如何自动化同义词并使用我们的 Synonyms API 进行上传
作者:来自 Elastic Andre Luiz

了解如何使用 LLM 来自动识别和生成同义词, 使术语可以通过程序方式加载到 Elasticsearch 同义词 API 中。
提高搜索结果的质量对于提供高效的用户体验至关重要。优化搜索的一种方法是通过同义词自动扩展查询词。这样可以更广泛地解释查询内容,覆盖语言变体,从而改进结果匹配。
本博客探讨了如何利用 大语言模型(LLMs) 自动识别和生成同义词,使这些术语可以通过程序方式加载到 Elasticsearch 的 synonym API 中。
何时使用同义词?
使用 同义词 相较于 向量搜索 是一种更快速且更具成本效益的解决方案。它的实现更简单,因为它不需要深入了解 embeddings 或复杂的向量摄取过程。
此外,同义词的 资源消耗更低,因为向量搜索需要更大的存储空间和内存来进行 embedding 索引和检索。
另一个重要方面是 搜索的区域化。通过 同义词,可以根据本地语言和习惯调整术语,这在 embeddings 可能无法匹配地区表达或特定国家术语的情况下非常有用。例如,一些单词或缩写在不同地区可能有不同的含义,但本地用户通常会将它们视为同义词:
-
在 巴西,"abacaxi" 和 "ananás" 都指 菠萝(pineapple),但在东北部,第二个词更常见。
-
在巴西东南部,常见的 "pão francês"(法式面包)在东北部可能被称为 "pão careca"。
这种 区域化 的差异使得 同义词 在搜索优化中发挥关键作用。
如何使用 LLMs 生成同义词?
为了自动获取同义词, 你可以使用 LLMs, 这些模型可以分析术语的上下文并建议合适的变体。 这种方法可以动态扩展同义词, 确保更广泛和更精准的搜索, 而无需依赖固定的词典。
在本示例中, 我们将使用 LLM 来为 电商产品 生成同义词。 许多搜索由于查询词的不同变体而返回较少甚至没有结果。 通过 同义词, 我们可以解决这个问题。 例如, 搜索 "smartphone" 时, 结果可以涵盖不同型号的手机, 确保用户能够找到他们需要的产品。
先决条件
在开始之前, 需要设置环境并定义所需的依赖项。 我们将使用 Elastic 提供的解决方案 在 Docker 中本地运行 Elasticsearch 和 Kibana。 代码将使用 Python v3.9.6 编写,并需要以下依赖项:
pip install openai==1.59.8 elasticsearch==8.15.1创建产品索引
首先, 我们将创建一个不支持同义词的产品索引。 这将使我们能够验证查询, 然后将其与包含同义词的索引进行比较。
要创建索引, 我们使用以下命令在 Kibana DevTools 中批量加载产品数据集:
POST _bulk
{"index": {"_index": "products", "_id": 10001}}
{"category": "Electronics", "name": "iPhone 14 Pro"}
{"index": {"_index": "products", "_id": 10007}}
{"category": "Electronics", "name": "MacBook Pro 16-inch"}
{"index": {"_index": "products", "_id": 10013}}
{"category": "Electronics", "name": "Samsung Galaxy Tab S8"}
{"index": {"_index": "products", "_id": 10037}}
{"category": "Electronics", "name": "Apple Watch Series 8"}
{"index": {"_index": "products", "_id": 10049}}
{"category": "Electronics", "name": "Kindle Paperwhite"}
{"index": {"_index": "products", "_id": 10067}}
{"category": "Electronics", "name": "Samsung QLED 4K TV"}
{"index": {"_index": "products", "_id": 10073}}
{"category": "Electronics", "name": "HP Spectre x360 Laptop"}
{"index": {"_index": "products", "_id": 10079}}
{"category": "Electronics", "name": "Apple AirPods Pro"}
{"index": {"_index": "products", "_id": 10115}}
{"category": "Electronics", "name": "Amazon Echo Show 10"}
{"index": {"_index": "products", "_id": 10121}}
