Spark运行架构 RDD相关概念Spark-Core编程
以下是今天学习的知识点:
第三节 Spark运行架构
运行架构
Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。
核心组件
对于 Spark 框架有两个核心组件:
Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Driver 在 Spark 作业执行时主要负责:
将用户程序转化为作业(job)
在 Executor 之间调度任务(task)
跟踪 Executor 的执行情况
通过 UI 展示查询运行情况
Executor
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。
Executor 有两个核心功能:
负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
Master & Worker
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master 和 Worker,这里的 Master 是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于 Yarn 环境中的 RM, 而Worker 呢,也是进程,一个 Worker 运行在集群中的一台服务器上,由 Master 分配资源对数据进行并行的处理和计算,类似于 Yarn 环境中 NM。
ApplicationMaster
Hadoop 用户向 YARN 集群提交应用程序时,提交程序中应该包含 ApplicationMaster,用于向资源调度器申请执行任务的资源容器 Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
核心概念
Executor 与 Core
Spark Executor 是集群中运行在工作节点(Worker)中的一个 JVM 进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点 Executor 的内存大小和使用的虚拟 CPU 核(Core)数量。
并行度(Parallelism)
在分布式计算框架中一般都是多个任务同时执行,由于任务分布在不同的计算节点进行计算,所以能够真正地实现多任务并行执行,记住,这里是并行,而不是并发。这里我们将整个集群并行执行任务的数量称之为并行度。那么一个作业到底并行度是多少呢?这个取决于框架的默认配置。应用程序也可以在运行过程中动态修改。
有向无环图(DAG)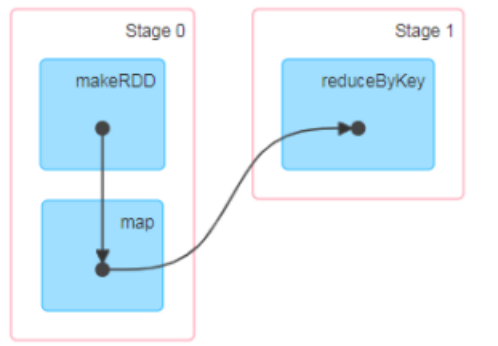
大数据计算引擎框架我们根据使用方式的不同一般会分为四类,其中第一类就是Hadoop 所承载的 MapReduce,它将计算分为两个阶段,分别为 Map 阶段 和 Reduce 阶段。
对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。 由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及实时计算。
这里所谓的有向无环图,并不是真正意义的图形,而是由 Spark 程序直接映射成的数据流的高级抽象模型。简单理解就是将整个程序计算的执行过程用图形表示出来,这样更直观,更便于理解,可以用于表示程序的拓扑结构。
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。
提交流程
所谓的提交流程,其实就是开发人员根据需求写的应用程序通过 Spark 客户端提交给 Spark 运行环境执行计算的流程。在不同的部署环境中,这个提交过程基本相同,但是又有细微的区别,这里不进行详细的比较,但是因为国内工作中,将 Spark 引用部署到Yarn 环境中会更多一些,所以这里提到的提交流程是基于 Yarn 环境的。
Spark 应用程序提交到 Yarn 环境中执行的时候,一般会有两种部署执行的方式:Client和 Cluster。两种模式主要区别在于:Driver 程序的运行节点位置。
Yarn Client 模式
Client 模式将用于监控和调度的 Driver 模块在客户端执行,而不是在 Yarn 中,所以一般用于测试。
Driver 在任务提交的本地机器上运行
Driver 启动后会和 ResourceManager 通讯申请启动 ApplicationMaster
ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster,负责向 ResourceManager 申请 Executor 内存
ResourceManager 接到 ApplicationMaster 的资源申请后会分配 container,然后ApplicationMaster 在资源分配指定的 NodeManager 上启动 Executor 进程
Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数
之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
Yarn Cluster 模式
Cluster 模式将用于监控和调度的 Driver 模块启动在 Yarn 集群资源中执行。一般应用于实际生产环境。
在 YARN Cluster 模式下,任务提交后会和 ResourceManager 通讯申请启动ApplicationMaster。
随后 ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster,此时的 ApplicationMaster 就是 Driver。
Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager 接到ApplicationMaster 的资源申请后会分配 container,然后在合适的 NodeManager 上启动Executor 进程。
Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数。
之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
第四节 RDD相关概念
