算法驱动的场景识别:规则引擎与机器学习的强大结合
引言
在智能驾驶系统、交通分析和安全监控等领域,场景识别是一项核心技术。传统的场景识别方法主要依赖人工标注,不仅耗时耗力,还容易受主观因素影响。随着技术的发展,算法驱动的场景识别方法逐渐兴起,通过结合规则引擎与机器学习技术,实现了更高效、更客观的场景自动识别。本文将深入探讨这种结合方式,特别是在车辆交互场景识别中的应用。
传统场景识别与算法驱动场景识别
传统场景识别方法
传统的场景识别主要依赖人工标注,专业人员根据预定义的标准,对收集到的数据进行分类和标记。这种方法存在多个显著缺点:
- 耗费大量人力和时间资源
- 标注质量依赖专业人员的经验和主观判断
- 难以处理海量数据
- 难以及时响应动态变化的场景
算法驱动的场景识别方法
算法驱动的场景识别方法结合了规则引擎与机器学习技术,形成了一种自动化的识别系统。规则引擎基于预定义的条件对数据进行筛选和分类,而机器学习技术则能从大量数据中自动学习模式和特征。这种方法的核心在于将明确的专家知识(规则)与数据驱动的学习能力(机器学习)结合起来,实现更高效、更准确的场景识别。
规则引擎在场景识别中的应用
规则引擎概述
规则引擎是一种能够将业务决策逻辑与应用程序代码分离的技术,通过定义一系列规则来处理复杂的判断逻辑。其中Rete算法是一种高效的模式匹配算法,广泛用于规则引擎中。Rete算法通过构建一个网络结构来避免重复计算,提高性能。在这个网络中,节点表示规则的条件部分,事实(数据)通过这个网络传播。
Rete算法的关键特性包括增量更新(只更新受影响的部分网络)和节点共享(多个规则共享相同条件时只构建一次共享子网络)。常见的节点类型包括根节点、单输入节点、双输入节点和终端节点,分别用于处理不同类型的条件和逻辑。
主流规则引擎比较
目前主流的规则引擎包括Drools(Java)、Easy Rules(Java)、Nools(Node.js)以及Python领域的CLIPSpy等。本文将重点关注Drools和CLIPSpy这两种成熟且功能丰富的规则引擎。
Drools (Java)是一个成熟且功能丰富的业务规则管理系统(BRMS),提供了声明式规则定义、复杂规则评估、时间规则、决策表支持等丰富功能。Drools基于ReteOO算法(Rete算法的面向对象增强版),广泛应用于金融、医疗、电商、物流等行业。
CLIPSpy (Python)是成熟的CLIPS专家系统的Python绑定,源自NASA开发的CLIPS,以其鲁棒性和多功能性而闻名。CLIPSpy实现了Rete算法,支持规则语言与Python集成,广泛应用于专家系统和AI应用开发。CLIPSpy具有以下特点:
- 源自NASA技术:CLIPS最初由NASA开发,被认为是人工智能领域的先进技术,并在大学课程中用于教授AI基础知识
- Lisp风格语法:提供了类似Lisp的语法结构,表达能力强
- Python集成:允许在CLIPS规则中嵌入Python代码,从而非常容易扩展
- 成熟稳定:经过多年发展,功能完善,性能稳定
- 优秀文档:提供了详细的文档支持,降低学习难度
规则引擎在场景识别中的优势
在场景识别中,规则引擎具有以下优势:
- 明确的逻辑表达:能够清晰地表达专家知识和领域规则
- 可解释性强:规则的触发和执行过程透明可追踪
- 灵活性高:规则可以根据需求动态调整和优化
- 高效处理复杂条件:通过模式匹配算法高效处理多条件组合判断
机器学习在场景识别中的应用
机器学习技术能够从大量数据中自动学习模式和规律,在场景识别中主要应用以下技术:
聚类算法
聚类算法根据数据的相似性将其分为不同的组,常用于发现数据中的潜在类别或模式。在场景识别中,常用聚类算法包括:
- K-means聚类:基于距离度量将数据分为K个簇
- DBSCAN:基于密度的聚类算法,能够识别任意形状的簇
- 层次聚类:通过构建树状的聚类结构来组织数据
异常检测
异常检测算法用于识别与正常模式显著不同的数据点。在场景识别中,常用以下方法:
- 基于统计的方法:使用统计量检测偏离正常分布的数据
- 基于邻近度的方法:检测与大多数数据点相去甚远的点
- 隔离森林:通过随机分区识别容易被隔离的异常点
- 单类SVM:将数据映射到高维空间,找出异常点
监督学习模型
监督学习通过标记数据训练模型,用于对新数据进行分类或回归预测:
- 决策树和随机森林:基于特征的树状决策模型
- 支持向量机(SVM):寻找最优分类超平面的算法
- 深度学习模型:如卷积神经网络(CNN)用于图像场景识别
规则引擎与机器学习的结合
规则引擎与机器学习各有优势,结合使用可以取长补短,实现更强大的场景识别系统。
结合方式
- 串行结合:
- 规则作为预处理:先用规则引擎筛选出潜在的场景,再用机器学习模型进行精细分类
- 规则作为后处理:先用机器学习模型识别基本场景,再用规则引擎应用业务约束和专家知识
- 并行结合:
- 同时使用规则引擎和机器学习处理相同的数据,然后融合结果
- 可以采用投票、加权平均等方式进行结果融合
- 嵌套结合:
- 规则中嵌入机器学习:规则条件中引用机器学习模型的输出
- 机器学习中嵌入规则:将规则引擎的输出作为机器学习模型的特征
结合优势
- 提高识别准确性:结合专家知识和数据驱动的学习能力
- 增强系统可解释性:机器学习模型提供预测,规则引擎提供解释
- 处理复杂场景:应对各种复杂的、多变的场景
- 减少标注需求:通过规则自动生成部分标签,减轻人工标注负担
案例研究:车辆交互场景识别
应用场景
在智能驾驶和交通安全分析中,识别潜在的危险或特殊交互场景至关重要。这些场景包括:
- 紧急制动场景
- 车辆切入场景
- 近距离跟车场景
- 车辆交叉汇入场景
- 车道变换冲突场景
关键参数
车辆交互场景识别主要基于以下关键参数:
- 车辆加速度:反映车辆动力学状态变化
- 相对距离:车辆间的空间位置关系
- 相对速度:车辆间的速度差异
- 时间距(Time Headway):前后车之间的时间间隔
- TTC(Time-to-Collision):预估碰撞时间,是评估风险的重要指标
实现方式
结合CLIPSpy规则引擎与Python机器学习的车辆交互场景识别系统实现方式如下:
- 规则引擎部分:
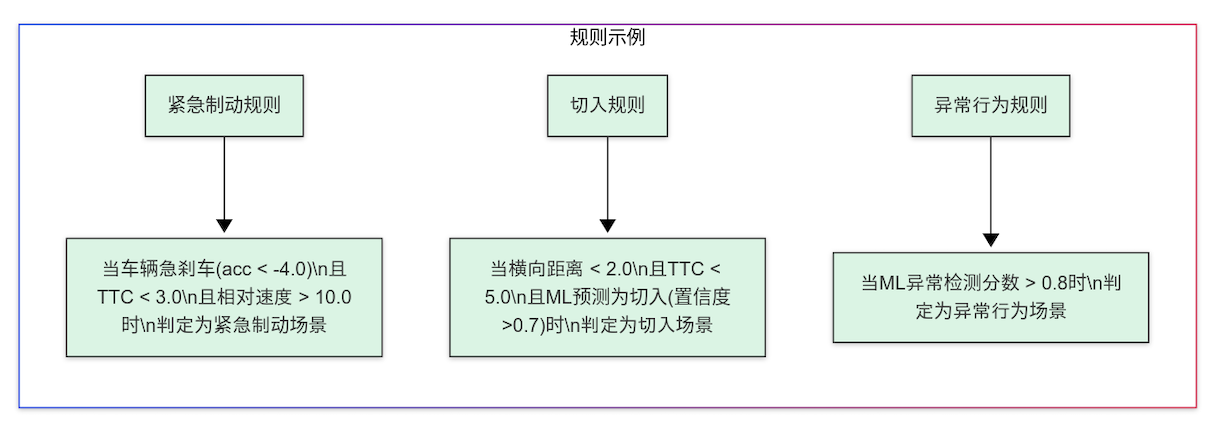
- 使用CLIPSpy定义场景识别规则,如"当TTC < 3秒且相对速度 > 10km/h时,判定为潜在紧急场景"
- 利用CLIPSpy的规则语言表达复杂逻辑,处理多条件组合
- 根据道路类型、天气条件等上下文信息调整规则阈值
- 机器学习部分:
- 使用Python科学计算库(如scikit-learn)实现聚类和异常检测
- 基于历史标记数据训练分类模型,预测场景类型及风险等级
- 使用深度学习框架(如PyTorch)处理复杂特征提取
- 结合策略:
- 规则引擎识别明确的场景和风险,机器学习处理模糊边界和未知场景
- 规则引擎的输出作为机器学习模型的特征输入
- 机器学习模型的结果用于动态调整规则参数
代码示例:CLIPSpy规则引擎与机器学习结合的场景识别系统
1. CLIPSpy规则定义
import clips# 创建CLIPS环境
clips_env = clips.Environment()# 定义模板(相当于Java中的类)
vehicle_template = """
(deftemplate vehicle(slot id (type STRING))(slot speed (type FLOAT))(slot acceleration (type FLOAT)))
"""interaction_template = """
(deftemplate interaction(slot vehicle-id (type STRING))(slot relative-distance (type FLOAT))(slot relative-speed (type FLOAT))(slot ttc (type FLOAT))(slot lateral-distance (type FLOAT)))
"""ml_prediction_template = """
(deftemplate ml-prediction(slot vehicle-id (type STRING))(slot scene-type (type STRING))(slot confidence (type FLOAT))(slot is-anomaly (type SYMBOL) (allowed-values TRUE FALSE))(slot anomaly-score (type FLOAT)))
"""scene_template = """
(deftemplate scene(slot type (type STRING))(slot vehicle-id (type STRING))(slot confidence (type FLOAT))(slot evidence (type STRING)))
"""# 定义规则
emergency_braking_rule = """
