SQL Server 2022 数据同步到 Elasticsearch 思考
公司的老项目了,采用的是sqlserver 2022作为数据卡做的,但是产品对接客户,发现对搜索的要求很高,尤其是全文检索,考虑到ES采用倒排所以效率上的优势和整体开发的成本,大佬们商量之后,果断的采用了Elasticsearch作为搜索引擎的策略,那么剩下的就是如何将数据同步到ES的问题了,这个的一部分也就是我的工作了,所以分享一下自己工作过程当中的思路和遇到的问题。
一、整体同步思路
1. 同步架构选择
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| CDC + Logstash | 实时性好,低延迟 | 配置复杂 | 需要准实时同步 |
| 定时批量导出导入 | 实现简单 | 数据延迟大 | 非实时分析场景 |
| 触发器+消息队列 | 灵活可控 | 影响源库性能 | 高定制化需求 |
| 第三方工具(如Debezium) | 开箱即用 | 额外成本 | 企业级解决方案 |
2. 采用方案:变更数据捕获(CDC) + Logstash 管道
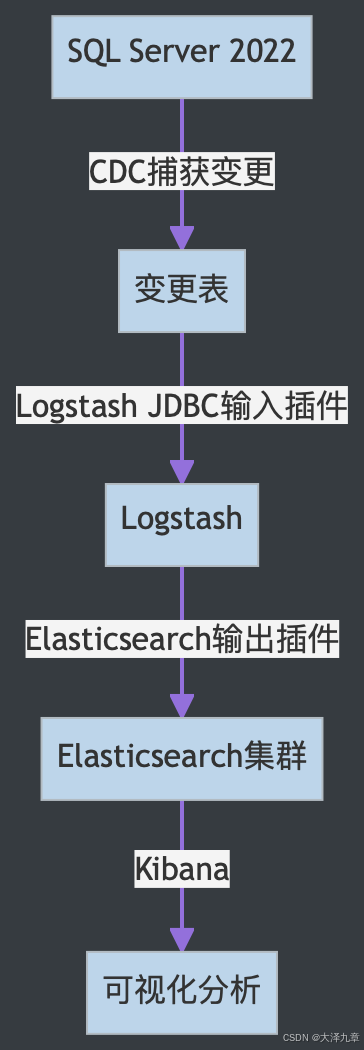
二、具体实现案例
步骤1:启用CDC
-- 在数据库级别启用CDC EXEC sys.sp_cdc_enable_db; -- 对特定表启用CDC EXEC sys.sp_cdc_enable_table@source_schema = 'dbo',@source_name = 'Products',@role_name = NULL,@supports_net_changes = 1;
步骤2:配置Logstash管道
input {jdbc {jdbc_driver_library => "D:/sqljdbc_12.2/enu/mssql-jdbc-12.2.0.jre11.jar"jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"jdbc_connection_string => "jdbc:sqlserver://localhost:1433;databaseName=YourDB"jdbc_user => "sa"jdbc_password => "yourpassword"schedule => "* * * * *" # 每分钟执行一次statement => "SELECT * FROM cdc.dbo_Products_CT WHERE __$start_lsn > ?"use_column_value => truetracking_column => "__$start_lsn"tracking_column_type => "numeric"last_run_metadata_path => "D:/logstash-8.12.0/products_last_run"}
}
output {elasticsearch {hosts => ["http://localhost:9200"]index => "sqlserver-products"document_id => "%{ProductID}"action => "update"doc_as_upsert => true}
}
案例2:批量全量+增量同步
使用Elasticsearch JDBC插件直接导入
# 全量导入 bin/elasticsearch-jdbc \-url "jdbc:sqlserver://localhost:1433;databaseName=YourDB" \-user sa -password yourpassword \-table "Products" \-index "products-index" \-type "product-type" \-id "ProductID" # 增量导入(基于时间戳) bin/elasticsearch-jdbc \-url "jdbc:sqlserver://localhost:1433;databaseName=YourDB" \-user sa -password yourpassword \-table "Products" \-index "products-index" \-type "product-type" \-id "ProductID" \-incremental "true" \-incremental_column "ModifiedDate" \-incremental_last_value "2024-01-01"
三、常见问题及解决方案
1. 性能问题
问题表现:
-
SQL Server CPU使用率高
-
Elasticsearch索引速度慢
-
网络带宽成为瓶颈
解决方案:
# Logstash优化配置示例
input {jdbc {# 增加分页大小jdbc_paging_enabled => truejdbc_page_size => 50000# 使用fetch_size提高性能jdbc_fetch_size => 1000}
}
output {elasticsearch {# 启用批量提交flush_size => 1000# 增加工作线程workers => 4}
}
2. 数据一致性问题
问题表现:
-
同步过程中数据不一致
-
漏同步或重复同步
-
数据类型映射错误
解决方案:
-- 1. 在SQL Server端添加版本控制字段 ALTER TABLE Products ADD SyncVersion ROWVERSION; -- 2. 使用事务一致性快照 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; -- 查询数据 COMMIT TRANSACTION;
3. 网络和连接问题
问题表现:
-
连接超时
-
断线后无法恢复
-
SSL/TLS配置问题
解决方案:
input {jdbc {# 连接池配置connection_retry_attempts => 3connection_retry_attempts_wait_time => 10# 连接验证validate_connection => true# 超时设置jdbc_connection_timeout => 60}
}
4. 映射和转换问题
问题表现:
-
字段类型不匹配
-
日期格式问题
-
特殊字符处理
解决方案:
filter {# 日期格式转换date {match => ["CreatedDate", "yyyy-MM-dd HH:mm:ss.SSS"]target => "CreatedDate"}# 字段类型转换mutate {convert => {"Price" => "float""Stock" => "integer"}}# 处理NULL值if [Description] == NULL {mutate {add_field => { "Description" => "" }}}
}
5. 监控和错误处理
推荐方案:
output {if "_jsonparsefailure" in [tags] {file {path => "D:/logstash-8.12.0/error_logs/%{+yyyy-MM-dd}-parse-errors.log"}}elasticsearch {# 主输出}# 监控管道性能pipeline {send_to => ["monitoring"]}
}
四、过去的思考
-
索引设计优化
PUT /products-index {"settings": {"number_of_shards": 3,"number_of_replicas": 1,"refresh_interval": "30s"},"mappings": {"properties": {"ProductName": { "type": "text", "fields": { "keyword": { "type": "keyword" } } },"Price": { "type": "scaled_float", "scaling_factor": 100 },"CreatedDate": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss||epoch_millis" }}} } -
使用Ingest Pipeline预处理
PUT _ingest/pipeline/sqlserver_pipeline {"description": "Process SQL Server data","processors": [{"remove": {"field": ["__$start_lsn", "__$update_mask"]}},{"script": {"source": """if(ctx['IsActive'] == false) {ctx['tags'] = ['inactive'];}"""}}] }
相关文章:

SQL Server 2022 数据同步到 Elasticsearch 思考
公司的老项目了,采用的是sqlserver 2022作为数据卡做的,但是产品对接客户,发现对搜索的要求很高,尤其是全文检索,考虑到ES采用倒排所以效率上的优势和整体开发的成本,大佬们商量之后,果断的采用…...

基于Spark的哔哩哔哩舆情数据分析系统
【Spark】基于Spark的哔哩哔哩舆情数据分析系统 (完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 本项目基于Python和Django框架进行开发,为了便于广大用户针对舆情进行个性化分析处…...

分布式事务解决方案全解析:从经典模式到现代实践
前言 在分布式系统中,数据一致性是一个核心问题。随着微服务架构的普及,跨服务、跨数据库的操作变得越来越普遍,如何保证这些操作的原子性、一致性、隔离性和持久性(ACID)成为了一个极具挑战性的任务。本文将全面介绍…...

迈向未来:数字化工厂管理如何重塑生产力
迈向未来:数字化工厂管理如何重塑生产力 随着工业4.0的浪潮席卷全球,“数字化工厂管理”成为制造业转型的关键一步。从传统生产模式到数据驱动的智能制造,企业在追求生产效率、质量与灵活性方面实现了飞跃式发展。然而,实施数字化管理不仅仅是技术问题,更关乎流程优化、数…...

