示组装机制 三、Memory类型选型指南 四、生产环境优化实践 1. 记忆容量控制 2. 记忆分片策略 3. 记忆检索增强 五、典型问题调试技巧 1. …...

GD32裸机程序-SFUD接口文件记录
SFUD gitee地址 SFUD spi初始化 /********************************************************************************* file : bsp_spi.c* author : shchl* brief : None* version : 1.0* attention : None* date : 25-…...

天元证券|调仓曝光!首批科技基金一季报出炉
4月15日,中欧基金、永赢基金、长城基金等公募基金公司旗下部分权益类基金产品一季报出炉。 券商中国记者梳理发现,永赢信息产业智选混合主要聚焦信息技术领域布局,前十大重仓股中9只股票属于信息技术行业,合计占基金资产净值比例达…...
:AlphaFold、Autoencoder)
【开源项目】Excel手撕AI算法深入理解(四):AlphaFold、Autoencoder
项目源码地址:https://github.com/ImagineAILab/ai-by-hand-excel.git 一、AlphaFold AlphaFold 是 DeepMind 开发的突破性 AI 算法,用于预测蛋白质的三维结构。它的出现解决了生物学领域长达 50 年的“蛋白质折叠问题”,被《科学》杂志评为…...
)
React-router v7 第四章(路由传参)
参数传递 React-router 一共有三种方式进行参数传递,参数传递指的是在路由跳转时,将参数传递给目标路由。 Query方式 Query的方式就是使用 ? 来传递参数,例如: #多个参数用 & 连接 /user?name小满zs&age18跳转方式&…...

常用密码技术初探
记得前几年有一部电影叫做《解除好友2:暗网》,它讲述了主角捡到一台电脑,并用它与好友进行视频通讯,但一名黑客通过网络技术篡改了通讯内容,最终导致所有参与视频通话的人都遭遇不测。 电影当然存在夸张成分ÿ…...

电脑知识 | TCP通俗易懂详解 <二>tcp首部
目录 一、👋🏻前言 二、🖃TCP快递单填写(必填部分) 1.🌸TCP快递单样式 2.🏢填写名称 3.🔢TCP序号 4. ✔️TCP确认号 编辑5.✅️确认号的确认号 6.📏首部长度 …...

09-RocketMQ 深度解析:从原理到实战,构建可靠消息驱动微服务
RocketMQ 深度解析:从原理到实战,构建可靠消息驱动微服务 一、RocketMQ 核心定位与架构探秘 1.1 分布式消息领域的中流砥柱 在分布式系统中,消息队列是实现异步通信、解耦服务、削峰填谷的关键组件。RocketMQ 作为阿里巴巴开源的分布式消息…...

MyBatis 如何使用
1. 环境准备 添加依赖(Maven) 在 pom.xml 中添加 MyBatis 和数据库驱动依赖: <dependencies><!-- MyBatis 核心库 --><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId&g…...

AI日报 - 2025年04月17日
🌟 今日概览(60秒速览) ▎🤖 AGI突破 | OpenAI新模型或证人类未解定理,研究达Level 4 OpenAI安全博客暗示模型将创造新科学,能连接概念提新实验。CEO预测AI将证明人类未解定理,研究员称已达AGI第四层级。 ▎Ǵ…...

【Leetcode-Hot100】缺失的第一个正数
题目 解答 有一处需要注意,我使用注释部分进行交换值,报错:超出时间限制。有人知道是为什么吗?难道是先给nums[i]赋值后,从而改变了后一项的索引? class Solution(object):def firstMissingPositive(sel…...

Servlet简单示例
Servlet简单示例 文章说明 Servlet 虽然是一门旧技术了,但是它的基础性和广泛性仍然不可忽视;我在实践中发现不少同学经常会被它的一些特性给困惑住;时常出现404等错误,这里我写下这篇文章,介绍Servlet的不同版本的特…...

spring:注解@Component、@Controller、@Service、@Reponsitory
背景 spring框架的一个核心功能是IOC,就是将Bean初始化加载到容器中,Bean是如何加载到容器的,可以使用spring注解方式或者spring XML配置方式。 spring注解方式直接对项目中的类进行注解,减少了配置文件内容,更加便于…...