(defrule emergency-braking-scene(vehicle (id ?id) (acceleration ?acc&:(< ?acc -4.0)))(interaction (vehicle-id ?id) (ttc ?ttc&:(< ?ttc 3.0)) (relative-speed ?rs&:(> ?rs 10.0)))=>(assert (scene (type "EMERGENCY_BRAKING") (vehicle-id ?id)(confidence 0.9)(evidence (str-cat "Hard braking with TTC=" ?ttc ", RelSpeed=" ?rs)))))
"""cut_in_rule = """
(defrule cut-in-scene(interaction (vehicle-id ?id) (lateral-distance ?ld&:(< ?ld 2.0))(ttc ?ttc&:(< ?ttc 5.0)))(ml-prediction (vehicle-id ?id) (scene-type "CUT_IN")(confidence ?conf&:(> ?conf 0.7)))=>(assert (scene (type "CUT_IN")(vehicle-id ?id)(confidence 0.85)(evidence (str-cat "Cut-in detected with ML confidence=" ?conf)))))
"""anomaly_rule = """
(defrule anomaly-scene(vehicle (id ?id))(ml-prediction (vehicle-id ?id)(is-anomaly TRUE)(anomaly-score ?score&:(> ?score 0.8)))=>(assert (scene (type "ANOMALY_BEHAVIOR")(vehicle-id ?id)(confidence ?score)(evidence (str-cat "Anomaly detected by ML with score=" ?score)))))
"""# 加载模板和规则到环境
clips_env.build(vehicle_template)
clips_env.build(interaction_template)
clips_env.build(ml_prediction_template)
clips_env.build(scene_template)
clips_env.build(emergency_braking_rule)
clips_env.build(cut_in_rule)
clips_env.build(anomaly_rule)2. 机器学习模型集成
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.ensemble import IsolationForest
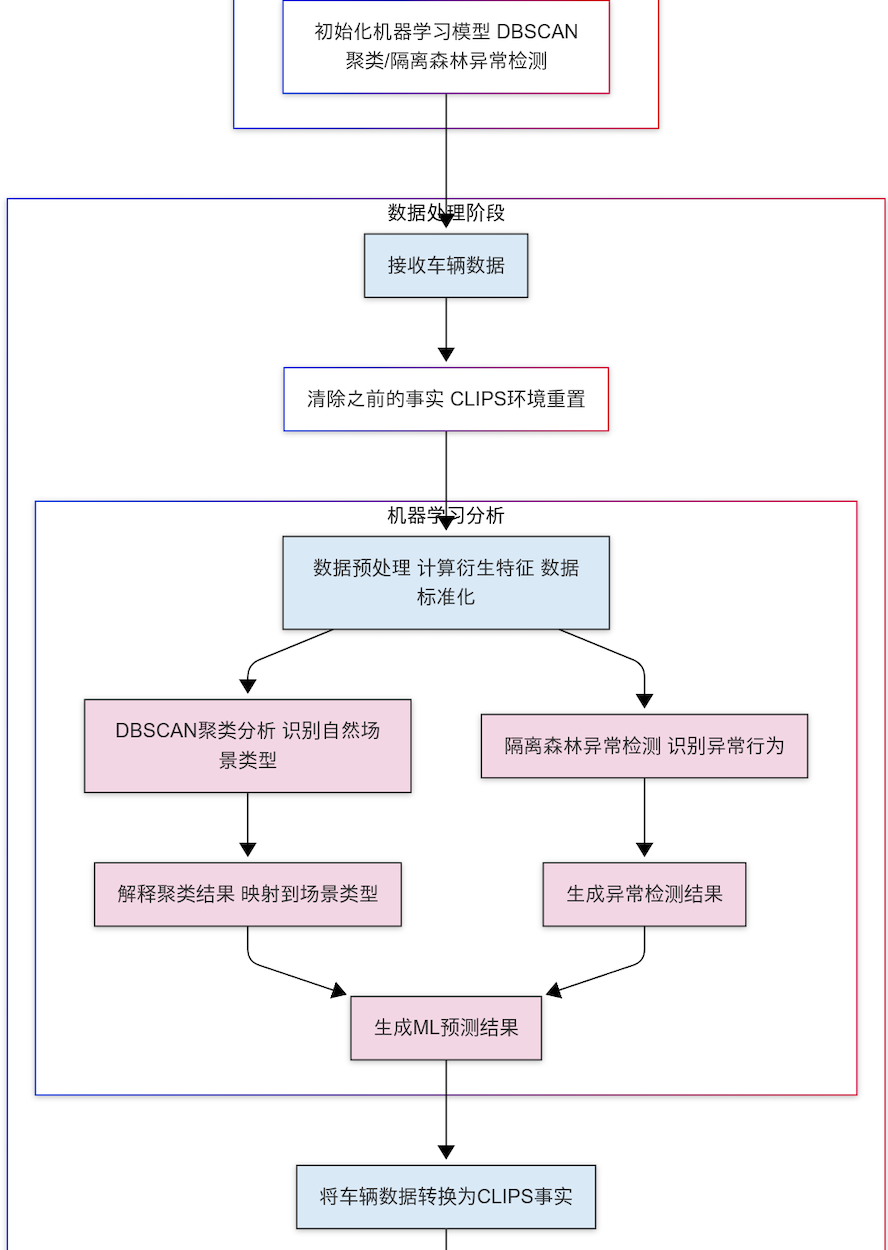
from sklearn.preprocessing import StandardScalerclass VehicleSceneDetection:def __init__(self):# 初始化机器学习模型# 1. 聚类模型 - 识别自然形成的场景类型self.clustering_model = DBSCAN(eps=0.5, min_samples=5)# 2. 异常检测模型 - 识别异常行为self.anomaly_model = IsolationForest(contamination=0.05, random_state=42)# 3. 数据标准化self.scaler = StandardScaler()# 存储历史数据self.historical_data = []def preprocess_data(self, data):"""预处理数据"""# 转换为DataFramedf = pd.DataFrame(data)# 计算特征if len(df) > 0:df['ttc_inverse'] = np.where(df['ttc'] > 0, 1.0 / df['ttc'], 10.0) # TTC倒数,TTC为0时设为较大值df['risk_factor'] = df['relativeSpeed'] * df['ttc_inverse'] # 风险因子# 标准化数值特征features = ['acceleration', 'relativeDistance', 'relativeSpeed', 'ttc', 'ttc_inverse', 'risk_factor']df_scaled = pd.DataFrame(self.scaler.fit_transform(df[features]), columns=features)return df_scaled, dfreturn None, dfdef detect_clusters(self, features_scaled):"""使用聚类识别场景类型"""if features_scaled is None or len(features_scaled) == 0:return []# 应用DBSCAN聚类clusters = self.clustering_model.fit_predict(features_scaled)# 分析每个簇的特性cluster_results = []for cluster_id in set(clusters):if cluster_id == -1:continue # 跳过噪声点cluster_points = features_scaled[clusters == cluster_id]# 计算簇的中心和特性centroid = cluster_points.mean().to_dict()# 根据特性判断可能的场景类型scene_type = self.interpret_cluster(centroid)cluster_results.append({'cluster_id': cluster_id,'scene_type': scene_type,'confidence': 0.8, # 可以基于簇的紧密度等指标计算置信度'centroid': centroid})return cluster_resultsdef interpret_cluster(self, centroid):"""解释聚类结果,映射到场景类型"""# 基于簇的特征推断场景类型if centroid['ttc_inverse'] > 0.5 and centroid['risk_factor'] > 0.7:return "EMERGENCY_SCENARIO"elif centroid['ttc'] < 0.3 and abs(centroid['acceleration']) > 0.5:return "HARD_BRAKING"elif centroid['relativeDistance'] < 0.2:return "CLOSE_FOLLOWING"elif centroid['relativeSpeed'] > 0.7:return "APPROACHING_FAST"else:return "NORMAL_DRIVING"def detect_anomalies(self, features_scaled, original_data):"""使用异常检测识别异常行为"""if features_scaled is None or len(features_scaled) == 0:return []# 应用隔离森林进行异常检测anomaly_scores = self.anomaly_model.fit_predict(features_scaled)# 转换分数(隔离森林中,-1表示异常,1表示正常)# 转换为0-1范围内的异常分数,1表示最异常normalized_scores = (1 - (anomaly_scores + 1) / 2)anomaly_results = []for i, score in enumerate(normalized_scores):if score > 0.6: # 异常阈值vehicle_id = original_data.iloc[i]['vehicleId']anomaly_results.append({'vehicle_id': vehicle_id,'is_anomaly': True,'anomaly_score': score,'features': original_data.iloc[i].to_dict()})return anomaly_resultsdef process_vehicle_data(self, vehicle_data):"""处理车辆数据,返回场景识别结果"""# 