深度学习基础--CNN经典网络之InceptionV1研究与复现(pytorch)
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
前言
- InceptionV1是提出并行卷积结构,是CNN的经典网络之一;
- 本次任务是探究InceptionV1结构并进行复现实验;
- 欢迎收藏 + 关注,本人将会持续更新。
1、InceptionV1
理论知识
GoogLeNet首次出现在2014年ILSVRC 比赛中获得冠军。这次的版本通常称其为Inception V1。
InceptionV1特点:
- 有22层深,参数量为5M,同一时期的VGGNet性能和InceptionV1差不多,但是参数量大。
InceptionV1的核心单元是Inception Module,这里提出来卷积并行结构,实现了在同一层就可以提取不同特征,如下图a所示。

👀 👀 a图分析:
并行:同时进行运算。
1 * 1卷积结构:维度不变,主要用于降维或升维,减少参数量和计算复杂度。3 * 3,5 * 5卷积结构:维度不变,于提取更复杂的局部特征。最大池化层:维度不变,用于特征压缩。
上面三层均不改变维度,最后进行矩阵相加运算,并在通道数进行拼接([batch_size,C1+C2+C3+C4,H,W]).
但是,虽然增加这样的网络结构可以提升性能,但是面临计算了大的问题,故后面参考Network-in-Network的思想,使用1 * 1卷积核来降维,这样虽然加大了网络深度,但是也减少了参数量和计算量,网络结构如上图b所示。
Network-in-Network(NiN)是一种深度学习架构,它在2013年由Lin等人提出,旨在提高传统卷积神经网络(CNNs)的性能。NiN通过引入微小的多层感知器(MLP)来替代传统的线性滤波器(即标准卷积核),以此增加模型对输入数据的表达能力
举例说明:

假设:前一层的输出为100 * 100 * 128
- 经过256个
5 * 5卷积核的卷积层之后(stride=1,padding=2),输出的数据为100*100*256,其中,卷积参数为:5 * 5 * 128 * 256 + 256 = 8.192e9
假设:前一层参数先通过1 * 1卷积(降低了通道数,但是维度不变)后。在经过5 * 5的卷积层,最后输出为数据是:100 * 100 * 256,卷积参数:1 * 1 * 128 * 32 + 32 +32 * 5 * 5 * 256 + 256 = 2.048e9,计算量减少3/4.
给定一个卷积层,其参数总数可以通过以下公式计算:
- 权重参数数量 = K_h * K_w * C_in * C_out
- 偏置参数数量 = C_out
所以,总参数数量 = K_h * K_w * C_in * C_out + C_out
从上面可以看出,1 * 1卷积核的最大作用是降低输入特征通道,减少参数量与计算量。
在Inception Module中,基本由1*1卷积,3*3卷积,5*5卷积,3*3最大池化这四个基本单元组成,对四个基本单元进行不同尺度的信息,进行融合,得到更好的特征表现,这就是Inception Module的核心思想。
算法结构

黄色是头部,主要用于数据处理的,绿色是上面介绍的Inception Module结构。
注意:这个网络结构增加了两个辅助分支,作用是:
- 避免梯度消失;
- 将中间的某一层输出用作分类,起到模型融合作用。
详细网络结果如下

2、模型复现与实验
去掉两个辅助分支,只复现主要分支(详细请看网络结构),并进行实验,对猴痘病图片进行分类。
1、导入数据
1、导入库
import torch
import torch.nn as nn
import torchvision
import numpy as np
import os, PIL, pathlib # 设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"device
'cuda'
2、查看数据信息和导入数据
data_dir = "./data/"data_dir = pathlib.Path(data_dir)# 类别数量
classnames = [str(path).split("\\")[0] for path in os.listdir(data_dir)]classnames
['Monkeypox', 'Others']
3、展示数据
import matplotlib.pylab as plt
from PIL import Image # 获取文件名称
data_path_name = "./data/Monkeypox/"
data_path_list = [f for f in os.listdir(data_path_name) if f.endswith(('jpg', 'png'))]# 创建画板
fig, axes = plt.subplots(2, 8, figsize=(16, 6))for ax, img_file in zip(axes.flat, data_path_list):path_name = os.path.join(data_path_name, img_file)img = Image.open(path_name) # 打开# 显示ax.imshow(img)ax.axis('off')plt.show()

4、数据导入
from torchvision import transforms, datasets # 数据统一格式
img_height = 224
img_width = 224 data_tranforms = transforms.Compose([transforms.Resize([img_height, img_width]),transforms.ToTensor(),transforms.Normalize( # 归一化mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225] )
])# 加载所有数据
total_data = datasets.ImageFolder(root="./data/", transform=data_tranforms)
5、数据划分
# 大小 8 : 2
train_size = int(len(total_data) * 0.8)
test_size = len(total_data) - train_size train_data, test_data = torch.utils.data.random_split(total_data, [train_size, test_size])
6、动态加载数据
batch_size = 32 train_dl = torch.utils.data.DataLoader(train_data,batch_size=batch_size,shuffle=True
)test_dl = torch.utils.data.DataLoader(test_data,batch_size=batch_size,shuffle=False
)
# 查看数据维度
for data, labels in train_dl:print("data shape[N, C, H, W]: ", data.shape)print("labels: ", labels)break
data shape[N, C, H, W]: torch.Size([32, 3, 224, 224])
labels: tensor([1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1,0, 0, 0, 0, 1, 0, 0, 0])
2、构建InceptionV1
注释很详细,只复现主干。