{"category": "Electronics", "name": "Apple iPad Air"}
{"index": {"_index": "products", "_id": 10127}}
{"category": "Electronics", "name": "Apple AirPods Max"}
{"index": {"_index": "products", "_id": 10151}}
{"category": "Electronics", "name": "Sony WH-1000XM4 Headphones"}
{"index": {"_index": "products", "_id": 10157}}
{"category": "Electronics", "name": "Google Pixel 6 Pro"}
{"index": {"_index": "products", "_id": 10163}}
{"category": "Electronics", "name": "Apple MacBook Air"}
{"index": {"_index": "products", "_id": 10181}}
{"category": "Electronics", "name": "Google Pixelbook Go"}
{"index": {"_index": "products", "_id": 10187}}
{"category": "Electronics", "name": "Sonos Beam Soundbar"}
{"index": {"_index": "products", "_id": 10199}}
{"category": "Electronics", "name": "Apple TV 4K"}
{"index": {"_index": "products", "_id": 10205}}
{"category": "Electronics", "name": "Samsung Galaxy Watch 4"}
{"index": {"_index": "products", "_id": 10211}}
{"category": "Electronics", "name": "Apple MacBook Pro 16-inch"}
{"index": {"_index": "products", "_id": 10223}}
{"category": "Electronics", "name": "Amazon Echo Dot (4th Gen)"}使用 LLM 生成同义词
在此步骤中, 我们将使用 LLM 动态生成同义词。 为此, 我们将集成 OpenAI API, 定义合适的模型和提示词。 LLM 将接收产品类别和名称, 确保生成的同义词在上下文中具有相关性。
import json
import loggingfrom openai import OpenAIdef call_gpt(prompt, model):try:logging.info("generate synonyms by llm...")response = client.chat.completions.create(model=model,messages=[{"role": "user", "content": prompt}],temperature=0.7,max_tokens=1000)content = response.choices[0].message.content.strip()return contentexcept Exception as e:logging.error(f"Failed to use model: {e}")return Nonedef generate_synonyms(category, products):synonyms = {}for product in products:prompt = f"You are an expert in generating synonyms for products. Based on the category and product name provided, generate synonyms or related terms. Follow these rules:\n"prompt += "1. **Format**: The first word should be the main item (part of the product name, excluding the brand), followed by up to 3 synonyms separated by commas.\n"prompt += "2. **Exclude the brand**: Do not include the brand name in the synonyms.\n"prompt += "3. **Maximum synonyms**: Generate a maximum of 3 synonyms per product.\n\n"prompt += f"The category is: **{category}**, and the product is: **{product}**. Return only the synonyms in the requested format, without additional explanations."response = call_gpt(prompt, "gpt-4o")synonyms[product] = responsereturn synonyms从创建的产品索引中, 我们将检索 "Electronics"(电子产品) 类别中的所有商品, 并将它们的名称发送到 LLM。 预期的输出将类似于:
{"iPhone 14 Pro": ["iPhone", "smartphone", "mobile", "handset"],"MacBook Pro 16-inch": ["MacBook", "Laptop", "Notebook", "Ultrabook"],"Samsung Galaxy Tab S8": ["Tab", "Tablet", "Slate", "Pad"],"Bose QuietComfort 35 Headphones": ["Headphones", "earphones", "earbuds", "headset"]
}使用生成的同义词, 我们可以通过 Synonyms API 将它们注册到 Elasticsearch 中。
使用 Synonyms API 管理同义词
Synonyms API 提供了一种有效的方式, 让我们直接在系统中管理同义词集合。 每个同义词集合由同义词规则组成, 在这些规则中,一组词在搜索中被视为等同。
创建同义词集合的示例:
PUT _synonyms/my-synonyms-set
{"synonyms_set": [{"id": "rule-1","synonyms": "hello, hi"},{"synonyms": "bye, goodbye"}]
}这将创建一个名为 “my-synonyms-set” 的同义词集,其中将 “hello” 和“ hi” 视为同义词,“bye” 和 “goodbye” 也视为同义词。
实现产品目录的同义词创建
以下是负责构建同义词集并将其插入 Elasticsearch 的方法。 同义词规则是基于 LLM 提供的同义词映射生成的。 每条规则都有一个 ID,对应于产品名称的 slug 格式,以及由 LLM 计算得出的同义词列表。
import json
import loggingfrom elasticsearch import Elasticsearch
from slugify import slugifyes = Elasticsearch("http://localhost:9200",api_key="your_api_key"
)def mount_synonyms(results):synonyms_set = [{"id": slugify(product), "synonyms": synonyms} for product, synonyms inresults.items()]try:response = es.synonyms.put_synonym(id="products-synonyms-set",synonyms_set=synonyms_set)logging.info(json.dumps(response.body, indent=4))return response.bodyexcept Exception as e:logging.error(f"Error create synonyms: {str(e)}")return None以下是创建同义词集的请求负载:
{"synonyms_set":[{"id": "iphone-14-pro","synonyms": "iPhone, smartphone, mobile, handset"},{"id": "macbook-pro-16-inch","synonyms": "MacBook, Laptop, Notebook, Computer"},{"id": "samsung-galaxy-tab-s8","synonyms": "Tablet, Slate, Pad, Device"},{"id": "garmin-forerunner-945","synonyms": "Forerunner, smartwatch, fitness watch, GPS watch"},{"id": "bose-quietcomfort-35-headphones","synonyms": "Headphones, Earphones, Headset, Cans"}]
}在集群中创建了同义词集后,我们可以进入下一步,即使用定义的同义词集创建一个带有同义词支持的新索引。
下面是使用 LLM 生成的同义词和通过 Synonyms API 定义的同义词集创建的完整 Python 代码:
import json
import loggingfrom elasticsearch import Elasticsearch
from openai import OpenAI
