Linux线程概念与控制:【线程概念(页表)】【Linux线程控制】【线程ID及进程地址空间布局】【线程封装】
目录
一. 线程概念
1.1什么是线程
1.2分页式存储管理
1.2.1虚拟地址和页表的由来
1.2.2物理内存管理
1.2.3页表
1.2.4页目录结构
1.2.5二级页表地址转换
1.3线程的优点
二.进程VS线程
三.Linux线程控制
3.1POSIX线程库
3.2创建线程
编辑
pthread库是个什么东西
tid???
返回值
3.3pthread_create参数可以是任意类型
3.4线程终止
3.5分离线程
四.线程ID及进程地址空间布局
4.1部分源码
4.2线程栈
五.线程封装
线程的局部存储
一. 线程概念
1.1什么是线程
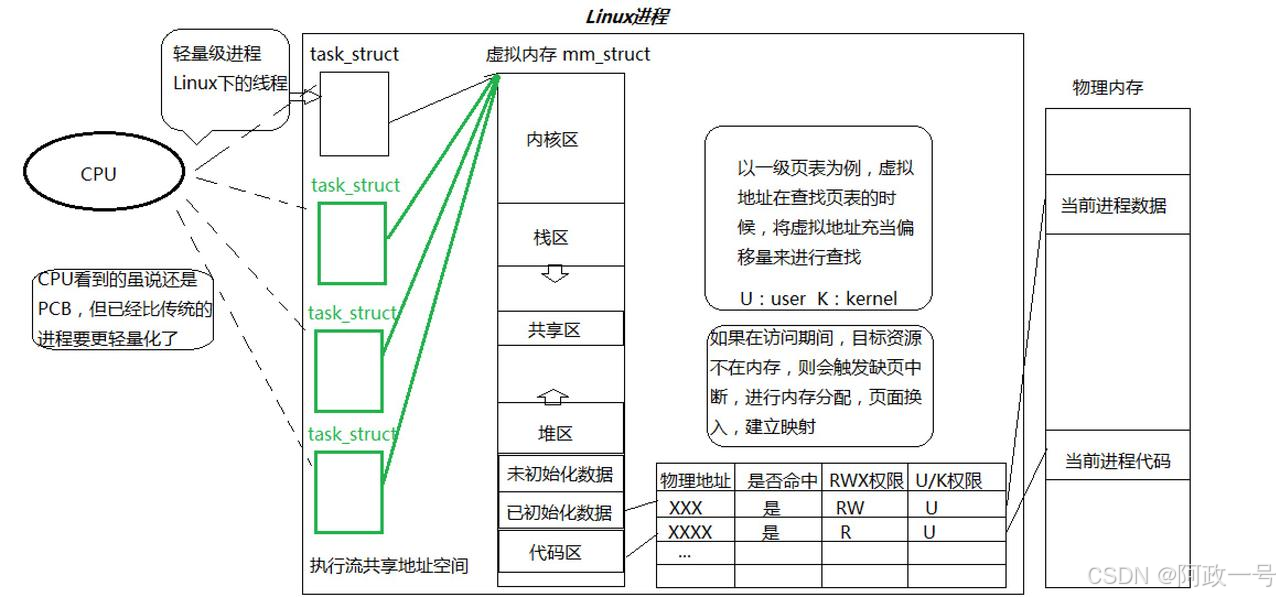
• 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”
• 一切进程至少都有一个执行线程
• 线程在进程内部运行,本质是在进程地址空间内运行
• 在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更加轻量化
• 透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形 成了线程执行流
1.2分页式存储管理
1.2.1虚拟地址和页表的由来
如果没有虚拟地址和页表的话,每一个用户程序在物理内存上所对应的空间必须是连续的:
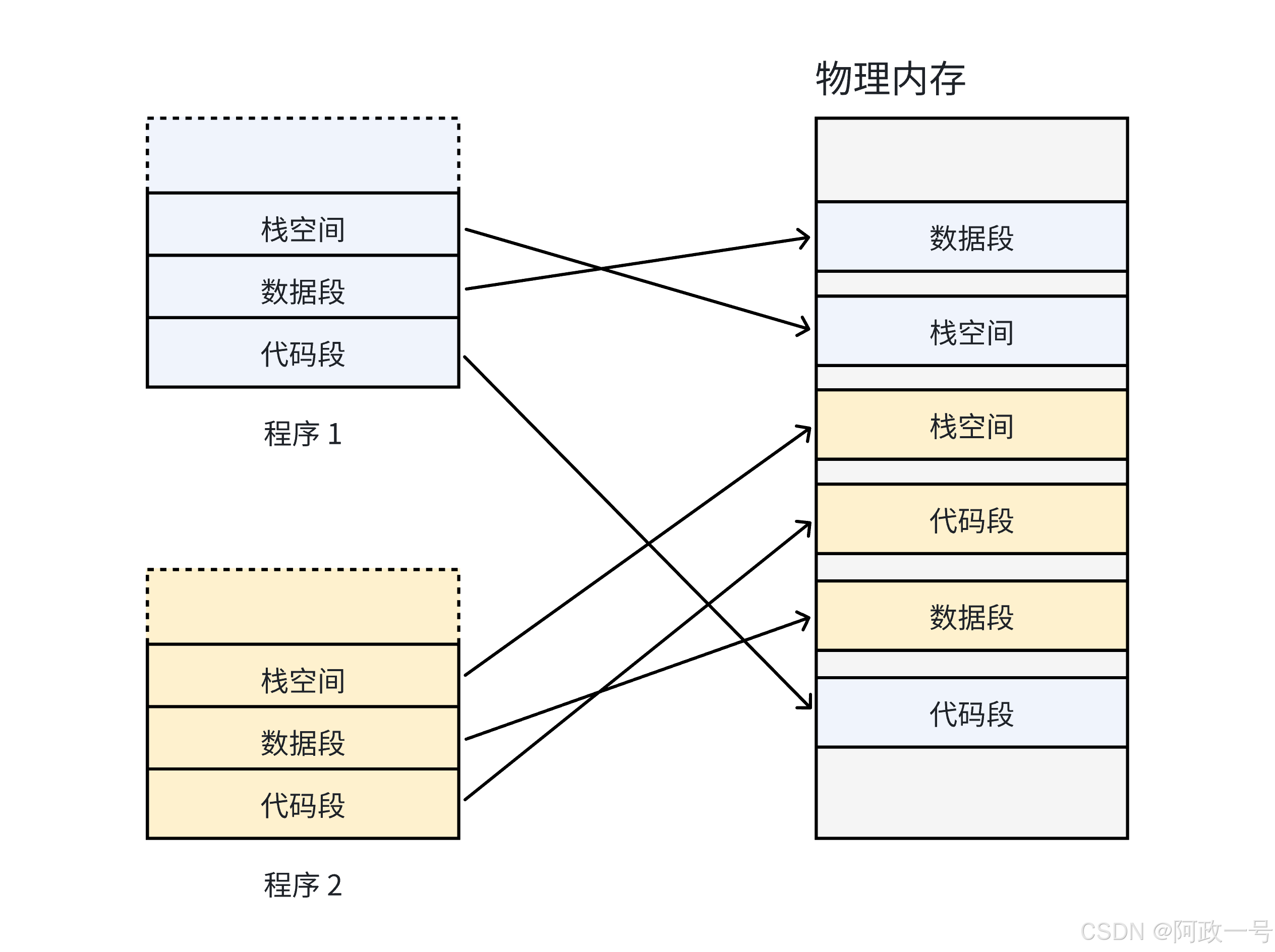
因为每一个程序的代码、数据长度都是不一样的,按照这样的映射方式,物理内存将会被分割成各种离散的、大小不同的块。经过一段运行时间之后,有些程序会退出,那么它们占据的物理内存空间可以被回收,导致这些物理内存都是以很多碎片的形式存在(假如程序一的栈空间被释放了4kb,现在要申请2kb,就必然有空间碎片)。而且如果我的代码段的函数跳转指向了其他程序的空间呢?这就出大问题了
我们希望操作系统提供用户的空间必须是连续的,但是物理内存最好不要连续。此时虚拟内存和分页便出现了:
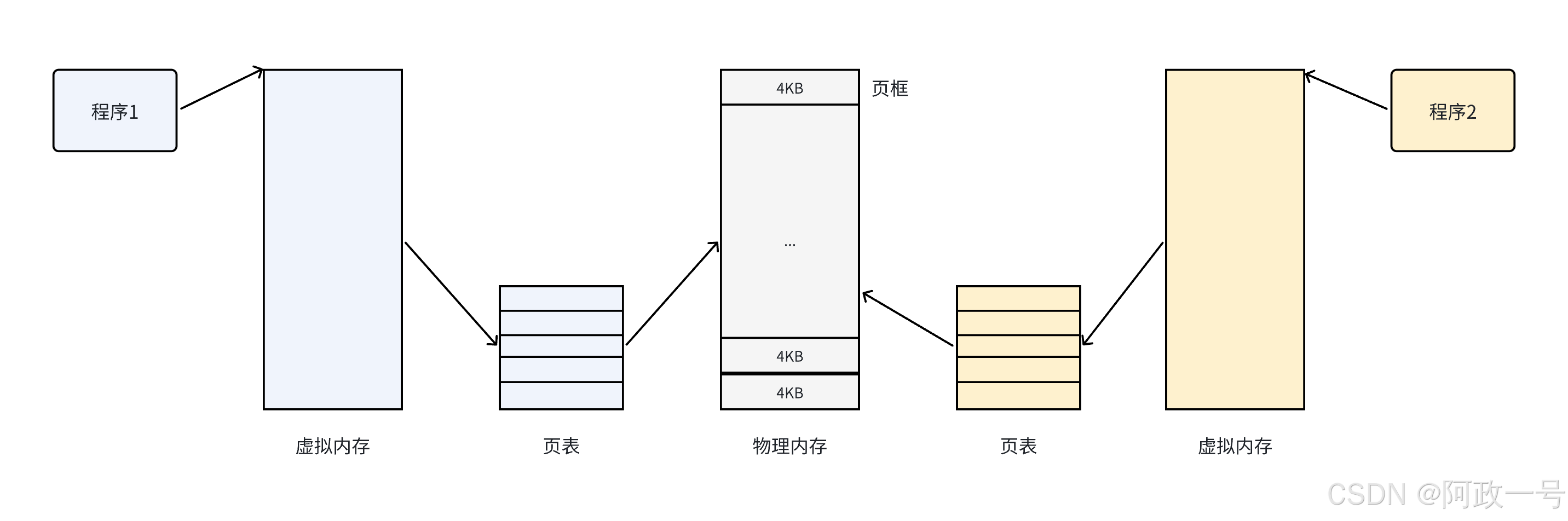
把物理内存按照一个固定的长度的页框进行分割,有时叫做物理页。每个页框包含一个物理页 (page)。一个页的大小等于页框的大小。大多数 32位 体系结构支持 4KB 的页,而 64位 体系结构一般会支持 8KB 的页。区分一页和一个页框是很重要的:
• 页框是一个存储区域;
• 而页是一个数据块,可以存放在任何页框或磁盘中。
页是虚拟内存的逻辑单位,用于把进程的地址空间划分成固定大小的块;而页框是物理内存的实际单位,用于存储和管理页面数据。
操作系统通过将虚拟地址空间和物理内存地址之间建立映射关系,也就是页表,这张表上记录了每一对页和页框的映射关系,能让CPU间接的访问物理内存地址。
其思想是将虚拟内存下的逻辑地址空间分为若干页,将物理内存空间分为若干页框,通过页表便能把连续的虚拟内存,映射到若干个不连续的物理内存页。这样就解决了使用连续的物理内存造成的碎片问题。
1.2.2物理内存管理
假设一个可用的物理内存有 4GB 的空间。按照一个页框的大小 4KB 进行划分, 4GB 的空间就是 4GB/4KB = 1048576 个页框。有这么多的物理页,操作系统肯定是要将其管理起来的,操作系统 需要知道哪些页正在被使用,哪些页空闲等等。
内核用 struct page 结构表示系统中的每个物理页,出于节省内存的考虑, struct page 中使用了大量的联合体union。

