Transformer由入门到精通(一):基础知识
基础知识
- 0 前言
- 1 EncoderDecoder
- 2 Bahdanau Attention
- 3 Luong Attention
- 4 Self Attention/Masked Self Attention
- 5 MultiHead Self Attention
- 6 Key-Value Attention
- 7 ResNet
- 8 总结
0 前言
我之前看transformer的论文《Attention Is All You Need》,根本看不懂,特别是QKV注意力机制那部分。后面在知乎上看到名为“看图学”的博主的一篇回答,按他回答阅读了一些论文,搞明白了 transformer 中的注意力机制的发展演变,才对 transformer 中的注意力机制有了了解,在此向他表示感谢!本文并不是面对零基础的同学,在学习这篇文章之间,需要知道什么是RNN、LSTM、GRU,什么是词嵌入。
1 EncoderDecoder
Transformer最初是用于机器翻译的,它的编码器-解码器结构最初来源于《Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》这篇论文。在这篇文章中,Kyunghyun Cho等人提出了基于编码器和解码器的模型(RNN Encoder-Decoder)用于机器翻译,其网络结构如下图所示:
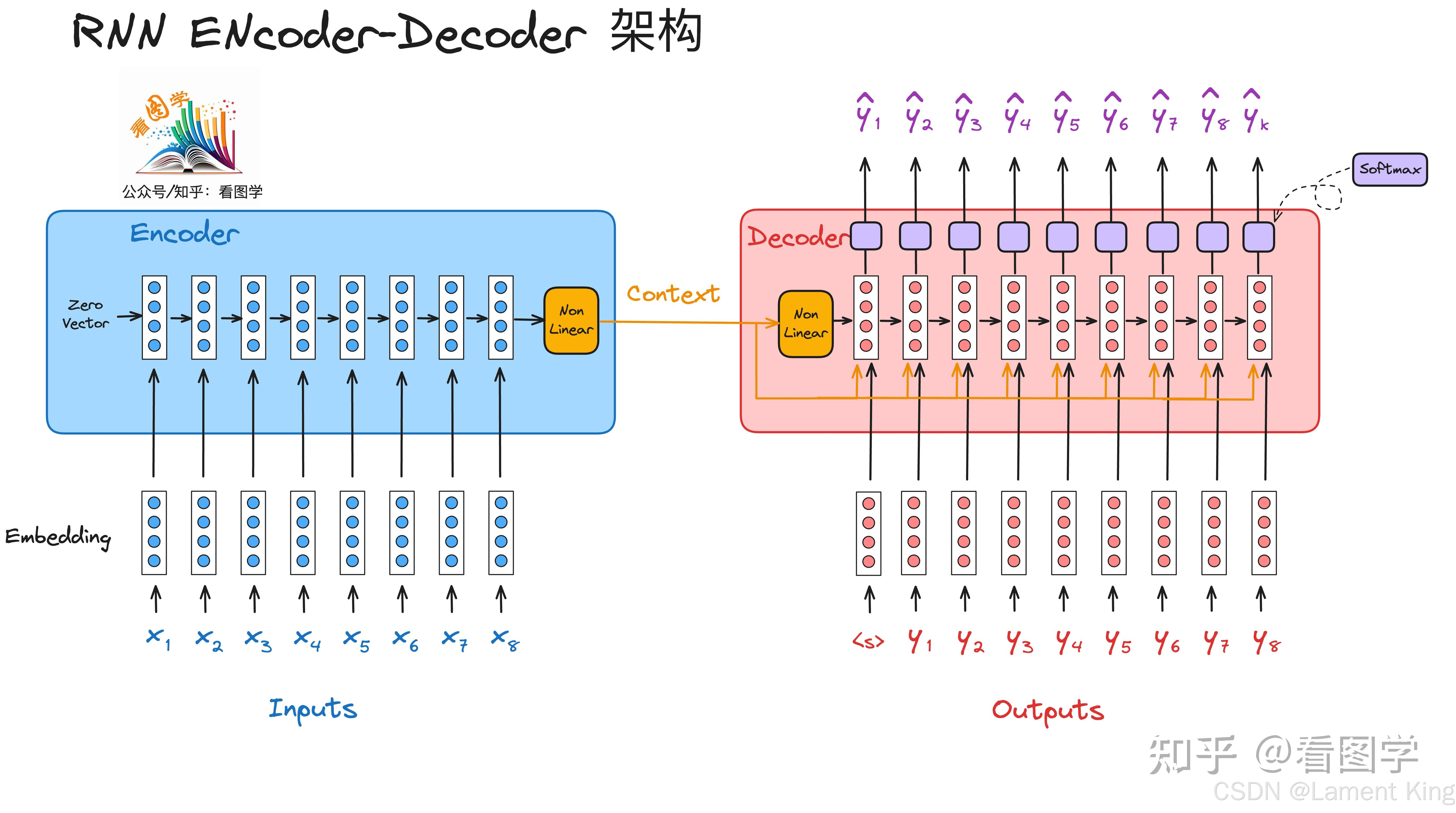
编码器的计算过程为(为了方便理解,我们省略了词嵌入过程,本文的后续内容也省略词嵌入):
h 0 = 0 h j = RNN G R U ( h j − 1 , x j ) c = tanh ( V ⋅ h T ) \begin{array}{l} \begin{aligned} h_{0} & =\mathbf{0} \\ h_{j} & =\operatorname{RNN}_{G R U}\left(h_{j-1}, x_{j}\right) \\ c & =\tanh \left(V \cdot h_{T}\right) \end{aligned}\\ \end{array} h0hjc=0=RNNGRU(hj−1,xj)=tanh(V⋅hT)
这里 T T T 是encoder中输入单词的个数, h T h_T hT 是最后一个单词输入RNN后获得的输出。
解码器的计算过程:
s 0 = tanh ( V ′ ⋅ c ) s t = RNN G R U ( s t − 1 , [ y t − 1 ; C ] ) P ( y t ) = softmax ( MLP ( s t ) ) \begin{array}{l} \begin{aligned} s_{0} & =\tanh \left(V^{\prime} \cdot c\right) \\ s_{t} & =\operatorname{RNN}_{G R U}\left(s_{t-1},\left[y_{t-1} ; C\right]\right) \\ P(y_{t}) & =\operatorname{softmax}\left(\operatorname{MLP}\left(s_{t}\right)\right) \end{aligned} \end{array} s0stP(yt)=tanh(V′⋅c)=RNNGRU(st−1,[yt−1;C])=softmax(MLP(st))
这里 V ′ V^{\prime} V′ 是一个可训练的矩阵, c c c 是来自encoder的上下文向量(context vector), s t − 1 s_{t-1} st−1是decoder中来自上一时步的隐藏层输出, P ( y t ) P(y_{t}) P(yt)是第 t t t 时步输出单词的分布。
编码器输出第 t {t} t 个单词的分布,可以简写为:
P ( y t ) = g ( y t − 1 , s t − 1 , c ) P(y_{t}) =g(y_{t-1}, s_{t-1}, c) P(yt)=g(yt−1,st−1,c)
2 Bahdanau Attention
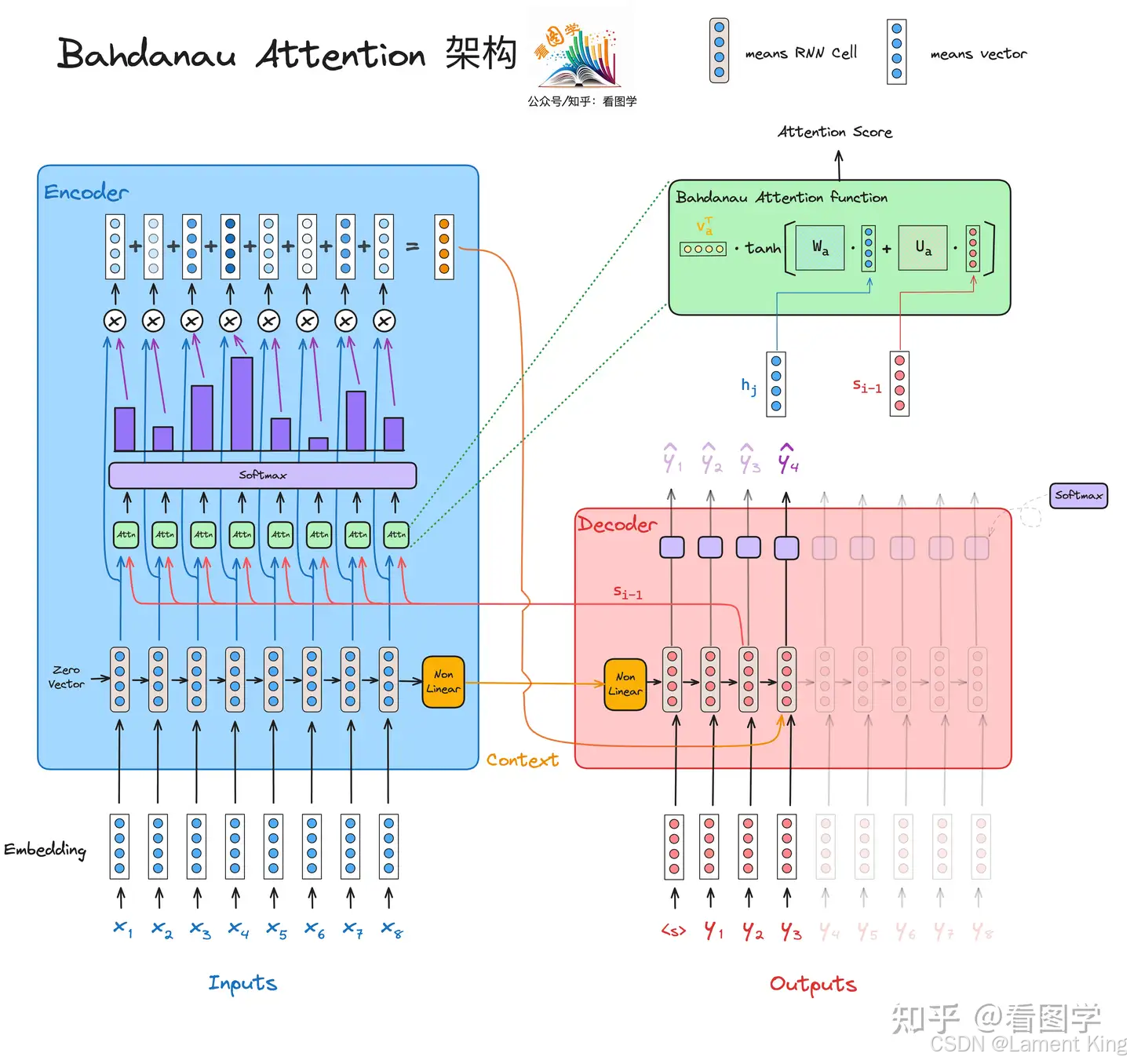
在 RNN Encoder-Decoder 中, P ( y t ) = g ( y t − 1 , s t − 1 , c ) P(y_{t}) =g(y_{t-1}, s_{t-1}, c) P(yt)=g(yt−1,st−1,c),无论 t t t 是0还是100,decoder每次输出时,来自encoder的上下文向量 c c c 是不变的,但实际上,翻译过程中,输出第 t t t 个单词时,对原文中所关注的位置是不同的。Bahdanau 在文章《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》中,认为上下文向量 c c c 应该是动态的,故提出了Bahdanau Attention用以计算上下文向量。
以下是Bahdanau Attention计算 c t c_t ct 的过程:
先计算对齐分数,即影响程度,它反应decoder在生成第 t t t 个位置上的单词时,受encoder位置 j j j 上的单词的影响:
e t j = v T t a n h ( W a s t − 1 + U a h j ) e_{tj}=v^Ttanh(W_as_{t-1}+U_ah_j) etj=vTtanh(Wast−1+Uahj)
这里之所以用 s t − 1 s_{t-1} st−1 是为了将已生成的序列也纳入考虑,之所以不用 s t s_{t} st ,是因为 s t = R N N ( s t − 1 , [ y t − 1 ; c t ] ) s_{t} =RNN(s_{t-1},[y_{t-1} ; c_t]) st=RNN(st−1,[yt−1;ct])。
我们把encoder上所有位置对decoder生成第 t t t 个位置时的影响归一化,然后再获得encoder位置 j j j 上的单词对生成 t t t 的影响,这里实际上是获得权重:
α t j = e x p ( e t j ) ∑ k = 1 T e x p ( e t j ) \alpha_{tj} = \frac{exp(e_{tj})}{\sum_{k=1}^{T} exp(e_{tj})} αtj=∑k=1Texp(etj)exp(etj)
这里 T T T 是encoder中输入单词的个数。
我们把encoder中获得的隐藏层按照上述权重进行加权,获得上下文向量:
c t = ∑ j = 1 T α t j h j c_t = {\textstyle \sum_{j=1}^{T}} \alpha _{tj}h_j ct=∑j=1Tαtjhj
我们可以认为, c t c_t ct 就是 h j h_j hj 的线性组合。
3 Luong Attention
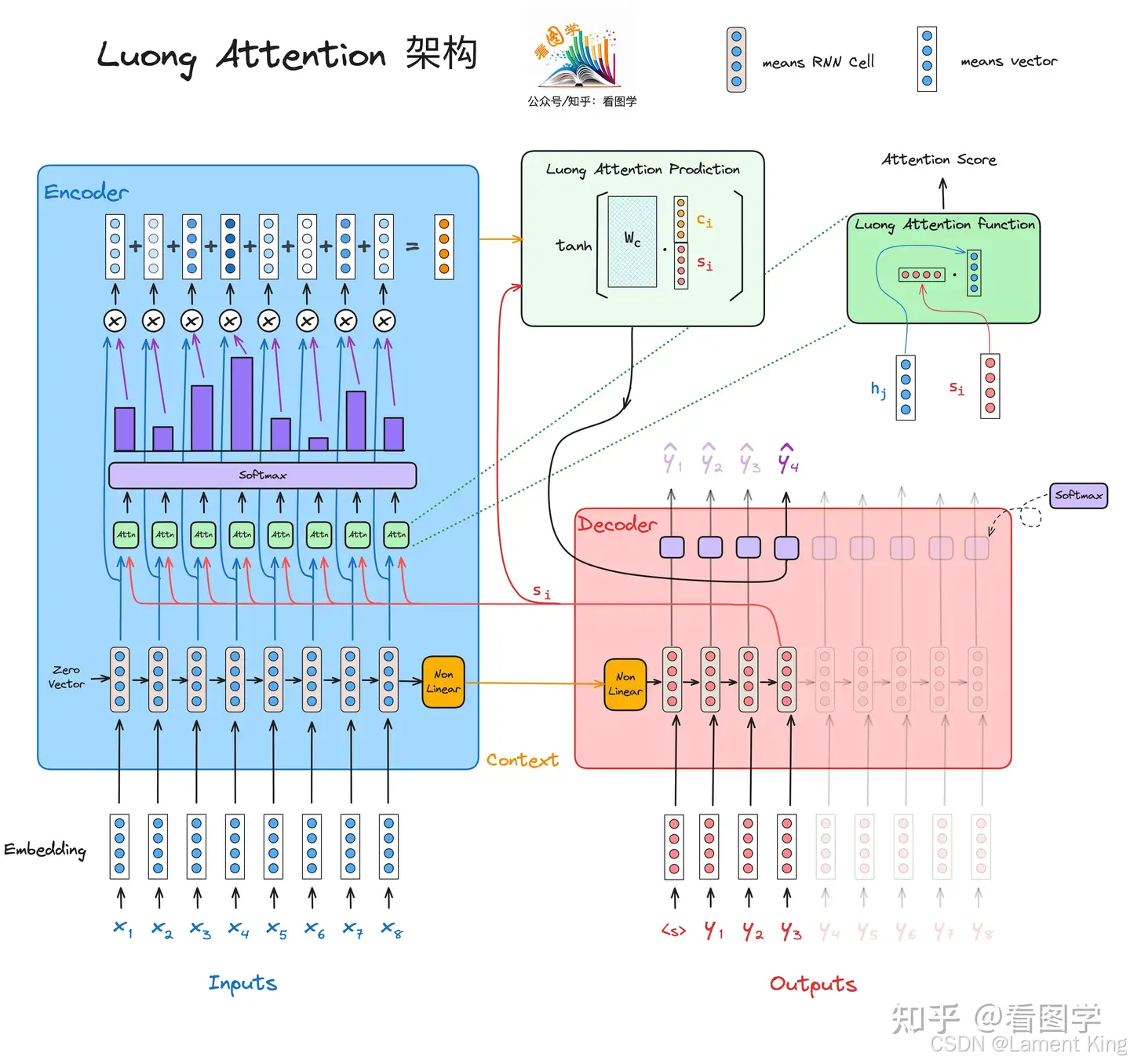
Bahdanau Attention在计算对齐分数的时候, e t j = v T t a n h ( W a s t − 1 + U a h j ) e_{tj}=v^Ttanh(W_as_{t-1}+U_ah_j) etj=vTtanh(Wast−1+Uahj),括号内用的是加法(即加性注意力机制Additive Attention)。Luong认为还可以使用其他方法,并在文章《Effective Approaches to Attention-based Neural Machine Translation》中提出了三种计算方式(为了和前面的内容符号能统一,我这里没有使用论文中的符号):
