Linux进程控制--进程创建 | 进程终止 | 进程等待 | 进程替换
1.进程创建
现阶段我们知道进程创建有如下两种方式,起始包括在以后的学习中有两种方式也是最常见的:
1、命令行启动命令(程序、指令)。
2、通过程序自身,使用fork函数创建的子进程。
1.1 fork函数
在linux操作系统中,fork函数是非常重要的函数,它从已经存在的进程中创建一个新进程。新进程为子进程,而原进程为父进程。
#include<unistd.h>
pid_t fork(void);
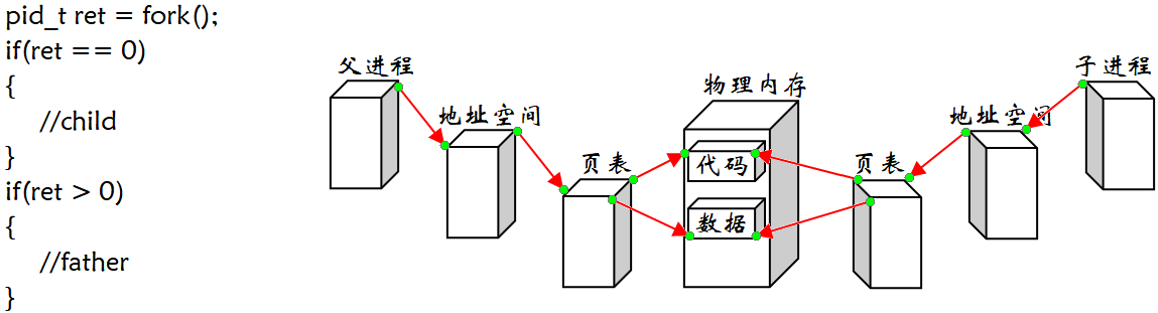
返回值:子进程返回 0,父进程返回子进程的 pid,出错返回 -1。父进程被创建时,是有自己的PCB、地址空间、页表的,在系统层面是通过用户级页表来维护地址空间和物理内存之间的映射关系。父进程根据PCB找到地址空间,通过地址空间这样的窗口找到资源。不论是进程还是地址空间,他都是某种struct结构体变量,其中就包含很多属性和属性值。父进程执行fork函数时,子进程是以父进程为模板来创建的。即子进程的大部分属性和属性值是继承父进程的,而小部分是子进程的调度时间要重置、子进程的pid、ppid要重置。其中上面的PCB、地址空间、页表都在内核中由操作系统维护,这也就意味着我们下只需要调用操作系统提供的接口fork,而具体的工作细节由操作系统完成。注意进程的创建看起来是由父进程完成的,实际上并不是父进程创建子进程,而是父进程通过调用fork函数开始了创建新进程的过程,本质还是由操作系统创建的。
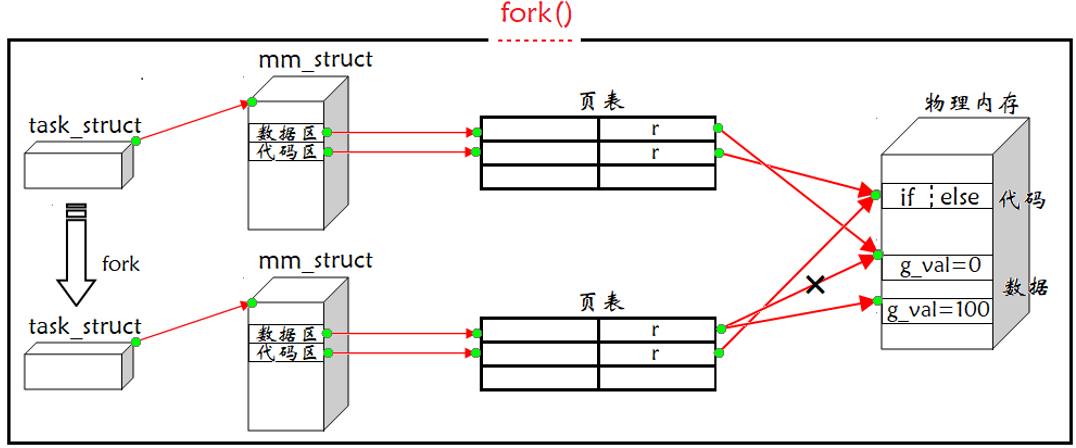
进程调用fork时,控制逻辑就由用户层转移至内核,内核做以下工作:
1、分配新的内存块和内核数据结构给子进程;
2、将父进程部分数据结构内容拷贝至子进程;
3、添加子进程到系统进程列表中;
4、fork返回、调度器调度。
1.2 fork函数的返回值
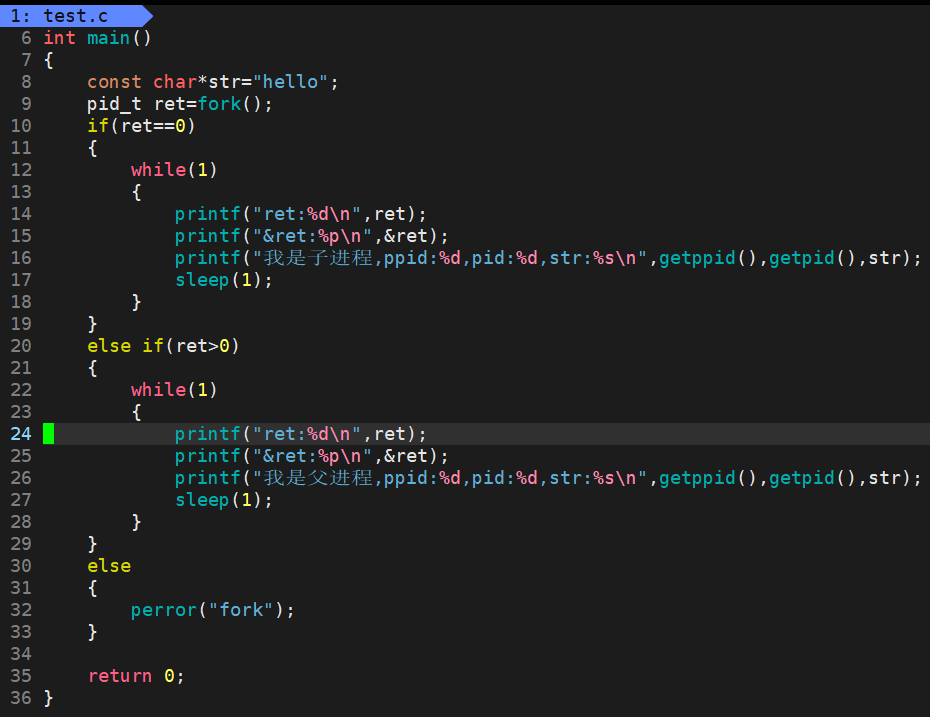
我们知道fork是一个系统函数,它会完成创建pcb、生成pid、创建地址空间、创建页表、构建映射关系、将子进程的pcb链入调度队列、返回pid等工作。在返回之前,这些工作看起来是由父进程完成的。我们曾经说过函数在返回时,函数的主要逻辑已经执行完了。
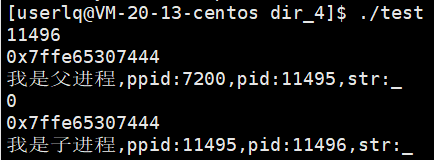
父进程的pid是11495,子进程的pid是11496。子进程的pid并不是由父进程给予的,包括父进程的pid也不是父进程的父进程给予的,而是由操作系统给予的。也就是说进程的创建看起来是由父进程创建的,但其实并不是,而是父进程通过调用fork函数开始了创建新进程的过程,任何进程的创建还是要由操作系统完成的。
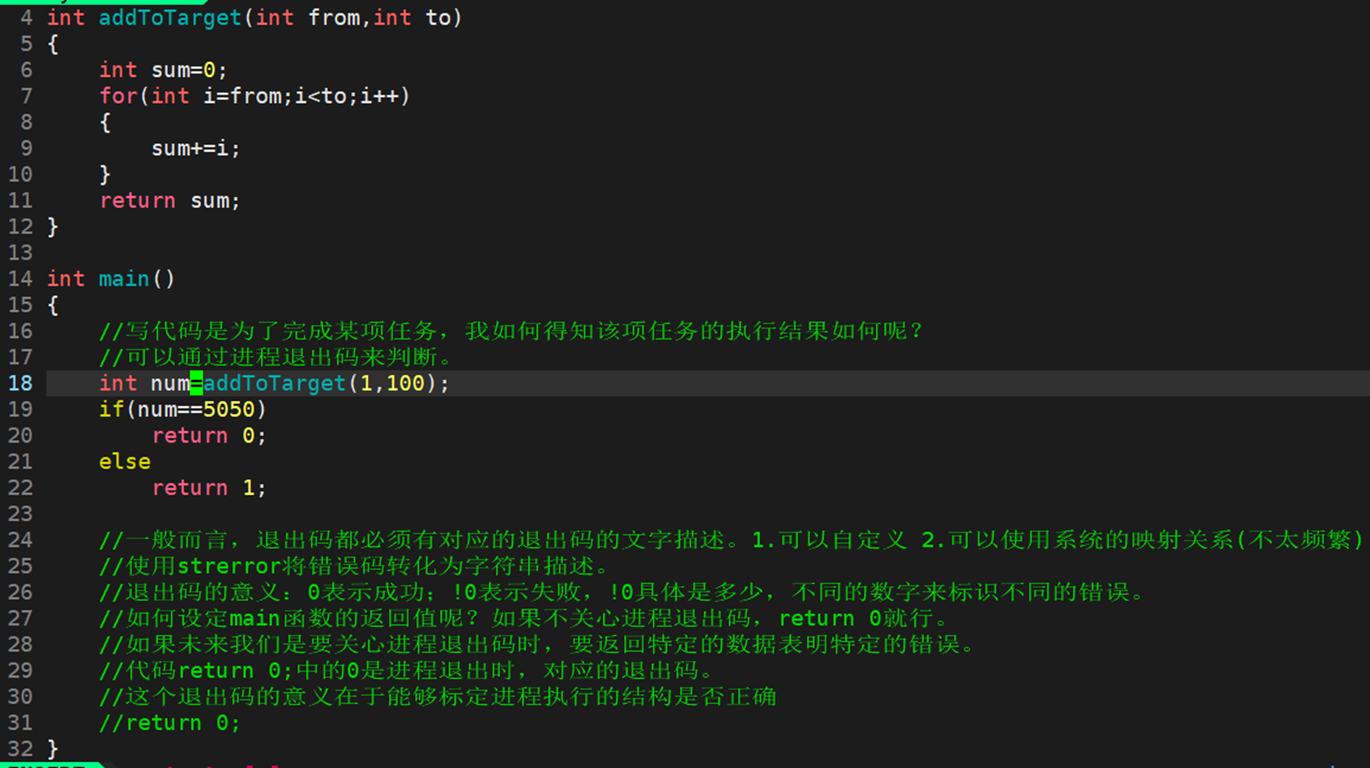
根据fork的返回值,执行不同的逻辑流,从这里我们需要回答两个问题:
fork同时有两个返回值,用于接收fork返回值的ret变量是怎么做到ret==0 && ret>0的?子进程创建后,父子进程是共享代码的,我们认定return是代码,是父子进程共享的代码,所以当父进程return时,子进程也要return,所以父子进程会return两个值。这里pid_t ret=fork(),父进程调用fork,在return时,子进程已经创建出来了,那么父进程就return 子进程的pid来初始化ret的局部变量,随后子进程就return 0,此时必定是通过写时拷贝来完成数据的各自私有。虽然父子进程的&ret是一样的,但是物理内存一定是两块不同的空间。当我们理解了为什么同一个变量,却可以是两个不同的值后,再看fork为什么会有两个返回值时就有了新的理解。
注意不是fork创建子进程,并写时拷贝,而是fork创建子进程之后,父子进程谁先写入谁就写时拷贝,这里发生写时拷贝的原因是父子进程return的值用于初始化局部变量ret了。
角度1:父子进程会使frok函数return 两个值。
角度2:返回时发生了写时拷贝。
最后,我们就可以明确了写时拷贝的价值就是保证父子进程的独立性。

