实战5:Python使用循环神经网络生成诗歌
实战5:Python使用循环神经网络生成诗歌
- 使用依赖
- 加载数据
- 词典构建和文本预处理
- 总代码
在我们学习了课程8后,我们在实战练习一个例子。
你的主要任务:学习如何使用简单的循环神经网络(Vanilla RNN)生成诗歌。亚历山大·谢尔盖耶维奇·普希金的诗体小说《叶甫盖尼·奥涅金》将作为训练的文本语料库。
使用依赖
# 不要更改下面的代码块!所有必要的import都列在这里
# __________start of block__________
import string
import os
from random import sampleimport numpy as np
import torch, torch.nn as nn
import torch.nn.functional as Ffrom IPython.display import clear_outputimport matplotlib.pyplot as plt
%matplotlib inline
# __________end of block__________
# 不要更改下面的代码块!
# __________start of block__________
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
print('{} device is available'.format(device))
# __________end of block__________
加载数据
# 不要更改下面块中的代码
# __________start of block__________
!wget https://raw.githubusercontent.com/MSUcourses/Data-Analysis-with-Python/main/Deep%20Learning/onegin_hw07.txt -O ./onegin.txtwith open('onegin.txt', 'r') as iofile:text = iofile.readlines()text = "".join([x.replace('\t\t', '').lower() for x in text]) # 删除多余的制表符,将所有字母转换为小写
# __________end of block__________
让我们输出输入文本的前几个字符。我们看到制表符已被删除,字母已转换为小写。我们保留 \n 符号,以便教会网络在需要转到新行时生成 \n 符号。
text[:36]
输出:

词典构建和文本预处理
此任务要求您在符号级别构建语言模型。让我们将所有文本转换为小写,并根据可用文本语料库中的所有字符构建字典。我们还将添加技术令牌<sos>。
# 不要更改下面的代码块!
# __________start of block__________
tokens = sorted(set(text.lower())) + ['<sos>'] # 我们构建一个包含所有符号标记的集合,并将服务标记 <sos> 添加到其中
num_tokens = len(tokens)assert num_tokens == 84, "Check the tokenization process"token_to_idx = {x: idx for idx, x in enumerate(tokens)} # 构建一个包含 token 键和 token 列表中索引值的字典
idx_to_token = {idx: x for idx, x in enumerate(tokens)} # 构建一个反向字典(这样你就可以通过索引获取一个标记)assert len(tokens) == len(token_to_idx), "Mapping should be unique"print("Seems fine!")text_encoded = [token_to_idx[x] for x in text]
# __________end of block__________
输出:Seems fine!
其中:
-
set(text.lower()):将原始文本text中的所有字符提取出来,并转换为小写形式,然后使用set函数去除重复字符,得到一个包含文本中所有不同小写字符的集合。
-
sorted(set(text.lower())):对上述集合进行排序,排序后的结果是一个有序的字符列表。这样做的目的是为了确保每次运行代码时,字符的顺序都是固定的,方便后续建立字符到索引的映射。
-
+ ['<sos>']:在排好序的字符列表末尾添加一个特殊的服务标记,通常表示 “句子起始(Start of Sentence)” 标记,在文本生成任务中用于指示生成文本的起始位置。 -
token_to_idx构建字符到索引的映射字典:使用字典推导式创建一个名为token_to_idx的字典。enumerate(tokens)会同时返回每个字符在tokens列表中的索引idx和字符本身x。字典中的键是字符x,值是对应的索引idx。这个字典用于将字符转换为模型可以处理的数字索引。 -
