AutoMQ x OSS 的 Iceberg 数据入湖的最佳实践
背景
在数字化转型进程中,用户交互行为产生的多维度数据已成为企业的重要战略资产。以短视频平台为例,基于用户点赞事件的实时推荐算法能显著提升用户活跃度和平台粘性。这类实时数据主要通过 Apache Kafka 流处理平台进行传输,通过其扇出(Fanout)机制实现多业务系统的并行消费。企业的数据应用需求呈现双重特性:一方面需要实时流处理能力,另一方面需要依托历史数据进行多维聚合分析。大数据分析技术经过多年演进,已从传统数据仓库架构发展为现代数据湖体系。
在数据湖技术生态中,Apache Iceberg 凭借其开放性设计已确立事实标准地位。该技术不仅获得全球企业广泛采用,还构建了包含 Apache Spark、Amazon Athena、Presto 等主流计算引擎的完整生态系统。2024 年 AWS re:Invent 大会上,基于 Iceberg 格式的 S3 Tables 服务正式发布,标志着云原生数据湖解决方案进入新阶段。
以 Apache Kafka、数据湖平台、Apache Iceberg 表格式为核心的现代化数据湖架构已成为新趋势。随之而来的挑战包括:
-
高效数据写入:数据写入模式和分区策略直接影响查询效率
-
运维、架构和管理复杂度提升:Apache Kafka 的流数据不感知 schema,需要经过处理和转化才能以 Iceberg 表格式存储到数据湖中。这带来了元数据管理、schema 演进以及流转表数据处理任务管理等新挑战。
本文将从三个维度展开论述:首先分析 Iceberg 的技术优势及其成为行业标准的原因,其次详细阐述数据入湖的最佳实践方法,最后重点介绍 AutoMQ 如何利用阿里云 OSS 高效解决 Kafka 数据入湖问题。通过 AutoMQ 和阿里云服务的结合,用户可以轻松实现 Kafka 数据入湖的最佳实践。
小贴士:AutoMQ 是构建在对象存储上的新一代 Kafka,能实现秒级自动弹性并显著降低成本,目前服务于吉利汽车、京东、知乎、小红书、Grab 等知名企业。作为阿里云的优秀合作伙伴,AutoMQ 可通过阿里云市场直接订阅部署。
Iceberg 的优势
ACID 事务
在并发控制机制方面,Iceberg 采用基于快照隔离的乐观并发控制(Optimistic Concurrency Control)实现 ACID 事务保障。该机制允许多个写入事务与读取事务并行执行,其核心设计假设事务冲突概率较低:在事务提交阶段通过版本号校验完成冲突检测,而非传统悲观锁的预锁定方式。这种设计有效降低锁争用,提升系统吞吐量。
具体写入流程包含以下关键步骤:1) 将增量数据写入新的数据文件(DataFile)及删除文件(DeleteFile);2) 生成新版本快照(Snapshot);3) 创建关联的元数据文件(MetadataFile);4) 通过 CAS(Compare and Swap)原子操作更新Catalog中的元数据指针指向新版本。只有当元数据指针更新成功时,本次写入才被视为有效提交。
Iceberg 的读写隔离机制建立在多快照之上:每个读取操作访问的是特定时间点的快照状态,而写入操作始终作用于新生成的数据文件并创建独立快照。由于快照的不可变性,读取操作无需任何锁同步机制即可实现:a) 不同 Reader 之间的隔离保障;b) Reader 与 Writer 的读写隔离。这种设计使得查询性能不会因写入操作的存在而出现劣化。
Partition 演进
在数据湖架构演进历程中,分区策略动态调整始终是核心挑战之一。传统数据湖方案实现分区优化时,需通过全表数据重分布完成物理存储结构调整,这在 PB 级数据集场景下会产生极高的计算与存储成本。
Iceberg通过逻辑层-物理层解耦设计创新性解决了这一难题:其分区策略作为元数据层的逻辑抽象存在,与底层数据存储路径完全解耦。当进行分区策略调整时,历史数据保持原有物理分布不变,仅新写入数据按更新后的分区规则组织,从而实现零数据迁移的分区演进。该机制使得分区优化操作从小时级降至秒级,资源消耗几乎为零。
