手搓多模态-06 数据预处理
前情回顾
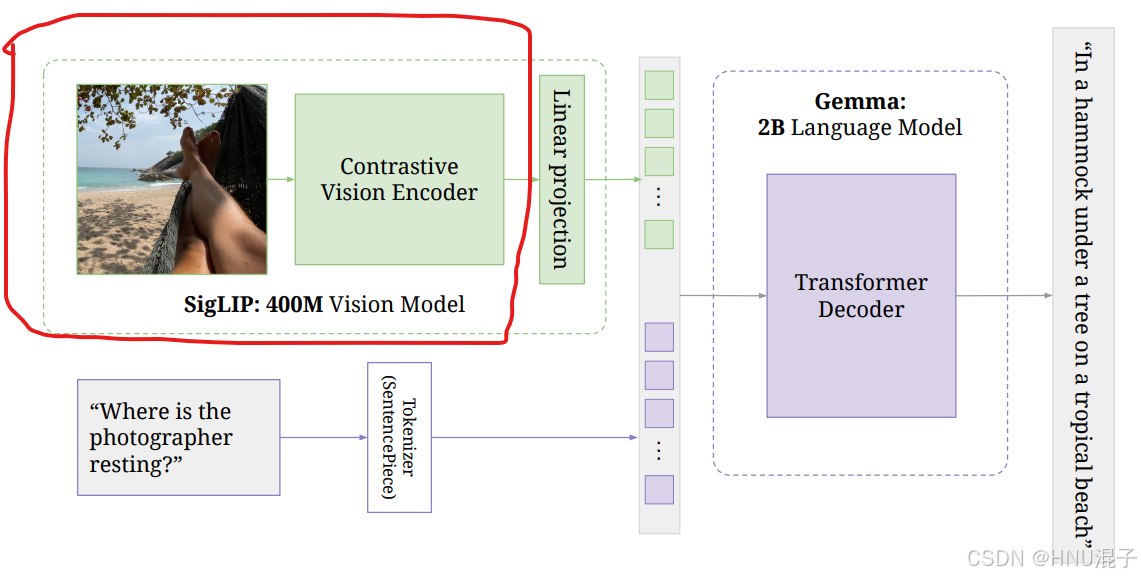
我们目前实现了视觉模型的编码器部分,然而,我们所做的是把一张图片编码嵌入成了许多个上下文相关的嵌入向量,然而我们期望的是一张图片用一个向量来表示,从而与文字的向量做点积形成相似度(参考手搓多模态-01 对比学习的优化)。所以我们需要加一个Linear Projection来将多个嵌入向量投影成一个嵌入向量,但这些可以之后再做,在数据准备阶段我们还有一些数据预处理的工作没有做,本文将着重描述如何进行数据预处理。
数据预处理
我们新建了一个文件,名叫paligemma_processer.py.

