【文献阅读】NVILA: Efficient Frontier Visual Language Models
发表于2025年3月6日
英伟达团队
摘要
近年来,视觉语言模型(VLMs)在准确性方面取得了显著进展。然而,其效率却较少受到关注。本文介绍了NVILA,这是一系列旨在优化效率和准确性的开源视觉语言模型。在VILA的基础上,我们通过先提高空间和时间分辨率,然后压缩视觉令牌来改进其模型架构。这种 “先缩放后压缩” 的方法使NVILA能够高效处理高分辨率图像和长视频。我们还进行了系统研究,以在NVILA从训练到部署的整个生命周期中提高其效率。在广泛的图像和视频基准测试中,NVILA的准确性与许多领先的开源和专有视觉语言模型相当,甚至超越它们。同时,它将训练成本降低了1.9 - 5.1倍,预填充延迟降低了1.6 - 2.2倍,解码延迟降低了1.2 - 2.8倍。我们提供了代码和模型,以促进可重复性研究。
https://github.com/NVlabs/VILA/
https://huggingface.co/collections/Efficient-Large-Model/nvila-674f8163543890b35a91b428
VILA Playground
1 引言
视觉语言模型(VLMs)在处理和整合视觉与文本信息方面展现出了卓越的能力,实现了先进的视觉 - 语言交互和对话。近年来,研究界在提高其准确性[1, 2, 3, 4, 5]以及拓展其在机器人[6, 7, 8]、自动驾驶[9]和医疗应用[10, 11]等不同领域的应用方面取得了巨大进展。然而,提高其效率却较少受到关注。
视觉语言模型在多个方面成本高昂。首先,训练一个视觉语言模型非常耗时。例如,训练一个最先进的70亿参数视觉语言模型[4]可能需要长达400个GPU天的时间,更不用说更大的模型了。这给研究人员设置了巨大的进入门槛。其次,视觉语言模型在应用于特定领域(如医学成像)时通常需要进行适配,但微调一个视觉语言模型需要大量内存。例如,完全微调一个70亿参数的视觉语言模型可能需要超过64GB的GPU内存,远远超出了大多数消费级GPU的可用内存。最后,视觉语言模型常常部署在计算资源有限的边缘应用(如笔记本电脑、机器人)中,因此部署视觉语言模型存在资源限制。解决这些挑战需要一个系统的解决方案,以在所有这些方面提高视觉语言模型的效率。
在本文中,我们介绍了NVILA,这是一系列开源视觉语言模型,旨在优化效率和准确性。在VILA [2]的基础上,我们通过先提高空间和时间分辨率,然后压缩视觉令牌来改进其模型架构。“缩放” 保留了视觉输入中的更多细节,提高了准确性上限,而 “压缩” 将视觉信息压缩到更少的令牌中,提高了计算效率。这种 “先缩放后压缩” 的策略使NVILA能够高效且有效地处理高分辨率图像和长视频。此外,我们进行了系统研究,以优化NVILA在其整个生命周期(包括训练、微调、部署)中的效率。
得益于这些创新,NVILA既高效又准确。它将训练成本降低了1.9 - 5.1倍,预填充延迟降低了1.6 - 2.2倍,解码延迟降低了1.2 - 2.8倍。在广泛的图像和视频基准测试中,它的准确性与领先的开源视觉语言模型[5, 3, 2]和专有视觉语言模型[12, 13]相当,甚至超越它们。此外,NVILA还实现了包括时间定位、机器人导航和医学成像等新功能。我们发布了代码和模型以支持完全可重复性研究。我们希望我们的工作将激发对高效视觉语言模型的进一步研究。
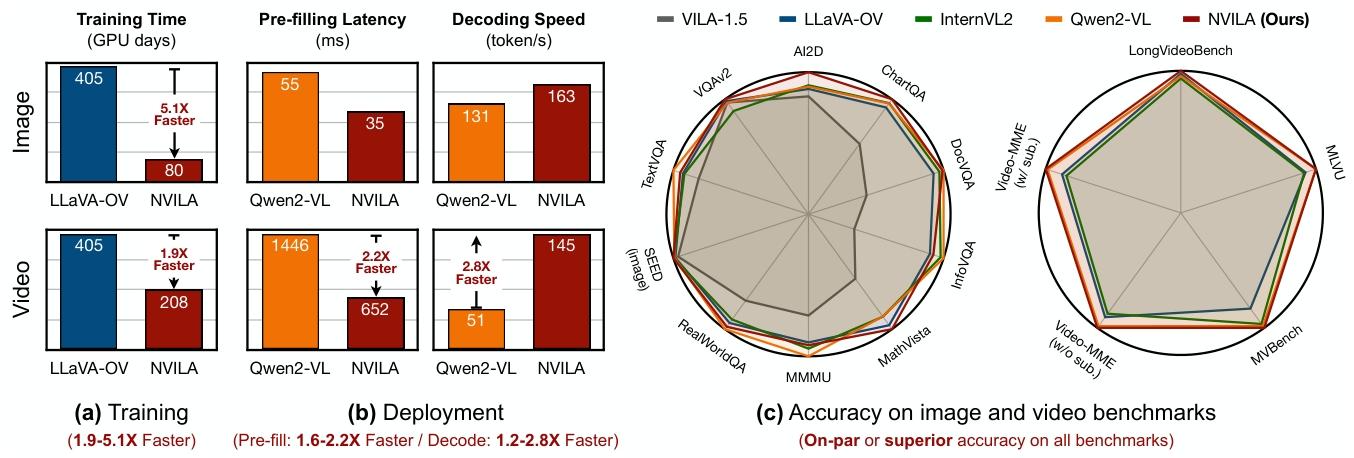
图1 NVILA -高效前沿VLM。(a)NVILA训练图像和视频模型的速度分别比LLaVA-OneVision(OV)快5.1倍和1.9倍,后者是唯一公开披露训练成本的基准模型。(b)与Qwen 2-VL相比,NVILA在预填充阶段实现了1.6-2.2倍的测量加速比,在解码阶段实现了1.2-2.8倍的加速比。(c)NVILA的效率是在不影响精度的情况下实现的;事实上,它在图像和视频基准测试中提供了相当甚至上级的精度。本表中的所有型号均具有8B参数。(a)中的训练时间是使用NVIDIA H100 GPU测量的,而(B)中的推理速度是使用单个NVIDIA GeForce RTX 4090 GPU测量的。(c)中的准确性数字相对于每个基准的最高分数进行归一化。
2 方法
在本节中,我们首先为NVILA设计一个高效的模型架构,先提高空间和时间分辨率,然后压缩视觉令牌。接下来,我们介绍在NVILA从训练、微调到部署的整个生命周期中提高其效率的策略。除非另有说明,本节中的所有分析都将基于80亿参数的模型。

