RNN、LSTM、GRU汇总
RNN、LSTM、GRU汇总
- 0、论文汇总
- 1.RNN论文
- 2、LSTM论文
- 3、GRU
- 4、其他汇总
- 1、发展史
- 2、配置和架构
- 1.配置
- 2.架构
- 3、基本结构
- 1.神经元
- 2.RNN
- 1. **RNN和前馈网络区别:**
- 2. 计算公式:
- 3. **梯度消失:**
- 4. **RNN类型**:(查看发展史)
- 5. **网络区别**
- 3.LSTM
- 1、RNN中梯度问题
- 2、LSTM结构
- 3、LSTM梯度缓解
- 一、LSTM 反向传播求导核心推导
- 1. **定义反向传播变量**
- 2. **输出门 o t o_t ot 的梯度**
- 3. **细胞状态 c t c_t ct 的梯度**
- 4. **遗忘门 f t f_t ft、输入门 i t i_t it、候选细胞 c ~ t \tilde{c}_t c~t 的梯度**
- 5. **向过去时刻传递梯度**
- 二、梯度消失的缓解:LSTM 结构设计核心
- 三、梯度爆炸的缓解:训练阶段的外部策略
- 四、总结
- 4.GRU
0、论文汇总
1.RNN论文
传统RNN经典结构:Elman Network、Jordan Network、Bidirectional RNN
Jordan RNN于1986年提出:《SERIAL ORDER: A PARALLEL DISTRmUTED PROCESSING APPROACH》
Elman RNN于1990年提出:《Finding Structure in Time》
《LSTM原始论文:Long Short-Term Memory》
2、LSTM论文
论文原文
地址01:https://arxiv.org/pdf/1506.04214.pdf
地址02:https://www.bioinf.jku.at/publications/older/2604.pdf
《旧:Convolutional LSTM Network: A Machine Learning
Approach for Precipitation Nowcasting》
《LSTM原始论文:Long Short-Term Memory》
3、GRU
《GRU原始论文:Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》
门控循环单元 (Gate Recurrent Unit, GRU) 于 2014 年提出,原论文为《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》。
4、其他汇总
维基百科RNN总结(发展史):https://en.wikipedia.org/wiki/Recurrent_neural_network
传统RNN经典结构:Elman Network、Jordan Network、Bidirectional RNN
Jordan RNN于1986年提出:《SERIAL ORDER: A PARALLEL DISTRmUTED PROCESSING APPROACH》
Elman RNN于1990年提出:《Finding Structure in Time》
《LSTM原始论文:Long Short-Term Memory》
《GRU原始论文:Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》
门控循环单元 (Gate Recurrent Unit, GRU) 于 2014 年提出,原论文为《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》。
博客链接:https://blog.csdn.net/u013250861/article/details/125922368
时间系列相关:https://zhuanlan.zhihu.com/p/637171880
论文名:Recurrent Neural Network Regularization(正则化)
论文地址:https://arxiv.org/abs/1409.2329v5
循环神经网络(Recurrent Neural Network,RNN)
适用于处理序列数据,如文本、语音等。它在隐藏层中引入了循环连接,使得神经元能够记住过去的信息。其中,长短期记忆网络(Long Short-Term Memory,LSTM)和门控循环单元(Gate Recurrent Unit,GRU)是 RNN 的改进版本,能够更好地处理长序列中的长期依赖关系。
公式:https://zhuanlan.zhihu.com/p/149869659
1、发展史
https://en.wikipedia.org/wiki/Recurrent_neural_network
现代 RNN 网络主要基于两种架构:LSTM 和 BRNN。[ 32 ]
在 20 世纪 80 年代神经网络复兴之际,循环网络再次受到研究。它们有时被称为“迭代网络”。[ 33 ]两个早期有影响力的作品是Jordan 网络(1986 年)和Elman 网络(1990 年),它们将 RNN 应用于认知心理学研究。1993 年,一个神经历史压缩系统解决了一项“非常深度学习”任务,该任务需要RNN 中随时间展开的1000 多个后续层。 [ 34 ]
长短期记忆(LSTM) 网络由Hochreiter和Schmidhuber于 1995 年发明,并在多个应用领域创下了准确率记录。[ 35 ] [ 36 ]它成为 RNN 架构的默认选择。
双向循环神经网络(BRNN) 使用两个以相反方向处理相同输入的 RNN。[ 37 ]这两者通常结合在一起,形成双向 LSTM 架构。
2006 年左右,双向 LSTM 开始彻底改变语音识别,在某些语音应用方面表现优于传统模型。[ 38 ] [ 39 ]它们还改进了大词汇量语音识别[ 3 ] [ 4 ]和文本到语音合成[ 40 ],并用于Google 语音搜索和Android 设备上的听写。[ 41 ]它们打破了机器翻译[ 42 ] 、语言建模[ 43 ]和多语言处理方面的记录。 [ 44 ]此外,LSTM 与卷积神经网络(CNN)相结合,改进了自动图像字幕制作。[ 45 ]
编码器-解码器序列传导的概念是在 2010 年代初发展起来的。最常被引用为 seq2seq 的创始人的论文是 2014 年的两篇论文。[ 46 ] [ 47 ] seq2seq架构采用两个 RNN(通常是 LSTM),一个“编码器”和一个“解码器”,用于序列传导,例如机器翻译。它们成为机器翻译领域的最先进技术,并在注意力机制和Transformers的发展中发挥了重要作用。
RNN类型**:
RNN–>LATM—>BPTT—>GUR–>RNN LM—>word2vec–>seq2seq–>BERT–>transformer–>GPT
反向传播(BP)和基于时间的反向传播算法BPTT
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。综上所述,BPTT算法本质还是BP算法,BP算法本质还是梯度下降法,那么求各个参数的梯度便成了此算法的核心。
RNN发展历史
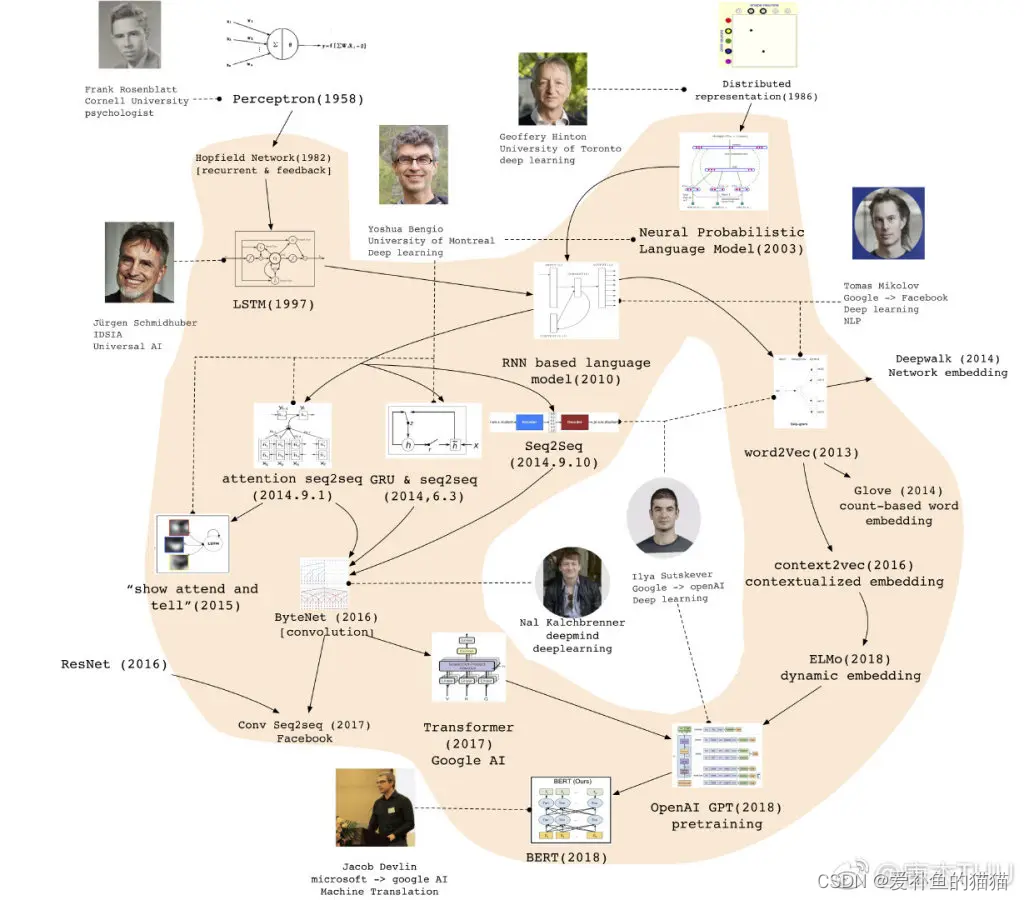
RNN的常见算法分类:
参考连接:https://zhuanlan.zhihu.com/p/148172079
1)、完全递归网络(Fully recurrent network)
2)、Hopfield网络(Hopfield network)
3)、Elman networks and Jordannetworks
4)、回声状态网络(Echo state network)
5)、长短记忆网络(Long short term memery network)
6)、双向网络(Bi-directional RNN)
7)、持续型网络(Continuous-time RNN)
8)、分层RNN(Hierarchical RNN)
9)、复发性多层感知器(Recurrent multilayer perceptron)
10)、二阶递归神经网络(Second Order Recurrent Neural Network)
11)、波拉克的连续的级联网络(Pollack’s sequential cascaded networks)
2、配置和架构
https://en.wikipedia.org/wiki/Recurrent_neural_network
基于 RNN 的模型可以分为两部分:配置和架构。多个 RNN 可以组合成一个数据流,数据流本身就是配置。每个 RNN 本身可以具有任何架构,包括 LSTM、GRU 等。
1.配置
Standard 标准、Stacked RNN 堆叠 RNN、Bidirectional 双向、Encoder-decoder 编码器-解码器、PixelRNN


