Kubernetes集群环境搭建与初始化
1.Kubernetes简介:
Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
在Kubernetes中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
1.1总体架构:
Kubernetes的架构包括以下主要组件:
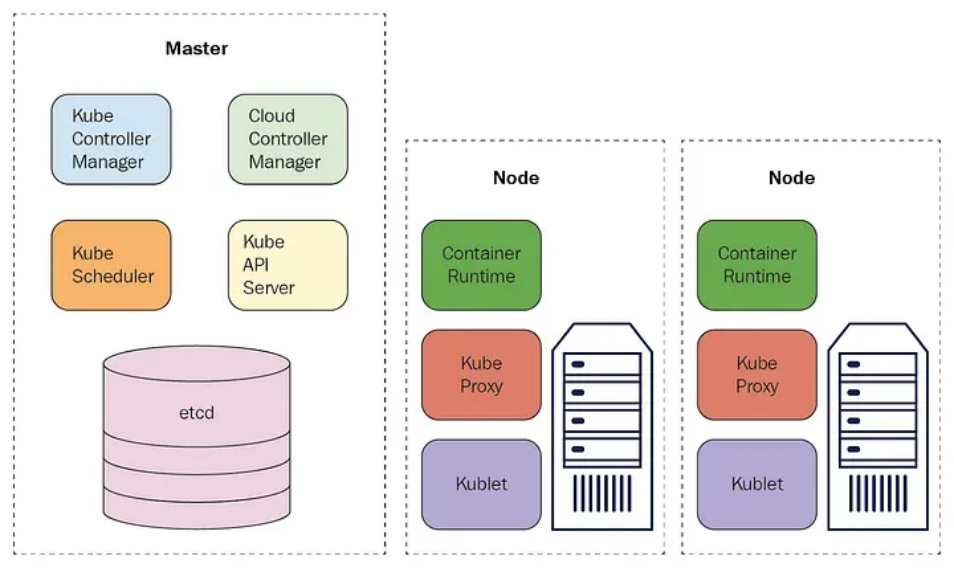
(1)控制平面(Control Plane):包括kube-apiserver、etcd、kube-scheduler、kube-controller-manager和cloud-controller-manager。控制平面负责管理集群的状态、调度Pod到合适的节点、监控节点和Pod的健康状况等。它是集群的大脑。
(2)工作节点(Worker Nodes):包括kubelet、kube-proxy和容器运行时。工作节点则负责运行实际的应用容器,每个工作节点都有一个kubelet进程来管理节点上的Pod,还有一个kube-proxy进程来处理网络代理和负载均衡。
1.2控制平面组建:
控制面组件的架构图:
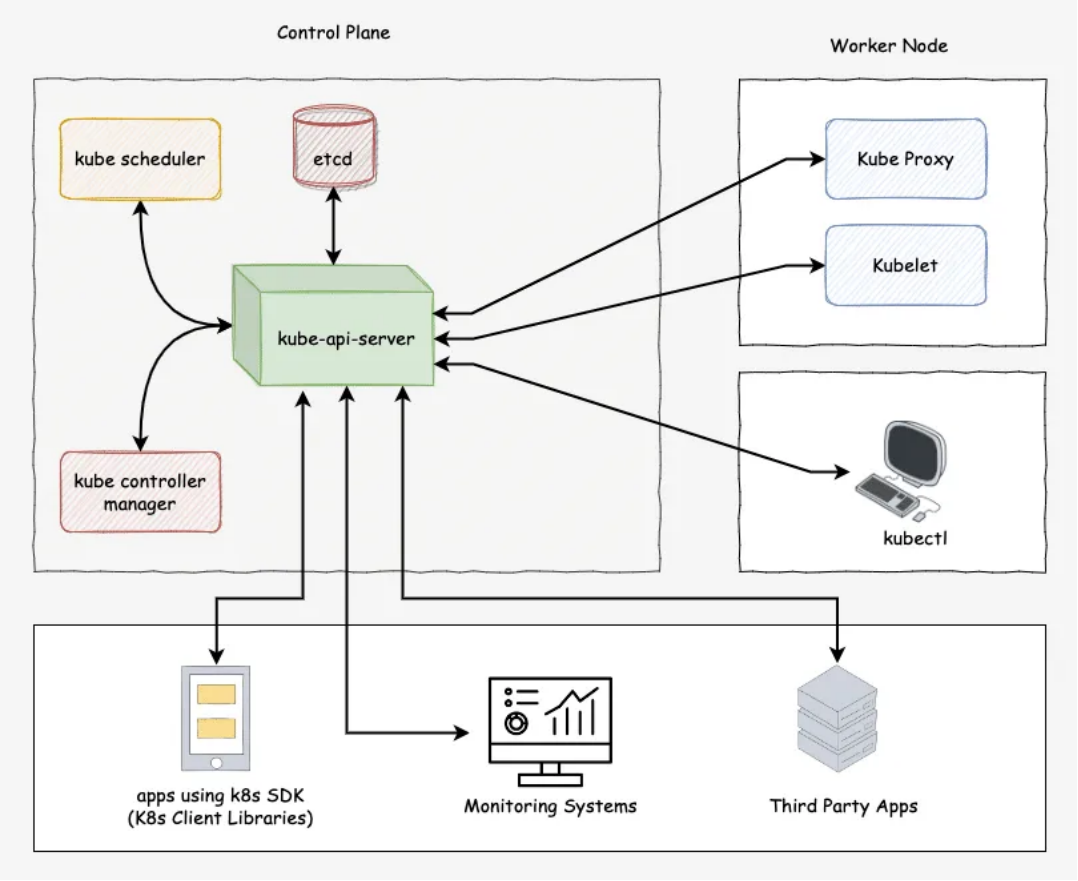
(1)Kube-APIServer
Kube-APIServer 是 Kubernetes 控制平面的核心组件,负责处理所有的 REST 操作,暴露 Kubernetes API。它是整个集群的前端,所有的控制请求都要经过它。
主要功能包括:
①验证和授权:Kube-APIServer 负责验证用户的身份,并根据配置的访问控制策略进行授权,确保只有合法的请求才能对集群进行操作。
②集群状态管理:APIServer 是集群的状态中心,所有的集群状态信息都通过它来访问和更新。
通信枢纽:Kube-APIServer 是其他控制平面组件和工作节点与集群进行通信的桥梁。所有的组件和节点都通过它来获取和更新集群状态。
③当用户或其他组件向 Kube-APIServer 发送请求时,APIServer 首先进行身份验证和授权检查,然后对请求的数据进行验证和处理。处理完成后,APIServer 会将数据存储到 etcd 中,同时通知其他组件进行相应的操作。
(2)Etcd
Etcd 是一个分布式键值存储,用于存储 Kubernetes 集群的所有数据。它是 Kubernetes 集群的源数据存储系统,所有的配置信息、状态信息都存储在 etcd 中。
主要功能:
① 数据存储:Etcd 负责存储所有的集群状态数据,包括 Pod、Service、ConfigMap、Secret 等。
② 数据可靠性:Etcd 通过分布式架构保证数据的高可用性和一致性,确保集群状态数据在发生故障时仍能可靠存储。
③ 数据访问:Etcd 提供了高效的键值对存储和访问接口,支持高频率的读写操作,满足 Kubernetes 对集群状态数据的高频访问需求。
Kube-APIServer 通过 etcd API 进行数据的读写操作。当集群状态发生变化时,APIServer 会将新的状态数据写入 etcd,同时其他组件可以监听 etcd 的变化,从而进行相应的处理。
(3)Kube-Scheduler
Kube-Scheduler 是 Kubernetes 的调度组件,负责将新创建的 Pod 调度到合适的工作节点上。它根据预设的调度策略和节点状态,选择最合适的节点来运行 Pod。
主要功能:
① 资源调度:Kube-Scheduler 根据节点的资源使用情况和 Pod 的资源需求,选择合适的节点来运行 Pod。
② 策略配置:Kube-Scheduler 支持多种调度策略,包括资源优先、亲和性、反亲和性等,用户可以根据需求自定义调度策略。
③ 负载均衡:通过合理的调度策略,Kube-Scheduler 能够有效地分配负载,避免节点过载,确保集群的高效运行。
Kube-Scheduler 通过监听 Kube-APIServer 上的调度请求,获取需要调度的 Pod 列表。然后,它根据预设的调度策略和节点的状态,选择最合适的节点,并将调度结果写回 APIServer,最终由相应的节点来运行 Pod。
(4)Kube-Controller-Manager
Kube-Controller-Manager 是 Kubernetes 控制平面的控制管理组件,负责管理集群的各种控制器。这些控制器是用于处理集群状态变化的后台进程。
主要功能:
① 控制器管理:包括 Node Controller、Replication Controller、Endpoint Controller、Namespace Controller 等,这些控制器分别负责节点管理、副本管理、服务发现、命名空间管理等功能。
自动化操作:控制器通过监听集群状态变化,自动执行相应的操作,如副本调整、故障节点隔离、服务更新等。
② 一致性保证:通过控制器的自动化操作,Kube-Controller-Manager 保证了集群状态的一致性和可靠性。
Kube-Controller-Manager 通过监听 Kube-APIServer 的事件,获取集群状态变化的信息。根据不同的控制器,它会执行相应的操作,如创建或删除 Pod、副本调整、节点故障处理等,并将结果写回 APIServer,从而更新集群状态。
(3)Cloud-Controller-Manager
Cloud-Controller-Manager 是 Kubernetes 控制平面的云服务管理组件,用于将 Kubernetes 与底层的云服务集成。它抽象了底层云平台的差异,使得 Kubernetes 可以在不同的云平台上运行。
功能:
① 云资源管理:包括节点管理、负载均衡、存储管理等功能,支持将 Kubernetes 与各种云服务(如 AWS、GCP、Azure)集成。
② 多云支持:通过抽象底层云平台的差异,Cloud-Controller-Manager 使得 Kubernetes 可以在多种云平台上无缝运行。
③ 自动化操作:通过自动化管理云资源,Cloud-Controller-Manager 提高了 Kubernetes 集群的可用性和灵活性。
Cloud-Controller-Manager 通过调用底层云平台的 API,执行相应的操作,如节点创建、负载均衡配置、存储卷管理等。它通过监听 Kube-APIServer 的事件,获取需要执行的操作,然后调用云平台的 API 来完成相应的操作,并将结果写回 APIServer,从而更新集群状态。
1.3工作节点组件:
工作节点组件的架构图:
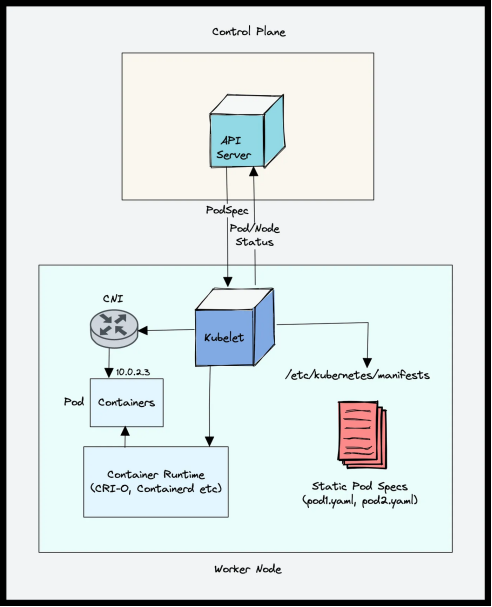
(1)Kubelet
Kubelet 是运行在每个工作节点上的主要代理进程,负责管理节点上的 Pod 和容器。它通过与 Kube-APIServer 交互,确保节点上容器的正确运行。
主要功能:
① Pod 管理:Kubelet 负责启动和停止节点上的 Pod,并监控它们的状态,确保每个 Pod 按照预期运行。
② 状态报告:Kubelet 定期向 Kube-APIServer 报告节点和 Pod 的状态,包括资源使用情况、健康状态等。
③ 配置管理:Kubelet 根据从 Kube-APIServer 获取的配置信息,配置和管理节点上的容器运行环境。
Kubelet 通过监听 Kube-APIServer 的调度信息,获取需要在本节点上运行的 Pod 列表。它根据 Pod 的配置文件,调用容器运行时(如 Docker、containerd)来启动和管理容器。同时,Kubelet 会定期向 Kube-APIServer 发送心跳信号和状态报告,确保控制平面能够及时了解节点和 Pod 的运行状况。
(2)Kube-Proxy
Kube-Proxy 是 Kubernetes 中的网络代理服务,运行在每个工作节点上,负责维护网络规则,管理 Pod 间的网络通信和负载均衡。