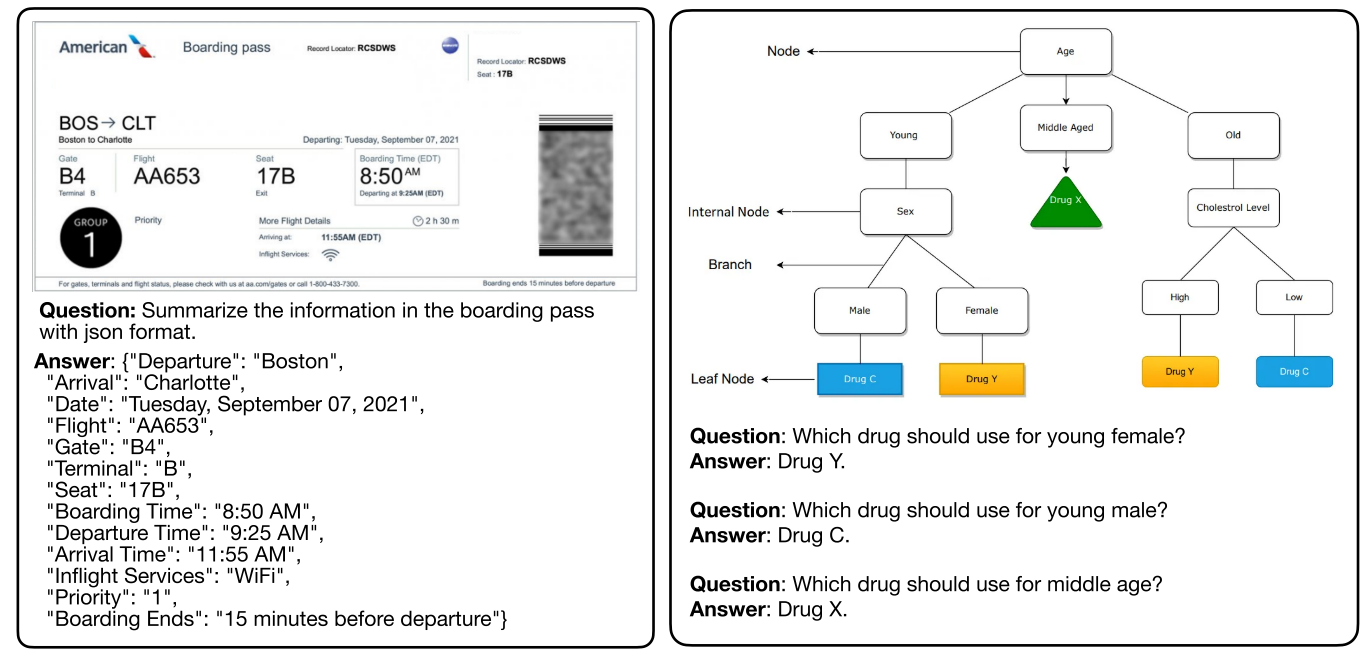

图2 定性例子
2.1 高效的模型架构
我们在VILA[2]的基础上构建NVILA。如图3所示,它是一个自回归视觉语言模型,由三个组件组成:一个从视觉输入(如图像、视频)中提取特征的视觉编码器;一个对齐视觉和语言模态嵌入的投影仪;以及一个通常由大语言模型实例化的令牌处理器,它将视觉和语言令牌作为输入,并输出语言令牌。具体来说,NVILA使用SigLIP[14]作为其视觉编码器,一个两层多层感知器作为其投影仪,并使用不同大小的Qwen2[15]作为其令牌处理器。
原始的VILA在空间和时间分辨率上非常有限:即,无论原始图像的大小或宽高比如何,它都会将所有图像调整为448×448,并从视频中最多采样14帧∗。空间调整大小和时间采样都会引入大量信息损失,限制了模型有效处理更大图像和更长视频的能力。这也可以在表8和表9中观察到,VILA在领先的视觉语言模型中表现滞后,特别是在文本密集型和长视频基准测试中。
在本文中,我们倡导 “先缩放后压缩” 的范式,即我们首先提高空间/时间分辨率以提高准确性,然后压缩视觉令牌以提高效率。提高分辨率提高了性能上限,但仅这样做会显著增加计算成本。例如,将分辨率翻倍将使视觉令牌的数量翻倍,这将使训练和推理成本增加超过2倍,因为自注意力与令牌数量呈二次方关系。然后,我们可以通过压缩空间/时间令牌来降低这种成本。压缩后的视觉令牌具有更高的信息密度,使我们能够用更少的总令牌保留甚至改善空间和时间细节。
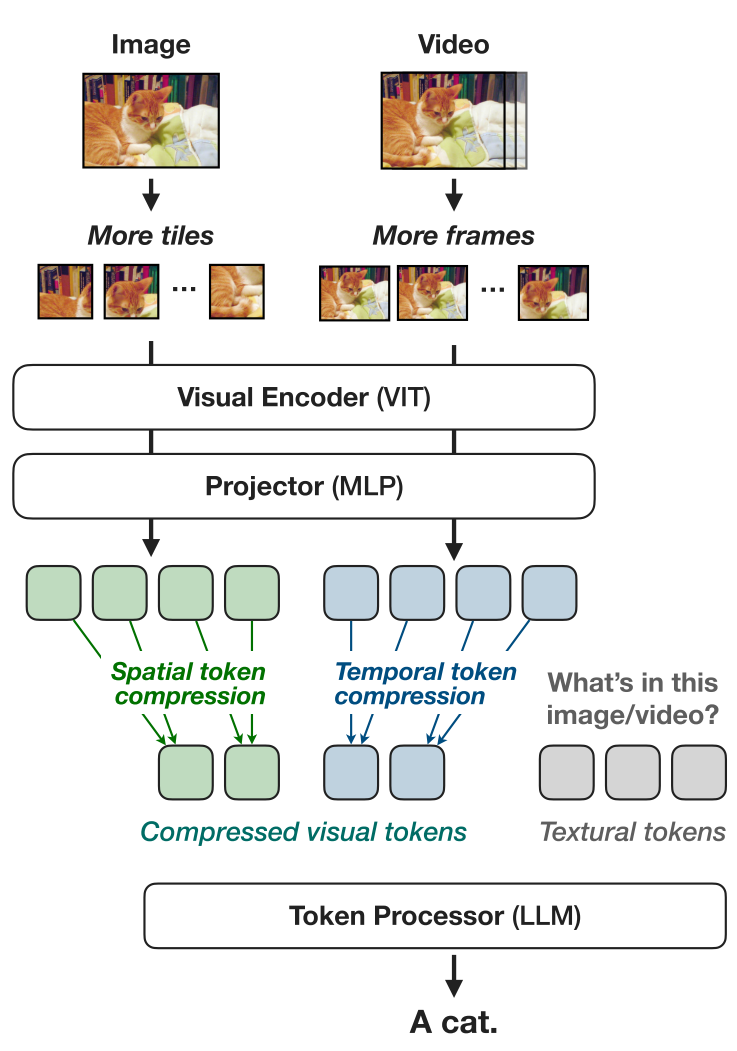
图3 模型体系结构。
2.1.1 空间 “先缩放后压缩”
对于空间缩放,直接提高视觉编码器的图像分辨率是很自然的,例如提高到896×896。虽然这可能会提高性能,但对所有图像应用统一的高分辨率效率较低,特别是对于不需要大量细节的较小图像。为了解决这个问题,我们应用\(S^{2}\)[16]通过图像分块来高效提取多尺度高分辨率特征。例如,给定一个在\(448^{2}\)分辨率下预训练的视觉编码器和任意大小的输入图像,\(S^{2}\)首先将图像调整为多个尺度(例如,\(448^{2}\),896²,\(1344^{2}\)),对于每个尺度,它将图像分割成\(448^{2}\)的图块。然后每个图块由编码器单独处理。来自同一尺度的每个图块的特征图被拼接回该尺度下整个图像的特征图。最后,不同尺度的特征图被插值到相同大小,并在通道维度上连接起来。
\(S^{2}\)总是将图像调整为正方形,而不考虑原始宽高比。这可能会导致失真,特别是对于高而窄或短而宽的图像。为了解决这个问题,我们提出了Dynamic-\(S^{2}\),它可以自适应地处理不同宽高比的图像。Dynamic \(S^{2}\)遵循\(S^{2}\)的方法,但在最大图像尺度上,它不是将图像调整为正方形,而是将图像尺寸调整为最接近的、保持原始宽高比且能被\(448^{2}\)图块整除的大小。这是受InternVL[17]中的动态分辨率策略启发。在处理完图块后,所有尺度的特征图被插值以匹配最大尺度的大小并连接起来。
