LLM 优化技术(1)——Scaled-Dot-Product-Attention(SDPA)
在 Transformer 中抛弃了传统的 CNN 和 RNN,整个网络结构完全由Scaled Dot Product Attention 和Feed Forward Neural Network组成。一个基于 Transformer 的可训练的神经网络可以通过堆叠 Transformer 的形式进行搭建,Attention is All You Need论文中通过搭建编码器(encoder)和解码器(decoder)各 6 层,总共 12 层的Encoder-Decoder,并在机器翻译中取得了 BLEU 值的新高。
作者采用 Attention 机制的原因是考虑到 RNN(或者 LSTM,GRU 等)的计算限制为是顺序的,也就是说 RNN 相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片 t 的计算依赖 t-1 时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管 LSTM 等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象 LSTM 依旧无能为力。
Transformer 的提出解决了上面两个问题:
- 首先它使用了 Attention 机制,将序列中的任意两个位置之间的距离是缩小为一个常量;
- 其次它不是类似 RNN 的顺序结构,因此具有更好的并行性,符合现有的 GPU 框架。
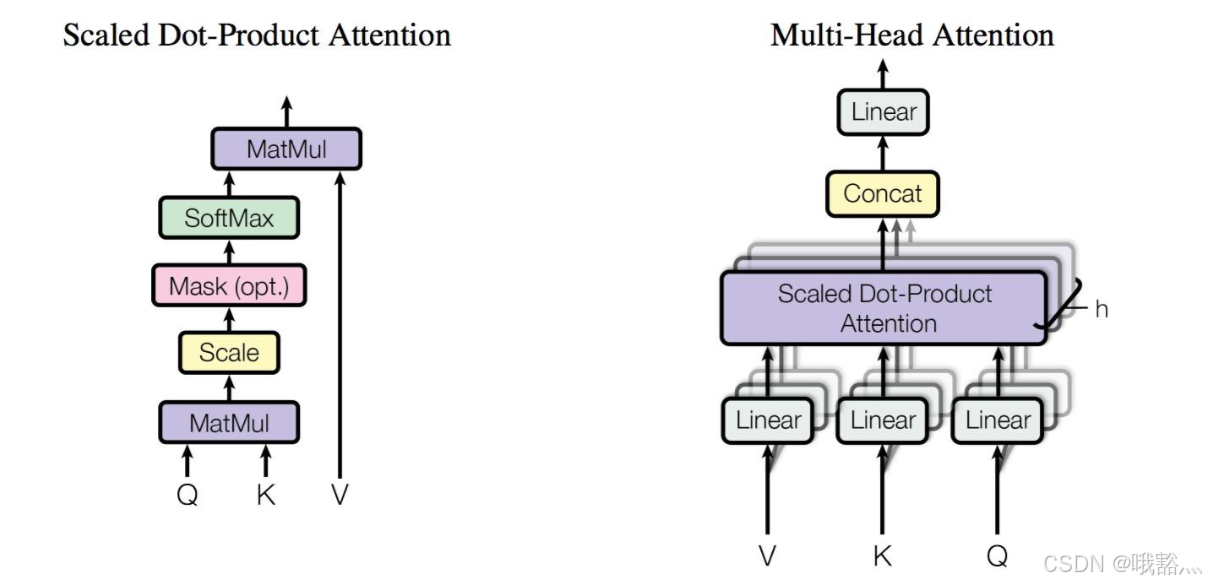
Scaled Dot Product Attention作为 Transformer 模型结构最核心的组件,pytorch 对其做了融合实现支持,并提供了丰富的 python 接口供用户轻松搭建 Transformer:
torch.nn.functional.scaled_dot_product_attention,
torch.nn.MultiheadAttention,
torch.nn.TransformerEncoderLayer,
torch.nn.Transformer,
torch.nn.TransformerDecoderLayer,
torch.ops.aten._scaled_dot_product_flash_attention,
torch.ops.aten._scaled_dot_product_efficient_attention_cuda
这里先之看torch.nn.functional.scaled_dot_product_attention这个接口。
1 Fused implementations
给定 CUDA 张量输入,torch.nn.functional.scaled_dot_product_attention函数将分派到以下实现之一:
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- Memory-Efficient Attention
- C++ 定义的原生 PyTorch 实现
import torch
import torch.nn as nn
import torch.nn.functional as F
device = "cuda" if torch.cuda.is_available() else "cpu"# Example Usage:
query, key, value = torch.randn(2, 3, 8, device=device), torch.randn(2, 3, 8, device=device), torch.randn(2, 3, 8, device=device)
F.scaled_dot_product_attention(query, key, value)
2 Explicit Dispatcher Control
torch.nn.functional.scaled_dot_product_attention函数将隐式分派到三个实现之一,但用户也可以通过使用上下文管理器显式控制分派。此上下文管理器允许用户明确禁用某些实现。如果用户确定对于特定输入某种实现是最快的实现的话,则可以使用上下文管理器来扫描测量性能。
# Lets define a helpful benchmarking function:
import torch.utils.benchmark as benchmark
def benchmark_torch_function_in_microseconds(f, *args, **kwargs):t0 = benchmark.Timer(stmt="f(*args, **kwargs)", globals={"args": args, "kwargs": kwargs, "f": f})return t0.blocked_autorange().mean * 1e6# Lets define the hyper-parameters of our input
batch_size = 32
max_sequence_len = 1024
num_heads = 32
embed_dimension = 32dtype = torch.float16query = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
key = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)
value = torch.rand(batch_size, num_heads, max_sequence_len, embed_dimension, device=device, dtype=dtype)print(f"The default implementation runs in {benchmark_torch_function_in_microseconds(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")# Lets explore the speed of each of the 3 implementations
from torch.backends.cuda import sdp_kernel, SDPBackend# Helpful arg mapper
backend_map = {SDPBackend.MATH: {"enable_math": True, "enable_flash": False, "enable_mem_efficient": False},SDPBackend.FLASH_ATTENTION: {"enable_math": False, "enable_flash": True, "enable_mem_efficient": False},SDPBackend.EFFICIENT_ATTENTION: {"enable_math": False, "enable_flash": False, "enable_mem_efficient": True}
}with sdp_kernel(**backend_map[SDPBackend.MATH]):print(f"The math implementation runs in {benchmark_torch_function_in_microseconds(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")with sdp_kernel(**backend_map[SDPBackend.FLASH_ATTENTION]):try:print(f"The flash attention implementation runs in {benchmark_torch_function_in_microseconds(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")except RuntimeError:print("FlashAttention is not supported. See warnings for reasons.")with sdp_kernel(**backend_map[SDPBackend.EFFICIENT_ATTENTION]):try:print(f"The memory efficient implementation runs in {benchmark_torch_function_in_microseconds(F.scaled_dot_product_attention, query, key, value):.3f} microseconds")except RuntimeError:print("EfficientAttention is not supported. See warnings for reasons.")
