2025最新版flink2.0.0安装教程(保姆级)
Flink支持多种安装模式。
local(本地)——本地模式
standalone——独立模式,Flink自带集群,开发测试环境使用
standaloneHA—独立集群高可用模式,Flink自带集群,开发测试环境使用
yarn——计算资源统一由Hadoop YARN管理,生产环境测试
flink1.13 (2021)和 flink2.0.0 (2025)之间的区别:

下载链接:
https://dlcdn.apache.org/flink/flink-2.0.0/flink-2.0.0-bin-scala_2.12.tgz
升级 jdk
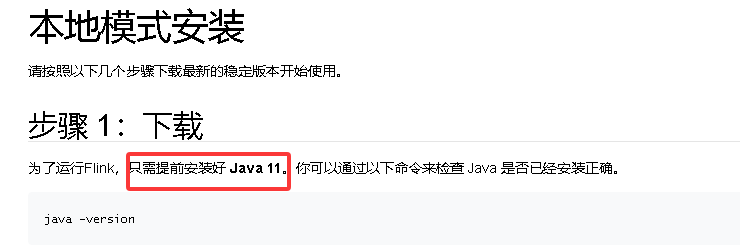
不升级 jdk,会报如下错误:

将 jdk1.8 升级到 jdk11
上传:
解压:
[root@node01 ~]# cd /opt/modules/
[root@node01 modules]# tar -zxvf jdk-11.0.25_linux-x64_bin.tar.gz -C /opt/installs重命名:
mv jdk-11.0.25 jdk11如果以前有安装的 jdk8,先将其重命名:
cd /opt/installs
mv jdk jdk8做超链接,指向新的 jdk
ln -s jdk11 jdk同步 jdk11 到 node02,node03 上
xsync.sh /opt/installs/jdk11将 node02 和 node03 上的 jdk 重命名为 jdk8
mv jdk jdk8然后在 node01 上同步超链接:
xsync.sh /opt/installs/jdk在三台电脑上,验证 java 的版本
java -version
上传Flink安装包,解压,配置环境变量
cd /opt/modules
tar -zxf flink-2.0.0-bin-scala_2.12.tgz -C /opt/installs/
cd /opt/installs
mv flink-2.0.0 flink
配置环境变量:
vim /etc/profile.d/custom_env.sh
export FLINK_HOME=/opt/installs/flink
export PATH=$PATH:$FLINK_HOME/bin
export HADOOP_CONF_DIR=/opt/installs/hadoop/etc/hadoop记得source /etc/profile
修改配置文件
① /opt/installs/flink/conf/config.yaml 【以前叫 flink-config.yaml】
yaml 格式检测器:YAML、YML在线编辑(校验、格式化)器工具(无广告) - WGCLOUD
编辑的话,可以使用 idea,由于 yaml 格式非常严格,所以使用 alt+部分选中,进行修改不容易报错
新的配置文件:
参考:OpenEuler部署Flink 1.19.2完全分布式集群_flink1.19部署-CSDN博客
第一步:要把该文件21-24行兼容jdk17的配置删掉或注释掉

