颠覆传统!复旦微软联合研发MagicMotion,重新定义图生视频可能性
导读简介:
尽管基于DiT的模型在生成高质量和长视频方面表现出色,但许多文本到视频的方法在精确控制物体运动和相机运动等属性方面存在不足。因此,细粒度轨迹可控的视频生成技术应运而生,这对于在现实场景中生成可控视频至关重要。
近年来,视频生成技术取得了显著进展,视觉质量和时间连贯性都有了大幅提高。在此基础上,轨迹可控的视频生成技术应运而生,它可以通过明确的空间路径实现对物体运动的精确控制。然而,现有方法在处理复杂物体运动和多物体运动控制时面临诸多挑战,导致轨迹跟踪不精确、物体一致性差以及视觉质量受损。此外,这些方法仅支持单一格式的轨迹控制,限制了它们在不同场景中的适用性。目前,还没有专门针对轨迹可控视频生成的公开可用数据集或基准,这阻碍了模型的稳健训练和系统评估。
为了解决这些挑战,我们提出了魔法运动(MagicMotion),这是一种新颖的图像到视频生成框架,它通过从密集到稀疏的三个级别的条件(掩码、边界框和稀疏边界框)实现轨迹控制。给定输入图像和轨迹,魔法运动可以使物体沿着定义的轨迹无缝动画化,同时保持物体的一致性和视觉质量。此外,我们还推出了魔法数据(MagicData),这是一个大规模的轨迹控制视频数据集,以及一个用于标注和过滤的自动化流程。我们还引入了魔法基准(MagicBench),这是一个全面的基准,用于评估不同数量物体的视频质量和轨迹控制精度。大量实验表明,魔法运动在各种指标上都优于以往的方法。
论文名:MagicMotion: Controllable Video Generation with Dense-to-Sparse Trajectory Guidance
论文链接:https://arxiv.org/pdf/2503.16421
开源代码:https://quanhaol.github.io/magicmotion-site/

方法与模型:
1. 概述


2. 模型架构
基于CogVideoX模型的图像到视频(I2V)生成流程,并且引入了轨迹控制网络(Trajectory ControlNet)来确保生成的视频遵循特定的运动模式。

、


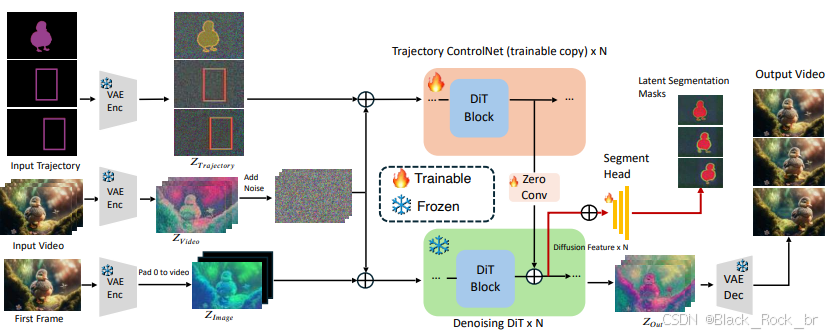

3. 从密集到稀疏:渐进式训练策略
密集轨迹条件(如分割掩码)能够提供更精确的控制,但对用户来说不太友好。为了解决这个问题,MagicMotion 采用了一种渐进式训练过程,其中每个阶段都使用前一阶段的权重来初始化其模型。这种策略使得模型能够实现从密集到稀疏的三种类型的轨迹控制,并且我们发现,与直接从头开始训练相比,这种渐进式训练策略有助于模型取得更好的性能。
具体训练流程
在各个阶段,我们采用了以下轨迹条件:
-
阶段 1:分割掩码
使用分割掩码作为轨迹条件,提供最精细的控制。 -
阶段 2:边界框
使用边界框作为轨迹条件,相较于分割掩码,边界框提供了更稀疏的控制。 -
阶段 3:稀疏边界框
使用稀疏边界框作为轨迹条件,其中少于 10 帧有边界框标注,进一步降低轨迹条件的密度。
此外,我们在每个阶段始终将轨迹条件的第一帧设置为分割掩码,以明确指定应该移动的前景对象。


4. 隐分割损失
1. 隐分割损失的引入
基于边界框的轨迹能够控制物体的位置和大小,但缺乏对物体细粒度形状的感知能力。为了解决这个问题,我们提出了隐分割损失(Latent Segmentation Loss) 。该损失在模型训练过程中引入了分割掩码信息,增强了模型对物体细粒度形状的感知能力。
以往的工作 [2, 61, 70, 79] 利用扩散生成模型进行感知任务,表明扩散模型提取的特征包含丰富的语义信息。然而,这些模型通常在像素空间中运行,这导致计算时间长且需要大量的 GPU 内存。
为了在合理的计算成本范围内融入密集轨迹信息,我们建议使用轻量级分割头直接在隐空间中预测分割掩码,从而无需进行解码操作。


5. 数据管道
轨迹可控的视频生成需要一个带有轨迹标注的视频数据集。然而,现有的大规模视频数据集[1, 7, 25]仅提供文本标注,缺乏轨迹数据。此外,几乎所有以往的工作[17, 31, 59, 75, 78]都使用私有整理的数据集,这些数据集并未公开。
为了解决这个问题,我们提出了一个全面且通用的数据管道,用于生成同时具有密集(掩码)和稀疏(边界框)标注的高质量视频数据。该管道由两个主要阶段组成:整理管道和过滤管道。整理管道负责从视频-文本数据集中构建轨迹信息,而过滤管道确保在训练前去除不合适的视频。