1.3 写时拷贝
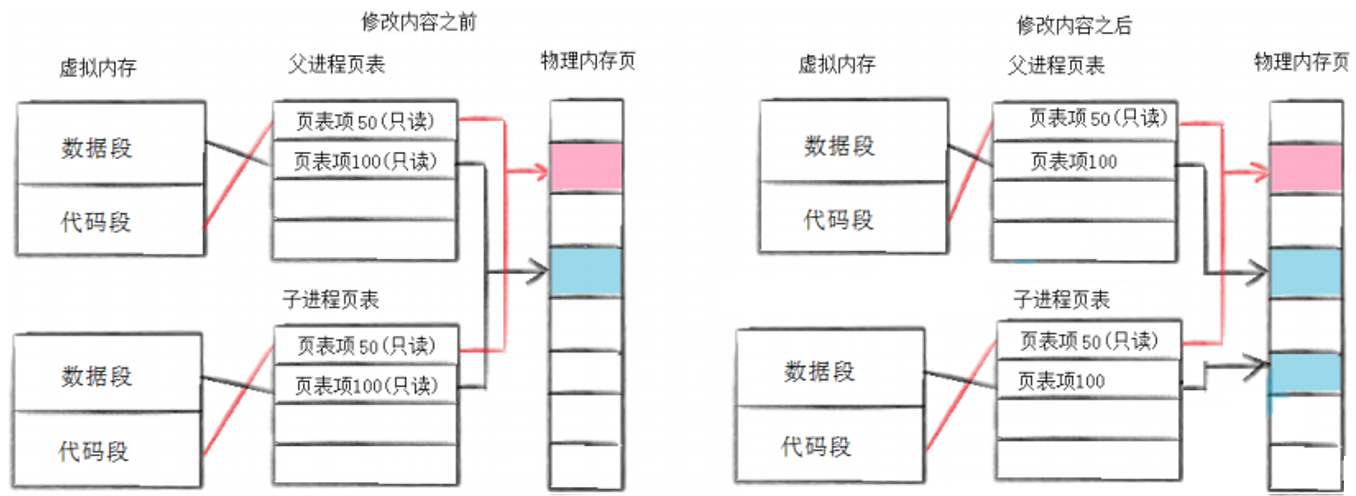
写时拷贝是一种机制或者策略,写时拷贝是根据父进程和子进程谁先写入的实时情况来完成拷贝的,它是一种延时操作的策略。
通常父子代码共享,父子进程不写入时,数据也是共享的,且他们都是只读的。当任意一方试图写入,一般情况下程序就会报错终止了(这里的报错是系统层面的,但是因为这里是父子关系,操作系统就需要做拦截工作),所以操作系统便以写时拷贝的方式生成一份副本于内存,修稿页表的映射关系,并且更改权限为可读可写,具体见上图。
这里要强调的是写时拷贝是针对数据的写时拷贝,这里留一个疑问----代码会发生类似的写时拷贝的问题吗?答案是会的,在后面的进程替换会说明。
为什么存在写时拷贝?
1、写时拷贝是为了保证父子进程的独立性。
2、节省内存和系统资源,提高fork的效率,减少fork失败的概率。
父子进程创建时,所有数据直接各自拷贝一份不行吗?
很明显,不使用写时拷贝也可以保证父子进程的独立性,为什么还要费劲使用写时拷贝。其根本原因是:a)所有的数据,父进程和子进程并不是都必须写入数据,有可能他们仅仅需要读取,而此时的各自拷贝是没有意义的,而且会浪费内存和系统资源。b)fork时,创建数据结构,如果还要将数据拷贝一份,那么fork的效率一定会降低。c)fork本质就是向系统申请更多的内存资源,资源申请多了,fork有可能就会失败。
1.4 fork常规用法
一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求,这个会在《Linux网络编程》中学习。
一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数,这个会在本文中学习。
1.5 fork调用失败的原因
fork是操作系统的接口,所以失败的原因一定是系统级别的原因。
1、系统中已经存在太多的进程了;
2、实际用户创建的进程超过了限制。
2.进程终止
为什么main函数中,总是return 0,return其他值可以吗?
对于main函数的返回值,我们称之为进程退出码,它代表进程退出后,结果是否正确,通常进程退出码为0代表成功,!0代表其他含义。如果你愿意你也可以return其他值。大部分情况下,main函数运行完之后,默认结果是正确的,所以以前返回的都是0。
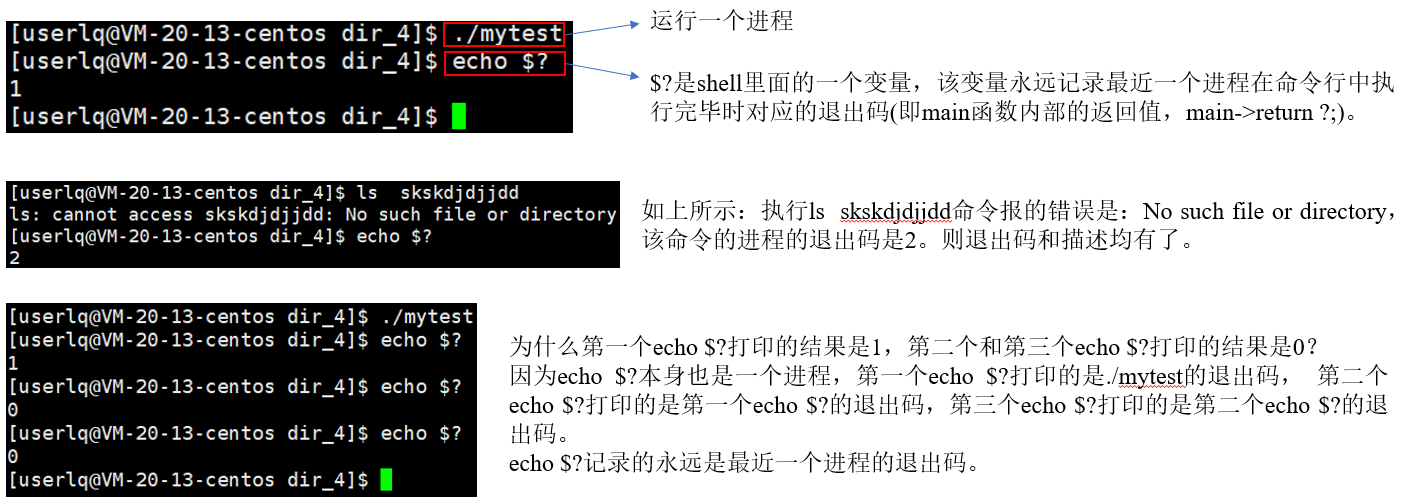
main函数return的值给谁看?
其实main函数return的值是给系统看的,以此来判断进程执行后的结果。
程序员怎么看main函数return的值?
echo $?用来保存最近一次程序运行结束时退出码的值是多少?
2.1 进程退出的场景
对于一个正在运行中的进程,存在两种终止方式:外部终止和内部终止。外部终止时,通过kill -9 PID指令,强行终止正在运行中的程序,或者ctrl+c终止前台运行中的程序。
内部终止是通过main函数return、函数exit()或者_exit()实现的。
众所周知,只有main函数return才标志进程退出,其他函数return仅仅代表函数返回,这说明进程执行的本质是return执行流执行。
进程退出的情况:
1、代码执行完了,结果正确。----return 0;
2、代码执行完了,结果不正确。----return !0;//退出码在这个时候起作用。
3、代码没执行完,程序异常了,退出码无意义。
进程如何退出?
1、main函数return返回;(即从main函数返回时,代表进程退出)
2、任意地方调用exit(code);(code是退出码)
3、调用_exit函数。
2.2 正常退出
2.2.1 main函数return
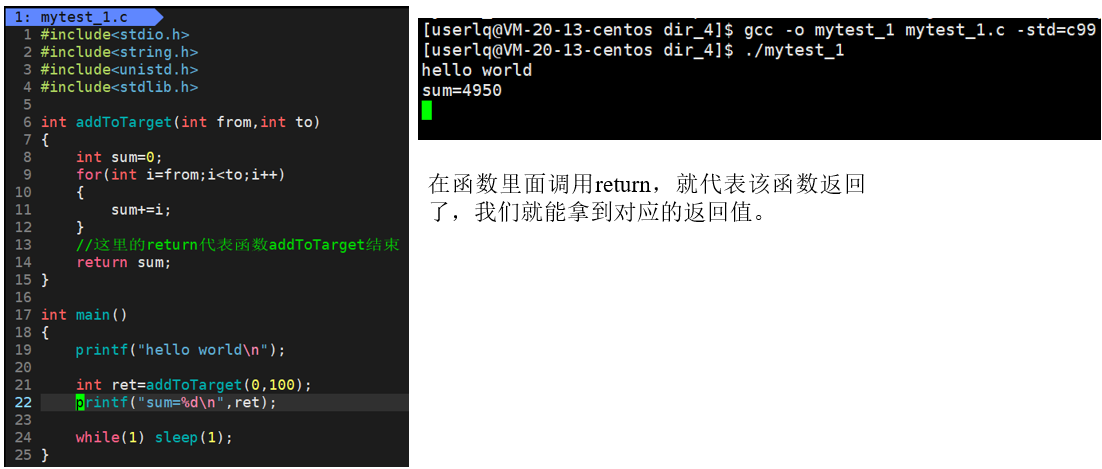
main函数return。可以看到只有main函数的return才是结束进程,非main函数的return是结束函数。
2.2.2 exit()
前面的内容已经介绍过return退出的方式,接下来讲解exit函数退出的方式。之前在程序编写时,发生错误行为时,可以通过exit(-1)的方式结束程序运行,代码中任意地方调用此函数,都可以提前终止程序:
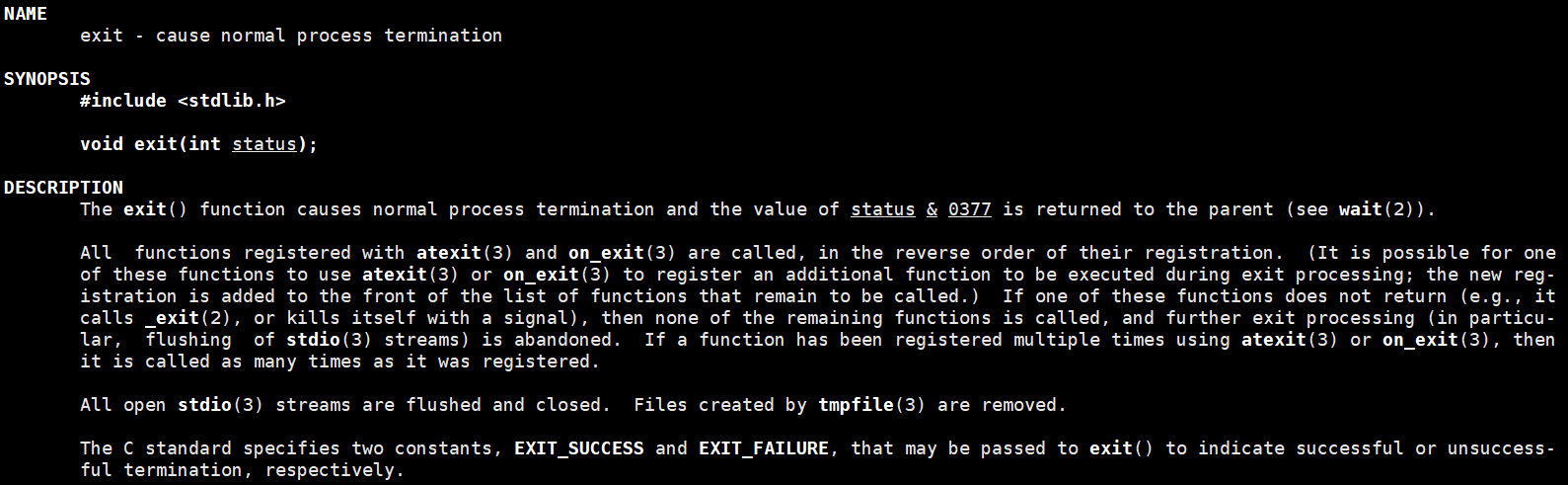
编写如下代码:
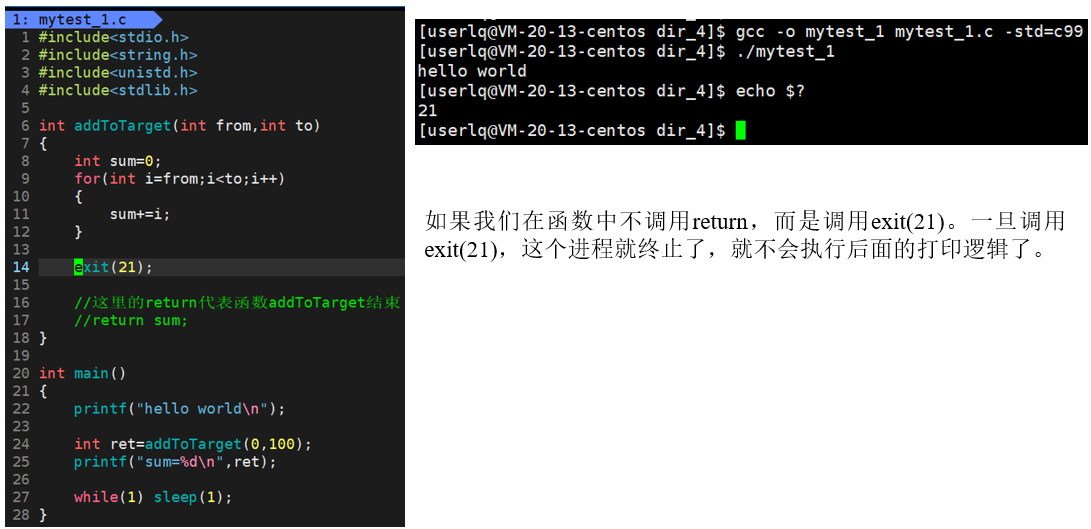
看到退出码为我们自己写入的21,由此我们得知函数exit(int code)中的参数code代表的就是进程退出码。在代码的任意地方调用exit函数表示进程退出。
2.2.3 _exit()
函数exit为C标准库函数,除此之外还有一个_exit函数,该函数为系统调用。
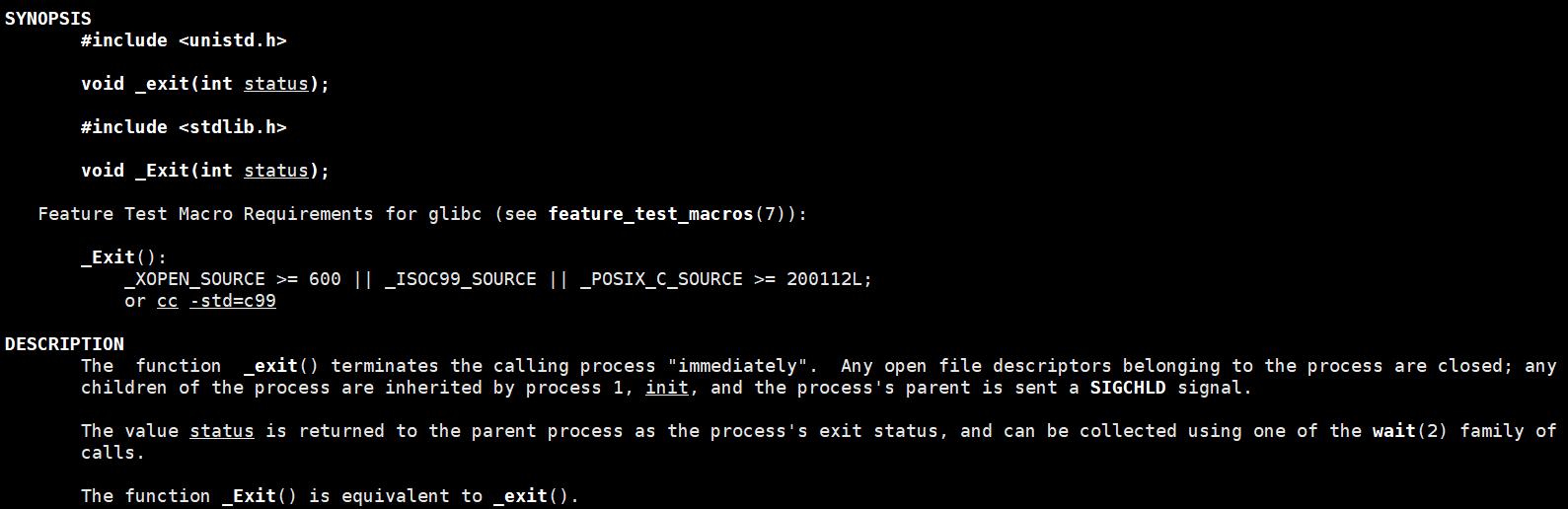
这两个退出函数,从本质上来说,没有区别,都是退出进程,但是在实际使用时,还是存在一些区别,推荐使用exit()。
比如在下面这段程序中,分别使用exit()和_exit()观察运行结果。



原因:由于打印语句没有\n,不会在显示器上立即刷新,而是保存在用户缓冲区当中,进程退出前会把缓冲区的内容刷新出来。
使用_exit()时,并没有任何语句输出。
结论:
1、exit终止进程,当一个进程终止之后,exit会主动刷新缓冲区。
2、_exit终止进程,当一个进程终止之后,_exit不会刷新缓冲区。
exit()与_exit()的区别在于,exit()中封装了_exit(),exit最后也会调用_exit,但在调用_exit之前,还做了其他工作:
1、执行用户通过atexit或on_exit定义的清理函数;
2、关闭所有打开的流,所有的缓存数据均被写入;
3、调用_exit。
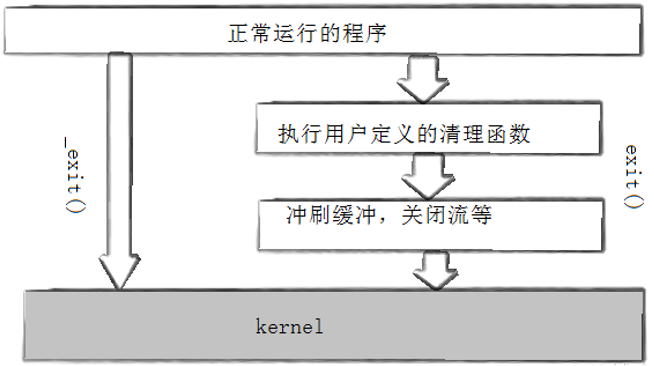
这也就能说明缓冲区不在kernel部分,否则_exit()也会刷新缓冲区,因此缓冲区不在操作系统层面上,而是用户缓冲区。

