bert自然语言处理框架
自然语言处理框架
目录
- 自然语言处理框架
- bert自然语言处理框架
- 概念
- 核心特点
- 应用场景
- 框架和数据集
- 结构
- 编码-解码框架
- Self-Attention 机制
- multi-headed机制
- 位置编码
- Add与Normalize
- 整体框架
- outputs
- 训练数据集
bert自然语言处理框架
概念
BERT(Bidirectional Encoder Representations from Transformers)是 Google 于 2018 年提出的,基于Transformer的双向编码器表示模型,它通过预训练学习到了丰富的语言表示,并可以用于各种自然语言处理任务。它的核心思想是通过双向上下文理解和大规模预训练,学习通用的语言表示,再通过微调(Fine-tuning)适配下游任务。
核心特点
双向上下文编码:与传统模型(如 LSTM 或 GPT)不同,BERT 通过 Transformer 的 Self-Attention 机制同时学习单词的左右上下文。例如,在句子 “The bank of the river” 中,“bank” 的语义会根据上下文双向编码,避免歧义。
Transformer 架构:基于 Transformer 的 Encoder 层(原始论文使用 12 或 24 层),无需循环结构即可捕捉长距离依赖关系。
预训练 + 微调范式:
- 预训练:在大规模无标签文本(如 Wikipedia、BookCorpus)上训练,学习通用语言表示。
- 微调:用少量标注数据对预训练模型进行轻微调整,适配具体任务(如分类、问答)。
应用场景
通过微调,BERT 可应用于几乎所有 NLP 任务:
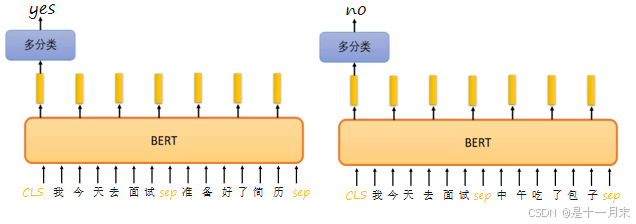
- 文本分类(如情感分析)
用 [CLS] 位置的输出向量作为分类特征。 - 命名实体识别(NER)
对每个单词的输出向量进行标签预测。 - 问答系统(SQuAD)
预测答案在文本中的起始和结束位置。 - 句子相似度
比较两个句子的嵌入表示。
框架和数据集
结构
- 传统RNN网络
- 串联,导致数据必须从h1-h2-…hm。数据训练时间变长,因为需要要等h1的结果出来才能计算h2。
- 并行计算效果不好,也就是不能多台服务器同时训练一个网络。
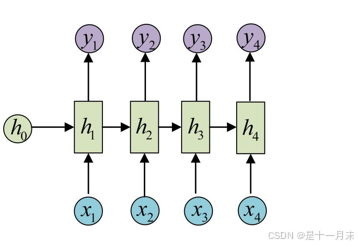
- 传统word2vec
- 词向量一旦训练好了,就不会改变
- 不同语境中的词含义不同,例如 【a、台湾人说机车。 b、机车】
因此根据上下文不同的语境,应该有多个不同的词向量。