部分参数:
1. flags :用来存放页的状态。这些状态包括页是不是脏的,是不是被锁定在内存中等。flag的每一位单独表示一种状态,所以它至少可以同时表示出32种不同的状态。这些标志定义在 中。其中一些比特位非常重要,如PG_locked用于指定页是否锁定, PG_uptodate用于表示页的数据已经从块设备读取并且没有出现错误。
2. _mapcount :表示在页表中有多少项指向该页,也就是这一页被引用了多少次。当计数值变 为-1时,就说明当前内核并没有引用这一页,于是在新的分配中就可以使用它。
3. virtual :是页的虚拟地址。通常情况下,它就是页在虚拟内存中的地址。有些内存(即所谓的高端内存)并不永久地映射到内核地址空间上。在这种情况下,这个域的值为NULL,需要的时候,必须动态地映射这些页。 (有时候操作系统需要从物理地址转换为虚拟地址)
要注意的是 struct page 与物理页相关,而并非与虚拟页相关。
算 struct page 占40个字节的内存吧,假定系统的物理页为 4KB 大小,系统有 4GB 物理内存。 那么系统中共有页面 1048576 个(1兆个),所以描述这么多页面的page结构体消耗的内存只不过 40MB ,相对系统 4GB 内存而言,仅是很小的一部分罢了。因此,要管理系统中这么多物理页面,这 个代价并不算太大。
要知道的是,页的大小对于内存利用和系统开销来说非常重要,页太大,页必然会剩余较大不能利 用的空间(页内碎片)。页太小,虽然可以减小页内碎片的大小,但是页太多,会使得页表太长而占用内存,同时系统频繁地进行页转化,加重系统开销。因此,页的大小应该适中,通常为 512B - 8KB ,windows系统的页框大小为4KB。
1.2.3页表
页表中的每一个表项,指向一个物理页的开始地址。在 32 位系统中,虚拟内存的最大空间是 4GB , 这是每一个用户程序都拥有的虚拟内存空间。既然需要让 4GB 的虚拟内存全部可用,那么页表中就需要能够表示这所有的 4GB 空间,那么就一共需要 4GB/4KB = 1048576 个表项。
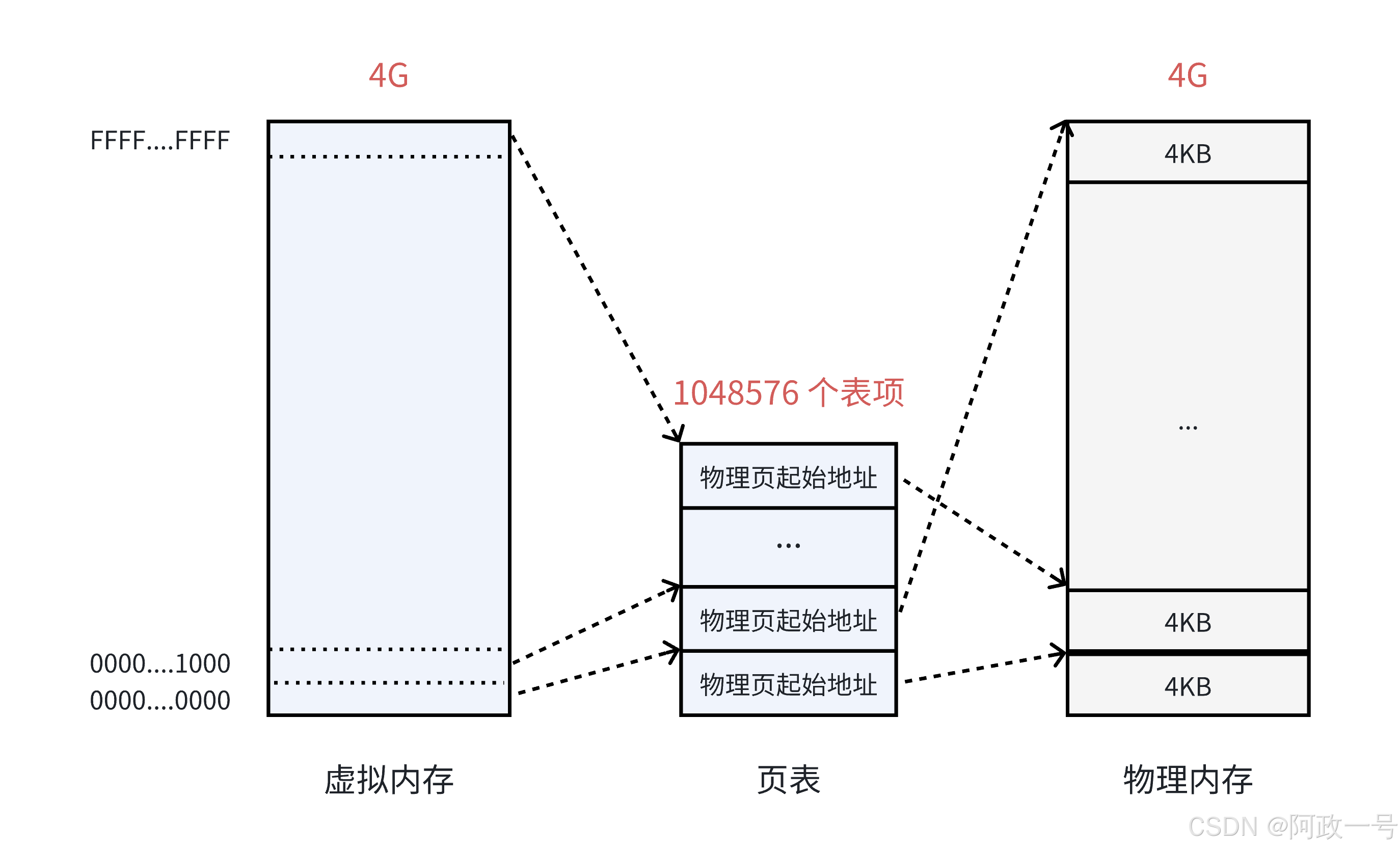
页表中的物理地址,与物理内存之间,是随机的映射关系,哪里可用就指向哪里(物理页)。虽然最终使用的物理内存是离散的,但是与虚拟内存对应的线性地址是连续的。处理器在访问数据、获取指令时,使用的都是线性地址,只要它是连续的就可以了,最终都能够通过页表找到实际的物理地址。
在 32 位系统中,地址的长度是 4 个字节,那么页表中的每一个表项就是占用 4 个字节。所以页表占据的总空间大小就是: 1048576*4 = 4MB 的大小。也就是说映射表自己本身,就要占用 4MB / 4KB = 1024 个物理页。
• 回想一下,当初为什么使用页表,就是要将进程划分为一个个页可以不用连续的存放在物理内存 中,但是此时页表就需要1024个连续的页框,似乎和当时的目标有点背道而驰了......
• 此外,根据局部性原理可知,很多时候进程在一段时间内只需要访问某几个页就可以正常运行 了。因此也没有必要一次让所有的物理页都常驻内存。
解决需要大容量页表的最好方法是:把页表看成普通的文件,对它进行离散分配,即对页表再分页, 由此形成多级页表的思想。为了解决这个问题,可以把这个单一页表拆分成 1024 个体积更小的映射表。如下图所示。这样一来,1024(每个表中的表项个数)*1024(表的个数),仍然可以覆盖 4GB 的物理内存空间。
