Python爬虫第10节-lxml解析库用 XPath 解析网页
目录
引言
一、XPath简介
二、XPath常用规则
三、实例讲解
四、节点的选取
4.1 所有节点的选取
4.2 子节点的选取
4.3 父节点选取
五、属性匹配获取及文本获取
5.1 属性匹配
5.2 文本获取
5.3 属性获取
5.4 属性多值匹配
5.5 多属性匹配
六、按序选择
七、节点轴选择
八、总结
引言
在上一节中,我们创建了一个基础的爬虫程序,并使用正则表达式来提取页面信息。然而,这种方法存在一定的局限性:如果正则表达式的编写不准确,可能会导致无法正确匹配所需内容。因此,在实际应用中,使用正则表达式进行页面信息提取并不是最方便的选择。
网页中的节点通常具有id、class等属性,且节点之间存在着层次关系。为了更高效地解析页面并定位特定节点,我们可以利用XPath或CSS选择器来进行操作。通过这些工具,我们可以轻松地从HTML文档中提取出所需的节点及其相关信息。
Python提供了多种强大的解析库,如lxml、BeautifulSoup和pyquery等,它们能够帮助我们更加便捷地处理HTML数据。借助这些库,我们无需担心复杂的正则表达式编写问题,同时还能显著提高解析效率。接下来,我们将重点探讨如何在Python中使用lxml库实现XPath功能。
XPath(XML Path Language)是一种专门用于在XML文档中查找信息的语言。尽管它最初是为XML设计的,但后来发现其同样适用于HTML文档的搜索需求。因此,在开发网络爬虫时,我们可以充分利用XPath来抽取网页上的相关数据。下面将详细介绍XPath的基本用法。
一、XPath简介
XPath以其简洁明了的路径选择表达式著称,并提供超过100个内置函数,涵盖了字符串、数值、时间等多种类型的匹配与处理能力。几乎任何想要定位的节点都可以通过XPath进行选择。
自1999年11月16日成为W3C标准以来,XPath被广泛应用于XSLT、XPointer以及其他XML解析软件的设计中。若想深入了解其详细规范及相关文档,请访问官方网址:https://www.w3.org/TR/xpath/。
二、XPath常用规则
下表列举了XPath的几个常用规则:
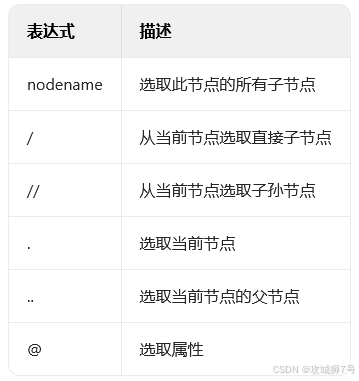
这里列出了XPath的常用匹配规则,示例如下:
//title[@lang='eng']
这条XPath规则的作用是,把所有名称是title,同时属性lang的值为eng的节点都选出来。后面我们会借助Python的lxml库,运用XPath对HTML进行解析。
三、实例讲解
在开始使用XPath之前,确保已经安装了lxml库。如果没有安装,请自行查阅相关资料完成安装过程。
以下是一个简单的实例,展示了如何使用XPath解析HTML文档:
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1">second item</li>
<li class="item-inactive">third item</li>
<li class="item-1">fourth item</li>
<li class="item-0">
<a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
result = etree.tostring(html)
print(result.decode('utf-8'))这里先把lxml库的etree模块导进来,接着弄了一段HTML文本,再用HTML类去初始化这段文本,这样就成功做出了一个XPath解析对象。要留意的是,那段HTML文本里最后一个li节点没闭合,不过etree模块能自动把这个HTML文本修正过来。
然后我们用tostring()方法,能输出修正后的HTML代码,只是输出的结果是bytes类型。再用decode()方法把它转成str类型,得到的结果如下:
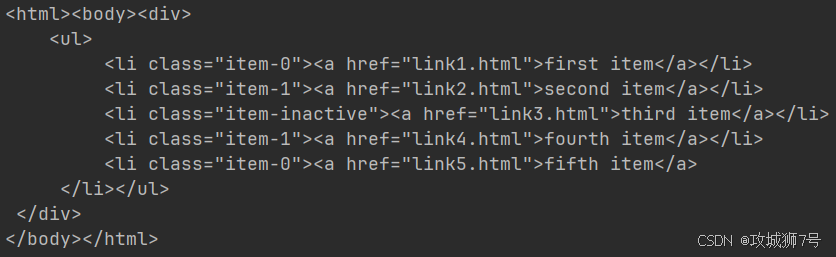
能看到,处理完后,li节点的标签补齐了,还自动加上了body和html节点。另外,也能直接读取文本文件来解析,示例如下:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = etree.tostring(html, method='html')
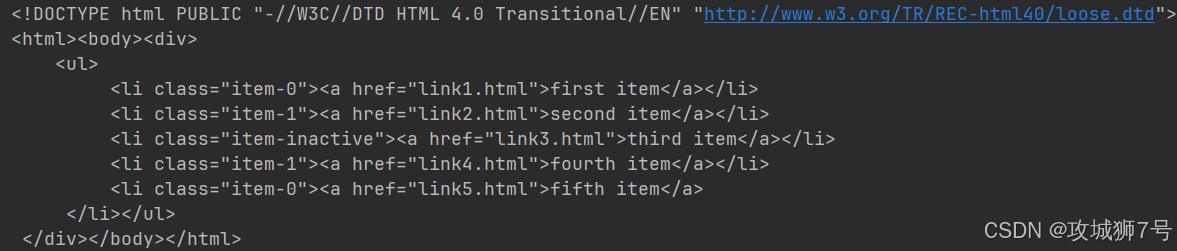
print(result.decode('utf-8'))其中test.html的内容就是上面例子中的HTML代码,内容如下:
<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul></div>执行上述代码后,可以看到输出结果包含了额外的DOCTYPE声明,但这并不会影响到我们的解析工作。结果如下:
四、节点的选取
4.1 所有节点的选取
要选择HTML文档中的所有节点,可以使用以双斜杠(//)开头的XPath表达式。例如,对于前面提到的HTML文本,可以通过以下方式获取全部节点:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//*')
print(result)运行结果如下:

