TF-IDF——自然语言处理——红楼梦案例
目录
一、红楼梦数据分析
(1)红楼梦源文件
(2)数据预处理——分卷实现思路
(3)分卷代码
二、分卷处理,删除停用词,将文章转换为标准格式
1.实现的思路及细节
2.代码实现(遍历所有卷的内容,并添加到内存中)
3、代码实现“1”中剩余的步骤
(1)数据展示
(2)代码及方法
三、计算红楼梦分词后文件的 TF_IDF的值
一、红楼梦数据分析
(1)红楼梦源文件
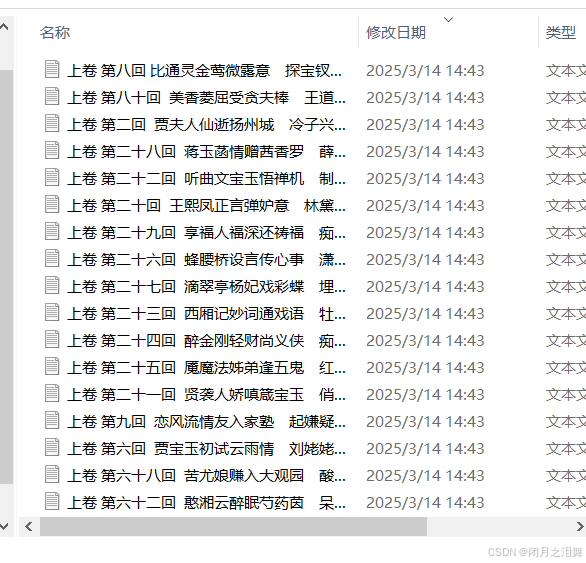
预计要实现的效果:观察下面的文件截图,我们希望将红楼梦每一回的文件内容存在文件中,将文件的“上卷 第一回 甄士隐梦幻识通灵 贾雨村风尘怀闺秀”第几回,这一整行作为文件的名字,每一回作为一个文件,储存到指定的路径下。



最终效果:
(2)数据预处理——分卷实现思路
(1)使用os是python的标准库,读取红楼梦源文件
(2)以写的格式打开一个以"红楼梦开头.txt"为名字的文件,用以存储文件开头的内容,如下:

(3)使用for循环,逐行读取文件内容,通过观察,每一回的开头,都会有“卷 第 ”这样的字,如下

我们可以通过in来判断是否读取到这一行,满足条件则对这行执行strip()方法,去除行前后的空格和换行符。
(4)使用os.path.join方法构建一个完整的路径,将路径(根据自己的实际情况来写)和文件名拼接在一起,这里是把前面写的路径,与后面读取的文件名拼接起来了,分卷最好放置在一个单独的文件夹中,为了更有条理。
os.path.join 会自动添加成斜杠,会根据系统自动补充路径中的斜杠,对不同系统有适配性,windows 斜杠\,macos 斜杠/,Linux 斜杠 /。
效果
![]()
(5)关闭先前存储文件开头的juan_file这个文件,使用close()方法。
(6)按照上面第(4)步拼接的路径,打开文件,然后使用continue跳出本次循环,向文件中逐行写入第一回的内容
(7)发现在每一回的下一行都会有这样一行内容,我们希望将其剔除,剔除方法如下:
![]()
if '手机电子书·大学生小说网' in line: #过滤掉无用的行 continue
这里表示如果发现读取的行中存在'手机电子书·大学生小说网'这个内容,就直接跳出循环,即跳过这一行,循环读取文件下一行的内容。
(8)按照上面的方法不断地循环,最终我们就能将整个红楼梦文件按照每一回存储在一个文件中的格式将红楼梦分卷处理。
效果:

(3)分卷代码
import osfile=open("./data/红楼梦/红楼原数据/红楼梦.txt",encoding='utf-8') #读取红楼梦原数据集
juan_file=open('./data/红楼梦/红楼梦开头.txt','w',encoding='utf-8') #这里会创建并打开,以红楼梦开头.txt为名字的文件
#逐行读取读取红楼梦.txt中的文件内容
for line in file:if '卷 第'in line: #为了将第几回这一行,每一回的标头作为文件的名字,这里需要能够识别到这样的行,通过文字匹配来匹配,如果满足这个条件则会执行下面的其他代码juan_name=line.strip()+'.txt' #去除行前后的空格和换行符,与.txt拼接成文件名path = os.path.join('.\\data\\红楼梦\\分卷\\',juan_name) #使用os.path.join方法将路径和文件名拼接在一起print(path)juan_file.close()juan_file=open(path,'w',encoding='utf-8')continueif '手机电子书·大学生小说网' in line: 过滤掉无用的行continuejuan_file.write(line) #将文件的其他内容写入到juan_file中
juan_file.close()二、分卷处理,删除停用词,将文章转换为标准格式
(词之间通过空格分隔),即进行分词处理
1.实现的思路及细节
(1)遍历所有卷的内容,并添加到内存中
(2)将红楼梦词库添加到jieba库中(jieba不一定能识别出红楼梦中所有的词,需要手动添加词库)
(3)读取停用词(删除无用的词)
(4)对每个卷进行分词,
(5)将所有分词后的内容写入到分词后汇总.txt
分词后汇总.txt的效果为:

可以看出,红楼梦的原文被分成上图的格式,词与词之间以空格分隔,同时每一行就是一个分卷的内容,也就是每一行是一回的内容。
2.代码实现(遍历所有卷的内容,并添加到内存中)
(1)os.walk():os.walk是直接对文件夹进行遍历,总共会有三个返回值第一个是文件的路径,第二个是路径下的文件夹,第三个是路径下的文件。
for root,dirs,files in os.walk(r"./data/红楼梦/分卷"):
这里我们分别用三个变量去接收,os.walk的返回值。
import pandas as pd
import os
filePaths=[] #用于保存文件的路径
fileContents=[] #用于保存文件的内容for root,dirs,files in os.walk(r"./data/红楼梦/分卷"):for name in files: #对files进行遍历,依次取出文件操作filePath=os.path.join(root,name) #将文件的路径和名字拼接到一起形成一个完整的路径,并将路径存储在filepath这个变量中print(filePath)filePaths.append(filePath) #将完整路径存储到filepathS这个列表中f=open(filePath,'r',encoding='utf-8') #根据上面拼接好的路径,打开文件fileContent=f.read() #读取文章内容,一次性读取全文f.close() #关闭文件减少内存占用fileContents.append(fileContent) #将文章内容添加到filecontents这个列表中
corpos=pd.DataFrame( #使用pandas的DataFrame方法,将filepath和filecontent存储成dataframe类型{"filePath":filePaths,"fileContent":fileContents}
)
print(corpos)corpos内部存储的效果:每一行是一个分卷的内容,第一列是文件存储的路径,第二列是每个分卷的内容。

3、代码实现“1”中剩余的步骤
(1)数据展示
红楼梦词库(红楼梦词库.txt):

停用词(StopwordsCN.txt):

(2)代码及方法
load_userdict():是jieba库中加载新词到jieba的辞海中,针对海量的新词可以使用这个方法,对文件格式也有要求,文件的每一行是一个停用词。
iterrows():遍历pandas数据,逐行读取,返回值有两个,行索引和pandas类型数据的全部内容
“if seg not in stopwords.stopword.values and len(seg.strip())>0:”其中stopwords.stopword.values是stopwords变量下stopword列对应的值调用。
import jiebajieba.load_userdict(r".\data\红楼梦\红楼原数据\红楼梦词库.txt")
#读取停用词
stopwords=pd.read_csv(r"./data/红楼梦/红楼原数据/StopwordsCN.txt",encoding='utf-8',engine='python',index_col=False)
file_to_jieba=open(r'./data/红楼梦/分词后汇总.txt','w',encoding='utf-8')
for index,row in corpos.iterrows():juan_ci=''filePath=row['filePath'] #获取文件路径fileContent=row['fileContent'] #获取文件内容 segs=jieba.cut(fileContent) #使用cut()方法对第一行的内容进行切分,也可以使用lcut(),并将分词后的结果存储在segs中for seg in segs: #利用for循环过滤掉文章中的停用词if seg not in stopwords.stopword.values and len(seg.strip())>0:#if如果满足,当前词不在停用词中,并且词不为空的前提下,将这个词添加到juan_ci+保存juan_ci+=seg+' '#将没一回的内容写入到file_to_jieba这个文件中,我们希望每一回在同一行,所以这里在每一回的内容后加上"\n"换行符file_to_jieba.write(juan_ci+'\n')file_to_jieba.close() #等所有分卷的内容全部写入后关闭file_to_jieba(分词后汇总.txt)这个文件,减少内存的占用为什么总是把处理完成的文件保存下来呢,预处理结束将文件保存到本地,这样做的目的是代码分块化实现,防止调试代码时每次都要全部执行,每做一步将处理好的结果保存下来,可以加快调试的效率。
三、计算红楼梦分词后文件的 TF_IDF的值
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd#读取分词后汇总,并逐行读取文件内容,存储在corpos变量中
inFile = open(r"./data/红楼梦/分词后汇总.txt","r",encoding='utf-8')
corpos = inFile.readlines()#实例化对象,使用fit_transfrom计算每个词的TF-IDF的值
vectorizer=TfidfVectorizer()
tfidf=vectorizer.fit_transform(corpos)
print(tfidf)#使用get_feature_names方法获取红楼梦的所有关键词
wordlist=vectorizer.get_feature_names()
print(wordlist)#将tfidf转化为稀疏矩阵
df=pd.DataFrame(tfidf.T.todense(),index=wordlist)
print(df)#逐列排序,输出tfidf排名前十的关键词及TF-IDF值
for i in range(len(corpos)):featurelist=df[[i]]feature_rank=featurelist.sort_values(by=i,ascending=False)print(f"第{i+1}回的关键词是:{feature_rank[:10]}")wordlistte特征值的个数33703个为:
![]()
输出效果为:我们就能得到每一回的关键词以及对应的TF-IDF值