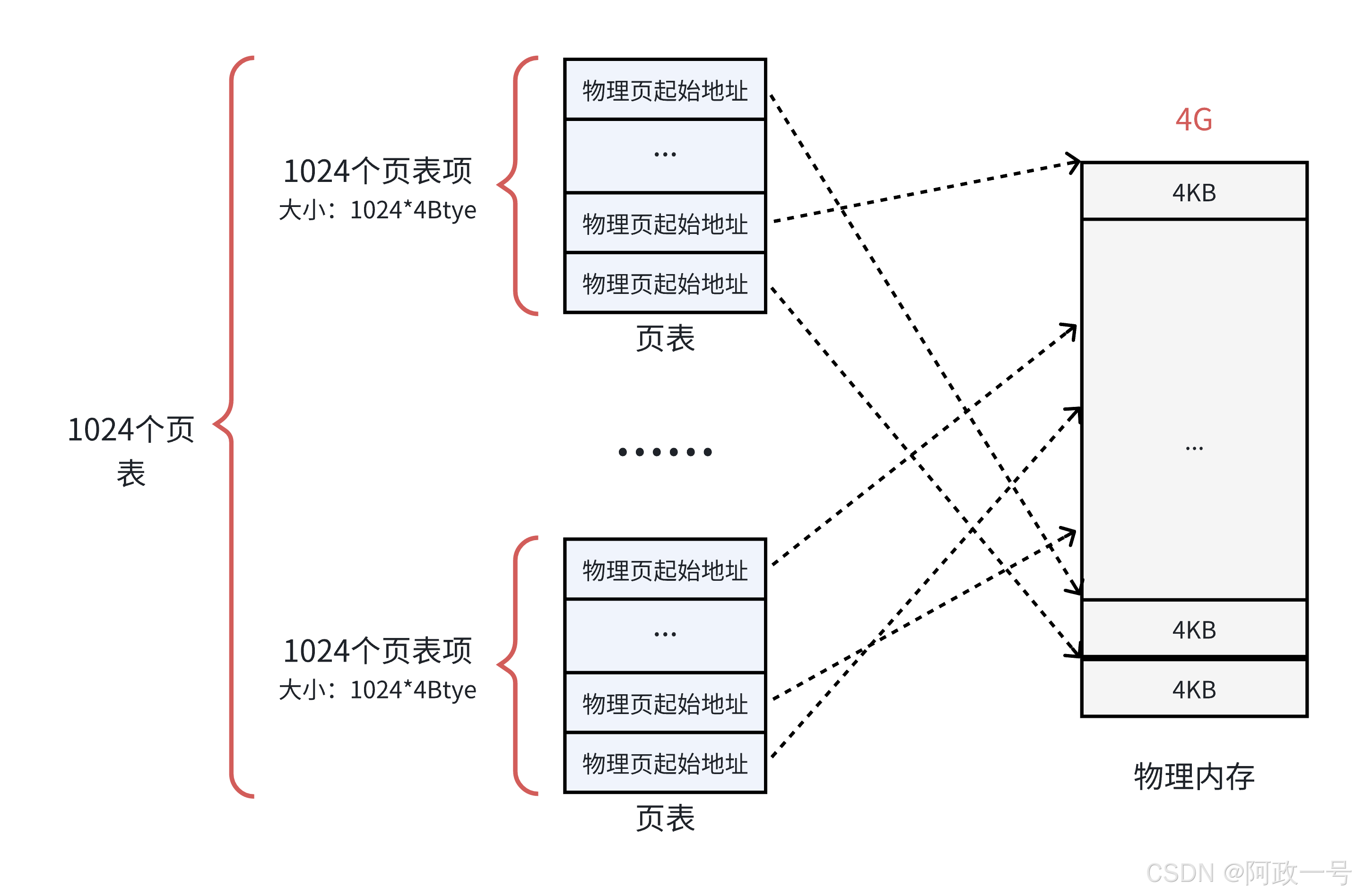
这里的每一个表,就是真正的页表,所以一共有 1024 个页表。一个页表自身占用 4KB ,那么 1024 个页表一共就占用了 4MB 的物理内存空间,和之前没差别啊?
从总数上看是这样,但是一个应用程序是不可能完全使用全部的 4GB 空间的,也许只要几十个页表就 可以了。例如:一个用户程序的代码段、数据段、栈段,一共就需要 10 MB 的空间,那么使用 3 个 页表就足够了。
每一个页表项指向一个4KB 的物理页,那么一个页表中 1024 个页表项,一共能覆盖 4MB 的物理内存;那么10MB的程序,向上对齐取整之后(4MB 的倍数,就是 12 MB),就需要 3 个页表就可以了。
1.2.4页目录结构
到目前为止,每一个页框都被一个页表中的一个表项来指向了,那么这 1024 个页表也需要被管理起来。管理页表的表称之为页目录表,形成二级页表。
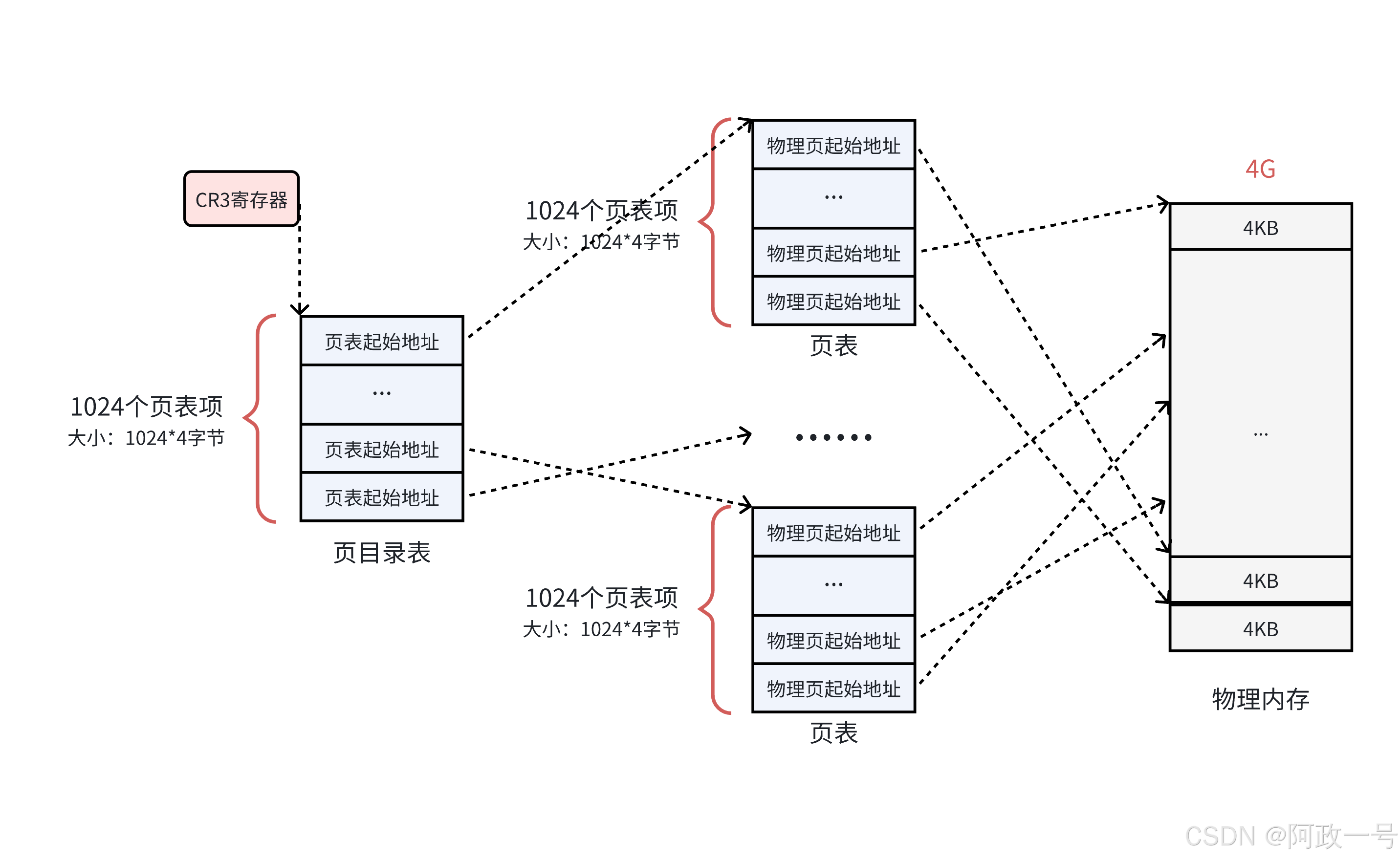
• 所有页表的物理地址被页目录表项指向
• 页目录的物理地址被 CR3 寄存器 指向,这个寄存器中,保存了当前正在执行任务的页目录地 址。
1.2.5二级页表地址转换
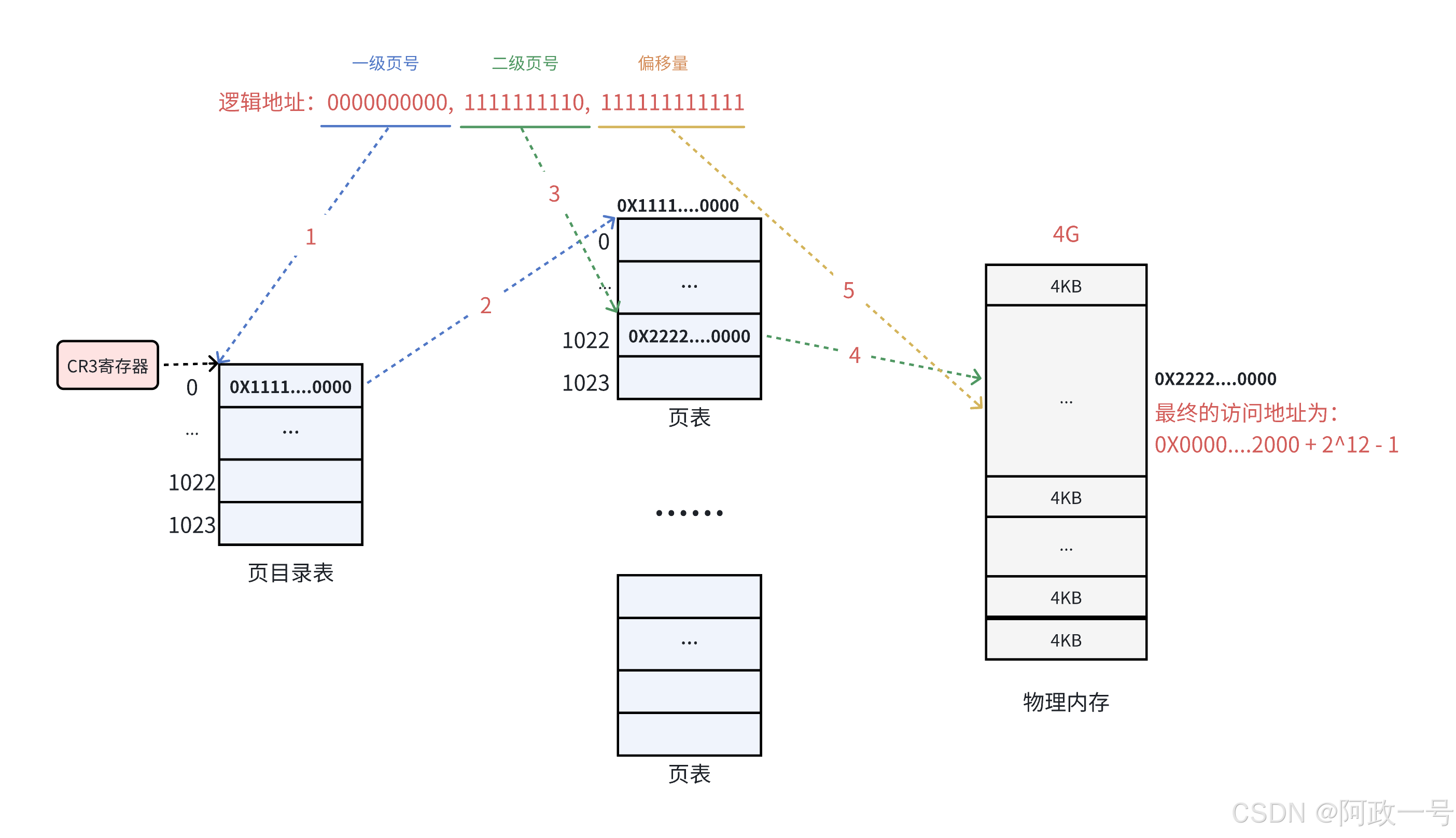
1. 在32位处理器中,采用4KB的页大小,则虚拟地址中低12位为页偏移,剩下高20位给页表,分成两级,每个级别占10个bit(10+10)。
2. CR3 寄存器 读取页目录起始地址,再根据一级页号查页目录表,找到下一级页表在物理内存中 存放位置。
3. 根据二级页号查表,找到最终想要访问的内存块号。
4. 结合页内偏移量得到物理地址。
5. 注:一个物理页的地址一定是 4KB 对齐的(最后的 12 位全部为 0 )(假如我们有物理地址,把物理地址的后12位全部清0,那么前面的地址就是页框的地址,这个数字除以4kb就是struct page mem[1048576]的数组下标,此时就可以找到page,page结构体里有virtual,此时可以找到虚拟地址),所以其实只需要记录物理页地址的高20位即可。
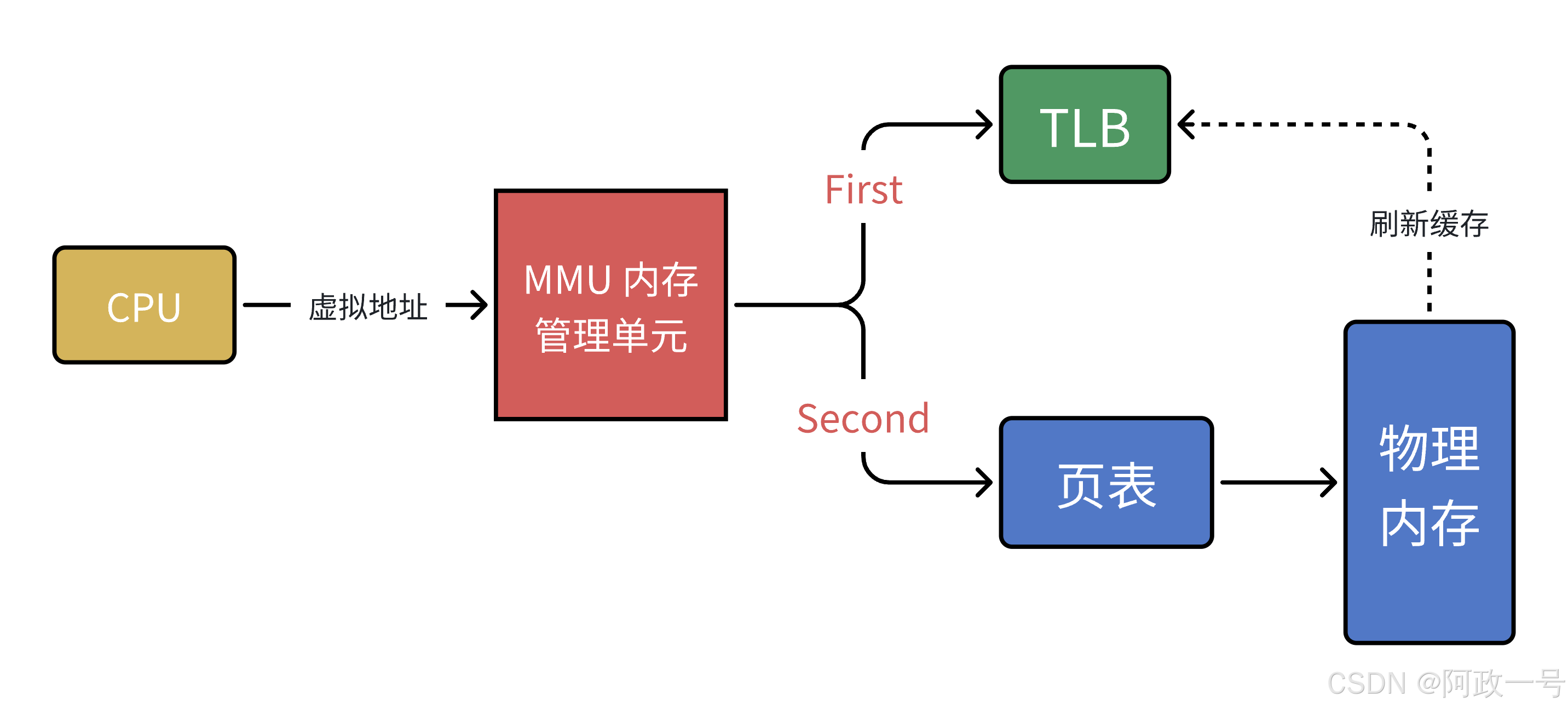
6. 以上其实就是 MMU 的工作流程。MMU(Memory Manage Unit)是一种硬件电路,其速度很快, 主要工作是进行内存管理,地址转换只是它承接的业务之一。
 单级页表对连续内存要求高,于是引入了多级页表,但是多级页表也是一把双 刃剑,在减少连续存储要求且减少存储空间的同时降低了查询效率。 有没有提升效率的办法呢?计算机科学中的所有问题,都可以通过添加⼀个中间层来解决。
单级页表对连续内存要求高,于是引入了多级页表,但是多级页表也是一把双 刃剑,在减少连续存储要求且减少存储空间的同时降低了查询效率。 有没有提升效率的办法呢?计算机科学中的所有问题,都可以通过添加⼀个中间层来解决。
MMU 引入 了新武器,江湖⼈称快表的 TLB (其实,就是缓存) 当 CPU 给 MMU 传新虚拟地址之后, MMU 先去问 TLB 那边有没有,如果有就直接拿到物理地址发到 总线给内存,齐活。
但 TLB 容量比较小,难免发生 Cache Miss ,这时候 MMU 还有保底的老武器页表,在页表中找到之后 MMU 除了把地址发到总线传给内存,还把这条映射关系给到TLB,让它记录一下刷新缓存。
假如申请一段空间,或者缺页中断,写时拷贝等等,先查找哪个页没有被用,申请这个内存,因为

