ElasticSearch学习篇17_《检索技术核心20讲》最邻近检索-局部敏感哈希、乘积量化PQ思路
目录
场景在搜索引擎和推荐引擎中,对相似文章去重是一个非常重要的环节,另外是拍照识花、摇一摇搜歌等场景都可以使用它快速检索。
基于敏感性哈希的检索更擅长处理字面上的相似而不是语义上的相似。
- 向量空间模型
- ANN检索加速思路
- 局部敏感哈希编码
- 随机超平面划分哈希编码思路
- Google的SimHash编码思路以及抽屉原理
- 聚类
- 乘积量化
- 局部敏感哈希编码
ANN与向量空间模型
对于高纬度数据近邻检索常见方式

将所有文档中的关键词都提取出来,如果总共n个关键词,那么就是一个n纬度的向量。具体到一篇文章,假如文档包含关键词数量是k,其中(0<=k<=n),如果文档包含的第k个关键词的权重为w,那么权重向量k位置的元素就是w,这个权重w一般是根据TF-IDF计算得出,如果文档不包含第k个关键词,那么权重w就是0。
关于TF-IDF词频-逆文档频率参考往期:
ElasticSearch学习篇15_《检索技术核心20讲》进阶篇之TopK检索-CSDN博客
本质就转化为计算两个向量的相似度,可用余弦相似度、欧式距离等计算,另外n纬向量放入到空间中就是一个点,也可理解为空间中的近邻检索ANN,在十几维量级的低维空间中,我们可以使用 k-d 树进行 k 维空间的近邻检索,这种思路就是前面说的精确检索的思路,它的性能还是不错的,但是纬度上来之后,因为基础k-d树特点当纬度大于20的时候可能出现线性灾难,搜索大量的邻域导致性能很慢。
关于KD树、KDB、BKD树参考往期:
ElasticSearch学习篇10_Lucene数据存储之BKD动态磁盘树(论文Bkd-Tree: A Dynamic Scalable kd-Tree)_bkd树-CSDN博客
向量空间模型可用来表示文字、图片等内容,从而进行文本、图像近邻搜索ANN,一些常见的ANN加速算法思想基本分为两类
- 缩小候选集
- 压缩向量存储空间
ANN搜索加速技术思想
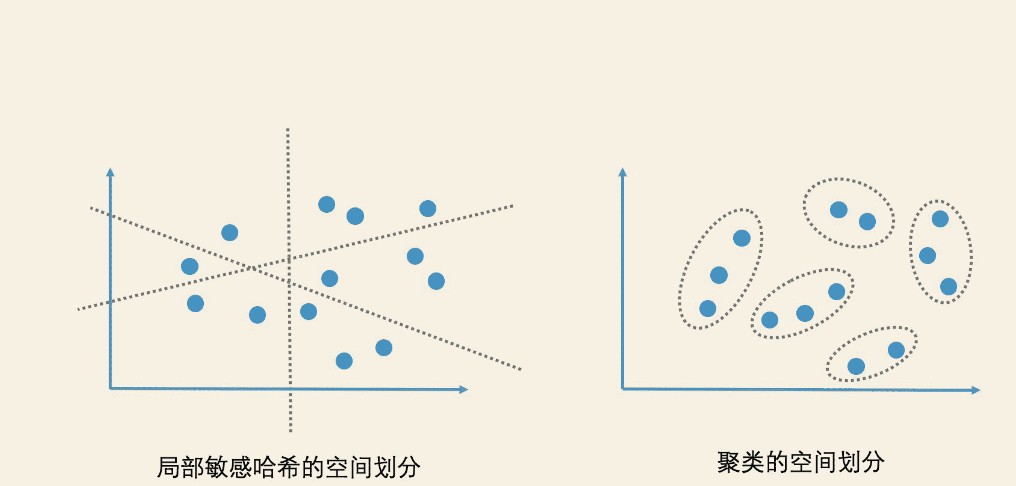
局部敏感哈希-缩小候选集数量
借助非精确检索的思路,可以将高纬空间中的点进行区域划分,然后给每个区域生成一个较短的编码,查询的时候先根据规则定位区域,达到缩小候选集的目的,再从该区域高效近邻检索。
这个规则就类似哈希,但是普通的哈希函数值不太可控,文章中变化很少的关键词就会导致哈希值很大的变动。
因此必须找出一个特殊的哈希规则,使得相似的数据哈希之后,得到的哈希值也是相近的,被称为局部敏感性哈希(Locality-Sensitive Hashing)
随机超平面划分哈希编码
以二维空间举例,找出一条线,将区域划分为两部分,处在区域1的点编码为1,处在另外区域的点编码为0,这条线需要尽可能合理,因此可以随机找出n条线,一条线切分下,会对点增加一位编码,这样n条线就会给一个点产生n位的编码。
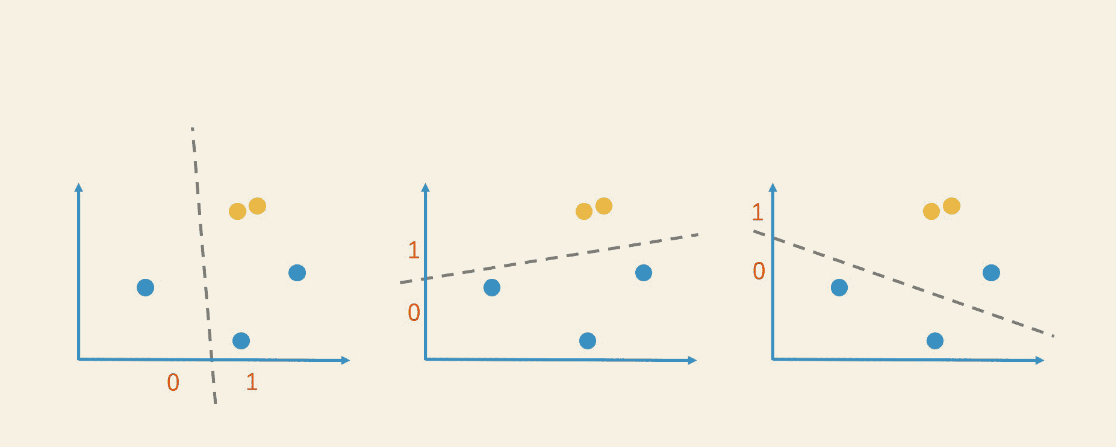
对于多维空间,就需要找超平面,如n个纬度就找n个超平面,然后这些超平面将空间中的点切割,位于超平面两侧的点(通过超平面法向量的余弦相似度计算)分别被编码0、1,这样可以将高维空间的点映射为一纬的编码。
如果两个点的哈希值是一样的,那么两个点大概率距离的非常近,即使哈希值不一样,只要他们在n个比特位中大大部分是相同的(具体的计算算法如海明距离),说明他们大概率相近。举个例子如果两篇文章内容是100%相同的,那么他们的哈希值就是相同的,也就相当于编码相同。
这种一般哈希编码有个缺点就是随着超线、超平面的划分编码,会丢失某些纬度权重信息。
SimHash编码
谷歌提出的局部敏感哈希策略,简化哈希函数,保留多维数据(点)项的权重信息。
它使用一个普通的哈希函数代替了n次随机超平面划分,这个哈希函数作用对象不是整体所有的高纬度数据项,而是一个个处理高纬度数据项,通过数据项哈希值编码与数据项权重计算的时候就能保留权重。