e ( t , j ) = { s t ⋅ h j s t W a h j v a ⊤ tanh ( W a [ s t ; h j ] ) \operatorname{e}\left(t, j\right)=\left\{\begin{array}{l} {s}_{t} \cdot h_j \\ {s}_{t} W_a h_j \\ {v}_{a}^{\top} \tanh \left({W}_{{a}}\left[{s}_{t} ; h_j\right]\right) \end{array}\right. e(t,j)=⎩ ⎨ ⎧st⋅hjstWahjva⊤tanh(Wa[st;hj])
这三种注意力机制分别是点乘(dot)、一般(general)、拼接(concat)。
论文中对计算 s t {s}_{t} st 的方式做了优化, s t = L S T M ( s t − 1 , y t − 1 ) s_t=LSTM(s_{t-1},y_{t-1}) st=LSTM(st−1,yt−1) ,即不再需要 c t {c}_{t} ct。计算得到 e t j e_{tj} etj 后,就能得到 α t j \alpha_{tj} αtj 和 c t c_t ct,计算方式与前面相同。
随后可以得到单词分布:
P ( y t ) = softmax ( W s t a n h ( [ c t ; s t ] ) ) P(y_{t}) =\operatorname{softmax}\left(W_stanh\left([c_t;s_t]\right)\right) P(yt)=softmax(Wstanh([ct;st]))
4 Self Attention/Masked Self Attention
前面介绍的注意力机制,在计算对齐分数的时候,都是拿目标语言的语义信息和源语言的语义信息进行计算,即它们是在两个不同的序列之间进行计算的,这种注意力机制被成为交叉注意力机制(Cross Attention)。除了交叉注意力机制,还有一种被称为“自注意力机制(Self Attention)”或者“内部注意力机制(Intra Attention)”的方式,它是在一个序列的内部进行注意力分数计算,即计算当前词与之前所有词的注意力分数。
Jianpeng Cheng在文章《Long Short-Term Memory-Networks for Machine Reading》中改进了LSTM,提出了一个名为LSTMN的网络结构,该网络在LSTM的基础上增加了注意力机制。
我们先复习一下LSTM的计算过程:
i t = σ ( W i [ h t − 1 , x t ] + b i ) f t = σ ( W f [ h t − 1 , x t ] + b t ) v t = σ ( W o [ h t − 1 , x t ] + b o ) c t ^ = tanh ( W c [ h t − 1 , x t ] + b c ) c t = f t ⊙ c t − 1 + i t ⊙ c t ^ h t = o t ⊙ tanh ( c t ) \begin{aligned} i_{t} & =\sigma \left(W_{i}\left[h_{t-1}, x_{t}\right]+b_{i}\right) \\ \\ f_{t} & =\sigma \left(W_{f}\left[h_{t-1}, x_{t}\right]+b_{t}\right) \\ \\ v_{t} & =\sigma \left(W_{o}\left[h_{t-1}, x_{t}\right]+b_{o}\right) \\ \\ \hat{c_t} & =\tanh \left(W_{c}\left[h_{t-1}, x_{t}\right]+b_{c}\right) \\ \\ c_{t} & =f_{t} \odot c_{t-1}+i_{t} \odot \hat{c_t} \\ \\ h_{t} & =o_{t} \odot \tanh \left(c_{t}\right) \end{aligned} itftvtct^ctht=σ(Wi[ht−1,xt]+bi)=σ(Wf[ht−1,xt]+bt)=σ(Wo[ht−1,xt]+bo)=tanh(Wc[ht−1,xt]+bc)=ft⊙ct−1+it⊙ct^=ot⊙tanh(ct)
这里 h t − 1 h_{t-1} ht−1 是上一时刻的隐藏层, i t i_{t} it 是更新门, t t t_{t} tt 是遗忘门, o t o_{t} ot 是输出门, c t ^ \hat{c_t} ct^是短期记忆, c t c_{t} ct 是长期记忆,它综合考虑了上一时刻的长期记忆和当前的短期记忆,如果遗忘门为0,则彻底遗忘上一时刻的记忆,如果更新门是1,则新记忆需要完全被考虑。
改进后的计算过程为:
e t j = v a ⊤ tanh ( W a h ~ t − 1 + U a h j + W x x t ) α t j = exp ( e t j ) ∑ k = 1 t exp ( e t k ) e_{t j}=v_{a}^{\top} \tanh \left(W_{a} \tilde{h}_{t-1}+U_{a} h_{j}+W_{x} x_{t}\right) \\ \alpha_{tj}=\frac{\exp \left(e_{tj}\right)}{\sum_{k=1}^{t} \exp \left(e_{tk}\right)} \\ etj=va⊤tanh(Wah~t−1+Uahj+Wxxt)αtj=∑k=1texp(etk)exp(etj)
注意求和符号的上标,已经不再是T。
[ h ~ t c ~ t ] = ∑ j = 1 t − 1 α t j ⋅ [ h j c j ] i t = σ ( W i [ h ~ t , x t ] + b i ) f t = σ ( W f [ h ~ t , x t ] + b f ) o t = σ ( W o [ h t ~ , x t ] + b o ) c ^ t = tanh ( W c [ h ~ t , x t ] + b c ) c t = f t ⊙ c ~ t + i t ⊙ c ^ t h t = o t ⊙ tanh ( c t ) \begin{array}{l} \left[\begin{array}{c} \tilde{h}_{t} \\ \tilde{c}_{t} \end{array}\right]=\sum_{j=1}^{t-1} \alpha_{tj} \cdot\left[\begin{array}{l} h_{j} \\ c_{j} \end{array}\right] \\ \\ \begin{array}{l} i_{t}=\sigma \left(W_{i}\left[\tilde{h}_{t}, x_{t}\right]+b_{i}\right)\\ \\ f_{t}=\sigma \left(W_{f}\left[\tilde{h}_{t}, x_{t}\right]+b_{f}\right) \\ \\ o_{t}=\sigma \left(W_{o}\left[\tilde{h_{t}}, x_{t}\right]+b_{o}\right) \\ \\ \hat{c}_{t}=\tanh \left(W_{c}\left[\tilde{h}_{t}, x_{t}\right]+b_{c}\right) \\ \\ c_{t}=f_{t} \odot \tilde{c}_{t}+i_{t} \odot \hat{c}_{t} \\ \\ h_{t}=o_{t} \odot \tanh \left(c_{t}\right) \end{array} \end{array} [h~tc~t]=∑j=1t−1αtj⋅[hjcj]it=σ(Wi[h~t,xt]+bi)ft=σ(Wf[h~t,xt]+bf)ot=σ(Wo[ht~,xt]+bo)c^t=tanh(Wc[h~t,xt]+bc)ct=ft⊙c~t+it⊙c^tht=ot⊙tanh(ct)
