LlamaIndex实现RAG增强:融合检索(Fusion Retrieval)与混合检索(Hybrid Search)
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀

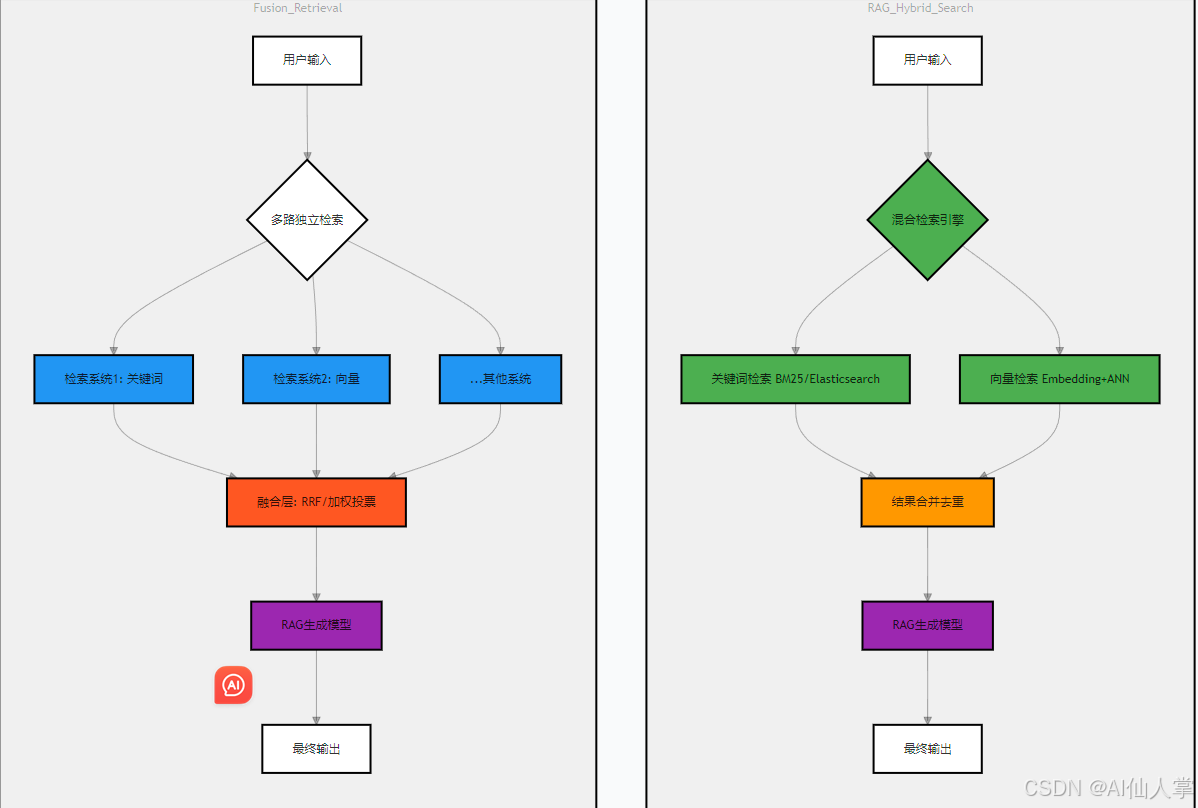
RAG Hybrid Search与Fusion Retrieval的技术对比及工作流程图:
Hybrid Search (混合搜索)
- 定义:结合关键词检索和向量检索的搜索方法
- 特点:同时利用传统BM25算法(精确匹配)和神经网络嵌入(语义匹配)
- 示例:
Elasticsearch + 向量数据库的联合查询
Fusion Retrieval (融合检索)
- 定义:对多种检索结果进行加权融合的算法
- 特点:通过线性加权/学习排序(Rank Fusion)整合不同检索系统的结果
- 示例:
Reciprocal Rank Fusion (RRF)算法
核心区别对比
| 维度 | RAG Hybrid Search | Fusion Retrieval |
|---|---|---|
| 目标 | 通过混合检索策略提升召回率 | 通过多路结果融合提升准确率 |
| 工作阶段 | 检索阶段(预处理层) | 后处理阶段(结果层) |
| 技术实现 | 同时执行关键词+向量检索,合并结果 | 多路独立检索后加权/重排序 |
| 计算开销 | 较高(并行执行两种检索) | 中等(依赖独立检索系统的输出) |
| 典型应用 | 开放域问答、知识密集型任务 | 多模态检索、跨语言检索 |
工作流程图
关键差异解析
-
架构层级差异
- Hybrid Search在检索阶段完成多策略整合(如BM25+向量),降低生成模型噪声
- Fusion Retrieval在检索完成后进行结果融合(如RRF算法),强调异构系统互补性
-
性能权衡
- Hybrid需维护双索引,但减少冗余计算(如ColBERT的混合压缩)
- Fusion支持异步检索(可并行化),但融合算法复杂度高(如RECIPROAL RANK FUSION)
-
适用场景
- Hybrid适合单一数据源下的多角度语义覆盖
- Fusion适合跨系统/跨模态检索(如文本+图像联合检索)
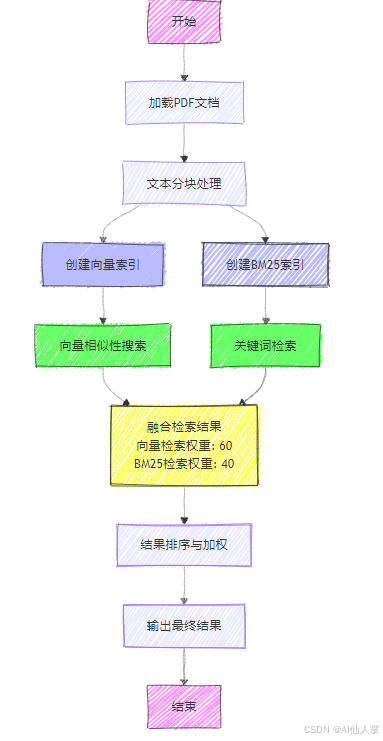
基于LlamaIndex实现RAG融合检索Fusion Retrieval
本代码实现了一个融合检索系统,将基于向量的相似性搜索与基于关键词的BM25检索相结合。该方法旨在综合两种技术的优势,提升文档检索的整体质量和相关性。
动机
传统检索方法通常依赖语义理解(基于向量)或关键词匹配(BM25)。每种方法都有其优缺点。融合检索通过结合这两种方法,构建更强大、更精确的检索系统,能够有效处理更广泛的查询场景。
核心组件
- PDF文档处理与文本分块
- 使用FAISS和OpenAI嵌入创建向量存储
- 构建基于关键词的BM25索引
- 融合BM25和向量搜索结果以优化检索效果
方法细节
文档预处理
- 加载PDF文档并使用SentenceSplitter进行分块
- 通过替换
\t为空格和清理换行符来净化文本块(针对特定格式问题)
向量存储创建
- 使用OpenAI嵌入生成文本块的向量表示
- 基于这些嵌入创建FAISS向量存储,实现高效的相似性搜索
BM25索引创建
- 使用与向量存储相同的文本块创建BM25索引
- 实现与基于向量方法并行的关键词检索
查询混合检索
在创建两种索引后,查询混合检索将它们结合起来,实现混合检索