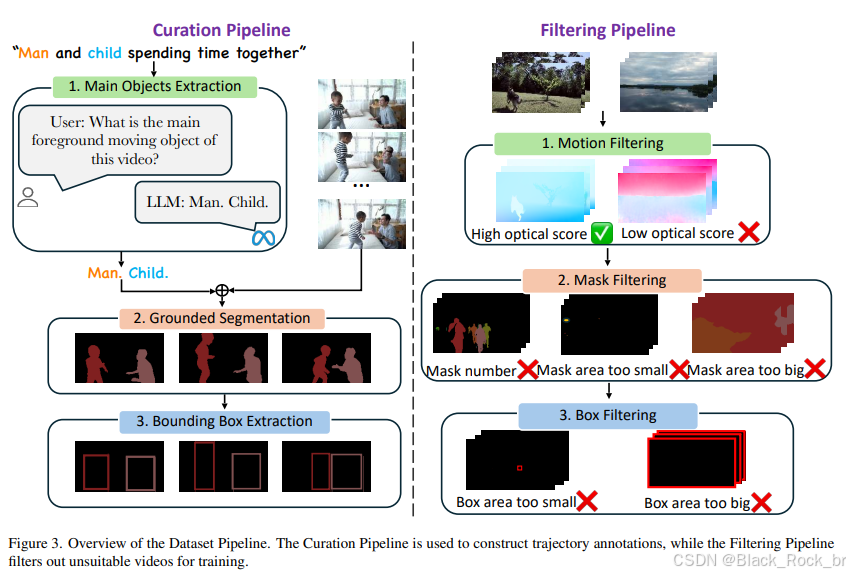
数据筛选与过滤流程
1. 数据集来源与初步筛选
我们的数据集筛选过程始于 **Pexels [24]**,这是一个大规模的视频-文本数据集,包含大量带有文本注释的视频片段。这些视频涵盖了不同主题、多样场景以及广泛动作的内容。为了提取视频中的前景移动物体,我们使用了 **Llama3.1 [53]** 这一强大的语言模型。
具体步骤如下:
- 将每个视频的标题输入到 Llama3.1 中,并提示模型识别句子中提到的主要前景物体。
- 如果模型确定句子中不包含任何前景物体,它将返回“空”,此类视频将被直接过滤掉。
通过这一过程,我们初步筛选出含有明确前景物体描述的视频,为后续处理奠定了基础。
2. 前景物体分割与边界框提取
接下来,我们利用 **Grounded-SAM2 [44, 46]**,这是一种基于文本的分割模型,能够根据视频及其主要物体生成分割掩码。具体步骤如下:
- 将视频及其主要物体作为输入,Grounded-SAM2 为每个主要物体生成分割掩码。
- 每个分割掩码对应一个唯一的颜色,用于一致地标注物体。
- 使用左上角和右下角的坐标从分割掩码中提取边界框,绘制相应的矩形框。
- 每个物体的边界框颜色与其分割掩码保持一致,确保标注的一致性和可解释性。
通过这一阶段,我们成功为视频中的前景物体生成了精确的分割掩码和边界框,为后续的运动分析和轨迹控制提供了关键信息。
3. 运动强度筛选:光流分数过滤
许多视频仅包含静态场景,这对训练轨迹可控的视频生成模型帮助有限。为了解决这个问题,我们引入了 **UniMatch [69]** 来提取帧之间的光流图,并计算光流图的平均绝对值作为 **光流分数**,以衡量视频的运动强度。
然而,单纯依赖整体光流分数可能会误判背景运动较多但前景静态的视频。因此,我们进一步结合分割掩码和边界框,使用 UniMatch 提取 **前景物体的光流分数**,并根据以下规则进行过滤:
- 过滤掉前景光流分数较低的视频,确保 MagicData 中的视频均包含显著的前景运动。
- 通过这种方式,我们有效剔除了背景运动强但前景静态的视频,保证了数据集的质量。
4. 轨迹注释的细化与约束
筛选流程生成的轨迹注释需要进一步细化,以满足轨迹可控视频生成的需求。具体而言,一些视频可能存在以下问题:
- 前景物体数量过多或过少;
- 注释区域尺寸过大或过小;
- 视频内容不符合预期的动态特征。
为了解决这些问题,我们基于大量人工评估经验,设置了以下约束条件:
- **光流分数阈值**:设置为 2.0,低于此阈值的视频将被过滤掉。
- **前景物体数量限制**:每个视频的前景物体数量限制在 1 到 3 之间,避免过于复杂的场景。
