RAG基建之PDF解析的“流水线”魔法之旅
将PDF文件和扫描图像等非结构化文档转换为结构化或半结构化格式是人工智能的关键部分。然而,由于PDF的复杂性和PDF解析任务的复杂性,这一过程显得神秘莫测。
在RAG(Retrieval-Augmented Generation)基建之PDF解析的“魔法”与“陷阱”中,我们介绍了PDF解析的主要任务,对现有方法进行了分类,并简要介绍了每种方法。RAG基建之PDF解析的“无OCR”魔法之旅中介绍了端到端方法。
本篇咱们来聊聊PDF解析的“流水线”大冒险!想象一下,PDF文件就像一座神秘的迷宫,里面藏着各种文字、表格、公式和图片。我们的任务就是把这些乱七八糟的东西整理得井井有条,变成结构化的数据。听起来是不是有点像在迷宫里找宝藏?
基于流水线的方法将PDF解析任务视为一系列模型或算法的流水线,如下所示。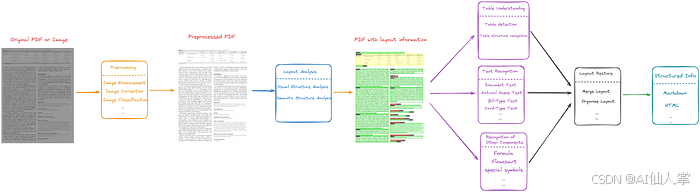
基于流水线的方法可以分为以下五个步骤:
- 预处理原始PDF文件:修复模糊或倾斜等问题。此步骤包括图像增强、图像方向校正等。
- 进行布局分析:主要包括视觉结构分析和语义结构分析。前者识别文档的结构并勾勒出相似区域,后者为这些区域标注特定的文档类型,如文本、标题、列表、表格、图表等。此步骤还涉及分析页面的阅读顺序。
- 分别处理布局分析中识别的不同区域:此过程包括理解表格、识别文本以及识别公式、流程图和特殊符号等其他组件。
- 整合之前的结果:恢复页面结构。
- 输出结构化或半结构化信息:如Markdown、JSON或HTML。
PDF解析的“流水线”方法四大天王:
-
- Marker:轻量级“宝藏猎人”
Marker是个轻量级的工具,速度快得像闪电侠,但它也有点小毛病。比如,它不太擅长处理表格,尤其是表格标题,简直像是迷路的小羊羔。不过,它对付公式倒是有一套,尤其是那些复杂的数学公式,Marker能用Texify模型把它们变成漂亮的LaTeX格式。可惜的是,它只懂英语,日语和印地语对它来说就像外星语。
- Marker:轻量级“宝藏猎人”
-
- Papermage:科学文档的“多面手”
Papermage是个专门对付科学文档的“多面手”。它不仅能把文档拆分成各种元素(文字、图表、表格等),还能灵活处理跨页、跨列的复杂内容。它的设计非常模块化,开发者可以轻松添加新功能,就像给乐高积木加新零件一样简单。不过,它目前还没有并行处理的能力,解析速度有点慢,像是在用老式打字机敲代码。
- Papermage:科学文档的“多面手”
-
- Unstructured:全能型“迷宫大师”
Unstructured是个全能型选手,布局分析做得非常细致。它不仅能识别文字和表格,还能处理复杂的文档结构。它的自定义能力也很强,开发者可以根据需要调整中间结果,就像在迷宫里随时调整路线一样灵活。不过,它在公式识别上表现一般,像是迷宫里的一块“绊脚石”。
- Unstructured:全能型“迷宫大师”
接下来,本文将讨论几种具有代表性的基于流水线的PDF解析框架,并分享从中获得的见解。
文章目录
- Marker
- 整体流程
- 从Marker中获得的见解
- Marker的缺点
- PaperMage
- 组件
- 基础数据类
- 整体流程和代码分析
- 句子分割
- 布局结构分析
- 逻辑结构分析
- 关于Papermage的见解和讨论
- Unstructured
- 关于布局分析
- 关于自定义
- 关于表格检测和识别
- 关于公式检测和识别
- MinerU:基于管道的开源文档解析框架
- MinerU 工作流程:
- MinerU所使用的主要模型和算法
- 评论
- 结论
Marker
Marker 是一个用于深度学习模型的流水线。它能够将PDF、EPUB和MOBI文档转换为Markdown格式。
整体流程
Marker的整体流程分为以下四个步骤:

步骤1:使用PyMuPDF和OCR将页面划分为块并提取文本。对应代码如下:
def convert_single_pdf(fname: str,model_lst: List,max_pages=None,metadata: Optional[Dict]=None,parallel_factor: int = 1
) -> Tuple[str, Dict]:......doc = pymupdf.open(fname, filetype=filetype)if filetype != "pdf":conv = doc.convert_to_pdf()doc = pymupdf.open("pdf", conv)blocks, toc, ocr_stats = get_text_blocks(doc,tess_lang,spell_lang,max_pages=max_pages,parallel=int(parallel_factor * settings.OCR_PARALLEL_WORKERS))
步骤2:使用布局分割器对块进行分类,并使用列检测器对块进行排序。对应代码如下:
def convert_single_pdf(fname: str,model_lst: List,max_pages=None,metadata: Optional[Dict]=None,parallel_factor: int = 1
) -> Tuple[str, Dict]:......# 从列表中解包模型texify_model, layoutlm_model, order_model, edit_model = model_lstblock_types = detect_document_block_types(doc,blocks,layoutlm_model,batch_size=int(settings.LAYOUT_BATCH_SIZE * parallel_factor))# 查找页眉和页脚bad_span_ids = filter_header_footer(blocks)out_meta["block_stats"] = {"header_footer": len(bad_span_ids)}annotate_spans(blocks, block_types)# 如果设置了调试标志,则转储调试数据dump_bbox_debug_data(doc, blocks)blocks = order_blocks(doc,blocks,order_model,batch_size=int(settings.ORDERER_BATCH_SIZE * parallel_factor))......
步骤3:过滤页眉和页脚,修复代码和表格块,并应用Texify模型处理公式。对应代码如下:
def convert_single_pdf(fname: str,model_lst: List,max_pages=None,metadata: Optional[Dict]=None,parallel_factor: int = 1
) -> Tuple[str, Dict]:......# 修复代码块code_block_count = identify_code_blocks(blocks)out_meta["block_stats"]["code"] = code_block_countindent_blocks(blocks)# 修复表格块merge_table_blocks(blocks)table_count = create_new_tables(blocks)out_meta["block_stats"]["table"] = table_countfor page in blocks:for block in page.blocks:block.filter_spans(bad_span_ids)block.filter_bad_span_types()filtered, eq_stats = replace_equations(doc,blocks,block_types,texify_model,batch_size=int(settings.TEXIFY_BATCH_SIZE * parallel_factor))out_meta["block_stats"]["equations"] = eq_stats......
步骤4:使用编辑器模型对文本进行后处理。对应代码如下:
def convert_single_pdf(fname: str,model_lst: List,max_pages=None,metadata: Optional[Dict]=None,parallel_factor: int = 1
) -> Tuple[str, Dict]:......# 复制以避免更改原始数据merged_lines = merge_spans(filtered)text_blocks = merge_lines(merged_lines, filtered)text_blocks = filter_common_titles(text_blocks)full_text = get_full_text(text_blocks)# 处理空块的连接full_text = re.sub(r'\n{3,}', '\n\n', full_text)full_text = re.sub(r'(\n\s){3,}', '\n\n', full_text)# 将项目符号字符替换为 -full_text = replace_bullets(full_text)# 使用编辑器模型对文本进行后处理full_text, edit_stats = edit_full_text(full_text,edit_model,batch_size=settings.EDITOR_BATCH_SIZE * parallel_factor)out_meta["postprocess_stats"] = {"edit": edit_stats}return full_text, out_meta
从Marker中获得的见解
到目前为止,我们已经介绍了Marker的整体流程。现在,让我们讨论从Marker中获得的见解。
见解1:布局分析可以分为多个子任务。第一个子任务涉及调用PyMuPDF API获取页面块。
def ocr_entire_page(page, lang: str, spellchecker: Optional[SpellChecker] = None) -> List[Block]:if settings.OCR_ENGINE == "tesseract":return ocr_entire_page_tess(page, lang, spellchecker)elif settings.OCR_ENGINE == "ocrmypdf":return ocr_entire_page_ocrmp(page, lang, spellchecker)else:raise ValueError(f"未知的OCR引擎 {settings.OCR_ENGINE}")def ocr_entire_page_tess(page, lang: str, spellchecker: Optional[SpellChecker] = None) -> List[Block]:try:full_tp = page.get_textpage_ocr(flags=settings.TEXT_FLAGS, dpi=settings.OCR_DPI, full=True, language=lang)blocks = page.get_text("dict", sort=True, flags=settings.TEXT_FLAGS相关文章:

RAG基建之PDF解析的“流水线”魔法之旅
将PDF文件和扫描图像等非结构化文档转换为结构化或半结构化格式是人工智能的关键部分。然而,由于PDF的复杂性和PDF解析任务的复杂性,这一过程显得神秘莫测。 在RAG(Retrieval-Augmented Generation)基建之PDF解析的“魔法”与“陷阱”中,我们介绍了PDF解析的主要任务,对现…...

leetcode刷题日记——跳跃游戏
[ 题目描述 ]: [ 思路 ]: 题目要求在给出的每次可移动最大步数中选择一个移动步数,如果有一种选择能达到终点就返回true,如果没有一种选择能够达到终点就返回false因为每次给出的最大步数不同,步数越大,…...

Scala 数组
Scala 数组 引言 Scala 作为一门多范式编程语言,融合了面向对象和函数式编程的特点。数组是编程语言中非常基础和常见的数据结构,在 Scala 中也不例外。本文将详细介绍 Scala 中的数组,包括其定义、操作以及在实际开发中的应用。 Scala 数…...

基于华为设备技术的端口类型详解
以下是基于华为设备技术网页的端口类型详解(截至2025年3月): 一、Access端口 定义:仅允许单个VLAN通过,用于连接终端设备(如PC、打印机) 处理流程: 接收帧:未带标签…...

使用 Go 和 Gin 实现高可用负载均衡代理服务器
前言 在现代分布式系统中,负载均衡是保障服务高可用性和性能的核心技术。本文将基于 Go 语言和 Gin 框架实现一个支持动态路由、健康检查、会话保持等特性的企业级负载均衡代理服务器,并提供完整的压力测试方案和优化建议。 通过本方案实现的负载均衡代理具备以下优势: 单…...

零基础驯服GitHub Pages
各位互联网流浪汉、赛博吉普赛人、以及不小心点进来的产品经理们!今天我们要用程序员的方式搞点大事情——不写代码、不买服务器、不氪金,免费拥有一个能吹牛的个人网站!准备好你的键盘和表情包收藏夹,我们的奇幻漂流开始了&#…...

OpenBMC:BmcWeb 生效路由5 优化trie
OpenBMC:BmcWeb 生效路由4 将路由添加到Trie中-CSDN博客 在url被添加到trie中后,validate的最后一步是优化trie void validate() {for (std::unique_ptr<BaseRule>& rule : allRules){if (rule){std::unique_ptr<BaseRule> upgraded = rule->upgrade();if…...
)
买卖股票的最佳时机(121)
121. 买卖股票的最佳时机 - 力扣(LeetCode) 解法: class Solution { public:int maxProfit(vector<int>& prices) {int cur_min prices[0];int max_profit 0;for (int i 1; i < prices.size(); i) {if (prices[i] > cur…...
—— Gamma)
强大的AI网站推荐(第四集)—— Gamma
网站:Gamma 号称:展示创意的新媒介 博主评价:快速展示创意,重点是展示,在几秒钟内快速生成幻灯片、网站、文档等内容 推荐指数:🌟🌟🌟🌟🌟&#x…...

Business Trip and Business Travel
Business Trip and Business Travel References Background I would like to introduce the background. Dave is going on a business trip, but he’s very busy, so he needs Leo’s help to buy the plane ticket. Panda is an agent of China Eastern /ˈiːstərn/ Airl…...

为pip设置国内镜像源
pip设置国内镜像源 在Python中使用pip安装软件包时,通常我们会遇到网络问题,尤其是在中国大陆地区。为了解决这个问题我们可以使用一些国内提供的镜像源。下面以清华大学的镜像源为例进行使用说明。 方法一:临时使用 在命令行中࿰…...

MySQL查询成本计算
对于如上SQL,只是因为查询字段不同,最终执行时选择的索引就不同,那么MySQL是如何决定选择使用哪个索引呢? 答案是MySQL会进行成本计算,对于各个场景查询进行成本预估,最终选择最优。 我们可以使用trace工具…...