我们前后对比一下:
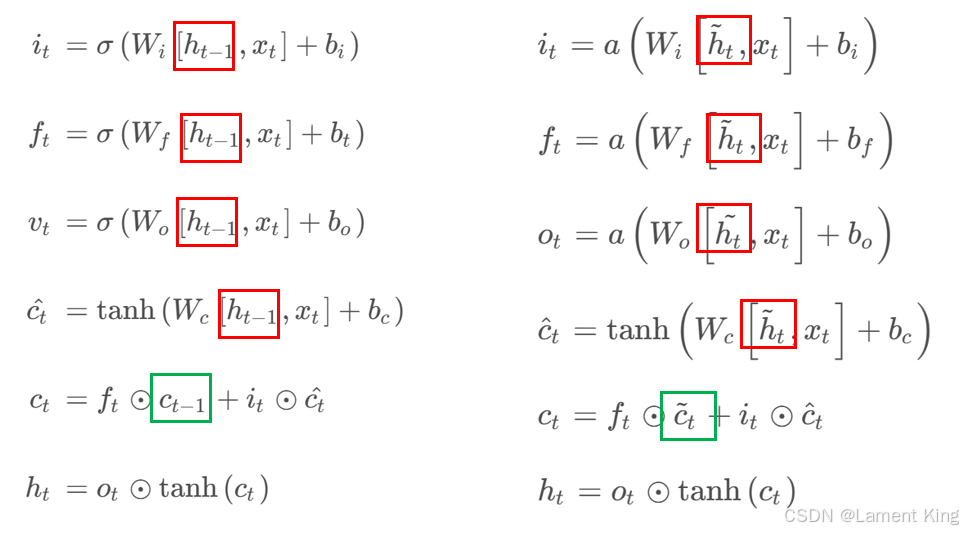
这里把 h t − 1 h_{t-1} ht−1 和 c t − 1 c_{t-1} ct−1 分别改成了 h ~ t \tilde{h}_{t} h~t 和 c ~ t \tilde{c}_{t} c~t,而 h ~ t \tilde{h}_{t} h~t 和 c ~ t \tilde{c}_{t} c~t 则是通过对前面 h j h_{j} hj 和 c j c_{j} cj 加权得到:
[ h ~ t c ~ t ] = ∑ j = 1 t − 1 α t j ⋅ [ h j c j ] \left[\begin{array}{c} \tilde{h}_{t} \\ \tilde{c}_{t} \end{array}\right]=\sum_{j=1}^{t-1} \alpha_{tj} \cdot\left[\begin{array}{l} h_{j} \\ c_{j} \end{array}\right] [h~tc~t]=j=1∑t−1αtj⋅[hjcj]
而计算权重的时候,也是对已经输入的位置计算:
α t j = exp ( e t j ) ∑ k = 1 t exp ( e t k ) \alpha_{tj}=\frac{\exp \left(e_{tj}\right)}{\sum_{k=1}^{t} \exp \left(e_{tk}\right)} αtj=∑k=1texp(etk)exp(etj)
也就是说,这种注意力机制只关注前面的词,故被称为Masked Self Attention。
5 MultiHead Self Attention
我们先来介绍一下句子嵌入(sentence embedding):把一段可变长度的文本,用一个固定长度的向量来表示。论文《A structured self-attentive sentence embedding》则提出了一种方法,把文本用固定维度的矩阵来表示,这篇文章更重要的是,提出了多头注意力机制。
假设一条句子有n个单词,经过词嵌入后,可以表示成:
s = ( w 1 , w 2 , . . . , w n ) s=(w_1, w_2, ... , w_n) s=(w1,w2,...,wn)
这里 w i w_i wi 是词嵌入向量。
将序列 s s s 输入一个双向LSTM网络:
h t → = L S T M → ( w t , h t − 1 → ) h t ← = L S T M ← ( w t , h t + 1 ← ) \begin{array}{l} \overrightarrow{h_t}=\overrightarrow{L S T M}\left(w_{t}, \overrightarrow{h_{t-1}}\right) \\ \overleftarrow{h_{t}}=\overleftarrow{L S T M}\left(w_{t}, \overleftarrow{h_{t+1}}\right) \end{array} ht=LSTM(wt,ht−1)ht=LSTM(wt,ht+1)
这里 h t → \overrightarrow{h_t} ht 和 h t ← \overleftarrow{h_{t}} ht 都是维度为u的向量,令:
h t = [ h t → , h t ← ] h_t = \left[\overrightarrow{h_t}, \overleftarrow{h_{t}}\right] ht=[ht,ht]
则 h t h_t ht 是维度为2u的向量。
令:
H = [ h 1 h 2 . . . h n ] H= \left[\begin{array}{c} h_{1} \\ h_{2} \\ ... \\ h_{n} \end{array}\right] H= h1h2...hn
则 H 的维度为(n, 2u)。
按下式计算 h 1 h_1 h1、 h 2 h_2 h2、……、 h n h_n hn的权重:
a = softmax ( w s 2 tanh ( W s 1 H T ) ) a=\operatorname{softmax}\left(w_{s2} \tanh \left(W_{s 1} H^{T}\right)\right) a=softmax(ws2tanh(Ws1HT))
这里 W s 1 W_{s 1} Ws1的维度为(da, 2u), H T H^{T} HT的维度为(2u, n), w s 2 w_{s 2} ws2 的维度为(1, da),那么 a 的维度为(1, n)。
上面的公式相当于将下面两步合并了:
e = w s 2 tanh ( w s 2 tanh ( W s 1 H T ) ) e=w_{s2} \tanh \left(w_{s2} \tanh(W_{s 1} H^{T})\right) e=ws2tanh(ws2tanh(Ws1HT))
a i = exp ( e i ) ∑ k = 1 n exp ( e k ) a_{i}=\frac{\exp \left(e_{i}\right)}{\sum_{k=1}^{n} \exp \left(e_{k}\right)} ai=∑k=1nexp(ek)exp(ei)
这里 e e e 不再是一个标量,而是一个向量。
m = a H m=aH m=aH
m的维度为(1, 2u),它相当于将 h 1 h_1 h1、 h 2 h_2 h2、……、 h n h_n hn 进行线性组合,其中 h i h_i hi 的权重为 a i a_i ai,m 就是我们前面说的上下文向量 c t c_t ct。
m是一个向量,它的长度与输入序列的单词个数无关,只与LSTM输出的隐藏层维度有关,因此,它实现了句子嵌入。
现在我们用 W s 2 W_{s 2} Ws2 替代 w s 2 w_{s 2} ws2, W s 2 W_{s 2} Ws2 是一个维度为(r, da)的矩阵,即相当于将上述求 a 的过程重复 r 次,那么有:
A = softmax ( W s 2 tanh ( W s 1 H T ) ) A=\operatorname{softmax}\left(W_{s2} \tanh \left(W_{s 1} H^{T}\right)\right) A=softmax(Ws2tanh(Ws1HT))
这里 A 的维度为(r, n),
M = A H M=AH M=AH
M 的维度为 (r, 2u),此时我们实现了将一个句子变成了一个矩阵,它的维度与输入的单词个数无关。
一个 m 只能反应句子语义中的一个方面或者组成部分,为了表示句子的整体语义,可以使用多个 m 来表示句子的不同方面,这就是所谓的多头注意力机制,有点类似于CNN里的多通道,每个通道处理不同的信息。
这里是 r 个头,将 r 个 m 拼接成 M,相当于对 h 1 h_1 h1、 h 2 h_2 h2、……、 h n h_n hn 做了 r 次线性组合,然后将这 r 次的结果合并成一个矩阵。
