【数据结构】排序算法(下篇·开端)·深剖数据难点


前引:前面我们通过层层学习,也就了解了Hoare大佬的排序思想,今天我们学习的东西可能稍微有点难度,因此我们必须学会思想,我很受感慨,因此借此分享一下:【用1520分钟去调试】,如果我们遇到了任何问题,必须先学会自己能不能解决,调试是每次代码找错的一个途径。通过每次调试,看它的数据变化是否达到了目前应该的预期,然后我们找到了错误,应该如何改进!下面小编通过拆分思想,一步步带你深解这些算法思想的奥妙!
目录
快排(双指针·递归)
算法思想:
实现步骤:
复杂度分析:
代码实现:
单趟实现:
递归实现:
代码优化:
优缺点分析:
快排(双指针·非递归)
算法思想:
实现步骤:
代码实现:
左区间:
右区间:
整体代码展示:
优缺点分析:
小编寄语
快排(双指针·递归)
大家在写部分题目的时候,是否有在评论区看见这样的评论:“双指针秒了”,小编当时见的很多,当时我不知道双指针是哈,但是现在领悟了!双指针是通过两个指针完成!这里的“指针”并非真正是指针,也可以是下标,因为arr【i】=*(p+i),它们都是指元素,下面我们看看哈是双指针!
算法思想:
双指针排序是利用两个指针协助操作来完成排序的任务,它们通常同向移动或者相向移动,典型的运用场景如下面两方面:
(1)快速排序:通过分区操作将数组分为小于/大于基准值的两部分进行递归(当前主讲)
(2)归并排序:合并两个有序子数组时,通过双指针比较元素大小
为了方便接下来思路拆分比较好理解,我先总结2个指针的原理(cur是前指针,prev是后指针):
(1)cur找小,找到小之后,prev再找大,然后二者交换对应的元素,cur再向前移动
(2)prev找大,找到大之后,与cur所指的值进行交换
实现步骤:
在进行正式的学习之前,我们先来看一下它的动图,好好感悟一下,然后我们进行思路拆分讲解:

1:老套路,我们先来实现单趟。我们发现,在开始前,数据的初始化是如下图这样的:
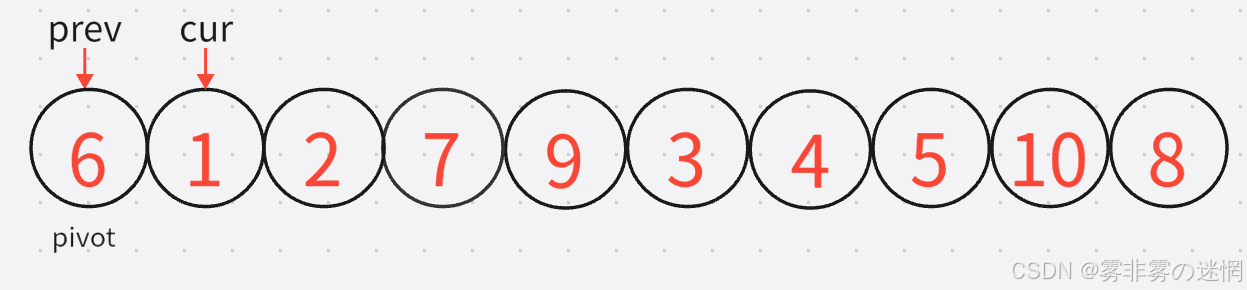
2:然后重点来了!为了清晰对比,我对这两个指针功能进行了拆分,为什么找小、找大?
cur :找小(对于基准值而言),因为我们需要与prev所指向的进行交换,小的交换到左边去
prev :找大(对于基准值而言)因为我们需要将其与cur所指的内容进行交换,大的要到右边去
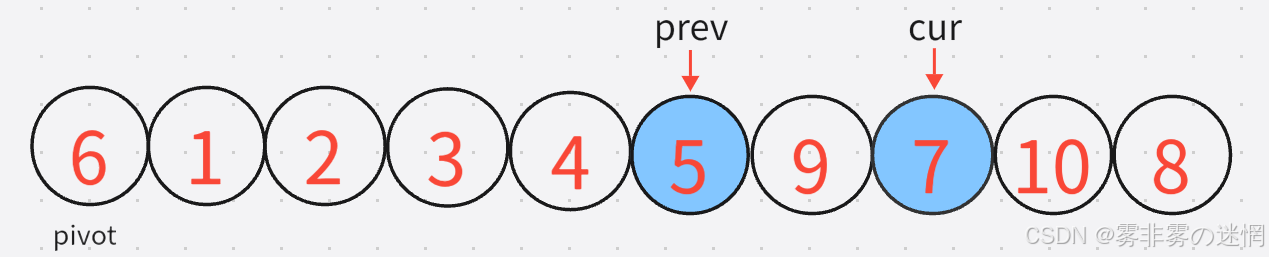
3:既然是前后指针法,cur是要先动,cur找到小之后,prev再动,直到找到较大的元素:【注意:prev不能跑到cur的前面去】
这里cur所指的元素刚好就是满足条件的,因此再移动prev就行了,如图:
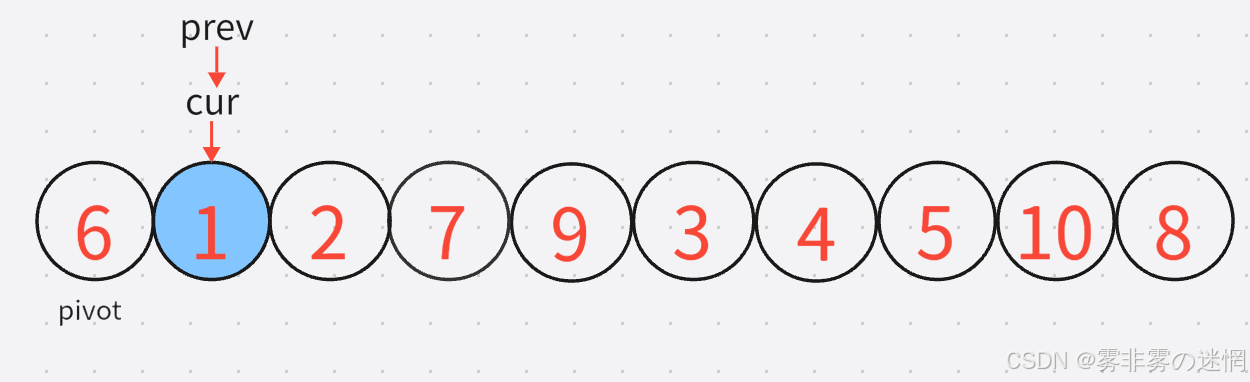
此时prev与cur重合了, 那么就进行交换,交换之后1还是在原来的地方,交换完之后cur再加加,进入新一轮的判断,这是第一轮结束的情况:
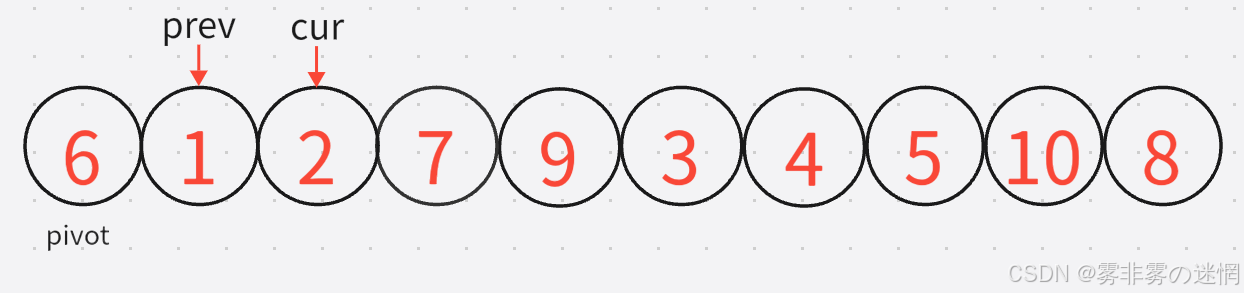
4:下面进行第二轮 。这里还是跟刚才情况一样,cur刚好满足情况,二者重合了,所以第二轮结尾的状况就是:
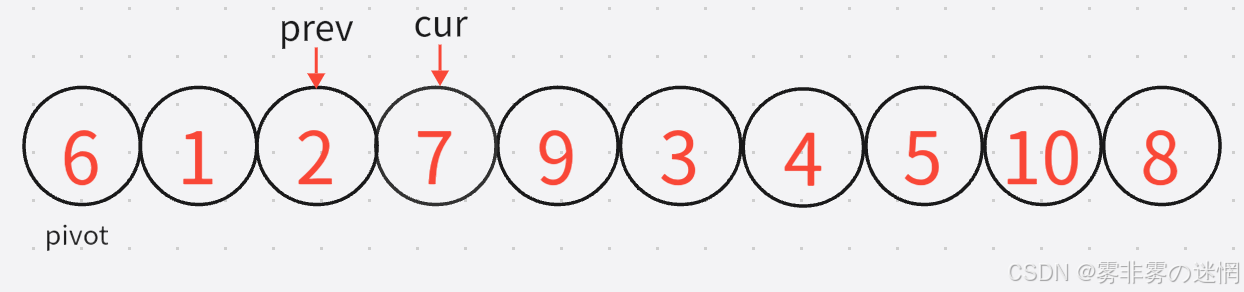
5: 第三轮:cur所指的元素是较大的,因此经过几轮循环加加,直到找到小于基准值所指的元素
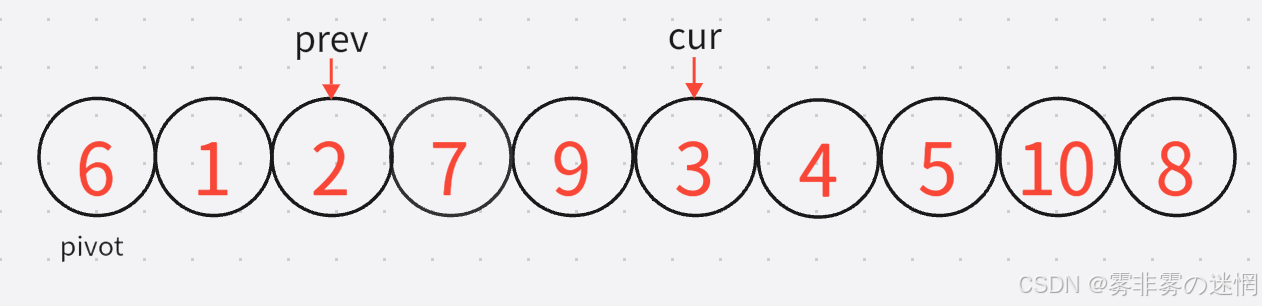
现在找到了较小的元素3,然后prev加加,直到找到较大的元素,二者再进行交换:
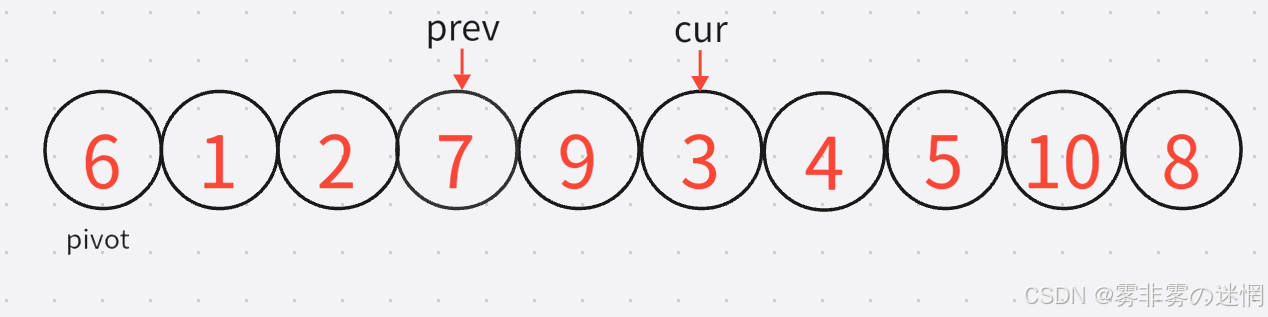
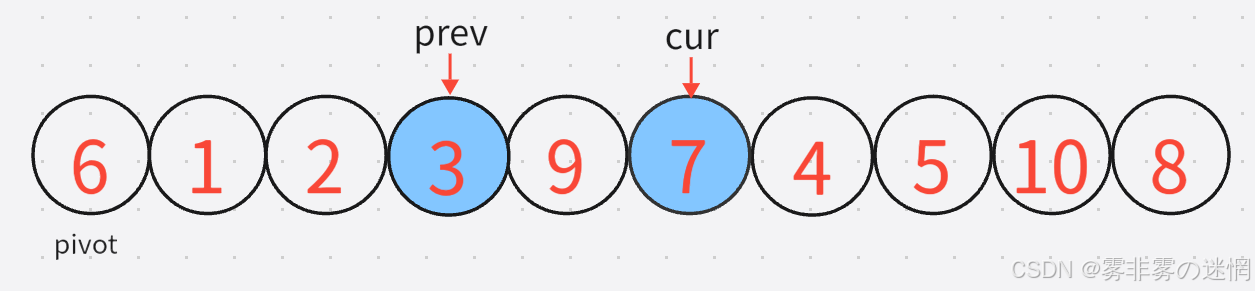
6:然后按照cur再加加,直到找到较小的元素,prev再找到较大的元素,进行交换:
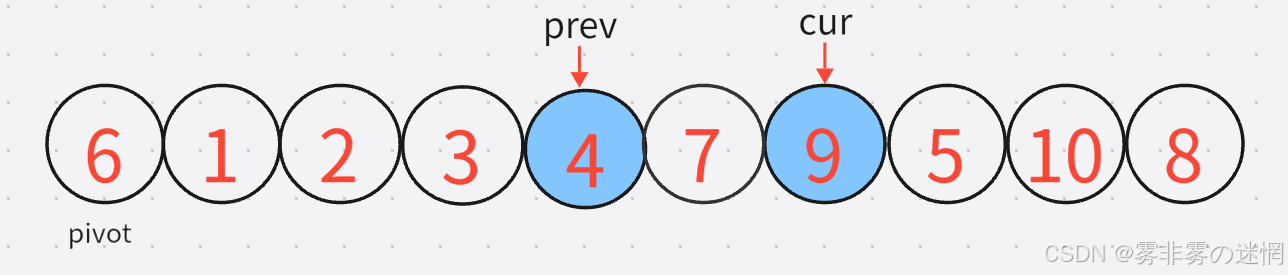
7:下一轮还是同理,先找小,再找大,再交换:
那么cur再出了数组界限,最后再将prev所指的与pivot位置进行交换,更新pivot,单趟就结束了

