自然语言处理(25:(终章Attention 1.)Attention的结构)
系列文章目录
终章 1:Attention的结构
终章 2:带Attention的seq2seq的实现
终章 3:Attention的评价
终章 4:关于Attention的其他话题
终章 5:Attention的应用
目录
系列文章目录
前言
Attention的结构
一.seq2seq存在的问题
二.编码器的改进
三.编码器的改进1
四.编码器的改进2
五.编码器的改进3
前言
上一章我们使用RNN生成了文本,又通过连接两个RNN,将一个时序数据转换为了另一个时序数据。我们将这个网络称为seq2seq,并用它成功求解了简单的加法问题。之后,我们对这个seq2seq进行了几处改进,几乎解决了这个简单的加法问题。 本章我们将进一步探索seq2seq的可能性(以及RNN的可能性)。这里,Attention这一强大而优美的技术将登场。Attention毫无疑问是近年来深度学习领域最重要的技术之一。本章的目标是在代码层面理解Attention的结构,然后将其应用于实际问题,体验它的奇妙效果。
Attention的结构
如上一章所述,seq2seq是一个非常强大的框架,应用面很广。这里我们将介绍进一步强化seq2seq的注意力机制(attention mechanism,简称 Attention)。基于Attention 机制,seq2seq 可以像我们人类一样,将“注意力”集中在必要的信息上。此外,使用Attention可以解决当前seq2seq 面临的问题。 本节我们将首先指出当前seq2seq存在的问题,然后一边说明Attention 的结构,一边对其进行实现(transformer中的核心就是注意力机制Attention,不过是多头注意力机制)
一.seq2seq存在的问题
seq2seq 中使用编码器对时序数据进行编码,然后将编码信息传递给解码器。此时,编码器的输出是固定长度的向量。实际上,这个“固定长度” 存在很大问题。因为固定长度的向量意味着,无论输入语句的长度如何(无论多长),都会被转换为长度相同的向量。以上一章的翻译为例,如下图所示,不管输入的文本如何,都需要将其塞入一个固定长度的向量中。
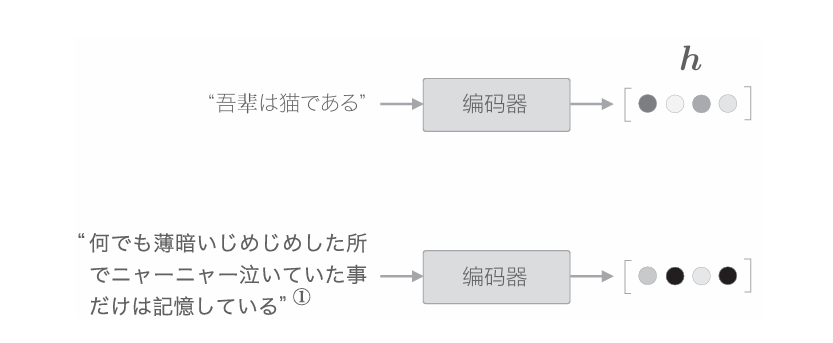
无论多长的文本,当前的编码器都会将其转换为固定长度的向量。就像 把一大堆西装塞入衣柜里一样,编码器强行把信息塞入固定长度的向量中。 但是,这样做早晚会遇到瓶颈。就像最终西服会从衣柜中掉出来一样,有用的信息也会从向量中溢出。
现在我们就来改进seq2seq。首先改进编码器,然后再改进解码器。
二.编码器的改进
到目前为止,我们都只将LSTM层的最后的隐藏状态传递给解码器, 但是编码器的输出的长度应该根据输入文本的长度相应地改变。这是编码器 的一个可以改进的地方。具体而言,如下图所示,使用各个时刻的LSTM 层的隐藏状态。
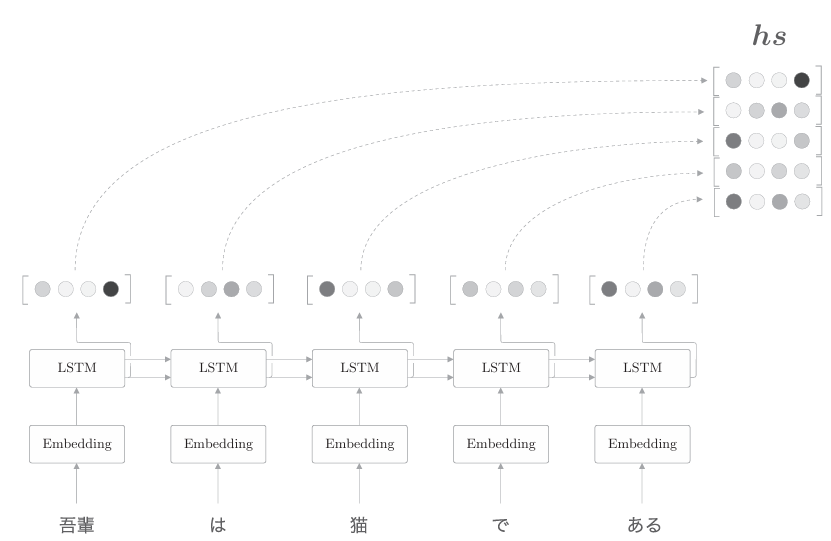
如上图所示,使用各个时刻(各个单词)的隐藏状态向量,可以获得和输入的单词数相同数量的向量。在上图的例子中,输入了5个单词,此时编码器输出5个向量。这样一来,编码器就摆脱了“一个固定长度的向量”的制约
上图中我们需要关注LSTM层的隐藏状态的“内容”。此时,各个时刻的LSTM层的隐藏状态都充满了什么信息呢?有一点可以确定的是,各个时刻的隐藏状态中包含了大量当前时刻的输入单词的信息。就上图的例子来说,输入“猫”时的LSTM层的输出(隐藏状态)受此时输入的单词“猫”的影响最大。因此,可以认为这个隐藏状态向量蕴含许多“猫的成分”。按照这样的理解,如下图所示,编码器输出的hs矩阵就可以视为各个单词对应的向量集合

