深度学习中模型量化那些事
在深度学习中模型量化可以分为3块知识点,数据类型、常规模型量化与大模型量化。本文主要是对这3块知识点进行浅要的介绍。其中数据类型是模型量化的基本点。常规模型量化是指对普通小模型的量化实现,通常止步于int8的量化,绝大部分推理引擎都支持该能力。而大模型的量化,需要再cuda层次进行能力的扩展,需要特殊的框架支持。
1、深度学习中的数据类型
1.1 常见的数据类型
在深度学习中常见的数据类型主要可以区分为int与float,在float中又可以区分为fp32、tf32、fp16、bf16等类型,这些float数据的差异在于指数位于小数位长度的差异。深度学习模型部署的参数数据类型有int64、int32、int8、int4等,int64与int32通常是用于模型进行索引操作时,int8与int4通常用于量化后模型参数的直接表示。关于模型量化还有二值量化、三值量化、稀疏量化等可以参考:https://zhuanlan.zhihu.com/p/20329244481
下图详细详细的展示了fp32、tf32、fp16、bf16等4种数据类型的差异。
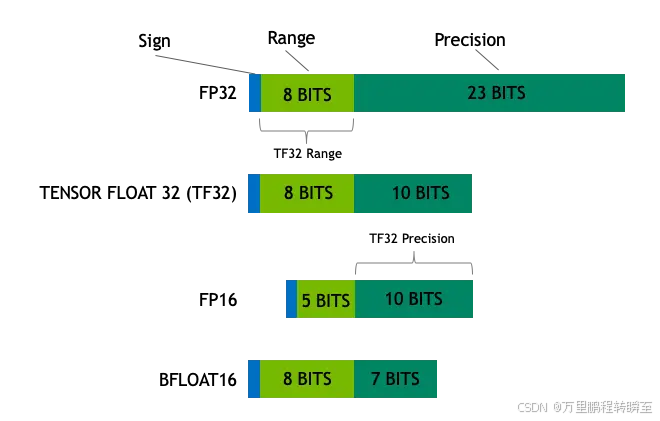
数据类型基本信息
| 数据类型 | 描述 | 特点 |
|---|---|---|
| FP32 | 32位单精度浮点数,符合IEEE 754标准,由1位符号位、8位指数位和23位尾数位组成。 | 能表示较宽的数值范围和较高的精度,可精确表示大多数实数,是深度学习中常用的默认数据类型。 |
| TF32 | 一种特殊的32位浮点数格式,主要用于NVIDIA的Tensor Core架构。它与FP32类似,但指数范围较小,为8位(与FP16相同),尾数位为23位。 | 相比传统FP32,TF32在保持一定精度的同时,能利用Tensor Core的硬件加速特性,提高计算效率。 |
| FP16 | 16位半精度浮点数,由1位符号位、5位指数位和10位尾数位组成。 | 占用空间是FP32的一半,数据传输和计算速度快,但数值范围和精度相对较低。 |
| BF16 | 16位脑浮点格式,由1位符号位、8位指数位和7位尾数位组成。 | 指数位与FP32相同,能表示较大数值范围,在精度和计算效率上有一定平衡,对某些深度学习任务能在减少内存占用的同时保持较好的模型性能。 |
| Int8 | 8位有符号整数,取值范围通常是 -128到127。 | 占用存储空间小,计算速度快,对硬件要求低,但只能表示整数,无法精确表示小数,精度有限。 |
| Int4 | 4位有符号整数,取值范围通常是 -8到7。 | 占用空间极小,是Int8存储空间的一半,计算速度更快,但精度损失更为严重,能表示的数值范围非常有限。 |
数据类型应用特性
| 数据类型 | 优势 | 劣势 | 应用场景 |
|---|---|---|---|
| FP32 | 计算精度高,模型训练和推理结果准确,适用于各种深度学习任务,尤其是对精度要求苛刻的场景。 | 占用内存和存储空间大,计算速度相对慢,在一些资源受限的环境中可能不太适用。 | 广泛应用于图像识别、自然语言处理、语音识别等各种深度学习领域,如大型复杂神经网络的训练和推理。 |
| TF32 | 能利用专门的硬件(如NVIDIA Tensor Core)实现高效计算,在不显著降低精度的情况下提高计算速度,减少训练时间。 | 依赖特定的硬件支持,不具有广泛的兼容性,如果硬件不支持TF32,则无法发挥其优势。 | 主要用于NVIDIA支持Tensor Core的GPU设备上进行深度学习计算,特别是在处理大规模矩阵运算的神经网络中表现出色,如一些需要快速训练的深度卷积神经网络。 |
| FP16 | 减少内存占用和传输带宽,提高计算速度,降低模型存储和传输成本,适用于对实时性要求较高的场景。 | 精度有限,在一些复杂模型训练中可能出现精度损失,导致模型性能下降。 | 常用于移动端、嵌入式设备以及一些对实时性要求高的场景,如自动驾驶中的实时目标检测、移动设备上的图像分类应用等。 |
| BF16 | 在大规模数据和复杂模型处理中,能较好地平衡精度和计算效率,可减少内存占用,同时利用硬件加速提高计算速度。 | 相比FP32精度有一定损失,虽然比FP16更能保持模型准确性,但在某些对精度要求极高的任务中可能不够精确。 | 常用于数据中心的深度学习训练,尤其是针对一些大型神经网络,如大规模的语言模型训练、图像生成模型等,可利用支持BF16的硬件来提高训练效率。 |
| Int8 | 降低存储和计算成本,提高运行效率,适合内存和计算资源有限的场景,如边缘计算设备和低功耗芯片。 | 精度丢失,不适用于高精度计算任务,在将浮点数转换为Int8时可能会引入量化误差,影响模型准确性。 | 常用于边缘计算设备,如智能摄像头中的目标检测模型、工业物联网设备中的预测模型等,通过量化为Int8类型,可以在不影响太多性能的前提下,减少内存占用和计算量。 |
| Int4 | 进一步降低存储和计算成本,适用于资源极度受限的环境,如一些物联网设备。 | 精度损失严重,能表示的数值范围非常有限,对模型的准确性影响较大,需要更复杂的量化和校准技术来保证模型性能。 | 目前相对较少单独使用,主要探索用于一些特定的超轻量级模型或对存储和能耗有极致要求的场景,如某些简单的物联网传感器数据处理模型,常与其他优化技术结合使用以平衡精度和性能。 |
1.2 不同数据类型下的算力差异
以抖音百科提炼的A100显卡的算力数据,可以发现a100显卡fp32计算的算力是156TFlops,但随着数据类型的精简,算力在翻倍。

