day1_Flink基础
文章目录
- Flink基础
- 今日课程内容目标
- 为什么要学Flink
- 技术更新迭代
- 市场需求
- 流式计算
- 批量计算
- 概念
- 特点
- 批量计算的优势和弊端
- 流式计算
- 生活中流场景
- 流式计算的概念
- Flink简介
- Flink历史
- Flink介绍
- Flink架构体系
- 已学过的框架技术
- Flink架构
- Flink集群搭建
- Flink的集群模式
- Standalone模式集群搭建
- 安装部署配置
- demo案例运行
- Flink入门案例
- Flink分层API
- Flink程序开发流程
- 搭建Flink工程
- 基于mvn创建项目
- 引入的基本依赖
- 入门案例
- 需求
- 分析
- 实现
- 批处理 - DataStream(从文件中读取批数据)
- 流处理 - DataStream(从socket中读取流数据)
- 流处理 - DataStream(扩展1:从socket中读取流数据,Lambda的方式实现)
- 流处理 - DataStream(扩展2:从socket中读取流数据,Lambda的方式实现)
- 流处理 -Table API
- 流处理 - SQL
- Flink程序提交部署
- Flink程序提交部署
- 以UI的方式递交
- 以命令的方式递交
- 今日总结
Flink基础
今日课程内容目标
- 为什么要学Flink
- 技术更新迭代
- 市场趋势
- 流式计算
- 批量计算
- 流式计算
- Flink简介
- Flink架构体系
- Flink安装部署
- Local
- Standalone
- Yarn【最后一天学习】
- Flink入门案例
- 批处理(已过期)
- 流处理(DataStream API、Table API、SQL)
为什么要学Flink
技术更新迭代

- 离线计算
Hadoop(MR) -> Tez(MR增强版) -> Spark(内存计算)
- 流式计算(实时计算)
Storm -> StructuredStreaming -> Flink
市场需求
小结:流式计算需求趋向于火热。同时,由于大公司在推进,因此,互联网实时需求越来越旺盛。
流式计算
批量计算
概念
批量计算,数据是一批一批地计算,来一批处理一批。
特点
数据是有界的,数据是有开始,也有结束的。
数据一旦产生,不会更改
时效性低
批量计算的优势和弊端
批量计算的优势,是对历史数据的处理。对于时效性要求不高。
但是,对于一些时效性要求高的场景:
- 实时监控网站的异常情况
- 实时监控道路拥堵情况
- 实时监控全国疫情爆发情况
- 实时监控网站成交情况
这个时候,就需要流式计算了。
流式计算
生活中流场景
生活中的流式场景比较多,比如水流,车流,人流(行人),气流,电流,如下图(以水流为例)

这些流式场景,他们的共同点是:
-
数据是源源不断,也就是不间断
-
有开始,没有结束
-
来一条处理一条
流式计算的概念
基于数据流的计算,就叫做流式计算。
数据流:数据是流动的,是源源不断的,是没有结束的。
流式计算的框架:
- Storm
- StructuredStreaming
- Flink(主角)
Flink简介
Flink历史
2010-2014年,起源于欧洲柏林大学的一个StratoSphere项目
2014年4月,捐赠给了Apache软件基金会
在2014年底,称为Apache的顶级项目
2019年,Flink的母公司,被阿里巴巴收购
Flink的最新版:1.20.0
我们这次课程,也是基于1.20.0来讲解。
Flink介绍

Flink官网:https://flink.apache.org/
Flink:基于数据流上的有状态的计算。
数据流:流动的数据。
有状态:Flink会保存每个算子的计算中间结果,不需要用户操心。这也是相比Storm框架的优势。
Flink的编程模型【扩展】
- 数据输入
- MySQL数据
- 日志数据
- 物联网数据
- 点击埋点数据
- 数据处理
- Flink程序
- 数据输出
- 关系型数据库
- 文件
- K-V存储介质
Flink架构体系
已学过的框架技术
- HDFS
- NameNode(主)
- DataNode(从)
- Yarn
- ResourceManager(主)
- NodeManager(从)
- Spark
- Master(主)
- Worker(从)
- Flink
- JobManager(主)
- TaskManager(从)
Flink架构