- **注释区域比例范围**:将注释区域的比例限制在 0.008 到 0.83 之间,确保物体大小适中且具有实际意义。
通过上述约束,我们进一步优化了数据集的质量,确保每条轨迹注释都符合轨迹可控视频生成的要求。
---
5. 最终数据集构建
经过以上筛选和过滤流程,我们成功构建了 **MagicData**,这是一个高质量的数据集,专为轨迹可控视频生成任务设计。MagicData 包含多个视频,每个视频都配有密集和稀疏的轨迹注释,能够支持从精细到粗略的不同级别控制。
整个数据筛选和过滤流程不仅提升了数据集的质量,还确保了其多样性与实用性,为后续模型训练提供了坚实的基础。
6. MagicBench
之前的研究[17, 31, 36, 50, 58, 64, 78]在轨迹控制视频生成方面主要在DAVIS(数据集规模相对较小)、VIPSeg(每个视频的标注帧不足)或自行构建的测试集上进行了验证。因此,迫切需要一个大规模且公开可用的基准,以便在该领域的不同模型之间进行公平的比较。为了解决这一问题,我们利用第3.5节中提到的数据管道构建了MagicBench,这是一个大规模的开放基准,包含600个带有相应轨迹标注的视频。MagicBench不仅评估视频质量和轨迹准确性,还将受控对象的数量作为一个关键评估因素。具体来说,它根据受控对象的数量分为6组,从1到5个对象以及超过5个对象,每个类别包含100个高质量视频。
换一种说法:
先前关于轨迹控制视频生成的研究[17, 31, 36, 50, 58, 64, 78]主要在DAVIS(数据集规模较小)、VIPSeg(每个视频的标注帧数量有限)或私有构建的测试集上进行了评估。因此,迫切需要一个大规模且公开可用的基准,以便在该领域的不同模型之间进行公平的比较。为了填补这一空白,我们利用第3.5节中提到的数据管道构建了MagicBench,这是一个大规模的开放基准,由600个带有相应轨迹标注的视频组成。MagicBench不仅评估视频质量和轨迹准确性,还将受控对象的数量作为一个关键评估因素。具体来说,它根据受控对象的数量分为6组,从1到5个对象以及超过5个对象,每个类别包含100个高质量视频。
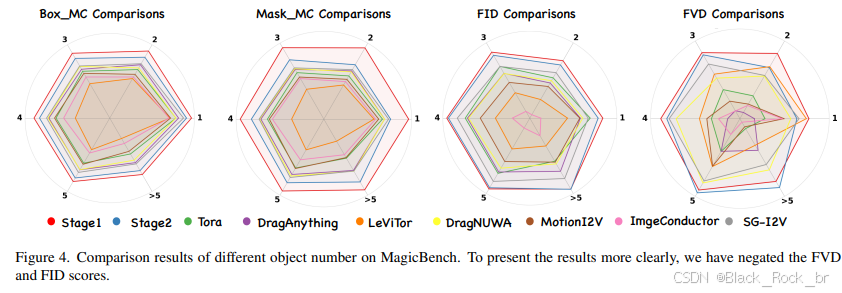
为了评估视频质量,我们采用了文献[17, 55, 59, 64]中提到的FVD(Fréchet Video Distance)指标。同时,为了评估图像质量,我们使用了FID(Fréchet Inception Distance)。为了量化运动控制的准确性,我们使用了掩码交并比(Mask_IoU)和边界框交并比(Box_IoU),这两个指标分别衡量掩码和边界框的准确性。