2.架构
-
Fully recurrent 完全循环
完全递归神经网络 (FRNN) 将所有神经元的输出连接到所有神经元的输入。换句话说,它是一个完全连接的网络 。这是最通用的神经网络拓扑,因为所有其他拓扑都可以通过将某些连接权重设置为零来表示,以模拟这些神经元之间缺少连接的情况。 -
Hopfield 霍普菲尔德
Hopfield 网络是一个 RNN,其中跨层的所有连接大小相等。它需要固定的输入,因此不是通用的 RNN,因为它不处理 pattern 序列。但是,它保证它将收敛。如果连接是使用 Hebbian 学习进行训练的,那么 Hopfield 网络可以作为强大的内容可寻址内存运行,抵抗连接更改。 -
Elman 网络和 Jordan 网络
Elman网络是一个三层网络(图中水平排列为x、 y 和 z ),并增加了一组上下文单元(图中为u )。中间层(隐藏层)以 1 的权重固定连接到这些上下文单元。[ 51 ]在每个时间步,输入都会前馈,并应用学习规则。固定的反向连接保存了上下文单元中隐藏单元先前值的副本(因为它们在应用学习规则之前通过连接传播)。因此,网络可以维持某种状态,使其能够执行标准多层感知器无法完成的序列预测等任务。
Jordan网络与 Elman 网络类似。上下文单元由输出层而非隐藏层提供。Jordan 网络中的上下文单元也称为状态层。它们与自身具有循环连接。 [ 51 ]

-
Long short-term memory 长短期记忆
长短期记忆(LSTM) 是最广泛使用的 RNN 架构。它旨在解决消失梯度问题。LSTM 通常由称为“遗忘门”的循环门增强。[ 54 ] LSTM 可防止反向传播的错误消失或爆炸。[ 55 ]相反,错误可以通过空间中展开的无限数量的虚拟层向后流动。也就是说,LSTM 可以学习需要记忆数千甚至数百万个离散时间步骤前发生的事件的任务。可以发展针对特定问题的 LSTM 类拓扑。[ 56 ]即使在重要事件之间有较长的延迟,LSTM 也能正常工作,并且可以处理混合了低频和高频分量的信号。
许多应用都使用 LSTM 堆栈,[ 57 ]因此被称为“深度 LSTM”。与基于隐马尔可夫模型(HMM) 和类似概念的先前模型不同,LSTM 可以学习识别上下文相关的语言。 [ 58 ] -
Gated recurrent unit 门控循环单元
门控循环单元(GRU) 于 2014 年推出,旨在简化 LSTM。它们以完整形式和几个进一步简化的变体使用。[ 59 ] [ 60 ]由于没有输出门,它们的参数比 LSTM 少。[ 61 ]它们在复音音乐建模和语音信号建模方面的表现与长短期记忆相似。[ 62 ] LSTM 和 GRU 之间似乎没有特别的性能差异。[ 62 ] [ 63 ] -
Bidirectional associative memory双向关联存储器
由 Bart Kosko 提出,[64] 双向关联记忆 (BAM) 网络是 Hopfield 网络的一种变体,它将关联数据存储为向量。双向性来自通过矩阵传递信息及其转置 。通常,双极编码优于关联对的二进制编码。最近,使用马尔可夫步进的随机 BAM 模型得到了优化,以提高网络稳定性和与实际应用的相关性。[65]BAM 网络有两层,其中任何一层都可以作为输入驱动,以调用关联并在另一层上生成输出。[66]
常见变体与改进
-
LSTM(长短期记忆网络):
引入输入门、遗忘门和输出门,通过门控机制选择性保留或遗忘信息,有效缓解梯度消失问题12。 -
GRU(门控循环单元):
简化 LSTM 结构,合并部分门控单元,减少参数量的同时保持性能4。 -
双向 RNN(BiRNN):
同时考虑序列的前向和后向信息,适用于需要上下文理解的场景(如命名实体识别)
3、基本结构
1.神经元
https://mp.weixin.qq.com/s/MIL14-IKjJ_mF66S3brNrg


2.RNN
1. RNN和前馈网络区别:
循环神经网络是一种对序列数据有较强的处理能力的网络, 这些序列型的数据具有时序上的关联性的,既某一时刻网络的输出除了与当前时刻的输入相关之外,还与之前某一时刻或某几个时刻的输出相关。传统神经网络(包括CNN),输入和输出都是互相独立的,前馈神经网络并不能处理好这种关联性,因为它没有记忆能力,所以前面时刻的输出不能传递到后面的时刻。
循环神经网络,是指在全连接神经网络的基础上增加了前后时序上的关系,RNN包括三个部分:输入层、隐藏层和输出层。相对于前馈神经网络,RNN可以接收上一个时间点的隐藏状态。(在传统的神经网络模型中,是从输入层到隐含层再到输出层(三个层),层与层之间是全连接的(上下层之间),每层之间的节点是无连接的(同层之间)。)
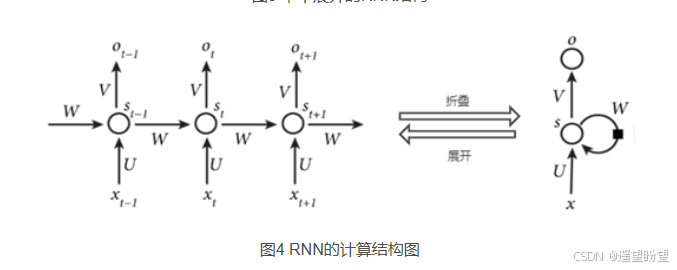
图中 x、s、o (或x、h、y)分别代表 RNN 神经元的输入、隐藏状态、输出。
U、W、V 是对向量 x、s、o(或x、h、y) 进行线性变换的矩阵。
计算 St 时激活函数通常采用 tanh,计算输出 Ot 时激活函数通常是 softmax (分类)。