构造SimHash的具体过程,以一篇文档进行局部敏感哈希编码来说明
- 文档分词,关键词项带权重:分词并计算每个关键词的权重w。
- 生成Hash值:使用一般的Hash函数,针对每个关键词生成如64位的0、1哈希值编码。
- 每个关键词哈希值变化:将哈希值的0改为-1,如10110 -> 1 -1 1 1 -1
- 每个关键词哈希值按位乘上词权重:如词权重3,变为 3 -3 3 3 -3。
- 按位相加所有关键词的哈希值:计算文档所有关键词哈希值按位加的结果。
- 文档哈希值编码转换:将编码转为0、1。
这样,文档的最终哈希编码是收到权重比较大的词影响比较多的,另外就是哈希函数比较简单,代替了复杂的随机选取超平面方式。
抽屉原理
对于文章查重领域,如果两个文章的SimHash编码的距离(使用汉明距离计算)小于k,那么就认为它们是相似的。举个例子当k=3的时候,需要找出k小于3的文章,然后遍历逐一计算对比,效率比较低,有没有加速方案?
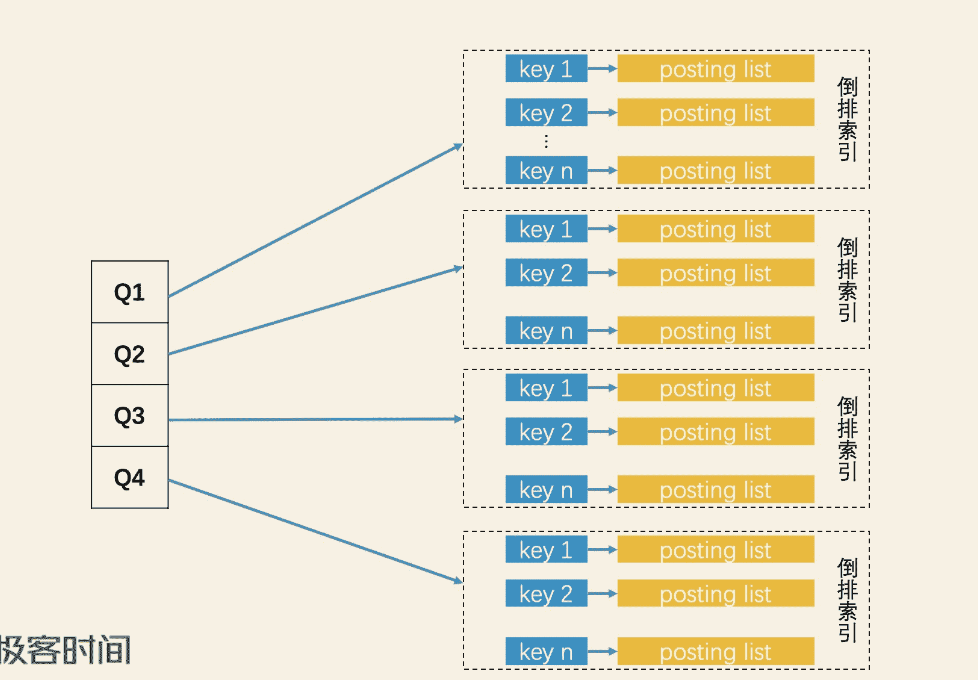
一个直观的想法,使用SimHash编码某一位bit作为key,使用文章内容作为value构建倒排索引,以64位的SimHash编码为例,key的数量为128个,构造的倒排索引key如
- 1xxxxx、0xxxxx
- x1xxxx、x0xxxx
- …
查找的时候,逐位查找64次,将第n为比特位对应key对应的文章全部取出来,然后计算对比。
这种方式效率不是很高,因为即使两篇文章64位bit任意两个位置的bit相同的话就会被召回,即使不太相似。
Google提出优化的抽屉原理:将文章的SimHash编码分4段,如果想找出和此文章bit位差异不超过3个的文章,那么4个段其中一定至少有一个段的bit是完全一致的。因此查询就被转化为了4段中有一段完全相同的文章会被召回。
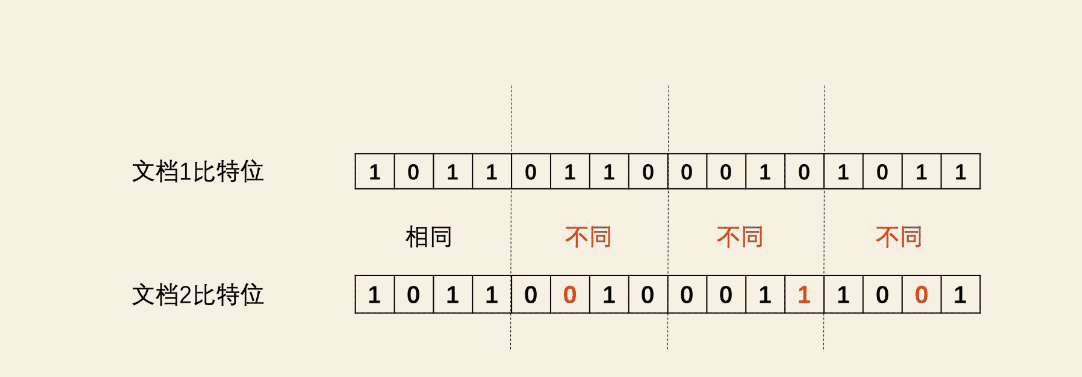
按照这个思路,
- 分段构建倒排索引:将每个文档的SimHash编码划分为四段,每段的16位bit作为一个倒排索引,
- 分段查询:查询的时候,当前文档的SimHash编码也会被划分为四段,如果找出汉明距离k<3的文档,只需召回四段中任一段完全相同的文档即可,然后从四段倒排索引找回的结果合并。
通过使用 SimHash 函数和分段检索(抽屉原理),使得 Google 能在百亿级别的网页中快速完成过滤相似网页的功能,从而保证搜索结果的数量。
思考1:对于 SimHash,如果将海明距离在 4 之内的文章都定义为相似的,那我们应该将哈希值分为几段进行索引和查询呢?分为5段,因为4为不同的bit位最多能影响四段,虽然除不尽,每段可以是12或者13,查询的时候也按照这种规则划分5段即可。
对比编辑距离、杰卡德算法计算文本相似性
对比杰卡德、莱文斯坦、SimHash三种计算文章相似度的效果,总结特点以及适用场景。
SimHash的一种实现参考:SimHash结合汉明距离判断文本相似性
下面选取一套初中语文的试卷,试卷包含大概20道试题,大概1w字符
手动创造不同的CASE,以下是包含完整CASE描述的表格:
| CASE | 描述 | 原文内容长度 | 内容长度 | simHash相似度 | simHash耗时 | levenshtein相似度 | levenshtein耗时 | jaccard相似度 | jaccard耗时 |
|---|---|---|---|---|---|---|---|---|---|
| CASE1 | 将21题和22题互相换位置 | 8556 | 8556 | 100.0 | 274ms | 0.84 | 298ms | 1.0 | 7ms |
| CASE2 | 删除试卷中间的11题 | 8556 | 8401 | 96.88 | 102ms | 0.98 | 274ms | 1.0 | 1ms |