实验与结果
1. 实验设置
1. 1模型实现细节
我们采用 **CogVideoX-5B [73]** 作为基础图像到视频生成模型。该模型经过训练后,能够生成分辨率为 $ 480 \times 720 $ 的 49 帧视频。
MagicMotion-- 的训练过程分为三个阶段,每个阶段都在 **MagicData** 数据集上进行一轮次的训练。具体步骤如下:
1. 阶段 1:轨迹控制网络(Trajectory ControlNet)训练
在这一阶段,从零开始训练轨迹控制网络(Trajectory ControlNet),使其学习如何根据输入轨迹条件生成对应的视频特征。
2. 阶段 2:分割头(Segment Head)引入与优化
在这一阶段:
- 使用阶段 1 中训练得到的权重进一步优化轨迹控制网络(Trajectory ControlNet)。
- 同时,从零开始训练分割头(Segment Head),用于在隐空间中预测分割掩码,增强模型对物体形状的感知能力。
3. 阶段 3:联合优化
在这一阶段:
- 轨迹控制网络(Trajectory ControlNet)和分割头(Segment Head)都使用阶段 2 的权重继续训练,以实现更精细的轨迹可控性。
所有训练实验均在 4 块 NVIDIA A100-80G GPU 上进行。我们采用 **AdamW [33]** 作为优化器,设置初始学习率为 $ 1e^{-5} $,每块 GPU 的批量大小为 1。在推理过程中,我们将步数设置为 50,引导尺度(Guidance Scale)设置为 6,并将轨迹控制网络(Trajectory ControlNet)的权重设置为 1.0。
---
2. 数据集与训练流程
在训练过程中,我们使用 **MagicData** 作为训练集。MagicData 是通过第 3.5 节中描述的数据筛选流程构建的,包含从密集到稀疏的轨迹信息。它总共包含 51,000 个 `<视频,文本,轨迹>` 三元组。
在训练过程中:
- 每个视频被调整为 $ 480 \times 720 $ 的分辨率;
- 从每个视频片段中采样出 49 帧,用于生成目标视频。
为了评估模型性能,我们在第 3.6 节中说明的基准测试框架 **MagicBench** 和 **DAVIS [39]** 上对所有方法进行了全面评估。
---
通过采用 CogVideoX-5B 作为基础模型,并结合多阶段训练策略,MagicMotion 实现了从图像到视频的可控生成。同时,借助 MagicData 这一高质量数据集,以及合理的训练配置和评估指标,我们的模型在轨迹可控视频生成任务中展现出优异的性能。
2. 与其他方法的比较
为了进行全面和公平的比较,我们将我们的方法与 7 种公开的轨迹可控图像到视频(I2V)方法进行了对比。下面展示了定量比较和定性比较的结果。
定量比较
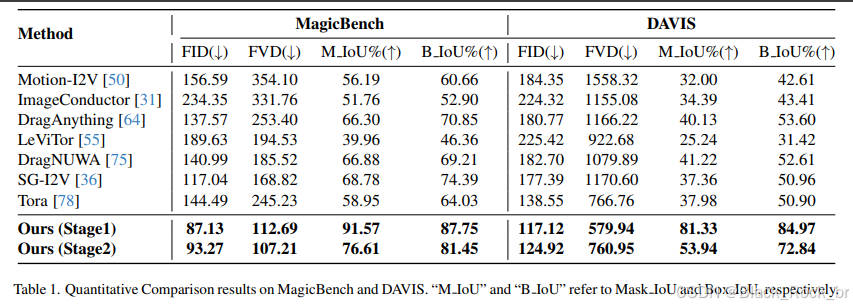
为了将 **MagicMotion** 与以往的工作进行对比,我们使用了 **DAVIS** 和 **MagicBench** 中每个视频的前 49 帧作为真实视频。由于部分方法 [31, 36, 50, 55, 64, 75, 78] 不支持生成长达 49 帧的视频,我们从这 49 帧中均匀采样 $ N $ 帧进行评估,其中 $ N $ 表示每种方法支持的视频长度。
基于掩码或边界框的方法:
我们利用这些选定帧的掩码和边界框注释作为输入,用于生成轨迹条件。
基于点或光流的方法:
对于基于点或光流的方法,我们提取每一帧掩码的中心点作为输入 [31, 50, 55, 64, 75, 78]。
通过这种方式,我们确保了所有方法在相同的条件下进行公平比较,并能够全面评估它们在轨迹可控视频生成任务中的性能表现。
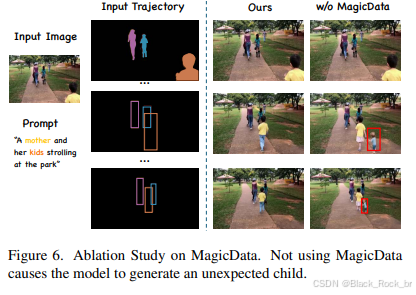
定性比较。定性比较结果如图5所示,同时提供了输入图像、提示和轨迹。如图5所示,Tora [78]能够准确控制运动轨迹,但难以保持对象的形状。而DragAnything [64]、ImageConductor [31]和MotionI2V [50]难以保持原始主体的一致性,导致后续帧出现大幅变形。同时,Drag - NUWA [75]、LeviTor [55]和SG - I2V [36]在精细细节上经常产生伪影和不一致性。相比之下,MagicMotion允许移动物体在保持高视频质量的同时,平滑地遵循指定轨迹。
3. 消融实验
为了评估 MagicData 的作用,我们构建了一个对比用的消融数据集,由两个公开视频目标分割(VOS)数据集 MeViS [9] 和 MOSE [10] 组合而成。实验设置如下:
- 使用 MagicData 或消融数据集分别训练 MagicMotion 的第二阶段,且两者均使用相同的第一阶段权重初始化。
- 在 MagicBench 和 DAVIS 数据集上评估模型性能,比较不同训练数据对结果的影响。
