python pandas模块
python pandas模块
终于也到介绍pandas的时候了,python中用于处理data的一个lib
从wiki中找到的关于pandas的介绍,如下,
Original author(s) Wes McKinney
Developer(s) Community
Initial release 11 January 2008; 17 years ago [citation needed]
Stable release
2.2.3[1] / 20 September 2024; 5 months ago
Preview release
2.0rc1 / 15 March 2023
Repository
github.com/pandas-dev/pandas Edit this at Wikidata
Written in Python, Cython, C
Operating system Cross-platform
Type Technical computing
License New BSD License
Website pandas.pydata.org
可以看的出来,pandas的诞生的很晚,而且时使用python/Cython/C开发的,自然就成了python中处理data的lib。
可以注意到的是,pandas不是python的内置的lib,在使用pandas时候,需要install,脚本中import pandas
一些pandas的优势如下,
Some other notes
pandas is fast. Many of the low-level algorithmic bits have been extensively tweaked in Cython code. However, as with anything else generalization usually sacrifices performance. So if you focus on one feature for your application you may be able to create a faster specialized tool.
pandas is a dependency of statsmodels, making it an important part of the statistical computing ecosystem in Python.
pandas has been used extensively in production in financial applications.
pandas处理的数据结构
Data structures
Dimensions / Name / Description
Series / 1D / labeled homogeneously-typed array
DataFrame / General 2D / labeled, size-mutable tabular structure with potentially heterogeneously-typed column
官网材料:
https://pandas.pydata.org/docs/getting_started/intro_tutorials/01_table_oriented.html
目录:
What kind of data does pandas handle?
How do I read and write tabular data?
How do I select a subset of a DataFrame?
How do I create plots in pandas?
How to create new columns derived from existing columns
How to calculate summary statistics
How to reshape the layout of tables
How to combine data from multiple tables
How to handle time series data with ease
How to manipulate textual data
(下内容来自官网内容)
pandas 处理什么样的数据?#
加载 pandas 包并开始使用它,请导入该包。社区一致将 pandas 的别名设为 pd,因此在所有 pandas 文档中,将 pandas 作为 pd 导入被视为标准做法。
pandas 数据表格表示#

定义一个DataFrame
#Python 2.7.12 (default, Oct 6 2016, 14:52:33)
#[GCC 4.8.1] on linux2
#Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas as pd
>>> df = pd.DataFrame(
... {
... "Name": [
... "Braund, Mr. Owen Harris",
... "Allen, Mr. William Henry",
... "Bonnell, Miss. Elizabeth"
... ],
... "Age":[
... 22, 35, 58
... ],
... "Sex":[
... "male","male","female"
... ]
... }
... )
>>> dfAge Name Sex
0 22 Braund, Mr. Owen Harris male
1 35 Allen, Mr. William Henry male
2 58 Bonnell, Miss. Elizabeth female
要手动将数据存储在表格中,创建一个DataFrame。使用 Python 字典列表时,字典的键将用作列标题,每个列表中的值作为DataFrame的列。
一个DataFrame是一个二维数据结构,可以存储不同类型的数据(包括字符、整数、浮点值、分类数据等)在列中。它类似于电子表格、SQL 表或 R 语言中的data.frame。
表格有 3 列,每列都有一个列标签。列标签分别是姓名,年龄和性别。
列姓名包含文本数据,每个值都是字符串,列年龄是数字,列性别也是文本数据。
每个 DataFrame 中的列是一个 Series #

