JavaEE--多线程
一、认识线程
1. 什么是线程
线程(Thread)是计算机科学中的基本概念,指的是程序内部的一条执行路径。一个进程可以包含多个线程,每个线程共享进程的资源,包括内存空间、文件描述符等。线程可以同时执行多个任务,提高程序的效率和性能。在多线程编程中,程序可以同时执行多个线程,每个线程独立执行自己的任务,但又共享进程的资源。线程之间可以通过共享内存进行通信,也可以互相协调合作完成任务。线程是操作系统能够进行调度和管理的最小单位,也是实现并发编程的重要手段。
2. 为什么要有线程
- 并发线程成为刚需
- 虽然多进程也能实现并发编程,但线程比进程更轻量
进程和线程的区别
- 线程虽然比进程轻量, 但是人们还不满足,,于是又有了 "线程池"和 "协程"
3. 线程调度
指线程在CPU上执行的过程。若一个进程包含多个线程,此时,多个线程之间是各自去CPU上调度执行的。
PCB进程控制块当中的调度相关、进程状态、优先级、记账信息、上下文,每个线程都有这样一份数据。一个进程有10个进程就有10份这样的数据,但这10个线程,共用一个文件描述符表和内存指针。
4. 第一个多线程程序
class MyThread extends Thread{//run 相当于线程的入口程序@Overridepublic void run() {while(true){System.out.println("hello thread");try {//sleep是一个静态方法,停止运行1000msThread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}}
}public class multiThreading {public static void main(String[] args) throws InterruptedException {Thread t = new MyThread();//在系统中创建出一个线程t.start();while (true) {System.out.println("hello main");Thread.sleep(1000);}}
}
打印“hello thread”“hello main”死循环:

在线程运行时可以使用jconsole命令观察线程:
根据此路径可以找到C:\Program Files\Java\jdk-17\bin

打开后连接进程:
此时会弹出一个警告,直接选择“不安全的连接”:
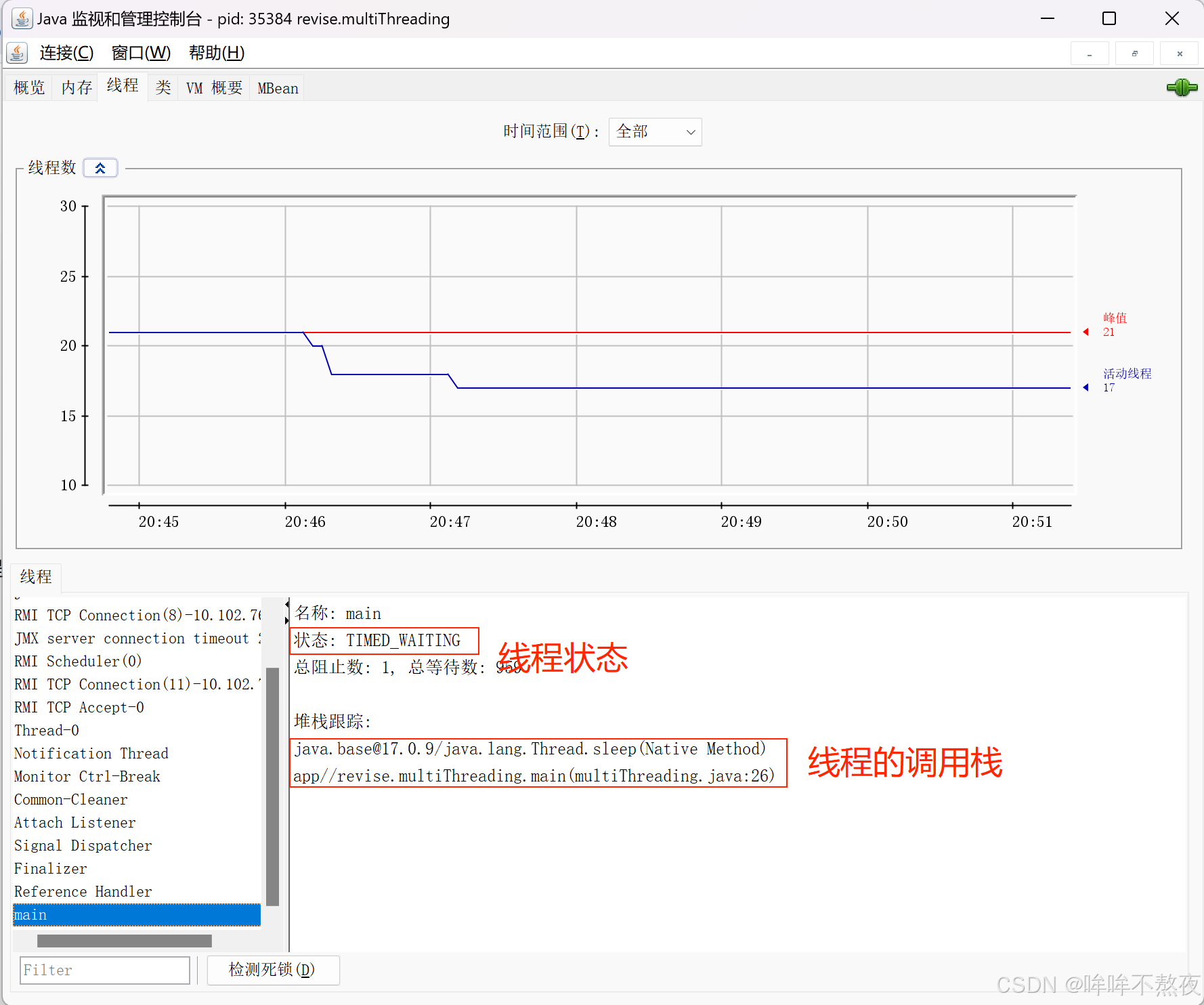
然后,选择“线程”:

最后,在此窗口中观察线程:

二、创建线程
有以下五种方法:
1. 继承Thread类,重写run
代码参考刚才的“第一个多线程程序”。
2. 实现Runnable接口,重写run
class MyRunnable implements Runnable {@Overridepublic void run() { // 线程的入口方法while (true) {System.out.println("hello thread");try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}}
}public class multiThreading {public static void main(String[] args) throws InterruptedException {Runnable runnable = new MyRunnable();Thread t = new Thread(runnable);t.start();// start方法真正在系统中创建线程while (true) {System.out.println("hello main");Thread.sleep(1000);}}
}3. 匿名内部类创建Thread子类对象
Thread thread = new Thread() {@Overridepublic void run() {System.out.println("Hello Thread");}
};
thread.start();
4. 匿名内部类创建Runnable子类对象
Thread thread = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("Hello Thread");}
});
thread.start();
5. lambda表达式创建Runnable子类对象(推荐)
Thread thread = new Thread(() -> {System.out.println("Hello Thread");
});
thread.start();
三、Thread类及常见方法
Thread类是Java中表示线程的类,它位于java.lang包中。通过Thread类,我们可以创建线程对象并控制线程的执行。每个Java应用程序都至少有一个主线程,可以通过创建Thread类的实例来创建额外的线程。
1. Thread的常见构造方法
| 方法 | 说明 |
|---|---|
| Thread() | 无参构造方法,创建一个新线程对象。 |
| Thread(Runnable target) | 接收一个Runnable接口实现类作为参数,创建一个新线程对象,并将目标任务指定为传入的Runnable实现类。 |
| Thread(String name) | 接收一个线程名称作为参数,创建一个新线程对象,并指定名称。 |
| Thread(Runnable target, String name) | 接收一个Runnable接口实现类和一个线程名称作为参数,创建一个新线程对象,并将目标任务和线程名称指定为传入的参数。 |
| Thread(ThreadGroup group, Runnable target) | 接收一个线程组和一个Runnable接口实现类作为参数,创建一个新线程对象,并将线程添加到指定的线程组中。 |
| Thread(ThreadGroup group, Runnable target, String name) | 接收一个线程组、一个Runnable接口实现类和一个线程名称作为参数,创建一个新线程对象,并将线程添加到指定的线程组中,同时指定名称。 |
2. Thread的几个常见属性
| 属性 | 获取方法 | 说明 |
|---|---|---|
| ID | getId() | ID是线程的唯一标识,不同线程不会重复。 |
| 名称 | getName() | 名称是各种调试工具用的。 |
| 状态 | getState() | 表示线程当前所处的状态,如新建状态、就绪状态、运行状态、阻塞状态、等待状态、终止状态等。 |
| 优先级 | getPriority() | 线程的优先级,用于指定线程在竞争CPU资源时的优先级。 |
| 是否是后台线程 | isDaemon() | JVM会在一个进程的所有非后台线程结束后,才会结束运行。 |
| 是否存活 | isAlive() | run方法是否运行结束。 |
| 是否被中断 | isInterrupted() | 仅用于检查当前线程的中断状态,不会对其他线程的中断状态产生影响。 |
public class multiThreading {public static void main(String[] args) throws InterruptedException {Thread thread = new Thread(() -> {for (int i = 0; i < 10; i++) {try {System.out.println(Thread.currentThread().getName() + ": 我还活着");Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}System.out.println(Thread.currentThread().getName() + ": 我即将死去");});System.out.println(Thread.currentThread().getName() + ": ID: " + thread.getId());System.out.println(Thread.currentThread().getName() + ": 名称: " + thread.getName());System.out.println(Thread.currentThread().getName() + ": 状态: " + thread.getState());System.out.println(Thread.currentThread().getName() + ": 优先级: " + thread.getPriority());System.out.println(Thread.currentThread().getName()+ ": 后台线程: " + thread.isDaemon());System.out.println(Thread.currentThread().getName() + ": 活着: " + thread.isAlive());System.out.println(Thread.currentThread().getName() + ": 被中断: " + thread.isInterrupted());thread.start();while (thread.isAlive()) {}System.out.println(Thread.currentThread().getName() + ": 状态: " + thread.getState());}
}