LeetCode 1863.找出所有子集的异或总和再求和
题解 根据上述图可以根据二进制运算获取所有的子集,但是可以使用二进制获取所有子集需要有题目的这一句话才能够使用注意:在本题中,元素相同的不同子集应多次计数。 也就是对于{2,2,3,4,5}的子集不会简化成{2,3,4,5} public static int sub…...

蓝桥云客---蓝桥速算
3.蓝桥速算【算法赛】 - 蓝桥云课 问题描述 蓝桥杯大赛最近新增了一项娱乐比赛——口算大赛,目的是测试选手的口算能力。 比赛规则如下: 初始给定一个长度为 N 的数组 A,其中第 i 个数字为 Ai。随后数组会被隐藏,并进行 Q 次…...

Kafka 概念
🌀 Kafka 是什么? Kafka 是一个分布式流处理平台,可以用来: 🚚 高效地收集、传输、存储、处理 实时数据流。 它最初由 LinkedIn 开发,用于解决海量日志处理的问题,后来开源给 Apache࿰…...

双向链表增删改查的模拟实现
本章目标 0.双向链表的基本结构 1.双向链表的初始化 2.头插尾插 3.头删尾删 4.查找与打印 5.在指定位置之前插入数据/在指定位置之后插入数据 6.在指定位置之前删除数据/在指定位置之后删除数据 7.销毁链表 0.双向链表的基本结构 本章所实现的双向链表是双向循环带头链表,是…...

配置ASP.NET Core+NLog配置日志示例
以下是一个精简且实用的 NLog 配置文件示例,适用于 ASP.NET Core 项目,包含文件日志、控制台日志和自动归档功能: NLog.config 示例 (保存到项目根目录) xml Copy Code <?xml version="1.0" encoding="utf-8" ?> <nlog xmlns="http:…...
)
Roo Code使用MCP服务(大模型上下文协议)
MCP概念火爆,但是理解起来有点难度,使用起来也有点难度。 启用MCP RooCode直接支持使用MCP服务,甚至可以帮助写MCP,为我们提供了很大的方便。单击 Roo Code 窗格顶部导航栏中的类似三个插座的图标,显示如下MCP的配置…...

【项目管理】第一部分 信息技术 1/2
相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 概要 知识点: 现代化基础设施、数字经济、工业互联网、车联网、智能制造、智慧城市、数字政府、5G、常用数据库类型、数据仓库、信息安全、网络安全态势感知、物联网、大数…...

《UNIX网络编程卷1:套接字联网API》第6章 IO复用:select和poll函数
《UNIX网络编程卷1:套接字联网API》第6章 I/O复用:select和poll函数 6.1 I/O复用的核心价值与适用场景 I/O复用是高并发网络编程的基石,允许单个进程/线程同时监控多个文件描述符(套接字)的状态变化,从而高…...

Three.js 系列专题 1:入门与基础
什么是 Three.js? Three.js 是一个基于 WebGL 的 JavaScript 库,它简化了 3D 图形编程,让开发者无需深入了解底层 WebGL API 就能创建复杂的 3D 场景。它广泛应用于网页游戏、可视化、虚拟现实等领域。 学习目标 理解 Three.js 的核心组件:场景(Scene)、相机(Camera)…...

Qt框架深度解析:核心技术、应用场景与实战指南
Qt(发音同“cute”)是一个跨平台的C应用程序开发框架,广泛用于开发图形用户界面(GUI)程序,但也支持非GUI的后台服务、命令行工具等。它由挪威的Trolltech公司于1995年推出,后由诺基亚、Digia等公…...

低代码开发平台:飞帆中的控件中转区
低代码开发平台:飞帆中的控件中转区的作用 当控件因为尺寸太大难以拖到 div 框中时,可以先拖到控件中转区中,此时控件会变成一个标签,然后将这个标签拖到 div 框中即可。 飞帆 fvi.cn...