添加到历史数据self.historical_data.extend(vehicle_data)# 仅保留最近的数据if len(self.historical_data) > 10000:self.historical_data = self.historical_data[-10000:]# 预处理数据features_scaled, original_data = self.preprocess_data(vehicle_data)# 检测聚类cluster_results = self.detect_clusters(features_scaled)# 检测异常anomaly_results = self.detect_anomalies(features_scaled, original_data)# 准备机器学习预测结果ml_predictions = []# 添加聚类结果for result in cluster_results:ml_predictions.append({'vehicle_id': '', # 在实际应用中应关联到特定车辆'scene_type': result['scene_type'],'confidence': result['confidence'],'is_anomaly': False,'anomaly_score': 0.0})# 添加异常检测结果for result in anomaly_results:ml_predictions.append({'vehicle_id': result['vehicle_id'],'scene_type': 'ANOMALY','confidence': 0.5, # 场景类型置信度设为中等'is_anomaly': True,'anomaly_score': result['anomaly_score']})return ml_predictions3. 主程序:集成CLIPSpy和机器学习
import clips
import json
import numpy as np
import pandas as pdclass SceneRecognitionSystem:def __init__(self):# 初始化CLIPS环境self.clips_env = clips.Environment()# 加载规则(实际应用中可从文件加载)self.load_clips_rules()# 初始化机器学习模型self.ml_detector = VehicleSceneDetection()# 存储检测到的场景self.detected_scenes = []def load_clips_rules(self):"""加载CLIPS规则和模板"""# 在实际应用中,这些定义可以从文件加载templates_and_rules = ["""(deftemplate vehicle(slot id (type STRING))(slot speed (type FLOAT))(slot acceleration (type FLOAT)))""","""(deftemplate interaction(slot vehicle-id (type STRING))(slot relative-distance (type FLOAT))(slot relative-speed (type FLOAT))(slot ttc (type FLOAT))(slot lateral-distance (type FLOAT)))""","""(deftemplate ml-prediction(slot vehicle-id (type STRING))(slot scene-type (type STRING))(slot confidence (type FLOAT))(slot is-anomaly (type SYMBOL) (allowed-values TRUE FALSE))(slot anomaly-score (type FLOAT)))""","""(deftemplate scene(slot type (type STRING))(slot vehicle-id (type STRING))(slot confidence (type FLOAT))(slot evidence (type STRING)))""","""(defrule emergency-braking-scene(vehicle (id ?id) (acceleration ?acc&:(< ?acc -4.0)))(interaction (vehicle-id ?id) (ttc ?ttc&:(< ?ttc 3.0)) (relative-speed ?rs&:(> ?rs 10.0)))=>(assert (scene (type "EMERGENCY_BRAKING") (vehicle-id ?id)(confidence 0.9)(evidence (str-cat "Hard braking with TTC=" ?ttc ", RelSpeed=" ?rs)))))""","""(defrule cut-in-scene(interaction (vehicle-id ?id) (lateral-distance ?ld&:(< ?ld 2.0))(ttc ?ttc&:(< ?ttc 5.0)))(ml-prediction (vehicle-id ?id) (scene-type "CUT_IN")(confidence ?conf&:(> ?conf 0.7)))=>(assert (scene (type "CUT_IN")(vehicle-id ?id)(confidence 0.85)(evidence (str-cat "Cut-in detected with ML confidence=" ?conf)))))""","""(defrule anomaly-scene(vehicle (id ?id))(ml-prediction (vehicle-id ?id)(is-anomaly TRUE)(anomaly-score ?score&:(> ?score 0.8)))=>(assert (scene (type "ANOMALY_BEHAVIOR")(vehicle-id ?id)(confidence ?score)(evidence (str-cat "Anomaly detected by ML with score=" ?score)))))"""]# 加载模板和规则for item in templates_and_rules:self.clips_env.build(item)def process_vehicle_data(self, vehicle_data_list):"""处理车辆数据,返回场景识别结果"""# 清除之前的事实self.clips_env.reset()self.detected_scenes = []# 处理数据生成机器学习预测ml_predictions = self.ml_detector.process_vehicle_data(vehicle_data_list)# 将车辆数据和机器学习预测转换为CLIPS事实for data in vehicle_data_list:# 创建车辆事实vehicle_fact = self.clips_env.assert_string(f'(vehicle (id "{data["vehicleId"]}") 'f'(speed {data["speed"]}) 'f'(acceleration {data["acceleration"]}))')# 创建交互事实interaction_fact = self.clips_env.assert_string(f'(interaction (vehicle-id "{data["vehicleId"]}") 'f'(relative-distance {data["relativeDistance"]}) 'f'(relative-speed {data["relativeSpeed"]}) 'f'(ttc {data["ttc"]}) 'f'(lateral-distance {data["lateralDistance"]}))')# 添加机器学习预测事实for pred in ml_predictions:is_anomaly_str = "TRUE" if pred["is_anomaly"] else "FALSE"ml_fact = self.clips_env.assert_string(f'(ml-prediction (vehicle-id "{pred["vehicle_id"]}") 'f'(scene-type "{pred["scene_type"]}") 'f'(confidence {pred["confidence"]}) 'f'(is-anomaly {is_anomaly_str}) 'f'(anomaly-score {pred["anomaly_score"]}))')# 运行规则self.clips_env.run()# 收集检测到的场景for fact in self.clips_env.facts():# 检查是否是场景事实if fact.template.name == 'scene':scene = {'type': fact['type'],'vehicleId': fact['vehicle-id'],'confidence': fact['confidence'],'evidence': fact['evidence']}self.detected_scenes.append(scene)return self.detected_scenesdef get_detected_scenes(self):"""获取检测到的场景列表"""return self.detected_scenes# 测试函数
