Pandas 库
Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。
Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据
Pandas 是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。
Pandas 主要引入了两种新的数据结构:Series 和 DataFrame。(可以理解为表格)
-
Series: 类似于一维数组或列表,是由一组数据以及与之相关的数据标签(索引)构成。Series 可以看作是 DataFrame 中的一列,也可以是单独存在的一维数据结构。

0、1、2 表示行索引
李四、王五、张三表示数据值
dtype 表示数据值的类型
-
DataFrame: 类似于一个二维表格,它是 Pandas 中最重要的数据结构。DataFrame 可以看作是由多个 Series 按列排列构成的表格,它既有行索引也有列索引,因此可以方便地进行行列选择、过滤、合并等操作。

0、1、2 表示行索引
name、age、gender表示列索引
1、安装pandas
直接安装:
pip install pandas
安装失败可以更换地址:
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装成功后,我们就可以导入 pandas 包使用:
import pandas导入 pandas 一般使用别名 pd 来代替
import pandas as pd查看 pandas 版本
import pandas as pd
print(pd.__version__)2、Series
Pandas Series 类似表格中的一个列,类似于一维数组,可以保存任何数据类型 Series 由索引(index)和列组成,函数:
| 函数名 | 参数 |
|---|---|
| pandas.Series(data,index,dtype) | data:一组数据(ndarray 类型) index:数据索引标签,如果不指定,默认从 0 开始 dtype:数据类型,默认会自己判断 copy:表示对 data 进行拷贝,默认为 False |
2.1创建Series对象
2.1.1列表创建Series对象
import pandas as pd# 列表形式
L = ['张三','李四','王五']
S = pd.Series(L)
print(S) 
import pandas as pd# 列表形式
L = ['张三','李四','王五']
S = pd.Series(L, index=['a', 'b', 'c'])
print(S) 
2.1.2字典创建 Series 对象
import pandas as pddata={'name':'Alice','age':25}
df=pd.Series(data)
print(df) 
2.2访问
import pandas as pddata={'name':'Alice','age':25,'city':'Beijing'}
df=pd.Series(data)
print(df['name'])
print(df['age'])
print(df['city'])# Alice
# 25
# Beijing2.3遍历
2.3.1使用 items()
import pandas as pddata={'name':'Alice','age':25,'city':'Beijing'}
df=pd.Series(data)#遍历Series对象
#使用 items(): 遍历Series对象的键值对
for a,b in df.items():print(f"键值:{a},数据:{b}")# 键值:name,数据:Alice
# 键值:age,数据:25
# 键值:city,数据:Beijing2.3.2使用 index
import pandas as pddata={'name':'Alice','age':25,'city':'Beijing'}
df=pd.Series(data)#遍历Series对象
# 使用 index 属性: 遍历Series对象的索引
for i in df.index:print(f"索引:{i}, 值:{df[i]}")# 索引:name, 值:Alice
# 索引:age, 值:25
# 索引:city, 值:Beijing2.3.3 values
import pandas as pddata={'name':'Alice','age':25,'city':'Beijing'}
df=pd.Series(data)#遍历Series对象
# values 属性:返回Series对象中所有的值
for i in df.values:print(f"数据:{i}")# 数据:Alice
# 数据:25
# 数据:Beijing3、DataFrame
| 函数名 | 参数 |
|---|---|
| pd.DataFrame( data, index, columns, dtype, copy) | data:一组数据(ndarray、series, map, lists, dict 等类型) index:索引值,或者可以称为行标签 columns:列标签 dtype:数据类型 copy:默认为 False,表示复制数据 data |
在 Pandas 中,DataFrame 的每一行或每一列都是一个 Series。
DataFrame 是一个二维表格,可以看作是由多个 Series 组成的。
3.1创建 DataFrame 对象
3.1.1列表创建
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]
df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
print(df)#[1,2,3]是一行,[4,5,6]是一行,以此类推
#有4行, 分别对应A、B、C、D
#有3列,分别对应X、Y、Z 
import pandas as pddata = [[1,2],[4,5,6],[7,8,9],[10,11]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
print(df) 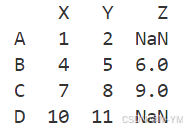
第1、4行比第2、3行少一个元素,则以NaN填充,数据类型转换为float
3.1.2字典创建
import pandas as pddata= {'name':['Alice','Bob','Charlie','David'],'age':[25,30,35,40]}
df=pd.DataFrame(data)
print(df) 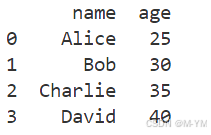
import pandas as pddata= {'name':['Alice','Bob','Charlie','David'],'age':[25,30,35,40]}
df=pd.DataFrame(data,index=['A','B','C','D'])
print(df) 
3.2列索引操作
DataFrame 可以使用列索(columns index)引来完成数据的选取、添加和删除操作
3.2.1获取数据
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
print(df['Y'])
#行不能这样获取,df['A']会报错
# A 2
# B 5
# C 8
# D 113.2.2添加列
1.直接添加
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
df['M'] = [10,20,30,40]
print(df)# X Y Z M
# A 1 2 3 10
# B 4 5 6 20
# C 7 8 9 30
# D 10 11 12 402.assign方法
assign方法添加数据是新建一个
assign()函数可以给DataFrame添加一列或多列数据,并返回一个新的DataFrame。
原DataFrame数据不变,新DataFrame包含原数据和新数据。
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
f=df.assign(M=[10,20,30,40])
print(df)
print(f)
df=df.assign(M=[10,20,30,40])
print(df)# X Y Z
# A 1 2 3
# B 4 5 6
# C 7 8 9
# D 10 11 12# X Y Z M
# A 1 2 3 10
# B 4 5 6 20
# C 7 8 9 30
# D 10 11 12 40# X Y Z M
# A 1 2 3 10
# B 4 5 6 20
# C 7 8 9 30
# D 10 11 12 40
3.insert方法
在指定的位置插入新列
使用insert方法在指定位置插入新列,参数:
-
loc: 插入位置的列索引。
-
column: 新列的名称。
-
value: 要插入的 Series。
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
#在列索引为1的位置插入一列W,并赋值为[100,200,300,400]
df.insert(1, 'W', [100,200,300,400])print(df)# X W Y Z
# A 1 100 2 3
# B 4 200 5 6
# C 7 300 8 9
# D 10 400 11 123.2.3修改数据
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
df['X']=[10,20,30,40]print(df)# X Y Z