代码汇总:
此处代码为上面的整合,去除了部分注释,可以将其放在一个.py文件中,安装好指定的库即可运行,需要注意文件的路径与你自己的文件路径对应,数据集文件可以到我的数据集中获取(有单独的一篇文章注明了数据集)
"""通过os系统标准库,读取红楼梦的原始数据,并将每一回的数据文本存储到不同的txt文件中。"""import osfile=open("./data/红楼梦/红楼原数据/红楼梦.txt",encoding='utf-8') #读取红楼梦原数据集
juan_file=open('./data/红楼梦/红楼梦开头.txt','w',encoding='utf-8') #这里会创建并打开,以红楼梦开头.txt为名字的文件
#逐行读取读取红楼梦.txt中的文件内容
for line in file:if '卷 第'in line: #为了将第几回这一行,每一回的标头作为文件的名字,这里需要能够识别到这样的行,通过文字匹配来匹配,如果满足这个条件则会执行下面的其他代码juan_name=line.strip()+'.txt' #去除行前后的空格和换行符,与.txt拼接成文件名path = os.path.join('.\\data\\红楼梦\\分卷\\',juan_name) #使用os.path.join方法将路径和文件名拼接在一起print(path)juan_file.close()juan_file=open(path,'w',encoding='utf-8')continueif '手机电子书·大学生小说网' in line: #过滤掉无用的行continuejuan_file.write(line) #将文件的其他内容写入到juan_file中
juan_file.close()import pandas as pd
import os
filePaths=[]
fileContents=[]for root,dirs,files in os.walk(r"./data/红楼梦/分卷"):for name in files:filePath=os.path.join(root,name)print(filePath)filePaths.append(filePath)f=open(filePath,'r',encoding='utf-8')fileContent=f.read()f.close()fileContents.append(fileContent)
corpos=pd.DataFrame({"filePath":filePaths,"fileContent":fileContents}
)print(corpos)import jiebajieba.load_userdict(r".\data\红楼梦\红楼原数据\红楼梦词库.txt")
stopwords=pd.read_csv(r"./data/红楼梦/红楼原数据/StopwordsCN.txt",encoding='utf-8',engine='python',index_col=False)
file_to_jieba=open(r'./data/红楼梦/分词后汇总.txt','w',encoding='utf-8')
for index,row in corpos.iterrows():juan_ci=''filePath=row['filePath']fileContent=row['fileContent']segs=jieba.cut(fileContent)for seg in segs:if seg not in stopwords.stopword.values and len(seg.strip())>0:juan_ci+=seg+' 'file_to_jieba.write(juan_ci+'\n')
file_to_jieba.close()from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pdinFile = open(r"./data/红楼梦/分词后汇总.txt","r",encoding='utf-8')
corpos = inFile.readlines()vectorizer=TfidfVectorizer()
tfidf=vectorizer.fit_transform(corpos)
print(tfidf)wordlist=vectorizer.get_feature_names()
print(wordlist)df=pd.DataFrame(tfidf.T.todense(),index=wordlist)
print(df)for i in range(len(corpos)):featurelist=df[[i]]feature_rank=featurelist.sort_values(by=i,ascending=False)print(f"第{i+1}回的关键词是:{feature_rank[:10]}")相关文章:

TF-IDF——自然语言处理——红楼梦案例
目录 一、红楼梦数据分析 (1)红楼梦源文件 (2)数据预处理——分卷实现思路 (3)分卷代码 二、分卷处理,删除停用词,将文章转换为标准格式 1.实现的思路及细节 2.代码实现&#…...

