分布式ID服务实现全面解析
分布式ID生成器是分布式系统中的关键基础设施,用于在分布式环境下生成全局唯一的标识符。以下是各种实现方案的深度解析和最佳实践。


一、核心需求与设计考量
1. 核心需求矩阵
| 需求 | 重要性 | 实现难点 |
| 全局唯一 | 必须保证 | 时钟回拨/节点冲突 |
| 高性能 | 高并发场景关键 | 锁竞争/网络开销 |
| 有序性 | 分页查询友好 | 时间戳精度问题 |
| 高可用 | 服务不可中断 | 故障转移/数据恢复 |
| 易用性 | 接入成本低 | 协议兼容性 |
2. 典型业务场景
- 电商订单号生成
- 金融交易流水号
- 物联网设备标识
- 分布式日志追踪
- 数据库分片键
二、主流实现方案对比
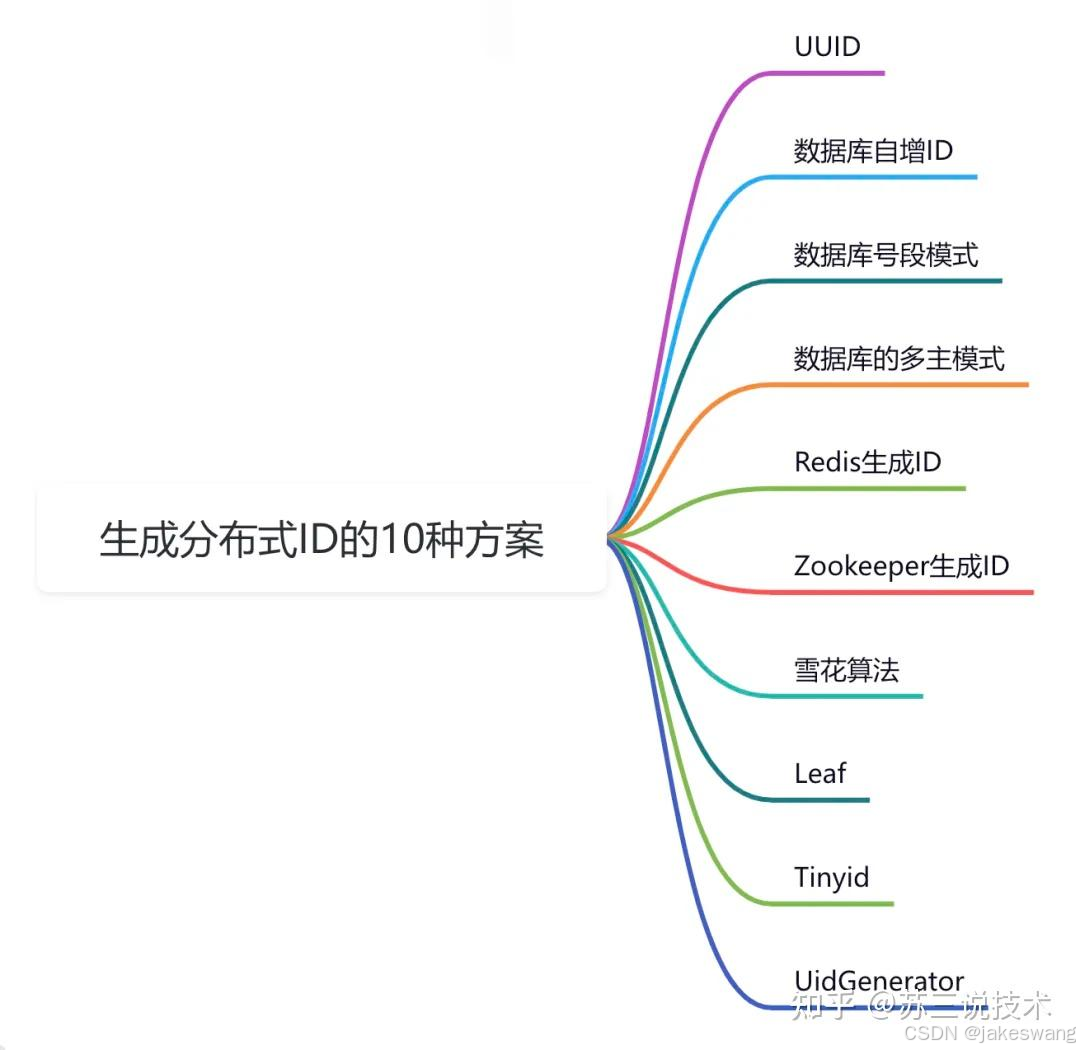
1. 方案全景图
mermaid
graph TDA[分布式ID] --> B[中心化]A --> C[去中心化]B --> D[数据库序列]B --> E[Redis原子操作]B --> F[Zookeeper节点]C --> G[UUID]C --> H[Snowflake]C --> I[Leaf/美团]2. 详细方案对比
| 方案 | 示例ID | 优点 | 缺点 | QPS |
| UUID |
| 无中心节点 | 无序存储效率低 | 100,000+ |
| 数据库自增 |
| 简单可靠 | 单点瓶颈 | 1,000~5,000 |
| Redis INCR |
| 性能较好 | 持久化问题 | 50,000~100,000 |
| Snowflake |
| 有序紧凑 | 时钟敏感 | 100,000+ |
| Leaf-Segment |
| 缓冲优化 | 需DB配合 | 50,000+ |
| Tinyid |
| 批量获取 | 强依赖ZK | 20,000+ |
三、Snowflake 深度实现
1. 标准位分配
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
|____________________________| |________| |_____| |________________________|时间戳(41bit) 数据中心(5bit) 机器ID(5bit) 序列号(12bit)2. Java优化实现
public class SnowflakeIdGenerator {private final long twepoch = 1288834974657L; // 起始时间戳(2010-11-04)private final long workerIdBits = 5L;private final long datacenterIdBits = 5L;private final long sequenceBits = 12L;private final long maxWorkerId = -1L ^ (-1L << workerIdBits);private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);private volatile long lastTimestamp = -1L;private volatile long sequence = 0L;public synchronized long nextId() {long timestamp = timeGen();// 时钟回拨处理if (timestamp < lastTimestamp) {throw new RuntimeException("Clock moved backwards");}if (lastTimestamp == timestamp) {sequence = (sequence + 1) & ((1 << sequenceBits) - 1);if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0;}lastTimestamp = timestamp;return ((timestamp - twepoch) << (workerIdBits + sequenceBits)) | (datacenterId << (workerIdBits + sequenceBits))| (workerId << sequenceBits) | sequence;}protected long tilNextMillis(long lastTimestamp) {// 阻塞到下一毫秒long timestamp;do {timestamp = timeGen();} while (timestamp <= lastTimestamp);return timestamp;}