第二步:修改其他配置项
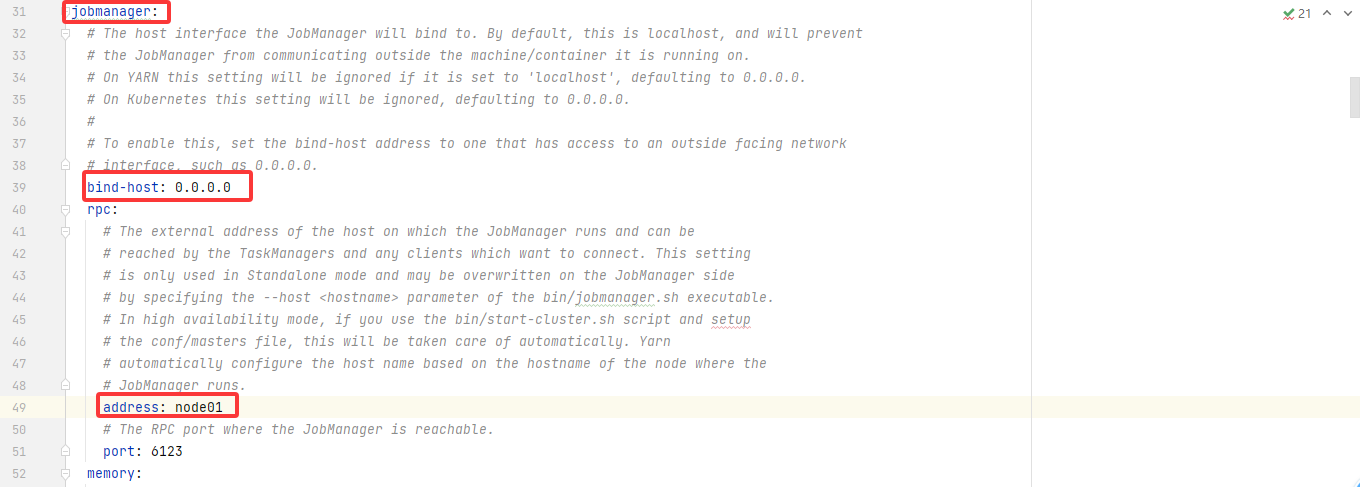
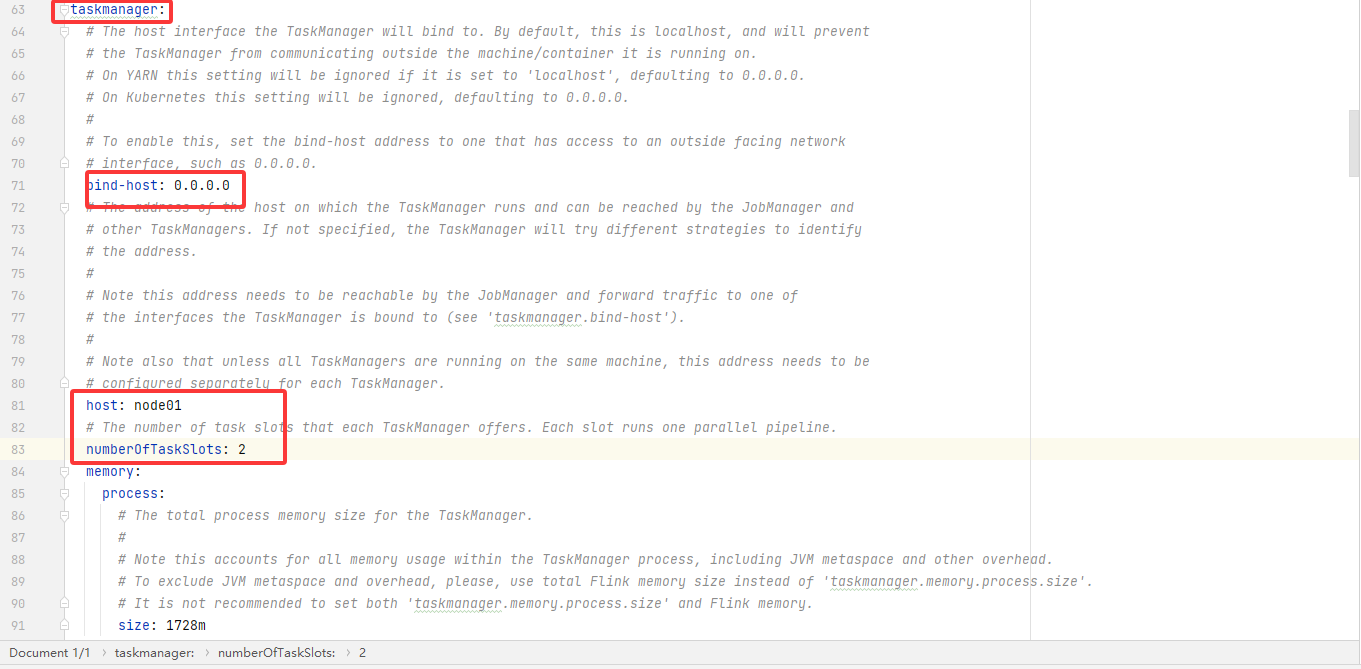
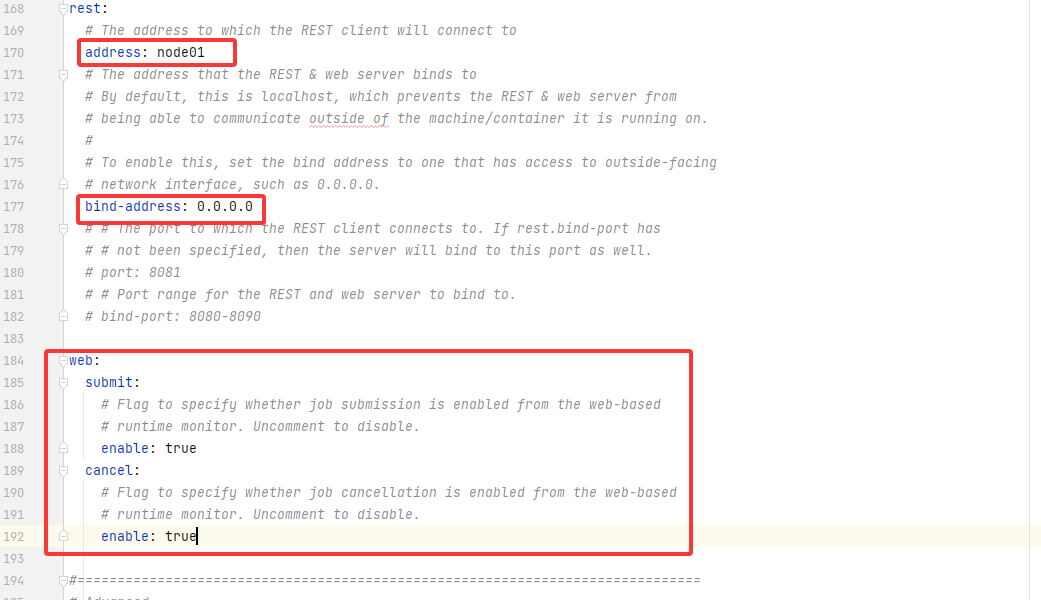
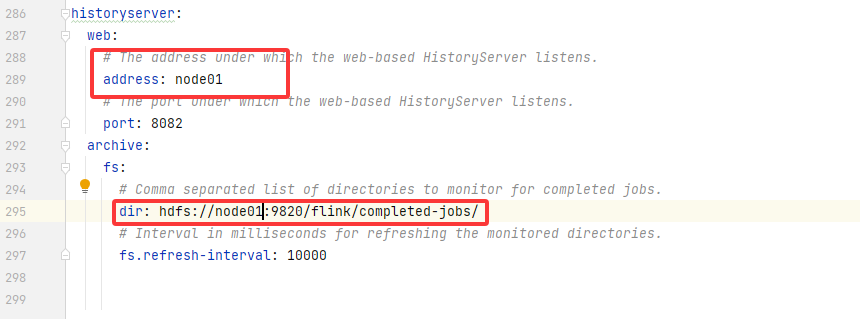
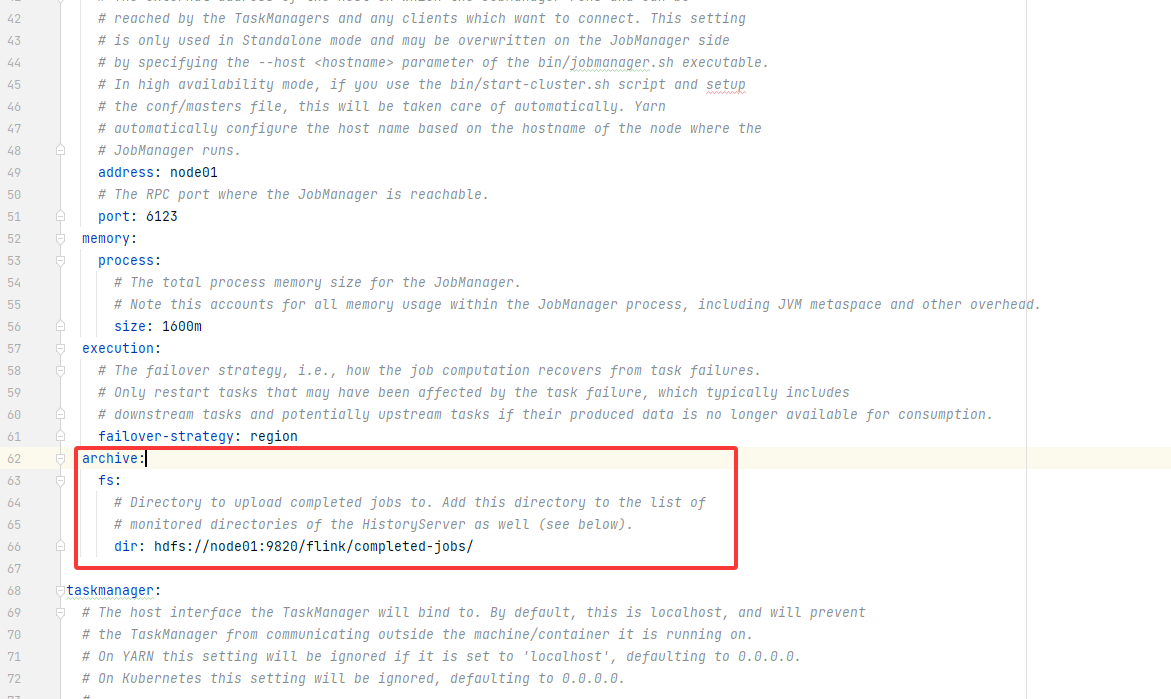
jobmanager:bind-host: 0.0.0.0rpc:address: node01# The RPC port where the JobManager is reachable.port: 6123memory:process:# The total process memory size for the JobManager.# Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead.size: 1600mexecution:# The failover strategy, i.e., how the job computation recovers from task failures.# Only restart tasks that may have been affected by the task failure, which typically includes# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.failover-strategy: regionarchive:fs:# Directory to upload completed jobs to. Add this directory to the list of# monitored directories of the HistoryServer as well (see below).dir: hdfs://node01:9820/flink/completed-jobs/taskmanager:bind-host: 0.0.0.0host: node01# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.numberOfTaskSlots: 2memory:process:size: 1728mparallelism:# The parallelism used for programs that did not specify and other parallelism.default: 1rest:# The address to which the REST client will connect toaddress: node01bind-address: 0.0.0.0web:submit:# Flag to specify whether job submission is enabled from the web-based# runtime monitor. Uncomment to disable.enable: truecancel:# Flag to specify whether job cancellation is enabled from the web-based# runtime monitor. Uncomment to disable.enable: truehistoryserver:web:# The address under which the web-based HistoryServer listens.address: node01# The port under which the web-based HistoryServer listens.port: 8082archive:fs:# Comma separated list of directories to monitor for completed jobs.dir: hdfs://node01:9820/flink/completed-jobs/# Interval in milliseconds for refreshing the monitored directories.fs.refresh-interval: 10000完整版的,仅供参考:
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################# These parameters are required for Java 17 support.
# They can be safely removed when using Java 8/11.
# # log4j 2 configuration
# log:
# level: TRACE
# max: 5
# dir: /tmp/flink_logs#==============================================================================
# Common
#==============================================================================jobmanager:# The host interface the JobManager will bind to. By default, this is localhost, and will prevent# the JobManager from communicating outside the machine/container it is running on.# On YARN this setting will be ignored if it is set to 'localhost', defaulting to 0.0.0.0.# On Kubernetes this setting will be ignored, defaulting to 0.0.0.0.## To enable this, set the bind-host address to one that has access to an outside facing network# interface, such as 0.0.0.0.bind-host: 0.0.0.0rpc:# The external address of the host on which the JobManager runs and can be# reached by the TaskManagers and any clients which want to connect. This setting# is only used in Standalone mode and may be overwritten on the JobManager side# by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.# In high availability mode, if you use the bin/start-cluster.sh script and setup# the conf/masters file, this will be taken care of automatically. Yarn# automatically configure the host name based on the hostname of the node where the# JobManager runs.address: node01# The RPC port where the JobManager is reachable.port: 6123memory:process:# The total process memory size for the JobManager.# Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead.size: 1600mexecution:# The failover strategy, i.e., how the job computation recovers from task failures.# Only restart tasks that may have been affected by the task failure, which typically includes# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.failover-strategy: regionarchive:fs:# Directory to upload completed jobs to. Add this directory to the list of# monitored directories of the HistoryServer as well (see below).dir: hdfs://node01:9820/flink/completed-jobs/taskmanager:# The host interface the TaskManager will bind to. By default, this is localhost, and will prevent# the TaskManager from communicating outside the machine/container it is running on.# On YARN this setting will be ignored if it is set to 'localhost', defaulting to 0.0.0.0.# On Kubernetes this setting will be ignored, defaulting to 0.0.0.0.