我只是想处理列Age中的数据
In [4]: df[“Age”]
Out[4]:
0 22
1 35
2 58
Name: Age, dtype: int64
选择 pandas 的单个列时,结果是一个 pandas 系列。要选择列,请使用列标签在方括号[]中。
你也可以从头创建一个 Series:
In [5]: ages = pd.Series([22, 35, 58], name=“Age”)
In [6]: ages
Out[6]:
0 22
1 35
2 58
Name: Age, dtype: int64
pandas 的 Series 没有列标签,因为它只是一个 DataFrame 的单列。Series 有行标签。
对 DataFrame 或 Series 做些什么#
我想知道乘客的最大年龄
In [7]: df[“Age”].max()
Out[7]: 58
或者对Series:
In [8]: ages.max()
Out[8]: 58
就像max()方法所展示的,你可以对一个 DataFrame 或 Series。pandas 提供了许多功能,每个功能都是你可以应用到 DataFrame 或 Series 上的一个方法。由于方法是函数,别忘了使用括号()。
我对数据表中的数值数据的一些基本统计感兴趣
In [9]: df.describe()
Out[9]:
Age
count 3.000000
mean 38.333333
std 18.230012
min 22.000000
25% 28.500000
50% 35.000000
75% 46.500000
max 58.000000
describe() 方法可以快速提供 DataFrame 中数值数据的概览。由于 姓名 和 性别 列是文本数据,默认情况下这些列不会被 describe() 方法考虑。
许多 pandas 操作返回一个DataFrame或一个Series。例如, describe()方法就是一个 pandas 操作返回一个 pandasSeries或一个 pandasDataFrame的例子。
NOTE:
import pandas as pd
DataFrame
Series
max()
describe()
如何读取和写入表格数据?#

In [2]: titanic = pd.read_csv(“data/titanic.csv”)
pandas 提供了 read_csv() 函数,用于将存储在 CSV 文件中的数据读取到一个 pandas DataFrame 中。pandas 支持多种不同的文件格式或数据源(CSV、Excel、SQL、JSON、Parquet 等),每种格式前缀都是 read_*。
读取数据后,请务必检查数据。默认情况下,显示一个 DataFrame 时,将显示前 5 行和后 5 行:
In [3]: titanic
Out[3]:
PassengerId Survived Pclass … Fare Cabin Embarked
0 1 0 3 … 7.2500 NaN S
1 2 1 1 … 71.2833 C85 C
2 3 1 3 … 7.9250 NaN S
3 4 1 1 … 53.1000 C123 S
4 5 0 3 … 8.0500 NaN S
… … … … … … … …
886 887 0 2 … 13.0000 NaN S
887 888 1 1 … 30.0000 B42 S
888 889 0 3 … 23.4500 NaN S
889 890 1 1 … 30.0000 C148 C
890 891 0 3 … 7.7500 NaN Q
[891 rows x 12 columns]
我想查看一个 pandas DataFrame 的前 8 行。
In [4]: titanic.head(8)
Out[4]:
PassengerId Survived Pclass … Fare Cabin Embarked
0 1 0 3 … 7.2500 NaN S
1 2 1 1 … 71.2833 C85 C
2 3 1 3 … 7.9250 NaN S
3 4 1 1 … 53.1000 C123 S
4 5 0 3 … 8.0500 NaN S
5 6 0 3 … 8.4583 NaN Q
6 7 0 1 … 51.8625 E46 S
7 8 0 3 … 21.0750 NaN S
[8 rows x 12 columns]
要查看 DataFrame 的前 N 行,请使用head()方法,并将所需的行数(在这种情况下为 8)作为参数传递。
可以通过请求 pandas 的 dtypes 属性来检查 pandas 对每一列数据类型的解释:
对于每一列,使用的数据类型都列出来了。在这个 DataFrame 中,数据类型是整数(int64),浮点数(float64)和字符串(object)。
当询问数据类型时,不需要使用括号! dtypes 是 DataFrame 和 Series 的属性。DataFrame 或 Series 的属性不需要使用括号。属性表示 DataFrame/Series 的特征,而方法(需要使用括号)会对 DataFrame/Series 进行操作。 如 第一教程 中介绍的 DataFrame/Series 所示。
请求将泰坦尼克号数据以电子表格的形式提供。
In [6]: titanic.to_excel(“titanic.xlsx”, sheet_name=“passengers”, index=False)
而read_*函数用于将数据读入 pandas,to_方法用于存储数据。to_excel()方法用于将数据存储为 Excel 文件。在这个例子中,sheet_name被命名为乘客,而不是默认的Sheet1。通过设置 to_ methods are used to store data. The to_excel() method stores the data as an excel file. In the example here, the sheet_name is named passengers instead of the default Sheet1. By setting index=False 不保存行索引标签到电子表格中。
对DataFrame的技术总结感兴趣
In [9]: titanic.info()