}3. 时钟回拨解决方案
| 方案 | 实现方式 | 适用场景 |
| 异常抛出 | 直接拒绝请求 | 严格要求时序 |
| 等待时钟 | 自旋直到时钟追回 | 短暂回拨(<100ms) |
| 备用ID池 | 提前生成备用ID | 容忍短暂无序 |
| 扩展位记录 | 增加回拨计数位 | 需要改造ID结构 |
四、Leaf-Segment 方案详解
1. 数据库设计
CREATE TABLE `leaf_alloc` (`biz_tag` varchar(128) NOT NULL,`max_id` bigint NOT NULL DEFAULT '1',`step` int NOT NULL,`update_time` timestamp NOT NULL,PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;2. 双Buffer优化流程
sequenceDiagramparticipant Clientparticipant Serviceparticipant DBClient->>Service: 获取ID(biz_tag=order)Service->>DB: 查询当前max_id和stepDB-->>Service: max_id=1000, step=1000Service->>Service: 分配本地缓存[1001-2000]Service->>Client: 返回1001Service->>DB: 异步更新max_id=2000Note right of Service: Buffer1耗尽前<br>提前加载Buffer23. 异常处理机制
- DB故障:使用本地缓存直到耗尽
- ID耗尽:动态调整step大小
- 双Buffer同时失效:降级到同步获取
五、高性能服务架构
1. 服务化部署架构
+-----------------+| Load Balancer |+--------+--------+|+----------------+----------------+| | |+------+------+ +------+------+ +------+------+| ID Service | | ID Service | | ID Service |+------+------+ +------+------+ +------+------+| | |+------+------+ +------+------+ +------+------+| Redis | | DB | | Zookeeper |+-------------+ +------------+ +-------------+2. 性能优化技巧
| 技术 | 效果 | 实现示例 |
| 本地缓存 | 减少网络IO |
存储Segment |
| 批量获取 | 降低DB压力 |
|
| 异步持久化 | 提高吞吐 | 先响应后写WAL日志 |
| 分层设计 | 故障隔离 | 内存->Redis->DB 三级获取 |
3. 容灾方案对比
| 方案 | 恢复时间 | 数据丢失风险 |
| 主从同步 | 秒级 | 少量异步数据 |
| 多活部署 | 几乎为零 | 无 |
| 定期快照 | 分钟级 | 取决于备份频率 |
六、生产实践案例
案例1:电商订单ID
需求:
- 每日亿级订单
- 需要时间有序
- 包含业务类型信息
实现:
// 格式: 业务类型(2位) + 时间(yyMMddHHmm) + 序列(6位) + 机器(3位)
public String generateOrderId(String bizType) {String timePart = new SimpleDateFormat("yyMMddHHmm").format(new Date());long seq = redis.incr("order:id:" + timePart);return String.format("%s%s%06d%03d", bizType, timePart, seq % 1000000, machineId);
}import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;@Service