3 Causal Self Attention
下面是受 Andrej Karpathy 的 NanoGPT 仓库启发的 multi-headed causal self attention 的示例实现:
class CausalSelfAttention(nn.Module):def __init__(self, num_heads: int, embed_dimension: int, bias: bool=False, is_causal: bool=False, dropout:float=0.0):super().__init__()assert embed_dimension % num_heads == 0# key, query, value projections for all heads, but in a batchself.c_attn = nn.Linear(embed_dimension, 3 * embed_dimension, bias=bias)# output projectionself.c_proj = nn.Linear(embed_dimension, embed_dimension, bias=bias)# regularizationself.dropout = dropoutself.resid_dropout = nn.Dropout(dropout)self.num_heads = num_headsself.embed_dimension = embed_dimension# Perform causal maskingself.is_causal = is_causaldef forward(self, x):# calculate query, key, values for all heads in batch and move head forward to be the batch dimquery_projected = self.c_attn(x)batch_size = query_projected.size(0)embed_dim = query_projected.size(2)head_dim = embed_dim // (self.num_heads * 3)query, key, value = query_projected.chunk(3, -1)query = query.view(batch_size, -1, self.num_heads, head_dim).transpose(1, 2)key = key.view(batch_size, -1, self.num_heads, head_dim).transpose(1, 2)value = value.view(batch_size, -1, self.num_heads, head_dim).transpose(1, 2)if self.training:dropout = self.dropoutis_causal = self.is_causalelse:dropout = 0.0is_causal = Falsey = F.scaled_dot_product_attention(query, key, value, attn_mask=None, dropout_p=dropout, is_causal=is_causal)y = y.transpose(1, 2).view(batch_size, -1, self.num_heads * head_dim)y = self.resid_dropout(self.c_proj(y))return ynum_heads = 8
heads_per_dim = 64
embed_dimension = num_heads * heads_per_dim
dtype = torch.float16
model = CausalSelfAttention(num_heads=num_heads, embed_dimension=embed_dimension, bias=False, is_causal=True, dropout=0.1).to("cuda").to(dtype).eval()
print(model)
4 NestedTensor and Dense tensor support
SDPA 支持 NestedTensor 和 Dense 张量输入。NestedTensors 处理输入是一批可变长度序列的情况,而不需要将每个序列填充到批中的最大长度。
import random
def generate_rand_batch(batch_size,max_sequence_len,embed_dimension,pad_percentage=None,dtype=torch.float16,device="cuda",
):if not pad_percentage:return (torch.randn(batch_size,max_sequence_len,embed_dimension,dtype=dtype,device=device,),None,)# Random sequence lengthsseq_len_list = [int(max_sequence_len * (1 - random.gauss(pad_percentage, 0.01)))for _ in range(batch_size)]# Make random entry in the batch have max sequence lengthseq_len_list[random.randint(0, batch_size - 1)] = max_sequence_lenreturn (torch.nested.nested_tensor([torch.randn(seq_len, embed_dimension,dtype=dtype, device=device)for seq_len in seq_len_list]),seq_len_list,)random_nt, _ = generate_rand_batch(32, 512, embed_dimension, pad_percentage=0.5, dtype=dtype, device=device)
random_dense, _ = generate_rand_batch(32, 512, embed_dimension, pad_percentage=None, dtype=dtype, device=device)# Currently the fused implementations don't support NestedTensor for training
model.eval()with sdp_kernel(**backend_map[SDPBackend.FLASH_ATTENTION]):try:print(f"Random NT runs in {benchmark_torch_function_in_microseconds(model, random_nt):.3f} microseconds")print(f"Random Dense runs in {benchmark_torch_function_in_microseconds(model, random_dense):.3f} microseconds")except RuntimeError:print("FlashAttention is not supported. See warnings for reasons.")
