大数据(一)MaxCompute
一、引言
作者后面会使用MaxCompute,所以在进行学习研究,总会有一些疑问产生,这里讲讲作者的疑问和思路
二、介绍
MaxCompute(原名 ODPS - Open Data Processing Service)是阿里云提供的大数据处理平台,专门用于批量数据存储和大规模并行计算。它广泛应用于数据分析和处理任务,为企业级数据处理提供高效的解决方案。
下面是 MaxCompute 的一些主要功能和应用场景:
-
大规模数据存储:MaxCompute 提供高效的数据存储解决方案,可以存储 PB 级别的数据,支持结构化和半结构化数据。它的存储系统具有高可用性和高可靠性。
-
大数据计算引擎:MaxCompute 提供了强大的计算能力,能够处理大规模数据集。它支持 SQL 、MapReduce 、Graph 和 UDF(用户自定义函数)等多种计算模型,为复杂数据分析提供支持。
-
高效的资源管理:MaxCompute 通过资源组、任务队列等资源管理机制,能够实现资源的高效调度和利用,确保计算任务的高效进行。
-
安全和权限管理:MaxCompute 提供了完善的安全机制,包括数据访问权限控制、数据加密等,确保数据的安全性。
-
数据处理和分析:适用于多种数据处理和分析任务,包括数据清洗、预处理、数据挖掘、统计分析等。它可以与阿里云其他大数据产品(如 DataWorks 、AnalyticDB)集成,形成完整的大数据解决方案。
-
扩展性和高可用性:MaxCompute 具有很强的扩展性,可以根据需要动态扩展计算资源。此外,它具有高可用性设计,确保服务的稳定运行。
-
多语言支持:MaxCompute 支持多种编程语言,如 SQL 、Python 、Java 等,方便用户编写数据处理和分析任务
三、问答
看了一段时间官方文档之后,常见的SQL问题以及优化示例_云原生大数据计算服务 MaxCompute(MaxCompute)-阿里云帮助中心作者有很多疑问
1、长尾问题是什么?
一般来说数据分布中存在少量出现频率非常高的“热点”数据,而同时也有大量出现频率低但多样性高的“长尾”数据
但是MaxCompute将Fuxi Instance 耗费时长高于平均值 2倍的实例判定为长尾
也就是将任务分配和执行的引擎实例时间执行过长的认为长尾
比如这个sql他就举例说会引起长尾问题
SELECT shop_id,sum(is_open) AS 营业天数 FROM table_xxx_diWHERE dt BETWEEN 'bizdate365′AND′bizdate365′AND′{bizdate}'GROUP BY shop_id;按照社区请教了一些朋友,这种可能是数据倾斜造成,比如一些 shop_id 的数据量远大于其他 shop_id,GROUP BY shop_id的处理时间会明显超过平均值,从而导致长尾现象
解决方案一般是
-
数据预处理和分区调整:
尝试在数据写入阶段使用均匀分布的分区键,如果可能,重新设计数据模型以减轻倾斜。 -
计算逻辑优化:
- 将复杂计算在 ETL 阶段提前处理或者分解为多个合理的小任务。
- 使用窗口函数或其他优化 SQL 技术来减少不必要的数据重计算。
这些说起来都比较笼统,作者对于这个长尾还是有一些模糊
比如数据是
| transaction_id | user_id | item_id | amount | category_id |
|---|---|---|---|---|
| 1 | 1001 | 501 | 100 | 10 |
| 2 | 1002 | 502 | 150 | 10 |
| 3 | 1003 | 503 | 200 | 20 |
| ... | ... | ... | ... | ... |
| 99999 | 1001 | 504 | 100 | 10 |
sql查询是
SELECT user_id, COUNT(*) AS transaction_count
FROM transactions
GROUP BY user_id
ORDER BY transaction_count DESC;这样会因为user_id 1001 存在大量记录(数据倾斜),导致数据在计算节点上分布不均。部分计算节点会因为数据量过大而成为瓶颈,其他节点却几乎无事可做。这会拖慢整个查询的执行时间,造成长尾问题
对应的解决方案是
1. 盐值处理(作者觉得类似hash进行key的分散)
将热点用户的记录通过添加附加前缀或后缀进行分散,来分配给不同的计算节点。
修改 SQL
首先在数据预处理时对user_id进行变换:
INSERT INTO transactions_with_salt
SELECT CONCAT(user_id, '_', CAST(RAND() * 10 AS INT)) AS user_salt, amount
FROM transactions;
然后在查询时进行逆变换处理:
SELECT SUBSTR(user_salt, 0, LENGTH(user_salt) - 2) AS user_id,SUM(transaction_count) AS total_transactions
FROM (SELECT user_salt, COUNT(*) AS transaction_countFROM transactions_with_saltGROUP BY user_salt
) AS salted_data
GROUP BY SUBSTR(user_salt, 0, LENGTH(user_salt) - 2)
ORDER BY total_transactions DESC;
这样相当于是多遍计算,因为要进行随机化再分组,然后把结果给去除之前处理进行重新分组,但是把计算压力给到了多个节点
2. 分区与并行化
对user_id分区或者引入合适的分区键,比如category_id,以在存储阶段给予更好的数据分配
2、为什么MapReduce需要本地Combiner?
看到示例的MapReduce,作息的理解是进行分布式的数据录入处理,然后进行集中处理,感觉很像是java的Fork/Join 框架进行分治
作者理解是吧线程映射成了机器,进行分布式处理然后合并
但是他为什么有个本地Combiner呢?
作者一开始是不理解的,后面再思考发现最明显的是作用范围不一样,
Combiner作用于单个 Mapper 节点的本地数据,仅对本节点的数据进行局部汇总,他主要是减少数据传输,本地先算一下会快很多
Reducer对所有 Mapper 节点输出的数据进行处理