这里使用的*通配符表示匹配任意类型的节点,因此最终返回的结果会涵盖整个HTML文档中的每一个元素。每个匹配到的节点都会以Element对象的形式存储在一个列表中,便于进一步的操作和分析。
当然,也可以指定具体的节点类型作为筛选条件。比如,如果我们只关心所有的<li>节点,则可以这样写:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li')
print(result)
print(result[0])想要选出所有的li节点,办法很简单,用//,紧接着写上节点名称“li”就行。在程序里调用的时候,直接用xpath()这个方法。 运行之后得到的结果是:

从这里能看出,提取出来的结果呈现为列表形式。列表里的每一个元素,都是一个Element对象。要是你想从里面拿出某一个对象,直接用中括号加上对应的索引值就行,比如用[0]就能取出第一个对象 。
4.2 子节点的选取
在确定了父节点之后,我们可能需要进一步选择其下的子节点或子孙节点。这可以通过在XPath表达式中连续使用单斜杠(/)或双斜杠(//)来实现。
假设现在我们要找出所有<li>节点下直接嵌套的<a>子节点,可以这样做:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li/a')
print(result)在已有的XPath表达式后面加上/a ,就能选中所有li节点下的直接a子节点。这是因为//li能选中所有的li节点,而/a专门用来选中li节点的直接a子节点,把它们合起来,自然就获取到所有li节点的直接a子节点了。运行之后的结果如下:

这里的/是用来选取直接子节点的。要是想获取所有子孙节点,那就用//。举个例子,要是想获取ul节点下的所有子孙a节点,可以像下面这样操作:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//ul//a')
print(result)运行结果如下:

因此,我们要注意/和//的区别,其中/用于获取直接子节点,//用于获取子孙节点。
4.3 父节点选取
我们都知道,用连续的 / 或者 // 能查找子节点或者子孙节点。当我们已经定位到了某个具体节点时,有时也需要回溯至其上级节点进行操作。这时,可以利用点号(.)或者parent::关键字来实现这一目的。
举个例子来说,假如我们需要先找到链接地址为"link4.html"的那个<a>标签,然后再向上追溯到它的父级<li>元素,并从中提取出该元素的"class"属性值。对应的代码片段如下所示:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//a[@href="link4.html"]/../@class')
print(result)运行结果如下:
['item-1']
查看结果后会发现,这恰好就是我们要获取的目标li节点的class。此外,我们还能用parent::这种方式来获取父节点,代码如下:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//a[@href="link4.html"]/parent::*/@class')
print(result)五、属性匹配获取及文本获取
5.1 属性匹配
在选择节点时,我们可以用@符号来筛选属性。在选择节点的过程中,我们常常需要根据特定的属性值来进行过滤。这可以通过在XPath表达式中加入方括号([])以及相应的属性名和期望值来达成。
例如,如果我们只想挑选出那些拥有"class"属性等于"item-0"的所有<li>节点,就可以按照下面的方式来构造查询语句:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]')
print(result)我们加上[@class="item-0"],限定节点的class属性必须是item-0。在HTML文本里,符合这个条件的li节点有两个,所以结果应该会返回两个匹配到的元素。