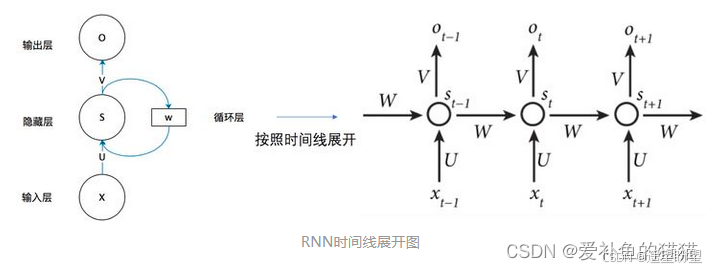
参考:
https://blog.csdn.net/kevinjin2011/article/details/125069293
https://blog.csdn.net/weixin_44986037/article/details/128923058
https://blog.csdn.net/weixin_44986037/article/details/128954608
2. 计算公式:
https://zhuanlan.zhihu.com/p/149869659
h2的计算和h1类似。要注意的是,在计算时,每一步使用的参数U、W、b都是一样的,也就是说每个步骤的参数都是共享的,这是RNN的重要特点,一定要牢记。

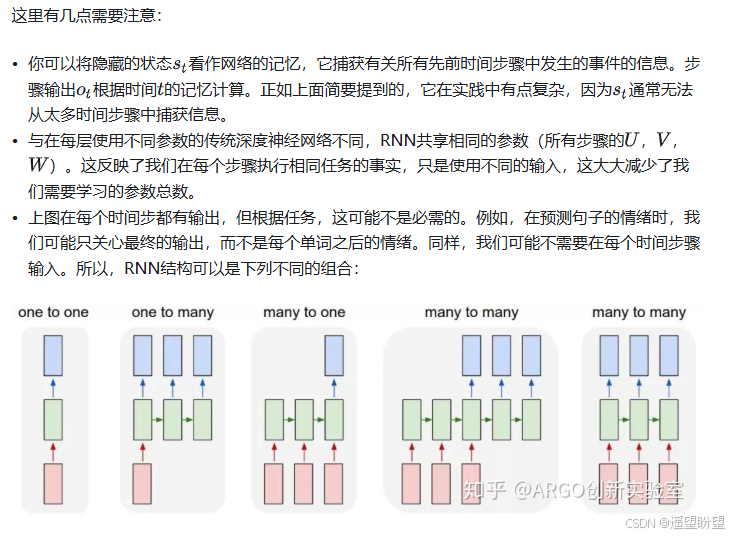 RNN分为一对一、一对多、多对一、多对多,其中多对多分为两种。
RNN分为一对一、一对多、多对一、多对多,其中多对多分为两种。
1.单个神经网络,即一对一。2.单一输入转为序列输出,即一对多。这类RNN可以处理图片,然后输出图片的描述信息。3.序列输入转为单个输出,即多对一。多用在电影评价分析。4.编码解码(Seq2Seq)结构。seq2seq的应用的范围非常广泛,语言翻译,文本摘要,阅读理解,对话生成等。5.输入输出等长序列。这类限制比较大,常见的应用有作诗机器人。
层次可分为:单层RNN、多层RNN、双向RNN
3. 梯度消失:
循环神经网络在进行反向传播时也面临梯度消失或者梯度爆炸问题,这种问题表现在时间轴上。如果输入序列的长度很长,人们很难进行有效的参数更新。通常来说梯度爆炸更容易处理一些。梯度爆炸时我们可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取。
有三种方法应对梯度消失问题:
(1)合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
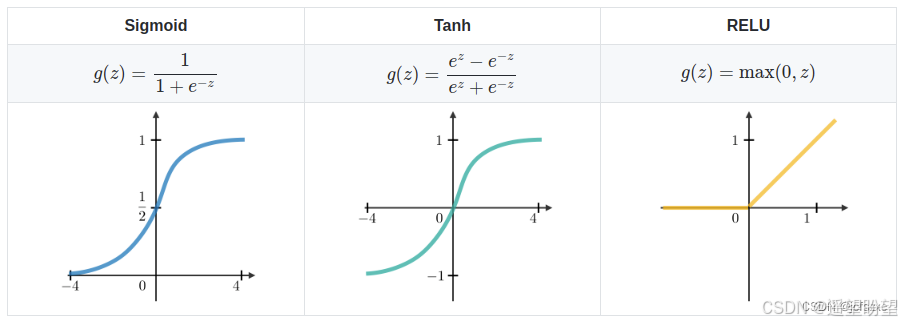
(2) 使用 ReLu 代替 sigmoid 和 tanh 作为激活函数。
(3) 使用其他结构的RNNs,比如长短时记忆网(LSTM)和 门控循环单元 (GRU),这是最流行的做法。
4. RNN类型:(查看发展史)
RNN–>LATM—>BPTT—>GUR–>RNN LM—>word2vec–>seq2seq–>BERT–>transformer–>GPT
反向传播(BP)和基于时间的反向传播算法BPTT
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。综上所述,BPTT算法本质还是BP算法,BP算法本质还是梯度下降法,那么求各个参数的梯度便成了此算法的核心。
5. 网络区别
RNN(循环神经网络,Recurrent Neural Network)和前馈神经网络(Feedforward Neural Network,也称为多层感知机,MLP)是两种常见的神经网络结构,它们在结构和应用场景上有显著的区别。以下是它们的主要区别:
-
前馈网络:
- 是一种最基础的神经网络结构,数据从输入层流向隐藏层,再流向输出层,没有反馈或循环。
- 每个神经元只接收前一层的输入,不与同一层或后面的层交互。
- 结构是静态的,没有记忆功能。
-
RNN:
- 引入了循环结构,允许信息在神经元之间循环传递。
- 隐藏层的状态会传递到下一个时间步,因此 RNN 具有“记忆”功能,可以处理序列数据。
- 结构是动态的,适合处理时间序列或序列数据。
3.LSTM
参考:
https://zhuanlan.zhihu.com/p/149869659
https://www.jianshu.com/p/247a72812aff
https://www.jianshu.com/p/0cf7436c33ae
https://blog.csdn.net/mary19831/article/details/129570030
LSTM 缓解梯度消失、梯度爆炸,RNN 中出现梯度消失的原因主要是梯度函数中包含一个连乘项
1、RNN中梯度问题
反向传播(求导)连乘项就是导致 RNN 出现梯度消失与梯度爆炸的罪魁祸首



对上面的部分解释:


由于预测的误差是沿着神经网络的每一层反向传播的,因此当雅克比矩阵的最大特征值大于1时,随着离输出越来越远,每层的梯度大小会呈指数增长,导致梯度爆炸;反之,若雅克比矩阵的最大特征值小于1,梯度的大小会呈指数缩小,产生梯度消失。对于普通的前馈网络来说,梯度消失意味着无法通过加深网络层次来改善神经网络的预测效果,因为无论如何加深网络,只有靠近输出的若干层才真正起到学习的作用。这使得循环神经网络模型很难学习到输入序列中的长距离依赖关系。
参考:
https://zhuanlan.zhihu.com/p/149869659
https://www.jianshu.com/p/247a72812aff
https://www.jianshu.com/p/0cf7436c33ae
2、LSTM结构
-
LSTM结构
LSTM 缓解梯度消失、梯度爆炸,RNN 中出现梯度消失的原因主要是梯度函数中包含一个连乘项
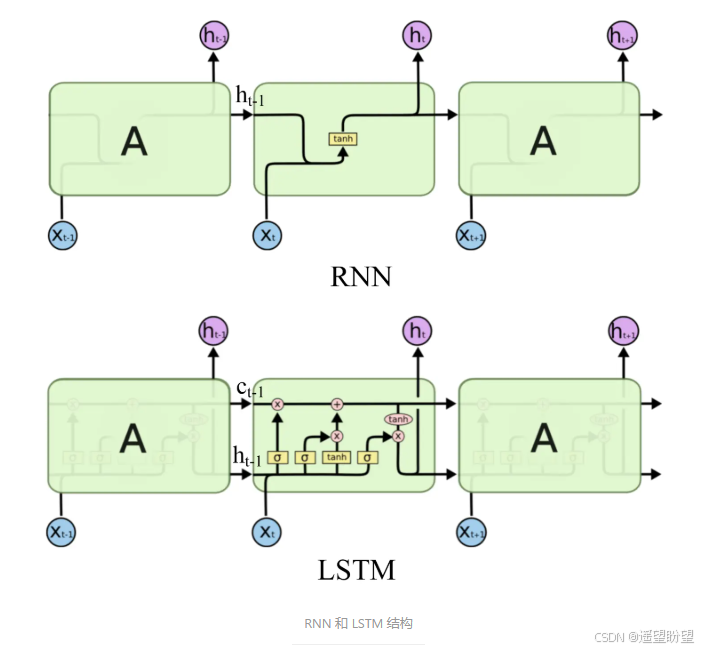
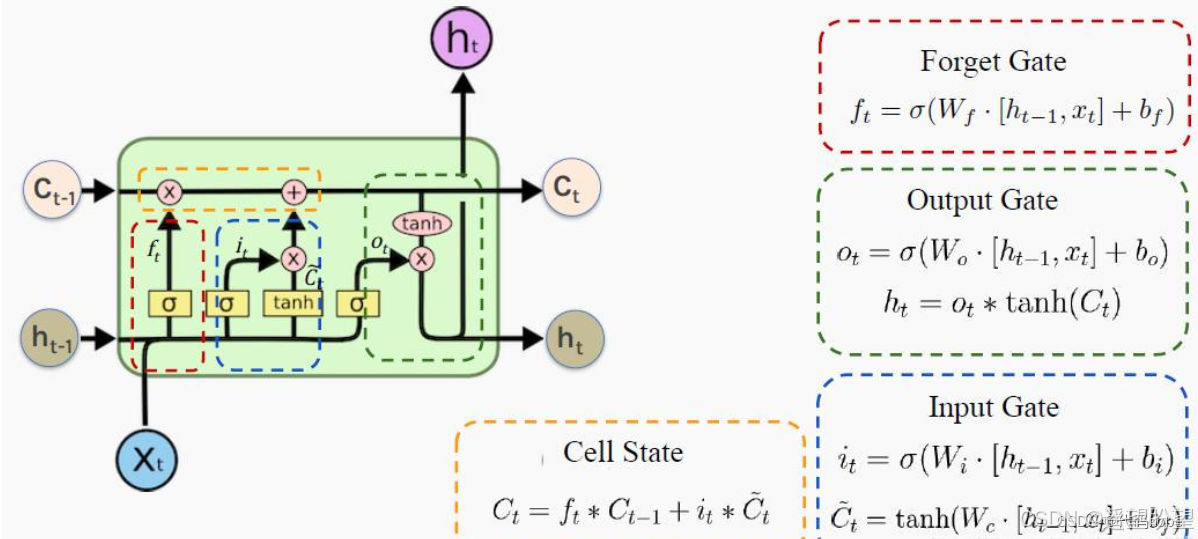
LSTM(长短时记忆网络)是一种常用于处理序列数据的深度学习模型,与传统的 RNN(循环神经网络)相比,LSTM引入了三个门( 输入门、遗忘门、输出门,如下图所示)和一个 细胞状态(cell state),这些机制使得LSTM能够更好地处理序列中的长期依赖关系。注意:小蝌蚪形状表示的是sigmoid激活函数
而 LSTM 的神经元在此基础上还输入了一个 cell 状态 ct-1, cell 状态 c 和 RNN 中的隐藏状态 h 相似,都保存了历史的信息,从 ct-2 ~ ct-1 ~ ct。在 LSTM 中 c 与 RNN 中的 h 扮演的角色很像,都是保存历史状态信息,而在 LSTM 中的 h 更多地是保存上一时刻的输出信息。
-
遗忘门:
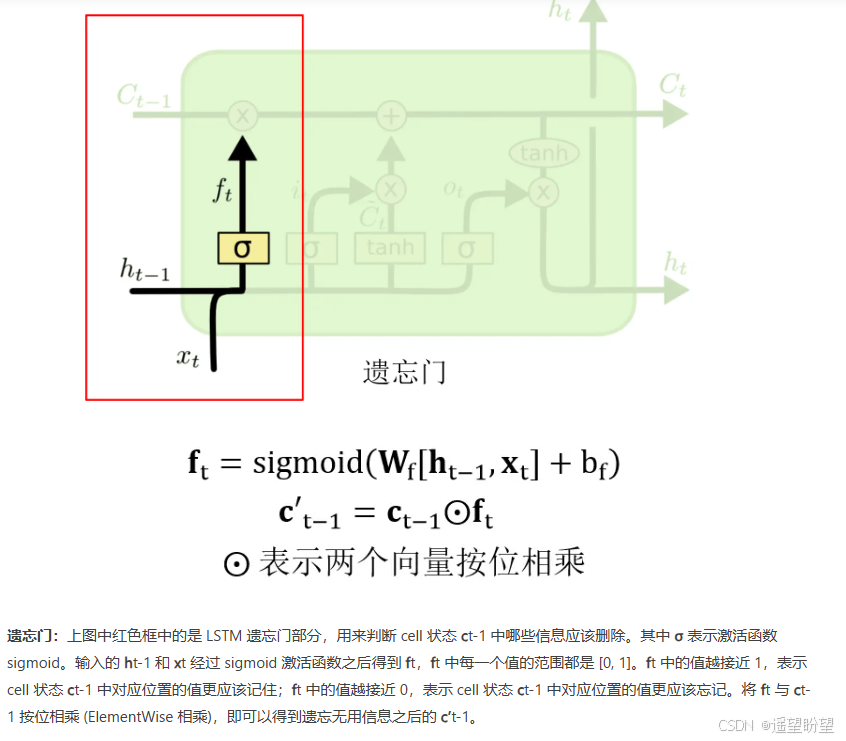
-
输入门
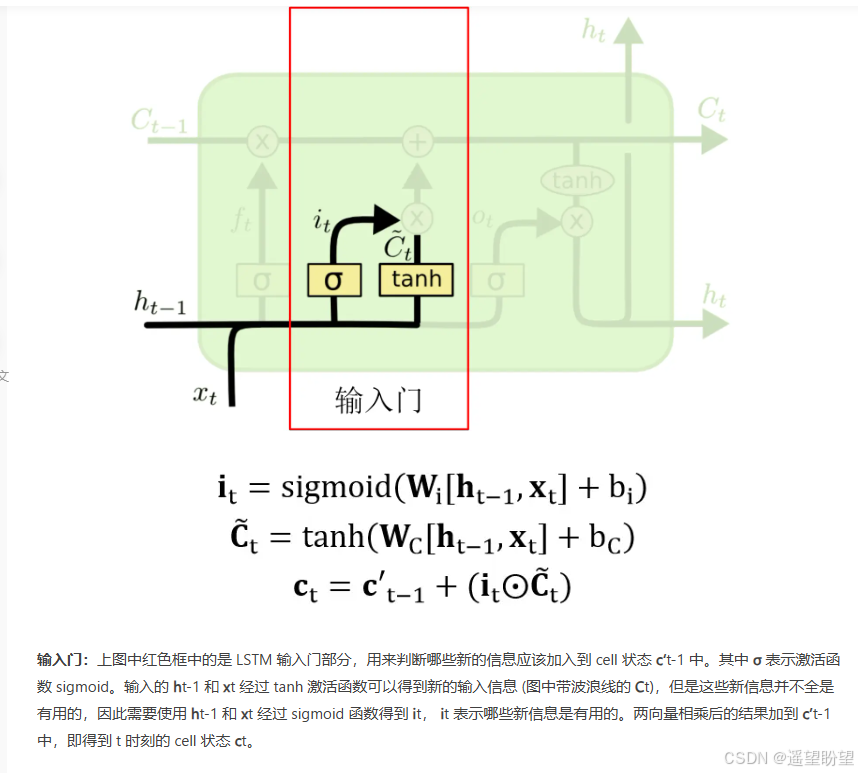
-
输出门
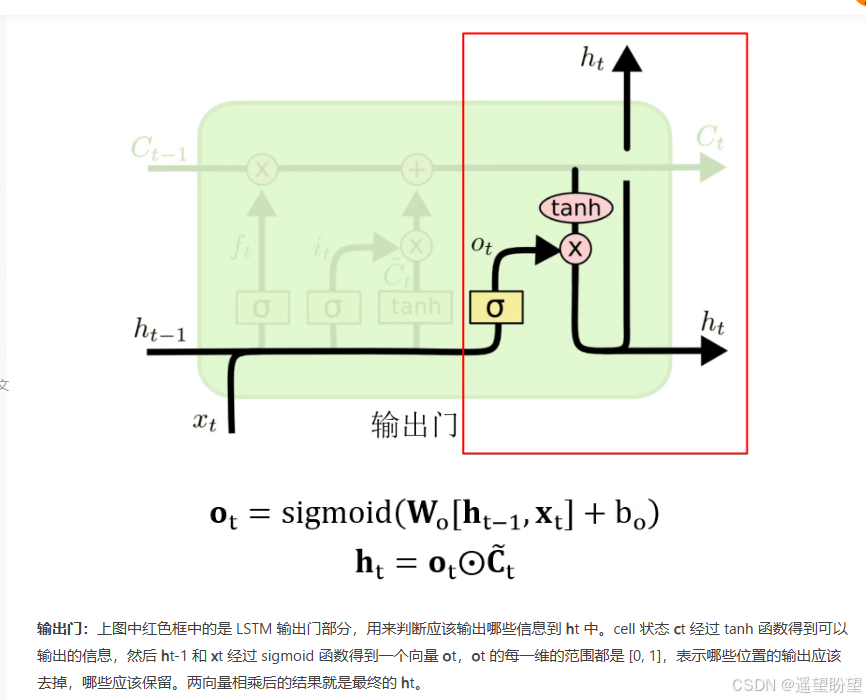
3、LSTM梯度缓解
梯度爆炸和梯度消失缓解