Oracle数据库数据编程SQL<2.3 DML增、删、改及merge into>
目录 一、DML数据操纵语言(Aate Manipulation Language) 二、【insert】插入数据 1、单行插入 2、批量插入 3、将数据同时插入到多张表insert all/insert first 三、【update】 更新数据 1、语法 2、举例 3、update使用注意事项: 四、【delete…...
)
面试计算机操作系统解析(一中)
判断 1. 一般来说,先进先出页面置换算法比最近最少使用页面置换算法有较少的缺页率。(✘) 正确答案:错误解释:FIFO(先进先出)页面置换算法可能导致“Belady异常”,即页面数增加反而…...

启山智软实现b2c单商户商城对比传统单商户的优势在哪里?
启山智软实现 B2C 单商户商城具有以下对比优势: 技术架构方面 先进的框架选型:基于 SpringCloud 等主流框架开发,是百万真实用户沉淀并检验的商城系统,技术成熟稳定,能应对高并发场景,保证系统在大流量访…...

蓝桥杯备考:贪心问题之均分纸牌
咱的贪心策略就是每次分好一个堆儿,如果某个堆已经是满足题意了,就不用管这个堆了,否则要向下一个堆借几个元素 #include <iostream> using namespace std; const int N 110; typedef long long ll; int a[N]; int n; ll x; int cnt…...

免去繁琐的手动埋点,Gin 框架可观测性最佳实践
作者:牧思 背景 在云原生时代的今天,Golang 编程语言越来越成为开发者们的首选,而对于 Golang 开发者来说,最著名的 Golang Web 框架莫过于 Gin [ 1] 框架了,Gin 框架作为 Golang 编程语言官方的推荐框架 [ 2] &…...

centos7 linux VMware虚拟机新添加的网卡,能看到网卡名称,但是看不到网卡的配置文件
问题现象:VMware虚拟机新添加的网卡,能看到网卡,但是看不到网卡的配置文件 解决方案: nmcli connection show nmcli connection add con-name ens36 ifname ens36 type ethernet #创建一个网卡连接配置文件,这里con…...

python的内置方法getitem和len
完整小测试: #python的内置函数,getitemclass Animal():def __init__(self,name):self.name namedef __str__(self):return f"This is {self.name}"class Zoo():def __init__(self,animal_list):self.animal_list animal_listdef __getite…...

深入理解 Git Stash:功能、用法与实战示例
文章目录 深入理解 Git Stash:功能、用法与实战示例一、Git Stash 的核心概念二、Git Stash 的基本用法1. 存储当前修改2. 查看 Stash 列表3. 恢复 Stash4. 恢复并删除 Stash5. 删除 Stash(1)删除指定 Stash(2)清空所有…...

SQL 复杂查询和性能优化
一、掌握复杂查询的核心技能 1. 理解 SQL 执行顺序 SQL 语句的逻辑执行顺序(非书写顺序): FROM → JOIN → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY → LIMIT 关键点:每一步的结果会传递给下一步&a…...

【web应用安全】关于web应用安全的几个主要问题的思考
文章目录 防重放攻击1. **Token机制(一次性令牌)**2. **时间戳 超时验证**3. **Nonce(一次性随机数)**4. **请求签名(如HMAC)**5. **HTTPS 安全Cookie**6. **幂等性设计****综合防御策略建议****注意事项…...

看懂roslunch输出
自编了一个demo 第一步:创建功能包 cd ~/catkin_ws/src catkin_create_pkg param_demo roscpp第二步:写 main.cpp 创建文件:param_demo/src/param_node.cpp #include <ros/ros.h> #include <string>int main(int argc, char*…...

