探索亮数据Web Unlocker API:让谷歌学术网页科研数据 “触手可及”
本文目录
- 一、引言
- 二、Web Unlocker API 功能亮点
- 三、Web Unlocker API 实战
- 1.配置网页解锁器
- 2.定位相关数据
- 3.编写代码
- 四、Web Scraper API
- 技术亮点
- 五、SERP API
- 技术亮点
- 六、总结
一、引言
网页数据宛如一座蕴藏着无限价值的宝库,无论是企业洞察市场动态、制定战略决策,还是个人挖掘信息、满足求知需求,网页数据都扮演着举足轻重的角色。然而,这座宝库常被一道道无形的封锁之门所阻拦,反机器人检测机制、验证码验证、IP限制等重重障碍,让数据获取之路困难重重。
但是,亮数据的 Web Unlocker API 宛如一把闪耀的“金钥匙”,横空出世。它凭借先进的技术,突破层层阻碍,致力于让网页数据真正“触手可及”,可以为企业开启通往数据宝藏的康庄大道,轻松解锁海量有价值的信息。
二、Web Unlocker API 功能亮点
网页解锁器API,即Web Unlocker API,是亮数据一款强大的三合一网站解锁和抓取解决方案,专为攻克那些最难访问的网站而设计,实现自动化抓取数据。主要有三大亮点,分别如下:
网站解锁方面,基于先进的AI技术,能实时主动监测并破解各类网站封锁手段。运用浏览器指纹识别、验证码(CAPTCHA)破解、IP轮换、请求重试等自动化功能,模拟真实用户行为,有效规避反机器人检测,可以轻松访问公开网页。
自动化代理管理是第二大亮点。无需耗费大量IP资源或配置复杂的多层代理,Web Unlocker会自动针对请求挑选最佳代理网络,全面管理基础架构,借助动态住宅IP,保障访问顺畅成功获取所需的重要网络数据。
对于使用JavaScript的网站,它具备用于JavaScript渲染的内置浏览器。当检测到此类网站时,能在后台自动启动内置浏览器进行渲染,完整显示页面上依赖JS的某些数据元素,无缝抓取准确的数据结果。此外,还支持使用自定义指纹和cookies ,进一步增强数据抓取的灵活性与隐蔽性,满足多样化的数据获取需求。
三、Web Unlocker API 实战
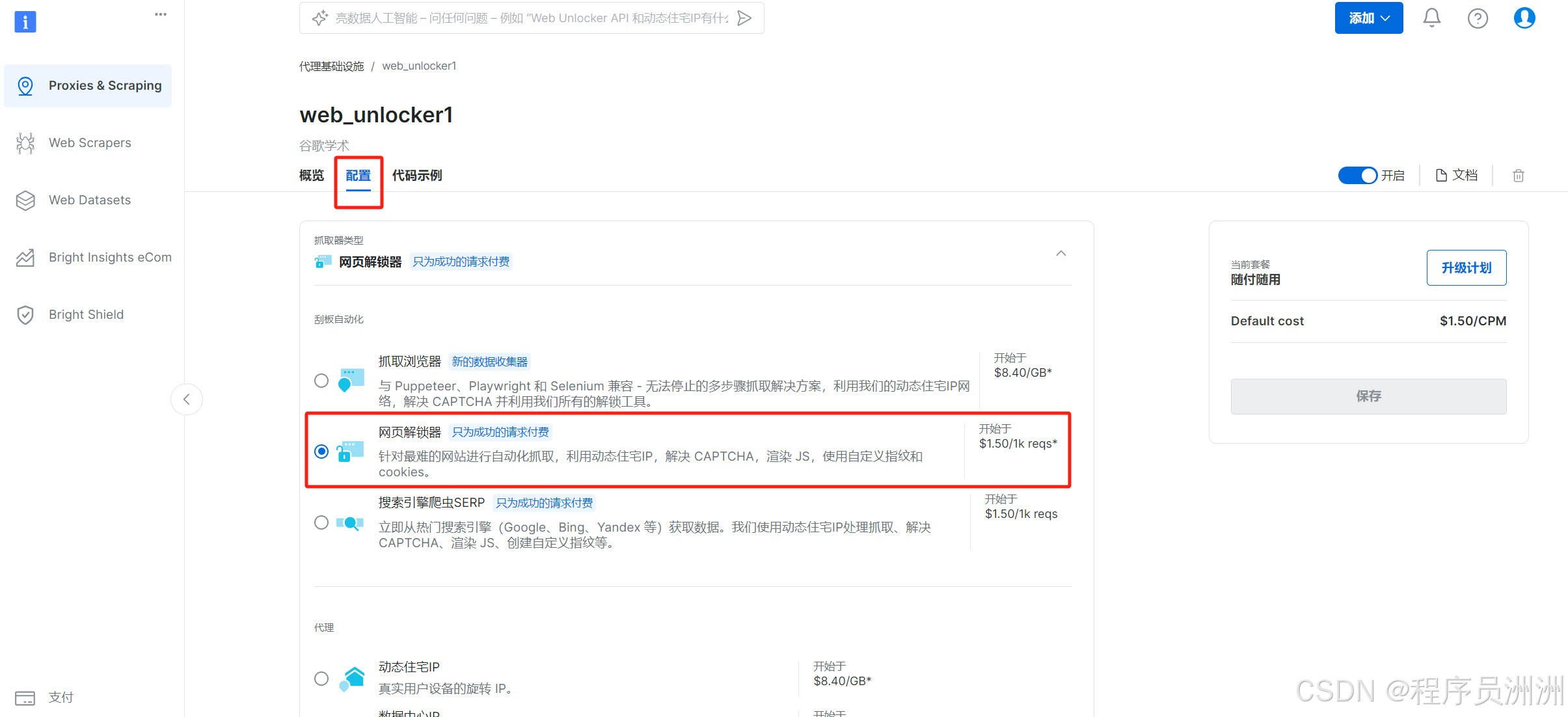
1.配置网页解锁器
首先在亮数据的功能页面中,选择“代理&抓取基础设施”,然后选择网页解锁器进行使用。
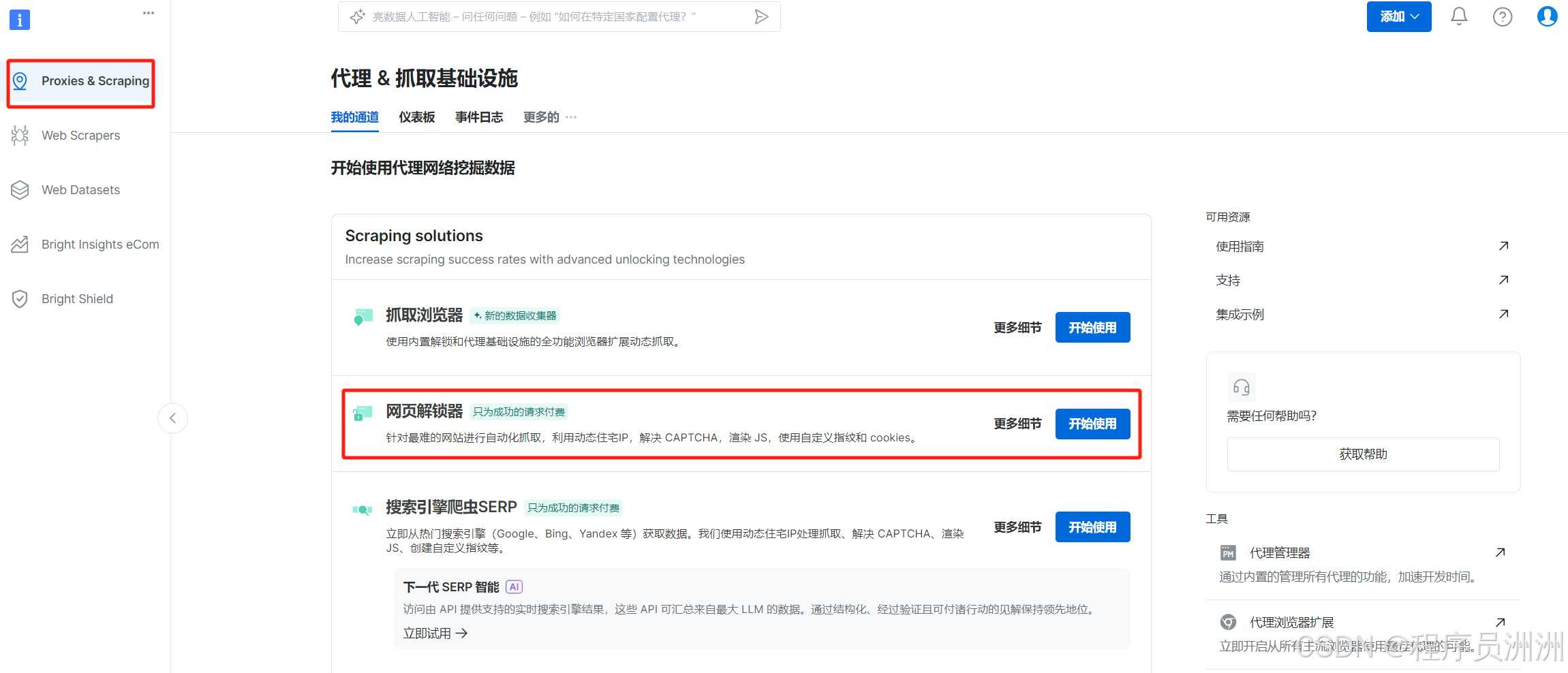
接下来操作基本设置,比如通道描述,方便我们后续进行分类管理。
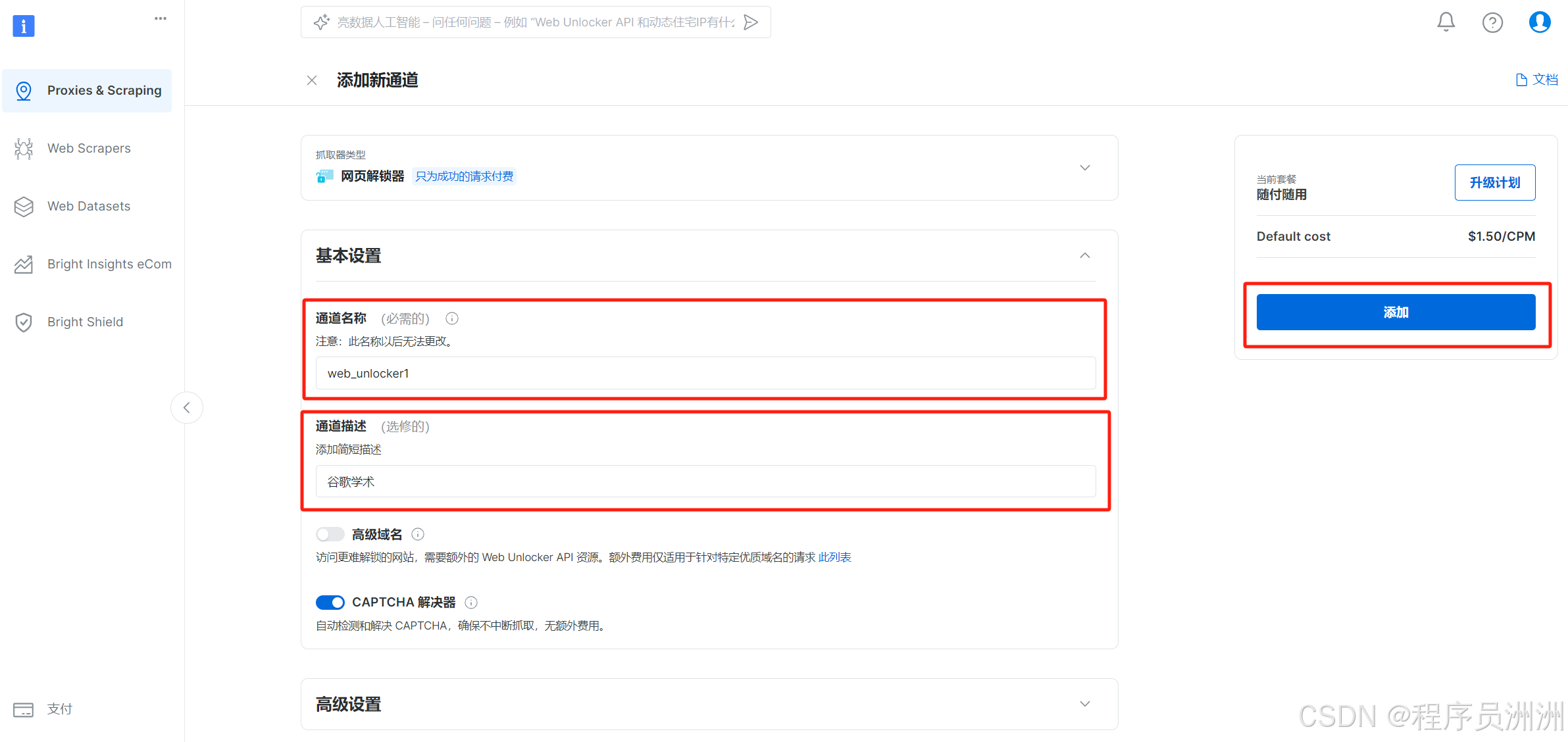
然后就会展示Web Unlocker1的详细信息了,有API访问信息、配置信息、代码示例等。
选择“配置”,选中“网页解锁器”进行使用。
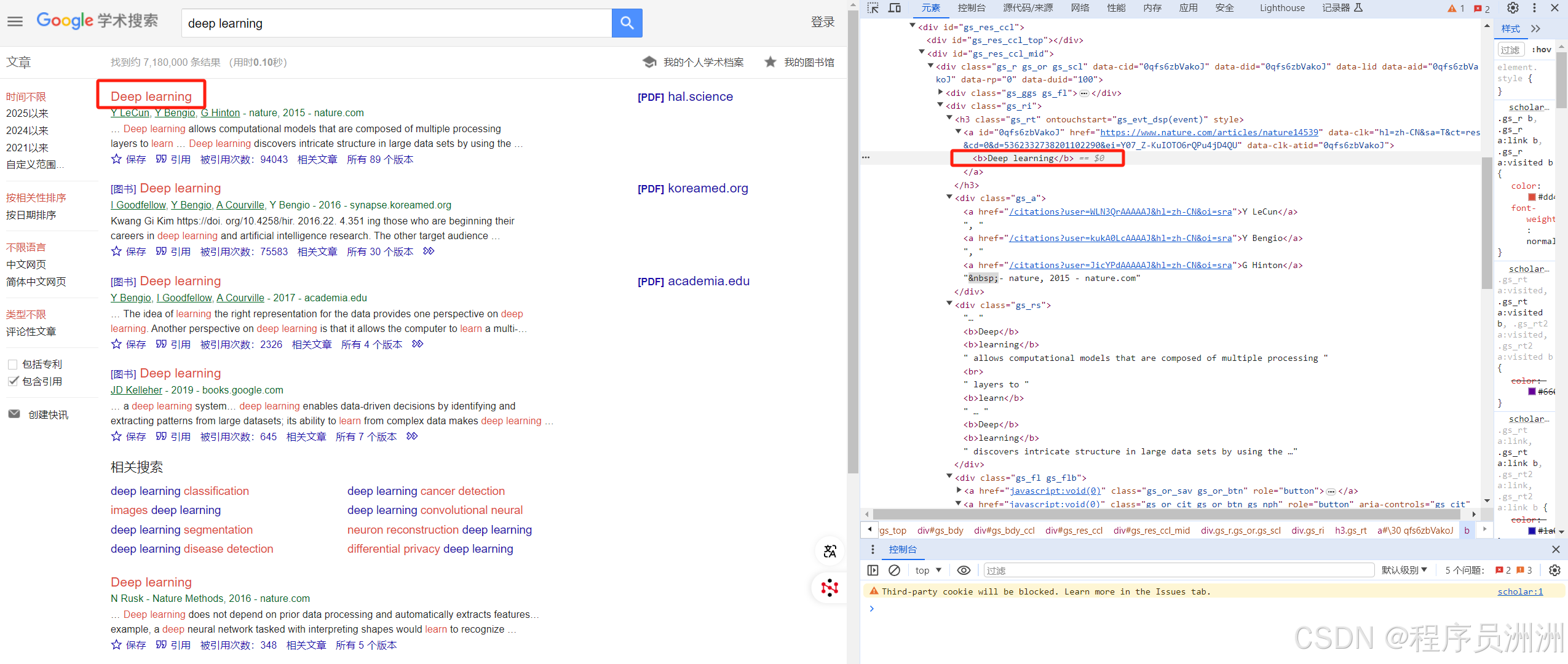
2.定位相关数据
这里我们用谷歌学术作为案例,因为谷歌学术的各种防范机制手段等比较多,对IP也有一定限制,还有人机交互验证登,现在我们通过python代码来展示怎么使用对应的Web Unlocker API,首先进入到谷歌学术页面,可以看到有很多论文信息,比如我们想获取论文题目、引用次数、论文摘要等重要信息,就可以先定位到这些相关数据。
3.编写代码
首先,导入了必要的 Python 模块,包括 requests 用于发送 HTTP 请求,BeautifulSoup 用于解析 HTML 内容,以及 warnings 用于处理警告信息。此外,还导入了 scholarly 模块,这是一个专门用于爬取 Google Scholar 数据的库。
然后配置 Bright Data亮数据的代理设置。通过定义 customer_id、zone_name 和 zone_password 来指定用户的身份验证信息,这些信息用于访问 Bright Data 提供的代理服务。接着,代码构建了一个代理 URL,并将其与 HTTP 和 HTTPS 协议关联起来,存储在 proxies 字典中。这样,后续使用 requests 发送请求时,就可以通过这个代理服务器进行网络访问。