5 Scaled Dot Product Attention (SDPA) 在 CPU 上的 性能优化
PyTorch 2.0 的主要 feature 是 compile,一起 release 的还有一个很重要的 feature 是 SDPA: Scaled Dot Product Attention 的优化。一共包含三个算法:
- Math: 把原始实现从 Python 挪到了 C++
- Efficient Attention
- Flash Attention
后两种算法是无损加速,不同于使用 low rank 或者 sparse 的方式,从数学上来说计算没有发生变化,所以不影响精度。
SDPA 主要是为了解决 LLM 中的两方面痛点:
- memory footprint: attn 的尺寸是 {B, H, T, T}。和 T 是 O(n2) 的关系,随着 sequence 变长,memory 开销太大;
- performance speedup: 针对 attn 的 pointwise 操作都是 memory bandwidth bound,速度太慢了
目前的版本中,后两种算法都只支持 CUDA device。
5.1 Previous Work
1.3 版本出现了 nn.MultiheadAttention 的优化,具体应用的 API 是 HuggingFace Optimum 的 BetterTransformer。思路是把 gemm 之间的 pointwise 统统 fuse 起来。
最大的收益来自于对 attn 操作的 fusion,因为 QKV 尺寸是和 T * K 成正比,而 attn 是和 T * T 成正比。这里的 K 是每个 head 上的 feature size,T 是 sequence length,一般来讲 T 会 比 K 大很多。
原始实现对于 masked softmax 的处理一共需要 4 reads + 5 writes:
对于 mask 的处理会非常繁琐:需要 4 次操作: ones, tril, not, masked_fill。共需要 3 reads + 4 writes。softmax 由于需要保障数值稳定性,需要 4 个 steps 完成,不过这 4 步只有 1 read + 1 write,原因在于 transformer 里面是在 lastdim 上做 softmax,正常情况下数据 parallel 的方式保障 L1 cache hit,所以只有 1 read + 1 write。
做了 fuse 之后,masked_softmax 一共需要 1 read + 1 write。attn 是个很大的 tensor,所以主要的性能收益来自这个地方。但即使只有 1次读和1次写,还是不够快,另外这个算法解决不了内存开销太大的问题。为了解决这些问题, SDPA 应运而生了,不管是 efficient attention 还是 flash attention,核心都是如何通过 blocking (或者叫 tiling)避免直接分配一块 {B, H, T, T} 这么大的 attn。通过让数据停留在 cache 上面,达到对 pointwise 操作的加速。
5.2 SDPA 优化
efficient attention 和 flash attention 2 在经过 fully optimized 之后这两种算法本质上没有区别。
5.2.1 naive
整个 scaled dot product attention 的原始计算过程如下图,对于每一个 {B, H} 的 slice:
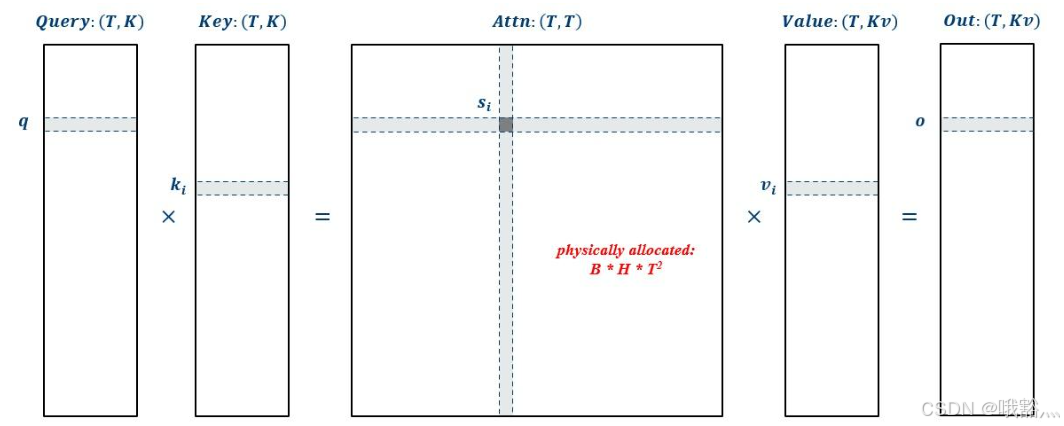
这里,把 V 看作一个 v 0 , v 1 , . . . , {v0, v1, ..., } v0,v1,..., 的向量会比较好理解。另外,我们认为这里 attn 还是做了实际的内存分配。
整个过程可以分解为 3 步:
- 一个 vec-vec 的 Dot Product
- 针对 attn 每一行元素的 pointwise
- 一个 vec-mat 的 GEMV
5.2.2 Lazy Softmax
引入 lazy softmax 可以避免为 attn 实际分配内存,在每个 thread 保留一些 momentum 信息即可:
m*记录当前的 max value;s*记录 sum value;v*记录 out 中每一行的累计值。
那么,可以很容易地算出来每个 thread 需要的额外内存只有:1 + 1 + Kv (Kv 是 V 每个 head 的 feature size)。
从性能角度出发我们更关心计算的性质,与原始形态计算量实际上发生了退化,不过好在不需要分配 {B, H, T, T} 这么大一个 tensor 了:
但是,这种实现依旧很原始,性能并不好,这个 kernel 大概会比原版还慢十几倍。主要原因有两点:
- 对于每一个
q_i,都需要遍历整个 K,才能完成 attn 中一行的计算; s_i需要和v_i相乘并累加到o_i中,这个过程中同样对于 V 有重复访问,并且要多次写入 O;
按模型中实际尺寸来算,KV是不可能被 cache 命中的,所以就是在不停地刷内存带宽,肯定快不了。
5.2.3 在 KV 上做 Blocking
在 KV 上做 blocking,即每一个 iteration 计算 q_i 和 一个 K block 和 V block,这么做是为了减少对 O 的写入次数,KV block 的数量就是减少写入次数的倍数。这个时候计算的性质已经发生了变化,每一步的计算量被放大了 NB 倍。
也需要一个额外的 s_i 来记录 qk 的内积结果,那么每个 thread 的额外内存变为:1 + 1 + NB + Kv
不过这样还是不能解决对 KV 的重复访问。
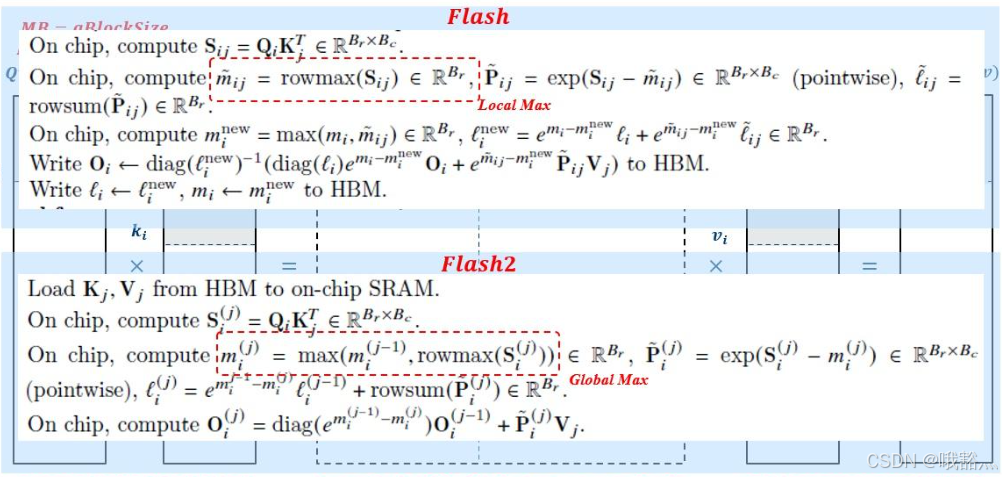
5.2.4 在 Q 上做 Blocking
在 Q 上做 blocking,即每一个 iteration 计算 一个 Q block 和 一个 KV block,这么做是为了减少对 KV 的读取次数,Q block 的数量就是减少读取次数的倍数。
每一步的计算量被再次放大了 MB 倍。
每个 thread 的额外内存变为:MB * (1 + 1 + NB + Kv),扩大了 MB 倍。不过我们还是可以通过计算保障这个 buffer 被 L2 命中(L1 大小是 32KB,L2 是 1MB,这个 buffer 大小可以设置 L2 的 25%)。
至此,我们完成了对 SDPA 基本形态的推导,从 efficient 算法入手,可以得到数学上和 flash2 完全一致的过程:
5.2.5 Float16 和 BFloat16 的实现
基本原则是用 float32 来做 accumulation。当然在 intel xeon 上得益于 AMX 的硬件加速,code 中使用了 MKL 中的 cblas_gemm_bf16bf16f32 函数,即 A(bf16) x B(bf16) = C(fp32)
5.2.6 Causal Mask
SDPA 对于 Causal mask 的处理是在 s_i 这个 buffer 里面加 mask,配合上 blocking,可以额外省掉上三角的 GEMM,所以在 causal mask 的情况下 SDPA 能拿到更大的加速比:
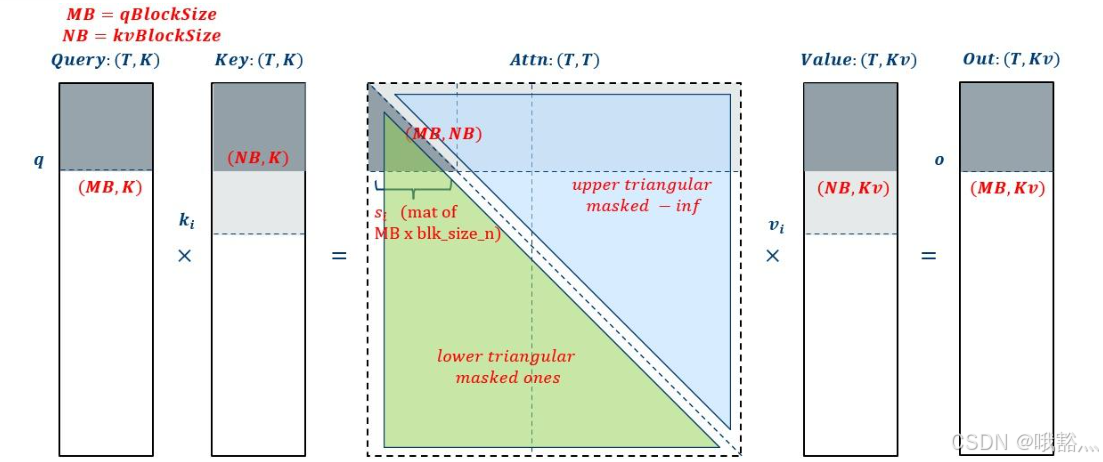
实际中因为配合了 blocking,所以中间的那条线应该是个阶梯状的,阶梯上面的 GEMM 会被省略掉。
5.2.7 一些问题
首先最显著的一个问题就是 load imbalance, 我们依赖在 B-H-MB (batch-head-q_block) 这三个维度上做 parallel,但每一个 q block 对应访问的 kv block 数量是不一样的,可能会导致 load imbalance:

这个问题其实很好解决,因为我们预先就可以算出每个 q block 对应几个 kv block。
还有一个比较难处理的问题是每个 thread memory 访问不均衡的问题。比如我们有 10 个 q block,但每个 thread 只能计算 8 个,那么 T0 只会访问一组 KV (都来自 Head_0);而 T2 会访问两组 KV (来自于 Head_0 和 Head_1)。
另外还有一个让 amx 和 avx512 并行的问题,也就是如何让 GEMM 和 pointwise 并行起来。
相关文章:
——Scaled-Dot-Product-Attention(SDPA))
LLM 优化技术(1)——Scaled-Dot-Product-Attention(SDPA)
在 Transformer 中抛弃了传统的 CNN 和 RNN,整个网络结构完全由Scaled Dot Product Attention 和Feed Forward Neural Network组成。一个基于 Transformer 的可训练的神经网络可以通过堆叠 Transformer 的形式进行搭建,Attention is All You Need论文中通…...

【深度学习】嘿马深度学习目标检测教程第1篇:商品目标检测要求、目标,1.1 项目演示【附代码文档】
教程总体简介:要求 目标 1.1 项目演示 学习目标 1.1 图像识别背景 1.2 什么是目标检测 1.2.1 目标检测定义 1.2.1.1 物体 1.3 目标检测应用场景 1.3.1 行业 1.3.2 应用类别 1.4 开发环境搭建 目标检测概述 3.1 目标检测任务描述 3.1.4 目标定位的简单实现 项目实现 …...