方法优势
- 提升检索质量:结合语义搜索和关键词匹配,系统能同时捕捉概念相似性和精确关键词匹配
- 灵活调整:通过
retriever_weights参数可调节向量搜索与关键词搜索的权重平衡 - 鲁棒性强:组合方法能有效处理更广泛的查询场景,弥补单一方法的不足
- 高度可定制:系统可轻松适配不同的向量存储或关键词检索方法
结论
融合检索代表了文档搜索的强大方法,结合了语义理解和关键词匹配的优势。通过同时利用基于向量和BM25的检索方法,它为信息检索任务提供了更全面、灵活的解决方案。这种方法在需要兼顾概念相似性和关键词相关性的领域具有广泛应用潜力,如学术研究、法律文档搜索或通用搜索引擎。
导入库
import os
import sys
from dotenv import load_dotenv
from typing import List
from llama_index.core import Settings
from llama_index.core.readers import SimpleDirectoryReader
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.schema import BaseNode, TransformComponent
from llama_index.vector_stores.faiss import FaissVectorStore
from llama_index.core import VectorStoreIndex
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.legacy.retrievers.bm25_retriever import BM25Retriever
from llama_index.core.retrievers import QueryFusionRetriever
import faisssys.path.append(os.path.abspath(os.path.join(os.getcwd(), '..'))) # 将父目录添加到路径中(适用于笔记本环境)
# 从.env文件加载环境变量
load_dotenv()# 设置OpenAI API密钥环境变量
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')# Llamaindex全局设置(LLM和嵌入模型)
EMBED_DIMENSION=512
Settings.llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=EMBED_DIMENSION)
读取文档
path = "../data/"
reader = SimpleDirectoryReader(input_dir=path, required_exts=['.pdf'])
documents = reader.load_data()
print(documents[0])
创建向量存储
# 创建FAISS向量存储用于保存嵌入
fais_index = faiss.IndexFlatL2(EMBED_DIMENSION)
vector_store = FaissVectorStore(faiss_index=fais_index)
文本清理转换
class TextCleaner(TransformComponent):"""在数据摄取管道中使用的转换组件用于清理文本中的杂乱内容"""def __call__(self, nodes, **kwargs) -> List[BaseNode]:for node in nodes:node.text = node.text.replace('\t', ' ') # 将制表符替换为空格node.text = node.text.replace(' \n', ' ') # 将段落分隔符替换为空格return nodes
数据摄取管道
# 管道实例化,包含:
# 节点解析器、自定义转换器、向量存储和文档
pipeline = IngestionPipeline(transformations=[SentenceSplitter(),TextCleaner()],vector_store=vector_store,documents=documents
)# 运行管道获取节点
nodes = pipeline.run()
检索器
BM25检索器
bm25_retriever = BM25Retriever.from_defaults(nodes=nodes,similarity_top_k=2,
)
向量检索器
index = VectorStoreIndex(nodes)
vector_retriever = index.as_retriever(similarity_top_k=2)
融合两种检索器
retriever = QueryFusionRetriever(retrievers=[vector_retriever,bm25_retriever],retriever_weights=[0.6, # 向量检索器权重0.4 # BM25检索器权重],num_queries=1, mode='dist_based_score',use_async=False
)
关于参数:
num_queries:查询混合检索器不仅能组合检索器,还能从给定查询生成多个问题。此参数控制传递给检索器的查询总数。设置为1时禁用查询生成,最终检索器仅使用初始查询。mode:此参数有4种选项:- reciprocal_rerank:应用互逆排序(由于缺乏标准化,不适合此类应用,因为不同检索器返回的分数范围不同)
- relative_score:基于所有节点中的最小和最大分数应用MinMax缩放,将分数缩放到0到1之间,最后根据
retriever_weights进行加权min\_score = min(scores) \\ max\_score = max(scores) - dist_based_score:与
relative_score的唯一区别在于MinMax缩放基于分数的均值和标准差,缩放和加权方式相同min\_score = mean\_score - 3 * std\_dev \\ max\_score = mean\_score + 3 * std\_dev - simple:此方法简单取每个块的最大分数
使用案例示例
# 查询
query = "气候变化对环境有哪些影响?"# 执行混合检索
response = retriever.retrieve(query)
打印最终检索节点及分数
for node in response:print(f"节点分数:{node.score:.2}")print(f"节点内容:{node.text}")print("-"*100)
基于LlamaIndex实现RAG混合检索
混合检索(Hybrid Search)结合了 关键词检索(如BM25) 和 向量相似度检索(如稠密向量),通过两者的互补性提升召回准确性。
- BM25 处理精确关键词匹配,适合直接相关查询;
- 向量检索 捕捉语义相似性,处理模糊或隐含的语义需求。