import torch.nn.functional as F# Inception 主要网络结构可以概括为 头部 数据处理,Inception Module组合
# 这是对于Inception Module组合的封装
class Inception_block(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super().__init__()# 1 * 1self.part1 = nn.Sequential(nn.Conv2d(in_channels, ch1x1, kernel_size=1),nn.BatchNorm2d(ch1x1),nn.ReLU(inplace=True))# 1 * 1 + 3 * 3self.part2 = nn.Sequential(nn.Conv2d(in_channels, ch3x3red, kernel_size=1),nn.BatchNorm2d(ch3x3red),nn.ReLU(inplace=True),nn.Conv2d(ch3x3red, ch3x3, kernel_size=3, padding=1),nn.BatchNorm2d(ch3x3),nn.ReLU(inplace=True))# 1 * 1 + 5 * 5self.part3 = nn.Sequential(nn.Conv2d(in_channels, ch5x5red, kernel_size=1),nn.BatchNorm2d(ch5x5red),nn.ReLU(inplace=True),nn.Conv2d(ch5x5red, ch5x5, kernel_size=5, padding=2),nn.BatchNorm2d(ch5x5),nn.ReLU(inplace=True))# 3 * 3 maxPool + 1 * 1self.part4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),nn.Conv2d(in_channels, pool_proj, kernel_size=1),nn.BatchNorm2d(pool_proj),nn.ReLU(inplace=True))def forward(self, x):out1 = self.part1(x)out2 = self.part2(x)out3 = self.part3(x)out4 = self.part4(x)outs = [out1, out2, out3, out4]return torch.cat(outs, 1) # 按照第一个维度进行拼接, [batch_size,C1+C2+C3+C4,H,W]'''
定义Inception,核心就是 数据头处理,Inception Module组合
'''
class InceptionV1(nn.Module):def __init__(self):super().__init__()# 头数据处理self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.conv2 = nn.Conv2d(64, 64, kernel_size=1, stride=1, padding=0)self.conv3 = nn.Conv2d(64, 192, kernel_size=3, stride=1, padding=1)self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# Inception Mdoule叠加self.inception3a = Inception_block(192, 64, 96, 128, 16, 32, 32)self.inception3b = Inception_block(256, 128, 128, 192, 32, 96, 64)self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.inception4a = Inception_block(480, 192, 96, 208, 16, 48, 64)self.inception4b = Inception_block(512, 160, 112, 224, 24, 64, 64)self.inception4c = Inception_block(512, 128, 128, 256, 24, 64, 64)self.inception4d = Inception_block(512, 112, 144, 288, 32, 64, 64)self.inception4e = Inception_block(528, 256, 160, 320, 21, 128, 128)self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.inception5a = Inception_block(832, 256, 160, 320, 32, 128, 128)self.inception5b = nn.Sequential(Inception_block(832, 384, 192, 384, 48, 128, 128),nn.AvgPool2d(kernel_size=7, stride=1, padding=0), # 平均池化nn.Dropout(0.4) # 防止过拟合)# 全连接,用于分类self.classifier = nn.Sequential(nn.Linear(in_features=1024, out_features=1024),nn.ReLU(),nn.Linear(in_features=1024, out_features=len(classnames)),nn.Softmax(dim=1) # 用Softmax分类)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = self.maxpool1(x)x = self.conv2(x)x = F.relu(x)x = self.conv3(x)x = F.relu(x)x = self.maxpool2(x)x = self.inception3a(x)x = self.inception3b(x)x = self.maxpool3(x)x = self.inception4a(x)x = self.inception4b(x)x = self.inception4c(x)x = self.inception4d(x)x = self.inception4e(x)x = self.maxpool4(x)x = self.inception5a(x)x = self.inception5b(x)x = torch.flatten(x, start_dim=1) # 展开x = self.classifier(x)return xmodel = InceptionV1().to(device)
model(torch.randn(32, 3, 224, 224).to(device)).shape
torch.Size([32, 2])
# 显示网络结构
import torchsummarytorchsummary.summary(model, (3, 224, 224))
print(model)
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 64, 112, 112] 9,472MaxPool2d-2 [-1, 64, 56, 56] 0Conv2d-3 [-1, 64, 56, 56] 4,160Conv2d-4 [-1, 192, 56, 56] 110,784MaxPool2d-5 [-1, 192, 28, 28] 0Conv2d-6 [-1, 64, 28, 28] 12,352BatchNorm2d-7 [-1, 64, 28, 28] 128ReLU-8 [-1, 64, 28, 28] 0Conv2d-9 [-1, 96, 28, 28] 18,528BatchNorm2d-10 [-1, 96, 28, 28] 192ReLU-11 [-1, 96, 28, 28] 0Conv2d-12 [-1, 128, 28, 28] 110,720BatchNorm2d-13 [-1, 128, 28, 28] 256ReLU-14 [-1, 128, 28, 28] 0Conv2d-15 [-1, 16, 28, 28] 3,088BatchNorm2d-16 [-1, 16, 28, 28] 32ReLU-17 [-1, 16, 28, 28] 0Conv2d-18 [-1, 32, 28, 28] 12,832BatchNorm2d-19 [-1, 32, 28, 28] 64ReLU-20 [-1, 32, 28, 28] 0MaxPool2d-21 [-1, 192, 28, 28] 0Conv2d-22 [-1, 32, 28, 28] 6,176BatchNorm2d-23 [-1, 32, 28, 28] 64ReLU-24 [-1, 32, 28, 28] 0Inception_block-25 [-1, 256, 28, 28] 0Conv2d-26 [-1, 128, 28, 28] 32,896BatchNorm2d-27 [-1, 128, 28, 28] 256ReLU-28 [-1, 128, 28, 28] 0Conv2d-29 [-1, 128, 28, 28] 32,896BatchNorm2d-30 [-1, 128, 28, 28] 256ReLU-31 [-1, 128, 28, 28] 0Conv2d-32 [-1, 192, 28, 28] 221,376BatchNorm2d-33 [-1, 192, 28, 28] 384ReLU-34 [-1, 192, 28, 28] 0Conv2d-35 [-1, 32, 28, 28] 8,224BatchNorm2d-36 [-1, 32, 28, 28] 64ReLU-37 [-1, 32, 28, 28] 0Conv2d-38 [-1, 96, 28, 28] 76,896BatchNorm2d-39 [-1, 96, 28, 28] 192ReLU-40 [-1, 96, 28, 28] 0MaxPool2d-41 [-1, 256, 28, 28] 0Conv2d-42 [-1, 64, 28, 28] 16,448BatchNorm2d-43 [-1, 64, 28, 28] 128ReLU-44 [-1, 64, 28, 28] 0Inception_block-45 [-1, 480, 28, 28] 0MaxPool2d-46 [-1, 480, 14, 14] 0Conv2d-47 [-1, 192, 14, 14] 92,352BatchNorm2d-48 [-1, 192, 14, 14] 384ReLU-49 [-1, 192, 14, 14] 0Conv2d-50 [-1, 96, 14, 14] 46,176BatchNorm2d-51 [-1, 96, 14, 14] 192ReLU-52 [-1, 96, 14, 14] 0Conv2d-53 [-1, 208, 14, 14] 179,920BatchNorm2d-54 [-1, 208, 14, 14] 416ReLU-55 [-1, 208, 14, 14] 0Conv2d-56 [-1, 16, 14, 14] 7,696BatchNorm2d-57 [-1, 16, 14, 14] 32ReLU-58 [-1, 16, 14, 14] 0Conv2d-59 [-1, 48, 14, 14] 19,248BatchNorm2d-60 [-1, 48, 14, 14] 96ReLU-61 [-1, 48, 14, 14] 0MaxPool2d-62 [-1, 480, 14, 14] 0Conv2d-63 [-1, 64, 14, 14] 30,784BatchNorm2d-64 [-1, 64, 14, 14] 128ReLU-65 [-1, 64, 14, 14] 0Inception_block-66 [-1, 512, 14, 14] 0Conv2d-67 [-1, 160, 14, 14] 82,080BatchNorm2d-68 [-1, 160, 14, 14] 320ReLU-69 [-1, 160, 14, 14] 0Conv2d-70 [-1, 112, 14, 14] 57,456BatchNorm2d-71 [-1, 112, 14, 14] 224ReLU-72 [-1, 112, 14, 14] 0Conv2d-73 [-1, 224, 14, 14] 226,016BatchNorm2d-74 [-1, 224, 14, 14] 448ReLU-75 [-1, 224, 14, 14] 0Conv2d-76 [-1, 24, 14, 14] 12,312BatchNorm2d-77 [-1, 24, 14, 14] 48ReLU-78 [-1, 24, 14, 14] 0Conv2d-79 [-1, 64, 14, 14] 38,464BatchNorm2d-80 [-1, 64, 14, 14] 128ReLU-81 [-1, 64, 14, 14] 0MaxPool2d-82 [-1, 512, 14, 14] 0Conv2d-83 [-1, 64, 14, 14] 32,832BatchNorm2d-84 [-1, 64, 14, 14] 128ReLU-85 [-1, 64, 14, 14] 0Inception_block-86 [-1, 512, 14, 14] 0Conv2d-87 [-1, 128, 14, 14] 65,664BatchNorm2d-88 [-1, 128, 14, 14] 256ReLU-89 [-1, 128, 14, 14] 0Conv2d-90 [-1, 128, 14, 14] 65,664BatchNorm2d-91 [-1, 128, 14, 14] 256ReLU-92 [-1, 128, 14, 14] 0Conv2d-93 [-1, 256, 14, 