首先我们创建了一个类,名叫processer,在processer中我们将实现数据预处理的功能。
所做的预处理主要包括
- 图像的放缩和标准化
- 对输入的图像-文本对解析形成token向量
- 为图像的token创建占位符,这表示在Gemma模型的输入中,有一部分输入向量是来自视觉编码器,那这部分向量暂时就用一个临时的image_token来表示,方便后面替换
- 对于图像的输入,我们需要将输入转换为形如[Batch_size,Channels,Height,Width]的输入,并转换为torch.tensor类型方便pytorch处理。
这部分的代码主要如下:
class PaligemmaProcessor: IMAGE_TOKEN = "<image>"def __init__(
self,
tokenizer,
num_image_tokens,
image_size ):super().__init__()
self.image_seq_lenth = num_image_tokens
self.image_size = image_size token_to_add = {"addtional_special_tokens": [self.IMAGE_TOKEN]} ##标识图像占位符
tokenizer.add_special_tokens(token_to_add)
EXTRA_TOKENS = [f"<loc:{i:04d}>" for i in range(1024)] ##用于目标检测
EXTRA_TOKENS += [f"<seg:<{i:04d}>" for i in range(1024)] ##用于语义分割 tokenizer.add_tokens(EXTRA_TOKENS)
self.image_token_id = tokenizer.convert_tokens_to_ids(self.IMAGE_TOKEN) ##图像占位符的id tokenizer.add_bos_token = False ##去掉默认的bos和eos
tokenizer.add_eos_token = False self.tokenizer = tokenizerdef __call__(
self,
text: List[str],
images: List[Image.Image],
padding: str = "longest",
truncation: bool = True):assert len(text) == 1 and len(images) == 1, "Only support one text and one image for now." pixel_values = process_images(
images,
size=(self.image_size, self.image_size),
resample= Image.Resampling.BICUBIC,
rescale_factor=1.0 / 255.0,
image_mean = IMAGENET_STANDARD_MEAN,
image_std = IMAGENET_STANDARD_STD) pixel_values = np.stack(pixel_values,axis=0)
pixel_values = torch.tensor(pixel_values) ##转换为torch.tensor##通过add_image_token_to_prompt函数,将图像占位符添加到文本中,形成一个输入prompt
input_string = [
add_image_token_to_prompt(
prefix_prompt = prompt,
bos_token = self.tokenizer.bos_token,
image_seq_len = self.image_seq_lenth,
image_token = self.IMAGE_TOKEN)for prompt in text]## 将string类型的prompt转换为嵌入向量,其实这里是根据string中的词元划分成一个token_id的向量## 比如输入的string是"<image><image><bos>hello,world<sep>" 然后tokenizer将其分割成[<image>,<image>,<bos>,hell,oworld,<sep>],这里假设hell和oworld都是token,并查找每个token的id,可能得到[0,0,1,11,15,2]作为嵌入向量
inputs = self.tokenizer(
input_string,
padding=padding,
truncation=truncation,
return_tensors="pt")## 返回待编码的图像以及嵌入好的文本向量
return_data = {"pixel_values": pixel_values, **inputs}return return_data
首先我们为tokenizer 添加了一些额外的特殊token,比如用于目标检测的特殊位置token,以及语义分割用的特殊token,但是我们暂时不会用到它们。
图像处理
在数据预处理部分,我们首先通过一个预处理函数来处理图像,这里面就包括了图像的缩放,归一化和标准化。
pixel_values = process_images(
images,
size=(self.image_size, self.image_size),
resample= Image.Resampling.BICUBIC,
rescale_factor=1.0 / 255.0,
image_mean = IMAGENET_STANDARD_MEAN,
image_std = IMAGENET_STANDARD_STD)
该函数的实现如下:
def process_images(
images: List[Image.Image],
size: Tuple[int, int] = None,
resample: Image.Resampling = None,
rescale_factor: float = None,
image_mean: Optional[Union[float,List[float]]] = None,
image_std: Optional[Union[float,List[float]]] = None
) -> List[np.ndarray]:
height, width = size
images = [
resize(image =image, size = (height,width), resample=resample) if image.size != size else image for image in images]
images = [np.array(image) for image in images]
images = [
rescale(image = image, factor = rescale_factor) for image in images] ## 归一化缩放
images = [
normalize(image = image, mean = image_mean, std = image_std) for image in images] ## 标准化## image : [Height,Width,Channel] --> [Channel,Height,Width]
images = [image.transpose(2,0,1) for image in images]return images
首先我们需要对图像进行缩放,那么这里会涉及到一个重采样函数,表示你用什么方法对图像进行缩放采样,不同的方法采样出来的效果也不一样,这里我们用Image.Resampling.BICUBIC方法,关于这个方法的详细信息请参考其他博客。
缩放操作是在将0-255的像素值缩放到0-1,防止之后模型嵌入时的数值不稳定。
随后的标准化其实就像Batch Normalization和Layer Normalization一样,对图像的像素分布标准化为正态分布,所以需要大量图像的RGB通道各自的均值和方差,故使用image_net的统计结果。
然后把图像三个维度的顺序改变一下。
其中resize,rescale,normalize函数依次如下:
IMAGENET_STANDARD_MEAN = [0.485, 0.456, 0.406]
IMAGENET_STANDARD_STD = [0.229, 0.224, 0.225]def resize(
image: Image.Image,
size: Tuple[int, int],
resample: Image.Resampling = None,
reducing_gap: Optional[int] = None
):
height,width = size
image.resize(size=(width,height),resample=resample,reducing_gap=reducing_gap)return imagedef rescale(
image: np.ndarray,
factor: float,
dtype: np.dtype = np.float32
):
image = image * factor
image = image.astype(dtype)return imagedef normalize(
image: np.ndarray,
mean: Optional[Union[float,List[float]]] = None,
std: Optional[Union[float,List[float]]] = None
) -> np.ndarray:if mean is None:
mean = IMAGENET_STANDARD_MEANif std is None:
std = IMAGENET_STANDARD_STD
mean = np.array(mean)
std = np.array(std)
image = (image - mean) / stdreturn image
然后我们还需要将输出的图像信息转换为torch.tensor,这里的转换代码如下:
pixel_values = np.stack(pixel_values,axis=0)
pixel_values = torch.tensor(pixel_values) ##转换为torch.tensor
首先用stack方法把一个numpy tensor list转换为一个大tensor,然后再把numpy的tensor转换为torch的tensor.
token 处理
token的处理主要在这一部分
##通过add_image_token_to_prompt函数,将图像占位符添加到文本中,形成一个输入prompt
input_string = [add_image_token_to_prompt(
prefix_prompt = prompt,
bos_token = self.tokenizer.bos_token,
image_seq_len = self.image_seq_lenth,
image_token = self.IMAGE_TOKEN)for prompt in text]## 将string类型的prompt转换为嵌入向量,其实这里是根据string中的词元划分成一个token_id的向量## 比如输入的string是"<image><image><bos>hello,world<sep>" 然后tokenizer将其分割成[<image>,<image>,<bos>,hell,oworld,<sep>],这里假设hell和oworld都是token,并查找每个token的id,可能得到[0,0,1,11,15,2]作为嵌入向量
inputs = self.tokenizer(
input_string,
padding=padding,
truncation=truncation,
return_tensors="pt")## 返回待编码的图像以及嵌入好的文本向量
return_data = {"pixel_values": pixel_values, **inputs}
首先我们会构造输入的string文本,这个构造主要依照论文的内容:
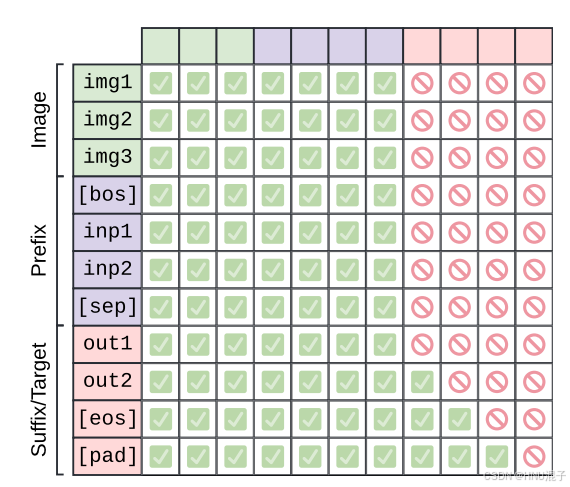
论文构造的输入首先是image token占位符,然后是一个bos表示文本信息的开始,然后是text input,然后是[sep],而论文用'\n'表示[sep]:

于是我们的add_image_token_to_prompt如下所示
def add_image_token_to_prompt(
prefix_prompt: str,
bos_token: str,
image_seq_len: int,
image_token: str
):##论文使用换行符当做[sep]token,但是可能会出现\n与前面的token重叠导致语义信息丢失。 return f"{image_token * image_seq_len}{bos_token}{prefix_prompt}\n"
但这里可能会出现一个问题,即论文使用换行符当做[sep]token,但是可能会出现\n与前面的token重叠导致语义信息丢失。但这里我们暂时不管这个问题。
随后tokenizer的调用实际上会把输入的string根据词汇表拆分成一个个token对应的id,而我们预选添加了image_token的占位符,也就是说我们构建的string_input可能类似于"<image><image><bos>hello,world<sep>",而tokenizer会根据词汇表划分这些token为一个list[<image>,<image>,<bos>,"hell,","oworld",<sep>],然后再通过查表的方式将这些token转换为数值id,比如查到我们加入的<image>对应的id是0,<bos>是1, <sep>是2,"hell,"是11,"oworld"是15,(注意,这里假设词汇表的"hell,"是一个token,"oworld"也是一个token)那么输出可能形如[0,0,1,11,15,2]。
## 将string类型的prompt转换为嵌入向量,其实这里是根据string中的词元划分成一个token_id的向量
## 比如输入的string是"<image><image><bos>hello,world<sep>" 然后tokenizer将其分割成[<image>,<image>,<bos>,hell,oworld,<sep>],这里假设hell和oworld都是token,并查找每个token的id,可能得到[0,0,1,11,15,2]作为嵌入向量
inputs = self.tokenizer(
input_string,
padding=padding,
truncation=truncation,
return_tensors="pt"
)
## 返回待编码的图像以及嵌入好的文本向量
return_data = {"pixel_values": pixel_values, **inputs}
return return_data
相关文章:

手搓多模态-06 数据预处理
前情回顾 我们目前实现了视觉模型的编码器部分,然而,我们所做的是把一张图片编码嵌入成了许多个上下文相关的嵌入向量,然而我们期望的是一张图片用一个向量来表示,从而与文字的向量做点积形成相似度(参考手搓多模态-01…...

[蓝桥杯] 求和
题目链接 P8772 [蓝桥杯 2022 省 A] 求和 - 洛谷 题目理解 这道题就是公式题,我们模拟出公式后,输出最终结果即可。 本题不难,相信很多同学第一次见到这道题都是直接暴力解题。 两个for循环,测试样例,直接拿下。 #in…...

INFINI Labs 产品更新 | Coco AI 0.3 发布 – 新增支持 Widget 外部站点集成
INFINI Labs 产品更新发布!此次更新涵盖 Coco AI 、Easysearch 等产品多项重要升级,重点提升 AI 搜索能力、易用性及企业级优化。 Coco AI v0.3 作为 开源、跨平台的 AI 搜索工具,新增快捷键设置,支持多个聊天会话等功能。Coco A…...

vue3+element-plus多个多选下拉框并搜索
一、下拉框组件: <template> <div class"top-select"> <div class"first-select"> <div v-for"(group, index) in selectGroups" :key"index" class"item-select" > <div class&quo…...
多类分类与SoftMax回归)
吴恩达深度学习复盘(9)多类分类与SoftMax回归
多类分类 概念 对于分类问题,并非只有0或1两个标签,而是可以有两个以上的开放标签。以手写数字分类问题为例,之前只是区分0和1, 但在实际生活中,如读取信封上的数字或邮政编码,会涉及十个可能的数字识别&…...
有效的括号)
【力扣hot100题】(068)有效的括号
犹记得第一次做这题的时候是怎样一番惨状,现在已经得心应手了。 class Solution { public:bool isValid(string s) {stack<char> zhan;for(int i0;i<s.size();i){if(s[i]{||s[i](||s[i][) zhan.push(s[i]);else{if(zhan.empty()) return 0;if(zhan.top(){…...

深度学习篇---Prophet时间序列预测工具
文章目录 前言一、什么是Prophet?易用性自动化灵活性鲁棒性快速拟合 二、Prophet的核心原理1. 趋势模型a. 分段线性模型(默认)b. 逻辑增长模型 2. 季节性模型3. 节假日效应 三、Prophet使用方法安装ProphetPython基本使用示例1. 准备数据2. 创…...

TDengine JAVA 语言连接器
简介 本节简介 TDengine 最重要且使用最多的连接器, 本节内容是以教科书式方式列出对外提供的接口及功能及使用过程中要注意的技术细节,大家可以收藏起来做为今后开发 TDengine 的参考资料。 taos-jdbcdriver 是 TDengine 的官方 Java 语言连接器,Java…...

vue3工程中使用vditor完成markdown渲染并防止xss攻击
vue3工程中使用vditor完成markdown渲染并防止xss攻击 背景环境解决方案引入依赖 组件封装实现效果 背景 做oj系统时,题目使用的时markdown语法字符串,前端查看时需要将markdown转html再渲染到页面上。 环境 vitevue3pnpm 解决方案 引入依赖 pnpm install vdit…...

Java面向对象编程详解
面向对象编程是Java的核心特性之一,它通过类和对象的概念来解决实际问题,使程序设计更加符合人类对事物的认知方式。本文将深入探讨Java中的面向对象编程概念和特性。 1. 面向对象的基本概念 1.1 什么是面向对象? 面向对象程序设计(Object …...

重温java 系列一 Java基础
文件拷贝的5种方式 传统字节拷贝 public static void main(String[] args) throws IOExecption{try(InputStream is new FileInputStream("source.txt");OutputStream os new FileOutputStream("target.txt")){byte[] buffer new byte[1024];int leng…...