# A 10 2 3
# B 20 5 6
# C 30 8 9
# D 40 11 12import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
df['X']=df['X']+10print(df)# X Y Z
# A 11 2 3
# B 14 5 6
# C 17 8 9
# D 20 11 12
修改列名
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
df.columns=['a','b','c']print(df)# a b c
# A 1 2 3
# B 4 5 6
# C 7 8 9
# D 10 11 12rename 方法修改列名 :
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
df = df.rename(columns={'X':'a'})print(df)# a Y Z
# A 1 2 3
# B 4 5 6
# C 7 8 9
# D 10 11 123.3 loc 选取数据
df.loc[] 只能使用标签索引,不能使用整数索引。当通过标签索引的切片方式来筛选数据时,它的取值前闭后闭,也就是包括边界值标签(开始和结束)
loc方法返回的数据类型:
1.如果选择单行或单列,返回的数据类型为Series
2.选择多行或多列,返回的数据类型为DataFrame
3.选择单个元素(某行某列对应的值),返回的数据类型为该元素的原始数据类型(如整数、浮点数等)。
:
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
print(df.loc['B']) # 输出B行数据
print(df.loc['B':'C']) # 输出B到C行数据print(df.loc['B','X']) # 输出B行X列数据
print(df.loc['B':'C','Y':'Z']) # 输出B到C行,Y列到Z列数据
print(df.loc[['A','D'],['X','Z']]) # 输出A和D行,X列和Z列数据# X 4
# Y 5
# Z 6# X Y Z
# B 4 5 6
# C 7 8 9# 4# Y Z
# B 5 6
# C 8 9
# X Z
# A 1 3
# D 10 123.4 iloc 选取数据
iloc 方法用于基于位置(integer-location based)的索引,即通过行和列的整数位置来选择数据。
语法:
DataFrame.iloc[row_indexer, column_indexer]
参数:
-
row_indexer:行位置或布尔数组。
-
column_indexer:列位置或布尔数组。
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
print(df.iloc[1]) # 输出B行数据
print(df.iloc[1:3]) # 输出B到C行数据print(df.iloc[1,0]) # 输出B行,X列数据
print(df.iloc[1:3,[1,2]]) # 输出B到C行,Y列到Z列数据
print(df.iloc[[0,3],[0,2]]) # 输出A和D行,X列和Z列数据# X 4
# Y 5
# Z 6# X Y Z
# B 4 5 6
# C 7 8 9# 4# Y Z
# B 5 6
# C 8 9
# X Z
# A 1 3
# D 10 123.5添加数据
3.5.1 loc方法添加
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
#添加一行
df.loc['E']=[13,14,15]
print(df)
#添加一列
df['W']=[16,17,18,19,20]print(df)X Y Z
# A 1 2 3
# B 4 5 6
# C 7 8 9
# D 10 11 12
# E 13 14 15
# X Y Z W
# A 1 2 3 16
# B 4 5 6 17
# C 7 8 9 18
# D 10 11 12 19
# E 13 14 15 203.5.2 concat拼接
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)参数:
objs: 要连接的 DataFrame 或 Series 对象的列表或字典。
axis: 指定连接的轴,0 或 'index' 表示按行连接,1 或 'columns' 表示按列连接。
join: 指定连接方式,'outer' 表示并集(默认),'inner' 表示交集。
ignore_index: 如果为 True,则忽略原始索引并生成新的索引。
keys: 用于在连接结果中创建层次化索引。
levels: 指定层次化索引的级别。
names: 指定层次化索引的名称。
verify_integrity: 如果为 True,则在连接时检查是否有重复索引。
sort: 如果为 True,则在连接时对列进行排序。
copy: 如果为 True,则复制数据。
#多行添加
#concat
#axis=0表示行合并
#axis=1表示列合并
#ignore_index参数指定是否重置索引,默认False,没有ignore_index就可能会出现重复索引
def f3(): df1=pd.DataFrame({'A':[1,2,3],'B':[4,5,6]})df2=pd.DataFrame({'A':[7,8,9],'B':[10,11,12]})df3=pd.concat([df1,df2],axis=0,ignore_index=True)print(df3)print("*****")# f3()#列合并
def f4():df1=pd.DataFrame({'A':[1,2,3],'B':[4,5,6]})df2=pd.DataFrame({'C':[7,8,9],'D':[10,11,12]})df3=pd.concat([df1,df2],axis=1)print(df3)
# f4()#join方法合并数据,outer表示合并所有行,inner表示合并匹配的行
def f5():df1=pd.DataFrame({'A':[1,2,3],'B':[4,5,6]})df2=pd.DataFrame({'A':[7,8,9],'B':[10,11,12],'C':[13,14,15]})df3 = pd.concat([df1,df2],axis=0) #join默认是outer,合并所有行,即保留df1和df2的所有行print(df3)print("*****")df4 = pd.concat([df1,df2],axis=0,join='inner') #join='inner'交集,即只保留df1和df2的交集,'C':[13,14,15]不会被保留print(df4)print("*****")
# f5()#DataFrame和Series的拼接
def f6():df1=pd.DataFrame({'A':[1,2,3],'B':[4,5,6]})print("行合并")s1=pd.Series([7,8,9],name='C')df2=pd.concat([df1,s1],axis=0)print(df2)print("列合并")df2=pd.concat([df1,s1],axis=1)print(df2)
# f6()3.5删除数据
通过drop方法删除 DataFrame 中的数据,默认情况下,drop() 不会修改原 DataFrame,而是返回一个新的 DataFrame。
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')参数:
-
labels:必写
-
类型:单个标签或列表。
-
描述:要删除的行或列的标签。如果 axis=0,则 labels 表示行标签;如果 axis=1,则 labels 表示列标签。
-
-
axis:必写
-
类型:整数或字符串,默认为 0。
-
描述:指定删除的方向。axis=0 或 axis='index' 表示删除行,axis=1 或 axis='columns' 表示删除列。
-
-
index:
-
类型:单个标签或列表,默认为 None。
-
描述:要删除的行的标签。如果指定,则忽略 labels 参数。
-
-
columns:
-
类型:单个标签或列表,默认为 None。
-
描述:要删除的列的标签。如果指定,则忽略 labels 参数。
-
-
level:
-
类型:整数或级别名称,默认为 None。
-
描述:用于多级索引(MultiIndex),指定要删除的级别。
-
-
inplace:
-
类型:布尔值,默认为 False。
-
描述:如果为 True,则直接修改原 DataFrame,而不是返回一个新的 DataFrame。
-
-
errors:
-
类型:字符串,默认为 'raise'。
-
描述:指定如何处理不存在的标签。'raise' 表示抛出错误,'ignore' 表示忽略错误。
-
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])f=df.drop('X',axis=1)
print(df)
print(f)# X Y Z
# A 1 2 3
# B 4 5 6
# C 7 8 9
# D 10 11 12
# Y Z
# A 2 3
# B 5 6
# C 8 9
# D 11 12则直接修改原 DataFrame,而不是返回一个新的 DataFrame。
import pandas as pddata = [[1,2,3],[4,5,6],[7,8,9],[10,11,12]]df=pd.DataFrame(data,index=['A','B','C','D'],columns=['X','Y','Z'])