14] 295,168BatchNorm2d-94 [-1, 256, 14, 14] 512ReLU-95 [-1, 256, 14, 14] 0Conv2d-96 [-1, 24, 14, 14] 12,312BatchNorm2d-97 [-1, 24, 14, 14] 48ReLU-98 [-1, 24, 14, 14] 0Conv2d-99 [-1, 64, 14, 14] 38,464BatchNorm2d-100 [-1, 64, 14, 14] 128ReLU-101 [-1, 64, 14, 14] 0MaxPool2d-102 [-1, 512, 14, 14] 0Conv2d-103 [-1, 64, 14, 14] 32,832BatchNorm2d-104 [-1, 64, 14, 14] 128ReLU-105 [-1, 64, 14, 14] 0Inception_block-106 [-1, 512, 14, 14] 0Conv2d-107 [-1, 112, 14, 14] 57,456BatchNorm2d-108 [-1, 112, 14, 14] 224ReLU-109 [-1, 112, 14, 14] 0Conv2d-110 [-1, 144, 14, 14] 73,872BatchNorm2d-111 [-1, 144, 14, 14] 288ReLU-112 [-1, 144, 14, 14] 0Conv2d-113 [-1, 288, 14, 14] 373,536BatchNorm2d-114 [-1, 288, 14, 14] 576ReLU-115 [-1, 288, 14, 14] 0Conv2d-116 [-1, 32, 14, 14] 16,416BatchNorm2d-117 [-1, 32, 14, 14] 64ReLU-118 [-1, 32, 14, 14] 0Conv2d-119 [-1, 64, 14, 14] 51,264BatchNorm2d-120 [-1, 64, 14, 14] 128ReLU-121 [-1, 64, 14, 14] 0MaxPool2d-122 [-1, 512, 14, 14] 0Conv2d-123 [-1, 64, 14, 14] 32,832BatchNorm2d-124 [-1, 64, 14, 14] 128ReLU-125 [-1, 64, 14, 14] 0Inception_block-126 [-1, 528, 14, 14] 0Conv2d-127 [-1, 256, 14, 14] 135,424BatchNorm2d-128 [-1, 256, 14, 14] 512ReLU-129 [-1, 256, 14, 14] 0Conv2d-130 [-1, 160, 14, 14] 84,640BatchNorm2d-131 [-1, 160, 14, 14] 320ReLU-132 [-1, 160, 14, 14] 0Conv2d-133 [-1, 320, 14, 14] 461,120BatchNorm2d-134 [-1, 320, 14, 14] 640ReLU-135 [-1, 320, 14, 14] 0Conv2d-136 [-1, 21, 14, 14] 11,109BatchNorm2d-137 [-1, 21, 14, 14] 42ReLU-138 [-1, 21, 14, 14] 0Conv2d-139 [-1, 128, 14, 14] 67,328BatchNorm2d-140 [-1, 128, 14, 14] 256ReLU-141 [-1, 128, 14, 14] 0MaxPool2d-142 [-1, 528, 14, 14] 0Conv2d-143 [-1, 128, 14, 14] 67,712BatchNorm2d-144 [-1, 128, 14, 14] 256ReLU-145 [-1, 128, 14, 14] 0Inception_block-146 [-1, 832, 14, 14] 0MaxPool2d-147 [-1, 832, 7, 7] 0Conv2d-148 [-1, 256, 7, 7] 213,248BatchNorm2d-149 [-1, 256, 7, 7] 512ReLU-150 [-1, 256, 7, 7] 0Conv2d-151 [-1, 160, 7, 7] 133,280BatchNorm2d-152 [-1, 160, 7, 7] 320ReLU-153 [-1, 160, 7, 7] 0Conv2d-154 [-1, 320, 7, 7] 461,120BatchNorm2d-155 [-1, 320, 7, 7] 640ReLU-156 [-1, 320, 7, 7] 0Conv2d-157 [-1, 32, 7, 7] 26,656BatchNorm2d-158 [-1, 32, 7, 7] 64ReLU-159 [-1, 32, 7, 7] 0Conv2d-160 [-1, 128, 7, 7] 102,528BatchNorm2d-161 [-1, 128, 7, 7] 256ReLU-162 [-1, 128, 7, 7] 0MaxPool2d-163 [-1, 832, 7, 7] 0Conv2d-164 [-1, 128, 7, 7] 106,624BatchNorm2d-165 [-1, 128, 7, 7] 256ReLU-166 [-1, 128, 7, 7] 0Inception_block-167 [-1, 832, 7, 7] 0Conv2d-168 [-1, 384, 7, 7] 319,872BatchNorm2d-169 [-1, 384, 7, 7] 768ReLU-170 [-1, 384, 7, 7] 0Conv2d-171 [-1, 192, 7, 7] 159,936BatchNorm2d-172 [-1, 192, 7, 7] 384ReLU-173 [-1, 192, 7, 7] 0Conv2d-174 [-1, 384, 7, 7] 663,936BatchNorm2d-175 [-1, 384, 7, 7] 768ReLU-176 [-1, 384, 7, 7] 0Conv2d-177 [-1, 48, 7, 7] 39,984BatchNorm2d-178 [-1, 48, 7, 7] 96ReLU-179 [-1, 48, 7, 7] 0Conv2d-180 [-1, 128, 7, 7] 153,728BatchNorm2d-181 [-1, 128, 7, 7] 256ReLU-182 [-1, 128, 7, 7] 0MaxPool2d-183 [-1, 832, 7, 7] 0Conv2d-184 [-1, 128, 7, 7] 106,624BatchNorm2d-185 [-1, 128, 7, 7] 256ReLU-186 [-1, 128, 7, 7] 0Inception_block-187 [-1, 1024, 7, 7] 0AvgPool2d-188 [-1, 1024, 1, 1] 0Dropout-189 [-1, 1024, 1, 1] 0Linear-190 [-1, 1024] 1,049,600ReLU-191 [-1, 1024] 0Linear-192 [-1, 2] 2,050Softmax-193 [-1, 2] 0
================================================================
Total params: 6,998,081
Trainable params: 6,998,081
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 69.56
Params size (MB): 26.70
Estimated Total Size (MB): 96.83
----------------------------------------------------------------
InceptionV1((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))(maxpool1): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(conv2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))(conv3): Conv2d(64, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(maxpool2): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(inception3a): Inception_block((part1): Sequential((0): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(part2): Sequential((0): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(96, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part3): Sequential((0): Conv2d(192, 16, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception3b): Inception_block((part1): Sequential((0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(part2): Sequential((0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part3): Sequential((0): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(32, 96, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(maxpool3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(inception4a): Inception_block((part1): Sequential((0): Conv2d(480, 192, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(part2): Sequential((0): Conv2d(480, 96, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(96, 208, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(208, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part3): Sequential((0): Conv2d(480, 16, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(16, 48, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(480, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception4b): Inception_block((part1): Sequential((0): Conv2d(512, 160, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(part2): Sequential((0): Conv2d(512, 112, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(112, 224, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part3): Sequential((0): Conv2d(512, 24, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(24, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception4c): Inception_block((part1): Sequential((0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(part2): Sequential((0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part3): Sequential((0): Conv2d(512, 24, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(24, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception4d): Inception_block((part1): Sequential((0): Conv2d(512, 112, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(part2): Sequential((0): Conv2d(512, 144, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(144, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part3): Sequential((0): Conv2d(512, 32, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception4e): Inception_block((part1): Sequential((0): Conv2d(528, 256, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(part2): Sequential((0): Conv2d(528, 160, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(160, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part3): Sequential((0): Conv2d(528, 21, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(21, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(21, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(528, 128, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(maxpool4): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(inception5a): Inception_block((part1): Sequential((0): Conv2d(832, 256, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(part2): Sequential((0): Conv2d(832, 160, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(160, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part3): Sequential((0): Conv2d(832, 32, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(32, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception5b): Sequential((0): Inception_block((part1): Sequential((0): Conv2d(832, 384, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(part2): Sequential((0): Conv2d(832, 192, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part3): Sequential((0): Conv2d(832, 48, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(48, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(part4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(1): AvgPool2d(kernel_size=7, stride=1, padding=0)(2): Dropout(p=0.4, inplace=False))(classifier): Sequential((0): Linear(in_features=1024, out_features=1024, bias=True)(1): ReLU()(2): Linear(in_features=1024, out_features=2, bias=True)(3): Softmax(dim=1))
)
3、模型训练
1、构建训练集
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)batch_size = len(dataloader)train_acc, train_loss = 0, 0 for X, y in dataloader:X, y = X.to(device), y.to(device)# 训练pred = model(X)loss = loss_fn(pred, y)# 梯度下降法optimizer.zero_grad()loss.backward()optimizer.step()# 记录train_loss += loss.item()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_acc /= sizetrain_loss /= batch_sizereturn train_acc, train_loss
2、构建测试集
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)batch_size = len(dataloader)test_acc, test_loss = 0, 0 with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_loss += loss.item()test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_acc /= sizetest_loss /= batch_sizereturn test_acc, test_loss
3、设置超参数
loss_fn = nn.CrossEntropyLoss() # 损失函数
learn_lr = 1e-4 # 超参数
optimizer = torch.optim.Adam(model.parameters(), lr=learn_lr) # 优化器
4、模型训练
train_acc = []
train_loss = []
test_acc = []
test_loss = []epoches = 40for i in range(epoches):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 输出template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}')print(template.format(i + 1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))print("Done")
Epoch: 1, Train_acc:64.2%, Train_loss:0.638, Test_acc:63.4%, Test_loss:0.650
Epoch: 2, Train_acc:70.9%, Train_loss:0.582, Test_acc:71.3%, Test_loss:0.584
Epoch: 3, Train_acc:77.0%, Train_loss:0.537, Test_acc:61.1%, Test_loss:0.680
Epoch: 4, Train_acc:79.0%, Train_loss:0.517, Test_acc:78.3%, Test_loss:0.519
Epoch: 5, Train_acc:81.8%, Train_loss:0.485, Test_acc:83.9%, Test_loss:0.475
Epoch: 6, Train_acc:82.6%, Train_loss:0.480, Test_acc:76.9%, Test_loss:0.533
Epoch: 7, Train_acc:87.4%, Train_loss:0.436, Test_acc:82.1%, Test_loss:0.483
Epoch: 8, Train_acc:87.6%, Train_loss:0.433, Test_acc:86.0%, Test_loss:0.433
Epoch: 9, Train_acc:89.5%, Train_loss:0.415, Test_acc:85.3%, Test_loss:0.456
Epoch:10, Train_acc:88.9%, Train_loss:0.425, Test_acc:87.9%, Test_loss:0.427
Epoch:11, Train_acc:89.6%, Train_loss:0.412, Test_acc:86.0%, Test_loss:0.442
Epoch:12, Train_acc:92.5%, Train_loss:0.388, Test_acc:89.0%, Test_loss:0.418
Epoch:13, Train_acc:91.7%, Train_loss:0.398, Test_acc:88.3%, Test_loss:0.424
Epoch:14, Train_acc:89.8%, Train_loss:0.414, Test_acc:86.2%, Test_loss:0.443
Epoch:15, Train_acc:91.5%, Train_loss:0.397, Test_acc:89.7%, Test_loss:0.414
Epoch:16, Train_acc:94.3%, Train_loss:0.369, Test_acc:89.7%, Test_loss:0.411
Epoch:17, Train_acc:93.3%, Train_loss:0.376, Test_acc:86.7%, Test_loss:0.445
Epoch:18, Train_acc:94.3%, Train_loss:0.369, Test_acc:90.4%, Test_loss:0.404
Epoch:19, Train_acc:93.9%, Train_loss:0.370, Test_acc:90.9%, Test_loss:0.401
Epoch:20, Train_acc:95.3%, Train_loss:0.359, Test_acc:90.4%, Test_loss:0.405
Epoch:21, Train_acc:94.7%, Train_loss:0.363, Test_acc:93.2%, Test_loss:0.378
Epoch:22, Train_acc:95.2%, Train_loss:0.360, Test_acc:90.2%, Test_loss:0.415
Epoch:23, Train_acc:95.6%, Train_loss:0.356, Test_acc:92.3%, Test_loss:0.388
Epoch:24, Train_acc:95.9%, Train_loss:0.355, Test_acc:90.7%, Test_loss:0.400
Epoch:25, Train_acc:93.2%, Train_loss:0.377, Test_acc:93.0%, Test_loss:0.385
Epoch:26, Train_acc:95.2%, Train_loss:0.358, Test_acc:90.9%, Test_loss:0.404
Epoch:27, Train_acc:96.1%, Train_loss:0.353, Test_acc:93.7%, Test_loss:0.380
Epoch:28, Train_acc:95.2%, Train_loss:0.359, Test_acc:87.4%, Test_loss:0.440
Epoch:29, Train_acc:95.5%, Train_loss:0.358, Test_acc:92.8%, Test_loss:0.394
Epoch:30, Train_acc:96.4%, Train_loss:0.348, Test_acc:88.3%, Test_loss:0.432
Epoch:31, Train_acc:96.6%, Train_loss:0.347, Test_acc:93.2%, Test_loss:0.385
Epoch:32, Train_acc:96.4%, Train_loss:0.347, Test_acc:93.7%, Test_loss:0.383
Epoch:33, Train_acc:96.3%, Train_loss:0.350, Test_acc:88.3%, Test_loss:0.434
Epoch:34, Train_acc:95.6%, Train_loss:0.356, Test_acc:91.1%, Test_loss:0.401
Epoch:35, Train_acc:95.3%, Train_loss:0.360, Test_acc:92.8%, Test_loss:0.391
Epoch:36, Train_acc:95.2%, Train_loss:0.360, Test_acc:91.8%, Test_loss:0.399
Epoch:37, Train_acc:95.4%, Train_loss:0.358, Test_acc:90.4%, Test_loss:0.404
Epoch:38, Train_acc:95.4%, Train_loss:0.359, Test_acc:91.4%, Test_loss:0.397
Epoch:39, Train_acc:97.0%, Train_loss:0.344, Test_acc:93.2%, Test_loss:0.385
Epoch:40, Train_acc:97.3%, Train_loss:0.338, Test_acc:91.6%, Test_loss:0.400
Done
5、结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息epochs_range = range(epoches)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training= Loss')
plt.show()