【蓝桥杯】单片机设计与开发,RTC实时时钟
一、RTC-DS1302概述 二、BCD码 三、三线协议概述 四、RTC的应用 五、DS1302的驱动函数 六、操作流程 七、三线协议驱动程序...

Java 各版本的新特性
Java 各版本的新特性主要集中在提升开发效率、性能优化、语言功能增强和模块化支持等方面。以下是 JDK 8 到 JDK 21(截至2023年)的主要新特性概览: JDK 8 (2014) - LTS Lambda 表达式:支持函数式编程,简化匿名内部类。…...

OpenGL中EBO的使用及原理
EBO 是什么? 在OpenGL中,EBO(Element Buffer Object),也称为索引缓冲对象 IBO(Index Buffer Object),是一种用于存储顶点索引数据的缓冲区对象。它的核心作用是通过复用顶点数据来减…...

应用分享 | AWG技术突破:操控钻石氮空位色心,开启量子计算新篇章!
利用AWG操作钻石中的氮空位色彩中心 金刚石中的颜色中心是晶格中的缺陷,其中碳原子被不同种类的原子取代,而相邻的晶格位点则是空的。由于色心具有明亮的单光子发射和光学可触及的自旋,因此有望成为未来量子信息处理和量子网络的固态量子发射…...