import requests
from bs4 import BeautifulSoup
import warnings
from scholarly import scholarly# 忽略SSL警告
warnings.filterwarnings('ignore', message='Unverified HTTPS request')# Bright Data的Web Unlocker API配置信息
customer_id = "brd-customer-hl_c2e4626a-zone-web_unlocker1"
zone_name = "web_unlocker1"
zone_password = "ti9xcyh503o5"# 代理设置
proxy_url = "brd.superproxy.io:33335"
proxy_auth = f"brd-customer-{customer_id}-zone-{zone_name}:{zone_password}"
proxies = {"http": f"http://{proxy_auth}@{proxy_url}","https": f"http://{proxy_auth}@{proxy_url}"
}
然后设置请求目标URL和请求头,模拟真实请求行为。
# 目标Google Scholar的URL
target_url = "https://scholar.google.com/scholar?hl=zh-CN&as_sdt=0%2C5&q=deep+learning&oq=deep"# 模拟真实浏览器
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Encoding": "gzip, deflate, br","Referer": "https://scholar.google.com/"
}
接着就是通过亮数据向谷歌学术发送HTTP请求,获取与“deep learning”深度学习相关的学术搜索结果,解析并打印前五个结果的标题、作者、摘要信息了。
# 使用代理发送请求
try:print("正在通过代理发送请求...")response = requests.get(target_url, proxies=proxies, headers=headers, verify=False)response.raise_for_status() # 检查请求是否成功print(f"请求状态码: {response.status_code}")# 解析HTML内容soup = BeautifulSoup(response.text, "html.parser")# 使用scholarly库获取数据print("正在获取Google Scholar数据...")search_query = scholarly.search_pubs('deep learning')# 检索前5个结果for i in range(5):try:publication = next(search_query)title = publication['bib']['title']authors = ', '.join(publication['bib']['author'])abstract = publication['bib'].get('abstract', '没有摘要可用')print(f"标题: {title}")print(f"作者: {authors}")print(f"摘要: {abstract}\n")except StopIteration:print("已获取所有可用结果。")breakexcept Exception as e:print(f"获取结果时出错: {e}")except requests.exceptions.RequestException as e:print(f"请求失败: {e}")