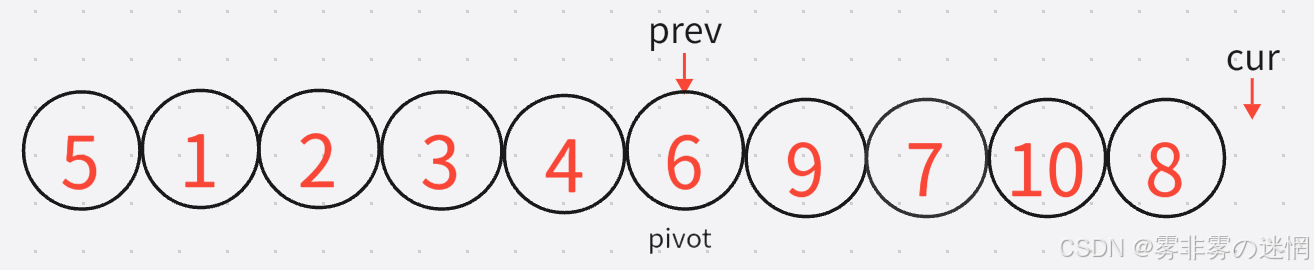
接下来这么将基准值为界限,分为左右2组进行递归就可以了!
复杂度分析:
最好时间复杂度、平均时间复杂度:
每次分区操作的时间复杂度为O(n),递归树的深度为 log n,总操作次数为O(n logn)
最坏时间复杂度:
每次分区之后,一个子数组为空,另一个子数组包含剩余的所有元素,时间复杂度为O(n^2)
空间复杂度:
递归树的深度为log n
代码实现:
单趟实现:
按照上面的原理,我们先实现单趟:
cur找小,找到之后prev再找大【prev不能超过cur】,交换之后,cur++
prev找大,找到之后交换
while (cur <= right)
{//找小if (arr[cur] < arr[pivot]){prev++;//交换Exchange(&arr[prev], &arr[cur]);cur++;}if (arr[cur] > arr[pivot]){cur++;}
}
//此时right=size,交换left与pivot下标的元素
Exchange(&arr[pivot], &arr[prev]);
//更改pivot的位置
pivot = prev;如果单趟有问题的小伙伴们可以去看看实现步骤,这里是重点讲解了单趟的实现的!
递归实现:
对于递归,我觉得很有必要强调一下思路,下面我们借助代码来分析:
int left = 0;
int right = size-1;void QuickSort(int* arr, int left, int right)
{//递归结束条件if(left >= right){return;}//找基准值int pivot= Pointer(arr, left, right);//左区间QuickSort(arr, left, pivot - 1);//右区间QuickSort(arr, pivot + 1, right);
}首先咱们的left初始位置是数组下标为0的位置,right是数组下标末尾的位置,不满足递归结束条件。我们第一次找基准值得到6,通过基准值来划分区间,也就是这里的单趟,如图划分区间:
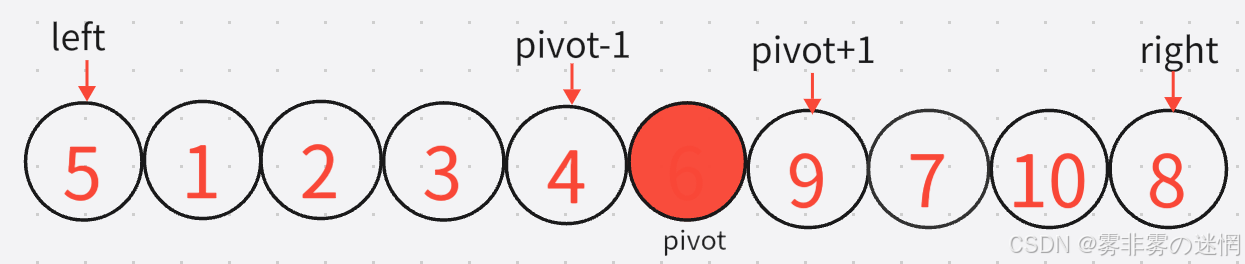
这里以左区间为例,QuickSort函数拿到的区间是【arr,left,pivot-1】 现在进入了单趟函数:
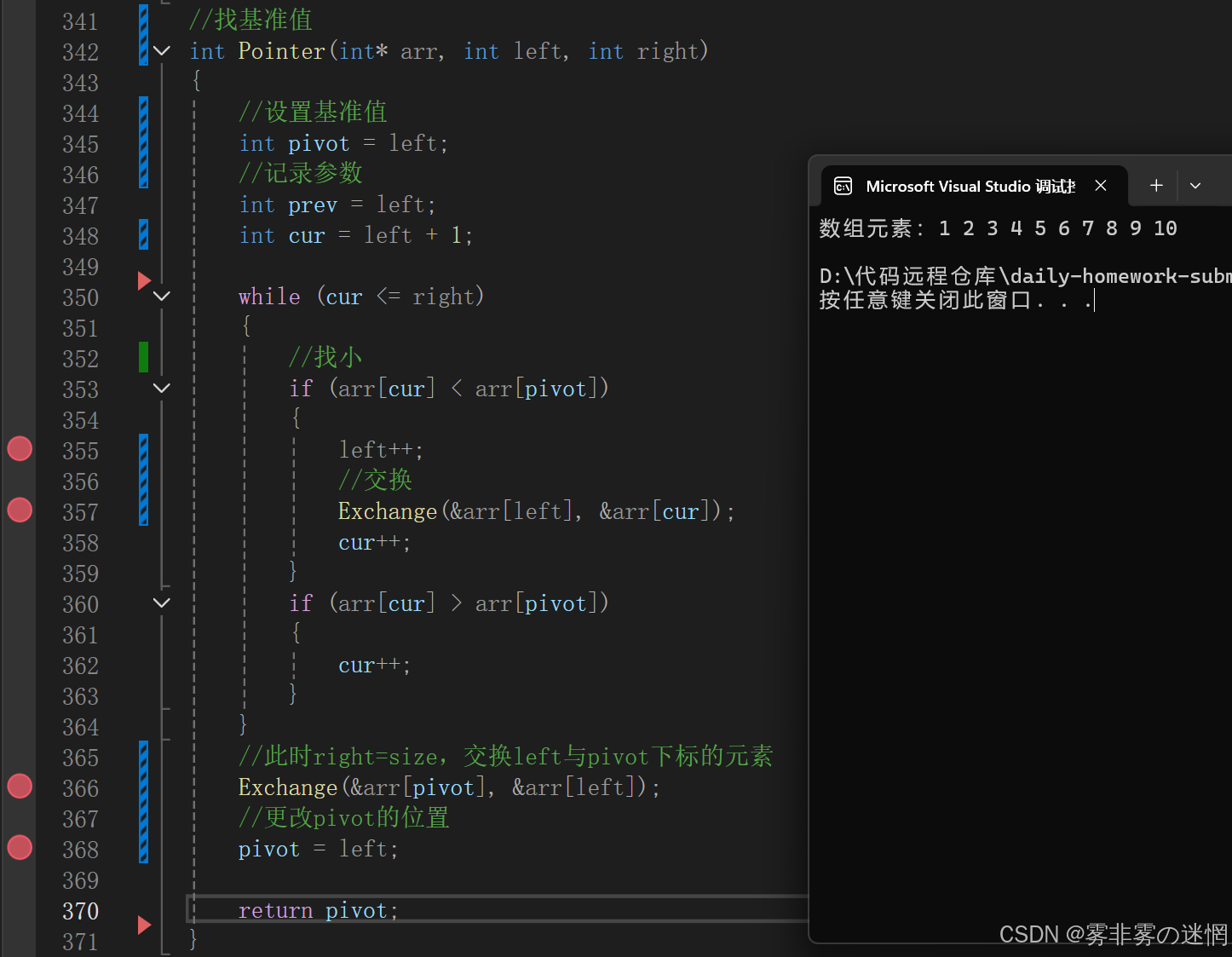