Java基础 4.7
1.成员方法传参机制 引用数据类型的传参机制 引用类型传递的是地址(其实也是值,只不过值是地址),可以通过形参影响实参! public class MethodParameter01 {public static void main(String[] args) {int[] arr {1,…...
之回顾C语言文件接口)
基础IO(一)之回顾C语言文件接口
文章目录 共识原理回顾C文件接口打开文件的方式以w的方式打开文件以a的方式打开文件 stdin & stdout & stderr 共识原理 1.文件内容属性 就算内容是空的,也会有属性,内容和属性(两者都是数据)都要在磁盘当中保存 2.文件分为 打开的文件 和 没…...

PandaAI:一个基于AI的对话式数据分析工具
PandaAI 是一个基于 Python 开发的自然语言处理和数据分析工具,支持问答式(ChatGPT)的数据分析和报告生成功能。PandaAI 提供了一个开源的框架,主要核心组件包含用于数据处理的数据准备层(Pandas)以及实现 …...

Rollup详解
Rollup 是一个 JavaScript 模块打包工具,专注于 ES 模块的打包,常用于打包 JavaScript 库。下面从它的工作原理、特点、使用场景、配置和与其他打包工具对比等方面进行详细讲解。 一、 工作原理 Rollup 的核心工作是分析代码中的 import 和 export 语句…...

【NLP 56、实践 ⑬ LoRA完成NER任务】
目录 一、数据文件 二、模型配置文件 config.py 三、数据加载文件 loader.py 1.导入文件和类的定义 2.初始化 3.数据加载方法 代码运行流程 4.文本编码 / 解码方法 ① encode_sentence(): ② decode(): 代码运行流程 ③ padding(): 代码…...

Unity ViewportConstraint
一、组件功能概述 ViewportConstraint是一个基于世界坐标的UI边界约束组件,主要功能包括: 将UI元素限制在父容器范围内支持自定义内边距(padding)可独立控制水平和垂直方向的约束 二、实现原理 1. 边界计算(世界坐…...

项目实战--路由权限
封装 单独抽象成组件,写一个新的关于路由的NewsRouter.jsx: import SideMenu from "../../components/sandbox/SideMenu"; import TopHeader from "../../components/sandbox/TopHeader"; import { Routes, Route } from "re…...

Async 注解原理分析
Async 注解由 Spring 框架提供,被该注解标注的类或方法会在 异步线程 中执行。这意味着当方法被调用时,调用者将不会等待该方法执行完成,而是可以继续执行后续的代码。 Async 注解的使用非常简单,需要两个步骤: 在启…...

pyTorch-迁移学习-图片数据增强-四种天气图片的多分类问题
目录 1.导包 2.加载数据、拼接训练与测试数据的文件夹路径 3数据预处理 3.1数据增强 3.2用分类存储的图片数据创建dataloader 4.加载预训练好的模型 (迁移学习) 4.1固定、修改预训练好的模型 5.将模型拷到GPU上 6.定义优化器与损失函数 7.学习率衰减 8.定义训…...

Linux脚本基础详解
一、基础知识 Linux 脚本主要是指在 Linux 系统中编写的用于自动化执行任务的脚本程序,其中最常用的便是 Bash 脚本。下面我们将从语法、使用方法和示例三个方面详细讲解 Linux 脚本。 1. 脚本简介 定义:Linux 脚本是一系列命令的集合,可以…...

MQTT-Dashboard-数据集成-WebHook、日志管理
常用的 Docker Volume 命令及其用法。 1、创建数据卷 使用 docker volume create 命令可以创建一个新的数据卷。例如,创建一个名为 my_volume 的数据卷: docker volume create my_volume 2、列出数据卷 使用 docker volume ls 命令可以列出所有的数据卷…...

Elixir语言的移动应用安全
Elixir语言的移动应用安全解析 引言 在当今的数字化时代,移动应用已经成为我们日常生活中不可或缺的一部分。从购物、社交到在线银行,几乎每一个生活领域都与移动应用紧密相连。然而,随着应用的普及,安全问题也随之而来。如何确…...