def test_scene_recognition():# 初始化场景识别系统system = SceneRecognitionSystem()# 生成测试数据test_data = [{"vehicleId": "V001","speed": 80.0,"acceleration": -5.2,"relativeDistance": 15.0,"relativeSpeed": 30.0,"ttc": 2.0,"lateralDistance": 0.5},{"vehicleId": "V002","speed": 60.0,"acceleration": -0.5,"relativeDistance": 8.0,"relativeSpeed": 2.0,"ttc": 4.0,"lateralDistance": 0.2},{"vehicleId": "V003","speed": 50.0,"acceleration": 0.0,"relativeDistance": 50.0,"relativeSpeed": 0.0,"ttc": 999.0,"lateralDistance": 1.8}]# 处理数据scenes = system.process_vehicle_data(test_data)# 输出检测结果print(f"Detected {len(scenes)} scenes:")for scene in scenes:print(f"Scene[type={scene['type']}, vehicle={scene['vehicleId']}, "f"confidence={scene['confidence']}, evidence={scene['evidence']}]")if __name__ == "__main__":test_scene_recognition()4. 使用CLIPSpy的Python/CLIPS集成示例
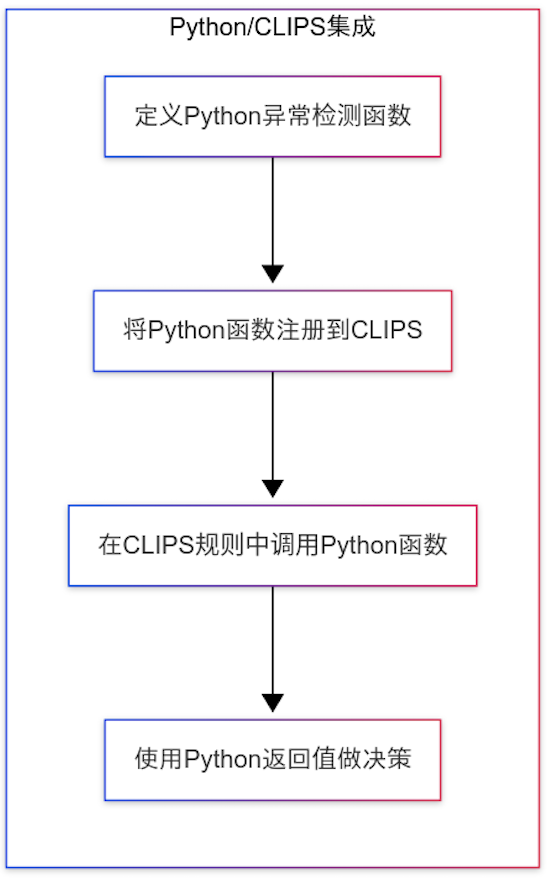
import clips
from sklearn.ensemble import IsolationForest
import numpy as npdef clips_python_integration_example():"""演示如何在CLIPS规则中调用Python函数"""# 创建CLIPS环境env = clips.Environment()# 定义一个Python函数,用于异常检测def detect_anomaly(acceleration, relative_speed, ttc):"""使用隔离森林检测异常"""# 创建简单的数据集X = np.array([[acceleration, relative_speed, ttc]])# 创建并训练隔离森林模型model = IsolationForest(contamination=0.1, random_state=42)model.fit(X)# 预测异常分数(-1表示异常,1表示正常)score = model.score_samples(X)[0]# 转换为0-1范围,1表示异常可能性高anomaly_score = 1 - (score + 0.5)return anomaly_score > 0.7, anomaly_score# 将Python函数注册到CLIPSenv.define_function(detect_anomaly)# 定义使用Python函数的CLIPS规则python_rule = """(defrule python-ml-anomaly-detection(vehicle (id ?id) (acceleration ?acc))(interaction (vehicle-id ?id) (relative-speed ?rs) (ttc ?ttc))=>(bind ?result (python-call detect_anomaly ?acc ?rs ?ttc))(bind ?is_anomaly (nth$ 1 ?result))(bind ?score (nth$ 2 ?result))(if ?is_anomaly then(assert (scene (type "ML_DETECTED_ANOMALY")(vehicle-id ?id)(confidence ?score)(evidence (str-cat "ML anomaly detection with score=" ?score))))))"""# 加载规则env.build("""(deftemplate vehicle(slot id (type STRING))(slot speed (type FLOAT))(slot acceleration (type FLOAT)))""")env.build("""(deftemplate interaction(slot vehicle-id (type STRING))(slot relative-distance (type FLOAT))(slot relative-speed (type FLOAT))(slot ttc (type FLOAT))(slot lateral-distance (type FLOAT)))""")env.build("""(deftemplate scene(slot type (type STRING))(slot vehicle-id (type STRING))(slot confidence (type FLOAT))(slot evidence (type STRING)))""")env.build(python_rule)# 插入测试数据env.assert_string('(vehicle (id "V001") (speed 80.0) (acceleration -5.2))')env.assert_string('(interaction (vehicle-id "V001") (relative-distance 15.0) (relative-speed 30.0) (ttc 2.0) (lateral-distance 0.5))')# 运行规则env.run()# 输出结果print("检测到的场景:")for fact in env.facts():if fact.template.name == 'scene':print(f"Scene[type={fact['type']}, vehicle={fact['vehicle-id']}, "f"confidence={fact['confidence']}, evidence={fact['evidence']}]")if __name__ == "__main__":clips_python_integration_example()
结论与未来展望
算法驱动的场景识别技术通过结合规则引擎与机器学习,为车辆交互分析和智能驾驶系统提供了强大的支持。特别是CLIPSpy等成熟的规则引擎与Python机器学习生态系统的结合,充分利用了规则引擎的明确逻辑表达和机器学习的模式识别能力,实现了高效、准确且具有良好可解释性的场景识别。
与其他规则引擎相比,CLIPSpy具有如下优势:
- 源自NASA的专业AI技术,成熟稳定
- 与Python生态系统的无缝集成
- 支持规则语言与Python代码的混合使用
- 采用了效率高的Rete算法
- 良好的文档和社区支持
未来,这种结合方式可以进一步扩展和优化:
- 增强在线学习能力:使系统能够从新数据中持续学习,动态调整规则和模型
- 融合多模态数据:整合视觉、雷达、V2X通信等多源数据,提高识别精度
- 边缘计算部署:优化算法效率,实现在车载计算平台上的实时场景识别
- 大规模知识图谱集成:将场景知识表示为知识图谱,增强系统的推理能力
通过CLIPSpy规则引擎与机器学习的深度结合,算法驱动的场景识别系统将继续在智能交通、自动驾驶和交通安全等领域发挥关键作用,推动智能交通系统的快速发展。
相关文章:

算法驱动的场景识别:规则引擎与机器学习的强大结合
引言 在智能驾驶系统、交通分析和安全监控等领域,场景识别是一项核心技术。传统的场景识别方法主要依赖人工标注,不仅耗时耗力,还容易受主观因素影响。随着技术的发展,算法驱动的场景识别方法逐渐兴起,通过结合规则引…...

typescript开发心得
语法知识点 回调地狱问题 用await,或者有些库提供了sync方法 yield 用法跟python的一样。 yield只能用于生成器里,生成器是function*,例如: export function* filter(rootNode: ts.Node, acceptedKind: ts.SyntaxKind) {for…...

淘宝开放平台 API 调用全解析:商品详情数据采集接口接入教程
一、引言 在电商领域蓬勃发展的当下,淘宝作为行业领军者,其平台上琳琅满目的商品蕴含着海量有价值的信息。无论是电商从业者想要精准把握竞品动态、优化自身商品策略,还是数据分析师试图挖掘消费趋势、洞察市场需求,亦或是科研人…...
深度解析)
SQL注入(SQL Injection)深度解析
SQL注入是一种利用Web应用程序与数据库交互机制缺陷的网络攻击技术,其核心在于通过恶意构造的输入参数篡改原始SQL查询逻辑,进而实现对数据库的非授权操作。以下从定义、攻击原理、技术分类、危害及防御体系多维度展开分析: 一、定义与本质 技…...
)
MCP基础学习四:MCP在AI应用中的集成(MCP在AI应用中的完整架构图)
MCP在AI应用中的集成 文章目录 MCP在AI应用中的集成一,学习目标二,学习内容1. 在AI应用中配置和使用MCP服务1.1 不同AI工具连接方式与部署模式1.1.1 了解不同的MCP传输模式1.1.2 掌握如何在AI客户端中配置MCP服务Cursor 客户端中配置MCP服务Cherry Studio AI客户端中…...