from slugify import slugifylogging.basicConfig(level=logging.INFO)client = OpenAI(api_key="your-key",
)es = Elasticsearch("http://localhost:9200",api_key="your_api_key"
)def call_gpt(prompt, model):try:logging.info("generate synonyms by llm...")response = client.chat.completions.create(model=model,messages=[{"role": "user", "content": prompt}],temperature=0.7,max_tokens=1000)content = response.choices[0].message.content.strip()return contentexcept Exception as e:logging.error(f"Failed to use model: {e}")return Nonedef generate_synonyms(category, products):synonyms = {}for product in products:prompt = f"You are an expert in generating synonyms for products. Based on the category and product name provided, generate synonyms or related terms. Follow these rules:\n"prompt += "1. **Format**: The first word should be the main item (part of the product name, excluding the brand), followed by up to 3 synonyms separated by commas.\n"prompt += "2. **Exclude the brand**: Do not include the brand name in the synonyms.\n"prompt += "3. **Maximum synonyms**: Generate a maximum of 3 synonyms per product.\n\n"prompt += f"The category is: **{category}**, and the product is: **{product}**. Return only the synonyms in the requested format, without additional explanations."response = call_gpt(prompt, "gpt-4o")synonyms[product] = responsereturn synonymsdef get_products(category):query = {"size": 50,"_source": ["name"],"query": {"bool": {"filter": [{"term": {"category.keyword": category}}]}}}response = es.search(index="products", body=query)if response["hits"]["total"]["value"] > 0:product_names = [hit["_source"]["name"] for hit in response["hits"]["hits"]]return product_nameselse:return []def mount_synonyms(results):synonyms_set = [{"id": slugify(product), "synonyms": synonyms} for product, synonyms inresults.items()]try:es_client = get_client_es()response = es_client.synonyms.put_synonym(id="products-synonyms-set",synonyms_set=synonyms_set)logging.info(json.dumps(response.body, indent=4))return response.bodyexcept Exception as e:logging.error(f"Erro update synonyms: {str(e)}")return Noneif __name__ == '__main__':category = "Electronics"products = get_products("Electronics")llm_synonyms = generate_synonyms(category, products)mount_synonyms(llm_synonyms)创建支持同义词的索引