2. LlamaIndex实现混合检索的步骤
步骤1:安装依赖与数据准备
pip install llama-index
pip install llama-index[milvus] # 若使用Milvus作为向量数据库
步骤2:构建索引
- BM25索引(关键词检索):基于文本内容的关键词匹配。
- 向量索引(稠密向量检索):将文本编码为向量并存储到数据库(如Weaviate、Milvus)。
from llama_index import GPTSimpleVectorIndex, SimpleDirectoryReader
from llama_index.retrievers import VectorIndexRetriever, BM25Retriever# 加载数据
documents = SimpleDirectoryReader('data/').load_data()# 创建BM25索引(默认)
bm25_index = GPTSimpleVectorIndex(documents) # 实际BM25索引需配置参数# 创建向量索引(需配置向量数据库)
vector_index = GPTSimpleVectorIndex(documents,service_context=service_context # 需配置Embedding模型
)
步骤3:配置混合检索器
LlamaIndex通过 HybridRetriever 或自定义逻辑组合两种检索结果:
from llama_index.retrievers import HybridRetriever# 初始化两个单独的检索器
vector_retriever = VectorIndexRetriever(vector_index)
bm25_retriever = BM25Retriever(bm25_index)# 创建混合检索器(可调整alpha参数权重)
hybrid_retriever = HybridRetriever(vector_retriever=vector_retriever,bm25_retriever=bm25_retriever,alpha=0.5 # 权重参数,调整向量与BM25的贡献比例
)
步骤4:执行混合检索
query = "在发现高血压显著降低的研究中,使用了哪些测量血压的方法?"
results = hybrid_retriever.retrieve(query)
3. 关键参数与调优
**(1) Alpha值调优
- 作用:控制向量检索和BM25检索的权重比例。
- 推荐实践:
- 通过实验确定最优值(如
alpha=0.2或0.6)。 - 使用LlamaIndex的评估模块(如MRR、命中率)进行量化优化。
- 通过实验确定最优值(如
**(2) 索引配置
- BM25优化:调整分块策略(如语义分块提升召回质量)。
- 向量索引优化:
- 选择合适的Embedding模型(如
text-embedding-ada-002); - 确保向量数据库支持混合查询(如Milvus 2.4+版本)。
- 选择合适的Embedding模型(如
4. 实现注意事项
- 数据库兼容性:
- 混合检索需要底层数据库支持联合查询(如Milvus 2.4+)。
- 性能权衡:
- 混合检索可能增加计算开销,需平衡召回率与效率。
- 重排器(Reranker):
- 可添加重排器(如
RerankRetriever)对混合结果进一步排序,提升相关性。
- 可添加重排器(如
5. 参考案例与资源
- BM25+向量的两路召回实现:
参考中LlamaIndex的HybridFusionRetrieverPack或自定义检索器配置。 - Alpha调优实验:
IBM研究指出,混合检索在单/多文档场景中均表现更优,尤其当alpha=0.2/0.6时。
相关文章:
与混合检索(Hybrid Search))
LlamaIndex实现RAG增强:融合检索(Fusion Retrieval)与混合检索(Hybrid Search)
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