如何查看Unity打包生成的ab文件
文章目录 前言AssetStudioab文件介绍1. 动态加载资源2. 资源分离与模块化3. 平台兼容性4. 资源压缩与加密5. 资源管理与更新6. 减少安装包大小7. 资源加载灵活性8. 资源打包与分发9. 实际应用场景10. 注意事项 总结 前言 问题来源于工作又回归到工作,当发现发布包里…...

从泛读到精读:合合信息文档解析如何让大模型更懂复杂文档
从泛读到精读:合合信息文档解析如何让大模型更懂复杂文档 一、引言:破解文档“理解力”瓶颈二、核心功能:合合信息的“破局”亮点功能亮点1:复杂图表的高精度解析图表解析:为大模型装上精准“标尺”表格数据精准还原 功…...

Python SciPy面试题及参考答案
目录 什么是 SciPy?它与 NumPy 有什么区别? 如何在 Python 中安装 SciPy? 如何导入 SciPy 库? SciPy 中有哪些子模块?简要介绍它们的功能。 如何使用 SciPy 进行数值积分?请举例说明。 SciPy 中提供了哪些求解微分方程的函数? 什么是插值?SciPy 中如何进行插值?…...

21.Excel自动化:如何使用 xlwings 进行编程
一 将Excel用作数据查看器 使用 xlwings 中的 view 函数。 1.导包 import datetime as dt import xlwings as xw import pandas as pd import numpy as np 2.view 函数 创建一个基于伪随机数的DataFrame,它有足够多的行,使得只有首尾几行会被显示。 df …...

【redis】数据类型之Stream
Redis Stream是Redis 5.0版本引入的一种新的数据类型,它提供了一种持久化的、可查询的、可扩展的消息队列服务。 它结合了Redis高性能的特性与持久化能力,支持: 多消费者组模式(Consumer Groups)消息回溯(…...

day17 周末两天偷懒没更新,今天炼丹加学习,完结STL常用容器部分
还剩下两个常用容器,一个是set(集合容器) , 一个是map容器 set/multiset 容器 set容器是关联式容器,该容器的特点是:所有元素都会在插入时被自动排序 set/multiset 都是关联式容器 ,其底层结构是使用二叉树实现的。…...

嵌入式开发场景中Shell脚本执行方式的对比
Shell脚本执行方式对比表 执行方式命令示例是否需要执行权限是否启动子Shell环境变量影响范围适用场景嵌入式开发中的典型应用直接执行脚本./script.sh是是子Shell内有效独立运行的脚本,需固定环境自动化构建脚本(…...

数据结构之多项式相加的链表实现
在计算机科学中,多项式的表示和运算经常会用到。使用链表来表示多项式是一种常见且有效的方法,它可以方便地处理多项式的各项,并且在进行多项式相加等运算时具有较好的灵活性。 多项式通常由一系列的项组成,每一项包含一个系数和…...

Java 实现将Word 转换成markdown
日常的开发中,需要将word 等各类文章信息转换成格式化语言,因此需要使用各类语言将word 转换成Markdown 1、引入 jar包 <dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version&g…...

IEEE PDF Xpress校验出现 :字体无法嵌入问题以及pdf版本问题
文章目录 问题描述一、字体嵌入问题首先查看一下,哪些字体没有被嵌入查看window的font文件夹里的字体下载字体的网站修复字体嵌入问题 二、pdf版本不对 问题描述 在处理IEEE的camera ready的时候,提交到IEEE express的文件没有办法通过validate…...

Sa-Token
简介 Sa-Token 是一个轻量级 Java 权限认证框架,主要解决:登录认证、权限认证、单点登录、OAuth2.0、分布式Session会话、微服务网关鉴权 等一系列权限相关问题。 官方文档 常见功能 登录认证 本框架 用户提交 name password 参数,调用登…...

StarRocks 中 CURRENT_TIMESTAMP 和 CURRENT_TIME 分区过滤问题
背景 本文基于Starrocks 3.3.5 最近在进行Starrocks 跑数据的时候,发现了一个SQL 扫描了所有分区的数据,简化后的SQL如下: select date_created from tableA where date_createddate_format(current_time(), %Y-%m-%d %H:%i:%S) limit 20其…...
)
GithubPages+自定义域名+Cloudfare加速+浏览器收录(2025最新排坑)
前言 最近刷到一个小视频,讲述了选择域名选择的三宗罪,分别是 不要使用 .net,因为它价格贵,但是在顶级域名中的 SEO 效果却不是很好,也就是性价比很低不要使用 .cn,因为国外访问该网站可能会很慢…...