6 Key-Value Attention
Michał Daniluk等人在《FRUSTRATINGLY SHORT ATTENTION SPANS IN NEURAL LANGUAGE MODELING》中认为,在带有注意力机制的语言生成模型中,RNN或者LTSM每一个时步输出一个 h(有的文献中是 s,例如Bahdanua Attention),在我们前面介绍的注意力机制中,这个 h 既要作为键(key)从历史记忆中获取上下文向量(作者是把对过去隐藏层向量进行加权得到上下文向量的过程,看成是使用Key-Value的方式从过去的记忆中进行查询的过程),又要用于预测下一个单词(token),还要传输给下一个时步(当前时步的 h h h 就是下一时步的 h t − 1 h_{t-1} ht−1。这种对 h 的过度使用使得模型训练变得困难,作者随即提出,可以把 h 分成多份,仅让一部分去计算注意力分数,一部分计算上下文向量,另一部分专注于预测下一个单词,这就是Key-Value Attention的思想。我们看下面介绍能更清楚的理解。
假设语言模型是基于LSTM,LSTM在 t t t 时刻的输出为 h t ∈ R k \boldsymbol h_t \in \mathbb{R}^{k} ht∈Rk ,此时有个长度为 L 的滑动窗口,它把前面 L 步的隐藏层给圈了出来,得到一个矩阵 Y t = ( h t − L , h t − L + 1 , . . . , h t − 1 ) ∈ R k × L \boldsymbol{Y_t}=(\boldsymbol{h}_{t-L}, \boldsymbol{h}_{t-L+1}, ... , \boldsymbol{h}_{t-1}) \in \mathbb{R}^{k \times L} Yt=(ht−L,ht−L+1,...,ht−1)∈Rk×L,那么可以使用注意力的方式,计算在 t t t 时刻的预测单词的概率分布(即输入第 t 个单词,然后预测第 t+1 个单词,第 t+1 个单词即为第 t 时步的输出):
M t = tanh ( W Y Y t + ( W h h t ) 1 T ) ∈ R k × L α t = softmax ( w T M t ) ∈ R 1 × L r t = Y t α T ∈ R k h t ∗ = t a n h ( W r r t + W x h t ) ∈ R k y t = softmax ( W ∗ h t ∗ + b ) ∈ R ∣ V ∣ \begin{aligned} \boldsymbol{M}_{t} & =\tanh \left(\boldsymbol{W}^{Y} \boldsymbol{Y}_{t}+\left(\boldsymbol{W}^{h} \boldsymbol{h}_{t}\right) \mathbf{1}^{T}\right) & & \in \mathbb{R}^{k \times L} \\ \boldsymbol{\alpha}_{t} & =\operatorname{softmax}\left(\boldsymbol{w}^{T} \boldsymbol{M}_{t}\right) & & \in \mathbb{R}^{1 \times L} \\ \boldsymbol{r}_{t} & =\boldsymbol{Y}_{t} \boldsymbol{\alpha}^{T} & & \in \mathbb{R}^{k} \\ \boldsymbol{h}_{t}^{*} & =tanh(\boldsymbol{W}^{r} \boldsymbol{r}_{t}+\boldsymbol{W}^{x} \boldsymbol{h}_{t}) & & \in \mathbb{R}^{k}\\ \boldsymbol{y}_{t} & =\operatorname{softmax}\left(\boldsymbol{W}^{*} \boldsymbol{h}_{t}^{*}+\boldsymbol{b}\right) & & \in \mathbb{R}^{|V|} \end{aligned} Mtαtrtht∗yt=tanh(WYYt+(Whht)1T)=softmax(wTMt)=YtαT=tanh(Wrrt+Wxht)=softmax(W∗ht∗+b)∈Rk×L∈R1×L∈Rk∈Rk∈R∣V∣
其中 W Y , W h , W r , W x ∈ R k × k W^Y, W^h, W^r, W^x \in \mathbb{R}^{k \times k} WY,Wh,Wr,Wx∈Rk×k, w ∈ R k w \in \mathbb{R}^k w∈Rk, W ∗ ∈ R ∣ V ∣ × k W^* \in \mathbb{R}^{|V| \times k} W∗∈R∣V∣×k, b ∈ R ∣ V ∣ b \in \mathbb{R}^{|V|} b∈R∣V∣ ,这些都是可训练参数。
可以看到,这里 h t \boldsymbol h_t ht 在 h t ∗ = t a n h ( W r r t + W x h t ) \boldsymbol{h}_{t}^{*} =tanh(\boldsymbol{W}^{r} \boldsymbol{r}_{t}+\boldsymbol{W}^{x} \boldsymbol{h}_{t}) ht∗=tanh(Wrrt+Wxht) 中,既要用于计算上下文向量 r t \boldsymbol r_t rt,又要用于预测下一个单词。
Michał Daniluk等人的工作,就是对这些功能解耦。所谓解耦,就是让不同的功能有各自独立的可训练参数,CV中有个名为YOLOX的模型,它们的检测头设计,也有解耦的思想在里面,让分类、位置和置信度得分在不同的路径中预测,思想和这个类似。
他们先把 h 分成了两份,一份称为 key 用来计算注意力权重,另一份称为 value,用来计算上下文向量和下一个单词的分布,上述注意力机制改进如下:
[ k t v t ] = h t ∈ R 2 k M t = tanh ( W Y [ k t − L ⋯ k t − 1 ] + ( W h k t ) 1 T ) ∈ R k × L α t = softmax ( w T M t ) ∈ R 1 × L r t = [ v t − L ⋯ v t − 1 ] α T ∈ R k h t ∗ = tanh ( W r r t + W x v t ) ∈ R k \begin{aligned} {\left[\begin{array}{c} \boldsymbol{k}_{t} \\ \boldsymbol{v}_{t} \end{array}\right] } & =\boldsymbol{h}_{t} & & \in \mathbb{R}^{2 k} \\ \boldsymbol{M}_{t} & =\tanh \left(\boldsymbol{W}^{Y}\left[\boldsymbol{k}_{t-L} \cdots \boldsymbol{k}_{t-1}\right]+\left(\boldsymbol{W}^{h} \boldsymbol{k}_{t}\right) \mathbf{1}^{T}\right) & & \in \mathbb{R}^{k \times L} \\ \boldsymbol{\alpha}_{t} & =\operatorname{softmax}\left(\boldsymbol{w}^{T} \boldsymbol{M}_{t}\right) & & \in \mathbb{R}^{1 \times L} \\ \boldsymbol{r}_{t} & =\left[\boldsymbol{v}_{t-L} \cdots \boldsymbol{v}_{t-1}\right] \boldsymbol{\alpha}^{T} & & \in \mathbb{R}^{k} \\ \boldsymbol{h}_{t}^{*} & =\tanh \left(\boldsymbol{W}^{r} \boldsymbol{r}_{t}+\boldsymbol{W}^{x} \boldsymbol{v}_{t}\right) & & \in \mathbb{R}^{k} \end{aligned} [ktvt]Mtαtrtht∗=ht=tanh(WY[kt−L⋯kt−1]+(Whkt)1T)=softmax(wTMt)=[vt−L⋯vt−1]αT=tanh(Wrrt+Wxvt)∈R2k∈Rk×L∈R1×L∈Rk∈Rk