什么是向量搜索Vector Search?
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

【接口重复请求】axios通过AbortController解决页面切换过快,接口重复请求问题
处理网络请求时,我们经常会遇到需要中途取消请求的情况,比如用户在两个tab之间反复横跳的场景,如果每个接口都从头请求到结束,那必然会造成很大的服务压力。 AbortController是一个Web API,它提供了一个信号对象&…...

GitHub与Gitee各是什么?它们的区别与联系是什么?
李升伟 整理 GitHub 介绍 GitHub 是一个基于 Git 的代码托管平台,主要用于版本控制和协作开发。它支持多人协作,提供代码托管、问题跟踪、代码审查、项目管理等功能。GitHub 是全球最大的开源社区,许多知名开源项目都在此托管。 主要功能&…...

OpenCV图像形态学:原理、操作与应用详解
一、引言 图像形态学(Image Morphology)是图像处理领域的一个重要分支,它基于集合论、格论、拓扑学和随机函数理论,主要用于分析和处理图像的几何结构。形态学操作通过特定的结构元素(Structuring Element)…...

ubuntu git cola gui
直接的方法, samba, win 里用 tortoiseSVN 需要先在命令行,运行 git 命令,看到操作提示, 按照提示做 然后右键看 git diff 其它的方法 linux下可视化git工具git-cola安装与使用(HTTP方式)_git…...

