大数据学习笔记
文章目录
- 1. 大数据概述
- 1.1 大数据的特性
- 1.2 大数据技术生态
- 1.2.1 Hadoop 的概念特性
- 1.2.2 Hadoop生态圈 — 核心组件与技术栈
- 1.2.3 Hadoop生态演进趋势
- 2. 数据处理流程与技术栈
- 2.1 数据采集
- 2.1.1 日志采集工具
- 2.1.2 实时数据流
- 2.1.3 数据迁移
- 2.2 数据预处理
- 2.2.1 批处理
- 2.2.2 流处理
- 2.2.3 混合处理
- 2.3 数据存储与管理
- 2.3.1 分布式文件系统
- 2.3.2 结构化/半结构化存储
- 2.3.3 实时存储优化
- 2.4 数据分析与挖掘
- 2.4.1 SQL引擎
- 2.4.2 OLAP分析
- 2.4.3 机器学习与AI
- 2.5 数据可视化
理解这些概念、框架、常用技术栈,后续学习、实践中大体有个数。
1. 大数据概述
1.1 大数据的特性
- 规模性
以 PB、EB、ZB 为计量单位。(M<G<T<P<E<Z)
1GB = 1024 MB、1TB = 1024GB
1PB = 1024TB、1EB = 1024PB、1ZB = 1024EB
- 多样性
数据来源多、类型复杂、数据关联性强
关于数据类型:
结构化数据——财务系统、业务系统、医疗系统等产生的数据
半结构化数据——html文档、xml文档、邮件等
非结构化数据——音视频、图片等
- 高速性
单位时间内流量高,数据增长速度快,且要求数据处理响应速度要快,一般要实时处理与分析 - 价值性
从大量不相关的各类数据中,挖掘出对未来趋势、模式预测有价值的数据。如金融风控、实时健康监控、零售业的精准营销等。 - 准确性
收集的数据要真实、准确、有意义。如根据电影评分、评论分析电影,进行购票 - 动态性
大数据是根据互联网技术产生的实时的、动态的数据 - 可视化
数据可视化,直观的解释数据的意义 - 合法性
数据收集必须遵照国家政策与法律规定,且规避掉个人隐私数据、企业内部数据的收集,除非得到授权许可。
1.2 大数据技术生态
1.2.1 Hadoop 的概念特性
Hadoop是分布式大数据处理的基础框架,其生态圈通过模块化组件解决了数据存储、计算、管理和分析的全流程问题。其核心价值在于低成本处理海量数据。Hadoop底层数据存储使用副本机制,默认为3个(高可靠);集群支持热插拔,增删节点后,无需重启集群(高扩展);MapReduce支持分布式的并行计算(高效率);能自动将失败任务重新分配(高容错);可运行在低成本的机器上(低成本)。
Hadoop核心设计理念:分布式存储(HDFS) 和 分布式计算(MapReduce),并在此基础上衍生出丰富的工具链。
1.2.2 Hadoop生态圈 — 核心组件与技术栈
- 存储层
-
HDFS(Hadoop Distributed File System)

功能:分布式文件系统,将数据分块存储在集群节点上,支持高容错、高吞吐。
场景:存储原始日志、非结构化数据(如文本、图片)。
优化:与纠删码(Erasure Coding)结合降低存储成本。

-
HBase
是一个分布式,面向列的开源数据库,适合存半结构化、非结构化数据。
功能:分布式 NoSQL 数据库,基于 HDFS 实现低延迟随机读写。

场景:实时查询(如用户画像、订单状态)。
特点:强一致性、列式存储、支持海量稀疏数据。 -
云存储集成
Amazon S3、阿里云 OSS:替代 HDFS 作为存储层,支持存算分离架构。
- 计算层
-
MapReduce

