使用 PyTorch TunableOp 加速 ROCm 上的模型
Accelerating models on ROCm using PyTorch TunableOp — ROCm Blogs (amd.com)

在这篇博客中,我们将展示如何利用 PyTorch TunableOp 在 AMD GPU 上使用 ROCm 加速模型。我们将讨论通用矩阵乘法(GEMM)的基础知识,展示调优单个 GEMM 的示例,最后通过 TunableOp 演示在 LLM(gemma)上实现的实际性能提升。
注意
PyTorch TunableOp 在 torch v2.3 或更高版本中可用。
要运行此博客中的代码,请参阅附录中的 运行此博客 .
引言
随着模型的规模和复杂性不断增加,以尽可能高效地运行这些模型的需求也在增加。PyTorch TunableOp 提供了一条简便的途径,通过调整底层的 GEMM 操作来实现现有训练和推理任务的适度性能提升。
通用矩阵乘法
GEMM 是神经网络中许多组件(包括全连接层、卷积、注意力机制等)的基本构建块。GEMM 是 Basic Linear Algebra Subprograms (BLAS) 库(如 hipBLAS)的多个组件之一。
GEMM 是一种矩阵乘法操作,其形式为:
C←αAB+βC
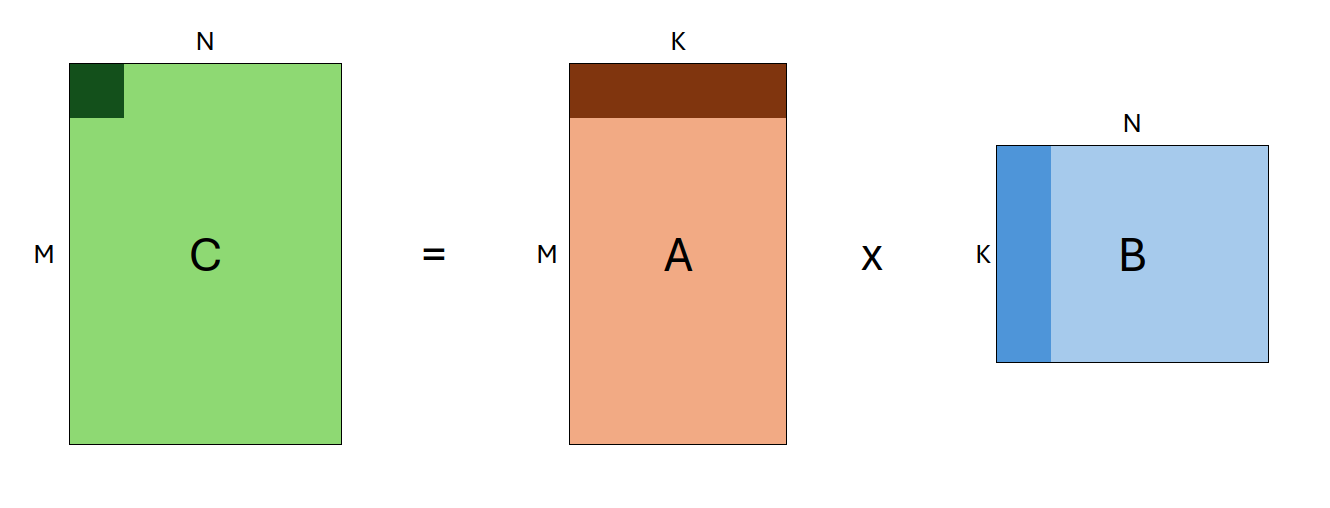
其中 A 和 B 是输入矩阵(可能会转置),α 和 β 是标量,C 是作为输出缓冲区的预先存在的矩阵。A、B 和 C 的形状分别定义为 (M, K)、`(K, N)` 和 (M, N)。因此,单个 GEMM 的定义由以下输入参数组成:`transA, transB, M, N, K`。这些参数统称为*问题规模*。
由于 GEMM 涉及神经网络的许多组件,尽可能快速高效地执行 GEMM 对于提高机器学习任务的性能至关重要。
对于任何给定的 GEMM(由问题规模定义),有许多不同的方法可以解决它!系统上可能存在多个 BLAS 库。每个 BLAS 库可能有多种不同的算法来解决给定的 GEMM,每种算法可以有数百种可能的独特参数组合。因此,*即使是单个 GEMM 也可能有数千种不同的解法*,其性能各不相同。
那么问题来了:当 PyTorch 执行矩阵乘法时,它如何知道哪种 GEMM 算法最快?答案是:它不知道。
在一个非常高的层次上,当你在 PyTorch 中运行矩阵乘法时,`C = A @ B`,会发生以下情况:
-
PyTorch 通过 (ATen) 将矩阵
A和B传递给 BLAS 库 -
BLAS 库使用内置的启发式方法(通常是查找表)来选择解决给定 GEMM 的算法
-
BLAS 库计算结果
C -
结果传递回 PyTorch
然而,这些启发式方法并不总是能够选择最快的算法,这可能取决于许多因素,包括你的具体环境、架构等。这就是 PyTorch TunableOp 的用武之地。
TunableOp 和 BLAS 库
TunableOp 不使用默认的 GEMM 运算,而是会针对您的特定环境_搜索最佳的 GEMM 运算_。它通过首先查询底层 BLAS 库以获取给定 GEMM 的所有解,并对每个解进行基准测试,然后选择最快的解来实现这一目标。TunableOp 之后将这些解写入磁盘,可以在后续运行中使用。这得益于支持调优的 hipBLAS 库。
我们通过设置环境变量 PYTORCH_TUNABLEOP_ENABLED=1 来启用 TunableOp,然后正常运行我们的程序。例如:
PYTORCH_TUNABLEOP_ENABLED=1 python my_model.py
另外,我们可以打开详细模式 PYTORCH_TUNABLEOP_VERBOSE=1 以查看 TunableOp 的执行情况。有关可用选项的完整列表,请参见 TunableOp README。
通过以下示例,我们将深入探讨 TunableOp 的功能。
PyTorch TunableOp
示例1:单个矩阵乘法
为了理解PyTorch TunableOp的工作原理,我们将调优一个单独的矩阵乘法。
首先,我们编写一个简单的Python程序`matmul.py`,具体步骤如下:
-
构造两个输入矩阵`A`和`B`,它们的形状分别为`(M, K)`和`(K, N)`
-
将它们相乘10000次,并记录操作时间
-
打印运算速度
以下是`src/matmul.py`的内容:
import torchdef time_matmul(M, N, K):n_iter = 10000 # 记录的迭代次数n_warmup = 10 # 预热迭代次数t0 = torch.cuda.Event(enable_timing=True)t1 = torch.cuda.Event(enable_timing=True)# 构造输入矩阵A = torch.rand(M, K, device="cuda")B = torch.rand(K, N, device="cuda")# 基准测试GEMMfor i in range(n_iter + n_warmup):if i == n_warmup:t0.record() # 直到预热完成后开始记录C = A @ B# 计算经过的时间t1.record()torch.cuda.synchronize()dt = t0.elapsed_time(t1) / 1000print(f"{n_iter/dt:0.2f} iter/s ({dt:0.4g}s)")time_matmul(512, 1024, 2048)
接下来,我们可以运行这个脚本:
python src/matmul.py
输出结果:
11231.81 iter/s (0.8903s)
然后我们启用PyTorch TunableOp,设置环境变量`PYTORCH_TUNABLEOP_ENABLED=1`。我们还可以通过设置`PYTORCH_TUNABLEOP_VERBOSE`打开详细输出,并通过`PYTORCH_TUNABLEOP_FILENAME`指定结果输出文件。
需要注意的是,`PYTORCH_TUNABLEOP_FILENAME`不是必须的,但我们在这里使用它是为了区分不同调优结果。通常情况下,你可以不设置这个变量,这样会写入默认文件`tunableop_results.csv`。
PYTORCH_TUNABLEOP_ENABLED=1\ PYTORCH_TUNABLEOP_VERBOSE=1\ PYTORCH_TUNABLEOP_FILENAME=src/matmul_result.csv\ python src/matmul.py
输出结果:
> reading tuning results from src/matmul_result0.csv could not open src/matmul_result0.csv for reading tuning results missing op_signature, returning null ResultEntry finding fastest for GemmTunableOp_float_NN(nn_1024_512_2048) out of 1068 candidates ├──verify numerics: atol=1e-05, rtol=1e-05 ├──tuning using warmup iters 1 [1.01208 ms] and tuning iters 29 [29.3505 ms] instance id=0, GemmTunableOp_float_NN(nn_1024_512_2048) Default ├──found better instance id=0. 0.280746ms. Default ├──unsupported id=1, GemmTunableOp_float_NN(nn_1024_512_2048) Gemm_Rocblas_1074 ├──unsupported id=2, GemmTunableOp_float_NN(nn_1024_512_2048) Gemm_Rocblas_1075 ... ... ... └──found fastest for GemmTunableOp_float_NN(nn_1024_512_2048) Gemm_Rocblas_4365 4.449s (2248 iter/s) writing file src/matmul_result0.csv
对于一个单独的GEMM操作,调优过程通常少于一分钟,但会产生数千行输出。以下是一些调优输出的关键片段:
-
首先,我们看到TunableOp找到一个GEMM进行调优。形状为(1024, 512, 2048),有4454个候选算法(这个数量可能根据你的环境变化)。
... finding fastest for GemmTunableOp_float_NN(nn_1024_512_2048) out of 4454 candidates ...
-
TunableOp基准测试每个算法以找到最快的。它首先检查算法是否数值稳定,然后记录每个算法的时间。我们可以看到三种不同类型的输出:
-
一些算法不受支持,跳过:
... ├──unsupported id=326, GemmTunableOp_float_TN(tn_1024_512_2048) Gemm_Rocblas_2702 ...
-
在一些情况下,GEMM在初始检查中被发现太慢,被跳过:
... ├──verify numerics: atol=1e-05, rtol=1e-05 ├──skip slow instance id=811, GemmTunableOp_float_NN(nn_512_1024_2048) Gemm_Rocblas_4381 ...
-
剩余的算法被基准测试:
... ├──verify numerics: atol=1e-05, rtol=1e-05 ├──tuning using warmup iters 1 [0.566176 ms] and tuning iters 52 [29.4412 ms] instance id=525, GemmTunableOp_float_TN(tn_1024_512_2048) Gemm_Rocblas_3901 ...
-
-
TunableOp最终会确定最快的算法,并将其写入结果文件 src/matmul_result0.csv。我们可以检查该文件的内容:
Validator,PT_VERSION,2.4.0 Validator,ROCM_VERSION,6.0.0.0-91-08e5094 Validator,HIPBLASLT_VERSION,0.6.0-592518e7 Validator,GCN_ARCH_NAME,gfx90a:sramecc+:xnack- Validator,ROCBLAS_VERSION,4.0.0-88df9726-dirty GemmTunableOp_float_NN,nn_1024_512_2048,Gemm_Hipblaslt_NN_52565,0.0653662
-
结果文件开始的几行是
Validator行,这些行指定生成该文件的环境版本。如果更改这些版本中的任何一个,该结果将不再有效——TunableOp也会检测到这些更改,并且不会加载之前的调优结果,而是重新运行调优。注意
如果由于验证器不匹配重新运行调优,现有的结果文件将被完全覆盖!
-
剩余的行表示为每个遇到的GEMM调优后的解决方案,包含四个字段:
-
操作符名称
-
参数
-
解决方案名称
-
平均执行时间
在我们的例子中,我们只有一个解决方案(名称:`GemmTunableOp_float_NN`),参数为
nn_1024_512_2048。参数中的前两个字母nn表示矩阵A和B都没有转置(`t` 表示转置),后面的三个数字分别是M、`N` 和K。 -
注意:在我们的脚本中,`M=512`,`N=1024`, 但是在解决方案中它们被交换了!这是因为 PyTorch 可以选择转置和交换A和B (因为
AB = C等效于BtAt = Ct), 因此在到达BLAS层之前,`M` 和N被交换。
现在我们已经运行了调优,我们将重新运行上面的脚本。这次,它将拾取并应用调优结果。
PYTORCH_TUNABLEOP_ENABLED=1 PYTORCH_TUNABLEOP_VERBOSE=1 PYTORCH_TUNABLEOP_FILENAME=src/matmul_result.csv python src/matmul.py
输出结果:
reading tuning results from src/matmul_result0.csv Validator,PT_VERSION,2.4.0 Validator,ROCM_VERSION,6.0.0.0-91-08e5094 Validator,HIPBLASLT_VERSION,0.6.0-592518e7 Validator,GCN_ARCH_NAME,gfx90a:sramecc+:xnack- Validator,ROCBLAS_VERSION,4.0.0-88df9726-dirty Loading results GemmTunableOp_float_NN,nn_1024_512_2048,Gemm_Hipblaslt_NN_52565,0.0653662 14488.24 iter/s (0.6902s)