表1|空间“先缩放后压缩”。使用Dynamic-S2提高空间分辨率可以极大提高模型的准确性,尤其是在文本密集的基准测试中。利用空间池技术压缩视觉标记,可以有效地减少图像块的数量和每个图像块的标记数,且精度损失较小。通过增加额外的视觉编码器预训练(VEP)阶段,可以进一步减少这种损失。在本表和下表中,“IM-10”是指表8中列出的10个基准测试的平均验证分数。
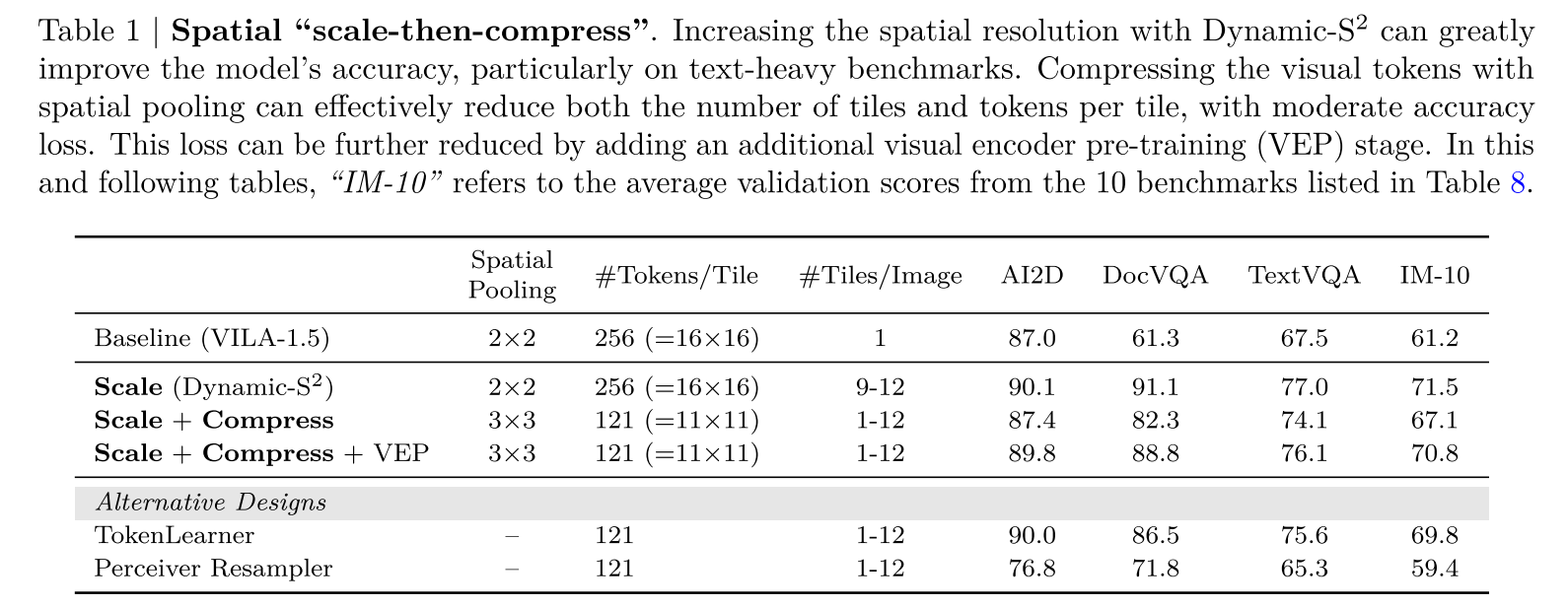
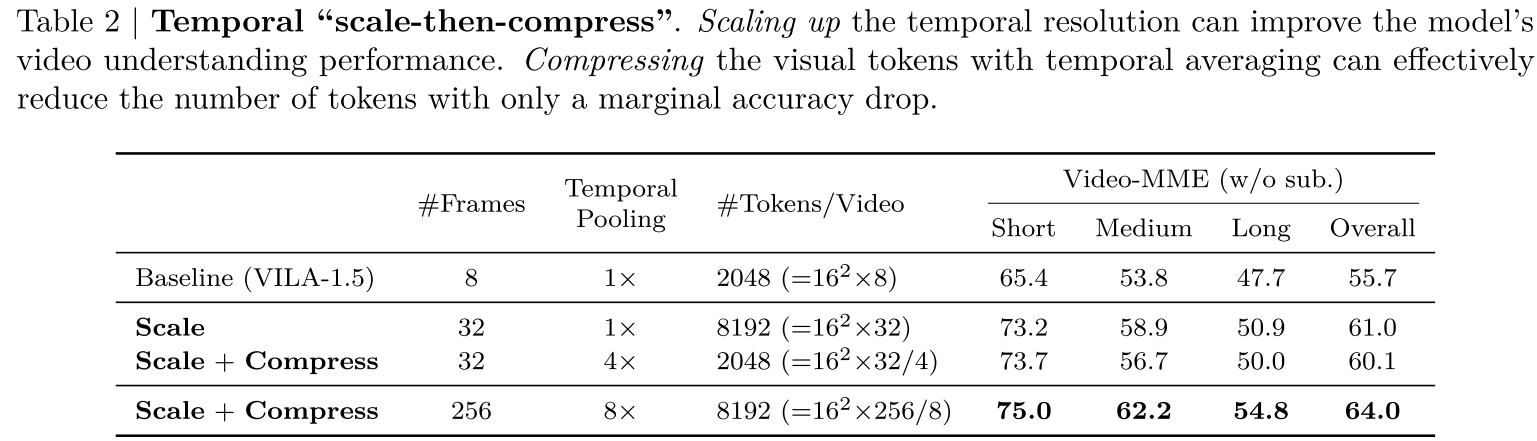
表2|时间“缩放然后压缩”。放大时间分辨率可以提高模型的视频理解性能。压缩的视觉令牌与时间平均可以有效地减少令牌的数量,只有一个边际精度下降。
配备了Dynamic-\(S^{2}\)后,模型受益于图像的高分辨率信息,在文本密集型基准测试中准确性提高了高达30%(表1)。然后,我们的目标转向压缩空间令牌。VILA[2]发现,应用简单的2×2空间到通道(STC)重塑可以在不牺牲准确性的情况下将令牌数量减少4倍。
然而,进一步推进这一操作会导致性能显著下降:例如,在DocQA任务中,当减少最小图块数量并将STC提高到3×3时,准确性下降了近10%。我们假设更激进的减少会使投影仪的训练变得更加困难。为了解决这个问题,我们引入了一个额外的视觉编码器预训练阶段,以联合调整视觉编码器和投影仪。这有助于恢复大部分因空间令牌减少而损失的准确性,在训练和推理中实现2.4倍的加速。
对于空间令牌压缩,有许多替代设计,如RT-1[6]中的TokenLearner和MiniCPM-V[18]中的Perceiver Resampler。然而,在相同的令牌减少率下,这些可学习的压缩方法出人意料地不如简单的空间到通道设计,即使增加了一个阶段1.5。我们认为这更多是一个优化问题,超出了本文的范围。
2.1.2 时间 “先缩放后压缩”
对于时间缩放,我们简单地增加从输入视频中均匀采样的帧数。遵循先前的方法[19],我们通过额外的视频监督微调(SFT)来训练模型,以扩展其处理更多帧的能力。从表9中可以看出,将帧数从8增加到32可以使模型在Video-MME任务上的准确性提高超过5%。然而,这也会使视觉令牌的数量增加4倍。
与空间令牌压缩类似,我们随后将减少这些视觉令牌。由于视频中存在固有的时间连续性,我们采用时间平均[20]进行压缩,它首先将帧划分为组,然后在每个组内对视觉令牌进行时间池化。这将减少时间冗余(因为连续的帧通常包含相似的信息),同时仍然保留重要的时空信息。根据经验,将视觉令牌压缩4倍会导致可接受的准确性下降。与具有相同令牌数量的原始基线相比,先缩放然后扩展的结果成本几乎相同,但†具有更高的准确性。我们还使用这种方法进一步扩展帧数和压缩比,在这个基准测试中得到了一个最先进的70亿参数模型(见表9)。
2.2 高效训练
虽然最先进的视觉语言模型具有令人印象深刻的能力,但训练这样一个视觉语言模型通常成本高昂且计算密集。本节探讨系统 - 算法协同设计,以实现高效的视觉语言模型训练。在算法方面,我们研究一种新颖的无监督数据集修剪方法,以简化训练数据。在系统层面,我们研究FP8混合精度以加速训练。
2.2.1 数据集修剪
