人脸检测-人脸关键点-人脸识别-人脸打卡-haar-hog-cnn-ssd-mtcnn-lbph-eigenface-resnet
链接:https://pan.baidu.com/s/1VhGdyIW5GWuTNkfbCEc5eA?pwd=z0eo
提取码:z0eo
--来自百度网盘超级会员V2的分享
创建环境
conda create -n 环境名称python=3.8 conda activate 环境名称然后配置环境
pip install requirements.txt运行程序,点击你想运行的ipynb,选择对应的内核
人脸检测速成
haar检测人脸
运行face_detection\1.haar.ipynb
Haar特征人脸检测是一种基于机器学习的传统目标检测方法,由Viola和Jones在2001年提出。它通过计算图像中的Haar-like特征(类似边缘、线、矩形区域的亮度差异),结合AdaBoost分类器和级联分类器(Cascade Classifier),实现高效的人脸检测。
1. Haar特征人脸检测的核心原理
**(1) Haar-like特征**
Haar特征是通过计算图像中矩形区域的像素和差异来描述的,例如:
-
边缘特征(Edge Features):检测垂直或水平边缘。
-
线特征(Line Features):检测线条结构。
-
中心环绕特征(Center-Surround Features):检测中心与周围区域的对比度。
示例:
[ 白色区域像素和 ] - [ 黑色区域像素和 ] = 特征值
https://docs.opencv.org/4.x/haar_features.jpg
**(2) 积分图(Integral Image)**
为了快速计算矩形区域的像素和,使用积分图(Integral Image)进行优化,使得特征计算复杂度从O(N²)降到O(1)。
**(3) AdaBoost分类器**
-
从大量Haar特征中,AdaBoost算法选择最具区分度的特征,构建一个强分类器。
-
每个弱分类器对应一个Haar特征,最终组合成一个强分类器。
**(4) 级联分类器(Cascade Classifier)**
-
采用多级分类器,每一级过滤掉大量非人脸区域,减少计算量。
-
只有通过所有级联分类器的区域,才被判定为人脸。
2. Haar人脸检测流程
步骤1:准备训练数据
-
正样本(人脸图片):包含人脸的图片,标注人脸位置。
-
负样本(非人脸图片):不包含人脸的背景图片。
步骤2:训练分类器
-
计算Haar特征:对每张图片计算所有可能的Haar特征。
-
AdaBoost训练:选择最佳特征,构建强分类器。
-
级联分类器训练:组合多个强分类器,形成级联检测模型。
步骤3:检测人脸(OpenCV实现)
python
import cv2
# 加载预训练的Haar级联分类器(OpenCV自带)
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# 读取图像并转为灰度图(Haar检测需要单通道)
img = cv2.imread("test.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_cascade.detectMultiScale(gray,scaleFactor=1.1, # 缩放因子(调整检测窗口大小)minNeighbors=5, # 最小邻居数(过滤误检)minSize=(30, 30) # 最小检测窗口
)
# 绘制检测框
for (x, y, w, h) in faces:cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
# 显示结果
cv2.imshow("Face Detection", img)
cv2.waitKey(0)
cv2.destroyAllWindows()步骤4:优化检测
detections = face_detector.detectMultiScale(img_gray,scaleFactor=1.3)
-
调整参数:
-
scaleFactor(默认1.1):控制检测窗口的缩放步长,越小越慢但更精确。 -
minNeighbors(默认3~6):越高误检越少,但可能漏检。 -
minSize/maxSize:限制检测的最小/最大人脸尺寸。
-
-
多尺度检测:适应不同大小的人脸。
1. scaleFactor:
作用:此参数用于控制图像的缩放比例。它告诉检测器在多大程度上缩放图像,以便检测不同尺寸的对象。
默认值:通常默认值为1.1(即每次图像尺寸增加10%)。
影响: 如果scaleFactor设置为大于1的值(如1.3),它会在每次缩放时减少图像的尺寸,从而提高检测速度,但可能会丢失较小物体的检测结果。 如果scaleFactor设置为较小的值(如1.05),则会更仔细地检查图像的每个细节,从而增加检测的准确性,但也会导致更长的计算时间。 对于scaleFactor=1.3,它意味着每次图像的尺寸减少30%,让检测器能够处理不同大小的物体,同时提高效率。选择此值通常在效率和准确性之间提供了一个良好的平衡。
2. minNeighbors:
作用:此参数用于控制检测结果的严格性,定义了每个检测区域周围需要多少个邻近的矩形框来保留该区域为有效检测。
影响: 增加minNeighbors值会导致检测更加严格,只有在该区域有更多的邻近矩形框时才会认为这是一个有效的检测区域,减少误报,但也可能错过一些真实的人脸。 减少minNeighbors值则会放宽条件,允许更多的区域被标记为有效检测,可能会增加误报。
3. minSize 和 maxSize:
作用:这两个参数用于定义检测器应该关注的最小和最大对象尺寸(例如人脸的尺寸)。 影响: minSize:设置人脸检测器可以检测到的最小物体尺寸。如果物体小于该尺寸,则不会被检测到。它有助于过滤掉那些非常小的目标(如背景噪声)。
maxSize:设置最大物体尺寸。如果物体大于该尺寸,则不会被检测到。这有助于防止过大的物体被错误检测为目标(例如,检测到过大的脸或背景中的大型物体)。
4. img_gray(输入图像): 作为detectMultiScale()方法的输入,必须提供一张灰度图像,通常是通过cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)将原始彩色图像转换为灰度图像。这是因为人脸检测通常在灰度图像上进行,速度更快且计算资源需求较低。
3. Haar检测的优缺点
✅ 优点
-
计算速度快(积分图优化)。
-
适合实时检测(如摄像头人脸检测)。
-
OpenCV内置预训练模型,开箱即用。
❌ 缺点
-
对光照、遮挡敏感。
-
只能检测正脸,侧脸效果较差。
-
不如深度学习(如MTCNN、YOLO)准确。
4. 改进方案
-
结合HOG+SVM(如Dlib人脸检测)。
-
使用深度学习模型(如MTCNN、RetinaFace、YOLO)。
-
Haar+CNN混合检测(提高精度)。


HOG检测人脸
代码位置:face_detection\2.hog.ipynb
如果缺失dlib
https://blog.csdn.net/qq_58691861/article/details/119116148
这里直接通过百度网盘提供的
dlib-19.19.0-cp38-cp38-win_amd64.whl进行下载
HOG(Histogram of Oriented Gradients)是一种基于图像局部梯度方向分布的特征描述方法,广泛应用于行人检测、人脸识别等计算机视觉任务。其核心思想是通过统计图像局部区域的梯度方向分布来表征目标特征,对光照变化和几何形变具有较好的鲁棒性。
HOG人脸检测流程
1.图像预处理
-
灰度化:将彩色图像转为灰度图,减少计算量并聚焦于纹理信息。
- Gamma校正:调整图像对比度,降低光照不均的影响。公式为
![]()
,通常取 γ=0.5。
2.梯度计算
-
使用Sobel算子等微分工具计算每个像素的水平梯度(gx)和垂直梯度(gy):
![]()
-
计算梯度幅值和方向:

-
方向范围约束为0-180度,以消除梯度符号影响。
3.’分块与直方图统计
- Cell划分:将图像划分为8×8像素的单元(Cell),每个Cell内统计梯度方向直方图。将方向分为9个区间(BIN),每个BIN覆盖20度范围,按梯度幅值加权投影。
- Block整合:将相邻的2×2个Cell组成16×16像素的块(Block),对块内所有Cell的直方图进行L2归一化,消除局部对比度差异。
4.特征向量生成
-
滑动窗口遍历图像,将每个Block的特征向量串联,形成整幅图像的HOG描述子。例如,64×128像素的窗口可生成3780维特征向量(7×15个Block × 36维/Block)。
5.分类与检测
-
训练分类器:常用支持向量机(SVM)或深度神经网络(DNN)对正负样本(人脸/非人脸)的HOG特征进行分类训练。
-
滑动窗口检测:在输入图像中多尺度滑动窗口,提取HOG特征并输入分类器判断是否包含人脸。通过非极大值抑制(NMS)消除重叠框。
HOG的优势与局限性
| 优点 | 局限性 |
| 对光照、阴影鲁棒性强 | 计算复杂度较高,实时性受限 |
| 能捕捉局部结构特征(如五官轮廓) | 对遮挡或极端角度人脸检测效果下降 |
| 无需依赖肤色或颜色信息 | 需手动调整参数(如Cell/Block大小) |
应用场景
-
实时人脸检测:结合轻量级HOG模型(如Dlib库)实现快速检测。
-
疲劳驾驶监测:通过HOG定位人脸后,结合眼部、嘴部特征和头部姿态分析疲劳状态。
-
安防与身份识别:用于门禁系统、视频监控中的人脸检测与跟踪。
与其他方法的对比
-
Haar级联:HOG在复杂背景下的准确率更高,但Haar级联速度更快。
-
深度学习(如CNN):HOG计算量较小,适合资源受限场景;深度学习在精度和泛化性上更优,但依赖大量数据和算力。
代码示例(Python + OpenCV)
python
import cv2
# 加载HOG+SVM预训练模型
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
# 检测人脸
image = cv2.imread("input.jpg")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces, _ = hog.detectMultiScale(gray, winStride=(4,4), padding=(8,8), scale=1.05)
# 绘制结果
for (x, y, w, h) in faces:cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.imshow("HOG Face Detection", image)
cv2.waitKey(0)CNN检测人脸
代码位置:face_detection\3.CNN.ipynb
1、介绍
CNN(Convolutional Neural Network,卷积神经网络)是一种深度学习模型,广泛应用于计算机视觉任务,包括人脸检测、识别和分类。相比于传统方法(如Haar、HOG),CNN能够自动学习图像的多层次特征(如边缘、纹理、形状等),具有更高的检测精度和鲁棒性。
CNN人脸检测的优势:
-
高精度:能够检测不同角度、光照、遮挡的人脸。
-
端到端训练:无需手动设计特征提取器(如Haar、HOG)。
-
适应性强:适用于复杂背景、多人脸场景。
-
可扩展性:可结合目标检测框架(如Faster R-CNN、YOLO、SSD)实现实时检测。
2. CNN人脸检测流程
(1)数据准备
-
正样本(人脸):标注人脸位置(bounding box)。
-
负样本(非人脸):背景图片或误检区域。
-
数据增强:旋转、缩放、翻转、亮度调整等,提高泛化能力。
(2)网络架构
CNN人脸检测通常采用以下结构:
-
输入层:输入图像(如224×224×3)。
-
卷积层(Conv):提取局部特征(如边缘、纹理)。
-
池化层(Pooling):降维,减少计算量(如Max Pooling)。
-
全连接层(FC):分类或回归人脸位置。
-
输出层:
-
分类任务:判断是否为人脸(Softmax)。
-
回归任务:预测人脸边界框(Bounding Box)。
-
常见CNN结构:
-
LeNet-5(早期CNN,适用于简单人脸检测)
-
AlexNet(更深的网络,提高检测精度)
-
VGG-16/VGG-19(小卷积核,深层网络)
-
ResNet(残差连接,解决梯度消失问题)
(3)训练CNN
-
损失函数:
-
分类损失:交叉熵损失(Cross-Entropy Loss)。
-
回归损失:Smooth L1 Loss(用于Bounding Box回归)。
-
-
优化器:Adam、SGD(随机梯度下降)。
-
训练技巧:
-
Dropout:防止过拟合。
-
Batch Normalization:加速训练,提高稳定性。
-
(4)检测阶段
-
滑动窗口(Sliding Window):
-
在图像上滑动不同大小的窗口,用CNN判断是否包含人脸。
-
缺点:计算量大,效率低。
-
-
基于区域提议(Region Proposal):
-
Faster R-CNN:使用RPN(Region Proposal Network)生成候选框。
-
YOLO(You Only Look Once):单次检测,速度快。
-
SSD(Single Shot MultiBox Detector):多尺度检测,平衡速度与精度。
-
import cv2
import numpy as np
import matplotlib.pyplot as plt
import dlib# 设置Matplotlib显示参数
plt.rcParams['figure.dpi'] = 200 # 提高图像显示分辨率# 读取输入图像
img = cv2.imread('./images/faces2.jpg')# 初始化Dlib的CNN人脸检测器
cnn_face_detector = dlib.cnn_face_detection_model_v1('./weights/mmod_human_face_detector.dat')# 执行人脸检测
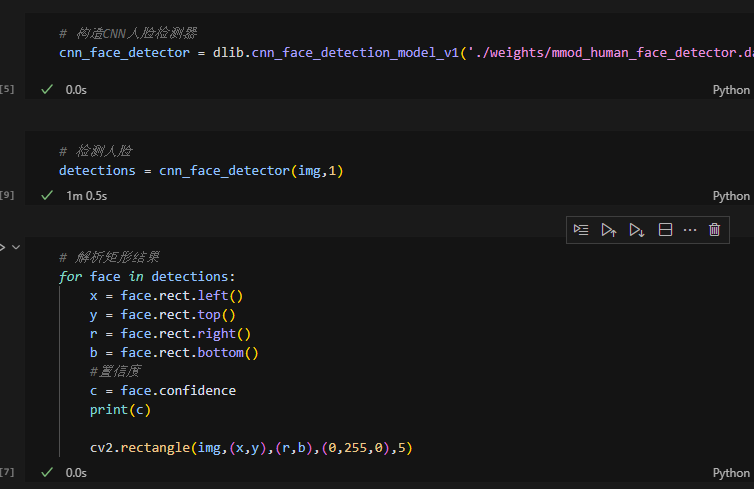
detections = cnn_face_detector(img, 1)# 遍历检测结果并绘制边界框
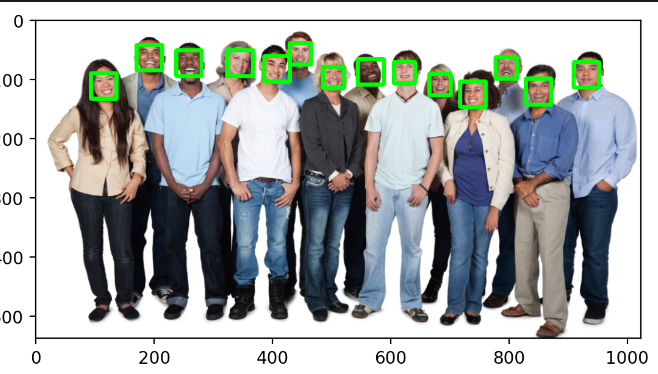
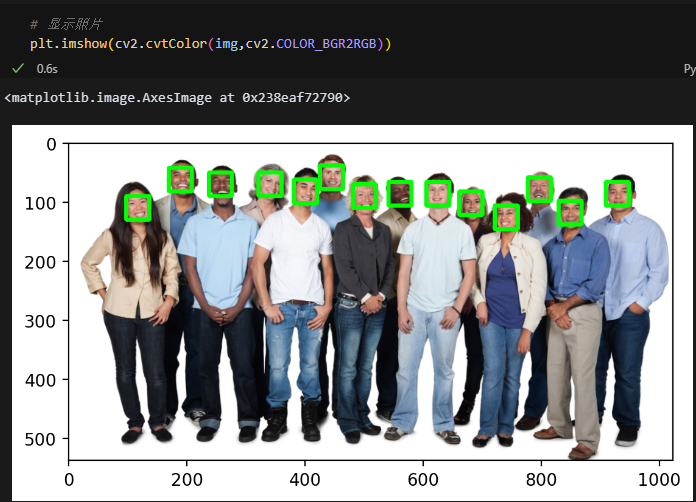
for face in detections:# 获取人脸边界框坐标x = face.rect.left()y = face.rect.top()r = face.rect.right()b = face.rect.bottom()# 获取检测置信度c = face.confidenceprint(f"Detection Confidence: {c:.4f}") # 打印置信度(保留4位小数)# 在图像上绘制绿色矩形框(线宽为5像素)cv2.rectangle(img, (x, y), (r, b), (0, 255, 0), 5)# 将BGR图像转为RGB格式并显示
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.axis('off') # 关闭坐标轴
plt.show()分步解析
1. 导入依赖库
import cv2 # OpenCV,用于图像处理和绘制矩形框
import numpy as np # 数值计算(本代码中未直接使用,但通常与OpenCV配合)
import matplotlib.pyplot as plt # 图像显示
import dlib # 加载Dlib的深度学习人脸检测器2. 设置Matplotlib参数
plt.rcParams['figure.dpi'] = 200-
作用:提高Matplotlib显示图像的分辨率,使输出更清晰。
3. 读取输入图像
img = cv2.imread('./images/faces2.jpg')-
作用:通过OpenCV读取图像文件,返回一个
BGR格式的NumPy数组。
4. 初始化Dlib CNN检测器
cnn_face_detector = dlib.cnn_face_detection_model_v1('./weights/mmod_human_face_detector.dat')-
作用:
-
加载Dlib预训练的CNN人脸检测模型(
mmod_human_face_detector.dat)。 -
该模型基于Max-Margin Object Detection (MMOD)算法,对遮挡和多角度人脸有较好效果。
-
5. 执行人脸检测
detections = cnn_face_detector(img, 1)-
参数说明:
-
img:输入图像(BGR格式)。 -
1:表示对图像进行上采样(upscale)1次,提高对小脸的检测率。
-
-
返回值:
-
detections:包含检测结果的列表,每个元素是一个mmod_rectang对象,包含边界框坐标和置信度。
-
6. 解析检测结果并绘制框
for face in detections:x = face.rect.left() # 左边界x坐标y = face.rect.top() # 上边界y坐标r = face.rect.right() # 右边界x坐标b = face.rect.bottom() # 下边界y坐标c = face.confidence # 检测置信度(0~1)print(f"Detection Confidence: {c:.4f}") # 打印置信度cv2.rectangle(img, (x, y), (r, b), (0, 255, 0), 5) # 绘制绿色矩形框-
作用:
-
遍历每个检测到的人脸,提取其边界框坐标和置信度。
-
用OpenCV的
rectangle函数在图像上绘制绿色矩形框(线宽5像素)。
-
7. 显示结果
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) # BGR转RGB
plt.axis('off') # 隐藏坐标轴
plt.show() # 显示图像-
关键点:
-
OpenCV默认使用
BGR格式,而Matplotlib使用RGB格式,需通过cv2.cvtColor转换。 -
axis('off')隐藏坐标轴,使显示更简洁。
-
补充说明
-
模型性能:
-
Dlib的CNN检测器精度高,但速度较慢(适合离线或GPU环境)。
-
若需实时检测,可改用Dlib的HOG检测器(
dlib.get_frontal_face_detector())。
-
-
置信度阈值:
-
可通过
if c > 0.5:过滤低置信度检测结果(示例未体现,但实际应用建议添加)。
-
-
输出优化:
-
可添加标题
plt.title('Face Detection Results')。 -
保存结果:
cv2.imwrite('output.jpg', img)。
-
代码执行流程总结
-
输入:图像文件 → 加载为NumPy数组。
-
检测:CNN模型生成人脸边界框和置信度。
-
输出:在原图上绘制检测框,并显示高分辨率结果。
SSD检测人脸
代码在:face_detection\4.SSD.ipynb
1.SSD简介
SSD(Single Shot MultiBox Detector)是一种单阶段目标检测算法,由Wei Liu等人在2016年提出。其核心特点是:
-
单次检测(Single Shot):直接在网络中预测目标类别和位置,无需区域提议(如Faster R-CNN)。
-
多尺度特征图(MultiBox):利用不同层级的卷积特征图检测不同大小的目标,适应多尺度人脸。
-
高效实时:比两阶段方法(如Faster R-CNN)更快,适合实时应用。
SSD的优势:
-
速度快:可达到实时检测(如30+ FPS)。
-
精度高:尤其对小目标(如远距离人脸)检测效果优于YOLO早期版本。
-
端到端训练:直接输出检测框和类别,无需后处理复杂步骤。
2. SSD人脸检测流程
(1)网络架构
SSD基于VGG16(或其他Backbone)改进,主要结构如下:
-
Backbone网络:提取基础特征(如VGG16的前几层)。
-
多尺度特征图:在Backbone后添加多个卷积层,生成不同尺度的特征图(如38×38、19×19、10×10等)。
-
Default Boxes(锚框):每个特征图单元预设不同长宽比的默认框(类似Faster R-CNN的Anchor)。
-
预测头:对每个Default Box预测:
-
类别得分(是否为人脸)。
-
边界框偏移量(调整Default Box的位置)。
-
(2)训练流程
-
数据准备:
-
标注人脸边界框(Bounding Box)。
-
数据增强:随机裁剪、翻转、颜色抖动等。
-
-
匹配Default Boxes:
-
将真实框(Ground Truth)与最接近的Default Box匹配。
-
-
损失函数:
-
分类损失:Softmax交叉熵(判断是否为人脸)。
-
定位损失:Smooth L1 Loss(调整边界框位置)。
-
-
难例挖掘:
-
针对负样本(背景)远多于正样本(人脸)的问题,保留分类损失最高的部分负样本。
-
(3)检测流程
-
输入图像:调整大小至固定尺寸(如300×300)。
-
前向传播:通过SSD网络,输出所有Default Box的类别和位置。
-
后处理:
-
非极大值抑制(NMS):去除重叠的冗余检测框。
-
阈值过滤:保留置信度高于阈值的检测结果(如0.5)。
-
代码在face_detection\4.SSD.ipynb
3.SSD vs. 其他人脸检测方法
| 方法 | 速度 | 精度 | 适用场景 |
| Haar | ⚡⚡⚡ | ⚡⚡ | 实时性要求高,资源受限设备 |
| HOG | ⚡⚡ | ⚡⚡⚡ | 中等精度,光照复杂场景 |
| YOLO | ⚡⚡⚡ | ⚡⚡⚡ | 实时检测,平衡速度与精度 |
| SSD | ⚡⚡⚡ | ⚡⚡⚡⚡ | 高精度实时检测,小目标优化 |
| Faster R-CNN | ⚡ | ⚡⚡⚡⚡⚡ | 高精度需求,非实时场景 |
MTCNN检测人脸
代码在face_detection\5.MTCNN.ipynb