package com.aliyun.odps.mapred.open.example;
import java.io.IOException;
import java.util.Iterator;
import com.aliyun.odps.data.Record;
import com.aliyun.odps.data.TableInfo;
import com.aliyun.odps.mapred.JobClient;
import com.aliyun.odps.mapred.MapperBase;
import com.aliyun.odps.mapred.ReducerBase;
import com.aliyun.odps.mapred.conf.JobConf;
import com.aliyun.odps.mapred.utils.InputUtils;
import com.aliyun.odps.mapred.utils.OutputUtils;
import com.aliyun.odps.mapred.utils.SchemaUtils;
public class WordCount {public static class TokenizerMapper extends MapperBase {private Record word;private Record one;@Overridepublic void setup(TaskContext context) throws IOException {word = context.createMapOutputKeyRecord();one = context.createMapOutputValueRecord();one.set(new Object[] { 1L });System.out.println("TaskID:" + context.getTaskID().toString());}@Overridepublic void map(long recordNum, Record record, TaskContext context)throws IOException {for (int i = 0; i < record.getColumnCount(); i++) {word.set(new Object[] { record.get(i).toString() });context.write(word, one);}}}/*** A combiner class that combines map output by sum them.**/public static class SumCombiner extends ReducerBase {private Record count;@Overridepublic void setup(TaskContext context) throws IOException {count = context.createMapOutputValueRecord();}/**Combiner实现的接口和Reducer一样,是可以立即在Mapper本地执行的一个Reduce,作用是减少Mapper的输出量。*/@Overridepublic void reduce(Record key, Iterator<Record> values, TaskContext context)throws IOException {long c = 0;while (values.hasNext()) {Record val = values.next();c += (Long) val.get(0);}count.set(0, c);context.write(key, count);}}/*** A reducer class that just emits the sum of the input values.**/public static class SumReducer extends ReducerBase {private Record result = null;@Overridepublic void setup(TaskContext context) throws IOException {result = context.createOutputRecord();}@Overridepublic void reduce(Record key, Iterator<Record> values, TaskContext context)throws IOException {long count = 0;while (values.hasNext()) {Record val = values.next();count += (Long) val.get(0);}result.set(0, key.get(0));result.set(1, count);context.write(result);}}public static void main(String[] args) throws Exception {if (args.length != 2) {System.err.println("Usage: WordCount <in_table> <out_table>");System.exit(2);}JobConf job = new JobConf();job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(SumCombiner.class);job.setReducerClass(SumReducer.class);/**设置Mapper中间结果的key和value的Schema, Mapper的中间结果输出也是Record的形式。*/job.setMapOutputKeySchema(SchemaUtils.fromString("word:string"));job.setMapOutputValueSchema(SchemaUtils.fromString("count:bigint"));/**设置输入和输出的表信息。*/InputUtils.addTable(TableInfo.builder().tableName(args[0]).build(), job);OutputUtils.addTable(TableInfo.builder().tableName(args[1]).build(), job);JobClient.runJob(job);}