2.3 异常退出
ctrl+c、信号终止。
3.进程等待
3.1 进程等待的必要性
进程等待是必要的,子进程退出,父进程如果不管不顾,就可能造成“僵尸进程”的问题,进而造成内存泄漏。另外,进程一旦变成僵尸状态,kill -9也无法结束僵尸进程,因为谁也没有办法杀死一个已经死去的进程。我们需要知道父进程派给子进程的任务完成的如何。如:子进程是否运行完成、子进程运行的结果是否正确、子进程是否正常退出。父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息。
1、回收僵尸进程,避免内存泄漏。
2、需要获取子进程的运行结束状态和运行结果。(这一点不是必须的,需要就获取,不需要就不获取。注意区分运行状态和运行结果,两者是有区别的)
3、尽量保证父进程要晚于子进程退出,可以规范化进行资源回收。
将来我们写代码时,所有要做的事情都交给子进程,子进程把事情办完了,由父进程统一回收。这其实是与编码相关的策略,而并非属于系统级别的要求。
信号部分结束,我们就可以知道有一种方案可以让给父进程既不等于子进程又没有内存泄漏的风险。
3.2 进程等待的方法
进程等待就是通过系统调用,获取子进程退出码或者退出信号的方式,顺便释放内存。
等待进程有两种方式,分别为wait()与waitpid(),在一些复杂的场景下,相比于wait,waitpid使用的更多,也能满足更多的需求。
3.2.1 wait
fork出子进程后,子进程和父进程可能都在运行,但并不确定谁先退出。因此,父进程需要等待子进程,这是因为:
1、通过获取子进程退出的信息,能够得知子进程执行结果。
2、保证在时序上,子进程先退出、父进程后退出。
3、进程退出时会先进入僵尸状态,会造成内存泄漏,需要通过父进程wait,释放子进程占用的资源。
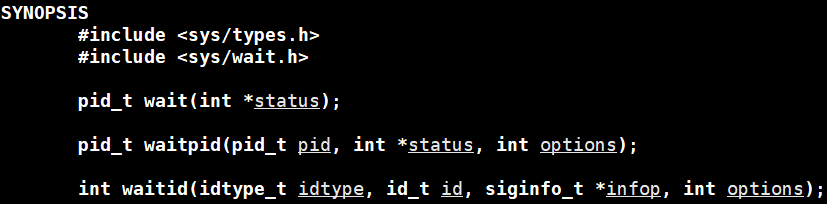
功 能:等待任意一个子进程(可以有多个),当子进程退出,wait就可以返回。
返回值:成功则返回被等待进程的pid,失败则返回-1。
参 数:输出型参数,获取子进程退出状态,不关心则可以设置为NULL。wait的参数int* status在waitpid中学习。
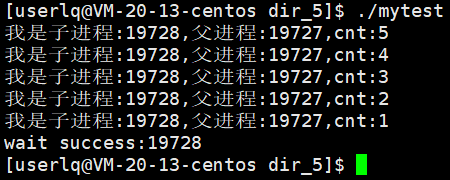
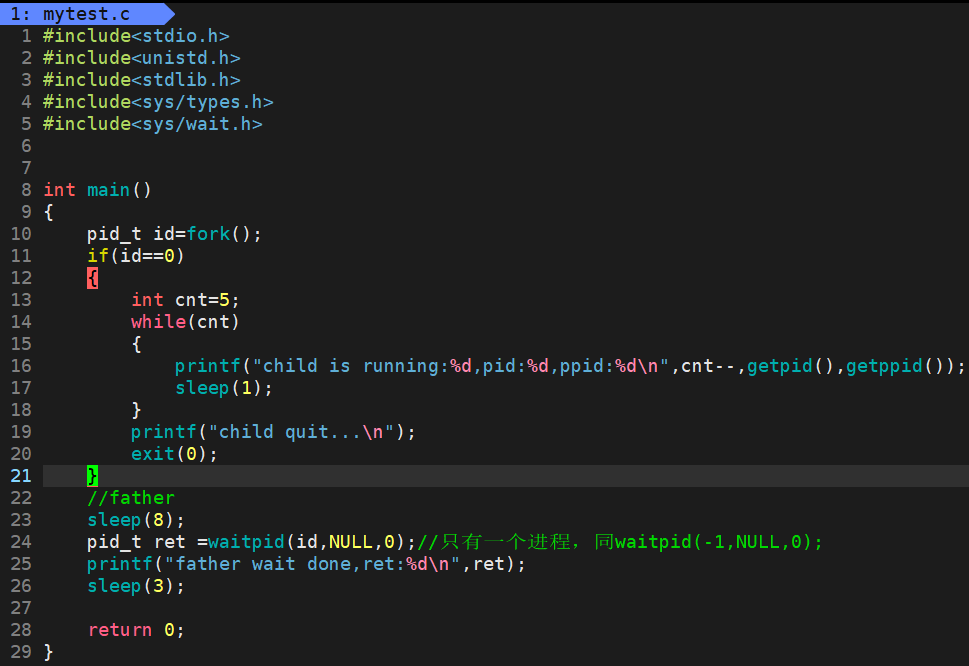
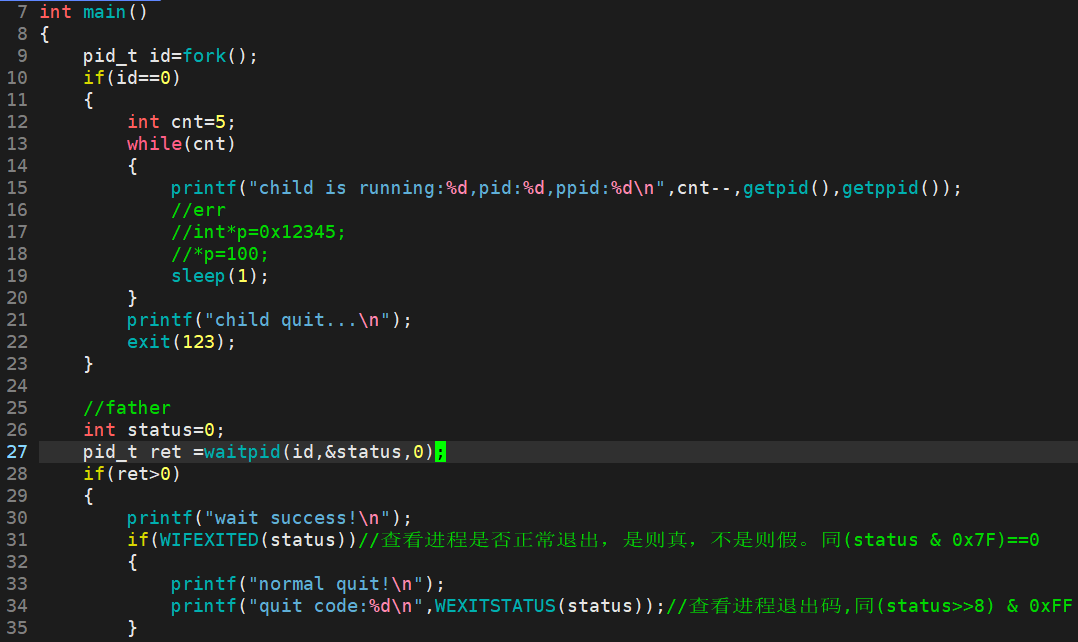
测试用例1:
父进程等待子进程退出后,wait获取子进程的pid。
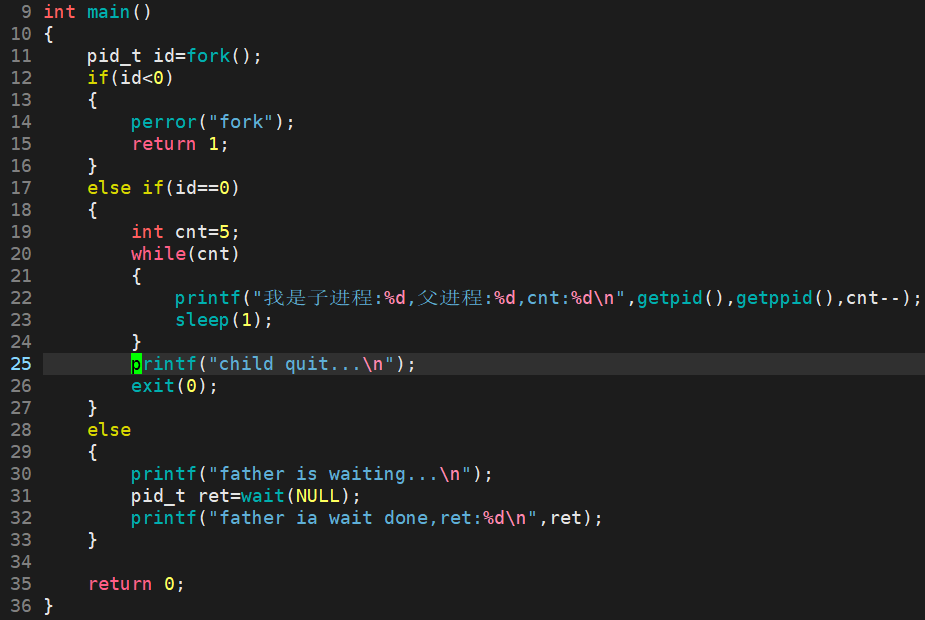
测试用例2:
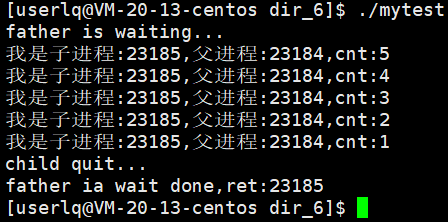
下面是运行结果:前5s打印,最后等待成功并打印出子进程pid。
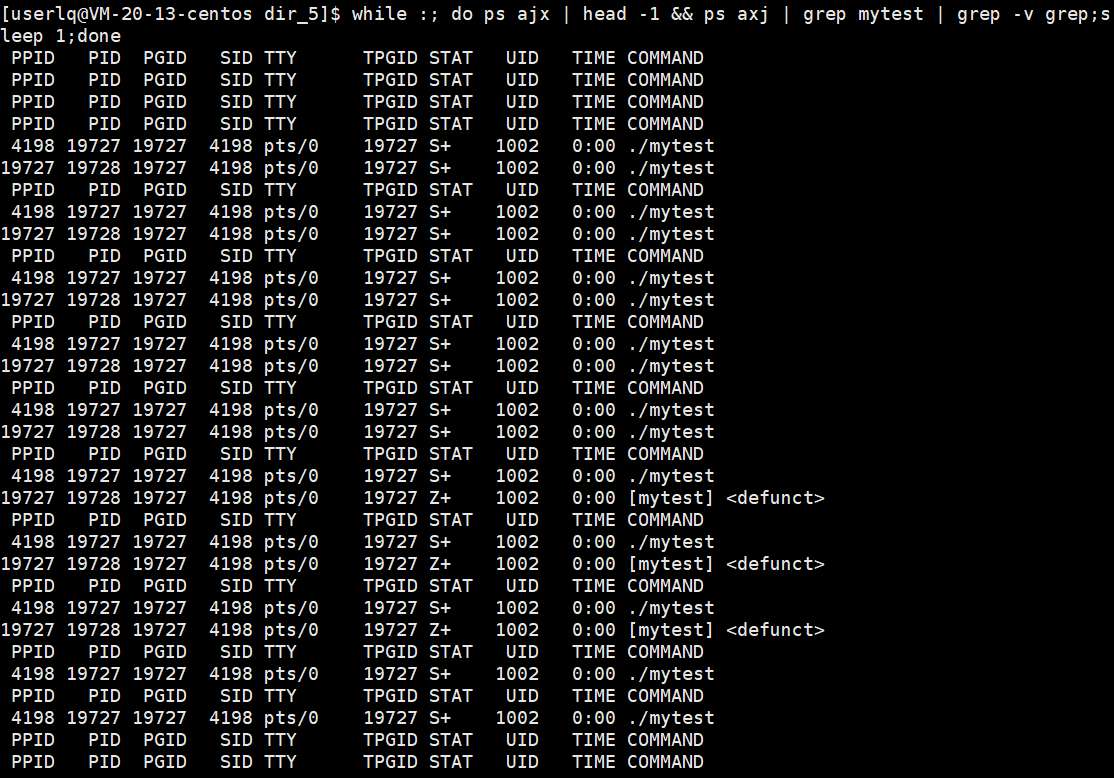
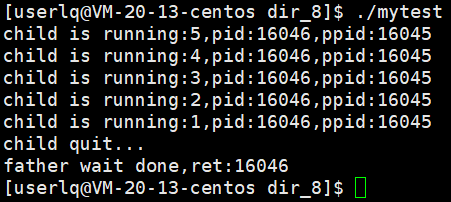
使用监控脚本查看父进程和子进程的进程状态:
1、前5秒父进程在等待子进程运行,父子进程的状态都是S+,持续5秒;
2、5秒后,子进程终止,子进程变成僵尸进程,状态为Z+,父进程依旧为S+,持续到第8秒;
3、8秒后,父进程等待子进程成功,并返回子进程pid,子进程退出,父进程继续运行。
这也就证明了:
1、wait能够回收僵尸进程;
2、子进程运行时,父进程一直在等待子进程;
3、在时序上,子进程先退出,父进程后退出。
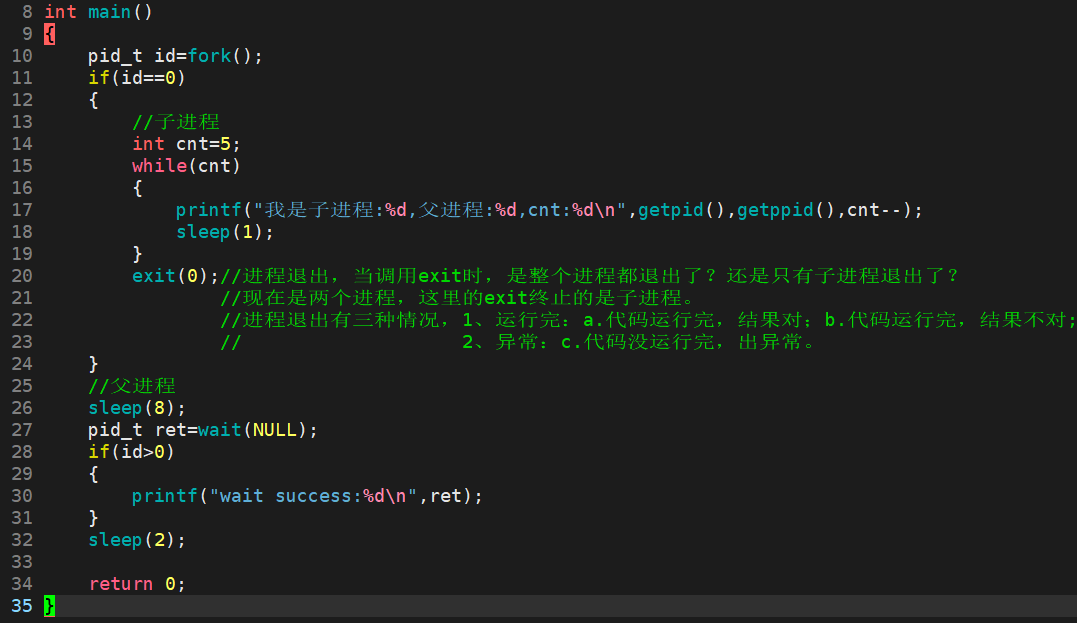
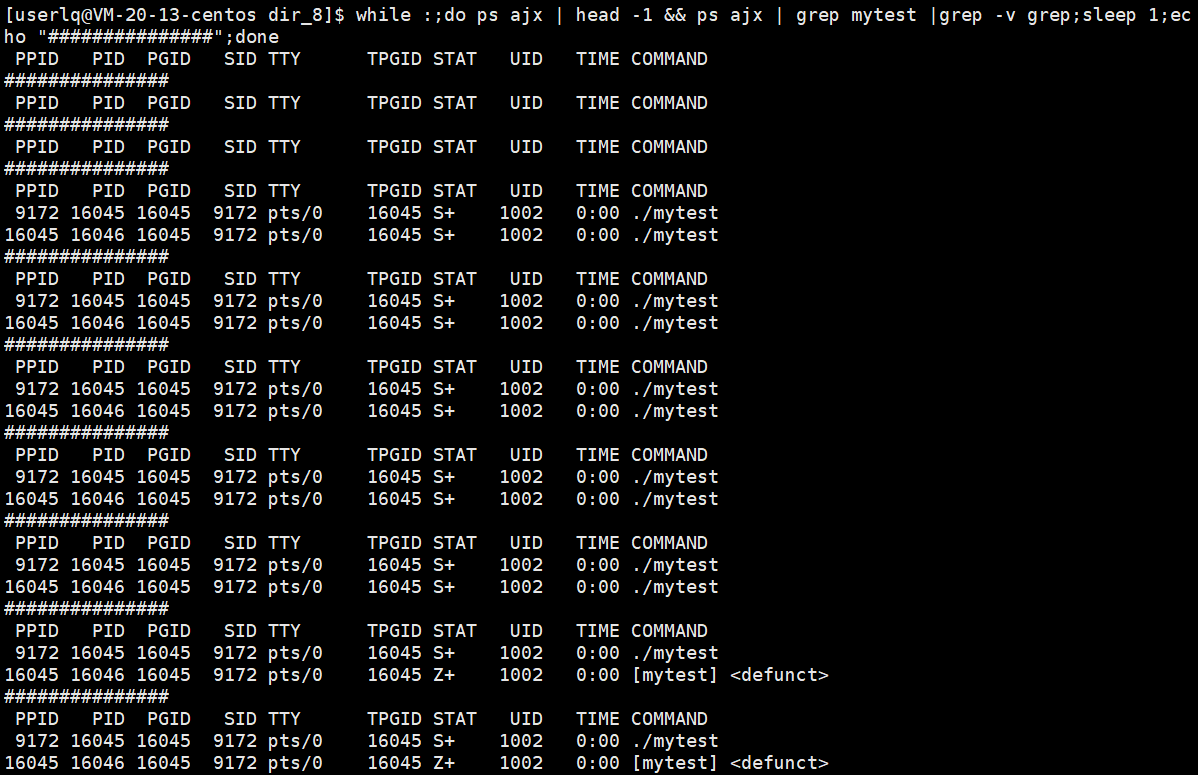
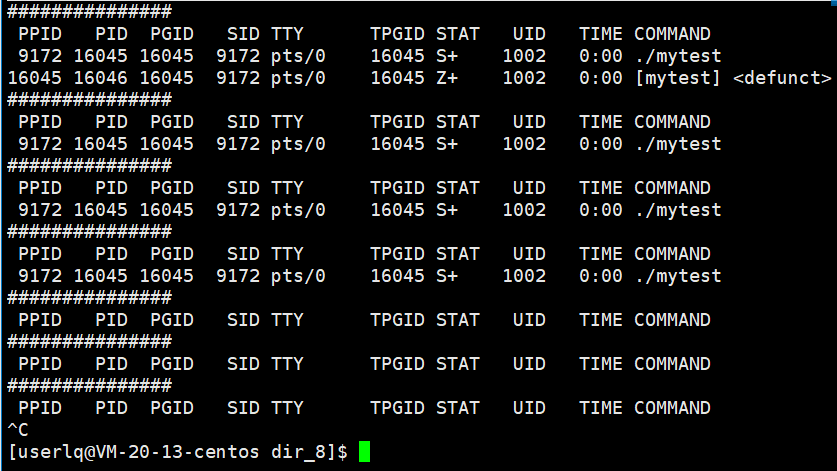
测试用例3:
fork 3个子进程后,父进程依次等待,并回收僵尸进程。
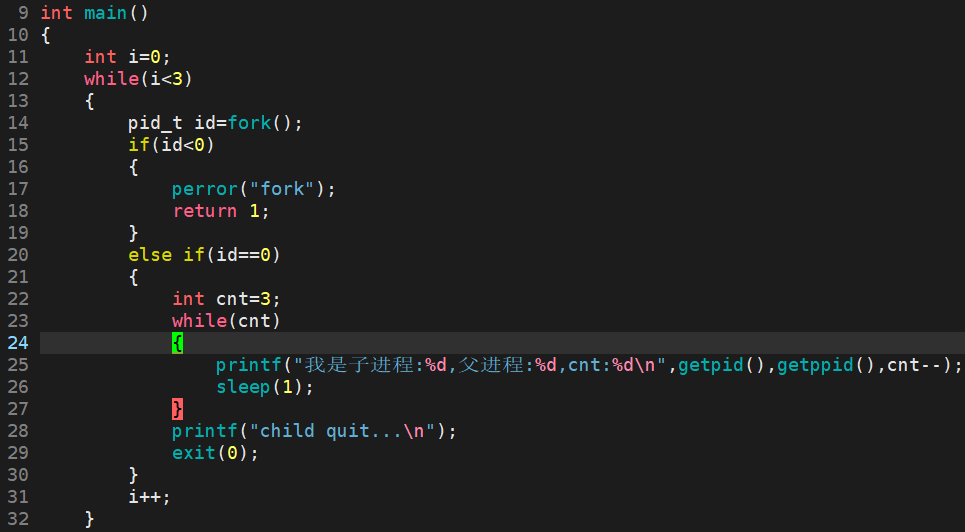
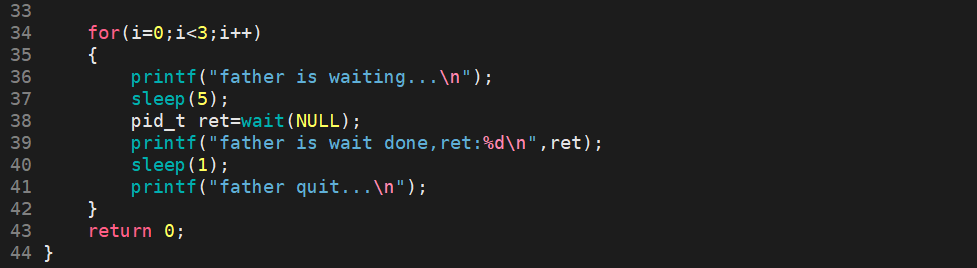
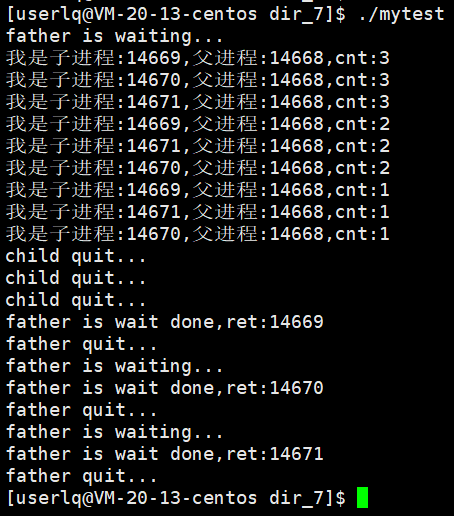
在1秒内,父进程很快就创建了3个子进程,并开始走for循环,并输出father is waiting...,随后父进程开始休眠5秒。前3秒3个子进程开始走while循环中的while循环,随后全部退出。3秒后父进程开始每隔6秒循环回收僵尸进程。
此时,ps ajx能否看到僵尸进程是不确定的。因为父进程退出,子进程会被操作系统领养。那么这个僵尸进程是在被操作系统领养后立马回收,还是积累到一定的僵尸进程再回收,这是由操作系统的策略决定,同时也跟当前操作系统的状态有关系,如果操作系统发现内存资源已经很紧张了,就会提前回收。
一般而言,我们需要fork之后,让父进程进行等待。
3.3.2 waitpid方法
返回值:
1、当正常返回时,waitpid返回收集到的子进程的进程ID。
2、如果设置了选项WNOHANG,而调用waitpid时,发现没有已退出的子进程可收集,则返回0。
3、如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在。
参数:
1、pid:
pid=-1,等待任一个子进程,与wait等效。
pid>0,等待其进程ID与pid相等的子进程。
因为父进程返回的是子进程的pid,所以父进程就可以等待指定的子进程,等待的本质是管理的一种方式。
2、status:
status为输出型参数,我们传了一个整数地址进去,最终通过指针解引用把期望的数据拿出 来。与之对应的是实参传递给形参是输入型参数。
WIFEXITED(status):若为正常终止子进程返回的状态,则为真,不是则假。(查看进程是否 是正常退出)
WEXITSTATUS(status):若WEXITSTATUS非零,提取子进程退出码。(查看进程的退出码)
需要 WEXITSTATUS(status)返回true, WEXITSTATUS(status)正 常退出则返回true。
WTERMSIG(status):返回导致子进程终止的信号的编号,需要WTERMSIG(status)返回 true,WTERMSIG(status)子进程被信号终止返回true。
3、options:
WNOHANG:若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结 束,则返回该子进程的ID。
1、status
1、wait和waitpid,都有一个status参数,该参数是一个输出型参数,由操作系统填充。
2、如果传递NULL,表示不关心子进程的退出状态信息。
3、否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程。
4、status不能简单的当作整型来看待,可以当作位图来看待,具体细节如下图(目前只研究status低16比特位)。
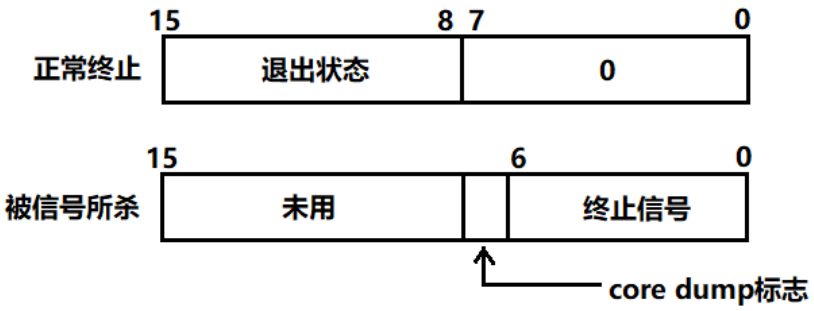
1、当进程正常终止时,信号为0,就说明没有收到退出信号,这就说明代码是正常跑完的。
2、如果信号不为0,就说明进程是异常退出。然后才关心bit8~bit15的退出码,否则不关心退出码。只有在正常退出时,我们才会关注退出码。
3、当进程异常终止时,会被信号所杀,bit0~bit6会收到终止信号。
4、至于core dump以后再讲。
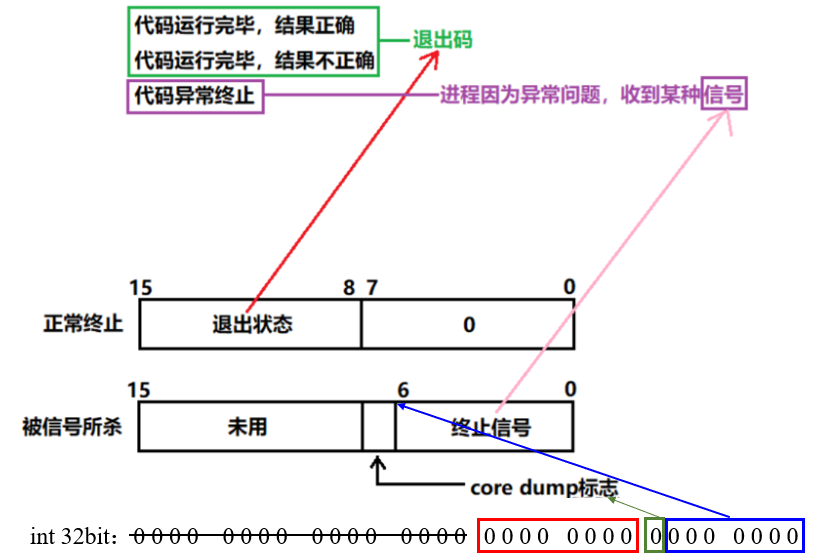
这里我们只关心低7位和次低8位。
正常终止包括代码跑完结果对和不对,所关心的16个bit位中次低8位表示子进程退出时的退出码,即exit(n),我们可以拿到n。取次低8位:(status>>8)&0xFF。异常终止就是运行中遇到野指针、被杀掉了。事实是,一般进程提前终止,本质是该进程收到了系统发送的信号(后面再详谈)。