更值得关注的是 Iceberg 的 Hidden Partitioning 特性:查询层无需显式指定分区键,计算引擎通过元数据自动完成数据文件过滤。这意味着业务系统可在不影响现有查询语句的前提下,持续优化数据分布策略,实现查询逻辑与存储架构的双向解耦。
Upsert
Iceberg 支持 copy-on-write (COW)和 merge-on-read (MOR)两种更新方式。COW 会将变更行所属的数据文件整个重写一遍生成新的文件,即使只更新了其中一行,该方式的查询效率最高,但需要付出较大的写入成本。而 MOR 为高频数据更新提供了更好的写入性能。当一行数据更新时,Writer 将要更新的数据特征到 DeleteFile 中,标记之前的数据被删除了,并且将更新的数据写入到 DataFile 中,通过该方式 MOR 将行更新的写入效率做到和追加写入保持一致。在查询时,计算引擎再将 DeleteFile 中的记录作为墓碑屏蔽旧的数据,完成读取时的结果合并。
Schema 演进
应用迭代的同时,底层的数据也会跟着演进。Iceberg 的 Schema 演进支持 Add、Drop、Rename、Update 和 Reorder,并且与 Partition 演进类似,在 Schema 演进的时候,所有的历史 DataFile 都不需要被重写。
Iceberg 数据入湖最佳实践
文件管理
避免高频 Commit:Iceberg 每次 Commit 都会生成新的 Snapshot,这些 Snapshot 信息都会维护在 MetadataFile 中。高频率 Commit 不更仅容易触发 Commit 冲突,而且会造成 MetadataFile 膨胀,导致存储和查询成本增加。建议控制 Commit 间隔在 1min 以上,并且由中心化的 Coordinator 进行提交。
避免生成大量小文件:每个 DataFile 对应一个 ManifestEntry,小文件数量多会导致 ManifestFile 体积激增,进而导致元数据存储成本上升和查询计划生成速度下降。对象存储是按照 API 调用次数计费,过多的小文件也会导致查询时 API 的调用成本上升。建议通过数据攒批写入来减少小文件的生成,后期也可以通过 Compaction 来将小文件合并。阿里云 OSS 提供了有竞争力的 PUT 和 GET 类 API 价格,并每月都提供了海量免费额度,可有效降低 API 费用。
Partition
采取合适的 Partition 策略:
加速查询:将高频筛选的字段(如时间、地区)优先作为分区键,在查询时通过分区裁剪减少扫描的数据量。
成本:在查询效率和存储成本之间平衡。分区粒度过细会产生过多小文件,导致存储效率下降。
Table Topic:阿里云上实时数据入湖的最佳选择
概览
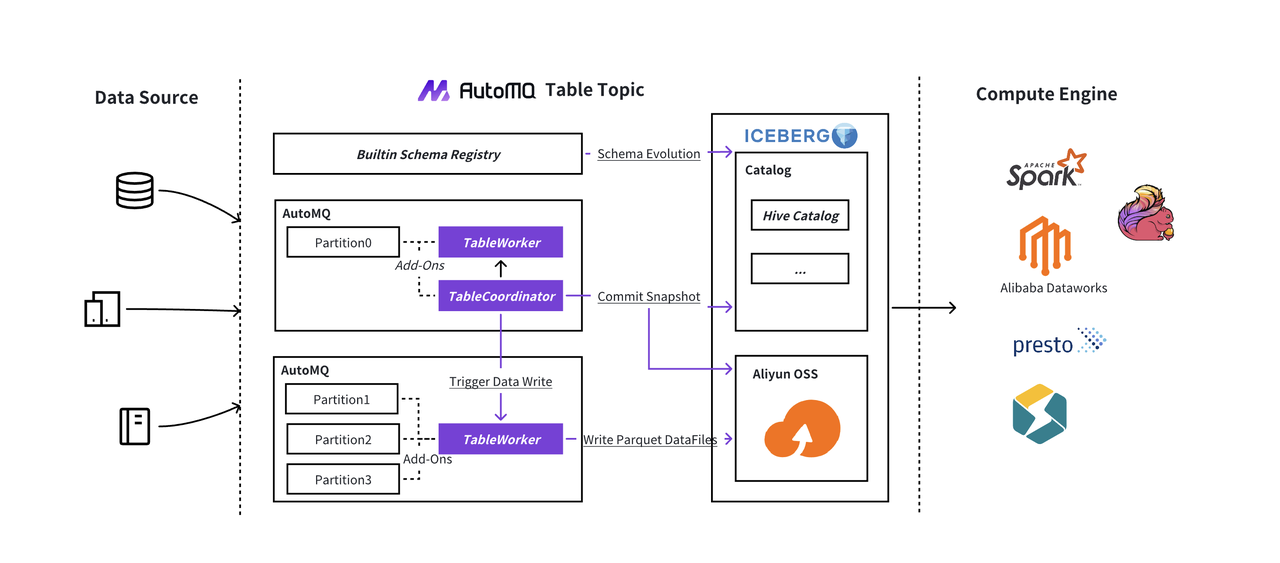
AutoMQ Enterprise(1.4.0版本) Table Topic 在 Kafka Topic 的基础上,将流格式存储进一步扩展成 Iceberg 表格式存储。数据的生产者仍旧使用 Kafka 协议向 AutoMQ 写入数据,数据可以是数据库 BinLog、ClickStream 和 IoT 等数据。AutoMQ 首先会将写进来的数据低延迟写入到流格式存储,后台经过攒批后将流格式的数据转换成 Iceberg 表格式的数据。至此 AutoMQ 通过 Iceberg 将 Kafka 里面的流数据以表格式共享给下游的数据湖计算引擎。企业无需再去维护复杂的 ETL 任务,仅需要使用 Kafka API 向 AutoMQ 写入数据,AutoMQ 会无感将数据入湖。数据产生即就绪,业务创新零等待。