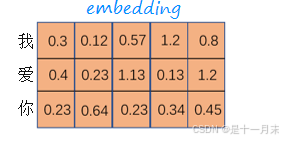
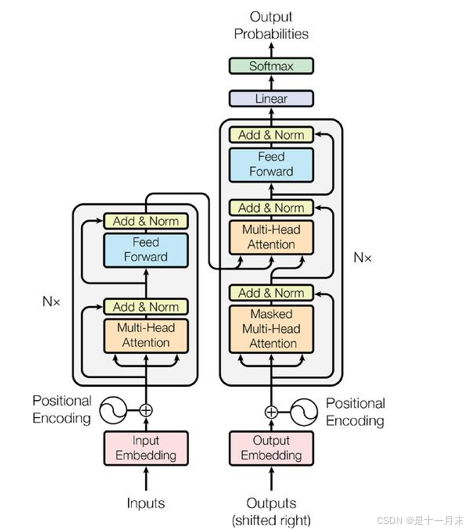
- Bert
Self-Attention 机制同时学习单词的左右上下文。
基于 Transformer 的 Encoder 层(原始论文使用 12 或 24 层),无需循环结构即可捕捉长距离依赖关系。- Multi-Head Self-Attention 层,计算输入序列中所有词对的关联权重,动态捕捉上下文依赖。
- 前馈神经网络(Feed-Forward Network, FFN)层,对每个位置的表示进行非线性变换。
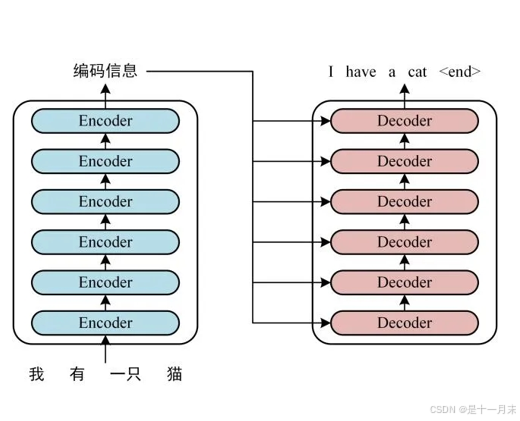
编码-解码框架
- Encoder-Decoder:也就是编码-解码框架,目前大部分attention模型都是依附于Encoder-Decoder框架进行实现。
- 在NLP中Encoder-Decoder框架主要被用来处理序列-序列问题。也就是输入一个序列,生成一个序列的问题。这两个序列可以分别是任意长度。
- Encoder:编码器,对于输入的序列<x1,x2,x3…xn>进行编码,使其转化为一个语义编码C,这个C中就储存了序列<x1,x2,x3…xn>的信息。
- Decoder:解码器,根据输入的语义编码C,然后将其解码成序列数据,解码方式也可以采用。Decoder和Encoder的编码解码方式可以任意组合。
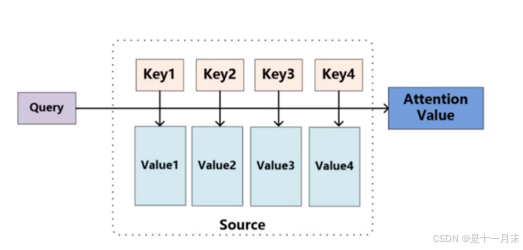
Self-Attention 机制
The animal didn’t cross the street because it was too tired.
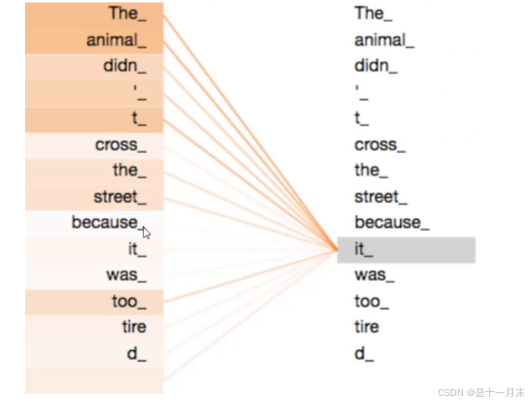
计算一段话中每个词之间的匹配程度,通过匹配程度得到每个词的特征重要性。
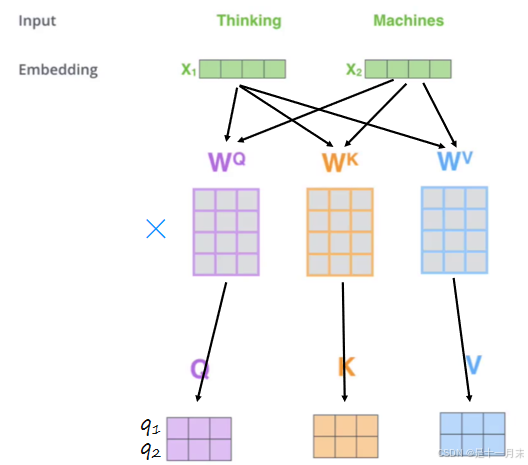
- 首先输入经过编码后得到的词向量
- 构建三个矩阵,相当于cnn的卷积核,分别为wQ、wK、wv矩阵。
- 将每一个词向量与矩阵相乘。得到QKV矩阵。
- 其中Q:为需要查询的
- K:为等着被查的
- V:实际的特征信息
q1和k1的内积表示第1个词和第1个词的匹配程度
q1和k2的内积表示第1个词和第2个词的匹配程度
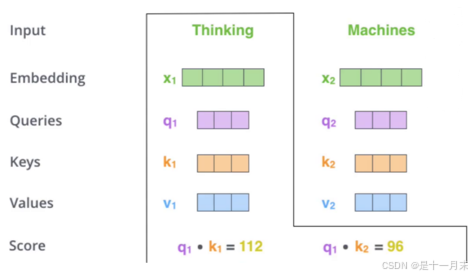
每个词的Q会跟整个序列中的每一个K计算得分,然后基于得分再分配特征。
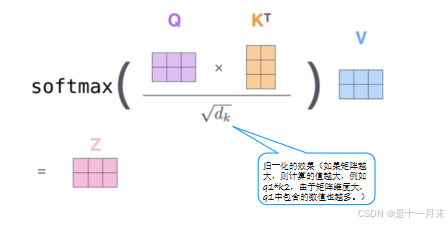

