Pytorch学习笔记(十二)Learning PyTorch - NLP from Scratch
这篇博客瞄准的是 pytorch 官方教程中 Learning PyTorch 章节的 NLP from Scratch 部分。
- 官网链接:https://pytorch.org/tutorials/intermediate/nlp_from_scratch_index.html
完整网盘链接: https://pan.baidu.com/s/1L9PVZ-KRDGVER-AJnXOvlQ?pwd=aa2m 提取码: aa2m
这篇教程中主要包含了三个例子:
- Classifying Names with a Character-Level RNN
- Generating Names with a Character-Level RNN
- Translation with a Sequence to Sequence Network and Attention
Classifying Names with a Character-Level RNN
- 官网链接: https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html
这篇文章将构建和训练一个基本的字符级循环神经网络 (RNN) 来对单词进行分类,展示了如何预处理数据以对 NLP 进行建模。字符级 RNN 将单词读取为一系列字符 - 在每个步骤输出预测和“隐藏状态”,将其先前的隐藏状态输入到下一步,最终预测作为输出,即单词属于哪个类。
官网在这里推荐了两个知识拓展链接:
- The Unreasonable Effectiveness of Recurrent Neural Networks
- Understanding LSTM Networks
Preparing Torch
设置默认的计算加速设备
import torchdevice = torch.device('cpu')
if torch.accelerator.is_available():device = torch.accelerator.current_accelerator().typetorch.set_default_device(device)
print(f"Device: {device}")
Preparing the Data
首先从 链接 中下载数据,下载后将其就地解压。data/names 中包含 18 个文本文件,名为 [Language].txt。每个文件包含一堆名称,每行一个名称。
首先,将 Unicode 转换为纯 ASCII 以限制 RNN 输入层。
import string
import unicodedataallowed_characters = string.ascii_letters + " .,;'" + "_"
n_letters = len(allowed_characters)def unicodeToAscii(s):return ''.join(c for c in unicodedata.normalize('NFD', s)if unicodedata.category(c) != 'Mn'and c in allowed_characters)print (f"converting 'Ślusàrski' to {unicodeToAscii('Ślusàrski')}")
Turning Names into Tensors
现在需要将字符串转换成Tensor才能使用。为了表示单个字母,用大小为 <1 x n_letters> 的“one-hot vector”。除了字母索引处的值为1,one-hot 向量的其他位置填充了 0,例如“b”= <0 1 0 0 0 ...>;为了组成一个单词,将一堆字母合并成一个二维矩阵 <line_length x 1 x n_letters>。额外的 1 个维度是因为 PyTorch 假设所有内容都是批量的,这里只使用 1 的批量大小。
定义字符转index与字母转matrix函数
# 字符转index
def letterToIndex(letter):if letter not in allowed_characters:return allowed_characters.find('_')else:return allowed_characters.find(letter)# 字母转matrix
def lineToTensor(line):tensor = torch.zeros(len(line), 1, n_letters)for li, letter in enumerate(line):tensor[li][0][letterToIndex(letter)] = 1return tensor
查看case
print (f"The letter 'a' becomes {lineToTensor('a')}") #notice that the first position in the tensor = 1
print (f"The name 'Ahn' becomes {lineToTensor('Ahn')}") #notice 'A' sets the 27th index to 1
接下来需要将所有case组合成一个数据集。使用 Dataset 和 DataLoader 类来保存数据集,每个 Dataset 都需要实现三个函数:__init__、__len__ 和 __getitem__。
定义Dataset
class NamesDataset(Dataset):def __init__(self, data_dir):# super().__init__()self.data_dir = data_dirself.load_time = time.localtimelabels_set = set()self.data = []self.data_tensors = []self.labels = []self.labels_tensors = []text_files = glob.glob(os.path.join(data_dir, '*.txt'))for filename in text_files:label = os.path.splitext(os.path.basename(filename))[0]labels_set.add(label)lines = open(filename, encoding='utf-8').read().strip().split('\n')for name in lines:self.data.append(name)self.data_tensors.append(lineToTensor(name))self.labels.append(label)self.labels_uniq = list(labels_set)for idx in range(len(labels_set)):tmp_tensor = torch.tensor([self.labels_uniq.index(self.labels[idx])], dtype=torch.long)self.labels_tensors.append(tmp_tensor)def __len__(self):return len(self.data)def __getitem__(self, idx):data_item = self.data[idx]data_label = self.labels[idx]data_tensor = self.data_tensors[idx]label_tensor = self.labels_tensors[idx]return label_tensor, data_tensor, data_label, data_item
加载数据
alldata = NamesDataset("data/names")
print(f"Loaded: {len(alldata)}")
print(f"example: {alldata[0]}")
将数据集拆分成训练集与测试集合
train_set, test_set = torch.utils.data.random_split(alldata, [0.85, 0.15], generator=torch.Generator(device=device).manual_seed(2025))
# generator = torch.Generator(device=device).manual_seed(2025) # 官网写法从在bugprint(f"Len train set {len(train_set)}; Len test set {len(test_set)}")
Creating the Network
在 autograd 之前,Torch 中创建RNN时络涉及从多个 timestep 中克隆一个层的参数。这些层保存隐藏状态和梯度,现在完全由图本身处理。
下面这个 CharRNN 类实现了一个包含三个组件的 RNN。使用 nn.RNN 实现,定义一个将 RNN 隐藏层映射到输出的层,最后应用 softmax 函数。与将每个层均为 nn.Linear 相比,使用 nn.RNN 可以显著提高性能。
import torch.nn as nn
import torch.nn.functional as fclass CharRNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(CharRNN, self).__init__()self.rnn = nn.RNN(input_size, hidden_size)self.h2o = nn.Linear(hidden_size, output_size)self.softmax = nn.LogSoftmax(dim=1)def forward(self, line_tensor):rnn_out, hidden = self.rnn(line_tensor)output = self.h2o(hidden[0])output = self.softmax(output)return output
创建一个具有 58 个输入节点、128 个隐藏节点和 18 个输出的 RNN:
n_hidden = 128
rnn =CharRNN(n_letters, n_hidden, len(alldata.labels_uniq))
print(rnn)
将 Tensor 传递给 RNN 以获得预测输出,使用辅助函数 label_from_output 为该类导出文本标签。
def label_from_output(output, output_labels):top_n, top_i = output.topk(1)label_i = top_i[0].item()return output_labels[label_i], label_iinput = lineToTensor('Albert')
output = rnn(input)
print(output)
print(label_from_output(output, alldata.labels_uniq))
Training
定义一个 train() 函数,该函数使用小批量在给定数据集上训练模型。RNN 的训练方式与其他网络类似,循环在调整权重之前计算批次中每个项目的损失,直到达到 epoch 数。
定义train函数
import random
import numpy as npdef train(rnn, training_data, n_epochs=10, n_batch_size=64, report_every=50, learning_rate=0.2, criterion=nn.NLLLoss()):current_loss = 0all_losses = []rnn.train()rnn.to(device)optimizer = torch.optim.SGD(rnn.parameters(), lr=learning_rate,)print(f"Trainint with data size={len(training_data)}")for iter in range(1, n_epochs+1):rnn.zero_grad()batchs = list(range(len(training_data)))random.shuffle(batchs)batchs = np.array_split(batchs, len(batchs) // n_batch_size)for idx, batch in enumerate(batchs):batch_loss = 0for i in batch:(label_tensor, text_tensor, label, text) = training_data[i]output = rnn.forward(text_tensor)loss = criterion(output, label_tensor)batch_loss += lossbatch_loss.backward()nn.utils.clip_grad_norm_(rnn.parameters(), 3)optimizer.step()optimizer.zero_grad()current_loss += batch_loss.item() / len(batch)all_losses.append(current_loss / len(batchs))if iter % report_every == 0:print(f"{iter} ({iter / n_epochs:.0%}): \t average batch loss = {all_losses[-1]}")current_loss = 0return all_losses
执行训练
start = time.time()
all_losses = train(rnn, train_set, n_epochs=27, learning_rate=0.15, report_every=5)
end = time.time()
print(f"Training took {end-start}s")
Plotting the Results
import matplotlib.pyplot as plt
import matplotlib.ticker as tickerplt.figure()
plt.plot(all_losses)
plt.show()
Evaluating the Results
为了查看网络在不同类别上的表现创建一个混淆矩阵,指出每种实际语言(行)对应的网络猜测的语言(列)。
def evaluate(rnn, testing_data, classes):confusion = torch.zeros(len(classes), len(classes))rnn.eval()with torch.no_grad():for i in range(len(testing_data)):(label_tensor, test_tensor, label, text) = testing_data[i]output = rnn(test_tensor)guess, guess_i = label_from_output(output, classes)label_i = classes.index(label)confusion[label_i][guess_i] += 1for i in range(len(classes)):denom = confusion[i].sum()if denom > 0:confusion[i] = confusion[i] / denomfig = plt.figure()ax = fig.add_subplot(111)cax = ax.matshow(confusion.cpu().numpy())fig.colorbar(cax)ax.set_xticks(np.arange(len(classes)), labels=classes, rotation=90)ax.set_yticks(np.arange(len(classes)), labels=classes)ax.xaxis.set_major_locator(ticker.MultipleLocator(1))ax.yaxis.set_major_locator(ticker.MultipleLocator(1))plt.show()
绘制混淆矩阵
evaluate(rnn, test_set, classes=alldata.labels_uniq)
Generating Names with a Character-Level RNN
- 官网链接: https://pytorch.org/tutorials/intermediate/char_rnn_generation_tutorial.html
这次将反过来根据语言生成姓名。
仍创建一个包含几个线性层的小型 RNN。最大的区别在于,不是在读完一个名字后预测类别,而是输入一个类别并一次输出一个字母,循环预测字符以形成语言,通常被称为“语言模型”
Preparing the Data
这里使用的数据与上一个case中使用的一样,所有不用二次下载,直接进入数据预处理阶段。
from io import open
import glob
import os
import unicodedata
import stringall_letters = string.ascii_letters + " .,;'-"
n_letters = len(all_letters) + 1def findFiles(path):return glob.glob(path)def readLines(filename):with open(filename, encoding='utf-8') as some_file:return [unicodeToAscii(line.strip()) for line in some_file]
定义 unicode 转 Ascii
def unicodeToAscii(s):return ''.join(c for c in unicodedata.normalize('NFD', s)if unicodedata.category(c) != 'Mn'and c in all_letters)
构建类别字典
category_lines = {}
all_categories = []for filename in findFiles('data/names/*.txt'):category = os.path.splitext(os.path.basename(filename))[0]all_categories.append(category)lines = readLines(filename)category_lines[category] = linesn_categories = len(all_categories)if n_categories == 0:raise RuntimeError('Data not found. Make sure that you downloaded data ''from https://download.pytorch.org/tutorial/data.zip and extract it to ''the current directory.')print('# categories:', n_categories, all_categories)
print(unicodeToAscii("O'Néàl"))
Creating the Network
该网络扩展了上一个教程的 RNN,为类别Tensor添加了一个额外的参数。类别Tensor与字母输入一样,是一个one-hot vector。
将输出解释为下一个字母的概率,采样时最可能的输出字母将用作下一个输入字母。添加第二个线性层 o2o(在结合隐藏层和输出层之后);还有一个 dropout 层,它以给定的概率(此处为 0.1)随机将其输入的部分归零,通常用于模糊输入以防止过度拟合。在网络末端使用它来故意增加一些混乱并增加采样多样性。