以上就是对编码器的改进。这里我们所做的改进只是将编码器的全部时刻的隐藏状态取出来而已。通过这个小改动,编码器可以根据输入语句的长度,成比例地编码信息。那么,解码器又将如何处理这个编码器的输出呢? 接下来,我们对解码器进行改进。因为解码器的改进有许多值得讨论的地方,所以我们分3部分进行。
三.编码器的改进1
编码器整体输出各个单词对应的LSTM层的隐藏状态向量hs。然后, 这个hs被传递给解码器,以进行时间序列的转换
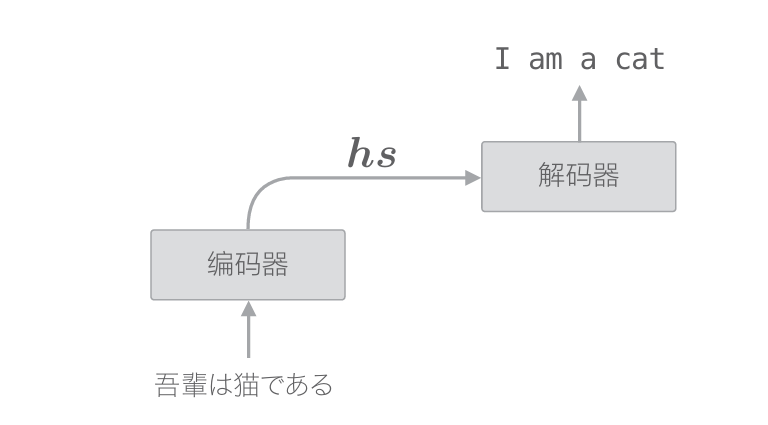
顺便说一下,在上一章的最简单的seq2seq中,仅将编码器最后的隐藏状态向量传递给了解码器。严格来说,这是将编码器的LSTM层的“最后” 的隐藏状态放入了解码器的LSTM层的“最初”的隐藏状态。用图来表示的话,解码器的层结构如下图所示
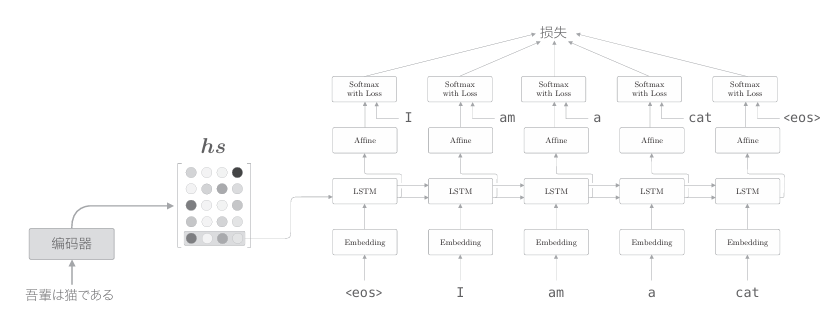
如上图所示,上一章的解码器只用了编码器的LSTM层的最后的隐藏状态。如果使用hs,则只提取最后一行,再将其传递给解码器。下面我 们改进解码器,以便能够使用全部hs。 我们在进行翻译时,大脑做了什么呢?比如,在将“吾輩は猫である” 这句话翻译为英文时,肯定要用到诸如“吾輩=I”“ 猫 =cat”这样的知识。 也就是说,可以认为我们是专注于某个单词(或者单词集合),随时对这个 单词进行转换的。那么,我们可以在seq2seq中重现同样的事情吗?确切地说,我们可以让seq2seq学习“输入和输出中哪些单词与哪些单词有关”这样的对应关系吗?
从现在开始,我们的目标是找出与“翻译目标词”有对应关系的“翻译 源词”的信息,然后利用这个信息进行翻译。也就是说,我们的目标是仅关 注必要的信息,并根据该信息进行时序转换。这个机制称为Attention,是本章的主题。
在介绍Attention的细节之前,这里我们先给出它的整体框架。我们要实现的网络的层结构如下图所示。
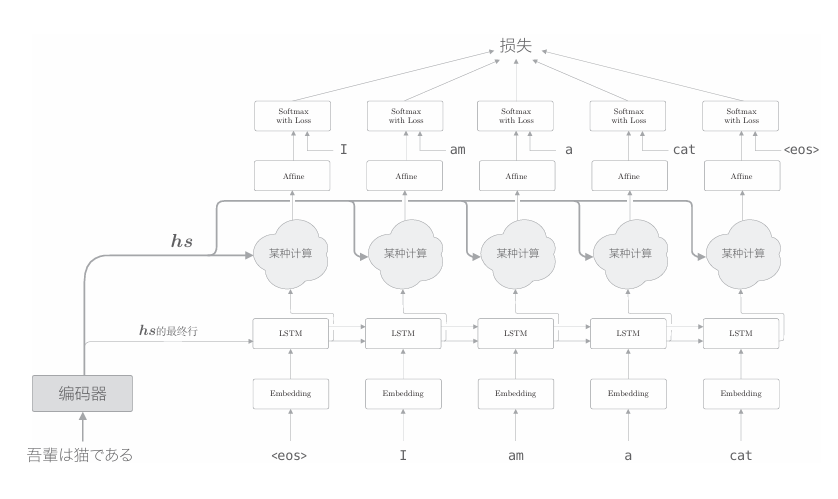
如上图所示,我们新增一个进行“某种计算”的层。这个“某种计算”接收(解码器)各个时刻的LSTM层的隐藏状态和编码器的hs。然后, 从中选出必要的信息,并输出到Affine层。与之前一样,编码器的最后的隐藏状态向量传递给解码器最初的LSTM层。 上图的网络所做的工作是提取单词对齐信息。具体来说,就是从hs 中选出与各个时刻解码器输出的单词有对应关系的单词向量。比如,当上图的解码器输出“I”时,从hs中选出“吾輩”的对应向量。也就是说, 我们希望通过“某种计算”来实现这种选择操作。不过这里有个问题,就是选择(从多个事物中选取若干个)这个操作是无法进行微分的。
可否将“选择”这一操作换成可微分的运算呢?实际上,解决这个问题的思路很简单(但是,就像哥伦布蛋一样,第一个想到是很难的)。这个思路就是,与其“单选”,不如“全选”。如下图所示,我们另行计算表示各个单词重要度(贡献值)的权重。
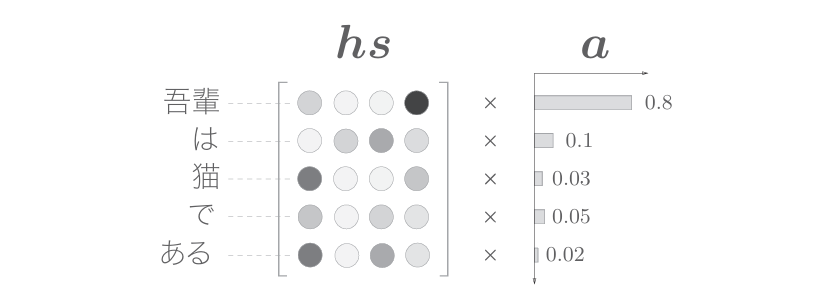
如下图所示,这里使用了表示各个单词重要度的权重(记为a)。此时,a像概率分布一样,各元素是0.0~1.0的标量,总和是1。然后,计算这个表示各个单词重要度的权重和单词向量hs的加权和,可以获得目标向量。这一系列计算如下图所示