因此当和不同的词组合成序列,就会得到不同的特征值。因为不同的组合序列语句,注意力不同。
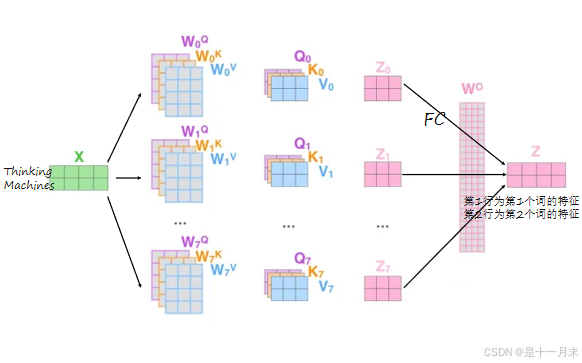
multi-headed机制
卷积神经网络种有多组卷积核,就会产生多个特征图。同理,在transformer中有多组q、k、v就会得到多种词的特征表达。
- 通过不同的head得到多个特征表达,一般8个head
- 将所有特征拼接在一起
- 降维,将Z0~Z7连接一个FC全连接实现降维
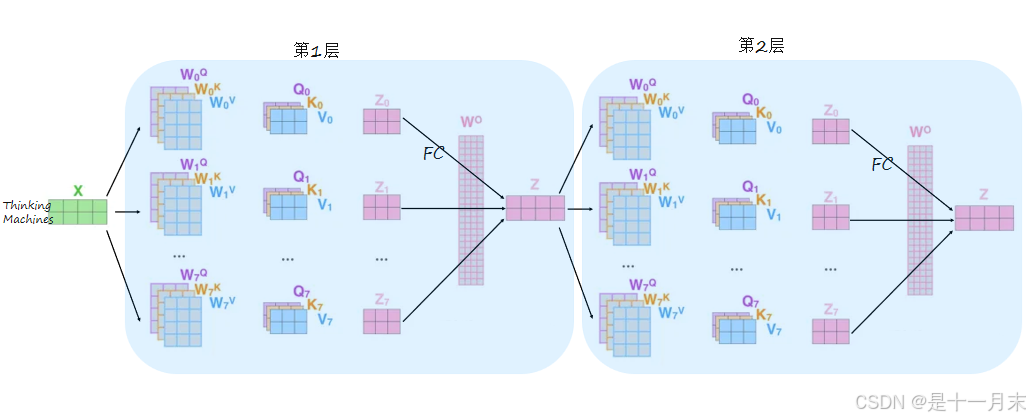
多层堆叠网络层
位置编码
还需要考虑词的顺序,长度,每个位置的真实的权重,Transformer的作者设计了一种可以满足上面要求的三角函数位置编码方式。
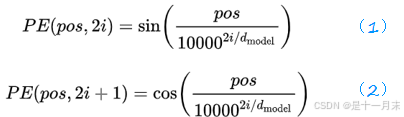
- word embedding:是词向量,由每个词根据查表得到
- pos embedding:就是位置编码。
- composition:word embedding和pos embedding逐点相加得到,既包含语义信息又包含位置编码信息的最终矩阵。
- pos:指当前字符在句子中的位置(如:”你好啊”,这句话里面“你”的pos=0),
- dmodel:指的是word embedding的长度(例“民主”的word embedding为[1,2,3,4,5],则dmodel=5),
- 2i表示偶数,2i+1表示奇数。取值范围:i=0,1,…,dmodel−1。偶数使用公式(1),奇数时使用公式(2)。
当pos=3,dmodel=128时Positional Encoding(或者说是pos embedding)的计算结果为:
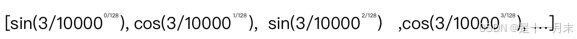
不同语句相同位置的字符PE值一样(如:当pos=0时,PE=0)。