-
MTCNN简介
MTCNN(Multi-Task Cascaded Convolutional Networks)是一种基于深度学习的高精度人脸检测算法,由Kaipeng Zhang等人在2016年提出。其核心特点是通过三级级联网络(P-Net、R-Net、O-Net)逐步细化检测结果,同时完成以下任务:
-
人脸检测:定位图像中的人脸边界框。
-
关键点检测:标记5个面部特征点(双眼、鼻尖、嘴角)。
-
人脸对齐:通过仿射变换矫正人脸角度。
优势:
-
高精度检测多角度、遮挡、小尺寸人脸。
-
实时性较好(在GPU上可达30+ FPS)。
-
开源实现广泛(如Python的
mtcnn库)。
2. MTCNN检测流程
(1)三级级联网络
| 网络 | 输入 | 作用 |
| P-Net (Proposal Net) | 原始图像金字塔 | 快速生成候选窗口,初步过滤非人脸区域。 |
| R-Net (Refinement Net) | P-Net输出的候选框 | 进一步剔除误检,优化边界框位置。 |
| O-Net (Output Net) | R-Net输出的候选框 | 精确定位人脸边界框和5个关键点,输出最终结果。 |
(2)具体步骤
-
图像金字塔构建
-
缩放原始图像至不同尺寸(如12×12、24×24等),以检测不同大小的人脸。
-
-
P-Net粗检测
-
对每个缩放后的图像滑动窗口,预测:
-
是否为人脸(二分类)。
-
边界框的偏移量(用于调整窗口位置)。
-
-
通过非极大值抑制(NMS)合并重叠候选框。
-
-
R-Net精炼
-
将P-Net的候选框resize到24×24,输入R-Net。
-
进一步过滤误检,优化边界框坐标。
-
-
O-Net输出结果
-
将R-Net的候选框resize到48×48,输入O-Net。
-
输出:
-
最终人脸边界框。
-
5个关键点坐标(左眼、右眼、鼻尖、左嘴角、右嘴角)。
-
-
3.完整代码示例
import cv2
from mtcnn import MTCNN
import matplotlib.pyplot as plt
# 初始化MTCNN检测器
detector = MTCNN()
# 读取图像
img = cv2.imread('test.jpg')
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # MTCNN需要RGB格式
# 检测人脸
results = detector.detect_faces(img_rgb)
# 绘制结果
for result in results:# 获取边界框和关键点x, y, w, h = result['box']keypoints = result['keypoints']# 绘制人脸矩形框cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)# 绘制5个关键点for point in keypoints.values():cv2.circle(img, (int(point[0]), int(point[1])), 3, (0, 255, 0), -1)
# 显示结果(BGR转RGB)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()输出结果解析
-
results列表中的每个元素包含:-
box: 人脸边界框坐标[x, y, width, height]。 -
confidence: 检测置信度(0~1)。 -
keypoints: 5个关键点的字典:
-
{'left_eye': (x, y),'right_eye': (x, y),'nose': (x, y),'mouth_left': (x, y),'mouth_right': (x, y)
}4. 参数调优
| 参数 | 作用 | 推荐值 |
| min_face_size | 最小人脸尺寸(像素),越小越能检测小脸,但会增加计算量。 | 20 |
| scale_factor | 图像金字塔缩放因子(0~1),越小检测越精细,但速度越慢。 | 0.709 |
| thresholds | 三级网络的置信度阈值(P-Net, R-Net, O-Net),越高误检越少,但可能漏检。 | [0.6, 0.7, 0.7] |
示例:
detector = MTCNN(min_face_size=20,scale_factor=0.709,thresholds=[0.6, 0.7, 0.7]
)5. 性能对比
| 方法 | 速度 | 精度 | 关键点支持 | 适用场景 |
| MTCNN | ⚡⚡ | ⚡⚡⚡⚡ | ✅ | 高精度检测+关键点需求 |
| Haar | ⚡⚡⚡ | ⚡⚡ | ❌ | 实时性要求高的简单场景 |
| Dlib (HOG) | ⚡⚡ | ⚡⚡⚡ | ✅ | 平衡速度与精度 |
| YOLO | ⚡⚡⚡ | ⚡⚡⚡ | ❌ | 多人脸快速检测 |
6. 常见问题解决
-
速度慢:
-
减小输入图像尺寸(如缩放到640×480)。
-
使用GPU加速(需安装
tensorflow-gpu)。
-
-
漏检小脸:
-
降低
min_face_size(如设为10)。 -
增大
scale_factor(如0.8)。
-
7. 应用场景
-
人脸识别预处理:检测+对齐(如FaceNet)。
-
美颜滤镜:基于关键点添加特效(如贴纸、美瞳)。
-
视频会议:实时人脸跟踪和虚拟背景。
总结
MTCNN通过三级级联网络实现高精度人脸检测和关键点定位,适合需要精细结果的场景(如人脸识别、AR应用)。若需更高速度,可尝试轻量化模型(如MobileNet-SSD)。
人脸检测训练模型
文件在face_recognition\1.Eigen_fisher_LBPH.ipynb
这个文件需要读取一些图片路径可能有问题,根据实际的路径进行修改
这里主要介绍3个不同分类器训练人脸检测的效果