public class BufferedOrderIdGenerator {private final Queue<String> idPool = new ConcurrentLinkedQueue<>();private final RedisOrderIdGenerator redisGenerator;private final ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);private static final int BATCH_SIZE = 100;private static final int REFILL_THRESHOLD = 20;public BufferedOrderIdGenerator(RedisOrderIdGenerator redisGenerator) {this.redisGenerator = redisGenerator;this.scheduler.scheduleAtFixedRate(this::refillPool, 0, 1, TimeUnit.SECONDS);}public String getOrderId() {String id = idPool.poll();if (id == null) {// 缓冲池为空时同步获取return redisGenerator.generateOrderId();}return id;}private void refillPool() {if (idPool.size() < REFILL_THRESHOLD) {// 批量预生成IDString date = LocalDate.now().format(DATE_FORMAT);Long startSeq = redisTemplate.opsForValue().increment(ORDER_ID_PREFIX + date, BATCH_SIZE);for (long i = startSeq - BATCH_SIZE + 1; i <= startSeq; i++) {idPool.add(String.format(ID_FORMAT, date, i));}redisTemplate.expire(ORDER_ID_PREFIX + date, 48, TimeUnit.HOURS);}}
}import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.concurrent.TimeUnit;@Service
public class RedisOrderIdGenerator {private final StringRedisTemplate redisTemplate;private static final String ORDER_ID_PREFIX = "order:id:";private static final DateTimeFormatter DATE_FORMAT = DateTimeFormatter.BASIC_ISO_DATE;// 订单ID格式:年月日(8位) + 序列号(8位)private static final String ID_FORMAT = "%s%08d"; public RedisOrderIdGenerator(StringRedisTemplate redisTemplate) {this.redisTemplate = redisTemplate;}/*** 生成订单ID*/public String generateOrderId() {String date = LocalDate.now().format(DATE_FORMAT);String key = ORDER_ID_PREFIX + date;// 使用Redis原子操作INCRLong sequence = redisTemplate.opsForValue().increment(key);// 设置48小时过期(避免跨日期问题)redisTemplate.expire(key, 48, TimeUnit.HOURS);return String.format(ID_FORMAT, date, sequence);}
}import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.transaction.annotation.Transactional;@Service