太好了!通过调优,我们达到了大约14500次迭代/秒(相比未优化前约11900次迭代/秒),代表着吞吐量增加了22%!
扩展调优
此外,我们可以在现有调优的基础上进行构建。当启用调优时,新的GEMM(广义矩阵乘法)将在遇到时进行调优,但现有的GEMM不会重新调优,即使在多次运行中也是如此。这在我们对网络设计进行迭代时非常有用,因为我们只需要在遇到新形状时进行调优。
为了演示这一点,可以尝试编辑并运行`src/matmul.py`脚本,将其修改为不同的GEMM大小,例如`128, 256, 512`,然后再次运行。你会看到TunableOp将会在`matmul_results0.csv`文件中添加一行新的解决方案,对于新的GEMM:
Validator,PT_VERSION,2.4.0 Validator,ROCM_VERSION,6.0.0.0-91-08e5094 Validator,HIPBLASLT_VERSION,0.6.0-592518e7 Validator,GCN_ARCH_NAME,gfx90a:sramecc+:xnack- Validator,ROCBLAS_VERSION,4.0.0-88df9726-dirty GemmTunableOp_float_NN,nn_1024_512_2048,Gemm_Hipblaslt_NN_52565,0.0653662 GemmTunableOp_float_NN,nn_256_128_512,Gemm_Rocblas_21,0.00793602
通过这个简单的例子,我们展示了TunableOp如何工作,如何选择和优化GEMM,并直接将我们的PyTorch代码与底层的GEMM调用链接起来。
接下来,让我们进入更复杂的内容。
示例二:Gemma
让我们在一个实际的例子中测试TunableOp:Gemma 2B,这是Google开源的一个轻量级语言模型。当在完整模型上使用TunableOp时,*我们应该尽量减少或避免动态形状*!这是因为TunableOp会对每一个遇到的_唯一GEMM_进行详尽的搜索。如果有数百甚至数千个独特的形状需要调整,这将花费相当长的时间!
在使用大型语言模型进行推理时,动态形状在两个地方引入:
-
填充阶段 - 在此阶段,模型处理输入提示并生成第一个标记。如果输入的长度不同,不同的形状将在模型中流动;对于每个新的输入提示长度,我们将遇到(并调整)多个新的GEMM。
我们通过填充输入序列来解决这个问题. 在极端情况下,我们可以将所有输入填充到最大输入长度。但是,这并不高效,因为对于较短的提示,我们将浪费在填充标记上的大量计算!*一个好的中间方案是离散化输入序列长度,例如填充到8的倍数*(比如序列长度7填充到8,14填充到16等)。事实上,HuggingFace的tokenizers通过 pad_to_multiple_of 参数支持内置的填充。或者,离散化到2的幂数也是一个不错的选择。
-
生成阶段(kv缓存) - 在生成第一个标记之后,LLM通过将上一次迭代的输出传递回输入,自动回归生成后续标记。在生成过程中,我们使用称为*kv缓存*的技术,这是一个推理时的优化,可以减少冗余计算(关于kv缓存的更多详细信息,请参阅此文章)。*然而,这个kv缓存引入了更多的动态形状!*随着每个新标记的生成,kv缓存的大小会增加,在每次迭代中引入多个新的GEMM需要调整。
我们通过使用“静态”kv缓存来解决这个问题。本质上,我们会前期分配一个最大大小的kv缓存,然后在每一步中屏蔽未使用的值。如果模型没有内置支持,设置静态kv缓存可能很困难。我们将在此使用HuggingFace的静态kv缓存,此支持包括Gemma在内的多个模型。
在尝试对LLMs进行`torch.compile`时会遇到上述两个问题,如 PyTorch’s GPT-Fast博文中讨论,然而它们有稍微不同的解决方案。为了解决填充阶段问题,他们使用 动态形状分别编译填充部分的网络,同时为生成阶段使用标准编译和静态kv缓存。
下面显示了`src/llm.py`的内容,我们将用它来对模型的延迟(即batch_size=1)进行评估,并在代码中提供注释说明各部分功能。
注意
由于`gemma`模型是受限访问的,你需要提供自己的Huggingface令牌来下载和运行此脚本。
import os
import torch
import transformers
import click# Use Click to parse command-line arguments
@click.command
@click.option("--tune", is_flag=True)
def main(tune):# Set some variablesseq_len = 256 # Max sequence length to generaten_batches = 8 # Number of batches to timen_warmup = 2 # Number of warmup batchesprompt = ["Hello Earthlings!"] # Input prompt# 我们可以通过在代码中设置环境变量来启用调整 - 只要在使用torch之前完成即可。# 这通常比每次传递环境变量要简便if tune:print("Tuning enabled")os.environ["PYTORCH_TUNABLEOP_ENABLED"] = "1" # Enable tuningos.environ["PYTORCH_TUNABLEOP_FILENAME"] = "src/llm_result.csv" # Specify output file# Retrieve the model and tokenizermodel = "google/gemma-2b"tokenizer = transformers.AutoTokenizer.from_pretrained(model)model = transformers.AutoModelForCausalLM.from_pretrained(model).to("cuda")# Set the model to use a static KV cache - see https://huggingface.co/docs/transformers/main/en/llm_optims?static-kv=generation_config#static-kv-cache-and-torchcompilemodel.generation_config.cache_implementation = "static"# Tokenize our input.