| CASE3 | 删除10题之后的所有内容 | 8556 | 1921 | 65.63 | 30ms | 0.22 | 41ms | 1.0 | 2ms |
| CASE4 | 完全打乱试题顺序 | 8556 | 8560 | 100.0 | 45ms | 0.45 | 183ms | 1.0 | 1ms |
| CASE5 | 删除11题之前的所有内容 | 8556 | 6635 | 92.19 | 40ms | 0.77 | 143ms | 1.0 | 1ms |
| CASE6 | 前11道题内容不相同,后面内容相同 | 8556 | 9184 | 89.06 | 40ms | 0.74 | 194ms | 0.9035971223021583 | 1ms |
| CASE7 | 在11题后面中间加入一道试题 | 8556 | 8741 | 98.44 | 37ms | 0.97 | 186ms | 1.0 | 1ms |
绘制成图表
在选取初中语文试卷内容1w字符文本相似度计算场景下,综合CASE分析文本相似度计算效率以及严格程度
- 效率:杰卡德 > SimHash > 莱文斯坦编辑距离
- 严格程度:莱文斯坦编辑距离 > SimHash > 杰卡德
针对CASE2、CASE3分析,即使试卷内容1和试卷内容2相差了一道或者十多道试题,但是杰卡德计算的文本相似度仍为100,SimHash计算的文本相似度较为准确,但是效率又要比莱文斯坦效率要高,使用SimHash可以避免查重中将不是完全一致的试卷内容(差别几道试题)误查,同时又兼顾相似度计算效率。
SimHash、杰卡德(Jaccard)和莱文斯坦(Levenshtein)是三种常用的文本相似度计算算法,它们各有特点和适用场景:
- SimHash:局部敏感性哈希
- 特点:SimHash是一种局部敏感哈希算法,主要用于快速计算大规模文本数据的相似性。它通过将文本转换为一个固定长度的二进制哈希值来表示文本特征。SimHash的优点是计算速度快,适合处理大规模数据。
- 适用场景:SimHash常用于海量数据的去重、近似重复检测和相似文档查找等场景。由于其计算效率高,特别适合需要快速处理和比较大量文本的应用。
- 杰卡德(Jaccard)相似系数:
- 特点:杰卡德相似系数用于衡量两个集合的相似度,定义为两个集合交集的大小除以并集的大小。对于文本相似性,通常将文本分割成词或字符的集合,然后计算这些集合的杰卡德相似度。
- 适用场景:杰卡德相似度适合用于比较短文本或关键词集合的相似性,如文档分类、标签推荐等。由于其计算简单,适合用于需要快速评估文本相似性的场合。
- 莱文斯坦(Levenshtein)距离:
- 特点:莱文斯坦距离,又称编辑距离,表示将一个字符串转换为另一个字符串所需的最小编辑操作次数(插入、删除、替换)。它能够精确地衡量两个字符串之间的差异。
- 适用场景:莱文斯坦距离适合用于需要精确比较字符串差异的场合,如拼写检查、DNA序列比对、文本纠错等。由于其计算复杂度较高,通常用于较短文本的比较。
总结来说,SimHash适合大规模文本的快速相似性检测,杰卡德相似度适合集合间的相似性比较,而莱文斯坦距离适合精确的字符串差异分析。选择合适的算法需要根据具体的应用场景和数据特征来决定。
汉明距离
主要是计算等长的两个二进制字符串之间差别的位数
def hamming_distance(str1, str2):if len(str1) != len(str2):raise ValueError("Strings must be of the same length")distance = 0for ch1, ch2 in zip(str1, str2):if ch1 != ch2:distance += 1return distance# 示例