import torch
import torch.nn as nnclass RNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(RNN, self).__init__()self.hidden_size = hidden_sizeself.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size)self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size)self.o2o = nn.Linear(hidden_size + output_size, output_size)self.dropout = nn.Dropout(0.1)self.softmax = nn.LogSoftmax(dim=1)def forward(self, category, input, hidden):input_combine = torch.cat((category, input, hidden), 1)hidden = self.i2h(input_combine)output = self.i2o(input_combine)output_combined = torch.cat((hidden, output), 1)output = self.o2o(output_combined)output = self.dropout(output)output = self.softmax(output)return output, hiddendef initHidden(self):return torch.zeros(1, self.hidden_size)
Training
训练的数据是一个 (category, line) 的二元组。
import randomdef randomChoice(l):return l[random.randint(0, len(l) - 1)]def randomTrainingPair():category = randomChoice(all_categories)line = randomChoice(category_lines[category])return category, line
对于每个 timestep(即训练单词中的每个字母),网络的输入是(category, current letter, hidden state),输出是 (next letter, next hidden state)。
由于每个timestep中根据当前字母预测下一个字母,因此字母对是来自该行的连续字母组 - 例如 “ABCD<EOS>”,需要创建(“A”,“B”), (“B”,“C”), (“C”,“D”), (“D”,“EOS”)。
类别Tensor是大小为<1 x n_categories> 的one-hot Tensor。训练时,在每个timestep将其输入到网络作为初始隐藏状态的一部分或某种其他策略。
def categoryTensor(category):li = all_categories.index(category)tensor = torch.zeros(1, n_categories)tensor[0][li] = 1return tensordef inputTensor(line):tensor = torch.zeros(len(line), 1, n_letters)for li in range(len(line)):letter = line[li]tensor[li][0][all_letters.find(letter)] = 1return tensordef targetTensor(line):letter_indexes = [all_letters.find(line[li]) for li in range(1, len(line))]letter_indexes.append(n_letters - 1) # EOSreturn torch.LongTensor(letter_indexes)
为了训练时的方便,创建一个 randomTrainingExample 函数,它获取随机(category, line) 对并将它们转换为所需的 (category, input, target) Tensor。
def randomTrainingExample():category, line = randomTrainingPair()category_tensor = categoryTensor(category)input_line_tensor = inputTensor(line)target_line_tensor = targetTensor(line)return category_tensor, input_line_tensor, target_line_tensor
定义训练函数
criterion = nn.NLLLoss()
learning_rate = 5e-4def train(category_tensor, input_line_tensor, target_line_tensor):target_line_tensor.unsqueeze_(-1)hidden = rnn.initHidden()rnn.zero_grad()loss = torch.Tensor([0])for i in range(input_line_tensor.size(0)):output, hidden = rnn(category_tensor, input_line_tensor[0], hidden)l = criterion(output, target_line_tensor[i])loss += lloss.backward()for p in rnn.parameters():p.data.add_(p.grad.data, alpha=-learning_rate)return output, loss.item() / input_line_tensor.size(0)
执行训练
rnn = RNN(n_letters, 128, n_letters)n_iters = 10000
print_every = 500
plot_every = 100
all_losses = []
total_loss = 0start = time.time()for iter in range(1, n_iters + 1):output, loss = train(*randomTrainingExample())total_loss += lossif iter % print_every == 0:print('%s (%d %d%%) %.4f' % (timeSince(start), iter, iter / n_iters * 100, loss))if iter % plot_every == 0:all_losses.append(total_loss / plot_every)total_loss = 0
绘制loss曲线
import matplotlib.pyplot as pltplt.figure()
plt.plot(all_losses)
Sampling the Network
给网络一个字母并询问下一个字母是什么,将其作为下一个字母输入,并重复直到 EOS。
- 为输入类别、起始字母和空隐藏状态创建Tensor;
- 使用起始字母创建一个字符串
output_name; - 最大输出长度
- 将当前字母输入网络;
- 从最高输出和下一个隐藏状态获取下一个字母;
- 如果字母是
EOS,则在此处停止; - 如果是普通字母,则添加到
output_name并继续;
- 返回最终名称
定义预测单个字符的函数
max_length = 20def sample(category, start_letter='A'):with torch.no_grad():category_tensor = categoryTensor(category)input = inputTensor(start_letter)hidden = rnn.initHidden()output_name = start_letterfor i in range(max_length):output, hidden = rnn(category_tensor, input[0], hidden)topv, topi = output.topk(1)topi = topi[0][0]if topi == n_letters - 1:breakelse:letter = all_letters[topi]output_name += letterinput = inputTensor(letter)return output_name
定义预测连续字符的函数
def samples(category, start_letters='ABC'):for start_letter in start_letters:print(sample(category, start_letter))
执行推理
samples('Russian', 'RUS')
samples('German', 'GER')
samples('Spanish', 'SPA')
samples('Chinese', 'CHI')
Translation with a Sequence to Sequence Network and Attention
- 官网链接: https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
在这个case中,将搭建一个神经网络将法语翻译成英语。
通过简单但强大的 sequence to sequence network, 网络实现的,其中两个RNN共同将一个序列转换为另一个序列。编码器网络将输入序列压缩为向量,解码器网络将该向量展开为新序列。