# Use padding with `pad_to_multiple_of` to minimize the number of GEMMs to tune# Larger values => Less GEMMs to tune, but more potential overhead for shorter promptsinputs = tokenizer(prompt, return_tensors="pt", padding=True, pad_to_multiple_of=8).to("cuda")# Determine how many tokens to generate. Here, we need to subtract the number of tokens in the prompt to keep the same# overall sequence lengthn_tokens = seq_len - inputs["input_ids"].shape[1] # number of tokens to generatet0 = torch.cuda.Event(enable_timing=True)t1 = torch.cuda.Event(enable_timing=True)for i in range(n_batches + n_warmup):# Don't start timing until we've finished our warmup itersif i == n_warmup:torch.cuda.synchronize()t0.record()# Generate!model.generate(**inputs,max_new_tokens=n_tokens, # Force the model to generate exactly n_tokens before stoppingmin_new_tokens=n_tokens,use_cache=True, # Ensure we use the kv-cache)# Complete timing, synchronize, and compute elapsed timet1.record()torch.cuda.synchronize()dt = t0.elapsed_time(t1) / 1000tokens_per_second = n_batches * n_tokens / dtprint(f" Tokens/second: {tokens_per_second:0.4f} ({n_tokens*n_batches} tokens, {dt:0.2f} seconds)")if __name__ == "__main__":main()
首先,让我们在未启用调优的情况下运行脚本:
python src/llm.py
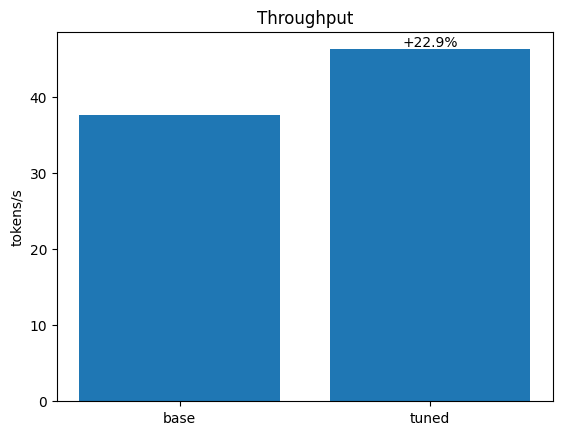
Tokens/second: 37.5742 (1984 tokens, 52.80 seconds)
我们实现了37.6个tokens/s的吞吐量。接下来,让我们启用调优。这里,我们使用命令行参数`--tune`,我们的脚本将解析它,然后为我们设置相关的环境变量。
Tuning will take some time, but will be silent, as we have not turned on verbosity! Feel free to edit the script to turn on verbosity.
python src/llm.py --tune
Tuning enabledTokens/second: 46.2401 (1984 tokens, 42.91 seconds)
仅仅通过启用调优,我们就获得了22.9%的加速(37.6 -> 46.2 tokens/s)!
结论
PyTorch TunableOp 通过调整模型中的 GEMMs,可以成为加速 AMD 上机器学习工作负载的一种简便且有效的方式。然而,在使用 TunableOp 时需要注意以下几点:
-
调整过程需要时间——根据工作负载的不同,调整可能比运行还要花费更多的时间。然而,这**是一次性的成本**,因为调整结果可以重复使用和扩展。这意味着,对于较长的训练任务和模型服务,以及在迭代开发过程中,调整将特别有效。
-
应避免或尽量减少动态形状,以减少需要调整的独特 GEMMs 的数量。
考虑到这些因素,将 TunableOp 集成到 PyTorch 工作流中,是在 AMD GPU 上实现适度性能提升的一种简便方法,而无需更改现有代码,只需最少的额外工作。
进一步阅读
TunableOp 只是几种推理优化技术之一。要了解更多,请参见 在 AMD GPU 上进行大型语言模型(LLM)推理优化。
附录
运行本博客
前提条件
要运行本文中的代码,您需要具备以下条件:
-
硬件:AMD GPU——请参见兼容 GPU 列表
-
操作系统:Linux——请参见 支持的 Linux 发行版
-
软件:ROCm——请参见 安装说明
安装
运行本文中的代码有两种方式。首先,您可以使用 Docker(推荐),或者您可以构建自己的 Python 环境并直接在主机上运行。
1. 在 Docker 中运行
使用 Docker 是构建所需环境的最简单和最可靠的方法。
-
确保您已安装 Docker。如果没有,请参见 安装说明
-
确保您在主机上安装了
amdgpu-dkms(ROCm 附带),以便从 Docker 内访问 GPU。请参见 ROCm Docker 说明。 -
克隆仓库,并进入博客目录
git clone git@github.com:ROCm/rocm-blogs.git cd rocm-blogs/blogs/artificial-intelligence/pytorch-tunableop
-
构建并启动容器。有关构建过程的详细信息,请参见
dockerfile。这将启动容器中的 Shell。cd docker docker compose build docker compose run blog
2. 在主机上运行
如果您不想使用 Docker,也可以直接在本机器上运行本博客——尽管这需要多做一些工作。
-
前提条件:
-
安装 ROCm 6.0.x
-
确保已安装 Python 3.10
-
安装 PDM——这里用于创建可重现的 Python 环境
-
-
在本博客的根目录中创建 Python 虚拟环境:
pdm sync
-
使用
pdm run前缀运行本文中的命令,例如:pdm run python src/matmul.py
相关文章:

使用 PyTorch TunableOp 加速 ROCm 上的模型
Accelerating models on ROCm using PyTorch TunableOp — ROCm Blogs (amd.com) 在这篇博客中,我们将展示如何利用 PyTorch TunableOp 在 AMD GPU 上使用 ROCm 加速模型。我们将讨论通用矩阵乘法(GEMM)的基础知识,展示调优单个 G…...

配置Springboot+vue项目在ubuntu20.04
一、jdk1.8环境配置 (1) 安装jdk8: sudo apt-get install openjdk-8-jdk (2) 检查jdk是否安装成功: java -version(3) 设置JAVA_HOME: echo export JAVA_HOME/usr/lib/jvm/java-17-openjdk-amd64 >> ~/.bashrc echo export PATH$J…...

基于SpringBoot的在线教育系统【附源码】
基于SpringBoot的在线教育系统 效果如下: 系统登录页面 系统管理员主页面 课程管理页面 课程分类管理页面 用户主页面 系统主页面 研究背景 随着互联网技术的飞速发展,线上教育已成为现代教育的重要组成部分。在线教育系统以其灵活的学习时间和地点&a…...

国土安全部发布关键基础设施安全人工智能框架
美国国土安全部 (DHS) 发布建议,概述如何在关键基础设施中安全开发和部署人工智能 (AI)。 https://www.dhs.gov/news/2024/11/14/groundbreaking-framework-safe-and-secure-deployment-ai-critical-infrastructure 关键基础设施中人工智能的角色和职责框架 https:/…...