str1 = "1101"
str2 = "1001"
print(hamming_distance(str1, str2)) # 输出: 1聚类-缩小候选集数量
图片如何相似性检索,检索图片和检索文章一样,首先要先用向量空间模型将图片表示出来,这样图像就变成了高纬度空间的一个点,搜素图片转化为了高纬度空间的ANN。
如何从图片抽取向量空间模型,如果把图像的每个像素看作一个纬度,像素上的RGB值作为纬度值,是一种思路,但是一张图片的纬度大概是百万级别,检索起来很复杂,因此另外一种方式就是使用CNN等进行图像特征提取,转为一个512或者1024纬度的向量空间模型。
如何加速ANN检索效率,有了向量空间模型,就可以使用ANN加速技术比如SimHash来加速检索,比如将高纬空间的点划分到有限区域,从而达到缩小候选集的目的。但是SimHash哈希函数比较简单,更适合计算字面上的相似性而不是语义上的相似性,同时SimHash是一种粒度很粗的非精确检索方案,他能将上百万的纬度压缩为64位bit,损失不少精度。因此一般使用聚类方案加速ANN检索,常见的一种是K-Means(K-平均算法)方案
K-Means聚类算法构建聚类计算步骤
- 初始聚类中心:随机从数据中选取k个数据作为初始聚类中心
- 计算距离:计算其他数据与ki 的距离,加入到最邻近的ki 聚类中
- 根据距离均值重新选取聚类中心:根据聚类中的点到聚类中心距离的均值,重新选一个聚类中心
重复2-3步,即重新计算其他还数据到聚类中心的距离,然后将节点划分到最近的聚类中,然后在更新聚类中心。
K-Means 聚类算法的优化目标是,类内的点到类中心的距离均值总和最短。构建好之后,以聚类中心数据ID作为key,单个聚类的数据创建倒排索引。
K-Means查询的时候,直接找出待查询数据距离最近的聚类中心ki 然后从倒排索引取出topK候选集,
- 如果不足topK数量,那么可以再查询邻近聚类的候选集。
- 如果数量很多同时topK又取得非常大,那么一个一个计算和待查询数据距离代价也很大,可以采用层级子聚类来继续缩小候选集。
乘积量化-压缩向量模型存储空间
对于向量的相似检索,除了检索算法本身,优化向量存储空间也是一个优化方向,因为向量的相似度计算需要加载进内存。
以一个1024纬度的向量距离,每个向量纬度是一个浮点数占4 Bytes = 32 bits,那么一个向量占用1KB空间,如果是上亿级的数据,存储向量需要占几百个G。(100 000 000 KB = 100 GB)
为了更好的将向量加载进去内存,需要对向量存储空间优化,一种思路是使用上面的聚类思想,减少加载进内存的数量,只把查询向量和聚类向量加载进内存,而不是聚类下所有向量,这样可能会损失结果粒度。另外一种思路就是使用向量量化-乘积量化来压缩。
乘积量化的概念
- 乘积:高纬空间向量可以看作是多个低纬空间向量相乘的结果,可以理解为笛卡尔集,如数轴的x、y轴分别表示一纬空间,数轴区域中的点(xi.yi)就是二维空间的点,假如xi的值为1、2、3,yi的值为5、6、7,那么组合笛卡尔集的二纬空间的点个数为9个。
- 量化:将区域划分为子区域,然后在编码,这样就能将区域转为1纬编码,上面聚类就是一种量化方式。
乘积量化就是将高纬空间划分为多个子空间,然后对子空间编码,针对子空间在进行聚类技术分为多个子区域,然后给每个子区域编码即聚类ID。好处:省空间,二纬空间存储的点数量为9,但是只存储一纬空间x、y的话,只需要存储的数量为6个一纬点。
举例假设一组1024纬度的向量进行乘积量化
- 首先将1024纬度向量拆分为4个256纬度子向量
- 在每一个256纬度子向量进行聚类,找出1-256和聚类ID,因此只使用8 bits就能表示1-256的聚类ID。