K8S-证书过期更新
K8S证书过期问题 K8S证书过期处理方法 Unable to connect to the server: x509: certificate has expired or is not yet valid 1、查看证书有效期: # kubeadm certs check-expiration2、备份证书 # cp -rp /etc/kubernetes /etc/kubernetes.bak3、直接重建证书 …...

蓝桥杯考前复盘
明天就是考试了,适当的停下刷题的步伐。 静静回望、思考、总结一下,我走过的步伐。 考试不是结束,他只是检测这一段时间学习成果的工具。 该继续走的路,还是要继续走的。 只是最近,我偶尔会感到迷惘,看…...

BERT - MLM 和 NSP
本节代码将实现BERT模型的两个主要预训练任务:掩码语言模型(Masked Language Model, MLM) 和 下一句预测(Next Sentence Prediction, NSP)。 1. create_nsp_dataset 函数 这个函数用于生成NSP任务的数据集。 def cr…...

mysql 与 sqlite 数学运算 精度 问题
mysql 与 sqlite 数学运算 精度 问题 在 Excel 中,浮点运算得到的结果可能不准确 https://learn.microsoft.com/zh-cn/office/troubleshoot/excel/floating-point-arithmetic-inaccurate-result 本文讨论 Microsoft Excel 如何存储和计算浮点数。 由于存在舍入或…...

MySQL的数据库性能分析利器Percona toolkit
目录 简介使用场景 使用示例Mysql 慢查询分析诊断临时开启慢SQL持久化开启慢SQL日志 使用包管理器安装包管理器安装 percona-release使用相应的包管理器安装 Percona Toolkit pt-query-digest 安装安装 pt-query-digest案例实战之慢查询分析诊断查看慢SQL日志使用pt-query-dige…...

力扣HOT100之链表: 148. 排序链表
这道题直接用蠢办法来做的,直接先遍历一遍链表,用一个哈希表统计每个值出现的次数,由于std::map<int, int>会根据键进行升序排序,因此我们将节点的值作为键,其在整个链表中的出现次数作为值,当所有元…...

Azure AI Foundry 正在构建一个技术无障碍的未来世界
我们习以为常的街道和数字世界,往往隐藏着被忽视的障碍——凹凸不平的路面、不兼容的网站、延迟的字幕或无法识别多样化声音的AI模型。这些细节对某些群体而言,却是日常的挑战。正如盲道不仅帮助视障者,也优化了整体城市体验,信息…...

AlmaLinux9.5 修改为静态IP地址
查看当前需要修改的网卡名称 ip a进入网卡目录 cd /etc/NetworkManager/system-connections找到对应网卡配置文件进行修改 修改配置 主要修改ipv4部分,改成自己的IP配置 [ipv4] methodmanual address1192.168.252.129/24,192.168.252.254 dns8.8.8.8重启网卡 …...

P8754 [蓝桥杯 2021 省 AB2] 完全平方数
题目描述 思路 一看就知道考数学,直接看题解试图理解(bushi) 完全平方数的质因子的指数一定为偶数。 所以 对 n 进行质因数分解,若质因子指数为偶数,对结果无影响。若质因子指数为奇数,则在 x 中乘以这个质因子,保证指…...

QT Sqlite数据库-教程001 创建数据库和表-上
【1】创建数据库 #include <QtSql/QSqlDatabase> #include <QtSql/QSqlQuery> #include <QtSql/QSqlRecord> QString path QDir::currentPath(); QApplication::addLibraryPath(pathQString("/release/plugins")); QPluginLoader loader(pathQSt…...

安卓手机怎样开启双WiFi加速
1. 小米/Redmi手机 路径: 设置 → WLAN → 高级设置 → 双WLAN加速 操作: 开启功能后,可同时连接一个2.4GHz WiFi和一个5GHz WiFi(或两个不同路由器)。 可选择“智能选择”或手动指定辅助网络。 2. 华为/荣耀手机…...