}3、Graph图识别使用场景?
看到他有个图识别的功能,作者挺感兴趣的,主要是想看看他在什么场景下可以使用
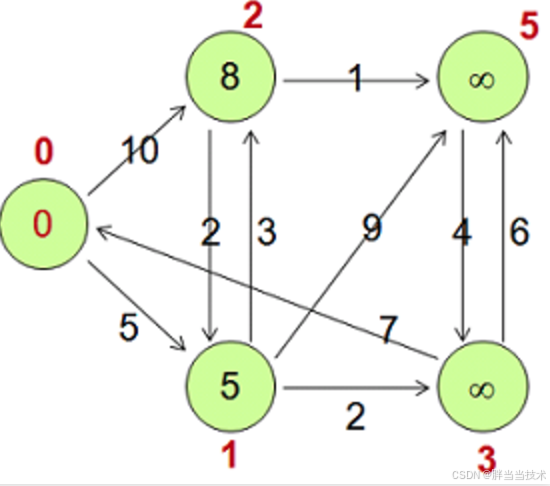
不过看起来也不多,程序示例只有三个,比较经典的是PageRank识别
看着里面的代码还有点疑惑,比如hasEdges这个没有具体的实现,想了一下应该是Vertex这个父类里面应该做了一些通用的实现
PageRank(i)为什么等于 0.15/TotalNumVertices+0.85*sum?
这也是一个不容易理解的点,他会考虑其连接的其他页面对其排名的“投票”权重,同时也引入了一个“随机跳转”的概率
作者想的是为什么会有自由跳转,每个页面被多少页面引用不是应该是确定的嘛?
作者理解他主要是防呆的
-
防止死循环和陷阱页面:
在某些情况下,一个算法可能会遇到“死循环”或者陷入一个“陷阱”。例如,一个圈子内的页面互相链接,但与外界没有链接。在没有自由跳转的情况下,PageRank 值可能会无限在这个局部循环中传播,而无法扩展到其他页面。
-
处理无出链接页面(dead-ends):
-
对于那些没有出链接的节点(也被称为“死角”或“孤立页面”),它们可能导致算法难以进行,因为 PageRank 值会留在这里,而无法流动到其他节点。
-
带有自由跳转机制,任何页面,包括孤立节点,始终有机会把 PageRank 值扩散到网络中的其他页面。
-
-
算法的数学稳定性:
-
自由跳转确保 PageRank 表示为马尔可夫链中的一次遍历,确保整个网络是强连通的。
-
这种做法保证算法能够收敛到一个唯一的解决方案(稳定的 PageRank 值),因为加了一种“外力”平衡系统,确保无论什么初值和结构,计算都可以在有限步内收敛。
-
-
现实浏览行为的模拟:
-
自由跳转还可以模拟真实用户在互联网浏览过程中的不确定行为。人们很可能会在阅读一段时间后通过打字地址栏或者点击收藏夹而不是继续点击当前链接进行跳转。
-
这种不确定性通过自由跳转体现出用户在网络上的随机行为。
-
sendMessageToNeighbors会将节点的 PageRank 值发送到所有直接连接的邻居节点,作者又有问题了:如果相邻节点已经计算过,发送过去有什么用呢?
-
每个节点在超级步骤开始时接收来自邻居的消息,根据这些消息更新自己的状态
-
计算完成后,将新的或调整过的信息发送给所有出链的邻居
-
这个过程在多个超级步骤中重复,直至达到一定的收敛条件
作者理解这就是区分了三个if的迭代过程,算好的值还会接受相邻节点再进行结合计算
import java.io.IOException;import org.apache.log4j.Logger;import com.aliyun.odps.io.WritableRecord;
import com.aliyun.odps.graph.ComputeContext;
import com.aliyun.odps.graph.GraphJob;
import com.aliyun.odps.graph.GraphLoader;
import com.aliyun.odps.graph.MutationContext;
import com.aliyun.odps.graph.Vertex;
import com.aliyun.odps.graph.WorkerContext;
import com.aliyun.odps.io.DoubleWritable;
import com.aliyun.odps.io.LongWritable;
import com.aliyun.odps.io.NullWritable;
import com.aliyun.odps.data.TableInfo;
import com.aliyun.odps.io.Text;
import com.aliyun.odps.io.Writable;public class PageRank {private final static Logger LOG = Logger.getLogger(PageRank.class);public static class PageRankVertex extendsVertex<Text, DoubleWritable, NullWritable, DoubleWritable> {@Overridepublic void compute(ComputeContext<Text, DoubleWritable, NullWritable, DoubleWritable> context,Iterable<DoubleWritable> messages) throws IOException {if (context.getSuperstep() == 0) {setValue(new DoubleWritable(1.0 / context.getTotalNumVertices()));} else if (context.getSuperstep() >= 1) {double sum = 0;for (DoubleWritable msg : messages) {sum += msg.get();}DoubleWritable vertexValue = new DoubleWritable((0.15f / context.getTotalNumVertices()) + 0.85f * sum);setValue(vertexValue);}if (hasEdges()) {context.sendMessageToNeighbors(this, new DoubleWritable(getValue().get() / getEdges().size()));}}@Overridepublic void cleanup(WorkerContext<Text, DoubleWritable, NullWritable, DoubleWritable> context)throws IOException {context.write(getId(), getValue());}}public static class PageRankVertexReader extendsGraphLoader<Text, DoubleWritable, NullWritable, DoubleWritable> {@Overridepublic void load(LongWritable recordNum,WritableRecord record,MutationContext<Text, DoubleWritable, NullWritable, DoubleWritable> context)throws IOException {PageRankVertex vertex = new PageRankVertex();vertex.setValue(new DoubleWritable(0));vertex.setId((Text) record.get(0));System.out.println(record.get(0));for (int i = 1; i < record.size(); i++) {Writable edge = record.get(i);System.out.println(edge.toString());if (!