【Ultralytics YOLO COCO 评估脚本 | 获得COCO评价指标】
文章目录 Ultralytics YOLO COCO 评估脚本 (coco_evaluate.py)1. 描述2. 依赖项3. 使用方法4. 输入文件格式5. 输出6. 注意7. 完整代码 Ultralytics YOLO COCO 评估脚本 (coco_evaluate.py) 这是一个 Python 脚本,用于评估以 COCO JSON 格式提供的目标检测结果。它…...

聊一聊,元件封装知多少?
目录 01 | 简 介 02 | 常见的无源器件封装 03 | 集成(IC)类封装 04 | 功率器件类封装 05 | 连接器类封装 06 | 总 结 01 | 简 介 由于平时工作中,经常需要查看封装的样式,以便初步规划PCB布局;遂萌发对常用的元件封装进行一次总结。 …...

企业需要使用防病毒系统保障数据安全的原因
数据作为企业的重要资产,正面临勒索病毒等极大威胁。在复杂严峻的网络安全形势下,企业的业务运营、数据安全和声誉遭遇诸多来自网络的挑战。2023年,国内发生多起严重网络安全事件,例如数据库漏洞导致数据泄露、钓鱼邮件窃取信息、…...

使用无人机进行露天矿运输道路分析
使用无人机进行露天矿运输道路分析 无人机正在彻底改变采矿业,为露天矿场的运输道路收集数据和分析提供了一种新方法。通过使用 UAS 技术,采矿公司可以更全面地了解道路状况,确定磨损区域,并提高安全性和效率。 本文介绍了无人机用…...

基于Vue.js网页开发相关知识:Vue-router
一、基础知识 vue-router 是 Vue.js 官方的路由管理器,用于实现单页面应用(SPA)的路由功能。以下从几个方面对 vue-router 进行详细分析: 1. 核心概念 路由配置 vue-router 通过定义路由配置对象来管理应用的路由。每个路由配置…...

同时使用Telnet和SSH登录思科交换机
同时使用Telnet和SSH登录思科交换机 1. 配置管理IP地址 首先,为交换机配置一个管理IP地址,以便可以通过网络进行远程管理: Switch(config)# interface vlan [VLAN_ID] Switch(config-if)# ip address [IP地址] [子网掩码] Switch(config-i…...

presto行转列
presto的行列转换和spark、hive一样也是通过外链语句实现的,只不过语法和关键子有点不同,如下 with tmp1 as (select 1,2,3 as a1,4,5,6 as a2 ) select * from tmp1 cross join unnest(split(tmp1.a1, ,),split(tmp1.a2, ,) ) as b(a1s,a2s) 结果如下...

App Usage v5.57 Pro版 追踪手机及应用使用情况
手机使用监控神器:让你的手机使用情况一目了然 现代人的生活已经离不开手机——通讯、娱乐、支付、购物…每天我们花在手机上的时间越来越多。你是否好奇: 每天在各个应用上花费了多少时间?一天中查看了多少次手机?哪些应用在后…...

24.3 CogView3多模态生成实战:从API调优到1024高清图像生成全解析
CogView3多模态生成实战:从API调优到1024高清图像生成全解析 CogView3 & CharGLM:多模态生成技术深度解析 关键词:CogView3 API 调用,图像生成与编辑,多模态提示工程,GLM 技术栈集成,参数优化策略 1. 智谱清言平台演示 CogView-3 核心能力 1.1 CogView3 技术架构…...
linux内核)
操作系统高频(六)linux内核
操作系统高频(六)linux内核 1.内核态,用户态的区别⭐⭐⭐ 内核态和用户态的区别主要在于权限和安全性。 权限:内核态拥有最高的权限,可以访问和执行所有的系统指令和资源,而用户态的权限相对较低&#x…...

Ubuntu系统安装Cpolar 实现内网穿透教程
文章目录 方法 1:使用官方脚本快速安装(推荐)方法 2:手动下载安装包配置与使用常见问题 方法 1:使用官方脚本快速安装(推荐) 下载安装脚本 打开终端,执行以下命令下载并运行安装脚本…...

Trustworthy Machine Learning
1. 可信任机器学习的核心概念 1.1 可信任性的定义 稳健性(Robustness): 机器学习模型在面对数据噪声、分布变化或对抗性攻击时仍能维持其预测性能的能力。 公平性(Fairness): 避免 AI 决策对某些群体存在…...

Enovia许可管理系统的特点
在当今竞争激烈的市场环境中,企业对于产品生命周期管理(PLM)的需求日益增加。Enovia许可管理系统,作为一款先进的许可证管理工具,凭借其卓越的特点,助力企业实现资源的高效管理和最大化利用。本文将详细介绍…...

【CSS】样式与效果
个人主页:Guiat 归属专栏:HTML CSS JavaScript 文章目录 1. CSS盒模型1.1 盒模型基础1.2 盒模型类型1.2.1 标准盒模型1.2.2 IE盒模型 2. CSS选择器2.1 基本选择器2.2 组合选择器2.3 伪类和伪元素 3. CSS布局技术3.1 Flexbox布局3.2 Grid布局3.3 定位 4. …...