主要功能:
① 服务发现:Kube-Proxy 负责维护节点上的网络规则,确保服务 IP 和端口能够正确映射到相应的 Pod 上。
② 负载均衡:Kube-Proxy 通过 IPTables 或 IPVS 实现服务的负载均衡,将请求分发到后端的多个 Pod 上。
③ 网络路由:Kube-Proxy 处理网络流量,确保节点内外的通信能够正确路由到目标 Pod。
Kube-Proxy 通过监听 Kube-APIServer 获取服务和端点的变化信息,然后根据这些信息动态更新节点上的网络规则。它使用 IPTables 或 IPVS 来实现网络流量的转发和负载均衡,确保请求能够正确分发到相应的 Pod 上。
(3)Pod
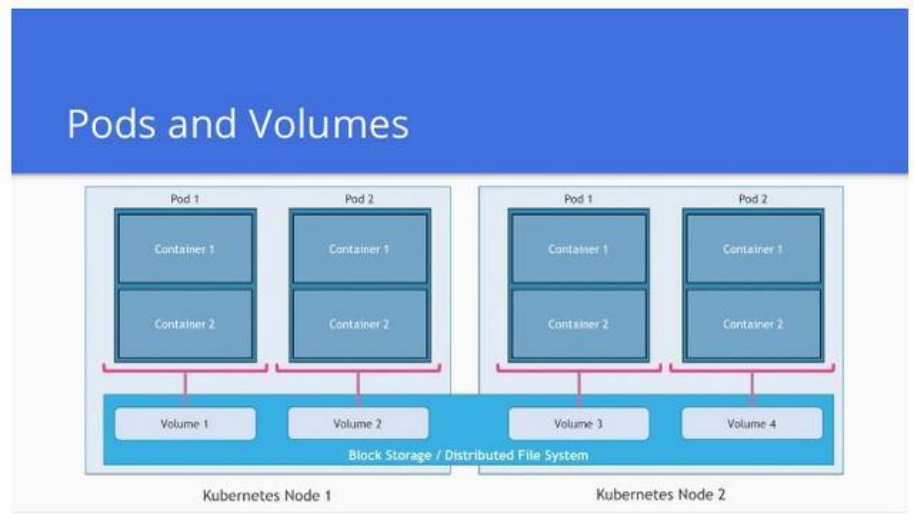
Kubernetes 的世界里,Pod 是对容器的进一步抽象和组织,最小的可部署计算单元,也是 Kubernetes 管理的最小对象。它包含一个或多个容器,是一组紧密相关的容器集合,这些容器共享存储、网络和一些配置信息,它们总是被一起调度和管理,在共享的上下文中运行。可以将 Pod 理解为一个 “逻辑主机”,其中包含一个或多个应用容器,这些容器相对紧密地耦合在一起,共同完成特定的任务。
以一个典型的 Web 应用为例,它可能包含一个 Web 服务器容器(如 Nginx)和一个应用程序容器(如基于 Node.js 或 Python 的后端服务)。为了实现两者之间的高效通信,我们可以将这两个容器放在同一个 Pod 中。由于它们共享相同的网络命名空间,Web 服务器容器可以直接通过localhost与应用程序容器进行通信,无需进行复杂的网络配置和地址解析,大大简化了通信流程。
同时,Pod 中的容器还可以共享存储资源。比如,我们可以为上述 Web 应用的 Pod 挂载一个存储卷,用于存储应用程序的日志文件。Web 服务器容器和应用程序容器都可以访问这个存储卷,将各自产生的日志写入其中,方便统一管理和分析。
(4)容器运行时
容器运行时(Container Runtime)是 Kubernetes 中用于运行和管理容器的组件,常见的容器运行时有 Docker、containerd、CRI-O 等。
主要功能:
① 容器管理:容器运行时负责启动、停止和监控容器的运行状态。
② 资源隔离:容器运行时通过 cgroup、namespace 等机制实现容器的资源隔离和限制。
③ 镜像管理:容器运行时负责从镜像仓库拉取容器镜像,并在节点上进行存储和管理。
Kubelet 通过 CRI(Container Runtime Interface)与容器运行时进行交互,向其发送启动和停止容器的指令。容器运行时根据这些指令,调用底层操作系统的容器技术(如 cgroup、namespace)来管理容器的生命周期和资源使用。同时,容器运行时还负责从镜像仓库拉取和管理容器镜像,确保容器能够按需启动。
(5)Node Local Controller
Node Local Controller 是 Kubernetes 中的一种节点本地控制器,负责在每个节点上执行一些特定的控制任务,如本地存储管理、节点健康检查等。
主要功能:
① 本地存储管理:Node Local Controller 负责管理节点上的本地存储资源,如临时存储卷、持久化存储卷等。
② 节点健康检查:通过定期检查节点的运行状态,Node Local Controller 能够及时发现并报告节点的健康问题。
③ 资源分配:根据节点的资源使用情况,Node Local Controller 可以调整资源分配策略,确保节点上的 Pod 能够高效运行。
Node Local Controller 运行在每个工作节点上,通过监听 Kubelet 和 Kube-APIServer 的事件,获取节点的状态信息。根据这些信息,它执行相应的控制操作,如调整存储卷、进行健康检查等,并将结果报告给 Kube-APIServer,从而更新集群的状态。
1.4Kubernetes网络模型:
(1)Pod 和 Service 的网络通信
Kubernetes 的网络模型基于 Pod 和 Service 的通信,通过统一的 IP 地址和端口分配,确保集群内的各个组件能够无缝通信。
(2)Pod 网络
每个 Pod 一个 IP:每个 Pod 都有一个唯一的 IP 地址,这个 IP 地址在整个集群内都是可达的。
① Pod 间通信:Pod 可以直接通过 IP 地址互相通信,无需进行 NAT(网络地址转换)。
② Pod 网络插件:Kubernetes 支持多种网络插件(如 Flannel、Calico、Weave),它们通过 CNI(Container Network Interface)接口与 Kubernetes 集成,提供灵活的网络实现。
(3)Service 网络
① 虚拟 IP:Service 在 Kubernetes 中有一个虚拟 IP 地址(Cluster IP),用于暴露一组 Pod。
② 服务发现:Service 的 IP 地址和端口通过 DNS 解析,使得客户端可以通过服务名访问相应的服务。
③ 负载均衡:Service 自动将请求分发到后端的多个 Pod 上,实现负载均衡。
1.5补充:
(1)kubeadm简介
kubeadm是Kubernetes主推的部署工具之一,主要用于快速创建和初始化Kubernetes集群
(2)kubectl简介
kubectl 是 Kubernetes 的一个命令行管理工具,可用于 Kubernetes 上的应用部署和日常管理。
2.Kubernetes集群的规划:
| 节点类型 | 主机名 | IP地址 | 硬件配置 |
| 控制平面节点 | master01 | 192.168.58.30 | CPU:4核;内存:2GB;硬盘:60GB |
| 工作节点 | node01 | 192.168.58.31 | CPU:2核;内存:2GB;硬盘:30GB |
| 工作节点 | node02 | 192.168.58.32 | CPU:2核;内存:2GB;硬盘:30GB |
3.准备主机节点:
3.1准备master01主机节点:
3.1.1克隆主机:
1.选中 配置好的CentOS-Stream-8主机(参考:基于VMware的Cent OS Stream 8安装与配置及远程连接软件的介绍_centos8stream-CSDN博客)。
2.然后通过,鼠标右键-》管理-》克隆,进入下图所示的克隆向导界面。
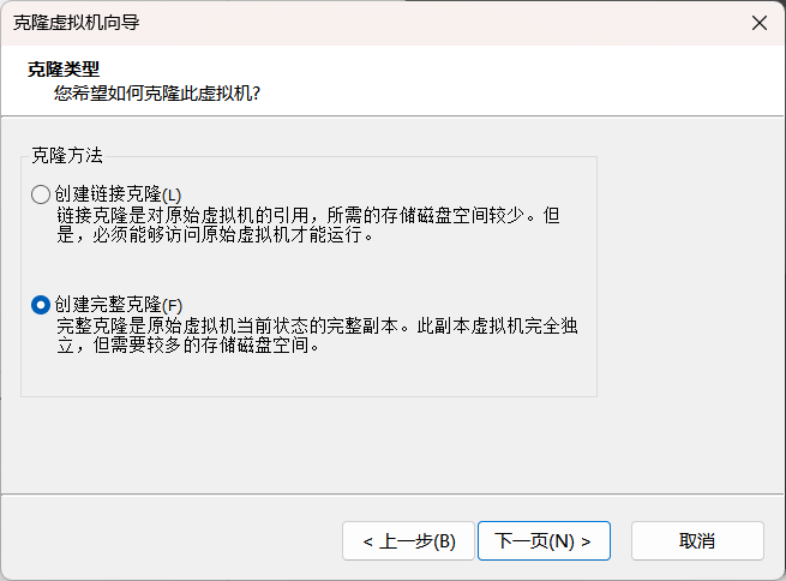
3.然后点击“下一页”,进入下图所示的界面。
4.然后点击“下一页”,进入下图所示的界面。
5.在上图所示的界面中,选择“创建完整克隆”,点击“下一页”,进入下图所示的界面。
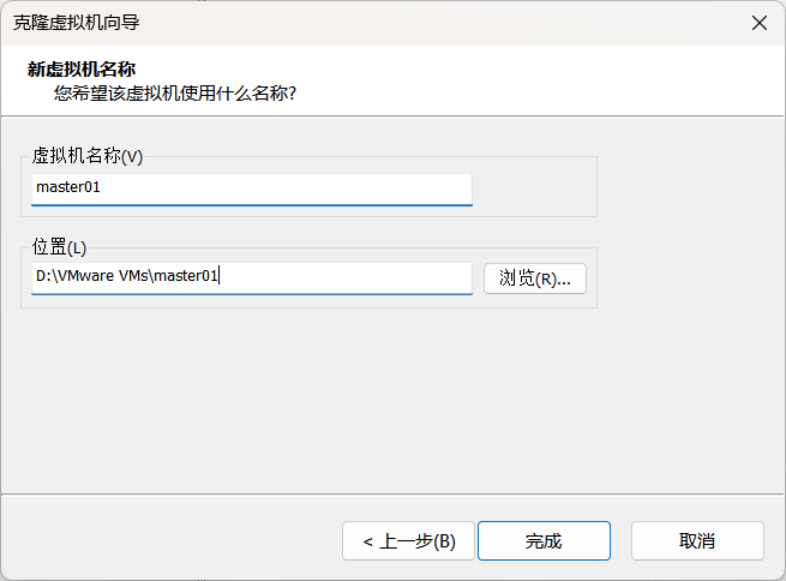
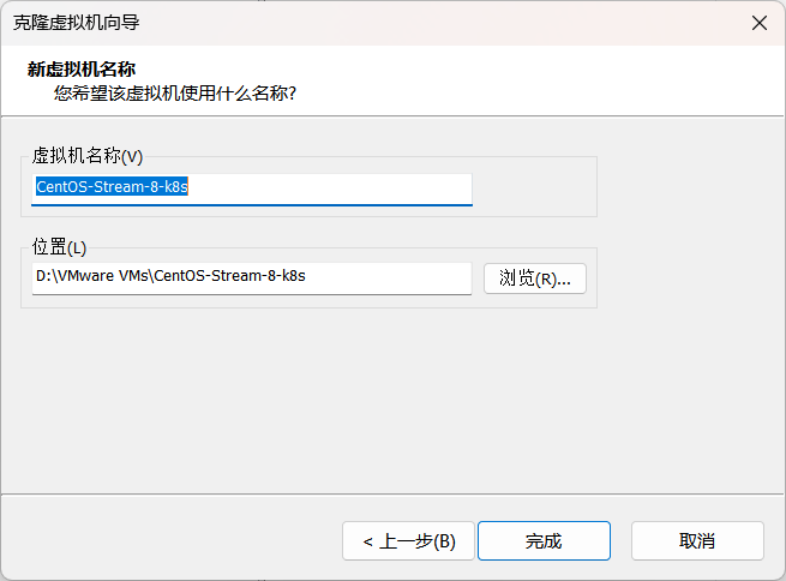
6.在上图所示的界面中,设置好新虚拟机的名字,点击完成,进行克隆,具体如下图所示。
7.克隆完成后,如下图所示。
8.在上图所示的界面中,点击关闭,查看新克隆出来的虚拟机master01,具体如下图所示。
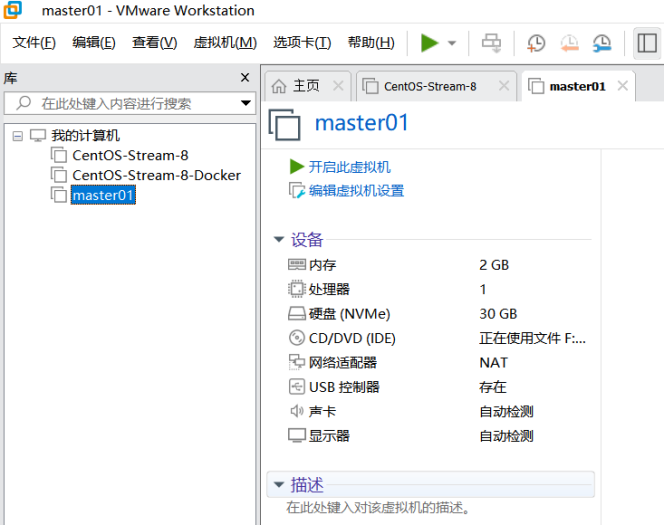
9.点击上图中的“开启此虚拟机”,启动master01,输入账号和密码,进入系统,如下图所示。
至此,通过从CentOS-Stream虚拟机进行克隆,我们完成了master的初始化。
3.1.2开启网络:
1.查看当前的网络连接信息。
nmcli connection show
2.使用以下命令修改网络连接配置。
nmcli connection modify ens160 ipv4.addr 192.168.58.30/24 ipv4.gateway 192.168.58.2 connection.autoconnect yes ipv4.dns "114.114.114.114"3.执行结果,具体如下图。