(edge.equals(NullWritable.get()))) {vertex.addEdge(new Text(edge.toString()), NullWritable.get());}}LOG.info("vertex edgs size: "+ (vertex.hasEdges() ? vertex.getEdges().size() : 0));context.addVertexRequest(vertex);}}private static void printUsage() {System.out.println("Usage: <in> <out> [Max iterations (default 30)]");System.exit(-1);}public static void main(String[] args) throws IOException {if (args.length < 2)printUsage();GraphJob job = new GraphJob();job.setGraphLoaderClass(PageRankVertexReader.class);job.setVertexClass(PageRankVertex.class);job.addInput(TableInfo.builder().tableName(args[0]).build());job.addOutput(TableInfo.builder().tableName(args[1]).build());// default max iteration is 30job.setMaxIteration(30);if (args.length >= 3)job.setMaxIteration(Integer.parseInt(args[2]));long startTime = System.currentTimeMillis();job.run();System.out.println("Job Finished in "+ (System.currentTimeMillis() - startTime) / 1000.0 + " seconds");}
}4、他的存储是什么结构?
根据资料,他使用的分布式文件系统专为大规模数据存储和处理设计,具备高可用性、高可靠性和高性能的特点。
在存储模型上,类似于对象存储,数据以对象的形式存储,便于快速访问和处理
为优化查询性能和存储效率,MaxCompute 在存储层面支持列式存储格式
看起来很类似 Hadoop 的 HDFS
-
NameNode:
负责管理元数据和文件系统的命名空间。 NameNode 知道每个文件和目录中每个数据块的位置。它是系统的中心,并不存储实际数据或文件 -
DataNode:
负责存储实际数据以及数据块。每个 DataNode 定期向 NameNode 报告其存储的块信息。在集群规模扩大时,可以通过增加 DataNode 来增加存储能力 -
Secondary NameNode:
协助 NameNode 的检查点和元数据快照工作,减少 NameNode 的启动时间
当然具体是不是,还需要看源代码才知道,他没有开源,作者后续再进行源码研究
5、他的索引结构是什么样子?
他是列式存储(列存)来提高查询性能,对数据进行分区(例如按日期、地理位置等字段),减小查询范围,加快查询速度。这种机制在做范围查询或按条件过滤时比较高效。
存储文件可能会被分成多个区块,每个区块内的数据在物理存储上是连续的,通常会根据统计信息(如最小值和最大值)对这些区块建立索引,从而快速跳过不相关的数据块。
对于一些离散型类别数据,常使用数据字典技术来进行压缩并加速查询。
6、histogram有什么用?
他介绍过一个sql优化,意思是拿直方图来作为分析
ANALYZE TABLE <tablename> compute statistics
FOR columns WITH histogram 256 buckets;256 BUCKETS 表示直方图中将数据分为 256 个桶,这个就是横坐标
比如数据值的范围是 0到 100,我们用 256 个桶来描述这列数据的直方图。那么可能的分布形式会类似于:
- Bucket 1: [0-0.39], Frequency: 5
- Bucket 2: [0.4-0.79], Frequency: 15
- ...
- Bucket 128: [50-50.39], Frequency: 25
- ...
- Bucket 256: [99.6-100], Frequency: 30
类似于
││ ││ │ ││ │ │ ││ │ │ │ ││ │ │ │ │ │└───┴──┴───┴───┴──0 20 40 60 80 100但是作者觉得还是不太理解这在什么时候要用到,等后面进项目看看
四、总结
他的内容很多,作者暂时看了四五分之一吧,作者会持续研究分享
目前没有进项目,也没有看到实际源码,很多问题和分析都是作者YY的,过几天进项目了再看看源码,很多疑问就会有确定的答案
作者认为带着问题去学习研究才是最快的,大胆假设疑问,小心分析求证,原理都是相通的,区别不会很大
相关文章:
MaxCompute)
大数据(一)MaxCompute
一、引言 作者后面会使用MaxCompute,所以在进行学习研究,总会有一些疑问产生,这里讲讲作者的疑问和思路 二、介绍 MaxCompute(原名 ODPS - Open Data Processing Service)是阿里云提供的大数据处理平台,专…...