查找数组的下标就可以找到page,找到物理页框的地址。

![]()
1.3线程的优点
• 创建一个新线程的代价要比创建一个新进程小得多
• 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
◦ 最主要的区别是线程的切换虚拟内存空间依然是相同的,但是进程切换是不同的。这两种上 下文切换的处理都是通过操作系统内核来完成的。内核的这种切换过程伴随的最显著的性能 损耗是将寄存器中的内容切换出。(切换完还是指向同一个进程地址空间,页表之间的映射还是不变,CR3寄存器不用变)
◦ 另外一个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。简单的说,一旦去切换上下文,处理器中所有已经缓存的内存地址一瞬间都作废了。还有一个显著的区别是当你改变虚 拟内存空间的时候,处理的页表缓冲 TLB (快表)会被全部刷新,这将导致内存的访问在一段时间内相当的低效。但是在线程的切换中,不会出现这个问题,当然还有硬件cache。(进程切换,会导致TLB,cache失效,需要重新缓存)
• 线程占用的资源要比进程少很
• 能充分利用多处理器的可并行数量
• 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
• 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
• I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
二.进程VS线程
• 进程是资源分配的基本单位
• 线程是调度的基本单位
• 线程共享进程数据,但也拥有自己的一部分数据:
◦ 线程ID
◦ ⼀组寄存器,线程的上下文数据(线程可以被独立调度)
◦ 栈
◦ errno
◦ 信号屏蔽字
◦ 调度优先级
三.Linux线程控制
3.1POSIX线程库
• 与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以“pthread_”打头的
• 要使用这些函数库,要通过引入头文件pthread.h
• 链接这些线程函数库时要使用编译器命令的“-lpthread”选项
3.2创建线程
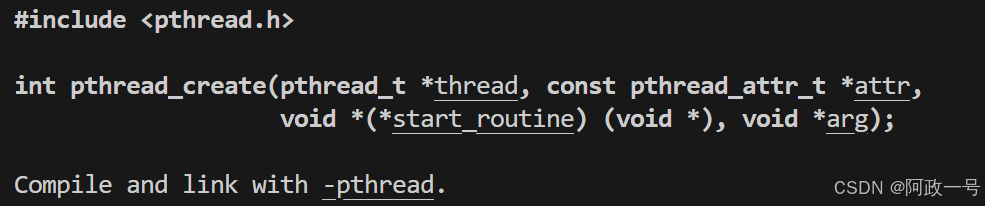


简单的代码了解pthread_create:
#include<iostream>
#include<pthread.h>
#include<unistd.h>
#include<string>void *threadrun(void *args)
{std::string name = (const char*)args;while(true){std::cout<<"我是新线程: name: "<<name<<std::endl;sleep(1);}
}int main()
{pthread_t tid;pthread_create(&tid,nullptr,threadrun,(void*)"thread-1");while(true){std::cout<<"我是主线程"<<std::endl;sleep(1);}return 0;
}这里需要注意的是在进行编译的时候要带上-lpthread:

之前在动静态库说过,需要找头文件(-I),需要路径(-L),还要指明哪个库(-l)。
这里前两个都可以找到:
路径:
头文件:

所以这里就只是指明是哪个库就行了(-lpthread)。
打印出:
这里的-l是指明库名的,因为OS会在系统找库。
pthread库是个什么东西
Linux系统不会存在真正意义上的线程,只不过是用轻量级进程模拟的。在OS中只有轻量级进程。所以Linux 只会提供创建轻量级进程的系统调用。而pthread库就是把轻量级进程封装起来,给用户提供一批创建线程的接口。Linux的线程实现,是在用户层实现的,我们称之为用户级线程。pthread就是原生线程库
所以我把库的链接放开会报错:

而C++11的多线程,在Linux下本质是封装了pthread库!!
tid???
ps -aL查看:
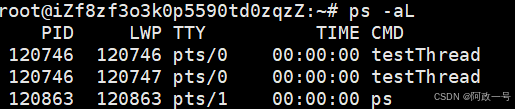
lwp就是轻量级进程的缩写 。
注意lwp是跟轻量级进程相关的,不是tid

实际上就是等待线程:
#include<iostream>
#include<unistd.h>
#include<pthread.h>
#include<string>void *threadrun(void* args)
{std::string name=static_cast<const char*> (args);int cnt=5;while(cnt--){std::cout<<"我是新线程:"<<name<<std::endl;sleep(1);}return nullptr;
}int main()
{pthread_t tid;int n = pthread_create(&tid,nullptr,threadrun,(void*)"thread-1");(void)n;pthread_join(tid,nullptr);return 0;
}
现在来探讨一下什么是tid,在主线程中可以带上这样一个函数,查看我们线程带出来的id值:

实际上就是用16进制打印出来id值。

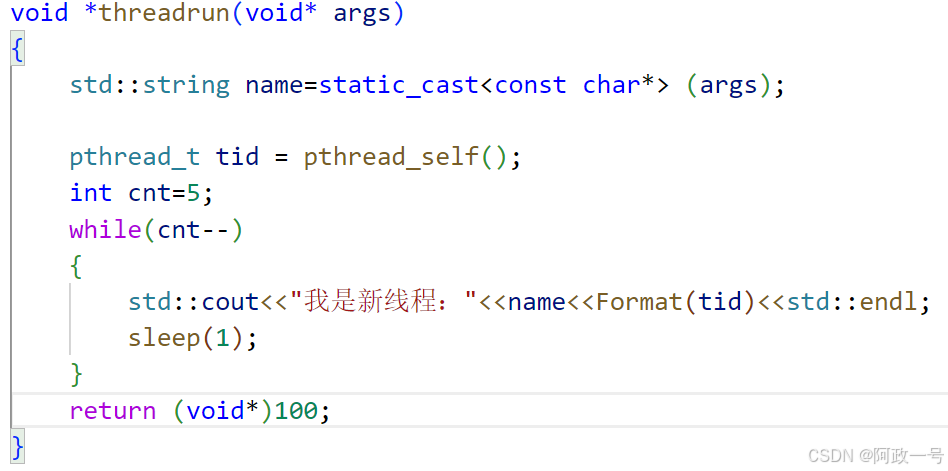
再来一个函数,查看我当前线程的id:这个是在线程中用

#include<iostream>
#include<unistd.h>
#include<pthread.h>
#include<string>void showtid(pthread_t &tid)
{printf("tid: 0x%lx\n",tid);
}std::string Format(pthread_t tid)
{char id[64];snprintf(id,sizeof(id),"0x%lx",tid);return id;
}void *threadrun(void* args)
{std::string name=static_cast<const char*> (args);pthread_t tid = pthread_self();int cnt=5;while(cnt--){std::cout<<"我是新线程:"<<name<<Format(tid)<<std::endl;sleep(1);}return nullptr;
}int main()
{pthread_t tid;int n = pthread_create(&tid,nullptr,threadrun,(void*)"thread-1");(void)n;showtid(tid);pthread_join(tid,nullptr);return 0;
}此时的主线程和线程获得的id是相同的:
现在我让主线程也获取自己的线程id,看一看新线程和主线程的差别:


返回值
注意是二级指针:
![]()
相当于retval是一个输出型参数,这里使用的话要用二级指针。
新线程还是上面的线程,返回是100.