RTX5080 安装torch,torchvision ,torchaudio 指南
一、前置准备 5080 显卡 是sm120 架构,只有torch的preview版本可以使用,而且该版本仅支持cuda12.8. 请你放弃下载以及使用低版本cuda cudnn torch 的想法。 请你学习conda 创建环境,激活环境,在虚拟环境里使用pip ,…...

ubuntu开发mcu环境
# 编辑 vim或者vscode # 编译 arm-none-eabi # 烧写 openocd 若是默认安装,会在/usr/share/openocd/scripts/{interface,target} 有配置接口和目标版配置 示例: openocd -f interface/stlink-v2.cfg -f target/stm32f1x.cfg 启动后,会…...

《UNIX网络编程卷1:套接字联网API》第5章 TCP客户服务器程序示例
《UNIX网络编程卷1:套接字联网API》第5章 TCP客户/服务器程序示例 5.1 本章目标与示例程序概述 本章通过一个完整的TCP回射(Echo)客户/服务器程序,深入解析TCP套接字编程的核心流程与关键问题。示例程序的功能为:客户…...

花洒洗澡完毕并关闭后过段时间会突然滴水的原因探究
洗澡完毕后的残留水 在洗澡的过程中,我们通常会使用到大量的水。这些水会通过花洒管子到达花洒顶喷流出。由于大顶喷花洒的喷头较大,关闭后里面的存水会更多。 气压失衡后的滴水 当花洒关闭后,内部的水管和花洒头中仍存有一定量的水。由于…...

子组件使用:visible.sync=“visible“进行双向的绑定导致该弹窗与其他弹窗同时显示的问题
问题描述:最近写代码时遇到了一个问题:点击A弹窗后关闭,继续点击B弹窗,这时会同时弹窗A、B两个弹窗。经过排查后发现在子组件定义时使用了:visible.sync"visible"属性进行双向的数据绑定 <template> <el-dial…...

TTL 值 | 在 IP 协议、ping 工具及 DNS 解析中的作用
注:本文为 “TTL” 相关文章合辑。 未整理去重。 如有内容异常,请看原文。 TTL 值的意义 2007-10-18 11:33:17 TTL 是 IP 协议包中的一个值,用于标识网络路由器是否应丢弃在网络中停留时间过长的数据包。数据包可能因多种原因在一定时间内…...

代码调试:VS调试实操
1.什么是BUG? BUG原意是“虫子”,在计算机领域是指未被发现的错误,又叫程序漏洞 2.什么是调试? 当你在写完代码时需要去找代码中的问题,这个过程就叫调试 我们必须承认有这个问题并且去修复问题,可以透…...
与组播技术深度解析)
IGMP(Internet Group Management Protocol)与组播技术深度解析
一、组播技术核心概念 1. 组播 vs 单播/广播 传输类型目标地址网络负载典型应用场景单播单一明确IP随接收者数量线性增长网页浏览、文件下载广播全网段(如255.255.255.255)强制全网设备处理ARP请求、DHCP发现组播D类地址(224.0.0.0~239.255…...
)
JWT(JSON Web Token)
目录 一 JWT简单介绍 二、JWT 的组成结构 1 Header(头部) 2 Payload(载荷) 三、JWT 工作原理 好文分享 session、cookie、token 详解_token session cookie-CSDN博客 一 JWT简单介绍 概念:是一种开放标准&#…...

深入理解多线程编程:从基础概念到实战应用
二进制信号量:线程同步的基础 什么是二进制信号量? 二进制信号量是一种特殊的信号量,其值只能是0或1。它是最简单的线程同步机制之一,常用于线程间的简单协调。 #include <semaphore.h>sem_t sem; // 声明二进制信号量 se…...
(代码+资料+论文))
【STM32设计】基于STM32的智能门禁管理系统(指纹+密码+刷卡+蜂鸣器报警)(代码+资料+论文)
本课题为基于单片机的智能门禁系统,整个系统由AS608指纹识别模块,矩阵键盘,STM32F103单片机,OLED液晶,RFID识别模块,继电器,蜂鸣器等构成,在使用时,用户可以录入新的指纹…...