df.drop('B',axis=0,inplace=True)
print(df)# X Y Z
# A 1 2 3
# C 7 8 9
# D 10 11 124、函数
4.1常用方法
isnull() 和 notnull() 用于检测 Series、DataFrame 中的缺失值。所谓缺失值,顾名思义就是值不存在、丢失、缺少
-
isnull():如果为值不存在或者缺失,则返回 True
-
notnull():如果值不存在或者缺失,则返回 False
4.2常用的统计学函数
| 函数名称 | 描述说明 |
|---|---|
| count() | 统计某个非空值的数量 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位数 |
| std() | 求标准差 |
| min() | 求最小值 |
| max() | 求最大值 |
| abs() | 求绝对值 |
| prod() | 求所有数值的乘积 |
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 30, 40, 50],'C': [100, 200, 300, 400, 500]
}
df = pd.DataFrame(data)# 计算每列的均值
mean_values = df.mean()
print(mean_values)# 计算每列的中位数
median_values = df.median()
print(median_values)#计算每列的方差
var_values = df.var()
print(var_values)# 计算每列的标准差
std_values = df.std()
print(std_values)# 计算每列的最小值
min_values = df.min()
print("最小值:")
print(min_values)# 计算每列的最大值
max_values = df.max()
print("最大值:")
print(max_values)# 计算每列的总和
sum_values = df.sum()
print(sum_values)# 计算每列的非空值数量
count_values = df.count()
print(count_values)4.3重置索引
重置索引(reindex)可以更改原 DataFrame 的行标签或列标签,并使更改后的行、列标签与 DataFrame 中的数据逐一匹配。通过重置索引操作,您可以完成对现有数据的重新排序。如果重置的索引标签在原 DataFrame 中不存在,那么该标签对应的元素值将全部填充为 NaN。
reindex
reindex() 方法用于重新索引 DataFrame 或 Series 对象。重新索引意味着根据新的索引标签重新排列数据,并填充缺失值。如果重置的索引标签在原 DataFrame 中不存在,那么该标签对应的元素值将全部填充为 NaN。
语法:
DataFrame.reindex(labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=np.nan, limit=None, tolerance=None)参数:
-
labels:
-
类型:数组或列表,默认为 None。
-
描述:新的索引标签。
-
-
index:
-
类型:数组或列表,默认为 None。
-
描述:新的行索引标签。
-
-
columns:
-
类型:数组或列表,默认为 None。
-
描述:新的列索引标签。
-
-
axis:
-
类型:整数或字符串,默认为 None。
-
描述:指定重新索引的轴。0 或 'index' 表示行,1 或 'columns' 表示列。
-
-
method:
-
类型:字符串,默认为 None。
-
描述:用于填充缺失值的方法。可选值包括 'ffill'(前向填充)、'bfill'(后向填充)等。
-
-
copy:
-
类型:布尔值,默认为 True。
-
描述:是否返回新的 DataFrame 或 Series。
-
-
level:
-
类型:整数或级别名称,默认为 None。
-
描述:用于多级索引(MultiIndex),指定要重新索引的级别。
-
-
fill_value:
-
类型:标量,默认为 np.nan。
-
描述:用于填充缺失值的值。
-
-
limit:
-
类型:整数,默认为 None。
-
描述:指定连续填充的最大数量。
-
-
tolerance:
-
类型:标量或字典,默认为 None。
-
描述:指定重新索引时的容差。
-
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])# 重新索引行
new_index = ['a', 'b', 'c', 'd']
df_reindexed = df.reindex(new_index)
print(df_reindexed)# 重新索引列
new_columns = ['A', 'B', 'C', 'D']
df_reindexed = df.reindex(columns=new_columns)
print(df_reindexed)# 重新索引行,并使用前向填充
# 新的行索引 ['a', 'b', 'c', 'd'] 包含了原索引中不存在的标签 'd',使用 method='ffill' 进行前向填充,因此 'd' 对应的行填充了前一行的值。
new_index = ['a', 'b', 'c', 'd']
df_reindexed = df.reindex(new_index, method='ffill')
print(df_reindexed)# 重新索引行,并使用指定的值填充缺失值
new_index = ['a', 'b', 'c', 'd']
df_reindexed = df.reindex(new_index, fill_value=0)
print(df_reindexed)4.4遍历
DataFrame 这种二维数据表结构,遍历会获取列标签
import pandas as pddata = {'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 30, 35]}
df = pd.DataFrame(data)
for i in df:print(i)# name
# age4.4.1itertuples() 遍历行
itertuples() 方法用于遍历 DataFrame 的行,返回一个包含行数据的命名元组。
itertuples() 是遍历 DataFrame 的推荐方法,因为它在速度和内存使用上都更高效。
#遍历行
#itertuples()方法可以将DataFrame转换成一个迭代器,每一行都是一个namedtuple,可以直接访问每一列的值。
#使用itertuples()方法遍历DataFrame,并打印每一行的索引、值、列名。for row in df.itertuples():print(row) #row是一个namedtuple,包含索引、值、列名# Pandas(Index=0, name='Alice', age=25)
# Pandas(Index=1, name='Bob', age=30)
# Pandas(Index=2, name='Charlie', age=35)index=False参数表示不显示索引
for row in df.itertuples(index=False):# print(row) for i in row:print(i)
# Alice
# 25
# Bob
# 30
# Charlie
# 354.4.2 items()遍历列
items() 方法用于遍历 DataFrame 的列,返回一个包含列名和列数据的迭代器。
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])# 使用 items() 遍历列
for column_name, column_data in df.items():print(f"Column Name: {column_name}, Column Data: {column_data}")
#输出:
Column Name: A, Column Data: a 1
b 2
c 3
Name: A, dtype: int64
Column Name: B, Column Data: a 4
b 5
c 6
Name: B, dtype: int64
Column Name: C, Column Data: a 7
b 8
c 9
Name: C, dtype: int644.4.3 使用属性遍历
loc 和 iloc 方法可以用于按索引或位置遍历 DataFrame 的行和列。
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])# 使用 loc 遍历行和列
for index in df.index:for column in df.columns:print(f"Index: {index}, Column: {column}, Value: {df.loc[index, column]}")# 输出:
Index: a, Column: A, Value: 1
Index: a, Column: B, Value: 4
Index: a, Column: C, Value: 7
Index: b, Column: A, Value: 2
Index: b, Column: B, Value: 5
Index: b, Column: C, Value: 8
Index: c, Column: A, Value: 3
Index: c, Column: B, Value: 6
Index: c, Column: C, Value: 94.5 排序
4.5.1 sort_index
sort_index 方法用于对 DataFrame 或 Series 的索引进行排序。