所以经过上述过程,1024纬度的向量使用 4 * 8 bits = 32 bit就能表示。

乘积量化PQ过程思想
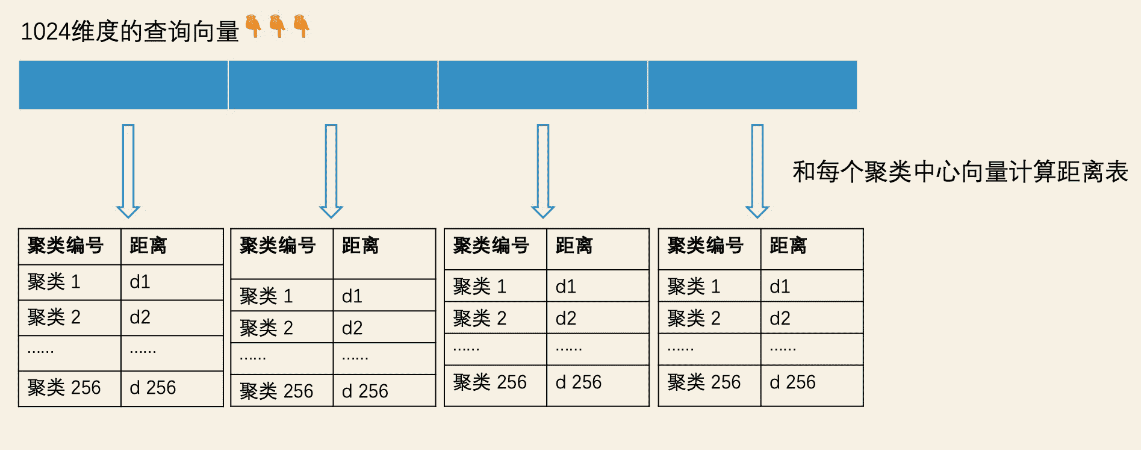
乘积量化向量相似查询的时候,涉及到三个向量
- 样本向量:1024纬度,乘积量化过程会被压缩为4段,每段进行聚类,每段会得到一个聚类中心ID,范围为1-256,最后所有样本处理完后,大概会得到 256 * 4 个聚类中心向量。
- 聚类中心向量:每段都有256个聚类中心ID,256 * 4 个聚类中心向量。
- 查询向量:1024纬度,查询过程会被压缩4段。
构造的时候,样本向量会被压缩为4段,会得到256 * 4的聚类中心向量,而样本向量也从1024纬度被压缩为32纬,1024 => 4 * 256 => 4 * 2 ^ 8,压缩含义就是以每段聚类中心ID的8为bit编码代替当前子向量段。
当计算查询向量和样本向量的距离时,
- 向量切分子空间:我们将查询向量和样本向量都分为 4 段子空间。
- 子空间计算聚类ID:计算查询向量切分的4段子空间的聚类ID,生成压缩向量。然后预生成一个距离表,该距离表纬度是256 * 4,记录了查询子向量和 子空间各个中心向量的距离。
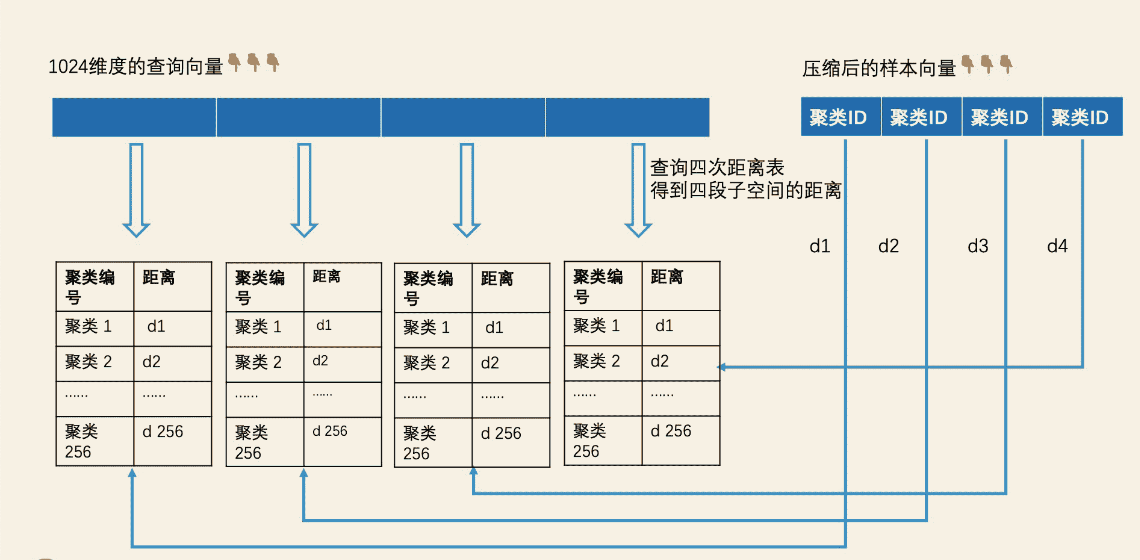
- 遍历全部样本数量计算查询向量距离:根据预处理阶段的距离表可以查询出查询向量每段到各个聚类ID的距离,数据库中全部的样本向量属于哪个聚类ID也可以计算出,然后就是求出每段距离:d1、d2、d3、d4,最终通过相关运算如欧式距离等计算两个向量的距离,进而返回topK。
PQ主要是为了压缩空间,计算距离算法不太关注。
其他参考:理解 product quantization 算法
这样,求查询子向量和样本子向量的距离,就转换为求查询子向量和对应的聚类中心向量的距离。那我们只需要将样本子向量所属的聚类中心的聚类 ID 作为 key 去查距离表,就能在 O(1) 的时间代价内知道这个距离了。
这里讲述的只是大致思想,具体的如何计算找出紧邻的topK向量还有 基于倒排的乘积量化IVFPQ缩小遍历全部样本空间向量,以及SDC、ADC向量相似检索算法还有很多小细节。
基于倒排索引的IVFPQ思想
上面说的计算查询向量和所有样本向量之间的距离是遍历全部的样本空间,还有一种维护样本向量倒排索引的方式加速检索。
构建倒排索引的具体的思路
- 样本向量切分子空间:1024纬切分为4段,每段256纬度
- 计算子空间聚类ID:可以采用KMeans聚类算法,最终每个子空间(段)聚类256个,每个子空间使用聚类ID代表当前样本子空间特征,最终每个子空间得到8位的聚类ID
- 建立倒排索引:得到的32位新向量,为每个子空间创建一个倒排索引,每个倒排索引的key可以设置为当前段的聚类ID,value设置为在当前段被聚类到该ID的所有样本数量。
查询的时候,查询向量进行切分子空间,PQ,然后逐段查倒排,这样将四个段的样本数量就是最有可能相近的样本数量,在进行距离计算找出TopK。
另外还有一种根据聚类ID向量残差创建倒排索引的做法,这样做精度会高一些。
思考
如果二维空间中有 16 个点,它们是由 x 轴的 1、2、3、4 四个点,以及 y 轴的 1、2、3、4 四个点两两相乘组合成的。那么,对于二维空间中的这 16 个样本点,如果使用乘积量化的思路,你会怎么进行压缩存储?当我们新增了一个点 (17,17) 时,它的查询过程又是怎么样的?
主要的思想就是使用两纬位置代替真实的二维点值,对于16个样本点,首先是定义x、y轴两个集合,然后将点的x、y轴的值压缩为对应x、y轴集合的索引值,索引值数值相对于点的值是比较小的,通过PQ可以节省存储空间。当新增了一个点(17,17),只需要向x、y轴集合添加17,查询的时候,先判断x、y轴集合是否有值17,若都有的话索引为(xi=5,yi=5),索引对应的点就是要找的(17,17)
相关文章:

ElasticSearch学习篇17_《检索技术核心20讲》最邻近检索-局部敏感哈希、乘积量化PQ思路
目录 场景在搜索引擎和推荐引擎中,对相似文章去重是一个非常重要的环节,另外是拍照识花、摇一摇搜歌等场景都可以使用它快速检索。 基于敏感性哈希的检索更擅长处理字面上的相似而不是语义上的相似。 向量空间模型ANN检索加速思路 局部敏感哈希编码 随…...

2024亚太杯国际赛C题参考文章50页+完整解题思路+数据处理+最终结果
中国宠物食品行业的发展趋势与汇率情景分析:基于多模型的量化预测与决策分析 一 、 摘要 本文针对宠物产业及相关产业的发展分析问题,采用多种数学建模方法和数据 分析技术,构建了一系列预测和评估模型。从宠物数量预测、全球市场分析、产业 …...

推荐几个 VSCode 流程图工具
Visual Studio Code(简称VSCode)是一个由微软开发的免费、开源的代码编辑器。 VSCode 发布于 2015 年,而且很快就成为开发者社区中广受欢迎的开发工具。 VSCode 可用于 Windows、macOS 和 Linux 等操作系统。 VSCode 拥有一个庞大的扩展市…...
)
渗透测试笔记——shodan(4)
声明: 学习视频来自B站up主 【泷羽sec】有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&am…...

一次封装,解放双手:Requests如何实现0入侵请求与响应的智能加解密
引言 之前写了 Requests 自动重试的文章,突然想到,之前还用到过 Requests 自动加解密请求的逻辑,分享一下。之前在做逆向的时候,发现一般医院的小程序请求会这么玩,请求数据可能加密也可能不加密,但是返回…...

c++中操作数据库的常用函数
在C中操作数据库,尤其是MySQL数据库,主要通过MySQL提供的C API或MySQL Connector/C库来实现。这些库提供了一系列的函数,使得开发者能够在C应用程序中执行数据库的连接、查询、更新、删除等操作。以下是C中操作MySQL数据库的一些常用函数&…...

CoAP 协议介绍:特性、应用与优劣势
CoAP 协议简介 CoAP 协议(Constrained Application Protocol)是一种专门为受限设备设计的互联网应用协议。它旨在让小型、低功耗的设备能够接入物联网(IoT)。该协议允许这些设备以最小的资源与更广泛的互联网进行通信。 CoAP 协…...

leetcode hot100【LeetCode 53.最大子数组和】java实现
LeetCode 53.最大子数组和 题目描述 给定一个整数数组 nums,找到一个具有最大和的连续子数组(至少一个元素),返回其最大和。 子数组是数组中的一个连续部分。 示例 1: 输入: nums [-2,1,-3,4,-1,2,1,-5,4] 输出: 6 解释: 连续…...

MAC C语言 Helloword
在 macOS 系统上编写并运行一个简单的 “Hello, World!” 程序,你可以使用多种编程语言。下面我将以 C 语言为例,展示如何在 macOS 上编写、编译和运行这个经典的 “Hello, World!” 程序。 步骤 1: 安装 Xcode Command Line Tools macOS 系统上通常没…...

【过程控制系统】第6章 串级控制系统
目录 6. l 串级控制系统的概念 6.1.2 串级控制系统的组成 6.l.3 串级控制系统的工作过程 6.2 串级控制系统的分析 6.2.1 增强系统的抗干扰能力 6.2.2 改善对象的动态特性 6.2.3 对负荷变化有一定的自适应能力 6.3 串级控制系统的设计 6.3.1 副回路的选择 2.串级系…...

springboot:责任链模式实现多级校验
责任链模式是将链中的每一个节点看作是一个对象,每个节点处理的请求不同,且内部自动维护一个下一节点对象。 当一个请求从链式的首段发出时,会沿着链的路径依此传递给每一个节点对象,直至有对象处理这个请求为止。 属于行为型模式…...

如何构建高效的接口自动化测试框架?
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 在选择接口测试自动化框架时,需要根据团队的技术栈和项目需求来综合考虑。对于测试团队来说,使用Python相关的测试框架更为便捷。无论选…...

spring-logback引用外部文件
背景 在spring微服务开发和云部署中,都涉及到日志的收集,很多时候为例方便管理和开发,很多公司都会开发一些基础配置代码。其中日志就是很重要的部分, 为了方便部署、收集、查看,所以日志文件需要存储在同一个…...

【MyBatisPlus·最新教程】包含多个改造案例,常用注解、条件构造器、代码生成、静态工具、类型处理器、分页插件、自动填充字段
文章目录 一、MyBatis-Plus简介二、快速入门1、环境准备2、将mybatis项目改造成mybatis-plus项目(1)引入MybatisPlus依赖,代替MyBatis依赖(2)配置Mapper包扫描路径(3)定义Mapper接口并继承BaseM…...

go项目中比较好的实践方案
工作两年来,我并未遇到太大的挑战,也没有特别值得夸耀的项目。尽管如此,在日常的杂项工作中,我积累了不少心得,许多实践方法也在思考中逐渐得到优化。因此,我在这里记录下这些心得。 转发与封装 这个需求…...