注意:
这里的线程没有异常的处理,还记得进程的异常处理,低7位是信号,然后一位是core dump标志,剩下的退出码。这里确没有,是因为线程退出,整个都结束,没有意义。
3.3pthread_create参数可以是任意类型
说的是第四个参数,因为参数类型是void*。这里就用两个类来实现
class Task
{
public:Task(int a,int b):_a(a),_b(b){}~Task(){}int Execute(){return _a+_b;}
private:int _a;int _b;
};class Result
{
public:Result(int result):_result(result){}~Result(){}int GetResult(){return _result;}
private:int _result;
};void *pthreadrun(void* args)
{Task* t = static_cast<Task*> (args);//强转// int ret = t->Execute();// Result* res = new Result(ret);Result* res = new Result(t->Execute());//在创建一个对象,作为退出码return res;
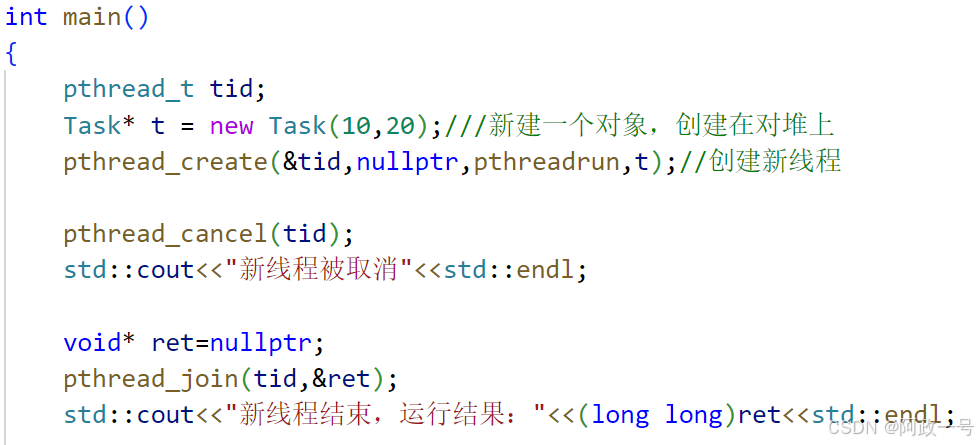
}int main()
{pthread_t tid;Task* t = new Task(10,20);///新建一个对象,创建在对堆上pthread_create(&tid,nullptr,pthreadrun,t);//创建新线程Result* ret=nullptr;//ret作为经过新线程后的输出结果pthread_join(tid,(void**)&ret);//等待新线程结束,因为要修改ret,所以要使用二级指针int n=ret->GetResult();std::cout<<"新线程结束,值为:"<<n<<std::endl;delete t;delete ret;return 0;
}打印出:

3.4线程终止
1. 从线程函数return。这种方法对主线程不适用,从main函数return相当于调用exit。
2. 线程可以调用pthread_exit终止自己。
3. 一个线程可以调用pthread_cancel止同一进程中的另一个线程。
注意:不要用exit终止新线程,exit是用来终止进程的。
return我们常用就不说。
pthread_exit:

void *pthreadrun(void* args)
{Task* t = static_cast<Task*> (args);//强转// int ret = t->Execute();// Result* res = new Result(ret);Result* res = new Result(t->Execute());//在创建一个对象,作为退出码//return res;pthread_exit(res);
}作用等价于return
pthread_cancel:

执行下面的代码:
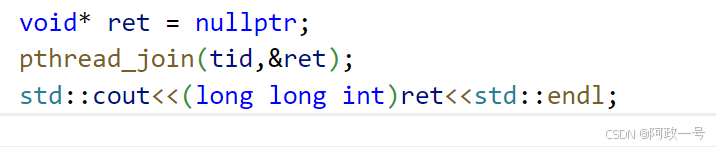
使用pthread_cancle取消新线程 ,这里拿到的ret 是-1??


其实就是一个宏值。
注意::
pthread_exit或者return返回的指针所指向的内存单元必须是全局的或者是用malloc分配的, 不能在线程函数的栈上分配,因为当其它线程得到这个返回指针时线程函数已经退出了。pthread_cancel取消的时候,新线程一定要启动了。
3.5分离线程
• 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
• 如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
这个函数:

void* pthreadrun(void* args)
{std::string name = static_cast<char*>(args);std::cout<<"我是新线程,name: "<<name<<std::endl;return nullptr;
}int main()
{pthread_t tid;int n = pthread_create(&tid,nullptr,pthreadrun,(void*)"thread-1");pthread_detach(tid);//分离if(n!=0){std::cout<<"create thread error"<<std::endl;return 1;}int num = pthread_join(tid,nullptr);if(num==0){std::cout<<"wait success"<<std::endl;}else{std::cout<<"wait failed"<<std::endl;}return 0;
}分离成功,这里的等待就没有了意义:

因为有一个细节的点,这里再重新发一遍,子进程也可以自己直接退出:
void* pthreadrun(void* args)
{pthread_detach(pthread_self());std::string name = static_cast<char*>(args);std::cout<<"我是新线程,name: "<<name<<std::endl;return nullptr;
}int main()
{pthread_t tid;int n = pthread_create(&tid,nullptr,pthreadrun,(void*)"thread-1");//pthread_detach(tid);//分离if(n!=0){std::cout<<"create thread error"<<std::endl;return 1;}sleep(1);很重要,要让线程先分离,再等待int num = pthread_join(tid,nullptr);if(num==0){std::cout<<"wait success"<<std::endl;}else{std::cout<<"wait failed"<<std::endl;}return 0;
}joinable和分离是冲突的,一个线程不能既是joinable又是分离的。
四.线程ID及进程地址空间布局
• pthread_create函数会产生一个线程ID,存放在第一个参数指向的地址中。该线程ID和前面说的 线程ID不是一回事。
• 前面讲的线程ID属于进程调度的范畴。因为线程是轻量级进程,是操作系统调度器的最小单位, 所以需要一个数值来唯一表示该线程。
• pthread_create函数第一个参数指向一个虚拟内存单元,该内存单元的地址即为新创建线程的线 程ID,属于NPTL线程库的范畴。线程库的后续操作,就是根据该线程ID来操作线程的。
• 线程库NPTL提供了pthread_self函数,可以获得线程自身的ID
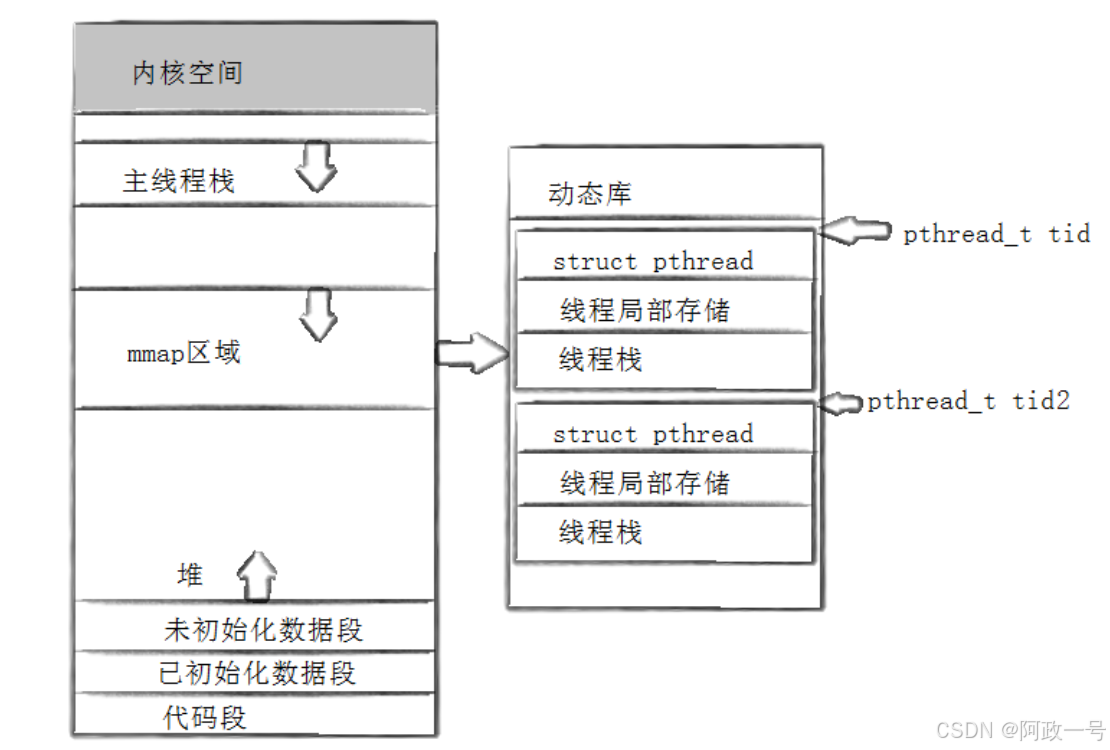
对于Linux目前实现的NPTL实现而言,pthread_t类 型的线程ID,本质就是一个进程地址空间上的一个地址。
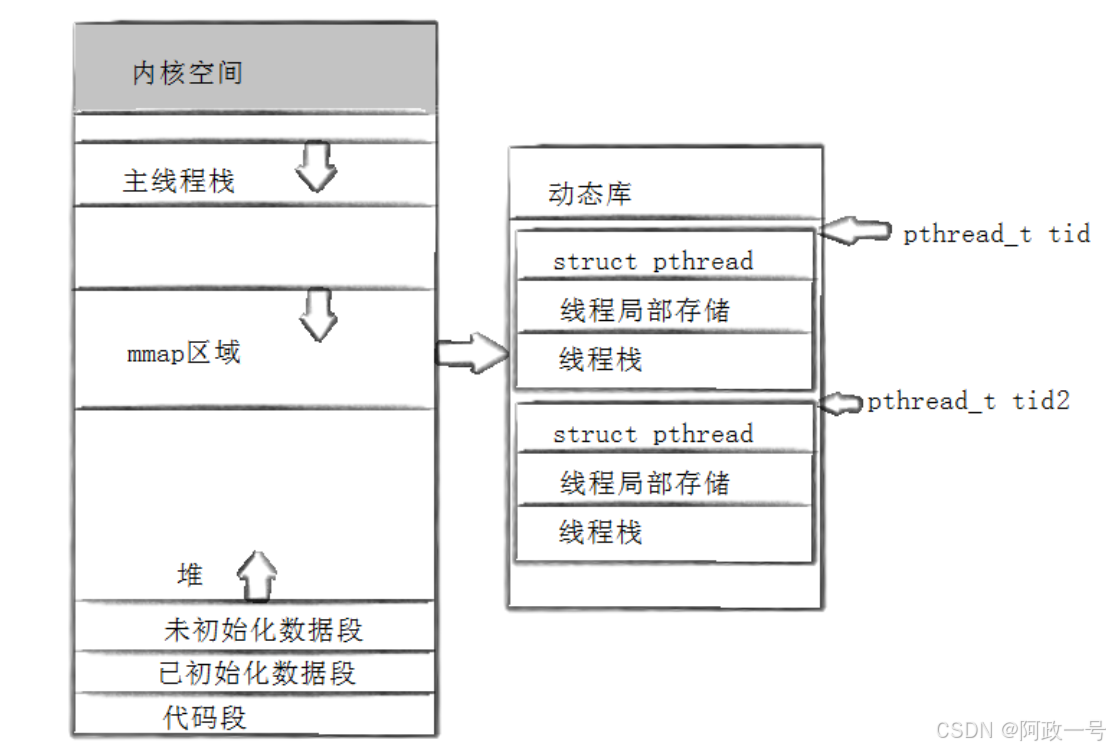
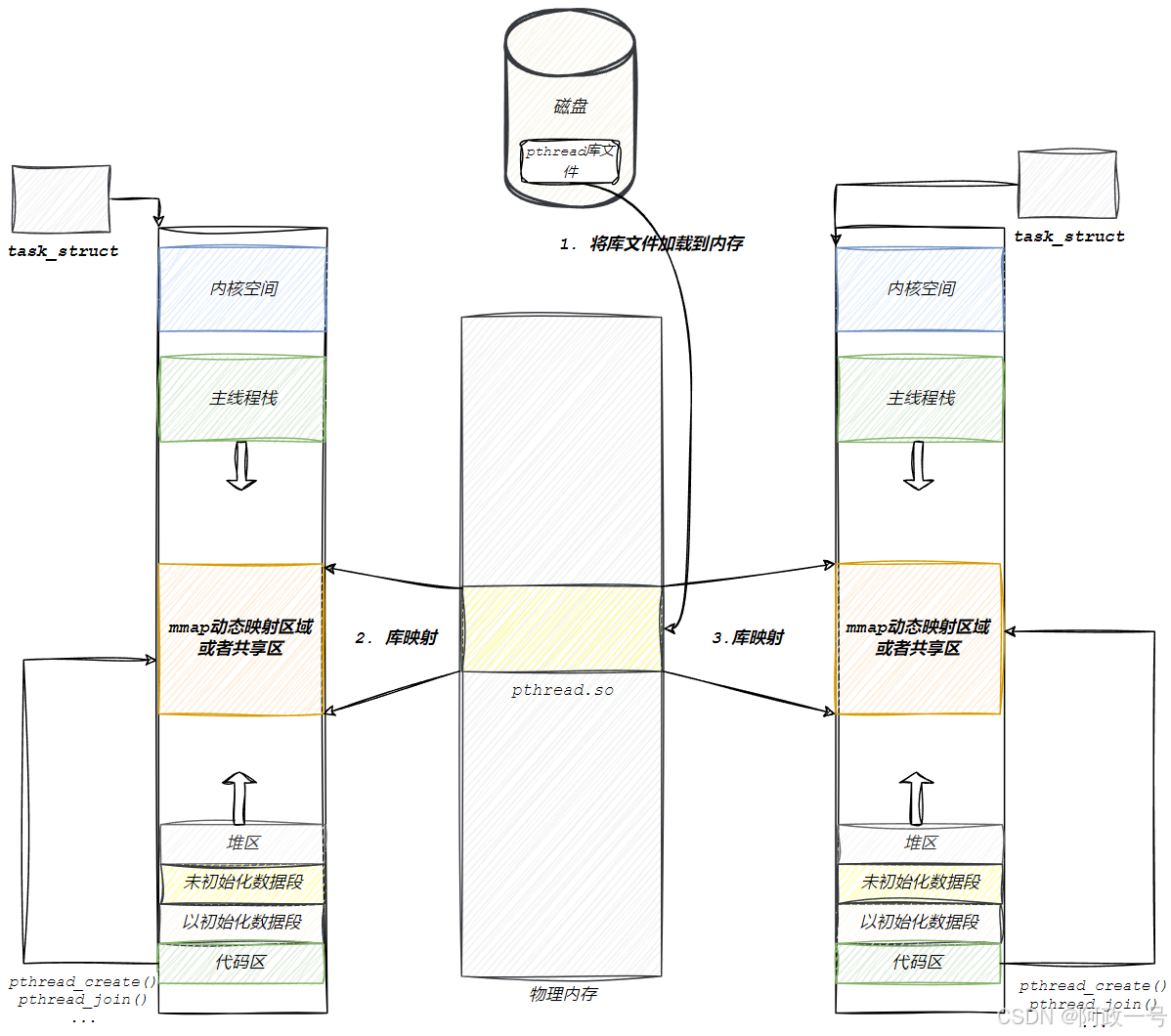
pthread_create在库中创建线程控制的管理块,要在内核中创建轻量级进程。
4.1部分源码
在源码中:
nptl/pthread_create.c:
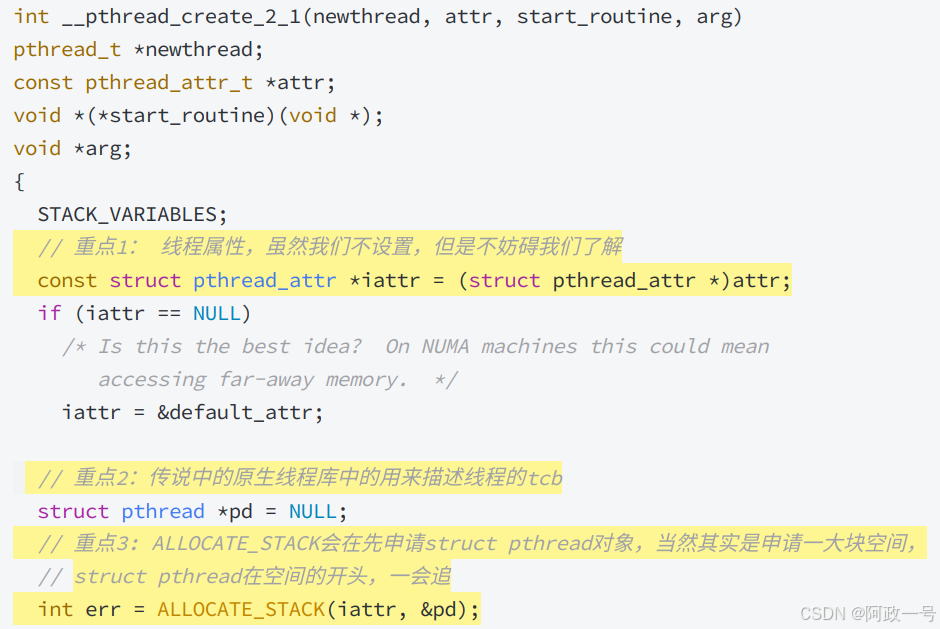
2其实就是上面第一个图的struct pthread。重点是3,会先申请一大块空间,struct pthread在开头的位置。 (这里是申请空间,在库中创建线程控制的管理块)
在struct pthread结构体中:
 其实就是lwp。
其实就是lwp。
我们在使用pthread_create的时候,第三个参数是让我们自定义函数,这个函数的返回的其实就是下面图中的result,类型是void*。用pthread_join可以获取,第二个参数是输出型参数所以要传二级指针.