LLM做逻辑推理题 - 野鸭蛋的故事
题目: 四个旅游家(张虹、印玉、东晴、西雨)去不同的岛屿去旅行,每个人都在岛上发现了野鸡蛋(1个到3个)。4人的年龄各不相同,是由18岁到21岁。已知: ①东晴是18岁。 ②印玉去了A岛。 ③21岁的女…...
)
Linux的目录结构(介绍,具体目录结构)
目录 介绍 具体目录结构 简洁的目录解释 详细的目录解释 介绍 Linux的文件系统是采用级层式的树状目录结构,在此结构的最上层是根目录“/”。Linux的世界中,一切皆文件(比如:Linux会把硬件映射成文件来管理) 具体目…...

C++Cherno 学习笔记day21 [86]-[90] 持续集成、静态分析、参数计算顺序、移动语义、stdmove与移动赋值操作符
b站Cherno的课[86]-[90] 一、C持续集成二、C静态分析三、C的参数计算顺序四、C移动语义五、stdmove与移动赋值操作符 一、C持续集成 Jenkins 商业软件 二、C静态分析 静态分析器会检查你的代码,并尝试检测各种错误,这些错误 可能是你无意中编写的&am…...

python学习 -- 综合案例1:设计一款基于python的飞机大战小游戏
本文目录 pygame模块介绍核心模块与功能开发流程 本文案例 - 飞机大战开发流程1. 导入必要的库2. 定义常量3. 创建精灵类4. 主程序 运行游戏 总结 pygame模块介绍 Pygame 是基于 Python 的开源、跨平台游戏开发库,依托 SDL(Simple DirectMedia Layer&am…...

开启 Python 编程之旅:基础入门实战班全解析
重要的东西放前面 开启 Python 编程之旅:基础入门实战班全解析 开启Python编程之旅:基础入门实战班全解析 在当下热门的编程语言中,Python凭借简洁易读的语法、强大的功能和丰富的库,在数据科学、人工智能、Web开发等诸多领域大…...
)
Linux笔记---动静态库(原理篇)
1. ELF文件格式 动静态库文件的构成是什么样的呢?或者说二者的内容是什么? 实际上,可执行文件,目标文件,静态库文件,动态库文件都是使用ELF文件格式进行组织的。 ELF(Executable and Linkable…...

SpringBoot整合Logback日志框架深度实践
一、依赖与默认集成机制 SpringBoot从2.x版本开始默认集成Logback日志框架,无需手动添加额外依赖。当项目引入spring-boot-starter-web时,该组件已包含spring-boot-starter-logging,其底层实现基于LogbackSLF4J组合。这种设计使得开发者只需…...

Spring Boot中接入DeepSeek的流式输出
第一步,添加依赖: <!-- WebFlux 响应式支持 --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId> </dependency> 第二步,配置We…...

路由交换网络专题 | 第四章 | 生成树 | VRRP | 边缘端口
拓扑图 (1)SW1、SW2、SW3 三台交换机之间存在环路问题,需要通过生成树协议破环,请简述二层环路可能导致的问题。 因为交换机在收到一个广播帧之后,会对非接收端口进行转发。每台交换机都转发的话,就行形成一…...
介绍)
SFOS2:常用容器(布局)介绍
一、前言 最近在进行sailfish os的开发,由于在此之前并没有从事过QT开发的工作,所以对这一套颇为生疏,以此记录一下。以下内容不一定完全准确,开发所使用的是Qt Quick 2.6与Sailfish.Silica 1.0两个库。 二、布局 1.Qt Quick 2.…...

VS qt 联合开发环境下的多国语言翻译
添加Linguist 文件方法,如同添加类文件的方式,那样: 其他跟QT的一样的流程,另外在main函数里要注册一下, QTextCodec::setCodecForLocale(textCodec); QTranslator translator5; QString trans5 fi…...

基于 Python 的 ROS2 应用开发全解析
引言 在机器人操作系统(ROS)不断发展的进程中,ROS2 作为新一代的机器人框架,带来了诸多显著的改进与新特性。Python 作为一种简洁、高效且具有强大数据处理能力的编程语言,在 ROS2 应用开发中占据着重要地位。本文将深…...

AI分析师
01 实操 人工 公司需要开发了一个XX系统,在文件夹中包含了XX.csv,其中每一行表示一个XX样本,最后一列为每个样本的标签,现需要设计模型与系统,请按照以下要求完成算法测试。根据要求完成以下任务,将完成的…...