功能:经典的批处理框架,分 Map(映射)和 Reduce(归约)两阶段。
局限:磁盘 I/O 开销大,适合离线场景(如历史数据统计)。


-
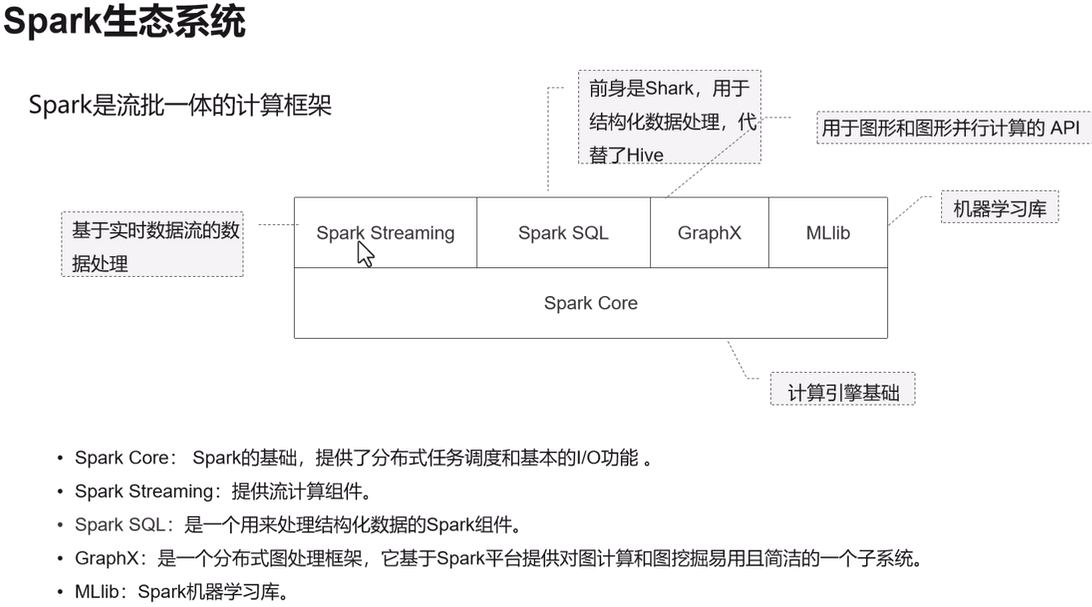
Spark
功能:基于内存的分布式计算引擎,兼容 MapReduce 但性能提升 10~100 倍。
场景:ETL、机器学习(MLlib)、图计算(GraphX)。
优势:支持 SQL(Spark SQL)、流处理(Spark Streaming)。
Spark支持实时计算,支持离线计算,基于内存计算,支持迭代计算。
-
Tez
功能:优化 Hive/Pig 等工具的 DAG(有向无环图)执行效率,替代传统 MapReduce。
- 资源管理与调度
-
YARN(Yet Another Resource Negotiator)
功能:Hadoop 2.0 引入的资源管理器,解耦计算与资源调度。
作用:支持多计算框架(如 MapReduce、Spark、Flink)共享集群资源。
。
- 数据管理与查询
-
Hive
是一个基于Hadoop的数据仓库ETL工具,完成数据提取、转换、加载的功能。
功能:基于 HDFS 的数据仓库工具,通过 SQL(HiveQL)查询大规模数据,解决结构化数据的查询与统计。
 优化:LLAP(Live Long and Process)实现近实时查询。
优化:LLAP(Live Long and Process)实现近实时查询。 -
Presto/Trino
功能:分布式 SQL 查询引擎,支持跨数据源(HDFS、MySQL、Kafka)联邦查询。
场景:交互式分析,替代 Hive 执行复杂查询。 -
Impala
功能:MPP(大规模并行处理)引擎,提供低延迟 SQL 查询(类似 Hive 但更高效)。
- 数据采集与同步
-
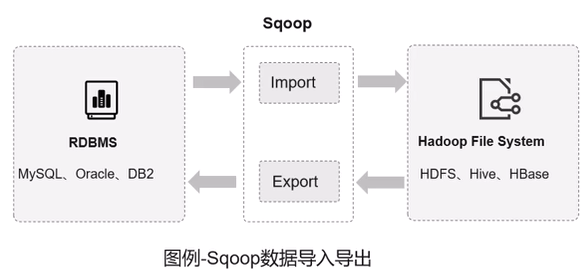
Sqoop
是一个在HDFS和RDMS间传数据的工具,负责关系型数据库(MySQL/Oracle)与 Hadoop(HDFS/Hive)之间的批量数据迁移。