以下是RTX 3060显卡在不同数据格式下的算力情况图表:
| 数据格式 | 算力 |
|---|---|
| FP32 | 12.7 TFLOPS |
| TF32 | 无官方明确数据,一般认为在利用Tensor Core加速时接近FP16性能(由于架构设计,RTX 3060的TF32性能不像A100那样有明确区分和突出优势) |
| FP16 | 25.4 TFLOPS |
| BF16 | 无官方明确数据,推测与FP16相近或略低,因为RTX 3060硬件对BF16的支持不是特别突出 |
| INT8 | 50.8 TOPS |
| INT4 | 暂无公开的准确官方数据,考虑到其数据位宽更窄,理论上在特定计算场景下会比INT8有更高的计算吞吐量,但具体数值需根据实际测试确定。 |
需要注意的是,实际应用中的算力表现可能会受到多种因素的影响,如显存带宽、算法实现、软件优化等,以上数据仅供参考。这里也同样可以发现表示数据的位数减少一半,显卡的算力基本上可以提升一倍。同时a100的算力是3060显卡的12倍以上
量化对于精度的影响
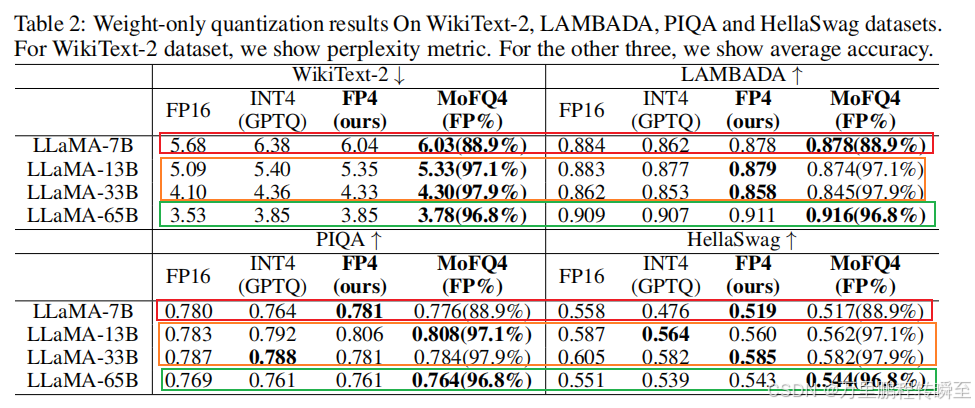
随意截取一个论文数据,可以发现对于10b以上的模型进行int量化操作基本上没有精度损失,而对于7b或更小的模型进行量化有一定的精度损失风险。
1.3 fp8与fp4
除了前面提到的各种float数据类型外,还有fp8与fp4两个不常见的类型。FP8是由Nvidia在Hopper和Ada Lovelace架构GPU上推出的数据类型,有如下两种形式:
- E4M3:具有4个指数位、3个尾数位和1个符号位
- E5M2:具有5个指数位、2个尾数位和1个符号位
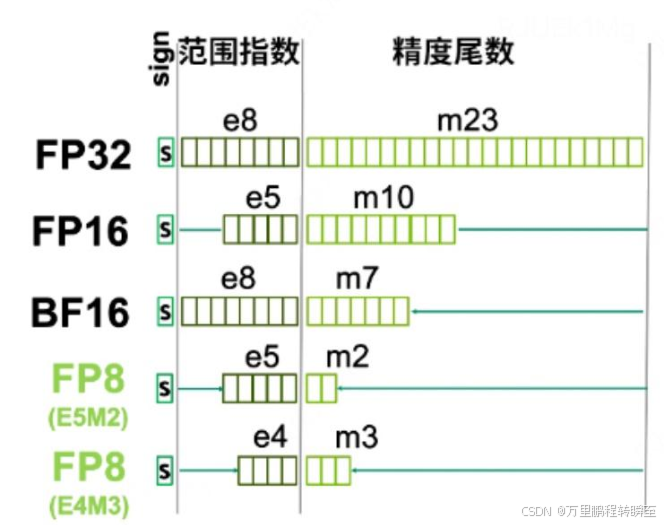
其中E4M3支持动态范围更小、精度更高的计算,而E5M2可提供更宽广的动态范围和更低的精度。LLM推理过程对精度要求较高,对数值范围要求偏低,因此FP8-E4M3更适合于LLM推理。
在论文Integer or Floating Point? New Outlooks for Low-Bit Quantization on Large Language Models中详细的对比了FP8与INT8的差异。以下是关键信息。整体来说,就是int8适用于权重的量化,fp8适用于激活值的量化。
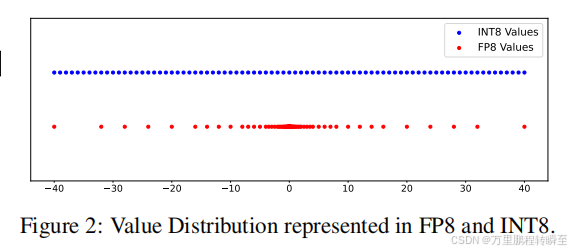
数值范围
FP8与INT8相比,整数格式在可表示范围内具有均匀的分布,两个连续数字之间的差值为1。而浮点格式由于结合了指数和尾数设计而表现出非均匀分布,从而为较小的数字提供较高的精度,为较大的数字提供较低的精度。
权重量化效果
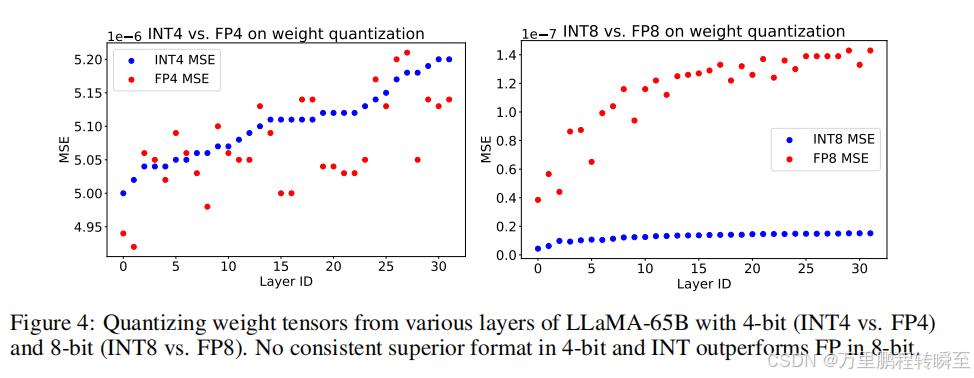
基于论文作者对于LLaMA-65B模型的权重量化实验,可以发现int8的效果部分fp8要好很多。int8量化后的差异比较稳定,而fp8量化后的差异增长较快。
这一分析结果表明,INT在8位权重量化中具有优势。然而,当位宽减小时,指数位也会减少,使得INT和FP的分布更加相似。在4位量化中,使用均匀分布的INT格式量化静态张量的优势逐渐消失,导致4位量化权重没有明确的最优解。
激活值量化
与推理过程中的静态权值张量不同,激活张量是动态的,并随着每个输入而变化。因此,校准是激活张量量化过程中确定适当尺度因子的重要步骤。作者比较了FP8和INT8量化的MSE误差,如图5所示。FP8的量化误差低于INT8因为校准过程总是在多个批次中选择最大的值来确定量化中的比例因子。这个过程倾向于为大多数批次得出一个大于合适的比例因子。然而,FP格式对于大值的精度较低,对于小值的精度较高,本质上更适合量化这种动态张量。
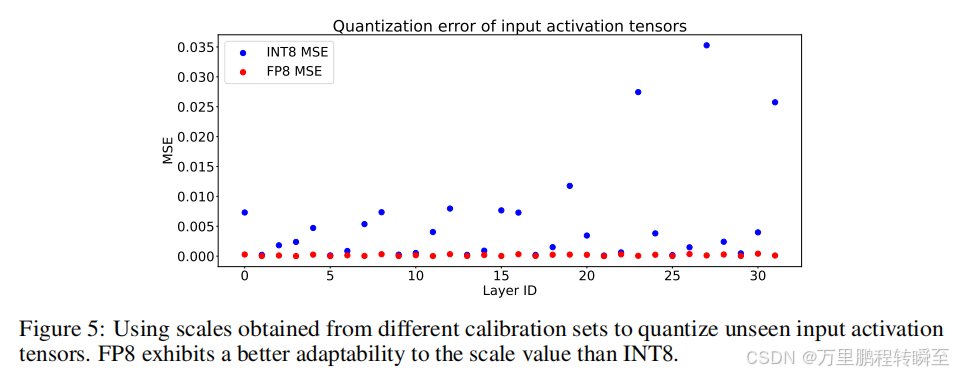
因为int8量化受极大值影响精度表示,而fp8量化不受极大值影响,反而对于极大值表示误差反而大。而极大值可能为异常值,int8量化为极大值浪费精度,而fp8为极小值提供高精度,故fp8量化激活值效果更好
2、模型的常规量化
模型量化的精度越低,模型尺寸和推理内存占用越少,为了尽可能的减少资源占用,量化算法被发明。FP32占用4个字节,量化为int8,只需要1个字节。
本节内容参考:https://zhuanlan.zhihu.com/p/29140505773