## To enable this, set the bind-host address to one that has access to an outside facing network# interface, such as 0.0.0.0.bind-host: 0.0.0.0# The address of the host on which the TaskManager runs and can be reached by the JobManager and# other TaskManagers. If not specified, the TaskManager will try different strategies to identify# the address.## Note this address needs to be reachable by the JobManager and forward traffic to one of# the interfaces the TaskManager is bound to (see 'taskmanager.bind-host').## Note also that unless all TaskManagers are running on the same machine, this address needs to be# configured separately for each TaskManager.host: node01# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.numberOfTaskSlots: 2memory:process:# The total process memory size for the TaskManager.## Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.# It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.size: 1728mparallelism:# The parallelism used for programs that did not specify and other parallelism.default: 1# # The default file system scheme and authority.
# # By default file paths without scheme are interpreted relative to the local
# # root file system 'file:///'. Use this to override the default and interpret
# # relative paths relative to a different file system,
# # for example 'hdfs://mynamenode:12345'
# fs:
# default-scheme: hdfs://mynamenode:12345#==============================================================================
# High Availability
#==============================================================================# high-availability:
# # The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
# type: zookeeper
# # The path where metadata for master recovery is persisted. While ZooKeeper stores
# # the small ground truth for checkpoint and leader election, this location stores
# # the larger objects, like persisted dataflow graphs.
# #
# # Must be a durable file system that is accessible from all nodes
# # (like HDFS, S3, Ceph, nfs, ...)
# storageDir: hdfs:///flink/ha/
# zookeeper:
# # The list of ZooKeeper quorum peers that coordinate the high-availability
# # setup. This must be a list of the form:
# # "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
# quorum: localhost:2181
# client:
# # ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
# # It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
# # The default value is "open" and it can be changed to "creator" if ZK security is enabled
# acl: open#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled. Checkpointing is enabled when execution.checkpointing.interval > 0.# # Execution checkpointing related parameters. Please refer to CheckpointConfig and CheckpointingOptions for more details.
# execution:
# checkpointing:
# interval: 3min
# externalized-checkpoint-retention: [DELETE_ON_CANCELLATION, RETAIN_ON_CANCELLATION]
# max-concurrent-checkpoints: 1
# min-pause: 0
# mode: [EXACTLY_ONCE, AT_LEAST_ONCE]
# timeout: 10min
# tolerable-failed-checkpoints: 0
# unaligned: false
# # Flag to enable/disable incremental checkpoints for backends that
# # support incremental checkpoints (like the RocksDB state backend).
# incremental: false
# # Directory for checkpoints filesystem, when using any of the default bundled
# # state backends.
# dir: hdfs://namenode-host:port/flink-checkpoints
# # Default target directory for savepoints, optional.
# savepoint-dir: hdfs://namenode-host:port/flink-savepoints# state:
# backend:
# # Supported backends are 'hashmap', 'rocksdb', or the
# # <class-name-of-factory>.
# type: hashmap#==============================================================================
# Rest & web frontend
#==============================================================================rest:# The address to which the REST client will connect toaddress: node01# The address that the REST & web server binds to# By default, this is localhost, which prevents the REST & web server from# being able to communicate outside of the machine/container it is running on.## To enable this, set the bind address to one that has access to outside-facing# network interface, such as 0.0.0.0.bind-address: 0.0.0.0# # The port to which the REST client connects to. If rest.bind-port has# # not been specified, then the server will bind to this port as well.# port: 8081# # Port range for the REST and web server to bind to.# bind-port: 8080-8090web:submit:# Flag to specify whether job submission is enabled from the web-based# runtime monitor. Uncomment to disable.enable: truecancel:# Flag to specify whether job cancellation is enabled from the web-based# runtime monitor. Uncomment to disable.enable: true#==============================================================================