进入单趟函数Pointer之后,此时单趟函数的参数也就是【arr,left,pivot-1】,这里为什么要设置这么多的参数呢?如下面的代码
//设置基准值
int pivot = left;
//记录参数
int prev = left;
int cur = left + 1;因为我们拿到的是区间,只有左右两个端点,首先cur prev是必须要设置的,因为是新变量。
既然传过来的只是形参,我为什么要设置一个一模一样的变量prev去代替left,这是为了方便统一,避免混淆,其实不换也是可以的, 大家可以看演示效果(标红点的地方是把prev->left的):
经过这个函数我们得到了新的基准值5,然后再次调用递归函数,得到新的区间是【left,pivot-1】
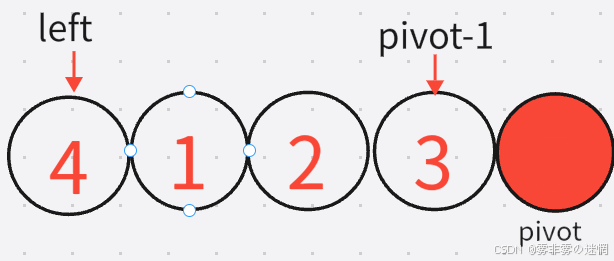
再就这样一直循环找基准值进行排序就可以了,递归结束的条件又是如何更改left 、right的?
这是第一次进入递归函数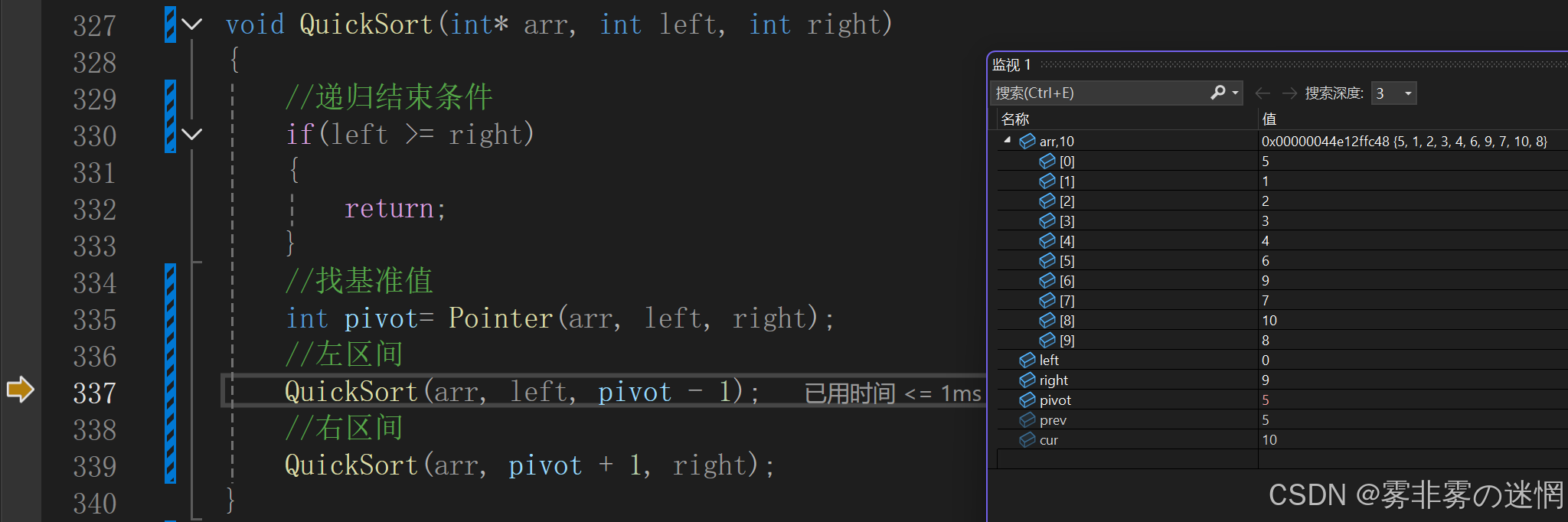
这是第二次进行递归函数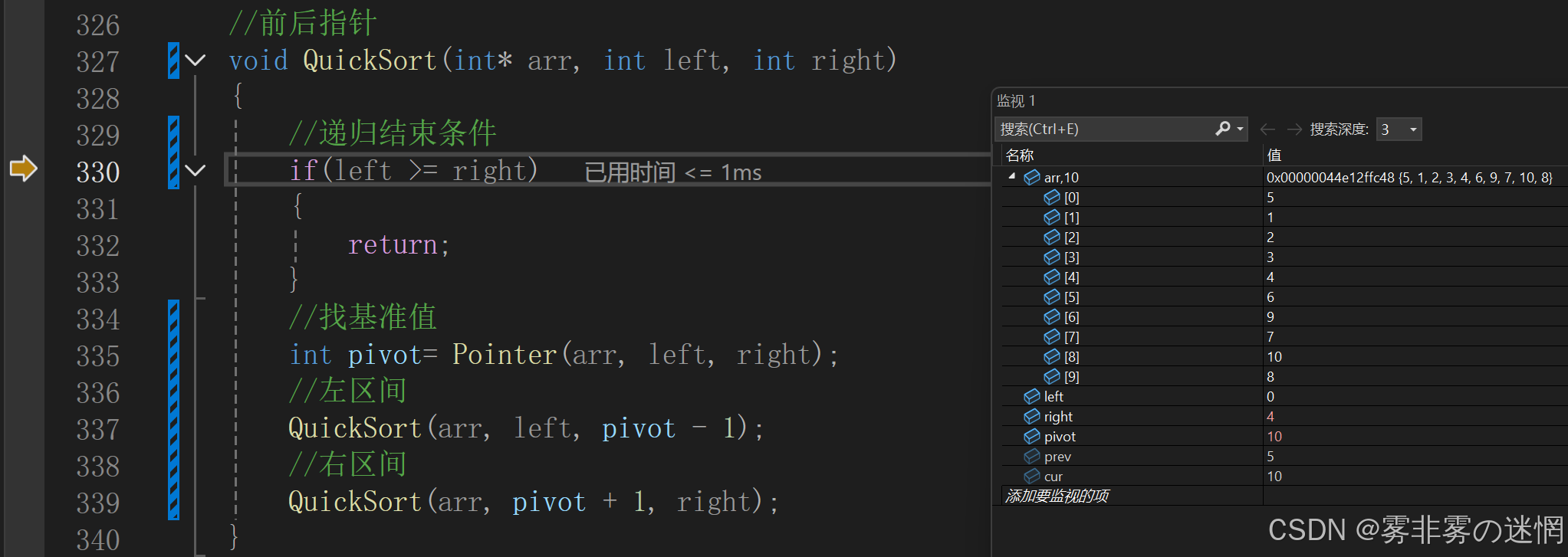
我们很明显的看到right的值发生了变化,请看下面这幅图,你就明白了,右区间递归函数同理:
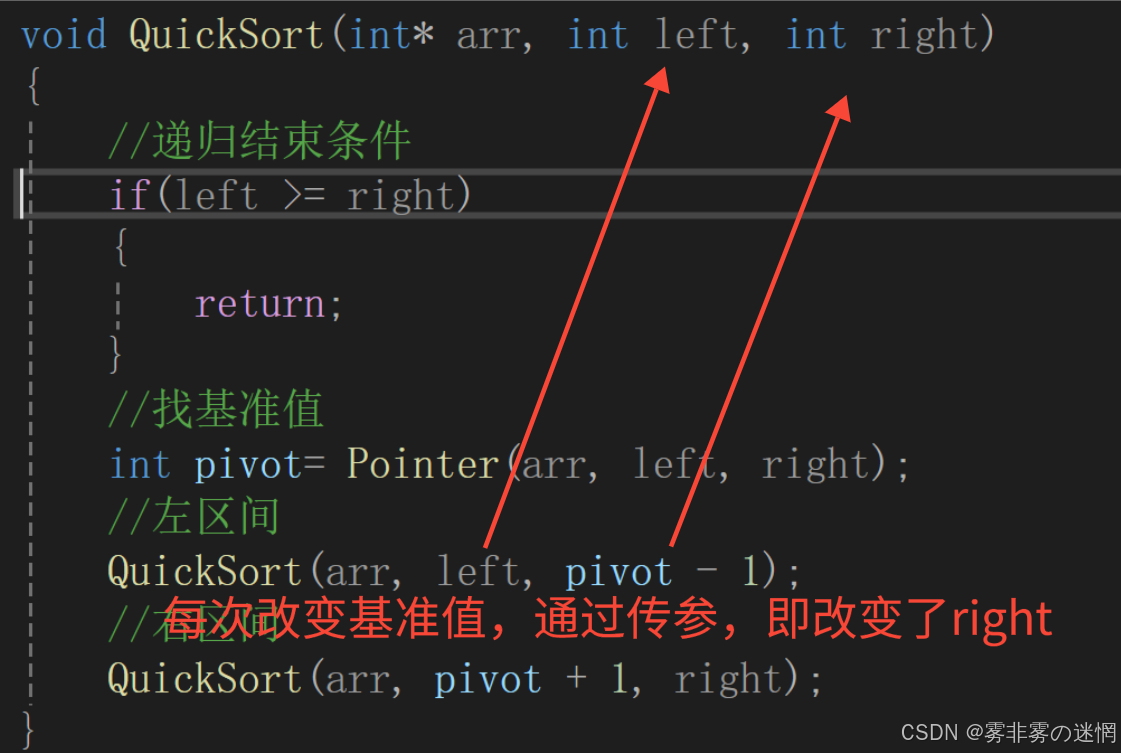
代码优化:
双指针:我们知道分组递归可以想象成【树】那样,一组变两组,两组变四组,这么循环下去,当最后一层时,它的分组是相当多的,双指针排序虽然平均时间复杂度达到O(n logn),但是它主要的开销还是在后面的分组,越往后分的越多。
插入排序:而插入排序虽然整体来说时间复杂度达到O(n^2),但是它对几乎有序的子数组来说效率很高,所以我们如果将二者结合,取一个界线,当剩余的元素到达某个阈值时,切换为插入排序,这是很常见的一种优化。
我们一般取10左右的数字为阈值。这里只需要看剩余数组元素个数即可,用分支判断:
我们总共的数组元素个数是right+1,那么剩余的元素个数不就是right+1-left吗!(如下图)
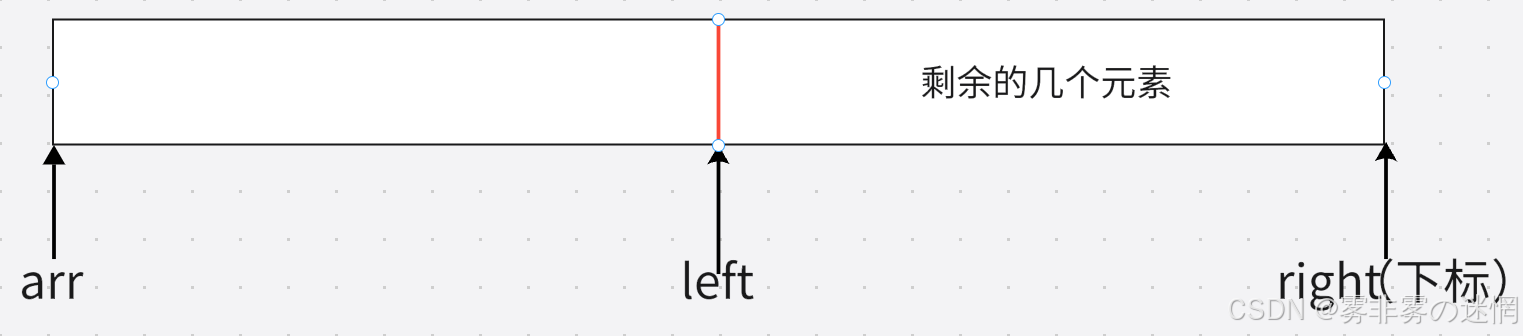
下面我来解释这个区间的开始位置应该如何表示:
首先我们的arr是数组名,如果我们直接传数组名过去是错误的,因为我们不能保证剩余的元素一定是从数组的起始位置开始的,如下图我们得到剩余元素的开始应该是arr+left