-
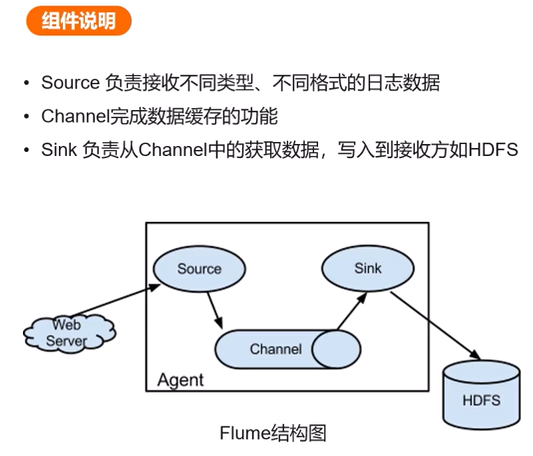
Flume
功能:是一个大数据集日志收集的框架,分布式日志采集工具,支持多级数据管道和容错传输。

-
Kafka
功能:高吞吐消息队列,用于实时数据流接入(如日志、传感器数据)。
- 工作流与治理
-
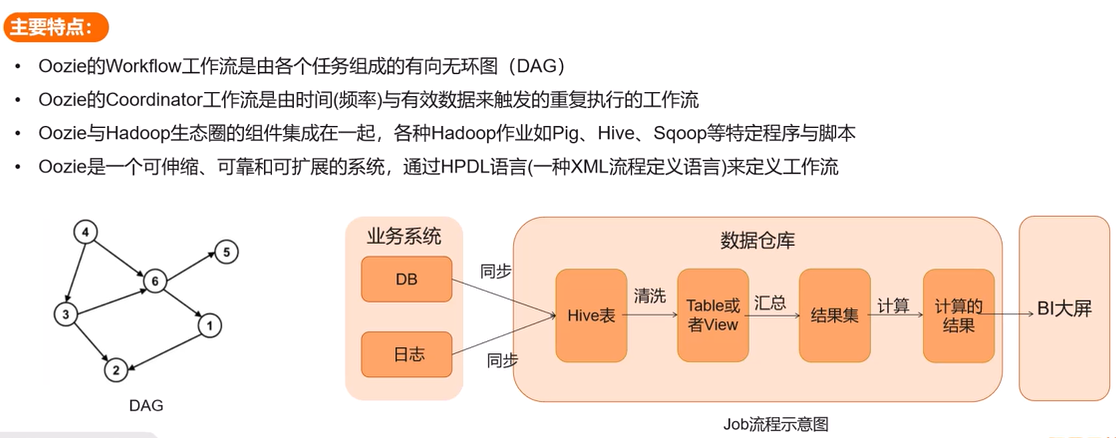
Oozie
功能:Hadoop 任务调度工具,支持复杂依赖关系的批处理作业编排,是一个管理Hadoop相关作业的工作流调度系统。
运行在Java Servlet容器中,用于定时调度任务、按执行的逻辑顺序调度多个任务。
-
Atlas
功能:元数据管理与数据治理,支持数据血缘追踪和合规审计。
-
Ranger
功能:统一权限管理框架,控制 HDFS、Hive、Kafka 等组件的访问权限。
- 其他重要组件
- Mahout
分布式机器学习库,专注于大规模数据集的机器学习算法(如分类、聚类、推荐系统)。
特点:
- 提供可扩展的算法实现,适合处理 TB 级数据。
- 支持多种计算框架(MapReduce → Spark → Flink)。
- 强调数学抽象,允许用户自定义算法扩展。
优势:支持超大规模数据集训练;算法可定制性强,适合科研和特殊业务需求;无缝对接 HDFS、Hive 等数据源。
劣势:需熟悉分布式计算和线性代数抽象,开发门槛高;落后于 Spark MLlib、TensorFlow 等框架。相比主流框架(如 PyTorch),更新和维护较慢。
- Pig
功能:主要用于简化大规模数据集的复杂处理与分析任务。
核心特性:Pig 脚本会被解析为逻辑执行计划(DAG),经过优化器优化后转换为 MapReduce 任务,自动处理数据分区、任务并行度等细节。
优势:Pig 更适合批处理场景,语法更贴近 SQL;Spark 则在迭代计算和实时处理上性能更优。逐渐支持在 Kubernetes 上运行,并与云存储(如 Amazon S3)集成,推动存算分离架构

- ZoopKeeper
功能:是一个分布式协调服务,用于解决分布式系统中的一致性、配置管理、命名服务、分布式锁等问题。

- Ambari
是 Hadoop 生态中的 集群管理与监控工具,旨在简化 Hadoop 组件的部署、配置、运维和监控,提供 Web UI 和 REST API,降低大数据平台的管理门槛。