为了改进这个模型将使用注意力机制,让解码器学会关注输入序列的特定范围。
Requirements
from __future__ import unicode_literals, print_function, division
from io import open
import unicodedata
import re
import randomimport torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as Fimport numpy as np
from torch.utils.data import TensorDataset, DataLoader, RandomSamplerdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Loading data files
从这个 链接 中下载该case需要用到的数据,下载好后原地解压。
与字符级 RNN 使用的字符编码类似,将语言中的每个单词表示为一个one-hot vector,或者除了单个 1(在单词的索引处)之外的全为零的巨型向量。与语言中可能存在的数十个字符相比,单词的数量要多得多,因此编码向量要大得多。不过可以将数据修剪为每种语言仅使用几千个单词。

需要每个单词都有一个唯一索引,以便稍后用作网络的输入和目标。为了跟踪这些对象,这里使用一个名为 Lang 的辅助类,它有单词 → 索引 (word2index) 和索引 → 单词 (index2word) 词典,以及每个单词的计数 word2count,用于替换罕见单词。
SOS_token = 0
EOS_token = 1class Lang:def __init__(self, name):self.name = nameself.word2index = {}self.word2count = {}self.index2word = {0: "SOS", 1: "EOS"}self.n_words = 2 # Count SOS and EOSdef addSentence(self, sentence):for word in sentence.split(' '):self.addWord(word)def addWord(self, word):if word not in self.word2index:self.word2index[word] = self.n_wordsself.word2count[word] = 1self.index2word[self.n_words] = wordself.n_words += 1else:self.word2count[word] += 1
将unicode编码成ascii
def unicodeToAscii(s):return ''.join(c for c in unicodedata.normalize('NFD', s)if unicodedata.category(c) != 'Mn')def normalizeString(s):s = unicodeToAscii(s.lower().strip())s = re.sub(r"([.!?])", r" \1", s)s = re.sub(r"[^a-zA-Z!?]+", r" ", s)return s.strip()
为了读取数据文件,文件拆分成行然后将行拆分成对。这些文件都是英语 → 其他语言,如果想从其他语言 → 英语进行翻译,需要添加反向标志来反转对。
def readLangs(lang1, lang2, reverse=False):print("Reading lines...")lines = open('data/%s-%s.txt' % (lang1, lang2), encoding='utf-8').\read().strip().split('\n')pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]if reverse:pairs = [list(reversed(p)) for p in pairs]input_lang = Lang(lang2)output_lang = Lang(lang1)else:input_lang = Lang(lang1)output_lang = Lang(lang2)return input_lang, output_lang, pairs
想要快速训练,需要将数据集精简为相对较短且简单的句子。这里的最大长度是 10 个单词(包括结尾标点符号),并筛选出翻译为“I am”或“He is”等形式的句子(考虑到先前替换的撇号)。
MAX_LENGTH = 10eng_prefixes = ("i am ", "i m ","he is", "he s ","she is", "she s ","you are", "you re ","we are", "we re ","they are", "they re "
)def filterPair(p):return len(p[0].split(' ')) < MAX_LENGTH and \len(p[1].split(' ')) < MAX_LENGTH and \p[1].startswith(eng_prefixes)def filterPairs(pairs):return [pair for pair in pairs if filterPair(pair)]
上面整个准备数据的过程如下:
- 读取文本文件并拆分成行,将行拆分成对;
- 规范化文本,按长度和内容进行过滤;
- 根据句子成对制作单词列表;
加载数据
def prepareData(lang1, lang2, reverse=False):input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse)print("Read %s sentence pairs" % len(pairs))pairs = filterPairs(pairs)print("Trimmed to %s sentence pairs" % len(pairs))print("Counting words...")for pair in pairs:input_lang.addSentence(pair[0])output_lang.addSentence(pair[1])print("Counted words:")print(input_lang.name, input_lang.n_words)print(output_lang.name, output_lang.n_words)return input_lang, output_lang, pairsinput_lang, output_lang, pairs = prepareData('eng', 'fra', True)
print(random.choice(pairs))
The Seq2Seq Model
RNN 是一种对序列进行操作并使用其自身输出作为后续步骤输入的网络。seq2seq 网络是一种由两个 RNN组成的模型,编码器读取输入序列并输出单个向量,解码器读取该向量以生成输出序列。
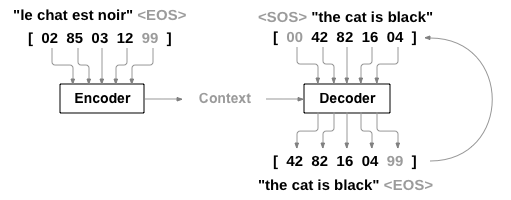
与使用单个 RNN 进行序列预测(每个输入对应一个输出)不同,seq2seq 模型摆脱了序列长度和顺序的束缚,成为两种语言之间翻译的理想选择。
例如句子 Je ne suis pas le chat noir → I am not the black cat。输入句子中的大多数单词在输出句子中都有直接翻译,但顺序略有不同,例如 chat noir 和 black cat。由于 ne/pas 结构,输入句子中还有一个单词,直接从输入单词序列生成正确的翻译会很困难。
使用 seq2seq 模型,编码器会创建一个向量,在理想情况下该向量将输入序列的“含义”编码为一个向量(句子的某个 N 维空间中的单个点)。
The Encoder
seq2seq 网络的编码器是一个 RNN,它为输入句子中的每个单词输出一些值。对于每个输入单词,编码器都会输出一个向量和一个隐藏状态,并将隐藏状态用于下一个输入单词。