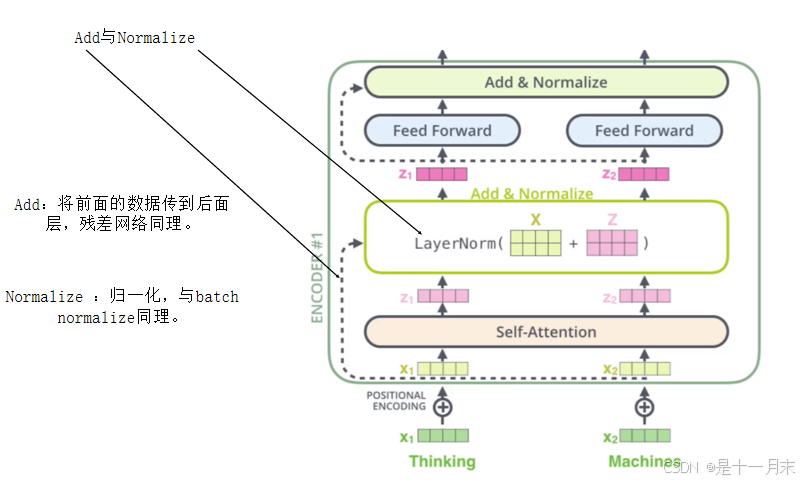
Add与Normalize
Add:将前面的数据传到后面层,残差网络同理。
Normalize :归一化,与batch normalize同理。
整体框架
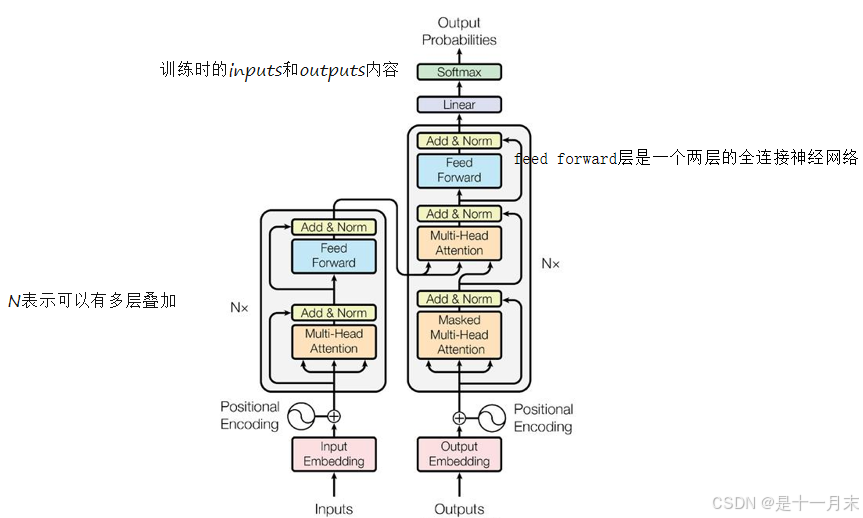
outputs
- outputs(shifted right):指在解码器处理过程中,将之前的输出序列向右移动一位,并在最左侧添加一个新的起始符(如“”或目标序列开始的特殊token)作为新的输入。这样做的目的是让解码器在生成下一个词时,能够考虑到已经生成的词序列。
- 作用:通过“shifted right”操作,解码器能够在生成每个词时,都基于之前已经生成的词序列进行推断。这样,解码器就能够逐步构建出完整的输出序列。
- 示例说明:假设翻译任务,输入是“我爱中国”,目标输出是“I love China”。在解码器的处理过程中:
在第一个步, 解码器接收一个起始符(如“”)作为输入,并预测输出序列的第一个词“I”。
在第二个步,解码器将之前的输出“I”和起始符一起作为新的输入(即“ I”),并预测下一个词 ,“love”。
以此类推,直到解码器生成完整的输出序列“I love China”。
训练数据集
- CLS:分类标记(Classification Token)用于表示输入序列的开始。在输入序列中,CLS应放置在句子的开头。在训练过程中,CLS也当作一个词参与训练,得到对应与其他词汇关系的词向量。
- SEP:分隔符标记(Separator Token)用于分隔两个句子或表示单个句子的结束。在处理多个句子时SEP应放置在每个句子的结尾。在训练过程中,SEP也当作一个词参与训练,得到对应与其他词汇关系的词向量。
-
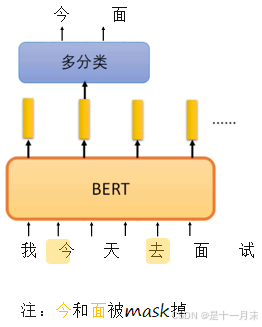
方法1:随机的将句子中的15%的词汇进行mask,让模型去预测mask的词汇。
解决传统语言模型只能单向预测的问题。
注:一般选择字进行mask,词的可能性太多,例如今天,明天,后天,上午,下午,没有,再次等等。
-
方法2:预测两个句子是否应该连在一起。
帮助模型理解句子间关系。
-
相关文章:

bert自然语言处理框架
自然语言处理框架 目录 自然语言处理框架bert自然语言处理框架概念核心特点应用场景 框架和数据集结构编码-解码框架Self-Attention 机制multi-headed机制位置编码Add与Normalize整体框架outputs训练数据集 bert自然语言处理框架 概念 BERT(Bidirectional Encoder …...

UE5学习笔记 FPS游戏制作33 游戏保存
文章目录 核心思想创建数据对象创建UIUI参数和方法打开UI存档文件的位置可以保存的数据类型 核心思想 UE自己有保存游戏的功能,核心节点,类似于json操作,需要一个数据类的对象来进行保存和读取 创建存档 加载存档 保存存档 创建数据对象…...

【超详细】一文解决更新小米澎湃2.0后LSPose失效问题
【超详细】一文解决更新澎湃2.0后LSPose失效问题 问题分析: 出现这个问题大多是因为本次为大版本更新A14->A15,因此原来的LSPose无法支持新系统特性导致的,因此我们从此出发解决这个问题。 方案一(magisk): 直接…...

Python爬虫教程007:scrapy结合实际案例的简单使用
文章目录 3.1 scrapy安装3.2 scrapy的基本使用3.2.1 scrapy项目的创建和运行3.3 58同城案例3.3.1 创建案例3.3.2 项目结构说明3.4 汽车之家案例3.1 scrapy安装 什么是scrapy: Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘、信息处…...

【可能性:如何从已有条件中分析一件事情是否会发生? 关键字摘抄】
是否可以直接从前提条件给出的信息中,推理出一件事情是否会发生呢?还真的可以,这一讲,我们就来说说,什么是逻辑上的必然性,可能性和排他性。 白马非马? 春秋战国百家争鸣时期,名家…...
-- 第四部分:函数与自定义功能开发)
WPS JS宏编程教程(从基础到进阶)-- 第四部分:函数与自定义功能开发
第四部分:函数与自定义功能开发 1. 函数的创建与调用**基础概念****1.1 命名函数与匿名函数****命名函数示例:计算矩形面积****匿名函数示例:动态赋值****1.2 箭头函数****特点**:简化语法,自动继承外层 `this`。2. 自定义函数实战**2.1 身份证信息提取函数****功能**:从…...

Pytorch 张量操作
在深度学习中,数据的表示和处理是至关重要的。PyTorch 作为一个强大的深度学习框架,其核心数据结构是张量(Tensor)。张量是一个多维数组,类似于 NumPy 的数组,但具有更强大的功能,尤其是在 GPU …...
和env(safe-area-inset-bottom)在uniapp中的使用方法解析)
constant(safe-area-inset-bottom)和env(safe-area-inset-bottom)在uniapp中的使用方法解析
在微信小程序中,padding-bottom: constant(safe-area-inset-bottom); 和 padding-bottom: env(safe-area-inset-bottom); 这两个 CSS 属性用于处理 iPhone X 及更高版本设备的安全区域(safe area)。这些设备的底部有一个“Home Indicator”&a…...

ROS相关学习笔记
以下是创建并初始化一个新的 catkin 工作空间的具体步骤 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src catkin_init_workspace #这会在 src 目录下创建一个 CMakeLists.txt 文件 构建工作空间 进入工作空间根目录并构建 cd ~/catkin_ws catkin_make 或者,…...

大模型专题10 —LangGraph高级教程:构建支持网页搜索+人工干预的可追溯对话系统
在本教程中,我们将使用 LangGraph 构建一个支持聊天机器人,该机器人能够: ✅ 通过搜索网络回答常见问题 ✅ 在多次调用之间保持对话状态 ✅ 将复杂查询路由给人工进行审核 ✅ 使用自定义状态来控制其行为 ✅ 进行回溯并探索替代的对话路径 我们将从一个基础的聊天机器人开…...

rbpf虚拟机-汇编和反汇编器
文章目录 一、概述二、主要功能三、关键函数解析3.1 汇编器3.1.1 parse -转换为Instruction列表3.1.2 assemble_internal-转换为Insn 3.2 反汇编器3.2.1 to_insn_vec-转换为机器指令 四、总结 Welcome to Code Blocks blog 本篇文章主要介绍了 [rbpf虚拟机-汇编和反汇编器] ❤…...