except Exception as e:print(f"解析失败: {e}")
完整代码如下:
import requests
from bs4 import BeautifulSoup
import warnings
from scholarly import scholarly# 忽略SSL警告
warnings.filterwarnings('ignore', message='Unverified HTTPS request')# 您的Bright Data凭证
customer_id = "brd-customer-hl_c2e4626a-zone-web_unlocker1"
zone_name = "web_unlocker1"
zone_password = "ti9xcyh503o5"# 代理设置
proxy_url = "brd.superproxy.io:33335"
proxy_auth = f"brd-customer-{customer_id}-zone-{zone_name}:{zone_password}"
proxies = {"http": f"http://{proxy_auth}@{proxy_url}","https": f"http://{proxy_auth}@{proxy_url}"
}# 目标Google Scholar的URL
target_url = "https://scholar.google.com/scholar?hl=zh-CN&as_sdt=0%2C5&q=deep+learning&oq=deep"# 模拟真实浏览器
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Encoding": "gzip, deflate, br","Referer": "https://scholar.google.com/"
}# 使用代理发送请求
try:print("正在通过代理发送请求...")response = requests.get(target_url, proxies=proxies, headers=headers, verify=False)response.raise_for_status() # 检查请求是否成功print(f"请求状态码: {response.status_code}")# 解析HTML内容soup = BeautifulSoup(response.text, "html.parser")# 使用scholarly库获取数据print("正在获取Google Scholar数据...")search_query = scholarly.search_pubs('deep learning')# 检索前5个结果for i in range(5):try:publication = next(search_query)title = publication['bib']['title']authors = ', '.join(publication['bib']['author'])abstract = publication['bib'].get('abstract', '没有摘要可用')print(f"标题: {title}")print(f"作者: {authors}")print(f"摘要: {abstract}\n")except StopIteration:print("已获取所有可用结果。")breakexcept Exception as e:print(f"获取结果时出错: {e}")except requests.exceptions.RequestException as e:print(f"请求失败: {e}")
except Exception as e:print(f"解析失败: {e}")
可以看到结果如下:

四、Web Scraper API
网页抓取 API (Web Scraper API)是亮数据一款强大的网页数据提取工具,可通过专用端点,从 120 多个热门域名提取最新的结构化网页数据,且完全合规、符合道德规范。用户无需开发和维护基础设施,就能轻松提取大规模网页数据,满足各类数据需求。
技术亮点
- 高效数据处理:支持批量处理请求,单次最多可处理 5,000 个 URL ,还能进行无限制的并发抓取任务。同时具备数据发现功能,可检测数据结构和模式,确保高效、有针对性地提取数据;数据解析功能则能将原始 HTML 高效转换为结构化数据,简化数据集成与分析流程,大幅提升数据处理效率。
- 灵活输出与交付:能够提供 JSON 或 CSV 等多种格式的结构化数据,还可通过 Webhook 或 API 交付,以 JSON、NDJSON 或 CSV、XLSX 文件获取数据,方便用户根据自身工作流程和需求进行选择,量身定制数据处理流程。
- 稳定且可扩展:依托全球领先的代理基础设施,保障无与伦比的稳定性,将故障降至最低,性能始终保持一致。同时具备出色的可扩展性,能轻松扩展抓取项目以满足不断增长的数据需求,在扩展规模的同时维持最佳性能,并且内置基础设施和解封功能,无需用户维护代理和解封设施,就能从任意地理位置轻松抓取数据,避免验证码和封锁问题。