1.2.3 Hadoop生态演进趋势
- 云原生转型
存储层:HDFS 逐步被云对象存储(S3/OSS)替代,实现存算分离。
计算层:Spark/Flink 等框架支持 Kubernetes 调度,提升弹性扩缩容能力。 - 实时化与流批一体
MapReduce 被 Spark/Flink 取代,Flink 成为流处理首选(低延迟、Exactly-Once 语义)。 - SQL 化与自动化
Hive LLAP、Flink SQL 等工具降低开发门槛,推动数据分析平民化。 - 与 AI 生态融合
Spark MLlib、TensorFlow on YARN 支持大规模机器学习模型训练。
随着云原生和实时计算的发展,其组件(如 HDFS、MapReduce)会逐渐被优化或替代。未来 Hadoop 将更多以混合架构形式存在(如 Hive on S3、Spark on K8s),与云服务、实时引擎(Flink)深度整合。
2. 数据处理流程与技术栈
大数据处理流程:
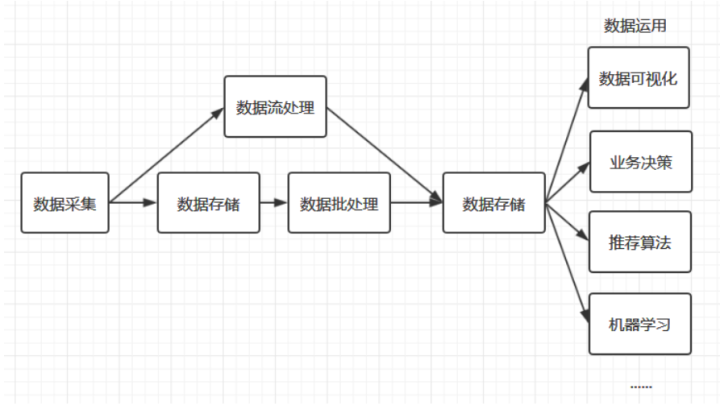
2.1 数据采集
2.1.1 日志采集工具
Flume:分布式日志收集系统,适用于多服务器场景。Logstash:支持多种数据源的采集与聚合,常与Elasticsearch、Kibana(ELK栈)结合使用。
2.1.2 实时数据流
Kafka:高吞吐量消息队列,用于数据缓冲和实时流处理。Canal:基于MySQL Binlog的实时数据同步工具,用于数据库增量数据抽取。
2.1.3 数据迁移
Sqoop:关系型数据库与Hadoop生态(HDFS/Hive/HBase)间的批量数据迁移。DataX:插件化数据同步工具,支持全量与增量数据迁移。
2.2 数据预处理
2.2.1 批处理
Apache Spark:基于内存的分布式计算引擎,支持复杂ETL和机器学习。Hadoop MapReduce:经典的离线处理框架,适合大规模数据批量计算。
2.2.2 流处理
流处理主导:Flink因低延迟和状态管理优势逐渐取代Storm,成为实时计算首选。
Apache Flink:低延迟的真流处理框架,支持流批一体和状态计算。Spark Streaming:微批处理模式,与Spark生态无缝集成。
2.2.3 混合处理
Flink SQL:通过SQL实现流批统一处理,简化开发流程
2.3 数据存储与管理
2.3.1 分布式文件系统
HDFS:Hadoop生态核心存储,支持海量非结构化数据存储。云存储:Amazon S3、阿里云OSS等对象存储服务。
2.3.2 结构化/半结构化存储
HBase:面向列的分布式NoSQL数据库,适合随机读写场景。MongoDB:文档型数据库,灵活存储半结构化数据。
2.3.3 实时存储优化
Kudu:兼顾随机读写与批量分析的列式存储系统,与HDFS互补。Alluxio:内存加速的分布式存储抽象层,提升跨系统数据访问效率。
2.4 数据分析与挖掘
2.4.1 SQL引擎
Hive:基于Hadoop的SQL查询工具,将SQL转换为MapReduce任务。Presto:分布式MPP查询引擎,支持跨数据源(HDFS、RDBMS等)快速查询。
2.4.2 OLAP分析
Apache Kylin:预计算多维分析引擎,适用于亚秒级查询响应。ClickHouse:高性能列式数据库,适合实时分析场景。
2.4.3 机器学习与AI
TensorFlow、PyTorch:分布式模型训练与推理框架。Spark MLlib:集成于Spark的机器学习库
2.5 数据可视化
Tableau、Power BI:交互式数据可视化与报表生成。
相关文章:

大数据学习笔记
文章目录 1. 大数据概述1.1 大数据的特性1.2 大数据技术生态1.2.1 Hadoop 的概念特性1.2.2 Hadoop生态圈 — 核心组件与技术栈1.2.3 Hadoop生态演进趋势 2. 数据处理流程与技术栈2.1 数据采集2.1.1 日志采集工具2.1.2 实时数据流2.1.3 数据迁移 2.2 数据预处理2.2.1 批处理2.2.…...