# Advanced
#==============================================================================# io:
# tmp:
# # Override the directories for temporary files. If not specified, the
# # system-specific Java temporary directory (java.io.tmpdir property) is taken.
# #
# # For framework setups on Yarn, Flink will automatically pick up the
# # containers' temp directories without any need for configuration.
# #
# # Add a delimited list for multiple directories, using the system directory
# # delimiter (colon ':' on unix) or a comma, e.g.:
# # /data1/tmp:/data2/tmp:/data3/tmp
# #
# # Note: Each directory entry is read from and written to by a different I/O
# # thread. You can include the same directory multiple times in order to create
# # multiple I/O threads against that directory. This is for example relevant for
# # high-throughput RAIDs.
# dirs: /tmp# classloader:
# resolve:
# # The classloading resolve order. Possible values are 'child-first' (Flink's default)
# # and 'parent-first' (Java's default).
# #
# # Child first classloading allows users to use different dependency/library
# # versions in their application than those in the classpath. Switching back
# # to 'parent-first' may help with debugging dependency issues.
# order: child-first# The amount of memory going to the network stack. These numbers usually need
# no tuning. Adjusting them may be necessary in case of an "Insufficient number
# of network buffers" error. The default min is 64MB, the default max is 1GB.
#
# taskmanager:
# memory:
# network:
# fraction: 0.1
# min: 64mb
# max: 1gb#==============================================================================
# Flink Cluster Security Configuration
#==============================================================================# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
# may be enabled in four steps:
# 1. configure the local krb5.conf file
# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
# 3. make the credentials available to various JAAS login contexts
# 4. configure the connector to use JAAS/SASL# # The below configure how Kerberos credentials are provided. A keytab will be used instead of
# # a ticket cache if the keytab path and principal are set.
# security:
# kerberos:
# login:
# use-ticket-cache: true
# keytab: /path/to/kerberos/keytab
# principal: flink-user
# # The configuration below defines which JAAS login contexts
# contexts: Client,KafkaClient#==============================================================================
# ZK Security Configuration
#==============================================================================# zookeeper:
# sasl:
# # Below configurations are applicable if ZK ensemble is configured for security
# #
# # Override below configuration to provide custom ZK service name if configured
# # zookeeper.sasl.service-name: zookeeper
# #
# # The configuration below must match one of the values set in "security.kerberos.login.contexts"
# login-context-name: Client#==============================================================================
# HistoryServer
#==============================================================================# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
#
# jobmanager:
# archive:
# fs:
# # Directory to upload completed jobs to. Add this directory to the list of
# # monitored directories of the HistoryServer as well (see below).
# dir: hdfs:///completed-jobs/historyserver:web:# The address under which the web-based HistoryServer listens.address: node01# The port under which the web-based HistoryServer listens.port: 8082archive:fs:# Comma separated list of directories to monitor for completed jobs.dir: hdfs://node01:9820/flink/completed-jobs/# Interval in milliseconds for refreshing the monitored directories.fs.refresh-interval: 10000② /opt/installs/flink/conf/masters
node01:8081③ /opt/installs/flink/conf/workers
node01
node02
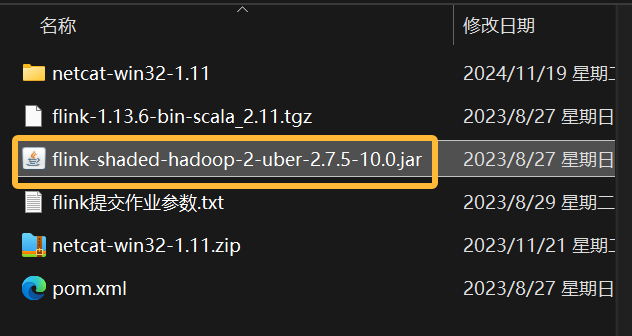
node03上传jar包
将资料下的flink-shaded-hadoop-2-uber-2.7.5-10.0.jar放到flink的lib目录下
分发
xsync.sh /opt/installs/flink
xsync.sh /etc/profile.d/custom_env.sh去 node02 和 node03 上修改一个主机名:
修改 node02 和 node03 上的 taskmanager 中的 host 为 node02 和 node03