结构如下图:
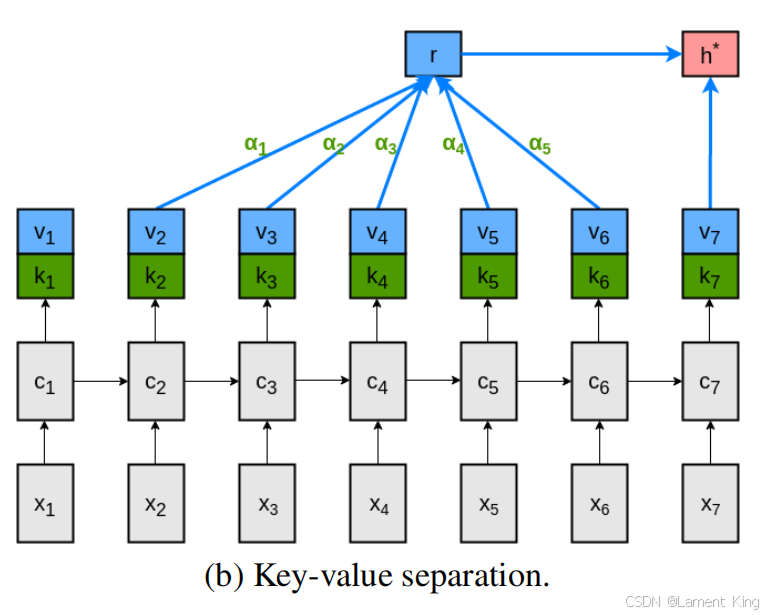
key 和 value 分离后,对于 v i v_i vi,既要在第 i i i 个时步用于计算下一个单词的分布,即 h i ∗ = tanh ( W r r i + W x v i ) h_i^{*} =\tanh (W^{r} r_{i}+W^{x} v_{i}) hi∗=tanh(Wrri+Wxvi)
又要在后续的 L L L 个时步中,用于计算上下文向量 r k \boldsymbol{r}_k rk,即 r k = [ v k − L ⋯ v k − 1 ] α T r_k =[v_{k-L} \cdots v_{k-1}] {\alpha}^{T} rk=[vk−L⋯vk−1]αT, k ∈ [ i + 1 , i + L ] k \in \mathbb [i+1, i+L] k∈[i+1,i+L]
因此可以把 value 的两个功能进一步解耦,从其中分出一部分(命名为 predict )专门用来预测下一个单词的分布,最后的注意力机制计算过程如下:
[ k t v t p t ] = h t ∈ R 2 k M t = tanh ( W Y [ k t − L ⋯ k t − 1 ] + ( W h k t ) 1 T ) ∈ R k × L α t = softmax ( w T M t ) ∈ R 1 × L r t = [ v t − L ⋯ v t − 1 ] α T ∈ R k h t ∗ = tanh ( W r r t + W x p t ) ∈ R k \begin{aligned} {\left[\begin{array}{c} \boldsymbol{k}_{t} \\ \boldsymbol{v}_{t} \\ \boldsymbol{p}_{t} \end{array}\right] } & =\boldsymbol{h}_{t} & & \in \mathbb{R}^{2 k} \\ \boldsymbol{M}_{t} & =\tanh \left(\boldsymbol{W}^{Y}\left[\boldsymbol{k}_{t-L} \cdots \boldsymbol{k}_{t-1}\right]+\left(\boldsymbol{W}^{h} \boldsymbol{k}_{t}\right) \mathbf{1}^{T}\right) & & \in \mathbb{R}^{k \times L} \\ \boldsymbol{\alpha}_{t} & =\operatorname{softmax}\left(\boldsymbol{w}^{T} \boldsymbol{M}_{t}\right) & & \in \mathbb{R}^{1 \times L} \\ \boldsymbol{r}_{t} & =\left[\boldsymbol{v}_{t-L} \cdots \boldsymbol{v}_{t-1}\right] \boldsymbol{\alpha}^{T} & & \in \mathbb{R}^{k} \\ \boldsymbol{h}_{t}^{*} & =\tanh \left(\boldsymbol{W}^{r} \boldsymbol{r}_{t}+\boldsymbol{W}^{x} \boldsymbol{p}_{t}\right) & & \in \mathbb{R}^{k} \end{aligned} ktvtpt Mtαtrtht∗=ht=tanh(WY[kt−L⋯kt−1]+(Whkt)1T)=softmax(wTMt)=[vt−L⋯vt−1]αT=tanh(Wrrt+Wxpt)∈R2k∈Rk×L∈R1×L∈Rk∈Rk
结构图如下:
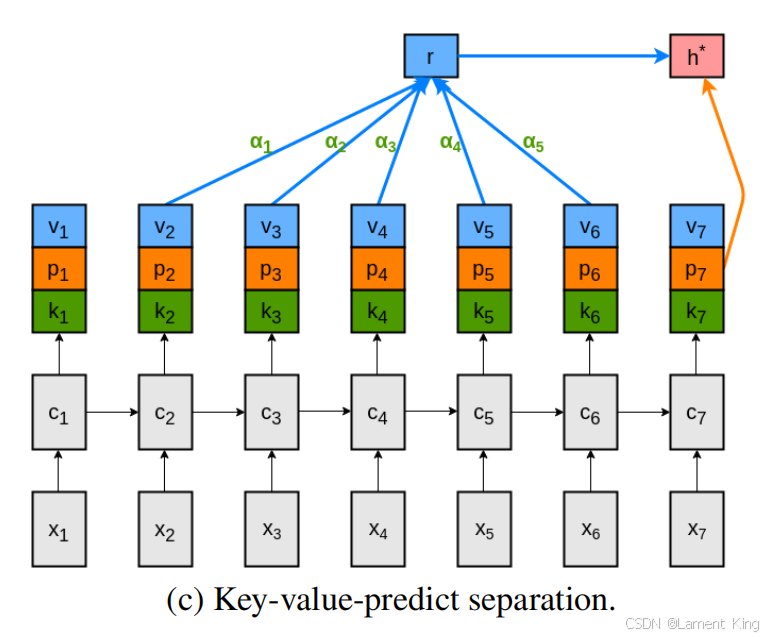
后面的 transformer 中的 QKV 注意力机制,其原型是来自于Key-Value注意力机制,并没有使用P,而是加了一个Query,这个我们会在下篇文章中介绍。
7 ResNet
这个熟悉CV的同学都知道,来源于何凯明的神作《Deep Residual Learning for Image Recognition》。ResNet中的残差块示意图如下:
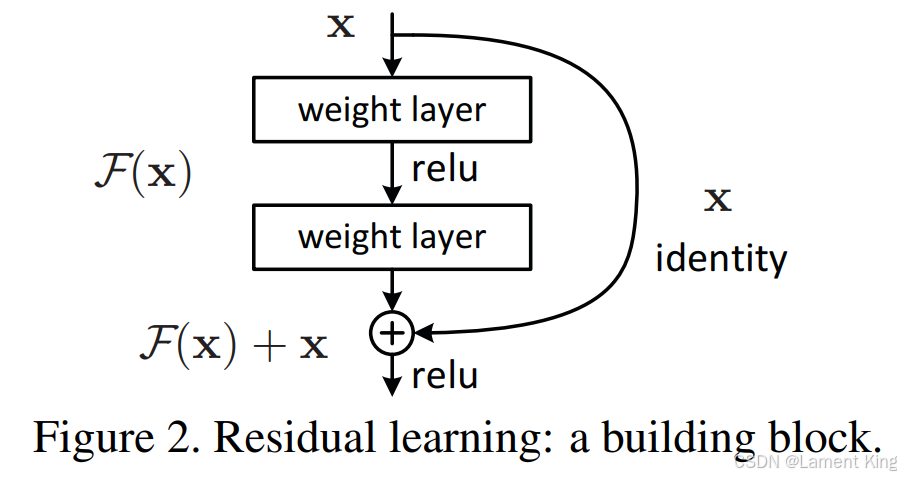
在它出现之前,CNN的网络层数不能太深,太深的话,靠近输出的层会出现梯度消失,导致参数更新困难,有了ResNet之后,因为短连接的存在,很好地解决了这个问题,使模型可以设计的更深。
8 总结
本文主要介绍的是 Transformer 的一些先修知识,通过这些知识,可以更好的理解 transformer 的结构和原理。本文读完之后,需要知道EncoderDecoder和Bahdanau Attention,什么是加性注意力机制,什么是点乘注意力机制,什么自注意力机制,什么是交叉注意力机制,什么是Mask自注意力机制,什么是多头注意力机制,什么是KV注意力机制。
https://zhuanlan.zhihu.com/p/690984212
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
Effective Approaches to Attention-based Neural Machine Translation
Long Short-Term Memory-Networks for Machine Reading
A structured self-attentive sentence embedding
FRUSTRATINGLY SHORT ATTENTION SPANS IN NEURAL LANGUAGE MODELING
Deep Residual Learning for Image Recognition
相关文章:
Transformer由入门到精通(一):基础知识
基础知识 0 前言1 EncoderDecoder2 Bahdanau Attention3 Luong Attention4 Self Attention/Masked Self Attention5 MultiHead Self Attention6 Key-Value Attention7 ResNet8 总结 0 前言 我之前看transformer的论文《Attention Is All You Need》,根本看不懂&…...