基于STM32的智能门禁系统设计与实现
一、项目背景与功能概述 在物联网技术快速发展的今天,传统门锁正在向智能化方向演进。本系统基于STM32F103C8T6微控制器,整合多种外设模块,实现了一个具备以下核心功能的智能门禁系统: 密码输入与验证(4x3矩阵键盘&a…...

maven项目打包jar给其他项目pom外部引用
maven项目打包jar给其他项目pom外部引用 在现实开发过程中,很多代码需要被重复利用的,但是代码量又是很多,这样的代码可以提出出来作为公共代码或者叫做工具使用,通常这样的工具会以jar包的形式被其他项目pom引入使用。第一步 创…...

Linux线程
一、线程的使用 线程创建 函数原型及头文件 #include <pthread.h> int pthread_create(pthread_t *restrict tidp, const pthread_attr_t *restrict attr, void *(*start_rtn)(void *), void *restrict arg); 参数: tidp:当pthread_create成功…...

Keepalive+LVS+Nginx+NFS高可用项目
项目架构 分析 主机规划 主机系统安装应用网络IPclientredhat 9.5无NAT172.25.250.115/24lvs-masterrocky 9.5ipvsadm,keepalivedNAT172.25.250.116/24 VIP 172.25.250.100/32lvs-backuprocky 9.5ipvsadm,keepalivedNAT172.25.250.117/24 VIP 172.25.2…...

在线编辑数学公式
参考工具: https://www.processon.com/mathtype https://www.latexlive.com/ 一、简单好用的数学公式编辑工具推荐 1. MathType / AxMath • 特点:专业公式编辑软件,支持与Word、WPS等办公软件无缝集成,提供丰富的数学符号和模…...

【spring Cloud Netflix】OpenFeign组件
1.概述 Feign旨在使编写Java Http客户端变得更容易。前面在使用RibbonRestTemplate进行服务的远程调用 时,利用RestTemplate对Http请求的封装处理,形成了一套模板化的调用方法。但是在实际开发中,由 于对服务的依赖调用可不止一处࿰…...

基于Flask的Windows命令大全Web应用技术解析与架构设计
基于Flask的Windows命令大全Web应用技术解析与架构设计 引言 Windows命令行工具是系统管理和开发调试的核心技能之一。然而,许多用户对常用命令的用法和场景并不熟悉。本文通过一个基于Flask框架开发的Web应用,系统性地整理了50个Windows命令的用法&…...

Qt中左侧项目菜单中构建设置功能中的构建步骤是怎么回事
在 Qt Creator 中,**构建设置(Build Settings)下的构建步骤(Build Steps)**是控制项目如何编译、链接和生成最终产物的核心配置区域。它允许你自定义编译过程中的各个阶段(如 qmake、make、cmake 等命令的具…...
从零开始:用 LangChain 和 ZhipuAI 搭建简单对话)
(一)从零开始:用 LangChain 和 ZhipuAI 搭建简单对话
最近一直在研究如何用 LangChain 和 ZhipuAI 搭建一个智能对话系统,发现这个组合真的非常强大,而且实现起来并不复杂。今天就来分享一下我的学习过程和一些心得体会,希望能帮到同样在探索这个领域的小伙伴们。 一、 环境搭建:从零…...
)
Java大厂面试题 -- JVM 优化进阶之路:从原理到实战的深度剖析(2)
最近佳作推荐: Java大厂面试题 – 深度揭秘 JVM 优化:六道面试题与行业巨头实战解析(1)(New) 开源架构与人工智能的融合:开启技术新纪元(New) 开源架构的自动化测试策略优…...

C++ 标准库参考手册深度解析
C 标准库参考手册是每个 C 开发者的必备工具。本文将系统性解析其架构设计、核心功能及实战应用技巧,帮助开发者构建高效的知识检索与代码开发工作流,涵盖从语法查询到编译器适配的全流程技术细节。 一、网站架构与技术细节 1. 信息组织体系 1.1 层级化…...