1.LBPH (Local Binary Patterns Histograms)
原理
-
基于局部二值模式(LBP),通过比较像素点与其邻域的灰度值生成二进制编码,统计直方图作为特征。
-
对光照变化鲁棒性强,计算效率高。
特点
-
训练速度快,适合小型数据集。
-
对局部纹理敏感,能捕捉人脸细节。
-
支持增量学习(可动态添加新样本)。
代码示例
recognizer = cv2.face.LBPHFaceRecognizer_create(radius=1, # LBP半径(默认1)neighbors=8, # 邻域像素数(默认8)grid_x=8, # 水平分块数grid_y=8, # 垂直分块数threshold=100.0 # 分类阈值
)
recognizer.train(train_images, labels) # 训练
label, confidence = recognizer.predict(test_image) # 预测适用场景
-
实时应用(如门禁系统)。
-
光照条件多变的环境。
2. EigenFaces (PCA-Based)
原理
-
使用主成分分析(PCA)将高维人脸图像降维,保留最大方差的特征向量(即“特征脸”)。
-
通过投影到特征空间进行识别。
特点
-
全局特征,对姿态和表情敏感。
-
要求所有输入图像尺寸相同。
-
对光照变化敏感,需预处理(如直方图均衡化)。
代码示例
python
recognizer = cv2.face.EigenFaceRecognizer_create(num_components=100, # 保留的主成分数量(默认80)threshold=5000.0 # 分类阈值
)
recognizer.train(train_images, labels)
label, confidence = recognizer.predict(test_image)适用场景
-
人脸数据库较小且对齐良好的场景。
-
需要快速原型验证时。
3. FisherFaces (LDA-Based)
原理
-
基于线性判别分析(LDA),在降维的同时最大化类间距离、最小化类内距离。
-
是EigenFaces的改进版,增强了分类判别能力。
特点
-
对光照和姿态变化比EigenFaces更鲁棒。
-
需要更多样本(每类至少2张图像)以优化类间分离。
-
计算复杂度高于EigenFaces。
代码示例
python
recognizer = cv2.face.FisherFaceRecognizer_create(num_components=100, # 保留的成分数量(默认80)threshold=5000.0 # 分类阈值
)
recognizer.train(train_images, labels)
label, confidence = recognizer.predict(test_image)适用场景
-
中等规模数据集(如员工考勤系统)。
-
需要更高精度的分类任务。
对比总结
| 分类器 | 核心算法 | 优点 | 缺点 | 适用场景 |
| LBPH | LBP直方图 | 光照鲁棒,计算快,支持增量学习 | 对全局特征不敏感 | 实时应用、动态环境 |
| EigenFaces | PCA | 简单高效,适合小数据集 | 对光照和姿态敏感 | 快速验证、对齐良好的图像 |
| FisherFaces | LDA | 分类精度高,比EigenFaces更鲁棒 | 需要更多样本,计算复杂 | 中等规模数据库、高精度需求 |
选择建议
-
优先尝试LBPH:
-
适用于大多数实时场景,尤其是光照多变的条件。
-
-
数据对齐良好时用FisherFaces:
-
若样本充足且需要高精度,FisherFaces优于EigenFaces。
-
-
EigenFaces用于基线测试:
-
适合快速验证算法可行性,但对环境敏感。
-
报错:
--------------------------------------------------------------------------- error Traceback (most recent call last) Cell In[4], line 1 ----> 1 plt.imshow(cv2.cvtColor(img,cv2.COLOR_BGR2RGB)) error: OpenCV(4.11.0) D:\a\opencv-python\opencv-python\opencv\modules\imgproc\src\color.cpp:199: error: (-215:Assertion failed) !_src.empty() in function 'cv::cvtColor'
解压文件,修改一下路径
运行到
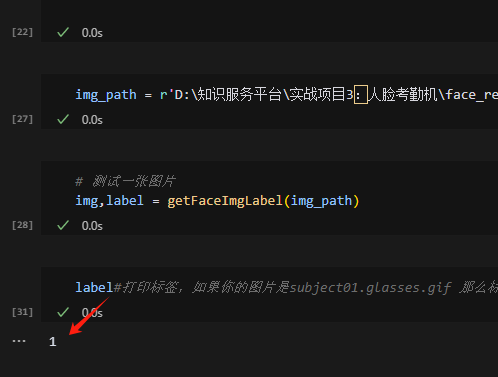
查看打印标签,发现和图片的id一致,则说明模型预测正确
resnet人脸关键点检测
文件在face_recognition\2.resnet.ipynb
这个文件需要读取一些图片路径可能有问题,根据实际的路径进行修改