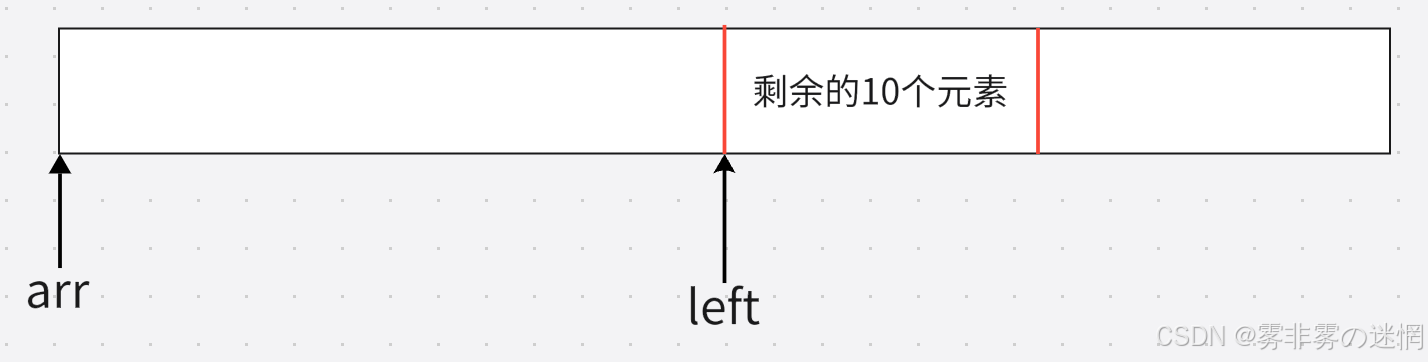
下面是优化代码
void QuickSort(int* arr, int left, int right)
{//递归结束条件if(left >= right){return;}if ((right - left + 1) > 10){//找基准值int pivot = Pointer(arr, left, right);//左区间QuickSort(arr, left, pivot - 1);//右区间QuickSort(arr, pivot + 1, right);}else//到达阈值时选用直接插入排序Insert(arr+left, right - left + 1);}
优缺点分析:
首先是时间复杂度,双指针排序的时间复杂度均为O(n logn),这是一个很大的优化,双指针可以在单次遍历中实现快速排序,减少了冗杂的操作,适用范围广,是比较推荐的一种快排方法,当然需要先理解哈。并且双指针还可以应用在两数之和、去重、合并区间等不同的其它问题,点赞!
快排(双指针·非递归)
首先我们已经学会了递归的形式去走快排,为什么还要去学习非递归?
我们平时写递归代码,数据还比较少,如果我们将递归放在几百万、上千万的数据里面呢?在上面我们只用了10个数据去走递归,每一层是上一层的两倍,呈现倍数的增长,那么它在实际应用中是不推荐的,数据如果太多太多,递归深度也就越深,容易发生栈溢出,因此递归方式我们能不用就不要用,在以后工作时,一般递归的代码会让我们改成非递归的,这也是在避免以后出现隐患
算法思想:
我们知道快排双指针的方式是通过 基准值 来实现对数组的分组,通过递归一步步调用函数来完成分组排序,那么它的本质是什么?
我们每次调用函数,改变的是它的参数,也就是改变它的区间,每个组一直通过基准值分下去:
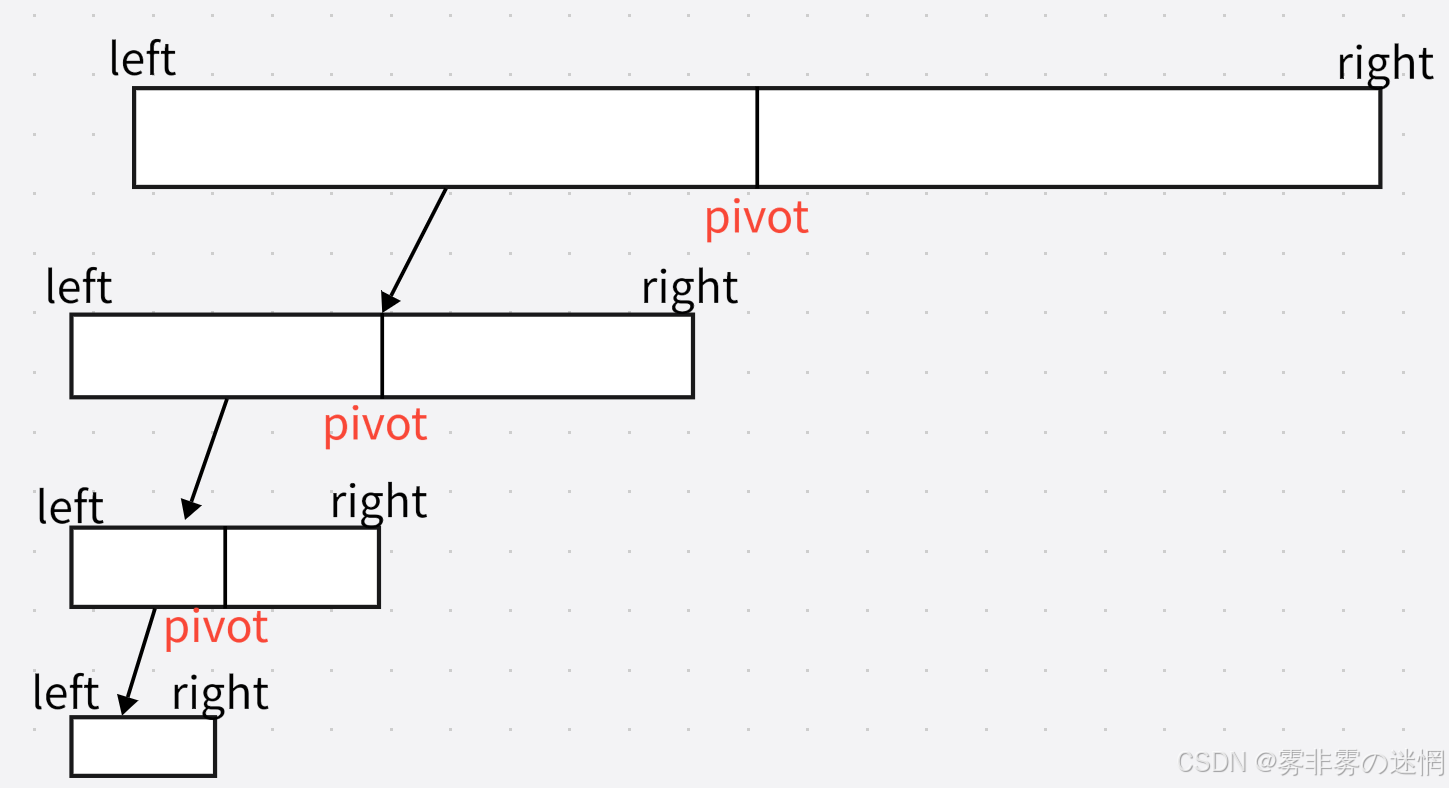
我们把它的区间存起来,每次改变获取不一样的区间,再传参给排序函数就达到了非递归的效果!
我们可以通过栈和队列来存储分组的区间,每次调用栈和队列的元素来进行传参给排序函数
在这里我推荐栈来实现,原因:
首先用队列也是可以的,这样就是一层一层的去排序了(层序遍历),如果我们换栈去实现,就是先将左边的分组分完了,再去分组右边(前序遍历),且栈的应用比较广泛,因此我们在这里选择栈去存储分组区间
实现步骤:
栈的存储特点:先进后出,就像将数据一个个放进容器
按照上面的思路,我们先从左边的分组开始:

我们发现左区间的left是不变的,变的只有pivot-1,也就是基准值在不断变化,因此我们可以通过每计算一个基准值,就存入栈里面,再拿出来,然后再通过出栈的值去做左区间的参数
右边的区间是只改变left,即右边区间是将基准值pivot+1作为每次参数的改变,如图:

代码实现:
左区间:
按照原理,先找基准值,再来实现对基准值的入栈,再出栈作为参数:
//找基准值
int pivot = Pointer(arr, left, cur);
//左区间的基准值入栈
Enter(s, pivot);
//再出栈,cur作为右边不断变化的区间
cur = Out(s);
//出栈元素作为左区间参数
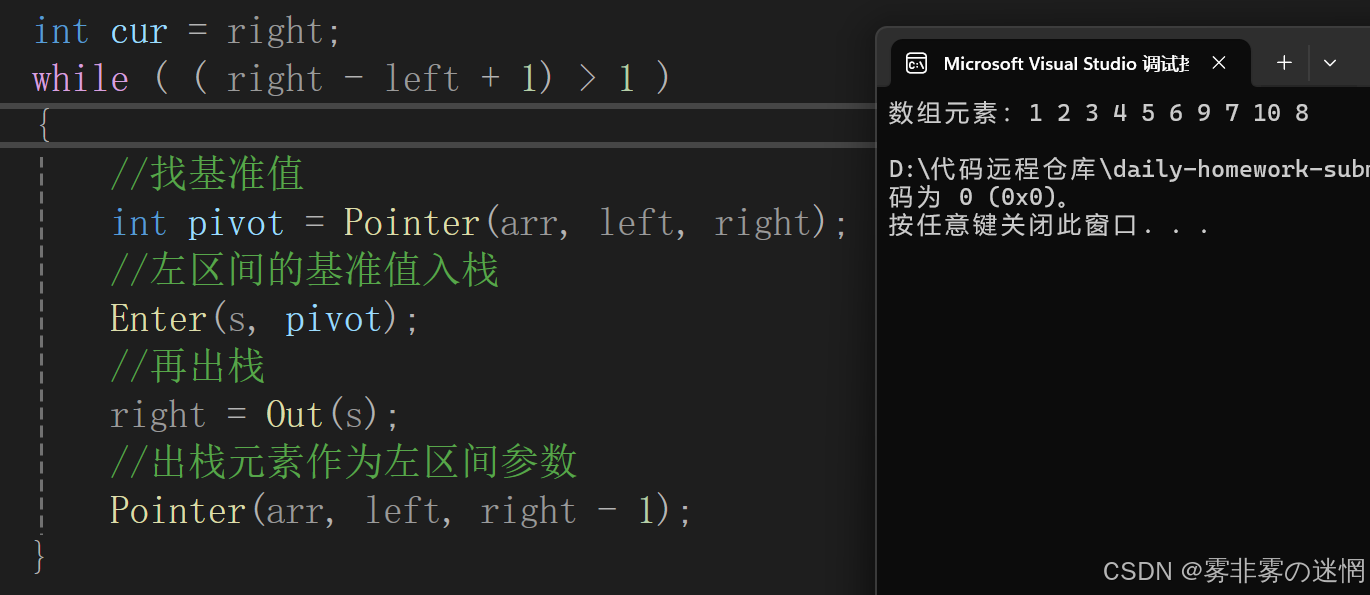
Pointer(arr, left, cur - 1);需要注意:我们此时已经获得了基准值,就不需要递归函数了,注意切换函数。这样我们就完成了单趟,我们外面再套一个循环,就完成了左边分组的排序,循环的条件就是当区间剩余一个元素时就停下【因为一个元素表示它已经是正确位置了】即right-left+1==0 注意:左边排序我们需要记录right,因为我们的参数是不断变化的,需要用一个变量去代替right,效果展示如下:
//标记
int cur = right;
while ( ( cur - left + 1) > 1 )
{//找基准值int pivot = Pointer(arr, left, cur);//左区间的基准值入栈Enter(s, pivot);//再出栈,cur作为右边不断变化的区间cur = Out(s);//出栈元素作为左区间参数Pointer(arr, left, cur - 1);
}
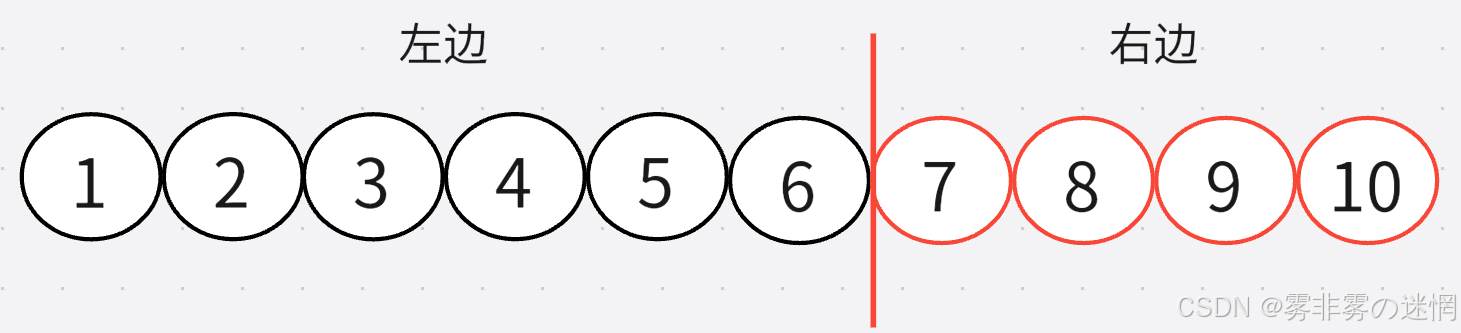
此时数组左边的数据通过非递归的方式已经完成排序了,如下图展示: 
右区间:
完成了左边,我们直接复制一下代码,稍微改动就行了【注意右边是改变left】,如下代码展示:
//标记
int prev = left;
while ((right - prev + 1) > 1)
{//找基准值int pivot = Pointer(arr, prev, right);//左区间的基准值入栈Enter(s, pivot);//再出栈prev = Out(s);//出栈元素作为左区间参数Pointer(arr, prev + 1, right);
}
整体代码展示:
void QuickSort(int* arr, Stack* s, int left, int right)
{//标记int cur = right;while ( ( cur - left + 1) > 1 ){//找基准值int pivot = Pointer(arr, left, cur);//左区间的基准值入栈Enter(s, pivot);//再出栈cur = Out(s);//出栈元素作为左区间参数Pointer(arr, left, cur - 1);}//标记int prev = left;while ((right - prev + 1) > 1){//找基准值int pivot = Pointer(arr, prev, right);//左区间的基准值入栈Enter(s, pivot);//再出栈prev = Out(s);//出栈元素作为左区间参数Pointer(arr, prev + 1, right);}
}int Pointer(int* arr, int left, int right)
{//设置基准值int pivot = left;//记录参数int prev = left;int cur = left + 1;while (cur <= right){//找小if (arr[cur] < arr[pivot]){prev++;//交换Exchange(&arr[prev], &arr[cur]);cur++;}if (arr[cur] > arr[pivot]){cur++;}}//此时right=size,交换left与pivot下标的元素Exchange(&arr[pivot], &arr[prev]);//更改pivot的位置pivot = prev;return pivot;
}优缺点分析:
我们最大的成功就是将递归改成了非递归,通过循环去实现整体的排序,这里避免了栈溢出,在未来我们去工作时,能不写递归就尽量不要写递归,出现递归能改则改。对于数据大的环境下,递归的深度很可怕的!而循环则不同,它不会出现栈溢出,只需要控制循环的条件即可
小编寄语
见证了Hoare大佬的排序思想,又衍生出了双指针的方式,感叹如此精妙的改进!排序的道路没有结束,此篇是难点的第一篇,领教双指针的魅力,快排和归并作为效率很高的两种排序,能够随时手撕代码是对这些思想的真正领悟,让排序算法成为技术世界里不停歇的实验场,预知归并如何,详见下篇!
相关文章:
·深剖数据难点)
【数据结构】排序算法(下篇·开端)·深剖数据难点
前引:前面我们通过层层学习,也就了解了Hoare大佬的排序思想,今天我们学习的东西可能稍微有点难度,因此我们必须学会思想,我很受感慨,因此借此分享一下:【用1520分钟去调试】,如果我们…...