换言之,如果一个进程收到了操作系统信号,且进程终止了,我就可以认为这个进程是提前终止或异常终止。
status这个输出型参数的低7位表示的是当前进程退出时的终止信号。低8位中的最后1位用来表示当前进程是否core dump(信号部分展开)。
可以看到Linux的普通信号并没有0号信号,换言之,此时检测低7位全是0,就能判断该进程是正常终止,然后再看退出状态,才是有意义的。如果检测低7位不是0,就不需要看它的退出状态了,因为此时已经没有意义了。
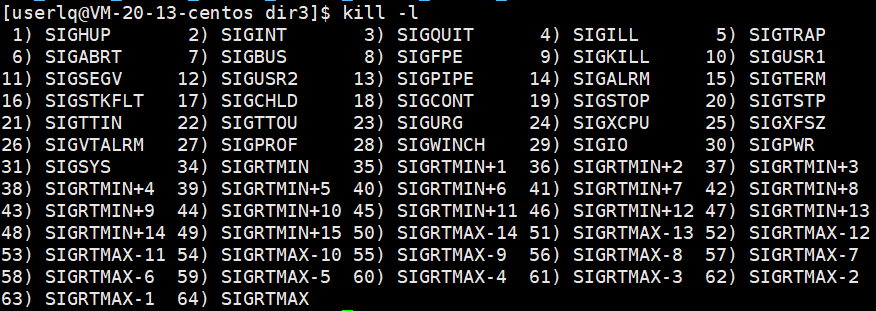
2、阻塞和非阻塞
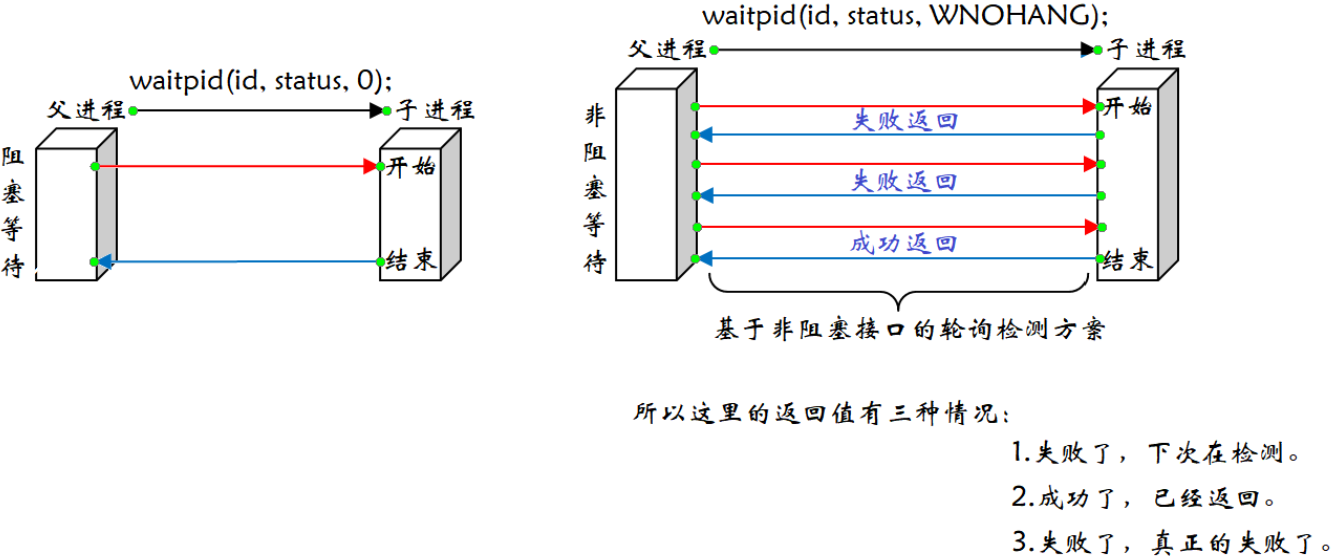
这个概念我们是第一次接触,也不会深入,后面在学习文件和网络时会经常接触。如果waitpid中的option传WNOHANG,那么等待方式就是非阻塞;如果传0,那么等待方式就是阻塞。
比如你的学习很差,所以打电话给楼上学习好的同学张三,说:张三,你下来,我请你吃个饭,然后你帮我复习一下。张三说:行,没问题,但是我在写代码,半个小时之后再来。你怕你电话一挂,有人又跟张三打电话求助,导致你不能及时复习,所以你又跟张三说:张三,你电话不要挂,你把电话放你旁边。然后你什么事都不做,就在那等待,直到张三下来。当然现实中很少有这种情况,但是这样的场景是存在的,一般是比较紧急的情况,比如你爸打电话让你做件事且告诉你不要挂电话。此时张三不下来,电话就不挂就类似于调用函数,这种等待方式就叫做阻塞等待。我们目前所调用的函数,全部是阻塞函数,不管是你自己写的、库里的、系统的,因为我们目前写的代码都是一跑就结束,所以压根就遇不到非阻塞的场景。阻塞函数最典型的特征是调用 ➡ 执行 ➡返回 ➡ 结束,其中调用方始终在等待,什么事情都没做。
又比如,你跟张三说:明天要考试了,一会我们去吃个饭,然后去自习室,你帮我复习下。张三说:没问题,但是我在写代码,你得等我下。你说:行吧,我在食堂等你,然后挂电话。过了两分钟,你给张三打电话说:张三,你来了没。张三说:我还得一会,你再等下。你说:行吧,然后挂电话。又过了两分钟,你又给张三打电话说:张三,你来了没 … … 。你不断重复的给张三打电话,这种场景在生活中比较多,我们经常催一个人做一件事时,他老是不动,你就不断重复给他打电话。你本质并不是给张三打电话,而是检测张三的状态,张三有没有达到我所期望的状态,每次检测张三是不一定立马就就绪的,如他有没有写完、开始下楼等。这里的检测张三的状态,只是想查看进度,所以这里打电话过程并不会把我卡住,我通过多次打电话来检测张三的进度。每次打电话挂电话的过程就叫做非阻塞等待。 我们只要看了它的状态不是就绪,就立马返回。这种基于多次的非阻塞的调用方案叫做非阻塞轮询检测方案。
为什么现实世界中大部分选择非阻塞轮询?
这种高效体现在:主要是对调用方高效,你给张三打电话,张三就要 10 分钟,那就是 10 分钟,类似于计算机,你再怎么催都没用,所以我们就不会死等,我们可以先做其它的事,反正不会让因为等待你,而让我做不了事情。
那为什么我们写的代码大部分都是阻塞调用 ?
根本原因在于我们的代码都是单执行流,所以选择阻塞调用更简单。
为什么是WNOHANG?
在服务器资源即将被吃完时,卡住了,我们一般称服务器hang住了,进而导致宕机。所以 W 表示等待,NO 表示不要,HANG 表示卡了,所以这个宏的意思是等待时不要卡住。
如何理解父进程等子进程中的等?
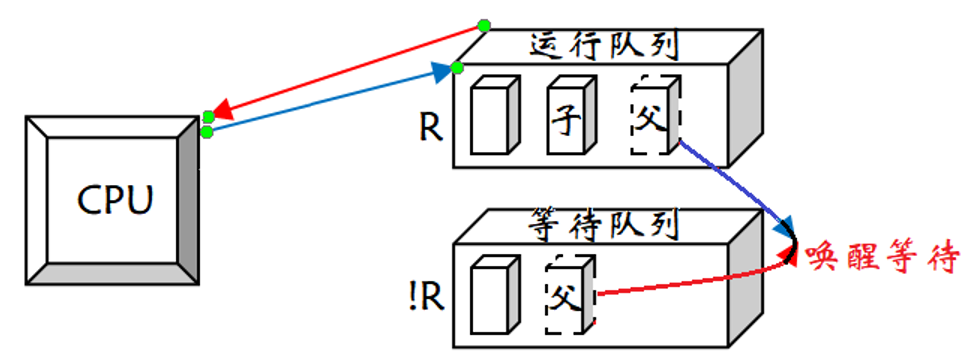
所谓的等并不是把父进程放在CPU上,让父进程在CPU上边跑边等。本来父子进程都在运行队列中等待CPU运行,当子进程开始被CPU运行后,就把父进程由R状态更改为!R状态,并放入等待队列中,此时父进程就不运行了,它就在等待队列中等待。当子进程运行结束后,操作系统就会把父进程放入运行队列,并将状态更改为R状态,让CPU运行,这个过程叫做唤醒等待的过程。
操作系统是怎么知道子进程退出时就应该唤醒对应的父进程呢?
wait 和 waitpid 是系统函数,是由操作系统提供的,你是因为调用了操作系统的代码导致你被等待了,操作系统当然知道子进程退出时该唤醒谁。
这里,我们只要能理解等待就是将当前进程放入等待队列中,将状态设置为 !R 状态。所以一般我们在平时使用计算机时,肉眼所发现的一些现象,如某些软件卡住了,根本原因是要么进程太多了,导致进程没有被 CPU 调度;要么就是进程被放到了等待队列中,长时间不会被 CPU 调度。我们曾经在写 VS 下写过一些错误代码,一旦运行,就会导致 VS 一段时间没有反应。所谓的没有反应就是因为程序导致系统出现问题,操作系统在处理问题区间,把 VS 进程设置成 !R 状态,操作系统处理完,再把 VS 唤醒。
验证子进程僵尸后,退出结果会保存在 PCB 中 ?
可以看到在 Linux 2.6.32 源码中,task_struct 里包含了退出码和退出信息。
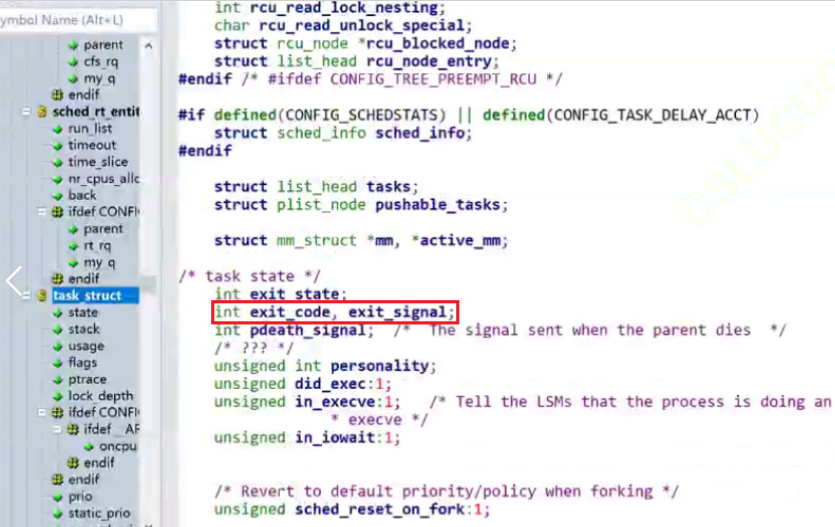
获取子进程退出信息
我们知道子进程拥有自己的PCB结构体 task_struct ,在task_struct中还存在两个变量,分别为 int exit_code 与 int exit_signal 。
当子进程退出时,操作系统会把退出码填写到 exit_code 中,把退出信号填写到 exit_signal 中,并维护子进程的 task_struct ,此时子进程的状态就是僵尸状态。通过 wait 或者 waitpid 系统调用可以访问到该内核数据结构,并把退出信息以上面所讲过的格式存放在 status 中,顺便释放该数据结构占用的内存空间。
了解了以上知识后,我们应该有一个疑问,父进程在等待子进程退出,并回收子进程。那么如果子进程一直都没有退出,父进程又在做什么呢?
默认情况下,在子进程没有退出的时候,父进程只能一直在调用 wait 或 waitpid 进行等待,我们称之为阻塞等待。
测试用例1:
测试用例2:
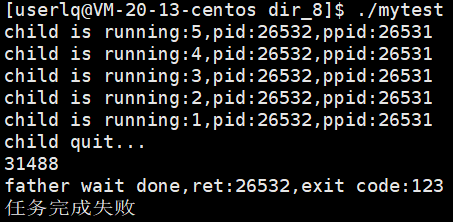
父进程fork派生一个子进程执行相应的任务,父进程通过status拿到进程的退出码,可以知道子进程把任务执行的怎么样。
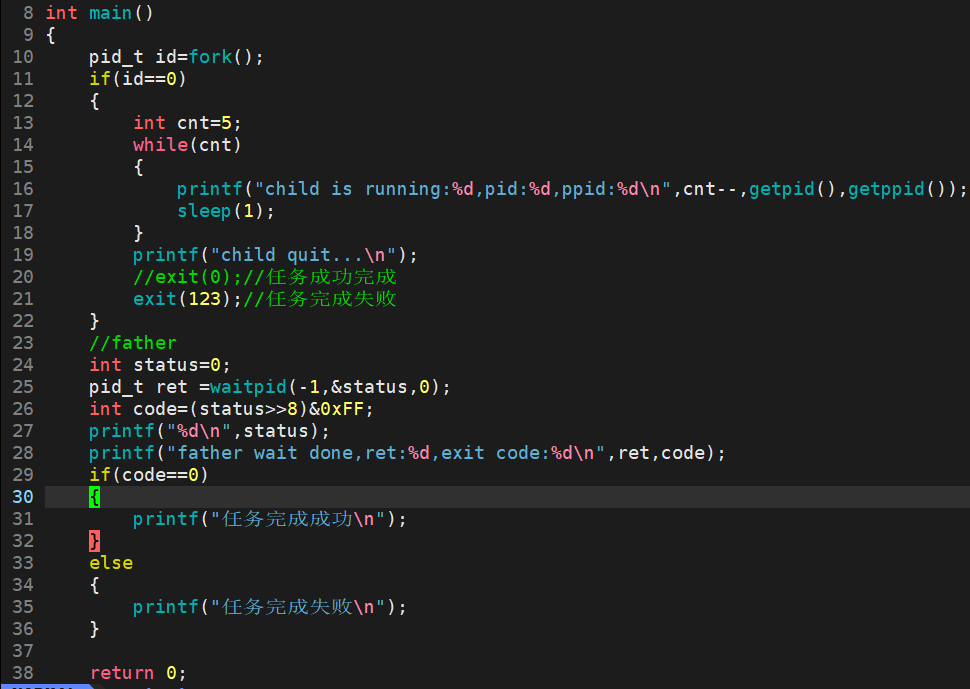
执行结果:
(31488)10 = (0111 1011 0000 0000)2 ;
0111 1011 0000 0000 >> 8 = 0111 1011;
(0111 1011)2 = (123)10 ;
子进程已经退出了,子进程的退出码放在哪?
换句话说,父进程通过 waitpid 要拿子进程的退出码应该从哪里去取呢,明明子进程已经退出了。子进程是结束了,但是子进程的状态是僵尸,也就是说子进程的相关数据结构并没有被完全释放。当子进程退出时,进程的 task_struct 里会被填入当前子进程退出时的退出码,所以 waitpid 拿到的 status 值是通过 task_struct 拿到的。
测试用例3:
针对测试用例2,父进程无非就是想知道子进程的工作完成的结果,那全局变量是否可以作为子进程退出码的设置,以此告知父进程子进程的退出码。
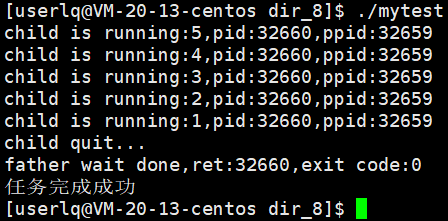
很显然,不可以。这里对于全局变量,发生了写时拷贝,在进程地址空间里我们说过父子是具有独立性的,虽然变量是同一个,但实际上子进程或父进程所写的数据,它们都是无法看到彼此的,所以不可能让父进程拿到子进程的退出结果。
测试用例4:
模拟异常终止----野指针。
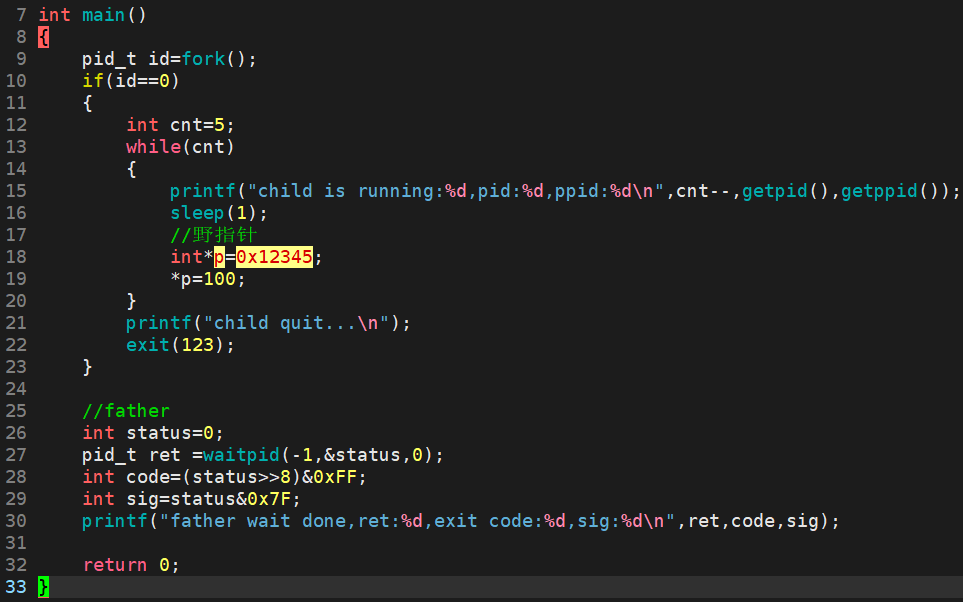
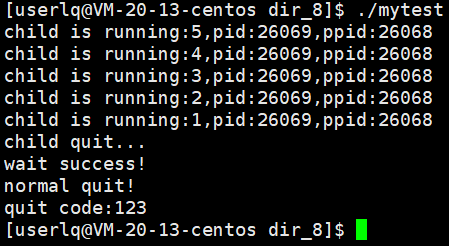
运行结果:

子进程崩溃后,立马退出,变成僵尸进程,并不会影响父进程,这叫做父子进程具有独立性,父进程等待成功(不管你是正常还是非正常退出),随后进行回收。此时子进程的退出码是无意义的,子进程的异常终止导致父进程获得了子进程退出时的退出信号,我们发现它的信号是第11号信号(SIGSEGV),它一般是段错误。
测试用例5:
模拟异常终止----使用kill -9信号杀死子进程。
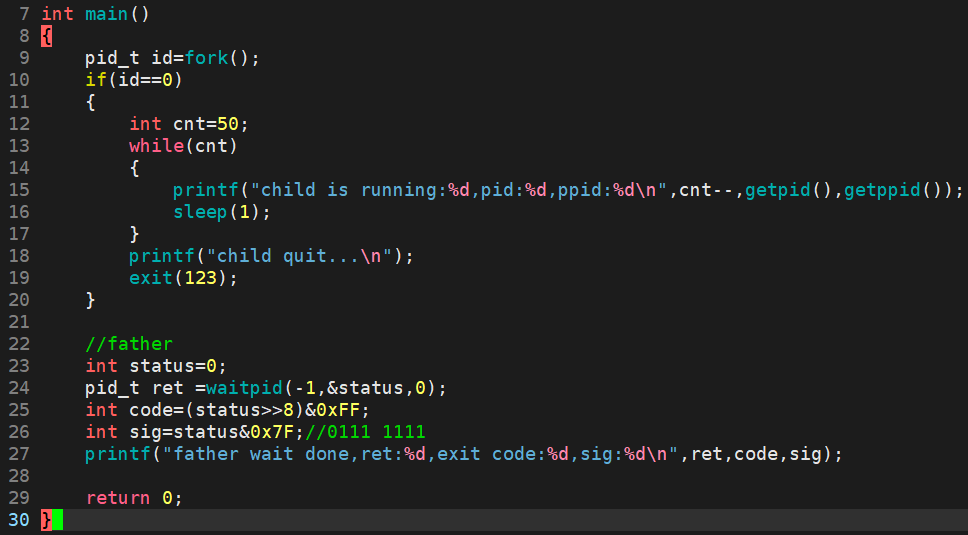
运行结果:
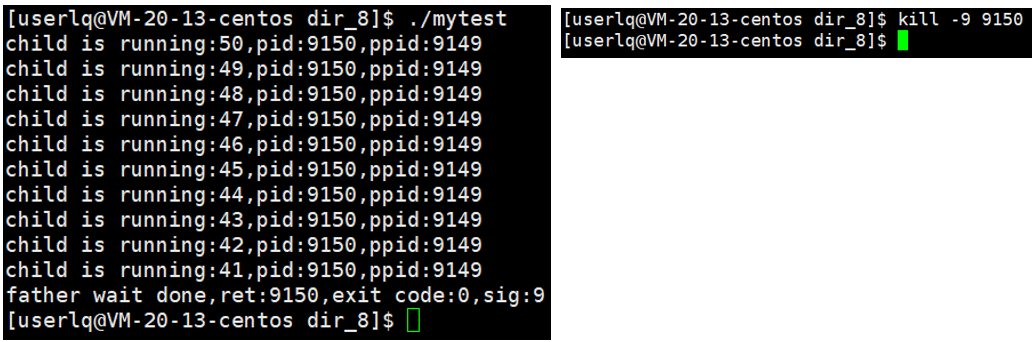
当我们把正在运行的子进程亲手杀掉后,父进程立马做回收工作,此时退出码是什么已经不重要了,父进程拿到的信号是第9号信号(SIGKILL),此时我们就知道子进程连代码都没跑完,是被别人杀掉才退出的。
测试用例6:
可以看到需要对数据进行加工才可以获取退出码和退出信号,比较麻烦,我们一般也不会自己加工。其实系统有提供一些宏(函数),可以直接使用,我们主要学习3个----WIFEXITED(status)、WEXITSTATUS(status)、WTERMSIG(status),其相关介绍可在waitpid手册里查找。