单片机学习笔记8.定时器
IAP15W4K58S4定时/计数器结构工作原理 定时器工作方式控制寄存器TMOD 不能进行位寻址,只能对整个寄存器进行赋值 寄存器地址D7D6D5D4D3D2D1D0复位值TMOD89HGATEC/(T低电平有效)M1M0GATEC/(T低电平有效)M1M000000000B D0-D3为T0控制,D4-D7为T1控制 GAT…...

神经网络入门:生动解读机器学习的“神经元”
神经网络作为机器学习中的核心算法之一,其灵感来源于生物神经系统。在本文中,我们将带领大家手把手学习神经网络的基本原理、结构和训练过程,并通过详细的 Python 代码实例让理论与实践紧密结合。无论你是编程新手还是机器学习爱好者…...
:过拟合与正则化)
2025-04-05 吴恩达机器学习5——逻辑回归(2):过拟合与正则化
文章目录 1 过拟合1.1 过拟合问题1.2 解决过拟合 2 正则化2.1 正则化代价函数2.2 线性回归的正则化2.3 逻辑回归的正则化 1 过拟合 1.1 过拟合问题 欠拟合(Underfitting) 模型过于简单,无法捕捉数据中的模式,导致训练误差和测试误…...

美团滑块 分析
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 逆向过程 距离识别不准简单学习一下&…...

C++ atomic 原子操作
一、原子操作简介 在多线程编程中,通常我们需要多个线程共享数据。但如果不加以控制,多个线程同时访问同一数据,可能会导致数据不一致或竞争条件(race conditions)。为了解决这个问题,我们引入了 原子操作…...

Leetcode - 双周赛153
目录 一、3498. 字符串的反转度二、3499. 操作后最大活跃区段数 I三、3500. 将数组分割为子数组的最小代价四、3501. 操作后最大活跃区段数 II 一、3498. 字符串的反转度 题目连接 本题直接模拟,代码如下: class Solution {public int reverseDegree(…...

25.4 GLM-4+RAG智能标注实战:标注成本暴降60%,检索准确率飙升40%!
使用 GLM-4 优化 RAG 程序:智能标注提升检索质量 关键词:GLM-4 数据标注, RAG 优化, 检索增强生成, 向量数据库, 语义关联度分析 1. RAG 数据标注的核心挑战 在检索增强生成(Retrieval-Augmented Generation)系统中,检索数据的标注质量直接影响最终生成效果。传统标注方…...

基于sklearn实现文本摘要思考
和各位小伙伴分享一下使用sklearn进行文本摘要的思考。 第一版本 原理 提取式文本摘要的基本原理是: 将文本分割成句子 计算每个句子的重要性(权重) 选择权重最高的几个句子组成摘要 常用的句子权重计算方法: TF-IDF:基于词频-逆文档频…...

Cortex-M3 NVIC可以控制异常向量表的哪些部分
Cortex-M3 的 NVIC(嵌套向量中断控制器)不直接控制整个异常向量表,但可以管理向量表中与中断相关的部分行为。以下是 NVIC 对异常向量表的具体控制范围和相关机制: 1. NVIC 直接控制的部分 NVIC 主要管理 外部中断(IRQ) 和部分 系统异常 的行为,但对向量表本身的存储位…...

AI朝代应避免AI幻觉:分析与应对策略
随着人工智能(AI)技术的不断发展,AI的应用领域已经涵盖了文本生成、图像与视频创作以及程序编写等多个方面。然而,AI的生成能力并非没有缺陷,其中最为显著的之一就是所谓的“AI幻觉”(AI hallucination&…...

网络传输H.264方法对比
一、引言 网络传输H.264有多种方法,包括但不限于:1.通过RTP直接传输H.264;2.通过UDP传输TS流;3.通过RTP传输TS流;4.通过RTP传输PS流。本文对这些方法进行对比。 二、通过RTP直接传输H.264 这种方案就是RTP包…...

第九章:可靠通信_《凤凰架构:构建可靠的大型分布式系统》
第九章 可靠通信 一、零信任网络模型 核心难点:理解安全模型从传统边界防护到动态信任验证的转变 零信任的核心原则 不再区分"内部可信网络"与"外部不可信网络"(传统防火墙模型失效)每次请求都需要进行身份验证和授权…...