Python中常用网络编程模块
学习籽料在下方自拿 一、网络基础 网络由下往上分为:物理层、数据链路层、网络怪、传输层、会话层、表示层和应用层。 TCP/IP协议是传输层协议,主要解决数据如何在网络中传输;socket则是对TCP/IP协议的封装,它本身不是协议&…...

python-flask
1.定时任务的时候一定要加--preload,防止 --preload gunicorn --config gunicorn-conf.py --preload index:app 2.source /usr/local/nginx/html/prod/pypd/venv/bin/activate 启动linux的python环境 3.pip freeze > requirements.txt 生成所有依赖 4.p…...

OpenIPC开源FPV之Adaptive-Link信号干扰
OpenIPC开源FPV之Adaptive-Link信号干扰 1. 源由2. 现象3. 分析3.1 冲突弃包3.2 传输丢包 4. 逻辑4.1 可调整参数4.2 可监测参数4.3 逻辑思路 5. 总结6. 参考资料 1. 源由 虽然,OpenIPC作为FPV图传在延时方面使用广播wfb-ng,性能上已经非常棒了。 在权…...

C++ 结构体与函数
一.结构体 1.概念: 结构体(struct)是一种用户自定义复合数据类型,其中可以包含不同类型的不同成员 2.结构体的应用场景: 我们在使用多个变量描述一个对象时,虽然也可以做到,但是难免显得杂乱…...

【Java全栈】Java + Vue 项目框架与运行流程详解
文章目录 ⭐前言⭐一、框架介绍🌟1、后端框架(Java Spring Boot)🌟2、前端框架(Vue 3 Element Plus) ⭐二、项目结构🌟1、后端目录(Spring Boot)🌟2、前端目…...

JAVA:利用 JSONPath 操作JSON数据的技术指南
1、简述 JSONPath 是一种强大的工具,用于查询和操作 JSON 数据。类似于 SQL 的语法,它为处理复杂的 JSON 数据结构提供了简单且高效的解决方案。✨ 代码样例:https://gitee.com/lhdxhl/springboot-example.git 本文将介绍 JSONPath 的基本…...

5.2.1 WPF 通过ItemControl自己做柱状图
1. 最终效果如下图: 1.1 准备数据 ViewModel public class PrimaryItemModel{public double Value { get; set; }public string XLabel { get; set; }}public class MainViewModel{public ObservableCollection<PrimaryItemModel> PrimaryList { get; set; }…...

3.31 代码随想录第三十一天打卡
1049.最后一块石头的重量II (1)题目描述: (2)解题思路: class Solution { public:int lastStoneWeightII(vector<int>& stones) {vector<int> dp(15001, 0);int sum 0;for (int i 0; i < stones.size(); i) sum stones[i];int target sum / 2;for (in…...

基于网启PXE服务器的批量定制系统平台
一.项目背景 公司新购了一批服务器和台式机,需要为台式机和服务器安装系统,一部分需要安装国产OpenEuler,一部分要求安装CentOS 7.9,同时也要满足定制化需求,即按要求分区安装相应软件。 二.项目环境 安装win10/11 …...
技术实现详解)
Unity光线传播体积(LPV)技术实现详解
一、LPV技术概述 光线传播体积(Light Propagation Volumes)是一种实时全局光照技术,通过将场景中的间接光信息存储在3D网格中,实现动态物体的间接光照效果。 核心优势: 实时性能:相比传统光照贴图,支持动态场景 硬件…...

蓝桥杯备考---》贪心算法之矩阵消除游戏
我们第一次想到的贪心策略一定是找出和最大的行或者列来删除,每次都更新行和列 比如如图这种情况,这种情况就不如直接删除两行的多,所以本贪心策略有误 so我们可以枚举选的行的情况,然后再贪心的选择列和最大的列来做 #include …...

python+playwright 学习-93 结合pands 抓取网页表格数据
playwright 结合 pands 抓取网页表格数据 pandas 直接抓取网页表格数据 web 网页表格数据 """ 上海 202501 天气抓取 """ import pandas as pddf = pd.read_html(fhttp://www.tianqihoubao.com/lishi/shanghai/month/202501.html,encoding...

MVC编程
MVC基本概述 例子——显示本地文件系统结构 先分别拖入ListView,TableView,TreeView 然后在进行布局 在widget.cpp 结果 mock测试 1,先加入json测试对象 2.创建后端目录 3,在src添加新文件 在models文件夹里 在mybucket.h,添加测试用例的三个字段 4.在…...

51单片机总结
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.03.31 51单片机学习总结(有感而发) 一、总结结语 一、总结 一路…...

端到端语音识别案例
《DeepSeek大模型高性能核心技术与多模态融合开发(人工智能技术丛书)》(王晓华)【摘要 书评 试读】- 京东图书 语音识别这一技术正如其名,是通过精密地解析说话人的语音来识别并准确转写出其所说的内容。它不仅仅是一个简单的转录过程&#…...
分页效果)
iOS自定义collection view的page size(width/height)分页效果
前言 想必大家工作中或多或少会遇到下图样式的UI需求吧 像这种cell长度不固定,并且还能实现的分页效果UI还是很常见的 实现 我们这里实现主要采用collection view,实现的方式是自定义一个UICollectionViewFlowLayout的子类,在这个类里对…...