效果不错
3、参考资料
经典神经网络论文超详细解读(三)——GoogLeNet InceptionV1学习笔记(翻译+精读+代码复现)_googlenet论文-CSDN博客
相关文章:
)
深度学习基础--CNN经典网络之InceptionV1研究与复现(pytorch)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 InceptionV1是提出并行卷积结构,是CNN的经典网络之一;本次任务是探究InceptionV1结构并进行复现实验;欢迎收藏 关注…...

用 Vue 3 + D3.js 实现动态数据流图
文章目录 一、项目背景与功能概览二、项目准备与依赖安装2.1 安装 Vue 3 项目2.2 安装 D3.js2.3 项目结构 三、实现动态数据流图3.1 创建 DataFlowChart 组件3.2 动态更新数据流3.2.1 动态更新边和节点位置3.2.2 动画效果 四、节点拖拽与编辑功能实现4.1 添加节点拖拽功能4.2 编…...
)
46、Spring Boot 详细讲义(三)
五、Spring Boot 与 Web 开发 1. 简介 Spring Boot 是基于 Spring Framework 开发的一个框架,旨在简化配置,快速构建应用。它内嵌 Tomcat 等 servlet 容器,支持 RESTful API 开发,处理静态资源,以及集成视图层技术如 Thymeleaf 和 Freemarker。 2. Spring MVC 集成 Sp…...