注意这里的ens160和图中的ens160是相对应的。
4.通过以下命令激活网络连接配置,使它生效。
nmcli connection up ens160
5. 在Firefox火狐狸浏览器中,访问百度首页,以确保网络联通。
3.1.3设置主机名:
1.使用以下命令将主机名更改为master01。
hostnamectl set-hostname master01
bash
3.1.4关闭交换区:
Linux中的交互区相当于与Window系统中的虚拟内存。交换器影响应用程序运行的性能与稳定性。从Kubernetes1.8版本开始要求关闭系统的交换区功能,否则Kubernetes1.8无法启动。
1.执行以下命令临时关闭交换区。
swapoff -a2.查看当前内存,可以发现Swap的各项值均为0,表明交换区已经关闭。
free -m
3. 为了重启后依然关闭交换区,使用sed命令将/etc/fstab中Swap自动挂载的语句注释掉。
sed -ri 's/.*swap.*/#&/' /etc/fstab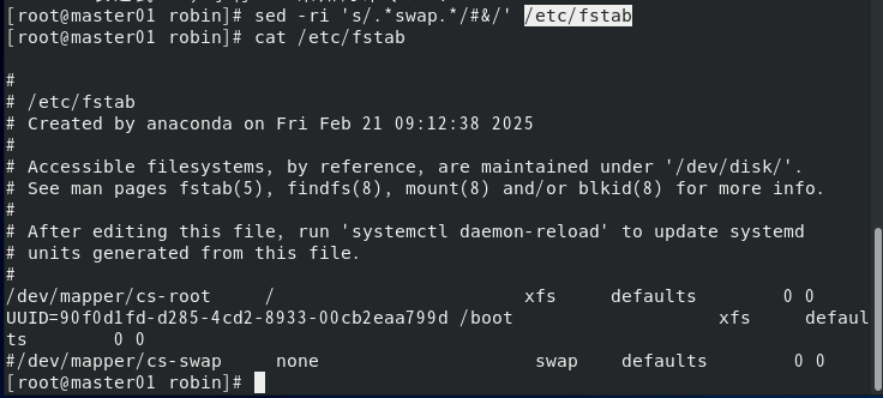
3.1.5设置系统同步时间:
1. Kubernetes集群各节点的时间必须同步。Linux系统中,通常通过安装npdate和chrony来提供时间同步功能。本实验安装chrony。
yum install -y chrony2.修改/etc/chrony.conf配置文件,注释掉原有的时间服务器地址(如果有),然后增加阿里云和腾讯云的时间服务器。
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp1.tencent.com iburst
server ntp2.tencent.com iburst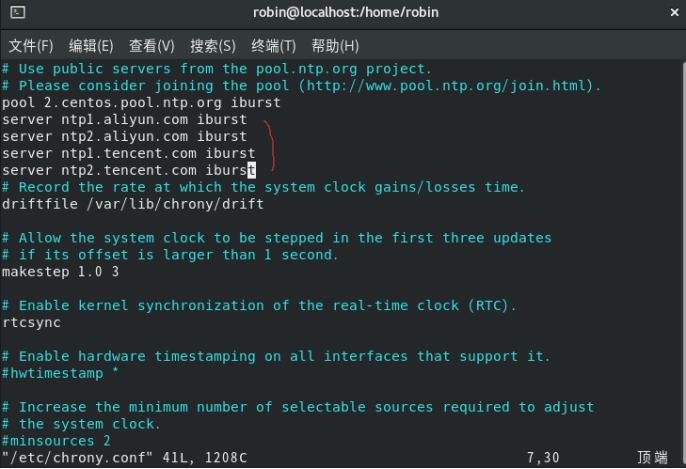
3. 重启chrony, 并查看同步情况以测试时间同步设置。
systemctl restart chronyd.service
chronyc sources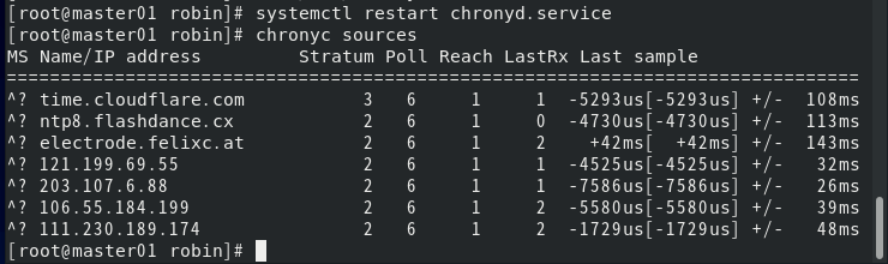
3.1.6配置主机名解析:
1.将以下主机名(主机域名)与IP地址之间的映射信息追加到/etc/hosts配置文件中。
# 这里使用自己规划主机的IP和域名
192.168.58.30 master01
192.168.58.31 node01
192.168.58.32 node02
3.1.7安装IPVS相关工具:
IPVS(IP Virtual Server)是Linux内核的一部分,主要用于实现高性能的第四层负载均衡。它运行在主机上,将来自客户端的请求根据预设的调度算法分发到一组真实服务器上,这些真实服务器提供实际的服务。
IPVS相比其他负载均衡解决方案(如LVS的NAT模式、HAProxy等)的优势在于其高性能和低延迟。由于IPVS在内核级别工作,它可以绕过用户空间的数据拷贝和上下文切换,从而提供更高的吞吐量和更低的延迟。此外,IPVS还支持多种调度算法和持久性机制,使其能够适应不同的负载均衡需求。
IPVS的管理程序是ipvsadm。ipvsadm支持直接路由、IP隧道和NAT这中转发模式。
ipset是Linux内核提供的一种高效的数据存储和查询工具,专为管理大规模IP地址设计。ipset允许管理员创建、管理和查询IP集合,这些集合可以包含IP地址、端口、网络等元素。通过使用ipset,管理员可以更方便地管理大量的IP地址,特别是在需要频繁更新或查询IP地址时。
1.安装ipset和ipvsadm。
yum install -y ipset ipvsadm2.为kub-proxy启用IPVS的前提是加载相应的Linux内核模块。配置/etc/sysconfig/ipvsadm/ipvs.modules脚本文件,以加载所需的内核模块。
mkdir -p /etc/sysconfig/ipvsadm
cat > /etc/sysconfig/ipvsadm/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF3.给定文件权限。
chmod 755 /etc/sysconfig/ipvsadm/ipvs.modules4.执行该脚本,检查是否已经加载IPVS所需的模块。
bash /etc/sysconfig/ipvsadm/ipvs.modules
lsmod | grep -e ip_vs -e nf_conntrack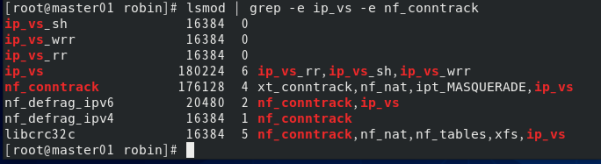
3.2安装containerd相关工具:
从Kubernetes1.23版本开始,容器运行时默认不再采用docker/dockershim,而建议采用containerd。因此,本实验采用containerd。
3.2.1调整内核参数:
1.与Docker作为容器运行时不同,containerd要配置相关内核参数。
执行以下命令加载所需的两个内核模块。
modprobe overlay
modprobe br_netfilter2.要允许iptables检查桥连接流量,就要显示加载br_netfilter模块。
通过以下命令,检查br_netfilter是否加载成功,具体下图所示。
lsmod | grep br_netfilter
3.通过以下命令在/etc/modules-load.d/目录下创建一个新的配置文件(br_netfilter.conf)。
echo "br_netfilter" | tee -a /etc/modules-load.d/br_netfilter.conf3.2.2开启路由转发及网桥过滤:
1.编辑/etc/modules-load.d/containerd.conf文件,在其中加入以下内容以配置containerd所需的内核参数。
cat > /etc/modules-load.d/containerd.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward=1
EOF2.前面两个参数的用途是让Linux节点的iptables能够正确查看桥接流量,最后一个参数用于启用IP转发。
执行以下命令使以上内核参数的调整生效。
sysctl -p /etc/modules-load.d/containerd.conf
3.2.3下载containerd软件包:
wget https://github.com/containerd/containerd/releases/download/v1.6.8/cri-containerd-1.6.8-linux-amd64.tar.gz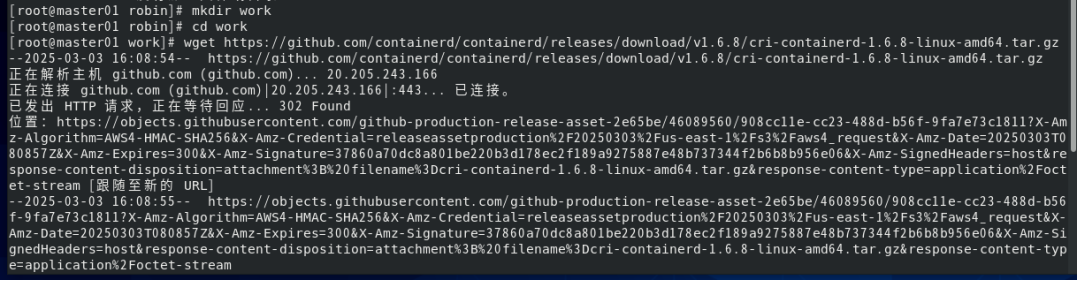