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
RDD : 弹性分布式数据集
累加器:分布式共享只写变量
广播变量:分布式共享只读变量
RDD
什么是 RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
弹性
存储的弹性:内存与磁盘的自动切换;
容错的弹性:数据丢失可以自动恢复;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片。
分布式:数据存储在大数据集群不同节点上
数据集:RDD 封装了计算逻辑,并不保存数据
数据抽象:RDD 是一个抽象类,需要子类具体实现
不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
可分区、并行计算
核心属性
分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算。
RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系。
分区器(可选)
当数据为 K-V 类型数据时,可以通过设定分区器自定义数据的分区。
首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算。
执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
RDD 是 Spark 框架中用于数据处理的核心模型,接下来我们看看,在 Yarn 环境中,RDD的工作原理:
- 启动 Yarn 集群环境
- Spark 通过申请资源创建调度节点和计算节点
- Spark 框架根据需求将计算逻辑根据分区划分成不同的任务
- 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
从以上流程可以看出 RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给Executor 节点执行计算。
RDD 序列化
1) 闭包检查
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行。那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测。Scala2.12 版本后闭包编译方式发生了改变
2) 序列化方法和属性
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行
3) Kryo 序列化框架Java 的序列化能够序列化任何的类。但是比较重(字节多),序列化后,对象的提交也比较大。Spark 出于性能的考虑,Spark2.0 开始支持另外一种 Kryo 序列化机制。Kryo 速度是 Serializable 的 10 倍。当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字符串类型已经在 Spark 内部使用 Kryo 来序列化。
注意:即使使用 Kryo 序列化,也要继承 Serializable 接口。
RDD 依赖关系
1) RDD 血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
2) RDD 依赖关系
这里所谓的依赖关系,其实就是两个相邻 RDD 之间的关系。包括打印依赖、shuffle依赖等。
3) RDD 窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,窄依赖我们形象的比喻为独生子女。
4) RDD 宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
5) RDD 阶段划分
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。
6) RDD 任务划分
RDD 任务切分中间分为:Application、Job、Stage 和 Task
RDD 持久化
1) RDD Cache 缓存
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD 的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢失的数据会被重算,由于 RDD 的各个 Partition 是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部 Partition。
Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用 persist 或 cache。
2) RDD CheckPoint 检查点
所谓的检查点其实就是通过将 RDD 中间结果写入磁盘由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
3) 缓存和检查点区别
··1)Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
·2)Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存储在 HDFS 等容错、高可用的文件系统,可靠性高。
·3)建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存中读取数据即可,否则需要再从头计算一次 RDD。
RDD 分区器
Spark 目前支持 Hash 分区和 Range 分区,和用户自定义分区。Hash 分区为当前的默认分区。分区器直接决定了 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 后进入哪个分区,进而决定了 Reduce 的个数。
RDD 文件读取与保存
Spark 的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。
文件格式分为:text 文件、csv 文件、sequence 文件以及 Object 文件;
文件系统分为:本地文件系统、HDFS、HBASE 以及数据库。
Spark-Core编程
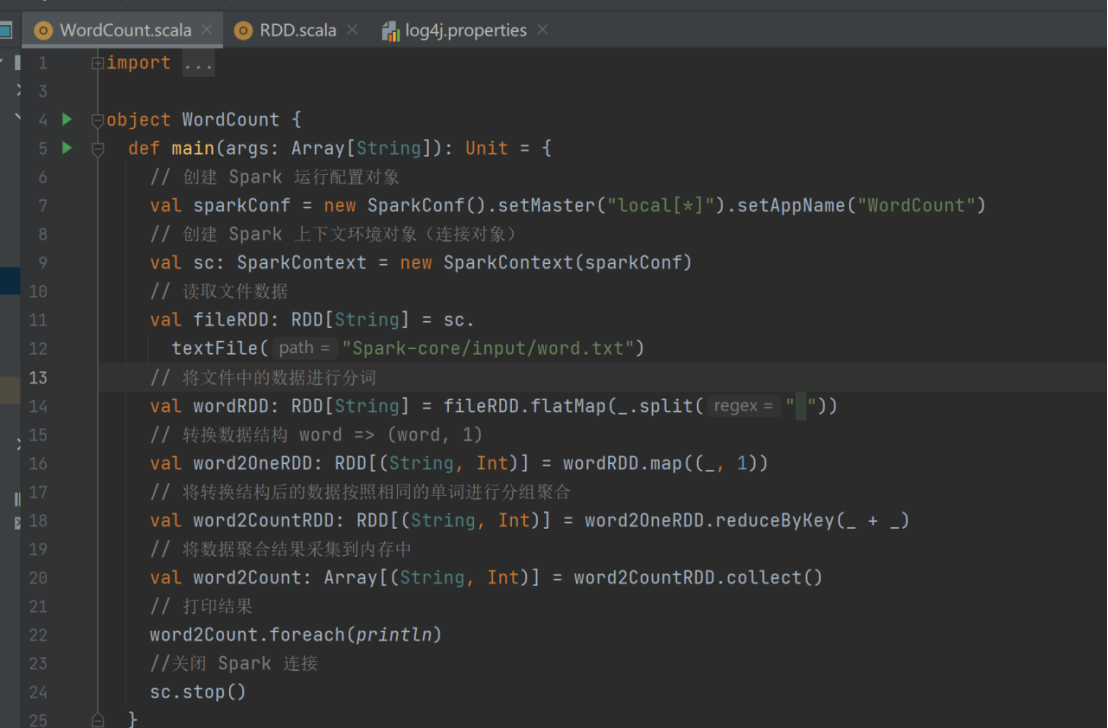