数据科学与大数据之间的区别
什么是数据科学? 数据科学是一个跨学科领域,它将统计学和计算方法相结合,旨在从数据中提取见解和知识。它涉及收集、处理、分析以及解读数据,以揭示可用于为决策过程提供依据并推动创新的模式、趋势和关系。 数据科学涵盖了广泛…...

IP 地理位置定位技术原理概述
本文深入探讨 IP 地理位置定位技术的原理。介绍了 IP 地址的基本概念及其在网络中的作用,随后阐述了基于数据库查询、基于网络拓扑分析以及基于机器学习算法的三种主要 IP 地理位置定位技术原理中的基于IP数据库查询。 IP 地址基础 IP 地址是互联网协议࿰…...

多进程multiprocessing通信multiprocessing.Queue
multiprocessing.Queue 通常只能在主模块(即 if __name__ "__main__": 块)中创建和使用。这是因为 multiprocessing 模块在 Windows 系统上需要通过 if __name__ "__main__": 块来避免递归导入问题。 from multiprocessing import…...

工业—使用Flink处理Kafka中的数据_ChangeRecord2
使用 Flink 消费 Kafka 中 ChangeRecord 主题的数据,每隔 1 分钟输出最近 3 分钟的预警次数最多的 设备,将结果存入Redis 中, key 值为...

微信小程序4-内容溢出滚动条
感谢阅读,初学小白,有错指正。 一、功能描述 在前一篇文章的隐藏框页面的功能里(《微信小程序3-显标记信息和弹框》),我想添加一个内容溢出的时候,可通过滑动滚动条,实现查看溢出部分的内容&a…...
)
python源码实例游戏开发小程序办公自动化网络爬虫项目开发源码(250+个项目、26.6GB)
文章目录 源代码下载地址项目介绍预览 项目备注源代码下载地址 源代码下载地址 点击这里下载源码 项目介绍 python源码实例游戏开发小程序办公自动化网络爬虫项目开发源码(250个项目、26.6GB) 预览 项目备注 1、该资源内项目代码都经过测试运行成功,功能ok的情…...
)
ProjectSend 身份认证绕过漏洞复现(CVE-2024-11680)
0x01 产品描述: ProjectSend 是一个开源文件共享网络应用程序,旨在促进服务器管理员和客户端之间的安全、私密文件传输。它是一款相当流行的应用程序,被更喜欢自托管解决方案而不是 Google Drive 和 Dropbox 等第三方服务的组织使用。0x02 漏洞描述: ProjectSend r1720 之前…...

算法训练-搜索
搜索 leetcode102. 二叉树的层序遍历 法一:广度优先遍历 leetcode103. 二叉树的锯齿形层序遍历 法一:双端队列 法二:倒序 法三:奇偶逻辑分离 leetcode236. 二叉树的最近公共祖先 法一:递归 leetcode230. 二叉…...

【C++】map和set
个人主页 : zxctscl 如有转载请先通知 文章目录 1. 关联式容器2. 键值对3. set3.1 set的模板参数列表3.2 set的构造3.3 set的迭代器3.4 set的容量3.5 set修改操作3.6 multiset 4. map4.1 map的模板参数说明4.2 map的构造4.3 map的迭代器4.4 map的容量与元素访问4.5 …...

MongoDB安装|注意事项
《疯狂Spring Boot讲义》是2021年电子工业出版社出版的图书,作者是李刚 《疯狂Spring Boot终极讲义》不是一本介绍类似于PathVariable、MatrixVariable、RequestBody、ResponseBody这些基础注解的图书,它是真正讲解Spring Boot的图书。Spring Boot的核心…...