【科学技术部政务服务平台-用户注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

HTTP 教程 : 从 0 到 1 全面指南 教程【全文三万字保姆级详细讲解】
目录 HTTP 的请求-响应 HTTP 方法 HTTP 状态码 HTTP 版本 安全性 HTTP/HTTPS 简介 HTTP HTTPS HTTP 工作原理 HTTPS 作用 HTTP 与 HTTPS 区别 HTTP 消息结构 客户端请求消息 服务器响应消息 实例 HTTP 请求方法 各个版本定义的请求方法 HTTP/1.0 HTTP/1.1 …...
(Go语言版))
【LeetCode 热题100】139:单词拆分(动态规划全解析+细节陷阱)(Go语言版)
🚀 LeetCode 热题 139:单词拆分(Word Break)| 动态规划全解析细节陷阱 📌 题目描述 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请判断 s 是否可以由字典中出现的单词拼接成。 说明:不要求字典…...

2025年招投标行业的深度变革:洞察趋势,把握未来
2025年,随着政府工作报告对招投标行业的一系列改革措施的提出,整个行业正面临一场前所未有的深度变革。这些政策旨在推动全国统一大市场的建设、加速数字化转型、促进绿色低碳发展,并强化风险防控。在这场变革中,企业不仅要适应新…...

树莓派学习专题<3>:使能VNC远程桌面与VNC文件传输
树莓派学习专题<3>:使能VNC远程桌面与VNC文件传输 1. 配置VNC2. 使用VNC viewer连接到树莓派3. 使用VNC viewer传输文件 1. 配置VNC 在终端或SSH中,使用如下命令打开树莓派系统配置项: sudo su raspi-config以上两项…...

AI烘焙大赛中的算法:理解PPO、GRPO与DPO最简单的方式
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

qt自定义信号槽需要注意的事项
在 Qt 中,自定义信号和槽是与事件和对象交互的核心机制之一。创建自定义信号和槽时,有几个重要事项需要注意,以确保它们能够正确工作。以下是一些需要注意的关键点: 1. 信号和槽的声明 信号声明:信号应该在 signals …...

OpenCV--图像轮廓检测
在图像处理与计算机视觉领域,轮廓检测是一项极为关键的技术。轮廓作为物体边界的重要表征,承载了图像中物体的形状、尺寸和位置等关键信息。通过轮廓检测,我们能够提取出图像中物体的轮廓,为后续的物体识别、图像分割、形状分析等…...

从搜索丝滑过渡到动态规划的学习指南
搜索&动态规划 前言砝码称重满分代码及思路solution 1(动态规划)solution 2(BFS) 跳跃满分代码及思路solution 1(动态规划)solution 2 (BFS) 积木画满分代码及思路动态规划思路讲解solution 前言 本文主要是通过一些竞赛真题…...

通用文字识别技术的出现,深刻改变信息的处理方式
在数字化浪潮席卷全球的今天,文字作为人类文明最基础的载体,正经历着一场前所未有的技术革命。通用文字识别(OCR,Optical Character Recognition)技术已经从简单的"图片转文字"工具,进化为能够理…...

linux 下du 和 ls-alh 的区别
我一直以为du -m 可以显示文件大小。发现不对。正确的做法你是用ls -alh 来使用...

【k8s学习之CSI】理解 LVM 存储概念和相关操作
鸟哥的 Linux 私房菜 – Quota, Software RAID, LVM, iSCSI 0 | 理解 vg 相关概念 在 Linux LVM(逻辑卷管理) 中,以下是 partition(分区)、PV(物理卷)、VG(卷组)、LV&am…...

【分享开发笔记,赚取电动螺丝刀】使用STM32F103的hal库,采用PWM+DMA发送方式驱动WS2812的RGB彩灯
简单和大家介绍一下本文章的主要内容:使用STM32F103C8最小系统板,使用STM32 cubeMX 6.14版本生成底层的驱动库、结合定时器的PWM 输出功能、使用DMA发送数据的 方式,驱动WS2812 的RGB三色灯。 本次小的DIY所需的物料:stm32f103c8…...
)
CubeMX配置STM32VET6实现网口通信(无操作系统版-附源码)
下面是使用CubeMX配置STM32F407VET6,实现以太网通讯(PHY芯片为LAN8720)的具体步骤总结: 一、硬件连接方式: 硬件原理图: 使用外部晶振为PHY芯片提供时钟。 STM32F407VET6 与 LAN8720 采用 RMII 模式连接。…...

一种反激式开关电源设计流程
引:随着生产和技术的发展,对环保和能源的要求也越来越高,开关电源的应用也越来越广泛,开关电源电路结构种类繁多,包括单端转换器和双端转换器。本文介绍一种利用反激式变换电路实现5V开关电源的设计方法,以…...