Flink也是主从架构,分为如下:
- JobManager:负责集群管理,资源管理、任务调度、容错等。
- TaskManager:负责任务执行,心跳汇报
- Slot(槽)就是Flink具体任务的场所。Standalone模式下,槽位在集群启动时,就固定了。在Yarn下,可以动态申请TaskManager,因此可以动态增加槽位。
Flink集群搭建
Flink的集群模式
- Local模式【本地模式, 开发环境可用】
- 一个进程模拟全部的角色,处理所有的代码流程。
- Standalone模式【独立模式,测试或者生产环境可用】
- 每个进程都是互相独立的。
- Yarn模式【生产模式常用,基础课最后一天介绍】
- 不需要额外的搭建,只需要把Yarn、HDFS启动即可。
- 基于Yarn来运行Flink。(需要添加Flink基于HDFS的依赖jar包)
Standalone模式集群搭建
安装部署配置
#0.准备
cd /export/software#1.下载
wget https://archive.apache.org/dist/flink/flink-1.12.0/flink-1.12.0-bin-scala_2.12.tgz#2.解压
tar -zxvf flink-1.20.0-bin-scala_2.12.tgz -C /export/server/#3.进入
cd /export/server/#4.创建软连接
ln -s flink-1.20.0 flink#5.修改配置
82行:numberOfTaskSlots: 4
170行:address: node1
177行:bind-address: node1
随便找一行,添加:classloader.check-leaked-classloader: false#6.启动Flink
bin/start-cluster.sh#7.停止Flink
bin/stop-cluster.sh#8.FLINK_HOME配置
#FLINK_HOME
export FLINK_HOME=/export/server/flink
export PATH=$PATH:$FLINK_HOME/bin#9.source环境变量
source /etc/profile#10.查看WebUI登录页面
http://node1:8081
Flink安装目录介绍

demo案例运行
cd $FLINK_HOME
bin/flink run examples/batch/WordCount.jar
WebUI运行结果如下:

后台结果如下:

Flink入门案例
Flink分层API
Flink还是一个非常易于开发的框架,因为它拥有易于使用的分层API,越往上抽象程度越高,使用起来越方便;越往下越底层,使用起来难度越大,如下图所示:

- SQL/Table API(最顶层)StreamTableEnvironment
- DataStream API(中间层)StreamExecutionEnvironment
- Stateful Function(最底层)
注意:2020年12月8日发布的新版本1.12.0,已经完全实现了真正的流批一体,DataSetAPI已经处于软性弃用(soft deprecated)的状态,用DataStream API写好的一套代码,既可以处理流数据,也可以处理批数据,只需要设置不同的执行模式,这与之前版本处理有界流的方式是不一样的,Flink已专门对批处理数据做了优化处理,本课程基于Flink1.20版本研发,因此后续的学习以介绍DataStream API为主。
Flink程序开发流程
一个完整的flink作业无论简单与复杂,flink程序都由如下几个部分组成:

- 构建流式执行环境:获取一个编程、执行入口环境env【固定写法】
- 数据输入:通过数据源组件,加载、创建datastream
- 数据处理: 对datastream调用各种处理算子表达计算逻辑
- 数据输出:通过sink算子指定计算结果的输出方式
- 启动流式任务:在env上触发程序提交运行【固定写法】
注意:写完输出(sink)操作并不代表程序已经结束。因为当main()方法被调用时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据——因为数据可能还没来。Flink是由事件驱动的,只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”。
所以我们需要显式地调用执行环境的execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
env.execute();
搭建Flink工程
基于mvn创建项目
-
创建一个新项目:
Create New Project
-
下一步,选择
maven项目,并且勾选:Create from archetype选项(目的是使用flink官方提供的项目模板快速生成项目结构)
如果是第一次创建项目,那么则需要添加一个新的模板文件,请选择:
Add Archetype按钮,并把官方提供的模板内容填写完整:

这里需要注意的是
Version字段,请确认你开发时的flink版本和你运行的环境版本是一致的,以免带来不必要的麻烦。比如:公司的
flink集群是是基于1.20.0版本,而你是基于1.10.0开发的代码,那么最终上线肯定会遇到兼容性问题的,所以请注意。添加好官方的模板后,我们便可以在以下的列表中选择基于该模板来创建项目基本结构:

-
下一步,配置项目名称,并且取一个唯一的
groupId名称: -
最后,直接下一步选择默认操作完成即可。整个项目目录结构创建完成,如下:

引入的基本依赖
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.20.0</flink.version><parquet-avro>1.12.2</parquet-avro><log4j.version>2.17.1</log4j.version><mysql.version>5.1.48</mysql.version><lombok.version>1.18.22</lombok.version><hadoop.version>3.3.0</hadoop.version><target.java.version>1.8</target.java.version><scala.binary.version>2.12</scala.binary.version><maven.compiler.source>${target.java.version}</maven.compiler.source><maven.compiler.target>${target.java.version}</maven.compiler.target></properties><repositories><repository><id>apache.snapshots</id><name>Apache Development Snapshot Repository</name><url>https://repository.apache.org/content/repositories/snapshots/</url><releases><enabled>false</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository></repositories><dependencies><!-- Apache Flink dependencies --><!-- These dependencies are provided, because they should not be packaged into the JAR file. --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java</artifactId><version>${flink.version}</version></dependency><!-- Add connector dependencies here. They must be in the default scope (compile). --><!-- Example:<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>3.0.0-1.17</version></dependency>--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>3.3.0-1.20</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.2.0-1.19</version></dependency><!-- flink连接器--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-parquet</artifactId><version>${flink.version}</version></dependency><!-- Add logging framework, to produce console output when running in the IDE. --><!-- These dependencies are excluded from the application JAR by default. --><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><!--lombok插件--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>${lombok.version}</version></dependency><!--第三方工具包--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.53</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.9</version></dependency></dependencies><build><plugins><!-- Java Compiler --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>${target.java.version}</source><target>${target.java.version}</target></configuration></plugin><!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. --><!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><!-- Run shade goal on package phase --><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><createDependencyReducedPom>false</createDependencyReducedPom><artifactSet><excludes><exclude>org.apache.flink:flink-shaded-force-shading</exclude><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>org.apache.logging.log4j:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>cn.itcast.DataStreamJob</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins><pluginManagement><plugins><!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. --><plugin><groupId>org.eclipse.m2e</groupId><artifactId>lifecycle-mapping</artifactId><version>1.0.0</version><configuration><lifecycleMappingMetadata><pluginExecutions><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><versionRange>[3.1.1,)</versionRange><goals><goal>shade</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><versionRange>[3.1,)</versionRange><goals><goal>testCompile</goal><goal>compile</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution></pluginExecutions></lifecycleMappingMetadata></configuration> </plugin></plugins></pluginManagement></build>
入门案例
需求
使用Flink程序,从文件里读取单词,进行Wordcount单词统计。
分析
#3.数据处理
#3.1,进行扁平化处理
hello hadoop hello
hello hive => 转换成如下 hadoophellohive#3.2把上述每个单词进行转换,转成(单词,1)
hello (hello,1)
hadoop => (hadoop,1)
hello (hello,1)
hive (hive,1)#3.3 把上述单词,按照word(单词)进行分组
(hello,1) (hello,1),(hello,1)
(hadoop,1) => (hadoop,1)
(hello,1) (hive,1)
(hive,1)#3.4 把相同组内的单词,进行sum求和
(hello,1),(hello,1) (hello,2)
(hadoop,1) => (hadoop,n)
(hive,1) (hive,n)
实现
批处理 - DataStream(从文件中读取批数据)
package day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @author: itcast* @date: 2022/10/26 16:48* @desc: Flink 程序实现Wordcount单词统计(批处理)*/
public class Demo01_WordCountBatch {public static void main(String[] args) throws Exception {//1.构建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.setRuntimeMode(RuntimeExecutionMode.BATCH);//2.数据输入(数据源)DataStreamSource<String> source = env.readTextFile("D:\\word.txt");//3.数据处理,匿名内部类 new 接口类(){}//3.1 flatMap进行扁平化处理SingleOutputStreamOperator<String> flatMapStream = source.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}});//3.2 使用map方法,进行转换(单词,1)int -> IntegerSingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}});//3.3 使用keyBy算子进行单词分组 (hello,1)KeyedStream<Tuple2<String, Integer>, String> keyedStream = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});//3.4进行reduce(sum)操作(hello,1),(hello,1)SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {return Tuple2.of(value1.f0, value1.f1 + value2.f1);}});//4.数据输出result.print();//5.启动流式任务env.execute();}
}
运行结果如下:

流处理 - DataStream(从socket中读取流数据)
package day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @author: itcast* @date: 2022/10/26 17:18* @desc: Flink 代码实现流处理,进行单词统计。数据源来自于socket数据。*/
public class Demo02_WordCountStream {public static void main(String[] args) throws Exception {//1.构建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.STREAMING);env.setParallelism(1);//2.数据输入(数据源)//从socket读取数据,socket = hostname + portDataStreamSource<String> source = env.socketTextStream("node1", 9999);//3.数据处理//3.1 使用flatMap进行扁平化处理SingleOutputStreamOperator<String> flatMapStream = source.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}});//3.2 使用map进行转换,转换成(单词,1)SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}});//3.3使用keyBy进行单词分组KeyedStream<Tuple2<String, Integer>, String> keyedStream = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});//3.4 使用reduce(sum)进行聚合操作,sum:就是根据第一个元素(Integer)进行sum操作SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedStream.sum(1);//4.数据输出result.print();//5.启动流式任务env.execute();}
}运行结果如下:

流处理 - DataStream(扩展1:从socket中读取流数据,Lambda的方式实现)
package day01;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @author: itcast* @date: 2022/10/27 9:21* @desc: 扩展2:采用Lambda表达式的方式来编写Flink wordcount入门案例*/
public class Demo04_WordCountStream_03 {public static void main(String[] args) throws Exception {//1.构建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.数据输入DataStreamSource<String> source = env.socketTextStream("node1", 9999);//3.数据处理SingleOutputStreamOperator<Tuple2<String, Integer>> result = source.flatMap((String value, Collector<String> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}).returns(Types.STRING).map(value -> Tuple2.of(value, 1)).returns(Types.TUPLE(Types.STRING,Types.INT)).keyBy(value -> value.f0).sum(1);//4.数据输出result.print();//5.启动流式任务env.execute();}
}运行结果如下:

流处理 - DataStream(扩展2:从socket中读取流数据,Lambda的方式实现)
package day01;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;import java.util.Arrays;/*** @author: itcast* @date: 2022/10/27 9:21* @desc: 扩展3:采用Lambda表达式的方式来编写Flink wordcount入门案例*/
public class Demo04_WordCountStream_04 {public static void main(String[] args) throws Exception {//1.构建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.数据输入DataStreamSource<String> source = env.socketTextStream("node1", 9999);//3.数据处理SingleOutputStreamOperator<Tuple2<String, Integer>> result = source.flatMap((String value, Collector<String> out) -> {Arrays.stream(value.split(" ")).forEach(out::collect);}).returns(Types.STRING).map(value -> Tuple2.of(value, 1)).returns(Types.TUPLE(Types.STRING,Types.INT)).keyBy(value -> value.f0).sum(1);//4.数据输出result.print();//5.启动流式任务env.execute();}
}任务运行截图:

流处理 -Table API
package day01;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Expressions;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.TableDescriptor;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import java.util.concurrent.ExecutionException;/*** @author: itcast* @date: 2022/10/27 9:55* @desc: 使用Flink Table API进行wordcount单词统计。* Table:表,(MySQL、Hive、Spark)* 是不是需要先准备好表?* 在Flink里面,同样如此。* //1.构建流式执行环境* //2.数据输入(数据输入表)* //3.数据输出(数据输出表)* //4.数据处理(基于数据输入表、数据输出表进行业务处理(单词统计)* //5.启动流式任务*/
public class Demo05_WordCountTable {public static void main(String[] args) throws Exception {//1.构建流式执行环境//env 对象是基于DataStream API构建的,如果需要使用Table API/SQL来提交Flink任务,则需要使用Flink里的StreamTableEnvironment对象StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment t_env = StreamTableEnvironment.create(env);t_env.getConfig().set("parallelism.default","1");//2.数据输入(数据输入表)/*** createTemporaryTable(String tableName,TableDescriptor tableDescriptor);* tableName:表名* tableDescriptor:描述表的schema,column等信息的* connector: 就类似于jdbc的驱动类,但是Flink不叫驱动包(驱动类),Flink叫做Connector,连接器。* 连接器:就是用来连接外部数据源的。*//*** | word |* | hello |* | hive |* | flink |*/t_env.createTemporaryTable("source", TableDescriptor.forConnector("datagen").schema(Schema.newBuilder().column("word", DataTypes.STRING()).build()).option("rows-per-second","1").option("fields.word.kind","random").option("fields.word.length","1").build());//3.数据输出(数据输出表)/*** | word | counts |* | a | 2 |* | 1 | 3 |*/t_env.createTemporaryTable("sink",TableDescriptor.forConnector("print").schema(Schema.newBuilder().column("word",DataTypes.STRING()).column("counts",DataTypes.BIGINT()).build()).build());//4.数据处理(基于数据输入表、数据输出表进行业务处理(单词统计)/*** 处理逻辑:* 首先从源表把数据读取出来,根据单词进行分组,然后按照分组后的字段(word,count(*))进行统计。* from:从源表读取数据* groupBy:根据xx字段分组* select:分组后选择需要的数据,选择的数据&类型需要和目标表匹配* executeInsert:把最终结果插入到目标表中去* insert into sink* select word ,count(*) from source group by word*/t_env.from("source").groupBy(Expressions.$("word")).select(Expressions.$("word"),Expressions.lit(1).count()).executeInsert("sink").await();//5.启动流式任务env.execute();}
}执行结果如下:

流处理 - SQL
package day01;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import java.util.concurrent.ExecutionException;/*** @author: itcast* @date: 2022/10/27 10:42* @desc: 使用Flink SQL完成单词统计*/
public class Demo06_WordCountSQL {public static void main(String[] args) throws Exception {//1.构建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment t_env = StreamTableEnvironment.create(env);t_env.getConfig().set("parallelism.default","1");//2.构建数据源表(数据输入)/*** | word |* | hello |* | hive |* | spark |* | flink |*/t_env.executeSql("create table source(" +"word varchar" +") with (" +"'connector' = 'datagen'," +"'rows-per-second' = '1'," +"'fields.word.kind' = 'random'," +"'fields.word.length' = '1'" +")");//3.构建数据输出表(数据输出)/** 表结构如下:* | word | counts |* | hello | 1 |* | hive | 2 |* | flink | 3 |*/t_env.executeSql("create table sink(" +"word varchar," +"counts bigint" +") with (" +"'connector' = 'print'" +")");//4.数据处理/*** 数据处理逻辑SQL如下:* insert into sink select word,count(*) from source group by word*/t_env.executeSql("insert into sink select word,count(*) from source group by word").await();//5.启动流式任务env.execute();}
}执行结果如下:

Flink程序提交部署
Flink程序提交部署
Flink程序递交方式有两种:
- 以UI的方式递交
- 以命令的方式递交
以UI的方式递交
提交步骤:
#1.使用idea自带的打包工具进行打包(双击package即可)
#2.使用瘦包即可(小的包)传到webUI上
#3.设置Entry class(day01.Demo02_WordCountStream)Parallelism(1)
#4.开启socket(nc -lk 9999)
#5.Submit提交
#6.在linux终端输入单词
-
指定递交参数

-
查看任务运行概述

-
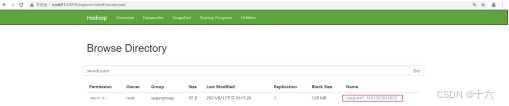
查看任务运行结果
以命令的方式递交
-
上传作业jar包到linux服务器

-
配置执行模式(可选)

-
指定递交命令
flink run -c day01.Demo02_WordCountStream original-flinkbase-1.0-SNAPSHOT.jar -
查看任务运行概述

今日总结
- 学习 Flink 的入门和综述,主要介绍了 Flink 的起源和应用场景,引出了流处理相关 的一些重要概念,并通过介绍数据处理架构发展演变的过程,展示了 Flink 作为新一代分布式流处理器的架构思想。
- 实现了一个Flink 开发的入门程序——词频统计 WordCount。通过批处理和流处理两种不同模式的实现,可以对Flink的API风格和编程方式有所熟悉,并且可以更加深刻地理解批处理和流处理的不同。另外,通过读取有界数据(文件)和无界数据(Socket 文本流)进行流处理的比较,可以更加直观地体会Flink流处理的方式和特点。
相关文章:

day1_Flink基础
文章目录 Flink基础今日课程内容目标为什么要学Flink技术更新迭代市场需求 流式计算批量计算概念特点 批量计算的优势和弊端流式计算生活中流场景流式计算的概念 Flink简介Flink历史Flink介绍 Flink架构体系已学过的框架技术Flink架构 Flink集群搭建Flink的集群模式Standalone模…...

43页可编辑PPT | 大数据管理中心设计规划方案大数据中心组织架构大数据组织管理
这份文档是一份关于大数据管理中心规划设计方案的详细报告,涵盖了背景与需求分析、整体规划方案、关键能力实现方案以及实施方案等内容。报告强调大数据在城市治理中的重要性,提出通过构建统一的大数据平台,整合城市各部门数据资源࿰…...

JavaScript数据结构
目录 JavaScript数据结构 一、基础数据结构 1. 数组(Array) 2. 对象(Object) 二、ES6 高级数据结构 1. Map 2. Set 3. WeakMap 与 WeakSet 三、类型化数组(Typed Arrays) 四、其他数据结构实现 …...

如何使用 FastAPI 构建 MCP 服务器
哎呀,各位算法界的小伙伴们!今天咱们要聊聊一个超酷的话题——MCP 协议!你可能已经听说了,Anthropic 推出了这个新玩意儿,目的是让 AI 代理和你的应用程序之间的对话变得更顺畅、更清晰。不过别担心,为你的…...

Js 主线程和异步队列哪个先执行
JavaScript 主线程与异步队列执行顺序详解 JavaScript 是单线程语言,通过事件循环(Event Loop)机制来处理同步和异步任务。以下是主线程与异步队列的执行顺序解析: 1. 执行顺序基本原则 console.log(1. 主线程同步任务);setTim…...

C#实现HTTP服务器:处理文件上传---解析MultipartFormDataContent
完整项目托管地址:https://github.com/sometiny/http HTTP还有重要的一块:文件上传。 这篇文章将详细讲解下,前面实现了同一个链接处理多个请求,为了方便,我们独立写了一个HTTP基类,专门处理HTTP请求。 ht…...

【hadoop】远程调试环境
根据上一节,我们已经安装完成hadoop伪分布式环境 hadoop集群环境配置_jdk1.8 441-CSDN博客 还没安装的小伙伴可以看看这个帖子 这一节我们要实现使用vscode进行远程连接,并且完成java配置与测试 目录 vscode 配置远程 安装java插件 新建java项目 …...
:强化 AI 智能体的知识 “武装”)
检索增强生成(RAG):强化 AI 智能体的知识 “武装”
技术点目录 第一章、智能体(Agent)入门第二章、基于字节Coze 构建智能体(Agent)第三章、基于其他平台构建智能体(Agent)第四章、国内外智能体(Agent)经典案例详解第五章、大语言模型应用开发框架LangChain入门第六章、基于LangChain的大模型API接入第七章…...