结果如下:可以看到,匹配结果确实是两个,这俩是不是我们要的,后面再验证。
5.2 文本获取
除了属性之外,另一个常见的需求是从选定的节点中提取文本内容。在XPath中,这通常是通过调用text()函数来完成的。
让我们尝试一下从前面提到过的那些<li>节点内部获取文本信息吧:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]/text()')
print(result)运行结果如下:
['\r\n ']
挺奇怪的,我们啥文本都没获取到,这是为啥呢?因为在XPath里,text()前面是/,这里的/意思是选直接子节点。很明显,li的直接子节点都是a节点,文本都在a节点里面。所以这里匹配到的结果就是修正后的li节点里的换行符,毕竟自动修正时li节点的尾标签换行了。
即选中的是这两个节点:
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li>有个节点因为自动修正,添加li节点的尾标签时换行了,所以提取文本得到的就只有li节点尾标签和a节点尾标签之间的换行符。
所以,要是想获取li节点里面的文本,有两种办法。一种是先选到a节点,然后获取文本;另一种是用 //。下面,我们来看看这两种方法有啥不一样。
先看选到a节点再获取文本,代码如下:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]/a/text()')
print(result)运行结果如下:
['first item', 'fifth item']
能看到,这里返回了两个值,内容都是class属性为item-0的li节点里的文本,这也说明前面根据属性匹配得到的结果是对的。
我们在这儿是一层一层选的,先选了li节点,接着用/选了它的直接子节点a,然后再选a里的文本,得到的这两个结果,跟我们预想的一样。
接下来看看用另一种办法(也就是用//)选取的结果,代码如下:
from lxml import etree html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]//text()')
print(result)运行结果如下:
['first item', 'fifth item', '\r\n ']
果不其然,这儿返回了3个结果。不难想到,这是把所有子孙节点的文本都选出来了。其中前两个是li的子节点a里面的文本,还有一个是最后一个li节点里的文本,也就是换行符。
所以,要是想获取子孙节点里面的全部文本,直接用//加text()这种方式就行,这么做能确保获取到最完整的文本信息,不过可能会混进一些像换行符这样的特殊字符。要是只想获取某些特定子孙节点下的所有文本,可以先选到那些特定的子孙节点,接着调用text()方法来获取里面的文本,这样得到的结果会比较干净。
虽然这两种策略都能达到基本的目的,但在实际效果上却存在一定差异。前者倾向于产生较为干净整洁的结果集,因为它严格限制了搜索范围;相比之下,后者则有可能引入一些不必要的空白字符或其他干扰因素,因为它的包容性更强。因此,在具体实施过程中应当根据实际情况灵活调整策略,以期获得最佳的输出质量。
5.3 属性获取
除了文本内容外,我们还经常需要从节点中提取各种各样的属性值。幸运的是,XPath为我们提供了一种非常直观的方式来完成这项任务——只需简单地在节点名称后面附加一个@符号再加上所感兴趣的属性名即可。
举例来说,如果我们想要收集所有<li>节点下属<a>标签的href属性值,可以这样做:
from lxml import etreehtml = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li/a/@href')
print(result)在这儿,用@href就能拿到节点的href属性。要注意,这和属性匹配的方法不一样。属性匹配是用中括号加上属性名和值来限定某个属性,像[@href="link1.html"];而这里的@href是获取节点的某个属性,这两种情况要区分清楚。
运行结果如下:

能看到,我们成功拿到了所有li节点下面a节点的href属性,这些属性以列表形式返回。
这样一来,系统就会遍历整个文档树,寻找所有符合条件的<a>节点,并逐一记录下它们各自的href属性值。最终,这些值将以列表的形式呈现出来,供我们进一步分析或处理。
需要注意的是,此处使用的@href标记与前面介绍过的属性匹配机制有所不同。在属性匹配中,我们是在方括号内使用@符号加属性名的方式来设定筛选条件;而在属性获取场景下,@符号则直接紧跟在节点名称之后,用来指示我们关注的重点所在。理解这两者之间的区别对于正确编写XPath表达式至关重要。
5.4 属性多值匹配
在某些情况下,一个节点的某个属性可能会包含多个不同的值。例如,考虑以下HTML片段:
from lxml import etree
text = '''
<li class="li li-first"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[@class="li"]/a/text()')
print(result)在这段HTML文本里,li节点的class属性有两个值,分别是li和li - first。要是还用之前那种属性匹配的方法,就匹配不上了,运行结果如下:
[ ]
这时候就得用contains()函数了,代码可以改成下面这样:
from lxml import etree
text = '''
<li class="li li-first"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class, "li")]/a/text()')
print(result)用contains()方法的时候,第一个参数填属性名,第二个参数填属性值。只要这个属性包含你填的属性值,就能完成匹配。
现在运行结果如下:
['first item']
这种方法在节点的某个属性有多个值的时候经常会用到,像节点的class属性就常常有好几个值。
这一次,我们不再拘泥于"class"属性必须完全等于某一个固定值,而是转而考察它是否至少包含"li"这个关键词。如此一来,即便面对像上面那样的复合型属性值,我们也能够从容应对,确保不会遗漏任何一个有价值的线索。
5.5 多属性匹配
除了处理单个属性的多值情形外,我们还可能遇到需要同时考量多个属性的情况。在这种场合下,单纯依靠contains()函数或许不足以解决问题,因为我们还需要保证所有相关的属性都满足各自独立的约束条件。
为此,XPath允许我们在同一个方括号内串联起多个由and连接的布尔表达式,以此来表达更为精细的筛选逻辑。例如,假设有这样一个HTML片段:
from lxml import etree
text = '''
<li class="li li-first" name="item"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class, "li") and @name="item"]/a/text()')
print(result)这里的`li`节点多了一个`name`属性。要精准找到这个节点,得同时依据`class`和`name`属性来筛选。一个条件是`class`属性里得包含`li`这个字符串,另一个条件是`name`属性得是`item`这个字符串,这两个条件必须同时满足,所以要用`and`操作符把它们连起来,连好后放在中括号里当作筛选条件。运行结果如下:
['first item']
这里的`and`属于XPath里的运算符。其实,XPath还有不少其他运算符,像`or`、`mod`等等,下面整理成表格供参考。
运算符及其介绍
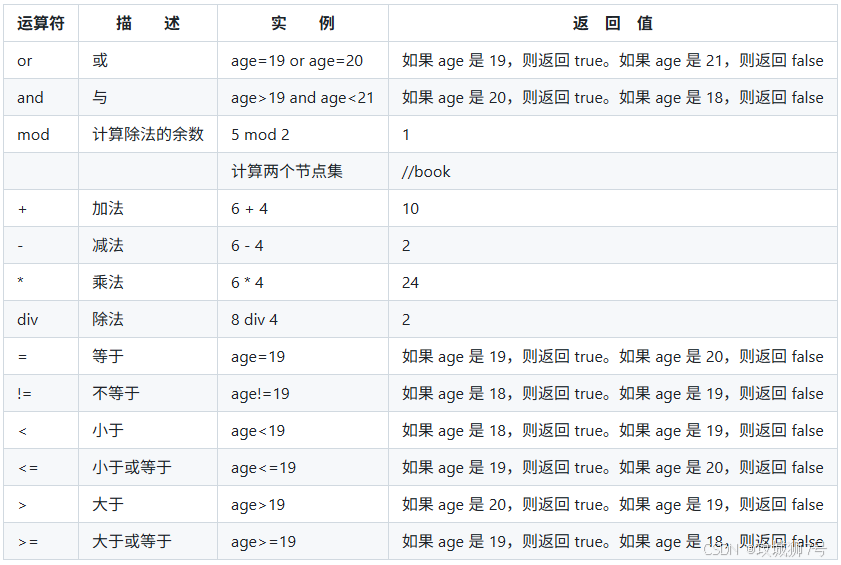
参考来源:http://www.w3school.com.cn/xpath/xpath_operators.asp
六、按序选择
有时候,我们选节点时,某些属性可能会匹配到好几个节点,但我们只想要其中特定的一个,比如第二个节点或者最后一个节点,这时候咋整呢?
在实际工作中,我们往往不仅仅关心某一类节点的整体分布状况,还会特别留意其中某些特定成员的位置信息。例如,当我们面对一组有序排列的项目列表时,可能只对其中的第一个、最后一个或是中间某个特定编号的条目感兴趣。针对这种情况,XPath提供了一系列基于序列位置的查询技巧,使我们能够精准地锁定目标节点。
最基本的用法是在中括号内填入一个整数索引来获取指定顺序的节点,例子如下:
from lxml import etreetext = '''
<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul></div>
'''
html = etree.HTML(text)
result = html.xpath('//li[1]/a/text()')
print(result)
result = html.xpath('//li[last()]/a/text()')
print(result)
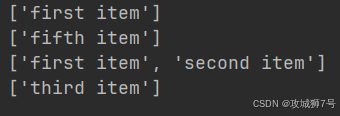
result = html.xpath('//li[position()<3]/a/text()')
print(result)
result = html.xpath('//li[last()-2]/a/text()')
print(result)第一次选的时候,我们要选第一个`li`节点,在中括号里写数字`1`就行。要注意,这里和代码里不一样,序号是从`1`开始,不是从`0`开始的。
第二次选的时候,我们要选最后一个`li`节点,在中括号里写`last()`就可以,这样返回的就是最后一个`li`节点。
第三次选的时候,我们要选位置序号小于`3`的`li`节点,也就是序号为`1`和`2`的节点,结果就是前两个`li`节点。
第四次选的时候,我们要选倒数第三个`li`节点,在中括号里写`last() - 2`就行。因为`last()`代表最后一个,所以`last() - 2`就是倒数第三个。
运行结果如下:
这里我们用到了`last()`、`position()`这些函数。在XPath里,有100多个函数,能处理存取、数值、字符串、逻辑、节点、序列等方面的操作。这些函数具体有啥用,可以参考:http://www.w3school.com.cn/xpath/xpath_functions.asp 。
七、节点轴选择
除了常规的父子关系查询外,XPath还提供了一些特殊的“轴”(axis)概念,用于描述节点间更为复杂的空间布局特征。借助这些轴的概念,我们可以沿着不同的方向探索文档树,从而发现更多隐藏在深处的信息宝藏。
以下是一些常用的轴选择示例:
- ancestor:选择当前节点的所有祖先节点。
- attribute:选择当前节点的所有属性。
- child:选择当前节点的所有直接子节点。
- descendant:选择当前节点的所有子孙节点。
- following:选择当前节点之后的所有节点。
- following-sibling:选择当前节点之后的所有同级节点。
- parent:选择当前节点的父节点。
- preceding:选择当前节点之前的所有节点。
- preceding-sibling:选择当前节点之前的所有同级节点。
XPath有很多选节点轴的方法,能获取子元素、兄弟元素、父元素、祖先元素这些,例子如下:
from lxml import etreetext = '''
<div><ul><li class="item-0"><a href="link1.html"><span>first item</span></a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul></div>
'''
html = etree.HTML(text)
result = html.xpath('//li[1]/ancestor::*')
print(result)
result = html.xpath('//li[1]/ancestor::div')
print(result)
result = html.xpath('//li[1]/attribute::*')
print(result)
result = html.xpath('//li[1]/child::a[@href="link1.html"]')
print(result)
result = html.xpath('//li[1]/descendant::span')
print(result)
result = html.xpath('//li[1]/following::*[2]')
print(result)
result = html.xpath('//li[1]/following-sibling::*')
print(result)运行结果如下:

第一次选节点时,我们用了`ancestor`轴,它能获取所有祖先节点。使用时后面要跟两个冒号,然后写节点选择器,这里我们直接用`*`,意思是匹配所有节点,所以返回的是第一个`li`节点的所有祖先节点,有`html`、`body`、`div`和`ul`。
第二次选节点,我们加了个条件,在冒号后面写了`div`,这样结果就只有`div`这一个祖先节点了。
第三次选节点,我们用了`attribute`轴,它能获取所有属性值。后面跟着的选择器还是`*`,就是获取节点的所有属性,返回的就是`li`节点的所有属性值。
第四次选节点,我们用了`child`轴,它能获取所有直接子节点。这里我们加了条件,选`href`属性是`link1.html`的`a`节点。因为示例文本里第一个`li`节点下面的`a`节点,`href`属性值不是`link1.html`,所以返回的是空列表。
第五次选节点,我们用了`descendant`轴,它能获取所有子孙节点。这里我们加了条件,只要`span`节点,所以结果里只有`span`节点,没有`a`节点。
第六次选节点,我们用了`following`轴,它能获取当前节点后面的所有节点。这里虽然用`*`匹配,但我们加了索引来选,所以只拿到了第二个后续节点。
第七次选节点,我们用了`following - sibling`轴,它能获取当前节点后面的所有同级节点。这里用`*`匹配,所以拿到了所有后续同级节点。
上面就是XPath轴的简单用法,更多轴的用法可以参考:http://www.w3school.com.cn/xpath/xpath_axes.asp 。
八、总结
至此,我们已经大致介绍了XPath语言的核心特性和主要用途。作为一种强大而又灵活的查询工具,XPath无疑为我们提供了许多便利之处,尤其是在处理大规模、高复杂度的HTML文档时更是如此。然而,要想充分发挥其潜力,还需不断实践积累经验,并时刻保持对新技术的关注和学习热情。
在此基础上,我们强烈推荐读者朋友们继续深入研究XPath的相关知识体系,包括但不限于其丰富的内置函数库、先进的模式匹配算法以及与其他编程语言的良好集成能力等方面。相信随着大家技术水平的不断提高,一定能够在未来的网络爬虫开发实践中取得更加丰硕的成果!
参考资料:
XPath官方文档:http://www.w3.org/TR/xpath/
W3Schools XPath教程:http://www.w3school.com.cn/xpath/index.asp
Python lxml库文档:http://lxml.de/
参考书籍:
《Python 3网络爬虫开发实战》
相关文章:

Python爬虫第10节-lxml解析库用 XPath 解析网页
目录 引言 一、XPath简介 二、XPath常用规则 三、实例讲解 四、节点的选取 4.1 所有节点的选取 4.2 子节点的选取 4.3 父节点选取 五、属性匹配获取及文本获取 5.1 属性匹配 5.2 文本获取 5.3 属性获取 5.4 属性多值匹配 5.5 多属性匹配 六、按序选择 七、节点…...

Prometheus有哪几种服务发现?
Prometheus 支持多种服务发现 (Service Discovery) 机制,用于自动发现需要监控的目标。这些服务发现机制主要分为以下几类: 1. 静态配置 (Static Configuration) Static Configuration: 手动定义静态目标列表。适用于小规模的、固定的目标环境…...

突破焊丝虚影干扰,端子焊点缺陷检测如何实现自动化?
端子焊点作为 3C 产品中连接电路的关键环节,其质量优劣对产品性能有着决定性影响。然而,传统人工检测端子焊点不仅效率低下,难以满足大规模生产需求,而且误判率高,无法精准把控产品质量,成为企业提质增效智…...

2025.04.10-拼多多春招笔试第二题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 02. 糖果店的优惠兑换计划 问题描述 K小姐开了一家糖果店,推出了一种特殊的兑换活动。商店有 n n n<...

linux系统下如何提交git和调试
我们默认的ubuntu20.04镜像是没有Git提交的工具,我们需要配置安装包。 安装和更新git的命令 sudo apt update //用于更新软件包索引sudo apt install git //用于安装git版本控制工具 git --version //检查git版本,确认是否安装成功 随便进入linux系统下的一…...

40页的IPD流程指标字典【全文精读】
该文档聚焦 IPD 流程指标,为企业在产品研发管理领域提供全面量化评估标准,主要适用于企业中与产品研发、管理、财务及市场相关的各类人员。 财务类指标:涵盖市场份额、新产品销售比重等,用于评估产品市场竞争力、投资效率…...