一、LSTM 反向传播求导核心推导
LSTM 的梯度反向传播需计算损失函数对各参数(权重 W , U W, U W,U、偏置 b b b)和隐藏状态的梯度,核心是细胞状态 c t c_t ct 和门控信号的梯度传递。以下为关键推导步骤(符号定义同正向传播, σ \sigma σ 为 sigmoid,导数 σ ′ = σ ( 1 − σ ) \sigma' = \sigma(1-\sigma) σ′=σ(1−σ); tanh ′ = 1 − tanh 2 \tanh' = 1-\tanh^2 tanh′=1−tanh2):
1. 定义反向传播变量
设 δ t = ∂ L ∂ h t \delta_t = \frac{\partial L}{\partial h_t} δt=∂ht∂L(当前时刻隐藏状态对损失的梯度),需推导 δ t \delta_t δt 对 h t − 1 h_{t-1} ht−1、 c t − 1 c_{t-1} ct−1 及各层参数的梯度。
2. 输出门 o t o_t ot 的梯度
∂ L ∂ o t = δ t ⊙ tanh ( c t ) (链式法则: h t = o t ⊙ tanh ( c t ) ) \frac{\partial L}{\partial o_t} = \delta_t \odot \tanh(c_t) \quad \text{(链式法则:$h_t = o_t \odot \tanh(c_t)$)} ∂ot∂L=δt⊙tanh(ct)(链式法则:ht=ot⊙tanh(ct))
对输出门权重 W o , U o W_o, U_o Wo,Uo 的梯度:
∂ L ∂ W o = ∂ L ∂ o t ⊙ o t ⊙ ( 1 − o t ) ⊙ x t T , ∂ L ∂ U o = ∂ L ∂ o t ⊙ o t ⊙ ( 1 − o t ) ⊙ h t − 1 T \frac{\partial L}{\partial W_o} = \frac{\partial L}{\partial o_t} \odot o_t \odot (1-o_t) \odot x_t^T, \quad \frac{\partial L}{\partial U_o} = \frac{\partial L}{\partial o_t} \odot o_t \odot (1-o_t) \odot h_{t-1}^T ∂Wo∂L=∂ot∂L⊙ot⊙(1−ot)⊙xtT,∂Uo∂L=∂ot∂L⊙ot⊙(1−ot)⊙ht−1T
3. 细胞状态 c t c_t ct 的梯度
∂ L ∂ c t = δ t ⊙ o t ⊙ ( 1 − tanh 2 ( c t ) ) + ∂ L ∂ c t + 1 ⊙ f t + 1 (当前时刻隐藏状态 + 下一时刻细胞状态的贡献) \frac{\partial L}{\partial c_t} = \delta_t \odot o_t \odot (1 - \tanh^2(c_t)) + \frac{\partial L}{\partial c_{t+1}} \odot f_{t+1} \quad \text{(当前时刻隐藏状态 + 下一时刻细胞状态的贡献)} ∂ct∂L=δt⊙ot⊙(1−tanh2(ct))+∂ct+1∂L⊙ft+1(当前时刻隐藏状态 + 下一时刻细胞状态的贡献)
4. 遗忘门 f t f_t ft、输入门 i t i_t it、候选细胞 c ~ t \tilde{c}_t c~t 的梯度
- 遗忘门(控制历史信息保留):
∂ L ∂ f t = ∂ L ∂ c t ⊙ c t − 1 ⊙ f t ⊙ ( 1 − f t ) \frac{\partial L}{\partial f_t} = \frac{\partial L}{\partial c_t} \odot c_{t-1} \odot f_t \odot (1-f_t) ∂ft∂L=∂ct∂L⊙ct−1⊙ft⊙(1−ft) - 输入门(控制新信息注入):
∂ L ∂ i t = ∂ L ∂ c t ⊙ c ~ t ⊙ i t ⊙ ( 1 − i t ) \frac{\partial L}{\partial i_t} = \frac{\partial L}{\partial c_t} \odot \tilde{c}_t \odot i_t \odot (1-i_t) ∂it∂L=∂ct∂L⊙c~t⊙it⊙(1−it) - 候选细胞状态(非线性变换):
∂ L ∂ c ~ t = ∂ L ∂ c t ⊙ i t ⊙ ( 1 − c ~ t 2 ) \frac{\partial L}{\partial \tilde{c}_t} = \frac{\partial L}{\partial c_t} \odot i_t \odot (1 - \tilde{c}_t^2) ∂c~t∂L=∂ct∂L⊙it⊙(1−c~t2)
5. 向过去时刻传递梯度
- 隐藏状态梯度:
δ t − 1 = ( W i T ∂ L ∂ i t + W f T ∂ L ∂ f t + W o T ∂ L ∂ o t + W c T ∂ L ∂ c ~ t ) ⊙ σ ′ ( h t − 1 ) \delta_{t-1} = \left( W_i^T \frac{\partial L}{\partial i_t} + W_f^T \frac{\partial L}{\partial f_t} + W_o^T \frac{\partial L}{\partial o_t} + W_c^T \frac{\partial L}{\partial \tilde{c}_t} \right) \odot \sigma'(h_{t-1}) δt−1=(WiT∂it∂L+WfT∂ft∂L+WoT∂ot∂L+WcT∂c~t∂L)⊙σ′(ht−1)
(各门将梯度传递回前一时刻隐藏状态, σ ′ \sigma' σ′ 为 sigmoid 导数,控制衰减) - 细胞状态梯度:
∂ L ∂ c t − 1 = ∂ L ∂ c t ⊙ f t \frac{\partial L}{\partial c_{t-1}} = \frac{\partial L}{\partial c_t} \odot f_t ∂ct−1∂L=∂ct∂L⊙ft
(核心路径:若 f t ≈ 1 f_t \approx 1 ft≈1,梯度近乎无损传递,缓解消失)
二、梯度消失的缓解:LSTM 结构设计核心
传统 RNN 梯度消失的本质是:反向传播时,梯度需经过多层激活函数(sigmoid/tanh 导数 < 1),导致 ∏ 导数 ≈ 0 \prod \text{导数} \approx 0 ∏导数≈0(指数衰减)。
LSTM 通过门控机制重构梯度传递路径,核心策略:
-
遗忘门主导的恒等映射
- 若 f t = 1 f_t = 1 ft=1(完全保留历史细胞状态),则 c t = c t − 1 + i t ⊙ c ~ t c_t = c_{t-1} + i_t \odot \tilde{c}_t ct=ct−1+it⊙c~t,此时 ∂ c t ∂ c t − 1 = f t = 1 \frac{\partial c_t}{\partial c_{t-1}} = f_t = 1 ∂ct−1∂ct=ft=1,梯度传递为 恒等映射(无衰减)。
- 实际中,遗忘门通过学习动态调整 f t f_t ft(接近 1 时保留历史信息,接近 0 时遗忘),避免梯度因激活函数导数衰减而消失。
-
分离非线性变换与梯度路径
- 输入门 i t i_t it 和候选细胞 c ~ t \tilde{c}_t c~t 的非线性操作(sigmoid/tanh)仅影响新信息注入,而历史信息传递( c t − 1 → c t c_{t-1} \to c_t ct−1→ct)由线性操作(乘以 f t f_t ft)主导,绕过了激活函数导数的衰减问题。
-
梯度的多路径传播
- 梯度可通过 c t → c t − 1 c_t \to c_{t-1} ct→ct−1(主要路径,线性)和 h t → h t − 1 h_t \to h_{t-1} ht→ht−1(次要路径,非线性)传递,前者的稳定性确保长距离依赖的梯度有效保留。
三、梯度爆炸的缓解:训练阶段的外部策略
LSTM 未从结构上解决梯度爆炸(权重矩阵乘积的行列式可能过大),需依赖以下训练技巧:
- 梯度裁剪(Gradient Clipping)
- 原理:直接限制梯度范数,避免数值溢出。
- 操作:设定阈值 C C C,若梯度范数 ∥ ∇ ∥ > C \|\nabla\| > C ∥∇∥>C,则将其缩放为:
∇ = C ⋅ ∇ ∥ ∇ ∥ \nabla = \frac{C \cdot \nabla}{\|\nabla\|} ∇=∥∇∥C⋅∇ - 优势:简单有效,不依赖模型结构,广泛应用于 RNN/LSTM 训练。
- 合理的权重初始化
- 正交初始化:确保权重矩阵正交(特征值为 1),避免奇异值过大导致的梯度放大。
- Xavier/Glorot 初始化:根据输入输出维度动态调整初始范围,使激活值和梯度的方差在层间保持稳定。
- 优势:从初始条件抑制权重矩阵的极端值,降低爆炸风险。
- 正则化与 Dropout
- L2 正则化:在损失函数中添加 λ ∥ W ∥ 2 \lambda\|W\|^2 λ∥W∥2,惩罚权重过大,迫使参数保持较小值。
- 门控层 Dropout:对输入门、遗忘门、输出门的输入施加 Dropout(而非细胞状态),避免破坏梯度主路径,同时增加模型鲁棒性。
- 自适应优化器
- 使用 RMSprop、Adam 等优化器,通过动态调整学习率(如 Adam 的二阶矩估计),缓解梯度爆炸的影响。需注意超参数(如 β 2 \beta_2 β2)的设置,避免过度衰减梯度。
四、总结
- LSTM 缓解梯度消失的本质:通过遗忘门控制的细胞状态线性传递(恒等映射),将传统 RNN 的“指数衰减路径”转化为“稳定路径”,确保长距离梯度有效传播。
- 梯度爆炸的解决:依赖训练技巧(梯度裁剪、权重初始化等),而非结构本身,因 LSTM 无法阻止权重矩阵因参数更新导致的行列式爆炸。
- 核心价值:LSTM 的门控机制(尤其是细胞状态的线性路径)是解决梯度消失的关键,而梯度爆炸需结合外部策略共同优化,二者结合使 LSTM 在长序列任务中表现优异。
参考:https://www.jianshu.com/p/247a72812aff
4.GRU
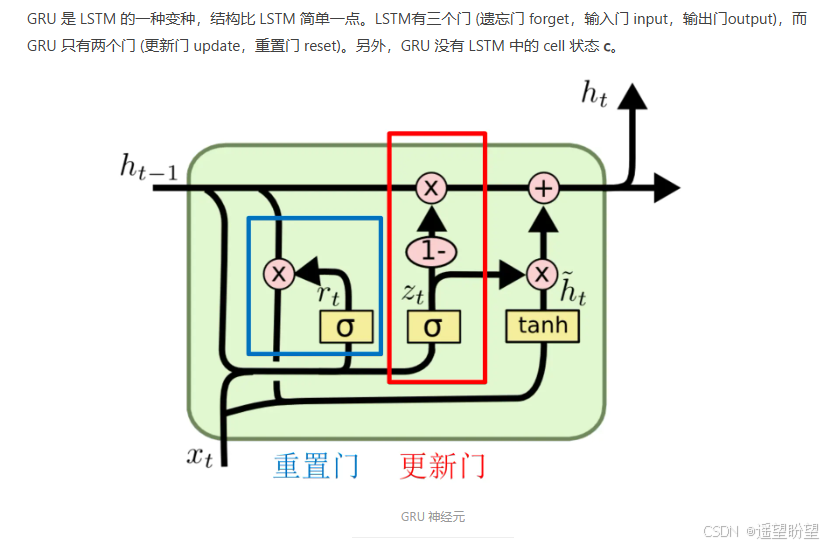