【MVP 和 MVVM 相比 MVC 有哪些优化点?】
MVP 和 MVVM 相比 MVC 的优化及原因 1. MVC 的痛点 在传统 MVC 模式中: 视图(View)和模型(Model)直接交互:View 可能直接监听 Model 的变化(如观察者模式),导致耦合。…...

蓝桥云客 刷题统计
刷题统计 问题描述 小明决定从下周一开始努力刷题准备蓝桥杯竞赛。他计划周一至周五每天做 a 道题目,周六和周日每天做 b 道题目。请你帮小明计算,按照计划他将在第几天实现做题数大于等于 n 题? 输入格式 输入一行包含三个整数 a, b 和 …...

【28BYJ-48】STM32同时驱动4个步进电机,支持调速与正反转
资料下载:待更新。。。。 先驱动起来再说,干中学!!! 1、实现功能 STM32同时驱动4个步进电机,支持单独调速与正反转控制 需要资源:16个任意IO口1ms定时器中断 目录 资料下载:待更…...
)
【第十三届“泰迪杯”数据挖掘挑战赛】【2025泰迪杯】【代码篇】A题解题全流程(持续更新)
【第十三届“泰迪杯”数据挖掘挑战赛】【2025泰迪杯】【代码篇】A题解题全流程(持续更新) 环境配置: 显存>24GBPyTorch 2.3.0Python 3.12(ubuntu22.04)CUDA 12.1autoDL服务器平台,(好处:可以分享镜像&…...

迅为RK3568开发板驱动开发指南helloworld驱动实验-驱动的基本框架
Linux 驱动的基本框架主要由模块加载函数,模块卸载函数,模块许可证声明,模块参数,块导出符号,模块作者信息等几部分组成,其中模块参数,模块导出符号,模块作者信息是选的部分…...

Spring Boot 3.4.3 基于 JSqlParser 和 MyBatis 实现自定义数据权限
前言 在企业级应用中,数据权限控制是保证数据安全的重要环节。本文将详细介绍如何在 Spring Boot 3.4.3 项目中结合 JSqlParser 和 MyBatis 实现灵活的数据权限控制,通过动态 SQL 改写实现多租户、部门隔离等常见数据权限需求。 一、环境准备 确保开发环境满足以下要求: …...
)
软件工程面试题(二十三)
1、public class Test {public static void add(Integer i){int val=i.intValue(); val+=3; i=new Integer(val); } public static void main(String[] args) {Integer i=new Integer(0); add(i); System.out.println(i.intValue());...

spring boot 集成redis 中RedisTemplate 、SessionCallback和RedisCallback使用对比详解,最后表格总结
对比详解 1. RedisTemplate 功能:Spring Data Redis的核心模板类,提供对Redis的通用操作(如字符串、哈希、列表、集合等)。使用场景:常规的Redis增删改查操作。特点: 支持序列化配置(如String…...
)
leetcode-热题100(3)
leetcode-74-搜索二维矩阵 矩阵最后一列升序排序,在最后一列中查找第一个大于等于target的元素 然后在该元素所在行进行二分查找 bool searchMatrix(int** matrix, int matrixSize, int* matrixColSize, int target) {int n matrixSize;int m matrixColSize[0];in…...

【大模型系列篇】大模型基建工程:使用 FastAPI 构建 SSE MCP 服务器
今天我们将使用FastAPI来构建 MCP 服务器,Anthropic 推出的这个MCP 协议,目的是让 AI 代理和你的应用程序之间的对话变得更顺畅、更清晰。FastAPI 基于 Starlette 和 Uvicorn,采用异步编程模型,可轻松处理高并发请求,尤…...