如何在Cherry Studio中配置MCP工具服务?国内MCP服务有哪些?
在当今数字化时代,AI助手已成为提升工作效率和创造力的重要工具。Cherry Studio作为一个全能的AI客户端,支持多平台(包括Windows、macOS和Linux),并提供了丰富的功能,如大模型对话、AI绘图和AI翻译等。为了…...

动态词槽管理系统深度设计
动态词槽管理系统深度设计 基于Dual-Encoder的实时增量式语义槽管理方案 一、Dual-Encoder架构优化 1.1 架构创新设计 增强型双塔模型结构: #mermaid-svg-DRhtmuANYnJBJzpu {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill…...

网络安全中信息收集需要收集哪些信息了?汇总
目录 1. 域名信息 2. IP地址与网络信息 3. 备案与注册信息 4. Web应用与中间件信息 5. 操作系统与服务器信息 6. 敏感文件与配置文件 7. 社交工程信息 8. 证书与加密信息 9. API与接口信息 10. 外部威胁情报 11. 历史数据与缓存 常用工具与技术: 在网络…...
)
代码模板-线段树(区间修改,区间查询和和最值)
题目链接:1270. 数列区间最大值 - AcWing题库 代码: // #pragma GCC optimize(1) // #pragma GCC optimize(2) // #pragma GCC optimize(3,"Ofast","inline")#include<bits/stdc.h> using namespace std; typedef long long…...

LLM介绍
一、核心概念与能力边界 LLM(Large Language Model:大语言模型)是基于海量文本训练的深度学习模型,其核心能力源于Transformer架构与自监督学习机制。关键特征包括: 参数规模:千亿级参数(如GP…...

[数据结构]排序
目录 1、排序的概念 2、常见排序算法 3、直接插入排序 4、希尔排序 5、直接选择排序 6、堆排序 7、冒泡排序 1、排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作 …...

Next.js + Droplet:高并发视频内容平台部署与优化扩展实战
在构建在线服务时,无论你是开发者还是企业技术负责人,扩展性和稳定性始终是绕不开的核心挑战。尤其在涉及高并发访问、大量数据传输和持续内容分发的场景中,系统架构的设计直接决定了用户体验与业务成效。 本文将以视频点播(Video…...

django寻味美食分享与交流网站-计算机毕业设计源码74984
摘 要 美食分享与交流网站是当前社交网络领域的一个热门话题。本研究旨在探讨用户在美食分享网站上的行为和互动模式,以及他们分享和获取美食信息的动机和方式。通过对美食分享网站上用户发文内容和互动数据的分析,揭示了用户在美食分享中的需求和行为规…...

把读写函数里的printf 打印到文件里
使用 fprintf 函数 将输出目标从标准输出(stdout)更改为一个文件指针 1、首先,在头文件或全局变量中定义一个 FILE 类型的指针,用于指向输出文件。 2、在程序启动时,打开文件并将文件指针赋值给上面定义的全局指针。…...

在idea中看spring源码
一、搭建环境 1.1 下载源码到本地 在github中找到spring-framework项目,或者这个地址(https://github.com/spring-projects/spring-framework) 然后把项目下载到本地目录,如图 1.2 然后用idea打开这个项目 1.3 然后等构建&…...
以及离散傅立叶变换(DFT))
用最简单的方式讲述离散傅里叶级数(DFS)以及离散傅立叶变换(DFT)
文章目录 前言 一、傅里叶变换的多种形式 二、浅谈离散傅里叶级数(DFS) 三、浅谈离散傅里叶变换(DFT) 总结 前言 本文对四种不同的傅里叶变换做了总结与梳理,并针对其中存在联系的形式做了推导。接着又讲述了离散傅里叶…...

python基础语法14-多线程与多进程
Python 多线程与多进程详解 在 Python 中,多线程和多进程是常用的并发编程技术,它们可以帮助程序在处理大量任务时提高效率。Python 提供了多个模块来支持多线程和多进程的开发,包括 threading、multiprocessing 和 asyncio。本文将详细介绍…...

深入解析策略模式在C#中的应用与实现
策略模式(Strategy Pattern)是一种行为型设计模式,它通过将一系列算法封装成不同的策略类,使得算法的选择和使用可以在运行时动态改变,且算法的变化对使用者透明。这种模式可以显著减少程序中的条件判断(如…...

ios按键精灵脚本开发游戏辅助工具的代码逻辑
iOS 按键精灵使用 MQ 语言开发游戏脚本,其代码逻辑围绕游戏内的各种操作展开。我将从常见的游戏操作,如点击、移动等方面, 点击操作逻辑 在游戏中,点击操作是最基础的交互方式之一。比如要实现点击游戏界面上某个固定位置的 “…...
容器类型的公共运算符和公共方法)
Pycharm(十三)容器类型的公共运算符和公共方法
一、容器类型的公共运算符 这些运算符是可以作用到 容器类型 中的。 常见的如下: :拼接,适用于字符串、列表、元组; *:复制,适用于字符串、列表、元组; in:是否包含,适用于字符串、列表、元…...