class EncoderRNN(nn.Module):def __init__(self, input_size, hidden_size, dropout_p=0.1):super(EncoderRNN, self).__init__()self.hidden_size = hidden_sizeself.embedding = nn.Embedding(input_size, hidden_size)self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)self.dropout = nn.Dropout(dropout_p)def forward(self, input):embedded = self.dropout(self.embedding(input))output, hidden = self.gru(embedded)return output, hidden
The Decoder
最简单的解码器是一个 RNN,用编码器输出向量并输出单词序列来创建翻译。
在最简单的 seq2seq 解码器中,仅使用编码器的最后一个输出。这个最后的输出有时被称为上下文向量,因为它对整个序列的上下文进行编码。此上下文向量用作解码器的初始隐藏状态。
在解码的每一步,解码器都会获得一个输入标记和隐藏状态。初始输入标记是字符串开头的 <SOS> 标记,第一个隐藏状态是上下文向量(编码器的最后一个隐藏状态)。

class DecoderRNN(nn.Module):def __init__(self, hidden_size, output_size):super(DecoderRNN, self).__init__()self.embedding = nn.Embedding(output_size, hidden_size)self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)self.out = nn.Linear(hidden_size, output_size)def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):batch_size = encoder_outputs.size(0)decoder_input = torch.empty(batch_size, 1, dtype=torch.long, device=device).fill_(SOS_token)decoder_hidden = encoder_hiddendecoder_outputs = []for i in range(MAX_LENGTH):decoder_output, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)decoder_outputs.append(decoder_output)if target_tensor is not None:decoder_input = target_tensor[:, i].unsqueeze(1)else:_, topi = decoder_output.topk(1)decoder_input = topi.squeeze(-1).detach()decoder_outputs = torch.cat(decoder_outputs, dim=1)decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)return decoder_outputs, decoder_hidden, Nonedef forward_step(self, input, hidden):output = self.embedding(input)output = F.relu(output)output, hidden = self.gru(output, hidden)output = self.out(output)return output, hidden
Attention Decoder
如果在编码器和解码器之间只传递上下文向量,那么这个单一向量就承担了编码整个句子的负担。
注意力机制允许解码器网络在解码器自身输出的每一步中“关注”编码器输出的不同部分。首先,计算一组注意力权重,这些权重将与编码器输出向量相乘以创建一个加权组合。结果(在代码中称为 attn_applied)包含有关输入序列特定部分的信息,从而帮助解码器选择正确的输出词。
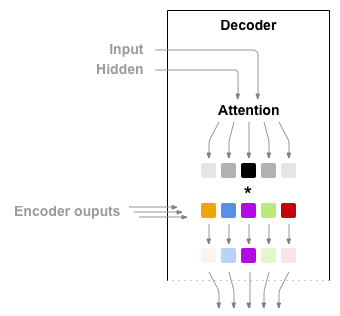
计算注意力权重是使用另一个前馈层 attn 完成的,使用解码器的输入和隐藏状态作为输入。由于训练数据中有各种大小的句子,因此要实际创建和训练此层必须选择它可以适用的最大句子长度。最大长度的句子将使用所有注意力权重,而较短的句子将仅使用前几个。