压测数据说话:如何用科学方法选择最优高防套餐?
一、压测数据到高防参数的映射规则 1. 带宽需求计算 所需防护带宽 压测崩溃带宽 安全系数(建议1.5倍) 示例:测试崩溃值50Gbps → 选择75G套餐(群联资费表“100G套餐¥8,500/月”) 2. 连接数容量评估 …...

【初阶数据结构】队列
文章目录 目录 一、概念与结构 二、队列的实现 队列的定义 1.初始化 2.入队列 3.判断队列是否为空 4.出队列 5.取队头数据 6.取队尾数据 7.队列有效个数 8.销毁队列 三.完整源码 总结 一、概念与结构 概念:只允许在一端进行插入数据操作,在另一端进行删除…...

ai说js的instanceof是什么怎么用
instanceof 是一个用于检测对象是否是某个构造函数的实例的操作符 (1)检测内置类型 对于 JavaScript 的内置类型,instanceof 可以用来检测对象是否是某种内置类型的实例。 let arr [1, 2, 3]; console.log(arr instanceof Array); // tru…...

PyTorch中知识蒸馏浅讲
知识蒸馏 在 PyTorch 中,使用 teacher_model.eval() 和冻结教师模型参数是知识蒸馏(Knowledge Distillation)中的关键步骤。 1. teacher_model.eval() 的作用 目的: 将教师模型切换到评估模式,影响某些特定层(如 Dropout、BatchNorm)的行为。 具体影响: Dropo…...

服务器自动备份到本地,服务器自动备份到本地的方法有哪些?
服务器自动备份到本地是确保数据安全和系统恢复能力的关键步骤。以下是几种常见的服务器自动备份到本地的方法: 一、使用系统自带的备份工具 Windows Server Windows Server Backup 简介:Windows Server Backup是Windows Server操作系统内置的备份和…...

Vue+Elementui首页看板
源码 <template><!-- 查询条件--><div class="optimize-norm" v-loading="selectDataLoading"><el-form :model="queryParams" ref="queryRef" style="padding-bottom:8px" :inline="true"…...

力扣HOT100之链表:141. 环形链表
这道题都已经刷烂了,没啥好说的,就是定义快慢指针,慢指针每次移动一步,快指针每次移动两步,如果链表中有环,那么快指针一定会追上慢指针,追上时直接返回true,否则快指针会直接到达链…...

vue实现俄罗斯方块
说明: vue实现俄罗斯方块 效果图: step1:C:\Users\wangrusheng\PycharmProjects\untitled3\src\views\Game.vue <script setup> import { ref, reactive, computed, onMounted, onUnmounted } from vueconst SHAPES [[[1, 1, 1, 1]], // I[[1, …...

Web3.0隐私计算与云手机的结合
Web3.0隐私计算与云手机的结合 Web3.0隐私计算与云手机的结合,标志着从“数据垄断”向“数据自主”的范式转变。通过技术互补,两者能够构建更安全、高效且用户主导的数字生态。尽管面临技术整合和成本挑战,但随着区块链、AI和分布式存储的成…...

git | 版本切换的相关指令
常见指令 git log --oneline #查看历史提交 git tag latest-backup # 对当前的提交进行标记,标记名为latest-backup git checkout -b old-version 55b16aa # 切换到[55b16aa]的提交中,并标记为[old-version]的分支 git checkout master …...

基于 Fluent-Bit 和 Fluentd 的分布式日志采集与处理方案
#作者:任少近 文章目录 需求描述系统目标系统组件Fluent BitFluentdKafka 数据流与处理流程日志采集日志转发到 Fluentd日志处理与转发到 KafkaKafka 作为消息队列 具体配置Fluent-Bit的CM配置Fluent-Bit的DS配置Fluentd的CM配置Fluentd的DS配置Kafka查询结果 需求…...