idx_to_token构建反向映射字典:同样使用字典推导式创建一个反向映射字典idx_to_token。与token_to_idx相反,这个字典的键是索引idx,值是对应的字符x,用于将模型输出的索引转换回实际的字符。 -
text_encoded使用列表推导式将原始文本text中的每个字符根据token_to_idx字典转换为对应的索引,得到一个编码后的文本列表text_encoded。这个编码后的文本列表将用于后续的模型训练和处理。
你的任务:训练一个经典的循环神经网络(Vanilla RNN)来预测给定文本语料库中的下一个字符,并为固定的初始短语生成长度为 100 的序列。
您可以使用课程7中的代码或参考以下链接:
- Andrej Karpathy 撰写的关于使用 RNN 的精彩文章:链接
- Andrej Karpathy 的 Char-rnn 示例:github 存储库
- 生成莎士比亚诗歌的一个很好的例子:github repo
这个任务相当有创意。如果一开始很难也没关系。在这种情况下,上面列表中的最后一个链接可能特别有用。
下面,为了您的方便,实现了一个函数,该函数从长度为“seq_length”的字符串中生成大小为“batch_size”的随机批次。您可以在训练模型时使用它。(随机生成数据批次,每个批次包含 256 个长度为 100 的字符序列,并且在每个序列的开头添加 标记,为模型训练提供数据:
# 不要更改下面的代码
# __________start of block__________
batch_size = 256 # 批量大小。批次是一组字符序列。
seq_length = 100 # 一批字符序列的最大长度
start_column = np.zeros((batch_size, 1), dtype=int) + token_to_idx['<sos>'] # 在每行开头添加一个技术符号——确定网络的初始状态def generate_chunk():global text_encoded, start_column, batch_size, seq_lengthstart_index = np.random.randint(0, len(text_encoded) - batch_size*seq_length - 1) # 随机选择批次中起始符号的索引# 构建一个连续的批次。# 为此,我们在源文本中选择一个以索引 start_index 开头且大小为 batch_size*seq_length 的子序列。# 然后我们将这个子序列分成大小为 seq_length 的 batch_size 个序列。这将是批次,大小为batch_size*seq_length的矩阵。# 矩阵的每一行将包含索引data = np.array(text_encoded[start_index:start_index + batch_size*seq_length]).reshape((batch_size, -1))yield np.hstack((start_column, data))
# __________end of block__________
其中:
- batch_size:指的是在一次训练迭代中同时处理的样本数量。在文本生成任务里,每个样本是一个字符序列。这里将 batch_size 设定为 256,意味着每次训练时会处理 256 个字符序列。
- seq_length:代表每个字符序列的最大长度。在训练时,会把文本分割成长度为 seq_length 的序列,这里设定为 100,即每个序列包含 100 个字符。
- start_column:这是一个 numpy 数组,形状为 (batch_size, 1)。借助 np.zeros((batch_size, 1), dtype=int) 生成一个全零的数组,再加上 token_to_idx[‘’],让数组的每个元素都变为 标记对应的索引。此数组用于在每个序列的开头添加 标记,以此确定模型的初始状态。
- start_index = np.random.randint(0, len(text_encoded) - batch_size*seq_length - 1):随机选取一个索引 start_index,作为当前批次数据在编码后的文本 text_encoded 中的起始位置。这样做的目的是为了让每次生成的批次数据都不同,增加训练数据的随机性。
- data = np.array(text_encoded[start_index:start_index + batch_size*seq_length]).reshape((batch_size, -1)):从 text_encoded 里选取从 start_index 开始、长度为 batch_size * seq_length 的子序列,将其转换为 numpy 数组,再调整形状为 (batch_size, seq_length) 的矩阵。这个矩阵的每一行就代表一个长度为 seq_length 的字符序列。
- yield np.hstack((start_column, data)):运用 np.hstack 函数把 start_column 和 data 按水平方向拼接起来,在每个序列的开头添加 标记。yield 关键字让这个函数成为一个生成器,每次调用该函数时,会生成一个新的数据批次,而不是一次性生成所有批次数据,这样可以节省内存。
批次示例:
next(generate_chunk())
输出:

编写网络:
# 定义 Vanilla RNN 模型
class VanillaRNN(nn.Module):def __init__(self, input_size, hidden_size, num_layers, output_size):super(VanillaRNN, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.embedding = nn.Embedding(input_size, hidden_size)self.rnn = nn.RNN(hidden_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x, hidden):x = self.embedding(x)out, hidden = self.rnn(x, hidden)out = self.fc(out)return out, hiddendef init_hidden(self, batch_size):return torch.zeros(self.num_layers, batch_size, self.hidden_size).to(device)
其中:
- input_size(输入特征的数量,即词汇表的大小)、hidden_size(隐藏层的大小,即隐藏状态的维度)、num_layers(RNN 的层数)和 output_size(输出特征的数量,通常也是词汇表的大小)。
构建模型训练和损失函数曲线图:
# 超参数设置
input_size = num_tokens
hidden_size = 128
num_layers = 2
output_size = num_tokens
learning_rate = 0.001
num_epochs = 2000 # 这里设置为 10 个 epoch,你可以根据需要调整# 初始化模型、损失函数和优化器
model = VanillaRNN(input_size, hidden_size, num_layers, output_size).to(device)
criterion = nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(), lr=learning_rate)# 用于存储每次迭代损失值的列表
history = []# 训练循环
for epoch in range(num_epochs):for i, batch in enumerate(generate_chunk()):inputs = torch.tensor(batch[:, :-1], dtype=torch.long).to(device)targets = torch.tensor(batch[:, 1:], dtype=torch.long).to(device)hidden = model.init_hidden(batch_size)logits, _ = model(inputs, hidden)predictions_logp = F.log_softmax(logits, dim=-1)loss = criterion(predictions_logp.contiguous().view(-1, num_tokens),targets.contiguous().view(-1))loss.backward()opt.step()opt.zero_grad()history.append(loss.item())if (epoch + 1) % 100 == 0:clear_output(True)plt.plot(history, label='loss')plt.legend()plt.show()
输出:
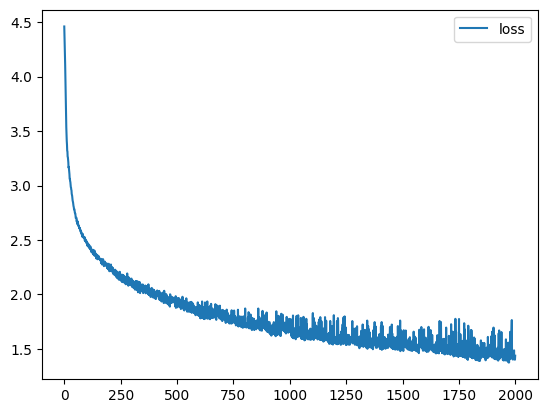
其中:
- inputs = torch.tensor(batch[:, :-1], dtype=torch.long).to(device) 和 targets = torch.tensor(batch[:, 1:], dtype=torch.long).to(device):将批次数据分为输入和目标。batch[:, :-1] 取批次数据的前 seq_length - 1 个字符作为输入,batch[:, 1:] 取批次数据的后 seq_length - 1 个字符作为目标。将它们转换为 torch.Tensor 类型,并移动到指定设备上。
紧接着我们编写文本生成函数,在训练语言模型之后(训练好的神经网络就是语言模型),我们开始进行数据生成。generate_sample 函数通过不断地根据模型的输出进行采样,逐步生成文本,直到达到指定的最大长度:
# 生成文本函数
def generate_sample(char_rnn, seed_phrase=None, max_length=200, temperature=1.0, device=device):'''The function generates text given a phrase of length at least SEQ_LENGTH.:param seed_phrase: prefix characters. The RNN is asked to continue the phrase:param max_length: maximum output length, including seed_phrase:param temperature: coefficient for sampling. higher temperature produces more chaotic outputs,smaller temperature converges to the single most likely output'''if seed_phrase is not None:x_sequence = [token_to_idx['<sos>']] + [token_to_idx[token] for token in seed_phrase]else:x_sequence = [token_to_idx['<sos>']]x_sequence = torch.tensor([x_sequence], dtype=torch.int64).to(device)hidden = char_rnn.init_hidden(1)# 输入种子短语for i in range(len(x_sequence[0]) - 1):_, hidden = char_rnn(x_sequence[:, i].unsqueeze(1), hidden)# 生成剩余文本for _ in range(max_length - len(x_sequence[0])):logits, hidden = char_rnn(x_sequence[:, -1].unsqueeze(1), hidden)probs = F.softmax(logits / temperature, dim=-1)next_token = torch.multinomial(probs.view(-1), num_samples=1)x_sequence = torch.cat([x_sequence, next_token.unsqueeze(0)], dim=1)return ''.join([tokens[ix] for ix in x_sequence.cpu().data.numpy()[0]])
- 参数:
- char_rnn:已经训练好的 RNN 模型,用于生成文本。
- seed_phrase:种子短语,是一个字符串,用于作为生成文本的起始部分。如果为 None,则从 标记开始生成。
- max_length:生成文本的最大长度,包含种子短语的长度,默认值为 200。
- temperature:采样系数,用于控制生成文本的随机性。较高的温度会产生更随机、混乱的输出;较低的温度会使输出更倾向于选择概率最大的字符,默认值为 1.0。
- device:指定运行模型的设备(如 CPU 或 GPU),默认使用之前定义的 device。
- 生成剩余文本:
通过循环不断生成新的字符,直到达到 max_length,在每次循环中:- 将当前序列的最后一个字符输入到 RNN 模型中,得到模型的输出 logits 和更新后的隐藏状态 hidden。
- logits / temperature:通过温度参数 temperature 调整 logits 的值,较高的温度会使概率分布更加均匀,增加随机性;较低的温度会使概率分布更加集中,输出更倾向于概率最大的字符。
- F.softmax(logits / temperature, dim=-1):对调整后的 logits 应用 softmax 函数,将其转换为概率分布 probs。
- torch.multinomial(probs.view(-1), num_samples=1):根据概率分布 probs 进行采样,随机选择一个字符的索引作为下一个字符。
- torch.cat([x_sequence, next_token.unsqueeze(0)], dim=1):将采样得到的下一个字符的索引添加到 x_sequence 中。
下面是经过训练的模型生成的文本示例。文本中包含大量不存在的单词并不可怕。所使用的模型非常简单:它是一个简单的经典 RNN。
print(generate_sample(model, ' мой дядя самых честных правил', max_length=500, temperature=0.8))
输出:

总代码
# 不要更改下面的代码块!所有必要的import都列在这里
# __________start of block__________
import string
import os
from random import sampleimport numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as Ffrom IPython.display import clear_outputimport matplotlib.pyplot as plt
%matplotlib inline
# __________end of block__________
# 不要更改下面的代码块!
# __________start of block__________
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
print('{} device is available'.format(device))
# __________end of block__________
# 不要更改下面块中的代码
# __________start of block__________
!wget https://raw.githubusercontent.com/MSUcourses/Data-Analysis-with-Python/main/Deep%20Learning/onegin_hw07.txt -O./onegin.txtwith open('onegin.txt', 'r') as iofile:text = iofile.readlines()text = "".join([x.replace('\t\t', '').lower() for x in text]) # Убираем лишние символы табуляций, приводим все буквы к нижнему регистру
# __________end of block__________
# 不要更改下面的代码块!
# __________start of block__________
tokens = sorted(set(text.lower())) + ['<sos>'] # 我们构建一个包含所有符号标记的集合,并将服务标记 <sos> 添加到其中
num_tokens = len(tokens)assert num_tokens == 84, "Check the tokenization process"token_to_idx = {x: idx for idx, x in enumerate(tokens)} # 构建一个包含 token 键和 token 列表中索引值的字典
idx_to_token = {idx: x for idx, x in enumerate(tokens)} # 构建一个反向字典(这样你就可以通过索引获取一个标记)assert len(tokens) == len(token_to_idx), "Mapping should be unique"print("Seems fine!")text_encoded = [token_to_idx[x] for x in text]
# __________end of block__________
# 不要更改下面的代码
# __________start of block__________
batch_size = 256 # 批量大小。批次是一组字符序列。
seq_length = 100 # 一批字符序列的最大长度
start_column = np.zeros((batch_size, 1), dtype=int) + token_to_idx['<sos>'] # 在每行开头添加一个技术符号——确定网络的初始状态def generate_chunk():global text_encoded, start_column, batch_size, seq_lengthstart_index = np.random.randint(0, len(text_encoded) - batch_size * seq_length - 1) # 随机选择批次中起始符号的索引# 构建一个连续的批次。# 为此,我们在源文本中选择一个以索引 start_index 开头且大小为 batch_size*seq_length 的子序列。# 然后我们将这个子序列分成大小为 seq_length 的 batch_size 个序列。这将是批次,大小为batch_size*seq_length的矩阵。# 矩阵的每一行将包含索引data = np.array(text_encoded[start_index:start_index + batch_size * seq_length]).reshape((batch_size, -1))yield np.hstack((start_column, data))
# __________end of block__________# 定义 Vanilla RNN 模型
class VanillaRNN(nn.Module):def __init__(self, input_size, hidden_size, num_layers, output_size):super(VanillaRNN, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.embedding = nn.Embedding(input_size, hidden_size)self.rnn = nn.RNN(hidden_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x, hidden):x = self.embedding(x)out, hidden = self.rnn(x, hidden)out = self.fc(out)return out, hiddendef init_hidden(self, batch_size):return torch.zeros(self.num_layers, batch_size, self.hidden_size).to(device)# 超参数设置
input_size = num_tokens
hidden_size = 128
num_layers = 2
output_size = num_tokens
learning_rate = 0.001
num_epochs = 2000 # 这里设置为 10 个 epoch,你可以根据需要调整# 初始化模型、损失函数和优化器
model = VanillaRNN(input_size, hidden_size, num_layers, output_size).to(device)
criterion = nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(), lr=learning_rate)# 用于存储每次迭代损失值的列表
history = []# 训练循环
for epoch in range(num_epochs):for i, batch in enumerate(generate_chunk()):inputs = torch.tensor(batch[:, :-1], dtype=torch.long).to(device)targets = torch.tensor(batch[:, 1:], dtype=torch.long).to(device)hidden = model.init_hidden(batch_size)logits, _ = model(inputs, hidden)predictions_logp = F.log_softmax(logits, dim=-1)loss = criterion(predictions_logp.contiguous().view(-1, num_tokens),targets.contiguous().view(-1))loss.backward()opt.step()opt.zero_grad()history.append(loss.item())if (epoch + 1) % 100 == 0:clear_output(True)plt.plot(history, label='loss')plt.legend()plt.show()# 生成文本函数
def generate_sample(char_rnn, seed_phrase=None, max_length=200, temperature=1.0, device=device):if seed_phrase is not None:x_sequence = [token_to_idx['<sos>']] + [token_to_idx[token] for token in seed_phrase]else:x_sequence = [token_to_idx['<sos>']]x_sequence = torch.tensor([x_sequence], dtype=torch.int64).to(device)hidden = char_rnn.init_hidden(1)# 输入种子短语for i in range(len(x_sequence[0]) - 1):_, hidden = char_rnn(x_sequence[:, i].unsqueeze(1), hidden)# 生成剩余文本while len(x_sequence[0]) < max_length:logits, hidden = char_rnn(x_sequence[:, -1].unsqueeze(1), hidden)probs = F.softmax(logits / temperature, dim=-1)next_token = torch.multinomial(probs.view(-1), num_samples=1)x_sequence = torch.cat([x_sequence, next_token.unsqueeze(0)], dim=1)# print(f"当前生成的序列长度: {len(x_sequence[0])}")return ''.join([tokens[ix] for ix in x_sequence.cpu().data.numpy()[0]])# 添加你提供的测试文本生成
print(generate_sample(model, 'мой дядя самых честных правил', max_length=500, temperature=0.8))
相关文章:

实战5:Python使用循环神经网络生成诗歌
实战5:Python使用循环神经网络生成诗歌 使用依赖加载数据词典构建和文本预处理总代码 在我们学习了课程8后,我们在实战练习一个例子。 你的主要任务:学习如何使用简单的循环神经网络(Vanilla RNN)生成诗歌。亚历山大谢…...
)
【网络安全】谁入侵了我的调制解调器?(二)
文章目录 针对 TR-069 协议 REST API 的攻击思路攻击百万台调制解调器意外发现 Cox 后端 API 的授权绕过漏洞确认我们能够进入任何人的设备访问和更新任何Cox商业客户账户通过泄露的加密密钥覆盖任何人的设备设置执行对任何调制解调器的命令影响最后想说阅读本文前,请先行浏览…...

当纺织车间遇上“数字魔法”--天拓四方飞鸟物联平台+边缘计算采集网关的智造革命
在传统印象里,纺织车间总是机器轰鸣、纱线纷飞,工人穿梭其间手动调整参数,次品率全凭经验“拿捏”。但如今,某纺织龙头企业的智能工厂里,一台台纺织机像被施了“聪明咒”,自己会“说话”、会“思考”&#…...

基于PLC的停车场车位控制系统的设计
2.1 设计目标 本课题为基于PLC的停车场车位控制系统来设计,在此将功能确定如下: 针对8个车位的停车场进行设计将停车场分为入口处,车位处、以及出口处三个部分;每个车位都有指示灯指示当前位置是否空闲,方便司机查找空…...

ios接入穿山甲【Swift】
1.可接入的广告,点击右下角查看接入文档 https://www.csjplatform.com/union/media/union/download/groMore 2.进入接入文档,选择最新版本进行接入 pod Ads-CN-Beta,6.8.0.2pod GMGdtAdapter-Beta, 4.15.22.0pod GDTMobSDK,4.15.30pod KSAdSDK,3.3.74.0p…...
)
【iOS】OC高级编程 iOS多线程与内存管理阅读笔记——自动引用计数(二)
自动引用计数 前言ARC规则所有权修饰符**__strong修饰符**__weak修饰符__unsafe_unretained修饰符__autoreleasing修饰符 规则属性数组 前言 上一篇我们主要学习了一些引用计数方法的内部实现,现在我们学习ARC规则。 ARC规则 所有权修饰符 OC中,为了处…...
)
智能语音识别+1.2用SAPI实现文本转语音(100%教会)
欢迎来到智能语音识别系列的第二篇文章. 上一篇文章的地址在这:智能语音处理1.1下载需要的库(100%实现)-CSDN博客 想必上一篇的操作(文本转语音)已经成功实现了 接下来,我们要学习用SAPI技术去实现文本转语音 一.简单介绍SAPI技术 SAPI是架构在COM基础上的,微软…...

Unity导出微信小游戏后无法调起移动端输入框
参考官方demo 参考demo https://gitee.com/wechat-minigame/minigame-unity-webgl-transform/tree/main/Demo/API_V2 里面有对输入文本框适配的处理方法,还有一些其他功能展示 1 使用Unity打开/Demo/API目录,API示例开发版本为Unity 2022.3.14f1。 2 若…...

16.使用豆包将docker-compose的yaml转为k8s的yaml,安装各种无状态服务
文章目录 docker方式httpbinit-toolslinux-commandmyipreference docker-compose安装k8s方式 docker方式 httpbin A simple HTTP Request & Response Service https://httpbin.org/ https://github.com/postmanlabs/httpbin https://github.com/mccutchen/go-httpbin do…...
_数学_C++_Java)
每日OJ_牛客_kotori和抽卡(二)_数学_C++_Java
目录 牛客_孩子们的游戏_约瑟夫环 题目解析 C代码 Java代码 牛客_孩子们的游戏_约瑟夫环 孩子们的游戏(圆圈中最后剩下的数)_牛客题霸_牛客网 描述: 每年六一儿童节,牛客都会准备一些小礼物和小游戏去看望孤儿院的孩子们。其中,有个游戏…...

整活 kotlin + springboot3 + sqlite 配置一个 SQLiteCache
要实现一个 SQLiteCache 也是很简单的只需要创建一个 cacheManager Bean 即可 // 如果配置文件中 spring.cache.sqlite.enable false 则不启用 Bean("cacheManager") ConditionalOnProperty(name ["spring.cache.sqlite.enable"], havingValue "t…...