DataFrame.sort_index(axis=0, ascending=True, inplace=False)
Series.sort_index(axis=0, ascending=True, inplace=False)参数:
-
axis:指定要排序的轴。默认为 0,表示按行索引排序。如果设置为 1,将按列索引排序。
-
ascending:布尔值,指定是升序排序(True)还是降序排序(False)。
-
inplace:布尔值,指定是否在原地修改数据。如果为 True,则会修改原始数据;如果为 False,则返回一个新的排序后的对象。
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['b', 'c', 'a'])# 按行索引标签排序,不对对应的值排序
df_sorted = df.sort_index()
#输出:A B C
a 3 6 9
b 1 4 7
c 2 5 8#按列索引标签降序排序
df_sorted = df.sort_index(axis=1,ascending=False)
print(df_sorted)
# 输出:C B A
b 7 4 1
c 8 5 2
a 9 6 34.5.2 sort_values
sort_values 方法用于根据一个或多个列的值对 DataFrame 进行排序。
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')参数:
-
by:列的标签或列的标签列表。指定要排序的列。
-
axis:指定沿着哪个轴排序。默认为 0,表示按行排序。如果设置为 1,将按列排序。
-
ascending:布尔值或布尔值列表,指定是升序排序(True)还是降序排序(False)。可以为每个列指定不同的排序方向。
-
inplace:布尔值,指定是否在原地修改数据。如果为 True,则会修改原始数据;如果为 False,则返回一个新的排序后的对象。
-
kind:排序算法。默认为 'quicksort',也可以选择 'mergesort'(归并排序) 或 'heapsort'(堆排序)。
-
na_position:指定缺失值(NaN)的位置。可以是 'first' 或 'last'。
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [3, 2, 1],'B': [6, 5, 4],'C': [9, 8, 7]
}
df = pd.DataFrame(data, index=['b', 'c', 'a'])# 按列 'A' 排序
df_sorted = df.sort_values(by='A')
print(df_sorted)# 按列 'A' 和 'B' 排序
df_sorted = df.sort_values(by=['A', 'B'])
print(df_sorted)# 按列 'A' 降序排序
df_sorted = df.sort_values(by='A', ascending=False)
print(df_sorted)# 按列 'A' 和 'B' 排序,先按A列降序排序,如果A列中值相同则按B列升序排序
df = pd.DataFrame({'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],'Age': [25, 30, 25, 35, 30],'Score': [85, 90, 80, 95, 88]
})
df_sorted = df.sort_values(by=['Age', 'Score'], ascending=[False, True])
print(df_sorted)4.6 去重
drop_duplicates 方法用于删除 DataFrame 或 Series 中的重复行或元素。
drop_duplicates(by=None, subset=None, keep='first', inplace=False)
Series.drop_duplicates(keep='first', inplace=False)参数:
-
by:用于标识重复项的列名或列名列表。如果未指定,则使用所有列。
-
subset:与 by 类似,但用于指定列的子集。
-
keep:指定如何处理重复项。可以是:
-
'first':保留第一个出现的重复项(默认值)。
-
'last':保留最后一个出现的重复项。
-
False:删除所有重复项。
-
-
inplace:布尔值,指定是否在原地修改数据。如果为 True,则会修改原始数据;如果为 False,则返回一个新的删除重复项后的对象。
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 2, 3],'B': [4, 5, 5, 6],'C': [7, 8, 8, 9]
}
df = pd.DataFrame(data)
print(df)
# 删除所有列的重复行,默认保留第一个出现的重复项
df_unique = df.drop_duplicates()
print(df_unique)# 删除重复行,保留最后一个出现的重复项
df_unique = df.drop_duplicates(keep='last')
print(df_unique)# 修改原数据
df.drop_duplicates(keep='last', inplace=True)
print(df)#原数据
# A B C
# 0 1 4 7
# 1 2 5 8
# 2 2 5 8
# 3 3 6 9# 删除所有列的重复行,默认保留第一个出现的重复项
# A B C
# 0 1 4 7
# 1 2 5 8
# 3 3 6 9# 删除重复行,保留最后一个出现的重复项# A B C
# 0 1 4 7
# 2 2 5 8
# 3 3 6 94.7 分组
4.7.1 groupby
groupby 方法用于对数据进行分组操作,这是数据分析中非常常见的一个步骤。通过 groupby,你可以将数据集按照某个列(或多个列)的值分组,然后对每个组应用聚合函数,比如求和、平均值、最大值等。
DataFrame.groupby(by, axis=0, level=None, as_index=True,
sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)参数:
-
by:用于分组的列名或列名列表。
-
axis:指定沿着哪个轴进行分组。默认为 0,表示按行分组。
-
level:用于分组的 MultiIndex 的级别。
-
as_index:布尔值,指定分组后索引是否保留。如果为 True,则分组列将成为结果的索引;如果为 False,则返回一个列包含分组信息的 DataFrame。
-
sort:布尔值,指定在分组操作中是否对数据进行排序。默认为 True。
-
group_keys:布尔值,指定是否在结果中添加组键。
-
squeeze:布尔值,如果为 True,并且分组结果返回一个元素,则返回该元素而不是单列 DataFrame。
-
observed:布尔值,如果为 True,则只考虑数据中出现的标签。
import pandas as pd# 创建一个示例 DataFramedata = {'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C': [1, 2, 3, 4, 5, 6, 7, 8],'D': [10, 20, 30, 40, 50, 60, 70, 80]}df = pd.DataFrame(data)# 按列 'A' 分组grouped = df.groupby('A')# 查看分组结果for name, group in grouped:print(f"Group: {name}")print(group)print()mean = df.groupby(['A']).mean()print(mean)#输出:C DA bar 4.0 40.0foo 4.8 48.0mean = grouped['C'].mean()print(mean)#输出:Abar 4.0foo 4.8# 在分组内根据C列求平均值# transform用于在分组操作中对每个组内的数据进行转换,并将结果合并回原始 DataFrame。mean = grouped['C'].transform(lambda x: x.mean())df['C_mean'] = meanprint(df)#输出:A B C D C_mean0 foo one 1 10 4.81 bar one 2 20 4.02 foo two 3 30 4.83 bar three 4 40 4.04 foo two 5 50 4.85 bar two 6 60 4.06 foo one 7 70 4.87 foo three 8 80 4.8# 在分组内根据C列求标准差std = grouped['C'].transform(np.std)df['C_std'] = stdprint(df)# 在分组内根据C列进行正太分布标准化norm = grouped['C'].transform(lambda x: (x - x.mean()) / x.std())df['C_normal'] = normprint(df)4.7.2 filter
通过 filter() 函数可以实现数据的筛选,该函数根据定义的条件过滤数据并返回一个新的数据集
import pandas as pd# 创建一个示例 DataFramedata = {'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C': [1, 2, 3, 4, 5, 6, 7, 8],'D': [10, 20, 30, 40, 50, 60, 70, 80]}df = pd.DataFrame(data)# 按列 'A' 分组,并过滤掉列 'C' 的平均值小于 4 的组