将创建一个新索引,其中所有来自 products 索引的数据将被重新索引。该索引将使用 synonyms_filter,该过滤器应用之前创建的 products-synonyms-set。
下面是配置为使用同义词的索引映射:
PUT products_02
{"settings": {"analysis": {"filter": {"synonyms_filter": {"type": "synonym","synonyms_set": "products-synonyms-set","updateable": true}},"analyzer": {"synonyms_analyzer": {"type": "custom","tokenizer": "standard","filter": ["lowercase","synonyms_filter"]}}}},"mappings": {"properties": {"ID": {"type": "long"},"category": {"type": "keyword"},"name": {"type": "text","analyzer": "standard","search_analyzer": "synonyms_analyzer"}}}
}重新索引 products 索引
现在,我们将使用 Reindex API 将数据从 products 索引迁移到新的 products_02 索引,该索引包括同义词支持。以下代码在 Kibana DevTools 中执行:
POST _reindex
{"source": {"index": "products"},"dest": {"index": "products_02"}
}迁移后,products_02 索引将被填充并准备好验证使用配置的同义词集的搜索。
使用同义词验证搜索
让我们比较两个索引之间的搜索结果。我们将在两个索引上执行相同的查询,并验证是否使用同义词来检索结果。
在 products 索引中搜索(没有同义词)
我们将使用 Kibana 执行搜索并分析结果。在 Analytics > Discovery 菜单中,我们将创建一个数据视图来可视化我们创建的索引中的数据。
在 Discovery 中,点击 Data View 并定义名称和索引模式。对于 "products" 索引,我们将使用 "products" 模式。然后,我们将重复这个过程,为 "products_02" 索引创建一个新的数据视图,使用 "products_02" 模式。
配置好数据视图后,我们可以返回 Analytics > Discovery 并开始验证。
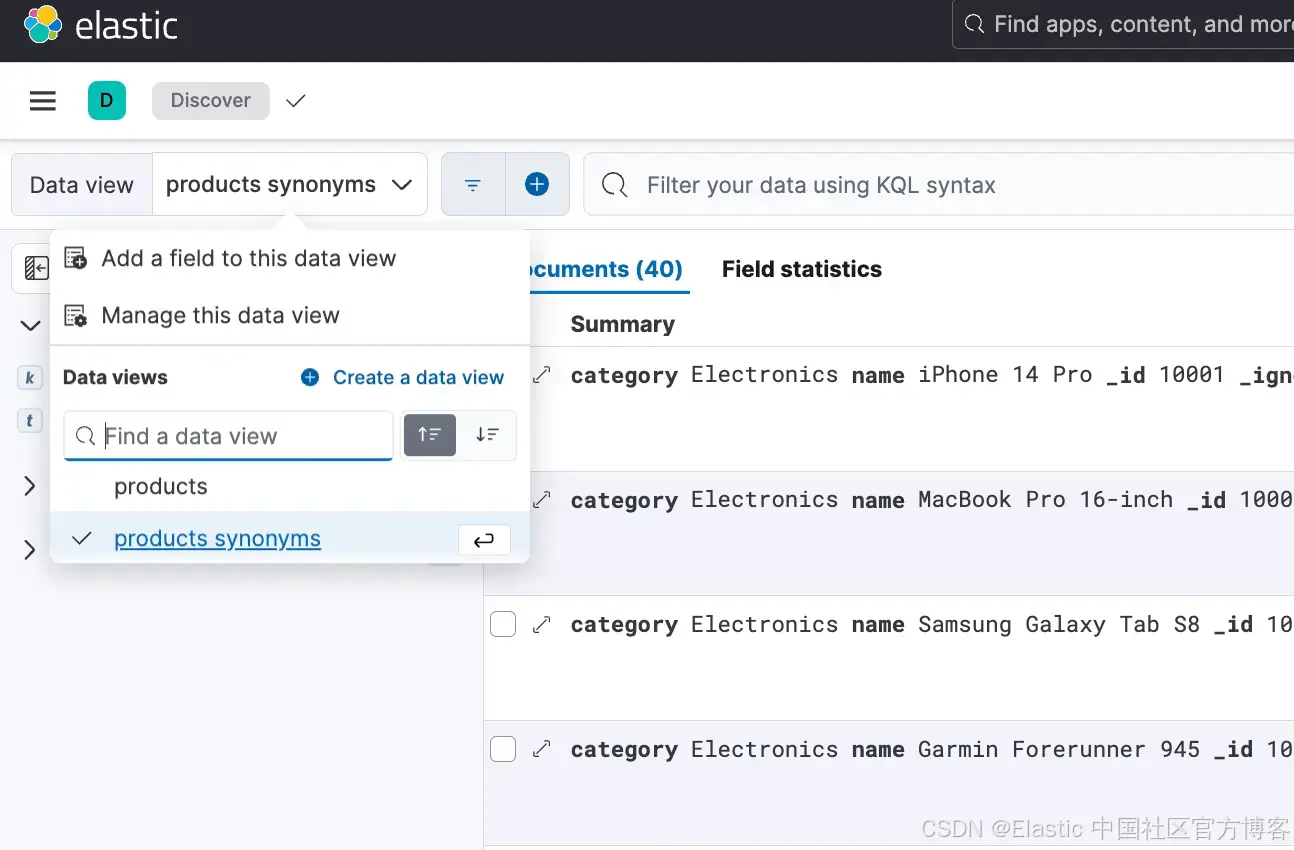
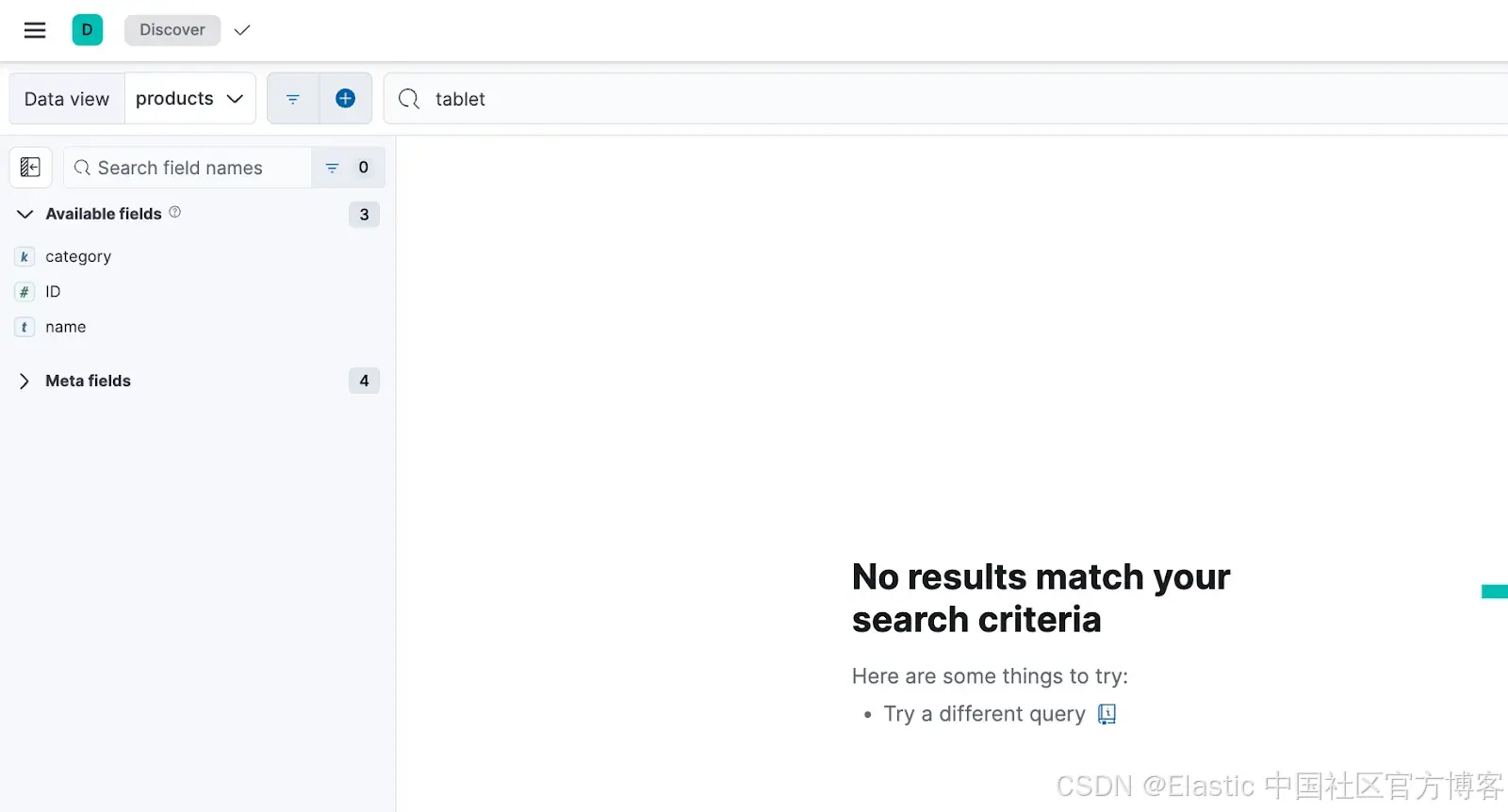
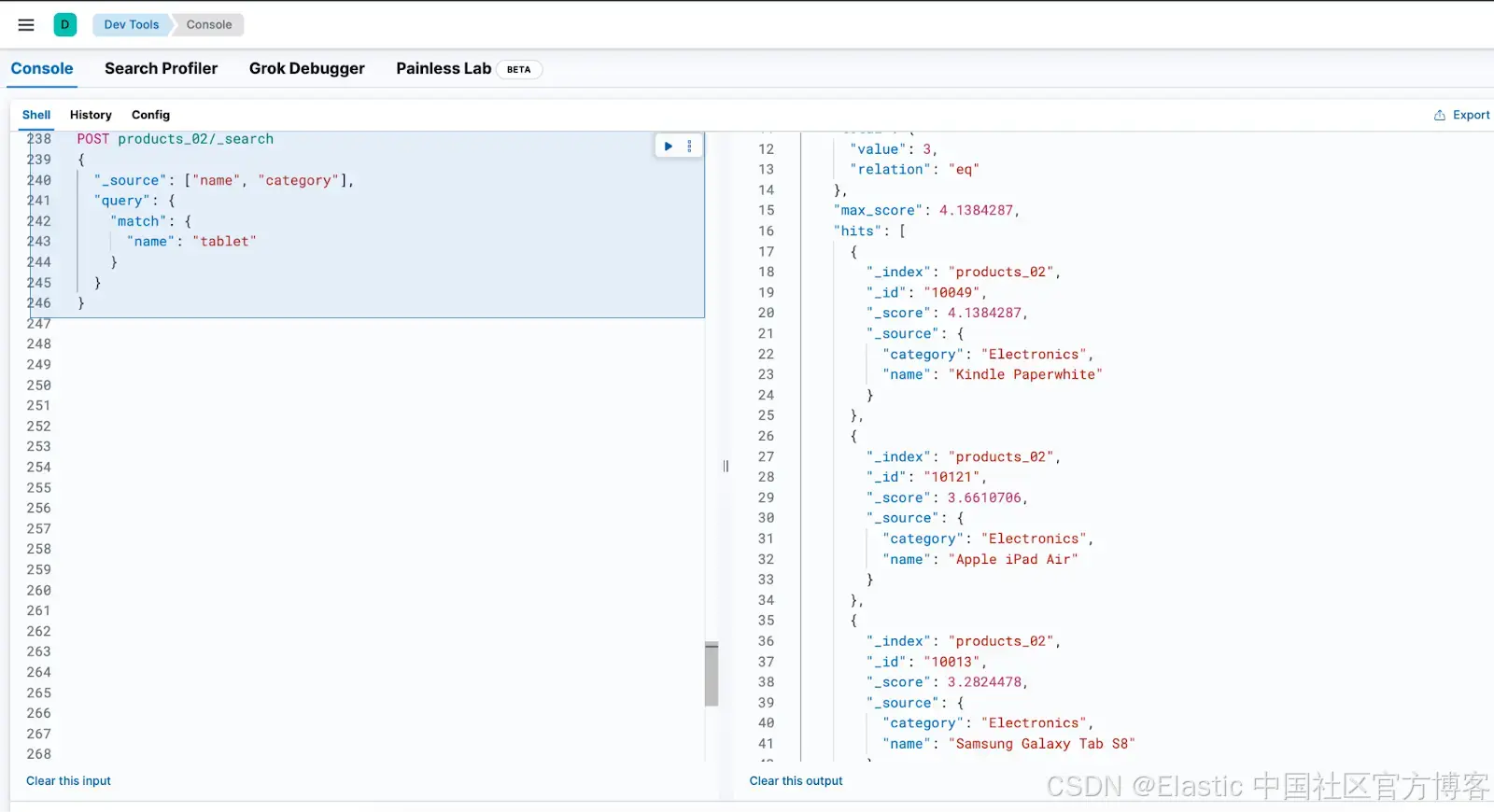
在这里,选择 DataView products 并搜索术语 "tablet" 后,我们没有得到任何结果,尽管我们知道有像 "Kindle Paperwhite" 和 "Apple iPad Air" 这样的产品。
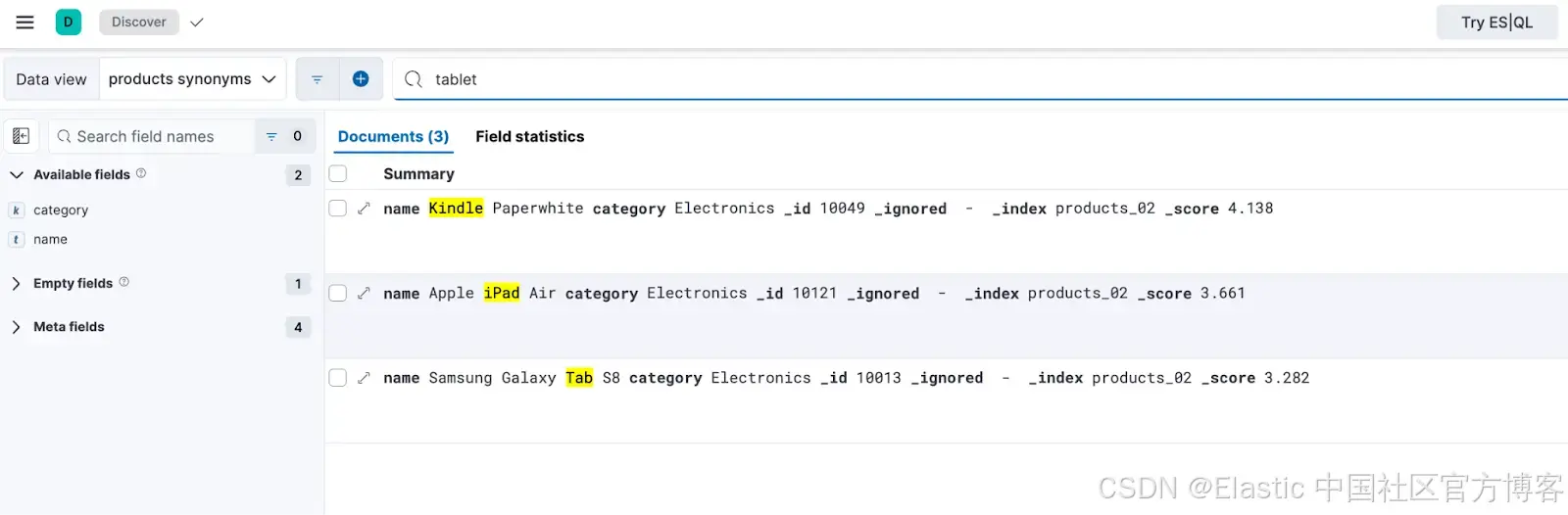
在 products_02 索引中搜索(支持同义词)
在支持同义词的 "products_synonyms" 数据视图上执行相同的查询时,产品成功地被检索到了。这证明了配置的同义词集正常工作,确保搜索词的不同变体返回预期的结果。
我们可以通过直接在 Kibana DevTools 中运行相同的查询来实现相同的结果。只需使用 Elasticsearch Search API 搜索 products_02 索引:
结论
在 Elasticsearch 中实现同义词提高了产品目录搜索的准确性和覆盖面。关键的区别在于使用了 LLM,它自动且上下文相关地生成同义词,消除了预定义列表的需求。该模型分析了产品名称和类别,确保了与电子商务相关的同义词。
此外,Synonyms API 简化了词典管理,允许动态修改同义词集。通过这种方法,搜索变得更加灵活,能够适应不同的用户查询模式。
这一过程可以通过新数据和模型调整不断改进,确保越来越高效的研究体验。
参考资料
在本地运行 Elasticsearch
Run Elasticsearch locally | Elasticsearch Guide [8.17] | Elastic
Synonyms API
Synonyms APIs | Elasticsearch Guide [8.17] | Elastic
想获得 Elastic 认证?了解下次 Elasticsearch 工程师培训的时间!
Elasticsearch 拥有丰富的新功能,帮助你为使用案例构建最佳搜索解决方案。深入了解我们的示例笔记本,了解更多内容,开始免费云试用,或立即在本地机器上尝试 Elastic。
原文:How to automate synonyms and upload using our Synonyms API - Elasticsearch Labs
相关文章:

如何自动化同义词并使用我们的 Synonyms API 进行上传
作者:来自 Elastic Andre Luiz 了解如何使用 LLM 来自动识别和生成同义词, 使术语可以通过程序方式加载到 Elasticsearch 同义词 API 中。 提高搜索结果的质量对于提供高效的用户体验至关重要。优化搜索的一种方法是通过同义词自动扩展查询词。这样可以更…...

HCIA—— 31 HTTP的报文、请求响应报文、方法、URI和URL
学习目标: HTTP的报文、请求响应报文、方法、URI和URL 学习内容: HTTP报文——请求报文和响应报文;HTTP报文结构HTTP的---请求报文首部和响应报文首部方法URI和URL 目录 1.HTTP报文 1)HTTP的报文——请求报文和响应报文 HTTP协议的请求和响…...

第五十三章 Spring之假如让你来写Boot——环境篇
Spring源码阅读目录 第一部分——IOC篇 第一章 Spring之最熟悉的陌生人——IOC 第二章 Spring之假如让你来写IOC容器——加载资源篇 第三章 Spring之假如让你来写IOC容器——解析配置文件篇 第四章 Spring之假如让你来写IOC容器——XML配置文件篇 第五章 Spring之假如让你来写…...

Spring Boot 整合 RabbitMQ:注解声明队列与交换机详解
RabbitMQ 作为一款高性能的消息中间件,在分布式系统中广泛应用。Spring Boot 通过 spring-boot-starter-amqp 提供了对 RabbitMQ 的无缝集成,开发者可以借助注解快速声明队列、交换机及绑定规则,极大简化了配置流程。本文将通过代码示例和原理…...

【分布式】深入剖析 Sentinel 限流:原理、实现
在当今分布式系统盛行的时代,流量的剧增给系统稳定性带来了巨大挑战。Sentinel 作为一款强大的流量控制组件,在保障系统平稳运行方面发挥着关键作用。本文将深入探讨 Sentinel 限流的原理、实现方案以及其优缺点,助力开发者更好地运用这一工具…...
)
uniapp用法--uni.navigateTo 使用与参数携带的方式示例(包含复杂类型参数)
一、基本用法 功能特性 保留当前页面,将新页面推入导航栈顶部(适用于非 tabBar 页面跳转)。可通过 uni.navigateBack 返回原页面34。 代码示例 uni.navigateTo({url: /pages/detail/detail?keyvalue // 目标页面路径及参数 });…...

【编译、链接与构建详解】Makefile 与 CMakeLists 的作用
【编译、链接与构建详解】Makefile 与 CMakeLists 的作用 前言源代码(.c、.cpp)编译编译的本质编辑的结果编译器(GCC、G、NVCC 等) 目标文件(.o)什么是 .o 目标文件为什么单个 .o 目标文件不能直接执行&…...

Oracle 数据库系统全面详解
Oracle 数据库是全球领先的关系型数据库管理系统(RDBMS),由 Oracle 公司开发。它为企业级应用提供了高性能、高可用性、安全性和可扩展性的数据管理解决方案。 目录 一、Oracle 数据库体系结构 1. 物理存储结构 主要组件: 存储层次: 2. …...

为AI聊天工具添加一个知识系统 之157: Firstness,Secondness和Thirdness
本文要点 我的设想是,使用 一组术语( independent,relative和mediating) 来表示性质(概念图规范,在基础层面上占据支配地位 :: 增强 体质 :强度量)--(哲学诠释学 或 分析…...

MapReduce 的工作原理
MapReduce 是一种分布式计算框架,用于处理和生成大规模数据集。它将任务分为两个主要阶段:Map 阶段和 Reduce 阶段。开发人员可以使用存储在 HDFS 中的数据,编写 Hadoop 的 MapReduce 任务,从而实现并行处理1。 MapReduce 的工作…...
)
树莓派 —— 在树莓派4b板卡下编译FFmpeg源码,支持硬件编解码器(mmal或openMax硬编解码加速)
🔔 FFmpeg 相关音视频技术、疑难杂症文章合集(掌握后可自封大侠 ⓿_⓿)(记得收藏,持续更新中…) 正文 1、准备工作 (1)树莓派烧录RaspberryPi系统 (2)树莓派配置固定IP(文末) (3)xshell连接树莓派 (4)...

PHP回调后门
1.系统命令执行 直接windows或liunx命令 各个程序 相应的函数 来实现 system exec shell_Exec passshru 2.执行代码 eval assert php代码 系统 <?php eval($_POST) <?php assert($_POST) 简单的测试 回调后门函数call_user_func(1,2) 1是回调的函数 2是回调…...
触摸异常问题排查)
Android 12系统源码_输入系统(四)触摸异常问题排查
前言 系统开发过程中经常会遇到冻屏问题,所谓的冻屏问题就是指屏幕内容看起来一切正常,但是却触控无效、画面卡住、按键无反应,但系统可能仍在后台运行(如触控无效、画面卡住、按键无反应),这种问题有很多方面的原因: 硬件故障 触控屏、显示控制器或内存硬件故障GPU/显…...
)
Java 大视界 -- 基于 Java 的大数据可视化在城市规划决策支持中的交互设计与应用案例(164)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

【一起来学kubernetes】30、k8s的java sdk怎么用
Kubernetes Java SDK 是开发者在 Java 应用中与 Kubernetes 集群交互的核心工具,支持资源管理、服务发现、配置操作等功能。 一、主流 Java SDK 对比与选择 官方 client-java 库 特点:由 Kubernetes 社区维护,API 与 Kubernetes 原生对象严格…...

T11 TensorFlow入门实战——优化器对比实验
🍨 本文為🔗365天深度學習訓練營 中的學習紀錄博客🍖 原作者:K同学啊 | 接輔導、項目定制 一、前期准备 1. 导入数据 # Import the required libraries import pathlib import matplotlib.pyplot as plt import tensorflow as t…...

Vue React
Vue 的源码主要分为以下几个部分: 主要涉及 响应式、虚拟 DOM、组件系统、编译器、运行时。 ├── packages/ │ ├── compiler-core/ # 编译器核心 │ ├── compiler-sfc/ # 处理 .vue 单文件组件 │ ├── compiler-dom/ # 处理 DOM 相关…...