使用 Provider 和 GetX 实现 Flutter 局部刷新的几个示例
1. 使用 Provider 实现局部刷新 示例 1:ChangeNotifier Consumer 通过 ChangeNotifier 和 Consumer 实现局部刷新。 import package:flutter/material.dart; import package:provider/provider.dart;void main() {runApp(ChangeNotifierProvider(create: (_) &g…...

notepad++ 正则表达式
注意:Notepad正则表达式字符串最长不能超过69个字符 \ 转义字符 如:要使用 “\” 本身, 则应该使用“\\” \t Tab制表符 注:扩展和正则表达式都支持 \r 回车符CR 注:扩展支持,正则表达式不支持 \n 换行符…...

一起学大语言模型-通过ollama搭建本地大语言模型服务
文章目录 Ollama的github地址链接安装下载需求配置更改安装目录安装更改下载的模型存储位置Ollama一些目录说明日志目录 运行一个模型测试下测试下更改服务监听地址和端口号 Ollama的github地址链接 https://github.com/ollama/ollama 安装 下载 mac安装包下载地址࿱…...

webpack配置详解+项目实战
webpack在vue中的配置,适合想重新认知webpack的你 webpack配置-初级配置 1、配置入口和出口文件 2、配置loader 3、配置eslint(可组装js、jsx检查工具) 4、配置babel(将高级的js语法转换成低版本的js语法) 5、使用 ht…...

【学习笔记】文件上传漏洞--js验证、mime验证、.user.ini、短标签、过滤、文件头
概念 文件上传漏洞 什么是文件上传漏洞? 文件上传漏洞是指由于程序员在对用户文件上传部分的控制不足或者处理缺陷,而导致的用户可以越过其本身权限向服务器上上传可执行的动态脚本文件。 这里上传的文件可以是木马,病毒,恶意脚…...
)
经典卷积神经网络LeNet实现(pytorch版)
LeNet卷积神经网络 一、理论部分1.1 核心理论1.2 LeNet-5 网络结构1.3 关键细节1.4 后期改进1.6 意义与局限性二、代码实现2.1 导包2.1 数据加载和处理2.3 网络构建2.4 训练和测试函数2.4.1 训练函数2.4.2 测试函数2.5 训练和保存模型2.6 模型加载和预测一、理论部分 LeNet是一…...

【VM虚拟机ip问题】
我就是我,不一样的烟火。 文章目录 前言一、启动VM虚拟机1. 开启虚拟机2. 输入账号密码登录3. 依次输入指令 二、主机ping地址测试1. ping ip地址-成功 三、安装-MobaXterm_Personal_21.51. 点击Session2. 选择SSH连接3. 输入信息4. 首次进入5. 连接成功 总结 前言 …...

【计算机视觉】YOLO语义分割
一、语义分割简介 1. 定义 语义分割(Semantic Segmentation)是计算机视觉中的一项任务,其目标是对图像中的每一个像素赋予一个类别标签。与目标检测只给出目标的边界框不同,语义分割能够在像素级别上区分不同类别,从…...
:矩阵乘法的SIMD优化与转置加速)
【C++游戏引擎开发】《线性代数》(3):矩阵乘法的SIMD优化与转置加速
一、矩阵乘法数学原理与性能瓶颈 1.1 数学原理 矩阵乘法定义为:给定两个矩阵 A ( m n ) \mathrm{A}(mn) A(mn)和 B ( n p ) \mathrm{B}(np) B(np),它们的乘积 C = A B \mathrm{C}=AB C=AB 是一个 m p \mathrm{m}p mp 的矩阵,其中: C i , j = ∑ k = 1…...

聚焦交易能力提升!EagleTrader 模拟交易系统打造交易成长新路径
在全球市场波动加剧的背景下,交易者面临的挑战已不仅限于技术分析层面。许多交易者在实盘操作中常因情绪干扰导致决策变形,如何构建科学的交易心理与风险控制体系成为行业关注焦点。 国内自营交易考试EagleTrader运用自己研发的模拟交易系统,…...

文件分片上传
1前端 <inputtype"file"accept".mp4"ref"videoInput"change"handleVideoChange"style"display: none;">2生成hash // 根据整个文件的文件名和大小组合的字符串生成hash值,大概率确定文件的唯一性fhash(f…...

C#Lambda表达式与委托关系
1. 核心关系图示 A[委托] --> B[提供方法容器] B --> C[Lambda表达式] C --> D[委托实例的语法糖] A --> E[类型安全约束] C --> F[编译器自动生成委托实例] 2. 本质联系 2.1 类型关系 Lambda表达式是编译器生成的委托实例表达式自动匹配符合签名的…...

机器翻译和文本生成评估指标:BLEU 计算公式
📌 BLEU 计算公式 BLEU 主要由**n-gram精确匹配率(Precision)和长度惩罚(Brevity Penalty, BP)**组成。 1️⃣ n-gram 精确匹配率 计算不同长度的 n-gram(1-gram, 2-gram, ..., n-gram)在生成…...