使用playwright自动化测试时,npx playwright test --ui打开图形化界面时报错
使用playwright自动化测试时,npx playwright test --ui打开图形化界面时报错 1、错误描述:2、解决办法3、注意符号的转义 1、错误描述: 在运行playwright的自动化测试项目时,使用npm run test无头模式运行正常,但使用…...

Linux ufw 命令详解
简介 UFW(Uncomplicated Firewall) 简单防火墙是一款基于 iptables 构建的、用于管理防火墙规则的用户友好型工具。它简化了在 Linux 系统上配置防火墙的过程。 安装 在 Ubuntu/Debian 上安装 sudo apt update sudo apt install ufw在 CentOS/Red Hat 上安装 sudo yum ins…...

3248. 矩阵中的蛇
3248. 矩阵中的蛇 题目链接:3248. 矩阵中的蛇 代码如下: class Solution { public:int finalPositionOfSnake(int n, vector<string>& commands){int i 0, j 0;for (string& command : commands){if (command "LEFT") { j…...

图片的懒加载
目录 懒加载的来源 事件监听 IntersectionObserver 懒加载的来源 图片的来加载其实就是延迟加载,我们知道浏览器的可视范围是有限的,现在网页的内容越来越丰富,一般网页的内容都是需要滚动才能完成浏览 如果网页有很多图片,然…...

网络脚本生成器
网络官网地址 网络配置生成工具 终端-接入-汇聚-核心-防火墙-互联网路由器 一 开局配置 华为设备配置命令 system-viewsysname SW-JR-Switchvlan 10 vlan 20 vlan 30 vlan 40 quitinterface Vlan-interface 40 ip address 192.168.40.1 255.255.255.0 quitip route-static 1…...

Kibana server is not ready yet
遇到“Kibana server is not ready yet”错误通常表示Kibana无法连接到Elasticsearch。以下是一些常见原因及其解决方案: 1.常见原因 1.1.Elasticsearch未运行: 确保Elasticsearch服务已启动并正常运行。您可以通过访问 http://localhost:9200 来检查…...

Git 高频命令及其功能、作用与使用场景
在软件开发的世界里,Git 已经成为了版本控制的代名词。无论你是开发小型项目还是参与大型团队协作,Git 都是你不可或缺的得力助手。今天我们来聊聊 Git 中的一些高频命令,了解它们的功能、作用以及常见的使用场景,帮助你在日常开发…...

将word里自带公式编辑器编辑的公式转换成用mathtype编辑的格式
文章目录 将word里自带公式编辑器编辑的公式转换成用mathtype编辑的格式MathType安装问题MathType30天试用延期MathPage.wll文件找不到问题 将word里自带公式编辑器编辑的公式转换成用mathtype编辑的格式 word自带公式编辑器编辑的公式格式: MathType编辑的格式&a…...

【HarmonyOS】Component组件引入报错 does not meet UI component syntax.
【HarmonyOS】Component组件引入报错 一、问题背景 有时会碰到引入组件时,无法import引入组件,导致引入的组件报错。 或者提示does not meet UI component syntax. (不符合UI组件语法。) 如下图所示,在引入组件时&a…...

力扣-图论-1【算法学习day.51】
前言 ###我做这类文章一个重要的目的还是给正在学习的大家提供方向和记录学习过程(例如想要掌握基础用法,该刷哪些题?)我的解析也不会做的非常详细,只会提供思路和一些关键点,力扣上的大佬们的题解质量是非…...
)
使用lumerical脚本语言创建定向耦合器并进行数据分析(纯代码实现)
本文使用lumerical脚本语言创建定向耦合器波导、计算定向耦合器的偶数和奇数模式、分析定向耦合器的波长依赖性、分析定向耦合器的间隙依赖性(代码均有注释详解)。 一、绘制定向耦合器波导 1.1 代码实现 # 这段代码主要实现了绘制定向耦合器波导几何结构的功能。通过定义各种…...

Java面试要点50 - List的线程安全实现:CopyOnWriteArrayList
文章目录 一、引入二、实现原理解析2.1 写时复制机制2.2 读写分离策略 三、性能测试分析四、应用场景分析4.1 事件监听器管理4.2 缓存实现 五、最佳实践建议5.1 性能优化技巧5.2 常见陷阱规避 总结 一、引入 在并发编程中,线程安全的集合类扮演着重要角色。CopyOnWriteArrayLi…...

python脚本实现csv中百度经纬度转84经纬度
数据准备 csv文件,带百度经纬度字段:bd09_x,bd09_y 目的 将百度经纬度转换为84经纬度,并在csv文件中添加两个字段:84_x,84_y python脚本 from ChangeCoordinate import ChangeCoordimport pandas as pd import numpy as npcoord = ChangeCoord()def bd09_to_wgs84...