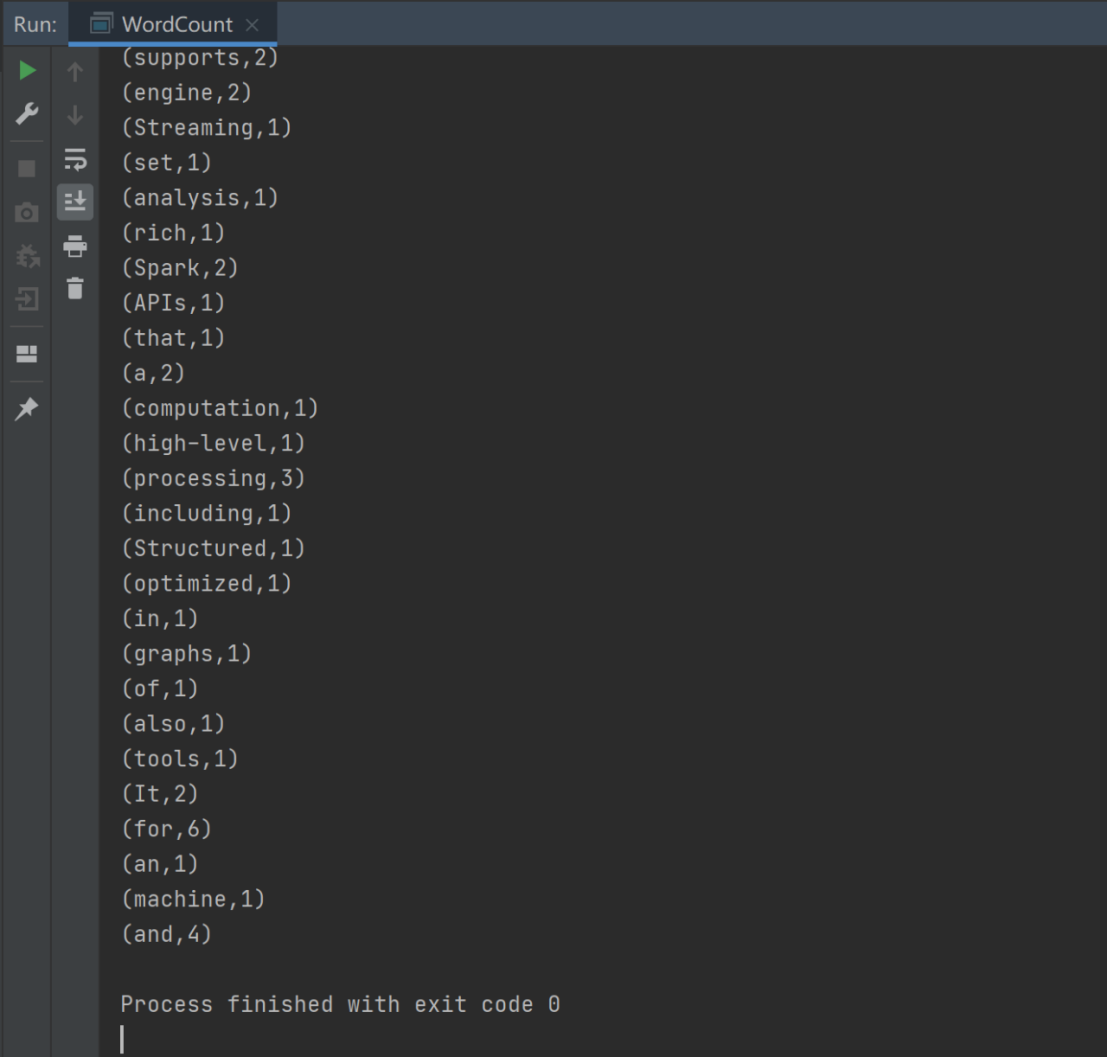
相关文章:

Spark运行架构 RDD相关概念Spark-Core编程
以下是今天学习的知识点: 第三节 Spark运行架构 运行架构 Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。 核心组件 对于 Spark 框架有两个核心组件: Driver Spark 驱动器节点,用…...

校园智能硬件国产化的现状与意义
以下是校园智能硬件国产化的现状与意义: 现状 政策支持力度大:近年来,国家出台了一系列政策推动教育数字化和国产化发展。如2022年教育部等六部门印发《关于推进教育新型基础设施建设构建高质量教育支撑体系的指导意见》,明确提出…...

Android里面如何优化xml布局
在 Android 开发中,以下是系统化的优化方案,从基础到高级分层解析: 一、基础优化策略 1. 减少布局层级 问题:每增加一层布局,测量/布局时间增加 1-2ms 解决方案: <!-- 避免嵌套 --> <LinearLayo…...

Android10.0 framework第三方无源码APP读写断电后数据丢失问题解决
1.前言 在10.0中rom定制化开发中,在某些产品开发中,在某些情况下在App用FileOutputStream读写完毕后,突然断电 会出现写完的数据丢失的问题,接下来就需要分析下关于使用FileOutputStream读写数据的相关流程,来实现相关 功能 2.framework第三方无源码APP读写断电后数据丢…...

LabVIEW驱动开发的解决思路
在科研项目中,常面临将其他语言开发的定制采集设备驱动转换为 LabVIEW 适用形式的难题。特别是当原驱动支持匮乏、开发人员技术支持不足时,如何抉择解决路径成为关键。以下提供具体解决思路,助力高效解决问题。 一、评估现有驱动死磕的可…...

【C++】 —— 笔试刷题day_13
一、牛牛冲钻五 题目描述 题目说,牛牛在玩炉石传说,现在牛牛进行了n场游戏,让我们判断牛牛上了几颗星。 首先输入一个T,表示T组数据; 然后输入n和k,表示一个进行了n场数据,k表示连胜三场及以上…...