Bahdanau 注意力机制,也称为附加注意力机制,是seq2seq模型中常用的注意力机制,尤其是在神经机器翻译任务中。Bahdanau 等人在题为《 Neural Machine Translation by Jointly Learning to Align and Translate》 的论文中介绍了该机制。该注意力机制采用学习对齐模型来计算编码器和解码器隐藏状态之间的注意力分数。它利用前馈神经网络来计算对齐分数。
还有其他可用的注意力机制,例如 Luong 注意力机制,它通过计算解码器隐藏状态和编码器隐藏状态之间的点积来计算注意力分数,不涉及 Bahdanau 注意力机制中使用的非线性变换。
在这个case中使用 Bahdanau 注意力机制。
class BahdanauAttention(nn.Module):def __init__(self, hidden_size):super(BahdanauAttention, self).__init__()self.Wa = nn.Linear(hidden_size, hidden_size)self.Ua = nn.Linear(hidden_size, hidden_size)self.Va = nn.Linear(hidden_size, 1)def forward(self, query, keys):scores = self.Va(torch.tanh(self.Wa(query) + self.Ua(keys)))scores = scores.squeeze(2).unsqueeze(1)weights = F.softmax(scores, dim=-1)context = torch.bmm(weights, keys)return context, weightsclass AttnDecoderRNN(nn.Module):def __init__(self, hidden_size, output_size, dropout_p=0.1):super(AttnDecoderRNN, self).__init__()self.embedding = nn.Embedding(output_size, hidden_size)self.attention = BahdanauAttention(hidden_size)self.gru = nn.GRU(2 * hidden_size, hidden_size, batch_first=True)self.out = nn.Linear(hidden_size, output_size)self.dropout = nn.Dropout(dropout_p)def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):batch_size = encoder_outputs.size(0)decoder_input = torch.empty(batch_size, 1, dtype=torch.long, device=device).fill_(SOS_token)decoder_hidden = encoder_hiddendecoder_outputs = []attentions = []for i in range(MAX_LENGTH):decoder_output, decoder_hidden, attn_weights = self.forward_step(decoder_input, decoder_hidden, encoder_outputs)decoder_outputs.append(decoder_output)attentions.append(attn_weights)if target_tensor is not None:# Teacher forcing: Feed the target as the next inputdecoder_input = target_tensor[:, i].unsqueeze(1) # Teacher forcingelse:# Without teacher forcing: use its own predictions as the next input_, topi = decoder_output.topk(1)decoder_input = topi.squeeze(-1).detach() # detach from history as inputdecoder_outputs = torch.cat(decoder_outputs, dim=1)decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)attentions = torch.cat(attentions, dim=1)return decoder_outputs, decoder_hidden, attentionsdef forward_step(self, input, hidden, encoder_outputs):embedded = self.dropout(self.embedding(input))query = hidden.permute(1, 0, 2)context, attn_weights = self.attention(query, encoder_outputs)input_gru = torch.cat((embedded, context), dim=2)output, hidden = self.gru(input_gru, hidden)output = self.out(output)return output, hidden, attn_weights
Training
为了进行训练,需要一个输入Tensor(输入句子中单词的索引)和目标Tensor(目标句子中单词的索引)。在创建这些向量时,将 EOS 令牌附加到两个序列中。
定义辅助工具以处理输入输出
def indexesFromSentence(lang, sentence):return [lang.word2index[word] for word in sentence.split(' ')]def tensorFromSentence(lang, sentence):indexes = indexesFromSentence(lang, sentence)indexes.append(EOS_token)return torch.tensor(indexes, dtype=torch.long, device=device).view(1, -1)def tensorsFromPair(pair):input_tensor = tensorFromSentence(input_lang, pair[0])target_tensor = tensorFromSentence(output_lang, pair[1])return (input_tensor, target_tensor)def get_dataloader(batch_size):input_lang, output_lang, pairs = prepareData('eng', 'fra', True)n = len(pairs)input_ids = np.zeros((n, MAX_LENGTH), dtype=np.int32)target_ids = np.zeros((n, MAX_LENGTH), dtype=np.int32)for idx, (inp, tgt) in enumerate(pairs):inp_ids = indexesFromSentence(input_lang, inp)tgt_ids = indexesFromSentence(output_lang, tgt)inp_ids.append(EOS_token)tgt_ids.append(EOS_token)input_ids[idx, :len(inp_ids)] = inp_idstarget_ids[idx, :len(tgt_ids)] = tgt_idstrain_data = TensorDataset(torch.LongTensor(input_ids).to(device),torch.LongTensor(target_ids).to(device))train_sampler = RandomSampler(train_data)train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)return input_lang, output_lang, train_dataloader
为了进行训练,将输入句子通过编码器并跟踪每个输出和最新的隐藏状态。然后,将 <SOS> 标记作为解码器的第一个输入,将编码器的最后一个隐藏状态作为其第一个隐藏状态。
“Teacher forcing” 概念是使用实际目标输出作为每个下一个输入,而不是使用解码器的猜测作为下一个输入。使用 Teacher forcing 能收敛得更快,但当使用已经训练好的网络时可能表现出不稳定性。
可以观察到 Teacher forcing 网络的输出,这些输出以连贯的语法读取,但给出错误的翻译 - 表示它已经学会了表示输出语法,并且可以在 Teacher 告诉它前几个单词后“拾取”含义,但它还没有正确地学会如何重建句子。
由于 PyTorch 的自动求导,可以通过一个简单的 if 语句随机选择是否使用 Teacher forcing 。
定义单次训练函数
def train_epoch(dataloader, encoder, decoder, encoder_optimizer,decoder_optimizer, criterion):total_loss = 0for data in dataloader:input_tensor, target_tensor = dataencoder_optimizer.zero_grad()decoder_optimizer.zero_grad()encoder_outputs, encoder_hidden = encoder(input_tensor)decoder_outputs, _, _ = decoder(encoder_outputs, encoder_hidden, target_tensor)loss = criterion(decoder_outputs.view(-1, decoder_outputs.size(-1)),target_tensor.view(-1))loss.backward()encoder_optimizer.step()decoder_optimizer.step()total_loss += loss.item()return total_loss / len(dataloader)
定义辅助函数:根据当前时间和进度百分比打印已用时间和预计剩余时间。
import time
import mathdef asMinutes(s):m = math.floor(s / 60)s -= m * 60return '%dm %ds' % (m, s)def timeSince(since, percent):now = time.time()s = now - sincees = s / (percent)rs = es - sreturn '%s (- %s)' % (asMinutes(s), asMinutes(rs))
整个训练过程如下:
- 启动计时器;
- 初始化优化器和loss;
- 创建一组训练对;
然后多次调用训练函数,偶尔打印进度(示例的百分比、到目前为止的时间、估计的时间)和平均损失。
定义训练函数
def train(train_dataloader, encoder, decoder, n_epochs, learning_rate=0.001,print_every=100, plot_every=100):start = time.time()plot_losses = []print_loss_total = 0 # Reset every print_everyplot_loss_total = 0 # Reset every plot_everyencoder_optimizer = optim.Adam(encoder.parameters(), lr=learning_rate)decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate)criterion = nn.NLLLoss()for epoch in range(1, n_epochs + 1):loss = train_epoch(train_dataloader, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion)print_loss_total += lossplot_loss_total += lossif epoch % print_every == 0:print_loss_avg = print_loss_total / print_everyprint_loss_total = 0print('%s (%d %d%%) %.4f' % (timeSince(start, epoch / n_epochs),epoch, epoch / n_epochs * 100, print_loss_avg))if epoch % plot_every == 0:plot_loss_avg = plot_loss_total / plot_everyplot_losses.append(plot_loss_avg)plot_loss_total = 0
Plotting results
import matplotlib.pyplot as plt
plt.switch_backend('agg')
import matplotlib.ticker as ticker
import numpy as npdef showPlot(points):plt.figure()fig, ax = plt.subplots()# this locator puts ticks at regular intervalsloc = ticker.MultipleLocator(base=0.2)ax.yaxis.set_major_locator(loc)plt.plot(points)
Evaluation
评估与训练基本相同但没有真值,因此只需将解码器的预测反馈给自身,每次它预测一个单词时,都会将其添加到输出字符串中,如果它预测的是 EOS 令牌就结束输出,同时还存储解码器的注意力输出以供稍后显示。
def evaluate(encoder, decoder, sentence, input_lang, output_lang):with torch.no_grad():input_tensor = tensorFromSentence(input_lang, sentence)encoder_outputs, encoder_hidden = encoder(input_tensor)decoder_outputs, decoder_hidden, decoder_attn = decoder(encoder_outputs, encoder_hidden)_, topi = decoder_outputs.topk(1)decoded_ids = topi.squeeze()decoded_words = []for idx in decoded_ids:if idx.item() == EOS_token:decoded_words.append('<EOS>')breakdecoded_words.append(output_lang.index2word[idx.item()])return decoded_words, decoder_attn
可以评估训练集中的随机句子,并打印出输入、目标和输出,以做出一些主观质量判断:
def evaluateRandomly(encoder, decoder, n=10):for i in range(n):pair = random.choice(pairs)print('>', pair[0])print('=', pair[1])output_words, _ = evaluate(encoder, decoder, pair[0], input_lang, output_lang)output_sentence = ' '.join(output_words)print('<', output_sentence)print('')
Training and Evaluating
输入句子经过了严格过滤。对于这个小数据集可以使用相对较小的网络,包含 256 个隐藏节点和一个 GRU 层。在 MacBook CPU 上大约 40 分钟后,将获得一些合理的结果。
hidden_size = 128
batch_size = 32input_lang, output_lang, train_dataloader = get_dataloader(batch_size)encoder = EncoderRNN(input_lang.n_words, hidden_size).to(device)
decoder = AttnDecoderRNN(hidden_size, output_lang.n_words).to(device)train(train_dataloader, encoder, decoder, 80, print_every=5, plot_every=5)
关闭dropout层用以评估
encoder.eval()
decoder.eval()
evaluateRandomly(encoder, decoder)
Visualizing Attention
注意力机制的一个有用特性是其高度可解释的输出。由于它用于加权输入序列的特定编码器输出,可以查看网络在每个timestep中最受关注的位置。
运行 plt.matshow(attentions) 以查看显示为矩阵的注意力输出。
定义可视化辅助工具
def showAttention(input_sentence, output_words, attentions):fig = plt.figure()ax = fig.add_subplot(111)cax = ax.matshow(attentions.cpu().numpy(), cmap='bone')fig.colorbar(cax)# Set up axesax.set_xticklabels([''] + input_sentence.split(' ') +['<EOS>'], rotation=90)ax.set_yticklabels([''] + output_words)# Show label at every tickax.xaxis.set_major_locator(ticker.MultipleLocator(1))ax.yaxis.set_major_locator(ticker.MultipleLocator(1))plt.show()def evaluateAndShowAttention(input_sentence):output_words, attentions = evaluate(encoder, decoder, input_sentence, input_lang, output_lang)print('input =', input_sentence)print('output =', ' '.join(output_words))showAttention(input_sentence, output_words, attentions[0, :len(output_words), :])
绘制注意力热力图
evaluateAndShowAttention('il n est pas aussi grand que son pere')
evaluateAndShowAttention('je suis trop fatigue pour conduire')
evaluateAndShowAttention('je suis desole si c est une question idiote')
evaluateAndShowAttention('je suis reellement fiere de vous')
相关文章:
Learning PyTorch - NLP from Scratch)
Pytorch学习笔记(十二)Learning PyTorch - NLP from Scratch
这篇博客瞄准的是 pytorch 官方教程中 Learning PyTorch 章节的 NLP from Scratch 部分。 官网链接:https://pytorch.org/tutorials/intermediate/nlp_from_scratch_index.html 完整网盘链接: https://pan.baidu.com/s/1L9PVZ-KRDGVER-AJnXOvlQ?pwdaa2m 提取码: …...