启动
#启动HDFS
start-dfs.sh
#启动集群
start-cluster.sh
#启动历史服务器
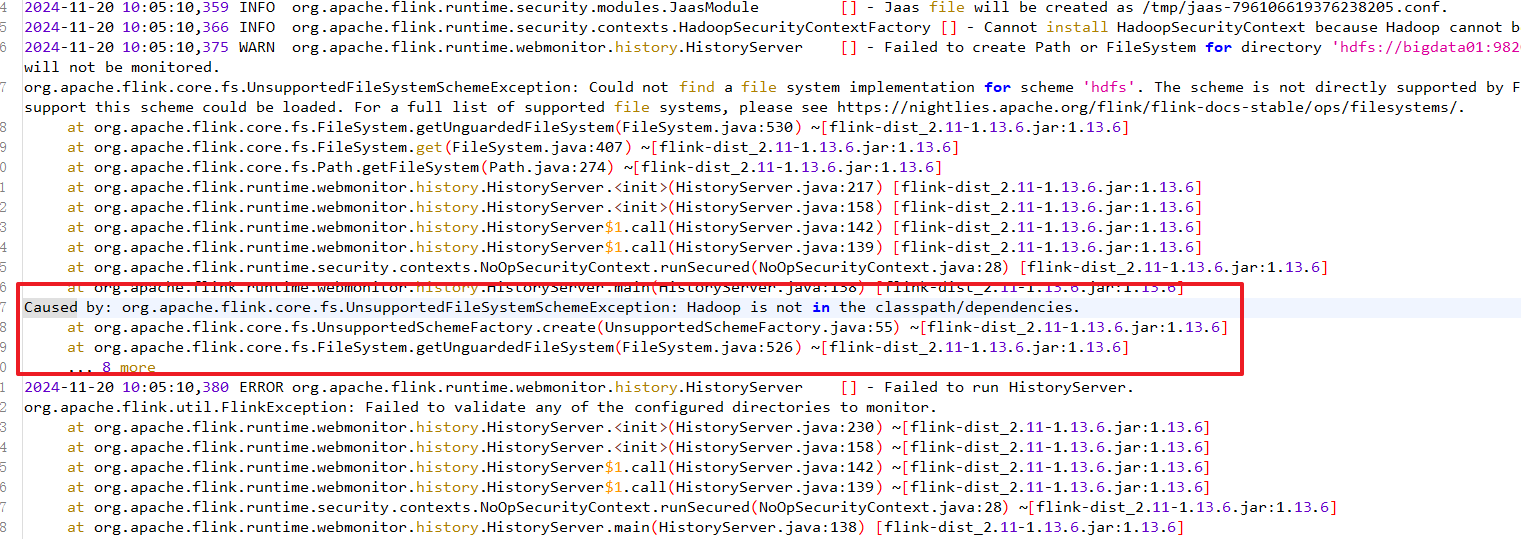
historyserver.sh start假如 historyserver 无法启动,也就没有办法访问 8082 服务,原因大概是你没有上传 关于 hadoop 的 jar 包到 lib 下:
观察webUI
http://node01:8081 -- Flink集群管理界面 当前有效,重启后里面跑的内容就消失了
能够访问8081是因为你的集群启动着呢
http://node01:8082 -- Flink历史服务器管理界面,及时服务重启,运行过的服务都还在
能够访问8082是因为你的历史服务启动着相关文章:
)
2025最新版flink2.0.0安装教程(保姆级)
Flink支持多种安装模式。 local(本地)——本地模式 standalone——独立模式,Flink自带集群,开发测试环境使用 standaloneHA—独立集群高可用模式,Flink自带集群,开发测试环境使用 yarn——计算资源统一…...