Elixir语言的计算机视觉
Elixir语言在计算机视觉中的应用 引言 计算机视觉作为一门交叉学科,近年来随着深度学习技术的发展而蓬勃发展。传统上,计算机视觉应用通常采用Python、C等语言进行开发,因为这些语言拥有强大的图像处理库和深度学习框架。然而,随…...
- 交互与Widget(二))
VTK知识学习(51)- 交互与Widget(二)
1、交互器样式 前面所讲的观察者/命令模式是 VTK实现交互的方式之一。在前面示例 所示的窗口中可以使用鼠标与柱体进行交互,比如用鼠标滚轮可以对柱体放大、缩小;按下鼠标左键不放,然后移动鼠标,可以转动柱体;按下鼠标左键,同时按…...

目标跟踪Deepsort算法学习2025.4.7
一.DeepSORT概述 1.1 算法定义 DeepSORT(Deep Learning and Sorting)是一种先进的多目标跟踪算法,它结合了深度学习和传统的目标跟踪技术,在复杂环境下实现了高精度和鲁棒性的目标跟踪。该算法的核心思想是通过融合目标的外观特征和运动特征,实现对多个目标的持续跟踪,…...

nacos集群启动问题
根据您的描述,Nacos集群只能启动两个节点,可能的原因和解决方法如下: 1. 集群配置问题 • 原因:cluster.conf文件中可能只配置了两个节点的地址,导致第三个节点无法加入集群。 • 解决方法: • 检查每个…...