JVM:运行时数据区和线程
一、运行时数据区概述 (1)整体架构 JVM 启动时,操作系统会为它分配相应的内存空间,接着 JVM 会对分配到的空间进行划分。当 JVM 退出,这些空间会被回收。JVM 将分配到的内存空间主要分成五部分:程序计数器…...

Lucene.NET + Jieba分词:核心词典与停用词配置详解
文章目录 前言一、dict.txt:核心分词词典1. 文件作用2. 文件格式3. 配置方法 二、cn_synonym.txt:同义词扩展库1. 文件作用2. 文件格式3. 在 Lucene 中使用 三、stopwords.txt:停用词表1. 文件作用2. 文件格式3. 配置方法 四、实战࿱…...
)
软件测试之测试数据生成(Excel版)
这是Excel生成测试数据的函数使用 1.时间 1.1.时间 例生成2022-05-01之前一年内任意时间点: =TEXT("2022-05-01"-RAND()-RANDBETWEEN(1,365),"yyyy-mm-dd hh:mm:ss")1.2.年月日 yyyy-mm-dd 以当前时间生成10年的日期 =TEXT(NOW()-RAND()-RANDBETWE…...

局域网内Docker镜像共享方法
在局域网内将Docker镜像构建并传输到另一台电脑,可以通过以下几种方法实现。以下是具体步骤及注意事项,结合不同场景的适用方案: 方法一:使用 docker save 和 docker load 传输镜像文件 步骤说明 在构建机上保存镜像 通过 docker…...

解决WinEdt编辑器出现文字不会适应软件宽度的问题
解决WinEdt编辑器出现文字不会适应软件宽度的问题 问题描述解决 问题描述 在使用WinEdt编辑Latex文本时,发现突然动了下键盘,或者突然就在编辑文本时不能自动换行,而是超出了软件屏幕的宽度。 解决 按住ctrl w ,直到界面变成下…...

跨境电商管理转型:日事清通过目标管理、流程自动化助力智优美科技项目管理升级与目标落地复盘
1.客户背景介绍 深圳市智优美科技有限公司是一家专业从事外贸B2C的电子商务公司,公司总部位于深圳市宝安区,旗下拥有三家子公司。目前销售的品类有:家居用品、电子产品、电子配件产品等,在深圳外贸电商行业销售额稳居行业前10名。…...

高防CDN、高防IP vs 高防服务器:核心优势与选型指南
一、高防服务器的核心局限 高防服务器是指通过机房部署硬件防火墙(如集群防火墙、流量清洗设备)来防御DDoS攻击的物理或虚拟服务器。其核心问题在于: 单点防御风险:依赖单一服务器硬扛攻击,若攻击流量超过防御阈值&am…...

入门-C编程基础部分:5、变量
飞书文档https://x509p6c8to.feishu.cn/wiki/PVnawQn5DiVhHhkMApqcDyDvnWg 变量的作用? 存储程序运行时,需要存储一些可能会变化的数据。 C 中每个变量都有特定的类型,类型决定了变量存储的大小和布局。 变量的名称可以由字母、数字和下划…...

Kafka深度解析与实战应用
Kafka深度解析与实战应用 作者:LedgerX技术团队 发布日期:2025年4月16日 引言 在当今数字时代,数据已成为企业的核心资产,而高效处理大规模数据流的能力则成为现代后端系统的关键挑战之一。Apache Kafka作为一个分布式流处理平台…...

数学教学通讯杂志数学教学通讯杂志社数学教学通讯编辑部2025年第6期目录
课程教材教法 “课程思政”视域下的高中数学教学探索与实践——以“函数概念的发展历程”为例 赵文博; 3-617 PBL教学模式下高中统计教学的探索与实践——以“随机抽样(第一课时)”为例 陈沛余; 7-10 “三新”背景下的高中数学教学困境与应对…...
)
【JavaEE初阶】多线程重点知识以及常考的面试题-多线程进阶(二)
本篇博客给大家带来的是多线程中synchronize的实现原理和JUC(java.util.concurrent) 常见类的相关知识点. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的…...

Flutter PIP 插件 ---- iOS Video Call 自定义PIP WINDOW渲染内容
以下是一篇关于在 iOS 中实现画中画(PiP)功能的技术博客: iOS 画中画(PiP)功能实现指南 效果 简介 画中画(Picture in Picture, PiP)是一项允许用户在使用其他应用时继续观看视频内容的功能。本文将详细介绍如何在 iOS 应用中实现 PiP 功能,包括自定义内容渲染和…...

【正点原子STM32MP257连载】第四章 ATK-DLMP257B功能测试——4G模块ME3630测试
1)实验平台:正点原子ATK-DLMP257B开发板 2)浏览产品:https://www.alientek.com/Product_Details/135.html 3)全套实验源码手册视频下载:正点原子资料下载中心 文章目录 第四章 ATK-DLMP257B功能测试——4G模…...
:内存释放原理与实现)
高并发内存池(四):内存释放原理与实现
前言:经过前3期的攻坚,我们已完整实现了内存动态申请的核心模块。接下来将进入关键阶段——内存释放机制的理解与实现,这是构建完整 高并发内存池 的最后一块技术拼图。该模块完成后,项目主体架构将基本成型(达90%&…...