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
方法info()提供了关于一个 DataFrame的技术信息,所以让我们更详细地解释输出:
-
它确实是一个DataFrame。
-
有 891 条记录,即 891 行。
-
每一行都有一个行标签(即索引),其值从 0 到 890 不等。
-
表格有 12 列。大多数列对每一行都有一个值(所有值均为非空)。有些列确实有缺失值,少于 891 个非空值。
-
列姓名、性别、船舱和登船港口包含文本数据(字符串,即对象)。其他列包含数值数据,其中一些是整数(即整数),而另一些是实数(即浮点数)。
-
不同列中的数据类型(字符、整数等)通过列出 dtypes 来总结。
-
提供了大约需要多少内存来存储 DataFrame 的信息。
NOTE:
read_csv()
head()
tail()
dtypes
read_ read_excel()
to_* to_excel()
info()*
如何选择 DataFrame 的子集?#
如何从DataFrame中选择特定的列?#

泰坦尼克号数据原始数据
In [2]: titanic = pd.read_csv(“data/titanic.csv”)
In [3]: titanic.head()
Out[3]:
PassengerId Survived Pclass … Fare Cabin Embarked
0 1 0 3 … 7.2500 NaN S
1 2 1 1 … 71.2833 C85 C
2 3 1 3 … 7.9250 NaN S
3 4 1 1 … 53.1000 C123 S
4 5 0 3 … 8.0500 NaN S
[5 rows x 12 columns]
对泰坦尼克号乘客的年龄感兴趣
In [4]: ages = titanic[“Age”]
In [5]: ages.head()
Out[5]:
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
Name: Age, dtype: float64
要选择单个列,使用方括号[]和感兴趣的列名。
每一列在 DataFrame 中是一个 Series。当我们选择单列时,返回的对象是一个 pandas Series。我们可以通过检查输出的类型来验证这一点:
In [6]: type(titanic[“Age”])
Out[6]: pandas.core.series.Series
查看输出的 shape:
In [7]: titanic[“Age”].shape
Out[7]: (891,)
DataFrame.shape 是一个属性(请参阅读取和写入教程,属性不需要使用括号),包含 pandas Series 和 DataFrame 中的行数和列数:(nrows, ncolumns)。pandas Series 是一维的,只返回行数。
对泰坦尼克号乘客的年龄和性别感兴趣。
In [8]: age_sex = titanic[[“Age”, “Sex”]]
In [9]: age_sex.head()
Out[9]:
Age Sex
0 22.0 male
1 38.0 female
2 26.0 female
3 35.0 female
4 35.0 male
要选择多个列,请在选择括号内使用列名列表[]。
返回的数据类型是 pandas DataFrame:
In [10]: type(titanic[[“Age”, “Sex”]])
Out[10]: pandas.core.frame.DataFrame
In [11]: titanic[[“Age”, “Sex”]].shape
Out[11]: (891, 2)
选择返回了一个DataFrame,包含 891 行和 2 列。请记住,一个 DataFrame是二维的,具有行和列两个维度。
我如何从DataFrame中筛选特定行?
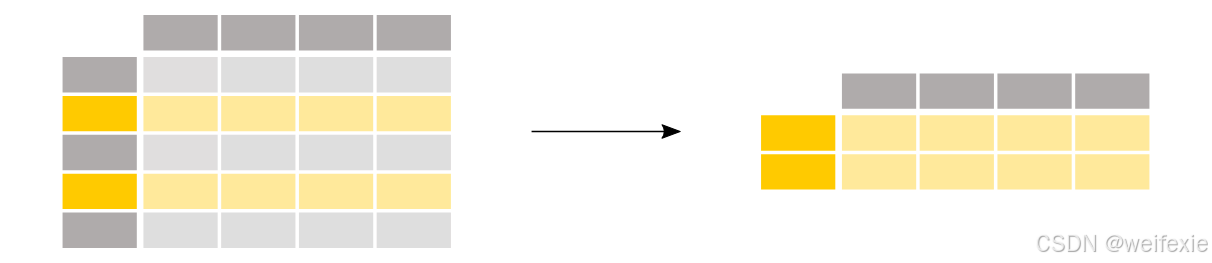
对年龄超过 35 岁的乘客感兴趣。
In [12]: above_35 = titanic[titanic[“Age”] > 35]
In [13]: above_35.head()
Out[13]:
PassengerId Survived Pclass … Fare Cabin Embarked
1 2 1 1 … 71.2833 C85 C
6 7 0 1 … 51.8625 E46 S
11 12 1 1 … 26.5500 C103 S
13 14 0 3 … 31.2750 NaN S
15 16 1 2 … 16.0000 NaN S
[5 rows x 12 columns]
要根据条件表达式选择行,请在选择括号内使用一个条件 []。
选择括号内的条件 泰坦尼克[“年龄”] > 35 会检查哪些行的 年龄 列的值大于 35:
In [14]: titanic[“Age”] > 35
Out[14]:
0 False
1 True
2 False
3 False
4 False
…
886 False
887 False
888 False
889 False
890 False
Name: Age, Length: 891, dtype: bool
条件表达式(如 >>,但也可以是 =, !=,<,<=,…)的输出实际上是一个包含布尔值(True 或 False)的 pandas Series,其行数与原始 DataFrame 相同。这样的 Series 可以用于通过将其放在选择括号 [] 之间来过滤 DataFrame。只有对于该值为 True 的行才会被选择。 的行才会被选择。
我们之前知道,原始的泰坦尼克DataFrame包含 891 行。让我们看看满足条件的行数,通过检查上面得到的shape属性来查看。 DataFrame.above_35:
In [15]: above_35.shape
Out[15]: (217, 12)
二等舱和三等舱的泰坦尼克乘客感兴趣。
In [16]: class_23 = titanic[titanic[“Pclass”].isin([2, 3])]
In [17]: class_23.head()
Out[17]:
PassengerId Survived Pclass … Fare Cabin Embarked
0 1 0 3 … 7.2500 NaN S