软件测试小讲
大家好,我是程序员小羊! 前言: 在 Web 项目开发中,全面的测试是保证系统稳定性、功能完整性和良好用户体验的关键。下面是一个详细的 Web 项目测试点列表,涵盖了不同方面的测试: 1. 功能测试 确保应用…...

DP35 【模板】二维前缀和 ---- 前缀和
目录 一:题目 二:算法原理 三:代码实现 一:题目 题目链接:【模板】二维前缀和_牛客题霸_牛客网 二:算法原理 三:代码实现 #include <iostream> #include <vector> using name…...

C语言——分支语句
在现实生活中,我们经常会遇到作出选择和判断的时候,在C语言中也同样要面临作出选择和判断的时候,所以今天,就让我们一起来了解一下,C语言是如何作出选择判断的。 目录 1.何为语句? 2.if语句 2.1 if语句的…...

使用Docker安装Jenkins
1、准备 2、安装 详见: https://www.jenkins.io/doc/book/installing/ https://www.jenkins.io/zh/doc/book/installing/ https://www.jenkins-zh.cn/tutorial/get-started/install/ # 方式1: # 详见:https://www.jenkins.io/doc/book/inst…...

东方博宜OJ ——2395 - 部分背包问题
贪心入门 ————2395 - 部分背包问题 2395 - 部分背包问题题目描述输入输出样例问题分析贪心算法思路代码实现总结 2395 - 部分背包问题 题目描述 阿里巴巴走进了装满宝藏的藏宝洞。藏宝洞里面有 N (N < 100)堆金币,第i堆金币的总重量和总价值分别是mi,vi (l …...

【期中准备特辑】计组,电路,信号
计组 以点带面地复习书中内容! 指令体系结构(ISA)是计算机硬件和软件的分界面 世界上第一台电子计算机是 ENIAC(埃尼阿克) 第一代计算机采用电子管作为主要器件;第二代计算机采用晶体管;第三代…...

经典算法 判断一个图是不是树
判断一个图是不是树 问题描述 给一个以0 0结尾的整数对列表,除0 0外的每两个整数表示一条连接了这两个节点的边。假设节点编号不超过100000大于0。你只要判断由这些节点和边构成的图是不是树。是输出YES,不是输出NO。 输入样例1 6 8 5 3 5 2 6 4 5…...

力扣 283 移动零的两种高效解法详解
目录 方法一:两次遍历法 方法二:单次遍历交换法 两种方法对比 在解决数组中的零移动到末尾的问题时,我们需要保持非零元素的顺序,并原地修改数组。以下是两种高效的解法及其详细分析。 方法一:两次遍历法 思路分析…...

代码随想录第18天:二叉树
一、修剪二叉树(Leetcode 669) 递归法 class Solution:def trimBST(self, root: TreeNode, low: int, high: int) -> TreeNode:# 如果当前节点为空,直接返回空节点(递归终止条件)if root is None:return None# 如果…...

KMP算法核心笔记:前后缀本质与nextval实现
KMP算法核心笔记:前后缀本质与nextval实现 核心疑问:为什么用「前后缀」而非「最大子串」? 1. 结构唯一性 前后缀限定在字符串首尾区域,最大子串可位于任意位置只有前后缀能保证滑动后的有效对齐 2. 移动确定性 文本…...

Breeze 40A FOC 电调:Vfast 观测器技术赋能无人机精准动力控制
核心技术特性 1. 全新Vfast 观测器技术 基于先进矢量控制算法(FOC 驱动),实现电机状态实时精准观测,适配性优于传统 FOC 方案,兼容主流无人机动力配置。高效算法设计,输出功率与力效超越多数方波电调&…...

如何处理ONLYOFFICE文档服务器与Java Web应用间的安全认证和授权
如何处理ONLYOFFICE文档服务器与Java Web应用间的安全认证和授权? 处理 ONLYOFFICE 文档服务器与 Java Web 应用之间的安全认证和授权,通常涉及以下几个关键步骤和技术: 1. JWT (JSON Web Token) 认证 启用 JWT: ONLYOFFICE 文档…...

手机上的PDF精简版:随时随地享受阅读
在移动互联网时代,随时随地阅读电子书和文档已经成为许多人的习惯。无论是学习、工作还是娱乐,一款好用的PDF阅读器都是必不可少的工具。今天,我们要介绍的 思读PDF精简版,就是这样一款简洁而强大的PDF阅读工具,能够让…...
)
XCTF-web(一)
view_source F12ctrluctrlshiftiURL前添加:view-source:curl http://192.168.1.1robots 根据题目提示,查看一下robots.txt /flag_ls_h3re.php backup /index.php.bak ┌──(kali㉿kali)-[~] └─$ cat index.php.bak <html> <…...

字节跳动开源 Godel-Rescheduler:适用于云原生系统的全局最优重调度框架
背景 在云原生调度中,一次调度往往无法解决所有问题,需要配合重调度来优化资源分配和任务摆放。传统的重调度框架主要集中在识别异常节点或任务,并通过迁移或删除来解决。然而,这些框架往往只能解决局部问题,无法提供…...
)
贪心算法day9(合并区间)
1.合并区间 56. 合并区间 - 力扣(LeetCode) 对于这种区间问题,我们应该先排序根据排序的结果总结一些规律,进而的得出解决该问题的策略。 class Solution {public static int[][] merge(int[][] intervals) {//第一步进行左端点…...

插件化设计,打造个性化音乐体验!
打工人们你们好!这里是摸鱼 特供版~ 今天给大家带来一款超酷的音乐播放器——MusicFree,它不仅功能强大,还支持插件化设计,让你的音乐体验更加个性化! 推荐指数:★★★★★ 1. 插件化设计 功能强大&#…...