【渗透测试】Vulnhub靶机-FSoft Challenges VM: 1-详细通关教程
下载地址:https://www.vulnhub.com/entry/fsoft-challenges-vm-1,402/ 目录 前言 信息收集 目录扫描 wpscan扫描 修改密码 反弹shell 提权 思路总结 前言 开始前注意靶机简介,当第一次开机时会报apache错误,所以要等一分钟后重启才…...

c语言strcat和strlen的注意事项
1 .strlen C库函数size_t strlen(const char* str)计算字符串str的长度,直到空字符,不包括空字符。在C语言中,字符串实际上是使用空字符\0结尾的一维字符数组。空字符(Null character)又称结束符,缩写NUL&…...

本地RAG知识库,如何进行数据结构化和清洗?
环境: 数据结构化和清洗 问题描述: 本地RAG知识库,如何进行数据结构化和清洗? 解决方案: 1. 数据结构化的重要性 RAG技术需求:在检索增强生成(Retrieval-Augmented Generation, RAG…...

开源测试用例管理平台
不可错过的10个开源测试用例管理平台: PingCode、TestLink、Kiwi TCMS、Squash TM、FitNesse、Tuleap、Robot Framework、SpecFlow、TestMaster、Nitrate。 开源测试用例管理工具提供了一种透明、灵活的解决方案,使团队能够在不受限的情况下适应具体的测…...

OpenAI最近放出大新闻,准备在接下来的几个月内推出一款“开放”的语言模型
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

锁策略--
文章目录 乐观锁和悲观锁轻量锁和重量锁自旋锁和挂起等待锁读写锁和互斥锁可重入锁和不可重入锁公平锁和非公平锁 乐观锁和悲观锁 乐观锁在执行任务前预期竞争不激烈,就先不添加锁等到了发生了真实的锁竞争再进行锁竞争 乐观锁适用于锁竞争不激烈的情况下 悲观锁在…...

IO多路复用
BIO(同步阻塞) 当客户端请求连接到服务端请求过程中其实是通过socket连接,socket的意思其实就是插座,可以理解成手机需要充电,这里的电要从服务端获取,手机的充电口和服务端的插座都是socket,假…...

AF3 OpenFoldSingleDataset类解读
AlphaFold3 data_modules 模块的 OpenFoldSingleDataset类 是 OpenFold 中的一个数据集类,继承自 torch.utils.data.Dataset,用于加载和处理蛋白质结构数据,以支持 AlphaFold3 相关的深度学习任务。OpenFoldSingleDataset 读取的多序列比对(MSA)数据、模板(template)特征…...

高级java每日一道面试题-2025年3月21日-微服务篇[Nacos篇]-什么是Nacos?
如果有遗漏,评论区告诉我进行补充 面试官: 什么是Nacos? 我回答: Nacos综合解析 一、Nacos的定义与功能 Nacos是阿里巴巴开源的一个专注于动态服务发现、配置管理和服务管理平台,其名称来源于Dynamic Naming and Configuration Service(…...

C++练习3
练习 终端上输出 3.14 要求实现 myDouble的 operator operator- operator* (不考虑进位) class myOut { 没有私有成员 只有公开函数 } myOut out; out << 1 终端输出1 out << 3.14 终端输出3.14 out << "hello" 终…...
)
Deepseek API+Python 测试用例一键生成与导出 V1.0.6(加入分块策略,返回更完整可靠)
随着Deepseek APIPython 测试用例一键生成与导出 V1.0.5的试用不断深入,在处理需求文档内容时,会出现由于文档内容过长导致大模型返回的用例远达不到我们的期望数量;另一方面,是接口文档的读取,如果接口数量过多&#…...

JDK 17 + Spring Boot 3 全栈升级实战指南--从语法革新到云原生,解锁企业级开发新范式
🚀 技术升级背景 随着 JDK 17(LTS) 与 Spring Boot 3 的发布,Java 生态迎来性能与开发效率的双重飞跃。相较于 JDK 8,JDK 17 在语法、API、GC 等方面均有显著优化,而 Spring Boot 3 则全面拥抱 Jakarta EE…...

phpStorm2021.3.3在windows系统上配置Xdebug调试
开始 首先根据PHP的版本下载并安装对应的Xdebug扩展在phpStorm工具中找到设置添加服务添加php web page配置完信息后 首先根据PHP的版本下载并安装对应的Xdebug扩展 我使用的是phpStudy工具,直接在php对应的版本中开启xdebug扩展, 并在php.ini中添加如下…...

DFS/BFS简介以及剪枝技巧
DFS简介 DFS含义 ⭐ DFS,即Depth-first-search,是深度优先搜索的简称。 它的主要思路是一直沿当前分支搜索,当搜索到尽头之后返回,再逐步向其他地方扩散。 我们可以通过一个树形结构说明DFS的遍历顺序 A/ | \B C D/ \ |E…...