极简 Data Ingest
上游的数据源使用的是 Kafka 协议,而不是直接面向的的 Iceberg。这么做有如下 2 个好处:
数据源生态:企业现有的 Kafka 生产者(如 Flink CDC、Logstash、Debezium)可直接接入,节省定制化开发成本。例如 MySQL 的 BINLOG 通过 Debezium 写入 Table Topic 后,AutoMQ 自动完成 Avro 到 Iceberg Schema 的映射与转换
低延迟 & 高吞吐:数据进入 AutoMQ 后首先会存储到 Stream Storage,AutoMQ 的 Stream Storage 具有毫秒级延迟和 GB 级吞吐的特征,因此企业可以获得低延迟和高吞吐的数据入湖能力。
表自动创建 & 演进
AutoMQ 通过深度集成 Kafka Schema 构建自动化数据治理闭环,从根本上解决传统入湖流程中的 Schema 管理顽疾。其设计利用 Kafka 原生的 Schema 注册机制作为数据质量闸门:当生产者发送数据时,Schema 验证层会即时拦截不符合预定义结构的脏数据(如字段类型错误、必填字段缺失等),将数据质量问题阻拦在入湖起点。
当上游业务系统发生 Schema 变更(如 MySQL 源表新增「用户等级」字段),AutoMQ 能够实时感知 Kafka 消息中的 Schema 版本迭代,自动完成 Iceberg 表结构的协同演进,同时保持数据持续写入不中断。这一过程完全无需人工介入,彻底消除了传统流程中多系统间 Schema 手动对齐的操作风险。
相较于传统架构中 Flink/Spark 任务与表结构的强耦合(每个同步任务需硬编码目标表 Schema),AutoMQ 实现了 Schema 管理的范式转移——将原先分散在数据管道脚本、数仓元数据库、流计算引擎等多处的 Schema 定义收敛为 Kafka Schema 单一源头。这种中心化管控模式不仅减少了的元数据维护工作量,更确保了从实时接入到湖仓存储的全链路 Schema 一致性。
数据分区
AutoMQ 为了提升查询时的数据过滤效率,支持同时对多个 Columns 进行分区,支持 year、month、day、hour、bucket 和 truncate 分区转换函数。
Properties
# config example
#The partition fields of the table.
automq.table.topic.partition.by=[bucket(user_name), month(create_timestamp)]
CDC
AutoMQ 支持数据以 Upsert 模式进行同步,AutoMQ 会根据设置的 Table 主键和 Record 指定的 CDC 操作来进行增删改。当 AutoMQ 接收到 Update 操作的 Record 时,AutoMQ 会首先将主键以 EqualityDelete 写入到 DeleteFile 中,标记历史记录失效,然后再在 DataFile 里追加更新的记录。
通过 AutoMQ Table Topic,企业可以将数据库的 BinLog 写入到 AutoMQ,AutoMQ 会将 BinLog 数据通过 Upsert 写入到 Iceberg 表。数据库服务于在线 OLTP 业务,Iceberg 服务于 OLAP 数据分析,通过 AutoMQ Table Topic 可以保持两者之间保持数据分钟级的新鲜度。
Properties
# config example
# The primary key, comma-separated list of columns that identify a row in tables.
automq.table.topic.id.columns=[email]