3.2.4将该软件包解压到系统根目录:
tar -zxvf cri-containerd-1.6.8-linux-amd64.tar.gz -C /3.2.5修改/etc/containerd/config.toml配置文件.
1.containerd 的配置文件位于/etc/containerd/config.toml,默认是没有的,通过以下命令生成一个默认配置。
mkdir /etc/containerd
containerd config default > /etc/containerd/config.toml2.将SystemCgroup值设置为true。
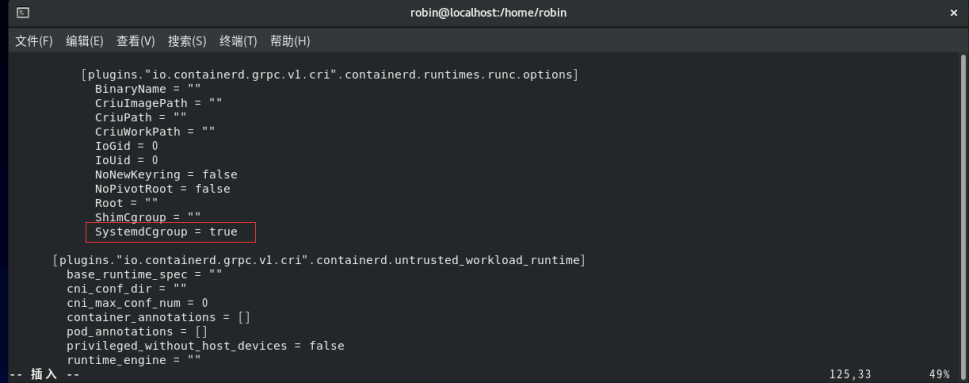
3. 将sandbox_image值设置为国内基础镜像源地址。
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.8"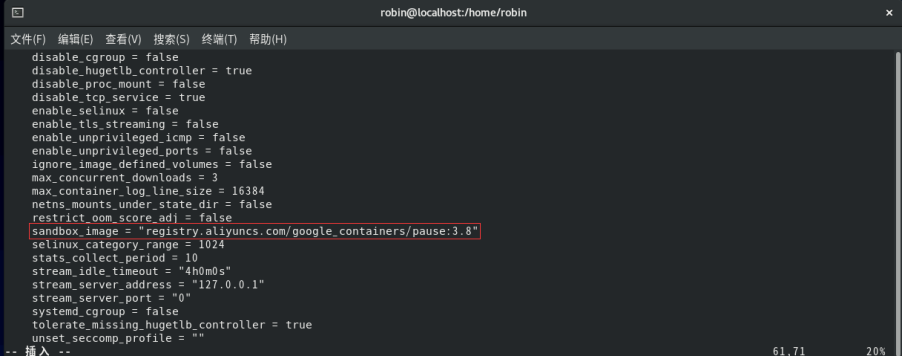
4. 修改中央仓库地址(镜像源)。
[plugins."io.containerd.grpc.v1.cri".registry.mirrors][plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]endpoint = ["https://docker.m.daocloud.io"][plugins."io.containerd.grpc.v1.cri".registry.mirrors."k8s.gcr.io"]endpoint = ["https://registry.cn-hangzhou.aliyuncs.com/google_containers"]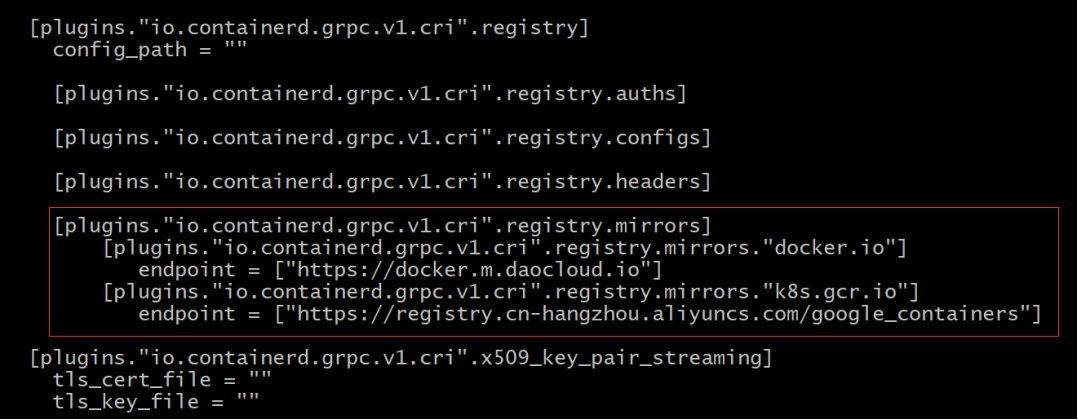
3.2.6 启动containerd并设置开机启动:
systemctl daemon-reload
systemctl enable containerd
systemctl start containerd3.2.7查看containerd的版本信息:
crictl version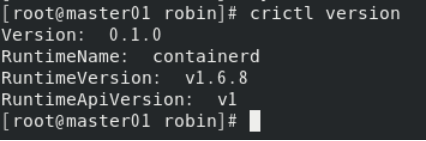
3.3添加Kubernetes组件的阿里云软件源:
1.创建/etc/yum.repos.d/kubernerts.repo,然后在其中添加以下配置。
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg2.执行以下命令查看当前可以安装的Kubernetes版本。
yum list kubeadm.x86_64 --showduplicates|sort -r |grep 1.25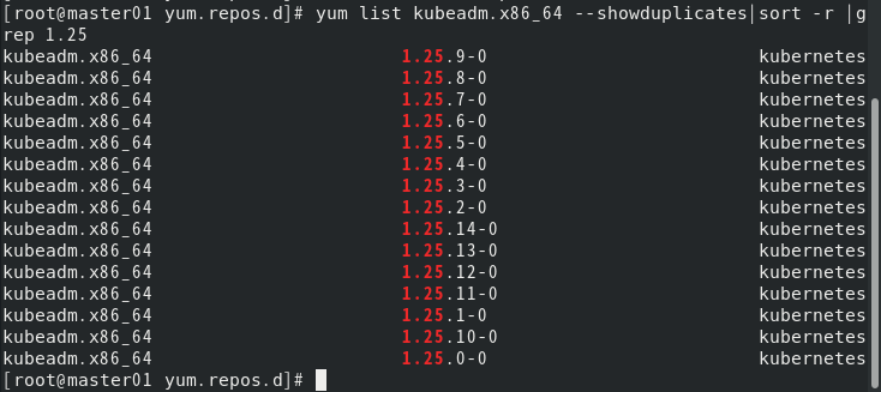
3.4 安装kubeadm、kubelet和kubectl:
kubeadm是用于初始化集群的工具
kubelet用来在集群的每个节点上启动Pop和容器
kubectl用来与集群通信的命令行工具。
1.执行以下命令进行安装。
yum install -y kubelet-1.25.4 kubeadm-1.25.4 kubectl-1.25.42.安装完毕后,启动kublete并将其设置为开机自动启动。
systemctl enable kubelet
systemctl start kubelet3.运行以下命令查看kubelet的当前版本。
kubelet --version
4. 拍摄快照和母机:
4.1拍摄快照存档:
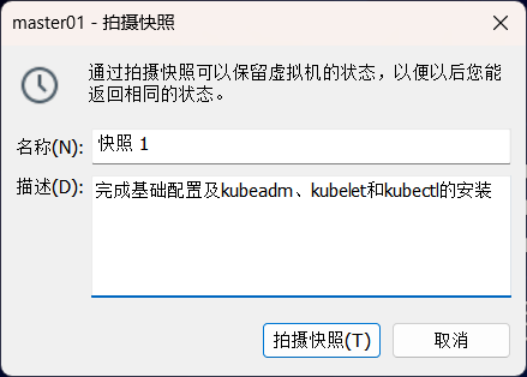
选中master01虚拟机,点击鼠标右键,通过拍照-》拍摄快照进行快照存档,具体如下图所示。
4.2母机克隆:
1.基于master01主机,克隆产生k8s母机,具体如下图所示。
5.准备node1节点主机:
5.1克隆node1节点主机:
基于CentOS-Stream-8-k8s主机克隆产生node1节点主机。
5.2设置IP地址:
1.查看当前的网络连接信息,具体命令如下所示。
nmcli connection show2.使用以下命令修改网络连接配置。
nmcli connection modify ens160 ipv4.addr 192.168.58.31/24 ipv4.gateway 192.168.58.2 connection.autoconnect yes ipv4.dns "114.114.114.114"3.通过以下命令激活网络连接配置,使它生效。
nmcli connection up ens1604.、在Firefox火狐狸浏览器中,访问百度首页,以确保网络联通。
5.3 设置主机名:
使用以下命令将主机名更改为node01。
hostnamectl set-hostname node01
bash6.准备node2节点主机:
6.1克隆node2节点主机:
基于CentOS-Stream-8-k8s主机克隆产生node2节点主机。
6.2设置IP地址:
1.查看当前的网络连接信息,具体命令如下所示。
nmcli connection show2.使用以下命令修改网络连接配置。
nmcli connection modify ens160 ipv4.addr 192.168.58.32/24 ipv4.gateway 192.168.58.2 connection.autoconnect yes ipv4.dns "114.114.114.114"3.通过以下命令激活网络连接配置,使它生效。
nmcli connection up ens1604.在Firefox火狐狸浏览器中,访问百度首页,以确保网络联通。
6.3 设置主机名:
使用以下命令将主机名更改为node02。
hostnamectl set-hostname node02
bash7.SSH免密登录配置:
7.1master01主机SSH免密登录:
7.1.1在master01主机中,使用以下指令创建master01主机自己的SSH密钥对(公钥+私钥):
ssh-keygen -t rsa注意这里一路回车就可以。
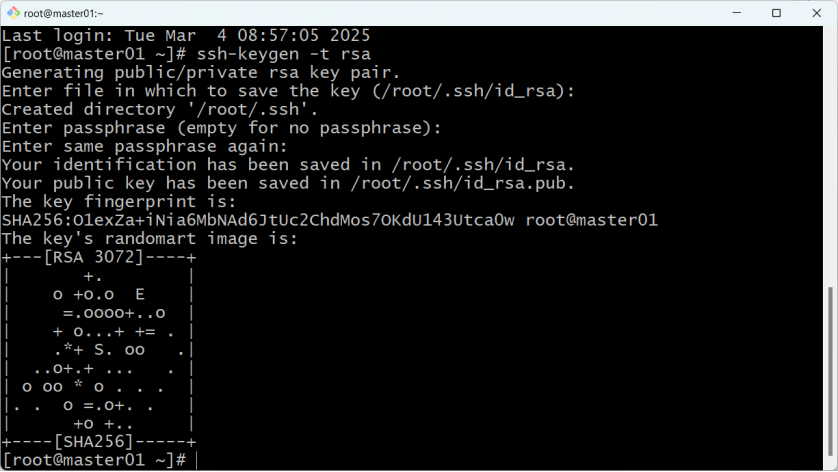
如果询问是否重新覆盖已有的密钥,请输入y就行。
7.1.2使用“ssh-copy-id 用户名@主机名”命令,把本机公钥拷贝到master01节点:
ssh-copy-id root@master01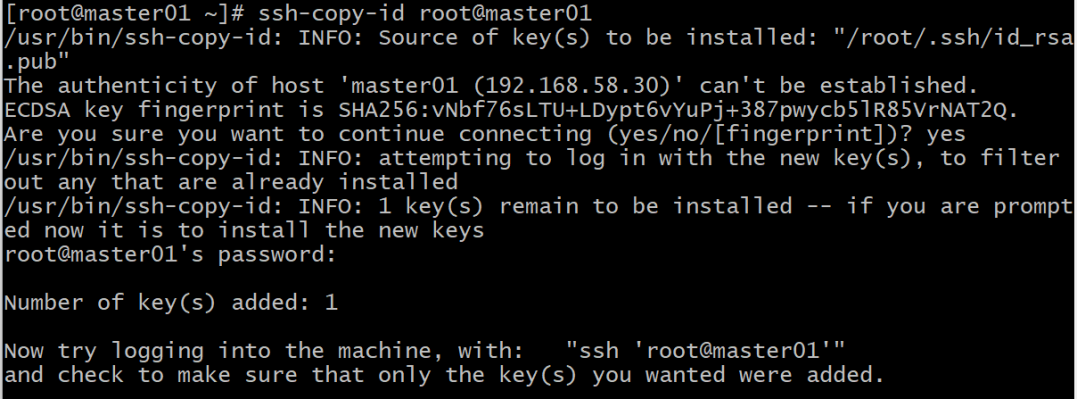
注意此过程中,需要输入master01主机root用户的密码。
接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@master01
如果执行该命令,不再需要输入密码,那么代表配置成功。否则,失败!
7.1.3使用“ssh-copy-id 用户名@主机名”命令,把本机公钥拷贝到node01节点:
ssh-copy-id root@node01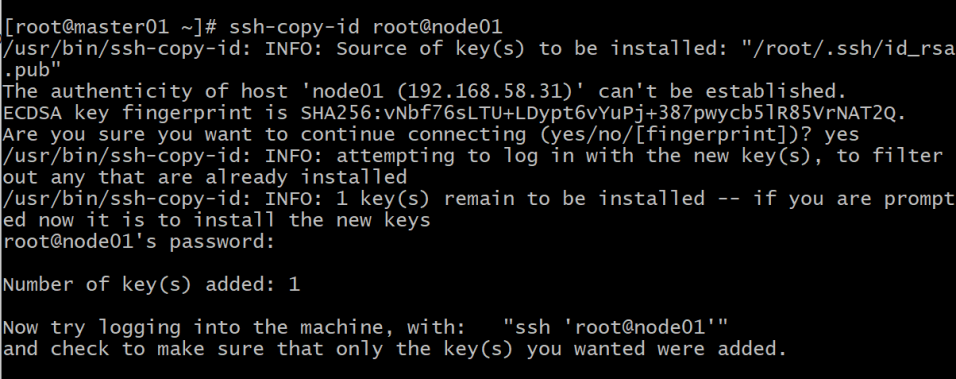
注意此过程中,需要输入node01主机root用户的密码。
接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@node01
如果执行该命令,不再需要输入密码,那么代表配置成功。否则,失败!
7.1.4 使用exit命令从node01回到master01主机:
exit然后使用“ssh-copy-id 用户名@主机名”命令,把本机RSA公钥拷贝到node02节点。
ssh-copy-id root@node02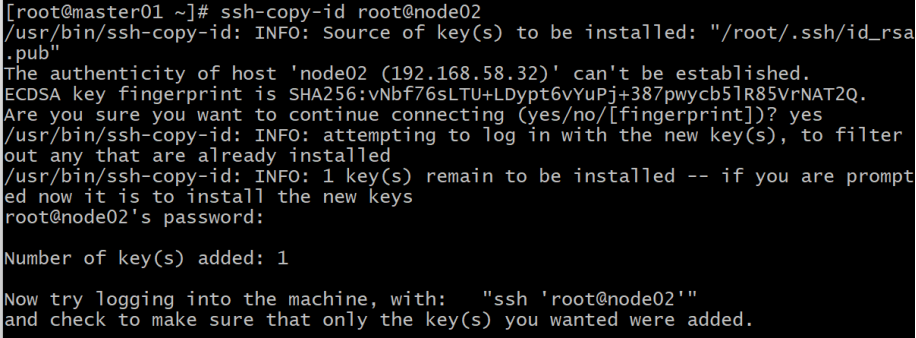
注意此过程中,需要输入node02主机root用户的密码。
接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@node02如果执行该命令,不再需要输入密码,且登录node02成功;那么代表配置成功。否则,失败!
7.2node01主机SSH免密登入:
7.2.1在node01主机中,使用以下指令创建node01主机自己的SSH密钥对(公钥+私钥):
ssh-keygen -t rsa注意这里一路回车就可以。
如果询问是否重新覆盖已有的密钥,请输入y就行。
7.2.2使用“ssh-copy-id 用户名@主机名”命令,把本机公钥拷贝到master01节点:
ssh-copy-id root@master01接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@master01如果执行该命令,不再需要输入密码,且登录master01成功;那么代表配置成功。否则,失败!
7.2.3使用exit命令回到node01主机:
exit然后使用“ssh-copy-id 用户名@主机名”命令,把本机公钥拷贝到node01节点。
ssh-copy-id root@node01接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@node01如果执行该命令,不再需要输入密码,那么代表配置成功。否则,失败!
7.2.4使用“ssh-copy-id 用户名@主机名”命令,把本机RSA公钥拷贝到node02节点:
ssh-copy-id root@node02接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@node02如果执行该命令,不再需要输入密码,且登录node02成功;那么代表配置成功。否则,失败!
7.3node02主机SSH免密登录:
7.3.1在node02主机中,使用以下指令创建node01主机自己的SSH密钥对(公钥+私钥):
ssh-keygen -t rsa注意这里一路回车就可以。
如果询问是否重新覆盖已有的密钥,请输入y就行。
7.3.2使用“ssh-copy-id 用户名@主机名”命令,把本机公钥拷贝到master01节点:
ssh-copy-id root@master01接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@master01如果执行该命令,不再需要输入密码,且登录master01成功;那么代表配置成功。否则,失败!
7.3.3使用exit命令回到node02主机:
exit然后使用“ssh-copy-id 用户名@主机名”命令,把本机公钥拷贝到node01节点。
ssh-copy-id root@node01接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@node01如果执行该命令,不再需要输入密码,那么代表配置成功。否则,失败!
7.3.4使用exit命令回到node02:
exit使用“ssh-copy-id 用户名@主机名”命令,把本机RSA公钥拷贝到node02节点。
ssh-copy-id root@node02接着,使用“ssh 用户名@主机名”的命令形式进行SSH免密登录。
ssh root@node02如果执行该命令,不再需要输入密码,且登录node02成功;那么代表配置成功。否则,失败!
8. Kubernetes集群初始化:
8.1初始化master01控制平面节点:
使用kubeadm命令初始化控制平面节点有以下两种方式。
①使用配置文件。这种方式使用--config选项指定配置文件。不过我们通常使用kubeadm config命令生成默认的配置文件,再根据需要修改后即可完成初始化。
②直接命令行选项参数进行初始化配置。
本实验采用直接命令行选项参数的方式初始化控制平面节点。
1.在master01中,执行以下命令。
kubeadm init \
--apiserver-advertise-address 192.168.56.30 \ # 使用自己主机IP
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.25.4 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=all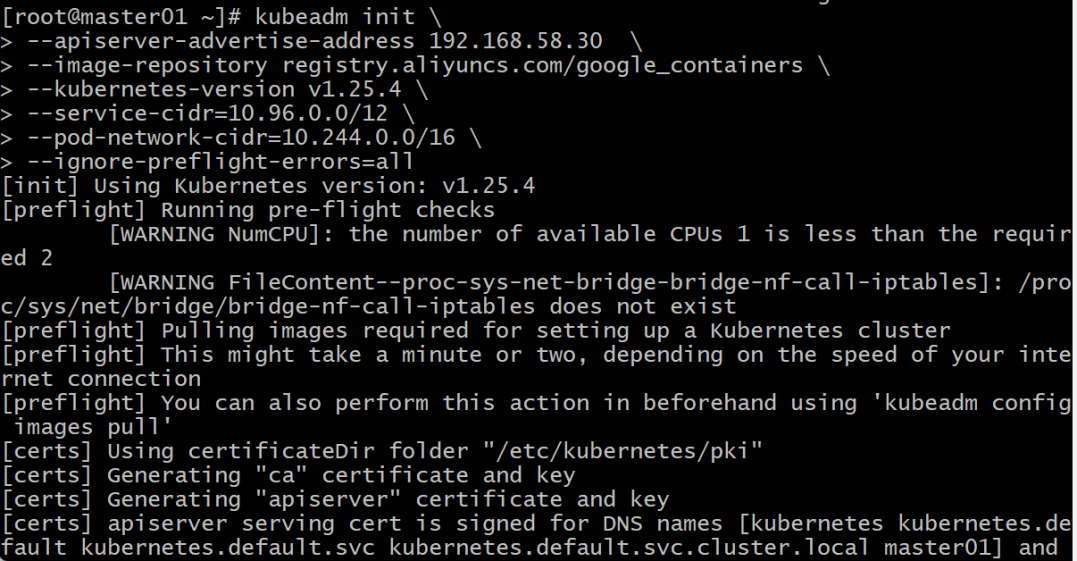
2.第一次执行该命令的时候,会非常慢。如果支持成功,最终结果如下图 :
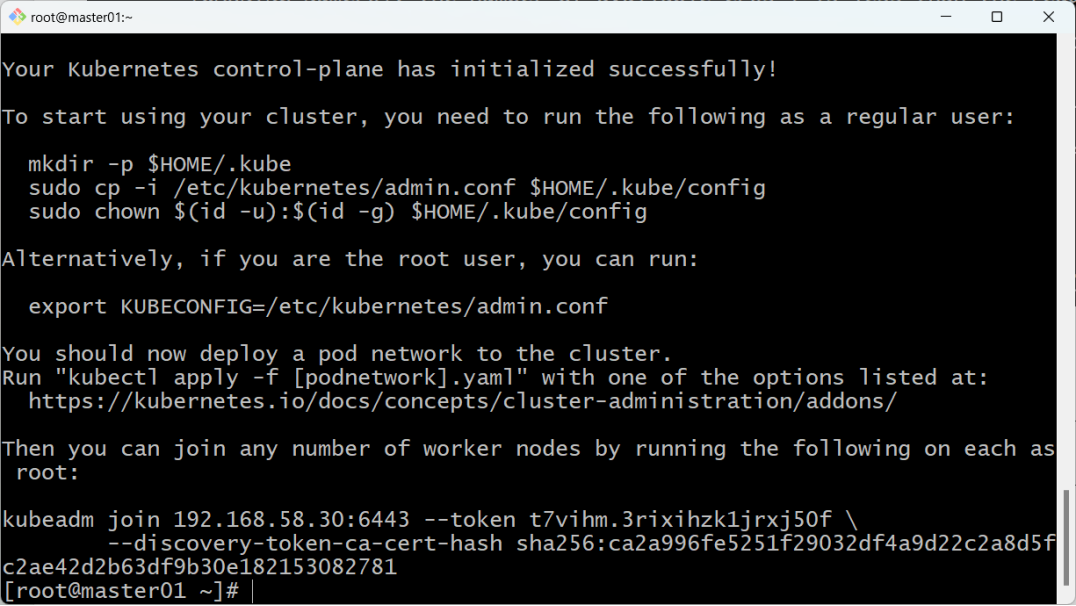
3. 同时,注意上图中的以下提示(复制自己生成的):
Then you can join any number of worker nodes by running the following on each as root:kubeadm join 192.168.58.30:6443 --token t7vihm.3rixihzk1jrxj50f \--discovery-token-ca-cert-hash sha256:ca2a996fe5251f29032df4a9d22c2a8d5fc2ae42d2b63df9b30e1821530827818.2为kubectl命令提供配置文件:
通过上一步的kubeadm init,系统为我们生成了一个Kubernetes系统管理员权限的认证配置文件/etc/kubernetes/admin.conf。
1.现在我们按照图8-2的提示,将该配置文件复制到该目录的config子目录以便运行kubectl。
mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/config2.执行完上述命令,我们就可以使用kubectl命令查看当前的集群节点信息。
kubectl get node
目前集群中有且仅有一个节点,master01控制平面节点。
8.3将工作节点加入集群:
8.3.1在node01主机中,根据图8-2的提示,执行以下命令将其加入到集群中:
使用自己生成的。
kubeadm join 192.168.58.30:6443 --token t7vihm.3rixihzk1jrxj50f \--discovery-token-ca-cert-hash sha256:ca2a996fe5251f29032df4a9d22c2a8d5fc2ae42d2b63df9b30e182153082781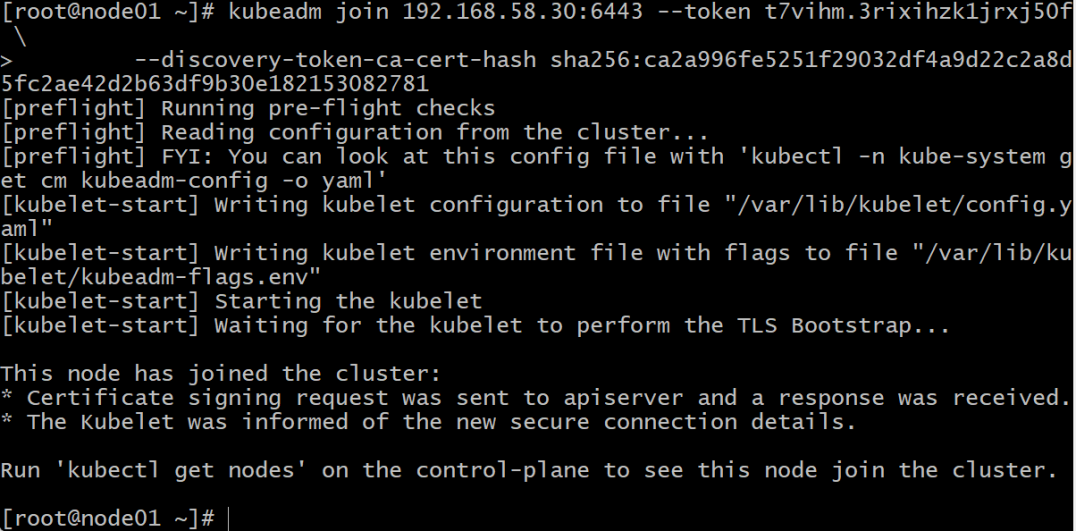
8.3.2 在node02主机中,根据图8-2的提示,执行以下命令将其加入到集群中:
kubeadm join 192.168.58.30:6443 --token t7vihm.3rixihzk1jrxj50f \--discovery-token-ca-cert-hash sha256:ca2a996fe5251f29032df4a9d22c2a8d5fc2ae42d2b63df9b30e182153082781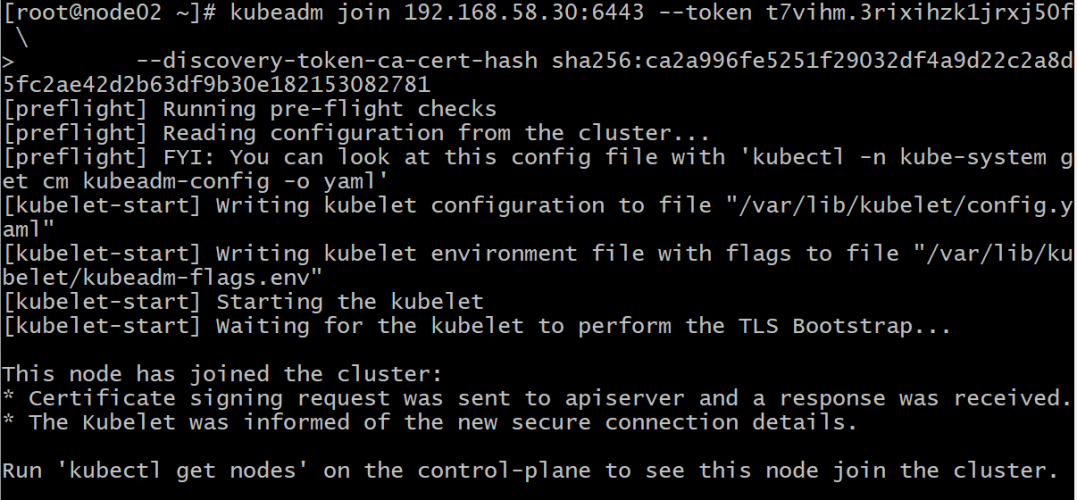
8.8.3 在master01主机中,执行以下命令,查看节点信息:
kubectl get node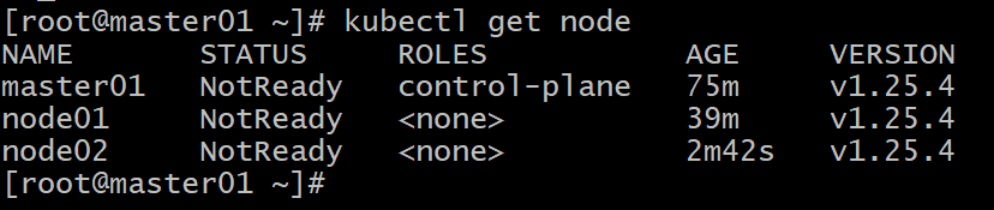
集群中右增加了两个工作节点。
另外,请注意加入工作节点令牌默认有效期为24小时,过去之后该令牌就不可用了。如果有需要。最简单的就是在master01主机,使用以下命令创建新的令牌。
kubeadm token create --print-join-command
9. 安装Pod网络插件:
Calico是一款开源的网络和安全解决方案,专为容器化应用而设计,基于Kubernetes的网络插件模型.Calico为每个容器或虚拟机分配一个独立的网络命名空间,以避免潜在的网络冲突。这些命名空间各自拥有独特的IP地址和路由表。
9.1在master01主机中,从官网下载安装Calico插件所需的配置文件calico.yaml:
wget https://docs.projectcalico.org/manifests/calico.yaml9.2修改calico.yam配置文件,将其中的值为之前执行kubeadm init命令时通过--pod-network-cidr选项指定的Pod网络地址:
-name:CALICO_IPV4POOL_CIDRValue:”10.244.0.0/16”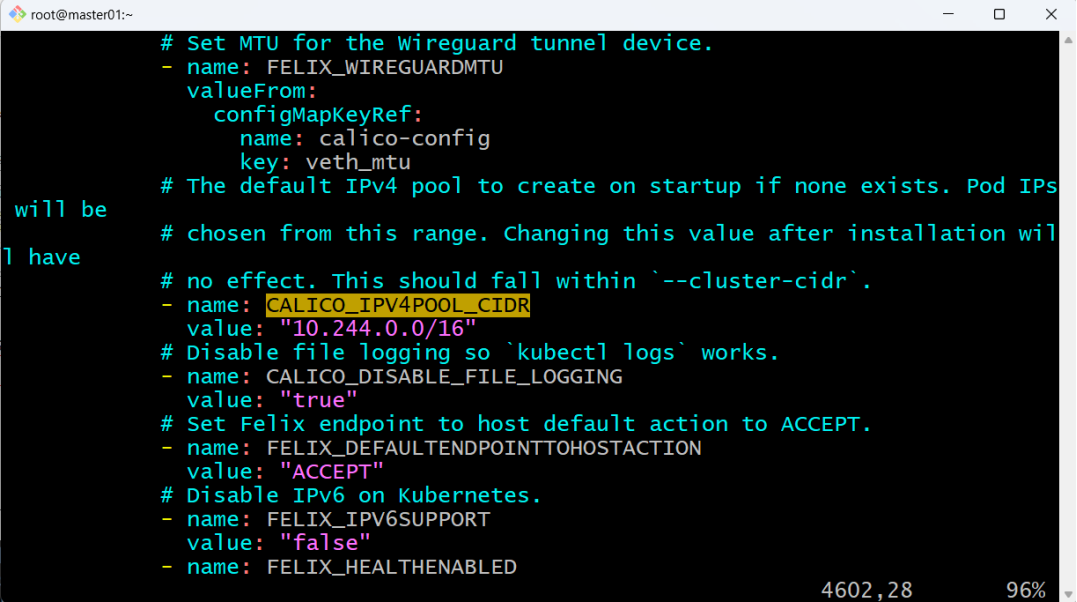
9.3 执行以下命令使用配置calico.yaml,在集群中部署Calico插件(创建多种Kubernetes资源):
kubectl apply -f calico.yaml
这个过程可能有点慢,请耐心等待。
9.4查看名称空间kube-system下的所有Pod:
kubectl get pods -n kube-system 9.5执行以下命令进一步查看Calica插件在各节点上的部署情况:
kubectl get po -A -o wide|grep calico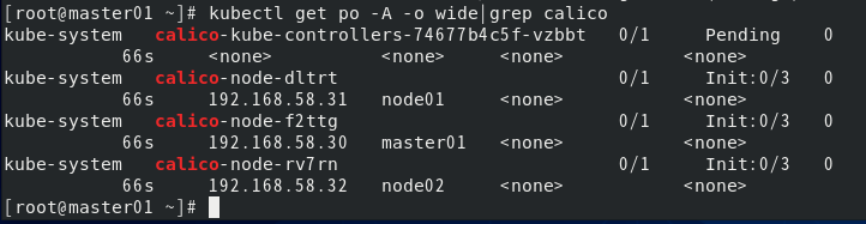
10. 测试Kubernetes集群:
尝试在Kubernetes集群部署运行nginx,以测试Kubernetes集群的可用性。
10.1在master01主机上,执行以下命令创建高一个简单的Deployment以运行nginx:
kubectl create deployment nginx --image=nginx:latest
10.2 在master01主机上,执行以下命令将该deployment 发布为Service以供外部访问:
kubectl expose deployment nginx --port 80 --type=NodePort
以上命令用于将一个名为 nginx 的 Deployment 暴露为一个 NodePort 类型的 Service,从而允许外部流量通过集群的节点访问该 Deployment 中的 Pod。
- kubectl expose deployment nginx:将名为 nginx 的 Deployment 暴露为一个 Service。
- --port 80:指定 Service 的端口为 80,这意味着从外部访问时,请求会被转发到 Pod 的 80 端口。
- --type=NodePort:指定 Service 的类型为 NodePort。NodePort 类型的 Service 会在每个节点上开放一个端口(通常在 30000-32767 范围内),从而允许外部流量通过节点访问集群内的 Pod。
10.3 在master01主机上,查看创建的Pod和Service是否正常运行:
kubectl get pod,svc
注意上图中的READY正常应该为1/1。
如果这里READY为0,可以通过使用 kubectl logs <pod-name> 查看容器日志或者使用 kubectl describe pod <pod-name> 查看详细信息。
如果日志显示拉取镜像失败,那么仔细检查图3-23中containerd镜像源配置或者使用以下命令强行直接拉取镜像。
ctr images pull docker.m.daocloud.io/library/nginx:latest10.4通过以下命令访问发布的nginx服务器:
curl http://master01:30478
curl http://node01:30478
curl http://node02:30478或者直接通过浏览器进行访问,具体如下图所示。
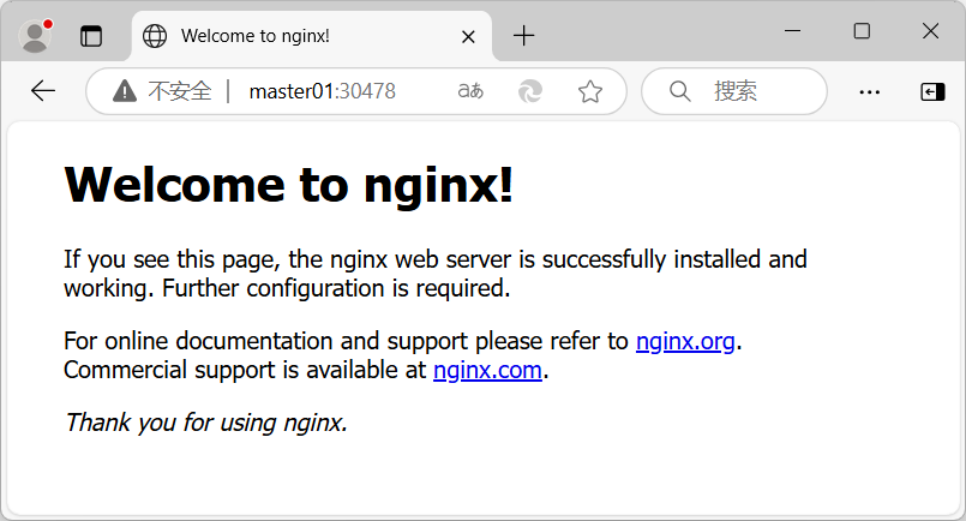
到此整个实验结束。
相关文章:

Kubernetes集群环境搭建与初始化
1.Kubernetes简介: Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。 在Kubernetes中,我…...

Compose 适配 - 响应式排版 自适应布局
一、概念 基于可用空间而非设备类型来设计自适应布局,实现设备无关性和动态适配性,避免硬编码,以不同形态布局更好的展示内容。 二、区分可用空间 WindowSizeClasses 传统根据屏幕大小和方向做适配的方式已不再适用,APP的显示方式…...

5G_WiFi_CE_DFS
目录 一、规范要求 1、法规目录 2、定义 3、运行模式 4、主/从设备相关的运行行为及具体的动态频率选择(DFS)要求 5、产品角色确定测试项目 6、测试项目 测试项1:信道可用性检查(Channel Availability Check) …...

Lalamove基于Flink实时湖仓演进之路
摘要:本文投稿自货拉拉国际化技术部 资深数据仓库工程师林海亮老师。内容分为以下几个部分: 1、业务简介 2、Flink 在业务中的应用与挑战 3、实时数仓架构的 Flink 驱动演进 4、未来展望 一、业务简介 Lalamove 于2013年在香港成立,是货拉拉的…...

【含文档+PPT+源码】基于微信小程序的卫生院预约挂号管理系统的设计与实现
项目视频介绍: 毕业作品基于微信小程序的卫生院预约挂号管理系统的设计与实现 课程简介: 本课程演示的是一款基于微信小程序的卫生院预约挂号管理系统的设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习…...

人工智能100问☞第2问:机器学习的核心原理是什么?
目录 一、通俗解释 二、专业解析 三、权威参考 机器学习的核心原理是通过数据训练模型,使计算机自动发现数据中的内在规律或模式,并利用这些规律对新数据做出预测或决策。这一过程强调数据驱动(从经验中学习)、模型优化(通过损失函数和参数调整提升性能)以及泛…...

【深度学习基础】——机器的神经元:感知机
感知机模型的原理之前已经讲过(【感知机模型 - CSDN App】https://blog.csdn.net/2401_88885149/article/details/145563837?sharetypeblog&shareId145563837&sharereferAPP&sharesource2401_88885149&sharefromlink)但主要是从数学和机…...
图像滤波-----GMat类)
OpenCV 图形API(29)图像滤波-----GMat类
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::GMat 是 OpenCV 的 G-API 模块中的一个核心类,用于定义计算图中的数据节点。G-API 是 OpenCV 中的一个模块,旨在通过…...

spark的堆外内存,是在jvm内还是操作系统内存内?
在 Apache Spark 中,堆外内存(Off-Heap Memory)是直接分配在操作系统的物理内存中,而非 JVM 堆内内存。以下是详细的解释: 1. 堆外内存的本质 操作系统管理 Spark 的堆外内存直接通过操作系统分配(例如使用…...

AD9253 LVDS 高速ADC驱动开发
1、查阅AD9253器件手册 2、查阅Xilinx xapp524手册 3、该款ADC工作在125Msps下,14bit - 2Lane - 1frame 模式。 对应:data clock时钟为500M DDR mode。data line rate:1Gbps。frame clock:1/4 data clock 具体内容:…...
)
swift菜鸟教程14(闭包)
一个朴实无华的目录 今日学习内容:1.Swift 闭包1.1闭包定义1.2闭包实例1.3闭包表达式1.3.1sorted 方法:据您提供的用于排序的闭包函数将已知类型数组中的值进行排序。1.3.2参数名称缩写:直接通过$0,$1,$2来顺序调用闭包的参数。1.3.3运算符函…...

【HarmonyOS NEXT+AI】问答02:有一点编程基础,可以学不?
在“HarmonyOS NEXTAI大模型打造智能助手APP(仓颉版)”课程里面,有学员问,有一点编程基础,可以学不? 这里统一做下回复。 学习本课程只需要掌握任一编程语言即可,拥有JavaScript、TypeScript、ArkTS或Java语言基础更佳…...

maven 依赖的优先级
最短路径优先 工程中依赖了a、b两个jar包, 在a jar包内引用了b jar包版本为1.0,路径为:Project > a > b(1.0) 工程中直接依赖的b jar包版本为2.0,路径为:Project > b(2.0) 由于b(2.0)路径最短࿰…...

Java实现音频录音播放机功能
Java实现一个简单的音频录音和播放功能,使用Swing创建图形用户界面,利用Java Sound API进行音频处理。下面是对此程序的详细剖析: 一、程序结构 程序主要由以下几个部分组成: RecorderFrm类:主框架类,继承自…...
图像滤波-----方框滤波函数boxFilter())
OpenCV 图形API(26)图像滤波-----方框滤波函数boxFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 使用方框滤波器模糊图像。 该函数使用以下内核来平滑图像: K α [ 1 1 … 1 1 1 … 1 ⋮ ⋮ ⋱ ⋮ 1 1 … 1 ] K \alpha \begin{b…...
)
oracle 表空间(Tablespace)
在 Oracle 11g 中,表空间(Tablespace) 是数据库存储架构的核心逻辑单元,其原理基于 逻辑存储与物理存储的分离,通过分层管理数据文件、段(Segment)、区(Extent)和数据块&…...

Git 高级操作
Git不仅是代码管理的基石工具,更是开发者提升效率的瑞士军刀。掌握基础操作只是起点,真正的高手都在使用进阶技巧优化工作流。本文将深入解析Git四大高阶操作,助你轻松应对复杂开发场景! 一、交互式暂存:精准控制提交粒…...

Go:程序结构
文章目录 名称声明变量短变量声明指针new 函数变量的生命周期 赋值多重赋值可赋值性 类型声明包和文件导入包初始化 作用域 名称 命名规则: 通用规则:函数、变量、常量、类型、语句标签和包的名称,开头须是字母(Unicode 字符 &a…...

sqlserver2017 分离附加数据库
分离数据库 分离数据库是指将数据库从 SQL Server 实例中移除,但会完整保留数据库及其数据文件和事务日志文件。 然后可以使用这些文件将数据库附加到任何 SQL Server 实例,包括分离该数据库的服务器。 如果存在下列任何情况,则不能分离数据…...