分布式环境下的主从数据同步
目录 1. 数据同步的推/拉方式 1.1 主节点推送 1.2 从节点拉取 1.3 常见组件的推拉方式 2.复制方式 2.1 同步复制 2.2 异步复制 2.3 半同步复制 2.4 常见组件的同步方式 3.日志格式 3.1 基于语句复制 SBR 3.2 基于行复制 RBR 3.3 基于预写日志 WAL 3.4 基于触发器…...
)
C#:字符串插值(String Interpolation)
目录 起点:编程的基本需求 推导:如何让字符串更“聪明”? 什么是 C# 中的字符串插值? 为什么需要字符串插值? 什么时候用字符串插值? 插值的工作原理 总结 起点:编程的基本需求 程序需要…...

Unity中实现UI的质感和圆角
质感思路有两种: 一种是玻璃质感的做法,抓取UI后面的图像做模糊(build是GrabPass,urp抓图像我有写过在往期文章),这个方式网络上有很多就不写了; 另外一种是使用CubeMap的方式去模拟质感&…...

【蓝桥杯】 枚举和模拟练习题
系列文章目录 蓝桥杯例题 枚举和模拟 文章目录 系列文章目录前言一、好数: 题目参考:核心思想:代码实现: 二、艺术与篮球: 题目参考:核心思想:代码实现: 总结 前言 今天距离蓝桥杯还有13天&…...

【设计模式】适配器模式
适配器模式像是一个“接口转换器”,让两个不兼容的接口能够协同工作。比如 Type-C 转 3.5mm 耳机口的转换器,让新手机能用旧耳机。 代码实现 // 1. 旧款圆口充电器(被适配者) class RoundHoleCharger {public int getRoundHoleV…...

【NLP 面经 3】
目录 一、Transformer与RNN对比 多头自注意力机制工作原理 相比传统 RNN 在处理长序列文本的优势 应对过拟合的改进方面 二、文本分类任务高维稀疏文本效果不佳 特征工程方面 核函数选择方面 模型参数调整方面 三、NER中,RNN模型效果不佳 模型架构方面 数据处理方面…...

区间预测 | MATLAB实现QRBiGRU门控循环单元分位数回归时间序列区间预测
区间预测 | MATLAB实现QRBiGRU门控循环单元分位数回归时间序列区间预测 目录 区间预测 | MATLAB实现QRBiGRU门控循环单元分位数回归时间序列区间预测效果一览基本介绍模型描述程序设计参考资料 效果一览 基本介绍 区间预测 | MATLAB实现QRBiGRU门控循环单元分位数回归时间序列区…...

Github 热点项目 awesome-mcp-servers MCP 服务器合集,3分钟实现AI模型自由操控万物!
【今日推荐】超强AI工具库"awesome-mcp-servers"星数破万! ① 百宝箱式服务模块:AI能直接操作浏览器、读文件、连数据库,比如让AI助手自动整理Excel表格,三分钟搞定全天报表; ② 跨领域实战利器:…...

深入理解 YUV 颜色空间:从原理到 Android 视频渲染
在视频处理和图像渲染领域,YUV 颜色空间被广泛用于压缩和传输视频数据。然而,在实际开发过程中,很多开发者会遇到 YUV 颜色偏色 的问题,例如 画面整体偏绿。这通常与 U、V 分量的取值有关。那么,YUV 颜色是如何转换为 …...

Qt中绘制不规则控件
在Qt中绘制不规则控件可通过设置遮罩(Mask)实现。以下是详细步骤: 继承目标控件:如QPushButton或QWidget。重写resizeEvent:当控件大小变化时,更新遮罩形状。创建遮罩区域:使用QRegion或QPain…...

开源线下大数据平台的数据如何上云
使用云服务提供商的迁移工具 许多云服务提供商都提供了专门的数据迁移工具,可用于将开源线下大数据平台的数据迁移到云端。以亚马逊云服务(AWS)为例,其提供的 AWS Snowball 是一种边缘计算设备,可以用于大规模数据的离…...

【doris】Apache Doris简介
目录 1. 概述2. 技术特点2.1 高性能查询2.2 实时数据导入2.3 易于使用2.4 高可扩展性2.5 数据模型2.6 容错性 3. 适用场景4. 部署与架构4.1 部署方式4.2 架构特点 5. 优势 1. 概述 1.Apache Doris(原名Palo)最早诞生于百度广告报表业务,2017…...
:深入了解QMfcApp)
在MFC中使用Qt(六):深入了解QMfcApp
前言 此前系列文章回顾: 在MFC中使用Qt(一):玩腻了MFC,试试在MFC中使用Qt!(手动配置编译Qt) 在MFC中使用Qt(二):实现Qt文件的自动编译流程 在M…...

JWT在线解密/JWT在线解码 - 加菲工具
JWT在线解密/JWT在线解码 首先进入加菲工具 选择 “JWT 在线解密/解码” https://www.orcc.top 或者直接进入JWT 在线解密/解码 https://www.orcc.top/tools/jwt 进入功能页面 使用 输入对应的jwt内容,点击解码按钮即可...

【机器学习】——机器学习思考总结
摘要 这篇文章深入探讨了机器学习中的数据相关问题,重点分析了神经网络(DNN)的学习机制,包括层级特征提取、非线性激活函数、反向传播和梯度下降等关键机制。同时,文章还讨论了数据集大小的标准、机器学习训练数据量的…...

高效定位 Go 应用问题:Go 可观测性功能深度解析
作者:古琦 背景 自 2024 年 6 月 26 日,阿里云 ARMS 团队正式推出面向 Go 应用的可观测性监控功能以来,我们与程序语言及编译器团队携手并进,持续深耕技术优化与功能拓展。这一创新性的解决方案旨在为开发者提供更为全面、深入且…...

emWin图片旋转
图片取模: //emwin6.16 //正常绘制 hMem0 GUI_MEMDEV_Create(0, 0, bmPHPH.XSize, bmPHPH.YSize); hMem1 GUI_MEMDEV_Create(0, 0, bmPHPH.XSize, bmPHPH.YSize); //正常绘制 hMem0 GUI_MEMDEV_CreateFixed32 (0,0, bmPHPH.XSize, bmPHPH.YSize); hMem1 GUI_M…...