Vue2和Vue3的区别
响应式系统 Vue 2 技术基础:使用 Object.defineProperty 实现响应式。局限性: 无法监听新增属性:如果在创建实例后添加新属性,这些属性不会自动成为响应式的。数组变更检测问题:直接通过索引设置值或长度不会触发更新…...

JavaEE-经典多线程样例
文章目录 单例模式设计模式初步引入为何存在单例模式饿汉式单例模式饿汉式缺陷以及是否线程安全懒汉式单例模式基础懒汉式缺陷以及是否线程安全懒汉式单例模式的改进完整代码(变量volatile) 阻塞队列生产者消费者模型生产者消费者模型的案例以及优点请求与响应案例解耦合削峰填…...
- OpenGL ES - Shader绘制三角形)
Android显示系统(04)- OpenGL ES - Shader绘制三角形
一、前言: OpenGL 1.0采用固定管线,OpenGL 2.0以上版本重要的改变就是采用了可编程管线,Shader 编程是指使用着色器(Shader)编写代码来控制图形渲染管线中特定阶段的处理过程。在图形渲染中,着色器是在 GP…...

PMP–一、二、三模、冲刺–分类–10.沟通管理
文章目录 技巧十、沟通管理 一模10.沟通管理--1.规划沟通管理--文化意识--军事背景和非军事背景人员有文化差异5、 [单选] 项目团队由前军事和非军事小组成员组成。没有军事背景的团队成员认为前军事团队成员在他们的项目方法中过于结构化和僵化。前军事成员认为其他团队成员更…...

flutter windows 使用c++、dll等实践记录
在flutter的windows平台引入dll文件 https://juejin.cn/post/7223676609794015287 google官方说法(感觉不太实用) https://groups.google.com/a/dartlang.org/g/misc/c/fyh2W38AEVo Using a C DLL in Flutter Windows desktop app(未尝试&…...

JUnit介绍:单元测试
1、什么是单元测试 单元测试是针对最小的功能单元编写测试代码(Java 程序最小的功能单元是方法)单元测试就是针对单个Java方法的测试。 2、为什么要使用单元测试 确保单个方法运行正常; 如果修改了代码,只需要确保其对应的单元…...

电脑插入耳机和音响,只显示一个播放设备
1. 控制面板-硬件和声音-Realtek高清音频-扬声器-设备高级设置-播放设备里选择使用前部和后部输出设备同时播放两种不同的音频流 在声音设置中就可以看到耳机播放选项...

【每日刷题】Day162
【每日刷题】Day162 🥕个人主页:开敲🍉 🔥所属专栏:每日刷题🍍 🌼文章目录🌼 1. 3302. 字典序最小的合法序列 - 力扣(LeetCode) 2. 44. 通配符匹配 - 力扣&…...

使用 EasyExcel 实现高效的 Excel 读写操作
在日常开发中,Excel 文件的读写操作是一个常见的需求。EasyExcel 是阿里巴巴开源的一个高性能、易用的 Excel 读写库,可以大幅提高处理 Excel 文件的效率。它通过事件驱动模型优化了大数据量 Excel 的读写性能,非常适合处理大文件或高并发场景…...

千益畅行,旅游卡有些什么优势?
千益畅行共享旅游卡是一种创新的旅游服务模式,旨在通过整合各类旅游资源,为用户提供一站式的旅游解决方案。这张旅游卡支持2至6人同行,涵盖了接机、酒店、用餐、大巴、导游、景区门票等服务,用户只需自行承担往返交通费用即可享受…...
详解)
Hive分区裁剪(Partition Pruning)详解
Hive分区裁剪是一种优化技术,旨在查询时只读取与条件匹配的分区,从而减少不必要的数据扫描。这种机制依赖于分区表的设计和查询优化器的工作,特别是在处理大规模数据时,分区裁剪可以显著提高查询性能。 1. 什么是分区裁剪…...

云原生数据库 PolarDB
PolarDB 是阿里云推出的一款云原生数据库,旨在为企业提供高性能、高可靠性的数据库解决方案。它基于云计算环境设计,特别适用于云上的大规模数据处理和存储需求。PolarDB 是一种兼具关系型数据库(RDS)和分布式数据库特性的新型数据…...