深入解析分类模型评估指标:ROC曲线、AUC值、F1分数与分类报告
标题:深入解析分类模型评估指标:ROC曲线、AUC值、F1分数与分类报告 摘要: 在机器学习中,评估分类模型的性能是至关重要的一步。本文详细介绍了四个核心评估指标:ROC曲线、AUC值、F1分数和分类报告。通过对比这些指标…...

2025第16届蓝桥杯省赛之研究生组F题01串求解
2025第16届蓝桥杯省赛之研究生组F题01串求解 一、题目概述二、解题思路2.1题目分析2.2解题思路 三、求解代码3.1求解步骤3.1.1求解x所在的二进制位数区间3.1.2求解总位数为cnt的含1数3.1.3求解cnt1~x之间的含1数 3.2完整代码3.3代码验证 四、小结 一、题目概述 给定一个由0,1,…...

【2-10】E1与T1
前言 之前我们简单介绍了人类从电话线思维到如今的数据报分组交换思维过渡时期的各种技术产物,今天我们重点介绍 E1/T1技术。 文章目录 前言1. 产生背景2. T13. E14. SONET4.1 OC-14.2 OC-3 及其它 5. SDH5.1. STM-1 6. SONET VS SDH后记修改记录 1. 产生背景 E1/…...

2025 年蓝桥杯 Java B 组真题解析分享
今年是我第二次参加蓝桥杯软件类Java B组的比赛,虽然赛前做了不少准备,但真正坐在考场上时,还是有种熟悉又紧张的感觉。蓝桥杯的题目一向以“基础创新”著称,今年也不例外,每道题都考验着我们对算法的理解、代码实现能…...

IMX6ULL2025年最新部署方案2在Ubuntu24.04上编译通过Qt5.12.9且部署到IMX6ULL正点原子开发板上
IMX6ULL2025年最新部署方案2:在Ubuntu24.04上编译通过Qt5.12.9且部署到IMX6ULL正点原子开发板上 前言 本篇方案部署是笔者这几天除了打蓝桥杯以外,笔者在研究的东西,现在写道这里的时候,笔者已经成功的在Ubuntu24.04上,使用默…...

通过微信APPID获取小程序名称
进入微信公众平台,登录自己的小程序后台管理端,在“账号设置”中找到“第三方设置” 在“第三方设置”页面中,将页面拉到最下面,即可通过appid获取到这个小程序的名称信息...

混合开发部署实战:PyInstaller + .NET 8 + Docker全链路配置
文章目录 一、PyInstaller打包Python环境1. 基础打包(Linux环境)2. 高级配置3. 验证打包结果 二、.NET 8与Python的集成模式1. 进程调用(推荐方案)2. REST API通信 三、Docker多阶段构建配置1. 完整Dockerfile示例2. 关键配置解析…...

使用 Sass 打造动态星空背景效果
在前端开发中,视觉效果越来越受到重视。本文将通过一个生动的示例,讲解如何利用 Sass 构建一个具有动态星空滚动效果的背景页面,同时也系统介绍 Sass 的核心功能与实践技巧。 一、Sass 的作用 Sass(Syntactically Awesome Style …...

低空经济有哪些GIS相关岗位?
在低空经济中,GIS(地理信息系统)技术发挥着重要作用。GIS开发工程师负责开发、维护和优化与低空经济相关的GIS系统,如无人机起降场布局、空域管理、气象监测等。一般会参与二、三维GIS项目数据处理与前端开发,以及相关…...

Python 垃圾回收机制全解析:内存释放与优化
在编写高效、稳定的 Python 程序时,内存管理往往是一个被忽视但至关重要的领域。对于 Python 开发者来说,最初的学习曲线通常集中在语法、库使用和应用框架上,而对于内存管理和垃圾回收(GC,Garbage Collection…...

性能优化实践
4.1 大规模量子态处理的性能优化 背景与问题分析 量子计算中的大规模量子态处理(如量子模拟、量子态可视化)需要高效计算和实时渲染能力。传统图形API(如WebGL)在处理高维度量子态时可能面临性能瓶颈,甚至崩溃(如表格中14量子比特时WebGL的崩溃)。而现代API(如WebGPU…...

opentelemetry笔记
span https://github.com/open-telemetry/opentelemetry-cpp/blob/f987c9c094f276336569eeea85f17e361de5e518/sdk/src/trace/span.h 在 OpenTelemetry C 的 sdk/src/trace 目录中,不同的 span 定义和实现是为了支持追踪(Tracing)功能的多样…...

【JavaScript】二十一、日期对象
文章目录 1、实例化日期对象2、相关方法3、时间戳4、案例:毕业🎓倒计时效果 1、实例化日期对象 获得当前时间 const date new Date()获得指定时间 const date new Date(2025-4-14 20:46:00) console.log(date)2、相关方法 方法作用说明getFullYear…...

GIT工具学习【1】:新安装git预操作
目录 1.写在前面2.为常用指令配置别名3.初始化4.解决中文乱码问题 1.写在前面 新安装git命令后,需要一些设置会用的比较的顺畅。 这篇文章只要跟着做即可,至于原理,后面会写清楚的。 2.为常用指令配置别名 #新建一个.bashrc touch ~/.bash…...

docker安装ES
ES安装步骤 1. 创建docker网络,使其docker内部通信 2. 下载 | 导入镜像文件(ES Kibana) 3. 创建容器,并访问 4. 安装Ik分词器(es对中文并不友好,所以需要安装IK分词使其适配中文) 1. 创建docke…...

【控制学】控制学分类
【控制学】控制学分类 文章目录 [TOC](文章目录) 前言一、工程控制论1. 经典控制理论2. 现代控制理论 二、生物控制论三、经济控制论总结 前言 控制学是物理、数学与工程的桥梁 提示:以下是本篇文章正文内容,下面案例可供参考 一、工程控制论 1. 经典…...