Windows安装Node.js+Express+Nodemon
Windows安装Node.jsExpressNodemon 陈拓 2025/4/3-2025/4/4 1. 概述 在《Node.jsExpressNodemonSocket.IO构建Web实时通信》 https://blog.csdn.net/chentuo2000/article/details/134651743?spm1001.2014.3001.5502 一文中我们介绍了在Linux系统上的安装过程,本…...

关于JVM和OS中的指令重排以及JIT优化
关于JVM和OS中的指令重排以及JIT优化 前言: 这东西应该很重要才对,可是大多数博客都是以讹传讹,全是错误,尤其是JVM会对字节码进行重排都出来了,明明自己测一测就出来的东西,写出来误人子弟… 研究了两天&…...

LeetCode hot 100—柱状图中最大的矩形
题目 给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。 求在该柱状图中,能够勾勒出来的矩形的最大面积。 示例 示例 1: 输入:heights [2,1,5,6,2,3] 输出:10 解释:最…...

从代码学习深度学习 - GRU PyTorch版
文章目录 前言一、GRU模型介绍1.1 GRU的核心机制1.2 GRU的优势1.3 PyTorch中的实现二、数据加载与预处理2.1 代码实现2.2 解析三、GRU模型定义3.1 代码实现3.2 实例化3.3 解析四、训练与预测4.1 代码实现(utils_for_train.py)4.2 在GRU.ipynb中的使用4.3 输出与可视化4.4 解析…...