2.1 量化方式的基本分类
量化可以分为对称量化与非对称量化
在对称量化中,值域为-127到127,由于模型参数不是对称分布的,故量化后权重的部分表示范围被浪费了。
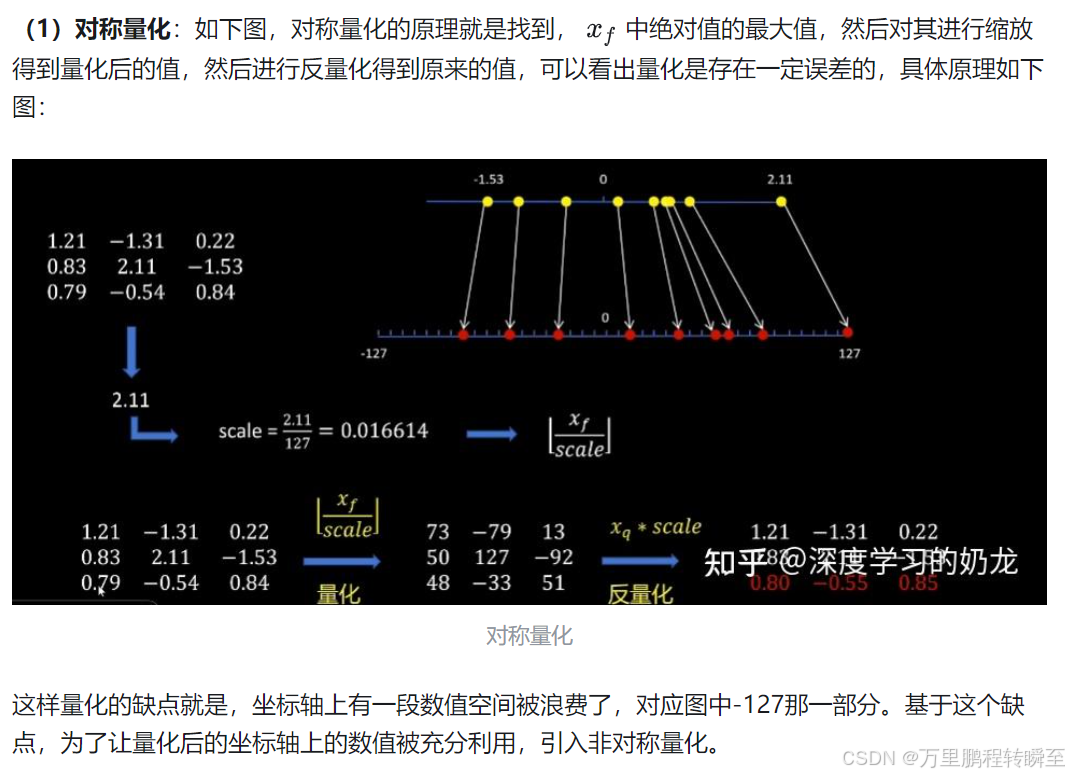
在非对称量化中,将参数的最小值平移到0点,故值域为0到255。故量化后权重的部分表示范围均被有效利用了。但非对称量化,每一次都需要多一个反平移操作,计算量略多,但精度较高。
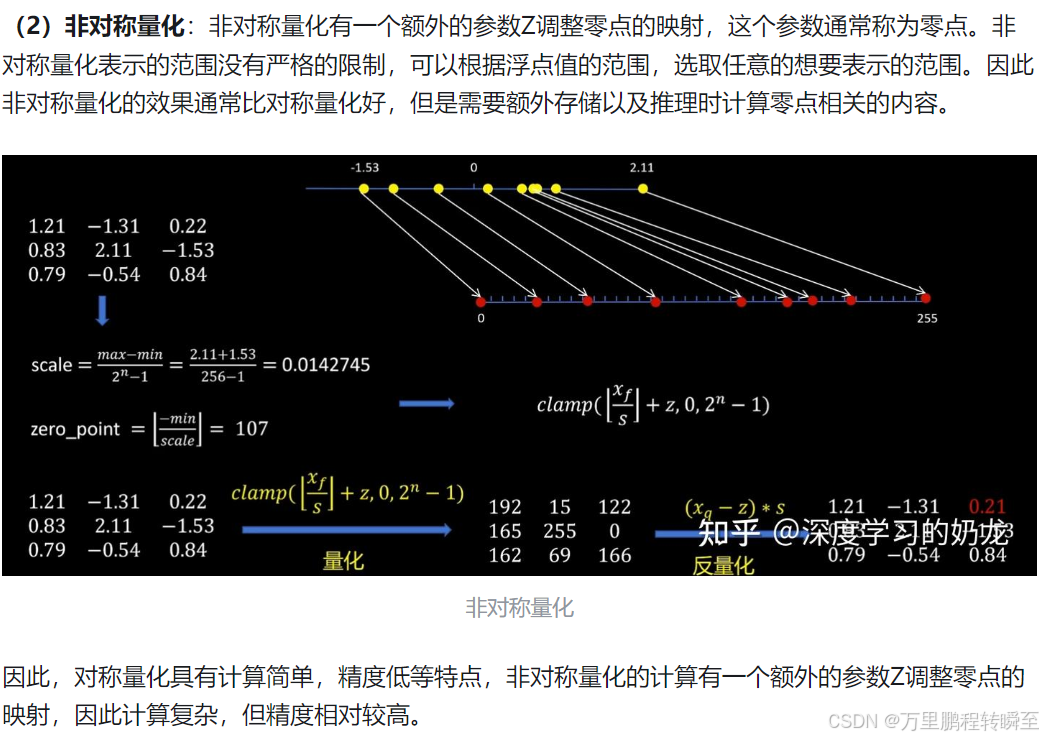
量化后的模型计算方式如下,可以看到下图,量化后的模型将float的矩阵乘法等价为 int的矩阵乘法+2个float乘法操作,该操作大幅度的发挥了机器的计算能力,同时计算误差较小。
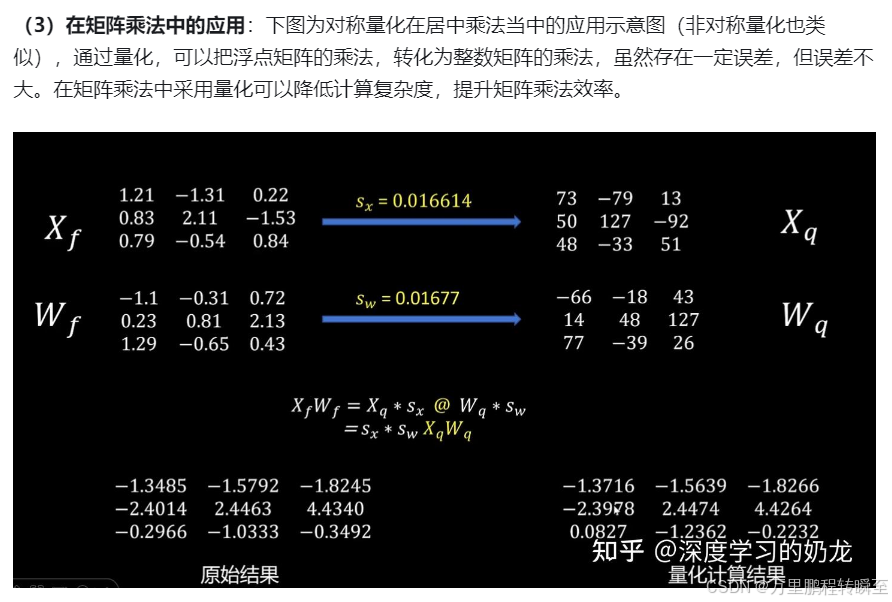
2.2 量化步骤的分类
根据量化的时机,有量化感知训练和训练后量化两条路径。PTQ(Post - Training Quantization,训练后量化)和 QAT(Quantization - Aware Training,量化感知训练)。
PTQ
- 原理:PTQ是
在模型训练完成后,对训练好的浮点数模型进行量化处理,将模型的权重和激活值从较高精度的浮点数格式转换为较低精度的定点数格式,如INT8、INT4等。其核心思想是通过对模型中的数值分布进行统计分析,确定合适的量化参数,使得量化后的模型在尽可能减少精度损失的情况下,能够在特定的硬件上高效运行。 - 优点
- 简单高效:不需要对模型的训练过程进行修改,只需在训练结束后进行一次量化操作,即可得到量化后的模型,操作相对简单,节省了大量的训练时间和计算资源。
- 通用性强:适用于各种已经训练好的模型,无论是深度学习模型还是传统的机器学习模型,只要其权重和激活值可以表示为数值形式,都可以应用PTQ进行量化。
- 缺点:由于是在训练后进行量化,无法在训练过程中考虑量化带来的误差,因此对于一些对精度要求较高的模型,可能会导致较大的精度损失。
- 应用场景:适用于对
模型精度要求不是特别高,但是希望能够快速部署到资源受限的设备上,如嵌入式设备、移动设备等,以减少模型的存储空间和计算量,提高推理速度。
在模型进行PTQ时通常需要收集部分校准数据,用于推断模型中各层的权重和激活值分布信息,用于计算每个张量(权重或激活值)的量化参数,包括量化比例因子(scale)和零点(zero - point)。这里比较重要的是激活值分布信息,不同的数据输入,激活值分布是不同的。
QAT
- 原理:QAT是一种
在模型训练过程中就考虑量化影响的技术。它通过在训练过程中模拟量化操作,将模型中的浮点数权重和激活值在训练过程中逐步转换为低精度的定点数表示。具体来说,在训练过程中的前向传播和反向传播过程中,插入量化和反量化操作,使得模型在训练过程中就能够适应量化带来的精度损失,从而在量化后能够保持较好的性能。 - 优点
- 精度保持较好:由于在训练过程中就对量化误差进行了优化,使得模型能够更好地适应量化后的数值表示,因此在量化后能够保持较高的精度,尤其适用于对精度要求较高的任务,如医学图像分析、金融风险预测等。
- 灵活性高:可以根据具体的任务和模型特点,在训练过程中动态调整量化参数,以达到最佳的量化效果。
- 缺点
- 训练时间长:由于在训练过程中增加了量化和反量化操作,以及额外的参数调整,使得训练过程变得更加复杂,训练时间也会显著增加。
- 实现复杂:需要对模型的训练框架进行一定的修改和扩展,以支持量化感知训练的相关操作,对开发人员的技术要求较高。
- 应用场景:适用于对模型精度要求严格,同时又希望通过量化来提高模型的运行效率和减少存储空间的场景,如数据中心的大规模模型部署、高性能计算等。
2.3 PAT(静态量化与动态量化)