public class PersistentOrderIdService {private final RedisOrderIdGenerator redisGenerator;private final JdbcTemplate jdbcTemplate;// WAL(Write-Ahead Log)表private static final String WAL_TABLE = "order_id_wal";public PersistentOrderIdService(RedisOrderIdGenerator redisGenerator, JdbcTemplate jdbcTemplate) {this.redisGenerator = redisGenerator;this.jdbcTemplate = jdbcTemplate;}/*** 带持久化保障的ID生成*/@Transactionalpublic String generatePersistentOrderId() {// 1. 先写入预写日志String pendingId = redisGenerator.generateOrderId();jdbcTemplate.update("INSERT INTO " + WAL_TABLE + " (order_id, create_time, status) VALUES (?, NOW(), 'PENDING')",pendingId);// 2. 确认写入Redis// 如果Redis操作失败会抛出异常触发事务回滚// 3. 更新日志状态jdbcTemplate.update("UPDATE " + WAL_TABLE + " SET status = 'CONFIRMED' WHERE order_id = ?",pendingId);return pendingId;}/*** 恢复未确认的ID*/@Scheduled(fixedRate = 60000) // 每分钟执行一次public void recoverPendingIds() {jdbcTemplate.query("SELECT order_id FROM " + WAL_TABLE + " WHERE status = 'PENDING' AND create_time > DATE_SUB(NOW(), INTERVAL 1 HOUR)",(rs, rowNum) -> rs.getString("order_id")).forEach(pendingId -> {if (!redisTemplate.hasKey(buildRedisKey(pendingId))) {redisTemplate.opsForValue().set(buildRedisKey(pendingId), extractSequence(pendingId));}});}private String buildRedisKey(String orderId) {return ORDER_ID_PREFIX + orderId.substring(0, 8); // 提取日期部分}private long extractSequence(String orderId) {return Long.parseLong(orderId.substring(8));}
}案例2:分布式追踪ID
需求:
- 全局唯一
- 高吞吐
- 可解析
实现(借鉴Twitter的Zipkin):
// 128-bit ID = 应用节点(32bit) + 时间(64bit) + 随机数(32bit)
public static String newTraceId() {return String.format("%08x%016x%08x",nodeId,System.currentTimeMillis(),ThreadLocalRandom.current().nextInt());
}七、监控与治理
1. 关键监控指标
| 指标 | 采集方式 | 告警阈值 |
| ID生成延迟 | Micrometer Timer | P99 > 10ms |
| 段缓存命中率 | 缓存统计 | <90% |
| 时钟偏移量 | NTP监控 | >50ms |
| DB连接池使用率 | Druid监控 | >80% |
2. 运维指令集
bash
# 动态调整Leaf步长
curl -X POST "http://id-service/segment/step?bizTag=order&step=5000"# 强制刷新缓存
redis-cli DEL leaf:order:cache# 节点下线
./admin.sh disableNode --nodeId=3八、选型决策树
mermaid
graph TDA[是否需要有序ID?] -->|是| B[考虑Snowflake/Leaf]A -->|否| C[考虑UUID]B --> D[QPS>10万?]D -->|是| E[Leaf-Segment+缓存]D -->|否| F[原生Snowflake]C --> G[需要可读性?]G -->|是| H[时间戳+序列组合]G -->|否| I[标准UUIDv4]通过深入理解这些实现方案和架构设计,可以构建出满足不同业务场景需求的分布式ID服务。建议根据实际业务规模、性能要求和运维能力进行技术选型。
相关文章:

分布式ID服务实现全面解析
分布式ID生成器是分布式系统中的关键基础设施,用于在分布式环境下生成全局唯一的标识符。以下是各种实现方案的深度解析和最佳实践。 一、核心需求与设计考量 1. 核心需求矩阵 需求 重要性 实现难点 全局唯一 必须保证 时钟回拨/节点冲突 高性能 高并发场景…...

浏览器与网络模块实践
浏览器渲染步骤 浏览器渲染大致分为以下四个步骤: 1. 构建 DOM 树 • 过程:当浏览器接收到 HTML 文档后,会从上到下依次解析 HTML 代码。每遇到一个开始标签,就会创建一个对应的 DOM 节点,并根据标签的嵌套关系将这些…...

谈谈Minor GC、Major GC和Full GC
目录 一、背景 二、三者之间的区分 1、Minor GC 2、Major GC (1)老年代空间不足: (2)晋升(Promotion)失败: (3)空间分配担保失败: &#x…...

基于SpringBoot实现的高校实验室管理平台功能四
一、前言介绍: 1.1 项目摘要 随着信息技术的飞速发展,高校实验室的管理逐渐趋向于信息化、智能化。传统的实验室管理方式存在效率低下、资源浪费等问题,因此,利用现代技术手段对实验室进行高效管理显得尤为重要。 高校实验室作为…...
)
梯度裁剪(Gradient Clipping)
梯度裁剪(Gradient Clipping)是一种用于防止梯度爆炸(Gradient Explosion)的技术,具体来说: 1. 梯度裁剪的作用 问题背景:在训练深度神经网络(尤其是RNN/LSTM)时&#x…...

联合办公空间WeWork的创新模式与私域流量时代的品牌温度——兼论开源AI大模型AI智能名片S2B2C商城小程序源码的潜在价值
摘要:本文聚焦于联合办公空间WeWork的成功模式,深入剖析其如何让创业用户摆脱传统租赁的束缚,打破空间与社交限制,为创业带来新的可能性与趣味性,并有效降低创业成本与风险。同时探讨了WeWork在私域流量时代所建立的平…...

Git配置
为什么要用:下载zip只是当前分支,不能进行仓库push、pull、checkout 1. 下载Git 先判断是否已经下过Git: git --version若没有版本号出来,就去下载:https://git-scm.com/downloads (Windows、linux、mac…...
)
Protobuf 的快速使用(二)
这个部分会对通讯录进⾏多次升级,使⽤ 2.x 表⽰升级的版本,最终将会升级如下内容: 不再打印联系⼈的序列化结果,⽽是将通讯录序列化后并写⼊⽂件中。 从⽂件中将通讯录解析出来,并进⾏打印。 新增联系⼈属性ÿ…...

网页设计思路
CSS实现思路: 用一个div直接父级继承 在这里插入图片描述 一LOGO结构 h1>a>搜索关键字 二导航栏结构 结构:ul>li>a 三搜索框结构 div>input/a 四用户头像结构 div>a>imgspan 处理行内块和行内垂直对齐方向使用 vertical-align...

Vue3 配合 fullPage.js 打造高效全屏滚动网页
引言 在现代网页设计中,整屏滚动(Full-page Scrolling)已成为展示内容的一种流行方式。通过将内容分成若干个全屏页面,并配合流畅的过渡动画,可以为用户带来身临其境的浏览体验。本文将介绍如何使用 fullPage.js 插件来…...

全排列 II:去重的技巧与实现
全排列 II:去重的技巧与实现 1. 引言:排列问题的坑 你有没有遇到过这样的问题? 当我们在做全排列(Permutation)的时候,如果输入的数组中包含重复元素,生成的排列中就会出现大量重复项。这样不…...

微型导轨和普通导轨有哪些区别?
微型导轨和普通导轨都是常用的工业机械传动装置,目前,市场上有各种各样的导轨产品。那么微型导轨和普通导轨有哪些区别呢? 1、尺寸:微型导轨尺寸较小,滑座宽度最小可达 8MM,长度最小可达 11MM 左右…...

Java 输入流到输出流
Java 输入流到输出流的复制方法主要有以下六种实现方式,根据性能、适用场景和实现原理可分为不同类别: 一、基础字节流方式 实现原理:通过 FileInputStream 和 FileOutputStream 逐字节或块读取数据并写入。 代码示例: try (In…...

Anaconda安装-Ubuntu-Linux
1、进入Anaconda官网,以下载最新版本,根据自己的操作系统选择适配的版本。 2、跳过注册: 3、选择适配的版本: 4、cd ~/anaconda_download 5、bash Anaconda3-2024.10-1-Linux-x86_64.sh 6、按Enter或PgDn键滚动查看协议&…...

每日一题之既约分数
题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 如果一个分数的分子和分母的最大公约数是 1,这个分数称为既约分数。 例如 3/4,1/8,7/1, 都是既约分数。 请问,有多少个既约分…...