使用 rsync 进行服务器文件同步与优化
使用 Rsync 工具在两台 Linux 服务器之间同步文件 Rsync 是一种高效的文件同步工具,它可以在本地或远程服务器之间同步文件和目录。Rsync 通过仅传输文件的变化部分来减少数据传输量,因此特别适合用于定期备份或同步大量数据。本文将详细介绍如何将 A 服…...

java面向对象从入门到入土
面向对象进阶 (写程序的套路) 面向:拿,找 对象:能干活的东西 面向对象编程:拿东西过来做对应的事情 (写程序的套路) 面向:拿,找 对象:能干活的东西 面向对象编程:拿东西过来做对应的事情 重点学习:学习已有对象并使用,学习如何自己设计对象并使用 设计对…...

Redis设计与实现-哨兵
哨兵模式 1、启动并初始化sentinel1.1 初始化服务器1.2 使用Sentinel代码1.3 初始化sentinel状态1.4 初始化sentinel状态的master属性1.5 创建连向主服务器的网络连接 2、获取主服务器信息3、获取从服务器的信息4、向主从服务器发送信息5、接受主从服务器的频道信息6、检测主观…...

vscode 打开工程 看不到文件目录
vscode 打开工程 看不到文件目录 View->Explorer 快捷键:CtrlShiftE...

[c++项目]基于微服务的聊天室服务端测试
项目概述 本测试报告针对基于C实现的微服务架构聊天室服务端进行全面测试。系统主要包含以下微服务: 用户认证服务(Auth Service)消息处理服务(Message Service)在线状态服务(Presence Service࿰…...

Java面试黄金宝典16
1. 各种排序算法的时间复杂度和空间复杂度 冒泡排序 定义: 冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,…...

pytorch中dataloader自定义数据集
前言 在深度学习中我们需要使用自己的数据集做训练,因此需要将自定义的数据和标签加载到pytorch里面的dataloader里,也就是自实现一个dataloader。 数据集处理 以花卉识别项目为例,我们分别做出图片的训练集和测试集,训练集的标…...

LabVIEW 燃气轮机气路故障诊断
在船用燃气轮机气路故障诊断领域,LabVIEW 软件以其独特的功能和优势,成为构建高效、精准诊断系统的关键技术支撑。它全面覆盖硬件在环仿真平台的各个环节,从硬件连接、数据交互到系统功能实现,都发挥着不可替代的作用,…...

[项目]基于FreeRTOS的STM32四轴飞行器: 十六.激光测距定高功能
基于FreeRTOS的STM32四轴飞行器: 十六.激光测距定高功能 一.芯片介绍二.配置CubeMX三.激光测距芯片驱动编写四.定高PID的计算五.定高PID作用到电机上 一.芯片介绍 激光测高芯片在飞控板下侧: 原理图如下: 型号为:VL53LX1,为国产…...

HTML跑酷
先看效果 再上代码 <!DOCTYPE html> <html> <head><title>火柴人跑酷</title><style>body {margin: 0;overflow: hidden;background: #87CEEB;}#gameCanvas {background: linear-gradient(to bottom, #87CEEB 0%, #87CEEB 50%, #228B22 …...
)
C++Primer学习(14.1 基本概念)
当运算符作用于类类型的运算对象时,可以通过运算符重载重新定义该运算符的含义。明智地使用运算符重载能令我们的程序更易于编写和阅读。举个例子,因为在Sales_item类中定义了输入、输出和加法运算符,所以可以通过下述形式输出两个Sales_item…...

【Goalng】第九弹-----文件操作、JSON处理
🎁个人主页:星云爱编程 🔍所属专栏:【Go】 🎉欢迎大家点赞👍评论📝收藏⭐文章 长风破浪会有时,直挂云帆济沧海 目录 1.文件操作 1.1文件介绍 1.2.文件流 1.3.打开和关闭文件 1…...

锐评|希捷NVMe闪存+磁盘混合存储阵列
近日,希捷在英伟达GTC 2025会议上展示了NVMe混合闪存/磁盘阵列技术。这个混合存储阵列确实在当前AI数据存储困境中撕开了一道新口子,但远称不上完美,优缺点都极为鲜明。 从优点来看,希捷切中了大多数企业的痛点。AI领域数据量呈爆…...