静态量化和动态量化是模型量化中两种不同的技术方法,本质上是对PTQ的不同实现步骤。
静态量化:就是在模型推理前已经基于部分数据得到了模型的激活值的比例因子(scale)和零点(zero - point)信息。该操作会降低模型精度,但推理速度较快
动态量化:是实时根据输入数据计算比例因子(scale)和零点(zero - point)。该操作需要对每一个输入都计算量化因子,若推理引擎支持性差,可能速度提升不明显,但精度保持性好
量化时机
- 静态量化:在模型训练后部署前,根据事先收集的数据来确定量化参数,然后一次性将模型的权重和激活值按照这些固定的量化参数进行量化,整个量化过程是在训练后静态进行的,不考虑模型在实际运行时数据的动态变化。
- 动态量化:是在模型部署运行时,根据当前处理的数据动态地计算量化参数,并对数据进行量化。这意味着量化参数会随着输入数据的不同而实时调整,以更好地适应数据的动态范围。
量化参数计算方式
- 静态量化:通常基于对训练数据或一小部分代表性数据的统计分析来确定量化参数。例如,计算权重或激活值的最大值、最小值,然后根据这些统计信息计算出固定的量化比例因子和零点,这些参数在模型部署后就不再改变。
- 动态量化:在模型推理过程中,对于每个要量化的张量,会根据当前批次数据的实际分布情况实时计算量化参数。例如,对于每一批输入数据,动态地计算其均值和标准差,然后根据这些动态统计信息来调整量化比例因子,使得量化能够更好地适应数据的变化。
模型性能影响
- 静态量化:优点是实现相对简单,不需要在运行时进行复杂的参数计算,因此推理速度较快,适用于对推理速度要求较高的场景。但由于量化参数是固定的,可能无法很好地适应不同输入数据的动态范围,导致一定的精度损失,尤其是在数据分布变化较大的情况下。
- 动态量化:能够更好地适应数据的动态变化,因此在量化后通常能保持较高的精度。然而,由于需要在运行时实时计算量化参数,会增加一定的计算开销,导致推理速度相对较慢。不过,随着硬件技术的发展,一些专门的硬件架构能够高效地支持动态量化计算,使得这种方法在一些对精度要求较高的场景中得到了广泛应用。
适用场景
- 静态量化:适用于数据分布相对稳定,对模型推理速度要求较高,且能够接受一定精度损失的场景,如一些嵌入式设备或移动设备上的模型部署,这些设备通常计算资源有限,静态量化可以在不显著降低性能的前提下减少模型存储空间和计算量。
- 动态量化:更适合于数据分布复杂且变化较大,对模型精度要求较高的场景,如在数据中心或高性能计算平台上运行的模型,这些场景通常有足够的计算资源来支持动态量化所需的额外计算,同时能够通过动态量化获得更好的模型性能。
3、GPTQ与AWQ量化
GPQT与AWQ量化是常见于大模型的量化方法。GPTQ 是一种后训练量化(PTQ)方法,主要聚焦于 GPU 推理和性能提升。它基于近似二阶信息的一次性权重量化方法,能实现高精度和高效的量化。AWQ 即激活感知权重量化,由 MIT - Han Lab 开发。该方法通过观察激活值来保护显著权重,而非权重本身,在指令微调的语言模型和多模态语言模型上表现出色。
这里的两个量化方法与章节2中的量化有所差异,量化后的模型需要特殊的引擎才能推理。通常来说两个量化方式在大模型上精度保持是差不多的,但是在7b及以下小模型上的量化,awq的量化方式效果保持更好。
3.1 GPTQ量化
这里可以详细参考:https://zhuanlan.zhihu.com/p/9270075965
GPTQ(GENERATIVE POST-TRAINING QUANTIZATION)量化基于OBQ量化方式改进。OBQ是2022年提出的一种基于二阶信息的量化方法,其主要目的就是优化量化后的权重,使量化前后的模型差异值最小。GPTQ量化是一种基于静态量化的后量化方法,只需要少量校准数据即可