诠视科技MR眼镜如何使用VLC 进行RTSP投屏到电脑
文章目录 一、应用开发部分(1)基础场景构建(2)添加XvCameraManager(3)添加XvMRVideoCaptureManager(4)添加XvRTSPStreamerManager(5)打包测试 二、VLC media …...

“头”里有什么——HTML 元信息
2025/3/28 向全栈工程师迈进! 一、看基本HTML <!doctype html> <html lang"zh-CN"><head><meta charset"utf-8" /><title>我的测试页面</title></head><body><p>这是我的页面</p&g…...

【Kafka】从理论到实践的深度解析
在当今数字化转型的时代,企业面临着数据量呈指数级增长、业务系统愈发复杂的挑战。在这样的背景下,高效的数据传输与处理技术成为了关键。Kafka,作为一款分布式消息队列系统,凭借其卓越的性能和丰富的特性,在众多企业的…...

Debezium系列之:使用Debezium和Apache Iceberg构建数据湖
Debezium系列之:使用Debezium和Apache Iceberg构建数据湖 Debezium Server Iceberg“Debezium Server Iceberg” 消费者设置数据复制Upsert 模式保留已删除的记录使用Upsert模式追加模式优化批处理大小在数据分析的世界中,数据湖是存储和管理大量数据以满足数据分析、报告或机…...
)
resnet网络迁移到昇腾执行(OM上篇)
目录 总体介绍 pytorch迁移OM模型 原始代码详细介绍 模型加载和初始化 初始化统计变量 数据推理及归一化 统计每个样本的结果 基本概念 Softmax(归一化指数函数) 作用 代码示例 应用场景 argmax取最大值索引 作用 代码示例 两者配合使用…...

RHCA核心课程技术解析5:红帽高可用性集群架构与深度实践
一、红帽高可用集群架构全景 1.1 核心组件交互逻辑 graph TD A[节点1] -->|Corosync 心跳| B[节点2] A -->|Pacemaker 资源管理| C[共享存储] B --> C D[Fencing设备] -->|STONITH| A D -->|STONITH| B C -->|GFS2锁管理| A C -->|GFS2锁管理| B 1.2 集…...
和SerDes 加解串应用)
Display Serializer、Camera Deserializer(Camera Des)和SerDes 加解串应用
1. 概述:三者的核心定位 (1) SerDes(Serializer/Deserializer) 定义:通用高速数据传输技术,实现并行↔串行双向转换。角色:数据链路的“翻译官”,解决并行传输的带宽与距…...

vue3+bpmn.js基本使用
一、案例使用依赖 // 必填"bpmn-js": "^7.3.1", "bpmn-js-properties-panel": "^0.37.2","bpmn-moddle":"^7.1.3","camunda-bpmn-moddle": "^7.0.1",// 可选"element-plus/icons-vue&qu…...

《数据结构:单链表》
“希望就像星星,或许光芒微弱,但永不熄灭。” 博主的个人gitee:https://gitee.com/friend-a188881041351 一.概念与结构 链表是一种物理存储上非连续、非顺序的存储结构,数据元素的顺序逻辑是通过链表中的指针链接次序实现的。 单…...
)
RedHatLinux(2025.3.22)
1、创建/www目录,在/www目录下新建name和https目录,在name和https目录下分别创建一个index.htm1文件,name下面的index.html 文件中包含当前主机的主机名,https目录下的index.htm1文件中包含当前主机的ip地址。 (1&…...

C++异常处理完全指南:从原理到实战
文章目录 异常的基本概念基本异常抛出与捕获多类型异常捕获异常重新抛出异常安全异常规范(noexcept)栈展开与析构标准库异常总结 异常的基本概念 异常是程序运行时发生的非预期事件(如除零、内存不足)。C通过try、catch和throw提…...

Oracle 19C 备份
在 Oracle 19c 中,备份数据库通常使用 RMAN(Recovery Manager) 工具,它是 Oracle 提供的官方备份和恢复工具。以下是通过 RMAN 备份 Oracle 19c 数据库的详细步骤和命令。 一、RMAN 基本概念 RMAN 是 Oracle 的备份和恢复工具&am…...