# The name of the field containing the CDC operation, I, U, or D
automq.table.topic.cdc.field=ops
免任务管理
AutoMQ 不像使用 Spark / Flink / Connector 等同步组件需要编写同步任务脚本和运维同步任务。用户仅仅需要在创建 Topic 时打开 Table Topic 开关。
Properties
# The configuration controls whether enable table topic
automq.table.topic.enable=true
AutoMQ 的 Topic Topic 能力内置在进程中,主要模块为 Coordinator 和 Worker:
Coordinator:管理 Table 同步进度和中心化提交。Coordinator 每个 Table Topic 独立占有一个,绑定到 Topic 的分区 0。Coordinator 根据用户设置的提交间隔触发提交,避免了每个 Worker 独立提交导致的提交冲突和元数据膨胀,降低存储成本和提升查询性能。
Wokrer:负责将 Kafka Record 转换成 Parquet 数据文件上传到阿里云对象存储 OSS。Table Topic 每一个分区在同进程内都有由对应的 Worker 绑定负责。
Coordinator 和 Worker 与分区绑定,在进程中内置具有以下好处:
运维简单:无需额外维护一套组件,只需要关心 AutoMQ 集群的生命周期,无需管理同步任务。
同步伸缩:AutoMQ 的消息写入能力与 Table Topic 同步能力同步匹配伸缩。当业务高峰来临,只需要根据流量上涨比例扩容 AutoMQ 集群即可。
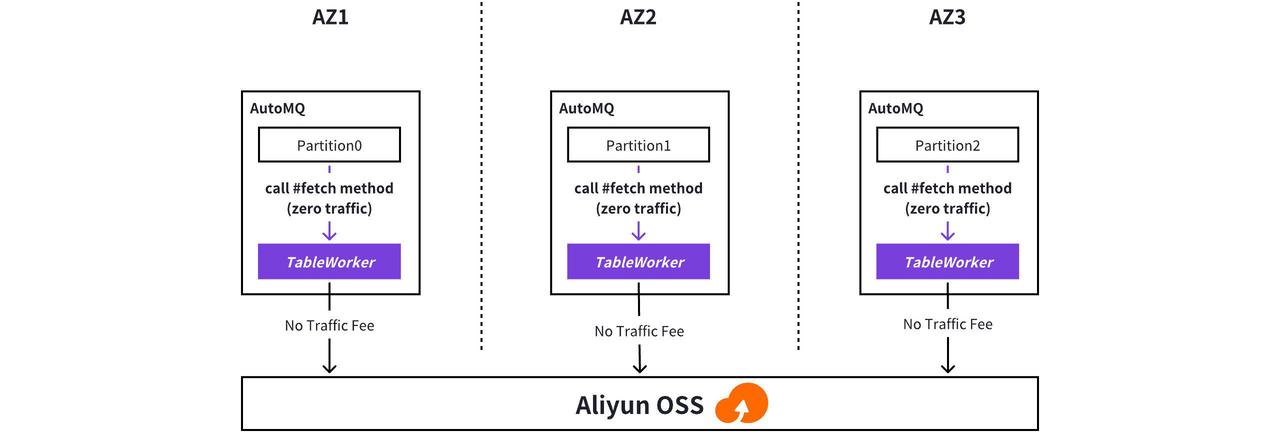
零跨 AZ 流量
在传统数仓同步架构中,采用 Spark、Flink 或各类 Connector 工具进行数据传输时,其分区调度机制通常存在显著的云环境适配性问题。由于 Worker 节点或 Executor 资源的分配策略未与云服务商可用区(AZ)拓扑结构对齐,导致同一分区的读写操作频繁跨越不同物理区域。这种设计缺陷在 AWS、GCP 等按流量计费的云平台中尤为突出(阿里云不会对跨 AZ 流量收取费用)——据统计,跨可用区数据传输成本往往占据企业大数据基础设施总支出的 80% 以上。
针对这一行业痛点,AutoMQ 提出了进程内绑定调度策略。通过将 Worker 节点与特定可用区的数据分区进行深度耦合,系统实现了计算资源与存储资源的拓扑感知。数据流转时 Worker 无需通过复杂网络路径获取数据,而是以本地方法调用的方式直接从内存缓冲区捕获实时写入的数据流,随后通过上传至阿里云 OSS 存储桶。这种数据传输机制可减少90%以上的跨区带宽消耗,为企业构建出兼具高性能与成本效益的云原生数据管道。
总结
本文系统解析了 Apache Iceberg 作为云原生数据湖核心技术的核心优势与最佳实践。Iceberg 通过快照隔离实现高性能 ACID 事务,借助逻辑-物理解耦的分区演进机制实现零成本存储优化,并支持 COW/MOR 两种更新模式平衡查询与写入效率。在数据入湖实践中,需关注高频提交规避与小文件治理,结合动态分区策略提升查询性能。针对实时数据入湖挑战,AutoMQ Table Topic 创新性地融合 Kafka 协议与 Iceberg 表格式,通过流批自动转换、Schema 自适配及进程内绑定调度实现分钟级数据新鲜度。其免ETL任务设计显著降低运维复杂度,独有的拓扑感知机制更减少 90% 跨可用区流量成本,为企业构建高吞吐、低延迟、低成本的一体化数据湖方案提供了新范式。阿里云 OSS 的 AZ 间流量免费,提供有竞争力的 PUT 和 GET 类 API 价格,和每月的 API 免费额度,可有效降低云上 AutoMQ方案的运行成本。
相关文章:

AutoMQ x OSS 的 Iceberg 数据入湖的最佳实践
背景 在数字化转型进程中,用户交互行为产生的多维度数据已成为企业的重要战略资产。以短视频平台为例,基于用户点赞事件的实时推荐算法能显著提升用户活跃度和平台粘性。这类实时数据主要通过 Apache Kafka 流处理平台进行传输,通过其扇出&a…...

深度学习大模型补充知识点
文章目录 VIT用途处理方法与CNN区别 多模态LLM:大语言模型预训练指令微调强化学习 总结 VIT ViT(Vision Transformer) 首次将 Transformer架构成功应用于计算机视觉领域(尤其是图像分类任务)。传统视觉任务主要依赖卷…...

定义模型生成数据表
1. 数据库配置 js import { Sequelize, DataTypes } from sequelize; // 创建一个 Sequelize 实例,连接到 SQLite 数据库。 export const sequelize new Sequelize(test, sa, "123456", { host: localhost, dialect: sqlite, storage: ./blog.db })…...

C++与C的基本不同
文章目录 变量定义规则1. 基本语法2. 初始化3. 作用域4. 存储类别 函数定义规则1. 基本语法2. 函数声明和定义3. 默认参数4. 内联函数 解析输出流void BluetoothA2DPSink::start(const char* name)class BluetoothA2DPSink : public BluetoothA2DPCommon C是在C语言基础上发展而…...

React19源码系列之createRoot的执行流程是怎么的?
2024年12月5日,react发布了react19版本。后面一段时间都将学习它的源码,并着手记录。 react官网:react19新特性 https://react.dev/blog/2024/12/05/react-19 在用vite创建react项目的使用,main.tsx主文件都会有以下代码。 //i…...

【CXX-Qt】1.5 使用CMake构建
在本示例中,我们将演示如何使用CMake将CXX-Qt代码集成到C应用程序中。Cargo将CXX-Qt代码构建为静态库,然后CMake将其链接到C可执行文件中。 我们首先需要修改项目结构,以分离项目的不同部分。 tutorial cpp qml rust将Rust项目移动到rust文…...

前端面试项目拷打
Axios相关 1.在Axios二次封装时,具体封装了哪些内容,如何处理请求拦截和响应拦截? axios二次封装的目的:为了统一处理请求和响应拦截器、错误处理、请求超时、请求头配置等,提高代码可维护性和复用性。 首先创建axios…...

“Ubuntu禁止root用户通过SSH直接登录”问题的解决
目录 1 前言 2 问题的解决 2.1 修改sshd_config文件 2.2 重启 SSH 服务 1 前言 最近在做毕设的时候,由于使用普通用户,在MobaXterm的图形界面上,无法正常查看/root文件夹内容,如下图所示: 于是我就想直接想用oot…...

Kafka的零拷贝
Kafka的零拷贝(Zero-Copy)技术是其实现高吞吐量的关键优化之一,主要通过减少数据在内核空间和用户空间之间的冗余复制及上下文切换来提升性能。以下是其核心要点: 1. 传统数据拷贝的问题 多次复制:传统文件传输需经历…...
)
《大语言模型》学习笔记(三)
GPT系列模型的技术演变 2022 年11月底,OpenAI推出了基于大语言模型的在线对话应用—ChatGPT。由于具备出色的人机对话能力和任务解决能力,ChatGPT一经发布就引发了全社会对于大语言模型的广泛关注,众多的大语言模型应运而生,并且…...
)
华为OD机试 - 最长回文字符串 - 贪心算法(Java 2024 E卷 100分)
题目描述 如果一个字符串正读和反读都一样(大小写敏感),则称之为一个「回文串」。例如: level 是一个「回文串」,因为它的正读和反读都是 level。art 不是一个「回文串」,因为它的反读 tra 与正读不同。Level 不是一个「回文串」,因为它的反读 leveL 与正读不同(因大小…...

K8S-etcd服务无法启动问题排查
一、环境、版本信息说明 k8s:v1.19.16 etcdctl version: 3.5.1 3台etcd(10.xxx.xx.129、10.xxx.xx.130、10.xxx.xx.131)组成的集群。 二、问题根因 129节点的etcd数据与其他两台数据不一致,集群一致性校验出错导致无法加入集…...