24 python 类
在办公室里,类就像一个部门(如销售部、财务部),定义了该部门员工的共同属性(姓名、职位)和行为(处理客户、提交报表)。 一、面向对象技术简介 作为一个要入门码农的牛马࿰…...

pycharm与python版本
python 3.6-3.9 pycharm 2021版本搭配最好 python 3.8 pycharm 2019版本搭配最好 pycharm各版本下载...

23种设计模式-结构型模式-外观
文章目录 简介问题解决方案示例代码总结 简介 也称:门面模式、Facade。外观是一种结构型设计模式,能为程序库、框架或其他复杂类提供一个简单的接口。 问题 假设你必须在代码中使用某个复杂的库或框架中的众多对象。正常情况下,你需要负责…...
点云的显示)
open3d教程 (三)点云的显示
官方文档位置: Visualization - Open3D 0.19.0 documentationhttps://www.open3d.org/docs/release/tutorial/visualization/visualization.html核心方法: o3d.visualization.draw_geometries([几何对象列表]) import open3d as o3dprint("Load …...

node.js、npm相关知识
Node.js 是一个基于 Chrome V8 JavaScript 引擎 构建的开源、跨平台的 JavaScript 运行时环境,主要用于服务器端编程。它允许开发者使用 JavaScript 编写高性能的后端服务,突破了 JavaScript 仅在浏览器中运行的限制。 npm(Node Package Man…...

大象如何学会太空漫步?美的:科技领先、To B和全球化
中国企业正处在转型的十字路口。一边是全新的技术、全新的市场机遇;一边是转型要面临的沉重负累和巨大投入,无数中国制造、中国品牌仍在寻路,而有的人已经走至半途。 近日,美的集团交出了一份十分亮眼的2024年财报。数据显示&…...

Go红队开发— 收官工具
文章目录 免责声明个人武器开发美观输出Whois查询反查ip目录扫描子域名爆破被动扫描主动扫描(字典爆破)CDN检测 免责声明 💡 本博客绝不涉及任何非法用途。 💡 使用者风险自担,违规后果自负。 💡 守法为先,技术向善。 …...

Android 应用程序包的 adb 命令
查看所有已安装应用的包名 命令:adb shell pm list packages说明:该命令会列出设备上所有已安装应用的包名。可以通过管道符|结合grep命令来过滤特定的包名,例如adb shell pm list packages | grep com.pm,这将只显示包名中包含co…...

北京南文观点:后糖酒会营销,以战略传播重构品牌信心坐标
第112届全国糖酒会落下帷幕,参展品牌面临一个关键命题。如何在流量洪流中沉淀品牌价值?北京南文(全称:南文乐园科技文化(北京)有限公司)认为,糖酒会的结束恰是算法时代品牌认知战的真…...

Qt - findChild
findChild 1. 函数原型2. 功能描述3. 使用场景4. 示例代码5. 注意事项6. 总结 在 Qt 中,每个 QObject 都可以拥有子对象,而 QObject 提供的模板函数 findChild 就是用来在对象树中查找满足特定条件的子对象的工具。下面我们详细介绍一下它的使用和注意事…...

2025年3月个人工作生活总结
本文为 2025年3月工作生活总结。 研发编码 一个curl下载失败问题的记录 问题: 某程序,指定IP和账户密码配置,再使用curl库连接sftp服务器,下载文件。在CentOS系统正常,但在某国产操作系统中失败,需要用命…...

Spring Boot 七种事务传播行为只有 REQUIRES_NEW 和 NESTED 支持部分回滚的分析
Spring Boot 七种事务传播行为支持部分回滚的分析 支持部分回滚的传播行为 REQUIRES_NEW:始终开启新事务,独立于外部事务,失败时仅自身回滚。NESTED:在当前事务中创建保存点(Savepoint),可局部…...

NVIDIA工业设施数字孪生中的机器人模拟
工业设施数字孪生中的机器人模拟 文章目录 工业设施数字孪生中的机器人模拟数字孪生技术的价值NVIDIA Omniverse平台工业机器人仿真的核心组件示例一:使用Isaac Sim创建基本机器人场景示例二:机器人运动规划和轨迹执行示例三:传感器集成与感知…...

docker安装jenkins
docker安装jenkins 1.安装javaJDK 服务器安装javaJDK ,因为我的服务器是直接集成了宝塔面板,我就直接从宝塔面板去安装JDK 最好安装17的JDK,因为后面会安装jenkins,需要17的版本 1.2查看安装是否完成 java --version 安装成功如下&#x…...

量子计算与人工智能融合的未来趋势
最近研学过程中发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击链接跳转到网站人工智能及编程语言学习教程。读者们可以通过里面的文章详细了解一下人工智能及其编程等教程和学习方法。 在当今科技飞速发展…...