深入理解MySQL聚集索引与非聚集索引
在数据库管理系统中,索引是提升查询性能的关键。MySQL支持多种类型的索引,其中最基础也是最重要的两种是聚集索引和非聚集索引。本文将深入探讨这两种索引的区别,并通过实例、UML图以及Java代码示例来帮助您更好地理解和应用它们。 一、概念…...

用Python打造智能宠物:强化学习的奇妙之旅
友友们好! 我是Echo_Wish,我的的新专栏《Python进阶》以及《Python!实战!》正式启动啦!这是专为那些渴望提升Python技能的朋友们量身打造的专栏,无论你是已经有一定基础的开发者,还是希望深入挖掘Python潜力的爱好者,这里都将是你不可错过的宝藏。 在这个专栏中,你将会…...
 specified for column)
OGG故障指南:OGG-01163 Bad column length (xxx) specified for column
报错 OGG-01163 Bad column length (xxx) specified for column AAA in table OWNER.TABLE, maximum allowable length is yyy原因 源端修改了字段长度。 虽然源端和目标端的长度已经通过DDL语句修改到一致,在extract进程未重启的情况下,生成的trail文…...

XML标签格式转换为YOLO TXT格式
针对的是多边形(<polygon>)来描述对象的边界,而不是传统的矩形框(<bndbox>) import xml.etree.ElementTree as ET import os from pathlib import Path# 解析VOC格式的XML文件,提取目标框的标…...

Java的string默认值
在Java中,String类型的默认值取决于其定义和实例化的方式。 以下是关于String默认值的详细说明 未实例化的String变量 如果定义一个String变量但未对其进行实例化(即未使用new关键字或直接赋值),其默认值为:ml-search[null]。这…...

侯捷 C++ 课程学习笔记:C++ 中引用与指针的深度剖析
目录 一、引言 二、引用与指针的基本概念 (一)引用 (二)指针 三、引用与指针的区别 (一)定义与初始化 (二)内存空间与 NULL 值 (三)自增操作 …...

llamafactory微调效果与vllm部署效果不一致如何解决
在llamafactory框架训练好模型之后,自测chat时模型效果不错,但是部署到vllm模型上效果却很差 这实际上是因为llamafactory微调时与vllm部署时的对话模板不一致导致的。 对应的llamafactory的代码为 而vllm启动时会采用大模型自己本身设置的对话模板信息…...

欢乐力扣:合并两个有序链表
文章目录 1、题目描述2、思路 1、题目描述 合并两个有序链表。 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 在这里插入图片描述 2、思路 参考官方题解,简单来说就是不断调整链表指针的指向,让…...

访问者模式_行为型_GOF23
访问者模式 访问者模式(Visitor Pattern)是一种行为型设计模式,核心思想是将算法与对象结构分离,使得在不修改现有对象结构的前提下,可以动态添加新的操作。这类似于“医生查房”——医生(访问者ÿ…...

排序算法2-选择排序
目录 1.常见排序算法 2.排序算法的预定函数 2.1交换函数 2.2测试算法运行时间的函数 2.3已经实现过的排序算法 3.选择排序算法的实现 3.1直接选择排序 3.2堆排序 4.下讲预告 1.常见排序算法 前面一讲已经讲解了插入排序,这一讲我将讲解选择排序,…...

openwrt24.10.0版本上安装istoreOS的屏幕监控插件
lcdsimple 插件支持在软路由下面显示统计信息到 HDMI 或者 VGA 上。 手动安装方法: 保证 quickstart 版本大于 0.9.7 安装 lcdsimple 具体方法: opkg update is-opkg install quickstart opkg install lcdsimple 手动下载 QUICKSTART 跟 LCD SIMPL…...

内网服务器无法通过公网地址访问映射到公网的内网服务
内网服务器无法通过公网地址访问映射到公网的内网服务 问题现象问题原因解决方法总结 前几天遇到一个网络问题,在这里做下记录,希望能帮助到有相同问题的朋友。 问题现象 网络拓扑如上所示,服务器1和服务器2在同一内网,网段均为1…...