通过这一实验,我们验证了 MagicData 在提升轨迹可控视频生成任务中的独特优势。
实验结果表明:
- 渐进式训练 帮助模型逐步适应从密集到稀疏的轨迹条件,显著提升了稀疏控制下的表现。
- 潜在分割损失 通过引入分割掩码信息,增强了模型对物体形状的精确理解,提高了轨迹控制的准确性
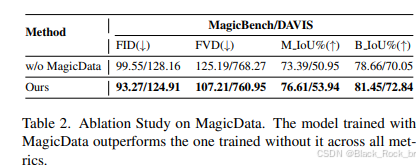
渐进式训练过程消融实验。渐进式训练过程允许模型利用前一阶段学到的权重,在稀疏轨迹条件下训练时融入密集轨迹控制信息。为了验证这种方法的有效性,我们以边界框作为轨迹条件,从头开始对模型进行一个轮次的训练。然后,我们将其性能与MagicMotion的第二阶段进行比较。
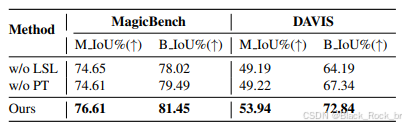
 潜在片段损失的消融实验。潜在片段损失使模型在使用稀疏轨迹进行训练时能够预测密集的分割掩码,增强了其在稀疏条件下感知细粒度物体形状的能力。为了评估该技术的有效性,我们从阶段1开始使用边界框作为轨迹条件对模型进行一个周期的训练,并将其性能与MagicMotion阶段2进行比较。表3显示,缺少潜在片段损失会降低模型对物体形状的处理能力,导致轨迹控制不够精确。图8中的定性比较进一步凸显了这种影响。没有潜在片段损失时,生成视频中女性的手臂看起来不完整。
潜在片段损失的消融实验。潜在片段损失使模型在使用稀疏轨迹进行训练时能够预测密集的分割掩码,增强了其在稀疏条件下感知细粒度物体形状的能力。为了评估该技术的有效性,我们从阶段1开始使用边界框作为轨迹条件对模型进行一个周期的训练,并将其性能与MagicMotion阶段2进行比较。表3显示,缺少潜在片段损失会降低模型对物体形状的处理能力,导致轨迹控制不够精确。图8中的定性比较进一步凸显了这种影响。没有潜在片段损失时,生成视频中女性的手臂看起来不完整。
 如表3所示,排除渐进式训练过程(Progressive Training Procedure)会削弱模型感知物体形状的能力,最终降低轨迹控制的准确性。图7中的定性比较进一步说明了这些影响,其中未采用渐进式训练过程(Progressive Training Procedure)训练的模型将女性的头部完全变成了头发。
如表3所示,排除渐进式训练过程(Progressive Training Procedure)会削弱模型感知物体形状的能力,最终降低轨迹控制的准确性。图7中的定性比较进一步说明了这些影响,其中未采用渐进式训练过程(Progressive Training Procedure)训练的模型将女性的头部完全变成了头发。
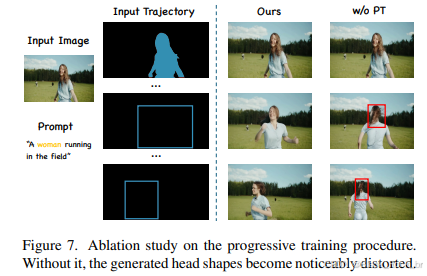
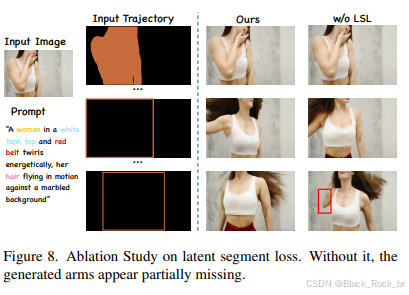
图8. 潜在片段损失的消融实验。没有潜在片段损失,生成的手臂部分缺失。
在本文中,我们重磅推出了 **MagicMotion** —— 一种革命性的轨迹控制图像到视频生成方法!通过采用类似 ControlNet 的架构,MagicMotion 精妙地将轨迹信息无缝融入扩散变压器中,实现了对视频生成过程的精准操控。
为了赋予模型更强的适应能力,我们创新性地引入了 **渐进式训练策略**,使 MagicMotion 能够灵活支持三种不同级别的轨迹控制:从精细的密集掩码,到简洁的边界框,再到稀疏的轨迹框,完美覆盖了从高精度到低密度的多样化需求。此外,我们还精心设计了 **潜在分割损失**,显著提升了模型在仅提供稀疏轨迹条件时感知细粒度物体形状的能力,确保即使在有限的信息输入下,也能生成高质量的动态效果。
与此同时,我们打造了一个堪称行业标杆的高质量数据集——**MagicData**。这一数据集通过强大的数据管道构建而成,专为轨迹控制视频生成任务量身定制,为模型训练提供了坚实的基础。不仅如此,我们还推出了一个全新的大规模基准测试平台——**MagicBench**。MagicBench 不仅全面评估视频质量和轨迹准确性,还深入考察了受控物体的数量,为领域研究设立了更高的标准。
经过在 **MagicBench** 和 **DAVIS** 上的大量实验验证,MagicMotion 的卓越性能得到了充分证明,其表现远超以往的工作,展现了我们在轨迹可控视频生成领域的领先地位!
---
核心亮点总结:
- MagicMotion:轨迹控制图像到视频生成的新范式,融合 ControlNet 架构与扩散模型。
- 渐进式训练:支持密集掩码、边界框和稀疏框三种轨迹控制级别。
- 潜在分割损失:提升稀疏轨迹条件下对细粒度物体形状的感知能力。
- MagicData:高质量标注数据集,助力模型训练。
- MagicBench:全新大规模基准,全面评估视频质量、轨迹准确性和受控物体数量。
- 实验结果:在 MagicBench 和 DAVIS 上的表现显著优于以往方法,彰显技术优势。
相关文章:

颠覆传统!复旦微软联合研发MagicMotion,重新定义图生视频可能性
导读简介: 尽管基于DiT的模型在生成高质量和长视频方面表现出色,但许多文本到视频的方法在精确控制物体运动和相机运动等属性方面存在不足。因此,细粒度轨迹可控的视频生成技术应运而生,这对于在现实场景中生成可控视频至关重要。…...

华为数字芯片机考2025合集5已校正
1. 题目内容 下列选项中()不是 Verilog HDL 的关键字。() A. tri B. for C. force D. edge 解析 1. Verilog 关键字分类 Verilog 关键字是语言预定义的保留字,用于语法结构或特定功能。 2. 选项分析 选项类型说明…...

QML Loader:延迟加载与动态切换
目录 引言相关阅读工程结构LoaderDelay.qml - 延迟加载实现完整代码HeavyComponent.qml代码解析运行效果 LoaderSwitch.qml - 动态切换组件完整代码代码解析运行效果 Main.qml - 主界面实现完整代码主界面结构代码解析 总结下载链接 引言 QML的Loader组件提供了一种强大的机制…...

C语言--常用的链表操作
利用C语言实现链表,并定义一些常用的操作 文章目录 链表定义新建一个链表结点打印链表插入结点头插法(常用)运行 尾插法(使用较少)运行 返回链表长度链表转置运行 合并两个有序的链表运行 删除最小结点运行 打印倒数第…...

ngx_conf_param
Ubuntu 下 nginx-1.24.0 源码分析 - ngx_conf_param-CSDN博客 定义在 src\core\ngx_conf_file.c char * ngx_conf_param(ngx_conf_t *cf) {char *rv;ngx_str_t *param;ngx_buf_t b;ngx_conf_file_t conf_file;param &cf->cycle->conf…...

C++day9
思维导图 牛客练习 练习: 将我们写的 myList 迭代器里面 operator[] 和 operator 配合异常再写一遍 #include <iostream> #include <cstring> #include <cstdlib> #include <unistd.h> #include <sstream> #include <vector>…...

算法题:两数相加
题目:2. 两数相加 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示和的链表。 你可以假设除了数字 0 之外&a…...

SCI科学论文的重要组成部分
科学论文的核心结构 科学论文通常遵循IMRAD结构,即: 引言(Introduction)方法(Methods)结果(Results)讨论(Discussion) 除此之外,还包括其他几个关键部分。让我为您详细介绍每个部分的作用和重要性: 1. 标题(Title) 标题是论文…...

Go 微服务框架 | 路由实现
文章目录 不用框架实现web接口实现简单的路由实现分组路由支持不同的请求方式支持同一个路径的不同请求方式前缀树应用前缀树完善路由代码 不用框架实现web接口 // blog main.go 文件 package mainimport ("fmt""log""net/http" )func main() {…...

2025年AI开发学习路线
目录 一、基础阶段(2-3个月) 1. 数学与编程基础 2. 机器学习入门 二、核心技能(3-4个月) 1. 深度学习与框架 2. 大模型开发(重点) 三、进阶方向(3-6个月) 1. 多模态与智能体…...

TimescaleDB 2.19.2 发布
TimescaleDB 2.19.2 已于 2025 年 4 月 7 日发布2。此次发布是基于 PostgreSQL 的开源时序数据库 TimescaleDB 的一次更新。 从 GitHub 上的 Pull Request 信息可知,此次发布主要是将相关更改合并到 2.19.x 分支,涉及到一系列的测试和构建配置,包括不同版本 PostgreSQL(如 …...

「Unity3D」TextMeshPro中的TMP_InputField,用来实现输入框的几个小问题
第一,正确设置Scrollbar。 设置Scrollbar之后,不能设置Text Component的Font Size为Auto Size,否则Scrollbar无法正确计算显示。 那么,要想自动适配字体大小,可以让Placeholder中的Font Size设置为Auto,这…...

HTML 是什么?网页创建的核心标记语言
原文:HTML 是什么?网页创建的核心标记语言 | w3cschool笔记 HTML 是什么? HTML 是一种标记语言,用于创建网页。简单来说,HTML 就像一本魔法书,它告诉电脑如何展示网页上的内容,比如文字、图片…...

考研单词笔记 2025.04.09
act v表现,行动,做事,扮演,充当,担任,起作用n行为,行动,法案,法令 action n行为,行动 behave v表现,行事,守规矩,举止端…...

map/multimap
1.概念 map中所有元素都是pair<key,value>,key 是map的键,value 是map的值 所有元素都会根据key自动排序 map/multimap属于关联式容器,底层结构是用二叉树实现。 map和multimap区别: map不允许容器中有重复key值元素 m…...

CSS 定位属性的生动比喻:以排队为例理解 relative 与 absolute
目录 一、理解标准流与队伍的类比 二、relative 定位:队伍中 “小范围活动” 的人 三、absolute 定位:队伍中 “彻底离队” 的人 在学习 CSS 的过程中,定位属性relative和absolute常常让初学者感到困惑。它们的行为方式和对页面布局的影响较…...

基于二叉堆实现的 PriorityQueue
基于二叉堆实现的 PriorityQueue 是一种常见的数据结构,广泛用于任务调度、路径搜索、事件模拟等场景。下面我将用 Java 语言实现一个简单的基于最小堆的 PriorityQueue,即优先级最小的元素先出队。 ✅ 实现目标 使用数组实现二叉最小堆(即父…...

大模型分布式推理和量化部署
一、小常识 1、计算大模型占用多少显存 对于一个7B(70亿)参数的模型,每个参数使用16位浮点数(等于 2个 Byte)表示,则模型的权重大小约为: 7010^9 parameters2 Bytes/parameter14GB 70亿个参数…...

循环神经网络 - 长程依赖问题及改进方案
循环神经网络在学习过程中的主要问题是由于梯度消失或爆炸问题,很难建模长时间间隔(Long Range)的状态之间的依赖关系。 本文我们来学习长程依赖问题及其对应的改进方案,在这部分知识的学习过程中,我建议大家着重理解,对于数学公…...