【ROS】分布式通信架构
【ROS】分布式通信架构 前言环境要求主机设置(Master)从机设置(Slave)主机与从机通信测试本文示例启动ROS智能车激光雷达节点本地计算机配置与订阅 前言 在使用 ROS 时,我们常常会遇到某些设备计算能力不足的情况。例…...

【第39节】windows编程:打造MFC版本任务管理器
目录 一、项目概述 二、项目开发的各种功能关键 2.1 进程信息的获取 2.2 线程信息的获取 2.3 进程模块信息的获取 2.3.1 模块快照 2.3.2 枚举模块 2.4 进程堆信息的获取 2.5 窗口信息的获取 2.6 文件信息的获取 2.7 内存信息和CPU占用率的获取 2.7.1 内存信息相关结…...

1.认识C语言
上层:应用软件 下层:操作系统、硬件 C语言擅长于下层方面 计算机语言的发展:低级 ——> 高级 用计算机的二进制指令写代码(低级语言) —— > 汇编指令(低级语言,用到了助记符ÿ…...

MySQL下200GB大表备份,利用传输表空间解决停服发版表备份问题
MySQL下200GB大表备份,利用传输表空间解决停服发版表备份问题 问题背景 在停服发版更新时,需对 200GB 大表(约 200 亿行数据)进行快速备份以预防操作失误。 因为曾经出现过有开发写的发版语句里,UPDATE语句的WHERE条…...

《Sqoop 快速上手:安装 + 测试实战》
推荐原文 见:http://docs.xupengboo.top/bigdata/di/sqoop.html Sqoop(SQL-to-Hadoop) 是 Apache 开源的工具,专门用于在 Hadoop 生态系统(如 HDFS、Hive、HBase) 和 关系型数据库(如 MySQL、O…...
)
MySQL体系架构(二)
MySQL中的目录和文件 2.2.1.bin目录 在MysQL的安装目录下有一个特别特别重要的bin目录,这个目录下存放着许多可执行文件。 其他系统中的可执行文件与此的类似。这些可执行文件都是与服务器程序和客户端程序相关的。 2.2.1.1.启动MySQL服务器程序 在UNIX系统中用来启动MySO…...

为什么反激采用峰值电流控制模式而非电压模式
电压模式控制是传统的控制方法,通过检测输出电压,与参考电压比较,然后调整PWM的占空比。这种方法的优点是简单,只需要一个电压反馈环路。但缺点可能包括对输入电压变化的响应较慢,动态性能不足,尤其是在负载…...

JavaScript逆向工程中的插桩技术完全指南
一、什么是插桩技术? 插桩(Instrumentation)是逆向工程中的核心技术之一,指的是在不改变程序原有逻辑的前提下,向目标程序中插入额外的代码或监控点,用于收集运行时信息、修改程序行为或进行调试分析。 插…...

LLM应用实战1-基本概念
文章目录 基本概念1. 提示词工程(Prompt Engineering)2. AI Agent(智能代理)3. Model Context Protocol (MCP)4. Function Calling(函数调用)5. Retrieval-Augmented Generation (RAG)6. FineTuning&#x…...

数据结构--堆
一、堆的定义 堆是一棵完全二叉树,树中的每个结点的值都不小于(或不大于)其左右孩子结点的值。其中,如果父亲结点的值始终大于或等于孩子结点的值,那么称这样的堆为大顶堆,这时每个结点的值都是以它为根节…...

第37次CCF计算机软件能力认证 / T4 / 集体锻炼
题目 代码 #include <bits/stdc.h> using namespace std; using LL long long;const int N 1e6 10; const int mod 998244353; int a[N]; int st[N][22];int get(int l, int r) {int x r - l 1;int k log2(x);return __gcd(st[l][k], st[r - (1 << k) 1][…...