Canvas粒子系统终极指南:从基础运动到复杂交互的全流程实现
文章目录 一、粒子系统基础架构1.1 粒子数据结构设计1.2 粒子系统管理器 二、基础粒子效果实现2.1 重力场模拟2.2 弹性碰撞效果 三、高级交互实现3.1 鼠标吸引效果3.2 颜色渐变粒子 四、性能优化策略4.1 粒子池复用4.2 分层渲染 五、复杂效果实现5.1 烟花爆炸效果5.2 流体模拟 …...
)
【QT】新建QT工程(详细步骤)
新建QT工程 1.方法(1)点击new project按钮,弹出对话框,新建即可,步骤如下:(2) 点击文件菜单,选择新建文件或者工程,后续步骤如上 2.QT工程文件介绍(1).pro文件 --》QT工程配置文件(2)main.cpp --》QT工程主…...

详解Http:在QT中使用Http协议
目录 一、HTTP 概述 1、主要特点 2、HTTP 方法 3、HTTP 状态码 4、HTTP 头部 5、HTTP的工作原理 二、在Qt中使用HTTP 1、发送简单的HTTP请求 2、发送POST请求 3、处理异步请求 4、使用QSslConfiguration进行HTTPS 5、 处理JSON响应 6、处理错误 三、总结 一、HTTP…...
 复现利用与原理分析)
Next.js 中间件鉴权绕过漏洞 (CVE-2025-29927) 复现利用与原理分析
免责声明 本文所述漏洞复现方法仅供安全研究及授权测试使用; 任何个人/组织须在合法合规前提下实施,严禁用于非法目的; 作者不对任何滥用行为及后果负责,如发现新漏洞请及时联系厂商并遵循漏洞披露规则。 漏洞原理 Next.js 是一个…...

AI时代的数据底座:火山引擎多模态数据湖的设计与实践
资料来源:火山引擎-开发者社区 随着大模型的发展和应用,文本的边界被拓宽,图像、视频、语音各种模态涌现,并给数据管理、检索、计算带来巨大挑战。 火山引擎多模态数据湖 解决方案则可实现海量结构化、半结构化及非结构化数据的统…...
)
Numpy用法(二)
一.数组变维 1.1 reshape reshape() 可以改变数组维度,但是返回的是一个新的数组,原数组的形状不会被修改.reshape后产生的新数组是原数组的一个视图,即它与原数组共享相同的数据,但可以有不同的形状或维度,且对视图…...

STM32 IIC通信
目录 IIC简介硬件电路连接I2C时序基本单元IIC完整数据帧MPU6050封装硬件IIC内部电路 IIC简介 IIC(Inter-Integrated Circuit)是 IIC Bus 简称,中文叫集成电路总线。它是一种串行通信总线,使用多主从架构,由飞利浦公司…...

快速入门 JSON 数据格式
引言 JSON,全称 JavaScript Object Notion,类似于XML,YAML,Properties等,是一种数据交换格式,相比于XML,更简单,更轻量,更容易理解。 JSON vs XML 使用 JSON 目前被广…...
)
FFmpeg —— 中标麒麟系统下使用FFmpeg内核+Qt界面,制作完整功能音视频播放器(附:源码)
🔔 FFmpeg 相关音视频技术、疑难杂症文章合集(掌握后可自封大侠 ⓿_⓿)(记得收藏,持续更新中…) 程序运行效果...

硬件测试工装设计不合理的补救措施
硬件测试工装设计不合理的补救措施主要包括重新评估设计需求、优化工装结构、强化工装校准与验证。其中,优化工装结构尤其重要,通过结构优化能够有效解决因设计不合理导致的测试准确性下降和可靠性不足的问题。根据工程实践数据,经过优化结构…...

任意文件读取漏洞
fofa语句:body"/vite/client" /fs/etc/passwd?import&raw?? https://35.175.173.157/fs/etc/passwd?import&raw?? http://geometer.dev.mvergely.com/fs/etc/passwd?import&raw??...

如何使用RK平台的spi驱动 spidev
RK平台spidev驱动读取RC522版本号示例 1. 硬件与驱动确认 确认SPI接口连接:RC522的SPI引脚与RK开发板的对应SPI控制器正确连接(CS、CLK、MOSI、MISO)检查内核配置: Bash # 内核需启用以下配置 CONFIG_SPIy CONFIG_SPI_MASTERy…...