HeidiSQL:多数据库管理工具
HeidiSQL 是一款广受欢迎的免费开源数据库管理工具,专为数据库管理员及开发者设计。无论您是刚接触数据库领域的新手,还是需要同时处理多种数据库系统的专业开发者,该工具都能凭借其直观的界面和强大的功能,助您轻松完成数据管理任…...
)
文件系统-inode/软硬件连接(未完结)
首先我们了解一下文件简洁理解来说就是:文件内容文件属性 ---> 磁盘上存储的文件存文件的内容存文件的属性;而文件的内容----存放在每个数据块 ;文件属性存放在iNode里面。 要明白:linux系统中的文件是存储在磁盘中的…...

数据库并发控制问题
并发控制问题是数据库管理系统(DBMS)中处理多个事务并发执行时,确保数据一致性、可靠性和完整性的一系列技术和挑战。并发控制问题通常与事务的隔离性和事务之间的相互影响有关。以下是并发控制中主要的几种问题及其解决方式的详细解释&#…...
智能体与工具协同——打造智能对话的超级助手)
(五)智能体与工具协同——打造智能对话的超级助手
上一篇:(四)数据检索与增强生成——让对话系统更智能、更高效 在前四个阶段,我们已经搭建了一个功能强大的智能对话,并深入探讨了输入输出处理、链式工作流构建和数据检索与增强生成的细节。现在,我们将进…...

第十三届蓝桥杯 2022 省 B 刷题统计
题目描述 小明决定从下周一开始努力刷题准备蓝桥杯竞赛。他计划周一至周五每天做 a a a 道题目,周六和周日每天做 b b b 道题目。请你帮小明计算,按照计划他将在第几天实现做题数大于等于 n n n 题? 输入格式 输入一行包含三个整数 a , b a, b a,b 和 n n n. 输出格…...

NLP/大模型八股专栏结构解析
1.transformer 结构相关 (1)transformer的基本结构有哪些,分别的作用是什么,代码实现。 NLP高频面试题(一)——Transformer的基本结构、作用和代码实现 (2)LSTM、GRU和Transformer结…...

不在 qtdesigner中提升,进行主题程序设计
以下是无需在Qt Designer中提升控件的完整主题化方案,保持现有代码结构的同时实现动态阴影效果管理: 一、增强主题管理器(支持动态控件发现) // thememanager.h #pragma once #include <QObject> #include <QSet> #…...

TDengine 3.3.6.0 版本中非常实用的 Cols 函数
简介 在刚刚发布的 TDengine 3.3.6.0 版本 中,新增了一个非常实用的 函数COLS ,此函数用于获取选择函数所在行列信息,主要应用在生成报表数据,每行需要出现多个选择函数结果,如统计每天最大及最小电压,并报…...

MessageQueue --- RabbitMQ WorkQueue and Prefetch
MessageQueue --- RabbitMQ WorkQueue and Prefetch 什么是WorkQueue分发机制 --- RoundRobin分发机制 --- PrefetchSpring example use prefetch --- Fair Dispatch 什么是WorkQueue Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同…...

第四章:透明多级分流系统_《凤凰架构:构建可靠的大型分布式系统》
第四章:透明多级分流系统 一、客户端缓存 核心目标:减少重复请求,降低服务端压力。 1. 强制缓存 定义:客户端直接根据缓存规则决定是否使用本地缓存,无需与服务端交互。关键HTTP头: Cache-Control&#…...

题解:AT_abc241_f [ABC241F] Skate
一道经典的 bfs 题。 提醒:本题解是为小白专做的,不想看的大佬请离开。 这道题首先一看就知道是 bfs,但是数据点不让我们过: 1 ≤ H , W ≤ 1 0 9 1\le H,W\le10^9 1≤H,W≤109。 那么我们就需要优化了,从哪儿下手…...

热题100-字母异位词分组
方法用Arrays.sort对每个String 进行排序,毕竟排序以后都一样了,然后放入Map中的key跟value,可以一对多,然后返回的时候只要返回Map中所有的values就可以了 class Solution {public List<List<String>> groupAnagram…...