人工智能应用开发中常见的 工具、框架、平台 的分类、详细介绍及对比
以下是人工智能应用开发中常见的 工具、框架、平台 的分类、详细介绍及对比: 一、工具(Tools) 定义:用于完成特定任务的软件或库,通常专注于开发流程中的某个环节(如数据处理、模型调试、部署等ÿ…...
、Linux文件系统的校验(xfs_repair、fsck_ext4))
Linux磁盘格式化(mkfs、mkfs.xfs、mkfs.ext4)、Linux文件系统的校验(xfs_repair、fsck_ext4)
在Linux系统中,磁盘格式化和文件系统校验是系统管理的重要任务。以下是关键步骤和命令的总结: 磁盘格式化 1. 选择文件系统类型 XFS:适用于大文件和高并发场景,支持高性能和扩展性。ext4:成熟稳定的通用文件系统,适合大多数场景。2. 格式化命令 通用格式: sudo mkfs -…...

Android学习总结之git篇
Git 的原理时,你可以从数据结构、对象存储、引用管理、分支与合并等方面结合源码进行分析。以下是详细介绍: 1. 基本数据结构和对象存储 Git 底层主要基于四种对象来存储数据:blob(数据块)、tree(树&…...

Python基础语法——类型
目录 类型的意义动态类型静态类型 类型的意义 不同的类型,占用的内存空间是不同的. 占几个字节 int 默认是 4 个字节.动态扩容 float 固定 8 个字节 bool 一个字节就足够了 str 变长的 不同的类型,对应能够进行的操作也是不同的 int/float, “” “-” “ * ” “/”——不能使…...

vue2中基于el-select封装一个懒加载下拉框
需求 当下拉选项的数据量过大时,后端接口是分页格式返回数据。 解决方案 自定义封装一个懒加载下拉组件,每次滚动到底部时自动获取下一页数据,这样可有效防止数据量过大时造成组件卡顿。 具体实现步骤 1、创建懒加载下拉选择组件 <t…...

uniapp的h5,打开的时候,标题会一闪而过应用名称,再显示当前页面的标题
问题: 微信小程序,通过webview打开了uniapp创建的h5,但是打开h5时,会先显示h5的应用名称,然后才切换为该页面的标题。 过程: 查过很多资料,有说修改应用名称,有说设置navigationS…...

HarmonyOS 5 开发环境全解析:从搭建到实战
鸿蒙来了,从 1.0 到 5.0,它不再只是“华为的操作系统”,而是万物互联生态的核心驱动。作为开发者,你准备好拥抱这个全新时代了吗? 你是否还在犹豫:HarmonyOS 5 开发门槛高不高?该用 DevEco Stu…...

2.2 函数返回值
1.回顾def def sum(x,y): return xy res sum(10,20) #调用函数 print(res) 2.函数的三个重要属性 -函数的类型:function -函数的ID:16进制的整数数值 -函数的值:封装在函数中的数据和代码 # - 函数是一块内存空间,通过…...

OpenAI发布GPT-4.1:开发者专属模型的深度解析 [特殊字符]
最近OpenAI发布了GPT-4.1模型,却让不少人感到困惑。今天我们就来深入剖析这个新模型的关键信息! 重要前提:API专属模型 💻 首先需要明确的是,GPT-4.1仅通过API提供,不会出现在聊天界面中。这是因为该模型主…...

Cython中操作C++字符串
使用Cython开发Python扩展模块-CSDN博客中文末对python代码做了部分C优化,并提及未对字符串类型做优化,并且提到如果不是真正搞懂了C字符串的操作和Python的C API中与字符串相关的知识,最好不要动Python中的字符串类型。为了搞明白在Cython中…...

Dify插件内网安装,解决Dify1.x插件安装总失败问题,手把手教你暴力破解:从镜像源到二进制打包全攻略
背景 自从dify升级到1.0以后,所有的工具和模型都改成了插件化,需要进行插件的安装。在手撕Dify1.x插件报错!从配置到网络到Pip镜像,一条龙排雷实录 已经指出了dify在线安装插件的各种问题。 首发地址 在前面的几个版本中&…...

二极管详解:特性参数、选型要点与分类
一、二极管的基本定义 二极管(Diode) 是由半导体材料(如硅、锗)构成的双端器件,核心特性是单向导电性。其结构基于PN结,正向偏置导通,反向偏置截止。 核心功能: 整流(交…...

BufferedOutputStream 终极解析与记忆指南
BufferedOutputStream 终极解析与记忆指南 一、核心本质 BufferedOutputStream 是 Java 提供的缓冲字节输出流,继承自 FilterOutputStream,通过内存缓冲区显著提升 I/O 性能。 核心特性速查表 特性说明继承链OutputStream → FilterOutputStream → …...

Google政策大更新:影响金融,新闻,社交等所有类别App
Google Play 4月10日 迎来了2025年第一次大版本更新,新政主要涉及金融(个人贷款),新闻两个行业。但澄清内容部分却使得所有行业都需进行一定的更新。下面,我们依次从金融(个人贷款),…...

【Linux网络与网络编程】10.网络层协议IP
前言 我们之前谈的主机B把数据传递给主机C过程都是黑盒式的,即并没有考虑它的中间过程。本篇博客和下一篇博客将要考虑的问题是:主机B和主机C并不是直接连接的,主机B想要把数据传输给主机C需要经过若干路由器的。我们就引出了两个问题&#x…...

Docker 搭建 RabbitMQ
Docker 搭建 RabbitMQ 前言一、准备工作二、设置目录结构三、编写启动脚本四、Host 网络模式 vs Port 映射模式1. Host 网络模式2. Port 映射模式 五、端口配置对比六、配置示例七、查看与管理八、扩展与高可用九、常用命令 前言 在现代微服务与分布式架构中,Rabbi…...