如上图所示,计算单词向量的加权和,这里将结果称为上下文向量, 并用符号c表示。顺便说一下,如果我们仔细观察,就可以发现“吾輩”对应的权重为0.8。这意味着上下文向量c中含有很多“吾輩”向量的成分, 可以说这个加权和计算基本代替了“选择”向量的操作。假设“吾輩”对应 的权重是1,其他单词对应的权重是0,那么这就相当于“选择”了“吾輩” 向量。
下面,我们从代码的角度来看一下目前为止的内容。这里随意地生成编码器的输出hs和各个单词的权重a,并给出求它们的加权和的实现,代码如下所示,请注意多维数组的形状
import numpy as np
T, H = 5, 4
hs = np.random.randn(T, H)
a = np.array([0.8, 0.1, 0.03, 0.05, 0.02])ar = a.reshape(5, 1).repeat(4, axis=1)
print(ar.shape)
# (5, 4)t = hs * ar
print(t.shape)
# (5, 4)c = np.sum(t, axis=0)
print(c.shape)
# (4, )
设时序数据的长度T=5,隐藏状态向量的元素个数H=4,这里给出了加权和的计算过程。我们先关注代码ar = a.reshape(5, 1).repeat(4, axis=1)。 如下图所示,这行代码将a转化为ar。
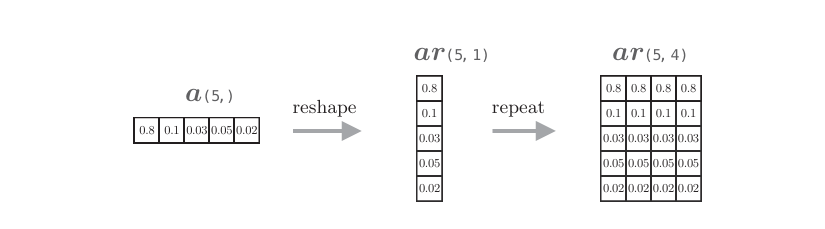
如上图所示,我们要做的是复制形状为(5,)的a,创建(5,4)的数组。 因此,通过a.reshape(5, 1) 将a的形状从(5,)转化为(5,1)。然后,在第1 个轴方向上(axis=0)重复这个变形后的数组4次,生成形状为(5,4)的数组。
此外,这里也可以不使用repeat()方法,而使用NumPy的广播功能。 此时,令ar = a.reshape(5, 1),然后计算hs * ar。如下图所示,ar会自动扩展以匹配hs的形状。
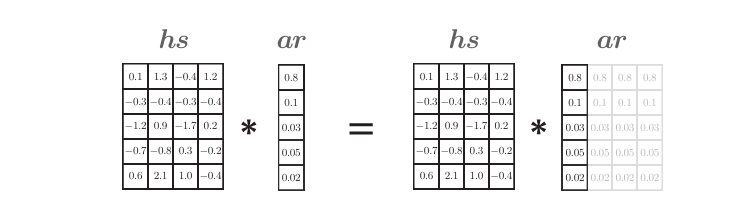
为了提高执行效率,这里应该使用NumPy的广播,而不是repeat()方 法。但是,在这种情况下,需要注意的是,在许多我们看不见的地方多维数组的元素被复制了。这相当于计算图中的Repeat节点。 因此,在反向传播时,需要执行Repeat节点的反向传播。 如上图所示,先计算对应元素的乘积,然后通过c = np.sum(hs*ar, axis=0) 求和。这里,通过参数axis可以指定在哪个轴方向(维度)上求和。 如果我们注意一下数组的形状,axis的使用方法就会很清楚。比如,当x的形状为(X, Y, Z)时,np.sum(x, axis=1) 的输出(和)的形状为(X, Z)。这里的重点是,求和会使一个轴“消失”。在上面的例子中,hs*ar的形状为 (5,4),通过消除第0个轴,获得了形状为(4,)的矩阵(向量)。
下面进行批处理版的加权和的实现,具体如下所示
N, T, H = 10, 5, 4
hs = np.random.randn(N, T, H)
a = np.random.randn(N, T)
ar = a.reshape(N, T, 1).repeat(H, axis=2)
# ar = a.reshape(N, T, 1) # 广播机制t = hs * ar
print(t.shape)
# (10, 5, 4)c = np.sum(t, axis=1)print(c.shape)
# (10, 4)这里的批处理与之前的实现几乎一样。只要注意数组的形状,应该很快就能确定repeat()和sum()需要指定的维度(轴)。作为总结,我们把加权 和的计算用计算图表示出来