Obsidian 文件夹体系构建 -INKA
Obsidian 文件夹体系构建 -INKA 本篇文章主要分享一下自己折腾学习实践过的 INKA 框架方法。原地址:Obsidian文件夹体系构建–INKA。 文章目录 Obsidian 文件夹体系构建 -INKA前言INKA简介INKA 理论最佳实践实际应用 反思 前言 上文 Obsidian文件夹体系构建-ACCES…...
)
QML与C++:基于ListView调用外部模型进行增删改查(性能优化版)
目录 引言相关阅读工程结构数据模型设计DataModel 类ContactProxyModel 类 为什么使用QSortFilterProxyModel?应用初始化与模型连接UI实现 性能分析与优化运行效果扩展思考总结下载链接 引言 在上一篇中介绍了基于ListView调用外部模型进行增删改查,本文…...

集合常用Stream操作
1、中间操作 filter()过滤 将流中的元素筛选出满足条件的元素 List<String> list Arrays.asList("abc","test","demo","frse","fesfes"); list.stream().filter(s -> s.startsWith("f")).forEach(Sy…...

ReactNative中处理安全区域问题
RN原生方案不支持android系统,所以在此使用三方组件react-native-safe-area-context 1、安装插件 yarn add react-native-safe-area-context2、安装完成后直接yarn ios可能会失败,需要先 cd ios && pod install && cd ..出来再继…...

二、The Power of LLM Function Calling
一、Function Calling 的诞生背景 1. 传统LLM的局限性 静态文本生成的不足:早期的LLM(如早期版本的ChatGPT)主要依赖预训练的知识库生成文本,但无法直接与外部系统或API交互。这意味着它们只能基于历史数据回答问题,…...
)
贪心算法day10(无重叠区间)
1.无重叠区间 435. 无重叠区间 - 力扣(LeetCode) 思路: 代码: class Solution {public static int eraseOverlapIntervals(int[][] intervals) {Arrays.sort(intervals,(v1,v2)->{return v1[0]-v2[0];});int left interva…...

reactive 解构赋值给 ref
在 Vue 3 中,当你执行以下操作时: javascript const applyBasicInfo ref(); applyBasicInfo.value { ...props.applyBasicInfo }; 最终的 applyBasicInfo.value 是响应式对象,但与原对象 props.applyBasicInfo 的响应性完全独立…...

MongoDB简单用法
图片中 MongoDB Compass 中显示了默认的三个数据库: adminconfiglocal 如果在 .env 文件中配置的是: MONGODB_URImongodb://admin:passwordlocalhost:27017/ MONGODB_NAMERAGSAAS💡 一、为什么 Compass 里没有 RAGSAAS 数据库?…...
: 可能形(かのうけい))
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(4): 可能形(かのうけい)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(4): 可能形(かのうけい) 1、前言(1)情况说明(2)工程师的信仰2、知识点(1)~んです 復習(ふくしゅう)(2)いただけませんか 復習(ふくしゅう)(3)可能形(かのうけい)(1)1グループ:(2)2グループ…...

Windows 下 MongoDB ZIP 版本安装指南
在开发和生产环境中,MongoDB 是一种非常流行的 NoSQL 数据库,以其灵活性和高性能而受到开发者的青睐。对于 Windows 用户来说,MongoDB 提供了多种安装方式,其中 ZIP 版本因其灵活性和轻量级的特点,成为很多开发者的首选…...