ES6规范新特性总结
ES6新特性 var、let和const不存在变量提升暂时性死区不允许重复声明 解构赋值用途:交换变量的值从函数返回多个值提取JSON数据遍历map结构输入模块的制定方法 字符串的扩展codePointAt()String.fromCharCode()at()includes(),startsWith(),endsWith()repeat()padSta…...

AI模型多阶段调用进度追踪系统设计文档
AI模型多阶段调用进度追踪系统设计文档 一、系统概述 为解决AI模型处理大型文件时响应时间长的问题,我们设计并实现了一套异步进度追踪系统。该系统采用Server-Sent Events (SSE) 技术,建立从服务器到客户端的单向实时通信通道,使前端能够实…...

[MSPM0开发]最新版ccs20.0安装、配置及导入第一个项目
一、ccs20.0 下载与安装 Code Composer Studio™ 集成式开发环境 (IDE),适用于 TI 微控制器和处理器的集成开发环境 (IDE)。它包含一整套丰富的工具,用于构建、调试、分析和优化嵌入式应用。 ccs下载地址 链接 安装比较简单,在次略过。 二、…...

Win10怎么关闭远程控制?
对于Windows 10用户来说,Win10关闭远程桌面可以有效防止不必要的远程连接,从而保护个人数据和系统安全。那么,Win10怎么关闭远程控制功能呢?接下来,我们将详细介绍Win10关闭远程控制的具体操作步骤。 步骤1.双击桌面上…...

AI重构知识生态:大模型时代的学习、创作与决策革新
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:从知识的获取到知识的共生 过去,我们对“知识”的理解,大多依赖书籍、老师、经验和专业的培训体系。而在大语言模型(Large Language Models, LLM)崛起之后,AI成为了一种新的“知识界面”:…...

牛客 小红杀怪
通过枚举所有使用y技能的次数来枚举出所有方案,选出最合适的 #include<iostream> #include<cmath> #include<algorithm> using namespace std;int a, b, x, y; int ans500;int main() {ios::sync_with_stdio(0);cin.tie(0);cout.tie(0);cin>&…...

Spring入门概念 以及入门案例
Spring入门案例 Springspring是什么spring的狭义与广义spring的两个核心模块IoCAOP Spring framework特点spring入门案例不用new方法,如何使用返回创建的对象 容器:IoC控制反转依赖注入 Spring spring是什么 spring是一款主流的Java EE轻量级开源框架 …...

SpringAI调用硅基流动免费模型
一、引入Spring AI 新建一个Spring Boot的工程,在工程中引入Spring AI的依赖,Spring AI支持Ollma、类OpenAI的接口,这两个引入的pom不一样,这里示例中是使用的硅基流动的模型 <!-- Spring Boot版本要 2.x 或者 3.x以上-->…...

Java 开发中主流安全框架的详细对比,涵盖 认证、授权、加密、安全策略 等核心功能,帮助开发者根据需求选择合适的方案
以下是 Java 开发中主流安全框架的详细对比,涵盖 认证、授权、加密、安全策略 等核心功能,帮助开发者根据需求选择合适的方案: 1. 主流安全框架对比表 框架名称类型核心功能适用场景优点缺点官网/文档Spring Security企业级安全框架认证、授…...
 Cortex(R)-M55 CPU 和 Ethos(TM)-U55 NPU 裸机上运行 TVM)
【TVM教程】在支持 CMSIS-NN 的 Arm(R) Cortex(R)-M55 CPU 和 Ethos(TM)-U55 NPU 裸机上运行 TVM
Apache TVM是一个深度的深度学习编译框架,适用于 CPU、GPU 和各种机器学习加速芯片。更多 TVM 中文文档可访问 →https://tvm.hyper.ai/ 作者:Grant Watson 本节使用示例说明如何使用 TVM 在带有 CMSIS-NN 的 Arm Cortex-M55 CPU 和 Ethos™-U55 NPU 的…...