人工智能在生物医药-新版ChatGPT-4o辅助一键生成机制图
新版ChatGPT-4o辅助一键生成机制图 作为一位生物医学教授专家,我将基于PubMed最新研究和科研大数据信息,遵循您的要求,一步一步进行思考和预测。 核心问题:乳酸化修饰促进肾透明细胞癌(ccRCC)恶性进展的机…...

支持 MCP 协议的开源 AI Agent 项目
关键要点 研究表明,目前有多个开源 AI Agent 项目支持 MCP 协议,包括 ChatMCP、HyperChat、5ire 和 Cherry Studio 等。这些项目主要用于聊天或桌面助手,允许通过 MCP 协议连接外部数据和工具。MCP 协议是 2024 年 11 月由 Anthropic 开源的…...

JavaRedis和数据库相关面试题
JavaRedis面试题 1. Redis是什么以及Redis为什么快? Redis(Remote Dictionary Server)是一个开源的内存键值数据库,支持多种数据结构(如字符串、哈希、列表、集合等),并提供持久化、复制、…...

Android开发RxJava3延迟操作
Android开发RxJava3延迟操作 直接上代码: /*** param timeMillis 毫秒单位* desc : 延迟多少毫秒操作,* 注:它和Activity生命周期绑定,界面关闭了不会再执行delayTodoListener.delayTodo()* author : congge on 2021-03-25 15:31**/p…...

android 设置状态栏背景
一 让activity ui界面和手机状态栏一样的背景 要让 Activity 的 UI 界面和手机状态栏具有相同的背景颜色,并且能够随着深色模式和非深色模式的切换而改变颜色,你可以按照以下步骤操作: 1. 让 Activity 和 状态栏背景颜色一致 使用 window.s…...

vue 常见优化手段
文章目录 vue常见的优化手段前言使用key(避免明明相同的dom,每次更新都要重新生成)使用冻结的对象(避免无意义的响应式数据)使用函数式组件(减少vue组件实例的生成)vue3vue2使用计算属性(减少数据计算的次数)非实时绑定的表单项(避免表单过多触发监听事件)保持对象的…...

vue生命周期、钩子以及跨域问题简介
Vue 的生命周期是指 Vue 实例从创建到销毁的整个过程。在这个过程中,Vue 提供了一系列的生命周期钩子(Lifecycle Hooks),允许开发者在特定的时间点执行代码。以下是 Vue 的生命周期和钩子的简单说明: Vue 的生命周期阶…...

主相机绑定小地图
资源初始化:在类中通过 property 装饰器定义主相机、小地图相机、小地图精灵等资源属性,便于在编辑器中赋值。在 start 方法里,当确认这些资源存在后,创建渲染纹理并设置其大小,将渲染纹理与小地图相机关联,…...

关于音频采样率,比特,时间轴的理解
是的,你的理解完全正确!-ar、-af aresampleasync1000 和 -b:a 64k 分别用于控制音频的采样率、时间戳调整和比特率。它们各自有不同的作用,但共同确保音频的质量和同步性。下面我将详细解释每个参数的作用和它们之间的关系。 1. -ar 参数 作用…...

三、FFmpeg学习笔记
FFmpeg是一个开源、跨平台的多媒体处理框架,能够实现音视频的录制、转换、剪辑、编码、解码、流媒体传输、过滤与后期处理等几乎所有常见的多媒体操作。其强大之处在于几乎支持所有的音视频格式、编解码器和封装格式,是业界公认的“瑞士军刀”。 FFmp…...

什么是 Java 泛型
一、什么是 Java 泛型? 泛型(Generics) 是 Java 中一种强大的编程机制,允许在定义类、接口和方法时使用类型参数。通过泛型,可以将数据类型作为参数传递,从而实现代码的通用性和类型安全。 简单来说&…...

从 WPF 到 MAUI:跨平台 UI 开发的进化之路
一、引言 在软件开发领域,用户界面(UI)开发一直是至关重要的环节。随着技术的不断发展,开发者对于创建跨平台、高性能且美观的 UI 需求日益增长。Windows Presentation Foundation(WPF)和 .NET Multi - pl…...
)
Docker学习之dockerfile篇(day8)
文章目录 前言一、问题描述二、具体内容1. Docker 镜像原理2. Docker 镜像制作3. Dockerfile 概念Dockerfile 的基本结构: 4. Dockerfile 关键字5. Docker 实战案例5.1 基于 Nginx 构建 Web 服务器 6. 验证与总结6.1 验证 Dockerfile6.2 总结 前言 Docker 是一种轻…...

Kotlin 作用域函数:apply、let、run、with、also
在 Kotlin 开发中,作用域函数(Scope Functions)是一组能让代码更简洁、更函数式的高阶函数。它们通过不同的作用域规则和返回值设计,解决了对象配置、空安全处理、链式操作等常见场景问题。本文将结合核心特性、代码示例和对比表格…...