OBQ其主要思想是:
- 逐个量化权重:按照权重对量化误差的影响,从大到小依次选择权重进行量化。
- 调整剩余权重:每次量化一个权重后,调整未量化的权重以补偿误差。
- 利用Hessian矩阵:通过二阶导数信息,计算权重调整的最优值。
然而,OBQ量化方式计算复杂度比较高,不适用于大模型的量化。

关于GPTQ量化方式(OBD -> OBS -> OBQ ->GPTQ)的演进可以参考:https://zhuanlan.zhihu.com/p/18714878738
按照:https://zhuanlan.zhihu.com/p/9270075965的总结,GPTQ量化进行以下改进

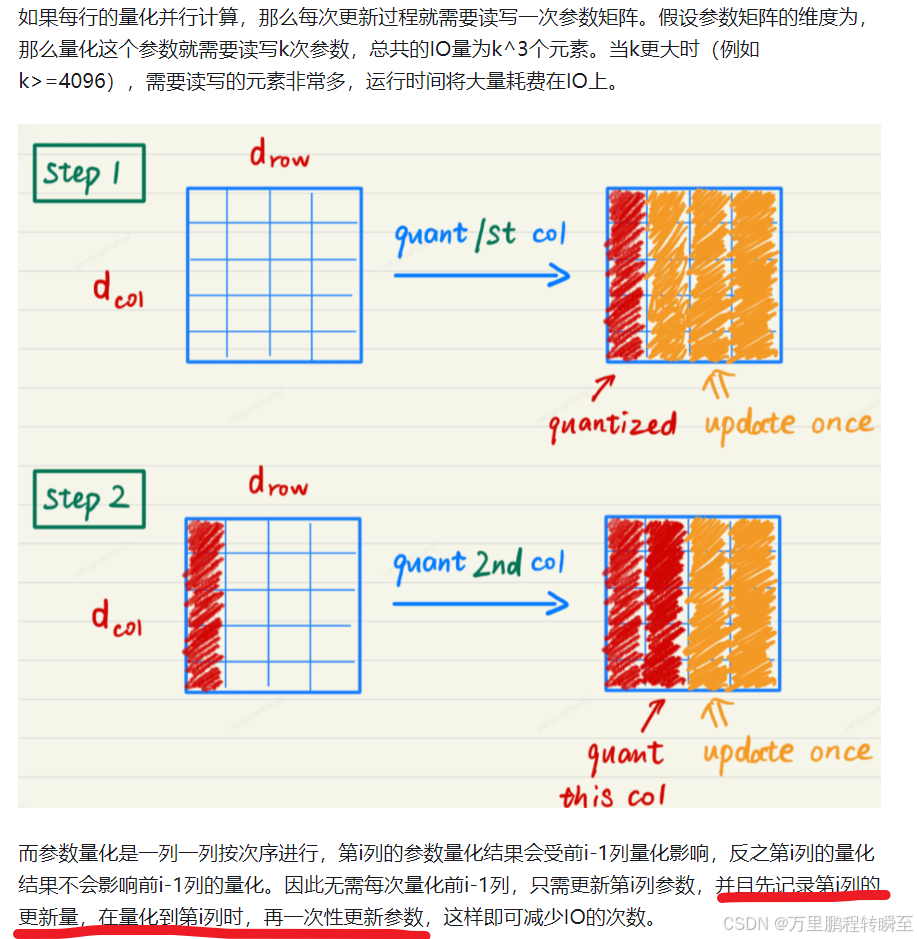
以下图片是GPTQ减少IO操作的原理示意,针对于后续列的更新,只是先累加记录更新值,不进行写操作,等到量化该列时才更新参数。
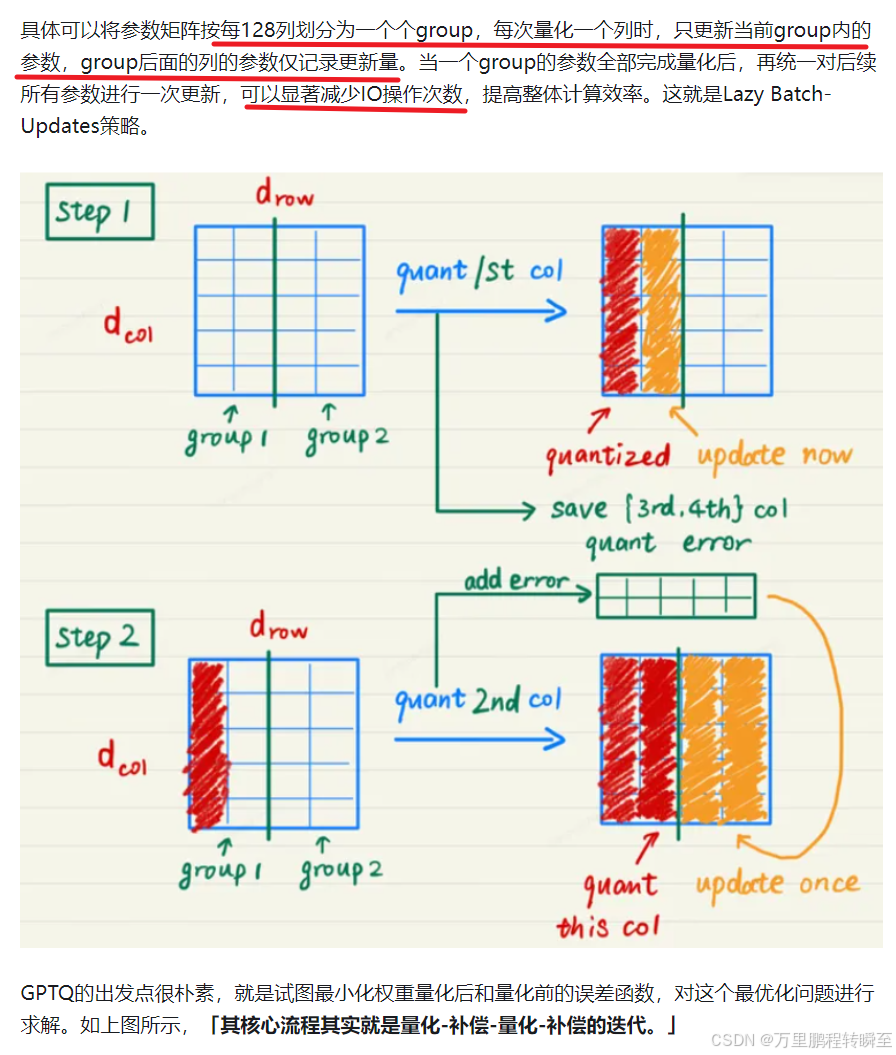
以下图片是GPTQ减少IO操作的具体流程,与原型示意相比补充了group跟新的概念,明显缓解了累加记录更新值的变量需求。