为了提高模型准确性,先前的工作[21, 4, 22]不断从各种来源获取高质量的微调数据集,并在基准测试分数上显示出改进。然而,并非所有数据对模型的贡献都相同,数据集的持续增长导致了大量冗余。在NVILA中,我们遵循 “先缩放后压缩” 的概念,首先增加我们的微调数据集混合,然后尝试压缩数据集。然而,从各种来源选择高质量的示例具有挑战性。虽然已经有对视觉输入[23, 24, 25]和纯文本输入[26, 27, 28]的探索,但很少有研究解决视觉语言模型训练中这个问题,在训练过程中图像和文本是混合的。NVILA的训练涉及超过1亿数据,因此在保持准确性的同时修剪训练集是必要的。
受最近知识蒸馏工作[29]的启发,我们利用DeltaLoss对训练集进行评分:
\[D'=\bigcup_{i = 1}^{K} top - K\left\{\log \frac{p_{large }(x)}{p_{small }(x)} | x \in D_{i}\right\}, (1)\]
其中\(D_{i}\)是完整微调数据集的第\(i\)个子集,\(D'\)是修剪后的训练集。\(p_{large }(x)\)和\(p_{small }(x)\)是答案令牌上的输出概率。主要动机是过滤掉要么太容易要么太难的示例。具体来说,
- 如果大小模型都正确或都错误地回答,\(\log \frac{p_{large }(x)}{p_{small }(x)}\)接近0。
- 当小模型正确回答但大模型失败时,\(\log \frac{p_{large }(x)}{p_{small }(x)}\)为负,表明这些示例倾向于干扰学习,最终会被更强大的模型遗忘。
- 当小模型错误回答但大模型解决了问题时,\(\log \frac{p_{large }(x)}{p_{small }(x)}\)为正,表明这些示例提供了强大的监督,对小模型来说具有挑战性,但大模型可以学习。
因此,我们可以将DeltaLoss应用于每个子数据集,并以不同的比例修剪训练集。
为了评估数据修剪标准,我们在表3中比较了DeltaLoss和随机修剪基线。对于随机修剪,数据是随机选择的,我们运行结果三次并报告平均值。对于聚类修剪,我们应用具有sigmoid特征的k-means聚类,并在每个质心均匀修剪数据。我们的实验报告了10个基准测试的平均性能,重点关注关键任务以展示该方法的有效性。我们研究了三个修剪阈值10%、30%和50%,并注意到DeltaLoss始终优于随机基线,特别是在GQA和DocVQA任务中,随机修剪显示出显著的性能下降,而DeltaLoss保持准确。我们注意到50%是一个相对安全的阈值,平均分数保持竞争力,同时训练可以加速2倍。因此,我们在后续实验中将阈值设置为50%。
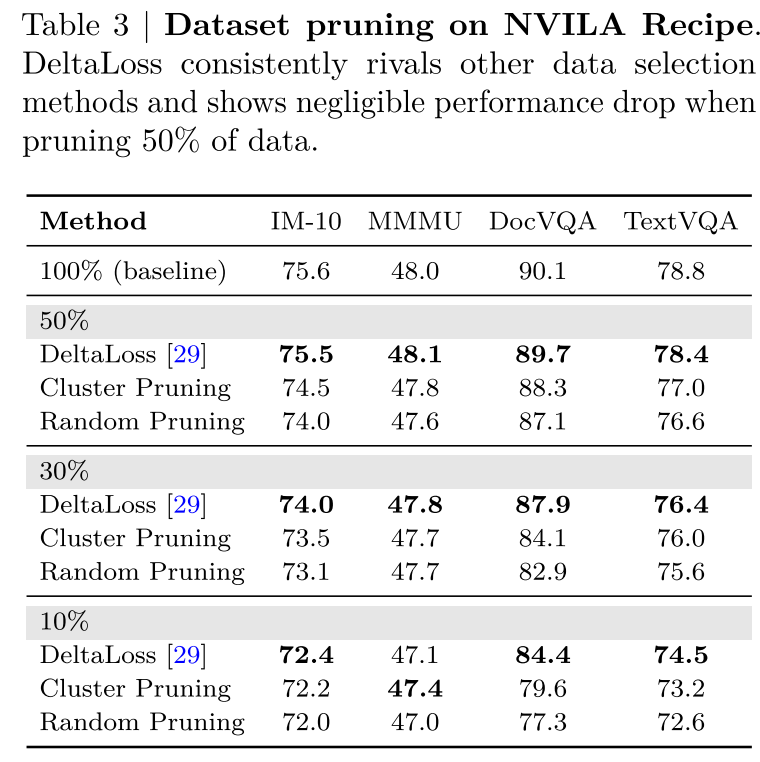
我们研究了数据修剪对新添加数据集的影响。我们将不同百分比的pixmo数据[30]纳入NVILA训练集。在表??中,我们观察到直接将pixmo数据与NVILA训练集合并会降低DocVQA和TextVQA基准测试的性能,同时仅提高MMMU分数。这表明激进地增加训练集大小实际上可能会损害性能。通过应用deltaloss修剪训练数据——过滤掉太容易或太难的示例——我们发现用修剪后的molmo数据集训练的模型在实验结果中显示出普遍的改进。