五、SERP API
SERP API 是亮数据一款用于轻松抓取搜索引擎结果页面(SERP)数据的工具。能自动适应搜索引擎结构和算法的变化,从 Google、Bing、DuckDuckGo 等所有主流搜索引擎,像真实用户一样抓取大量数据 。提供 JSON 或 HTML 格式的结构化数据输出,支持定制化搜索参数,助力用户获取精准的搜索结果数据。
技术亮点
- 自适应与精准抓取:可自动调整适应不断变化的 SERP,结合各种定制化搜索参数,充分考虑搜索历史、设备、位置等因素,如同真实用户操作般精准抓取数据,避免因位置等原因被搜索引擎屏蔽 。
- 高效快速响应:数据输出速度超快,能在短时间内以 JSON 或 HTML 格式快速、准确地输出数据,满足用户对时效性的需求,即使在高峰时段也能高效处理大量抓取任务。
- 成本效益与易用性:采用成功后付款模式,仅在成功发送抓取请求后收费,节省运营成本。用户无需操心维护,可专注于抓取所需数据,使用便捷。
六、总结
在数据驱动的当今时代,网页数据无疑是一座亟待挖掘的富矿。亮数据的 Web Unlocker API、Web Scraper API 以及 SERP API,构成了一套全面且强大的数据获取解决方案。
Web Unlocker API 凭借先进 AI 技术,巧妙突破网站封锁,自动管理代理网络,支持 JavaScript 渲染,为数据抓取扫除障碍,让解锁网站变得轻而易举。Web Scraper API 则以高效的数据处理能力,支持批量与并发抓取,提供多种灵活的数据输出格式,依托稳定且可扩展的基础设施,实现从热门域名的合规、精准数据提取。SERP API 更是能够自动适应搜索引擎的频繁变化,依据定制化参数精准抓取,快速输出数据,以成功付费模式降低成本,使用便捷。
无论是企业期望通过海量数据进行深度市场分析、精准制定战略,还是个人为学术研究、兴趣探索收集资料,亮数据的这一系列 API
都能成为得力助手。它们打破数据获取的重重壁垒,助力用户轻松解锁网页数据的无限价值,开启数据驱动发展的新征程。不要犹豫,立即尝试亮数据的API产品(跳转链接),让数据获取变得高效、智能、无阻碍。
相关文章:

探索亮数据Web Unlocker API:让谷歌学术网页科研数据 “触手可及”
本文目录 一、引言二、Web Unlocker API 功能亮点三、Web Unlocker API 实战1.配置网页解锁器2.定位相关数据3.编写代码 四、Web Scraper API技术亮点 五、SERP API技术亮点 六、总结 一、引言 网页数据宛如一座蕴藏着无限价值的宝库,无论是企业洞察市场动态、制定…...

【后端】【python】利用反射器----动态设置装饰器
📘 Python 装饰器进阶指南 一、装饰器本质 ✅ 本质概念 Python 装饰器的本质是 函数嵌套 返回函数,它是对已有函数的增强,不修改原函数代码,使用语法糖 decorator 实现包裹效果。 def my_decorator(func):def wrapper(*args, …...

Oracle 中的 NOAUDIT CREATE SESSION 命令详解
Oracle 中的 NOAUDIT CREATE SESSION 命令详解 NOAUDIT CREATE SESSION 是 Oracle 数据库中用于取消对用户登录会话审计的命令,它与 AUDIT CREATE SESSION 命令相对应。 一、基本语法 NOAUDIT CREATE SESSION [BY user1 [, user2]... | BY [SESSION | ACCESS]] …...

《Chronos: Learning the Language of Time Series》
全文摘要 本文提出了Chronos,一个简单而有效的预训练概率时间序列模型框架。Chronos通过缩放和量化将时间序列值标记化为固定词汇,并利用现有的基于变换器的语言模型架构进行训练。我们在多个公开数据集和合成数据集上预训练了Chronos模型,并…...

git UserInterfaceState.xcuserstate 文件频繁更新
1> 退出 Xcdoe,打开终端(Terminal),进入到你的项目目录下。 2> 在终端键入 git rm --cached <YourProjectName>.xcodeproj/project.xcworkspace/xcuserdata/<YourUsername>.xcuserdatad/UserInterfaceState.x…...

Day92 | 灵神 | 二叉树 路径总和
Day92 | 灵神 | 二叉树 路径总和 112.路径总和 112. 路径总和 - 力扣(LeetCode) 思路: 1.递归函数意义 如果在根节点为t的树中可以找到长度为target的路径就返回true,找不到就返回false 2.参数和返回值 bool tra(TreeNode …...

数据集 handpose_x_plus 3D RGB 三维手势 - 打篮球 场景 play basketball
数据集 handpose 相关项目地址:https://github.com/XIAN-HHappy/handpose_x_plus 样例数据下载地址:数据集handpose-x-plus3DRGB三维手势-打篮球场景playbasketball资源-CSDN文库...

GitLab本地安装指南
当前GitLab的最新版是v17.10,安装地址:https://about.gitlab.com/install/。当然国内也可以安装极狐GitLab版本,极狐GitLab 是 GitLab 中国发行版(JH)。极狐GitLab支持龙蜥,欧拉等国内的操作系统平台。安装…...

云数据库:核心分类、技术优势与创新、应用场景、挑战应对和前沿趋势
李升伟 整理 云数据库技术是云计算与数据库技术融合的产物,它通过云服务模式提供数据库功能,彻底改变了数据的存储、管理和访问方式。以下从核心概念、技术优势、应用场景及挑战等方面展开分析: 一、云数据库的核心分类 按部署模式 托管数…...

算力狂飙时代:解码2024年上海及周边区域IDC市场的三重构局
2025年3月,科智咨询《2024-2025年上海及周边地区IDC市场研究报告》正式发布。报告对上海及周边地区IDC市场发展情况进行全面分析与深入解读。 在长三角地区数字经济蓬勃发展的背景下,上海及周边区域的数据中心产业正迎来深刻转型。随着上海市政府陆续出台…...

循环首差链码的通俗解释
循环首差链码的通俗解释 1. 链码是什么? 链码是一种用数字序列描述图像中物体轮廓的方法。例如,在 4-链码 中: 0 表示向右移动;1 表示向上移动;2 表示向左移动;3 表示向下移动。 假设有一段轮廓的链码为…...

✅ MySQL 事务 MVCC ROLLBACK
🧠 一、MVCC 与可重复读(REPEATABLE READ) 项目内容MVCC 概念多版本并发控制,事务中读到的是开启事务时的数据快照实现机制依赖 Read View trx_id Undo Log 实现版本判断快照读普通 SELECT,使用 MVCC,不…...

信息系统项目管理工程师备考计算类真题讲解四
一、三点估算(PERT) PERT(Program Evaluation and Review Technique):计划评估技术,又称三点估算技术。PERT估算是一种项目管理中用于估算项目工期或成本的方法,以下是其详细介绍: …...

winfrom 查询某字符串 找到它在 richTextbox 的位置 定位 并高亮 并且滚动定位到所查询的字符串所在的行
如图: 代码: //查找关键字private void buttonSearch_Click(object sender, EventArgs e){string searchText textBoxSearch.Text;if (!string.IsNullOrEmpty(searchText)){TextBoxFinds(txtJSON, searchText);TextBoxFinds(txtSQL, searchText);}}//查…...

数据结构学习笔记 :线性表的链式存储详解
目录 单链表 1.1 无头单链表 1.2 有头单链表单向循环链表双链表 3.1 双链表 3.2 双向循环链表总结与对比 一、单链表 1. 无头单链表(Headless Singly Linked List) 定义:链表无头结点,直接由头指针指向第一个数据节点。 特点&…...

MyBatis-Plus 详解:快速上手到深入理解
一、前言 🌟 🧩 MyBatis & MyBatis-Plus 是啥关系? MyBatis 是一个优秀的 ORM 框架(Object Relational Mapping,面向对象关系映射),它让我们可以通过编写 SQL 来操作数据库,同…...

【软件工程大系】净室软件工程
净室软件工程(Cleanroom Software Engineering)是一种以缺陷预防(正确性验证)为核心的软件开发方法,旨在通过严格的工程规范和数学验证,在开发过程中避免缺陷的产生,而非依赖后期的测试和调试。…...

[区块链lab2] 构建具备加密功能的Web服务端
实验目标: 掌握区块链中密码技术的工作原理。在基于Flask框架的服务端中实现哈希算法的加密功能。 实验内容: 构建Flash Web服务器,实现哈希算法、非对称加密算法的加密功能。 实验步骤: 哈希算法的应用:创建hash…...
--java版)
2025年- H10-Lc117-560.和为K的子数组(子串)--java版
1.题目描述 2.思路 例子1: 3.代码实现 class Solution {public int subarraySum(int[] nums, int k) {// List<Integer> listnew ArrayList<>();// int cnt0;// for(int i0;i<nums.length;i)// {// for(int ji1;j<nums.length;j)// {// …...
)
肾脏系统触发 “元数据泄漏警报“(蛋白尿+)
肾脏系统触发 "元数据泄漏警报"(蛋白尿) 核心故障模块:肾小球滤过屏障(GlomerularFilter v2.5.0) 漏洞类型:孔径屏障漏洞 电荷屏障校验失败 → 元数据(蛋白质)越界泄漏 …...