点击抽奖功能总结
首先用户打开网页,映入眼帘的是一个输入框和一个提交按钮。当用户在输入框中输入自己的年龄并点击提交后,系统会根据输入的年龄给出相应提示。若年龄达到 60 岁,页面将显示一个新的抽奖区域,用户可以点击 “抽奖” 按钮开始抽奖。…...

AWS Bedrock生成视频详解:AI视频创作新时代已来临
💡 TL;DR: AWS Bedrock现已支持AI视频生成功能,让企业无需深厚AI专业知识即可创建高质量视频内容。本文详解Bedrock视频生成能力的工作原理、应用场景和实操指南,助你快速掌握这一革命性技术。 🎬 AWS Bedrock视频生成:改变内容创作的游戏规则 还记得几年前,制作一个专…...

理解 TOGAF®标准中的架构原则
原则是帮助组织实现其使命的基本规则和指南。它们旨在长期稳定且很少修改,在各个领域中充当决策和行动的指南针。在企业架构(EA)的背景下,原则在指导架构框架的开发和应用方面发挥着至关重要的作用。本文将探讨企业原则和架构原则…...

基于视觉密码的加密二值图像可逆数据隐藏
接下来,分享一篇论文,标题为《Multi-Party Reversible Data Hiding in Ciphertext Binary Images Based on Visual Cryptography》,由Bing Chen等人发表在《IEEE Signal Processing Letters》上。该论文提出了一种基于视觉密码学的多方可逆数…...

ubuntu22.04 中 No module named ‘_bz2‘问题解决方案
前言 本篇是介绍ubuntu22.04中 No module named ‘_bz2‘问题解决方案 网上版本很多,比如安装libbz库什么的,可能别人有用,但是我自己这边出了一堆问题 一、流程 1.1 查看bz2.xx.so文件 看自己的python版本,我新安装了个pyth…...

什么是声波,声波的传播距离受哪些因素影响?
一、声波的定义: 声波是一种机械波,它是通过介质(如空气、水、固体等)传播的振动。以下是关于声波的详细介绍: 1、声波的产生 声波是由物体的振动产生的。例如,人说话时,声带振动产生声波&…...

用PHPExcel 封装的导出方法,支持导出无限列
用PHPExcel 封装的导出方法,支持导出无限列 避免PHPExcel_Exception Invalid cell coordinate [1 异常错误 /*** EXCEL导出* param [string] $file_name 保存的文件名及表格工作区名,不加excel后缀名* param [array] $fields 二维数组* param [array] $…...

STL-stack栈和queue队列
stack栈和queue队列 在STL中 stack 和 queue 设计为容器适配器,容器适配器是使用特定容器类的封装对象作为其基础容器的类,提供一组特定的成员函数来访问其元素。 在我的STL系列中之前的容器 vector、list、deque 都是从底层类型一步步封装而来的,但是 stack 和 queue 没有…...

AI 提示词不会写?试试 PromptIDE
这段时间,AI 技术大爆炸 已经改变了我们的工作方式,而 会不会用 AI,已经成为区分工作能力的关键! 💡 在这个AI重构工作方式的时代,会用和不会用AI的人正在拉开巨大差距: √ 高手用AI——效率飙…...

【python读取并显示遥感影像】
在Python中读取并显示遥感影像,可以使用rasterio库读取影像数据,并结合matplotlib进行可视化。以下是一个完整的示例代码: import rasterio import matplotlib.pyplot as plt import numpy as np# 打开遥感影像文件 with rasterio.open(path…...

代码随想录算法训练营第十三天
LeetCode题目: 110. 平衡二叉树257. 二叉树的所有路径404. 左叶子之和222. 完全二叉树的节点个数3375. 使数组的值全部为 K 的最少操作次数(每日一题) 其他: 今日总结 往期打卡 110. 平衡二叉树 跳转: 110. 平衡二叉树 学习: 代码随想录公开讲解 问题: 给定一个二叉树&#…...

TQTT_KU5P开发板教程---高速收发器之XDMA实现PCIE
文档功能介绍 本文档主要实现了通过一个叫做XDMA的IP,实现PCIE的测试例子。工程新建方法请参考文档《流水灯》。 Vivado创建项目 起始页(或 file-->Project-->New 创建新工程(Create New Project) 向导起始页面 点击 Next--> Project Name(…...
)
蓝桥杯速成刷题清单(上)
一、1.排序 - 蓝桥云课 (快速排序)算法代码: #include <bits/stdc.h> using namespace std; const int N 5e5 10; int a[N];int main() {int n;cin >> n;for (int i 0; i < n; i) {cin >> a[i];}sort(a, a n);for …...

【FreeRTOS】二值信号量 是 消息队列 吗
在读FreeRTOS内核实现与应用开发实战指南的时候,书中第16章有这么一句话:可以将二值信号量看作只有一个消息的队列,incident这个队列只能为空或满(因此称为二值),在运用时只需要之傲队列中是否由消息即可&a…...

BOTA六维力矩传感器在三层AI架构中的集成实践:从数据采集到力控闭环
随着机器人技术的迅猛发展,Bota六维力矩传感器成为三层AI架构中的核心组件。它通过高精度的力与力矩感知能力,为感知层提供实时数据支持,优化了决策层的判断效率,并确保执行层操作的精确性和安全性。 Bota贯通式力矩传感器PixOne&…...