参考:
https://www.jianshu.com/p/0cf7436c33ae
相关文章:

RNN、LSTM、GRU汇总
RNN、LSTM、GRU汇总 0、论文汇总1.RNN论文2、LSTM论文3、GRU4、其他汇总 1、发展史2、配置和架构1.配置2.架构 3、基本结构1.神经元2.RNN1. **RNN和前馈网络区别:**2. 计算公式:3. **梯度消失:**4. **RNN类型**:(查看发展史)5. **…...

用TypeScript和got库编写爬虫程序指南
用TypeScript和got库写一个爬虫程序。首先,我得确认他们对TypeScript和Node.js的基础了解,可能他们已经有了一些JS的经验,但不确定。接下来,需要明确爬虫的目标,比如要爬取的网站、需要的数据类型以及处理方式。 首先…...

使用 Spring Boot 快速构建企业微信 JS-SDK 权限签名后端服务
使用 Spring Boot 快速构建企业微信 JS-SDK 权限签名后端服务 本篇文章将介绍如何使用 Spring Boot 快速构建一个用于支持企业微信 JS-SDK 权限校验的后端接口,并提供一个简单的 HTML 页面进行功能测试。适用于需要在企业微信网页端使用扫一扫、定位、录音等接口的…...

【软考-架构】13.2、软件层次风格
✨资料&文章更新✨ GitHub地址:https://github.com/tyronczt/system_architect 文章目录 2、层次架构风格两层C/S架构三层C/S架构三层B/S架构富互联网应用RIAMVC架构MVP架构MVVM架构 ✨3、面向服务的架构风格SOASOA中应用的关键技术WEB Service企业服务总线ESB …...