人脸关键点检测(Facial Landmark Detection)是计算机视觉中的核心任务,用于定位人脸的五官轮廓(如眼睛、鼻子、嘴角等)。ResNet(残差网络)因其强大的特征提取能力和训练稳定性,被广泛用于高精度关键点检测。以下是详细解析:
1. ResNet在人脸关键点检测中的优势
**(1) 深层网络的优势**
-
残差连接(Residual Block):解决深层网络的梯度消失问题,支持训练超过100层的网络。
-
多尺度特征融合:通过不同层级的特征图捕捉局部细节和全局结构。
-
高精度:在300W、WFLW等公开数据集上达到SOTA(State-of-the-Art)性能。
**(2) 适用场景**
-
人脸对齐:为后续的人脸识别、表情分析提供标准化输入。
-
AR/VR:虚拟化妆、表情驱动。
-
医学分析:唇语识别、面部肌肉运动研究
2.与其他方法的对比
| 方法 | 优点 | 缺点 |
| ResNet | 高精度,支持端到端训练 | 计算量大 |
| Dlib (HOG+SVM) | 速度快,适合实时应用 | 对遮挡和侧脸效果差 |
| MTCNN | 多任务(检测+关键点),轻量级 | 关键点数量少(仅5点) |
| HRNet | 保持高分辨率,适合密集关键点 | 训练复杂 |
代码思路:
LBPH训练的是人脸和id,然后辨别是哪个人
resnet用的是人脸和关键点进行训练,然后辨别是哪个人
人脸识别
代码在demo_course.py
在用之前先查看data\feature.csv和data\attendance.csv是否有内容,如果有内容的话就清空,因为这里面注册的是作者的人脸信息。
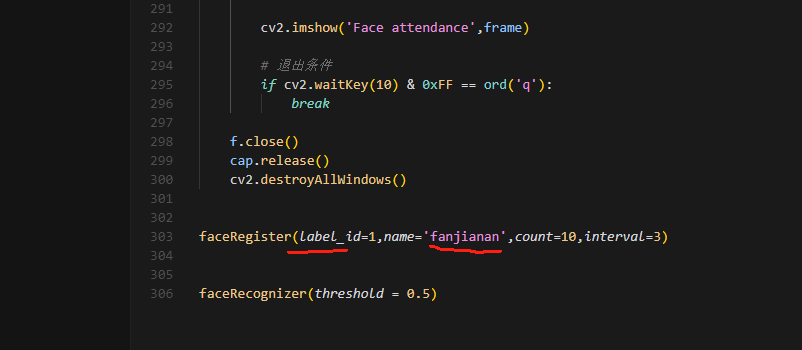
修改这个两个信息,第一个是人脸的id号,然后这个id号叫什么名字。
我们在识别的时候会匹配id号特征,如果匹配上了就输出id号的名称。
所以你需要清空原先的data\feature.csv和data\attendance.csv,否则我人脸id号是1,你的人脸id号也是1就会出错。不同人脸需要有不同id号,同一个人可以用同一个id号。
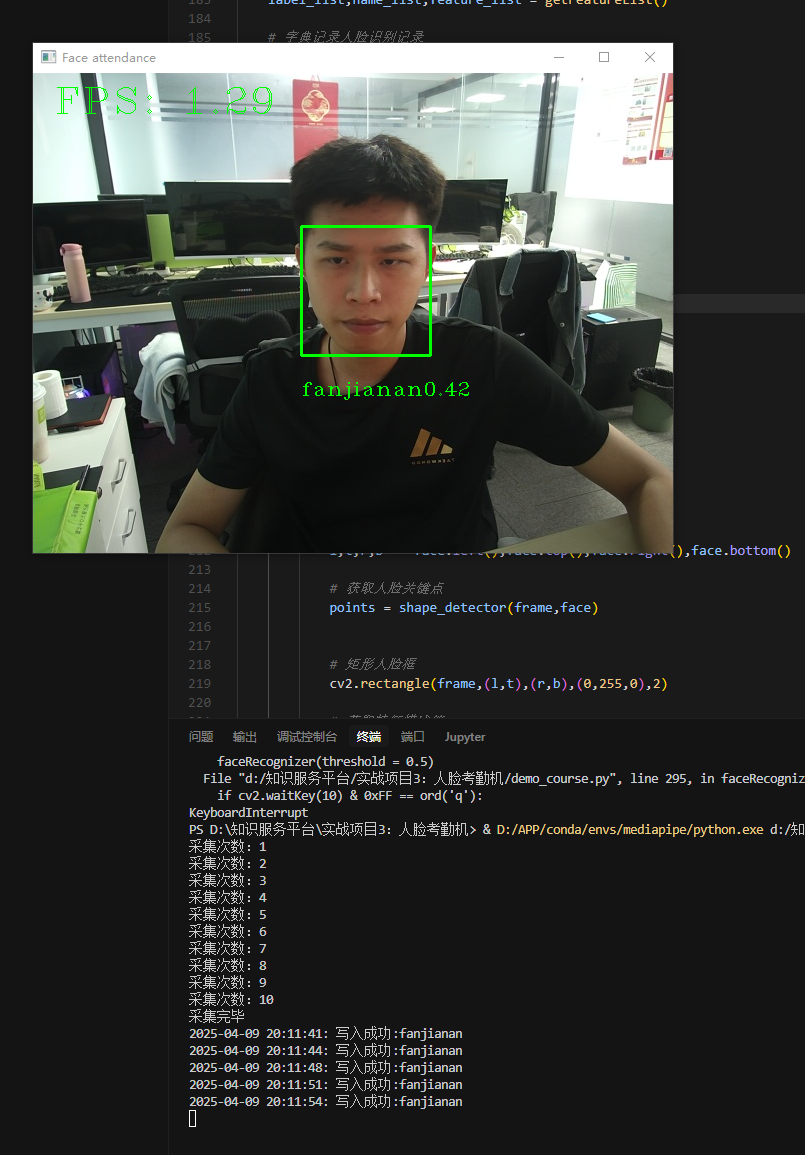
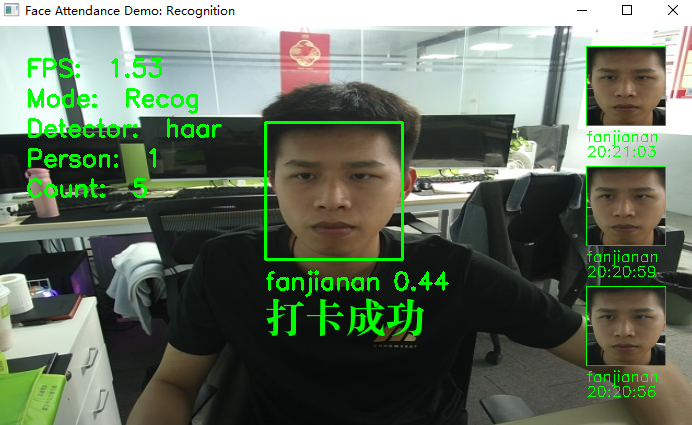
人脸打卡
代码在demo_full.py
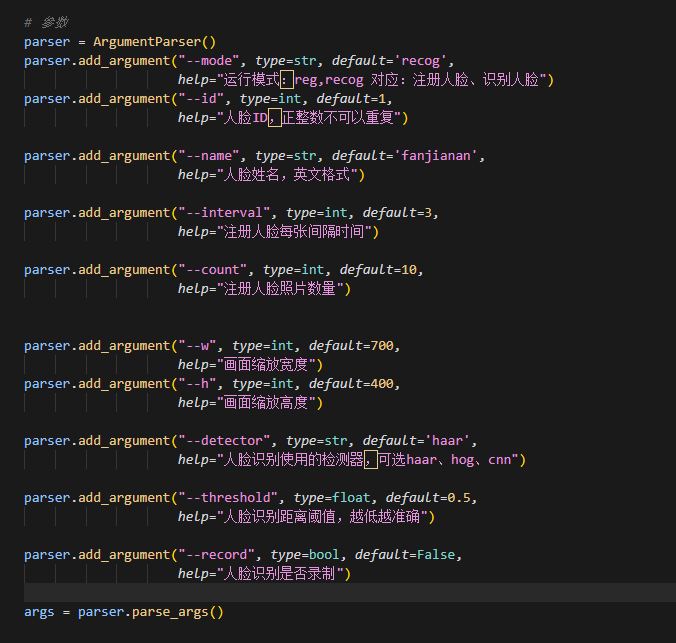
可以修改这些参数,比如mode选择是注册还是识别
name是名称
相关文章:

人脸检测-人脸关键点-人脸识别-人脸打卡-haar-hog-cnn-ssd-mtcnn-lbph-eigenface-resnet
链接:https://pan.baidu.com/s/1VhGdyIW5GWuTNkfbCEc5eA?pwdz0eo 提取码:z0eo --来自百度网盘超级会员V2的分享 创建环境 conda create -n 环境名称python3.8 conda activate 环境名称 然后配置环境 pip install requirements.txt 运行程序&…...

Gobuster :dir、dns、vhost
Gobuster 及其相关技术知识必须用于法律明确允许的场景!!! 1. dir 模式:目录/文件枚举 用途:扫描目标网站的目录和文件,常用于发现隐藏资源或敏感文件。 关键参数: -u URL&am…...

Vue+Threejs项目性能优化
使用Vue和Three.js开发的项目,但运行一段时间后电脑内存就满了,导致性能下降甚至崩溃,分析内存泄漏的原因优化如下: 资源释放管理 手动释放Three.js资源: 在Vue组件的beforeDestroy或destroyed生命周期中࿰…...

Leetcode - 双周赛135
目录 一、3512. 使数组和能被 K 整除的最少操作次数二、3513. 不同 XOR 三元组的数目 I三、3514. 不同 XOR 三元组的数目 II四、3515. 带权树中的最短路径 一、3512. 使数组和能被 K 整除的最少操作次数 题目链接 本题实际上求的就是数组 nums 和的余数,代码如下&…...

[特殊字符] PostgreSQL MCP 开发指南
简介 🚀 PostgreSQL MCP 是一个基于 FastMCP 框架的 PostgreSQL 数据库交互服务。它提供了一套简单易用的工具函数,让你能够通过 API 方式与 PostgreSQL 数据库进行交互。 功能特点 ✨ 🔄 数据库连接管理与重试机制🔍 执行 SQL…...
)
等离子体浸没离子注入(PIII)
一、PIII 是什么?基本原理和工艺 想象一下,你有一块金属或者硅片(就是做芯片的那种材料),你想给它的表面“升级”,让它变得更硬、更耐磨,或者有其他特殊功能。怎么做呢?PIII 就像是用…...

TinyEngine 2.4版本正式发布:文档全面开源,实现主题自定义,体验焕新升级!
本文由体验技术团队李璇原创。 前言 TinyEngine低代码引擎使开发者能够定制低代码平台。它是低代码平台的底座,提供可视化搭建页面等基础能力,既可以通过线上搭配组合,也可以通过cli创建个人工程进行二次开发,实时定制出自己的低…...

gemini讲USRP
您好!USRP (Universal Software Radio Peripheral) 是一种软件无线电 (SDR) 设备系列,由 Ettus Research (现为 National Instruments 旗下公司) 开发和销售。USRP 提供了一个灵活且可配置的平台,用于设计、原型开发和部署各种无线通信系统。…...