如何缩短研发周期,降低研发成本?全星APQP软件为您提供解决方案
如何缩短研发周期,降低研发成本?全星APQP软件为您提供解决方案 一、 系统概述 全星研发管理APQP软件系统是一款专为产品研发和质量管控打造的智能化平台,旨在帮助企业高效推进APQP(先期产品质量策划)流程,…...

Centos7安装cat美化工具lolcat
Centos7安装cat美化工具lolcat Centos7安装lolcat使用ruby安装lolcat配置cat系统别名 结果验证 Centos7安装lolcat lolcat :一个在Linux 终端中输出彩虹特效的命令行工具 使用ruby安装lolcat # 安装ruby和zip yum install -y ruby# 查看ruby版本 ruby --version# …...

bluecode-20240913_1_数据解码
时间限制:C/C 1000MS,其他语言 2000MS 内存限制:C/C 256MB,其他语言 512MB 难度:困难 数据解码 指定有一段经过编码的二进制数据,数据由0个或多个"编码单元"组成。"编码单元"的编码方式…...

【 <二> 丹方改良:Spring 时代的 JavaWeb】之 Spring Boot 中的缓存技术:使用 Redis 提升性能
<前文回顾> 点击此处查看 合集 https://blog.csdn.net/foyodesigner/category_12907601.html?fromshareblogcolumn&sharetypeblogcolumn&sharerId12907601&sharereferPC&sharesourceFoyoDesigner&sharefromfrom_link <今日更新> 一、开篇整…...
→ 贪心算法)
典范硬币系统(Canonical Coin System)→ 贪心算法
【典范硬币系统】 ● 典范硬币系统(Canonical Coin System)是指使用贪心算法总能得到最少硬币数量解的货币面值组合。 ● 给定一个硬币系统 ,若使其为典范硬币系统,则要求其各相邻面值比例 ,及各开区间 内各金额…...

hbuilderx打包iOS上传苹果商店的最简流程
无需Mac电脑,无需安装xcode和transporter,其实使用hbuilderx开发的ios软件,也可以上架到苹果的app store商店的。 只需要有苹果开发者中心的苹果开发者账号就行了。 假如你还在了解上架阶段,还没打包,也还没有创建任…...

DeepSeek详解:探索下一代语言模型
文章目录 前言一、什么是DeepSeek二、DeepSeek核心技术2.1 Transformer架构2.1.1 自注意力机制 (Self-Attention Mechanism)(a) 核心思想(b) 计算过程(c) 代码实现 2.1.2 多头注意力 (Multi-Head Attention)(a) 核心思想(b) 工作原理(c) 数学描述(d) 代码实现 2.1.3 位置编码 (…...

python的内存管理
目录 1. 引用计数 2. 垃圾收集(GC) python的内存管理主要是引用计数和垃圾回收器来进行内存管理 1. 引用计数 每个 Python 对象都有一个引用计数,当引用计数为零时,对象的内存会被释放。 import sysa [] # 创建一个空列表对…...

【STL】list
l i s t list list 是 C C C 标准模板库( S T L STL STL)中的一个序列容器( S e q u e n c e C o n t a i n e r Sequence\ Container Sequence Container),它允许在容器的任意位置快速插入和删除元素,是一…...

证券公司主要业务分析及当前佣金最低免五情况探讨
我是StockMasterX,今日想分析证券公司主要业务,并探讨当前佣金最低且免五的证券公司情况,此议题具有一定研究价值,我从事股票交易多年,与证券公司互动频繁,前日晚间饮茶之际,浏览手机时对此深思…...
)
C++ 变量的声明与定义分离式编译与静态类型(十六)
1. 声明与定义的区别 声明(declaration):向编译器表明某个变量(或其他实体)的类型与名字,使它在后续的编译过程中可见或可用。定义(definition):除了声明变量的名字和类…...
)
黑盒测试的等价类划分法(输入数据划分为有效的等价类和无效的等价类)
重点: 有效等价和单个无效等价各取1个即可 1、正向用例:一条尽可能覆盖多条2、逆向用例:每一条数据,都是一条单独用例。 步骤: 1、明确需求 2、确定有效和无效等价 3、根据有效和无效造数据编写用例 3、适用场景 针对:需要有大量数据测试输入, …...