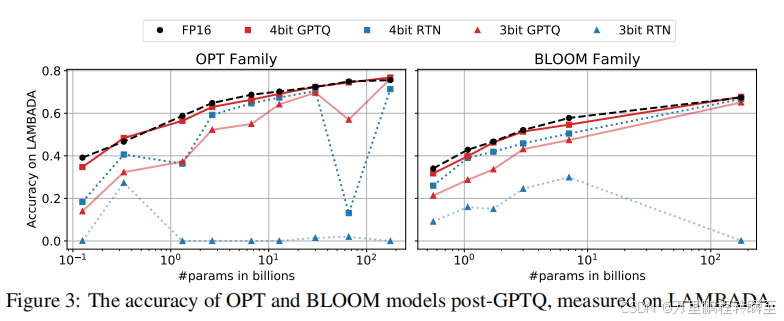
根据GPTQ论文中的数据,可以发现int4量化后于fp16保持了相同的精度
3.2 AWQ量化
激活感知权重量化 (AWQ),这是一种适合硬件的 LLM 低位权重(比如 w4)量化方法。AWQ 发现,并非所有 LLM 权重都同等重要,仅保护 1% 的显著权重便能大幅减少量化误差。AWQ 不依赖反向传播或重构,因此可以泛化到不同领域和模态而不会对校准集过拟合。
以下信息参考自:https://www.armcvai.cn/2024-11-01/llm-quant-awq.html
如何选择出重要权重
对激活值的每一列求绝对值的平均值,然后把平均值较大的一列对应的通道视作显著通道,保留 FP16 精度。

如果权重矩阵中有的元素用FP16格式存储,有的用INT4格式存储,不仅存储时很麻烦,计算时取数也很麻烦,kernel函数写起来会很抽象。于是,作者想了一个变通的方法——Scaling。
如何利用重要权重
对于所有的元素进行int量化,但引入逐通道缩放减少关键权重的量化误差,避免硬件效率问题。量化时对显著权重进行放大即引入缩放因子 s,是可以降低量化误差的。
计算缩放因子 s*
作者统计各通道的激活值平均值(计算输入矩阵各列绝对值的平均值)sX ,将此作为各通道的缩放系数。

相关文章:

深度学习中模型量化那些事
在深度学习中模型量化可以分为3块知识点,数据类型、常规模型量化与大模型量化。本文主要是对这3块知识点进行浅要的介绍。其中数据类型是模型量化的基本点。常规模型量化是指对普通小模型的量化实现,通常止步于int8的量化,绝大部分推理引擎都…...

手写JSX实现虚拟DOM
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》 🍚 蓝桥云课签约作者、…...

Redis的Spring客户端的使用
Redis 的 Spring 客户端使用 前面使用 Jedis 时, 是借助 Jedis 对象中的各种方法来对 Redis 进行操作. 而在 Spring 框架中, 则是通过 StringRedisTemplate 来操作 Redis. 最开始提供的类是 RedisTemplate, StringRedisTemplate 是 RedisTemplate 的子类, 专门用于处理文本数据…...

7.4 SVD 的几何背景
一、SVD 的几何解释 SVD 将矩阵分解成三个矩阵的乘积: ( 正交矩阵 ) ( 对角矩阵 ) ( 正交矩阵 ) (\pmb{正交矩阵})\times(\pmb{对角矩阵})(\pmb{正交矩阵}) (正交矩阵)(对角矩阵)(正交矩阵),用几何语言表述其几何背景: ( 旋转 ) ( 伸缩 )…...

WEB安全--内网渗透--LMNTLM基础
一、前言 LM Hash和NTLM Hash是Windows系统中的两种加密算法,不过LM Hash加密算法存在缺陷,在Windows Vista 和 Windows Server 2008开始,默认情况下只存储NTLM Hash,LM Hash将不再存在。所以我们会着重分析NTLM Hash。 在我们内…...

BN 层做预测的时候, 方差均值怎么算
✅ 一、Batch Normalization(BN)回顾 BN 层在训练和推理阶段的行为是不一样的,核心区别就在于: 训练时用 mini-batch 里的均值方差,预测时用全局的“滑动平均”均值方差。 🧪 二、训练阶段(Trai…...
)
【AI热点】meta新发布llama4深度洞察(快速认知)
以下是一份针对新发布的 Llama 4 模型的深度洞察报告。报告将从模型家族整体概览、技术创新与架构特点、功能与性能表现、多模态与超长上下文、与主流竞品比较、应用场景与未来展望六大部分进行分析和总结。 一、Llama 4 家族整体概览 家族成员 Llama 4 Scout 总参数量约 10…...

大厂机考——各算法与数据结构详解
目录及其索引 哈希双指针滑动窗口子串普通数组矩阵链表二叉树图论回溯二分查找栈堆贪心算法动态规划多维动态规划学科领域与联系总结 哈希 学科领域:计算机科学、密码学、数据结构 定义:通过哈希函数将任意长度的输入映射为固定长度…...

前端面试的ACM模式笔试输入模式
在前端面试的ACM模式笔试中,输入参数的读取是核心技能之一,以下是常见场景的代码实现及注意事项: 一、JavaScript的两种输入模式 1. V8模式(浏览器环境/部分OJ平台) • 核心方法:通过 read_line() 或 rea…...

AIP-215 API特定proto
编号215原文链接AIP-215: API-specific protos状态批准创建日期2018-10-01更新日期2018-10-01 API通常使用API特定proto定义,偶尔依赖通用组件。保持API相互隔离可以避免版本问题和客户端库打包问题。 指南 所有特定于某个API的protos 必须 位于带有主版本号的包…...

计算机毕业设计指南
哈喽各位大四的小伙伴们,以下是一份详细的计算机专业毕业设计指南,涵盖选题、流程、技术选型、开发建议和常见问题解决方案,帮助你高效完成毕业设计,如有其他问题,欢迎点击文章末尾名片进行咨询,可免费赠送…...

内网渗透-Linux提权之suid提权
Linux提权之suid提权 suid简介 在Linux系统中的文件,通常有rwx也就是读、写、执行三种权限,但其实还有第四种权限,也就是suid权限。在执行拥有suid权限的文件的过程中,会获得文件属主的权限。例如,当cat命令具有suid…...