2 3 1 3 … 7.9250 NaN S
4 5 0 3 … 8.0500 NaN S
5 6 0 3 … 8.4583 NaN Q
7 8 0 3 … 21.0750 NaN S
[5 rows x 12 columns]
类似于条件表达式,isin() 条件函数会返回一个布尔值,表示每一行的值是否在提供的列表中。要根据这样的函数过滤行,可以在选择括号 [] 内使用该条件函数。在这种情况下,选择括号内的条件 titanic[“Pclass”].isin([2, 3]) 检查 Pclass 列的值是否为 2 或 3。
上述内容等价于筛选 class 为 2 或 3 的行,并使用 |(或)运算符将两个语句结合在一起:
In [18]: class_23 = titanic[(titanic[“Pclass”] == 2) | (titanic[“Pclass”] == 3)]
In [19]: class_23.head()
Out[19]:
PassengerId Survived Pclass … Fare Cabin Embarked
0 1 0 3 … 7.2500 NaN S
2 3 1 3 … 7.9250 NaN S
4 5 0 3 … 8.0500 NaN S
5 6 0 3 … 8.4583 NaN Q
7 8 0 3 … 21.0750 NaN S
[5 rows x 12 columns]
注意:
当结合多个条件语句时,每个条件必须用括号包围 ()。此外,不能使用 or/and 而需要使用 or 操作符 | 和 and 操作符 &。
想处理年龄已知的乘客数据
In [20]: age_no_na = titanic[titanic[“Age”].notna()]
In [21]: age_no_na.head()
Out[21]:
PassengerId Survived Pclass … Fare Cabin Embarked
0 1 0 3 … 7.2500 NaN S
1 2 1 1 … 71.2833 C85 C
2 3 1 3 … 7.9250 NaN S
3 4 1 1 … 53.1000 C123 S
4 5 0 3 … 8.0500 NaN S
[5 rows x 12 columns]
The notna() 条件函数返回一个布尔值,对于每行中不是 Null 值的项为 True。因此,可以将此与选择括号 [] 结合使用来过滤数据表。
你可能会好奇到底有什么变化,因为前 5 行的值仍然是相同的。一种验证方法是检查形状是否发生了变化:
In [22]: age_no_na.shape
Out[22]: (714, 12)
如何从DataFrame中选择特定的行和列?#

想要查询年龄超过 35 岁的乘客的名字
In [23]: adult_names = titanic.loc[titanic[“Age”] > 35, “Name”]
In [24]: adult_names.head()
Out[24]:
1 Cumings, Mrs. John Bradley (Florence Briggs Th…
6 McCarthy, Mr. Timothy J
11 Bonnell, Miss. Elizabeth
13 Andersson, Mr. Anders Johan
15 Hewlett, Mrs. (Mary D Kingcome)
Name: Name, dtype: object
在这种情况下,需要同时选择行和列,仅仅使用选择方括号 [] 已经不够了。此时需要在选择方括号 [] 前面使用 loc/iloc 操作符。 使用 loc/iloc 操作符时,方括号 [] 之前的部分是您想要选择的行,方括号 [] 之后的部分是您想要选择的列。
使用列名、行标签或条件表达式时,在选择括号[]前面使用loc操作符。在逗号前后部分,你可以使用单个标签、标签列表、标签切片、条件表达式或冒号。使用冒号表示你想要选择所有行或列。
使用列名、行标签或条件表达式时,在选择括号[]前面使用loc操作符。在逗号前后部分,你可以使用单个标签、标签列表、标签切片、条件表达式或冒号。使用冒号表示你想要选择所有行或列。
In [25]: titanic.iloc[9:25, 2:5]
Out[25]:
Pclass Name Sex
9 2 Nasser, Mrs. Nicholas (Adele Achem) female
10 3 Sandstrom, Miss. Marguerite Rut female
11 1 Bonnell, Miss. Elizabeth female
12 3 Saundercock, Mr. William Henry male
13 3 Andersson, Mr. Anders Johan male
… … … …
20 2 Fynney, Mr. Joseph J male
21 2 Beesley, Mr. Lawrence male
22 3 McGowan, Miss. Anna “Annie” female
23 1 Sloper, Mr. William Thompson male
24 3 Palsson, Miss. Torborg Danira female
[16 rows x 3 columns]
再次选取行和列的子集是一起完成的,仅仅使用选择括号 [] 已经不够了。如果具体感兴趣的是表格中某些行和/或列的位置,可以在选择括号 [] 前使用 iloc 操作符。
使用 loc 或 iloc 选择特定行和/或列时,可以为选定的数据分配新值。例如,将名称 anonymous 分配给第四列前三个元素:
In [26]: titanic.iloc[0:3, 3] = “anonymous”
In [27]: titanic.head()
Out[27]:
PassengerId Survived Pclass … Fare Cabin Embarked
0 1 0 3 … 7.2500 NaN S
1 2 1 1 … 71.2833 C85 C
2 3 1 3 … 7.9250 NaN S
3 4 1 1 … 53.1000 C123 S
4 5 0 3 … 8.0500 NaN S
[5 rows x 12 columns]
NOTE:
[]
loc/iloc
notna()
isin()
条件表达式 > < >= <= != >> <<
操作符 | &
我在 pandas 中如何创建图表?