2.2.2 FP8训练
FP16[31]和BF16[32]是模型训练的标准精度,因为它们在不损失准确性的情况下提供加速,并且得到NVIDIA GPU的原生支持。随着NVIDIA Hopper和Blackwell架构的出现,新的GPU(如H100和B200)现在原生支持FP8,由于其在计算和内存效率方面的潜力,FP8已成为一种有前途的精度。
许多研究人员已经将FP8应用于大语言模型训练。NVIDIA的Transformer Engine以FP8精度执行矩阵乘法(GEMM),从而实现更快的训练速度。FP8-LM[33]在此基础上进一步将梯度、权重主副本和一阶动量量化为FP8,从而减少通信开销和内存占用。COAT[34]进一步压缩激活和优化器的二阶动量,以提高内存效率,同时保持准确性。
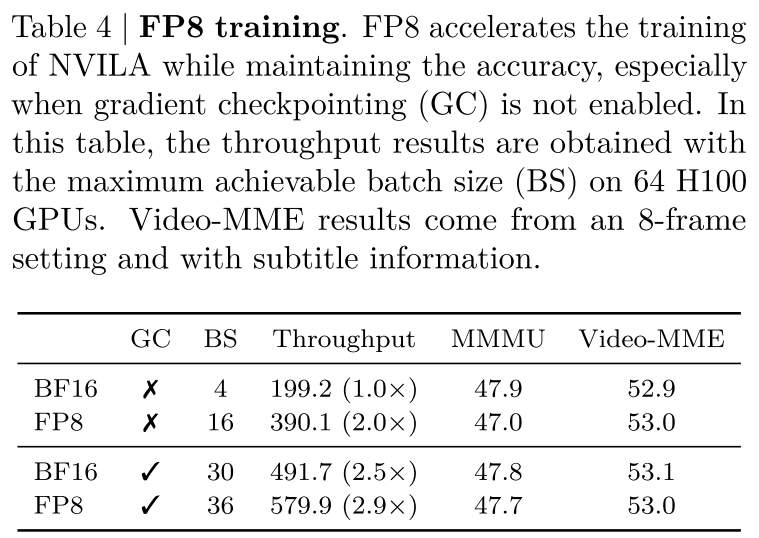
在本文中,我们借鉴COAT[34]的FP8实现来加速NVILA的训练。大语言模型和视觉语言模型训练工作负载之间的一个关键区别在于批次中序列长度的可变性。在大语言模型训练中,样本通常具有统一的长度,并且将批次大小增加到超过某个点对训练吞吐量的影响最小。然而,在视觉语言模型训练中,样本的长度可能有很大差异:视频样本可能需要数万个令牌,图像样本可能需要数百个,而纯文本样本需要的则少得多。因此,令牌较少的工作负载通常未得到充分利用,可以从增加批次大小中受益匪浅。如表4所示,对权重和激活都应用FP8使NVILA能够将批次大小从4增加到16,从而实现2倍的加速。当启用梯度检查点时,量化激活变得不那么重要。相反,我们集成了来自Liger[35]的交叉熵内核,以减少由于Qwen的大词汇量导致的峰值内存使用。在这种情况下,与BF16训练相比,FP8训练仍然可以提供1.2倍的加速。
表4| FP 8。FP 8在保持精度的同时加快了NVILA的训练速度,尤其是在梯度检查点(GC)未启用时。在该表中,吞吐量结果是在64个H100 GPU上使用最大可实现批量大小(BS)获得的。Video-MME结果来自8帧设置并具有字幕信息。
2.3 高效微调
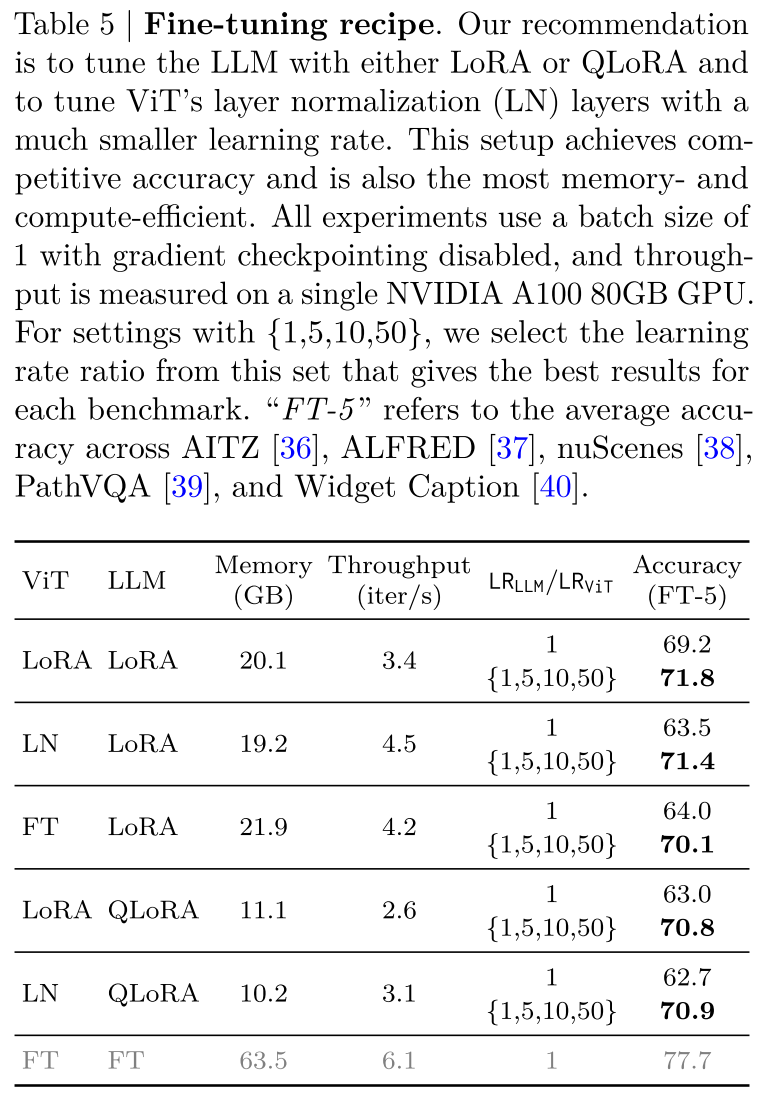
一旦训练了基础视觉语言模型,就需要进行特定领域的微调,以使模型适应专门的任务或领域。虽然微调有效地提高了特定领域的词汇和概念,但传统的参数高效微调主要集中在大语言模型和文本相关任务上,如何最好地微调视觉语言模型仍有待探索。在NVILA中,我们发现(i)对于视觉Transformer(ViT)和大语言模型(LLM),学习率应设置不同;(ii)应根据不同的下游任务选择调整部分。
当使用参数高效微调方法(PEFT)同时微调视觉编码器(ViT)和大语言模型(LLM)时,我们观察到ViT部分的学习率应比LLM部分的学习率小5 - 50倍。另一方面,我们还观察到,使用层归一化(Layernorm)微调视觉编码器可以实现与低秩适应(LoRA)相当的性能(表5),同时计算效率更高:与对视觉编码器应用LoRA相比,它可以将训练时间减少25%。通过精心策划的配置设置,NVILA可以在24GB内存下快速微调以适应各种下游任务,并且性能相当。
表5 | fine-tuning。我们的建议是使用LoRA或QLoRA调整LLM,并使用小得多的学习速率调整ViT的层归一化(LN)层。这种设置可实现极具竞争力的精度,同时也是内存和计算效率最高的。所有实验均使用批量大小为1的测试,禁用梯度检查点,并在单个NVIDIA A100 80 GB GPU上测量吞吐量。对于{1,5,10,50}的设置,我们从该集合中选择可为每个基准提供最佳结果的学习率比率。“FT-5”指的是AITZ [36]、ALFRED [37]、nuScenes [38]、PathVQA [39]和微件标题[40]的平均准确度。
2.4 高效部署
视觉语言模型通常集成在计算资源紧张的边缘应用(如机器人)中。在本节中,我们将介绍我们的带有量化的推理引擎,以加速部署。
我们开发了一种带有量化技术的专用推理引擎,以高效部署NVILA。推理过程分为两个阶段:预填充和解码。在计算受限的预填充阶段,我们首先应用令牌压缩技术(第2.1节)来减少大语言模型骨干的推理工作量,此后视觉塔成为主要瓶颈,占预填充延迟的90%以上。
为了解决这个问题,我们对视觉塔实施W8A8量化,以减少NVILA在这个计算受限阶段的首次令牌生成时间(TTFT)。在内存受限的解码阶段,我们遵循AWQ [41] 对大语言模型骨干进行W4A16量化以加速。我们通过在W4A16 GEMM内核中引入FP16累加,进一步优化了原始的AWQ实现,在不影响精度的情况下,内核速度总共提升了1.7倍。我们在图5中附上了详细的对比。
3 实验
3.1 训练细节
我们遵循五阶段的流程来训练NVILA:(1)投影仪初始化;(2)视觉编码器预训练;(3)令牌处理器预训练;(4)图像指令调整;(5)视频指令调整。其中,阶段1、3和4也包含在VILA的训练中。额外的阶段2用于恢复由于空间令牌压缩导致的精度损失(如表1所示),额外的阶段5有助于扩展模型对长视频的理解能力。我们在表7中提供了详细的训练方法,在表A1中提供了数据方法。
我们的实现基于PyTorch 2.3.0 [42, 43] 和Transformers 4.46.0 [44]。我们使用DeepSpeed 0.9.5 [45] 在设备间分片大型模型,并使用梯度检查点来减少内存使用。我们采用FlashAttention-2 [46] 来加速大语言模型和视觉编码器的训练。我们还实现了功能保持的即时序列打包,以融合不同长度的样本,这带来了大约30%的加速。我们使用128个NVIDIA H100 GPU在所有阶段训练所有模型,全局批次大小为2048。所有优化都使用AdamW且不进行权重衰减。我们采用余弦退火学习率衰减调度,并在前3%的调度中进行线性热身。初始学习率在不同阶段有所不同,详见表7。
3.2 准确性结果
3.2.1 图像基准测试
如表8所示,我们在各种图像基准测试中进行了全面评估:AI2D [47]、ChartQA [48]、DocVQA [49]、InfographicVQA [50]、MathVista [51]、MMMU [52](带零样本思维链)、RealworldQA [53]、SEED-Bench [54]、TextVQA [55] 和VQAv2 [56]。
我们的NVILA在每个规模类别中与顶级开源模型表现相当,包括Qwen2-VL [5]、InternVL [3] 和Pixtral。对于一般的视觉问答任务(ChartQA、DocVQA、InfoVQA、TextVQA、VQAv2、Seed),NVILA-8B和NVILA-15B与专有模型(GPT-4o、Gemini)相比,取得了有竞争力甚至更好的结果。在与科学相关的基准测试(AI2D)中,NVILA-8B在开源模型中达到了最先进的性能。当扩展到150亿参数时,NVILA与专有模型相比表现出竞争力。
此外,在推理和知识基准测试(如MMMU、RealworldQA和MathVista)中,随着模型规模的增加,分数提升更为显著。对于需要光学字符识别(OCR)能力的基准测试(如TextVQA、AI2D、ChartQA、DocVQA、InfoVQA),80亿参数的模型也能表现出色。我们还在图??中展示了一些定性示例,以展示NVILA模型的OCR、推理和多图像能力。
3.2.2 视频基准测试