如上图所示,这里使用Repeat节点复制a。之后,通过“×”节点 计算对应元素的乘积,通过Sum节点求和。现在考虑这个计算图的反向传播。其实,所需要的知识都已经齐备。这里重述一下要点:“Repeat的反向传播是Sum”“ Sum的反向传播是Repeat”。只要注意到张量的形状,就不难知道应该对哪个轴进行Sum,对哪个轴进行Repeat。
现在我们将上图的计算图实现为层,这里称之为Weight Sum层, 其实现如下所示
class WeightSum:def __init__(self):self.params, self.grads = [], []self.cache = Nonedef forward(self, hs, a):N, T, H = hs.shapear = a.reshape(N, T, 1).repeat(H, axis=2)t = hs * arc = np.sum(t, axis=1)self.cache = (hs, ar)return cdef backward(self, dc):hs, ar = self.cacheN, T, H = hs.shapedt = dc.reshape(N, 1, H).repeat(T, axis=1)dar = dt * hsdhs = dt * arda = np.sum(dar, axis=2)return dhs, da
以上就是计算上下文向量的Weight Sum层的实现。因为这个层没有要学习的参数,所以根据代码规范,此处为self.params = []。其他应该没有特别难的地方,我们继续往下看。
四.编码器的改进2
有了表示各个单词重要度的权重a,就可以通过加权和获得上下文向量。那么,怎么求这个a呢?当然不需要我们手动指定,我们只需要做好让 模型从数据中自动学习它的准备工作。 下面我们来看一下各个单词的权重a的求解方法。首先,从编码器的处理开始到解码器第一个LSTM层输出隐藏状态向量的处理为止的流程如下图所示
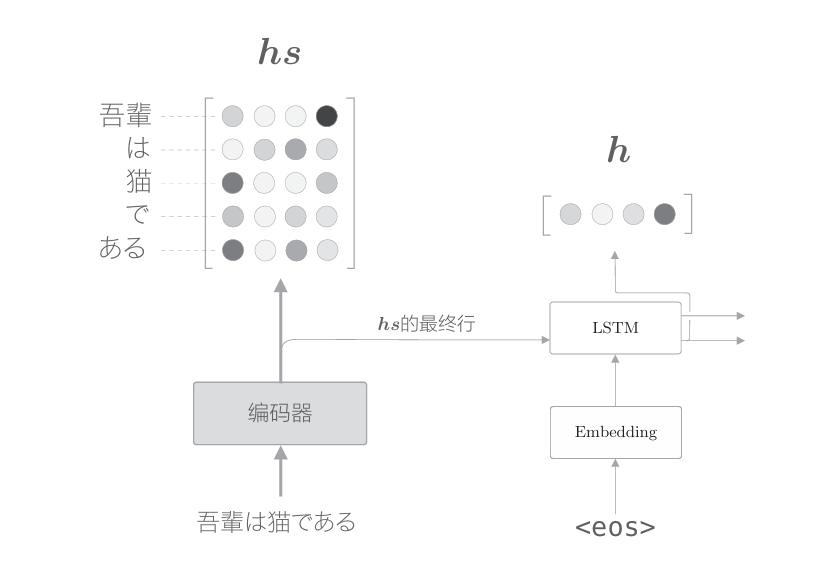
在上图中,用h表示解码器的LSTM层的隐藏状态向量。此时,我们的目标是用数值表示这个h在多大程度上和hs的各个单词向量“相似”。 有几种方法可以做到这一点,这里我们使用最简单的向量内积。顺便说一下,向量a=(a1,a2,···,an)和向量b =(b1,b2,···,bn)的内积为:
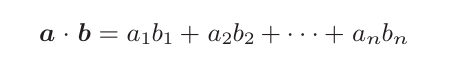
上式的含义是两个向量在多大程度上指向同一方向,因此使用内积作为两个向量的“相似度”是非常自然的选择。
下面用图表示基于内积计算向量间相似度的处理流程
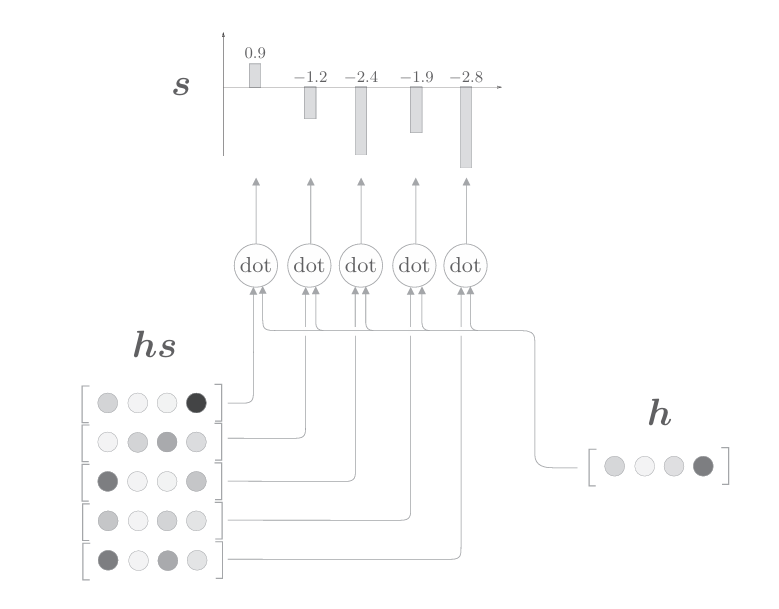
如上图所示,这里通过向量内积算出h和hs的各个单词向量之间的相似度,并将其结果表示为s。不过,这个s是正规化之前的值,也称为得分。接下来,使用老一套的Softmax函数对s进行正规化(下图)
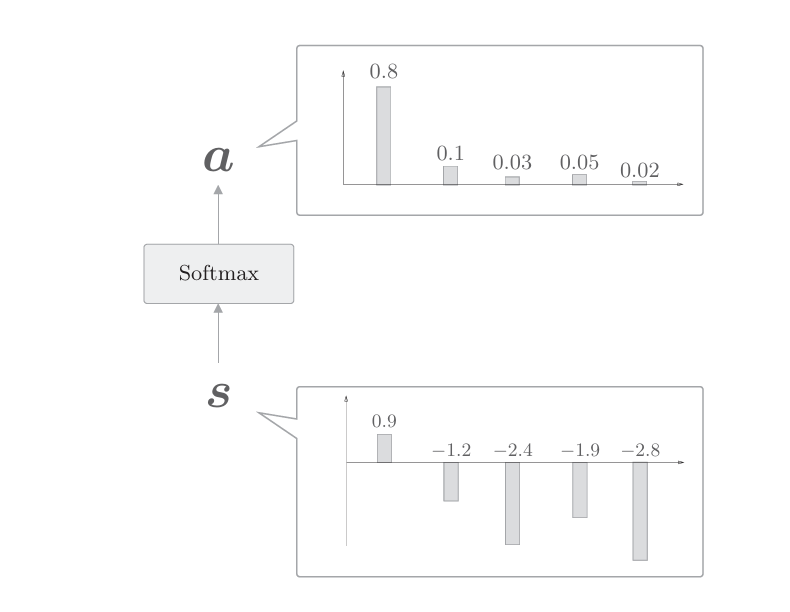
使用Softmax函数之后,输出的a的各个元素的值在0.0~1.0,总和为1,这样就求得了表示各个单词权重的a。现在我们从代码角度来看一下这些处理。
from common.layers import Softmax
import numpy as npN, T, H = 10, 5, 4
hs = np.random.randn(N, T, H)
h = np.random.randn(N, H)
hr = h.reshape(N, 1, H).repeat(T, axis=1)t = hs * hrprint(t.shape)
# (10, 5, 4)s = np.sum(t, axis=2)
print(s.shape)
# (10, 5)softmax = Softmax()
a = softmax.forward(s)
print(a.shape)
# (10, 5)以上就是进行批处理的代码。如前所述,此处我们通过reshape()和 repeat() 方法生成形状合适的hr。在使用NumPy的广播的情况下,不需要 repeat()。此时的计算图如下图所示。
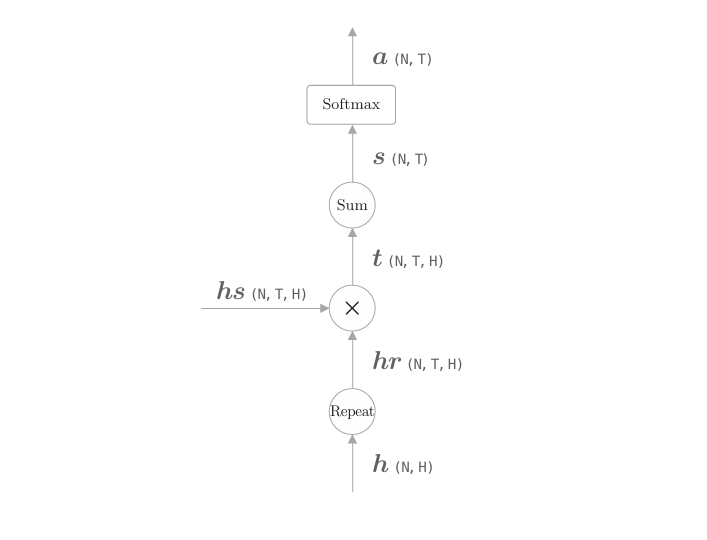
如上图所示,这里的计算图由Repeat节点、表示对应元素的乘积的 “×”节点、Sum节点和Softmax层构成。我们将这个计算图表示的处理实现为AttentionWeight 类
class AttentionWeight:def __init__(self):self.params, self.grads = [], []self.softmax = Softmax()self.cache = Nonedef forward(self, hs, h):N, T, H = hs.shapehr = h.reshape(N, 1, H).repeat(T, axis=1)t = hs * hrs = np.sum(t, axis=2)a = self.softmax.forward(s)self.cache = (hs, hr)return adef backward(self, da):hs, hr = self.cacheN, T, H = hs.shapeds = self.softmax.backward(da)dt = ds.reshape(N, T, 1).repeat(H, axis=2)dhs = dt * hrdhr = dt * hsdh = np.sum(dhr, axis=1)return dhs, dh
类似于之前的Weight Sum层,这个实现有Repeat和Sum运算。只要注意到这两个运算的反向传播,其他应该就没有特别难的地方。下面,我 们进行解码器的最后一个改进。
五.编码器的改进3
在此之前,我们分两节介绍了解码器的改进方案。上面分别实现了Weight Sum层和Attention Weight层。现在,我们将这两层组合起来,结果如下图所示。
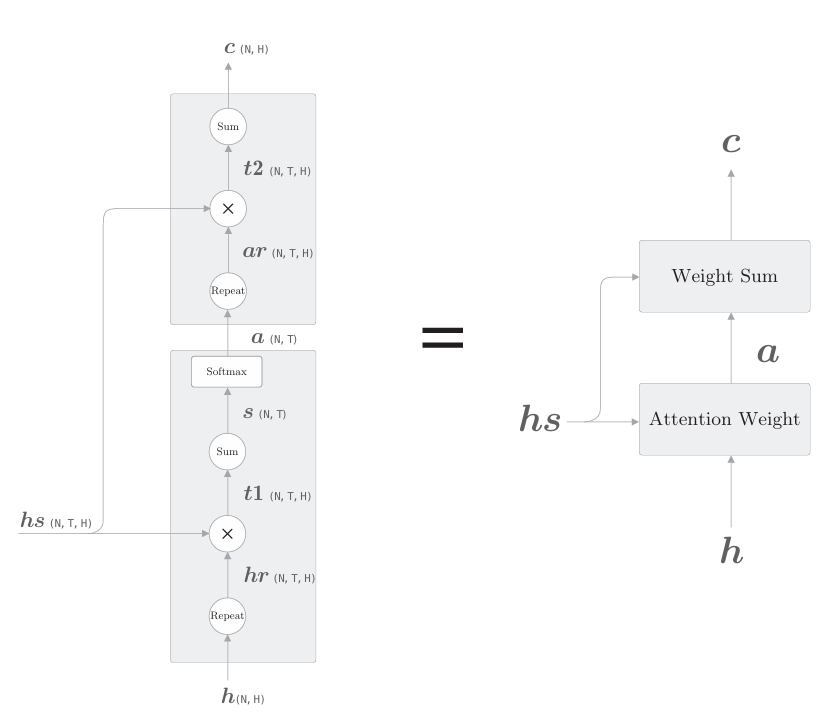
上图显示了用于获取上下文向量c的计算图的全貌。我们已经分为 Weight Sum 层和Attention Weight 层进行了实现。重申一下,这里进行的计算是:Attention Weight 层关注编码器输出的各个单词向量hs,并计算各个单词的权重a;然后,Weight Sum层计算a和hs的加权和,并输出上下文向量c。我们将进行这一系列计算的层称为Attention层(如下图)
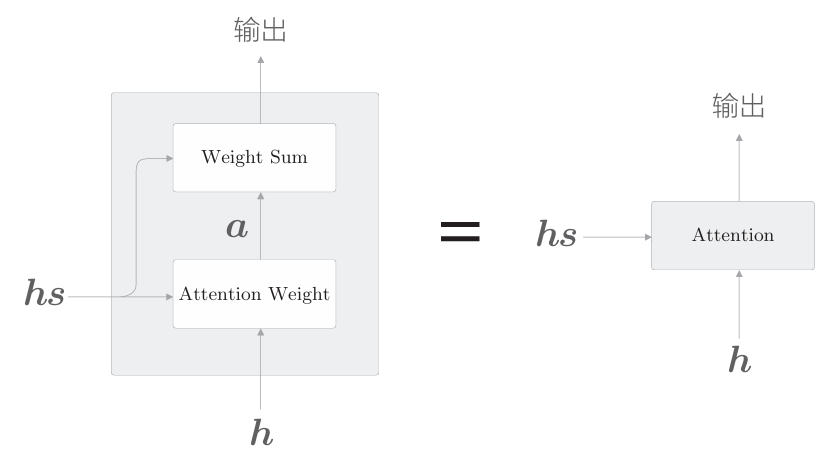
以上就是Attention技术的核心内容。关注编码器传递的信息hs中的重要元素,基于它算出上下文向量,再传递给上一层(这里,Affine层在上 一层等待)。下面给出Attention层的实现
class Attention:def __init__(self):self.params, self.grads = [], []self.attention_weight_layer = AttentionWeight()self.weight_sum_layer = WeightSum()self.attention_weight = Nonedef forward(self, hs, h):a = self.attention_weight_layer.forward(hs, h)out = self.weight_sum_layer.forward(hs, a)self.attention_weight = areturn outdef backward(self, dout):dhs0, da = self.weight_sum_layer.backward(dout)dhs1, dh = self.attention_weight_layer.backward(da)dhs = dhs0 + dhs1return dhs, dh以上是Weight Sum层和Attention Weight层的正向传播和反向传播。 为了以后可以访问各个单词的权重,这里设定成员变量attention_weight, 如此就完成了Attention层的实现。我们将这个Attention层放在LSTM层 和Affine 层的中间,如下图
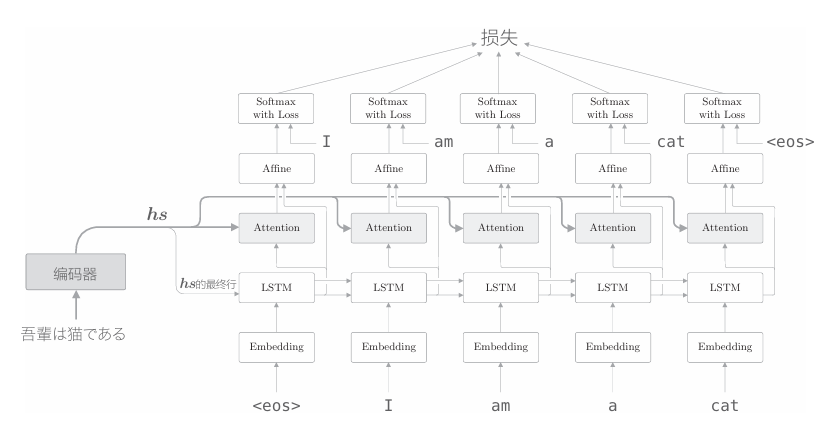
如上图所示,编码器的输出hs被输入到各个时刻的Attention层。 另外,这里将LSTM层的隐藏状态向量输入Affine层。根据上一章的解码器的改进,可以说这个扩展非常自然。如下图所示,我们将Attention信息“添加”到了上一章的解码器上。