散户持股增厚工具:智能T0算法交易
最近市场很多都说牛市,但是大多数朋友怎么来的又怎么吐出去了。这会儿我们用T0的智能算法交易又可以增厚我们的持仓收益。简单来说,就是基于用户原有的股票持仓,针对同一标的,配合智能T0算法,每天全自动操作࿰…...

28、js基本数据类型
<!DOCTYPE html> <html> <head> <meta charset"UTF-8"> <title></title> </head> <body> </body> <script> //JS是弱语言类型,只有一种var,由隐藏类型 //基本数据类型…...

MacOS下的Opencv3.4.16的编译
前言 MacOS下编译opencv还是有点麻烦的。 1、Opencv3.4.16的下载 注意,我们使用的是Mac,所以ios pack并不能使用。 如何嫌官网上下载比较慢的话,可以考虑在csdn网站上下载,应该也是可以找到的。 2、cmake的下载 官网的链接&…...

[免费]SpringBoot+Vue毕业设计论文管理系统【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的SpringBootVue毕业设计论文管理系统,分享下哈。 项目视频演示 【免费】SpringBootVue毕业设计论文管理系统 Java毕业设计_哔哩哔哩_bilibili 项目介绍 现代经济快节奏发展以及不断完善升级的信…...

科研深度学习:如何精选GPU以优化服务器性能
GPU在科研深度学习中的核心价值 在科研深度学习的范畴内,模型训练是核心环节。面对大规模参数的模型训练,这往往是科研过程中最具挑战性的部分。传统CPU的计算模式在处理复杂模型时,训练时间会随着模型复杂度的增加而急剧增长,这…...

嵌入式系统与OpenCV
目录 一、OpenCV 简介 二、嵌入式 OpenCV 的安装方法 1. Ubuntu 系统下的安装 2. 嵌入式 ARM 系统中的安装 3. Windows10 和树莓派系统下的安装 三、嵌入式 OpenCV 的性能优化 1. 介绍嵌入式平台上对 OpenCV 进行优化的必要性。 2. 利用嵌入式开发工具,如优…...

C++学习——编译的过程
编译的过程——预处理 引言预处理包含头文件宏定义指令条件编译 编译、链接 引言 C程序编译的过程:预处理 -> 编译(优化、汇编)-> 链接 编译和链接的内容可以查阅这篇文章(点击查看) 预处理 编译预处理是指&a…...

接口测试和单元测试
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 接口测试的本质:就是通过数据驱动,测试类里面的函数。 单元测试的本质:通过代码级别,测试函数。 单元测试的框架…...
)
redis工程实战介绍(含面试题)
文章目录 redis单线程VS多线程面试题**redis是多线程还是单线程,为什么是单线程****聊聊redis的多线程特性和IO多路复用****io多路复用模型****redis如此快的原因** BigKey大批量插入数据测试数据key面试题海量数据里查询某一固定前缀的key如果生产上限值keys * ,fl…...

深度学习:GPT-1的MindSpore实践
GPT-1简介 GPT-1(Generative Pre-trained Transformer)是2018年由Open AI提出的一个结合预训练和微调的用于解决文本理解和文本生成任务的模型。它的基础是Transformer架构,具有如下创新点: NLP领域的迁移学习:通过最…...

内嵌编辑器+AI助手,Wave Terminal打造终端新体验
作为新一代终端工具的佼佼者,Wave Terminal 突破性地将传统命令行与现代图形界面相结合,为开发者带来全新的操作体验。这款创新的开源终端工具跨越了操作系统的界限,完美支持 macOS、Windows 和 Linux 平台,特别适合需要频繁处理远…...

《Object类》
目录 一、Object类 1.1 定义与地位 1.2 toString()方法 1.3 equals()方法 1.4 hashcode()方法 一、Object类 1.1 定义与地位 Object类是Java语言中的根类,所有的类(除了Object类)都直接或间接继承自Object。这就意味着在Java中…...

GPTZero:高效识别AI生成文本,保障学术诚信与内容原创性
产品描述 GPTZero 是一款先进的AI文本检测工具,专为识别由大型语言模型(如ChatGPT、GPT-4、Bard等)生成的文本而设计。它通过分析文本的复杂性和一致性,判断文本是否可能由人类编写。GPTZero 已经得到了超过100家媒体机构的报道&…...
)
2024 APMCM亚太数学建模C题 - 宠物行业及相关产业的发展分析和策略 完整参考论文(1)
摘要 近年来,中国宠物食品行业迅速增长,但面临复杂的国际形势和多变的市场环境,因此科学地分析和预测该行业的发展趋势至关重要。本研究通过构建多个机器学习与统计回归模型,量化分析中国宠物食品行业的关键驱动因素,预测未来宠物食品总产值和出口值。 在数据处理部分,…...

深入实践 Shell 脚本编程:高效自动化操作指南
一、什么是 Shell 脚本? Shell 脚本是一种用 Shell 编写的脚本程序,用于执行一系列的命令。它是 Linux/Unix 系统中自动化管理任务的利器,能够显著提升工作效率,特别适合批量处理文件、监控系统状态、自动部署等任务。 二、Shell…...