我们在一系列视频理解基准测试 [57, 58, 59, 60] 上评估了我们的模型,涵盖了从几秒的短视频到长达一小时的长视频。表9展示了NVILA与基线模型 [61, 62, 5, 4, 63, 19] 相比的性能。NVILA具有长上下文能力,可以处理多达256帧。通过先缩放后压缩的设计,NVILA-8B取得了令人瞩目的结果,在所有基准测试中都创造了新的最先进性能。值得注意的是,NVILA仅用80亿参数就达到了与GPT-4o mini相当的性能水平,并且优于许多更大的模型。
3.3 效率结果
NVILA通过“先缩放后压缩”在图像和视频基准测试中实现了有竞争力的性能,同时保持了高效性。在架构方面,我们最初将分辨率提高到原生分辨率(1 - 12倍更多的图块),然后将令牌压缩2.4倍,使用比以前的解决方案稍多的令牌实现了更高的准确性。在数据集方面,我们整理了一个多样化的1000万样本数据集,使用DeltaLoss进行压缩,并修剪为一个高质量的500万子集,始终优于在800万 + 数据上训练的LLaVA-OneVision。此外,我们集成FP8进行加速,优化微调的学习率,并使用W8A8格式提高延迟和吞吐量。这些全栈优化使NVILA能够在使用更少资源的情况下实现更好的性能、更低的内存使用和更快的推理。
我们将NVILA的推理性能与Qwen2-VL [5] 进行了比较,如图5所示。为了进行公平比较,两个模型都通过采样64帧来处理视频输入,所有实验都在单个NVIDIA RTX 4090 GPU上进行。Qwen2-VL被量化为W4A16,并使用vLLM [64](一种具有最先进推理速度的大语言模型/视觉语言模型服务引擎)进行部署。对于NVILA,我们将大语言模型骨干量化为W4A16,将视觉塔量化为W8A8。通过我们的专用推理引擎,NVILA在预填充阶段实现了高达2.2倍的加速,在解码吞吐量上比Qwen2-VL高出高达2.8倍。
4 更多能力
4.1 时间定位
遵循LITA,我们还在NVILA中添加了对时间定位的支持。我们添加离散时间令牌来指示视频中的时间戳,并使用平滑交叉熵损失来训练模型。从表10的结果中,我们可以清楚地看到,在所有指标上,NVILA都大幅优于所有基线模型。
4.2 机器人导航
NVILA可以作为视觉语言导航 [65] 中机器人智能体的强大基础,并支持在资源受限的边缘设备上进行实时部署。在每个时间步t,智能体接收语言指令和视频观察,规划下一个动作,并转移到下一个状态t + 1,在那里它接收新的观察。NVILA对多帧输入的高效灵活处理,使其能够将历史和当前观察无缝集成到视觉语言模型中。NaVILA框架 [8] 引入了定制的导航提示,并使用从模拟器 [66] 整理的导航特定的微调数据对NVILA进行微调。表11中的定量结果表明,NVILA的简单设计在VLN-CE任务上取得了最先进的结果。基于NVILA-8B的导航模型在单个笔记本电脑GPU上进行导航任务的实时部署的视觉结果,如图6所示。整个系统可以以1Hz的速度无缝运行端到端(相机→GPU→动作)的管道。
4.3 医疗应用
NVILA在医疗领域也具有变革性的潜力。这种集成有望在诊断准确性、临床决策和数据解释方面取得进展。NVILA-M3框架 [11] 引入了一种新颖的方法,通过集成多个针对特定医疗任务(如图像分割和分类)定制的领域专家模型。这些专家模型旨在提取和解释一般视觉语言模型难以辨别的复杂特征。通过将这些专用模型与视觉语言学习范式相结合,NVILA-M3实现了性能提升,有助于学习视觉输入与其文本注释之间的细微关系。这种集成不仅提高了特定任务的结果,还为在医疗保健领域开发更强大、更具上下文感知的视觉语言模型奠定了基础。NVILA-M3表明,通过使用专家模型,与现有的最先进模型相比,整体性能可以提高9%,在表12中可以观察到一些关键结果。这强调了利用领域专业知识弥合通用人工智能能力与特定应用需求之间差距的重要性,展示了视觉语言模型在精度和特异性至关重要的领域进行革命的潜力。
5 相关工作
5.1 视觉语言模型
在过去两年中,视觉语言模型,尤其是专有模型,发展迅速。例如,OpenAI已从GPT-4V [67] 升级到GPT-4o [12],在图像和视频问答基准测试中性能提升了5 - 10%。谷歌将Gemini Pro 1.5 [68] 的上下文长度扩展到100万,相比Gemini 1.0 [69] 有了显著改进。它现在在Video-MME排行榜 [60] 上的长视频理解任务中排名第一。Anthropic发布了Claude 3.5 [13],其基准测试分数优于GPT-4o,展示了相比Claude 3 [70] 的显著改进。其他专有模型也有类似的进展,如苹果从MM1升级到MM1.5 [71],以及xAI从Grok-1.5 [53] 升级到Grok-2 [72]。
与此同时,开源视觉语言模型也在不断发展,在系统/框架层面 [73] 和算法/方法层面 [2] 都有所改进,逐渐缩小了专有模型和开源模型之间的性能差距 [19, 74, 75, 76, 5]。这些最新进展使得许多开源视觉语言模型声称其性能水平与领先的专有模型(如GPT-4V和GPT-4o)相当,甚至超越它们。一些代表性的例子包括InternVL2 [3]、Qwen2-VL [5]、LLaVA-OneVision [4]、Llama 3.2 Vision [77]、Molmo [30]、NVLM [76] 和MiniCPM-V [18]。
尽管模型性能取得了显著进步,但这些模型在训练、推理和微调效率方面的提升却很少受到关注。本文旨在探索如何开发不仅高度准确,而且在端到端效率方面进行优化的视觉语言模型。
5.2 效率
先前的工作 [78, 79, 80, 62, 81, 82, 83, 84] 已经在空间和时间维度上探索了令牌减少技术。然而,没有一项工作专注于减少前沿视觉语言模型(VLM)的令牌数量。对于数据集修剪,已经提出了有前景的方法来选择大语言模型(LLM)的预训练数据,如领域混合 [85]、样本级数据选择 [27, 86] 和理论驱动的最优选择 [28]。在这项工作中,我们特别关注修剪视觉语言模型的监督微调(SFT)数据集。关于低精度训练,FP8训练 [87, 88] 在大语言模型中越来越受欢迎,但之前没有工作证明其在不牺牲准确性的情况下对视觉语言模型的可行性。剪枝、蒸馏和量化等技术通常应用于大语言模型。[89, 90] 将剪枝/蒸馏应用于大语言模型。然而,它们在视觉语言模型中的应用仍是一个开放问题:是在集成视觉编码器之前先对大语言模型进行剪枝或蒸馏,还是在训练后对视觉语言模型本身进行剪枝或蒸馏?同样,像AWQ [41] 和GPTQ [91] 这样的量化技术在大语言模型中已有详细记录,VILA [2] 已经表明AWQ可以直接应用于视觉语言模型。然而,对视觉编码器进行量化却很少受到关注,在处理更高分辨率的图像或视频时,由于计算需求的增加,这一点变得至关重要。像LoRA [92]、DoRA [93]、QLoRA [94] 和GaLoRA [95] 这样的参数高效微调方法被广泛用于大语言模型以减少内存需求。然而,对于结合了视觉编码器和大语言模型的视觉语言模型来说,高效的微调技术仍未得到充分探索。解决这一差距对于在有限计算资源下推进视觉语言模型的微调至关重要。
6 结论
本文介绍了NVILA,这是一系列开源视觉语言模型,旨在在效率和准确性之间取得最佳平衡。通过采用“先缩放后压缩”的范式,NVILA可以高效处理高分辨率图像和长视频,同时保持高精度。我们还在从训练到微调再到推理的整个生命周期中系统地优化了其效率。NVILA的性能与当前领先的视觉语言模型相当或超越它们,同时资源效率显著更高。此外,NVILA为时间定位、机器人导航和医学成像等应用开辟了新的可能性。我们很快将发布我们的模型。我们希望NVILA能够赋能研究人员和开发者在广泛的应用和研究领域中充分挖掘其潜力。
相关文章:

【文献阅读】NVILA: Efficient Frontier Visual Language Models
发表于2025年3月6日 英伟达团队 摘要 近年来,视觉语言模型(VLMs)在准确性方面取得了显著进展。然而,其效率却较少受到关注。本文介绍了NVILA,这是一系列旨在优化效率和准确性的开源视觉语言模型。在VILA的基础上&am…...

驱动-创建设备节点
字符设备相关的知识面:已经了解了 申请设备号、注册字符设备。 已经将字符设备添加进入内核了,那么如何使用这个字符设备呢? Linux 里面一切皆文件,对内核中的字符设备进行文件操作如打开、关闭、读、写等,但是并不支持…...
-- 动画)
Vue知识点(5)-- 动画
CSS 动画是 Vue3 中实现组件动画效果的高效方式,主要通过 CSS transitions 和 keyframes 动画 CSS Keyframes(关键帧动画) 用来创建复杂的动画序列,可以精确控制动画的各个阶段。 核心语法: keyframes animationNa…...

基于AT89C52单片机的植物浇水与智能空气土壤环境监测报警系统
点击链接获取Keil源码与Project Backups仿真图: https://download.csdn.net/download/qq_64505944/90579535?spm1001.2014.3001.5503 功能介绍: 1、功能:液晶器显示检测到的土壤湿度与空气温度与光照强度;温度和光照大于设置的…...
)
指针进阶( 上 )
内容大纲 一.字符指针 二.指针数组 三.数组指针 四. 数组传参和指针传参 引言 指针是什么呢?指针是用来干什么的呢?指针的大小是多少呢?指针的大小具有什么属性呢? 解答:指针是个变量,用来存放变量地…...

java设计模式-外观模式
外观模式(facade) 基本介绍 1、外观模式也叫过程模式,外观模式为子系统中的一组接口提供一个一致的界面,次模式定义一个高层接口,这个接口是的这一子系统更加容易使用。 2、外观模式通过定义一个一直的接口,用以屏蔽内部子系统的细节&#x…...

selenium元素获取
from selenium import webdriver from selenium.webdriver.common.by import Bydriver webdriver.Chrome()driver.maximize_window()#最大化窗口 #隐式等待 driver.implicitly_wait(10)#打开网页 driver.get("https://www.zhipin.com/beijing/?kacity-sites-101010100&q…...

23种设计模式-行为型模式-访问者
文章目录 简介场景解决完整代码核心实现 总结 简介 访问者是一种行为设计模式,它能把算法跟他所作用的对象隔离开来。 场景 假如你的团队开发了一款能够使用图像里地理信息的应用程序。图像中的每个节点既能代表复杂实体(例如一座城市)&am…...

springMVC-拦截器详解
拦截器 概述 SpringMVC的处理器拦截器类似于Servlet开发中的过滤器Filter,用于对处理器进行预处理和后处理。开发者可以自己定义一些拦截器来实现特定的功能。 过滤器与拦截器的区别:拦截器是AOP思想的具体应用。 过滤器 servlet规范中的一部分,任何ja…...

centos练习docker<基础>
这半喇月发生了很多事,很无谓很闹心,今天重拾起自己,做做功课写写字 文章目录 一、准备二、实践2.1 安装docker2.2docker镜像操作2.2.1 下载镜像等基本操作2.2.2 启动容器等基本操作2.2.3 修改页面2.2.4 保存镜像2.2.5 分享社区 总结 一、准…...

GPT-5、o3和o4-mini即将到来
原计划有所变更: 关于我们应有何期待的一些零散想法。 深度研究(Deep Research)确实强大但成本高昂且速度较慢(当前使用o3模型)。即将推出的o4-mini在性能上可能与o3相近,但将突破这些限制,让全球用户——甚至免费用户(尽管会有速率限制)——都能用上世界顶级AI研究助…...

EchoMimic 音频驱动照片生成视频部署测试
环境:Windows 11 NVIDIA RTX 3070 Laptop 16GB 我配置了阿里云的镜像,要实现一样的效果,你也可以在每一行的命令后加 -i https://mirrors.aliyun.com/pypi/simple/ 如: pip install package_name -i https://mirrors.aliyun.…...
的用法)
React 和 JSX 中,这些符号 (=>, <, ? :)的用法
在 React 和 JSX 中,这些符号 (>, <, ? :) 都是 JavaScript 的语法特性,但它们在 JSX 中有特殊的用法和规则。下面我会详细解释每个符号的用途、语法规则以及在 React/JSX 中的具体应用。 1. 箭头函数 > (Arrow Function) 基本语法࿱…...

mindie1.0新特性及调试问题总结
说明 最近在ascend 310P3上使用mindie 1.0部署模型,跟我以前使用的mindie 1.0_rc2比,有很多新的特性和变化,导致部署出现了不少问题。这里罗列下我的发现,希望对其他人有用。 特性1:需要显式配置share_memory 报错信…...

【Axure原型案例】悦购APP产品原型设计
一、项目背景 在时尚潮流蓬勃发展的当下,潮流服装市场潜力巨大。悦购APP作为一款专注于潮流服装的商城APP,旨在为用户提供丰富多样的潮流服装选择,打造便捷、时尚的购物体验。本次使用Axure进行产品原型设计,旨在将产品理念和功能…...

React 列表渲染
你可能经常需要通过 JavaScript 的数组方法 来操作数组中的数据,从而将一个数据集渲染成多个相似的组件。在这篇文章中,你将学会如何在 React 中使用 filter() 筛选需要渲染的组件和使用 map() 把数组转换成组件数组。 1.如何通过 JavaScript 的 map() 方…...

《深度解析LightGBM与MySQL数据集成:高效机器学习的新范式》
在机器学习工程实践中,数据与模型的高效交互一直是制约算法性能发挥的关键瓶颈。LightGBM作为梯度提升决策树框架的杰出代表,其与关系型数据库MySQL的深度集成能力,为数据科学家提供了从原始数据到预测结果的完整解决方案。这种集成不是简单的…...

使用 node.js 和 MongoDB 编写一个简单的增删改接口 demo
文章目录 前言一、环境准备二、项目结构三、环境变量四、连接数据库3.1. connect.js 文件 五、定义数据模型5.1. BannerModel.js 文件 六、实现 server 接口6.1. server.js 文件 七、服务文件7.1. app.js 文件 八、感谢 前言 Mongoose 是一个在 Node.js 环境中操作 MongoDB 数据…...
 ))
React-06React中refs属性(字符串refs,回调形式,React.createRef() )
1.React中refs属性 绑定到render输出的任何组件上,通过this.ref.绑定名直接操作DOM元素或获取子组件的实例。 2.绑定refs实例 2.1 字符串refs(已经过时参考官网API) 字符串(string)的ref存在一定的效率问题 <input refinput1 type"text" placehole…...

如何在 Windows 系统上安装 n8n:两种方法详解
如何在 Windows 系统上安装 n8n:两种方法详解 摘要 本文详细介绍了在 Windows 系统上安装 n8n 的两种方法:直接安装和 Docker 部署。直接安装适合初学者,通过 Node.js 和 npm 快速完成;Docker 部署适合需要更高灵活性和可移植性…...
)
LETTERS(信息学奥赛一本通-1212)
【题目描述】 给出一个rowcol的大写字母矩阵,一开始的位置为左上角,你可以向上下左右四个方向移动,并且不能移向曾经经过的字母。问最多可以经过几个字母。 【输入】 第一行,输入字母矩阵行数R和列数S,1≤R,S≤20。 接…...

【kind管理脚本-3】脚本函数说明文档 —— 便捷使用 kind 创建、删除、管理集群脚本
下面是一份详细的说明文档,介绍该脚本的功能、用法及各部分的含义,供您参考和使用: Kind 集群管理脚本说明文档 此脚本主要用于管理 Kind(Kubernetes IN Docker)集群,提供创建、删除、导出 kubeconfig、加…...

【kind管理脚本-1】便捷使用 kind 创建、删除、管理集群脚本
目录结构 . ├── cluster-demo-setting │ ├── 3node-demo.yaml │ └── ingress-cluster-demo.yaml └── kind-tool.sh简单使用 # 进入防止 kind-tool.sh 的目录 $ cd kt-dir/ # 用 alias 给个别名,更便于使用 $ alias kt"./kind-tool.sh"…...

Python-Django+vue仓库管理系统功能说明
❥(^_-) 上千个精美定制模板,各类成品Java、Python、PHP、Android毕设项目,欢迎咨询。 ❥(^_-) 程序开发、技术解答、代码讲解、文档,💖文末获取源码+数据库+文档💖 💖软件下载 | 实战案例 💖文章底部二维码,可以联系获取软件下载链接,及项目演示视频。 本项目…...
:树的直径与重心)
蓝桥备赛指南(14):树的直径与重心
树的直径 什么是树的直径?树的直径是树上最长的一条链,当然这条链并不唯一,所以一棵树可能有多条直径。直径由两个顶点u、v来决定,若由一条直径(u,v),则满足一下性质: 1)u、v的度数…...

Java RPC 框架是什么
Java RPC 框架是什么 Java RPC 框架 是用于在分布式系统中实现远程过程调用(Remote Procedure Call,RPC)的工具集。RPC 是一种通信协议,它允许程序调用位于远程服务器上的函数或方法,就像调用本地函数一样透明。RPC 框…...

MySQL 查询重写怎样把复杂查询变简单,让查询提高一个“速”!
目录 一MySQL 查询重写基础概念 什么是查询重写 为什么需要查询重写 二MySQL 查询重写的工作原理 查询解析阶段 重写规则应用阶段 生成执行计划阶段 查询重写流程图 三MySQL 查询重写的实现方式 使用 MySQL 内置的查询优化器 自定义查询重写插件 查询重写介绍图 四…...
——阜阳剪纸介绍设计制作(1个页面))
HTML静态网页成品作业(HTML+CSS)——阜阳剪纸介绍设计制作(1个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有1个页面。 二、作品演示 三、代…...