FreeCAD傻瓜教程-钣金工作台SheetMetal的安装和简单使用
起因: 因为需要在平面上固定一段比较短的铝型材,角码太占用横向空间,所以想做两个Z字固定片,将型材从两端进行螺丝固定。在绘图的时候想到,板材折弯后的长度。开孔位置等都会有所变化,如何确定相关的尺寸&a…...
)
语法: ptr=malloc(size)
MALLOC( ) 语法: ptrmalloc(size) 参数: size是一个整数,表示被分配的字节个数; 返回值: 如果允许的话,返回值是一个指向被分配存储器的指针;否则的话, 返回值是一个非指针; 功能: 该函数用来分配一定大小的空间给一个对象,其大小为size,但该空间的值为不确定值; 有…...
安卓开发中的滚动布局(ScrollView / HorizontalScrollView)使用详解)
(五)安卓开发中的滚动布局(ScrollView / HorizontalScrollView)使用详解
在安卓开发中,滚动布局是一种非常重要的布局方式,它允许用户在屏幕上滚动查看超出屏幕范围的内容。本文将详细讲解滚动布局的基本概念、主要属性、代码示例以及具体的使用场景,帮助开发者深入理解并灵活运用。 基本概念 滚动布局本质上是一个…...

Matlab:三维绘图
目录 1.三维曲线绘图命令:plot3 实例——绘制空间直线 实例——绘制三角曲线 2.三维曲线绘图命令:explot3 3.三维网格命令:mesh 实例——绘制网格面 实例——绘制山峰曲面 实例——绘制函数曲线 1.三维曲线绘图命令:plot3 …...

Java中String、Array、List的相互转换工具类
Java中的数组与集合类的使用,系列文章: 《Java数组》 《Java集合类》 《Java中String、Array、List的相互转换工具类》 《Java8使用Stream流实现List列表的查询、统计、排序、分组》 《Java实现List集合的排序:Comparable接口、Comparator接口、stream().sorted()方法的使用…...

【HFP】蓝牙HFP应用层核心技术研究
免提配置文件(Hands-Free Profile, HFP)作为实现设备间音频通信的关键协议,广泛应用于车载系统、蓝牙耳机等场景。本文将基于最新技术规范,深入剖析HFP应用层的功能要求、协议映射及编解码器支持,为蓝牙开发工程师提供详尽的技术指南。 一、HFP应用层功能全景图 HFP定义…...
)
P1734 最大约数和(dp)
题目描述 选取和不超过 S 的若干个不同的正整数,使得所有数的约数(不含它本身)之和最大。 输入格式 输入一个正整数 S。 输出格式 输出最大的约数之和。 输入输出样例 输入 #1复制 11 输出 #1复制 9 说明/提示 【样例说明】 取数…...
)
P1596 [USACO10OCT] Lake Counting S(DFS)
题意翻译 由于近期的降雨,雨水汇集在农民约翰的田地不同的地方。我们用一个 NM(1≤N≤100,1≤M≤100) 的网格图表示。每个网格中有水(W) 或是旱地(.)。一个网格与其周围的八个网格相连,而一组相连的网格视…...

ROS Bag 数据裁剪教程
ROS Bag 数据裁剪教程 文章目录 ROS Bag 数据裁剪教程1. Bag 数据显示2. Bag 数据裁剪2.1 基本命令2.2 过滤更多条件2.3 注意事项 在使用 ROS 进行机器人开发和调试时,我们经常需要使用 rosbag 工具来记录和回放传感器数据、日志等信息。本文将介绍如何使用 rosba…...

AF3 OpenFoldDataLoader类解读
AlphaFold3 data_modules 模块的 OpenFoldDataLoader 类继承自 PyTorch 的 torch.utils.data.DataLoader。该类主要对原始 DataLoader 做了批数据增强与控制循环迭代次数(recycling)相关的处理。 源代码: class OpenFoldDataLoader(torch.utils.data.DataLoader):def __in…...
)
基于内容的课程推荐网站的设计与实现00(SSM+htmlL)
基于内容的课程推荐网站的设计与实现(SSMhtml) 该系统是一个基于内容的课程推荐网站,旨在为用户提供个性化的课程推荐。系统包含多个模块,如教学视频、教学案例、课程信息、系统公告、个人中心和后台管理。用户可以通过首页访问不同的课程分类ÿ…...
)
【Linux网络】以太网(数据链路层)
认识以太网 两台主机在同一个局域网下是可以进行通信的,因为每台主机都有自己的标识符. 太网是负责直接相连的两个设备之间的可靠数据传输,"以太网" 不是一种具体的网络, 而是一种技术标准; 既包含了数据链路层的内容, 也包含了一些物理层的内容.在局域网中&#x…...

大模型学习五:DeepSeek Janus-Pro-7B 多模态半精度本地部署指南:环境是腾讯cloudstudio高性能GPU 16G免费算力
一、说明介绍 由于前面玩过了,所以啥也别说,就是显存不够玩,要优化,没钱就是这么回事,看下图,显存实际只有15360M,确实是16G 如何获取算力 二、如何获取算力 1、进入网址 Cloud Studio 2、没有…...

Spring 中的事务
🧾 一、什么是事务? 🧠 通俗理解: 事务 一组操作,要么全部成功,要么全部失败,不能只做一半。 比如你转账: A 账户扣钱B 账户加钱 如果 A 扣了钱但 B 没收到,那就出问…...

2025-04-06 NO.2 Quest3 基础配置与打包
文章目录 1 场景配置1.1 开启手势支持1.2 创建 OVRCameraRig1.3 创建可交互 Cube 2 打包配置 环境: Windows 11Unity6000.0.42f1 Quest3 开发环境配置见 2025-03-17 NO.1 Quest3 开发环境配置教程_quest3 unity 开发流程-CSDN博客。 1 场景配置 1.1 开启手势支持 …...
)
人脸考勤管理一体化系统(人脸识别系统,签到打卡)
人脸考勤管理一体化系统 项目介绍 本项目是基于Flask、SQLAlchemy、face_recognition库的人脸考勤管理一体化系统。 系统通过人脸识别技术实现员工考勤打卡、人脸信息采集、人脸模型训练等功能。 项目采用前后端分离的技术框架,基于Flask轻量级Web框架搭建后端服务…...

LeetCode 每日一题 2025/3/31-2025/4/6
记录了初步解题思路 以及本地实现代码;并不一定为最优 也希望大家能一起探讨 一起进步 目录 3/31 2278. 字母在字符串中的百分比4/1 2140. 解决智力问题4/2 2873. 有序三元组中的最大值 I4/3 2874. 有序三元组中的最大值 II4/4 1123. 最深叶节点的最近公共祖先4/5 1…...

mybatis plus 实体类基于视图,更新单表的时候报视图或函数‘v_视图名‘不可更新,因为修改会影响多个基表的错误的简单处理方法。
1、之前的文章中写了一下基于视图的实体,因为当前测试通过了,可能有缓存。 2、然后今天又用到了这个方法,发现报错了: 建了一下视图,将实体类绑定到了视图中,并不是原表中。 3、用mybatis提供的注解或者x…...
;)
语法: i8=make8( var, offset);
MAKE8( ) 语法: i8make8( var, offset); 参数: var是16位或32位整数; offset是字节的偏移量,为1,2或3; 返回值: 返回值是一个8位整数; 功能: 该函数用来摘取以var为基址, offset为偏移量,所指向单元的字节;除了执行单字节复制之外,还相当于i8( ( var>>(offset…...