热门面试题第15天|最大二叉树 合并二叉树 验证二叉搜索树 二叉搜索树中的搜索
654.最大二叉树 力扣题目地址(opens new window) 给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下: 二叉树的根是数组中的最大元素。左子树是通过数组中最大值左边部分构造出的最大二叉树。右子树是通过数组中最大值右边部分构造出的最大…...

为了避免unboundLocalError和为什么X的值一直不变呢?
## 1.为了避免unboundLocalError 发生unboundLocalError! def generate_integer(level):if level 1:X randint(1,9)return X这里出错的原因在于,一旦if 后面的条件没有成立,然后X根本没出生,然后你去使用它,这是有…...
详解:从零开始掌握(1))
Express中间件(Middleware)详解:从零开始掌握(1)
1. 中间件是什么? 想象中间件就像一个"加工流水线",请求(Request)从进入服务器到返回响应(Response)的过程中,会经过一个个"工作站"进行处理。 简单定义:中间件是能够访问请求对象(req)、响应对象(res)和下…...

Linux升级gcc版本
目录 1.安装 scl 工具集 2.安装新版本gcc 3.启用新版本 gcc 4.将启动新版本gcc指令写入配置文件 本文主要讲述如何去升级 linux 操作系统下的 gcc 编译器版本。 1.安装 scl 工具集 sudo yum install centos-release-scl scl-utils-build 由于作者已经安装过,…...
什么是UX(User experience)?)
【概念】什么是UI(User interface)什么是UX(User experience)?
1. 软件生命周期管理 (Software Life Cycle Management) 解释: 中文: 软件生命周期管理是指从软件规划、设计、开发、测试、部署到后续维护甚至退役的整个过程。English: Software Life Cycle Management refers to the systematic process of plannin…...

【GIT】git pull --rebase 功能解析
1. git pull 命令基础 git pull 是一个常用的 Git 命令,用于从远程仓库获取最新的更改,并尝试将这些更改合并到当前分支中。这通常涉及两个步骤:首先,git fetch 命令从远程仓库下载最新的更改;然后,git me…...

难度偏低,25西电人工智能学院821、833、834考研录取情况
1、人工智能学院各个方向 2、人工智能学院近三年复试分数线对比 学长、学姐分析 由表可看出: 1、智能院25年院线相对于24年院线 全部专业下降比较多,其中控制科学与工程下降20分,计算机科学与技术下降20分,计算机技术[专硕]下降…...

L2-051 满树的遍历
L2-051 满树的遍历 - 团体程序设计天梯赛-练习集 (pintia.cn) 题解 数据结构选择 为了表示树的结构,我们可以使用邻接表。邻接表是一种常用的图和树的表示方法,它能够高效地存储每个节点的子节点信息。在本题中,我们可以使用一个数组 g&am…...

2025年电子电气与新材料国际学术会议
重要信息 官网:www.iceenm.org(点击了解详情) 时间:2025年4月25-27日 地点:中国-杭州 部分介绍 征稿主题 电子电气 新材料 电力电子器件和系统设计 可再生能源与电网集成技术 下一代半导体…...
)
数字人:打破次元壁,从娱乐舞台迈向教育新课堂(4/10)
摘要:数字人正从娱乐领域的璀璨明星跨界到教育领域的智慧导师,展现出无限潜力。从虚拟偶像、影视游戏到直播短视频,数字人在娱乐产业中大放异彩,创造巨大商业价值。在教育领域,数字人助力个性化学习、互动课堂和虚拟实…...

【Hyperlane 】轻松实现大文件分块上传!
【Hyperlane 】轻松实现大文件分块上传! 痛点直击:大文件上传不再是难题 在云存储、音视频处理、文件协作等场景中,大文件上传常面临中断重试成本高、内存占用大、网络不稳定等挑战。传统方案要么复杂笨重,要么性能瓶颈明显。 现…...

【深入浅出 Git】:从入门到精通
这篇文章介绍下版本控制器。 【深入浅出 Git】:从入门到精通 Git是什么Git的安装Git的基本操作建立本地仓库配置本地仓库认识工作区、暂存区、版本库的概念添加文件添加文件到暂存区提交文件到版本库提交文件演示 理解.git目录中的文件HEAD指针与暂存区objects对象 …...

APP动态交互原型实例|墨刀变量控制+条件判断教程
引言 不同行业的产品经理在绘制原型图时,拥有不同的呈现方式。对于第三方软件技术服务公司的产品经理来说,高保真动态交互原型不仅可以在开发前验证交互逻辑,还能为甲方客户带来更直观、真实的体验。 本文第三部分将分享一个实战案例&#…...

第二节:React 基础篇-受控组件 vs 非受控组件
一、场景题:设计一个实时搜索输入框,说明选择依据 受控组件 vs 非受控组件 核心区别 特征受控组件非受控组件数据管理由React状态(state)控制通过DOM元素(ref)直接访问更新时机每次输入触发onChange提交…...

电脑的usb端口电压会大于开发板需要的电压吗
电脑的USB端口电压通常不会大于开发板所需的电压,以下是详细解释: 1. USB端口电压标准 根据USB规范,USB接口的标称输出电压为5V。实际测量时,USB接口的输出电压会略有偏差,通常在4.75V到5.25V之间。USB 2.0和USB 3.0…...

软件界面设计:打造用户喜爱的交互体验
在数字化飞速发展的当下,软件已渗透进生活的各个角落,从日常使用的社交、购物软件,到专业领域的办公、设计软件,其重要性不言而喻。而软件界面作为用户与软件交互的桥梁,直接决定了用户对软件的第一印象与使用体验。出…...

7、linux基础操作2
一、linux调度 1、crontab [选项] 1.1、了解 定时任务调度:指每隔指定的时间,执行特定的命令或程序。 基本语法:crontab [选项] 常用选项: e: 编辑定时任务l:查询定时任务r:删除当前用户的所有定时任务…...

大数据管理专业想求职数据分析岗,如何提升面试通过率?
从技能到策略,解锁高薪岗位的六大核心逻辑 在数字化浪潮席卷全球的今天,数据分析岗位的竞争愈发激烈。对于大数据管理专业的学生而言,如何从众多求职者中脱颖而出?本文结合行业趋势与实战经验,提炼出提升面试通过率的…...