通过Appium理解MCP架构
MCP即Model Context Protocol(模型上下文协议),是由Anthropic公司于2024年11月26日推出的开放标准框架,旨在为大型语言模型与外部数据源、工具及系统建立标准化交互协议,以打破AI与数据之间的连接壁垒。 MCP架构与Appi…...

uWebSockets开发入门
一、常用C++ WebSocket开源库 一些常用的 C++ WebSocket 开源库,它们支持 WebSocket 协议的实现,适用于客户端或服务器端开发。 1. Boost.Beast (推荐) 特点:基于 Boost.Asio 的高性能库,支持 HTTP/WebSocket,属于 Boost 官方库的一部分,稳定且跨平台。 适用场景:需要高…...

Python自动化模块:开启高效编程新时代
一、写在前面 在数字化时代,自动化技术已成为提高效率、降低成本的关键手段。Python 作为一种简洁、高效且功能强大的编程语言,凭借其丰富的库和框架,在自动化领域占据了举足轻重的地位,成为众多开发者的首选工具之一。从简单的文…...
Linux 驱动层输入事件管理)
Android7 Input(二)Linux 驱动层输入事件管理
概述 在Linux系统中,将键盘,鼠标,触摸屏等这类交互设备交由Linux Input子系统进行管理,Linux Input驱动子系统由于具有良好的和用户空间交互的接口。因此Linux Input驱动子系统,不止于只管理输入类型的设备。也可以将其…...
)
前端给后端发送数据时都需要包含哪些内容?(HTTP请求的基本组成部分)
1 [TOC](1)一、**必须传递的内容**1. **URL(请求地址)** 二、**可选内容**1. **请求方法(HTTP Method)**2. **请求头(Headers)**3. **请求体(Body)**4. **其他配置** 技术无关 一、必…...

记录vite引入sass预编译报错error during build: [vite:css] [sass] Undefined variable.问题
vite.config.ts resolve: {alias: {: path.resolve(__dirname, src),},},css: {// css预处理器preprocessorOptions: {scss: {additionalData: use "/assets/styles/block.scss" as *;,}}},block.scss $colorGreen: #00ff00;index.vue :v-deep .font-size-14{colo…...

智慧运维平台:赋能未来,开启高效运维新时代
在当今数字化浪潮下,企业IT基础设施、工业设备及智慧城市系统的复杂度与日俱增,传统人工运维方式已难以满足高效、精准、智能的管理需求。停机故障、低效响应、数据孤岛等问题直接影响企业运营效率和成本控制。大型智慧运维平台(AIOps, Smart…...

【log4j】配置Slf4j
配置Slf4j 引入lombok包 <dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.36</version><scope>provided</scope> </dependency>引入log4j相关api <dependency…...

静态网页应用开发环境搭建实战教程
1. 前言 静态网页开发是前端工程师的基础技能之一,无论是个人博客、企业官网还是简单的Web应用,都离不开HTML、CSS和JavaScript。搭建一个高效的开发环境,能够极大提升开发效率,减少重复工作,并优化调试体验。 本教程…...
 :OceanBase 读写分离策略解析)
AP 场景架构设计(一) :OceanBase 读写分离策略解析
说明:本文内容对应的是 OceanBase 社区版,架构部分不涉及企业版的仲裁副本功能。OceanBase社区版和企业版的能力区别详见: 官网链接。 概述 当两种类型的业务共同运行在同一个数据库集群上时,这对数据库的配置等条件提出了较高…...

未来村庄智慧灯杆:点亮乡村智慧生活
在乡村振兴与数字乡村建设的时代进程中,未来村庄智慧灯杆凭借其多功能集成与智能化特性,已成为乡村基础设施建设领域的崭新焦点,为乡村生活带来了前所未有的便利,推动着乡村生活模式的深刻变革。 多功能集成:一杆多能…...

MySQL基础语法DDLDML
目录 #1.创建和删除数据库 #2.如果有lyt就删除,没有则创建一个新的lyt #3.切换到lyt数据库下 #4.创建数据表并设置列及其属性,name是关键词要用name包围 编辑 #5.删除数据表 #5.查看创建的student表 #6.向student表中添加数据,数据要与列名一一对应 #7.查询studen…...

利用 VSCode 配置提升 vibe coding 开发效率
利用 VSCode 配置提升 vibe coding 开发效率 Vibe Coding(氛围编程)是一种基于AI的编程方法,其核心在于通过自然语言描述软件需求,再由大规模语言模型(LLM)自动生成代码,从而实现对传统手写编程…...