如上图所示,我们向上一章的解码器“添加”基于Attention层的上下文向量信息。因此,除了将原先的LSTM层的隐藏状态向量传给 Affine 层之外,追加输入Attention层的上下文向量。
最后,我们将在上上个图的时序方向上扩展的多个Attention层整体实现为Time Attention 层,如下图所示。
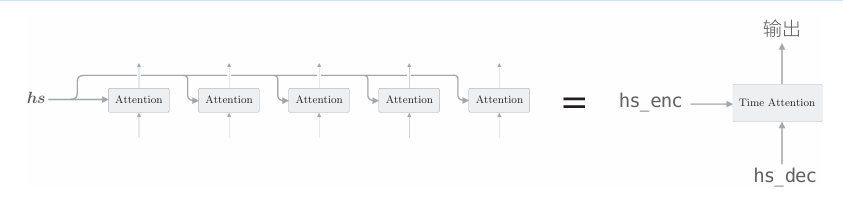
由上图可知,Time Attention 层只是组合了多个Attention层,其实现如下所示
class TimeAttention:def __init__(self):self.params, self.grads = [], []self.layers = Noneself.attention_weights = Nonedef forward(self, hs_enc, hs_dec):N, T, H = hs_dec.shapeout = np.empty_like(hs_dec)self.layers = []self.attention_weights = []for t in range(T):layer = Attention()out[:, t, :] = layer.forward(hs_enc, hs_dec[:,t,:])self.layers.append(layer)self.attention_weights.append(layer.attention_weight)return outdef backward(self, dout):N, T, H = dout.shapedhs_enc = 0dhs_dec = np.empty_like(dout)for t in range(T):layer = self.layers[t]dhs, dh = layer.backward(dout[:, t, :])dhs_enc += dhsdhs_dec[:,t,:] = dhreturn dhs_enc, dhs_dec这里仅创建必要数量的Attention层(代码中为T个),各自进行正向 传播和反向传播。另外,attention_weights列表中保存了各个Attention层 对各个单词的权重。
以上,我们介绍了Attention的结构及其实现。下一节我们使用Attention来实现seq2seq,并尝试挑战一个真实问题,以确认Attention的效果。
相关文章:
Attention的结构))
自然语言处理(25:(终章Attention 1.)Attention的结构)
系列文章目录 终章 1:Attention的结构 终章 2:带Attention的seq2seq的实现 终章 3:Attention的评价 终章 4:关于Attention的其他话题 终章 5:Attention的应用 目录 系列文章目录 前言 Attention的结构 一.seq…...