重要头文件下的函数
1、<cctype> #include<cctype>加入这个头文件就可以调用以下函数: 1、isalpha(x) 判断x是否为字母 isalpha 2、isdigit(x) 判断x是否为数字 isdigit 3、islower(x) 判断x是否为小写字母 islower 4、isupper(x) 判断x是否为大写字母 isupper 5、isa…...

JSON-lib考古现场:在2025年打开赛博古董店的奇妙冒险
各位在代码海洋里捡贝壳的探险家们!今天我们要打开一个尘封的Java古董箱——JSON-lib!这货可是2003年的老宝贝,比在座很多程序员的工龄还大!准备好穿越回Web 1.0时代,感受XML统治时期的余晖了吗? …...

实操日志之Windows Server2008R2 IIS7 配置Php7.4.3
Windows7IIS7PHPMySQL - 适用于(2008 R2 / 8 / 10) 配置需求 操作系统:windows2008IIS版本:7.0 PHP版本:7.4.3 MySQL版本:5.7.12 及以上第一步: 安装 IIS 默认”Internet 信息服务“打勾安…...

Paraformer和SenseVoice模型训练
0.数据准备 如果是训练paraformer模型,我们只需要准备train_wav.scp和train_text.txt以及验证集val_wav.scp和val_text.txt即可。 如果是训练SenseVoice模型,我们需要准备下面几个文件: train_text.txt train_wav.scp train_text_language.…...

Axure数据可视化科技感大屏设计资料——赋能多领域,展示无限价值
可视化大屏如何高效、直观地展示数据,并将其转化为有价值的决策依据,成为了许多企业和组织面临的共同挑战。Axure大屏可视化模板,作为一款强大的数据展示工具,正在以其出色的交互性和可定制性,赋能多个领域,…...
之简单的抽奖系统邮件)
C# Winform 入门(7)之简单的抽奖系统邮件
由于比较喜欢英语,这里就把汉字属性名都改成英语了 声明变量,生成随机数 int key 0;Random random new Random(); 窗体加载 private void Form1_Load(object sender, EventArgs e) {timer1.Enabledfalse; } 开始按钮 private void txt_begin_Click(ob…...

scala编程语言
一、抽象类 1、抽象属性和抽象方法 1)基本语法 (1)定义抽象类:abstract class Person{} //通过 abstract 关键字标记抽象类 (2)定义抽象属性:val|var name:String //一个属性没有初始化…...
)
光流 | Farneback、Horn-Schunck、Lucas-Kanade、Lucas-Kanade DoG四种光流算法对比(附matlab源码)
🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅 以下是对四种光流算法的对比分析及MATLAB验证方案,包含原理说明、应用场景和可执行代码🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅 🍓🍓🍓🍓🍍🍍🍍🍍🍍🍍🍍🍍🍍🍍…...
)
146. LRU 缓存 带TTL的LRU缓存实现(拓展)
LRU缓存 方法一:手动实现双向链表 哈希表 struct Node{int val;int key;Node* prev;Node* next;Node(int a, int b): key(a), val(b), prev(nullptr), next(nullptr) {}Node():key(0), val(0), prev(nullptr), next(nullptr) {} }; class LRUCache { private:Node* removeTai…...

【C++代码整洁之道】第九章 设计模式和习惯用法
文章目录 1. 设计原则与设计模式2. 常见的设计模式及应用场景2.1 单例模式2.2 依赖注入2.3 Adapter模式2.4 Strategy模式2.5 Command模式2.6 Command处理器模式2.7 Composite模式2.8 Observer模式2.9 Factory模式2.10 Facade模式2.11 Money Class模式2.12 特例模式 3. 常见的设…...

【动态规划】混合背包模板
混合背包问题题解 题目传送门:AcWing 7. 混合背包问题 一、题目描述 有 N 种物品和一个容量是 V 的背包。物品分为三类: 01背包:只能用1次(si -1)完全背包:可以用无限次(si 0)多…...

Linux 线程1-线程的概念、线程与进程区别、线程的创建、线程的调度机制、线程函数传参
目录 1.线程概念 1.1 线程的核心特点 1.2线程的工作模型 1.3线程的潜在问题 1.4 进程和线程区别 1.4.1执行与调度 1.4.2进程和线程区别对比表 1.4.3应用场景 1.4.4总结 2.线程的创建 2.1验证进程结束后,进程中所有的线程都会强制…...

Python 助力人工智能与机器学习的深度融合
技术革新的 “源动力” 在当今数字化时代,人工智能(AI)与机器学习(ML)无疑是最具影响力的技术领域,它们如同强大的引擎,推动着各个行业的变革与发展。Python 凭借其简洁易读的语法、丰富的库和…...

【GPT写代码】动作视频切截图研究器
目录 背景源代码 end 背景 用python写一个windows环境运行的动作视频切截图研究器,用路径浏览的方式指定待处理的视频文件,然后点击分析按钮,再预览区域显示视频预览画面,然后拖动时间轴,可以在预览区域刷新显示相应的…...

从0到神谕:GPT系列的进化狂想曲——用AI之眼见证人类语言的终极形态
开始:语言模型的星际跃迁 在人工智能的浩瀚星海中,GPT系列如同光年加速器,推动人类语言的理解与生成突破维度限制。从2018年GPT-1的初试啼声,到2025年GPT-4o的全模态智慧,这场进化狂想曲不仅是技术的迭代史,…...

Go并发编程终极指南:深入内核与工程实践
Go并发编程终极指南:深入内核与工程实践 Go并发编程终极指南:深入内核与工程实践 Go并发编程终极指南:深入内核与工程实践一、Goroutine调度器深度解构1.1 调度器演进史1.2 调度器源码级解析1.3 调度器可视化诊断 二、Channel底层实现揭秘2.1…...
)
Neo4j操作数据库(Cypher语法)
Neo4j数据库操作语法 使用的数据库版本 (终端查询) >neo4j --version 2025.03.0批量上传数据 UNWIND [{name: Alice, age: 30},{name: Bob, age: 25} ] AS person CREATE (p:Person) SET p.name = person.name, p.age = person.age RETURN p;查询结点总数 MATCH (n) RETU…...

DHCP之中继 Relay-snooping及配置命令
随着网络规模的不断扩大,网络设备不断增多,企业内不同的用户可能分布在不同的网段,一台 DHCP 服务器在正常情况下无法满足多个网段的地址分配需求。如果还需要通过 DHCP 服务器分配 IP 地址,则需要跨网段发送 DHCP 报文 DHCP Rel…...

小迪安全110-tp框架,版本缺陷,不安全写法,路由访问,利用链
入口文件 前端页面显示文件 就是这串代码让我们看到前端的笑脸图 不用入口文件我们要访问这个文件就要按照开发手册的url访问模式 那就是index.php/index/index/index 对应的就是模块,控制器,操作,函数名 如果想要创建新模块,和操…...
技术革新自然语言转SQL)
Vanna:用检索增强生成(RAG)技术革新自然语言转SQL
引言:为什么我们需要更智能的SQL生成? 在数据驱动的业务环境中,SQL 仍然是数据分析的核心工具。然而,编写正确的 SQL 查询需要专业知识,而大型语言模型(LLM)直接生成的 SQL 往往存在**幻觉&…...
)
大语言模型应用和训练(人工智能)
RAG(Retrieval Augmented Generation,检索增强生成) 定义:是一种将外部知识检索与语言模型生成能力相结合的技术。在传统的大语言模型中,模型的知识是在预训练阶段学到的,可能存在知识过时或不完整的问题。…...
——LLaMA / ChatGLM / BLOOM的区别)
NLP高频面试题(三十五)——LLaMA / ChatGLM / BLOOM的区别
一、LLaMA 训练数据 LLaMA由Meta开发,拥有多个参数规模的版本:7B、13B、33B和65B。其中,较小的7B和13B版本采用了约1万亿tokens进行训练,而更大的33B和65B版本使用了约1.4万亿tokens进行训练。 模型结构特点 LLaMA采用与GPT类似的causal decoder-only Transformer结构,…...
:递归下降分析器)
【Python Cookbook】字符串和文本(五):递归下降分析器
目录 案例 目录 案例 字符串和文本(一)1.使用多个界定符分割字符串2.字符串开头或结尾匹配3.用 Shell 通配符匹配字符串4.字符串匹配和搜索5.字符串搜索和替换字符串和文本(三)11.删除字符串中不需要的字符12.审查清理文本字符串1…...