摄像头的工作原理与应用摄像头的工作原理与应用
一、摄像头的工作原理与应用 基本概念 V4L2的全称是Video For Linux Two,其实指的是V4L的升级版,是linux系统关于视频设备的内核驱动,同时V4L2也包含Linux系统下关于视频以及音频采集的接口,只需要配合对应的视频采集设备就可以…...

一个由通义千问以及FFmpeg的AVFrame、buffer引起的bug:前面几帧影响后面帧数据
目录 1 问题描述 2 我最开始的代码----错误代码 3 正确的代码 4 为什么前面帧的结果会叠加到了后面帧上----因为ffmpeg新一帧只更新上一帧变化的部分 5 以后不要用通义千问写代码 1 问题描述 某个项目中,需要做人脸马赛克,然后这个是君正的某款芯片…...

MyBatis-动态SQL
MyBatis Plus 作为 MyBatis 的增强工具,简化了 CRUD 操作,但在复杂查询时,仍需使用 MyBatis 的动态 SQL 功能。以下是一些常用的动态标签、用法示例及注意事项: 常用动态标签及用法示例 <if> 标签 用途:条件判…...
和链表(Linkedlist))
顺序表(Arraylist)和链表(Linkedlist)
List List是一个接口,继承自Collection。 从数据结构角度来说,List就是一个线性表,即用n个相同类型的有限序列,可以在此序列中可以进行增删改查操作。 List是接口不能直接实例化,Linkedlist和Arraylist都实现了List…...

【python】django sqlite版本过低怎么办
方法一:下载最新版本 复制上面的内容的链接 在服务器上进行操作 wget https://sqlite.org/2025/sqlite-autoconf-3490100.tar.gz tar -zxvf sqlite-autoconf-3490100.tar.gz cd sqlite-autoconf-3490100 ./configure --prefix/usr/local make && make in…...

解决Dify使用Docker Compose部署中无法通过OpenAI插件等国外大模型厂商的插件访问其API的问题
解决Dify使用Docker Compose部署中无法通过OpenAI插件等国外大模型厂商的插件访问其API的问题 问题描述 在使用Docker Compose部署Dify时,发现无法通过OpenAI等国外大模型厂商的插件访问其API。这主要是因为Docker容器内的网络环境与宿主机不同,导致无…...

【ROS】代价地图
【ROS】代价地图 前言代价地图(Costmap)概述代价地图的参数costmap_common_params.yaml 参数说明costmap_common_params.yaml 示例说明global_costmap.yaml 参数说明global_costmap.yaml 示例说明local_costmap.yaml 参数说明local_costmap.yaml 示例说明…...

Deno 统一 Node 和 npm,既是 JS 运行时,又是包管理器
Deno 是一个现代的、一体化的、零配置的 JavaScript 运行时、工具链,专为 JavaScript 和 TypeScript 开发设计。目前已有数十万开发者在使用 Deno,其代码仓库是 GitHub 上 star 数第二高的 Rust 项目。 Stars 数102620Forks 数5553 主要特点 内置安全性…...

把城市变成智能生命体,智慧城市的神奇进化
智能交通系统的建立与优化 智能交通系统(ITS)是智慧城市建设的核心部分之一,旨在提升交通管理效率和安全性。该系统利用传感器网络、GPS定位技术以及实时数据分析来监控和管理城市中的所有交通流动。例如,通过部署于道路两侧或交…...

青少年编程与数学 02-016 Python数据结构与算法 23课题、分布式算法
青少年编程与数学 02-016 Python数据结构与算法 23课题、分布式算法 课题摘要:一、一致性算法Paxos 算法 二、领导者选举算法Bully 算法 三、分布式锁算法基于 ZooKeeper 的分布式锁 四、分布式事务处理算法两阶段提交(2PC) 五、负载均衡算法最少连接法 …...

Windows10系统RabbitMQ无法访问Web端界面
项目场景: 提示:这里简述项目相关背景: 项目场景: 在一个基于 .NET 的分布式项目中,团队使用 RabbitMQ 作为消息队列中间件,负责模块间的异步通信。开发环境为 Windows 10 系统,开发人员按照官…...

人工智能之数学基础:特征值分解与奇异值分解的区别分析
本文重点 矩阵分解是线性代数的核心工具,广泛应用于数据分析、信号处理、机器学习等领域。特征值分解与奇异值分解在数学定义、适用范围、几何意义、计算方法、应用场景及稳定性方面存在显著差异。EVD 适用于方阵,强调矩阵的固有属性;SVD 适用于任意矩阵,揭示矩阵的内在结…...

UDP概念特点+编程流程
UDP概念编程流程 目录 一、UDP基本概念 1.1 概念 1.2 特点 1.2.1 无连接性: 1.2.2 不可靠性 1.2.3 面向报文 二、UDP编程流程 2.1 客户端 cli.c 2.2 服务端ser.c 一、UDP基本概念 1.1 概念 UDP 即用户数据报协议(User Datagram Protocol &…...

Go语言实现OAuth 2.0认证服务器
文章目录 1. 项目概述1.1 OAuth2 流程 2. OAuth 2.0 Storage接口解析2.1 基础方法2.2 客户端管理相关方法2.3 授权码相关方法2.4 访问令牌相关方法2.5 刷新令牌相关方法 2.6 方法调用时序2.7 关键注意点3. MySQL存储实现原理3.1 数据库设计3.2 核心实现 4. OAuth 2.0授权码流程…...