UE5 matcap学习笔记
没难度节点,但是要记住这种思维,移动端常用: 原视频:(美学阿姨)MatCap材质原理讲解与UE5中的实现方法_哔哩哔哩_bilibili...

神经网络 - 关于简单的激活函数的思考总结
最近一直在学习神经网络,有一些收获,也有一些迷惑,所以驻足思考:为什么简单的激活函数如sigmoid函数、ReLU函数,当应用在神经网络的模型中,却可以实现对现实世界复杂的非线性关系的模拟呢?本文我…...

pig 权限管理开源项目学习
pig 源码 https://github.com/pig-mesh/pig 文档在其中,前端在文档中,官方视频教学也在文档中有。 第一次搭建,建议直接去看单体视频,照着做即可。 文章目录 项目结构Maven 多模块项目pig-boot 启动核心模块pig-auth 实现认证和…...
)
excel中的VBA指令示例(二)
。。。接上篇。 Range("D1").Select ’选择D1单元格 ActiveCell.FormulaR1C1 "装配数量" ‘单元格内容为装配数量 Range("D1").Select Selection.AutoFilter …...

基于vue3与supabase系统认证机制
1. 认证框架概述 系统采用 Supabase 作为认证和数据服务提供商,实现了完整的用户身份验证流程。系统使用基于 JWT (JSON Web Token) 的认证方式,提供了安全可靠的用户身份管理机制。 1.1 技术栈 前端: Vue 3 TypeScript状态管理: Pinia认证服务: Sup…...

【算法笔记】并查集详解
🚀 并查集(Union-Find)详解:原理、实现与优化 并查集(Union-Find)是一种非常高效的数据结构,用于处理动态连通性问题,即判断若干个元素是否属于同一个集合,并支持集合合…...

基于Redis实现短信防轰炸的Java解决方案
基于Redis实现短信防轰炸的Java解决方案 前言 在当今互联网应用中,短信验证码已成为身份验证的重要手段。然而,这也带来了"短信轰炸"的安全风险 - 恶意用户利用程序自动化发送大量短信请求,导致用户被骚扰和企业短信成本激增。本…...

编程中,!! 双感叹号的理解
在编程中,!! 双感叹号的含义取决于上下文。通常情况下,!! 是逻辑非操作符的双重使用,用来将一个值强制转换为布尔类型。 1. 逻辑非操作符 在 JavaScript 中,! 是逻辑非操作符,它会将一个值转换为布尔类型:…...

ARM内核与寄存器
ARM内核与寄存器详解 目录 ARM架构概述ARM处理器模式 Cortex-M3内核的处理器模式Cortex-A系列处理器模式 ARM寄存器集 通用寄存器程序计数器(PC)链接寄存器(LR)堆栈指针(SP)状态寄存器(CPSR/SPSR) 协处理器寄存器NEON和VFP寄存器寄存器使用规范常见ARM指令与寄存器操作 ARM架…...

【C++进阶】关联容器:set类型
目录 一、set 基本概念 1.1 定义与特点 1.2 头文件与声明 1.3 核心特性解析 二、set 底层实现 2.1 红黑树简介 2.2 红黑树在 set 中的应用 三、set 常用操作 3.1 插入元素 3.2 删除元素 3.3 查找元素 3.4 遍历元素 3.5 性能特征 四、set 高级应用 4.1 自定义比较…...

Linux内核——X86分页机制
X86分页机制 x86的分页单元支持两种分页模式:常规分页与扩展分页。 常规分页采用两级结构,固定页大小为4KB。线性地址被划分为三个字段: 页目录索引(最高10位)页表索引(中间10位)页内偏移&am…...

重温Java - Java基础二
工作中常见的6中OOM 问题 堆内存OOM 堆内存OOM 是最常见的OOM了。出现堆内存OOM 问题的异常信息如下 java.lang.OutOfMemoryError: Java heap space此OOM是由于Java中的heap的最大值,已经不能满足需求了。 举个例子 Test public void test01(){List<OOMTest…...
)
回溯算法+对称剪枝——从八皇后问题到数独问题(二)
引入: 本节我们进一步完善八皇后问题,学习剪枝、八皇后残局问题 进一步领会逻辑编程的概念,深入体会回溯算法,回顾上一节提到的启发搜索策略。 回顾: 八皇后问题:我们需要在一个空棋盘上放置 n 个皇后&a…...
)
基于 Spring Boot 瑞吉外卖系统开发(三)
基于 Spring Boot 瑞吉外卖系统开发(三) 分类列表 静态页面 实现功能所需要的接口 定义Mapper接口 Mapper public interface CategoryMapper extends BaseMapper<Category> {}定义Service接口 public interface CategoryService extends ISe…...

Pascal VOC 2012 数据集格式与文件结构
Pascal VOC 2012 1 Pascal VOC 2012 数据集1.1 数据集概述1.2 文件结构1.3 关键文件和内容格式(1) Annotations/ 目录(2) ImageSets/ 目录(3) JPEGImages/ 目录(4) SegmentationClass/ 和 SegmentationObject/ 目录 1.4 标注格式说明(1) 目标检测标注(2) 语义分割标注(3)实例分…...

11:00开始面试,11:08就出来了,问的问题有点变态。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到8月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40%…...