nptl/pthread_create.c:
看了部分的struct pthread,下面堆pd指针的修改也就可以理解了:

下面的newthread就是我们pthread_create传入的第一个参数 ,要对其进行修改,得到的就是线程控制块地址:
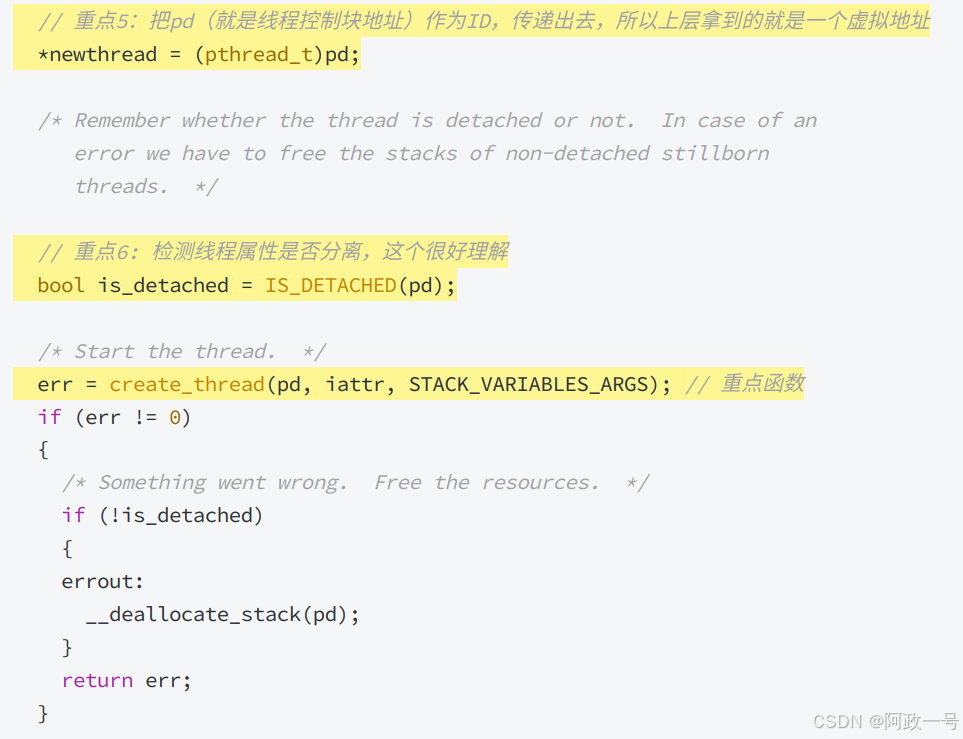
create_thread创建线程:




 所以,在创建线程的时候,其实就是在pthread库内部,创建好描述线程的结构体对象,填充属性。第二步就是调用clone,让内核创建轻量级进程,并执行传入的回调函数和参数 。 其实,库提供的无非就是未来操作线程的API,通过属性设置线程的优先级之类,而真正调度的过程,还是内核来的。 但是如果我们自己在上层,设计一些让线程暂停出让CPU,然后我们上次自定义队列,让线程的tcb 进行排队那么我们其实也可以基于内核,在用户层实现线程的调度,很多更高级的语言,可能会做这个工作。
所以,在创建线程的时候,其实就是在pthread库内部,创建好描述线程的结构体对象,填充属性。第二步就是调用clone,让内核创建轻量级进程,并执行传入的回调函数和参数 。 其实,库提供的无非就是未来操作线程的API,通过属性设置线程的优先级之类,而真正调度的过程,还是内核来的。 但是如果我们自己在上层,设计一些让线程暂停出让CPU,然后我们上次自定义队列,让线程的tcb 进行排队那么我们其实也可以基于内核,在用户层实现线程的调度,很多更高级的语言,可能会做这个工作。
clone就是创建轻量级进程,可以用AI测试一下。
pthread库,原生级线程库实际上就是创建一段空间(充当我们的独立栈结构),模拟线程,最本质还是对轻量级进程的封装。
4.2线程栈
虽然 Linux 将线程和进程不加区分的统一到了 task_struct ,但是对待其地址空间的 stack 还是 有些区别的
• 对于Linux进程或者说主线程,简单理解就是main函数的栈空间,在fork的时候,实际上就是复 制了父亲的 stack 空间地址,然后写时拷贝(cow)以及动态增长。如果扩充超出该上限则栈溢出 会报段错误(发送段错误信号给该进程)。进程栈是唯一可以访问未映射页而不一定会发生段错误--超出扩充上限才报。
• 然而对于主线程生成的子线程而言,其 stack 将不再是向下生生长的,而是事先固定下来的。线 程栈一般是调用glibc/uclibc等的 pthread 库接口 pthread_create 创建的线程,在文件映射区(或称之为共享区)。其中使用 mmap 系统调用,这个可以从 glibc 的 nptl/allocatestack.c 中的 allocate_stack 函数中看到:

此调用中的 size 参数的获取很是复杂,你可以手工传入stack的大小,也可以使用默认的,一般而言就是默认的 8M 。这些都不重要,重要的是,这种stack不能动态增长,一旦用尽就没了,这是和生成进程的fork不同的地⽅。在glibc中通过mmap得到了stack之后,底层将调用 sys_clone 系 统调用:
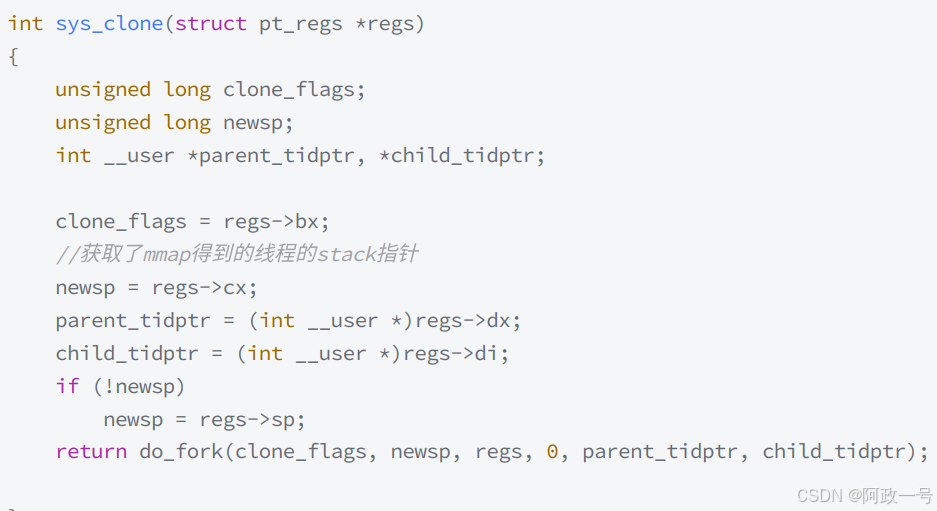 对于子线程的 stack ,它其实是在进程的地址空间中map出来的一块内存区域,原则上是线程私有的,但是同一个进程的所有线程生成的时候,是会浅拷贝生成者的 task_struct 的很多 字段,如果愿意,其它线程也还是可以访问到的。
对于子线程的 stack ,它其实是在进程的地址空间中map出来的一块内存区域,原则上是线程私有的,但是同一个进程的所有线程生成的时候,是会浅拷贝生成者的 task_struct 的很多 字段,如果愿意,其它线程也还是可以访问到的。
五.线程封装
#ifndef _THREAD_H_
#define _THREAD_H_#include <iostream>
#include <string>
#include <pthread.h>
#include <cstdio>
#include <cstring>
#include <functional>
#include <unistd.h>namespace ThreadModlue
{static uint32_t number = 1;class Thread{using func_t = std::function<void()>;private:void EnableRuning(){_isruning = true;}void EnableDetach(){std::cout<<"线程被分离"<<std::endl;_isdetach = true;}static void *Routine(void *args){Thread *self = static_cast<Thread *>(args);self->EnableRuning(); // 设置运行标志位if (self->_isdetach)//检查有没有被分离,如果已经被分离了,不允许重复分离self->Detach();self->_func();return nullptr;}public:Thread(func_t func): _tid(0), _isdetach(false), _isruning(false), res(nullptr), _func(func){_name = "Thread-" + std::to_string(number++);}void Detach(){if (_isdetach)//这里是为了不让重复分离return;if (_isruning)//如果正在运行就调用phread_detach来分离pthread_detach(_tid);EnableDetach();}bool Start(){if (_isruning) // 不让重复启动return false;int n = pthread_create(&_tid, nullptr, Routine, this); // 创建线程,传this指针,为了在类内用我们外部定义的方法if (n != 0){std::cout << "create thread error: " << strerror(n) << std::endl;return false;}else{std::cout << "start success" << std::endl;return true;}}bool Stop(){if (_isruning){int n = pthread_cancel(_tid);if (n != 0){std::cout << "stop thread error: " << strerror(n) << std::endl;return false;}else{_isruning = false;std::cout << _name << "stop success" << std::endl;return true;}}return false;}void Join(){if (_isdetach){std::cout<<"线程被分离"<<std::endl;return;}int n = pthread_join(_tid, &res);if (n != 0){std::cout << "join thread error: " << strerror(n) << std::endl;return;}else{std::cout << "join success" << std::endl;}}~Thread(){}private:pthread_t _tid;std::string _name;bool _isdetach;bool _isruning;void *res;func_t _func;};
}#endif#include"Thread.hpp"using namespace ThreadModlue;int main()
{Thread t([](){while (true){std::cout<<"我是新线程"<<std::endl;sleep(1);}});//t.Detach();t.Start();//t.Detach();sleep(5);t.Stop();sleep(5);t.Join();return 0;
}
线程的局部存储
下面是一个全局变量
__thread int count = 1;成功count就叫做线程的局部存储。有什么用?全局变量我又不想让其他的线程看到,线程的局部存储只能存储内置类型和部分指针。
也就是说这个count在不同的线程里是不同的变量。
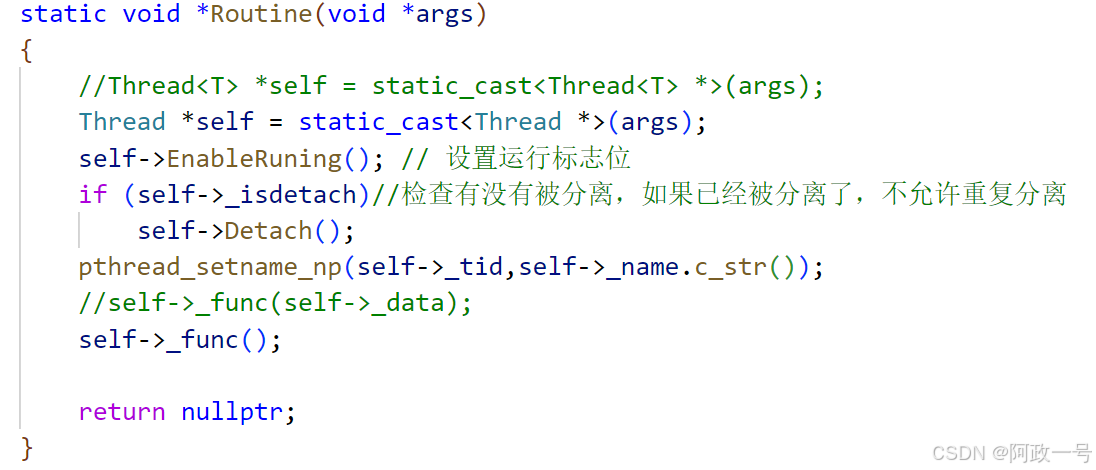

这两个函数的原理其实就是线程局部存储,设置名字,方便debug。
相关文章:
】【Linux线程控制】【线程ID及进程地址空间布局】【线程封装】)
Linux线程概念与控制:【线程概念(页表)】【Linux线程控制】【线程ID及进程地址空间布局】【线程封装】
目录 一. 线程概念 1.1什么是线程 1.2分页式存储管理 1.2.1虚拟地址和页表的由来 1.2.2物理内存管理 1.2.3页表 1.2.4页目录结构 1.2.5二级页表地址转换 1.3线程的优点 二.进程VS线程 三.Linux线程控制 3.1POSIX线程库 3.2创建线程 编辑 pthread库是个什么东西 …...

7-6 混合类型数据格式化输入
本题要求编写程序,顺序读入浮点数1、整数、字符、浮点数2,再按照字符、整数、浮点数1、浮点数2的顺序输出。 输入格式: 输入在一行中顺序给出浮点数1、整数、字符、浮点数2,其间以1个空格分隔。 输出格式: 在一行中…...

最新全开源码支付系统,赠送3套模板
最新全开源码支付系统,赠送3套模板 码支付是专为个人站长打造的聚合免签系统,拥有卓越的性能和丰富的功能。它采用全新轻量化的界面UI 让您能更方便快捷地解决知识付费和运营赞助的难题,同时提供实时监控和管理功能,让您随时随地…...
 笔记)
Eclipse Leshan 常见问题解答 (FAQ) 笔记
本笔记基于 Eclipse Leshan Wiki - F.A.Q. 页面内容,旨在解答关于 Eclipse Leshan(一个开源的 LwM2M 服务器和客户端 Java 实现)的常见问题,帮助您更好地理解和使用该工具。 一、Leshan 是什么,我该如何使用它&#x…...

【6】数据结构的栈篇章
目录标题 栈的定义顺序栈的实现顺序栈的初始化入栈出栈获取栈顶元素顺序栈总代码与调试 双端栈的实现双端栈的初始化入栈出栈双端栈总代码与调试 链栈的实现链栈的初始化入栈出栈获取栈顶元素链栈总代码与调试 栈的定义 定义:栈(Stack)是一种…...

开源虚拟化管理平台Proxmox VE部署超融合
Proxmox VE 是一个功能强大、开源的虚拟化平台,结合了 KVM 和 LXC,同时支持高可用集群、存储管理(ZFS、Ceph)和备份恢复。相比 VMware ESXi 和 Hyper-V,PVE 具有开源、低成本、高灵活性的特点,适用于中小企…...
:输出ASCII码表)
C语言基础要素(019):输出ASCII码表
计算机以二进制处理信息,但二进制对人类并不友好。比如说我们规定用二进制值 01000001 表示字母’A’,显然通过键盘输入或屏幕阅读此数据而理解它为字母A,是比较困难的。为了有效的使用信息,先驱者们创建了一种称为ASCII码的交换代…...
介绍(一种将接受多个参数的函数转换为一系列接受单一参数的函数的技术))
函数柯里化(Currying)介绍(一种将接受多个参数的函数转换为一系列接受单一参数的函数的技术)
文章目录 柯里化的特点示例普通函数柯里化实现使用Lodash进行柯里化 应用场景总结 函数柯里化(Currying)是一种将接受多个参数的函数转换为一系列接受单一参数的函数的技术。换句话说,柯里化将一个多参数函数转化为一系列嵌套的单参数函数。 …...

基于大模型的主动脉瓣病变预测及治疗方案研究报告
目录 一、引言 1.1 研究背景 1.2 研究目的 1.3 研究意义 二、大模型预测主动脉瓣病变原理 2.1 大模型介绍 2.2 数据收集与处理 2.3 模型训练与优化 三、术前预测与评估 3.1 主动脉瓣病变类型及程度预测 3.2 患者整体状况评估 3.3 手术风险预测 四、术中应用与监测…...

VSCode开发者工具快捷键
自动生成浏览器文件.html的快捷方式 在文本里输入: ! enter VSCode常用快捷键列表 代码格式化:Shift Alt F向上或向下移动一行:Alt Up 或者 Alt Down快速复制一行代码:Shift Alt Up 或者 Shift Alt Down快速保…...

AI助力PPT制作,让演示变得轻松高效
AI助力PPT制作,让演示变得轻松高效!随着科技的进步,AI技术早已渗透到各行各业,特别是在办公领域,AI制作PPT已不再是未来的梦想,而是现实的工具。以前你可能需要花费数小时来制作一个完美的PPT,如…...

行业专家视角下的技术选型与任务适配深度解析
行业专家视角下的技术选型与任务适配深度解析 一、任务属性与技术栈的映射逻辑 (1)学术类项目需优先考虑技术严谨性、可复现性和理论深度: 机器学习模型开发:PyTorchJupyterMLflow形成完整实验闭环,TensorFlow Exte…...
)
从零构建大语言模型全栈开发指南:第五部分:行业应用与前沿探索-5.2.1模型偏见与安全对齐(Red Teaming实践)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 大语言模型全栈开发指南:伦理与未来趋势 - 第五部分:行业应用与前沿探索5.2.1 模型偏见与安全对齐(Red Teaming实践)一、模型偏见的来源与影响1. 偏见的定义与分类2. 偏见的实际影响案例二、安全对齐…...

JUC系列JMM学习之随笔
JUC: JUC 是 Java 并发编程的核心工具包,全称为 Java Util Concurrent,是 java.util.concurrent 包及其子包的简称。它提供了一套强大且高效的并发编程工具,用于简化多线程开发并提高性能。 CPU核心数和线程数的关系:1核处理1线程(同一时间单次) CPU内核结构: 工作内…...

OpenRouter开源的AI大模型路由工具,统一API调用
简介 OpenRouter是一个开源的路由工具,它可以绕过限制调用GPT、Claude等国外模型。以下是对它的详细介绍: 一、主要功能 OpenRouter专注于将用户请求智能路由到不同的AI模型,并提供统一的访问接口。它就像一个“路由器”,能…...

3.9/Q2,Charls最新文章解读
文章题目:Association between remnant cholesterol and depression in middle-aged and older Chinese adults: a population-based cohort study DOI:10.3389/fendo.2025.1456370 中文标题:中国中老年人残留胆固醇与抑郁症的关系࿱…...