Minimind 训练一个自己专属语言模型
发现了一个宝藏项目, 宣传是完全从0开始,仅用3块钱成本 2小时!即可训练出仅为25.8M的超小语言模型MiniMind,最小版本体积是 GPT-3 的 17000,做到最普通的个人GPU也可快速训练 https://github.com/jingyaogong/minimi…...

Android里面内存优化
核心思路 在Android开发中,内存优化是保证应用性能稳定和用户体验的关键。我通常从以下几个方面进行内存优化: 1. 内存泄漏检测与修复 使用LeakCanary等工具检测内存泄漏 常见内存泄漏场景: 静态变量持有Activity/Fragment引用 非静态内部…...

Git操作指南
Git操作指南 1.安装并配置Git Git官网:https://git-scm.com/downloads 安装完成后,打开Git Bash,配置Git: git config --global user.email "emailexample.com" git config --global user.name "Your Name&quo…...
)
【蓝桥杯—单片机】通信总线专项 | 真题整理、解析与拓展 (更新ing...)
通信总线专项 前言SPI第十五届省赛题 UART/RS485/RS232UARTRS485RS232第十三届省赛题小结和拓展:传输方式的分类第十三届省赛 其他相关考点网络传输速率第十五届省赛题第十二届省赛题 前言 在本文中我会把 蓝桥杯单片机赛道 历年真题 中涉及到通信总线的题目整理出…...

深入探究C语言中的二进制世界:从原理到实践
文章目录 深入探究C语言中的二进制世界:从原理到实践一、进制的本质与C语言实现1. 进制系统全景2. C语言中的进制表示3. 格式化输出进阶 二、进制转换的工程实践1. 转换算法实现2. 实际应用中的转换技巧快速二进制 - 十六进制转换位运算优化转换 3. 进制转换详细示例…...

【android bluetooth 协议分析 13】【RFCOMM详解 2】【通俗易懂 rfcomm 基本流程】
RFCOMM 协议 基本流程 一、连接建立流程(附 BTsnoop 实例解析) 1. L2CAP 通道建立 BTsnoop 表现: L2CAP_Connection_Request (PSM0x0003) // 请求建立RFCOMM专用通道L2CAP_Connection_Response (Success) // 对方同意作用:相…...
:SpringBoot的常用注解(上))
万字知识篇(2):SpringBoot的常用注解(上)
SpringBoot的常用注解非常的多,一篇文章根本讲不完,将分为上下两章,通过本章你将会系统的学习到: 1. 注解在SpringBoot中的作用 2. SpringBoot 常用注解速查表 3. 核心启动类注解 4. Configuration 5. Bean 6. PropertySource 7. …...

Postman —— postman实现参数化
什么时候会用到参数化 比如:一个模块要用多组不同数据进行测试 验证业务的正确性 Login模块:正确的用户名,密码 成功;错误的用户名,正确的密码 失败 postman实现参数化 在实际的接口测试中,部分参数每…...