CI/CD基础知识
什么是CI/CD CI:持续集成,开发人员频繁地将代码集成到主干(主分支)中每次集成都通过自动化构建和测试来验证,从而尽早发现集成错误,常用的CI工具包括Jenkins、Travis CI、CircleCI、GitLab CI等 CD&#…...

MySQL 的 SQL 语句执行顺序
MySQL 的 SQL 语句执行顺序并不完全按照代码的书写顺序执行,而是遵循一套固定的逻辑流程 1. FROM 和 JOIN 作用:确定查询的数据来源,包括表和它们的连接方式(如 INNER JOIN, LEFT JOIN 等)。 细节: 先执行…...
如何配置Dubbo的注册中心?)
Dubbo(21)如何配置Dubbo的注册中心?
在分布式系统中,注册中心是一个关键组件,用于服务的注册和发现。Dubbo 支持多种注册中心,包括 ZooKeeper、Nacos、Consul、Etcd 等。下面详细介绍如何配置 Dubbo 的注册中心,以 ZooKeeper 为例。 配置步骤 引入依赖:…...

AISEO中的JSON 如何部署?
一、JSON 是什么? JSON(JavaScript Object Notation) 是一种轻量级的数据格式,用于在不同系统之间传递结构化信息。它的核心特点是: 易读:用简单的 {键: 值} 对表示数据,例如: json…...
)
力扣hot100——最长连续序列(哈希unordered_set)
题目链接:最长连续序列 1、错解:数组做哈希表(内存超出限制) int longestConsecutive(vector<int>& nums) {vector<bool> hash(20000000010, false);for(int i0; i<nums.size();i){hash[1000000000nums[i]]t…...

几种常见的.NET单元测试模拟框架介绍
目录 1. Moq 2. NSubstitute 3. AutoFixture 4. FakeItEasy 总结对比 单元测试模拟框架是一种在软件开发中用于辅助单元测试的工具。 它的主要作用是创建模拟对象来替代真实对象进行测试。在单元测试中,被测试的代码可能依赖于其他组件或服务,如数…...

装饰器模式与模板方法模式实现MyBatis-Plus QueryWrapper 扩展
pom <dependency><groupId>com.github.yulichang</groupId><artifactId>mybatis-plus-join-boot-starter</artifactId> <!-- MyBatis 联表查询 --> </dependency>MPJLambdaWrapperX /*** 拓展 MyBatis Plus Join QueryWrapper 类&…...

11-SpringBoot3入门-整合aop
1、概念(个人理解) AOP(Aspect Oriented Programming),面向切面编程。 1)切面(Aspect):提供切入连接点的方法 2)连接点(Joinpoint)…...

naive_admin项目实战03 基于Go语言的后端
01.使用Goland打开项目 02.使用Goland连接MySQL 03.执行SQL脚本 set names utf8mb4; set foreign_key_checks 0;-- ---------------------------- -- table structure for permission -- ---------------------------- drop table if exists permission; create table permiss…...
)
基于卷积神经网络的眼疾识别系统,resnet50,efficentnet(pytorch框架,python代码)
更多图像分类、图像识别、目标检测、图像分割等项目可从主页查看 功能演示: 眼疾识别系统resnet50,efficentnet,卷积神经网络(pytorch框架,python代码)_哔哩哔哩_bilibili (一)简介…...

Python数据可视化-第1章-数据可视化与matplotlib
环境 开发工具 VSCode库的版本 numpy1.26.4 matplotlib3.10.1 ipympl0.9.7教材 本书为《Python数据可视化》一书的配套内容,本章为第1章 数据可视化与matplotlib 本文主要介绍了什么是数据集可视化,数据可视化的目的,常见的数据可视化方式…...

Ansible playbook-ansible剧本
一.playbook介绍 便于功能的重复使用 本质上就是文本文件,一般都是以.yml结尾的文本文件。 1.遵循YAML语法 1.要求同级别代码要有相同缩进,建议4个空格。【同级别代码是同一逻辑的代码】 在计算机看来空格和Tob键是两个不同的字符。 2.一个键对应一…...

UDP网络通信
UDP网络通信: 步骤1 创建套接字: #include <sys/types.h> #include <sys/socket.h>int socket(int domain, int type, int protocol);参数一 domain: AF_UNIX Local communication unix(7) 本地通信 AF_INET IPv4 Inte…...
)
【学习笔记】计算机网络(六)
第6章应用层 文章目录 第6章应用层6.1 域名系统DNS6.1.1 域名系统概述6.1.2 互联网的域名结构6.1.3 域名服务器域名服务器的分区管理DNS 域名服务器的层次结构域名服务器的可靠性域名解析过程-两种查询方式DNS 高速缓存机制 6.2 文件传送协议6.2.1 FTP 概述6.2.2 FTP 的基本工作…...