用代码如何创建Python代理池
1. 导入所需库 这里使用requests库来发送HTTP请求获取网页内容和测试代理是否可用,BeautifulSoup用于解析网页(比如从提供代理列表的网页提取代理信息),random用于随机选择代理,time用于设置请求间隔等操作。 2. 获取…...

python蓝桥杯刷题2
1.最短路 题解:这个采用暴力枚举,自己数一下就好了 2.门牌制作 题解:门牌号从1到2020,使用for循环遍历一遍,因为range函数无法调用最后一个数字,所以设置成1到2021即可,然后每一次for循环&…...

跨境出海安全:如何防止PayPal账户被风控?
今天咱们聊聊那些让人头疼的事儿——PayPal账户被风控。不少跨境电商商家反馈,我们只是想要安安静静地在网上做个小生意,结果不知道为什么,莫名其妙账户就被冻结了。 但其实每个封禁都是有原因的,今天就来给大家分享分享可能的原…...

学习与理解LabVIEW中多列列表框项名和项首字符串属性
多列列表框控件在如下的位置: 可以对该控件右击,如下位置,即可设置该控件的显示项: 垂直线和水平线指的是上图中组成单元格的竖线和横线(不包括行首列首) 现在介绍该多列列表框的两个属性,分别…...

多摩川编码器协议及单片机使用
参考: https://blog.csdn.net/qq_28149763/article/details/132718177 https://mp.weixin.qq.com/s/H4XoR1LZSMH6AxsjZuOw6g 1、多摩川编码器协议 多摩川数据通讯是基于485 硬件接口标准NRZ 协议,通讯波特率为2.5Mbps 的串行通讯,采用差分两…...

小雪时节,阴盛阳衰,注意禁忌
宋张嵲《小雪作》 霜风一夜落寒林,莽苍云烟结岁阴。 把镜渐无勋业念,爱山唯驻隐沦心。 冰花散落衡门静,黄叶飘零一迳深。 世乱身穷无可奈,强将悲慨事微吟。 网络图片:小雪时节 笔者禁不住喟然而叹:“冰…...

shell脚本
一.要求 1.接收用户部署的服务名称 2.判断服务是否安装 已安装;自定义网站配置路径为/www;并创建共享目录和网页文件;重启服务 没有安装;安装对应的软件包 3.测试 判断服务是否成功运行; 已运行&#…...

[371]基于springboot的高校实习管理系统
摘 要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统高校实习管理系统信息管理难度大,容错率低&am…...

NVR管理平台EasyNVR多个NVR同时管理:全方位安防监控视频融合云平台方案
EasyNVR是基于端-边-云一体化架构的安防监控视频融合云平台,具有简单轻量的部署方式与多样的功能,支持多种协议(如GB28181、RTSP、Onvif、RTMP)和设备类型(IPC、NVR等),提供视频直播、录像、回放…...

Trains-04练习-函数
#基础练习 练习目标 01.计算车费 题目描述 小红打车,起步价8元(3公里), 每公里收费 2 元,她打车行驶了 n 公里,通过函数封装并计算车费 输入描述 输入一个公里数 输出描述 输出应付车费 示例 输入: 5 输出: 1…...

常用docker应用部署,wordpress、mysql、tomcat、nginx、redis
案例一、 wordpress 创建网络 docker network create wordpress-network创建容器 docker volume create --name mariadb_data docker run -d --name mariadb --restartalways \-p 3306:3306 \--env MARIADB_ALLOW_EMPTY_ROOT_PASSWORDyes \--env ALLOW_EMPTY_PASSWORDyes \--…...

设计模式之 模板方法模式
模板方法模式是行为型设计模式的一种。它定义了一个算法的骨架,并将某些步骤的实现延迟到子类中。模板方法模式允许子类在不改变算法结构的情况下重新定义算法的某些特定步骤。 模板方法模式的核心在于: 封装算法的骨架:通过父类中的模板方…...

GitLab|数据迁移
注意:新服务器GitLab版本需和旧版本一致 在旧服务器执行命令进行数据备份 gitlab-rake gitlab:backup:create 备份数据存储在 /var/opt/gitlab/backups/ 将备份数据传输到新服务器的/var/opt/gitlab/backups/下,并修改文件权限(下载前和上传…...

[CISCN 2019初赛]Love Math 详细题解
知识点: 数学函数转换字符串 GET传参外部赋值 eval()函数解析执行命令 PHP动态调用函数名 源码: <?php error_reporting(0); //听说你很喜欢数学,不知道你是否爱它胜过爱flag if(!isset($_GET[c])){show_source(__FILE__); }else{//例子 c20-1$content $_GET[c];if (…...

第N8周:使用Word2vec实现文本分类
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 本周任务: 结合Word2Vec文本内容预测文本标签 加载数据 import torch import torch.nn as nn import torchvision from torchvision import tra…...

SQL,力扣题目1635,Hopper 公司查询 I
一、力扣链接 LeetCode_1635 二、题目描述 表: Drivers ---------------------- | Column Name | Type | ---------------------- | driver_id | int | | join_date | date | ---------------------- driver_id 是该表的主键(具有唯一值的列)。 该表的每一行…...