基于WebRTC的嵌入式音视频通话SDK:EasyRTC跨平台兼容性技术架构实时通信的底层实现
EasyRTC的核心架构围绕WebRTC技术构建,同时通过扩展信令服务、媒体服务器和NAT穿透机制,解决了WebRTC在实际部署中的痛点。其架构可以分为以下几个核心模块: 1)WebRTC基础层 媒体捕获与处理:通过getUserMediaAPI获取…...

SpringBoot-已添加并下载的依赖,reload和mvn clean 后还是提示找不到jar包问题
背景: 添加spring-jdbc依赖时,原来是指定版本的,担心版本冲突,就改成依赖托管,悲剧的是反复reload和mvn clean,import到类的该包一直标红,提示jar包找不到。。。 解决方案: Idea左上…...

HTML5扫雷游戏开发实战
HTML5扫雷游戏开发实战 这里写目录标题 HTML5扫雷游戏开发实战项目介绍技术栈项目架构1. 游戏界面设计2. 核心类设计 核心功能实现1. 游戏初始化2. 地雷布置算法3. 数字计算逻辑4. 扫雷功能实现 性能优化1. DOM操作优化2. 算法优化 项目亮点技术难点突破1. 首次点击保护2. 连锁…...
)
机器学习——数据清洗(缺失值处理、异常值处理、数据标准化)
数据清洗(缺失值处理、异常值处理、数据标准化) 在数据处理与分析流程中,数据清洗占据着极为关键的地位。原始数据往往充斥着各种问题,如缺失值、异常值,且数据的尺度和分布也可能存在差异,这些问题会严重影响后续数据分析和机器学习模型的准确性与性能。因此,有效的数据…...

【综述】An Introduction to Vision-Language Modeling【一】
介绍 发表在预印本上的综述,长达76页,其中正文46页。 来自Meta 在Meta工作期间完成 ‡蒙特利尔大学, Mila ♡麦吉尔大学, Mila †多伦多大学 ♠卡内基梅隆大学 ♣麻省理工学院 ∧纽约大学 △加州大学伯克利分校 ▽马里兰大学 ♢阿卜杜拉国王科技大学 •…...

MySQL常用函数详解及SQL代码示例
MySQL常用函数详解及SQL代码示例 引言当前日期和时间函数字符串函数数学函数聚合函数结论 引言 MySQL作为一种广泛使用的关系型数据库管理系统,提供了丰富的内置函数来简化数据查询、处理和转换。掌握这些函数可以大大提高数据库操作的效率和准确性。本文将详细介绍…...
技能系统 分身技能)
Unity教程(二十二)技能系统 分身技能
Unity开发2D类银河恶魔城游戏学习笔记 Unity教程(零)Unity和VS的使用相关内容 Unity教程(一)开始学习状态机 Unity教程(二)角色移动的实现 Unity教程(三)角色跳跃的实现 Unity教程&…...

RTSPtoWeb, 一个将rtsp转换成webrtc的开源项目
RTSPtoWeb是一个开源项目,旨在将RTSP流转换为可在现代web浏览器中消费的格式,如Media Source Extensions (MSE)、WebRtc或HLS。该项目完全使用golang编写,不依赖于ffmpeg或gstreamer,确保了高效的性能和轻量…...

AIAgent有哪些不错的开源平台
AIAgent领域有许多优秀的开源平台和框架,以下是一些值得推荐的开源平台: AutoGPT AutoGPT 是一个基于 OpenAI 的 GPT-4 和 GPT-3.5 大型语言模型的开源框架,能够根据用户给定的目标自动生成所需提示,并利用多种工具 API 执行多步骤…...
)
Java---JavaSpringMVC解析(1)
Spring Web MVC 是基于 Servlet API 构建的原始 Web 框架,从⼀开始就包含在 Spring 框架中。它的正式名称“Spring Web MVC”来⾃其源模块的名称(Spring-webmvc),但它通常被称为"Spring MVC" 1.MVC MVC是Model View Controller的缩写&#…...

Vector 的模拟实现:从基础到高级
文章目录 1. 引言2. vector的核心设计3. vector的常用接口介绍3.1 构造函数和析构函数3.1.1 默认构造函数3.1.2 带初始容量的构造函数3.1.3 析构函数 3.2 拷贝构造函数和拷贝赋值运算符3.2.1 拷贝构造函数3.2.2 拷贝赋值运算符 3.5 数组长度调整和动态扩容3.5.1 调整大小&#…...
)
【大模型科普】大模型:人工智能的前沿(一文读懂大模型)
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈人工智能与大模型应用 ⌋ ⌋ ⌋ 人工智能(AI)通过算法模拟人类智能,利用机器学习、深度学习等技术驱动医疗、金融等领域的智能化。大模型是千亿参数的深度神经网络(如ChatGPT&…...