Docker学习--容器生命周期管理相关命令--docker create 命令
docker create 命令作用: 会根据指定的镜像和参数创建一个容器实例,但容器只会在创建时进行初始化,并不会执行任何进程。 语法: docker create[参数] IMAGE(要执行的镜像) [COMMAND](在容器内部…...

算法基础_基础算法【高精度 + 前缀和 + 差分 + 双指针】
算法基础_基础算法【高精度 前缀和 差分 双指针】 ---------------高精度---------------791.高精度加法题目介绍方法一:代码片段解释片段一: 解题思路分析 792. 高精度减法题目介绍方法一:代码片段解释片段一: 解题思路分析 7…...

C语言深度解析:从零到系统级开发的完整指南
一、C语言的核心特性与优势 1. 高效性与直接硬件控制 C语言通过编译为机器码的特性,成为系统级开发的首选语言。例如,Linux内核通过C语言直接操作内存和硬件寄存器,实现高效进程调度。 关键点: malloc/free直接管理内存&#…...
)
Axure疑难杂症:完美解决中继器筛选问题(时间条件筛选、任性筛选)
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢! 课程主题:中继器筛选专题 主要内容:时间条件筛选、多条件组合筛选、多个单一条件混合筛选 应用场景:各类数据表的多条件筛选均可使用…...

汇编学习之《扩展指令指针寄存器》
什么是指令指针寄存器? EIP (Extended Instruction Pointer): 保存cpu 下一次将要执行的代码的地址。 通过OllyGbd可以看到CPU即将执行指令的地址和EIP 内部放入的地址一致,多次F8依然是这样。 这里要区分下,之前比如EAX,ECX我…...

oracle-blob导出,在ob导入失败
导出: [oraclelncs dmp]$ /home/oracle/sqluldr2 gistar/res#pwd192.168.205.58:1521/lndb query"select * from an_odn_picture where length(PIC_CONTENT)<25000" filean_odn_picture.csv Charsetutf8 textCSV 0 rows exported at 2025-…...

【Linux笔记】进程间通信——匿名管道||进程池
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:Linux 🌹往期回顾🌹:【Linux笔记】动态库与静态库的理解与加载 🔖流水不争,争的是滔滔不 一、Linux进程间通…...

Spring Boot 3.4.3 基于 Caffeine 实现本地缓存
在现代企业级应用中,缓存是提升系统性能和响应速度的关键技术。通过减少数据库查询或复杂计算的频率,缓存可以显著优化用户体验。Spring Boot 3.4.3 提供了强大的缓存抽象支持,而 Caffeine 作为一款高性能的本地缓存库,因其优异的…...

windows使用nvm管理node版本
1.下载地址:https://github.com/coreybutler/nvm-windows/releases 选择nvm-setup.exe 2.安装,下载完成后,以管理员身份运行 nvm-setup.exe,选择默认安装,一路next 3.使用,安装完成后会打开一个命令行窗口࿰…...
【详细自用版】)
vscode集成deepseek实现辅助编程(银河麒麟系统)【详细自用版】
针对开发者用户,可在Visual Studio Code中接入DeepSeek,实现辅助编程。 可参考我往期文章在银河麒麟系统环境下部署DeepSeek:基于银河麒麟桌面&&服务器操作系统的 DeepSeek本地化部署方法【详细自用版】 一、前期准备 (…...
PyCharm的调试指南)
智谱大模型(ChatGLM3)PyCharm的调试指南
前言 最近在看一本《ChatGLM3大模型本地化部署、应用开发和微调》,本文就是讨论ChatGLM3在本地的初步布设。(模型文件来自魔塔社区) 1、建立Pycharm工程 采用的Python版本为3.11 2、安装对应的包 2.1、安装modelscope包 pip install model…...

MySQL GROUP BY分组获取非聚合列值方法
在使用MySQL进行数据库查询时,如果你需要对数据按照某个或某些列进行分组(GROUP BY),并且希望在结果中包含非聚合列的值,你可以通过以下几种方法来实现: 1. 使用聚合函数 虽然这不是直接获取非聚合列值的…...

多路径 TCP 调度的另一面
参考前面的文章 一个原教旨的多路径 TCP 和 MP-BBR 公平性推演,一直都破而不立,不能光说怎样不好,还得说说现状情况下,该如何是好。 如果 receiver 乱序重排的能力有限(拜 TCP 所赐),如果非要在多路径上传输 TCP&…...

在Qt中判断输入的js脚本是否只包含函数
目前在使用QtScriptEngine,在利用evaluate注册子函数时,要求用户输入的js文件中的内容仅仅是函数,函数体外不能出现一些变量的声明、函数的调用等其他代码。 反复咨询DeepSeek后,终于给出了一个目前测试可用的代码: b…...

【Easylive】MySQL中LEFT JOIN与INNER JOIN的使用场景对比
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 在MySQL数据库查询中,JOIN操作是最常用的操作之一,而LEFT JOIN和INNER JOIN是两种最基础的JOIN类型。理解它们的区别和适用场景对于编写高效、准确的SQL查询至关重要…...

Boost库中的谓词函数
Boost库中的谓词函数 谓词函数基础概念 在编程中,谓词函数(Predicate Function)是指返回布尔值(true或false)的函数,用于检测输入是否满足特定条件。谓词函数在STL算法和Boost库中被广泛使用,…...

人工智能之数学基础:基于初等反射矩阵完成矩阵的QR分解
本文重点 QR分解是矩阵分解中的一种重要方法,它将一个矩阵分解为一个正交矩阵Q和一个上三角矩阵R的乘积,即A=QR。这种分解在求解线性方程组、最小二乘问题、特征值计算等领域有着广泛应用。 QR分解的定义 QR分解就是应用了初等反射矩阵,不断的通过初等反射矩阵,然后将A变…...
——智能工牌和会话质检)
AI应用案例(1)——智能工牌和会话质检
今天开辟一个新的模块,自己平时也搜集一些典型的行业应用案例,不如就记录到C站,同时和大家也是个分享好了。 今天分享的企业和产品,是循环智能的智能工牌。 这个产品应用场景清晰,针对的行业痛点合理,解决…...

碰一碰发视频系统--基于H5场景开发
碰一碰发视频#碰一碰发视频#开发基于H5的"碰一碰发视频"交互系统(类似华为/苹果的NFC碰传但通过移动端网页实现),需要结合近场通信(NFC/H5 API)和媒体传输技术。以下是具体实现方案 #碰一碰营销系统# #碰一…...

kotlin扩展函数的实现原理
1. 编译时转换 在编译时,Kotlin 扩展函数会被转换为静态函数。这个静态函数的第一个参数是接收者类型(也就是被扩展的类),而调用扩展函数时,实际上是调用这个静态函数,并将接收者对象作为第一个参数传入。…...