基于大模型预测风湿性心脏病二尖瓣病变的多维度诊疗研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与创新点 二、大模型技术概述 2.1 大模型的原理与架构 2.2 在医疗领域的应用现状 三、术前评估与预测 3.1 患者数据收集与分析 3.1.1 临床数据收集 3.1.2 影像数据处理 3.2 大模型预测模型建立 3.2.1 数据预处理 3.…...

5.模型训练-毕设篇
vgg: base_model_vgg13 models.vgg13(pretrainedTrue) base_model_vgg13.classifier[-1] nn.Linear(4096, num_classes) base_model_vgg13.to(device)(b_img_rgb.to(device)).shapebase_model_vgg13 models.vgg13(pretrainedTrue) 作用:加载预训练的…...

[物联网iot]对比WIFI、MQTT、TCP、UDP通信协议
第一步:先理解最基础的关系(类比快递) 假设你要给朋友寄快递: Wi-Fi:相当于“公路和卡车”,负责把包裹从你家运到快递站。 TCP/UDP:相当于“快递公司的运输规则”。 TCP:顺丰快递&…...

【含文档+PPT+源码】基于Python的股票数据可视化及推荐系统的设计与实现
项目介绍 本课程演示的是一款基于Python的股票数据可视化及推荐系统的设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Python学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行…...
_23)
LeetCode算法题(Go语言实现)_23
题目 给你一个下标从 0 开始、大小为 n x n 的整数矩阵 grid ,返回满足 Ri 行和 Cj 列相等的行列对 (Ri, Cj) 的数目。 如果行和列以相同的顺序包含相同的元素(即相等的数组),则认为二者是相等的。 一、代码实现 func equalPairs…...

Windows家庭版如何开启Hyper-V与关闭Hyper-V
在Windows中如果要安装桌面版Docker,那么Hyper-V一定是需要开启的,在专业版操作系统上,这个功能直接就可以勾选开启,重启之后就即可生效,但在家庭版的操作系统上,默认是没有这个选择项的,这时候我们就需要借助于命令去开启它。本文,整理了一键开启Hyper-V服务和一键关闭…...

C# 中充血模型和贫血模型
在C#中,充血模型(Rich Domain Model)和贫血模型(Anemic Domain Model)是两种截然不同的领域建模方式,核心区别在于业务逻辑的归属。以下是通俗易懂的解释: 1. 贫血模型ÿ…...

C++中的继承
#include <iostream> using namespace std;// 武器类(基类) class Weapon { protected:int atk; // 攻击力public:// 构造函数Weapon(int atk 0) : atk(atk) {}// 虚拟析构函数virtual ~Weapon() {}// set 和 get 接口void setAtk(int atk) {this…...

Uubuntu20.04复现SA-ConvONet步骤
项目地址: tangjiapeng/SA-ConvONet: ICCV2021 Oral SA-ConvONet: Sign-Agnostic Optimization of Convolutional Occupancy Networks 安装步骤: 一、系统更新 检查系统是否已经更新到最新版本: sudo apt-get update sudo apt-get upgra…...

Blender模型导入虚幻引擎设置
单位系统不一致 Blender默认单位是米(Meters),而虚幻引擎默认使用**厘米(Centimeters)**作为单位。 当模型从Blender导出为FBX或其他格式时,如果没有调整单位,虚幻引擎会将1米(Blen…...
:Spark框架及特点)
大数据Spark(五十五):Spark框架及特点
文章目录 Spark框架及特点 一、Spark框架介绍 二、Spark计算框架具备以下特点 Spark框架及特点 一、Spark框架介绍 Apache Spark 是一个专为大规模数据处理而设计的快速、通用的计算引擎。最初由加州大学伯克利分校的 AMP 实验室(Algorithms, Machines, and Pe…...

深入理解Python asyncio:从入门到实战,掌握异步编程精髓
文章目录 前言一、asyncio基础概念1.1 什么是异步编程?1.2 asyncio核心组件 二、asyncio核心用法详解2.1 事件循环管理2.2协程与任务2.3 异步上下文管理器 三、asyncio高级特性3.1 异步生成器3.2异步队列3.3 异步锁和信号量 四、asyncio实战项目4.1 高性能Web爬虫4.…...