[漏洞修复]用yum update修openssh漏洞
[漏洞修复]用yum update修openssh漏洞 1. 需求2. 更新Yum仓库2.1 生成本地仓库2.2 生成内网仓库2.3 将Openssh的包更新到仓库 3. 客户端升级3.1 客户端repo文件配置3.2 升级Openssh3.3 升级后的确认 1. 需求 最近经常有朋友问Openssh 漏洞修复的问题,我也在自己的gitee仓库里更…...

[RH342]iscsi配置与排错
[RH342]iscsi配置与排错 1. 服务端配置1.1 安装targetcli1.2 准备磁盘1.3 服务端配置1.4 防火墙配置 2. 客户端配置2.1 安装客户端软件2.2 配置客户端2.3 连接登录服务端2.4 挂载使用 3. 安全验证扩展3.1 服务端3.2 客户端 4. 常见的排错点4.1 服务端常见错误4.2 客户端常见错误…...

Nginx 代理访问一个 Web 界面时缺少内容
1. 资源路径问题 Web 页面中的静态资源(如图片、CSS、JavaScript 文件)可能使用了相对路径或绝对路径,而这些路径在代理后无法正确加载。 解决方法: 检查资源路径:打开浏览器的开发者工具(按 F12…...

HOVER:人形机器人的多功能神经网络全身控制器
编辑:陈萍萍的公主一点人工一点智能 HOVER:人形机器人的多功能神经网络全身控制器HOVER通过策略蒸馏和统一命令空间设计,为人形机器人提供了通用、高效的全身控制框架。https://mp.weixin.qq.com/s/R1cw47I4BOi2UfF_m-KzWg 01 介绍 1.1 摘…...

SEO新手基础优化三步法
内容概要 在网站优化的初始阶段,新手常因缺乏系统性认知而陷入技术细节的误区。本文以“三步法”为核心框架,系统梳理从关键词定位到内容布局、再到外链构建的完整优化链路。通过拆解搜索引擎工作原理,重点阐明基础操作中容易被忽视的底层逻…...

遨游科普:三防平板是哪三防?有哪些应用场景?
在工业智能化与数字化转型的浪潮中,电子设备的耐用性和环境适应性成为关键需求。普通消费级平板电脑虽然功能强大,但在极端环境下往往“水土不服”。而三防平板凭借其独特的防护性能,正逐步成为“危、急、特”场景的核心工具。 AORO P300 Ult…...

Etcd 服务搭建
💢欢迎来到张胤尘的开源技术站 💥开源如江河,汇聚众志成。代码似星辰,照亮行征程。开源精神长,传承永不忘。携手共前行,未来更辉煌💥 文章目录 Etcd 服务搭建预编译的二进制文件安装下载 etcd 的…...

C++《红黑树》
在之前的篇章当中我们已经了解了基于二叉搜索树的AVL树,那么接下来在本篇当中将继续来学习另一种基于二叉搜索树的树状结构——红黑树,在此和之前学习AVL树类似还是通过先了解红黑树是什么以及红黑树的结构特点,接下来在试着实现红黑树的结构…...

Axios 请求取消:从原理到实践
Axios 请求取消:从原理到实践 在现代前端开发中,网络请求是不可或缺的一部分。Axios 是一个基于 Promise 的 HTTP 客户端,广泛应用于浏览器和 Node.js 环境中。然而,在某些场景下,我们可能需要取消正在进行的请求&…...

【css酷炫效果】纯CSS实现照片堆叠效果
【css酷炫效果】纯CSS实现照片堆叠效果 缘创作背景html结构css样式完整代码基础版进阶版(增加鼠标悬停查看) 效果图 想直接拿走的老板,链接放在这里:https://download.csdn.net/download/u011561335/90492022 缘 创作随缘,不定时更新。 创…...
论文精度:Transformers without Normalization
前言 论文题目:Transformers without Normalization 作者:Jiachen Zhu 1,2 , Xinlei Chen 1 , Kaiming He 3 , Yann LeCun 1,2 , Zhuang Liu 1,4,† 论文地址:https://arxiv.org/pdf/2503.10282 摘要 这篇论文探讨了现代神经网络中广泛使用的归一化层是否是必不可少的。…...
——pytorch 模型迁移)
基于香橙派 KunpengPro学习CANN(3)——pytorch 模型迁移
通用模型迁移适配可以分为四个阶段:迁移分析、迁移适配、精度调试与性能调优。 迁移分析 迁移支持度分析: 准备NPU环境,获取模型的源码、权重和数据集等文件;使用迁移分析工具采集目标网络中的模型/算子清单,识别第三方…...