智能超表面通信控制板--通道电压并行控制版
可重构智能超表面(Reconfigurable Intelligent Surface, RIS)技术是一种新兴的人工电磁表面技术,它通过可编程的方式对电磁波进行智能调控,从而在多个领域展现出巨大的应用潜力。超表面具有低成本、低能耗、可编程、易部署等特点&…...
)
Spring Task(笔记)
介绍: 应用场景: cron表达式: cron表达式在线生成器: 入门案例:...

YOLOv3的改进思路与方法:解析技术难点与创新突破
YOLOv3作为目标检测领域的经典算法,凭借其出色的速度和性能平衡获得了广泛应用。然而,随着计算机视觉技术的不断发展,YOLOv3在某些场景下的局限性也逐渐显现。本文将深入分析YOLOv3的不足之处,并系统介绍常见的改进策略和方法&…...

【解锁元生代】ComfyUI工作流与云原生后端的深度融合:下一代AIGC开发范式革命
## 从单机到云原生的认知跃迁 当2023年Stable Diffusion WebUI还在争夺本地显卡性能时,ComfyUI已悄然开启工作流模块化革命;当2024年AI绘画工具陷入"参数调优内卷",云原生技术正重塑AI开发的基础设施层。二者的深度融合࿰…...

shell 编程之正则表达式与文本处理器
目录 一、正则表达式 1. 概念 2. 作用 3. 分类 二、基础正则表达式(BRE) grep 命令选项 三、扩展正则表达式(ERE) 与 BRE 的区别 四、文本处理器 1. sed 工具 2. awk 工具 五、总结 总结对比 元字符总结 工具对比与…...

Shell编程之正则表达式与文本处理器
目录 一、引言 二、正则表达式 2.1 定义与用途 2.2 基础正则表达式 2.2.1 查找特定字符 2.2.2 利用中括号 “[]” 查找集合字符 2.2.3 查找行首 “^” 与行尾字符 “$” 2.2.4 查找任意一个字符 “.” 与重复字符 “*” 2.2.5 查找连续字符范围 “{}” 2.3 元字符总结…...

TMDOG——语言大模型进行意图分析驱动后端实践
语言大模型进行意图分析驱动后端实践 项目概述 项目地址:https://github.com/TMDOG666/AI_Backend_Demo 该项目通过语言大模型,通过分析用户意图、拆分任务、构建API调用链来驱动后端实践。 以一个简单的教务系统后端为例,将教务系统后端…...

未启用CUDA支持的PyTorch环境** 中使用GPU加速解决方案
1. 错误原因分析 根本问题:当前安装的PyTorch是CPU版本,无法调用GPU硬件加速。当运行以下代码时会报错:model YOLO("yolov8n.pt").to("cuda") # 或 .cuda()2. 解决方案步骤 步骤1:验证CUDA可用性 在Pyth…...

【mysql】Mac 通过 brew 安装 mysql 、启动以及密码设置
Mac 通过 brew 安装 mysql 、启动以及密码设置 使用 brew 安装 mysqlmysql 启动mysql密码设置参考文章: 使用 brew 安装 mysql brew install mysqlmysql 启动 下载完毕,终端告诉我们mysql数据库没有设置密码的,我们可以直接执行 mysql -u r…...

Vue2 nextTick
核心源码位置 Vue 2 的 nextTick 实现主要在 src/core/util/next-tick.js 文件中。 完整源码结构 import { noop } from shared/util import { handleError } from ./error import { isIE, isIOS, isNative } from ./envexport let isUsingMicroTask falseconst callbacks …...

Ubuntu 安装 NVIDIA显卡驱动、CUDA 以及 CuDNN工具
文章目录 一、简介二、查看显卡设备三、安装显卡驱动四、安装CUDA工具箱五、安装CuDNN小结 一、简介 NVIDIA 驱动:操作系统与 NVIDIA 显卡硬件之间的桥梁,负责驱动显卡硬件的运行,显卡的“底层操作系统”,一切的基础。CUDA&#…...
_50)
LeetCode算法题(Go语言实现)_50
题目 现有一个包含所有正整数的集合 [1, 2, 3, 4, 5, …] 。 实现 SmallestInfiniteSet 类: SmallestInfiniteSet() 初始化 SmallestInfiniteSet 对象以包含 所有 正整数。 int popSmallest() 移除 并返回该无限集中的最小整数。 void addBack(int num) 如果正整数 …...

idea报错java: 非法字符: ‘\ufeff‘解决方案
解决方案步骤以及说明 BOM是什么?1. BOM的作用2. 为什么会出现 \ufeff 错误?3. 如何解决 \ufeff 问题? 最后重新编译,即可运行!!! BOM是什么? \ufeff 是 Unicode 中的 BOM࿰…...

WPF依赖注入IHostApplicationLifetime关闭程序
WPF依赖注入IHostApplicationLifetime关闭程序 使用Application.Current.Shutdown();退出会报异常 应该使用 app.Dispatcher.InvokeShutdown(); Application.Current.Shutdown();app.Dispatcher.InvokeShutdown();static App app new();[STAThread]public static void Main(…...

如何在 IntelliJ IDEA 中安装通义灵码 - AI编程助手提升开发效率
随着人工智能技术的飞速发展,AI 编程助手已成为提升开发效率和代码质量的强大工具。在众多 AI 编程助手之中,阿里云推出的通义灵码凭借其智能代码补全、代码解释、生成单元测试等丰富功能,脱颖而出,为开发者带来了全新的编程体验。…...

【力扣】两两交换链表中的节点
两两交换链表中的节点 代码: /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *n…...

数据共享交换平台之文件交换
数据共享交换平台的文件交换管理功能提供部门与部门之间的文件交换通道,满足跨部门之间文件交换需求。文件交换需要能够按照交换业务场景对交换通道进行分类管理。文件交换管理需满足如下要求: 1.文件交换统计:支持查看本部门与其他部门之间…...

什么是全球代理?如何选择全球代理服务?
在全球化不断深化的今天,互联网已经成为人类沟通、工作和学习的重要纽带。而全球代理则是这一纽带上的关键技术之一,它赋予了我们探索不同地区网络资源的能力。今天,我们来聊聊什么是全球代理、它能做什么,以及如何选择合适的全球…...

Spring Boot整合Kafka的详细步骤
1. 安装Kafka 下载Kafka:从Kafka官网下载最新版本的Kafka。 解压并启动: 解压Kafka文件后,进入bin目录。 启动ZooKeeper:./zookeeper-server-start.sh ../config/zookeeper.properties。 启动Kafka:./kafka-server-…...

【正点原子STM32MP257连载】第四章 ATK-DLMP257B功能测试——USB WIFI测试 #WIFI蓝牙二合一 #RTL8733BU
1)实验平台:正点原子ATK-DLMP257B开发板 2)浏览产品:https://www.alientek.com/Product_Details/135.html 3)全套实验源码手册视频下载:正点原子资料下载中心 文章目录 第四章 ATK-DLMP257B功能测试——USB…...