学习日记0327
A cross-domain knowledge tracing model based on graph optimal transport 我们使用gnn来学习这些节点的特征。在此基础上,我们使用显式分布距离度量对齐来自两个不同域的特征向量,旨在最小化域差异,实现最大的跨域知识转移。 AEGOT-CDKT…...

Postman 下载文件指南:如何请求 Excel/PDF 文件?
在 Postman 中进行 Excel/PDF 文件的请求下载和导出,以下是简明的步骤,帮助你轻松完成任务。首先,我们将从新建接口开始,逐步引导你完成整个过程。 Postman 请求下载/导出 excel/pdf 文件教程...

【HTML】验证与调试工具
个人主页:Guiat 归属专栏:HTML CSS JavaScript 文章目录 1. HTML 验证工具概述1.1 验证的重要性1.2 常见 HTML 错误类型 2. W3C 验证服务2.1 W3C Markup Validation Service2.2 使用 W3C 验证器2.3 验证结果解读 3. 浏览器开发者工具3.1 Chrome DevTools…...

头歌实践教学平台--【数据库概论】--SQL
一、表结构与完整性约束的修改(ALTER) 1.修改表名 USE TestDb1; alter table your_table rename TO my_table; 2.添加与删除字段 #语句1:删除表orderDetail中的列orderDate alter table orderDetail drop orderDate; #语句2:添加列unitPrice alter t…...

2025.03.27【基因分析新工具】| MAST:解锁基因表达差异分析与网络构建
文章目录 1. MAST工具简介:探索生物信息分析的新利器1.1 什么是MAST工具?1.2 MAST工具的优势1.3 MAST工具的应用场景 2. MAST的安装方法:轻松入门的第一步2.1 安装R语言环境2.2 安装MAST包2.3 安装依赖库 3. MAST常用命令:掌握数据…...

JVM - 垃圾回收基本问题
通过一些问题来讨论在 JVM 中,垃圾回收的一些基本问题 为什么要有垃圾回收?Java 垃圾回收中是如何判断一个对象死亡的?请简单介绍一下刚才说到了引用计数法,引用计数法存在什么问题?刚才说到了可达性分析,…...

Python 爬虫案例
以下是一些常见的 Python 爬虫案例,涵盖了不同的应用场景和技术点: 1. 简单网页内容爬取 案例:爬取网页标题和简介 import requests from bs4 import BeautifulSoup url "https://www.runoob.com/" response requests.get(url) …...
)
从零构建大语言模型全栈开发指南:第三部分:训练与优化技术-3.1.3分布式数据加载与并行处理(PyTorch DataLoader优化)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 3.1.3 分布式数据加载与并行处理(`PyTorch DataLoader`优化)1. 大规模数据加载的挑战与瓶颈分析1.1 数据加载流程的时间分解2. PyTorch DataLoader的深度优化策略2.1 核心参数调优2.2 分布式数据分片策…...

2025年- G31-Lc105-102. 二叉树层次遍历--java版
1.题目描述 2.思路 思路一: 使用 队列 Queue 来存储当前层的所有节点。关键点在于 levelSize queue.size() 这一行,它决定了当前层的节点数量。 3.代码实现 /*** Definition for a binary tree node.* public class TreeNode {* int val;* Tr…...