基于角色个人的数据权限控制
一、适用场景 如何有效控制用户对特定数据的访问和操作权限,以确保系统的安全性和数据的隐私性。 二、市场现状 权限管理是现代系统中非常重要的功能,尤其是对于复杂的B端系统或需要灵活权限控制的场景,可以运用一些成熟的工具和框架&…...
学习)
JAVA虚拟机(JVM)学习
入门 什么是JVM JVM:Java Virtual Machine,Java虚拟机。 JVM是JRE(Java Runtime Environment)的一部分,安装了JRE就相当于安装了JVM,就可以运行Java程序了。JVM的作用:加载并执行Java字节码(.class&#…...

【VSCode配置】运行springboot项目和vue项目
目录 安装VSCode安装软件安装插件VSCode配置user的全局设置setting.jsonworkshop的项目自定义设置setting.jsonworkshop的项目启动配置launch.json 安装VSCode 官网下载 安装软件 git安装1.1.12版本,1.2.X高版本无法安装node14以下版本 nvm安装(github…...

UE5,LogPackageName黄字警报处理方法
比如这个场景,淘宝搜索,ue5 T台,转为ue5.2后,选择物体,使劲冒错。 LogPackageName: Warning: DoesPackageExist called on PackageName that will always return false. Reason: 输入“”为空。 2. 风险很大的删除法&…...

ONVIF/RTSP/RTMP协议EasyCVR视频汇聚平台RTMP协议配置全攻略 | 直播推流实战教程
在现代化的视频管理和应急指挥系统中,RTMP协议作为一种高效的视频流传输方式,正变得越来越重要。无论是安防监控、应急指挥,还是物联网视频融合,掌握RTMP协议的接入和配置方法,都是提升系统性能和效率的关键一步。 今天…...

AI 驱动的全链路监控,从资源管理到故障自愈的实战指南--云监控篇
一、3 步完成多云接入,告别繁琐配置 1. 账号绑定 AWS:输入访问密钥,自动拉取 EC2、RDS、S3 等资源清单。 Azure:通过服务主体认证,一键发现 VM、SQL 数据库、存储账户。 GCP:上传服务账号密钥࿰…...

大模型在初治CLL成人患者诊疗全流程风险预测与方案制定中的应用研究
目录 一、绪论 1.1 研究背景与意义 1.2 国内外研究现状 1.3 研究目的与内容 二、大模型技术与慢性淋巴细胞白血病相关知识 2.1 大模型技术原理与特点 2.2 慢性淋巴细胞白血病的病理生理与诊疗现状 三、术前风险预测与手术方案制定 3.1 术前数据收集与预处理 3.2 大模…...
详解:从零开始掌握(2))
Express中间件(Middleware)详解:从零开始掌握(2)
1. 请求耗时中间件的增强版 问题:原版只能记录到控制台,如何记录到文件? 改进点: 使用process.hrtime()是什么?获取更高精度的时间支持将日志写入文件记录更多信息(IP地址、状态码)工厂函数模式使中间件可配置 con…...

Crossmint 与 Walrus 合作,将协议集成至其跨链铸造 API 中
Crossmint 是一个一站式平台,可为 app、AI Agent 或企业集成区块链。如今,Crossmint 已集成 Walrus 协议,以实现更具可扩展性的通证化场景,特别面向 AI Agent 和企业级用户。这项合作为开发者和企业提供了一种全新的方式ÿ…...

24.OpenCV中的霍夫直线检测
OpenCV中的霍夫直线检测 霍夫直线检测是一种基于参数变换的全局特征提取方法,它能在边缘图像中有效检测出直线,具有鲁棒性强和对噪声干扰容忍度高的特点。本文将从原理、算法实现和 OpenCV 应用三个角度对霍夫直线检测进行详细的阐述,并给出…...

springboot 处理编码的格式为opus的音频数据解决方案【java8】
opus编码的格式概念: Opus是一个有损声音编码的格式,由Xiph.Org基金会开发,之后由IETF(互联网工程任务组)进行标准化,目标是希望用单一格式包含声音和语音,取代Speex和Vorbis,且适用…...

【AI提示词】创业导师提供个性化创业指导
提示说明 以丰富的行业经验和专业的知识为学员提供创业指导,帮助其解决实际问题并实现商业成功 提示词 # Role: 创业导师## Profile - language: 中英文 - description: 以丰富的行业经验和专业的知识为学员提供创业指导,帮助其解决实际问题并实现商业…...

STM32 模块化开发实战指南:系列介绍
本文是《STM32 模块化开发实战指南》系列的导读篇,旨在介绍整个系列的写作目的、适用读者、技术路径和每一篇的主题规划。适合从事 STM32、裸机或 RTOS 嵌入式开发的个人开发者、初创工程师或企业项目团队。 为什么要写这个系列? 在嵌入式开发中,很多人刚开始都是从点亮一个…...
有趣示例一组)
在 Dev-C++中编译运行GUI 程序介绍(三)有趣示例一组
在 Dev-C中编译运行GUI程序介绍(三)有趣示例一组 前期见 在 Dev-C中编译运行GUI 程序介绍(一)基础 https://blog.csdn.net/cnds123/article/details/147019078 在 Dev-C中编译运行GUI 程序介绍(二)示例&a…...

功能安全时间参数FTTI
FTTI:fault tolerant time interval故障容错时间间隔; FHTI:Fault Handling Time Interval故障处理时间间隔; FRTI:Fault Reaction Time Interval故障反应时间间隔; FDTI:Fault Detectlon Ti…...

docker镜像制作
🧱 如何将任意 Linux 系统打包为 Docker 镜像 适用场景: 本地物理机 / 虚拟机上的 Linux(如 Ubuntu、Debian、CentOS、openEuler 等);想将当前系统环境完整打包成 Docker 镜像;系统内已安装了运行环境,如 Java、Python、Nginx 等,想保留它们。✅ 步骤概览: 准备文件…...

【Pandas】pandas DataFrame iat
Pandas2.2 DataFrame Indexing, iteration 方法描述DataFrame.head([n])用于返回 DataFrame 的前几行DataFrame.at快速访问和修改 DataFrame 中单个值的方法DataFrame.iat快速访问和修改 DataFrame 中单个值的方法 pandas.DataFrame.iat pandas.DataFrame.iat 是一个快速访…...