【Ai/Agent】Windows11中安装CrewAI过程中的错误解决记录
CrewAi是什么,可以看之下之前写的 《初识CrewAI多智能代理团队协框架》 (注:这篇是基于linux系统下安装实践的) 基于以下记录解决问题后,可以再回到之前的文章继续进行CrewAI的安装 遇到问题 在windows系统中安装 CrewAi 不管是使用 pip 或者…...

洛谷 P11962:[GESP202503 六级] 树上漫步 ← dfs + 邻接表
【题目来源】 https://www.luogu.com.cn/problem/P11962 【题目描述】 小 A 有一棵 n 个结点的树,这些结点依次以 1,2,⋯,n 标号。 小 A 想在这棵树上漫步。具体来说,小 A 会从树上的某个结点出发,每⼀步可以移动到与当前结点相邻的结点&…...

Linux shell脚本编程
什么是Shell程序设计? 也就是给计算机发命令,让它帮你做事,你通过shell 的小工具,用键盘输入指令,linux就会根据这些指令去执行任务,就像你法号一个指令一样。 shell的强大之处? 文件处理&a…...

嵌入式硬件篇---Uart和Zigbee
文章目录 前言一、UART(通用异步收发传输器)1. 基本概念2. 工作原理帧结构起始位数据位校验位停止位 异步通信波特率 3. 特点优点缺点 4. 典型应用 二、ZigBee1. 基本概念2. 技术细节工作频段2.4GHz868MHz 网络拓扑星型网络网状网络簇状网络 协议栈物理层…...

Linux Makefile-概述、语句格式、编写规则、多文件编程、Makefile变量分类:自定义变量、预定义变量
目录 1.make 1.1 make 命令格式 2.Makefile 核心概念 2.1创建并运行 Makefile步骤 3. Makefile编写 3.1最基础Makefile 3.1.1使用默认make命令 3.1.2使用make -f 命令 3.1.3 gcc编译常用组合选项 3.1.4 make 和 make all区别 3.1.4.1 all 是默认目标 3.1.4.2 al…...

Kotlin日常使用函数记录
文章目录 前言字符串集合1.两个集合的差集2.集合转数组2.1.集合转基本数据类型数组2.2.集合转对象数组 Map1.合并Map1.1.使用 操作符1.2.使用 操作符1.3.使用 putAll 方法1.4.使用 merge 函数 前言 记录一些kotlin开发中,日常使用的函数和方式之类的,…...

【JavaScript】异步编程
个人主页:Guiat 归属专栏:HTML CSS JavaScript 文章目录 1. 异步编程基础1.1 同步与异步1.1.1 同步执行1.1.2 异步执行 1.2 JavaScript 事件循环 2. 回调函数2.1 基本回调模式2.2 错误处理2.3 回调地狱 3. Promise3.1 Promise 基础3.2 Promise 链式调用3…...

批量合并多张 jpg/png 图片为长图或者 PDF 文件,支持按文件夹合并图片
我们经常会碰到需要将多张图片拼成一张图片的场景,比如将多张图片拼成九宫格图片,或者将多张图片拼成一张长图。还有可能会碰到需要将多张图片合并成一个完整的 PDF 文件来方便我们进行打印或者传输等操作。那这些将图片合并成一张图片或者一个完整的文档…...

使用docker 安装向量数据库Milvus
Miluvs 官网 www.milvus.io/ https://milvus.io/docs/zh/install_standalone-docker-compose-gpu.md 一、基本概念 向量数据库:Milvus是一款云原生向量数据库,它支持多种类型的向量,如浮点向量、二进制向量等,并且可以处理大规模…...

在线PDF文件拆分工具,小白工具功能实用操作简单,无需安装的文档处理工具
小白工具中的在线 PDF 文件拆分工具是一款功能实用、操作便捷的文档处理工具,以下是其具体介绍: 操作流程 上传 PDF 文档:打开小白工具在线PDF文件拆分工具 - 快速、免费拆分PDF文档 - 小白工具的在线 PDF 文件拆分页面,通过点击 …...