In [1]: import pandas as pd
In [2]: import matplotlib.pyplot as plt
row_data path
https://github.com/pandas-dev/pandas/blob/main/doc/data/air_quality_no2.csv air_quality_no2.csv
In [3]: air_quality = pd.read_csv(“data/air_quality_no2.csv”, index_col=0, parse_dates=True)
In [4]: air_quality.head()
Out[4]:
station_antwerp station_paris station_london
datetime
2019-05-07 02:00:00 NaN NaN 23.0
2019-05-07 03:00:00 50.5 25.0 19.0
2019-05-07 04:00:00 45.0 27.7 19.0
2019-05-07 05:00:00 NaN 50.4 16.0
2019-05-07 06:00:00 NaN 61.9 NaN
注意:
使用 index_col 和 parse_dates 参数定义 read_csv 函数的结果的第一个(0th)列为索引,并将列中的日期转换为 Timestamp 对象。
快速查看一下数据。
In [5]: air_quality.plot()
Out[5]: <Axes: xlabel=‘datetime’>
In [6]: plt.show()
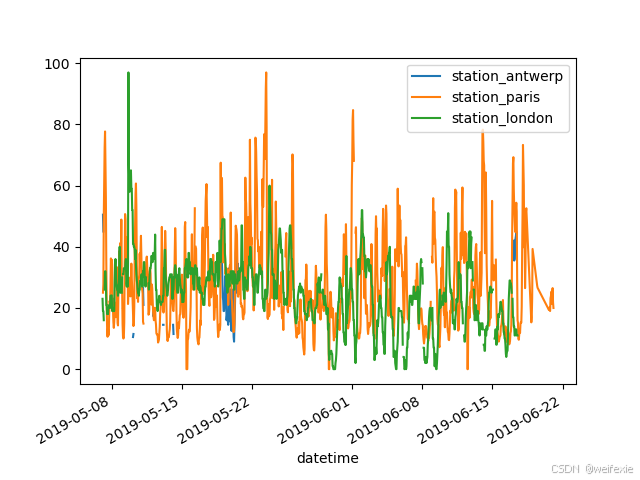
使用一个 DataFrame ,pandas 默认会为数据表中的每个数值列创建一条线图。
我只想绘制数据表中来自巴黎的列的图表。
In [7]: air_quality[“station_paris”].plot()
Out[7]: <Axes: xlabel=‘datetime’>
In [8]: plt.show()
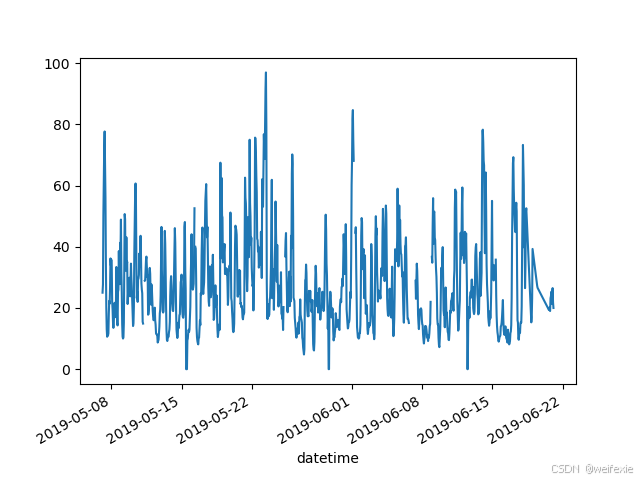
要绘制特定的列,请使用数据子集教程中的选择方法结合 plot() 方法。因此, plot() 方法适用于 Series 和 DataFrame 。