线段树,单点,区间修改查阅
#PermanentNotes/algorithm 思想 首先关于树有许多类型,这里我们主要首线段树,整体思想就是将一个大区间进行拆分,拆分成各个小区间,在我们进行查找,更新时,就是对区间的查找更新 类型 初始化,构建树 代码 const int Z 1e7; const ll INF 1e18; const int maxn 1e5 10…...
ffmpeg编译及推流)
音视频(二)ffmpeg编译及推流
FFmpeg 大名鼎鼎,就不多介绍了 1:环境 win11_amd64 ffpmeg download:https://git.ffmpeg.org/ffmpeg.git ffmpeg msys2 download:https://www.msys2.org/ vs2022 (c 写demo用) 用别的也行 usb2.0 摄像头(有点老) opencv 看上传的…...

syslog 与 Linux 内核日志系统全面解析
在 Linux 系统中,日志是进行系统调试、故障排查和系统安全分析的重要手段。syslog 和内核日志是 Linux 日志组成的核心组件。本文将从原理、实现、配置、常见问题分析等综合解析,全面解读 Linux 下的日志机制。 一、syslog 系统概述 1.1 什么是 syslog …...
——关键信息(2))
SQL问题分析与诊断(8)——关键信息(2)
8.2. 关键信息 8.2.2. 警告 查询计划中,可能会看到出现于操作符上的小图标,特别是黄色或红色的感叹号。这些图标都是警告。并非每个警告都指示一个严重问题,但发现时请检查该图标的属性窗口,其将包含该警告图标的具体细节。 8.…...

HCIA/HCIP基础知识笔记汇总
HCIA/HCIP基础知识笔记汇总 ICT产业链: 上游:芯片制造、元器件生产、光纤光缆制造 中游:硬件组装、软件开发、网络建设维护 下游:电信服务、互联网服务、终端产品 VLAN端口类型: access :…...

vue3 动态路由
定义: 对路由的添加通常是通过 routes 选项来完成的,但是在某些情况下,你可能想在应用程序已经运行的时候添加或删除路由 1. 动态添加路由规则 场景 在应用初始化时,可能需要根据用户的角色或权限动态添加路由规则。 实现 im…...

《Linux内存管理:实验驱动的深度探索》大纲
《Linux内存管理:实验驱动的深度探索》 ——通过递进式实验与问题剖析,从入门到精通 第一部分:初探内存——基础概念与简单实验 目标:理解内存的基本行为,学会观察和提问 第1章 内存初体验:从"free…...
:sizeof、strlen与数组指针的那些事儿)
【C语言】深入理解指针(五):sizeof、strlen与数组指针的那些事儿
前言 在C语言的学习中,指针始终是一个让人又爱又恨的话题。它强大而灵活,但同时也充满了陷阱。今天,我们就来深入探讨一下指针相关的几个重要知识点:sizeof和strlen的区别,以及数组和指针在笔试题中的那些常见问题。希…...

CMake学习-- install 指令详细说明
目录 CMake中install命令的用法背景知识使用方法项目结构示例代码CMakeLists.txt构建和安装 详细介绍安装库和头文件安装可执行文件安装额外的文件安装目录结构使用安装的库 总结 CMake中install命令的用法 背景知识 在软件开发过程中,构建和安装是两个重要的环节…...

Cannot find a valid baseurl for repo: centos-sclo-sclo/x86_64
rpm -Uvh https://repo.zabbix.com/zabbix/5.0/rhel/7/x86_64/zabbix-release-latest-5.0.el7.noarch.rpmyum clean allyum macache fast 编辑配置文件 /etc/yum.repos.d/zabbix.repo and enable zabbix-frontend repository. [zabbix-frontend]...enabled1... 下载相关…...

uniapp 微信小程序 使用ucharts
文章目录 前言一、组件功能概述二、代码结构分析2.1 模板结构 总结 前言 本文介绍一个基于 Vue 框架的小程序图表组件开发方案。该组件通过 uCharts 库实现折线图的绘制,并支持滚动、缩放、触摸提示等交互功能。文章将从代码结构、核心方法、交互实现和样式设计等方…...