filtered = df.groupby('A').filter(lambda x: x['C'].mean() >= 4)print(filtered)
4.8 合并
merge 函数用于将两个 DataFrame 对象根据一个或多个键进行合并,类似于 SQL 中的 JOIN 操作。这个方法非常适合用来基于某些共同字段将不同数据源的数据组合在一起,最后拼接成一个新的 DataFrame 数据表。
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'),
copy=True, indicator=False, validate=None)参数:
-
left:左侧的 DataFrame 对象。
-
right:右侧的 DataFrame 对象。
-
how:合并方式,可以是 'inner'、'outer'、'left' 或 'right'。默认为 'inner'。
-
'inner':内连接,返回两个 DataFrame 共有的键。
-
'outer':外连接,返回两个 DataFrame 的所有键。
-
'left':左连接,返回左侧 DataFrame 的所有键,以及右侧 DataFrame 匹配的键。
-
'right':右连接,返回右侧 DataFrame 的所有键,以及左侧 DataFrame 匹配的键。
-
-
on:用于连接的列名。如果未指定,则使用两个 DataFrame 中相同的列名。
-
left_on 和 right_on:分别指定左侧和右侧 DataFrame 的连接列名。
-
left_index 和 right_index:布尔值,指定是否使用索引作为连接键。
-
sort:布尔值,指定是否在合并后对结果进行排序。
-
suffixes:一个元组,指定当列名冲突时,右侧和左侧 DataFrame 的后缀。
-
copy:布尔值,指定是否返回一个新的 DataFrame。如果为 False,则可能修改原始 DataFrame。
-
indicator:布尔值,如果为 True,则在结果中添加一个名为 __merge 的列,指示每行是如何合并的。
-
validate:验证合并是否符合特定的模式。
内连接
import pandas as pd# 创建两个示例 DataFrame
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']
})right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K4'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']
})# 内连接
result = pd.merge(left, right, on='key')print(result)#输出:K3、K4被忽略key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2左连接
import pandas as pd# 创建两个示例 DataFrame
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']
})right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K4'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']
})# 左连接,以左侧表为准
result = pd.merge(left, right, on='key', how='left')print(result)
# 输出:key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 NaN NaN4.9 随机抽样
DataFrame.sample(n=None, frac=None, replace=False, weights=None,
random_state=None, axis=None)参数:
-
n:要抽取的行数
-
frac:抽取的比例,比如 frac=0.5,代表抽取总体数据的50%
-
replace:布尔值参数,表示是否以有放回抽样的方式进行选择,默认为 False,取出数据后不再放回
-
weights:可选参数,代表每个样本的权重值,参数值是字符串或者数组
-
random_state:可选参数,控制随机状态,默认为 None,表示随机数据不会重复;若为 1 表示会取得重复数据
-
axis:表示在哪个方向上抽取数据(axis=1 表示列/axis=0 表示行)
4.10 空值处理
4.10.1 检测空值
isnull()用于检测 DataFrame 或 Series 中的空值,返回一个布尔值的 DataFrame 或 Series。
notnull()用于检测 DataFrame 或 Series 中的非空值,返回一个布尔值的 DataFrame 或 Series。
import pandas as pd
import numpy as np# 创建一个包含空值的示例 DataFrame
data = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, np.nan, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)# 检测空值
is_null = df.isnull()
print(is_null)# 检测非空值
not_null = df.notnull()
print(not_null)4.10.2 填充空值
fillna() 方法用于填充 DataFrame 或 Series 中的空值。
# 创建一个包含空值的示例 DataFrame
data = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, np.nan, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)# 用 0 填充空值
df_filled = df.fillna(0)print(df_filled)
4.10.3 删除空值
dropna() 方法用于删除 DataFrame 或 Series 中的空值。
# 创建一个包含空值的示例 DataFrame
data = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, np.nan, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)# 删除包含空值的行
df_dropped = df.dropna()
print(df_dropped)
#输出:A B C
0 1.0 5.0 9
3 4.0 8.0 12# 删除包含空值的列
df_dropped = df.dropna(axis=1)
print(df_dropped)
#输出:C
0 9
1 10
2 11
3 12
5、读取CSV文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本);
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
5.1 to_csv()
to_csv() 方法将 DataFrame 存储为 csv 文件
import pandas as pd# 创建一个简单的 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)# 将 DataFrame 导出为 CSV 文件
df.to_csv('output.csv', index=False)5.2 read_csv()
read_csv() 表示从 CSV 文件中读取数据,并创建 DataFrame 对象。
import pandas as pddf = pd.read_csv('output.csv')
print(df)6、绘图
Pandas 在数据分析、数据可视化方面有着较为广泛的应用,Pandas 对 Matplotlib 绘图软件包的基础上单独封装了一个plot()接口,通过调用该接口可以实现常用的绘图操作;
Pandas 之所以能够实现了数据可视化,主要利用了 Matplotlib 库的 plot() 方法,它对 plot() 方法做了简单的封装,因此您可以直接调用该接口;
只用 pandas 绘制图片可能可以编译,但是不会显示图片,需要使用 matplotlib 库,调用 show() 方法显示图形。
import pandas as pdimport matplotlib.pyplot as plt# 创建一个示例 DataFramedata = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 25, 30, 40]}df = pd.DataFrame(data)# 绘制折线图df.plot(kind='line')# 显示图表plt.show()# 绘制柱状图df.plot(kind='bar')# 显示图表plt.show()# 绘制直方图df['A'].plot(kind='hist')# 显示图表plt.show()# 绘制散点图df.plot(kind='scatter', x='A', y='B')# 显示图表plt.show()饼图
import pandas as pd
import matplotlib.pyplot as plt# 创建一个示例 Seriesdata = {'A': 10,'B': 20,'C': 30,'D': 40}series = pd.Series(data)# 绘制饼图series.plot(kind='pie', autopct='%1.1f%%')# 显示图表plt.show()相关文章:

Pandas 库
Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。 Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据 Pandas 是数据科学和分析领域中常用的工具之一,它使得用户能够…...

4.8学习总结
完成摆动序列的算法题(比较难,想不出方法) 学习了HashMap,TreeMap 的源码(看完一遍对其理解没有太清楚,还需再多刷几遍理解源码及其底层逻辑的概念) 学习了可变参数和Collections工具类...

C语言之九九乘法表
一、代码展示 二、运行结果 三、代码分析 首先->是外层循环是小于等于9的 然后->是内层循环是小于等于外层循环的 最后->就是\n让九九乘法表的格式更加美观(当然 电脑不同 有可能%2d 也有可能%3d) 四、与以下素数题目逻辑相似 五、运行结果...

【Linux操作系统】:信号
Linux操作系统下的信号 一、引言 首先我们可以简单理解一下信号的概念,信号,顾名思义,就是我们操作系统发送给进程的消息。举个简单的例子,我们在写C/C程序的时候,当执行a / 0类似的操作的时候,程序直接就挂…...

skynet.call使用详解
目录 skynet.call 详细解析1. 函数签名与参数2. 内部实现机制3. 会话ID与协程调度4. 超时与错误处理5. 返回值处理6. 协议类型的影响7. skynet.call vs skynet.send8. 示例代码分析9. 最佳实践10. 总结 skynet.call 详细解析 1. 函数签名与参数 函数签名: skynet…...

uniapp 打包 H5 向 打包的APP 使用 @dcloudio/uni-webview-js 传值
1.安装 dcloudio/uni-webview-js npm install dcloudio/uni-webview-js -save 这个模块的 uni. 会与H5的uniapp的 uni. 冲突,所以需要改下名称,一共需要改3处 2.引入并使用 import uniWeb from dcloudio/uni-webview-js;uniWeb.postMessage({data: {action: message,content…...

c语言 文件操作
c语言 文件操作 one 打开/usr/dev.txt文件,在第1行 覆盖写入 "MAC1q23456789" #include <fcntl.h> #include <unistd.h> #include <string.h> int main() { const char *line_1 "MAC1q23456789\n"; // 要写入的内容…...

企业电子招投标采购系统——功能模块功能描述+数字化采购管理 采购招投标
功能描述 1、门户管理:所有用户可在门户页面查看所有的公告信息及相关的通知信息。主要板块包含:招标公告、非招标公告、系统通知、政策法规。 2、立项管理:企业用户可对需要采购的项目进行立项申请,并提交审批,查看…...
)
Python 序列构成的数组(序列的增量赋值)
序列的增量赋值 增量赋值运算符 和 * 的表现取决于它们的第一个操作对象。简单起 见,我们把讨论集中在增量加法()上,但是这些概念对 * 和其他 增量运算符来说都是一样的。 背后的特殊方法是 iadd (用于“就地加法”&…...

力扣hot100【链表】
160.相交链表 题目 我的思路:两个链表一长一短,先把长的提前遍历使两个链表的长度相等,然后同时遍历,如果遍历的节点相等时说明相交,否则不相交。 /*** Definition for singly-linked list.* struct ListNode {* …...

PyTorch 生态迎来新成员:SGLang 高效推理引擎解析
SGLang 现已正式融入 PyTorch 生态系统!此次集成确保了 SGLang 符合 PyTorch 的技术标准与最佳实践,为开发者提供了一个可靠且社区支持的框架,助力大规模语言模型(LLM)实现高效且灵活的推理。 如需深入了解 PyTorch…...

C++ Primer Plus 编程练习题 第六章 分支语句和逻辑运算符
1.大小写转换 使用cctype库里的函数进行大小写转换,但要注意使用toupper或tolower时要进行强制类型转换,否则会输出ASCII值 #include <iostream> #include<cctype> using namespace std;int main() {cout << "请输入字符串(大…...

一文详解OpenGL环境搭建:Windows使用CLion配置OpenGL开发环境
在计算机图形学的广阔领域中,OpenGL作为行业标准的图形库,为开发者提供了强大的工具集来创建从简单的2D图形到复杂的3D世界。然而,对于初学者和经验丰富的开发者而言,选择一个合适的开发环境是迈向成功的第一步。尤其是在Windows平台上,配置一个既支持现代C++编程实践又能…...