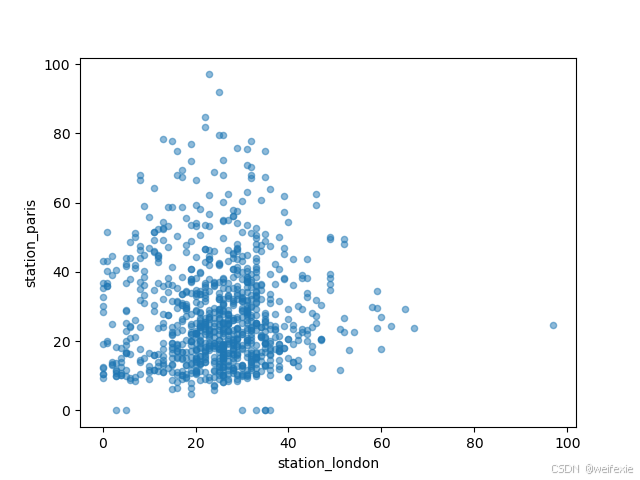
I want to visually compare the (NO_2) values measured in London versus Paris.我想可视化比较伦敦和巴黎的 (NO_2) 值。
In [9]: air_quality.plot.scatter(x=“station_london”, y=“station_paris”, alpha=0.5)
Out[9]: <Axes: xlabel=‘station_london’, ylabel=‘station_paris’>
In [10]: plt.show()
除了使用 plot 函数时默认的 line 图外,还有许多其他选项可以绘制数据。让我们使用标准 Python 代码来概览可用的绘图方法:
In [11]: [
…: method_name
…: for method_name in dir(air_quality.plot)
…: if not method_name.startswith(“_”)
…: ]
…:
Out[11]:
[‘area’,
‘bar’,
‘barh’,
‘box’,
‘density’,
‘hexbin’,
‘hist’,
‘kde’,
‘line’,
‘pie’,
‘scatter’]
注意:
在许多开发环境中,以及 IPython 和 Jupyter Notebook 中,使用 TAB 键可以概览可用的方法,例如 air_quality.plot. + TAB。
(一些关于Jupyter的介绍,官网:https://zh.wikipedia.org/wiki/Jupyter)
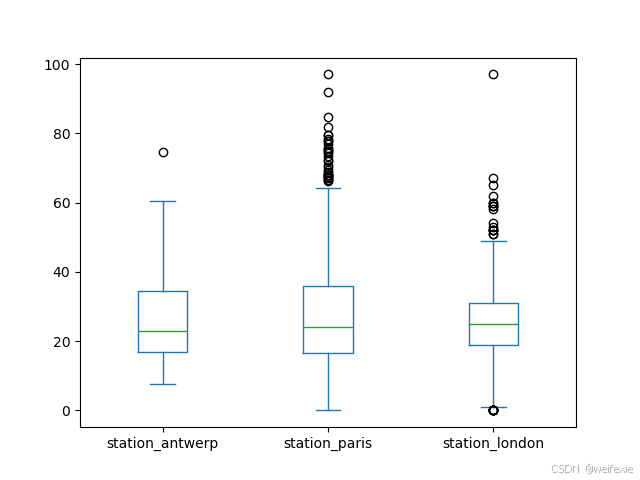
其中一个选项是 DataFrame.plot.box(),它指的是一个 箱形图。box() 方法适用于空气质量示例数据:
In [12]: air_quality.plot.box()
Out[12]: <Axes: >
In [13]: plt.show()
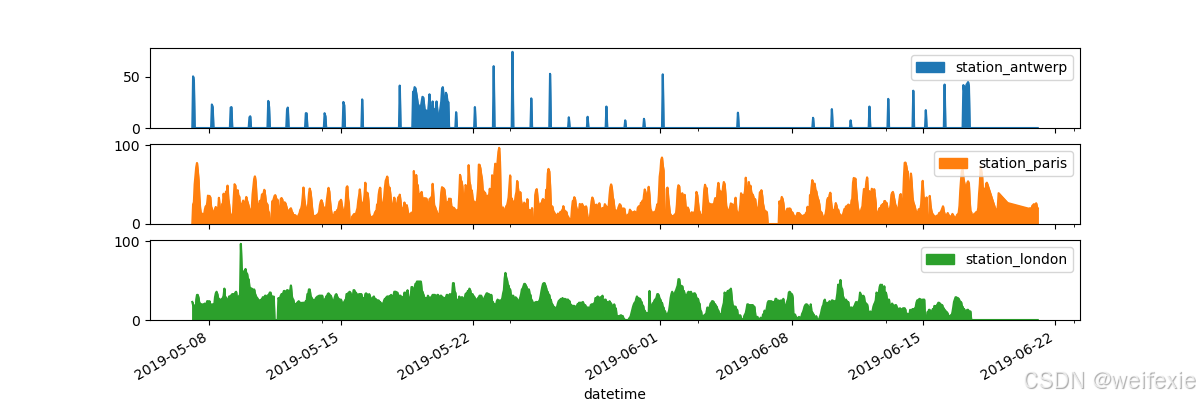