网路传输层UDP/TCP
一、端口号 1.端口号 1.1 五元组 端口号(port)标识了一个主机上进行通信的不同的应用程序. 如图所示, 在一个机器上运行着许多进程, 每个进程使用的应用层协议都不一样, 比如FTP, SSH, SMTP, HTTP等. 当主机接收到一个报文中, 网络层一定封装了一个目的ip标识我这台主机, …...

1.2-WAF\CDN\OSS\反向代理\负载均衡
WAF:就是网站应用防火墙,有硬件类、软件类、云WAF; 还有网站内置的WAF,内置的WAF就是直接嵌在代码中的安全防护代码 硬件类:Imperva、天清WAG 软件:安全狗、D盾、云锁 云:阿里云盾、腾讯云WA…...

Dify 服务器部署指南
1. 系统要求 在开始部署之前,请确保你的服务器满足以下要求: 操作系统:Linux(推荐使用 Ubuntu 20.04 或更高版本)内存:至少 4GB RAM存储:至少 20GB 可用空间网络:稳定的互联网连接…...

从车间到数字生态:MES如何引领制造业智能化革命
在全球制造业加速迈向工业4.0的浪潮中,传统生产模式正经历颠覆性变革。制造执行系统(MES)作为连接物理车间与数字世界的核心纽带,正从“生产辅助工具”升级为“智能决策大脑”,推动制造业向数据驱动、柔性化与可持续化…...

Error:Flash Download failed
出现这个就是编译器要换...

Spring容器生命周期详解
Spring容器生命周期详解 Spring容器的生命周期从启动到关闭分为多个阶段,包括Bean的加载、实例化、初始化、使用和销毁。以下是详细流程和关键点: 1. 容器启动阶段 1.1 容器实例化 核心接口:BeanFactory(基础容器)或…...

革新测试管理 2.0丨Storm UTP统一测试管理平台智能化升级与全流程优化
承接上篇:从基础架构到深度协同 在首篇文章《革新测试管理 | 统一测试管理平台如何实现远程、协同、自动化?》中,我们探讨了Storm UTP如何通过云端协作、自动化测试框架和分布式执行能力打破传统测试壁垒。经过一年多的客户实践与技术迭代&a…...

将 char [] str = “hello,you,world” 改为 “world,you,hello“,要求空间复杂度为1
题目: 将 char [] str “hello,you,world” 改为 "world,you,hello",要求空间复杂度为1 (也就是使用的变量只能是单个字符或者常数,不能使用数组!!!!!) 解…...
)
运维规则之总结(Summary of Operation and Maintenance Rules)
运维规则之总结 在运维领域,经验和流程往往决定了系统的稳定性与可靠性。一个运维人,总结出了以下10条运维规则,涵盖了从基础管理到高级策略的全面内容,旨在帮助运维人员更好地应对各种挑战,确保系统的平稳运行。 1.…...

MongoDB 创建数据库
MongoDB 创建数据库 引言 MongoDB 是一款高性能、可扩展的 NoSQL 数据库,广泛应用于大数据领域。在 MongoDB 中,创建数据库是进行数据存储的第一步。本文将详细介绍 MongoDB 数据库的创建方法,包括手动创建和自动创建两种方式。 MongoDB 数…...

SpringSecurity OAuth2:授权服务器与资源服务器配置
文章目录 引言一、OAuth2基础概念与架构二、授权服务器配置三、令牌策略与存储方式四、资源服务器配置五、远程令牌验证与内省总结 引言 在现代分布式应用架构中,OAuth2已成为实现安全授权与认证的事实标准。Spring Security对OAuth2提供了全面支持,使开…...

Vue 2 探秘:visible 和 append-to-body 是谁的小秘密?
🚀 Vue 2 探秘:visible 和 append-to-body 是谁的小秘密?🤔 父组件:identify-list.vue子组件:fake-clue-list.vue 嘿,各位前端探险家!👋 今天我们要在 Vue 2 的代码丛林…...

C#高级:启动、中止一个指定路径的exe程序
一、启动一个exe class Program {static void Main(string[] args){string exePath "D:\测试\Test.exe";// 修改为你要运行的exe路径StartProcess(exePath);}private static bool StartProcess(string exePath){// 创建一个 ProcessStartInfo 对象来配置进程启动参…...