Windows之使用putty软件以ssh的方式连接Linux中文显示乱码
项目场景: 运行环境:Windows10 使用软件:putty 操作说明:以ssh的方式连接Linux 中文显示乱码 问题描述 Windows之使用putty软件以ssh的方式连接Linux中文显示乱码 原因分析: linux 机器的系统语言字符集与putty软件…...

springboot整合hive
springboot整合hive pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.…...

vxe-form table 修改表单数据校验的主题样式
在使用 vxe-form 表单校验时,数据校验可以支持2种主题样式 官网:https://vxeui.com 普通样式 通过设置 valid-config.theme‘normal’ 设置为普通样式 高亮样式 通过设置 valid-config.theme‘beautify’ 设置为高亮样式 <template><div&…...

【UE5】使用基元数据对材质传参,从而避免新建材质实例
在项目中,经常会遇到这样的需求:多个模型(例如 100 个)使用相同的材质,但每个模型需要不同的参数设置,比如不同的颜色或随机种子等。 在这种情况下,创建 100 个实例材质不是最佳选择。正确的做…...

一个计算频率的模块
先上代码 module _sync_reg #(parameter INIT 0,parameter ASYNC_RESET 0 ) (input clk,input rst,input in,output out );(* ASYNC_REG "TRUE" *) reg sync1; (* ASYNC_REG "TRUE" *) reg sync2;assign out sync2;generate if (ASYNC_RE…...

在SpringBoot项目中集成MongoDB
文章目录 1. 准备工作2. 在SpringBoot项目中集成MongoDB2.1 引入依赖2.2 编写配置文件2.3 实体类 3. 测试4. 文档操作4.1 插入操作4.1.1 单次插入4.1.2 批量插入 4.2 查询操作4.2.1 根据id查询4.2.2 根据特定条件查询4.2.3 正则查询4.2.4 查询所有文档4.2.5 排序后返回 4.3 删除…...

OpenJudge - 24:输出保留3位小数的浮点数
【题目来源】http://shnoip.openjudge.cn/level1/24/【题目描述】 读入一个单精度浮点数,保留3位小数输出这个浮点数。【输入格式】 只有一行,一个单精度浮点数。【输出格式】 也只有一行,读入的单精度浮点数。【输入样例】 12.34521【输出样…...

华为流程L1-L6业务流程深度细化到可执行
该文档主要介绍了华为业务流程的深度细化及相关内容,包括流程框架、建模方法、流程模块描述、流程图建模等,旨在帮助企业构建有效的流程体系,实现战略目标。具体内容如下: 华为业务流程的深度细化 流程层级:华为业务流程分为 L1 - L6 六个层级,L1 为流程大类,L2 为流程…...
入门详解)
Python中Tushare(金融数据库)入门详解
文章目录 Python中Tushare(金融数据库)入门详解一、引言二、安装与注册1、安装Tushare2、注册与获取Token 三、Tushare基本使用1、设置Token2、获取数据2.1、获取股票基础信息2.2、获取交易日历2.3、获取A股日线行情2.4、获取沪股通和深股通成份股2.5、获…...

Odoo中,要实现实时数据推送,SSE 与 WebSocket 该如何选择
目录 1. 技术特点对比 2. 使用场景 适合使用 SSE 的场景: 适合使用 WebSocket 的场景: 3. 优缺点总结 SSE 优点: SSE 缺点: WebSocket 优点: WebSocket 缺点: 4. 选择建议 选择 SSE 的条件&#x…...

02. Python基础知识
一、注释 在开发程序过程中,如果一段代码的逻辑比较复杂,不是特别容易理解,可以适当添加注释,以辅助自己或其他开发人员解读代码。注释是给程序员看的,为了让程序员方便阅读代码,解释器会忽略注释。在 Pyto…...

Mac 修改默认jdk版本
当前会话生效 这里演示将 Java 17 版本降低到 Java 8 查看已安装的 Java 版本: 在终端(Terminal)中运行以下命令,查看已安装的 Java 版本列表 /usr/libexec/java_home -V设置默认 Java 版本: 找到 Java 8 的安装路…...

数字赋能,气象引领 | 气象景观数字化服务平台重塑京城旅游生态
在数字化转型的浪潮中,旅游行业正以前所未有的速度重塑自身,人民群众对于高品质、个性化旅游服务需求的日益增长,迎着新时代的挑战与机遇,为开展北京地区特色气象景观预报,打造“生态气象旅游”新业态,助推…...

C语言项⽬实践-贪吃蛇
目录 1.项目要点 2.窗口设置 2.1mode命令 2.2title命令 2.3system函数 2.Win32 API 2.1 COORD 2.2 GetStdHandle 2.3 CONSOLE_CURSOR_INFO 2.4 GetConsoleCursorInfo 2.5 SetConsoleCursorInfo 2.5 SetConsoleCursorPosition 2.7 GetAsyncKeyState 3.贪吃蛇游戏设…...

springboot整合kafka
springboot整合kafka pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven…...

量子计算机全面解析:技术、应用与未来
标题:量子计算机全面解析:技术、应用与未来 一、什么是量子计算机? 量子计算机是一种利用量子力学原理(如叠加、纠缠和干涉)进行计算的新型计算设备。与传统计算机基于比特(0 和 1)的运算方式不…...

提升软件测试报告的质量:Allure2中添加用例失败截图、日志、HTML块和视频的方法
Allure2的用途 Allure2是一个用于生成测试报告的框架,广泛应用于自动化测试和手动测试中。它支持多种测试框架,如JUnit、TestNG、MSTest等,通过生动的图表和详细的日志,使得非技术人员也能轻松地理解测试结果。许多团队选用Allur…...

Mysql启动报错:本地计算机上的mysql服务启动后停止,某些服务在未由其他服务或程序使用时将自动停止
原因 是手动去改了mysql的配置文件my.ini的内容,重新启动服务启动不了。 看了很多文章最终找到了恢复数据的办法。 第一步备份 先备份mysql数据存的文件夹Data,如果找不到则去看配置文件那一行datadir 第二步重新安装mysql 卸载篇可以看我之前发的文…...