Blender画图——阵列使用
如图我需要多个图示的图形,并且排成一个阵列效果。 如图依次点击效果。不要用相对偏移,要用恒定偏移。 如图设置数量。 如图完成x方向的画图后,我们需要在y方向再用一个阵列。...

VSCode 常用快捷键
Visual Studio Code (VSCode) 提供了许多快捷键,以帮助开发者提高编码效率。以下是一些常用的 VSCode 快捷键,这些快捷键适用于大多数操作系统,但在 macOS 上可能会有所不同(通常是将 Ctrl 替换为 Cmd)。 1. 文件和编…...

缓存相关问题
Redis 持久化机制 缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级等问题 热点数据和冷数据是什么 Memcache与Redis的区别都有哪些? 单线程的redis为什么这么快 redis的数据类型,以及每种数据类型的使用场景,Redis 内部结构 redis的过期策略以及内存淘汰机制 Redis 为什么…...
暴力娱乐篇22)
每日一题(小白)暴力娱乐篇22
为什么要经常学习暴力和一些娱乐呢?因为对于我们来说,暴力是最直接的方式是肯定能满足一部分答案的方法,娱乐是为了让算法变得更有趣,你愿意多去尝试多去练习,这才是最要紧的。 由题意知,就是计算两个数字…...

深入理解 Vuex:核心概念、API 详解与最佳实践
目录 Vuex 简介核心概念与工作流程核心 API 详解模块化开发 (modules)插件(Plugins)与扩展高级技巧与最佳实践 Vuex 简介 Vuex 是 Vue.js 的官方状态管理库,专为复杂应用设计,用于集中管理所有组件的共享状…...

成为一种国家战略范畴的新基建的智慧园区开源了。
智慧园区场景视频监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。用户只需在界…...

拜特科技助力科达制造,资金管理信息化迈入新阶段
近日,拜特科技成功签约科达制造股份有限公司(以下简称“科达制造”)资金管理系统升级项目。科达制造通过资金管理系统的不断迭代升级和优化,能够更加高效地管理和运用资金,提高企业的资金利用效率,满足企业…...
暴力娱乐篇20)
每日一题(小白)暴力娱乐篇20
这个题用瞪眼法解决,snakeaekns 代码如下👇 public static void main(String[] args) {Scanner scannew Scanner(System.in);System.out.println("aekns");scan.close();} 第二种方式:将snack拆解,按照大小进行排序。…...

Flutter iOS 项目中 VolumeControllerPlugin 报错解决方案
Flutter iOS 项目中 VolumeControllerPlugin 报错解决方案 在开发 Flutter 应用时,有时会遇到 iOS 项目构建失败的情况,其中一种较为常见的错误是与 VolumeControllerPlugin 相关的报错,错误信息如下: Could not build the prec…...

Java实战报错 tcp
为什么报错tcp Preview 从图片中的错误信息来看,程序遇到了 java.net.BindException,具体错误信息是 "Address already in use: bind"。这意味着你的程序试图绑定到一个已经被其他进程占用的端口(在本例中是9999端口)。…...
)
【补题】P10424 [蓝桥杯 2024 省 B] 好数(数位dp)
题意: 一个整数如果按从低位到高位的顺序,奇数位(个位、百位、万位……)上的数字是奇数,偶数位(十位、千位、十万位……)上的数字是偶数,我们就称之为“好数”。 给定一个正整数 N…...

控制 ElementUI el-table 树形表格多选框的显示层级
1、你可以通过 selectable 属性来控制哪些行可以选择(显示多选框) <el-table:data"tableData"row-key"id"default-expand-all:tree-props"{children: children, hasChildren: hasChildren}"select"handleSelect&…...

今日行情明日机会——20250409
今日行情还需要考虑关税对抗~ 2025年4月8日涨停的主要行业方向分析 1. 军工(19家涨停) 细分领域:国防装备、航空航天、军民融合。催化因素:国家安全战略升级、国防预算增加、重大军工项目落地预期。 2. 免税(15家涨…...