基于Web的交互式智能成绩管理系统设计
目录 摘要 绪论 一、应用背景 二、行业发展现状 三、程序开发的重要意义 四、结语 1 代码 2 数据初始化模块 3 界面布局模块 4 核心功能模块 5 可视化子系统 6 扩展功能模块 7 架构设计亮点 功能总结 一、核心数据管理 二、智能分析体系 三、可视化系统 四、扩…...

从虚拟现实到可持续设计:唐婉歆的多维创新之旅
随着线上线下融合逐渐成为全球家居与建材行业的发展趋势,全球市场对高品质、个性化家居和建材产品的需求稳步攀升,也对设计师提出更高的要求。在这一背景下,设计师唐婉歆将以产品设计师的身份,正式加入跨国企业AmCan 美加集团,投身于备受行业瞩目的系列设计项目。她将负责Showr…...

PHP MySQL 预处理语句
PHP MySQL 预处理语句 引言 在PHP中与MySQL数据库进行交互时,预处理语句是一种非常安全和高效的方法。预处理语句不仅可以防止SQL注入攻击,还可以提高数据库查询的效率。本文将详细介绍PHP中预处理语句的用法,包括其基本概念、语法、优势以及在实际开发中的应用。 预处理…...

基于飞腾/龙芯+盛科CTC7132全国产交换机解决方案
产品介绍 盛科CTC7132,内置ARM-Cortex A53 主频1.2GHz;支持24个千兆电口,24个万兆光口(850nm多模),1个千兆管理网口,1个管理串口;支持1个百兆健康管理网口:用于设备端口状态、电压、…...

Vue动态添加或删除DOM元素:购物车实例
Vue 指令系列文章: 《Vue插值:双大括号标签、v-text、v-html、v-bind 指令》 《Vue指令:v-cloak、v-once、v-pre 指令》 《Vue条件判断:v-if、v-else、v-else-if、v-show 指令》 《Vue循环遍历:v-for 指令》 《Vue事件处理:v-on 指令》 《Vue表单元素绑定:v-model 指令》…...

深入理解Agentic Workflows
本文来源:https://weaviate.io/blog/what-are-agentic-workflows 这篇文章将带你深入理解AI Agent、Agentic AI、Agentic Workflows、Agentic Architectures等概念,非常值得推荐。 一、什么是 AI Agents? AI Agents 是结合了大模型进行推理和…...

深入理解:阻塞IO、非阻塞IO、水平触发与边缘触发
深入理解:阻塞IO、非阻塞IO、水平触发与边缘触发 在网络编程和并发处理中,理解不同的 I/O 模型和事件通知机制至关重要。本文将深入探讨阻塞IO(Blocking IO)、非阻塞IO(Non-Blocking IO)、水平触发&#x…...

deepseek 技术的前生今世:从开源先锋到AGI探索者
一、引言:中国AI领域的“超越追赶”样本 DeepSeek(深度求索)作为中国人工智能领域的代表性企业,自2023年创立以来,凭借开源生态、低成本技术路径与多模态创新,迅速从行业新秀成长为全球AI竞赛中的关键力量…...

合规+增效 正也科技携智能营销产品出席中睿论坛
正也科技作为医药数字化领域的标杆企业,受邀参展第二届中睿医健产业企业家年会暨第十三届中睿医药新春论坛,本次论坛以“合力启新程”为主题,吸引了800多位医药健康企业的董事长、总经理参与,并通过主论坛、分论坛、路演等形式探讨…...
)
Python小练习系列 Vol.5:数独求解(经典回溯 + 剪枝)
🧠 Python小练习系列 Vol.5:数独求解(经典回溯 剪枝) 🧩 数独不仅是益智游戏,更是回溯算法的典范!本期我们将用 DFS 剪枝 的方式一步步求解一个标准 9x9 数独。 🧩 一、题目描述 …...
)
基于kafka的分布式日志收集平台项目(续)
#第一个容易错的地方 上次做到测试集群的创建topic时出现了错误 具体错误是配置信息出错了,然后报错如下: #现在来具体警戒哪些地方要特别注意: ### node.id 和listeners 和advertised.listeners这三行是每一台机器(每个节点&…...