Backtrader从0到1——第一个回测策略
Backtrader从0到1——第一个回测策略 0. 前言1. lines && index2. 生成大脑3. 设置起始资金和佣金4. 添加数据(重点)5. 第一个策略——双均线5.1 策略类5.2 策略参数5.3 添加指标5.4 买卖与订单order5.5 完整策略代码 0. 前言 本人翻阅了大量资料…...
)
GPT - 因果掩码(Causal Mask)
本节代码定义了一个函数 causal_mask,用于生成因果掩码(Causal Mask)。因果掩码通常用于自注意力机制中,以确保模型在解码时只能看到当前及之前的位置,而不能看到未来的信息。这种掩码在自然语言处理任务(如…...

lombok的坑
我使用lombok的Data注解带来的坑。 代码如下: 公共类: package com.tyler.oshi.common;import lombok.Data; import lombok.NoArgsConstructor;/*** author: TylerZhong* description:*/Data NoArgsConstructor public class R {private int code;priv…...

基于Python的网络爬虫技术研究
基于Python的网络爬虫技术研究 以下从多个方面为你介绍基于 Python 的网络爬虫技术: 概述 网络爬虫是一种自动获取网页内容的程序,在 Python 中可以借助诸多强大的库和工具实现。网络爬虫能应用于数据采集、搜索引擎、舆情监测等众多领域。 核心库 …...

微信小程序跳6
//金额格式化 rmoney: function(money) { return parseFloat(money).toFixed(2).toString().split().reverse().join().replace(/(\d{3})/g, $1,) .replace( /\,$/, ).split().reverse().join(); }, daysUntil: function(milliseconds) { const endDate new Date(milliseconds…...

项目1笔记
Data Data 是一个常用的 Lombok 注解,主要用于 Java 类中,可以自动生成以下内容: Getter(所有字段) Setter(所有非 final 字段) toString() 方法 equals() 和 hashCode() 方法 无参构造函…...

分享:批量识别图片文字并重命名,根据图片文字内容对图片批量重命名,Python和Tesseract OCR的完成方案
一、项目背景 在日常工作中,处理大量图片文件时,常常需要从图片中提取文字信息,并根据提取的文字对图片进行重命名。传统的手动操作方式效率低下且容易出错。通过OCR(光学字符识别)技术,可以自动从图片中提取文字信息,并基于提取的文字对图片进行批量重命名。 Tesserac…...

【安全】加密算法原理与实战
为了理解SSL/TLS原理,大家需要掌握一些加密算法的基础知识。当然,这不是为了让大家成为密码学专家,所以只需对基础的加密算法有一些了解即可。基础的加密算法主要有哈希(Hash,或称为散列)、对称加密(Symm…...

STM32STM8芯片擦除与读保护
连接STM单片机与断开单片机连接, 点击擦除就可以了。 文件选HEX在选择Verify进行下载。...

Qwen2.5技术报告阅读
论文概述 ⸻ 🧠 1. 模型概述 Qwen2.5 是阿里巴巴推出的一系列大语言模型(LLMs),在 预训练数据量 和 后训练方法 上都比前一代 Qwen2 有了显著提升。 ⸻ 📈 2. 模型特点 • 预训练数据量提升:从 7 万亿…...
)
HDCP(二)
HDCP加密算法实现详解 HDCP(高带宽数字内容保护)的加密算法实现涉及对称加密、密钥派生、动态同步机制等核心环节,其设计兼顾实时性与安全性。以下从算法类型、流程实现、硬件集成等角度展开分析: 1. 加密算法类型与版本差异 •…...
库:线程的终止与管理)
POSIX线程(pthread)库:线程的终止与管理
在POSIX线程(pthread)库中,线程的终止和管理涉及多个关键函数。以下是关于线程终止的pthread系列函数的详细介绍: 1. pthread_exit:线程主动退出 ✨ 功能: 允许线程主动终止自身,并返回一个退出…...

Elasticsearch 系列专题 - 第三篇:搜索与查询
搜索是 Elasticsearch 的核心功能之一。本篇将介绍如何构建高效的查询、优化搜索结果,以及调整相关性评分,帮助你充分发挥 Elasticsearch 的搜索能力。 1. 基础查询 1.1 Match Query 与 Term Query 的区别 Match Query:用于全文搜索,会对查询词进行分词。 GET /my_index/_…...

【AI提示词】Emoji风格排版艺术与设计哲学
提示说明 Emoji风格排版艺术与设计哲学。 提示词 请使用 Emoji 风格编辑以下段落,该风格以引人入胜的标题、每个段落中包含表情符号和在末尾添加相关标签为特点。请确保保持原文的意思。使用案例(春日穿搭) 🌸 2025春季穿搭灵…...

C语言 ——— 认识C语言
认识 main 函数 main 函数是程序的入口,程序执行时会从 main 函数的第一行开始执行,且一个工程中 main 函数有且只有一个 标准的 main 函数格式: int main() {return 0; } int 是类型,这里指的是 main 函数的返回类型 return…...
)
44、Spring Boot 详细讲义(一)
Spring Boot 详细讲义 目录 Spring Boot 简介Spring Boot 快速入门Spring Boot 核心功能Spring Boot 技术栈与集成Spring Boot 高级主题Spring Boot 项目实战Spring Boot 最佳实践总结 一、Spring Boot 简介 1. Spring Boot 概念和核心特点 1.1、什么是 Spring Boot&#…...