Redis 和 MySQL双写一致性的更新策略有哪些?常见面试题深度解答。
目录 一. 业务数据查询,更新顺序简要分析 二. 更新数据库、查询数据库、更新缓存、查询缓存耗时对比 2.1 更新数据库(最慢) 2.2 查询数据库(较慢) 2.3 更新缓存(次快) 2.4 查询缓存&#…...

【DFS】羌笛何须怨杨柳,春风不度玉门关 - 4. 二叉树中的深搜
本篇博客给大家带来的是二叉树深度优先搜索的解法技巧,在后面的文章中题目会涉及到回溯和剪枝,遇到了一并讲清楚. 🐎文章专栏: DFS 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的…...

【Exception】MybatisPlusException: can not find lambda cache for this entity
文章目录 环境 | Environment复现步骤 | Reproduction steps报错日志 | Error log源码 | Source CodeUserServiceImpl.javaAddressServiceImpl.javaAbstractSubTableBaseServiceImpl.javaUserEntity.javaAddressEntity.javaSubTableBaseEntity.java 原因分析 | Analysis解决方案…...

Spring Security 全面指南:从基础到高级实践
一、Spring Security 概述与核心概念 1.1 Spring Security 简介 Spring Security 是 Spring 生态系统中的安全框架,为基于 Java 的企业应用提供全面的安全服务。它起源于 2003 年的 Acegi Security 项目,2008 年正式成为 Spring 官方子项目,…...

IP组播 C++简单应用
引言 在当今的网络世界中,数据的传输效率和带宽的合理利用是至关重要的。传统的单播和广播通信方式在某些场景下存在着局限性,而IP组播技术的出现为解决这些问题提供了一种有效的方案。本文将详细介绍IP组播的概念、工作原理、应用场景,并通…...

CentOS 7安装 mysql
CentOS 7安装 mysql 1. yum 安装 mysql 配置mysql源 yum -y install mysql57-community-release-el7-10.noarch.rpm安装MySQL服务器 yum -y install mysql-community-server启动MySQL systemctl start mysqld.service查看MySQL运行状态,运行状态如图ÿ…...

“十五五”时期航空弹药发展环境分析
1.“十五五”时期航空弹药发展环境分析 (标题:小二号宋体居中) 一、建言背景介绍 (一级标题:黑体三号,首行空两格) 航空弹药作为现代战争的核心装备,其发展水平直接关乎…...

es6的100个问题
基础概念 解释 let、const 和 var 的区别。什么是块级作用域?ES6 如何实现它?箭头函数和普通函数的主要区别是什么?解释模板字符串(Template Literals)的用途,并举例嵌套变量的写法。解构赋值的语法是什么…...

在直播间如何和观众进行互动
在抖音直播间实现高效互动需要**技术话术工具**的立体化组合,以下是程序员可落地的深度互动方案: --- ### 一、技术驱动型互动策略 #### 1. **实时代码演示(硬核互动)** - **OBS虚拟摄像头屏幕共享** python # 用Flask创建实…...

mysql--用户管理
MySQL 用户管理完整指南 1. 查看用户信息 查看所有用户 SELECT User, Host, authentication_string FROM mysql.user;查看用户详细信息 SELECT * FROM mysql.user \G查看当前登录用户 SELECT CURRENT_USER();查看特定用户的权限 SHOW GRANTS FOR usernamehost;2. 创建用户…...

.NET三层架构详解
.NET三层架构详解 文章目录 .NET三层架构详解引言什么是三层架构表示层(Presentation Layer)业务逻辑层(Business Logic Layer,BLL)数据访问层(Data Access Layer,DAL) .NET三层架构…...

机器学习之回归
1. 引言 回归分析是机器学习中的基本技术之一,广泛用于预测连续型变量。本文调研了线性回归、多项式回归、岭回归、Lasso回归及弹性网络回归,重点分析其数学原理、算法推导、求解方法及应用场景。 2. 线性回归 2.1 概述 线性回归假设因变量与自变量之间存在线性关系,其目…...

危险化合物安全处理,有机反应淬灭操作解析
化学淬灭操作是指在化学反应过程中,通过人为干预快速终止反应的技术。在有机化学反应中,某一反应底物是过量的,当化学反应进行到一定程度,目标产物已经获得,该过量反应底物继续存在会进一步反应生成副产物或者影响后处…...

【前端】使用 HTML、CSS 和 JavaScript 创建一个数字时钟和搜索功能的网页
文章目录 ⭐前言⭐一、项目结构⭐二、HTML 结构⭐三、CSS 样式⭐四、JavaScript 功能⭐五、运行效果⭐总结 标题详情作者JosieBook头衔CSDN博客专家资格、阿里云社区专家博主、软件设计工程师博客内容开源、框架、软件工程、全栈(,NET/Java/Python/C)、数…...

【Linux】调试器——gdb使用
目录 一、预备知识 二、常用指令 三、调试技巧 (一)监视变量的变化指令 watch (二)更改指定变量的值 set var 正文 一、预备知识 程序的发布形式有两种,debug和release模式,Linux gcc/g出来的二进制…...

Windows10清理机器大全集
Windows10清理机器大全集 写在前面先这么个标题,逐渐补充禁止Update移除Microsoft Compatibility Telemetrywindows-defender-remover其它 写在前面 看到标题,读者已经就吐了。 我是说,我非常认可: IT从业者,如果你银子比较充足&…...

解决IDEA中maven找不到依赖项的问题
直接去官网找到对应的依赖项jar包,并且下载到本地,然后安装到本地厂库中。 Maven官网:https://mvnrepository.com/ 一、使用mvn install:install-file命令 Maven提供了install:install-file插件,用于手动将jar包安装到本地仓库…...

端游熊猫脚本游戏精灵助手2025游戏办公脚本工具!游戏脚本软件免费使用
在当下这个崇尚高效与便捷的时代,自动化工具已然成为诸多开发者与企业提升工作效率的关键选择。熊猫精灵脚本助手作为一款极具实力的自动化工具,凭借其多样的功能以及广泛的应用场景,逐步成为众多用户的首要之选。 熊猫精灵脚本助手整合了丰…...

知识就是力量——物联网应用技术
基础知识篇 一、常用电子元器件1——USB Type C 接口引脚详解特点接口定义作用主从设备关于6P引脚的简介 2——常用通信芯片CH343P概述特点引脚定义 CH340概述特点封装 3——蜂鸣器概述类型驱动电路原文链接 二、常用封装介绍贴片电阻电容封装介绍封装尺寸与功率关系࿱…...

第4.1节:使用正则表达式
1 第4.1节:使用正则表达式 将正则表达式用斜杠括起来,就能用作模式。随后,该正则表达式会与每条输入记录的完整文本进行比对。(通常情况下,它只需匹配文本的部分内容就能视作匹配成功。)例如,以…...