Redis核心数据类型在实际项目中的典型应用场景解析
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 Redis作为高性能的键值存储系统,在现代软件开发中扮演着重要角色。其多样化的数据结构为开发者提供了灵活的解决方案,本文将通过真实项…...

LLamaIndex中经常使用的三个模块
from aiostream import stream from fastapi import Request from fastapi.responses import StreamingResponse from llama_index.core.chat_engine.types import StreamingAgentChatResponse这四个模块每一个都很实用,在实际开发中经常用到,下面我就详…...

Idea集成AI:CodeGeeX开发
当入职新公司,或者调到新项目组进行开发时,需要快速熟悉项目代码 而新的项目代码,可能有很多模块,很多的接口,很复杂的业务逻辑,更加有与之前自己的代码风格不一致的现有复杂代码 更别提很多人写代码不喜…...

软考 中级软件设计师 考点知识点笔记总结 day12 计算机网络基础知识
文章目录 计算机网络基础5.1、计算机网络基础知识5.1.1 计算机网络分类5.1.2 七层网络体系结构5.1.3 网络标准5.1.4 TCP/IP协议族5.1.5 IP地址和IPv6简介5.1.6 Internet服务 计算机网络基础 要求掌握以下内容 5.1、计算机网络基础知识 网络体系结构 传输介质 传输技术 传输…...
】Break-A-Scene 可控生成,原理与代码详解(中)Cross Attn Loss 代码篇)
【扩散模型(十三)】Break-A-Scene 可控生成,原理与代码详解(中)Cross Attn Loss 代码篇
系列文章目录 【扩散模型(一)】中介绍了 Stable Diffusion 可以被理解为重建分支(reconstruction branch)和条件分支(condition branch)【扩散模型(二)】IP-Adapter 从条件分支的视…...

C语言数字图像处理---2.31统计滤波器
本文介绍空域滤波器中的一种:统计滤波器 [定义与算法] 统计滤波(Statistic Filter)定义:基于图像处理中的邻域统计方法,对邻域内的像素信息进行统计,如基于均值和方差的信息,用于平滑或去噪图像,同时保留边缘信息。 算法步骤如下: 统计滤波器的优点和缺点主要包…...

流程设计实战:流程架构设计六步法
目录 简介 1、梳理业务模式及场景 2、甄别核心业务能力 3、搭建差异化的业务流程框架 4、定义L4流程能力 5、L4流程串联 6、展开L5业务流程 作者简介 简介 以往在设计流程的时候,我多数都是采用的自下而上的方式,从具体场景、具体问题出发去做流…...

SDK游戏盾如何接入?复杂吗?
接入SDK游戏盾(通常指游戏安全防护类SDK,如防DDoS攻击、防作弊、防外挂等功能)的流程和复杂度取决于具体的服务商(如腾讯云、上海云盾等)以及游戏类型和技术架构。以下是一般性的接入步骤、复杂度评估及注意事项&#…...

STM32F103C8T6 单片机入门基础知识及点亮第一个 LED 灯
目录 一、引言 二、STM32F103C8T6 基本特性 1. 内核与性能 2. 存储器 3. 时钟系统 4. GPIO(通用输入输出) 5. 外设 三、开发环境搭建 1. 硬件准备 2. 软件安装 四、点亮第一个 LED 灯 1. 硬件连接 2. 软件实现 (1)创…...

JavaScript Worker池实现教程
JavaScript Worker池实现教程 Worker池是一种管理和复用Web Workers的有效方法,可以在不频繁创建和销毁Worker的情况下,充分利用多线程能力提升应用性能。下面我将详细介绍如何在JavaScript中实现一个功能完善的Worker池。 为什么需要Worker池…...

【统信UOS操作系统】python3.11安装numpy库及导入问题解决
一、安装Python3.11.4 首先来安装Python3.11.4。所用操作系统:统信UOS 前提是准备好Python3.11.4的安装包(可从官网下载(链接)),并解压到本地: 右键,选择“在终端中打开”ÿ…...

Navicat导入JSON数据到MySQL表
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Navicat导入JSON数据到MySQL表1. 导入入口2.…...

体育比分小程序怎么提示日活
要提高体育比分小程序的日活跃用户(DAU),您可以考虑以下几个方面的策略: 一、核心功能优化 1.实时推送:确保比分更新真正实时,延迟不超过2秒,推荐接入熊猫比分API体育数据,比分实时更新 2.个性化订阅&am…...