专为 零基础初学者 设计的最简前端学习路线,聚焦核心内容,避免过度扩展,帮你快速入门并建立信心!
第一阶段:HTML CSS(2-3周) 目标:能写出静态网页,理解盒子模型和布局。 HTML基础 常用标签:<div>, <p>, <img>, <a>, <ul>, <form> 语义化标签:<head…...

大模型-爬虫prompt
爬虫怎么写prompt 以下基于deepseek r1 总结: 以下是为大模型设计的结构化Prompt模板,用于生成专业级网络爬虫Python脚本。此Prompt包含技术约束、反检测策略和数据处理要求,可根据具体需求调整参数: 爬虫脚本生成Prompt模板1 …...

PyTorch深度实践:基于累积最大值的注意力机制设计与性能优化
引言:注意力机制的创新与挑战 在自然语言处理和序列建模中,注意力机制(Attention)是提升模型性能的关键技术。传统基于 softmax 的注意力机制虽然成熟,但在计算效率和长序列建模中存在局限。本文将介绍一种创新的注意…...
)
编程bug001:off by one (差一错误)
为什么看似简单的编码错误可能造成大灾难? Off-by-One Error(简称OBOE),即由于边界条件处理不当,导致循环、计数或索引时多算一次或少算一次的错误。这是非常常见的编程bug类型,尤其在处理数组、字符串或范…...

JavaScript 中常见的鼠标事件及应用
JavaScript 中常见的鼠标事件及应用 在 JavaScript 中,鼠标事件是用户与网页进行交互的重要方式,通过监听这些事件,开发者可以实现各种交互效果,如点击、悬停、拖动等。 在 JavaScript 中,鼠标事件类型多样࿰…...

使用Expo框架开发APP——详细教程
在移动应用开发日益普及的今天,跨平台开发工具越来越受到开发者青睐。Expo 是基于 React Native 的一整套工具和服务,它能够大幅降低原生开发的门槛,让开发者只需关注业务逻辑和界面实现,而不用纠结于复杂的原生配置。本文将从零开…...

深入探究 Hive 中的 MAP 类型:特点、创建与应用
摘要 在大数据处理领域,Hive 作为一个基于 Hadoop 的数据仓库基础设施,提供了方便的数据存储和分析功能。Hive 中的 MAP 类型是一种强大的数据类型,它允许用户以键值对的形式存储和操作数据。本文将深入探讨 Hive 中 MAP 类型的特点,详细介绍如何创建含有 MAP 类型字段的表…...

前端开发工厂模式的优缺点是什么?
一、什么是工厂模式? 工厂模式属于创建型设计模式,核心思想是将对象的实例化过程封装到特定方法或类中,让客户端不需要直接通过new关键字创建对象。 举个例子:就像奶茶店不需要顾客自己调配饮品,而是通过"点单-…...
)
框架PasteForm实际开发案例,换个口味显示数据,支持echarts,只需要标记几个特性即可在管理端显示(2)
PasteForm框架的主要思想就是对Dto进行标记特性,然后管理端的页面就会以不一样的UI呈现 使用PasteForm框架开发,让你免去开发管理端的烦恼,你只需要专注于业务端和用户端! 在管理端中,如果说表格是基本的显示方式,那么图表chart就是一个锦上添花的体现! 如果一个项目拥…...
— 从0到1构建Linux系统镜像)
QEMU学习之路(5)— 从0到1构建Linux系统镜像
QEMU学习之路(5)— 从0到1构建Linux系统镜像 一、前言 参考:从内核到可启动镜像:0到1构建你的极简Linux系统 二、linux源码获取 安装编译依赖 sudo apt install -y build-essential libncurses-dev flex bison libssl-dev li…...

AI Agent设计模式一:Chain
概念 :线性任务流设计 ✅ 优点:逻辑清晰易调试,适合线性处理流程❌ 缺点:缺乏动态分支能力 from typing import TypedDictfrom langgraph.graph import StateGraph, END# 定义后续用到的一些变量 class CustomState(TypedDict):p…...
Linux)
实操(进程状态,R/S/D/T/t/X/Z)Linux
1 R 状态并不直接代表进程在运行,而是该进程在运行队列中进行排队,由操作系统在内存维护的队列 #include <stdio.h> #include <unistd.h>int main() {while(1){printf("我在运行吗\n");sleep(1);}return 0; }查看状态(…...

T-SQL语言的自动化运维
T-SQL语言的自动化运维 引言 在现代IT环境中,自动化运维成为了提高效率、降低成本、提升稳定性的重要手段。数据库作为系统的重要组成部分,运维工作往往需要耗费大量的人力物力。T-SQL(Transact-SQL)作为Microsoft SQL Server的…...

Day06 分割编译与中断处理
文章目录 1. 例程harib03c(c源文件分割并整理makefile文件)2. 例程harib03c(用于描述段的信息)3. 例程harib03d(初始化PIC)4. 例程harib03e(中断处理程序) 1. 例程harib03cÿ…...

数字化三维实训室:无穿戴动作捕捉技术如何赋能体育与舞蹈
在高校体育与舞蹈教学中,精准的动作训练至关重要。传统训练方式依赖教练的肉眼观察与手动记录,存在效率低下、误差较大的情况。尤其在快速连续动作或复杂肢体形态的捕捉中,人工判读易受主观经验限制,难以实现标准化评估。面对传统…...

6. RabbitMQ 死信队列的详细操作编写
6. RabbitMQ 死信队列的详细操作编写 文章目录 6. RabbitMQ 死信队列的详细操作编写1. 死信的概念2. 消息 TTL 过期(触发死信队列)3. 队列超过队列的最大长度(触发死信队列)4. 消息被拒(触发死信队列)5. 最后: 1. 死信的概念 先从概念上解释上搞清楚这个定义&#…...

AI浪潮下,新手短视频制作的破局之道
AI浪潮下,新手短视频制作的破局之道 引言:短视频新时代,AI 带来的机遇与挑战 在当下这个信息飞速流转的时代,短视频已然成为了人们生活中不可或缺的一部分。无论是在通勤路上、午休间隙,还是茶余饭后,打开…...

合肥SMT贴片制造工艺全解析
内容概要 作为电子制造领域的核心工艺,SMT(表面贴装技术)在合肥地区电子产业链中占据重要地位。本解析以合肥本地化生产场景为基础,系统梳理从焊膏印刷到成品检测的全流程工艺框架。具体而言,制造流程涵盖四大核心阶段…...

ctfshow VIP题目限免 协议头信息泄露
根据提示是协议头信息泄露,那就我们抓个包,抓包才能看到请求体响应体里的协议头啊,抓包之后在响应包里发现了 flag...

【国产工具链发展,生态链分析,TSMaster VS Zcanpro的技术对比】
黎明篇:国产汽车测试工具链的崛起、差距与未来 副标题: 从跟随到超越,中国技术如何重塑全球研发体系 一、国产工具链的崛起逻辑 政策驱动:信创战略与供应链安全需求 国家“十四五”规划明确提出支持关键领域技术自主化࿰…...

Linux线程同步与互斥:【线程互斥】【线程同步】【线程池】
目录 一.线程互斥 1.1相关概念 1.2互斥量 为什么会出现负数?? 互斥量的接口 问题: 1.3互斥量实现原理探究 1.4互斥量封装 二.线程同步 2.1条件变量 2.2同步概念与竞态条件 2.3接口 2.4生产者消费者模型 优点 2.5基于BlockingQueue的…...

网络安全基础知识总结
什么是网络安全 采取必要措施,来防范对网络的攻击,侵入,干扰,破坏和非法使用,以及防范一些意外事故,使得网络处于稳定可靠运行的状态,保障网络数据的完整性、保密性、可用性的能力(CIA)。 举例…...