3. 启动线程--start()
之前我们已经看到了如何通过覆写 run 方法创建⼀个线程对象,但线程对象被创建出来并不意味着线程就开始运行了。调用start方法,才真的在操作系统的底层创建出一个线程。
一个thread方法,只能调用一次。
4. 中断线程--interrupt()
在线程的执行过程中,可以通过调用interrupt()方法来设置线程的中断状态,使得线程在合适的时候能够进行中断。
public class multiThreading {public static void main(String[] args) throws InterruptedException {Thread thread = new Thread(() -> {while(!Thread.currentThread().isInterrupted()){System.out.println("hello thread");try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}System.out.println("t结束");});thread.start();Thread.sleep(3000);thread.interrupt();System.out.println("main线程尝试终止thread线程...");}
}

每次执行循环,绝大部分时间都是在sleep,主线程中调用Interrupt能够唤醒sleep,sleep则会抛出InterruptedException,我们可以在catch异常时用break来结束。
修改后:
public class multiThreading {public static void main(String[] args) throws InterruptedException {Thread thread = new Thread(() -> {while(!Thread.currentThread().isInterrupted()){System.out.println("hello thread");try {Thread.sleep(1000);} catch (InterruptedException e) {//throw new RuntimeException(e);break;}}System.out.println("t结束");});thread.start();Thread.sleep(3000);thread.interrupt();System.out.println("main线程尝试终止thread线程...");}
}

若上述代码不加break(空着的),那么线程不会终止:

针对上述代码,其实是sleep在搞鬼。正常来说,调用Interrupt方法就会修改isInterruptted方法内部的标志位,设为true,由于Interrupt方法把sleep给提前唤醒了,sleep就会把isInterruptted的标志位设置回false。因此在这样的情况下,如果继续执行到循环条件判定,就会发现能够继续执行。
5. 等待线程--join()
在主线程中调用thread.join,就是让主线程等待thread线程结束。
虽然可以通过sleep设置休眠时间来控制线程结束的顺序,但是有的时候,我们希望thread先结束,main就可以紧跟着结束了,此时通过设置时间的方式不一定靠谱。
public class multiThreading {public static void main(String[] args) throws InterruptedException {Thread thread = new Thread(() -> {for (int i = 0; i < 300; i++) {System.out.println("hello thread");try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}System.out.println("thread线程结束");});thread.start();thread.join(); //main线程等待thread线程结束System.out.println("main线程结束");}
}

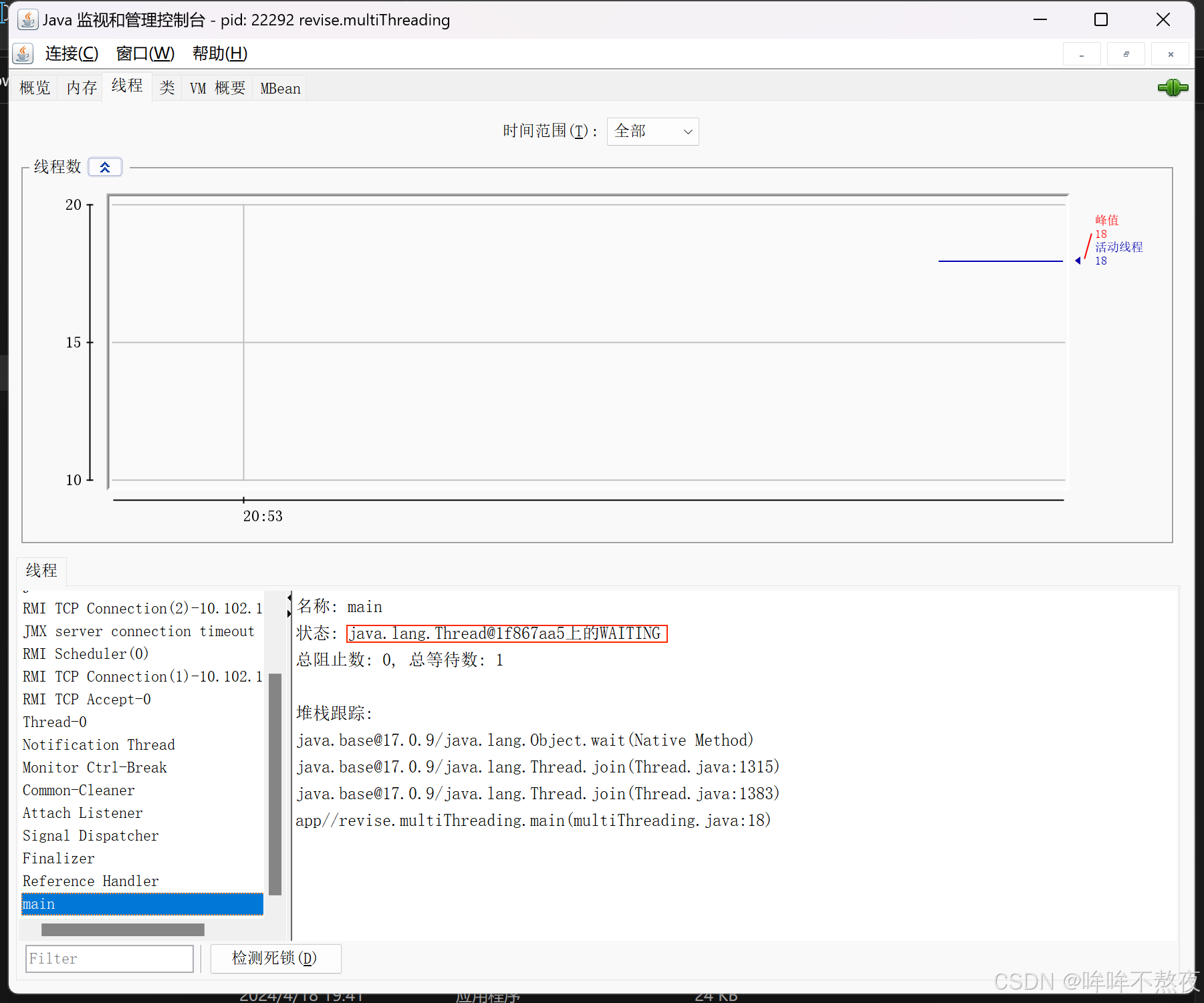
只要thread不结束,主线程就会一直一直等下去。这个方法也不怎么科学……
join提供了带参数的版本,可以指定“等待的最大时间”:
| 方法 | 说明 |
|---|---|
| public void join(long millis) | 等待线程结束,最多等millis毫秒 |
| public void joid(long millis, int nanos) | 可以精确到纳秒 |
6. 获取当前线程的引用--currentThread()
类似于this的用法。
7. 休眠线程--sleep()
因为线程的调度是不可控的,所以这个方法只能保证实际休眠时间大于等于参数设置的休眠时间。
时间到,意味着允许被调度了,而不是就立即执行了。
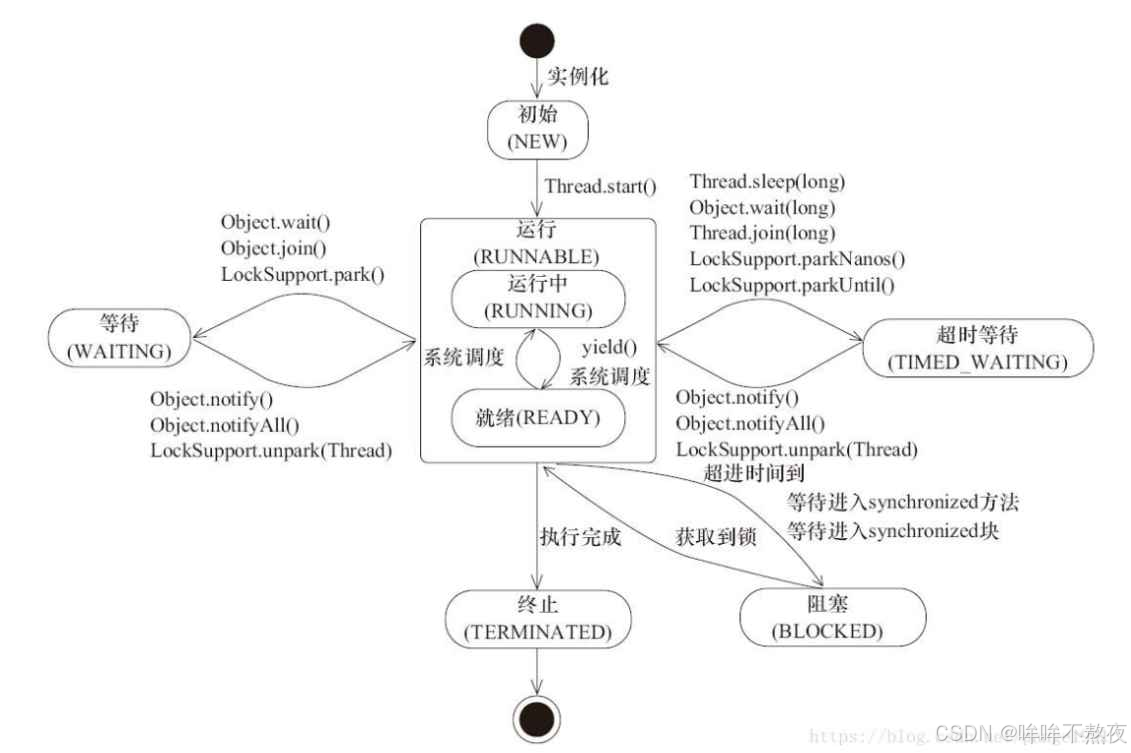
四、线程状态
线程状态是指线程在其生命周期中所处的不同状态,包括新建状态、就绪状态、运行状态、阻塞状态和终止状态。线程的状态会随着不同的操作和条件而发生变化。
线程状态的概念和应用对于多线程编程非常重要,通过控制线程的状态,可以实现线程的同步、协作和调度。在实际应用中,开发人员需要根据具体的需求和场景合理地管理线程的状态,避免出现死锁、饥饿等并发问题,提高程序的性能和可靠性。
观察线程状态:
public class ThreadState {public static void main(String[] args) {for (Thread.State state : Thread.State.values()) {System.out.println(state);}}
}有以下几种状态:
- NEW:安排了工作,还未开始行动
- RUNNABLE:线程正在CPU上运行或线程随时可以去CPU上运行
- TIMED_WAITING:指定了超时时间的阻塞
- WAITING:没有超时时间的阻塞
- BLOCKED:由于锁而导致的阻塞
- TERMINATED:线程终止状态
五、线程安全问题
1. 观察线程不安全
public class multiThreading {private static int count = 0;public static void main(String[] args) throws InterruptedException {Thread thread1 = new Thread(() -> {for (int i = 0; i < 50000; i++) {count++;}});Thread thread2 = new Thread(() -> {for (int i = 0; i < 50000; i++) {count++;}});thread1.start();thread2.start();thread1.join();thread2.join();System.out.println(count);}
}这段代码预期输出100000,实际输出……