移动端六大语言速记:第15部分 - 其他方面
移动端六大语言速记:第15部分 - 其他方面 本文将对比Java、Kotlin、Flutter(Dart)、Python、ArkTS和Swift这六种移动端开发语言的其他重要特性,帮助开发者全面了解各语言的独特优势和应用场景。 15.1 语言特有功能 各语言特有功能对比: 语言特有功能描述Java注解(Annotat…...

3.1.3.4 Spring Boot使用使用Listener组件
在Spring Boot中,使用Listener组件可以监听和响应应用中的各种事件。首先,创建自定义事件类CustomEvent,继承自ApplicationEvent。然后,创建事件监听器CustomEventListener,使用EventListener注解标记监听方法。接下来…...

基于关键字定位的自动化PDF合同拆分
需求背景: 问题描述: 我有一份包含多份合同的PDF文件,需要将这些合同分开并进行解析。 传统方法(如以固定页数作为分割点)不够灵活,无法满足需求。 现有方法的不足: 网上找到的工具大多依赖手动…...

ssh连接远程Host key verification failed.
问题描述 在对已部署的项目进行维护过程中,遇到的一个小问题,记录一下。 SSH连接云服务器ssh xxx云服务器IP地址,提示: The authenticity of host xxxxxx (xx.xxx.123.321) cant be established. ECDSA key fingerprint is SHA…...

Matlab 汽车ABS的bangbang控制和模糊PID控制
1、内容简介 Matlab 197-汽车ABS的bangbang控制和模糊PID控制 可以交流、咨询、答疑 2、内容说明 略 摘要:本文旨在设计一种利用模糊控制理论优化的pid控制器,控制abs系统,达到对滑移率最佳控制范围的要求 ,所提出的方案采用级联…...

kotlin的takeIf使用
takeIf用于判断指定对象是否满足条件,满足就返回该对象自身,不满足返回null。因为可以返回对象自身,所以可以用作链式调用,以简化代码,又因takeIf可能返回空,所以常常和let结合使用,示例如下&am…...
)
MySQL 进阶 - 2 ( 9000 字详解)
一: SQL 优化 1.1 插入数据 1.1.1 批量插入 单条 INSERT 语句执行时,需经历语法解析、事务提交、磁盘 I/O 等多个步骤。批量插入将多条数据合并为一条 SQL,能够减少网络通信和事务开销。 -- 单条插入(低效) INSERT…...

Devops之GitOps:什么是Gitops,以及它有什么优势
GitOps 定义 GitOps 是一种基于版本控制系统(如 Git)的运维实践,将 Git 作为基础设施和应用程序的唯一事实来源。通过声明式配置,系统自动同步 Git 仓库中的期望状态到实际运行环境,实现持续交付和自动化运维。其核心…...

VSCode和Fitten Code
提示:本文为学习记录,若有错误,请联系作者。 文章目录 一、离线安装二、在线安装总结 一、离线安装 访问 Open VSX 镜像站 打开 https://open-vsx.org,搜索 Fitten Code 点击“从VSIX安装”,选择下载的VSIX即可。安装…...

在 Visual Studio Code 中安装 Python 环境
在 Visual Studio Code 中安装 Python 环境 1. 安装 Visual Studio Code 首先,下载并安装 Visual Studio Code(VS Code): 下载链接:Visual Studio Code 官网安装步骤:按照下载页面的说明进行安装。 2. …...

[问题帖] vscode 重启远程终端
原理 有的时候,在vscode 远程ssh连接到服务器的时候,可能遇到需要重启终端才能生效的配置,比如add group的时候,而此时无论你是关闭vscode终端重启,还是reload窗口都是没用的。 因为不管你本地是否连接了远程的vscode服…...

PostgreSQL技术大讲堂 - 第86讲:数据安全之--data_checksums天使与魔鬼
PostgreSQL技术大讲堂 - 第86讲,主题:数据安全之--data_checksums天使与魔鬼 1、data_checksums特性 2、避开DML规则,嫁接非法数据并合法化 3、避开约束规则,嫁接非法数据到表中 4、避开数据检查,读取坏块中的数据…...

No staged files match any configured task
我在拉取一个新项目的时候,进行 git commit 的时候就出现了这个问题 然后我现在来说一下我出现这个问题的解决思路 我们点击 “显示命令输出” 我们把第二行的错误 subject may not be empty [subject-empty] 复制搜索一下 这是其他人写的 博客:subje…...

Sqlite3 查看db文件
以下是一些 SQLite3 常用命令的整理,涵盖数据库操作、表管理、数据查询等场景: 1. 数据库连接与退出 打开/创建数据库:sqlite3 filename.db # 打开或创建数据库文件退出 SQLite3 命令行:.exit # 退出 .quit …...

【leetcode hot 100 152】乘积最大子数组
错误解法:db[i]表示以i结尾的最大的非空连续,动态规划:dp[i] Math.max(nums[i], nums[i] * dp[i - 1]); class Solution {public int maxProduct(int[] nums) {int n nums.length;int[] dp new int[n]; // db[i]表示以i结尾的最大的非空连…...