希望每个列在单独的子图中
In [14]: axs = air_quality.plot.area(figsize=(12, 4), subplots=True)
In [15]: plt.show()
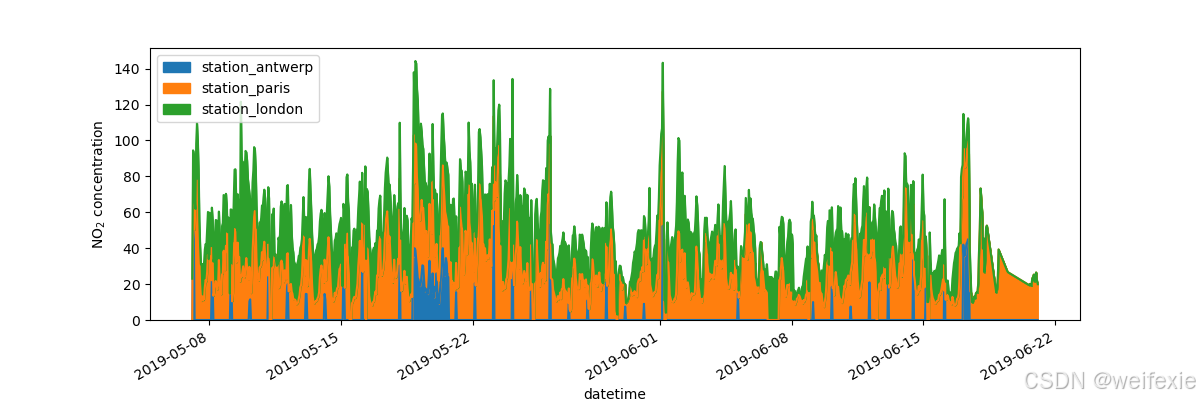
希望进一步自定义、扩展或保存生成的图表
In [16]: fig, axs = plt.subplots(figsize=(12, 4))
In [17]: air_quality.plot.area(ax=axs)
Out[17]: <Axes: xlabel=‘datetime’>
In [18]: axs.set_ylabel(“NO 2 _2 2 concentration”)
Out[18]: Text(0, 0.5, ‘NO 2 _2 2 concentration’)
In [19]: fig.savefig(“no2_concentrations.png”)
In [20]: plt.show()
每个由 pandas 创建的绘图对象都是一个 matplotlib 对象。由于 matplotlib 提供了许多自定义图表的选项,明确 pandas 和 matplotlib 之间的联系可以使所有 matplotlib 的功能应用于绘图。这一策略在之前的示例中得到了应用:
fig, axs = plt.subplots(figsize=(12, 4)) # Create an empty Matplotlib Figure and Axes
air_quality.plot.area(ax=axs) # Use pandas to put the area plot on the prepared Figure/Axes
axs.set_ylabel(“NO 2 _2 2 concentration”) # Do any Matplotlib customization you like
fig.savefig(“no2_concentrations.png”) # Save the Figure/Axes using the existing Matplotlib method.
plt.show() # Display the plot
NOTE:
.plot.