再多运行几次会发现,每次的输出结果都不一样,且都小于100000。
当前bug是由于多线程的并发执行代码引起的,成为“线程安全问题”,或者叫作“线程不安全”。
出现bug的原因:
站在线程的角度:线程是并发执行的,调度是随机的。
站在cpu执行指令的角度:
count++ 这句代码实际上对应到3个cpu指令:
- load 把内存中的值(count变量)读取到cpu寄存器
- add 把指定寄存器中的值,进行 +1 操作(结果还是在这个寄存器中)
- save 把寄存器中的值,写回到内存中
cpu执行这三条指令的过程中,随时可能触发线程调度的切换,如:
123 线程切走……
12 线程切走…… 线程切回来 3
1 线程切走…… 线程切回来 23
1 线程切走…… 线程切回来 2 线程切走…… 线程切回来 3
……
由于操作系统的调度是随机的,执行任何一个指令的过程中,都可能触发上述的“线程切换”操作。
所以,将上述代码改成串行执行,就可以解决这个bug。
public class multiThreading {private static int count = 0;public static void main(String[] args) throws InterruptedException {Thread thread1 = new Thread(() -> {for (int i = 0; i < 50000; i++) {count++;}});Thread thread2 = new Thread(() -> {for (int i = 0; i < 50000; i++) {count++;}});// 修改后thread1.start();thread1.join();thread2.start();thread2.join();System.out.println(count);}
}
![]()
2. 线程安全原因的产生原因
- (根本原因)操作系统对于线程的调度是随机的
- 多个线程同时修改同一个变量,如上述代码中的“count”
- 修改操作不是原子的
什么事原子性?
原子性是指一个操作要么全部执行成功,要么全部不执行,不会出现部分执行的情况。在并发编程中,原子性是指一个操作在执行时不会被中断,要么完全执行成功,要么完全不执行,不会出现中间状态。
在多线程或多进程环境下,多个线程或进程同时访问共享的资源时,如果某个操作是原子的,那么就可以保证多个线程或进程在对这个操作的访问不会相互影响,不会出现数据不一致的情况。
常见的原子操作包括自增、自减、赋值等简单的操作。在并发编程中,原子性是确保数据一致性和线程安全的重要概念,通常通过同步机制(比如锁、信号量、原子操作等)来实现原子操作。
4. 内存可见性
内存可见性是指在多线程编程中,当一个线程修改了共享变量的值后,其他线程能够立即看到这个修改后的值。
在现代计算机系统中,每个线程有自己的工作内存,线程在执行时会把共享变量从主内存中拷贝到自己的工作内存中进行操作,而不是直接在主内存中进行操作。这就导致了一个问题:当一个线程修改了共享变量的值后,其他线程可能无法立即看到这个修改,因为它们可能仍在使用自己的工作内存中的旧值。
5. 指令重排序
指令重排序是现代处理器为了提高性能而采取的一种优化技术。在计算机执行指令的过程中,处理器为了提高执行效率,可能会对指令进行重新排序,以减少空闲等待时间和提高并行度。
下面说明如何解决线程安全问题 ↓
六、synchronized关键字
在Java中,使用synchronized关键字可以实现线程同步,通过对关键代码块或方法进行加锁,确保在同一时刻只有一个线程可以执行该代码块或方法,从而避免多线程访问共享资源时可能引发的数据竞争和不一致性问题。
所以在刚才出现bug的代码中,给count++上锁,就不会出现线程切换的问题了。
public class multiThreading {private static int count = 0;public static void main(String[] args) throws InterruptedException {Object locker = new Object();Thread thread1 = new Thread(() -> {for (int i = 0; i < 50000; i++) {synchronized (locker) {count++;}}});Thread thread2 = new Thread(() -> {for (int i = 0; i < 50000; i++) {synchronized (locker) {count++;}}});thread1.start();thread2.start();thread1.join();thread2.join();System.out.println(count);}
}
![]()
1. synchronized特性
1)互斥
synchronized会起到互斥效果,某个线程执行到某个对象的synchronized中时,其他线程如果也执行到同一个对象synchronized就会阻塞等待。
- 进入synchronized修饰的代码块,相当于加锁
- 退出synchronized修饰的代码块,相当于解锁
synchronized() 括号中填写的是用来加锁的对象。在Java中,任何一个对象都可以用作“锁”。这个对象的类型是啥不重要,重要的是,是否有多个线程尝试针对这同一个对象加锁(是否在竞争同一个锁)。
两个线程只有针对同一个对象加锁,才会产生互斥效果(一个线程加上锁了,另一个线程就会阻塞等待,等到第一个线程释放锁,才有机会)。如果是不同的锁对象,此时不会出现互斥效果,线程安全问题就不会得到改善。
也可以用synchronized代码块把for循环包起来。这个写法中,只是每次count++之间是串行的,for循环中的i < 50000 和i++则是并发的,这样写,执行速度会更慢。
Java中为什么很多使用synchronized+代码块做法,而不是采用lock+unlock函数的方式来搭配呢?
因为写了lock()就要立即加上unlock(),有时会忘记加,不能确保每个条件都加上unlock()。
synchronized的变种写法:也可以使用synchronized修饰方法(相当于对this进行加锁)。
class Counter{private int count = 0;synchronized public void add(){count++;}public int getCount(){return count;}
}public class multiThreading {public static void main(String[] args) throws InterruptedException {Counter counter = new Counter();Thread thread1 = new Thread(() -> {for (int i = 0; i < 50000; i++){counter.add();}});Thread thread2 = new Thread(() -> {for (int i = 0; i < 50000; i++){counter.add();}});thread1.start();thread2.start();thread1.join();thread2.join();System.out.println("count = " + counter.getCount());}
}

2)可重入
synchronized的可重入特性指的是线程在持有某个对象的锁时,如果再次进入同步代码块或方法,不会出现“死锁”的问题,而是可以继续执行,也就是说可以重复获得同一个对象的锁。
理解“死锁”
public class multiThreading {private static int count = 0;public static void main(String[] args) throws InterruptedException {Object locker = new Object();Thread thread = new Thread(() -> {for (int i = 0; i < 50000; i++){synchronized (locker) {synchronized (locker) {count++;}}}});thread.start();thread.join();System.out.println("count = " + count);} }这段代码看上去会造成“阻塞等待”的问题:
第一次进行加锁操作能够成功;第二次进行加锁时,锁对象是被占用的状态,就会触发阻塞等待。这样的问题就称为“死锁”。
如何避免死锁?
产生死锁的四个必要条件:
- 互斥使用,即当资源被一个线程使用(占有)时,别的线程不能使用;
- 不可抢占,资源请求者不能强制从资源占有者手中夺取资源,资源只能由资源占有者主动释放;
- 请求和保持,即当资源请求者在请求其他的资源同时保持对原有资源的占有;
- 循环等待,即存在一个等待队列:P1占有P2的资源,P2占有P3的资源,P3占有P1的资源。这样就形成了一个等待环路。
当上述四个条件都成立的时候,便形成了死锁。当然,死锁的情况下如果打破上述任何一个条件,便可以让死锁消失。其中最容易破坏的是“循环等待”。
破坏循环等待:
最常用的一种死锁阻止技术就是锁排序。
假设有N个线程尝试获取M把锁,就可以针对M把锁进行编号(1,2,3,……,M)。N个线程尝试获取锁的时候,都按照固定的按编号由小到大顺序来获取锁,这样就可以避免循环等待。
为了解决上述问题,Java的synchronized就引入了可重入的概念:
当某个线程针对一个对象加锁成功之后,后续该线程再次对这个对象加锁,不会触发阻塞,而是继续往下执行。因此,上述代码输出:


站在JVM视角,看到多个“}”需要执行,JVM如何知道哪个“}”是真正解锁的那个?
先引入一个变量 -> 计数器;
每次触发“{”的时候,计数器++;
每次触发“}”的时候,计数器--;
当计数器--为0的时候,就是真正需要解锁的时候。
2. Java标准库中的线程安全类
Java标准库中有很多都是线程不安全的。这些类可能会涉及到多线程修改共享数据,没有任何加锁措施。如:
- ArrayList
- LinkedList
- HashMap
- TreeMap
- HashSet
- TreeSet
- StringBuilder
还有一些是线程安全的,使用了一些锁机制来控制。如:
- Vector
- HashTable
- ConcurrentHashMap
- StringBuffer
但是,Vector、HashTable和StringBuffer虽然有synchronized,不推荐使用。因为加锁不是没有代价的。一旦代码中加了锁,意味着代码可能会因为锁的竞争产生阻塞,那么,程序的执行效率会大打折扣。
七、volatile关键字
volatile关键字的主要作用是保证变量的可见性和禁止指令重排序。具体来说,当一个线程修改了一个volatile变量的值时,这个修改会立即被其他线程所看到,而不会出现数据不一致的情况。此外,volatile还可以防止编译器和处理器对代码进行优化,确保代码的执行顺序不会被重排序。
需要注意的是,虽然volatile可以保证变量的可见性和禁止重排序,但并不能保证原子性。如果需要保证变量的原子性操作,需要使用Atomic类或synchronized关键字等其他手段。

代码在写入volatile修饰的变量的时候:
- 改变线程工作内存中volatile变量副本的值
- 将改变后的副本的值从工作内存刷新到主内存
代码在读取volatile修饰的变量的时候:
- 从主内存中读取volatile变量的最新值到线程的工作内存中
- 从工作内存中读取volatile变量的副本
在这个代码中预期当用户输入非 0 的值的时候, t1 线程结束:
import java.util.Scanner;public class multiThreading {private static int flag = 0;public static void main(String[] args) {Thread thread1 = new Thread(() -> {while(flag == 0){}System.out.println("t1线程结束");});Thread thread2 = new Thread(() -> {Scanner scanner = new Scanner(System.in);System.out.println("请输入flag的值:");flag = scanner.nextInt();});thread1.start();thread2.start();}
}![]()
此时虽然输入了非0的值,但thread1线程仍在运行,可以使用jconsole观察:

但如果给flag加上volatile:
private static volatile int flag = 0;运行程序:

这样就能解决内存可见性的问题。
八、wait和notify
在Java中,wait()和notify()是Object类中用于协调线程之间的执行逻辑的顺序。
可以让后执行的逻辑,等待先执行的逻辑,先运行。虽然无法直接干预调度器的调度顺序,但是可以让后执行的逻辑(线程)等待,等待到先执行的逻辑跑完了,通知一下当前的线程,让它继续执行。
1. wait()方法
wait要搭配synchronized来使用,脱离synchronized使用wait会直接抛出异常。
wait做的事情:
- 使当前执行代码的线程等待(把线程放到等待队列中)
- 释放当前的锁
- 满足一定条件时被唤醒,重新尝试获取这个锁
wait结束等待的条件:
- 其他线程调用该对象的notify方法
- wait等待时间超时(wait方法提供一个带有timeout参数的版本,来指定等待时间)
- 其他线程调用该等待线程的interrupted方法,导致wait抛出InterruptedException异常
public class multiThreading {public static void main(String[] args) throws InterruptedException {Object object = new Object();System.out.println("wait之前");synchronized (object) {// 加锁的object.wait();// 解锁的// wait就是先释放Object对象对应的锁 (前提是:Object对象应该处于加锁状态,才能释放)// 加锁的}// 要求synchronized的锁对象必须和wait的对象是同一个System.out.println("wait之后");}
}

这样在执行到object.wait()之后就一直等待下去,那么程序肯定不能一直这么等待下去了。这个时候就需要使用到了另外一个方法唤醒的方法notify()。
2. notify()方法
notify()方法用来唤醒等待的线程。
方法notify()也要在同步方法或同步块中调用,该方法是用来通知那些可能等待该对象的对象锁的其他线程,对其发出通知notify,并使它们重新获取该对象的对象锁。
如果有多个线程等待,则有线程调度器随机挑选出一个呈wait状态的线程。
在notify()方法后,当前线程不会马上释放该对象锁,要等到执行notify()方法的线程将程序执行完,也就是退出同步代码块之后才会释放对象锁。

这4处必须是相同的对象。wait和notify是针对同一个对象,才能生效;如果是两个不同的对象,则没有任何相互的影响和作用。
代码示例:
import java.util.Scanner;public class multiThreading {public static void main(String[] args) throws InterruptedException {Object locker = new Object();Thread thread1 = new Thread(() -> {try{Thread.sleep(3000);System.out.println("wait之前");synchronized (locker){locker.wait();}System.out.println("wait之后");} catch (InterruptedException e) {throw new RuntimeException(e);}});Thread thread2 = new Thread(() -> {try (Scanner scanner = new Scanner(System.in)) {System.out.println("please input:");scanner.next();}synchronized (locker) {locker.notify();}});thread1.start();thread2.start();}
}
题目:有三个线程,分别只能打印A,B和C,要求按顺序打印ABC,打印5次。
输出示例:
ABC
ABC
ABC
ABC
ABC
public class multiThreading {public static void main(String[] args) throws InterruptedException {Object locker1 = new Object();Object locker2 = new Object();Object locker3 = new Object();Thread t1 = new Thread(() -> {try {for (int i = 0; i < 5; i++) {synchronized (locker1) {locker1.wait();}System.out.print('A');synchronized (locker2) {locker2.notify();}}} catch (InterruptedException e) {throw new RuntimeException(e);}});Thread t2 = new Thread(() -> {try {for (int i = 0; i < 5; i++) {synchronized (locker2) {locker2.wait();}System.out.print('B');synchronized (locker3) {locker3.notify();}}} catch (InterruptedException e) {throw new RuntimeException(e);}});Thread t3 = new Thread(() -> {try {for (int i = 0; i < 5; i++) {synchronized (locker3) {locker3.wait();}System.out.println('C');synchronized (locker1) {locker1.notify();}}} catch (InterruptedException e) {throw new RuntimeException(e);}});t1.start();t2.start();t3.start();//主线程中通知locker1Thread.sleep(1000);synchronized (locker1) {locker1.notify();}}
}
notify()方法一次只能唤醒一个,那么有什么办法能一次唤醒多个线程呢?
3. notifyAll()方法
import java.util.Scanner;public class multiThreading {public static void main(String[] args) throws InterruptedException {Object locker = new Object();Thread thread1 = new Thread(() -> {try{System.out.println("t1 wait之前");synchronized (locker){locker.wait();}System.out.println("t1 wait之后");} catch (InterruptedException e) {throw new RuntimeException(e);}});Thread thread2 = new Thread(() -> {try{System.out.println("t2 wait之前");synchronized (locker){locker.wait();}System.out.println("t2 wait之后");} catch (InterruptedException e) {throw new RuntimeException(e);}});Thread thread3 = new Thread(() -> {Scanner scanner = new Scanner(System.in);System.out.println("输入任意内容,唤醒线程");scanner.next();synchronized (locker){locker.notifyAll();}});thread1.start();thread2.start();thread3.start();}
}
虽然是同事唤醒3个线程,但是这3个线程需要竞争锁,所以并不是同时执行,而仍然是有先有后的执行。
4. wait和sleep的区别
在多线程编程中,wait()和sleep()是两个常用的方法,但它们有着不同的作用和使用方式:
- wait()是Object类的一个方法,需要在synchronized块或方法内调用;sleep()是Thread类的一个静态方法,可以在任何地方调用。
- 当线程执行wait()方法时,会释放锁并进入等待状态,直到其他线程调用notify()或notifyAll()方法唤醒它;当线程执行sleep()方法时,会暂时停止执行,但不会释放锁。
- wait()通常用于线程间的通信和协调,让线程等待某个条件满足或某个事件发生;sleep()通常用于暂停线程的执行一段指定时间,而不需要其他线程的干预。
九、多线程案例
1. 单例模式
单例模式是设计模式中的一种,它确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。单例模式通常用于需要全局共享访问的对象,例如线程池、配置对象、日志对象等。
什么是设计模式?
设计模式是在软件工程中常见的解决特定问题的经验总结和最佳实践的集合。设计模式为开发人员提供了一种通用的语言和思维方式,通过使用设计模式能够提高代码的可读性、可维护性和可扩展性,降低软件开发过程中的错误和风险。
单例模式具体的实现方式有很多,最常见的是“饿汉”和“懒汉”两种。
饿汉模式
类加载的同时创建实例。
class Singleton{//静态成员的初始化实在类加载的阶段触发的private static Singleton instance = new Singleton();//后续通过getInstance这个方法获取这里的实例public static Singleton getInstance() {return instance;}//单例模式中的“点睛之笔”,在类外面进行new操作,都会编译失败private Singleton() {}
}懒汉模式
类加载的时候不创建实例,第一次使用的时候才创建实例。
class SingletonLazy{private static SingletonLazy instance = null;public static SingletonLazy getInstance() {if(instance == null) {instance = new SingletonLazy();}return instance;}private SingletonLazy() {}
}这里的懒汉模式的实现是线程不安全的:
- 线程安全问题发生在首次创建实例时,如果在多个线程中同时调用getInstance方法,就可能导致创建出多个实例
- 一旦实例已经创建好了,后面在多线程环境调用getInstance就不在有线程安全问题了
加上synchronized就可以改善这里的线程安全问题。
class SingletonLazy {private static volatile SingletonLazy instance = null;private SingletonLazy() {}public static SingletonLazy getInstance() {if (instance == null) {synchronized (SingletonLazy.class) {if (instance == null) {instance = new SingletonLazy();}}}return instance;}
}2. 阻塞队列
阻塞队列(Blocking Queue)是一种特殊的队列数据结构,在多线程编程中常用于实现生产者消费者模式。阻塞队列在队列为空时,获取元素的操作会被阻塞,直到队列中有元素可用;在队列已满时,插入元素的操作会被阻塞,直到队列有空间可用。
阻塞队列是一种线程安全的数据结构,并且具有以下特性:
- 当队列满的时候,继续入队列就会阻塞,直到有其他线程从队列中取走元素
- 当队列空的时候,继续出队列也会阻塞,直到有其他线程往队列中插入元素
阻塞队列的主要作用是协调生产者和消费者线程,通过阻塞的特性可以避免生产者过度生产导致队列溢出,也避免消费者尝试获取空队列中的元素。
生产者消费者模型
生产者消费者模型是一种经典的并发编程模型,用于解决生产者和消费者之间的数据交换和同步问题。在生产者消费者模型中,生产者负责生成数据并放入共享数据结构(如队列)中,而消费者则负责从共享数据结构中获取数据并进行处理。
两个重要优势:
1. 解耦合(不一定是两个线程之间,也可以是两个服务器之间)
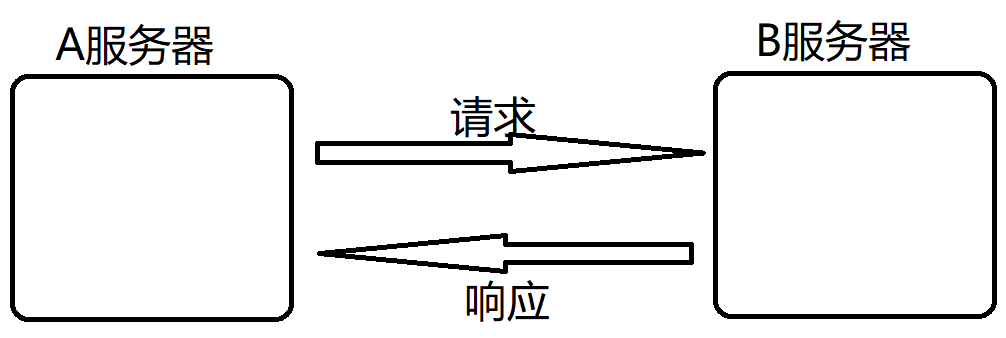
如果是A直接访问B,此时A和B的耦合就更高。
编写A的代码的时候,多多少少会有一些和B相关的逻辑。
编写B的代码的时候,也会有一些A的相关逻辑。
2. 削峰填谷
-
平滑处理数据波动:通过合理设置缓冲区的大小,控制生产者和消费者的速度,可以平滑处理系统中数据量的波动,避免瞬时的数据爆发或骤降,减少系统的压力。
-
减少系统资源浪费:在高峰期快速生产数据,低谷期快速消费数据,可以避免资源的过度消耗和浪费,提高系统的资源利用率。
-
提高系统稳定性:削峰填谷可以避免系统由于数据量剧烈波动引起的不稳定情况,保持系统的平稳运行状态,提高系统整体稳定性和可靠性。
-
提高系统性能:通过平滑处理数据量的波动,减少资源浪费,保持系统的稳定运行状态,可以提高系统的整体性能和效率,提升用户体验。
标准库中的阻塞队列
在Java标准库中内置了阻塞队列,如果我们需要在一些程序中使用阻塞队列,直接使用标准库中的即可。
- BlockingQueue是一个接口,真正实现的类是LinkedBlockingQueue
- put方法用于阻塞式的入队列,take用于阻塞式的出队列
- BlockingQueue也有offer,poll,peek等方法,但是这些方法不带有阻塞特性
BlockingQueue<String> queue = new LinkedBlockingQueue<>();
//入队列
queue.put("abc");
String elem = queue.take();
System.out.println(elem);
生产者消费者模型
import java.util.concurrent.*;public class multiThreading {public static void main(String[] args) throws InterruptedException {BlockingDeque<Integer> queue = new LinkedBlockingDeque<>(100);Thread producer = new Thread(() -> {int n = 0;while(true){try {queue.put(n);System.out.println("生产元素" + n);n++;} catch (InterruptedException e) {throw new RuntimeException(e);}}},"producer");Thread consumer = new Thread(() -> {while (true){try {Integer n = queue.take();System.out.println("消费元素" + n);Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}},"consumer");producer.start();consumer.start();}
}
阻塞队列实现
- 通过“循环队列”的方式来实现
- 使用synchronized进行加锁控制
- put插入元素的时候,判定如果队列满了,就进行wait(注意:要在循环中进行wait,被唤醒时不一定队列就不满了,因为同时可能是唤醒了多个线程)
- take取出元素的时候,判定如果队列为空,就进行wait
class myBlockingDeque{private String[] data = null;private int head = 0;private int tail = 0;private int size = 0;public myBlockingDeque(int capacity){data = new String[capacity];}public void put(String elem) throws InterruptedException {synchronized (this) {if (size >= data.length) {this.wait(); //队列不满的时候才要唤醒}data[tail] = elem;tail++;if (tail >= data.length) {tail = 0;}//简洁写法:tail = (tail + 1) % data.length;size++;this.notify();}}public String take() throws InterruptedException {synchronized (this) {if (size == 0) {this.wait(); //队列不空的时候才要唤醒}String ret = data[head];head++;if (head >= data.length) {head = 0;}size--;this.notify();return ret;}}
}public class multiThreading {public static void main(String[] args) throws InterruptedException {myBlockingDeque queue = new myBlockingDeque(1000);Thread producer = new Thread(() -> {int n = 0;while(true){try {queue.put(n+"");System.out.println("生产元素" + n);n++;} catch (InterruptedException e) {throw new RuntimeException(e);}}},"producer");Thread consumer = new Thread(() -> {while (true){try {String n = queue.take();System.out.println("消费元素" + n);} catch (InterruptedException e) {throw new RuntimeException(e);}}},"consumer");producer.start();consumer.start();}
}3. 线程池
线程池是一种在程序启动时创建一定数量的线程并将它们放入一个池中,然后当有任务需要执行时,从池中取出线程执行任务,任务执行完毕后线程不被销毁而是放回池中等待下次任务。线程池的主要作用是重用线程、管理线程的数量以及提高系统性能。
线程池的优点包括:
-
降低线程创建和销毁的开销:线程创建和销毁是比较昂贵的操作,在线程池中可以重用线程,减少创建和销毁线程的开销,提高系统性能。
-
提高系统响应速度:线程池中的线程可以立即执行任务,不需要等待线程创建,可以提高系统的响应速度。
-
控制并发数量:线程池可以限制并发执行的线程数量,避免因并发线程过多而导致系统资源不足或性能下降的情况。
-
提高系统稳定性:通过对线程进行统一管理,线程池可以避免线程数量过多而导致系统崩溃或资源耗尽的情况,提高系统的稳定性。
-
提供可调节的线程数量:线程池一般会提供动态调整线程数量的功能,可以根据系统的负载情况自动调整线程数量,更好地适应系统的需求。
总的来说,线程池可以提高系统的性能、响应速度和稳定性,是多线程编程中常用的一种技术手段。在实际开发中,合理设计线程池的参数,如线程数量、任务队列大小等,能够更好地发挥线程池的优势,提升系统的整体性能。
标准库中的线程池
- 使用Executors.newFixedThreadPool(10)能创建出固定包含10个线程的线程池
- 返回值类型为ExecutorService
- 通过ExecutorService.submit可以注册一个任务到线程池中
ThreadPoolExecutor提供了更多的可选参数,可以进一步细化线程池行为的设定:

- corePoolSize:核心线程数
- maximumPoolSize:最大线程数
- keepAliveTime:非核心线程允许空闲的最大时间
- unit:枚举
- workQueue:工作队列
- threadFactory:工作模式
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class multiThreading {public static void main(String[] args) throws InterruptedException {ExecutorService threadPool = Executors.newCachedThreadPool();for (int i = 0; i < 1000; i++) {int id = i;threadPool.submit(() -> {System.out.println("hello " + id + " " + Thread.currentThread().getName());});}}
}

实现线程池
import java.util.concurrent.*;//实现一个固定线程个数的线程池
class myThreadPool{private BlockingQueue<Runnable> queue = null;public myThreadPool(int n){// 初始化线程池,创建固定个数线程的线程池// 这里使用ArrayBlockingQueue作为任务队列,容量为1000queue = new ArrayBlockingQueue<>(1000);// 创建n个线程for (int i = 0; i < 100; i++) {Thread thread = new Thread(() -> {try {while(true) {Runnable task = queue.take();task.run();}} catch (InterruptedException e) {throw new RuntimeException(e);}});thread.start();}}public void submit(Runnable task) throws InterruptedException {// 将任务放在队列中queue.put(task);}
}4. 定时器
定时器是一种用于实现定时任务的机制,可以在指定的时间间隔或指定的时间点执行特定的任务。定时器在软件开发中有着广泛的应用,常用于定时执行任务、定时触发事件等场景。
标准库中的定时器
标准库中提供了一个Timer类,Timer类的核心方法为schedule。
schedule包含两个参数,第一个参数指定即将要执行的任务代码,第二个参数指定多长时间之后执行(单位为毫秒)。
import java.util.Timer;
import java.util.TimerTask;public class multiThreading {public static void main(String[] args) throws InterruptedException {Timer timer = new Timer();timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("hello");}}, 3000);}
}
实现定时器
在Java中,可以使用java.util.Timer类或者java.util.concurrent.ScheduledExecutorService接口来实现定时器。这里介绍一下两种方式的简单示例:
1. 使用java.util.Timer类实现定时器:
import java.util.Timer;
import java.util.TimerTask;public class MyTimerTask extends TimerTask {public void run() {System.out.println("定时任务执行");}public static void main(String[] args) {Timer timer = new Timer();// 延迟1秒后开始执行,每隔2秒执行一次timer.schedule(new MyTimerTask(), 1000, 2000);}
}
2.使用java.util.concurrent.ScheduledExecutorService接口实现定时器:
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;public class MyScheduledTask implements Runnable {public void run() {System.out.println("定时任务执行");}public static void main(String[] args) {ScheduledExecutorService scheduledExecutor = Executors.newScheduledThreadPool(1);// 延迟1秒后开始执行,每隔2秒执行一次scheduledExecutor.scheduleAtFixedRate(new MyScheduledTask(), 1, 2, TimeUnit.SECONDS);}
}
这两个示例分别使用了Timer类和ScheduledExecutorService接口来实现定时任务的执行。开发者可以根据自己的需求选择合适的方式来实现定时器,通常推荐使用ScheduledExecutorService,因为它提供了更加灵活和高效的定时任务执行机制。
十、常见的锁策略
1. 乐观锁 VS 悲观锁
乐观:加锁的时候,预测接下来的锁竞争的情况不激烈,就不需要做额外工作;
悲观:加锁的时候,预测接下来的锁竞争的情况非常激烈,就需要针对这样的激烈情况额外做一些工作。
2. 重量级锁 VS 轻量级锁
重量级锁:重量级锁的实现比较笨重,因为涉及到用户态和内核态的切换以及线程的阻塞和唤醒,会带来较高的性能开销。因此,在高并发场景下,重量级锁可能会导致线程竞争激烈,性能下降。
轻量级锁:轻量级锁在低竞争情况下性能优于重量级锁,因为无需进行线程阻塞等操作,减少了线程切换的开销。但是在高竞争情况下,轻量级锁会升级为重量级锁,此时会涉及到线程的阻塞和唤醒,性能会受到影响。
3. 自旋锁
自旋锁是一种基于忙等待的锁实现方式,在获取锁时,线程不会立即被挂起,而是会通过循环反复尝试获取锁,这个过程称为自旋。自旋锁适用于锁竞争短暂的情况,通过自旋等待来减少线程的上下文切换和线程阻塞造成的开销。
4. 公平锁 VS 非公平锁
公平锁:非公平锁是指线程在竞争锁时,不考虑自己是否比其他线程等待时间更长,而是直接尝试获取锁。即当前线程可以在未持有锁的情况下直接抢占锁。
非公平锁:公平锁是指线程在竞争锁时,按照等待时间的先后顺序获取锁。先来后到,等待时间长的线程优先获取锁。
5. 可重入锁 VS 不可重入锁
可重入锁:可重入锁允许同一个线程多次获取同一个锁,而不会导致死锁。即线程可以重复地获取已经持有的锁,每次获取锁时需要对锁的持有计数进行增加,释放锁时需要对计数进行减少。
不可重入锁:不可重入锁不允许同一个线程多次获取同一个锁,即线程在持有锁时再次请求获取锁会造成死锁。因此,线程在持有锁时再次尝试获取同一个锁会导致阻塞。
6. 读写锁
读写锁(Read-Write Lock)是一种特殊的锁机制,允许多个线程同时读取共享资源,但在写操作时会独占资源,保证数据的一致性和并发性。读写锁解决了读多写少的场景下,读操作与写操作之间的互斥问题,提高了系统的并发性能。
十一、synchronized原理
1. 基本特点
结合上面是锁策略,我们就可以总结出synchronized具有以下特性:
- 开始时是乐观锁,如果锁冲突频繁,就转换为悲观锁
- 开始时是轻量级锁实现,如果锁被持有的时间较长,就转换成重量级锁
- 实现轻量级锁的时候大概率用到的自旋锁策略
- 是不公平锁
- 是可重入锁
- 不是读写锁
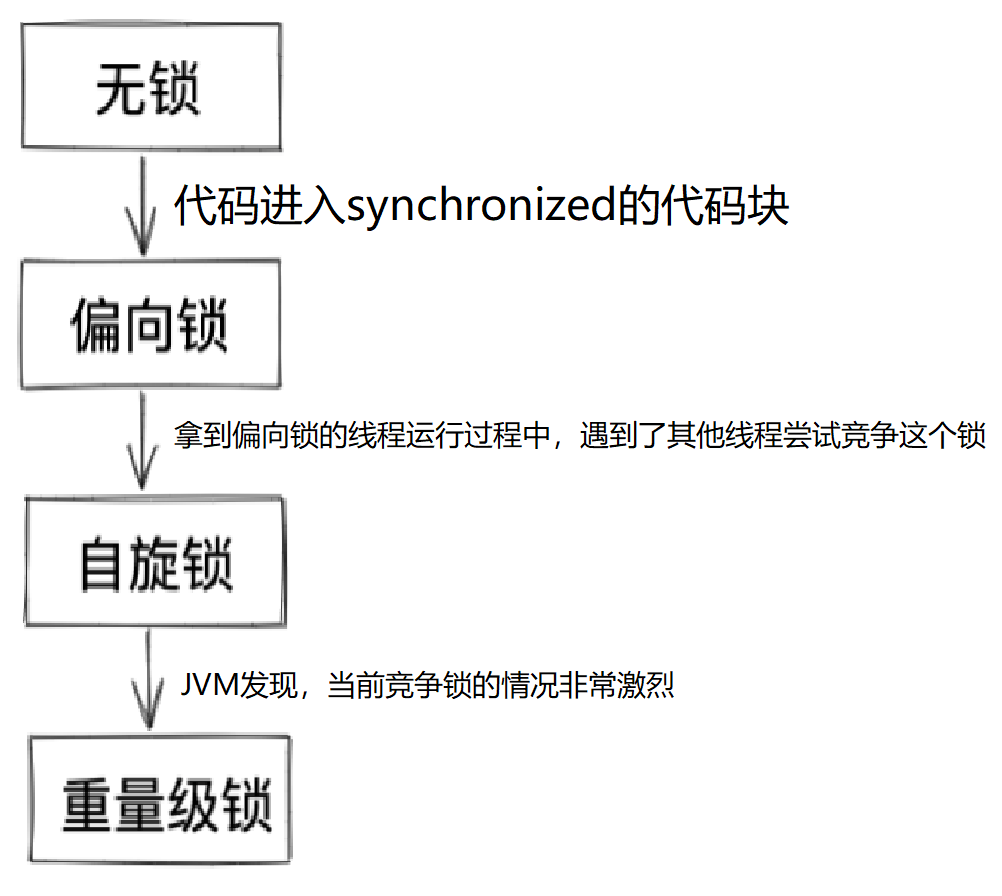
2. 加锁工作过程
JVM将synchronized锁分为无锁、偏向锁、轻量级锁、重量级锁状态。会根据情况,进行依次升级:
3. 其他优化操作
锁消除
锁消除是一种编译器和运行时优化技术,用于检测并消除在并发编程中对共享数据进行同步的锁操作。这种技术的主要思想是在编译阶段或运行时检测出代码中对锁的使用是不必要的,然后将这些锁操作优化掉,从而提高程序的性能。
锁消除通常发生在以下情况下:
- 当编译器可以确定某个锁对象只能被单个线程所拥有,且不会被其他线程访问到时,可以消除针对该锁对象的锁操作。
- 当编译器可以确定某个锁对象的作用范围仅限于方法内部,不会逃逸到方法外部时,可以消除对该锁对象的锁操作。
- 当编译器可以通过静态分析确定多个线程之间并不会发生竞争条件时,可以消除部分锁操作。
锁消除的好处是可以减少锁的粒度,降低线程竞争,提高程序的并发性能。然而,需要注意的是,锁消除可能会导致某些情况下的潜在问题,比如在锁消除后如果出现了竞争条件,可能会导致数据不一致性或程序出现错误。