万字长篇————C语言指针学习汇总
经过一段时间的学习,我们已经接触到了C语言的很多知识了。不过目前我们接下来我们要接触C语言中一个最大的“门槛”:指针。 什么是指针? 在介绍指针之前,我们首先要明白变量与地址之间的关系。 举一个生活中的案例:一…...

day29图像处理OpenCV
文章目录 一、图像预处理6 图像色彩空间转换6.3灰色/BGR/HSV相互转化 7 彩图转灰图方法7.1 最大值法7.2 平均值法7.3 加权均值法7.4 案例 8 图像二值化处理8.1 阈值法(typecv2.THRESH_BINARY)8.2 反阈值法(THRESH_BINARY_INV)8.3 截断阈值法(THRESH_TRUNC)8.4 低阈值零处理(THR…...

Spring Boot 项目三种打印日志的方法详解。Logger,log,logger 解读。
目录 一. 打印日志的常见三种方法? 1.1 手动创建 Logger 对象(基于SLF4J API) 1.2 使用 Lombok 插件的 Slf4j 注解 1.3 使用 Spring 的 Log 接口(使用频率较低) 二. 常见的 Logger,logger,…...

KrillinAI:视频跨语言传播的一站式AI解决方案
引言 在全球内容创作领域,跨语言传播一直是内容创作者面临的巨大挑战。传统的视频本地化流程繁琐,涉及多个环节和工具,不仅耗时耗力,还常常面临质量不稳定的问题。随着大语言模型(LLM)技术的迅猛发展,一款名为Krillin…...

PDF处理控件Aspose.PDF指南:使用 C# 从 PDF 文档中删除页面
需要从 PDF 文档中删除特定页面?本快速指南将向您展示如何仅用几行代码删除不需要的页面。无论您是清理报告、跳过空白页,还是在共享前自定义文档,C# 都能让 PDF 操作变得简单高效。学习如何以编程方式从 PDF 文档中选择和删除特定页面&#…...
)
在 IntelliJ IDEA 中开发 Java Web 项目时,遇到包内明明存在某个类但类名仍然爆红(显示红色错误提示)
在 IntelliJ IDEA 中开发 Java Web 项目时,遇到包内明明存在某个类但类名仍然爆红(显示红色错误提示),而项目却能正常运行,重启 IDEA 后问题依旧,这通常是由以下原因及解决方法导致的: 1. 缓存…...

【4】k8s集群管理系列--harbor镜像仓库本地化搭建
一、harbor基本概念 Harbor是一个由VMware开源的企业级Docker镜像仓库解决方案,旨在解决企业在容器化应用部署中的痛点,提供镜像存储、管理、安全和分发的全生命周期管理。Harbor扩展了Docker Registry,增加了企业级功能,如…...

Active Directory域服务管理与高级应用技术白皮书
目录 一、Active Directory核心架构解析 1.1 AD域服务核心组件 1.2 域功能级别演进 1.3 AD LDS应用场景 二、企业级域环境部署最佳实践 2.1 域控制器部署规划 2.2 高可用架构设计 2.3 客户端入域优化 三、高级域管理技术 3.1 精细化权限管理 3.2 组策略深度配置 3.3…...

OCP中的OCS operator介绍及应用示例
一、OCS operator介绍 在 Red Hat OpenShift Container Platform(OCP4.8版之前,包含4.8) 中,OCS Operator(OpenShift Container Storage Operator) 是用于在 OpenShift 集群中部署、配置和管理 OpenShift …...

Linux-服务器添加审计日志功能
#查看audit软件是否在运行(状态为active而且为绿色表示已经在运行) systemctl start auditd #如果没有在运行的话,查看是否被系统禁用 (audit为0表示被禁用) cat /proc/cmdline | grep -w "audit=0" #修改/etc/default/grub里面audit=0 改为audit=1 #更新GRUB…...

ARM Cortex-M中断处理全解析
今天我们聊一聊ARM Cortex-M中断处理。在嵌入式系统中,中断是实现实时响应的核心机制。想象一下,如果没有中断: 按键按下时,系统可能忙于其他任务而错过响应通信数据到来时,可能因为没及时处理而丢失定时任务难以精确…...

douyin_search_tool | 用python开发的抖音关键词搜索采集软件
本软件工具仅限于学术交流使用,严格遵循相关法律法规,符合平台内容合法性,禁止用于任何商业用途! 抖音作为国内颇受欢迎的短视频社交平台,汇聚了大量用户群体和活跃用户。分析平台上的热门视频可用于市场调研和竞品分析…...