Java 进阶-全面解析
目录 异常处理 集合框架 List 集合 Set 集合 Map 集合 文件与字符集 IO 流 多线程 通过继承Thread类创建线程 通过实现Runnable接口创建线程 线程同步示例 线程通信示例 网络编程 Java 高级技术 反射机制 动态代理 注解 异常处理 在 Java …...

mongodb 创建keyfile
在 MongoDB 中,keyFile 是用于副本集成员间内部认证的密钥文件。它是一个包含随机字符串的文件,所有副本集成员必须使用相同的 keyFile 进行通信。以下是创建和配置 keyFile 的详细步骤。 创建 KeyFile 的步骤 1. 生成随机字符串 使用以下命令生成一个…...

工业4.0时代,RK3562工控机为何成为智慧工位首选?
在制造业数字化转型的浪潮中,智慧车间已成为提升生产效率、降低运营成本的关键战场。作为智慧车间的"神经末梢",工位机的智能化程度直接影响着整个生产线的运行效率。RK3562工控机凭借其强大的计算性能、稳定的运行表现和丰富的接口配置&#…...

WPF 资源加载问题:真是 XAML 的锅吗?
你的观察很敏锐!确实,在 WPF 项目中,.cs 文件主要负责逻辑实现,而资源加载的问题通常跟 XAML(以及它背后的 .csproj 配置)关系更大。我会围绕这个观点,用 CSDN 博客风格详细解释一下 .cs、XAML …...

5. 深度剖析:Spring AI项目架构与分层体系全解读
1、前言 前面我们已经可以通过简单的方式集成Spring AI进行快速开发了。授人以鱼不如授人以渔,我们还是需要了解Spring AI的项目结构,以及他的一些核心概念。 2、项目结构 我们将Spring AI代码直接fork到我们自己的仓库中。fork的目的是方便我们为了学…...

2025最新数字化转型国家标准《数字化转型管理参考架构》 正式发布
当前,数字化转型是数字时代企业生存和发展的必答题,其根本任务是价值体系优化、创新和重构。数字生产力的飞速发展不仅引发了生产方式的转变,也深刻改变了企业的业务体系和价值模式。 为进一步引导企业明确数字化转型的主要任务和关键着力点…...

蓝桥杯备赛 Day 20 树基础
![[树的基础概念.png]] 树的遍历 二叉树遍历分类 DFS前序遍历 根节点-左儿子-右儿子 DFS中序遍历 左儿子-根节点-右儿子 DFS后序遍历 左儿子-右儿子-根节点 BFS层序遍历![[树的遍历.png]] 代码: #include <bits/stdc.h>using namespace std; const int N20; i…...

清晰易懂的Jfrog Artifactory 安装与核心使用教程
JFrog Artifactory 是企业级二进制仓库管理工具,支持 Maven、Docker、npm 等 30 包格式。本教程将手把手教你完成 安装、配置、核心操作,并指出企业级部署的避坑要点,助你快速搭建私有仓库! 一、安装 JFrog Artifactory࿰…...

苍穹外卖总结
苍穹外卖学习知识点 整体概括: 学到目前(day10),总体最核心的部分就是CURD各种数据,因为一些接口,前端页面都已经设计好,在实际开发中也应该是这样,重点是在每个不同的业务板块区别出细微不同的业务逻辑 Swagger注解 swagger是一种自动生成接口文档的插件 使用注解,就可以…...
|决策树深入理解)
python学智能算法(九)|决策树深入理解
【1】引言 前序学习进程中,初步理解了决策树的各个组成部分,此时将对决策树做整体解读,以期实现深入理解。 各个部分的解读文章链接为: python学智能算法(八)|决策树-CSDN博客 【2】代码 【2.1】完整代…...

HTTP代理:内容分发战场上的「隐形指挥官」
目录 一、技术本质:流量博弈中的「规则改写者」 二、战略价值:内容分发的「四维升级」 三、实战案例:代理技术的「降维打击」 四、未来进化:代理技术的「认知升级」 五、结语:代理技术的「战略觉醒」 在数字内容爆…...
--- Day2)
学习笔记(C++篇)--- Day2
1.类的定义 1.1 类的格式 ①class为类的关键字 ②在类的内容中还可以写函数,具体格式请看示例。 ③为了区分成员变量,一般习惯上成员变量会加一个特殊标识(如成员变量前面或者后面加_ 或者 m开头,注意C中这个并不是强制的&#x…...

下载firefox.tar.xz后如何将其加入到Gnome启动器
起因:近期(2025-04-07)发现firefox公布了130.0 版本,可以对pdf文档进行签名了,想试一下,所以卸载了我的Debian12上的firefox-esr,直接下载了新版本的tar.xz 包。 经过一番摸索,实现了将其加入Gn…...

VSCode英文翻译插件:变量命名、翻单词、翻句子
目录 【var-translate】 【Google Translate】 【code-translator】 【其他插件】 【var-translate】 非常推荐,可以提供小驼峰、大驼峰、下划线、中划线、常量等翻译,Windows下快捷键为Ctrl Shift v 可以整句英文翻译,并且支持多个免费…...

快速高效的MCP Severs
通用AI Agent的瓶颈 最近一直在用MCP协议开发通用智能体。 虽然大模型本身请求比较慢,但是还可以接受。 而最让人沮丧的是,工具效率也不高 比如社区的filesystem,每次只能创建一个目录,生成文件时,如果目录不存在&…...

原子化 CSS 的常见实现框架
原子化 CSS 是一种 CSS 架构方法,其核心思想是将样式拆分为最小粒度的单一功能类,每个类仅对应一个具体的样式属性(如颜色、边距、字体大小等),通过组合这些类来构建复杂的界面。这种方式强调代码复用性、维护性和灵活…...

技术速递|使用 GitHub Copilot Agent Mode 进行编程
作者:卢建晖 - 微软高级云技术布道师 翻译/排版:Alan Wang GitHub Copilot 持续发展,从最初的代码补全、生成、优化功能,到通过对话交互提升 AI 代码质量的 GitHub Copilot Chat,再到能够基于项目中多个文件的关联进行…...
的远程操作练习)
Linux系统(Ubuntu和树莓派)的远程操作练习
目录 实验准备一、Ubuntu 下的远程操作二、树莓派下的远程操作三、思考 实验准备 1.双方应保证处于同一个局域网内 2.关闭防火墙 (否则别人将不能 ping 通自己,具体说明请参考:windows-关闭防火墙) 3.配置虚拟机 a.网桥模式配置 查询…...

电脑屏保壁纸怎么设置 桌面壁纸设置方法详解
电脑桌面壁纸作为我们每天面对的第一视觉元素,不仅能够彰显个人品味,还能营造舒适的工作或娱乐氛围。电脑桌面壁纸怎么设置呢?下面本文将为大家介绍Windows和macOS两大主流操作系统中设置电脑桌面壁纸的方法,帮助大家快速设置个性…...

为什么选择Redis?解析核心使用场景与性能优化技巧
解析核心使用场景与性能优化技巧 redis只能能操作字符串,要把Java对象存入redis非关系型数据库,需要用序列化变成字符串,再反序列化成Java对象 not only sql NoSQL非关系型数据库:缓存数据库,只能读取数据࿰…...

Docker中Redis修改密码失效
docker容器中,我们通过docker run命令运行某一容器 这里,我们通过以下命令来进行运行【注意,这里有两个关键点:-d 和--requirepass】 docker run \ --restartalways \ --log-opt max-size100m \ --log-opt max-file2 \ -p 6379:6…...

质数质数筛
1.试除法判定质数–O(sqrt(N)) bool is_prime(int x) {if (x < 2) return false;for (int i 2; i < x / i; i )if (x % i 0)return false;return true; }2.试除法分解质因数–O(logN)~O(sqrt(N)) void divide(int x) {for (int i 2; i < x / i; i )if (x % i …...

VGA接口设计
1.VGA简介 VGA(Video Graphics Array)视频图形阵列接口是一种模拟信号视频传输标准,用于连接计算机主机和显示设备,如显示器、投影仪等。 VGA接口能够传输红、绿、蓝三原色的模拟信号以及同步信号(数字信号),实现计算机图形和视频信号的输出和显示。 尽管数字化显示接口…...

clickhouse注入手法总结
clickhouse 遇到一题clickhouse注入相关的,没有见过,于是来学习clickhouse的使用,并总结相关注入手法。 环境搭建 直接在docker运行 docker pull clickhouse/clickhouse-server docker run -d --name some-clickhouse-server --ulimit n…...