一次奇怪的enq: TX - row lock contention锁问题处理
某天上午客户告知数据库库有锁导致数据库卡死,需排查出问题的原因,从根本上解决问题。 按正常步骤,查询V$SESSION中BLOCKING_SESSION列不为空的,发现没有进程互相阻塞的情况;而查询ACTIVE会话,则有大量进程…...

STL常用容器整理
STL常用容器操作整理 STL常用容器操作整理(string/vector/set/map)一、string(字符串)构造函数元素访问修改操作容量操作子串与查找 二、vector(动态数组)构造函数元素访问修改操作容量操作 三、set&#x…...

深入 PostgreSQL 内部:5 个关键阶段拆解查询处理全流程
引言 当您向 PostgreSQL 发送查询时,后端会经历多个处理阶段。每个阶段承担着不同的职责,以确保您能在最短时间内获得准确响应。虽然这些阶段可能庞大而复杂,但理解它们在查询处理中的角色对 PostgreSQL 开发者至关重要。本文将概述每个查询…...

解析 LILIkoi 光纤力传感器:FBG 原理铸就耐高温抗干扰优势
LILIkoi光纤力传感器通过光纤光栅(FBG)技术实现高精度力测量。其核心原理基于光纤内光栅栅距的微小变化,用以感知外界施加的力。该传感器在高温、强辐射等恶劣环境中表现出色,能够有效抵抗电磁干扰和温度漂移。凭借卓越的性能&…...

SU-YOLO:基于脉冲神经网络的高效水下目标检测模型解析
论文地址:https://arxiv.org/pdf/2503.24389 目录 一、论文概述 二、创新点解析 1. 基于脉冲的水下图像去噪(SpikeDenoiser) 原理与结构 2. 分离批归一化(SeBN) 原理与结构 3. 优化的残差块(SU-Block) 原理与结构 三、代码复现指南 环境配置 模型训练 四、…...

有关eeprom以及pwm
a0 a1就是对应的 芯片的 写和读 0写 1读 使用操作 主函数读一次 然后信息里一直写入。 用level设置挡位 如 10个格子 设置2 3 这样占空比就有了...

JMeter教程|0到1学会接口性能压测第14课-JMeter接口性能测试全流程讲解
Apache JMeter是一款纯java编写负载功能测试和性能测试开源工具软件。相比Loadrunner而言,JMeter小巧轻便且免费,逐渐成为了主流的性能测试工具,是每个测试人员都必须要掌握的工具之一。 本文以百度搜索接口为例,全流程讲解JMeter接口性能测试。从JMeter下载安装到编写一个…...

系统思考:问题诊断
“做事不怕困难,怕的是不明白困难出在哪里。” —— 亨利福特 最近发现,有些领导者或者团队,常常急于给出解决方案,却忽视了最关键的一步——诊断问题的根源。团队甚至在集体心智模式的影响下,连问题本身都搞错了方向…...

有效压缩 Hyper-v linux Centos 的虚拟磁盘 VHDX
参考: http://www.360doc.com/content/22/0505/16/67252277_1029878535.shtml VHDX 有个不好的问题就是,如果在里面存放过文件再删除,那么已经使用过的空间不会压缩,导致空间一直被占用。那么就需要想办法压缩空间。 还有一点&a…...

使用 redis 实现消息队列
方案1: 使用list做消息队列问题1: 如何保证消息不丢失问题 2: 重复消费/幂等 方案 2: zset实现消息队列方案 3: 发布/订阅(pub/sub)问题1: 如何保证消息不丢失问题 2: 重复消费/幂等 方案 4: Stream 实现消息队列问题1: 如何保证消息不丢失问题 2: 重复消费/幂等 方案1: 使用li…...
)
2025 XYCTF Pwn-wp(含附件)
前言 总体来说Pwn方向题目难度属于中等,属于那种一眼看不出要咋做,但多试试又能做出来的那种,比赛的时候甚至有几只队伍AK了Pwn方向。感觉题目还是很不错的尽管比赛中有一些小意外像是有些题目附件给错了,但是XYCTF的师傅们都是无偿出题纯热爱向大伙分享自己的题目…...

verilog有符号数的乘法
1、单周期乘法器 对于低速要求的乘法器,可以简单的使用 * 实现。 module Mult(input wire [7:0] multiplicand ,input wire [7:0] multipliter ,output wire [7:0] product);assign product multiplicand * multipliter …...

【python3】关于等额本金和等额本息计算
【python3】关于等额本金和等额本息计算 1.背景2.计算3.总结4.推导 1.背景 在贷款买房的宝子们一定有了解等额本金和等额本息,年轻的时候只听销售在那里计算, 您可能听得云里雾里。 等额本金:每个月还的本金固定,利息逐渐减少。…...

git怎么删除远程分支
删除远程分支 引言删除远程分支查看远程分支查看远程分支详情删除远程分支 引言 本文旨在记录一下,git如何通过命令行删除远程分支。 删除远程分支 查看远程分支 使用指令: git branch -r查看远程分支详情 使用指令: git remote show …...

【C++】函数直接返回bool值和返回bool变量差异
函数直接返回bool值和返回bool变量差异 背景 在工作中遇到一个比较诡异的问题,场景是给业务方提供的SDK有一个获取状态的函数GetStatus,函数的返回值类型是bool,在测试过程中发现,SDK返回的是false,但是业务方拿到的…...
)
蓝桥杯-蓝桥幼儿园(并查集)
并查集的核心思想 并查集主要由两个操作构成: Find:查找某个元素所在集合的根节点。并查集的特点是,每个元素都指向它自己的父节点,根节点的父节点指向它自己。查找过程中可以通过路径压缩来加速后续的查找操作,即将路…...
)
Ensemble of differential evolution variants(EDEV)
差分进化变体的集成1 在这项研究中,一个基于多种群的框架(MPF)被提议用于多个差分进化变体的集合。与PAP2不同,PAP通过时间预算分配策略和个体移民算子实现算法组合,MPF将整个种群划分为子种群,包括几个指…...

《AI开发工具和技能实战》第1集 Windows CMD 命令行操作指南:从基础到进阶
第1集 Windows CMD 命令行操作指南:从基础到进阶 在日常使用 Windows 系统时,命令提示符(Command Prompt,简称 CMD)是一个强大且灵活的工具。无论是文件管理、系统配置,还是网络诊断,CMD 都能提…...