基于FreeBSD的Unix服务器网络配置
Unix系统版本 FreeBSD-10.1-i386 网络配置 1.配置网络ip及网关 #编辑配置文件 ee /etc/rc.conf #参照如下内容设置 ifconfig_em0”inet 192.168.1.189 netmask 255.255.255.0” defaultrouter”192.168.1.1” #回到命令模式 esc #保存 a a 2.配置dns #编辑配置文件 ee /etc/…...

Margin和Padding在WPF和CSS中的不同
CSS和WPF中 margin 与 padding 在方向上的规定基本一致,但在使用场景和一些细节上有所不同。 CSS - 方向规定: margin 和 padding 属性可以分别指定上、右、下、左四个方向的值。例如 margin:10px 20px 30px 40px; 表示上外边距为10px、右外边距为20…...

JVM 概述
JVM概述 JVM的全为 Java Virtual Machine,但是目前的 JVM 已经不再与任何语言进行深度耦合了,其本质就是运行在计算机上的程序,职责是运行处理 Java 字节码文件。 JVM 功能 解释和运行 JVM 会对字节码文件中的指令,实时的解释为…...
,源码可白嫖!)
基于django云平台的求职智能分析系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 时代在飞速进步,每个行业都在努力发展现在先进技术,通过这些先进的技术来提高自己的水平和优势,招聘信息管理系统当然不能排除在外。求职智能分析系统是在实际应用和软件工程的开发原理之上,运用Python语言、爬虫技术以及Dj…...

在 Ubuntu 上通过 Docker 部署 Misskey 服务器
在这篇博客中,我们将探讨如何在 Ubuntu 上通过 Docker 部署 Misskey 服务器。Misskey 是一个开源的社交网络平台,支持丰富的社交功能,适合个人和小型社群使用。而 Docker 则是一个便捷的容器化平台,允许开发者轻松地打包、发布和运…...

Pytorch 第十五回:神经网络编码器——GAN生成对抗网络
Pytorch 第十五回:神经网络编码器——GAN生成对抗网络 本次开启深度学习第十五回,基于Pytorch的神经网络编码器。本回分享的是GAN生成对抗网络。在本回中,通过minist数据集来分享如何建立一个GAN生成对抗网络。接下来给大家分享具体思路。 本…...

gitlab如何查看分支的创建时间
在 GitLab 上查看分支创建时间,常规的界面不会直接显示,但可以通过以下几种方法查到准确时间: 方法一:通过 GitLab Web 界面查看首次提交时间(近似) 打开你的项目仓库。点击左侧的「Repository(…...

centos时间不正确解决
检查当前系统时间 date如果时间明显不正确,可以进一步检查硬件时钟(BIOS 时间): bash复制代码hwclock --show同步时间(推荐方式) 为了确保系统时间准确,建议使用 NTP(网络时间协议…...

ubuntu启动 Google Chrome 时默认使用中文界面,设置一个永久的启动方式
方法 :通过桌面快捷方式设置 编辑 Chrome 的桌面快捷方式: 找到您的 Google Chrome 快捷方式文件。如果是通过菜单启动,通常会在以下路径找到与 Chrome 相关的 .desktop 文件: sudo vim /usr/share/applications/google-chrome.d…...

opencv腐蚀的操作过程
在腐蚀操作的详细流程中,遍历图像的过程如下: 初始化: 设置一个起始位置(通常从图像的左上角开始)。 准备好结构元素(structuring element),它是一个小的矩阵,大小通常是…...

Docker--Docker镜像原理
docker 是操作系统层的虚拟化,所以 docker 镜像的本质是在模拟操作系统。 联合文件系统(UnionFS) 联合文件系统(UnionFS) 是Docker镜像实现分层存储的核心技术,它通过将多个只读层(Image Laye…...

HL7消息编辑器的使用手册
REDISANT 提供互联网与物联网开发测试套件 # 互联网与中间件: Redis AssistantZooKeeper AssistantKafka AssistantRocketMQ AssistantRabbitMQ AssistantPulsar AssistantHBase AssistantNoSql AssistantEtcd AssistantGarnet Assistant 工业与物联网࿱…...
)
技术与情感交织的一生 (六)
目录 食色性也 Z 姐 Pizza “修罗场” 之战 大二 下 EP 混乱 危机 撤退 离别 初创 重逢 食色性也 美食、美器、美女。追求美好的事物是人的天性。八部众里,天众界:因修行,有美食而无美女;阿修罗界:因产力…...