八大排序——c++版
本次排序都是按照升序排的 冒泡排序 void bubbleSort(vector<int>& nums) {int nnums.size();for(int i0;i<n-1;i){bool swappedfalse;for(int j0;j<n-1-i;j){if(nums[j]>nums[j1]){swap(nums[j],nums[j1]);swappedtrue;}}if(!swapped)break;} } //算法原…...

关于Spring MVC中传递数组参数的详细说明,包括如何通过逗号分隔的字符串自动转换为数组,以及具体的代码示例和总结表格
以下是关于Spring MVC中传递数组参数的详细说明,包括如何通过逗号分隔的字符串自动转换为数组,以及具体的代码示例和总结表格: 1. 核心机制 Spring MVC支持直接通过逗号分隔的字符串将请求参数自动转换为数组(String[]、int[]等&…...

VBA之Word应用:利用Range方法进行字体及对齐方式设置
《VBA之Word应用》(版权10178982),是我推出第八套教程,教程是专门讲解VBA在Word中的应用,围绕“面向对象编程”讲解,首先让大家认识Word中VBA的对象,以及对象的属性、方法,然后通过实…...

区块链技术:重塑供应链管理的未来
在当今全球化的商业环境中,供应链管理的复杂性和重要性日益凸显。从原材料采购到产品交付,供应链的每一个环节都可能影响企业的运营效率和客户满意度。随着区块链技术的兴起,供应链管理迎来了新的变革机遇。本文将深入探讨区块链技术在供应链…...

请回答集成测试和系统测试的区别,以及它们的应用场景主要是什么?
导语: 深夜收到粉丝私信:"面了5家大厂,4家都问集成测试和系统测试的区别,求大佬支招!" 作为经历过200+项目实战的测试老司机,今天用4个真实项目案例+3张原理图,带你彻底吃透这两个核心测试阶段!(文末送测试用例模板) 一、灵魂三问:到底测什么? 1.1 集成…...

SVT-AV1学习-svt_aom_get_sg_filter_level,svt_av1_selfguided_restoration_c
SVT-AV1学习-svt_aom_get_sg_filter_level,svt_av1_selfguided_restoration_c 一 函数的作用 根据编码模式,输入分辨率和快速解码标志动态计算自引导恢复(Self Guide Restoration)过滤器的启动级别,以下是详细解析; 1 参数说明 EncMode enc_m…...

第七章总结:集合
一、集合简介 Scala集合分为三大类:序列(Seq)、集(Set)、映射(Map),所有集合都扩展自Iterable特质。集合分为可变集合和不可变集合: 不可变集合:scala.collec…...

玄机靶场:apache日志分析
什么是Apache日志 Apache日志是Apache Web服务器在处理HTTP请求时记录的所有事件的详细信息。Apache是全球最受欢迎的Web服务器软件之一,支持约30.2%的所有活跃网站。Apache通过记录每次请求的信息,包括时间、来源IP、请求的资源等,帮助分…...

Laravel 使用 事件和监听器实现 数据状态变更
首先知道事件是什么 1.事件的概念 事件(Event)是 Laravel 中实现观察者模式的一种机制,它允许应用程序中的不同部分进行松耦合的通信。 通俗一点就是,发生在应用程序中的动作或者事情。例如: 用户注册成功后,需要发邮件&#…...

uniapp App页面通过 web-view 调用网页内方法
先是报这个错 A parser-blocking, cross site (i.e. different eTLD1) script, https://api.map.baidu.com/getscript?v3.0&akpgJsRF87Fjia&services&t20250225111334, is invoked via document.write. The network request for this script MAY be blocked by t…...

Daz3D角色UE5材质优化
解决Daz3D人物角色导入UE5后材质不真实的问题 1. 引言:跨平台3D资产传输中的材质保真度挑战 在当今的数字内容创作领域,对高质量3D人物角色的需求日益增长,广泛应用于游戏开发、电影制作、虚拟现实等多种应用场景。Daz3D因其丰富的人物模型…...

Android studio
问题:没有界面可以操作,页面没有hello wolrd 原因:gradle没同步完,依赖项没有下载完整,所以布局预览看不了...

Playwright快照测试:如何让UI回归测试变得轻松高效
引言 使用带有模拟数据的PlaywrightP快照可以显著提高UI回归测试的速度。它能够快速自动化检查三大主流浏览器(Chromium、Firefox、Webkit)中的 UI 元素。你可以将多个断言绑定到一个快照上,这极大地提高了 UI 测试的效率。在 GUI 应用快速扩…...

控制理论-传递函数
【硬核】终于有人把传递函数和卷积定理讲明白了!自动控制原理入门-传递函数 | 卷积定理 | 频率响应 | 喵星考拉...

虚拟世界的AI魔法:AIGC引领元宇宙创作革命
云边有个稻草人-CSDN博客——个人主页 热门文章_云边有个稻草人的博客-CSDN博客——本篇文章所属专栏 ~ 欢迎订阅~ 目录 1. 引言 2. 元宇宙与虚拟世界概述 2.1 什么是元宇宙? 2.2 虚拟世界的构建 3. AIGC在元宇宙中的应用 3.1 AIGC生成虚拟世界环境 3.2 AIGC…...

带QT界面的文件管理系统
下载地址 下载&完整介绍地址:https://www.mcso.top/course-design/qt-filesystem/ 开源地址:https://github.com/mcdudu233/FileSystem.git 软件包含 (1)设计数据的结构 (2)设计文件管理系统 &…...
)
【区块链安全 | 第二十六篇】表达式与控制结构(二)
文章目录 表达式与控制结构赋值结构化赋值与返回多个值数组和结构体的赋值复杂性作用域和声明检查或不检查的算术运算错误处理:Assert、Require、Revert 和异常通过 assert 进行 Panic 和通过 require 进行 Errorreverttry/catch表达式与控制结构 赋值 结构化赋值与返回多个…...

2025年前端框架全景解析:React、Vue、Angular的生态与未来之争
一、市场格局:全球与国内的双重差异12 全球市场React:凭借Facebook的支持和庞大的社区,全球使用率超40%,尤其在数据密集型应用(如金融、社交平台)中占据主导。其跨平台能力(React Native)和灵活生态(Next.js、Redux)是核心竞争力。Vue:亚洲市场占比显著,中国开发者…...

【VScode】C/C++使用教程
编辑器 1. VScode本质上是一款代码编辑器,上面包含了许多插件。 VScode下载 1. 下载链接:Download Visual Studio Code - Mac, Linux, Windowshttps://code.visualstudio.com/download2. 在拓展部分下载汉化包:Chinese。 编译器 1. 我们使用M…...

【Node】如何使用PM2高效部署nodejs前端应用
引言 Node.js 这个服务端 JavaScript 运行时,能帮你打造高性能的实时 Web 和移动应用。不过相比传统的 Apache 或 Nginx 这类 Web 服务器,Node 应用的管理可要多花点心思。 PM2 就是专为生产环境设计的 Node 应用进程管理系统。这篇指南将手把手教你安…...
——图的概念,图的存储,图的遍历与图的拓扑排序)
从零开始的图论讲解(1)——图的概念,图的存储,图的遍历与图的拓扑排序
目录 前言 图的概念 1. 顶点和边 2. 图的分类 3. 图的基本性质 图的存储 邻接矩阵存图 邻接表存图 图的基本遍历 拓扑排序 拓扑排序是如何写的呢? 1. 统计每个节点的入度 2. 构建邻接表 3. 将所有入度为 0 的节点加入队列 4. 不断弹出队头节点,更新其…...