Docker Swarm集群搭建与管理全攻略
文章目录 一、节点准备二、初始化 manager 节点三、管理 swarm 集群中的 worker 节点1、添加 worker 节点2、查看 worker 节点3、删除 worker 节点 四、管理 swarm 集群服务1、创建服务2、查看服务3、删除服务 五、管理 swarm 节点服务1、节点标签管理2、创建服务3、查看服务4、…...

kafka消费延迟
一、背景 PAAS1220 CRM系统 系统版本: BC Linux For Euler release 21.10 二、故障现象 grafana上kafka指标:指标消费延迟过高 容器内部kafka消费情况:没有消费者进行消费 查看webgate页面:应用性能--信息总览,查看到实例全…...
:ReentrantLock 源码分析)
Java学习笔记(多线程):ReentrantLock 源码分析
本文是自己的学习笔记,主要参考资料如下 JavaSE文档 1、AQS 概述1.1、锁的原理1.2、任务队列1.2.1、结点的状态变化 1.3、加锁和解锁的简单流程 2、ReentrantLock2.1、加锁源码分析2.1.1、tryAcquire()的具体实现2.1.2、acquirQueued()的具体实现2.1.3、tryLock的具…...

计算机视觉算法实战——实例分割算法深度解析
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 一、实例分割领域概述 实例分割(Instance Segmentation)是计算机视觉领域中的一个重要任务,它…...

ARM分拣机vs传统PLC:实测数据揭示的4倍效率差
在苏州某新能源汽车零部件仓库,凌晨3点的分拣线上依然灯火通明。8台搭载ARM Cortex-A72处理器的智能分拣机正在以每秒3件的速度处理着形状各异的电池包组件,它们通过MES系统接收订单信息,自主规划最优路径,将不同规格的零部件精准…...

IDEA 中遇到 Git Log 界面不显示问题的解决方案
IntelliJ IDEA 中遇到 Git Log 界面不显示问题的解决方案。以下是根据文章内容整理的解决步骤: (我清理 IDEA 缓存后成功解决) 问题描述 在 IntelliJ IDEA 中,Git 的 Log 界面没有任何显示。其他选项和界面工作正常。使用命令行查询 Git 日…...

虚幻引擎UActorComponent的TickComponent详解
文章目录 前言一、TickComponent 的作用二、函数签名与参数三、 使用步骤1.启用 Tick2. 重写 TickComponent 四、实际示例:旋转组件4.1 头文件 URotatingComponent.h4.2 源文件 URotatingComponent.cpp4.3 使用组件 五、注意事项六、常见问题总结 前言 在虚幻引擎&…...

如何迁移 GitHub 仓库到 GitLab?
如何迁移 GitHub 仓库到 GitLab? 一、基础迁移方法(保留完整历史) 1.在 GitLab 创建空仓库 1.登录 GitLab 并新建项目,选择「空白项目」,不要初始化 README 或 LICENSE 文件 2.复制新建仓库的 HTTPS/SSH 地址&a…...

深入理解C++面向对象特性之一 多态
欢迎来到干货小仓库,堪比沙漠!!! 从“Hello World”到改变世界,中间隔着千万次再试一次. 1.多态的概念 多态的概念:通俗来说,就是多种形态, 具体点就是去完成某个行为,当不同的对象去完成时会 产生出不同的…...

linux下MMC_TEST的使用
一:打开如下配置,将相关文件编译到内核里: CONFIG_MMC_TEST CONFIG_MMC_DEBUG CONFIG_DEBUG_FS二:将mmc设备和mmc_test驱动进行绑定 2.1查看mmc设备编号 ls /sys/bus/mmc/drivers/mmcblk/mmc0:aaaa2.2将mmc设备与原先驱动进行解绑 echo mmc0:aaaa >...
)
数字人技术的核心:AI与动作捕捉的双引擎驱动(2/10)
摘要:数字人技术从静态建模迈向动态交互,AI与动作捕捉技术的深度融合推动其智能化发展。尽管面临表情僵硬、动作脱节、交互机械等技术瓶颈,但通过多模态融合技术、轻量化动捕方案等创新,数字人正逐步实现自然交互与情感表达。未来…...
)
Java Web从入门到精通:全面探索与实战(二)
Java Web从入门到精通:全面探索与实战(一)-CSDN博客 目录 四、Java Web 开发中的数据库操作:以 MySQL 为例 4.1 MySQL 数据库基础操作 4.2 JDBC 技术深度解析 4.3 数据库连接池的应用 五、Java Web 中的会话技术ÿ…...

从个人博客到电商中台:EdgeOne Pages的MCP Server弹性架构×DeepSeek多场景模板实测报告
什么是EdgeOne Pages? EdgeOne Pages 是腾讯云推出的一站式边缘开发与部署平台,基于全球边缘节点网络和 Serverless 架构,为开发者提供从代码托管到全球分发的全流程服务。其核心价值在于将边缘计算能力与现代 Web 开发范式深度融合…...

【C++】优先级队列+反向迭代器
priority_queue的介绍 通常用堆来实现,能在O(log n)的时间复杂度内插入和提取最高(或最低)优先级的元素。 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的(默认情况)。此…...
)
HOW - 缓存 React 自定义 hook 的所有返回值(包括函数)
目录 场景优化方案示例延伸例子:为什么这很重要?常见的请求 hook 封装优化前优化后优化点一览优化后的 useLoadData使用方式示例:优点回顾 场景 如果你写了一个自定义 Hook,比如 useMyHook(),它暴露出某些值或函数给外…...

AIDD-人工智能药物设计-网络药理学-多组学与网络药理学分析揭示龟龄集治疗少精症的机制
IF6.7|多组学与网络药理学分析揭示龟龄集治疗少精症的机制 2024年10月28日,海军军医大学张卫东教授团队在Phytomedicine(IF6.7)上发表了题为“Multi-omics and network pharmacology approaches reveal Gui-Ling-Ji alleviates oligoastheno…...

打破单一视角!融合红外和可见光,YOLO算法实现全天候无人机检测
目录 一、摘要 二、系统概述 三、数据集 视频记录 数据集标注 四、数据集分析 五、基于深度学习的无人机探测 基于规则的跟踪方法 六、结论 论文题目:Drone Detection and Tracking with YOLO and a Rule-based Method 论文链接:https://arxiv.…...

Go 语言数据类型
Go 语言数据类型 概述 Go 语言(也称为 Golang)是一种静态强类型、编译型、并发型、具有垃圾回收功能的编程语言。自2009年发布以来,Go 语言因其简洁的语法、高效的执行速度和强大的并发处理能力而广受欢迎。本文将详细介绍 Go 语言中的数据类型,帮助读者更好地理解和掌握…...
)
<tauri><rust><GUI>基于rust和tauri,将tauri程序打包为window系统可安装的安装包(exe、msi)
前言 本文是基于rust和tauri,由于tauri是前、后端结合的GUI框架,既可以直接生成包含前端代码的文件,也可以在已有的前端项目上集成tauri框架,将前端页面化为桌面GUI。 发文平台 CSDN 环境配置 系统:windows 10平台:visual studio code语言:rust、javascript库:taur…...

ragflow开启https访问:ssl证书为pem文件,window如何添加证书
在 Windows 系统中安装 PEM 格式的证书(通常用于 SSL/TLS 或客户端认证)可以通过以下步骤完成: 方法 1:通过证书管理器(MMC)安装 打开证书管理器 按 Win + R,输入 mmc 回车。点击菜单栏的 文件 > 添加/删除管理单元。选择 证书 > 添加,然后选择 计算机账户 或 当…...

自己搭建cesium应用程序
Cesium项目开发基础(1)——Cesium环境搭建_cesium版本怎么看-CSDN博客 看这篇的时候: 所以要用IIS搭建网站。下载一些东西看这篇的这部分:Tomcat IIS 在局域网中搭建网站(最全最详细教程)_tomcat iis-CSDN博客 然后在IIS里怎么…...

本地项目HTTPS访问问题解决方案
本地项目无法通过 HTTPS 访问的原因通常是默认配置未启用 HTTPS 或缺少有效的 SSL 证书。以下是详细解释和解决方案: 原因分析 默认开发服务器仅支持 HTTP 大多数本地开发工具(如 Vite、Webpack、React 等)默认启动的是 HTTP 服务器ÿ…...