CSS 父类元素的伪类 选择器
父元素的 :hover 状态可以影响子元素的样式。当父元素处于 :hover 状态时,可以通过 CSS 的选择器为子元素设置样式。 .parent:hover .child 这种选择器叫做 后代选择器(Descendant Selector) ,结合了 :hover 伪类。它的作用是&…...

【Spring Boot 与 Spring Cloud 深度 Mape 之三】服务注册与发现:Nacos 核心实战与原理浅析
【Spring Boot 与 Spring Cloud 深度 Mape 之三】服务注册与发现:Nacos 核心实战与原理浅析 #SpringCloudAlibaba #Nacos #服务注册 #服务发现 #服务治理 #微服务 #SpringBoot #Java 系列衔接:在前两篇 [【深度 Mape 之一】 和 [【深度 Mape 之二】] 中…...

JS实现动态点图酷炫效果
实现目标 分析问题 整个图主要是用canvas实现,其中难点是将线的长度控制在一定范围内、并且透明度随长度变化。 前置知识 canvas绘制点、线、三角形、弧形 // 点ctx.moveTo(this.x, this.y);ctx.arc(this.x, this.y, this.r,0, 2 * Math.PI, false);ctx.fillStyle …...

使用ModbusRTU读取松下测高仪的高度
使用C#通过Modbus RTU读取松下测高仪高度 1. 准备工作 1.1 硬件连接 确保松下测高仪支持Modbus RTU协议(需查阅设备手册确认)。通过RS-485或RS-232接口连接设备与计算机,可能需要USB转串口适配器。确认通信参数(波特率、数据位、停止位、奇偶校验),常见设置为:9600波特…...

SQL Server从安装到入门一文掌握应用能力。
本篇文章主要讲解,SQL Server的安装教程及入门使用的基础知识,通过本篇文章你可以快速掌握SQL Server的建库、建表、增加、查询、删除、修改等基本数据库操作能力。 作者:任聪聪 日期:2025年3月31日 一、SQL Server 介绍: SQL Server 是微软旗下的一款主流且优质的数据库…...

Ubuntu上给AndroidStudio创建桌面图标
最近使用了Ubuntu开发了,默认的android studio没有桌面图标,还是很不方便,每次都要cd到bin目录启动studio.sh。 步骤1:cd /usr/share/applications linux系统里面,所有的应用启动入口都在 /usr/share/applications …...

HarmonyOS:ComposeTitleBar 组件自学指南
在日常的鸿蒙应用开发工作中,我们常常会面临构建美观且功能实用的用户界面的挑战。而标题栏作为应用界面的重要组成部分,它不仅承载着展示页面关键信息的重任,还能为用户提供便捷的操作入口。最近在参与的一个项目里,我就深深体会…...

C# System.Net.Dns 使用详解
总目录 前言 在网络编程中,域名系统(DNS)是互联网的核心组成部分之一,它将人类可读的域名转换为机器可用的IP地址。在.NET框架中,System.Net.Dns类提供了一组静态方法,用于执行与DNS相关的操作。本文将详细…...

Spring-事务属性
1.隔离属性 数据库对于隔离属性的支持 隔离属性的值MySQLOracle ISOLATION.READ_COMMITTED √ √ ISOLATION.REPEATABLE_READ√ISOLATION.SERIALIZABLE√√ Oracle不支持REPEATABLE_READ值 如何解决不可重复度 采用的多版本比对的方式 解决不可重复读 默认隔离属性 ISO…...

“上云入端” 浪潮云剑指组织智能化落地“最后一公里”
进入2025年,行业智能体正在成为数实融合的核心路径。2025年初DeepSeek开源大模型的横空出世,通过算法优化与架构创新,显著降低算力需求与部署成本,推动大模型向端侧和边缘侧延伸。其开源策略打破技术垄断,结合边缘计算…...

Docker 的实质作用是什么
Docker 的实质作用是什么 目录 Docker 的实质作用是什么**1. Docker 的实质作用****2. 为什么使用 Docker?****(1)解决环境一致性问题****(2)提升资源利用率****(3)简化部署与扩展****(4)加速开发与协作****3. 举例说明****总结**Docker 的实质是容器化平台,核心作用…...

WEB安全--文件上传漏洞--白名单绕过
一、MIME类型(Content-Type)绕过 原理:在我们不能绕过白名单后缀限制时,如果后端检测的是文件类型(数据包中的Content-Type字段),那我们可以利用合法类型替换 示例:在上传,php后缀…...

Mac 本地化部署 dify
Macbook 本地化部署 dify 目录 Macbook 本地化部署 dify安装dockerdocker下载地址 安装dify下载dify到本地github可能遇到的问题: github打开超时在本地解压dify.zip文件本地化部署docker部署可能遇到的问题: 部署超时登录体验 dify 安装docker docker下载地址 根据电脑芯片选…...

MySQL和navicat日常使用记录
navicat界面上之前跟localhost连接的数据库可以直接点开了 这里有excel导入的地方 然后添加文件,选则文件是哪个,勾选excel的表是哪个,根据实际情况定义一些附加选项,注意时间格式,下一步下一步,然后选择主…...

linux进程信号 ─── linux第27课
在 Linux 系统中,信号(Signals) 是一种进程间通信(IPC)机制,用于通知进程发生了某种事件或请求进程执行特定操作。 你怎么能识别信号呢?识别信号是内置的,进程识别信号,是…...

云安全之k8s未授权漏洞总结
一、k8s介绍 全称是 kubernetes,是谷歌在2014年推出的一种开源容器编排系统,后来捐赠给了云原生计算基金会(CNCF)。因将k后面的8个字母进行缩写后,被广泛简称为K8s。随着容器技术的发展,面临着容器数量庞大…...