Doip功能寻址走UDP协议
目前使用 connect()函数的UDP客户端 ,这里接收数据 解析的地方 查看一下。 如果使用 bind()、sendto()、recvfrom() 组合 那么返回值 和发送要在做调整,,根据业务需要后续在调整 其余的 和原来的 逻辑都是一样的,只是协议变了而已。 if serv…...
)
硬件电路设计之51单片机(2)
声明:绘制原理图和PCB的软件为嘉立创EDA。根据B站尚硅谷嵌入式之原理图&PCB设计教程学习所作个人用笔记。 目录 一、原理图详解 1、TypeC接口 (1)TypeC接口介绍 (2)TypeC原理图 2、5V转3.3V 3、单片机电源开…...
—— Pytorch 和 Tensor 简介)
Deeplizard 深度学习课程(一)—— Pytorch 和 Tensor 简介
前言 该pytorch笔记参考deeplizard官方网站课程,有相应视频和博客,链接如下: deeplizardhttps://deeplizard.com/learn/video/v5cngxo4mIg 1.Pytorch 简介 PyTorch 是一个深度学习框架和一个科学计算包。PyTorch 的科学计算方面主要是 PyTo…...

Delphi HMAC算法
1. 前言 今天做一个三方接口,接口文档描述签名采用MD5,但是实际测试过程中,始终校验不通过,经过和三方沟通,才知道采用的是HMAC-MD5。由于Delphi7没有对HMAC的支持,则采用XE版本来支持。本次使用Delphi XE …...

Ubuntu服务器性能调优指南:从基础工具到系统稳定性提升
一、性能监控工具的三维应用 1.1 监控矩阵构建 通过组合工具搭建立体监控体系: # 实时进程监控 htop --sort-keyPERCENT_CPU# 存储性能采集 iostat -dx 2# 内存分析组合拳 vmstat -SM 1 | awk NR>2 {print "Active:"$5"MB Swpd:"$3"…...

深度解析C++开源OCR引擎:架构、编译优化与工业级部署指南
1. 引言:OCR技术演进与现状分析 光学字符识别(OCR)技术经历了从传统模式识别到深度学习的三代发展: 第一代:基于模板匹配(1970s-1990s) 第二代:特征提取+分类器(1990s-2010s) 第三代:端到端深度学习(2010s-至今) 当前工业界主流方案呈现"双轨制"发展态势…...

关于Newtonsoft.Json
历史 Newtonsoft.Json(也称为 Json.NET)是由 James Newton - King 开发的一个开源的 JSON 处理库,它于 2007 年首次发布。在早期,.NET 平台缺乏一个强大且灵活的 JSON 处理工具,Newtonsoft.Json 应运而生,…...
)
Spark-Sql编程(三)
一、数据加载与保存 通用方式:使用spark.read.load和df.write.save,通过format指定数据格式(如csv、jdbc、json等),option设置特定参数(jdbc格式下的url、user等),load和save指定路…...

CTF--好像需要管理员
一、原网页: 二、步骤: 1.扫描: 发现:robots.txt 2.打开robots.txt: 3.打开resul.php: 4.代码解析: if ($_GET[x]$password) //检查通过 URL 参数 x 传递的值是否等于变量 $password 的值 详…...

耀圣控制设备有限公司总经理李雨蔓的创业之路
破浪者李雨蔓:从零到行业标杆的铿锵之路 在浙江永嘉这片被誉为“中国泵阀之乡”的热土上,一位86年出生的女性企业家,用十年光阴书写了一段白手起家的传奇。她,是一曲关于勇气、智慧与匠心的赞歌。从技术员到行业标杆的缔造者&…...

Spring Boot JPA 开发之Not an entity血案
项目状况介绍 项目环境 JDK 21Spring Boot 3.4.3Hibernate: 6.6.13.Final项目描述 因为是微服务架构,项目层级如下 project-parent project-com project-A … project-X 其中: project-parent定义依赖库的版本project-com 定义了一些公用的方法和配置,包括持久层的配置。…...

什么是车规级MCU?STM32也能上车规级场景?
一、车规级MCU的定义 车规级MCU(Microcontroller Unit)是专为汽车电子系统设计的微控制器芯片,集成CPU、存储器、外设接口等功能模块,用于实现车辆控制、数据处理和实时响应。其核心特点包括: 高可靠性:需在…...

vue3.2 + element-plus 实现跟随input输入框的弹框,弹框里可以分组或tab形式显示选项
效果 基础用法(分组选项) 高级用法(带Tab栏) <!-- 弹窗跟随通用组件 SmartSelector.vue --> <template><div class"smart-selector-container"><el-popover :visible"visible" :w…...

go 指针接收者和值接收者的区别
go 指针接收者和值接收者的区别 指针接收者和值接收者的区别主要有两点: Go 中函数传参是传值,因此指针接收者传递的是接收者的指针拷贝,值接收者传递的是接收者的拷贝---在方法中指针接收者的变量会被修改,而值接收者的成员变量…...

部署qwen2.5-VL-7B
简单串行执行 from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor from qwen_vl_utils import process_vision_info import torch, time, threadingdef llm(model_path,promptNone,imageNone,videoNone,imagesNone,videosNone,max_new_tokens2048,t…...

Go:测试
go test 工具 go test是 Go 语言包的测试驱动程序 ,包依据特定约定组织 。包目录中以_test.go结尾的文件是go test编译对象,而非go build的编译目标 。 特殊测试函数 在*_test.go文件中有三种特殊函数 : 功能测试函数:以Test为…...

用微信小程序制作一个性行为同意协议系统
用微信小程序制作一个性行为同意协议系统 用微信小程序制作一个性行为同意协议系统,具备查询、修改、增加和演示的Web功能。首先,我需要明确这个系统的核心功能和法律合规性。性同意是一个敏感且法律相关的话题,必须确保系统的设计符合法律法…...

leetcode 122. Best Time to Buy and Sell Stock II
题目描述 这道题可以用贪心思想解决。 本文介绍用动态规划解决。本题分析方法与第121题一样,详见leetcode 121. Best Time to Buy and Sell Stock 只有一点区别。第121题全程只能买入1次,因此如果第i天买入股票,买之前的金额肯定是初始金额…...

FairyGUI图标文字合批失败的原因
1)FairyGUI图标文字合批失败的原因 2)为什么Cubemap的内存占用超高 3)如何找到网格某个切面的中心点 4)为什么SafeZone在倒屏后方向相反 这是第428篇UWA技术知识分享的推送,精选了UWA社区的热门话题,涵盖了…...

C/C++ 通用代码模板
✅ C 语言代码模板(main.c) 适用于基础项目、算法竞赛或刷题: #include <stdio.h> #include <stdlib.h> #include <string.h> #include <stdbool.h> #include <math.h>// 宏定义区 #define MAX_N 1000 #defi…...
为什么我在QT里面没有connect,也能触发点击效果)
void MainWindow::on_btnOutput_clicked()为什么我在QT里面没有connect,也能触发点击效果
在 Qt 中,即使你没有显式调用 connect 函数,某些信号(如按钮的 clicked() 信号)仍然可以触发槽函数。这是因为 Qt 提供了一种自动连接机制,称为 自动连接(Auto-Connection)。以下是可能的原因和…...

基于YOLO11的车牌识别分析系统
【包含内容】 【一】项目提供完整源代码及详细注释 【二】系统设计思路与实现说明 【三】系统数据统计与可视化分析支持 【技术栈】 ①:系统环境:Windows/macOS/Linux ②:开发环境:Python 3.8 ③:技术栈&#x…...