STM32硬件IIC+DMA驱动OLED显示——释放CPU资源,提升实时性
目录 前言 一、软件IIC与硬件IIC 1、软件IIC 2、硬件IIC 二、STM32CubeMX配置KEIL配置 三、OLED驱动示例 1、0.96寸OLED 2、OLED驱动程序 3、运用示例 4、效果展示 总结 前言 0.96寸OLED屏是一个很常见的显示模块,其驱动方式在用采IIC通讯时,常用软件IIC…...

Android 中绕过hwbinder 实现跨模块对audio 的HAL调用
需求 Audio 模块中专门为 TV 产品添加了一些代码,需要在 hdmi 的 HAL 代码中进行调用以完成某些功能。 解决方法 首先将 hdmi HAL 要调用的 audio 接口函数所在的 .so 链接到最基本的 lib.primay.amlogic.so 中(其它平台上这个 .so 文件的名字也可能是…...

基于单片机技术的手持式酒精检测电路设计
基于STC89C52单片机的酒精检测仪设计 目录 基于STC89C52单片机的酒精检测仪设计一、简介二、酒精测试仪总体方案设计2.1 酒精检测仪设计要求分析2.2 设计框图 三、硬件设计3.1 酒精检测电路3.2 模数转换电路3.3 STC89c52单片机电路3.4 LED显示电路3.5 声光报警电路3.6 按键和复…...
】卷首语)
【车道线检测(0)】卷首语
车道线检测领域,早期的LaneNet、CondLaneNet等模型。现在在精度、实时性、复杂场景适应性等方面有了更多进展。 Head(输出头)的设计角度分类 在车道线检测任务中,Head(输出头)的设计角度直接影响模型的…...

记一次某网络安全比赛三阶段webserver应急响应解题过程
0X01 任务说明 0X02 靶机介绍 Webserver(Web服务器)是一种软件或硬件设备,用于接收、处理并响应来自客户端(如浏览器)的HTTP请求,提供网页、图片、视频等静态或动态内容,是互联网基础设施的核心…...

AI 越狱技术剖析:原理、影响与防范
一、AI 越狱技术概述 AI 越狱是指通过特定技术手段,绕过人工智能模型(尤其是大型语言模型)的安全防护机制,使其生成通常被禁止的内容。这种行为类似于传统计算机系统中的“越狱”,旨在突破模型的限制,以实…...

项目进度延误的十大原因及应对方案
项目进度延误主要源于以下十大原因:目标不明确、需求频繁变更、资源配置不足或不合理、沟通不畅、风险管理不足、缺乏有效的项目监控、技术难题未及时解决、团队协作效率低下、决策链过长、外部因素影响。其中,需求频繁变更是导致延误的关键因素之一&…...

瑞友客户端登录GS_ERP时,报错: 由于安全许可证服务器不能提供许可证,连接被中断的解决方法
瑞友客户端登录GS_ERP时,报错:由于安全许可证服务器不能提供许可证,连接被中断的解决方法 瑞友客户端登录GS_ERP时, 报错:由于安全许可证服务器不能提供许可证,连接被中断的解决方法是由于远程桌面连接协议…...

android wifi通过命令行打开2.4G热点
android系统支持2G和5G,但车机系统应用只支持5G,但是需要测试2.4G的射频 方法如下: 1、adb shell 进去,su 指定root权限,确保热点处于关闭状态 2、开启热点为www99999, 密码为12345678, wpa2的加密协议 cm…...

truncate,drop,delete分析
truncate,drop,delete对比分析 特性 TRUNCATE DROP DELETE **操作对象** 表中的所有数据 整个表及其所有数据 表中的特定数据 **是否保留表结构** 是 否 是 **是否可恢复** 不可恢复 不可恢复 可恢复 **性能** 高 高 低(逐行删除) …...

vue+flask图书知识图谱推荐系统
文章结尾部分有CSDN官方提供的学长 联系方式名片 文章结尾部分有CSDN官方提供的学长 联系方式名片 关注B站,有好处! 编号: F025 架构: vueflaskneo4jmysql 亮点:协同过滤推荐算法知识图谱可视化 支持爬取图书数据,数据超过万条&am…...

什么是微前端?有什么好处?有哪一些方案?
微前端(Micro Frontends) 微前端是一种架构理念,借鉴了微服务的思想,将一个大型的前端应用拆分为多个独立、自治的子应用,每个子应用可以由不同团队、使用不同技术栈独立开发和部署,最终聚合为一个整体产品…...

prompts提示词经典模板
prompts.py 中的提示词模板详解 文件中定义了两个核心提示词模板:REASON_PROMPT 和 RELEVANT_EXTRACTION_PROMPT。这两个模板在 DeepResearcher 的推理过程中扮演着关键角色。下面我将详细解析这两个模板的结构和功能。 REASON_PROMPT 详解 REASON_PROMPT 是用于指…...