微信小程序实时日志记录-接口监控
文章目录 微信小程序如何抓取日志,分析用户异常问题可查看用户具体页面行为操作web体验分析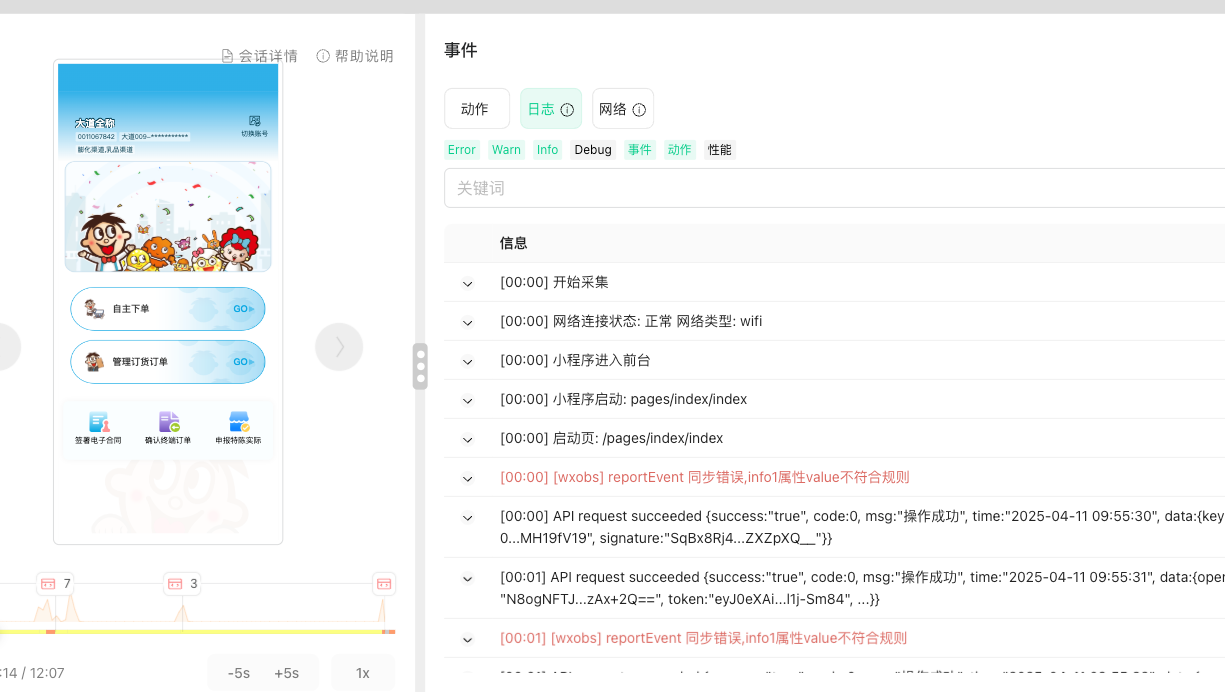 腾讯小程序平台,提供了非常好用的,。 web分析工…...

【C++刷题】二叉树基础OJ题
📝前言说明: 本专栏主要记录本人的基础算法学习以及刷题记录,使用语言为C。 每道题我会给出LeetCode上的题号(如果有题号),题目,以及最后通过的代码。没有题号的题目大多来自牛客网。对于题目的…...

CSS高级技巧
目录 一、精灵图 二、字体图标 三、CSS制作三角形 四、CSS用户界面样式 1、鼠标样式 cursor 2、轮廓线 outline 3、防止拖拽文本域 resize 五、vertical-align 属性 六、溢出的文字省略号显示 1、单行文本溢出显示省略号 2、多行文本溢出显示省略号 七、常见布局技…...

70. 爬楼梯:动态规划
题目来源 70. 爬楼梯 - 力扣(LeetCode) 题目描述 思路 1.观察每个较少的台阶的方法 2.dp[0,1,2,3,5,8,13]---->dp[i]表示爬上第i阶的方法数 3.观察dp:dp[i]dp[i-1]dp[i-2]; 代码 public int climbStairs(int n) {int[] dp new int…...

使用治疗前MR图像预测脑膜瘤Ki-67的多模态深度学习模型
大家好,我是带我去滑雪! 脑膜瘤是一种常见的脑部肿瘤,Ki-67作为肿瘤细胞增殖的标志物,对于评估肿瘤的生物学行为、预后以及治疗方案的制定具有至关重要的作用。然而,传统的Ki-67检测依赖于组织学切片和免疫组化染色等方…...

Skynet.socket 函数族使用详解
目录 Skynet.socket 函数族使用详解核心功能分类一、TCP 连接管理1. 监听端口2. 建立连接3. 关闭连接 二、数据读写操作1. 阻塞式读取2. 写入数据2.1 socket.write(fd, data) 的返回值2.2 示例代码2.3 关键注意事项2.4 与其他函数的区别2.5 底层原理2.6 总结 三、UDP 处理1. 创…...

Python signal 模块详解:优雅处理异步事件
诸神缄默不语-个人技术博文与视频目录 在 Linux 或类 Unix 系统中,信号(Signal)是一种用于进程间通信的机制,允许操作系统或其他进程向目标进程发送异步通知。 Python 的 signal 模块提供了对这些信号的访问和处理能力࿰…...

[LeetCode 189] 轮转数组
[LeetCode 189] 轮转数组 题目描述: 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 示例 2: 输入:nums [-1,-100,3,99], k 2 …...
 << “中文测试“; 乱码问题)
【Qt】qDebug() << “中文测试“; 乱码问题
环境 Qt Creator版本:4.7.1 编译器:MSVC2015_32bit 解法一 在.pro文件中添加 msvc:QMAKE_CXXFLAGS -execution-charset:utf-8注意: 1、需要清理项目,并重新qmake,然后构建。 测试项目下载:https://do…...

解析Java根基:Object类核心方法
Object类常见方法解析 在Java编程中,Object类是所有类的根类,它包含了许多实用的方法,这些方法在不同的场景下发挥着重要作用。下面我们来详细了解一下Object类中的一些常见方法。 1. toString方法 toString方法是用于将对象转换为字符串表…...

最近在工作中感受到了设计模式的重要性
之前了解设计模式:只是应付一下面试 在之前一年多的工作中也没遇到使用场景 最近在搭建验证环境的时候,才发现这玩意这么重要 首先是设计模式的使用场景一定是在很复杂繁琐的场景下进行的 之所以说是复杂/繁琐的场景,因为一些场景也许逻辑不难…...

Docker 镜像、容器与数据卷的高效管理:最佳实践与自动化脚本20250411
Docker 镜像、容器与数据卷的高效管理:最佳实践与自动化脚本 引言 在现代软件开发中,容器化技术正变得越来越重要。Docker 作为容器化的代表工具,在各大企业中得到了广泛的应用。然而,随着容器化应用的增多,如何高效…...
)
[UEC++]UE5C++各类变量相关知识及其API(更新中)
基础变量 UE自己定义的目的:1.跨平台;2.兼容反射;3.方便宏替换 FString 基础赋值与初始化 遍历与内存 迭代器访问 清除系列操作 合并 插入与移除 RemoveFromStart是从开头看,没有则移除失败返回false; RemoveFromEnd是…...

C++中的设计模式
设计模式是软件工程中用于解决常见问题的可复用解决方案。它们提供了一种标准化的方法来设计和实现软件系统,从而提高代码的可维护性、可扩展性和可重用性。C 是一种支持多种编程范式(如面向对象、泛型编程等)的语言,因此可以方便…...