QuarkPi-CA2 RK3588S卡片电脑:6.0Tops NPU+8K视频编解码+接口丰富,高性能嵌入式开发!
QuarkPi-CA2 RK3588S卡片电脑:6.0Tops NPU8K视频编解码接口丰富,高性能嵌入式开发! 芯片框架 视频介绍 https://www.bilibili.com/video/BV1btdbYkEjY 开发板介绍 核心升级,产品炸裂 QuarkPi-CA2卡片电脑搭载瑞芯微RK3588S芯片…...

对称加密与非对称加密与消息摘要算法保证https的数据交互的完整性和保密性
一、对称加密与非对称加密的作用 1. 对称加密 作用: 保密性:对称加密使用相同的密钥对数据进行加密和解密,确保数据在传输过程中不被窃听。效率:对称加密算法(如AES)计算速度快,适合加密大量数…...

Lab Cloud FPGA 硬件在线实验云平台介绍
友晶科技依托其在FPGA技术领域的深厚积累,成功研发出了一套完整的FPGA云平台解决方案(即FPGA 硬件在线实验云,简称LabCloud )。LabCloud 是一个高效、实用的学习平台,目前已在多个学校成功部署。 LabCloud 是通过 B/S …...

相机回调函数为静态函数原因
在注册相机SDK的回调函数时,是否需要设置为静态函数取决于具体SDK的设计要求,但通常需要遵循以下原则: 1. 必须使用静态函数的情况 当相机SDK是C语言接口或要求普通函数指针时,回调必须声明为静态成员函数或全局函数:…...
)
实验室纯水器实验室超纯水机(常见类型、选型建议、维护保养)
不同实验室用水级别有何差异? 实验室用水级别由ASTM或ISO 3696等质量标准定义,有助于特定应用选择适合的水质。这些标准也考虑了生产成本,如1级(Type 1)超纯水的生产成本远高于2级(Type 2)或3级(Type 3)纯水。 1级超纯水 不含离子ÿ…...

腾讯云COS与ZKmall 开源商城的存储集成方案
ZKmall 开源商城与腾讯云对象存储(COS)的集成,可通过云端资源托管、自动化数据同步、高性能存储架构实现本地存储负载降低与访问效率提升。以下是基于搜索结果的集成路径与核心优化点: 一、存储架构升级:本地与云端协同…...

Python 深度学习实战 第3章 Keras和TensorFlowKeras 训练和评估模型实例
Python 深度学习实战 第3章 Keras和TensorFlow&Keras 训练和评估模型实例 内容概要 第3章介绍了Keras和TensorFlow的基本概念及其关系,并指导如何设置深度学习工作区。本章还概述了核心深度学习概念如何转化为Keras和TensorFlow API。通过本章,读者…...
)
基于SpringBoot的动物救助中心系统(源码+数据库)
500基于SpringBoot的动物救助中心系统,本系统共分为2个角色:系统管理员、用户,主要功能如下 【管理员】: 1. 登录:管理员可以通过登录系统来管理各种功能。 2. 用户管理:管理员可以查看用户列表࿰…...

【多模态大模型】《Qwen2.5-Omni》 论文解读
《Qwen2.5-Omni:重新定义端到端全模态大模型的技术范式》 论文解读 论文: https://arxiv.org/abs/2503.20215 (2025.03.26)代码: https://github.com/QwenLM/Qwen2.5-OmniNews: https://mp.weixin.qq.com/…...

go 通过汇编分析函数传参与返回值机制
文章目录 概要一、前置知识二、汇编分析2.1、示例2.2、汇编2.2.1、 寄存器传值的汇编2.2.2、 栈内存传值的汇编 三、拓展3.1 了解go中的Duff’s Device3.2 go tool compile3.2 call 0x46dc70 & call 0x46dfda 概要 在上一篇文章中,我们研究了go函数调用时的栈布…...

蓝桥杯C/C++省赛/国赛注意事项及运行环境配置
大佬的蓝桥杯考前急救指南 对拍(手动生成测试数据)代码: #include <bits/stdc.h> // 包含所有标准库的头文件 using namespace std; // 使用标准命名空间int main() {srand(time(0)); // 设置随机数种子为当前时间,确保每次…...

CSS高度坍塌?如何解决?
一、什么是高度坍塌? 高度坍塌(Collapsing Margins)是指当父元素没有设置边框(border)、内边距(padding)、内容(content)或清除浮动时,其子元素的 margin 会…...

redis的基本使用
简介 redis,Remote Dictionary Server,远程字典服务,一个基于内存的、存储键值对的数据库。redis是开源的,使用C语言编写。因为redis的数据是存储在内存中的,所以redis通常被用来做数据库的缓存 优点: re…...

【蓝桥杯】单片机设计与开发,第十二届
/*头文件声明区*/ #include <STC15F2K60S2.H>//单片机寄存器头文件 #include <init.h>//初始化底层驱动头文件 #include <led.h>//led,蜂鸣器,继电器底层驱动头文件 #include <key.h>//按键底层驱动头文件 #include <seg.h>//数码管底层驱动头…...

主流时序数据库深度对比:TDengine、InfluxDB与IoTDB的技术特性、性能及选型考量
目录 引言 一、 核心架构与技术特性对比 1.1、 TDengine:面向物联网的特定优化 1.2. InfluxDB:成熟的通用时序平台 1.3. Apache IoTDB:面向工业场景的精细化设计 二、 核心性能指标对比分析 2.1、写入性能 2.2、查询性能 三、 关键技…...

使用人工智能大模型腾讯元宝,如何免费快速做高质量的新闻稿?
今天我们学习使用人工智能大模型腾讯元宝,如何免费快速做高质量的新闻稿? 手把手学习视频地址:https://edu.csdn.net/learn/40402/666431 第一步在腾讯元宝对话框中输入如何协助老师做新闻稿,通过提问,我们了解了老师…...

国产Linux系统统信安装redis教程步骤
系统环境 uname -a Linux FlencherHU-PC 6.12.9-amd64-desktop-rolling #23.01.01.18 SMP PREEMPT_DYNAMIC Fri Jan 10 18:29:31 CST 2025 x86_64 GNU/Linux官网下载源码包并解压 下载链接 https://download.redis.io/releases/redis-7.0.15.tar.gz?_gl11h424d3_gcl_au*ODQ5…...

leetcode590 N叉树的后序遍历
前序遍历 的顺序是:根 → 子节点1 → 子节点2 → ... → 子节点N 后序遍历 的顺序是:子节点1 → 子节点2 → ... → 子节点N → 根 首先一个办法就是前序遍历结果进行翻转 在 迭代法 实现 后序遍历 时,如果采用 前序遍历 反转 的方式&…...

docker desktop 的安装和使用
一、Docker Desktop 是什么? Docker Desktop 是一款专为开发者设计的工具,可以在本地计算机(Windows/macOS)上快速运行和管理容器(Container)环境。以下是核心功能: 核心特点说明容器化开发基于…...

QCustomPlot频谱图
使用QCutomPlot做的读取txt文件显示频谱图的demo,帮助大家了解QCustomPlot的基本使用 1.运行结果 demo比较简单,用于文件读取,鼠标放大缩小,右键截图等基础功能. 2.绘图详解 绘图核心是将类提升为QCustomPlot之后进行重绘,重绘之前设计图表曲线,图标标题,坐标轴,坐标轴范围,背…...

Python 和 JavaScript两种语言的相似部分-由DeepSeek产生
Python 和 JavaScript 作为两种流行的编程语言,虽然在设计目标和应用场景上有差异(Python 偏向后端和脚本,JavaScript 偏向前端和动态交互),但它们的语法存在许多相似之处。以下是两者在语法上的主要共同点及对比&…...

记一次 .NET某云HIS系统 CPU爆高分析
一:背景 1. 讲故事 年前有位朋友找到我,说他们的系统会偶发性的CPU爆高,有时候是爆高几十秒,有时候高达一分多钟,自己有一点分析基础,但还是没找到原因,让我帮忙看下怎么回事? 二&…...

ESP32开发入门:基于VSCode+PlatformIO环境搭建指南
前言 ESP32作为一款功能强大的物联网开发芯片,结合PlatformIO这一现代化嵌入式开发平台,可以大幅提升开发效率。本文将详细介绍如何在VSCode中搭建ESP32开发环境,并分享实用开发技巧。 一、环境安装(Windows/macOS/Linux…...

在 macOS 上设置来电自启动
在 macOS 中,系统本身并不支持直接通过“接上电源适配器”自动开机(此功能涉及硬件底层控制)。但针对 Intel 处理器的 Mac 机型,可以通过以下方法间接实现类似效果。对于 Apple Silicon(M1/M2/M3)芯片的 Ma…...
)
【技术】Ruby 生态概念速查表,通过对比nodejs生态(入门)
以下是 Ruby 生态 对应概念的速查表,并使用与 Node.js 生态 对比的方式来参照,涵盖名称、作用(或解释)、简单用法、可能的替代方案,以及 Node.js 中最相似或可类比的工具(如果有的话)。有些工具…...

入门级宏基因组数据分析教程,从实验到分析与应用
宏基因组学彻底改变了研究人员对微生物群落的认识,微生物组不仅是环境组分,更作为共生体深刻影响着宿主的健康与功能。 鉴于微生物群落固有的复杂性及其所处环境的多样性,研究者进行一些宏基因组学研究时必须精心设计以获取能真实反映目标群体…...

解决 Vue 中 input 输入框被赋值后,无法再修改和编辑的问题
目录 需求: 出现 BUG: Bug 代码复现 解决问题: 解决方法1: 解决方法2 关于 $set() 的补充: 需求: 前段时间,接到了一个需求:在选择框中选中某个下拉菜单时,对应的…...

聚划算!CNN-GRU、CNN、GRU三模型多变量回归预测
聚划算!CNN-GRU、CNN、GRU三模型多变量回归预测 目录 聚划算!CNN-GRU、CNN、GRU三模型多变量回归预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 聚划算!CNN-GRU、CNN、GRU三模型多变量回归预测 (Matlab2023b 多输入单输出) 1.程…...

list的常见接口使用
今天,我们来讲解一下C关于STL标准库中的一个容器list的常见接口。 在我们之前c语言数据结构中,我们已经了解过了关于链表的知识点了,那么对于现在理解它也是相对来说比较容易的了。 数据结构--双向循环链表-CSDN博客 1. 定义与包含头文件 …...

5. 蓝桥公园
题目描述 小明喜欢观景,于是今天他来到了蓝桥公园。 已知公园有 N 个景点,景点和景点之间一共有 M 条道路。小明有 Q 个观景计划,每个计划包含一个起点 stst 和一个终点 eded,表示他想从 stst 去到 eded。但是小明的体力有限&am…...

零基础开始学习鸿蒙开发-智能家居APP离线版介绍
目录 1.我的小屋 2.查找设备 3.个人主页 前言 好久不发博文了,最近都忙于面试,忙于找工作,这段时间终于找到工作了。我对鸿蒙开发的激情依然没有减退,前几天做了一个鸿蒙的APP,现在给大家分享一下! 具体…...