微软远程桌面即将下架?Splashtop:更稳、更快、更安全的 RDP 替代方案
近日,Windows 官方博客宣布:将于2025年5月27日起,在 Windows 10 和 Windows 11 应用商店中下架“Microsoft 远程桌面”应用,建议用户迁移至新的 Windows App。这一变动引发了广大用户对远程访问解决方案的关注。作为全球领先的远程…...

【Python】Python与算法有应用关系吗?
李升伟 整理 是的,Python与算法有着密切的应用关系。Python作为一种高级编程语言,因其简洁的语法和强大的库支持,被广泛应用于算法设计、实现和应用中。以下是Python与算法之间的一些主要应用关系: 1. 算法学习与教学࿱…...

js,html,css,vuejs手搓级联单选
<!DOCTYPE html> <html lang"zh"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>级联选择器</title><script src"h…...

将Django连接到mysql
将Django连接到mysql 文章目录 将Django连接到mysql一.按照我的文章 在Django模型中的Mysql安装 此篇 的步骤完成mysql的基础配置二.Django配置 一.按照我的文章 ‘在Django模型中的Mysql安装’ 此篇 的步骤完成mysql的基础配置 基础配置具体内容 1.打开PowerShell 安装mysql的…...

每天五分钟深度学习框架pytorch:基于pytorch搭建循环神经网络RNN
本文重点 我们前面介绍了循环神经网络RNN,主要分析了它的维度信息,其实它的维度信息是最重要的,一旦我们把维度弄清楚了,一起就很简单了,本文我们正式的来学习一下,如何使用pytorch搭建循环神经网络RNN。 RNN的搭建 在pytorch中我们使用nn.RNN()就可以创建出RNN神经网络…...

【力扣刷题实战】无重复的最长字串
大家好,我是小卡皮巴拉 文章目录 目录 力扣题目: 无重复的最长字串 题目描述 解题思路 问题理解 算法选择 具体思路 解题要点 完整代码(C) 兄弟们共勉 !!! 每篇前言 博客主页&#x…...

vulhub/joker 靶机----练习攻略
1. 靶机下载地址 https://download.vulnhub.com/ha/joker.zip 下载下来是ova文件,直接双击,在VMware打开,选择保存位置,点击导入。 2. 设置网卡模式为NAT,打开靶机 3.老规矩,打开kali,扫同C…...

Nuxt2 vue 给特定的页面 body 设置 background 不影响其他页面
首先认识一下 BODY_ATTRS 他可以在页面单独设置 head () {return {bodyAttrs: {form: form-body}};},设置完效果是只有这个页面会加上 接下来在APP.vue中添加样式...

【Go】运算符笔记
基本数学运算 Go 语言支持常见的 算术运算符,用于执行数学计算。 运算符说明加法-减法*乘法/除法%取余自增--自减 整数运算只能得到整数部分 package mainimport ("fmt""math" )func main() {go_math() }func go_math() {x, y : 8, 5fmt.Pr…...

常见的前端安全问题
前端安全是 Web 开发中至关重要的一环,以下是常见的前端安全问题及对应的防御措施: 1. XSS(跨站脚本攻击) 攻击原理 攻击者向页面注入恶意脚本(如 JavaScript),在用户浏览器中执行,…...
)
基于Spring Boot的项目申报系统的设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...
 -- SPI_Master驱动程序)
SPI驱动(九) -- SPI_Master驱动程序
文章目录 参考资料:一、SPI传输概述二、SPI传输的两种方法2.1 旧方法2.2 新方法 参考资料: 参考资料: 参考内核源码: drivers\spi\spi.c 一、SPI传输概述 SPI控制器的作用是发起与它下面挂接的SPI设备之间的数据传输,那么控制…...
Transformer网络发展概述2025.3.18
一.Transformer概述 1.1 定义与原理 Transformer是一种基于自注意力机制的深度学习模型,在处理序列数据时表现卓越。其核心原理包括: 自注意力机制 :允许模型同时考虑输入序列中的所有位置,捕捉语义关系多头注意力 :…...

3.4 二分查找专题:LeetCode 69. x 的平方根
1. 题目链接 LeetCode 69. x 的平方根 2. 题目描述 给定一个非负整数 x,计算并返回 x 的平方根的整数部分(向下取整)。 示例: 输入:x 4 → 输出:2输入:x 8 → 输出:2࿰…...