【版本控制】idea中使用git
大家好,我是jstart千语。接下来继续对git的内容进行讲解。也是在开发中最常使用,最重要的部分,在idea中操作git。目录在右侧哦。 如果需要git命令的详解: 【版本控制】git命令使用大全-CSDN博客 一、配置git 要先关闭项目…...

永磁同步电机控制中,滑模观测器是基于反电动势观测转子速度和角度的?扩展卡尔曼滤波观测器是基于什么观测的?扩展卡尔曼滤波观测器也是基于反电动势吗?
滑模观测器在PMSM中的应用: 滑模观测器是一种非线性观测器,利用切换函数设计,使得状态估计误差迅速趋近于零,实现快速响应和对外部干扰的鲁棒性。 在永磁同步电机(PMSM)无传感器控制中,滑模观测…...

十倍开发效率 - IDEA 插件之RestfulBox - API
提高效率不是为了完成更多的任务,而是有充足的时间摸鱼。 快速体验 RestfulBox - API 是 IDEA 的插件,适合本地测试接口,完全不需要对项目进行任何以来。 接口管理:支持接口扫描、浏览、搜索、跳转、导入和导出。支持接口请求&a…...

HTML、CSS 和 JavaScript 常见用法及使用规范
一、HTML 深度剖析 1. 文档类型声明 HTML 文档开头的 <!DOCTYPE html> 声明告知浏览器当前文档使用的是 HTML5 标准。它是文档的重要元信息,能确保浏览器以标准模式渲染页面,避免怪异模式下的兼容性问题。 2. 元数据标签 <meta> 标签&am…...

人工智能概念股投资:10大潜力标的深度研究
人工智能概念股投资:10大潜力标的深度研究 一、人工智能概念股投资的基本概念 人工智能(Artificial Intelligence,AI)是指利用计算机程序模拟人类智能的一种技术,通过对数据的分析和学习,实现类似人类思维和…...

centos部署的openstack发布windows虚拟机
CentOS上部署的OpenStack可以发布Windows虚拟机。在CentOS上部署OpenStack后,可以通过OpenStack平台创建和管理Windows虚拟机。以下是具体的步骤和注意事项: 安装和配置OpenStack: 首先,确保系统满足OpenStack的最低硬件…...

Fortran 中使用 C_LOC 和 C_F_POINTER 结合的方法来实现不同类型指针指向同一块内存区域
在 Fortran 中,可以使用 C_LOC 和 C_F_POINTER 结合的方法来实现不同类型指针指向同一块内存区域。以下是具体方法和示例: 关键步骤: 获取内存地址:用 C_LOC 获取原始数组的 C 地址。类型转换:用 C_F_POINTER 将地址转…...

两个 STM32G0 I2C 通信异常的案例分析
1. 案例一问题描述 客户反馈其产品在使用 STM32G0C1NEY6TR 和一个充电管理 IC 通信时,速率为100KHz 时通信正常,但工作在 400KHz 时,有时会产生 I2C 错误。 把 I2C GPIO 配置为推挽输出后产生错误的概率会下降。 2. 案例一问题确认 针对客…...

尚硅谷-react[1-6集]
目录 步骤 1. devlopment.js 2. react-dom.devopment.js 3. babel.min.js // 将jsx转为js体验 // 这个虚拟dom的内容不能够写引号,单引号双引号 const VDOM <h1>nihao react</h1> // 可以使用括号进行编写 const VDOM1 (<h1>nihao react</h1> )…...

树状数组简单介绍
树状数组简单介绍 前言树状数组(Binary Indexed Tree)JavaScript 详细指南一、什么是树状数组?二、核心概念(前置知识):lowbit 函数三、树状数组的实现1. 初始化树状数组2. 使用示例 四、详细原理解释1. 树…...

使用Redis实现分布式限流
一、限流场景与算法选择 1.1 为什么需要分布式限流 在高并发系统中,API接口的突发流量可能导致服务雪崩。传统的单机限流方案在分布式环境下存在局限,需要借助Redis等中间件实现集群级流量控制。 1.2 令牌桶算法优势 允许突发流量:稳定速…...

【MySQL学习】存储过程
目录 一、定义 二、基本语法 1.创建存储过程 2.删除存储过程 3.查看存储过程 三、控制语句 1.变量声明与赋值 四、游标(Cursor) (1)声明游标 (2)处理游标结束 (3)打开游标 …...

Bp靶场 - Jwt
你知道JWT漏洞如何进行攻击利用吗?快来看一看如何利用JWT漏洞进行攻击利用把!https://mp.weixin.qq.com/s/2iBIEGnkiliprsuHyY5Udg...

手机上的APN是什么,该怎么设置
网上说改个APN就可以让网速快几倍,那到底APN是个什么东西,真的能让网速快几倍吗? APN的作用 网络连接基础:APN(接入点名称)是手机连接移动网络的“桥梁”,负责识别运营商网络类型(…...

[bug]langchain agent报错Invalid Format: Missing ‘Action Input:‘ after ‘Action:‘
在学习langchain的agent时候,采用ollama调用本地的deepseek-r1:32b来做一个agent,代码如下: def create_custom_agent():llm ChatOllama(model"deepseek-r1:32b", temperature0.5)memory ConversationBufferWindowMemory(memory…...

blender关联复制与Three.js网格和材质共享验证
blender和three.js小白的学习之路。 最近看到Three.js官网上说,模型合并是一个很好的优化性能的方式,因为渲染2000个物体总要比一次性渲染一个模型要来的慢。很有道理! 但此时就不禁思考一个问题,现有的模型进行合并通过blender…...