Linux目录及文件管理
目录 一.Linux目录基本结构 1.常见目录及其作用 二.常用文件处理命令 1.七类常见的linux的文件 2.cat(查看文件内容) 3.more(分页查看文件内容) 4.less(分页查看文件内容) 5.head(从头部查看文件内容࿰…...
)
【MySQL】从零开始:掌握MySQL数据库的核心概念(五)
由于我的无知,我对生存方式只有一个非常普通的信条:不许后悔。 前言 这是我自己学习mysql数据库的第五篇博客总结。后期我会继续把mysql数据库学习笔记开源至博客上。 上一期笔记是关于mysql数据库的增删查改,没看的同学可以过去看看…...

进军场景智能体,云迹机器人又快了一步
(图片来源:Pixels) 2025年,AI和机器人行业都发生了巨大改变。 数科星球原创 作者丨苑晶 编辑丨大兔 2025年,酒店行业正掀起一股批量采购具备AI功能的软硬一体解决方案的热潮。 在DeepSeek、Manus等国产AI软件的推动…...
)
【实战ES】实战 Elasticsearch:快速上手与深度实践-5.2.1 多字段权重控制(标题、品牌、类目)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 电商商品搜索实战:多字段权重控制策略1. 业务场景与核心挑战1.1 典型搜索问题1.2 权重失衡的影响数据 2. 权重控制核心方案2.1 字段权重分配矩阵2.2 多策略组合方…...

Ubuntu24.04 离线安装 MySQL8.0.41
一、环境准备 1.1 官方下载MySQL8.0.41 完整包 1.2 上传包 & 解压 上传包名称是:mysql-server_8.0.41-1ubuntu24.04_amd64.deb-bundle.tar # 切换到上传目录 cd /home/MySQL8 # 解压: tar -xvf mysql-server_8.0.41-1ubuntu24.04_amd64.deb-bundl…...

【Django】教程-3-数据库相关介绍
【Django】教程-1-安装创建项目目录结构介绍 【Django】教程-2-前端-目录结构介绍 4.数据库连接配置 需要手动创建数据库,数据库无法自动创建 ,ORM可以创建表,操作表 注意:负责app下mondels.py写类时,无法在数据库中…...

OpenGL绘制文本
一:QPainter绘制 在 OpenGL 渲染的窗口中(如 QOpenGLWidget),通过 QPainter 直接绘制文本。Qt 会自动将 2D 内容(文本、图形)与 OpenGL 内容合成。在paintGL()里面绘制,如果有其他纹理…...
之添加行拖拽排序功能示例6,TableView16_06 分页表格拖拽排序)
DeepSeek 助力 Vue3 开发:打造丝滑的表格(Table)之添加行拖拽排序功能示例6,TableView16_06 分页表格拖拽排序
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 Deep…...
【解决】导入PNG图片,转 Sprite 格式成功但资产未生效问题
开发平台:Unity 6.0 图片格式:.png 问题描述 当 PNG 成功转换为 Sprite(精灵)时,资产状态将显示扩展箭头,即表明该资产可 Sprite 使用。 解决方法:设置正确的 Sprite Mode Single 关于 Spr…...
)
【科研绘图系列】R语言绘制重点物种进化树图(taxa phylogenetic tree)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包数据下载导入数据数据预处理画图输出图片系统信息介绍 【科研绘图系列】R语言绘制重点物种进化树图(taxa phylogenetic tree) 加载R包 library(tidyverse) library(ape…...

Flutter入门教程:从零开始的Flutter开发指南
Flutter入门教程:从环境搭建到应用发布 概述 本文提供了全面的Flutter入门教程,涵盖环境搭建、基础Widget使用、界面设计与美化,以及实战项目开发等内容。通过本教程,开发者能够快速上手Flutter开发,掌握开发跨平台应…...

CentOS 7 源码安装libjsoncpp-1.9.5库
安装依赖工具 sudo yum install cmake make gcc cmake 需要升级至 3.8.0 以上可参考:CentOS安装CMakegcc 需要升级至9.0 以上可参考:CentOS 7升级gcc版本 下载源码 wget https://github.com/open-source-parsers/jsoncpp/archive/refs/tags/1.9.5.…...

调用高德天气Api,并展示对应天气图标
1、申请高德key 点击高德官网申请 必须有key才能调用高德api 小提示:每日/每秒调用api次数有限,尽量不要循环调用。 每日大概5000,每秒3次 2、查看文档 高德官网天气api接口文档 请求示例: https://restapi.amap.com/v3/weat…...

DSP开发板的JTAG接口
(1)普中DSP28335 (2)研旭DSP28388 (3)延华DSP28335 (3)M新动力28377D电机控制板...

1.25-20GHz/500ns超快跳频!盛铂SWFA300国产捷变频频率综合器模块赋能雷达/5G/电子战高频精密控制 本振/频综模块
盛铂SWFA300捷变频频率综合器模块简述: 盛铂科技国产SWFA300捷变频频率综合器是一款在频率范围内任意两点频率的跳频时间在500nS以内的高速跳频源,其输出频率范围为1.25GHz至20GHz,频率的最小步进为10kHz。同时它拥有优秀的相位噪声特性&…...

nestjs 多环境配置
这里使用yaml进行多环境配置,需要安装nestjs/config、js-yaml、types/js-yaml js-yaml、types/js-yaml 主要用来读取yaml文件以及指定类型使用 官方教程:Documentation | NestJS - A progressive Node.js framework 1、下载 npm i --save nestjs/confi…...

CentOS7系统更新yum源教程
由于CentOS 7 在2024年6月30号以后官方不再维护。很多yum源也陆续关掉了,所以我们要更换镜像源。yum是一个用于软件包管理的工具,它能够从特定的存储库中自动下载和安装软件包。然而,系统默认的yum源可能不包含所有软件包,因此需要…...
)
Python正则表达式(二)
目录 六、re.findall()函数和分组 1、0/1分组情况 2、多分组情况 七、或“|”的用法 1、作用域 2、用法 八、贪婪模式和懒惰模式 1、量词的贪婪模式 2、量词的懒惰模式 九、匹配对象 1、相关函数 六、re.findall()函数和分组 1、0/1分组情况 在正则表达式中&#x…...

MySQL中如何进行SQL调优?
SQL 调优是提高 MySQL 数据库性能的关键环节。以下是 MySQL SQL 调优的主要方法和技巧 一、使用 EXPLAIN 分析查询 EXPLAIN SELECT * FROM users WHERE user_name 张三;查看执行计划,了解 MySQL 如何处理查询重点关注 type、key、rows、Extra 列type 最好能达到 …...

Android15查看函数调用关系
Android15 Camera3中打印函数调用栈 1.使用CallStack跟踪函数调用 修改涉及三个内容: Android.bp中添加对CallStack的引用。CallStack被打包在libutilscallstack.so。代码中包含CallStack的头文件。代码中调用CallStack接口,打印函数调用栈。 例子&am…...