数据库原理-期末基础知识
1、数据库管理系统有哪些功能? 数据定义功能、数据操作功能、数据库的运行管理、数据库的建立与维护。 2、数据库设计分哪几个阶段? 需求分析->概念设计->逻辑设计->物理设计->数据库实施->数据的运营与维护 3、简述三级封锁协议的内…...

Java版-速通数据结构-树基础知识
现在面试问mysql,红黑树好像都是必备问题了。动不动就让手写红黑树或者简单介绍下红黑树。然而,我们如果直接去看红黑树,可能会一下子蒙了。在看红黑树之前,需要先了解下树的基础知识,从简单到复杂,看看红黑树是在什么…...

量化交易系统开发-实时行情自动化交易-8.4.MT4/MT5平台
19年创业做过一年的量化交易但没有成功,作为交易系统的开发人员积累了一些经验,最近想重新研究交易系统,一边整理一边写出来一些思考供大家参考,也希望跟做量化的朋友有更多的交流和合作。 接下来会对于MT4/MT5平台介绍。 MetaT…...

Git 的基本概念和使用方式
Git是一个分布式版本控制系统,用于跟踪文件内容的变化和协作开发。 Git的主要概念包括: 仓库(Repository):存储代码和历史记录的地方。可以是本地仓库(Local Repository)或远程仓库(…...

Conda-Pack打包:高效管理Python环境
在Python开发中,环境管理是一个不可忽视的重要环节。Conda是一个流行的包管理器和环境管理器,它允许用户创建隔离的环境,以避免不同项目之间的依赖冲突。Conda-pack是一个工具,可以帮助我们将一个conda环境打包成一个可移植文件&a…...

Python语法基础---正则表达式
🌈个人主页:羽晨同学 💫个人格言:“成为自己未来的主人~” 我们这个文章所讲述的,也是数据分析的基础文章,正则表达式 首先,我们在开始之前,引出一个问题。也是我们接下来想要解决的问题。…...

深入理解ROS中的参数服务器及其应用
深入理解ROS中的参数服务器及其应用 在Robot Operating System (ROS) 中,参数服务器(Parameter Server)是一个中心化服务,它允许节点在运行时存储和检索配置信息。这种机制是为了支持数据的共享和灵活的参数管理而设计的…...

Kafka 常见面试题深度解析
一、基础概念 1. 请简要介绍 Kafka 的基本架构。 Kafka 主要由生产者(Producer)、消费者(Consumer)、代理(Broker)、主题(Topic)和分区(Partition)等组成。…...

数学建模之熵权法
熵权法 概述 **熵权法(Entropy Weight Method,EWM)**是一种客观赋权的方法,原理:指标的变异程度越小,所包含的信息量也越小,其对应的权值应该越低(例如,如果对于所有样本而言,某项指标的值都相…...

交易所 Level-2 历史行情数据自动化导入攻略
用户部署完 DolphinDB 后,需要将历史股票数据批量导入数据库,再进行数据查询、计算和分析等操作。DolphinDB 开发了 ExchData 模块,主要用于沪深交易所 Level-2 行情原始数据的自动化导入,目前已支持的数据源包括: 沪…...

从 scratch开始构建一个最小化的 Hello World Docker 镜像-docker的镜像源头
在这篇文章中,我们将学习如何从零开始构建一个最小化的 Docker 镜像,基于 scratch 镜像,并在其中运行一个简单的 “Hello World” 程序。 Scratch 是一个空白的基础镜像,适用于构建轻量化、独立的容器。由于 scratch 不包含任何系…...

【openGauss︱PostgreSQL】openGauss或PostgreSQL查表、索引、序列、权限、函数
【openGauss︱PostgreSQL】openGauss或PostgreSQL查表、索引、序列、权限、函数 一、openGauss查表二、openGauss查索引三、openGauss查序列四、openGauss查权限五、openGauss或PostgreSQL查函数六、PostgreSQL查表七、PostgreSQL查索引八、PostgreSQL查序列九、PostgreSQL查权…...

MySQL - 性能优化
使用 Explain 进行分析 Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。 比较重要的字段有: select_type : 查询类型,有简单查询、联合查询、子查询等 key : 使用的索引 rows : 扫描的行数 type :…...

数据结构:二叉树遍历
在 JavaScript 中实现二叉树的遍历,可以使用递归或迭代的方式。以下是三种常见的遍历方式:前序遍历(Pre-order)、中序遍历(In-order)和后序遍历(Post-order)。 定义二叉树节点类 c…...