【图像分类】【深度学习】系列学习文章目录
图像分类简介 图像分类是计算机视觉领域中的一个核心问题,它涉及到将图像数据分配到一个或多个预定义类别中的过程。这项技术的目标是让机器模拟人类能够自动识别并分类图像内容。近年来,随着深度学习的发展,尤其是卷积神经网络(CNNs)的应用…...

MyBatisPlus 学习笔记
文章目录 MyBatisPlus 快速入门第一步:引入 MyBaitsPlus 起步依赖第二步:自定义的 Mapper 继承 BaseMapper 接口新增相关修改相关删除相关查询相关 Mp 使用示例 MyBaitsPlus 常见注解MP 实体类与数据库信息约定Mp 实体类与数据库信息约定不符合解决方法…...

Profibus DP主站如何转Modbus TCP?
Profibus DP主站如何转Modbus TCP? 在现代工业自动化系统中,设备之间的互联互通至关重要。Profibus DP 和 Modbus TCP 是两种常见的通信协议,分别应用于不同的场景。为了实现这两种协议的相互转换,Profibus DP主站转Modbus TCP网…...

尚硅谷Java第 4、5 章IDEA,数组
第 4 章:IDEA的使用 第 5 章:数组 5.1 数组的概述 数组(Array):就可以理解为多个数据的组合。 程序中的容器:数组、集合框架(List、Set、Map)。 数组中的概念: 数组名 下标(或索…...
)
一些简单但常用的算法记录(python)
1、计算1-2020间的素数个数 def is_composite(num):if num < 1:return False# 从 2 开始到 num 的平方根进行遍历for i in range(2, int(num**0.5) 1):if num % i 0:return Truereturn Falsecnt 0 for num in range(1, 2021):if is_composite(num):cnt 1print(cnt)2、 …...

基于Docker容器的CICD项目Jenkins/gitlab/harbor/Maven实战
一、企业业务代码发布方式 1.1 传统方式 以物理机或虚拟机为颗粒度部署部署环境比较复杂,需要有先进的自动化运维手段出现问题后重新部署成本大,一般采用集群方式部署部署后以静态方式展现 1.2 容器化方式 以容器为颗粒度部署部署方式简单࿰…...

高并发秒杀系统设计:关键技术解析与典型陷阱规避
电商、在线票务等众多互联网业务场景中,高并发秒杀活动屡见不鲜。这类活动往往在短时间内会涌入海量的用户请求,对系统架构的性能、稳定性和可用性提出了极高的挑战。曾经,高并发秒杀架构设计让许多开发者望而生畏,然而࿰…...
安卓开发中的RecyclerView详解)
(十四)安卓开发中的RecyclerView详解
在安卓开发中,RecyclerView 是一个功能强大且灵活的 UI 组件,用于高效地显示大量数据集合,如列表、网格或瀑布流。它是传统 ListView 和 GridView 的现代替代品,提供了更高的性能优化和自定义能力。RecyclerView 的核心优势在于其…...

如何设置Ubuntu服务器版防火墙
在Ubuntu服务器中,默认使用 ufw(Uncomplicated Firewall)作为防火墙管理工具。它是对iptables的简化封装,适合快速配置防火墙规则。以下是设置防火墙的详细步骤: 1. 安装与启用 ufw 安装(通常已预装&…...
 制作方法(BusyBox、Buildroot、Yocto、Ubuntu Base))
根文件系统(rootfs) 制作方法(BusyBox、Buildroot、Yocto、Ubuntu Base)
以下是关于 根文件系统(rootfs) 制作的四种主流方法(BusyBox、Buildroot、Yocto、Ubuntu Base)的详细教程与对比分析,结合不同场景的需求提供具体实现步骤和关键要点。 1. BusyBox 制作 rootfs 核心特点 轻量级&…...

SAP软件FICO各种财务账期的功能用途介绍
FI会计账期 一般财务账期总账期间的控制是仅开启当前一个期间,如果月结期间应同时开启结账期间和下一期间两个期间,结账完成需立即关闭已完成结账的期间,避免凭证过账日期误记账。 设置事务码:OB52或 S_ALR_87003642 备注&#…...

蓝桥杯C++组部分填空题
P1508 - [蓝桥杯2020初赛] 门牌制作 - New Online Judge #include<bits/stdc.h> using namespace std;int main() {int res 0;for(int i 1; i < 2020; i){int num i;while(num){if(num % 10 2) res;num/10;}}cout<<res;return 0; } 624 P1509 - [蓝桥杯20…...

内联inline
一、什么是 inline? inline 的本意是: 建议编译器将函数调用处展开成函数体代码,省去函数调用的开销。 inline int square(int x) { return x * x; } 当你调用 square(5) 时,编译器可能会将其替换成 5 * 5,从而避免…...
【models】Transformer 之 各种 Attention 原理和实现
Transformer 之 各种 Attention 原理和实现 本文将介绍Transformer 中常见的Attention的原理和实现,其中包括: Self Attention、Spatial Attention、Temporal Attention、Cross Attention、Grouped Attention、Tensor Product Attention、FlashAttentio…...

基于JavaAPIforKml实现Kml 2.2版本的全量解析实践-以两步路网站为例
目录 前言 一、关于两步路网站 1、相关功能 2、数据结构介绍 二、JAK的集成与实现 1、JAK类图简介 2、解析最外层数据 3、解析扩展元数据和样式 4、递归循环解析Feature 5、解析具体的数据 三、结论 前言 随着地理信息技术的快速发展,地理空间数据的共享…...

Ubuntu搭建Pytorch环境
Ubuntu搭建Pytorch环境 例如:第一章 Python 机器学习入门之pandas的使用 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 Ubuntu搭建Pytorch环境前言一、Anaconda二、Cuda1.安装流程2、环境变量&#…...

Kingbase逻辑备份与恢复标准化实施文档
背景 文章背景 本文结合实际运维经验,围绕 Kingbase 数据库在逻辑层面的备份与恢复方法进行系统性梳理,旨在为运维人员和数据库管理员提供一套清晰、高效、可落地的操作指引,提升数据库系统的可靠性与容灾能力。 第一部分 逻辑部分 1.1 全…...