在Java中,虚拟机(如HotSpot)会对代码进行优化,其中包括锁消除。通过适当的代码编写和优化,在某些情况下,虚拟机可以自动进行锁消除,提高程序的性能。要想确认锁消除是否生效,可以使用相应的工具或技术进行性能分析和监控。
锁粗化
锁粗化是一种优化技术,用于减少由于频繁对锁进行加锁和解锁而带来的性能开销。在并发编程中,如果一段代码中存在多个独立的临界区,并且这些临界区之间紧密相邻,可能会导致频繁的锁争用。锁粗化的目的就是将这些独立的锁操作合并成一个更大的锁范围,从而减少锁操作次数,提高程序的性能。
锁粗化通常发生在以下情况下:
- 当某个线程在短时间内多次对同一个锁对象进行加锁和解锁操作时,可以将这些独立的临界区锁粗化为一个更大的锁范围。
- 当某个线程在较短时间内多次对相邻的临界区进行加锁和解锁操作时,可以将这些相邻的锁操作合并为一个更大的锁范围。
- 当某个线程频繁地对一个锁对象进行加锁和解锁,并且其他线程在此期间无法竞争到这个锁时,可以将这些独立的锁操作合并为一个更大的锁范围。
通过锁粗化,可以减少线程上下文切换的开销,减少锁争用所带来的性能损失。但需要注意的是,过度的锁粗化可能会导致锁操作范围过大,影响程序的并发性能。因此,在应用锁粗化时需要根据具体情况进行权衡和优化,以达到最佳的性能效果。Java虚拟机在执行代码优化时也可能会进行锁粗化的操作。
十二、CAS
1. 什么是CAS
CAS(Compare and Swap)是一种原子性操作,通常用于实现并发编程中的非阻塞算法。CAS操作包括三个操作数:一个内存位置(V),旧的预期值(A)和即将要更新的值(B)。CAS操作会比较内存位置的值与预期值,如果相等,则更新为新的值,如果不相等则不作任何操作。整个CAS操作要么成功(即原来的预期值与内存位置的值匹配),要么失败。
CAS伪代码:
boolean CAS(address, expectValue, swapValue) {if (&address == expectedValue) {&address = swapValue;return true;} return false;
}address:内存地址;
expectValue:寄存器的值;
swapValue:另一个寄存器的值。
&address = swapValue判定内存中的值和寄存器1的值是否一致,如果一致,就把内存中的值和寄存器2进行交换。但是,由于基本上只是关心交换后内存中的值,不关心寄存器2的值。
2. CAS是怎么实现的
在Java中,CAS操作的实现主要依赖于sun.misc.Unsafe类,它提供了底层操作系统级别的原子操作方法,可以直接操作内存。Java提供的AtomicInteger、AtomicLong等原子操作类底层就是利用Unsafe类来实现CAS操作的。虽然Unsafe类是Java标准库的一部分,但它并不是公开的API,建议不要直接使用Unsafe类,而是使用java.util.concurrent.atomic包提供的原子类来进行并发编程。
3. CAS的应用
1)实现原子类
在Java中,CAS操作的实现通常通过java.util.concurrent.atomic包提供的原子类来实现。这些原子类提供了一种线程安全的方式来进行并发操作,底层利用了CAS操作来确保操作的原子性。以下是常见的一些原子类:
1. AtomicInteger:提供了对int类型数据的原子操作,包括加减、比较并设置值等操作。
AtomicInteger atomicInt = new AtomicInteger(0);
atomicInt.incrementAndGet(); // 原子地将当前值加1
2. AtomicLong:提供了对long类型数据的原子操作。
AtomicLong atomicLong = new AtomicLong(0L);
atomicLong.getAndIncrement(); // 原子地获取当前值并加1
3. AtomicBoolean:提供了对boolean类型数据的原子操作。
AtomicBoolean atomicBoolean = new AtomicBoolean(true);
atomicBoolean.compareAndSet(true, false); // 原子地比较并设置值
4. AtomicReference:提供了对引用类型数据的原子操作。
AtomicReference<String> atomicRef = new AtomicReference<>("hello");
atomicRef.compareAndSet("hello", "world"); // 原子地比较并设置引用值
这些原子类底层使用了CAS操作,保证了线程安全的并发访问。通过使用这些原子类,可以避免使用synchronized关键字或者Lock来实现锁,提高并发编程的性能和简化编程。
2)实现自旋锁
CAS(Compare and Swap)操作可以用来实现自旋锁。自旋锁是一种基于忙等待的锁,线程在尝试获取锁时不会被挂起,而是会一直循环检查锁的状态直到成功获取为止。
下面是一个简单的示例,使用CAS操作实现自旋锁:
import java.util.concurrent.atomic.AtomicReference;public class SpinLock {private AtomicReference<Thread> owner = new AtomicReference<>();public void lock() {Thread currentThread = Thread.currentThread();while (!owner.compareAndSet(null, currentThread)) {// 自旋等待}}public void unlock() {Thread currentThread = Thread.currentThread();owner.compareAndSet(currentThread, null);}
}
在这个示例中,SpinLock类使用AtomicReference来维护锁的拥有者。lock()方法中,线程会不断尝试使用CAS操作将当前线程设置为锁的拥有者,直到成功获取锁为止。unlock()方法中,线程释放锁时会将拥有者设置为null。
需要注意的是,自旋锁可能会导致线程长时间处于忙等待状态,对于锁竞争激烈的情况下可能会降低性能。因此,自旋锁适用于锁竞争不激烈的情况下,对于高竞争的情况,通常会选择使用基于信号量或者阻塞队列的锁来避免不必要的CPU消耗。
4. CAS的ABA问题
CAS的ABA问题是指在多线程环境下,一个线程在读取一个共享变量的值A,然后另一个线程将这个值A修改为B,再修改回A,此时第一个线程可能会误以为共享变量的值没有发生变化,从而可能会引发一些意外错误。
例如,线程T1读取共享变量的值A为1,然后线程T2将A修改为2,再修改回1,最后线程T1进行CAS操作时,比较共享变量的值为1,和最初读取到的值相同,于是CAS操作成功,然而实际上共享变量的值已经经历了变化。
为了解决ABA问题,可以引入版本号或者时间戳等机制,从而在CAS操作中除了比较值之外,还需要对版本号进行比较,确保在修改变量的过程中没有其他线程对其进行了修改。
Java中,AtomicStampedReference类提供了解决ABA问题的方案,通过引入版本号(stamp)来避免这种问题。在使用CAS操作时,除了比较值之外,还需要比较版本号,从而避免产生ABA问题。
十三、JUC的常见类
JUC(Java Util Concurrent)是Java中用于并发编程的工具包,其中包含了许多常见的类,用于支持多线程编程和并发控制。以下是JUC中常见的类:
-
Lock 接口:Lock接口提供了比synchronized关键字更灵活的锁机制,它的常用实现类包括ReentrantLock、ReentrantReadWriteLock等。
-
Semaphore 类:Semaphore是一个计数信号量,用来控制同时访问特定资源的线程数量,可以用来实现资源池、限流等功能。
-
CountDownLatch 类:CountDownLatch是一个同步工具类,用来等待多个线程完成某个操作。
-
CyclicBarrier 类:CyclicBarrier也是一个同步工具类,用来等待多个线程到达某个状态后再一起继续执行。
-
BlockingQueue 接口:BlockingQueue是一个阻塞队列接口,它提供了线程安全的生产者-消费者模式的实现类,如ArrayBlockingQueue、LinkedBlockingQueue等。
-
ConcurrentHashMap 类:ConcurrentHashMap是并发环境下的线程安全的哈希表实现类,用于代替HashTable及Collections.synchronizedMap()。
-
Executor 接口:Executor接口是JUC中线程池的基础接口,它定义了线程池的执行方法,常用的实现类包括ThreadPoolExecutor、ScheduledThreadPoolExecutor等。
-
Future 接口:Future接口用来表示一个异步计算的结果,可以通过它来获取异步任务的执行结果。
-
CompletableFuture 类:CompletableFuture是一种异步编程的工具类,它可以方便地实现异步任务的执行和结果处理。
这些是JUC中常见的类和接口,它们提供了丰富的工具和方法来帮助开发者编写高效的并发程序。
相关文章:

JavaEE--多线程
一、认识线程 1. 什么是线程 线程(Thread)是计算机科学中的基本概念,指的是程序内部的一条执行路径。一个进程可以包含多个线程,每个线程共享进程的资源,包括内存空间、文件描述符等。线程可以同时执行多个任务&…...

自动化测试之等待方式
在自动化测试中,等待是一个重要的技术,用于处理页面加载、元素定位、元素状态改变等延迟问题。 等待能够确保在条件满足后再进行后续操作,提高自动化测试的稳定性以及可靠性。 等待方式:显示等待、隐式等待、线程睡眠 1. 显式等…...

git中用于生成commitId与其父commitId间的文件差异文件树
生成commitId与其父commitId间的文件差异文件树 #!/bin/bash # # 用于生成目标commitId与其父commitId间文件差异 # commit_id$1 # 输入目标commit的哈希值 old_dir"old_version" new_dir"new_version"# 创建目录 mkdir -p "$old_dir" "$…...

Ubuntu / Debian 创建快捷方式启动提权
简述 在 Linux 系统中,.desktop 文件是 桌面入口文件,用于在桌面环境(如 GNOME、KDE)中定义应用程序的启动方式、图标、名称等信息。当你执行 touch idea.desktop 时,实际上创建了一个空的 .desktop 文件(…...
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion)
VLA 论文精读(三)Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
这篇笔记用来描述 2023年 发表在arxiv上的一篇有关VLA领域的论文,这篇笔记记录的是该论文 2024年03月的改版后。 写在最前面 为了方便你的阅读,以下几点的注意事项请务必了解: 该系列文章每个字都是我理解后自行翻译并写上去的,…...

ASP.NET Core 中实现 SSE 流式响应的简单例子
[HttpGet] public async Task<IActionResult> SseExample() {// 请求头Response.Headers.Add("Content-Type", "text/event-stream");Response.Headers.Add("Cache-Control", "no-cache");Response.Headers.Add("Connectio…...

「Unity3D」TMP_InputField关闭虚拟键盘后,再次打开虚拟键盘,此时无法回调onSelect的问题
TMP_InputField可以注册一个onSelect回调函数,在InputField选中的时候回调,但在虚拟键盘手动关闭或被返回取消的时候,此时再打开虚拟键盘时,就不会调用onSelect。 原因在于,虚拟键盘有三种关闭的操作方式:…...

手工排查后门木马的常用姿势
声明!本文章所有的工具分享仅仅只是供大家学习交流为主,切勿用于非法用途,如有任何触犯法律的行为,均与本人及团队无关!!! 1. 检查异常文件 (1)查找最近修改的文件 # 查…...

VRRP协议
基础概念 Master 路由器:“Master 路由器”在一个 VRRP 组中承担报文转发任务。在每一个 VRRP 组中,只有 Master 路由器才会响应针对虚拟 IP 地址的 ARP Request。Master 路由器会以一定的时间间隔周期性地发送 VRRP 报文,以便通知同一个 VRRP 组中的 B…...
)
【JavaEE】MyBatis 综合练习(图书管理系统)
目录 一、数据库表二、引入依赖:三、Model创建四、用户登录五、添加图书六、图书列表七、修改图书八、删除图书九、批量删除十、强制登录 图书管理系统 一、数据库表 我们使用两张表,一张用户表uset_test来记录登录的用户信息,一张图书表boo…...

ArkUI —— 组件导航
创建导航页 // src\main\ets\pages\Index.ets Entry Component struct Index {// 路由栈Provide(pathInfos) pathInfos: NavPathStack new NavPathStack()build() {Navigation(this.pathInfos) {}} }创建导航子页 this.navPath.pushPathByName(AccountTag, 账本分类管理)// …...

数据处理与机器学习入门
一、数据处理概述 数据处理是通过统计学、机器学习和数据挖掘方法从原始数据中提取有价值信息的过程。数据处理的目标是将杂乱无章的原始数据转化为可用于分析和建模的结构化数据。对于小规模数据处理,常用工具分为两类: • 可视化分析工具:…...

Markdown在线转word格式
1、打开网址 https://dillinger.io/ 2、输入markdown格式文章 3、直接转换为右边的word格式 4、复制粘贴即可。...

Redis延时队列在订单超时未报到场景的应用分享
一、引言 在电商、医疗预约等众多业务场景中,经常会遇到需要处理超时任务的情况。比如医疗预约订单,如果患者在支付成功后,到了预约结束时间还未报到,系统需要自动取消订单。为了实现这样的功能,我们可以利用 Redis 延…...

vue前端代码作业——待办事项
美化样式示意图: 后端IDEA代码示意图: 代码解释: 1. isAllChecked 计算属性的作用 isAllChecked 用于实现 “全选 / 全不选” 功能,它是一个 双向绑定 的计算属性(因为 v-model 需要同时支持读取和设置值)…...

docker镜像拉取失败
hub.docker.com中提供的docker pull命令在服务器拉取镜像时报错Error response from daemon: Get https://registry-1.docker.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) 这个错误通常表明Docker客户…...

Ruby 简介
Ruby 简介 引言 Ruby 是一种广泛使用的动态、开源的编程语言,自 1995 年由日本程序员 Yukihiro Matsumoto(通称 Matz)设计以来,它以其优雅的语法、强大的库支持和跨平台特性赢得了全球开发者的青睐。本文将详细介绍 Ruby 的起源、特点、应用领域以及它在现代软件开发中的…...
)
解决 FFmpeg 使用 C/C++ 接口时,解码没有 shell 快的问题(使用多线程)
一、问题 硬件设备为香橙派 5Plus,最近需要使用硬件视频解码来加速 YOLO 的检测,shell 窗口的FFmpeg已经调通,详见文章: 编译支持 RKmpp 和 RGA 的 ffmpeg 源码_rk3588 ffmpeg mpp-CSDN博客https://blog.csdn.net/plmm__/article…...

sqlalchemy:将mysql切换到OpenGauss
说明 之前python的项目使用的mysql,近期要切换到国产数据库OpenGauss。 之前的方案是fastapisqlalchemy,测试下来发现不用改代码,只要改下配置即可。 切换方案 安装openGauss-connector-python-psycopg2 其代码工程在:https:…...

缓存使用纪要
一、本地缓存:Caffeine 1、简介 Caffeine是一种高性能、高命中率、内存占用低的本地缓存库,简单来说它是 Guava Cache 的优化加强版,是当下最流行、最佳(最优)缓存框架。 Spring5 即将放弃掉 Guava Cache 作为缓存机…...

Qt之Service开发
一、概述 基于Qt的用于开发系统服务(守护进程)和后台服务,有以下几个优秀的开源 QtService 框架和库。 1. QtService (官方解决方案) GitHub: https://github.com/qtproject/qt-solutions/tree/master/qtservice 特点: 官方提供的服务框架 支持 Windows 服务和 Linux 守护…...

ssm框架之Spring
Spring框架介绍 Spring框架是一个轻量级的企业级应用框架 通过它可以贯穿表现层、业务层、持久层。集成方便,简单易用,具有如下特点: Spring框架特色 Spring设计理念 是面向Bean的编程 Spring两大核心技术 控制反转(IoC:Inver…...