【正点原子STM32MP257连载】第四章 ATK-DLMP257B功能测试——EEPROM、SPI FLASH测试 #AT24C64 #W25Q128
1)实验平台:正点原子ATK-DLMP257B开发板 2)浏览产品:https://www.alientek.com/Product_Details/135.html 3)全套实验源码手册视频下载:正点原子资料下载中心 文章目录 第四章 ATK-DLMP257B功能测试——EEP…...

《突破控件限制:用Qt绘图API解锁高级界面定制能力》
一、基本概念 虽然 Qt 已经内置了很多的控件,但是不能保证现有控件就可以应对所有场景。很多时候我们需要更强的 “自定制” 能力。 Qt 提供了画图相关的 API,允许我们在窗口上绘制任意的图形形状来完成更复杂的界面设计 所谓的 “控件” 本质上也是通…...

MyBatis-Plus 中BaseMapper接口是如何加速微服务内部开发的?
假设我们有一个简单的微服务项目,需要对 User 实体进行基本的数据库操作。 场景一:使用原生 MyBatis 的开发流程 (作为对比) 定义实体类 (Entity): // package com.yourcompany.usermicroservice.entity; public class User {private Long id;private S…...
)
AIGC-十款数据分析类智能体完整指令直接用(DeepSeek,豆包,千问,Kimi,GPT)
Unity3D特效百例案例项目实战源码Android-Unity实战问题汇总游戏脚本-辅助自动化Android控件全解手册再战Android系列Scratch编程案例软考全系列Unity3D学习专栏蓝桥系列AIGC(GPT、DeepSeek、豆包、千问、Kimi)👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资…...
开发篇1·主页面的tabs布局)
鸿蒙应用(医院陪诊系统)开发篇1·主页面的tabs布局
引言: 首先可在鸿蒙开发者官网找到DevEco Studio的安装教程。 安装好了之后,我们开始开发。 知识点: tabs布局,鸿蒙官方文档地址:https://developer.huawei.com/consumer/cn/doc/harmonyos-references-V5/ts-contai…...

【大模型】DeepSeek + Coze 打造个人专属AI智能体使用详解
目录 一、前言 二、AI智能体介绍 2.1 什么是AI智能体 2.2 AI智能体核心能力 2.3 AI智能应用场景 三、coze 介绍 3.1 coze是什么 3.1.1 平台概述 3.1.2 平台适用人群 3.2 平台核心功能 3.3 coze可以做什么 3.4 为什么选择coze 四、coze 搭建AI智能体操作实践 4.1 搭…...
弹性布局(flex布局))
7.(vue3.x+vite)弹性布局(flex布局)
1:效果截图 2:代码实现 <template><span style="font-size: 20px">右边固定,左边自适应</span><div class=<...
之字典)
Python基础总结(五)之字典
文章目录 一、字典的格式二、字典的操作2.1 增加项2.1.1 直接增加项2.1.1 formkeys方法 2.2 删除项2.2.1 clear()方法2.2.2 pop()方法 2.3 修改项2.3.1 直接修改2.3.2 update()方法 2.4 查找项2.4.1 get()方法2.4.2 直接查询2.4.3 items()方法2.4.4 keys()方法2.4.5 values()方…...

MCP简介:重构人机交互底层逻辑
在人工智能技术飞速发展的今天,大语言模型(LLM)的应用场景正不断拓展,但模型与外部系统之间的连接方式却成为制约其潜力发挥的关键瓶颈。为了解决这一难题,由AI领域顶尖公司Anthropic(Claude模型背后的开发…...
)
LangChain缓存嵌入技术完全指南:CacheBackedEmbedding原理与实践(附代码示例)
一、嵌入缓存技术背景与应用场景 1.1 为什么需要嵌入缓存? 算力消耗问题:现代嵌入模型(如text-embedding-3-small)单次推理需要约0.5-1秒/文本 资源浪费现状:实际业务中约30%-60%的文本存在重复计算 成本压力&#…...

国产DPU芯片+防火墙,能否引领网络安全新跨越?
近日,国内首款搭载国产DPU芯片的800Gbps下一代防火墙——中科网威NSFW - 12000正式发布,引发行业广泛关注。 国产DPU芯片与防火墙的结合,正在推动网络安全领域实现技术突破与体系升级。以下从技术特性、应用场景和产业价值三个维度分析其引领…...