AI搜索引擎的局限性
# 揭秘AI搜索引擎的局限性与深度爬取技巧 > 摘要:本文深入分析了基于关键词的AI搜索引擎局限性,探讨了深网内容难以被发现的原因,并提供了一系列实用技巧来提高信息获取的全面性。无论是开发者、研究人员还是普通用户,了解这些…...

IPD项目管理的“黄金三角“在2025年是否需要重构?
——技术革命下的组织进化与实践创新 一、时空背景:IPD黄金三角的底层逻辑与时代挑战 IPD(集成产品开发)管理体系自1998年引入中国以来,其"黄金三角"——跨职能团队协作、结构化流程体系、决策评审机制——始终是企业…...

Jarpress 开源项目重构公告
项目背景 经过长达三个月的技术攻坚,我们正式宣布完成对九年历史开源项目的全面重构升级!原项目基于JFina框架开发,现采用SpringBootMyBatis技术栈重构,正式更名为Jarpress。 架构升级 采用最小组件依赖实现,减少系…...

Redshift 2025.4.1 版本更新:多平台兼容性与功能修复
2025 年 4 月 10 日,Redshift 发布 2025.4.1 版本(2025.04),聚焦宿主软件兼容性提升与核心功能修复,具体更新如下: 各平台适配与优化 Maya/3ds Max/Blender:新增对 Maya 2026、3ds Max 2026、…...

使用crxjs插件编写浏览器扩展插件遇到的问题 Waiting for the extension service worker...
目前最新的vitejs/plugin-vue和crxjs/vite-plugin不兼容,在crxjs官网有写 修改插件版本如下: "devDependencies": {"crxjs/vite-plugin": "^1.0.14","vitejs/plugin-vue": "^2.3.4","vite"…...

数据库学习通期末复习一
🌟 各位看官好,我是maomi_9526! 🌍 种一棵树最好是十年前,其次是现在! 🚀 今天来学习C语言的相关知识。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更…...

数据分析实战案例:使用 Pandas 和 Matplotlib 进行居民用水
原创 IT小本本 IT小本本 2025年04月15日 18:31 北京 本文将使用 Matplotlib 及 Seaborn 进行数据可视化。探索如何清理数据、计算月度用水量并生成有价值的统计图表,以便更好地理解居民的用水情况。 数据处理与清理 读取 Excel 文件 首先,我们使用 pan…...

生态环境影响评价全解析
生态环境影响评价的原则、方法、工作程序、指标选择、参数计算、模型模拟、报告编制 一 :生态环境影响评价的基本程序 生态环境影响评价的涵义、生态影响的类型;生态环境影响评价的原则、流程、等级确定及工作范围。 图1 空间尺度上长江对中华鲟的累积…...

【Netty篇】Netty的线程模型
目录 一、Netty 线程模型是啥?二、Netty 线程模型有啥作用?三、Netty 线程模型解决了什么问题?四、如何使用 Netty 线程模型?五、Netty 线程模型的优缺点?六、总结 🌟我的其他文章也讲解的比较有趣…...

PyTorch实现权重衰退:从零实现与简洁实现
一、权重衰退原理 权重衰退(L2正则化)通过向损失函数添加权重的L2范数惩罚项,防止模型过拟合。其损失函数形式为: 二、从零开始实现 1.1 导入库与数据生成 %matplotlib inline import torch from torch import nn from d2l imp…...

Webflux声明式http客户端:Spring6原生HttpExchange实现,彻底摒弃feign
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...
函数用法; 字符串切片操作)
python的strip()函数用法; 字符串切片操作
python的strip()函数用法 目录 python的strip()函数用法代码整体功能概述代码详细解释1. `answer["output_text"]`2. `.strip()`3. `final_answer = ...`字符串切片操作:answer[start_index + len("Helpful Answer:"):].strip()整体功能概述代码详细解释1…...
)
多模态大语言模型arxiv论文略读(二十一)
EgoPlan-Bench: Benchmarking Multimodal Large Language Models for Human-Level Planning ➡️ 论文标题:EgoPlan-Bench: Benchmarking Multimodal Large Language Models for Human-Level Planning ➡️ 论文作者:Yi Chen, Yuying Ge, Yixiao Ge, Mi…...

MCP学习资料
Anthropic 官方:https://modelcontextprotocol.io/introduction 中文站:https://mcpcn.com/docs/examples/...