国际环境和背景下的云计算领域
前言 在当前国际环境和背景下,云计算领域呈现出复杂多变的局面,其发展深受技术创新、地缘政治、全球经济以及监管政策的影响。以下从技术趋势、市场竞争、地缘政治和监管环境四个方面详细解析云计算领域的现状。 一、技术趋势:多云与边缘计算…...

网络安全-企业环境渗透2-wordpress任意文件读FFmpeg任意文件读
一、 实验名称 企业环境渗透2 二、 实验目的 【实验描述】 操作机的操作系统是kali 进入系统后默认是命令行界面 输入startx命令即可打开图形界面。 所有需要用到的信息和工具都放在了/home/Hack 目录下。 本实验的任务是通过外网的两个主机通过代理渗透到内网的两个主机。…...

C# 超链接控件LinkLabel无法触发Alt快捷键
在C#中,为控件添加快捷键的方式有两种,其中一种就是Windows中较为常见的Alt快捷键,比如运行对话框,记事本菜单等。只需要按下 Alt 框号中带下划线的字母即可触发该控件的点击操作。如图所示 在C#开发中,实现类似的操作…...

一分钟学习数据安全——数据安全风险的系统化应对思路
数据是组织的重要资产,未经授权的数据访问可能导致数据泄露、数据篡改、隐私侵犯和合规风险等问题。企业可以通过数据访问控制来提高信息系统在数据全生命周期管理中的安全性。企业可以引入IAM系统,来控制身份来管理权限。通过对用户访问权限的管理和合适…...

深入了解 Spring Security 的授权核心功能
Spring Security 是一个强大且灵活的安全框架,能够帮助开发者为 Spring 应用程序提供认证和授权服务。在实际应用中,Spring Security 主要涉及用户的认证(谁是用户)和授权(用户能做什么)。本文将深入讲解 S…...

【Web前端】创建我的第一个 Web 表单
Web 开发中,表单是不可或缺的组成部分。无论是用户注册、登录还是反馈收集,表单都是与用户交互的重要方式。 什么是 Web 表单? Web 表单是一种用于收集用户输入数据的界面元素。它们允许用户在浏览器中输入信息并提交这些信息到服务器。Web …...

“人工智能+高职”:VR虚拟仿真实训室的发展前景
在当今科技日新月异的时代,人工智能(AI)与虚拟现实(VR)技术的融合正逐步改变着各行各业,教育领域也不例外。特别是在高等职业教育(简称“高职”)体系中,VR虚拟仿真实训室…...

状态模式之状态机
状态机的背景 在软件开发过程中,尤其是涉及到复杂的系统行为控制时,我们常常会遇到这样的情况:一个对象或者系统会在多种状态之间进行转换,并且在不同状态下对相同事件的响应是不同的。 以自动售卖机为例,自动售卖机…...
)
NUXT3学习日记四(路由中间件、导航守卫)
前言 在 Nuxt 3 中,中间件(Middleware)是用于在页面渲染之前或导航发生之前执行的函数。它们允许你在路由切换时执行逻辑,像是身份验证、重定向、权限控制、数据预加载等任务。中间件可以被全局使用,也可以只在特定页…...

基于重复控制补偿的高精度 PID 控制
1. 背景与原理 重复控制(Repetitive Control, RC)是一种适用于周期性信号跟踪和周期性扰动抑制的控制方法,通过在控制回路中引入周期补偿器来提高系统的控制精度。将 RC 与 PID 控制相结合,利用 PID 的快速响应特性和 RC 的周期补…...

Linux之日志
日志 在编写网络服务器, 各种软件时, 程序一定要打印一些日志信息. 1. 可以向显示器打印, 也可以向文件中写入. 2. 日志是软件在运行时记录的流水账, 用于排查服务进程挂掉的信息. 其中必须要有的是: 日志等级, 时间, 日志内容.可选的是文件名, 代码行数, 进程pid 等 日志…...

【LeetCode面试150】——202快乐数
博客昵称:沈小农学编程 作者简介:一名在读硕士,定期更新相关算法面试题,欢迎关注小弟! PS:哈喽!各位CSDN的uu们,我是你的小弟沈小农,希望我的文章能帮助到你。欢迎大家在…...

云原生之k8s服务管理
文章目录 服务管理Service服务原理ClusterIP服务 对外发布应用服务类型NodePort服务Ingress安装配置Ingress规则 Dashboard概述 认证和授权ServiceAccount用户概述创建ServiceAccount 权限管理角色与授权 服务管理 Service 服务原理 容器化带来的问题 自动调度:…...

【Vue】 npm install amap-js-api-loader指南
前言 项目中的地图模块突然打不开了 正文 版本太低了,而且Vue项目就应该正经走项目流程啊喂! npm i amap/amap-jsapi-loader --save 官方说这样执行完,就这结束啦!它结束了,我还没有,不然不可能记录这篇文…...

RocketMQ: 部署结构与存储特点
RocketMQ 是什么 它是一个队列模型的消息中间件,具有高性能、高可靠、高实时、分布式特点 Producer、Consumer、队列都可以分布式Producer 向一些队列轮流发送消息 队列集合称为 TopicConsumer 如果做广播消费则一个 consumer 实例消费这个 Topic 对应的所有队列如果…...

Android OpenGL ES详解——绘制圆角矩形
1、绘制矩形 代码如下: renderer类: package com.example.roundrectimport android.content.Context import android.opengl.GLES30 import android.opengl.GLSurfaceView.Renderer import com.opengllib.data.VertexArray import com.opengllib.prog…...

【大数据学习 | Spark】Spark的改变分区的算子
当分区由多变少时,不需要shuffle,也就是父RDD与子RDD之间是窄依赖。 当分区由少变多时,是需要shuffle的。 但极端情况下(1000个分区变成1个分区),这时如果将shuffle设置为false,父子RDD是窄依赖关系&…...