【Apache Paimon】-- 6 -- 清理过期数据
目录 1、简要介绍 2、操作方式和步骤 2.1、调整快照文件过期时间 2.2、设置分区过期时间 2.2.1、举例1 2.2.2、举例2 2.3、清理废弃文件 3、参考 1、简要介绍 清理 paimon (表)过期数据可以释放存储空间,优化资源利用并提升系统运行效率等。本文将介绍如何清理 Paim…...

nginx 配置lua执行shell脚本
1.需要nginx安装lua_nginx_module模块,这一步安装时,遇到一个坑,nginx执行configure时,一直提示./configure: error: unsupported LuaJIT version; ngx_http_lua_module requires LuaJIT 2.x。 网上一堆方法都试了,都…...

C++:设计模式-单例模式
单例模式(Singleton Pattern)是一种设计模式,确保一个类只有一个实例,并且提供全局访问点。实现单例模式的关键是防止类被多次实例化,且能够保证实例的唯一性。常见的实现手法包括懒汉式、饿汉式、线程安全的懒汉式等。…...

优先级队列
概述 优先级队列(Priority Queue)是一种抽象数据类型(ADT),类似于普通的队列,不同之处在于每个元素都有一个与之相关的优先级。在优先级队列中,元素的出队顺序不是按照它们被入队的顺序&#x…...

一、Docker 安装集
一、Docker CentOS https://docs.docker.com/engine/install/centos/ 在 CentOS 上安装 Docker Engine # Docker要求CentOS系统的内核版本高于3.10:# Docker从1.13版本之后,采用时间线的方式作为版本号: 1. 分为社区版CE和企业版EE。 2. 社…...

软件测试——自动化测试常见函数
在上一篇文章软件测试——自动化测试概念篇-CSDN博客中,给大家演示了一下自动化程序,而本篇文章会带大家详细学习selenium库。 selenium库是python官方的库,里面包含了很多操控浏览器的函数。 本节重点 元素定位操作测试对象窗口等待导航弹…...

SEO网站都用哪里的服务器
在当今这个信息爆炸的时代,网站的加载速度已经成为衡量其质量的重要指标之一。对于SEO网站来说,速度不仅关乎用户体验,更是影响搜索引擎排名的重要因素。在众多服务器提供商中,鼎峰新匯凭借其卓越的性能和优质的服务,成…...

【从零开始的LeetCode-算法】3233. 统计不是特殊数字的数字数量
给你两个 正整数 l 和 r。对于任何数字 x,x 的所有正因数(除了 x 本身)被称为 x 的 真因数。 如果一个数字恰好仅有两个 真因数,则称该数字为 特殊数字。例如: 数字 4 是 特殊数字,因为它的真因数为 1 和…...
)
shell脚本(五)
声明! 学习视频来自B站up主 泷羽sec 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&#…...

Windows中指定路径安装DockerDesktop
Windows中指定路径安装DockerDesktop 文章目录 Windows中指定路径安装DockerDesktop1. 先卸载干净(如果已安装过的话)2. 指定路径安装1. 新建需要安装的文件目录2. 指定路径安装 3. WSL子系统下载1. GitHub下载地址2. 指定版本直接下载 Widnows中直接安装docker desktop&#x…...

阿里云私服地址
1.解压apache-maven-3.6.1-bin 2.配置本地仓库:修改conf/dettings.xml中的<localReoisitory>为一个指定目录。56行 <localRepository>D:\apache-maven-3.6.1-bin\apache-maven-3.6.1\mvn_repo</localRepository> 3.配置阿里云私服:…...

深入探究 Vue 实例挂载过程与场景 —— 代码实例详解
Vue 实例挂载过程及使用场景分析 Vue 实例的挂载过程是 Vue 应用启动的核心,它决定了 Vue 组件如何与 DOM 进行绑定。在理解 Vue 实例挂载的过程后,我们可以根据不同的使用场景来选择合适的挂载方式。下面详细讲解 Vue 实例的挂载过程、常见使用场景,并通过实际项目示例进行…...

特征交叉-MaskNet文章总结代码实现
MaskNet 这个模型是微博21年提出的,23年twitter(X)开源的推荐系统排序模块使用的backbone结构。 核心思想是认为DNN为主的特征交叉是addictive,交叉效率不高;所以设计了一种multiplicatvie的特征交叉 如何设计muliplicative特征交叉呢&#x…...

【第八课】Rust中的函数与方法
目录 前言 函数指针 函数当作另一个函数的参数 函数当作另一个函数的返回值 闭包 方法 关联函数 总结 前言 在前面几课中,我们都或多或少的接触到了rust中的函数,rust中的函数和其他语言的并没有什么不同,简单的语法不在这篇文章中赘…...
)
PyQt飞机大战游戏(附下载地址)
欢迎下载体验! 文件大小:22.9 M 下载地址:链接:https://wwrr.lanzoul.com/iybV22frvcng pyqt5-飞机大战 一.前言 up主最近高产,再给大家分享一个博主开发的小游戏-飞机大战,这是一款飞行射击游…...