运行结果:
正常:
异常:
4.进程替换
4.1 为什么要进程替换 && 什么是进程替换
创建子进程的目的:
1、执行父进程的部分代码;(我们前面的文章中所写的代码就属于这种情况)
2、执行其他程序的代码;(不要父进程的代码和数据,所以要学习进程替换)
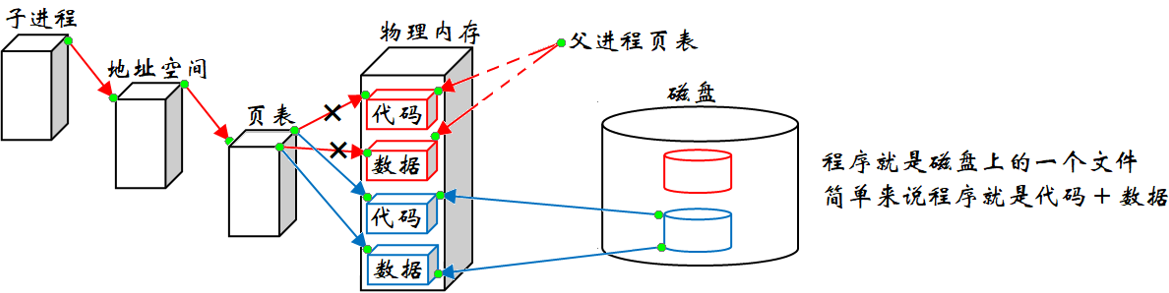
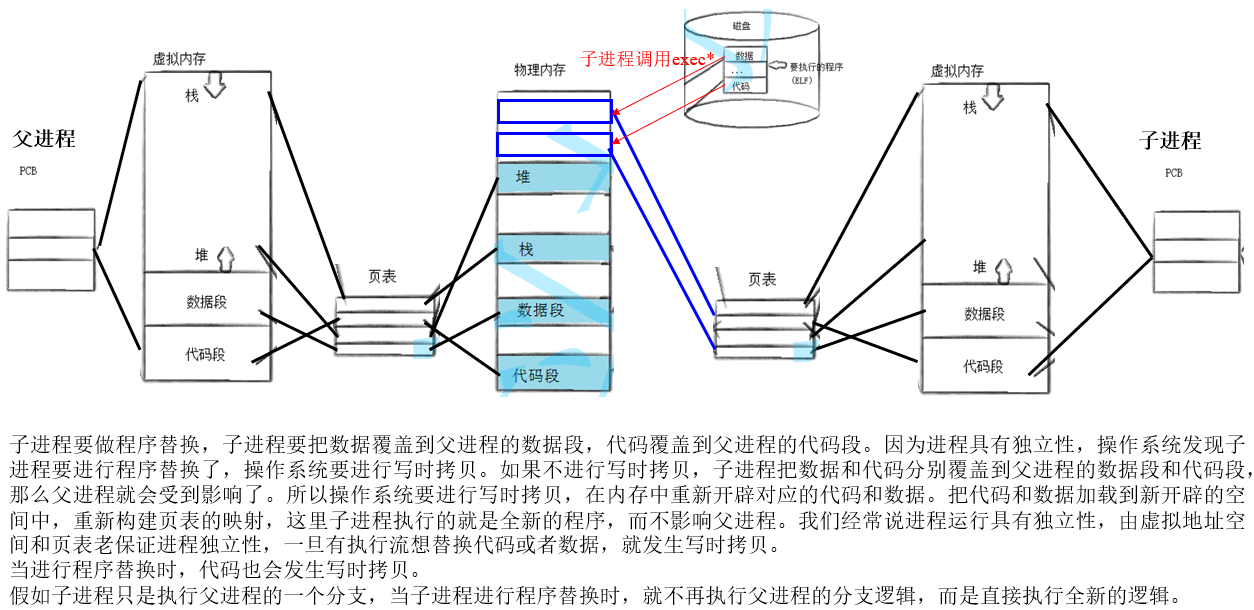
进程替换是为了让子进程能够执行其他程序的代码,进程替换就是以写时拷贝的策略,让第三方进程的代码和数据替换到父进程的代码和数据,并给子进程使用。因为进程间具有独立性,所以不会影响父进程。
把其他程序的代码放到内存中让子进程看到,以前子进程看到的是父进程的代码,现在有新的代码来了,此时也要对代码进行写时拷贝。99%的情况是对数据进行写时拷贝、代码只读。1%的情况代码依旧是只读,本质就是对父进程不可写,而子进程后续调用某些系统调用,实际是给子进程重新开辟空间,把新进程的代码加载,此时就不让子进程执行父进程的代码,这个过程叫做程序替换。
4.2 替换原理
4.2.1 进程的角度
进程替换第一阶段的理解:
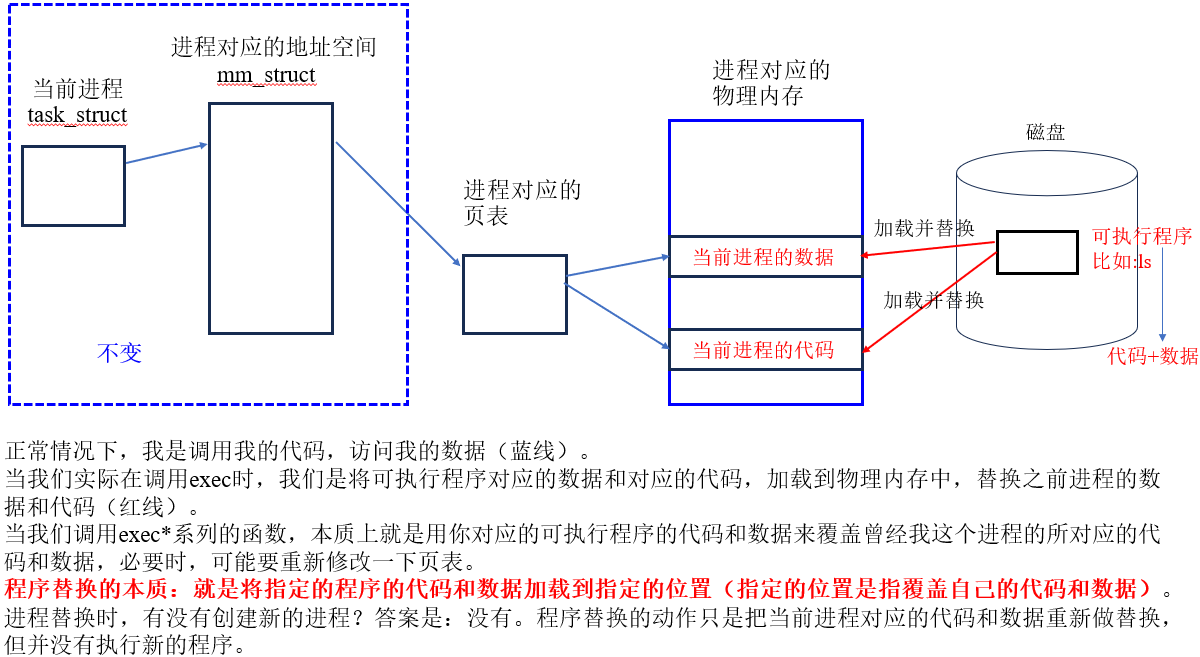
使用fork创建子进程后,子进程执行的是和父进程相同的程序(有可能是执行不同的代码分支),子进程往往要调用一种exec函数以执行另一个程序。当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。调用exec并不创建新进程,所以调用exec前后该进程的id并未改变。
我们想让子进程里面执行新的程序,可以一步到位在内存中重新开辟两块空间来加载新程序的代码和数据,再修改子进程页表的映射关系,之后父子进程就彻底脱离了,这个过程就是进程替换。
系统是如何做到重新建立映射关系的呢?
当子进程里要加载新的程序时,操作系统可以设置一些特殊信号让该进程对全部代码和数据进行写入。子进程就会自动触发写时拷贝,重新开辟空间,再重新加载新的代码和数据。
在进程替换时,有没有创建新进程?
我们并不需要重新开辟新的PCB、地址空间、页表,没有创建新进程的最有力的证据是pid没有变。程序要运行起来,必须先加载到内存,这句话没问题;但是程序只要加载到内存了,一定变成一个进程,这句话有纰漏。
进程替换不会改变进程内核的数据结构,只会修改部分页表数据,然后将新程序的代码和数据加载至内存,重新构建页表映射关系,和父进程彻底脱离。
4.2.2 程序的角度
程序原本存放在磁盘中,当调用exec函数时,程序的代码和数据分别加载到当前进程对应的代码段和数据段,代码和数据一旦替换之后,相当于用一个老进程的壳子,去执行一个新程序的代码和数据。程序替换就相当于程序加载器,我们平常所说的程序被加载到内存中,起始就是调用了exec。在创建进程时,是先创建进程的PCB,再把代码和数据加载到内存。
4.3 替换函数
进程替换的本质就是把程序的进程代码+数据加载到特定进程的上文中,C/C++程序要运行,必须要先使用加载器加载到内存中,这就要用到exec*系列程序替换函数,他们充当了加载器,把磁盘中的程序加载到内存。
严格来说有7种以exec开头的系列函数,统称为exec函数:
#include<unistd.h>int execl(const chaar* path, const char* arg, ...);
int execlp(const char* file, const chr* arg, ...);
int execv(const char* path, char* const argv[]);
int execvp(const char* file, char* const argv[]);
int execle(const chra* path, const char* arg, ..., char* const envp[]);
int execve(const char* path, char* const argv[], char* const envp[]);
int execvpe(const char* file, char* const argv[], char* const envp[]);这些函数的功能都是一样的,如果用C++去设计这样的接口,一定是重载。这里是使用C语言设计的,函数名的命名也有区分。
这里为什么将execve单独拎出来?
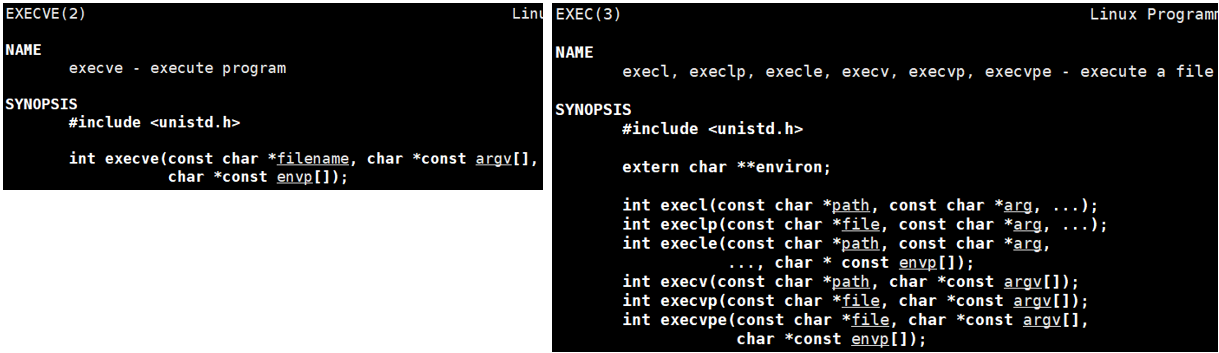
虽然头文件都是<unistd.h>,但实际上只有execve是系统提供的函数,其余6个都是封装的,最后底层调用的依旧是execve,这样做的原因是需要根据不同的用户来定制不同的使用场景。
1、这些函数如果调用成功则加载新的程序从启动代码开始执行,不再返回;
2、如果调用出错则返回-1;
3、所以exec函数只有出错的返回值而没有成功的返回值。
4.3.1 execl
![]()
1、path表示要执行的程序,包括路径、程序名;
2、arg为命令+命令参数,如:"ls","-a","-l",它与path中的程序名并不冲突,也不冗余,其一是在哪找、其二是怎么执行;
3、函数参数列表中的 "..." 为可变参数列表,可以让我们给C函数传递任意个数的参数。最后一定要以NULL为结尾,表示选项传递结束。l:list,将参数一个一个的传入exec*,列表式的传参方式。
将指定的程序(磁盘中的二进制文件)加载到内存中,让指定进行执行。
单进程,父进程亲自干活:
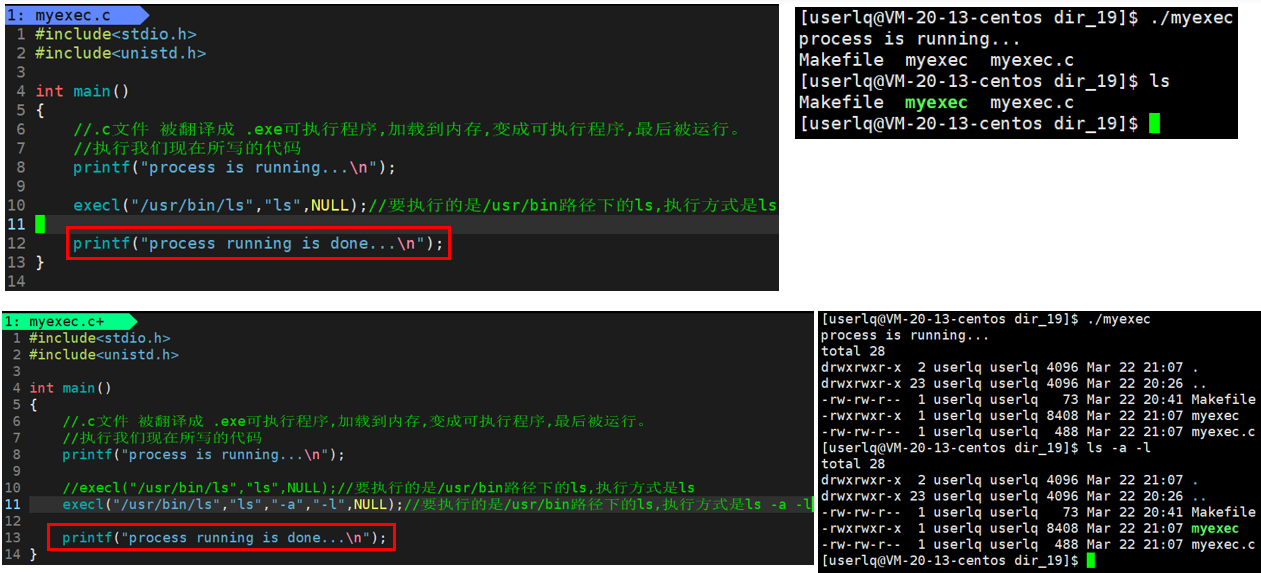
多进程,父进程创建子进程干活:
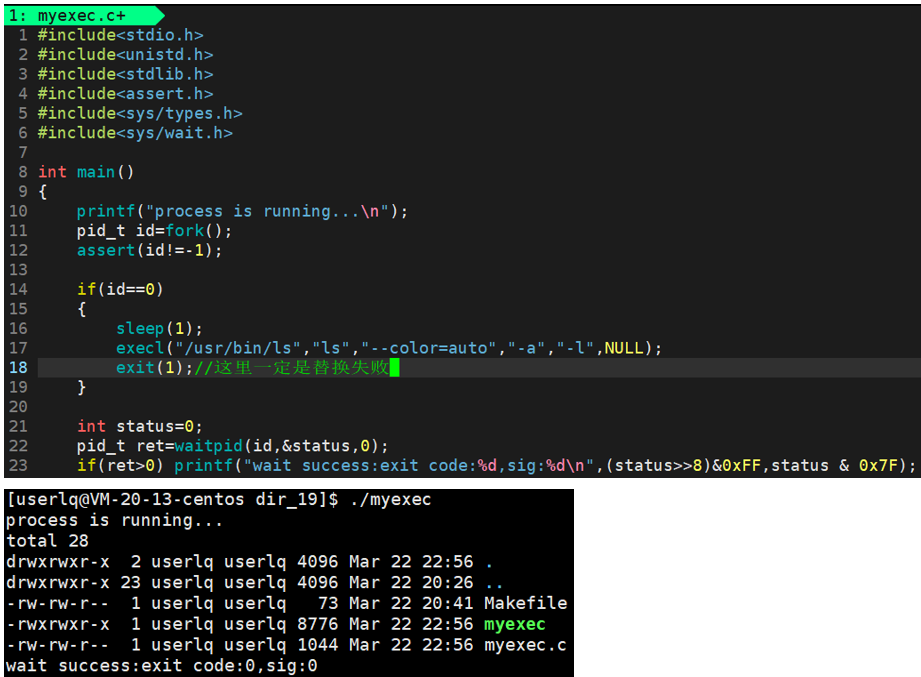
那么为什么红框中的代码 printf("process running is done...\n")没有执行呢,而且上图中的程序的退出码是0呢?
因为printf("process running is done...\n")代码是在execl之后的,因为在printf("process running is done...\n")以及exit(1)之前,execl以及程序替换了,所以execl后面的代码已经不是当前进程的代码了(这里的当前进程的代码指的是ls -a -l)。所以上图中获取的退出码0是ls的退出码。换言之,一旦程序替换,到底执行正确与否是取决于ls程序。
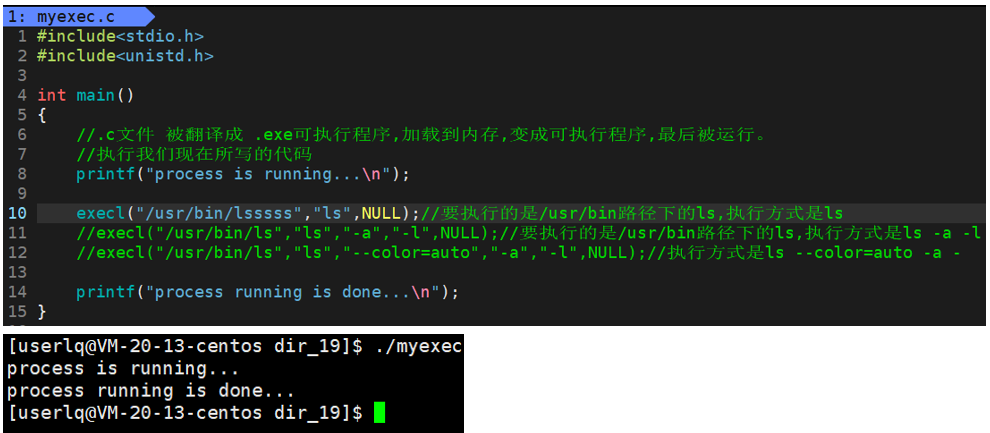
此时,printf("process running is done...\n")代码正常执行。因为execl程序替换调用失败,只要是一个函数,调用就有可能失败,调用失败就是没有替换成功,就是没有替换。
exec系列的函数调用成功后为什么没有返回值呢?因为execl系列函数调用成功后,就和接下来的代码无关了,判断就毫无意义了。execl只要返回了,一定是调用失败了。
进程替换第二阶段的理解:
4.3.2 execlp
![]()
1、file为程序名
2、arg为命令+命令参数
3、"..."为可变参数
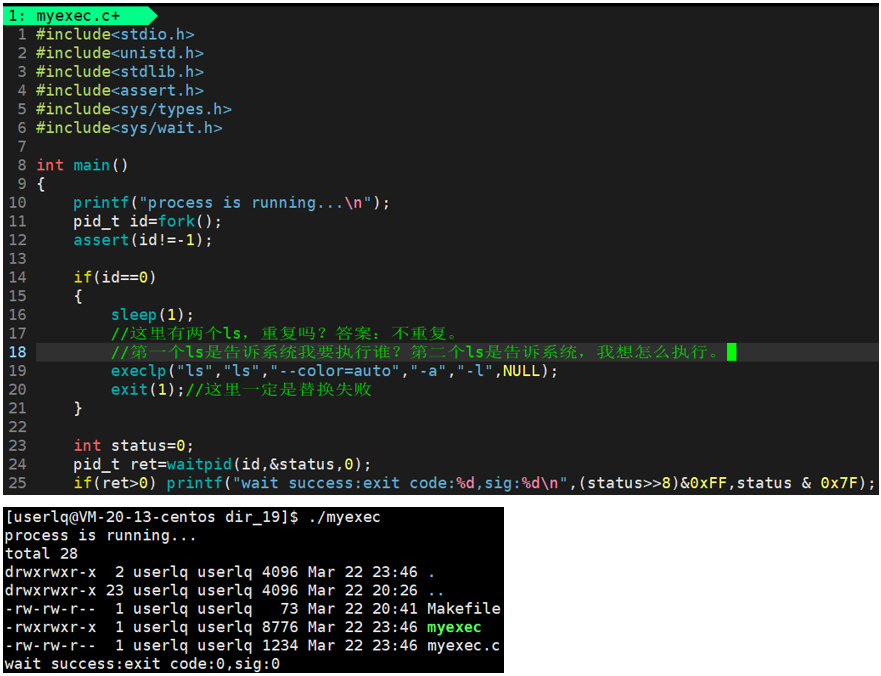
除了file之外,其他用法与execl相同。
execlp中的p是path的意思,表示能够自动搜索环境变量PATH,在执行特定程序时,只要知道程序名,系统就会自动在环境变量PATH中搜索程序位置,不需要知道这个程序在哪里。使用execlp替换程序更加方便,只要待替换的程序的路径位于PATH中,就不会替换失败。
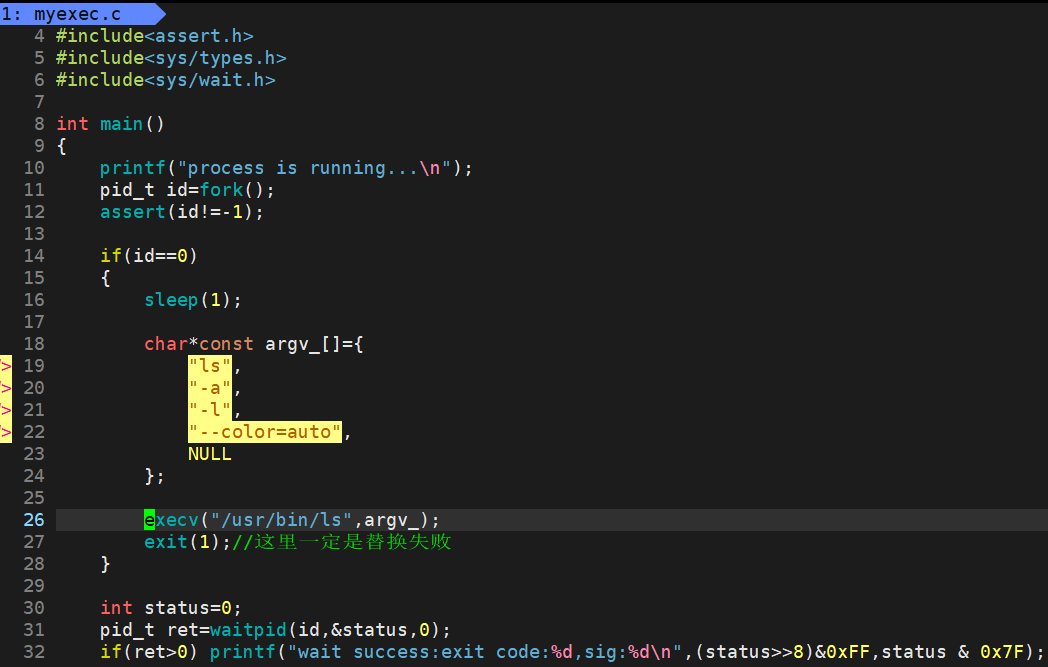
4.3.3 execv
![]()
1、path为 程序路径
2、argv数组内存放 命令+命令参数
3、execl与execv只在传参形式上有所不同,execl用的是可变参数列表,而execv用的是指针数组,数组元素个数由我们来定。v:vector,可以将所有的执行参数,放入数组中,统一传递,而不用进行使用可变参数方案。
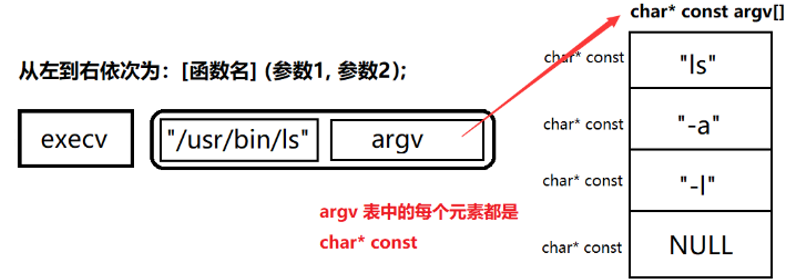
注意:虽然execv只需要传递两个参数,但在创建argv表时,最后一个元素仍然要为NULL。
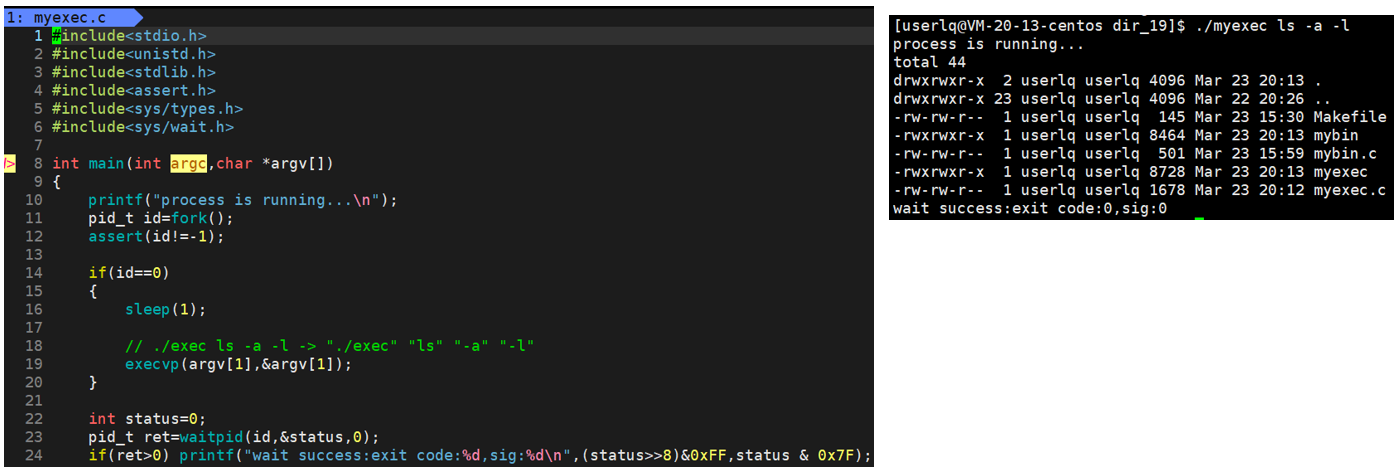
4.3.4 execvp
![]()
execv加个p也能实现自动查询替换,即execvp。
1、file为程序名;
2、argv数组内存放 命令+命令参数。
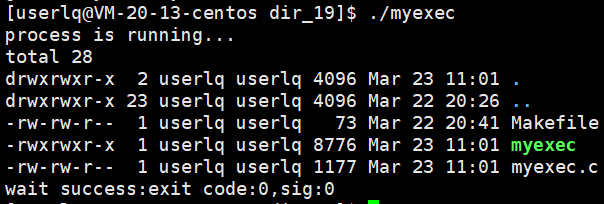
使用子进程来运行自己写的程序 mybin.c。
mybin.c:
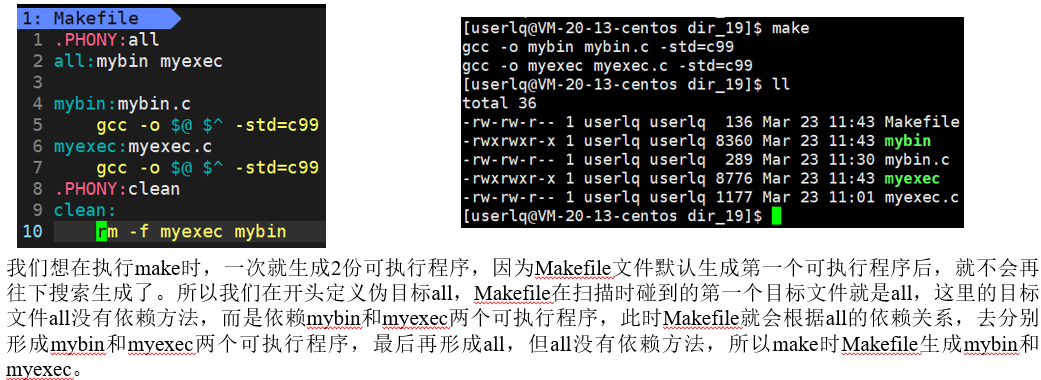
Makefile里面需要执行make指令时,一次生成2份可执行程序。
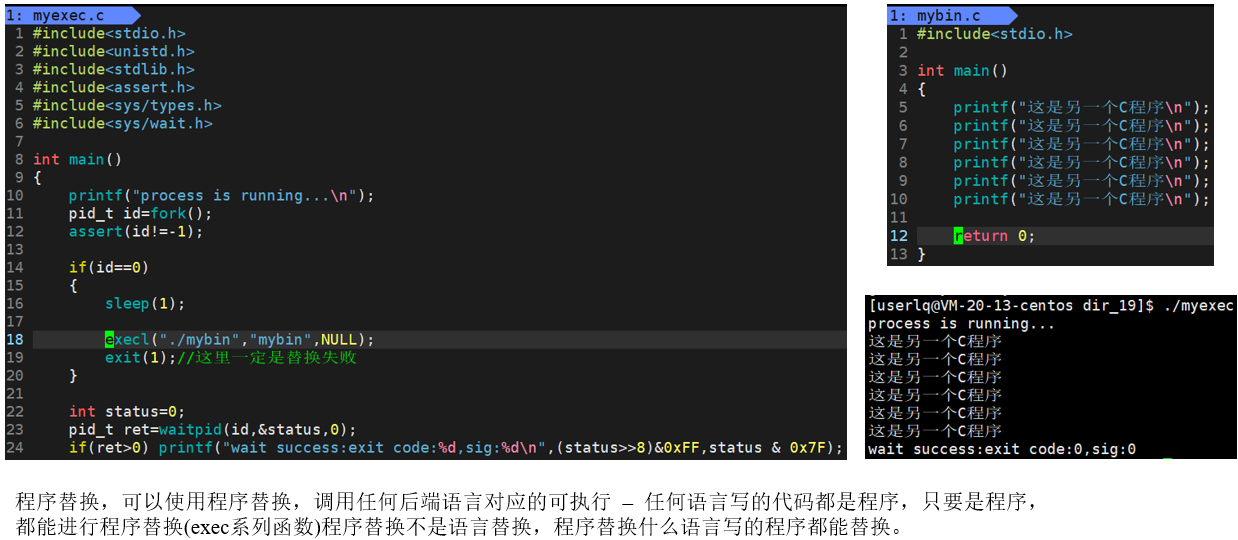
4.3.5 execle
![]()
envp为自定义环境变量,可以将自定义或当前程序中的环境变量表传给待替换程序。
我们在当前目录中再编写一个.c文件mybin.c:
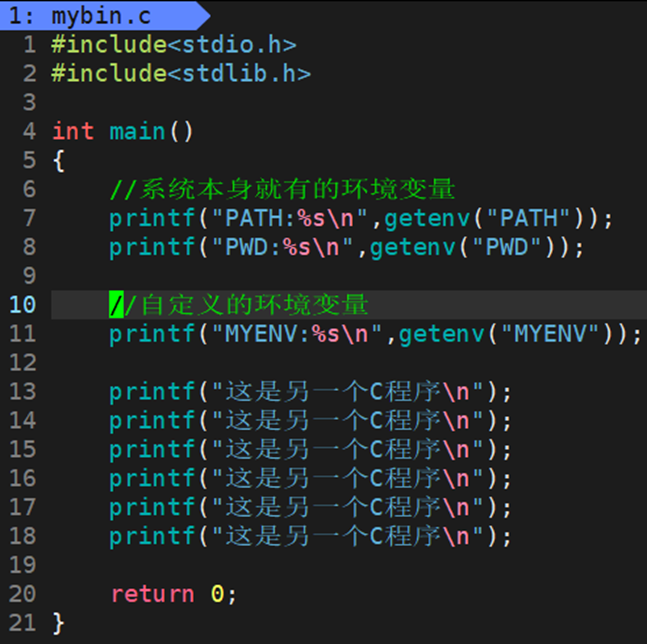
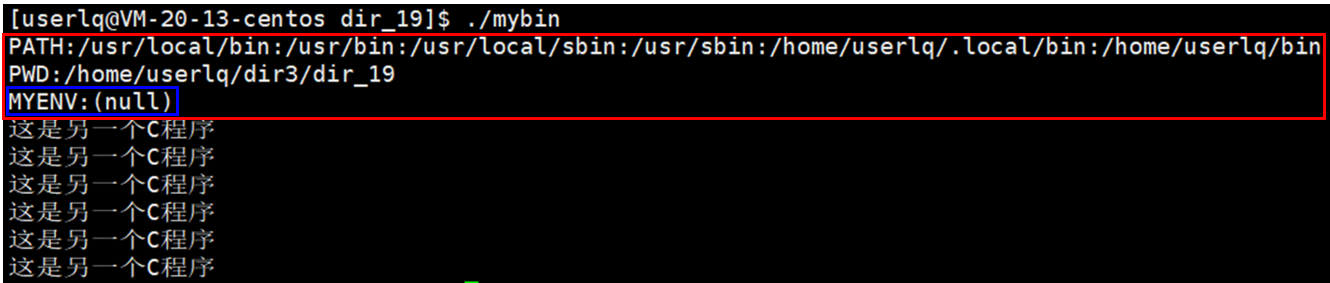
此时,系统中原本存在的环境变量被成功获取并打印出来了。因为没有添加MYENV,MYENV为空。
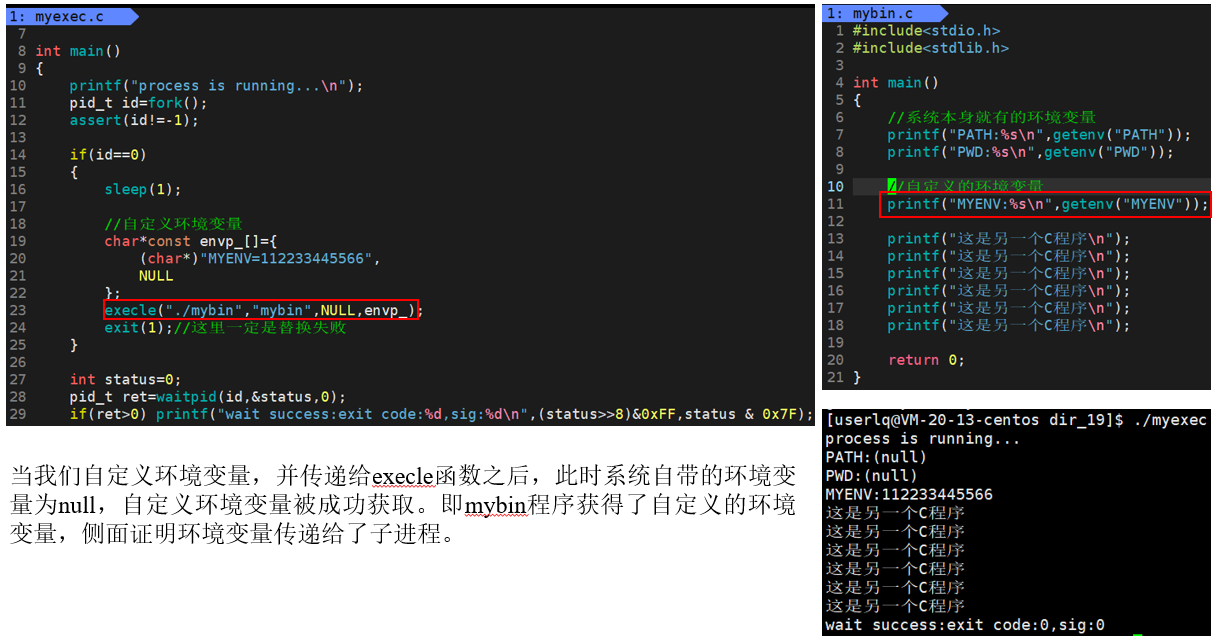
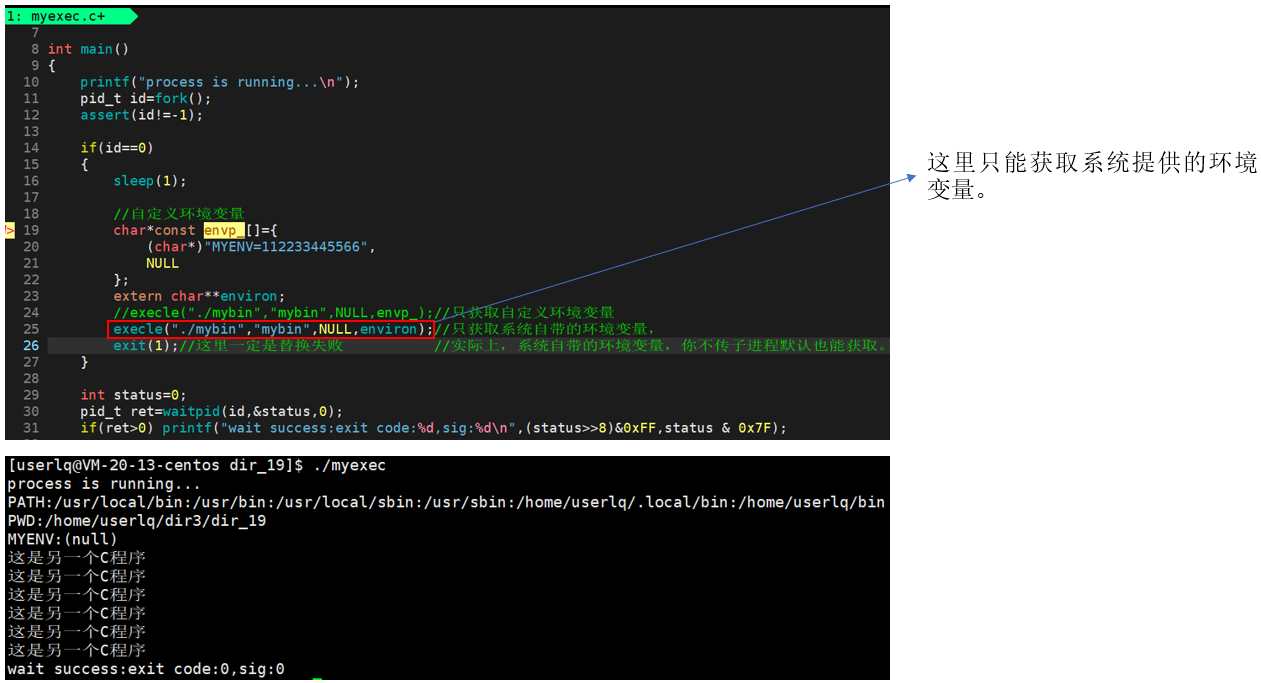
如果我们想让子进程在拥有系统的环境变量的基础上再添加新的自定义环境变量,则可以使用函数putenv。
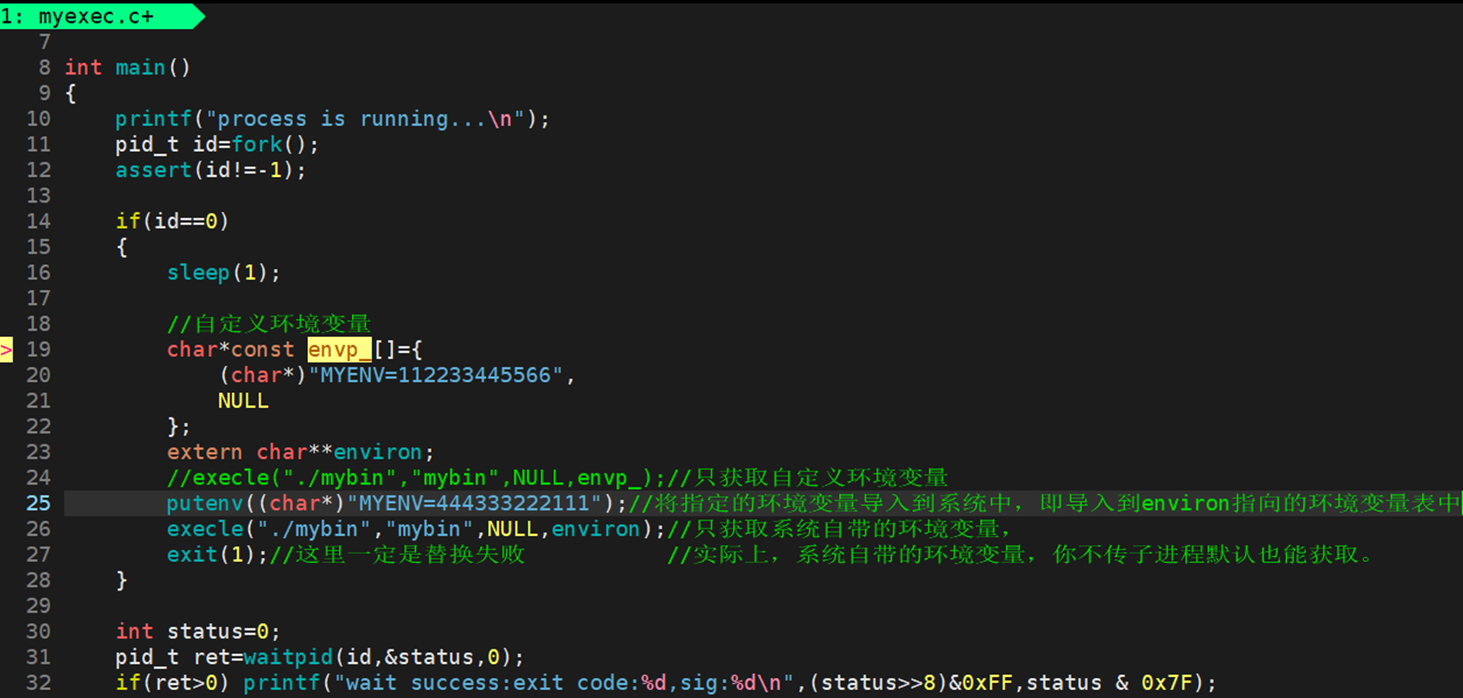
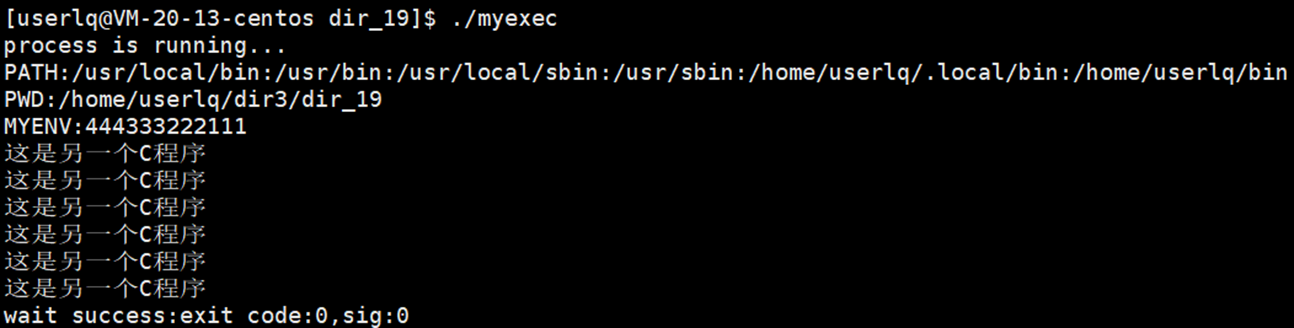
现在可以理解了为什么在bash中创建程序并运行,程序能够继承bash中的环境变量表了。在bash下执行程序,等价于在bash下替换子进程为指定程序,并将bash中的环境变量表environ传递给指定程序使用。其他没有带e的替换函数,如:execl、execlp、execv、execvp等函数,默认通过地址空间的方式让子进程拿到当前程序中的环境变量表。因此,我们称环境变量具有全局属性。