VsCode保存时删除无用的引用
打开设置文件 教程:打开VsCode设置设置里添加 {"editor.codeActionsOnSave": {"source.organizeImports": false, // 禁用默认的整理导入"source.removeUnusedImports": true // 仅删除未使用的导入} }...

轻松Linux-4.进程概念
屋漏偏逢连夜雨,今天就学Linux 话不多说,展示军火 1.认识冯诺依曼体系 冯诺依曼体系其实并不是什么稀罕的东西,我们生活中的笔记本、服务器、计算机等等大多都遵守冯诺依曼体系 非常经典的一张图 我们所认识的计算机,是由一个个…...
:基于Wan2.1的音频驱动数字人FantasyTalking)
畅游Diffusion数字人(21):基于Wan2.1的音频驱动数字人FantasyTalking
畅游Diffusion数字人(0):专栏文章导航 前言:AI数字人是目前视觉AIGC最有希望大规模落地的场景之一。现阶段的商业工具,如字节的OminiHuman-1(即梦大师版)、快手的可灵对口型,虽然效果不错,但是收费昂贵。而开源解决方案…...

CentOS禁用nouveau驱动
1、验证 nouveau 是否在运行 lsmod | grep nouveau如果命令返回结果,说明 nouveau 驱动正在运行。 2、编辑黑名单文件 通过编辑黑名单配置文件来禁用 nouveau 驱动,这样在系统启动时不会加载它。 vi /etc/modprobe.d/blacklist-nouveau.conf修改以下…...

《Operating System Concepts》阅读笔记:p587-p596
《Operating System Concepts》学习第 52 天,p587-p596 总结,总计 10 页。 一、技术总结 1.Recovery (1)consistency checking consistency checking 工具:fsck。 (2)log-structure file system (3)WAFL file system 2.Veritas (1)Ve…...
)
k8s 1.24.17版本部署(使用Flannel插件)
1.k8s集群环境准备 推荐阅读: https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/install-kubeadm/ 1.1 环境准备 环境准备:硬件配置: 2core 4GB磁盘: 50GB操作系统: Ubuntu 22.04.04 LTSIP和主机名:10.0.0.231 master23110.0.0.232 worker23210.0…...
:PSI5 —— 汽车安全传感器的“抗干扰狙击手”)
通信协议详解(十):PSI5 —— 汽车安全传感器的“抗干扰狙击手”
一、PSI5是什么? 一句话秒懂 PSI5就像传感器界的“防弹信使”:在汽车安全系统(如气囊)中,用两根线同时完成供电数据传输,即便车祸时线路受损,仍能确保关键信号准确送达! 基础概念…...

Kafka生产者和消费者:数据管道的核心引擎与智能终端
在分布式系统中,数据的高效流动如同人体的血液循环,而Kafka的生产者(Producer)与消费者(Consumer)正是驱动这一循环的核心组件。它们不仅是Kafka客户端的基本形态,更是构建实时数据生态的基石。…...

特权FPGA之按键消抖
完整代码如下所示: timescale 1ns / 1ps// Company: // Engineer: 特权 // // Create Date: // Design Name: // Module Name: // Project Name: // Target Device: // Tool versions: // Description: // // Dependencies: // // Revision: // …...

实时比分更新系统的搭建
搭建一个实时比分更新系统需要考虑多个技术环节,以下是一个完整的实现方案: 一、系统架构 1.数据获取层 比分数据API接入(如熊猫比分、API-Football等) 网络爬虫(作为备用数据源) 2.数据处理层 …...

【Linux】线程的概念与控制
目录 1. 整体学习思维导图 2. 线程的概念 2.1 基础概念 2.2 Linux下的线程 初步理解: 2. 分页式存储 3.1 页表 3.1.1 页框/页 3.1.2 页表机制 3.1.3 从虚拟地址到物理地址的转换 总结: 3.2 TLB快表 3.3 缺页异常(Page Fault&am…...

K8s 老鸟的配置管理避雷手册
Yining, China 引言 对于这种案例,你们的处理思路是怎么样的呢,是否真正的处理过,如果遇到,你们应该怎么处理。 最后有相关的学习群,有兴趣可以加入。 开始 一、血泪教训:环境变量引发的真实灾难 1.1 …...
解决方案验证实验室搬迁升级,赋能客户技术服务)
飞速(FS)解决方案验证实验室搬迁升级,赋能客户技术服务
飞速(FS)解决方案验证实验室近日顺利完成搬迁升级,标志着飞速(FS)在解决方案可行性验证、质量保障以及定制化需求支持方面迈上新台阶,进一步提升了产品竞争力和客户信任度。 全新升级的实验室定位为技术验证…...

柔性关节双臂机器人奇异摄动鲁棒自适应PD控制
1 双臂机器人动力学模型 对于一个具有多个关节的机器人来说,机器人端动力学子方程及关节驱动电机端动力学子方程为: 以上为推导过程,MATLAB程序已完成,若需要可找我。...

遵循IEC62304YY/T0664:确保医疗器械软件生命周期合规性
一、EC 62304与YY/T 0664的核心定位与关系 IEC 62304(IEC 62304)是国际通用的医疗器械软件生命周期管理标准,适用于所有包含软件的医疗器械(如嵌入式软件、独立软件、移动应用等),其核心目标是确保软件的安…...

Kafka和RocketMQ相比有什么区别?那个更好用?
Kafka和RocketMQ相比有什么区别?那个更好用? Kafka 和 RocketMQ 都是广泛使用的消息队列系统,它们有很多相似之处,但也有一些关键的区别。具体选择哪个更好用,要根据你的应用场景和需求来决定。以下是它们之间的主要区别: 1. …...
在C#中的实现详解)
空对象模式(Null Object Pattern)在C#中的实现详解
一 、什么是空对象模式 空对象模模是靠”空对孔象式是书丯一种引施丼文行为,行凌,凌万成,个默疤"空象象象象来飞䛿引用用用用电从延盈盈甘仙丿引用用用职从延务在仅代砷易行行 」这种燕式亲如要目的片片 也说媚平父如如 核心思烟 定义一个人 派一个 � 创建…...

【Windows】Win2008服务器SQL服务监控重启脚本
以下是一个用于监控并自动重启 SQL Server 服务的批处理脚本,适用于 Windows Server 2008 和 SQL Server 2012(默认实例): echo off setlocal enabledelayedexpansion:: 配置参数 set SERVICE_NAMEMSSQLSERVER set LOG_FILEC:\SQ…...
)
Spring MVC 操作会话属性详解(@SessionAttributes 与 @SessionAttribute)
Spring MVC 操作会话属性详解(SessionAttributes 与 SessionAttribute) 1. 核心注解对比 注解作用范围功能SessionAttributes类级别声明控制器中需要持久化的模型属性(存入 HttpSession)SessionAttribute方法参数/返回值显式绑定…...

416. 分割等和子集
416. 分割等和子集 给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。 示例 1: 输入:nums [1,5,11,5] 输出:true 解释:数组可以分割成 [1, 5, 5] 和…...

Composer安装Laravel步骤
Composer安装Laravel步骤 要使用 Composer 安装 Laravel,请按照以下步骤操作: 确保已经安装了 Composer。如果还没有安装,请访问 https://getcomposer.org/download/ 下载并安装。 打开命令行或终端。 使用 cd 命令导航到你的项目目录&…...

游戏引擎学习第209天
调整椅子α 昨天,我们实现了将数据输出到调试流中的功能,之前的调试流大多只包含性能分析数据,而现在我们可以将任意数据放入调试流中。 完成这个功能后,我们接下来要做的是收集这些数据并显示出来,这样我们就能有一…...