无人机双频技术及底层应用分析!
一、双频技术的核心要点 1. 频段特性互补 2.4GHz:穿透力强、传输距离远(可达5公里以上),适合复杂环境(如城市、建筑物密集区),但易受Wi-Fi、蓝牙等设备的干扰。 5.8GHz:带宽更…...

基础知识补充篇:认识区块链浏览器
专栏:区块链入门到放弃查看目录-CSDN博客文章浏览阅读218次。为了方便查看将本专栏的所有内容列出目录,按照顺序查看即可。https://blog.csdn.net/qq_22502303/article/details/147022618?spm=1001.2014.3001.5501 前言 在《基础知识补充篇:什么是区块链RPC节点》文中笔者…...

git rebase复杂场景验证
经常面临复杂的分支管理,这里对几种场景的行为做一些验证。 结论总结 git rebase br_name:等价与新建br_name分支,然后找到当前分支与br_name分支的分叉点。然后把分叉点以后的提交(当前分支)一个一个的cherry-pick过…...

安宝特应用 | 工业AR技术赋能高端制造领域验收流程数字化转型
引言 随着高端制造行业对效率与安全要求的不断提升,传统验收模式正迎来智能化升级。针对特殊行业产品验收过程中存在的跨区域协作难、人工核验效率低等痛点,基于AR增强现实技术的智能验收方案正在成为转型新方向。 01 可视化协同提升验收效能 安宝特AR…...

Spring启示录、概述、入门程序以及Spring对IoC的实现
一、Spring启示录 阅读以下代码: dao package org.example1.dao;/*** 持久层* className UserDao* since 1.0**/ public interface UserDao {/*** 根据id删除用户信息*/void deleteById(); } package org.example1.dao.impl;import org.example1.dao.UserDao;/**…...

Oracle 23ai Vector Search 系列之4 VECTOR数据类型和基本操作
文章目录 Oracle 23ai Vector Search 系列之4 VECTOR数据类型和基本操作VECTOR 数据类型基本语法Vector 维度限制和向量大小向量存储格式(DENSE vs SPARSE)1. DENSE存储2. SPARSE存储3. 内部存储与空间计算 Oracle VECTOR数据类型的声明格式VECTOR基本操…...

如何用开源工具,把“定制动漫面具”做成柔性制造?
原文链接:https://www.nocobase.com/cn/blog/kigland。 引言 在苏州,有一支团队正在悄悄改变个性化制造的方式。他们不做快消品,也不靠规模取胜,却在全球角色扮演爱好者圈子里收获了不少“忠粉”。 他们叫 KIGLAND,一…...

《命理学》专项探究与研习
基础论调 八字是什么 八字:用天干地支表示一个人的出生时间 例如: 如上图:某人的干支历出生时间:甲申年--己巳月--戊戌日--癸丑时 十天干 甲乙丙丁戊己庚辛壬癸 奇数位为阳,偶数位为阴 十二地支 子丑寅卯辰巳午未申酉…...

Linux 指令初探:开启终端世界的大门
前言 当我们初次接触 Linux,往往会被一串串在黑底屏幕中跳动的字符震撼甚至吓退。然而,正是这些看似晦涩的命令,构建了服务器、嵌入式系统乃至云计算的世界。 本篇将带你从最基础的 Linux 指令开始,逐步揭开命令行的神秘面纱。从…...

CentOS 7 yum 无法安装软件的解决方法
一、解决方法 1、备份原有的 CentOS 7 默认 YUM 源配置文件 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup2、从阿里云镜像源下载 CentOS 7 的 YUM 源配置文件,并覆盖原有的配置文件 wget -O /etc/yum.repos.d/CentOS-Base.re…...

oracle 游标的管理
8.2.1游标的概念和类型 游标(CURSOR)存储于服务器端,当服务器执行了一个查询后,查询返回的记录集存放在光标中,通过光标上的操作可以把这些记录检索到客户端的应用程序。光标是一种变量,它对应于一个查询语句确定的结果集。它用于…...

深入理解PCA降维:原理、实现与应用
1. 引言 在机器学习与数据科学领域,我们经常会遇到高维数据带来的"维度灾难"问题。随着特征数量的增加,数据稀疏性、计算复杂度等问题会显著加剧。主成分分析(PCA, Principal Component Analysis)作为一种经典的降维技术,能够有效解…...
》)
AI重构农业:从“面朝黄土“到“数字原野“的产业跃迁—读中共中央 国务院印发《加快建设农业强国规划(2024-2035年)》
在东北黑土地的万亩良田上,无人机编队正在执行精准施肥作业;在山东寿光的智慧大棚里,传感器网络实时调控着番茄生长的微环境;在云南的咖啡种植园中,区块链溯源系统记录着每粒咖啡豆的旅程。这场静默的农业革命…...

当前主流的LLM Agent架构、能力、生态和挑战
一、LLM Agent的基本架构 尽管LLM Agent的具体实现五花八门,但大部分系统在架构层面上可以归纳为以下几个关键模块: 感知(Perception) Agent需要感知外界的信息。对于文本环境,感知往往是读取输入(如用户指…...

网站缓存怎么检查是否生效?
为何选择CDN缓存技术? 部署内容缓存系统可有效提升网页响应效率,降低服务器资源占用与流量消耗,改善访客交互体验,强化系统架构容错能力,促进搜索引擎优化效果,达成资源分配与运行效能的动态平衡。 科学配…...

Qt的稳定版本与下载
Qt的稳定版本主要包括Qt5和Qt6的长期支持(LTS)版本。以下是详细的版本信息: Qt5的稳定版本 Qt5.6 LTS:2016年3月15日发布,是一个长期支持版本。 Qt5.9 LTS:2017年6月16日发布,也…...

用 OpenCV 给图像 “挑挑拣拣”,找出关键信息!
目录 一、背景 二、OpenCV 关键词提取基础概念 什么是关键词提取 OpenCV 在关键词提取中的作用 三、OpenCV 关键词提取的流程 整体流程概述 详细步骤及作用 流程图 四、OpenCV 关键词提取的代码实现 环境准备 代码演示 代码说明 五、常见问题及解决方法 特征提取不…...
))
14-Hugging Face 模型微调训练(基于 BERT 的中文评价情感分析(二分类))
1. datasets 库核心方法 1.1. 列出数据集 使用 datasets 库,你可以轻松列出所有 Hugging Face 平台上的数据集: from datasets import list_datasets # 列出所有数据集 all_datasets list_datasets() print(all_datasets)1.2. 加载数据集 你可以通过…...

php-cgi参数注入攻击经历浅谈
起因: 阿里云服务器再次警告出现挖矿程序。上一次服务器被攻击后,怕有恶意程序残留,第一时间重装了系统,也没有详查攻击入口。不过事后还是做了一些防范,这台留作公网访问的服务器上并未保留业务数据,只作…...

istio流量治理——重试
Istio 的重试功能的底层原理主要依赖于其数据平面组件 Envoy 代理(Sidecar 或 Gateway)的实现。Envoy 是一个高性能的代理服务器,负责处理所有流入和流出的流量,并在 Istio 的服务网格中执行流量管理策略,包括重试逻辑…...

Spring Cloud之服务入口Gateway之Route Predicate Factories
目录 Route Predicate Factories Predicate 实现Predicate接口 测试运行 Predicate的其它实现方法 匿名内部类 lambda表达式 Predicate的其它方法 源码详解 代码示例 Route Predicate Factories The After Route Predicate Factory The Before Route Predicate Fac…...

测试分类篇
文章目录 目录1. 为什么要对软件测试进行分类2. 按照测试目标分类2.1 界面测试2.2 功能测试2.3 性能测试2.4 可靠性测试2.5 安全性测试2.6 易用性测试 3. 按照执行方式分类3.1 静态测试3.2 动态测试 4. 按照测试方法分类4.1 白盒测试4.1.1 语句覆盖4.1.2 判定覆盖4.1.3 条件覆盖…...
)
Django接入 免费的 AI 大模型——讯飞星火(2025年4月最新!!!)
上文有介绍deepseek接入,但是需要 付费,虽然 sliconflow 可以白嫖 token,但是毕竟是有限的,本文将介绍一款完全免费的 API——讯飞星火 目录 接入讯飞星火(免费) 测试对话 接入Django 扩展建议 接入讯飞星火…...

使用NVM下载Node.js管理多版本
提示:我解决这个bug跟别人思路可能不太一样,因为我是之前好用,换个项目就不好使了,倦了 文章目录 前言项目场景一项目场景二解决方案:下载 nvm安装 nvm重新下载所需Node 版本nvm常用命令 项目结构说明 前言 提示&…...