实现一个拖拽排序组件:Vue 3 + TypeScript + Tailwind CSS
文章目录 一、项目背景与需求分析需求: 二、搭建基础项目1. 初始化 Vue 3 项目2. 安装 Tailwind CSS 三、设计拖拽排序组件1. 创建拖拽排序组件2. 说明: 四、完善样式与功能1. 样式调整2. 拖拽顺序更新 五、进一步优化与拓展1. 添加排序指示器2. 支持动态…...
的实现)
哈希表(开散列)的实现
目录 引入 开散列的底层实现 哈希表的定义 哈希表的扩容 哈希表的插入 哈希表查找 哈希表的删除 引入 接上一篇,我们使用了闭散列的方法解决了哈希冲突,此篇文章将会使用开散列的方式解决哈希冲突,后面对unordered_set和unordered_map的…...

解决 Jetpack Compose 中 State 委托报错:“no method getValue“ 的终极指南
1. 必须的导入 ✅ import androidx.compose.runtime.getValue // 核心关键!作用:为 State 类型添加 getValue() 操作符,使其支持 by 委托语法。为什么需要:Kotlin 的委托属性需要对象实现 getValue() 方法,Compose 通…...

我们如何思考AI创业投资
🎬 Verdure陌矣:个人主页 🎉 个人专栏: 《C/C》 | 《转载or娱乐》 🌾 种完麦子往南走, 感谢您的点赞、关注、评论、收藏、是对我最大的认可和支持!❤️ 声明:本文作者转载,原文出自…...

1.ElasticSearch-入门基础操作
一、介绍 The Elastic Stack 包含ElasticSearch、Kibana、Beats、LogStash 这就是所说的ELK 能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。Elaticsearch,简称为ES,ES是一个开源的高扩展的分布式全文搜索引擎,是…...

2.ElasticSearch-Java API
一、基础使用 1.1 Maven 坐标 <dependencies><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.8.0</version></dependency><!--es的客户端--><dependenc…...
)
蓝桥杯-小明的彩灯(差分)
问题描述: 差分数组 1. 什么是差分数组? 差分数组 c 是原数组 a 的“差值表示”,其定义如下: c[0] a[0]c[i] a[i] - a[i-1] (i ≥ 1) 差分数组记录了相邻元素的差值。例如,原数组 a [1, …...

vim定位有问题的脚本/插件的一般方法
在使用vim的过程中可能会遇到一些报错或其他不符合预期的情况,本文介绍一些我自己常用的定位有问题脚本/插件的方法(以下方法同样适用于neovim) 执行了某些命令的情况 这种情况最简单,使用:h 命令,如果插件有文档的话…...
)
EasyExcel实现图片导出功能(记录)
背景:在旧系统的基础上,导出一些工单信息时,现需要新添加处理人的签名或者签章,这就涉及图片的上传、下载、写入等几个操作。 1、EasyExcel工具类 (1)支持下拉框的导出。 import com.alibaba.excel.Easy…...

PCL拟合空间3D圆周 fit3DCircle
PCL版本 1.15.0 main.cpp #include<vector> #include<iostream> #include <array> #include <string> #include <windows.h> #include <omp.h> #include <charconv> // C17 #include <cstdlib> #include<chrono> #in…...

ansible 实现达梦7数据库初始化数据脚本写入
关于使用ansible 对ARM版达梦7的k8s自动化部署参考我的这篇操作 ansible-playbook 写arm版达梦7数据库的一键安装脚本-CSDN博客文章浏览阅读303次,点赞5次,收藏3次。达梦官方提供镜像目前是dm8_x86 版本,因为众所周知的国产化方面的需求&…...

leetcode每日刷题
Day18 Title45.jump(跳跃游戏 II) 解法一:动态规划 依然分三步走: 1.状态方程 2.dp[i]的意义 3.边界条件及初始值 优先思考第二个问题: dp[i]表示到达i时需要的最少跳数 第一个问题: dp[ij]min(dp[i]1,dp[ij]) 为什么&am…...

Ubuntu安装Nginx
Ubuntu安装Nginx 由于 Ubuntu 的 apt 命令内置了 nginx 源,因此不用配置 apt 就可以直接下载安装: apt install nginx -y查看 nginx 是否启动: ps -ef |grep nginx如果没有启动则需要手动启动: nginx1. 配置Nginx 使用浏览器…...

Hadoop的序列化
(一)什么是序列化与反序列化 序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。 反序列化就是将收到字节序列(或其他数据传输协议…...

拼多多商品详情接口爬虫实战指南
一、引言 在电商运营和数据分析中,获取商品详情数据是至关重要的一步。拼多多作为国内知名的社交电商平台,提供了丰富的商品详情接口,允许开发者通过API获取商品的详细信息。本文将详细介绍如何通过爬虫技术结合拼多多商品详情接口ÿ…...

python网络爬虫
一、Python爬虫核心库 HTTP请求库 requests:简单易用的HTTP请求库,处理GET/POST请求。aiohttp:异步HTTP客户端,适合高并发场景。 HTML/XML解析库 BeautifulSoup:基于DOM树的解析库,支持多种解析器…...

java线程安全-单例模式-线程通信
首先看看单例模式的写法 首先我们先来回顾一下饿汉式单例模式: class Singleton{private static Singleton singletonnew Singleton();private Singleton(){}public static Singleton getInstrance(){return singleton;} } public class Test{public static void …...

ASP.NET中将 PasswordHasher 使用的 PBKDF2 算法替换为更现代的 Scrypt 或 Argon2 算法
相关博文: .Net实现SCrypt Hash加密_scrypt加密-CSDN博客 密钥派生算法介绍 及 PBKDF2(过时)<Bcrypt(开始淘汰)<Scrypt< Argon2(含Argon2d、Argon2i、Argon2id)简介-CSDN博客 浅述.Net中的Hash算法(顺带对称、非对称…...
)
力扣刷题-热题100题-第34题(c++、python)
23. 合并 K 个升序链表 - 力扣(LeetCode)https://leetcode.cn/problems/merge-k-sorted-lists/?envTypestudy-plan-v2&envIdtop-100-liked 顺序合并 合并两个有序链表作为子函数,创建一个空链表,然后对含有多个链表的数组进…...