4.3.6 execve
execve是系统调用函数,其他替换函数都是execve函数的封装。

1、execl相当于将链式信息转化为argv表,供execve参数2使用;
2、execlp相当于在PATH中找到目标路径信息后,传给execve参数1使用;
3、execle的envp最终也是传给execve中的参数3。
4.4 简单模拟shell解释器
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<assert.h>#define NUM 1024
#define OPT_NUM 64char lineCommand[NUM];
char *myargv[OPT_NUM];//指针数组
int lastCode=0;
int lastSig=0;int main()
{while(1){//输出提示符,包括用户名、主机名、当前路径printf("用户名@主机名 当前路径# ");fflush(stdout);//获取用户输入,char *s=fgets(lineCommand,sizeof(lineCommand)-1,stdin);assert(s!=NULL);(void)s;//消除最后一个\n,假如在键盘中输入了abcd,其中回车后面就多了一个\n,即最终输入的是abcd\nlineCommand[strlen(lineCommand)-1]=0;//最后将abcd\n字符中的\n置为0//printf("tset:%s\n",lineCommand);//假设在命令行输入的字符串是 "ls -a -l -i",程序替换exec系列的接口要求将输入的一个字符串//变为 "ls" "-a" "-l" "-i"等4个字符串。//字符串切割 myargv[0]=strtok(lineCommand," ");int i=1;if(myargv[0] != NULL && strcmp(myargv[0],"ls")==0) {myargv[i++]=(char*)"--color=auto";}//如果没有子字符串了,strtok会返回NULL,myargv[end]必须以NULL结尾 while(myargv[i++]=strtok(NULL," "));//测试是否成功,条件编译
#ifdef DEBUGfor(int i=0;myargv[i];i++){printf("myargv[%d]:%s\n",i,myargv[i]);} #endif//内建命令--echo//执行命令pid_t id=fork();assert(id!=-1);if(id==0){execvp(myargv[0],myargv);exit(1);}int status=0;pid_t ret = waitpid(id,&status,0);assert(ret>0);(void)ret;lastCode=((status>>8)&0xFF);lastSig=(status & 0x7F);}
}执行结果:
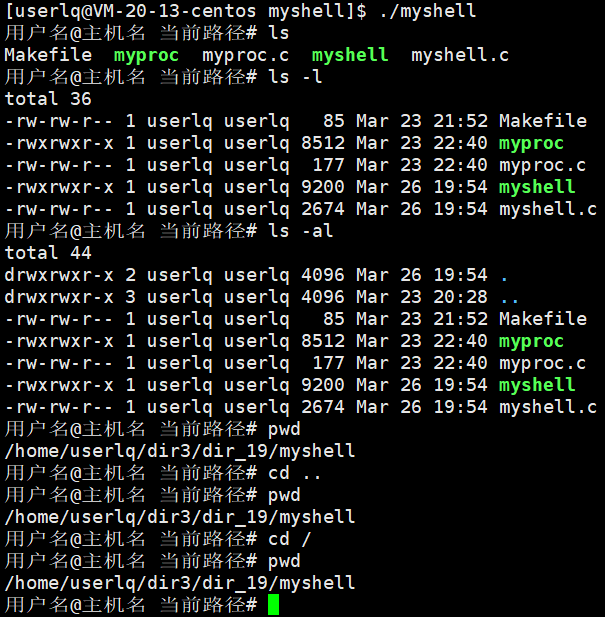
我们自己实现的shell解释器可以实现一些简单的shell命令,但是当执行cd .. 以及 cd /等切换路径的命令时,路径并没有被切换成功。那么路径为什么没有发生变化呢?
在这里我们需要明确一件事,在执行cd ..命令时,是期望修改子进程的路径还是父进程的路径?子进程是目标程序,父进程是myshell。实际上我们想修改的不是子进程,因为子进程的路径一改,子进程就退出了,改就没有意义了。所以我们要改的是父进程的路径,换言之,你要修改父进程的路径的前提是不能创建子进程来执行cd命令。父进程不能执行cd,因为父进程一旦替换就会把父进程的代码替换成cd的代码,父进程本身的工作也就不能进行了。
实际上,这里执行cd ..切换路径没有成功,是因为我们在自己写的shell中执行各种指令之前,都要先执行fork函数来创建子进程,并让子进程来执行cd ..命令。这里子进程有自己的工作目录,则这里执行cd ..命令更改的是子进程的工作目录。在执行完cd ..命令后,再执行pwd命令,是两条命令,而pwd命令查询的是父进程的路径,与子进程没有任何关系。
什么是当前路径?
下面我们就介绍一下当前路径:
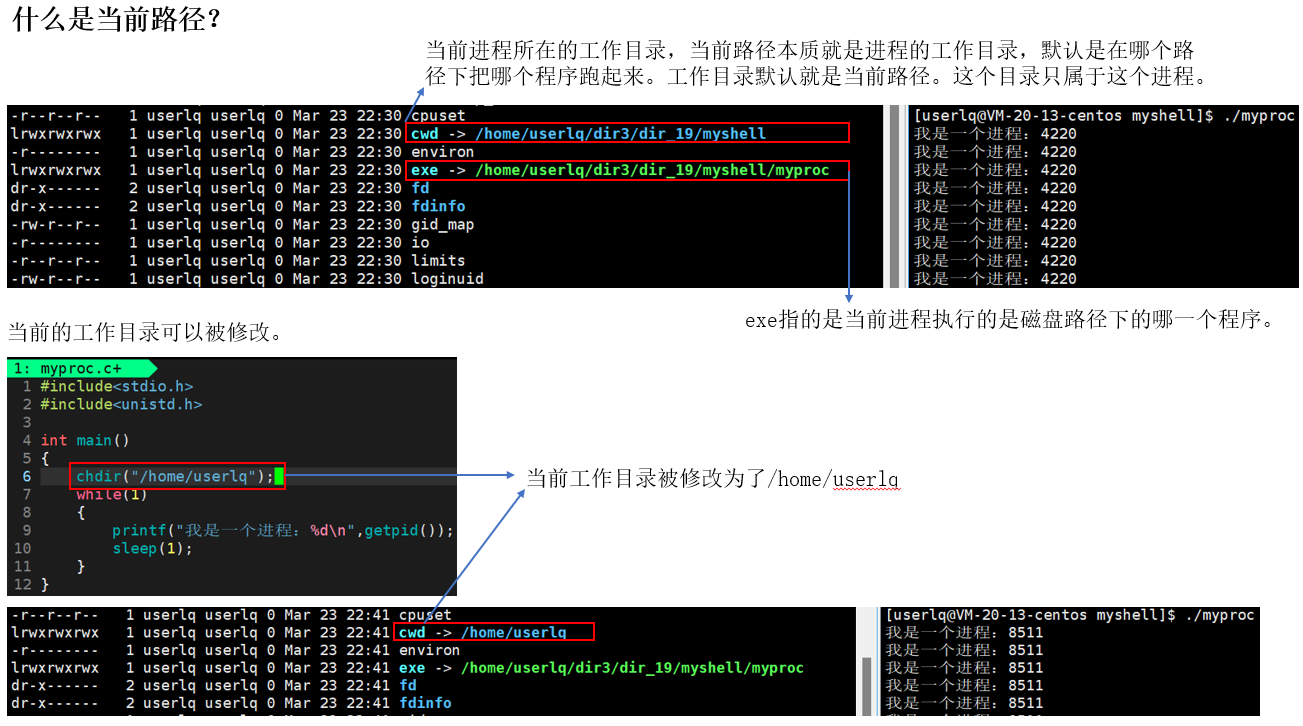
实际上在shell中不能使用程序替换来执行cd命令,它使用系统接口来完成命令的执行,这个接口是chdir。
#include<unistd.h>int chdir(const char* path);支持cd和echo命令的代码:
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<assert.h>#define NUM 1024
#define OPT_NUM 64char lineCommand[NUM];
char *myargv[OPT_NUM];//指针数组
int lastCode=0;
int lastSig=0;int main()
{while(1){//输出提示符,包括用户名、主机名、当前路径printf("用户名@主机名 当前路径# ");fflush(stdout);//获取用户输入,char *s=fgets(lineCommand,sizeof(lineCommand)-1,stdin);assert(s!=NULL);(void)s;//消除最后一个\n,假如在键盘中输入了abcd,其中回车后面就多了一个\n,即最终输入的是abcd\nlineCommand[strlen(lineCommand)-1]=0;//最后将abcd\n字符中的\n置为0//printf("tset:%s\n",lineCommand);//假设在命令行输入的字符串是 "ls -a -l -i",程序替换exec系列的接口要求将输入的一个字符串//变为 "ls" "-a" "-l" "-i"等4个字符串。//字符串切割 myargv[0]=strtok(lineCommand," ");int i=1;if(myargv[0] != NULL && strcmp(myargv[0],"ls")==0) {myargv[i++]=(char*)"--color=auto";}//如果没有子字符串了,strtok会返回NULL,myargv[end]必须以NULL结尾 while(myargv[i++]=strtok(NULL," "));//如果是cd命令,不需要创建子进程,让shell自己执行对应的命令,本质就是执行系统接口//像这种不需要让子进程来执行,而是让shell自己执行的命令--称为内建(内置)命令if(myargv[0] != NULL && strcmp(myargv[0], "cd")==0) { if(myargv[1]!=NULL) chdir(myargv[1]);continue; } if(myargv[0]!=NULL && myargv[1]!=NULL&& strcmp(myargv[0],"echo")==0){ if(strcmp(myargv[1],"$?")==0){ printf("%d,%d\n",lastCode,lastSig);} else { printf("%s\n",myargv[1]);}continue;}//测试是否成功,条件编译
#ifdef DEBUGfor(int i=0;myargv[i];i++){printf("myargv[%d]:%s\n",i,myargv[i]);} #endif//内建命令--echo//执行命令pid_t id=fork();assert(id!=-1);if(id==0){execvp(myargv[0],myargv);exit(1);}int status=0;pid_t ret = waitpid(id,&status,0);assert(ret>0);(void)ret;lastCode=((status>>8)&0xFF);lastSig=(status & 0x7F);}
}执行结果:
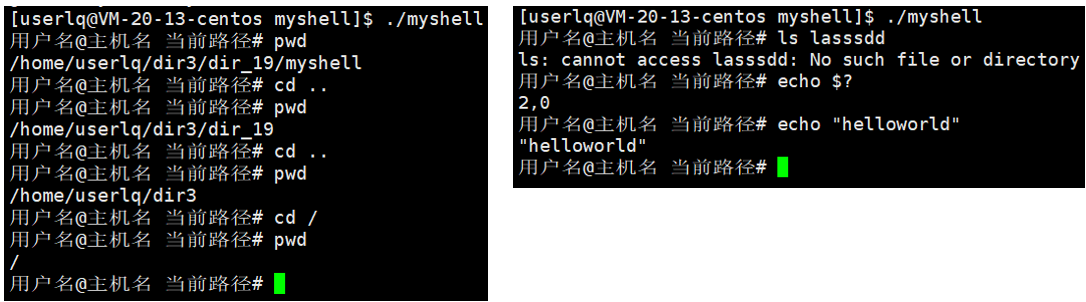
可以看到这样的cd命令并没有创建子进程去执行,本质cd命令是内置命令,是shell内的一个函数调用。所以这里简单的工作,shell自己去做,复杂的工作就交给子进程去做。
相关文章:

Linux进程控制--进程创建 | 进程终止 | 进程等待 | 进程替换
1.进程创建 现阶段我们知道进程创建有如下两种方式,起始包括在以后的学习中有两种方式也是最常见的: 1、命令行启动命令(程序、指令)。 2、通过程序自身,使用fork函数创建的子进程。 1.1 fork函数 在linux操作系统中,fork函数是…...
——套接字编程简介)
Linux 网络编程(二)——套接字编程简介
文章目录 2 Socket 套接字 2.1 什么是 Socket 2.2 Socket编程的基本操作 2.3 地址信息的表示 2.4 网络字节序和主机字节序的转换 2.4.1 字节序转换 2.4.2 网络地址初始化与分配 2.5 INADDR_ANY 2.6 Socket 编程相关函数 2.7 C标准中的 main 函数声明 2.8 套接字应用…...

串行通信 与 并行通信 对比
总目录 一、并行通信 1. 定义与核心特点 1) 定义 并行通信是指通过多条数据线同时传输一组数据的各个位(如8位、16位或更多),以字节或字为单位进行数据交换的通信方式。 2)核心特点 特点描述传输速度快多位同时传…...

基于springboot+vue的北部湾地区助农平台
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:…...

Docker技术系列文章,第七篇——Docker 在 CI/CD 中的应用
在当今快速发展的软件开发领域,持续集成与持续部署(CI/CD)已经成为提高软件交付效率和质量的关键实践。而 Docker 作为一种流行的容器化技术,为 CI/CD 流程提供了强大的支持。通过将应用及其依赖项打包成容器,Docker 确…...

Hive SQL中 ?+.+ 的用法,字段剔除
一、含义 ?. 的用法代表剔除表中的特定字段,建议按照字段顺序列出以确保正确性。 二、参数设置 -- 首先需要设置一个参数: set hive.support.quoted.identifiersNone; --然后指定要剔除哪个字段 select (dateline)?. from test.dm_user_add三、举例…...

Vue学习笔记集--pnpm包管理器
pnpm包管理器 官网: https://www.pnpm.cn/ pnpm简介 pnpm全称是performant npm,意思为“高性能的npm”,它通过硬链接和符号链接共享依赖,提升安装速度并减少存储占用。 功能特点 节省磁盘空间:依赖包被存放在一个统…...
)
游戏交易系统设计与实现(代码+数据库+LW)
摘 要 在如今社会上,关于信息上面的处理,没有任何一个企业或者个人会忽视,如何让信息急速传递,并且归档储存查询,采用之前的纸张记录模式已经不符合当前使用要求了。所以,对游戏交易信息管理的提升&#x…...

为什么视频文件需要压缩?怎样压缩视频体积即小又清晰?
在日常生活中,无论是为了节省存储空间、便于分享还是提升上传速度,我们常常会遇到需要压缩视频的情况。本文将介绍为什么视频需要压缩,压缩视频的好处与坏处,并教你如何使用简鹿视频格式转换器轻松完成MP4视频文件的压缩。 为什么…...

腾讯pcg客户端一面
Java 基本引用类型 常见异常以及怎么处理 所有类的父类是什么,有哪些常用方法 常用线程池有哪些 线程池的创建参数 如何实现线程同步 常用锁有哪些 Lock和reentrantlock有什么不一样 Reentrantlock要手动释放锁吗 数据结构 数组和链表的区别 队列和栈的区别 为什么…...

解决vscode终端和本地终端python版本不一致的问题
🌿 问题描述 本地终端: vscode终端: 别被这个给骗了,继续往下看: 难怪我导入一些包的时候老提示找不到,在本地终端就不会这样,于是我严重怀疑vscode中的python版本和终端不一样,…...

常见几种网络攻击防御方式
xss跨站脚本攻击 反射型 XSS(Reflected XSS): 恶意脚本是通过 URL 参数或者表单提交直接传递给服务器的,并且立即在响应页面中反射返回给用户。 假设有一个登录页面,用户可以通过 URL 参数传递一个消息: &…...

操作系统之输入输出
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...

TCP/IP的网络连接设备
TCP/IP层物理层网卡、集线器、中继器数据链路层网桥、交换机网络层路由器传输层网关应用层 1.网桥:网桥主要功能是将一个网络的数据沿通信线路复制到另一个网络中去,可以有效的连接两个局域网 2.网关:网关又称协议转换器,是将两…...

记一次feign调用400,参数过长导致,修改解决
feign客户端PostMapping("/website/checkChooseColumn") boolean checkChooseColumn(RequestParam("chooseColumn") String chooseColumn);服务端 PostMapping("/checkChooseColumn") public boolean checkChooseColumn(RequestParam("cho…...

【大模型基础_毛玉仁】4.3 参数选择方法
目录 4.3 参数选择方法4.3.1 基于规则的方法4.3.2 基于学习的方法1)公式:2)Child-tuning 的两种变体模型3)Child-tuning总结 4.3 参数选择方法 参数选择方法: 对预训练模型中部分参数微调,不添加额外参数以避免推理时…...

企业级Linux服务器初始化优化全流程
实战指南:企业级Linux服务器初始化优化全流程 本文基于某电商平台百万级并发服务器的真实调优案例整理,所有操作均在Rocky Linux8.5验证通过,不同发行版请注意命令差异 一、服务器安全加固(Situation-Task-Action-Resultÿ…...
- 垂直拆分(服务治理体系、安全架构升级))
亿级分布式系统架构演进实战(十一)- 垂直拆分(服务治理体系、安全架构升级)
亿级分布式系统架构演进实战(一)- 总体概要 亿级分布式系统架构演进实战(二)- 横向扩展(服务无状态化) 亿级分布式系统架构演进实战(三)- 横向扩展(数据库读写分离&#…...
InfiniBand解决方案助力领先科技公司网络升级)
飞速(FS)InfiniBand解决方案助力领先科技公司网络升级
国家:越南 行业:信息技术 网络类型:InfiniBand网络 方案类型:HPC网络 案例亮点 通过真实使用场景的全面测试,确保出色兼容性和高可用性,显著降低部署风险和运营成本。 借助飞速(FS…...

[Qt5] QMetaObject::invokeMethod使用
📢博客主页:https://loewen.blog.csdn.net📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!📢本文由 丶布布原创,首发于 CSDN,转载注明出处🙉📢现…...

深入理解垃圾收集算法:从分代理论到经典回收策略
垃圾收集(Garbage Collection, GC)是现代虚拟机自动内存管理的核心机制。它不仅能自动回收不再使用的对象,还能极大减轻开发者在内存管理上的负担。本文将详细讲解垃圾收集算法的基本思想、分代收集理论以及几种经典的垃圾收集算法。 注&…...

数据降维——PCA与LDA
特征选择和特征提取 特征选择和特征提取是数据降维的重要步骤。 1. 定义与目标 特征提取: 目标:通过变换(如投影、编码)将原始高维特征映射到新的低维空间,新特征是原始特征的组合(线性或非线性ÿ…...

机器学习中的 K-均值聚类算法及其优缺点
K-均值聚类是一种常用的无监督学习算法,用于将数据集中的样本分为 K 个簇。其工作原理是通过迭代优化来确定簇的中心点,实现样本的聚类。 算法步骤如下: 随机选择 K 个样本作为初始簇中心。根据每个样本和簇中心的距离将样本归类到最近的簇…...

RAID原理
一、RAID 0 原理 核心特点 条带化(Striping):数据被分割成块(Block),交替写入多个磁盘(至少2块)。无冗余:不提供数据备份或校验,依赖所有磁盘同…...

2025系统分析师---软件工程:深度剖析常见软件开发方法
在软件工程这一复杂而精妙的领域中,软件开发方法的选择与实施无疑是项目成功的关键所在。作为一名资深软件技术专家,我深知不同的开发方法适用于不同的业务场景,各自具备独特的优缺点。本文将深入探讨几种常见的软件开发方法,包括…...
)
中文字符计数器,助力所有python对齐业务(DeepSeek代笔)
编码制式反推双宽,精准字宽库力推中文对齐。 笔记模板由python脚本于2025-03-26 23:49:24创建,本篇笔记适合为中文终端显示和文本输出对齐烦恼的coder翻阅。 【学习的细节是欢悦的历程】 博客的核心价值:在于输出思考与经验,而不仅…...

扫描注解指定路径
10.扫描注解 在 Spring Boot 中,EnableConfigurationProperties 和 ConfigurationPropertiesScan 是两个用于显式启用和管理 ConfigurationProperties 类的注解。它们提供了更灵活的方式来注册和扫描 ConfigurationProperties 类,尤其是在某些复杂场景或…...

像素到数据:Selenium,OpenCV,Tesseract,Python构建的智能解析系统
基于Selenium与OCR技术的网页信息智能提取方案 一、应用场景解析 在Web自动化测试和数据分析领域,经常需要处理动态渲染的网页信息,特别是当页面元素以图像形式呈现时。本文介绍的解决方案结合了浏览器自动化与图像识别技术,有效解决了以下典型场景: 动态渲染的可视化数据…...

徘徊检测:视觉分析技术的安防新方向
利用视觉分析的方式检测徘徊检测 背景 随着时代的发展,失业率上升导致社会不稳定因素增加,安保问题愈发突出。特别是在住宅区、工厂、办公园区等公共场所,对于徘徊人员的检测成为确保安全的关键一环。传统的安保手段如人工巡逻、监控录像回…...

CentOS 7 挂载与卸载文件系统
一、挂载文件系统 1. 查看系统磁盘与分区情况 在挂载文件系统之前,需要先了解系统中的磁盘和分区信息。使用fdisk -l命令,可列出所有磁盘和分区的详细信息,示例如下: [rootlocalhost ~]# fdisk -lDisk /dev/sda: 53.7 GB, …...
)
MySQL实战(尚硅谷)
要求 代码 # 准备数据 CREATE DATABASE IF NOT EXISTS company;USE company;CREATE TABLE IF NOT EXISTS employees(employee_id INT PRIMARY KEY,first_name VARCHAR(50),last_name VARCHAR(50),department_id INT );DESC employees;CREATE TABLE IF NOT EXISTS departments…...

JavaScript 改变 HTML 内容
JavaScript 改变 HTML 内容 JavaScript 改变 HTML 内容的核心在于通过 DOM(文档对象模型)操作实现动态更新,以下是主要方法及场景解析: 一、直接修改元素内容 1. innerHTML 属性 用于获取或设置元素的 HTML 内容(包…...
)
第十四届蓝桥杯大赛软件赛省赛C/C++ 大学 B 组(部分题解)
文章目录 前言日期统计题意: 冶炼金属题意: 岛屿个数题意: 子串简写题意: 整数删除题意: 总结 前言 一年一度的🏀杯马上就要开始了,为了取得更好的成绩,好名字写了下前年2023年蓝桥…...

机器学习——Bagging、随机森林
相比于Boosting的集成学习框架,Bagging(Bootstrap Sampling,自助聚集法,又称为自助采样)作为一种自助聚集且并行化的集成学习方法,其通过组合多个基学习器的预测结果来提高模型的稳定性和泛化能力。其中随机森林是Bagging学习框架…...

数据库——MySQL基础操作
一、表结构与初始数据 假设存在以下两张表: 1. student 表 字段名数据类型描述idINT学生唯一标识符nameVARCHAR(100)学生姓名ageINT学生年龄sexVARCHAR(10)学生性别 初始数据: idnameagesex1张三20男2李四22女3王五21男 2. course 表 字段名数据类…...
)
存储过程、存储函数与触发器详解(MySQL 案例)
存储过程、存储函数与触发器详解(MySQL 案例) 一、存储过程(Stored Procedure) 定义 存储过程是预先编译好并存储在数据库中的一段 SQL 代码集合,可以接收参数、执行逻辑操作(如条件判断、循环)…...

2025年注册安全工程师考试练习题
注册安全工程师练习题,涵盖了不同的知识点和题型: 单选题 某机械制造企业委托具有相应资质的中介服务机构的专业技术人员为其提供安全生产管理服务。依据《安全生产法》,保证该企业安全生产的责任由( )负责。 A. 专业…...

Photoshop 2025安装包下载及Photoshop 2025详细图文安装教程
文章目录 前言一、Photoshop 2025安装包下载二、Photoshop 2025安装教程1.解压安装包2.运行程序3.修改安装路径4.设安装目录5.开始安装6.等安装完成7.关闭安装向导8.启动软件9.安装完成 前言 无论你是专业设计师,还是初涉图像处理的小白,Photoshop 2025…...
)
ESP32通过WiFi获取网络时间(NTP)
代码部分 代码由station_example_main的官方例程修改 /* WiFi station ExampleThis example code is in the Public Domain (or CC0 licensed, at your option.)Unless required by applicable law or agreed to in writing, thissoftware is distributed on an "AS IS&…...

docker使用命令笔记
docker使用命令笔记 1. 安装docker2. 拉取镜像3. 镜像与容器4. 基于镜像创建容器4. 操作创建好的容器5. docker文件传输6. ubuntu的docker的一些基本环境搭建 记录docker的一些使用命令 1. 安装docker 遵循官方安装说明即可,windows需要下载docker desktop后在doc…...

关于服务器只能访问localhost:8111地址,局域网不能访问的问题
一、问题来源: 服务器是使用的阿里云的服务器,服务器端的8111端口没有设置任何别的限制,但是在阿里云服务器端并没有设置相应的tcp连接8111端口。 二、解决办法: 1、使用阿里云初始化好的端口;2、配置新的阿里云端口…...

触发器及报警
一、触发器介绍 Trigger 作用:报警 触发某一个监控项状态的变化 基于监控项创建 一个监控项可以有多个触发器 1、创建触发器语法 {<server>:<key>.<function>(<parameter>)}<operator><constant> {被监控主机:键值.函数…...

如何用 Postman 发送 GET 请求?详解
Postman 是一款广泛用于 API 开发和测试的工具,通过它,我们可以轻松地发送 GET 请求。首先,需要新建接口并设置为 GET 请求,然后填写相关的 URL 地址和参数,最后点击“Send”按钮即可发起请求。 Postman 如何发送 get…...

主流软件工程模型全景剖析
一、瀑布模型 阶段划分 需求分析:与用户深入沟通,全面了解软件的功能、性能、可靠性等要求,形成详细的需求规格说明书。设计阶段:包括总体设计和详细设计。总体设计确定软件的体系结构,如模块划分、模块之间的接口等&…...

NVMe协议
一、NVMe 的诞生背景 传统协议瓶颈: 早期的SATA接口SSD使用 AHCI协议,设计初衷是适配机械硬盘(HDD),其单队列、高延迟的特性无法发挥SSD的高速性能。PCIe接口的潜力: NVMe专为 PCIe接口的SSD 设…...

开关磁阻电机类型及其控制技术
开关磁阻电机( Switched Reluctance Motors,SRM) 具有结构简单、坚固、成本低、 工作可靠、控制灵活、运行效率高,适于高速与恶劣环境运行等优点, 由其构成的传动系统( Switched Reluctance Drives, SRD) 具有交、直流传动系统所没有的优点, 为此,世界各…...

CMake 构建的Qt 项目中的构建套件的配置
在Qt 框架中,使用CMake 构建工具时,需要自己给构建套件添加相关配置,否则已经添加的构建套件将不可选择使用。 创建CMake 项目后,如果打开项目配置时,出现如下构建套件不可选的情况, 需要先确认是否安装…...
:移动端特色广告与创意策略探秘)
程序化广告行业(34/89):移动端特色广告与创意策略探秘
程序化广告行业(34/89):移动端特色广告与创意策略探秘 大家好!在程序化广告的学习之旅中,每一次探索都像是发现了新大陆。今天,我依旧怀揣着和大家共同进步的想法,来和大家深入聊聊程序化广告行…...

IT行业项目管理风险规避策略
在IT项目中,前端、后端、测试等不同角色的协同工作会带来各种项目管理风险。以下是针对这些风险的规避策略: 一、跨职能团队协作风险 1. 沟通不畅风险 解决方案: 建立每日站会机制(15分钟以内)使用协作工具(如Jira、飞书、钉钉)制定明确的接口文档标准(Swagger/YAPI)…...

24届非科班硕士入职做上位机开发,后续往工业软件还是音视频、后端发展?
今天给大家分享的是一位粉丝的提问,24届非科班硕士入职做上位机开发,后续往工业软件还是音视频、后端发展? 接下来把粉丝的具体提问和我的回复分享给大家,希望也能给一些类似情况的小伙伴一些启发和帮助。 同学提问: …...