Flutter 开发环境配置--宇宙级教学!
目录 一、安装环境(Windows)二、Android 创建Flutter项目三、VSCode 搭建环境四、补充 一、安装环境(Windows) Flutter SDK 下载 推荐使用中国镜像站点下载 Flutter SDK,速度更快:中国环境 或者从官网下载…...

音视频 YUV格式详解
前言 本文介绍YUV色彩模型,YUV的分类和常见格式。 RGB色彩模型 在RGB颜色空间中,任意色光F都可以使用R、G、B三色不同的分量混合相加而成即: F = R + G + B.。即我们熟悉的三原色模型。 RGB色彩空间根据每个分量在计算机中占用的存储字节数可以分为以下几种类型,字节数…...

力扣 第 153 场双周赛 讲题
文章目录 Q1.字符串的反转度Q2.操作后最大活跃区段数I3500.将数组分割为子数组的最小代价 Q1.字符串的反转度 签到题,直接建立一个映射表即可 class Solution:def reverseDegree(self, s: str) -> int:# 先建立映射表ss "abcdefghijklmnopqrstuvwxyz"store {}i…...

grafana 配置页面告警
添加告警规则 1.登录grafana 点击 Alerting > Alert rules 点击 New alert rule 2.填写告警规则名字 3.配置告警规则 选择数据源为 Loki 单机 Builder 单机Label brower 单机 node_name 标签,选择一个主机,选好后单机 Show logs 这时候查询语…...

Cent OS7+Docker+Dify
由于我之前安装了Dify v1.0.0,出现了一些问题:无法删除,包括:知识库中的文件、应用、智能体、工作流,都无法删除。现在把服务器初始化,一步步重新安装,从0到有。 目录 1、服务器重装系统和配置…...

【自学笔记】PHP语言基础知识点总览-持续更新
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1. PHP 简介2. PHP 环境搭建3. 基本语法变量与常量数据类型运算符 4. 控制结构条件语句循环语句 5. 函数函数定义与调用作用域 6. 数组7. 字符串8. 表单处理9. 会话…...

Android Gradle 下载插件或依赖太慢
问题与处理策略 问题描述 Android 项目中,settings.gradle 文件中,有如下配置,Gradle 插件或依赖下载速度慢 pluginManagement {repositories {gradlePluginPortal()google()mavenCentral()} }dependencyResolutionManagement {repositori…...

python-59-基于python内置库解析html获取标签关键信息
文章目录 1 html.parser1.1 初始化和基础使用1.1.1 handle_starttag(self, tag, attrs)1.1.2 handle_endtag(self, tag)1.1.3 handle_startendtag(self, tag, attrs)1.1.4 handle_data(self, data)1.1.5 handle_comment(self, data)1.2 解析HTML文档的流程2 百度搜索关键词链接…...

elementplus的el-tabs路由式
在使用 Element Plus 的 el-tabs 组件,实现路由式的切换(即点击标签页来切换不同的路由页面)。下面是一个基于 Vue 3 和 Element Plus 实现路由式 el-tabs 的基本步骤和示例。 步骤 1: 安装必要的库 在vue3项目安装 Vue Router 和 Element …...

ArcGIS地理信息系统空间分析实验教程学习
ArcGIS 作为地理信息系统领域的经典软件,以其强大的功能和广泛的应用场景,成为了众多学者、研究人员和专业人士的首选工具。它不仅可以高效地处理和可视化地理空间数据,还能通过复杂的空间分析模型,揭示地理现象背后的规律和趋势。…...

mac部署CAT监控服务
在 Mac 上部署美团点评开源的 CAT 监控服务端,可以按照以下步骤操作: 1. 环境准备 1.1 安装依赖 确保已安装以下工具: JDK 8(建议 OpenJDK 11) MySQL 5.7(存储监控数据)(8.0不支持…...

鸿蒙OS 5 架构设计探秘:从分层设计到多端部署
文章目录 鸿蒙OS架构设计探秘:从分层设计到多端部署一、鸿蒙的分层架构设计二、模块化设计的精髓三、智慧分发设计:资源的动态调度四、一次开发,多端部署的实践总结与思考 鸿蒙OS架构设计探秘:从分层设计到多端部署 最近两年来&a…...

深入解析:ElasticSearch Query 查询方式
全文目录: 开篇语前言摘要概述ElasticSearch Query 查询方式详解1. Match 查询(全文搜索)1.1 Match 查询示例1.2 Match 查询参数扩展 2. Term 查询(精准查询)2.1 Term 查询示例2.2 Terms 查询 3. Bool 查询(…...

HTML5贪吃蛇游戏开发经验分享
HTML5贪吃蛇游戏开发经验分享 这里写目录标题 HTML5贪吃蛇游戏开发经验分享项目介绍技术栈核心功能实现1. 游戏初始化2. 蛇的移动控制3. 碰撞检测4. 食物生成 开发心得项目收获后续优化方向结语 项目介绍 在这个项目中,我使用HTML5 Canvas和原生JavaScript实现了一…...

桥接模式_结构型_GOF23
桥接模式 桥接模式(Bridge Pattern)是一种结构型设计模式,核心思想是将抽象与实现分离,使两者能独立变化。它像一座连接两岸的桥梁,让“抽象层”和“实现层”自由组合,避免因多维度变化导致的“类爆炸”问…...
)
卡尔曼滤波入门(二)
核心思想 卡尔曼滤波的核心就是在不确定中寻找最优,那么怎么定义最优呢?答案是均方误差最小的,便是最优。 卡尔曼滤波本质上是一种动态系统状态估计器,它回答了这样一个问题: 如何从充满噪声的观测数据中,…...

有关pip与conda的介绍
Conda vs. Pip vs. Virtualenv 命令对比 任务Conda 命令Pip 命令Virtualenv 命令安装包conda install $PACKAGE_NAMEpip install $PACKAGE_NAMEX更新包conda update --name $ENVIRONMENT_NAME $PACKAGE_NAMEpip install --upgrade $PACKAGE_NAMEX更新包管理器conda update con…...

【Portainer】Docker可视化组件安装
Portainer Portainer 是用于管理容器化环境的一体化平台工程解决方案,提供广泛的定制功能,以满足个人开发人员和企业团队的需求。 官方地址: https://www.portainer.io/ 安装 在 WSL / Docker Desktop 上使用 Docker 安装 Portainer CE 通过命令或UI页…...

基于深度神经网络的图像防篡改检测方法研究
标题:基于深度神经网络的图像防篡改检测方法研究 内容:1.摘要 随着数字化时代的发展,图像篡改现象日益普遍,严重影响了图像信息的真实性和可靠性。本文旨在研究基于深度神经网络的图像防篡改检测方法,以有效识别被篡改的图像。通过收集大量真…...

MATLAB导入Excel数据
假如Excel中存在三列数据需要导入Matlab中。 保证该Excel文件与Matlab程序在同一目录下。 function [time, voltage, current] test(filename)% 读取Excel文件并提取时间、电压、电流数据% 输入参数:% filename: Excel文件名(需包含路径,如C:\data\…...

华为GaussDB数据库的手动备份与还原操作介绍
数据库的备份以A机上的操作为例。 1、使用linux的root用户登录到GaussDB服务器。 2、用以下命令切换到 GaussDB 管理员用户,其中,omm 为当前数据库的linux账号。 su - omm 3、执行gs_dump命令进行数据库备份: 这里使用gs_dump命令进行备…...

MySQL数据库BUG导致查询不到本该查到的数据
在数据库的日常使用中,我们常常会遇到一些看似匪夷所思的查询问。最近就看到一个因为MySQL BUG导致无法查到本该查询到数据的案例。 1. 问题背 数据库版本:MySQL8.0.40 假设我们创建了一个名为 product_info 的表,用于存储产品的相关信息。该…...
如何配置Dubbo的协议和端口?)
Dubbo(25)如何配置Dubbo的协议和端口?
配置Dubbo的协议和端口是设置分布式服务通信的基础步骤。Dubbo支持多种协议(如Dubbo、RMI、HTTP等),你可以根据需求选择合适的协议并配置相应的端口。下面以一个完整的Spring Boot项目为例,详细介绍如何配置Dubbo的协议和端口。 …...

服务器磁盘卷组缓存cache设置介绍
工具1: storcli a. 确认软件包是否安装 [rootlocalhost ~]#rpm -qa | grep storcli storcli-1.21.06-1.noarch 备注:若检索结果为空,需要安装对应的软件安装包。安装命令如下: #rpm -ivh storcli-xx-xx-1.noarch.rpm b. 查看逻辑…...

StarVector:开启多模态SVG生成的新纪元——开源AI模型的革新之作
在AI技术蓬勃发展的今天,图像生成模型已不再局限于像素级的输出。StarVector作为一款开源的多模态SVG生成模型,凭借其独特的代码与视觉融合能力,正在重新定义矢量图形的创作方式。它不仅让图像生成更灵活、更轻量化,还为设计师、开…...

MySQL日期时间函数
函数分类 函数名 功能描述 语法示例 获取当前日期和时间 NOW() 返回包含年、月、日、时、分、秒的完整时间戳,格式为 YYYY-MM-DD HH:MM:SS SELECT NOW(); CURDATE() / CURRENT_DATE() 获取当前日期,格式为 YYYY-MM-DD SELECT CURDATE(); 或 SE…...
)
WinSCP使用教程:(SFTP、SCP、FTP 和 WebDAV)
WinSCP 是一款免费开源的 Windows 环境下的 SFTP、SCP、FTP 和 WebDAV 客户端,主要用于在本地计算机与远程服务器之间安全地传输文件,并提供基本的文件管理功能。 WinSCP是Windows环境下使用SSH的开源图形化的SFTP的客户端 SSH 的全称是 Secure Shell&…...

备份是个好习惯
##解题思路 首先看到题目说备份是个好习惯,说明可能存在备份文件泄露 用dirsearch或者其他的目录扫描工具扫一扫,发现两个网址状态码正常,其中一个刚好是.bak的备份文件 至于flag文件,无法读取源码,都是空的 下载备份…...