LeetCode[15]三数之和
思路: 一开始我想的用哈希表来做,但是怎么想怎么麻烦,最后看解析,发现人家用的双指针,那我来讲一下我这道题理解的双指针。 这道题使用双指针之前一定要给数组进行排序,ok为什么排序?因为我需要…...

高性能计算面经
高性能计算面经 C八股文真景一面凉经自我介绍,介绍一下你做过的加速的模块(叠噪,噪声跟原图有什么关系?)OpenGL和OpenCL有什么区别?**1. 核心用途****2. 编程模型****3. 硬件抽象****4. API设计****5. 典型应用场景****6. 互操作性…...

HTML 标签类型全面介绍
HTML 标签类型全面介绍 HTML(HyperText Markup Language)是构建 Web 页面结构的基础语言。HTML 由不同类型的标签组成,每种标签都有特定的用途。本文将全面介绍 HTML 标签的分类及其用法。 1. HTML 标签概述 HTML 标签通常成对出现…...
)
【漫话机器学习系列】168.最大最小值缩放(Min-Max Scaling)
在机器学习和数据预处理中,特征缩放(Feature Scaling) 是一个至关重要的步骤,它可以使模型更稳定,提高训练速度,并优化收敛效果。最大最小值缩放(Min-Max Scaling) 是其中最常见的方…...

Spring Boot中对同一接口定义多个切面的示例,分别通过接口方式和注解方式实现切面排序,并对比差异
以下是Spring Boot中对同一接口定义多个切面的示例,分别通过接口方式和注解方式实现切面排序,并对比差异: 一、接口方式实现切面排序 1. 定义接口 // 服务接口 public interface MyService {void methodA();void methodB(); }// 接口实现类…...

基于SpringBoot的高校学术交流平台
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

数据治理的专题库
数据治理专题库的全面解析 一、专题库的定义与定位 数据治理专题库是围绕特定业务领域或场景构建的专业化数据库,其核心在于业务导向性和自主性。与基础库(如人口、法人、地理信息等跨部门核心实体数据)和主题库(如市场监管中的…...

【MathType】MathType安装和嵌入word
MathType 是一款功能强大的数学公式编辑器,广泛应用于学术论文、教材编写、科研报告等领域。它支持多种数学符号、公式排版,并且与 Microsoft Word、Google Docs、WPS 等办公软件兼容,极大地方便了数学公式的输入和编辑 记录一下安装的过程 …...

mediacodec服务启动时加载media_codecs.xml
media.codec服务启动时, 会创建 implementation::Omx 和 implementation::OmxStore, 构造 Omx时, 会解析codec相关的xml文件,一般从会如下目录中, // from getDefaultSearchDirs() { "/product/etc",&quo…...
)
Scala(三)
本节课学习了函数式编程,了解到它与Java、C函数式编程的区别;学习了函数的基础,了解到它的基本语法、函数和方法的定义、函数高级。。。学习到函数至简原则,高阶函数,匿名函数等。 函数的定义 函数基本语法 例子&…...

kafka 报错消息太大解决方案 Broker: Message size too large
kafka-configs.sh --bootstrap-server localhost:9092 \ --alter --entity-type topics \ --entity-name sim_result_zy \ --add-config max.message.bytes10485880 学习营课程...

APScheduler定时
异步IO 定时(协程) import asyncio import logging from apscheduler.schedulers.asyncio import AsyncIOScheduler from apscheduler.triggers.cron import CronTriggerlogging.basicConfig(levellogging.INFO) logger logging.getLogger(__name__)class Schedul…...

[GESP202503 C++六级题解]:P11962:树上漫步
[GESP202503 C++六级题解]:P11962:树上漫步 题目描述 小 A 有一棵 n n n 个结点的树,这些结点依次以 1 , 2 , ⋯ , n 1,2,\cdots,n 1,2,⋯,n 标号。 小 A 想在这棵树上漫步。具体来说,小 A 会从树上的某个结点出发,每⼀步可以移动到与当前结点相邻的结点,并且小 A…...

JavaScript基础-常见网页特效案例
在现代Web开发中,JavaScript不仅是处理业务逻辑的核心工具,也是实现丰富交互体验的关键。通过JavaScript,我们可以轻松地为网页添加各种动态效果和交互特性,从而提升用户体验。本文将介绍几种常见的网页特效案例,并提供…...