Spark-SQL与Hive的连接及数据处理全解析
Spark-SQL与Hive的连接及数据处理全解析 在大数据处理领域,Spark-SQL和Hive都是重要的工具。今天就来聊聊Spark-SQL如何连接Hive以及相关的数据处理操作。 Spark-SQL连接Hive有多种方式。内嵌Hive虽然使用简单,直接就能用,但在实际生产中…...
——9版本与10版本区别)
ArcGIS Desktop使用入门(四)——9版本与10版本区别
系列文章目录 ArcGIS Desktop使用入门(一)软件初认识 ArcGIS Desktop使用入门(二)常用工具条——标准工具 ArcGIS Desktop使用入门(二)常用工具条——编辑器 ArcGIS Desktop使用入门(二&#x…...

使用 chromedriver 实现网络爬虫【手抄】
1、引用 selenium 包 <dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>4.29.0</version> </dependency> <dependency><groupId>org.seleniumhq.seleniu…...

ERROR: Unknown host CPU architecture: arm64
1、先检查NDK版本是否支持arm64,NDK版本21.3以上 2、检查gradle中,有关NDK版本是否设置arm64-v8a 例如: ndkVersion "21.4.7075529"ndk {abiFilters "armeabi-v7a","arm64-v8a"} local.properties中&#x…...

从 SQL2API 到 Text2API:开启数据应用开发的新征程
在技术革新浪潮的席卷下,数据应用开发领域正经历着深刻变革。曾经,构建数据 API 需要开发者具备扎实的数据库知识和编程技能,手动编写复杂的 SQL 查询与 API 代码,这一过程不仅耗时费力,还将众多非技术人员阻挡在数据应…...
——角点检测)
OpenCv高阶(四)——角点检测
一、角点检测 在计算机视觉中,角点检测是识别图像中局部区域(角点)的关键技术,这些区域通常是两条或多条边缘的交点,具有丰富的结构信息,常用于图像匹配、跟踪、三维重建等任务。 Harris角点检测算法是一…...

centos8 部署 openstack
在 CentOS 8 上部署 OpenStack 是一个复杂的过程,涉及多个组件的安装和配置。OpenStack 是一个开源的云计算平台,它提供了基础设施即服务(IaaS)的功能。下面我将指导你通过基本的步骤来部署 OpenStack。 前提条件 系统要求&#…...

智能云图库-8-AI编辑
一、基础图片编辑 需求分析 在日常的图片管理中,用户经常需要对图片进行简单处理,比如裁剪多余部分、旋转图片、放大缩小尺寸等。 因此,我们首先要引入基础图片编辑功能,帮助用户快速完成以下操作: 裁剪&#…...

libwebsocket建立服务器需要编写LWS_CALLBACK_ADD_HEADERS事件处理
最近在使用libwebsocket,感觉它搭建Http与websocket服务器比较简单,不像poco库那么庞大,但当我使用它建立websocket服务器后,发现websocket客户端连接一直没有连接成功,不知道什么原因,经过一天的调试&…...

L1-002 打印沙漏
L1-002 打印沙漏 - 团体程序设计天梯赛-练习集 (pintia.cn) 本题要求你写个程序把给定的符号打印成沙漏的形状。例如给定17个“*”,要求按下列格式打印 ************ *****所谓“沙漏形状”,是指每行输出奇数个符号;各行符号中心对齐&#…...

JSP技术入门指南【一】利用IDEA从零开始搭建你的第一个JSP系统
Jsp技术入门指南【一】利用IDEA从零开始搭建你的第一个JSP系统 前言一、什么是JSP1.1 JSP是干什么的?1.2 JSP与Servlet的关系是什么? 二、在Idea中创建第一个JSP系统三、JSP和HTML的差别3.1 格式区别3.2 注释区别 前言 在前面的内容中,我们已…...
——RLHF过程中的马尔科夫决策过程及对话场景MDP设计)
NLP高频面试题(四十四)——RLHF过程中的马尔科夫决策过程及对话场景MDP设计
什么是马尔科夫决策过程(MDP)? 马尔科夫决策过程(MDP)是描述序贯决策问题的数学框架,由五元组( (S, A, P, R, \gamma) )组成,其中: (S):状态集合,描述环境的所有可能状态。(A):动作集合,描述智能体可以采取的所有可能动作。(P):状态转移概率函数,表示从一个状态…...

青少年编程与数学 02-016 Python数据结构与算法 24课题、密码学算法
青少年编程与数学 02-016 Python数据结构与算法 24课题、密码学算法 课题摘要:一、对称加密算法AES(高级加密标准)DES(数据加密标准)3DES(三重数据加密标准) 二、非对称加密算法RSAECC(椭圆曲线…...

艺术字体AI生成阿里云WordArt锦书、通义万相、SiliconFlow、Pillow+OpenCV本地生成艺术字体
基于您的需求,结合最新API技术和搜索结果,以下是Python调用主流艺术字API的代码案例及对应充值链接方案: 一、大厂API服务(付费方案) 1. 阿里云WordArt锦书API # 文字纹理生成(需安装dashscopeÿ…...