水下图像增强与目标检测:标签缺失的“锅”?
水下图像增强与目标检测:标签缺失的“锅”? 在水下计算机视觉领域,图像增强和目标检测一直是研究热点。然而,一个有趣的现象引起了研究者的关注:在某些情况下,增强后的水下图像用于目标检测时,…...

从扩展黎曼泽塔函数构造物质和时空的结构-13
得到这些数据到底有什么用呢?无非都是振动,只有频率不同。电性振动和磁性振动的正交环绕关系,本质上只是某个虚数单位的平方倍数, 既然如此,我们就可以考虑,把电和磁当成同一种东西。比如通过改变真空介电常…...

Android学习总结之handler源码级
一、核心类关系与线程绑定(ThreadLocal 的核心作用) 1. Looper 与 ThreadLocal 的绑定 每个线程的 Looper 实例通过 ThreadLocal<Looper> sThreadLocal 存储,确保线程隔离: public final class Looper {// 线程本地存储&…...
:2022 TPAMI——U2Fusion: A Unified Unsupervised Image Fusion Network)
多模态学习(八):2022 TPAMI——U2Fusion: A Unified Unsupervised Image Fusion Network
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp&arnumber9151265 目录 一.摘要 1.1 摘要翻译 1.2 摘要解析 二.Introduction 2.1 Introduciton翻译 2.2 Introduction 解析 三. related work 3.1 related work翻译 3.2 relate work解析 四…...

adb检测不到原来的设备List of devices attached解决办法
进设备管理器-通用串行总线设备 卸载无法检测到的设备驱动 重新拔插数据线...

探索高通骁龙光线追踪技术
什么是光线追踪? 光线追踪(Raytracing)是通过模拟现实世界中光线的传播过程并生成更加真实的效果的一种图形渲染技术。 早期在电影,动画,设计等领域已经使用软件摸拟光线追踪来渲染更加真实的图像。一般的做法是从相…...

qRegisterMetaType函数使用
一、有两种形式: 1、int qRegisterMetaType(const char *typeName) template <typename T> int qRegisterMetaType(const char *typeName #ifndef Q_CLANG_QDOC, T * dummy nullptr, typename QtPrivate::MetaTypeDefinedHelper<T, QMetaTypeId2<T&g…...

【北京化工大学】 神经网络与深度学习 实验6 MATAR图像分类
本次实验使用老师发的雷达奇妙数据 实验要求 读取图像形式的MASTAR数据 1、划分数据集为test/train 2、归一化 题目1:定义并训练线性分类器的神经网络 注:本次老师的要求是不限方法,使用pytorch尽可能提升精度 1、准备函数 #本文用的…...

Flutter 的开发环境搭建教程
为了配置Flutter的运行环境,首先我们需要确保你的开发环境支持Flutter,且相关工具都已经安装好。以下是详细的配置步骤: 1. 安装Flutter SDK Flutter是Google推出的用于开发跨平台应用的框架,支持Android、iOS、Web、桌面等多平台…...

MCP:让 AI 应用更聪明,只需几分钟
用 Leonardo.AI 和 FLUX Dev 模型生成(作者制作) 现在 AI 世界最新的趋势是 MCP(模型上下文协议)。 如果听起来无聊或者很复杂,别担心 —— 这是个非常简单又有效的工具,可以帮你从零开始构建更好的 AI 智能…...

【编程之路】动态格式化字符串
动态格式化字符串 1.代码功能2.关键组件解析3.完整流程4.示例场景5.注意事项6.典型用途7.总结 🚀 本文讨论的代码段来自《Python Cookbook》的《2.15.字符串中插入变量》。 针对下面这段代码,我们一起来分析一下。 class safesub(dict):""&qu…...

接收灵敏度的基本概念与技术解析
接收灵敏度是指接收机在特定条件下能够正确提取有效信号的最小输入功率。其技术原理可概括如下:灵敏度主要受热噪声、系统噪声系数及解调所需信噪比共同影响。根据公式(S 10lg(kTB) NF SNR)计算,其中k为玻尔兹曼常数(1.3810⁻ J/K…...

KUKA机器人软件WorkVisual更改语言方法
KUKA机器人的常用的工作软件WorkVisual软件在使用时也可以更改软件操作界面的语言。如果安装时语言没有选择中文,安装完成后也可以进行更改。以下通过WorkVisual 5.0版本进行简单介绍。 一、打开WorkVisual软件5.0版本; 二、在菜单栏选择【Ext…...
)
图形渲染: tinyrenderer 实现笔记(Lesson 5 - 7)
目录 Lesson 5: Gouraud shadingLesson 6: Shaders for the software rendererphongShading法线贴图Specular mapping 高光贴图tangent space normal mapping 切线空间法线贴图 Lesson 7: Shadow mapping GitHub主页:https://github.com/sdpyy 项目仓库:https://g…...

AiCube 试用 - 创建流水灯工程
AiCube 试用 - 创建流水灯工程 本文介绍了 Aiapp-ISP 仿真调试平台软件的 AiCube 工具,实现流水灯工程的快速创建的主要流程。 下载运行 下载 最新版 AIapp-ISP 软件; 解压并打开该软件,右侧操作界面选择并进入 Keil 仿真设置 标签项&…...

DBAPI设置服务器开机自启动
在 /etc/systemd/system 目录下创建一个新的服务文件,例如 dbapi.service [Unit] Descriptiondbapi standalone Service Afternetwork.target[Service] ExecStart/your-path/dbapi-enterprise-4.2.2/bin/dbapi.sh start standalone Restartalways Userroot[Install…...

“Nural”传感科技带给高速吹风筒的技术革命---其利天下技术
风筒界的革命,戴森将高速风筒带到了我们生活里,高速风筒的产生,将无刷电机的运用再一次向推到了我们新的产品领域。 然而随着智能家居领域的运用越来越广泛,戴森又将智能温控概念引入高速吹风筒,HD16引入“Nural”传感…...

DeepSeek-R1模型现已登录亚马逊云科技
在今年的Amazon re:Invent大会上,亚马逊CEO安迪贾西分享了公司内部开发近 1,000 个生成式 AI应用程序的经验教训。基于如此大规模的AI部署实践,贾西提出了三个关键观察,这些观察塑造了亚马逊在企业AI实施方面的方法。 第一点是,当…...
:文件)
Python入门(8):文件
1. 文件基本概念 文件:存储在计算机上的数据集合,Python 通过文件对象来操作文件。 文件类型: 文本文件:由字符组成,如 .txt, .py 二进制文件:由字节组成,如 .jpg, .mp3 2. 文件打开与关闭…...
)
408 计算机网络 知识点记忆(4)
前言 本文基于王道考研课程与湖科大计算机网络课程教学内容,系统梳理核心知识记忆点和框架,既为个人复习沉淀思考,亦希望能与同行者互助共进。(PS:后续将持续迭代优化细节) 往期内容 408 计算机网络 知识…...

《Java编程思想》读书笔记:第九章 接口
目录 9.1抽象类和抽象方法 9.2接口 9.3完全解耦 9.4Java的多重继承 9.5通过继承来扩展接口 9.5.1组合接口时的名字冲突 9.6适配接口 9.7接口中的域 9.7.1初始化接口中的域 9.8嵌套接口 9.9接口与工厂 9.1抽象类和抽象方法 在第8章所有“乐器”的例子中,基…...

【gdutthesis模板】章节标题有英文解决方案
按下面格式修改代码即可 \section{中文{\rmfamily{English}}中文}{Chinese English Chinese}效果如下:...

【C语言入门】由浅入深学习指针 【第二期】
目录 1. 指针变量为什么要有类型? 2. 野指针 2.1 未初始化导致的野指针 2.2 指针越界导致的野指针 2.3 如何规避野指针 3. 指针运算 3.1 指针加减整数 3.2 指针减指针 3.3 指针的关系运算 4. 二级指针 5. 指针数组 5.1 如何使用指针数组模拟二维数组 上…...

循环神经网络 - 机器学习任务之异步的序列到序列模式
前面我们学习了机器学习任务之同步的序列到序列模式:循环神经网络 - 机器学习任务之同步的序列到序列模式-CSDN博客 本文我们来学习循环神经网络应用中的第三种模式:异步的序列到序列模式! 一、基本概述: 异步的序列到序列模式…...
)
Java 8 到 Java 21 系列之 Optional 类型:优雅地处理空值(Java 8)
Java 8 到 Java 21 系列之 Optional 类型:优雅地处理空值(Java 8) 系列目录 Java8 到 Java21 系列之 Lambda 表达式:函数式编程的开端(Java 8)Java 8 到 Java 21 系列之 Stream API:数据处理的…...

.NET 创建MCP使用大模型对话二:调用远程MCP服务
在上一篇文章.NET 创建MCP使用大模型对话-CSDN博客中,我们简述了如何使用mcp client使用StdIo模式调用本地mcp server。本次实例将会展示如何使用mcp client模式调用远程mcp server。 一:创建mcp server 我们创建一个天气服务。 新建WebApi项目&#x…...

podman和与docker的比较 及podman使用
Podman 与 Docker 的比较和区别 架构差异 Docker:采用客户端 - 服务器(C/S)架构,有一个以 root 权限运行的守护进程 dockerd 来管理容器的生命周期。客户端(docker 命令行工具)与守护进程进行通信&#x…...

智慧农业总体实施方案
智慧农业概念与背景智慧农业是结合现代信息技术,对农业生产全过程进行智能化管理和服务的新型农业模式。它基于物联网、云计算等技术,实现资源节约、效率提高,解决食品安全和环境污染问题。 农业发展现状与问题当前农业面临资源短缺、食品安…...

基础科学中的人工智能︱如何用机器学习方法求解排列型组合优化问题?
排列(permutation)作为一个重要的离散数学概念,许多实际问题可以被刻画为n个候选对象的排列。基于给定的目标函数求解最优排列具有丰富的理论和应用价值。特别地,在以排列型问题为代表的组合优化问题中,近年来机器学习…...

脑影像分析软件推荐 | NBS-Predict:基于脑网络的机器学习预测工具包
目录 1.软件界面 2.工具包功能简介 3.软件安装注意事项 1.软件界面 2.工具包功能简介 NBS-Predict(Network-based Statistic Predict)工具包是一种用于神经影像数据分析的预测性扩展工具,它结合了网络基础统计(Network-based S…...

一个alignment trap的解决办法
在移植一份代码时,遇到一个alignment trap的错误: 经过定位,触发alignment trap的汇编语句如下: printk("status %#x\r\n", stData.info->status); 38c0: f8d4 3181 ldr.w r3, [r4, #385] ; 0x181 38…...

AI+自动化测试:如何让测试编写效率提升10倍?
文章目录 摘要传统自动化测试的痛点编写测试用例太费时间测试覆盖率难以保证UI 测试维护成本高 AI 如何优化自动化测试?AI 生成单元测试:减少重复工作,提高覆盖率传统方法 VS AI 方法 使用 AI 生成 Python 单元测试自动补全边界情况传统方法 …...

服务器磁盘io性能监控和优化
服务器磁盘io性能监控和优化 全文-服务器磁盘io性能监控和优化 全文大纲 磁盘IO性能评价指标 IOPS:每秒IO请求次数,包括读和写吞吐量:每秒IO流量,包括读和写 磁盘IO性能监控工具 iostat:监控各磁盘IO性能,…...

使用typescript实现游戏中的JPS跳点寻路算法
JPS是一种优化A*算法的路径规划算法,主要用于网格地图,通过跳过不必要的节点来提高搜索效率。它利用路径的对称性,只扩展特定的“跳点”,从而减少计算量。 deepseek生成的总是无法完整运行,因此决定手写一下。 需要注…...