激活函数学习笔记
Sigmoid:梯度消失、指数计算复杂运行慢、输出不是以0为中心,梯度平滑便于求导tanh:以0为中心,其他与sigmoid相似ReLu:transformer常用,解决了梯度消失问题、计算复杂度低,存在神经元死亡问题和梯…...

【含文档+PPT+源码】基于Python爬虫二手房价格预测与可视化系统的设计与实现
项目介绍 本课程演示的是一款基于Python爬虫二手房价格预测与可视化系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 带你从零开始部署运行本套系统 该项…...

基于 Swoole 的高性能 RPC 解决方案
文章精选推荐 1 JetBrains Ai assistant 编程工具让你的工作效率翻倍 2 Extra Icons:JetBrains IDE的图标增强神器 3 IDEA插件推荐-SequenceDiagram,自动生成时序图 4 BashSupport Pro 这个ides插件主要是用来干嘛的 ? 5 IDEA必装的插件&…...

# 实时人脸识别系统:基于 OpenCV 和 Python 的实现
实时人脸识别系统:基于 OpenCV 和 Python 的实现 在当今数字化时代,人脸识别技术已经广泛应用于各种场景,从手机解锁到安防监控,再到智能门禁系统。今天,我将通过一个完整的代码示例,详细讲解如何使用 Pyt…...

python的global在编译层面的进阶理解
目录 报错情况 编译执行过程 (1)源代码(.py 文件) (2)编译阶段:解析 & 生成字节码 (3)解释执行:Python 虚拟机(PVM) 字节码…...

OpenCV、YOLO与大模型的区别与关系
OpenCV、YOLO 和大模型的区别与关系 1. OpenCV(Open Source Computer Vision Library) 定位:开源的计算机视觉基础库。功能:提供传统的图像处理算法(如图像滤波、边缘检测、特征提取)和基础工具ÿ…...

Buzz1.2.0视频语音转成TXT、SRT、VTT工具
buzz0.9.0.exe下载 https://download.csdn.net/download/u011000529/90551347 特征 导入音频和视频文件并导出文本到 TXT、SRT 和 VTT从您计算机的麦克风转录和翻译成文本(资源密集型且可能不是实时的,Demo)支持Whisper、 Whisper.cpp、Fast…...

Vue 2 和 Vue 3 中的钩子函数
Vue 钩子函数也被叫做生命周期钩子函数,它是 Vue 实例在其生命周期的不同阶段自动调用的函数。可以利用这些钩子函数在特定阶段执行自定义代码。 Vue 2 生命周期钩子函数 在 Vue 2 里,生命周期钩子函数可以在组件选项对象中定义。下面是一个简单的 Vue…...

零基础如何学会Appium自动化测试?
前言 appium是一款移动自动化测试工具,经常被用于实现UI自动化测试,其可支持安卓和IOS两大平台,还支持多种编程,因而得到了广泛的应用。此处便是立足于安卓平台,借助appium工具,使用python语言实现简单的自…...

用Python实现TCP代理
依旧是Python黑帽子这本书 先附上代码,我在原书代码上加了注释,更好理解 import sys import socket import threading#生成可打印字符映射 HEX_FILTER.join([(len(repr(chr(i)))3) and chr(i) or . for i in range(256)])#接收bytes或string类型的输入…...

SQL复杂查询与性能优化:医药行业ERP系统实战指南
SQL复杂查询与性能优化:医药行业ERP系统实战指南 一、医药行业数据库特性分析 在医药ERP系统中,数据库通常包含以下核心表结构: -- 药品主数据 CREATE TABLE drug_master (drug_id INT PRIMARY KEY,drug_name VARCHAR(255),specification …...

问题大集10-git使用commit提交中文显示乱码
(1)问题 (2)解决步骤 1) 设置全局编码为 UTF-8 git config --global core.quotepath false git config --global i18n.commitEncoding utf-8 git config --global i18n.logOutputEncoding utf-8 2) 显示或设…...
)
vue前端项目技术架构(第二版)
vue技术架构介绍 如下图所示,展示了项目系统的软件层次架构。该系统采用基于SOA(面向服务架构)思想的分层架构,分为四个主要层次:视图层、编译层、代码层和数据层。 视图层 浏览器:核心职责是解析并展示…...

Java 开发中的 AI 黑科技:如何用 AI 工具自动生成 Spring Boot 项目脚手架?
在 Java 开发领域,搭建 Spring Boot 项目脚手架是一项耗时且繁琐的工作。传统方式下,开发者需要手动配置各种依赖、编写基础代码,过程中稍有疏忽就可能导致配置错误,影响开发进度。如今,随着 AI 技术的迅猛发展&#x…...
计算机网络体系结构)
计算机网络知识点汇总与复习——(一)计算机网络体系结构
Preface 计算机网络是考研408基础综合中的一门课程,它的重要性不言而喻。然而,计算机网络的知识体系庞大且复杂,各类概念、协议和技术相互关联,让人在学习时容易迷失方向。在进行复习时,面对庞杂的的知识点,…...

Copilot完全指南:AI编程助手的革命性实践
一、智能编程新时代:从代码补全到AI结对编程 1.1 Copilot的进化历程 2021年GitHub Copilot的诞生标志着编程辅助工具进入新纪元。与传统IDE补全工具相比,Copilot展现出三大革命性特征: 语义理解:基于GPT模型理解代码上下文跨文…...

Redis 梳理汇总目录
Redis 哨兵集群(Sentinel)与 Cluster 集群对比-CSDN博客 如何快速将大规模数据保存到Redis集群-CSDN博客 Redis的一些高级指令-CSDN博客 Redis 篇-CSDN博客...

5、无线通信基站的FPGA实现架构
基站(Base Station,BS),也称为公用移动通信基站,是无线电台站的一种形式,具体则指在一定的无线电覆盖区中,通过移动通信交换中心,与移动电话终端之间的信息传递的无线电收发信电台。…...

MySQL - 索引原理与优化:深入解析B+Tree与高效查询策略
文章目录 引言一、BTree索引核心原理1.1 索引数据结构演化1.2 BTree的存储结构通过主键查询(主键索引)商品数据的过程通过非主键(辅助索引)查询商品数据的过程 MySQL InnoDB 的索引原理 二、执行计划深度解析三、索引失效的六大陷…...

2025年数智化电商产业带发展研究报告260+份汇总解读|附PDF下载
原文链接:https://tecdat.cn/?p41286 在数字技术与实体经济深度融合的当下,数智化产业带正成为经济发展的关键引擎。 从云南鲜花产业带的直播热销到深圳3C数码的智能转型,数智化正重塑产业格局。2023年数字经济规模突破53.9万亿元ÿ…...

html实现手势密码
<!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>手势密码</title><style>body {font-fam…...