Seata TCC模式是怎么实现的?
Seata TCC 模式实现原理 TCC(Try-Confirm-Cancel)是 Seata 提供的分布式事务解决方案之一,适用于 高并发、高性能 场景,通过 业务补偿 保证最终一致性。其核心思想是将事务拆分为三个阶段: Try:预留资源(冻结数据,检查约束)。Confirm:确认提交(真正扣减资源)。Can…...

sentinel新手入门安装和限流,热点的使用
1 sentinel入门 1.1下载sentinel控制台 🔗sentinel管理后台官方下载地址 下载完毕以后就会得到一个jar包 1.2启动sentinel 将jar包放到任意非中文目录,执行命令: java -jar 名字.jar如果要修改Sentinel的默认端口、账户、密码ÿ…...

对责任链模式的理解
对责任链模式的理解 一、场景1、题目【[来源](https://kamacoder.com/problempage.php?pid1100)】1.1 题目描述1.2 输入描述1.3 输出描述1.4 输入示例1.5 输出示例 二、不采用责任链模式1、代码2、缺点 三、采用责任链模式1、代码2、优点 四、思考 一、场景 1、题目【来源】 …...
:RAG系统)
AGI大模型(11):RAG系统
1 RAG概念 RAG(Retrieval Augmented Generation)顾名思义,通过检索外部数据,增强大模型的生成效果。 RAG即检索增强生成,为LLM提供了从某些数据源检索到的信息,并基于此修正生成的答案。RAG基本上是Search + LLM 提示,可以通过大模型回答查询,并将搜索算法所找到的信…...

请问你了解什么测试方法?
测试方法在软件测试中是保障软件质量的关键手段,我将从黑盒测试、白盒测试、灰盒测试等方面为你介绍常见的测试方法: 黑盒测试方法 黑盒测试把软件看作一个黑盒子,不考虑内部结构和实现细节,只关注输入和输出。 等价类划分法:将输入数据划分为有效等价类和无效等价类,从…...
)
【springcloud】快速搭建一套分布式服务springcloudalibaba(三)
第三篇 基于nacos搭建分布式项目 分布式事务(分布式锁事务) 项目所需 maven nacos java8 idea git mysql(下单) redis(分布式锁) 本文主要讲解客户下单时扣减库存的操作,网关系统/用户系统/商品系统/订单系统 请先准备好环境࿰…...

Nginx-keepalived-高可用
Nginx 高可用 通常 借助 Keepalived 实现, Keepalived 能通过 VRRP (虚拟路由冗余协议)让多个 Nginx 服务器 组成一个 热备集群,当主服务器故障时自动切换到备用服务器,保障服务不间断。 一、环境准备 角色IP 地址主…...
——欧拉系统硬盘挂载、网络配置以及Docker环境安装)
Linux系统管理(十九)——欧拉系统硬盘挂载、网络配置以及Docker环境安装
挂载硬盘 如果数据盘在安装操作系统的时候没有挂载,需要自己做一下硬盘的挂载 查看需要挂载硬盘的路径 fdisk -l这里的可挂载的硬盘路径为:/dev/sdb MBR分区方式转换成GPT MBR分区能挂载的硬盘空间有限,无法挂载全部硬盘空间࿰…...

vue记忆卡牌游戏
说明: 我希望用vue做一款记忆卡牌游戏 游戏规则如下: 游戏设置:使用3x4的网格,包含3对字母(A,B,C,D,E,F)。 随机洗牌:初始字母对被打乱顺序,生成随机布局。 游戏流程:…...

LearnOpenGL-笔记-其九
今天让我们完结高级OpenGL的部分: Instancing 很多时候,在场景中包含有大量实例的时候,光是调用GPU的绘制函数这个过程都会带来非常大的开销,因此我们需要想办法在每一次调用GPU的绘制函数时尽可能多地绘制,这个过程就…...

开源软件与自由软件:一场理念与实践的交锋
在科技的世界里,“开源软件”和“自由软件”这两个词几乎无人不知。很多人或许都听说过,它们的代码是公开的,可以供所有人查看、修改和使用。然而,若要细究它们之间的区别,恐怕不少朋友会觉得云里雾里。今天࿰…...

关于使用HAL_ADC_Start函数时为什么要放在while里的解释
HAL_ADC_Start() 是一个用于启动 ADC(模数转换器)转换的函数,那为什么有时候我们会看到它被放在 while 循环里呢?其实取决于你使用的是哪种ADC采样方式,我们来细说👇: 🧠 一、先搞清…...

Qt 入门 2 之窗口部件 QWidget
Qt 入门2之窗口部件 QWidget Qt Creator 提供的默认基类只有QMainWindow、QWidget和QDialog 这3种,这3种窗体也是以后用得最多的,QMainWindow是带有菜单栏和工具栏的主窗口类,QDialog是各种对话框的基类,而它们全部继承自QWidget。不仅如此,其实所有的窗…...

在 Windows 上安装 WSL Ubuntu 的完整避坑指南:从报错到成功运行
问题背景 最近在尝试通过 Windows Subsystem for Linux (WSL) 安装 Ubuntu 时,遇到了一系列报错。最初的步骤是直接使用 wsl --install 命令,但安装完成后发现系统中并未自动安装默认的 Ubuntu 发行版。随后尝试通过命令行手动选择发行版&a…...
 | 零基础入门STM32第九十四步)
STM32看门狗原理与应用详解:独立看门狗 vs 窗口看门狗(上) | 零基础入门STM32第九十四步
主题内容教学目的/扩展视频看门狗什么是看门狗,原理分析,启动喂狗方法,读标志位。熟悉在程序里用看门狗。 师从洋桃电子,杜洋老师 📑文章目录 一、看门狗核心原理1.1 工作原理图解1.2 经典水桶比喻 二、STM32看门狗双雄…...

Hyperlane 框架路由功能详解:静态与动态路由全掌握
Hyperlane 框架路由功能详解:静态与动态路由全掌握 Hyperlane 框架提供了强大而灵活的路由功能,支持静态路由和动态路由两种模式,让开发者能够轻松构建各种复杂的 Web 应用。本文将详细介绍这两种路由的使用方法。 静态路由:简单…...

webpack js 逆向 --- 个人记录
网站 aHR0cDovL2FlcmZheWluZy5jb20v加密参数 参数加密位置 方法: 1. 构造自执行函数 !function(e) {// 加载器 }(// 模块1;// 模块2 )2. 找到js的加载器 3. 把上述代码放入第一步构造的自执行函数(完整扣取一整个加载器里的代码),并用一…...

代码随想录回溯算法03
93.复原IP地址 本期本来是很有难度的,不过 大家做完 分割回文串 之后,本题就容易很多了 题目链接/文章讲解:代码随想录 视频讲解:回溯算法如何分割字符串并判断是合法IP?| LeetCode:93.复原IP地址_哔哩哔…...

SOMEIP通信矩阵解读
目录 1 摘要2 SOME/IP通信矩阵详细属性定义与示例2.1 服务基础属性2.2 数据类型定义2.3 服务实例与网络配置参数2.4 SOME/IP-SD Multicast 配置(SOME/IP服务发现组播配置)2.5 SOME/IP-SD Unicast 配置2.6 SOME/IP-SD ECU 配置参数详解 3 总结 1 摘要 本…...