数据结构实验3.2:链栈的基本操作与括号匹配问题
文章目录 一,问题描述二,基本要求三,算法分析(一)链栈的存储结构设计(二)链栈基本操作的时间复杂度分析(三)括号匹配算法分析 四,示例代码五,实验…...

一周学会Pandas2 Python数据处理与分析-NumPy算术运算和统计计算
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili 算术运算 数组的灵魂就在于可以进行批量的运算而不是要在循环里面进行元素的运算: 示例: …...
试题速浏、分类及浅析)
2011年-全国大学生数学建模竞赛(CUMCM)试题速浏、分类及浅析
2011年-全国大学生数学建模竞赛(CUMCM)试题速浏、分类及浅析 全国大学生数学建模竞赛(China Undergraduate Mathematical Contest in Modeling)是国家教委高教司和中国工业与应用数学学会共同主办的面向全国大学生的群众性科技活动,目的在于激励学生学习数学的积极性,提高学…...

科普:GBDT与XGBoost比较
本文不去讲GBDT与XGBoost算法的原理及算法本身,而是从应用者的角度,对二者比较,以便选择。 XGBoost是GBDT的“工程化增强版”,在保持Boosting核心思想的同时,通过数学优化(二阶导数、正则化)和工…...
)
大数据技术之 Scala(5)
以下是今天学习的知识点与代码测试: 一、不可变数组与可变数组的转换 说明 arr1.toBuffer //不可变数组转可变数组arr2.toArray //可变数组转不可变数组 arr2.toArray 返回结果才是一个不可变数组,arr2 本身没有变化arr1.toBuffer 返回结果才是一个可变…...

int 与 Integer 的区别详解
1. 本质区别 特性intInteger类型基本数据类型(Primitive)包装类(Wrapper Class)存储位置栈(或作为对象成员在堆中)堆(对象实例)默认值0null(可能导致 NullPointerExcept…...
顺序表)
初阶数据结构(3)顺序表
Hello~,欢迎大家来到我的博客进行学习! 目录 1.线性表2.顺序表2.1 概念与结构2.2 分类2.2.1 静态顺序表2.2.2 动态顺序表 2.3 动态顺序表的实现初始化尾插头插尾删头删查找指定位置之前插入数据删除指定位置的数据销毁 1.线性表 首先我们需要知道的是,…...

智能DNS解析:解决高防IP地区访问异常的实战指南
摘要:针对高防IP在部分地区无法访问的问题,本文设计基于智能DNS的流量调度方案,提供GeoDNS配置与故障切换代码示例。 一、问题背景 运营商误拦截或线路波动可能导致高防IP在福建、江苏等地访问异常。传统切换方案成本高,智能DNS可…...
)
瑞芯微RK3568嵌入式AI项目实战:项目方向(三)
基于RK3568的成熟开源项目和实战资源丰富,以下是针对小白的精选推荐及学习路径规划,结合多个开源项目和详细教程,帮助快速入门嵌入式开发: 一、OpenHarmony智能设备开发 1. 凌蒙派-RK3568开发板项目 项目特点:支持Op…...

go游戏后端开发26:红中麻将发牌逻辑
首先,麻将游戏创建房间的逻辑与之前我们做过的“赢三张”创建房间的逻辑是一致的,整体上没有问题。不同之处在于,我们在创建房间时会根据游戏类型来创建对应的“game”,即创建的是麻将的“game”。大家之前写过相关代码࿰…...

DataFrame的遍历、排序、去重与分组
一.遍历 1.1 series遍历 import pandas as pds pd.Series([a,b,c,d,e,f],index[1,2,3,4,5,6])for i in s:print(i) a b c d e f 可见,遍历series会直接拿到其中的值 1.2 DataFrame遍历 1.2.1 直接遍历 import pandas as pd data {name: [Alice, Bob, Charlie]…...
)
QEMU源码全解析 —— 块设备虚拟化(17)
接前一篇文章:QEMU源码全解析 —— 块设备虚拟化(16) 本文内容参考: 《趣谈Linux操作系统》 —— 刘超,极客时间 《QEMU/KVM源码解析与应用》 —— 李强,机械工业出版社 《KVM实战 —— 原理、进阶与性能调优》—— 任永杰 程舟,机械工业出版社...