任何由pandas创建的图表都是Matplotlib对象*
如何从现有列创建新列#

我想表达位于伦敦的站点的 (NO_2) 浓度为 mg/m (^3) 。
(如果假设温度为 25 摄氏度且压力为 1013 百帕,转换因子为 1.882),需要一个换算将结果放到最后一列中
In [4]: air_quality[“london_mg_per_cubic”] = air_quality[“station_london”] * 1.882
In [5]: air_quality.head()
Out[5]:
station_antwerp … london_mg_per_cubic
datetime …
2019-05-07 02:00:00 NaN … 43.286
2019-05-07 03:00:00 50.5 … 35.758
2019-05-07 04:00:00 45.0 … 35.758
2019-05-07 05:00:00 NaN … 30.112
2019-05-07 06:00:00 NaN … NaN
[5 rows x 4 columns]
要创建新列,请使用方括号 [],并在赋值时将新列名放在左侧。
想检查paris与antwerp之间的值比率,并将结果保存到新列中
In [6]: air_quality[“ratio_paris_antwerp”] = (
…: air_quality[“station_paris”] / air_quality[“station_antwerp”]
…: )
…:
In [7]: air_quality.head()
Out[7]:
station_antwerp … ratio_paris_antwerp
datetime …
2019-05-07 02:00:00 NaN … NaN
2019-05-07 03:00:00 50.5 … 0.495050
2019-05-07 04:00:00 45.0 … 0.615556
2019-05-07 05:00:00 NaN … NaN
2019-05-07 06:00:00 NaN … NaN
[5 rows x 5 columns]
计算是逐元素进行的,因此/应用于每一行中的值。
其他数学运算符(+,-,*,/,…)或逻辑运算符(<,>,==,…)也逐元素工作。后者已经在子集数据教程中使用,通过条件表达式过滤表格中的行。
如果需要更复杂的逻辑,可以使用任意的 Python 代码通过apply()。
希望将数据列重命名为由OpenAQ使用的相应站标识符
In [8]: air_quality_renamed = air_quality.rename(
…: columns={
…: “station_antwerp”: “BETR801”,
…: “station_paris”: “FR04014”,
…: “station_london”: “London Westminster”,
…: }
…: )
…:
In [9]: air_quality_renamed.head()
Out[9]:
BETR801 FR04014 … london_mg_per_cubic ratio_paris_antwerp
datetime …
2019-05-07 02:00:00 NaN NaN … 43.286 NaN
2019-05-07 03:00:00 50.5 25.0 … 35.758 0.495050
2019-05-07 04:00:00 45.0 27.7 … 35.758 0.615556
2019-05-07 05:00:00 NaN 50.4 … 30.112 NaN
2019-05-07 06:00:00 NaN 61.9 … NaN NaN
[5 rows x 5 columns]
rename()函数可以用于行标签和列标签的重命名。提供一个字典,其中键是当前名称,值是新名称,以更新相应的名称。
重命名映射不仅限于固定名称,也可以是一个映射函数。例如,将列名转换为小写字母也可以使用函数来完成:
In [10]: air_quality_renamed = air_quality_renamed.rename(columns=str.lower)
In [11]: air_quality_renamed.head()
Out[11]:
betr801 fr04014 … london_mg_per_cubic ratio_paris_antwerp
datetime …
2019-05-07 02:00:00 NaN NaN … 43.286 NaN
2019-05-07 03:00:00 50.5 25.0 … 35.758 0.495050
2019-05-07 04:00:00 45.0 27.7 … 35.758 0.615556
2019-05-07 05:00:00 NaN 50.4 … 30.112 NaN
2019-05-07 06:00:00 NaN 61.9 … NaN NaN
[5 rows x 5 columns]
NOTE:
创建新列使用[]
rename()
apply()
算术运算符
逻辑运算符
如何计算汇总统计信息#
聚合统计指标#

泰坦尼克号乘客的平均年龄?
In [4]: titanic[“Age”].mean()
Out[4]: 29.69911764705882
不同的统计信息可用于数值列的数据。通常会排除缺失数据,并且操作默认是按行进行的。

乘客的中位年龄和票务费用价格是多少?
In [5]: titanic[[“Age”, “Fare”]].median()
Out[5]:
Age 28.0000
Fare 14.4542
dtype: float64
对一个 DataFrame 的多个列(选择两个列返回一个 DataFrame,参见 子集数据教程)应用的统计量会为每个数值列分别计算。
可以同时为多个列计算聚合统计量。还记得 第一教程 中的 describe 函数吗?
In [6]: titanic[[“Age”, “Fare”]].describe()
Out[6]:
Age Fare
count 714.000000 891.000000
mean 29.699118 32.204208
std 14.526497 49.693429
min 0.420000 0.000000
25% 20.125000 7.910400
50% 28.000000 14.454200
75% 38.000000 31.000000
max 80.000000 512.329200
而不是预定义的统计量,可以使用特定的统计量组合, 对给定列进行统计聚合可以使用 DataFrame.agg() 方法:
In [7]: titanic.agg(
…: {
…: “Age”: [“min”, “max”, “median”, “skew”],
…: “Fare”: [“min”, “max”, “median”, “mean”],
…: }
…: )
…:
Out[7]:
Age Fare
min 0.420000 0.000000
max 80.000000 512.329200
median 28.000000 14.454200
skew 0.389108 NaN
mean NaN 32.204208
按类别聚合统计#
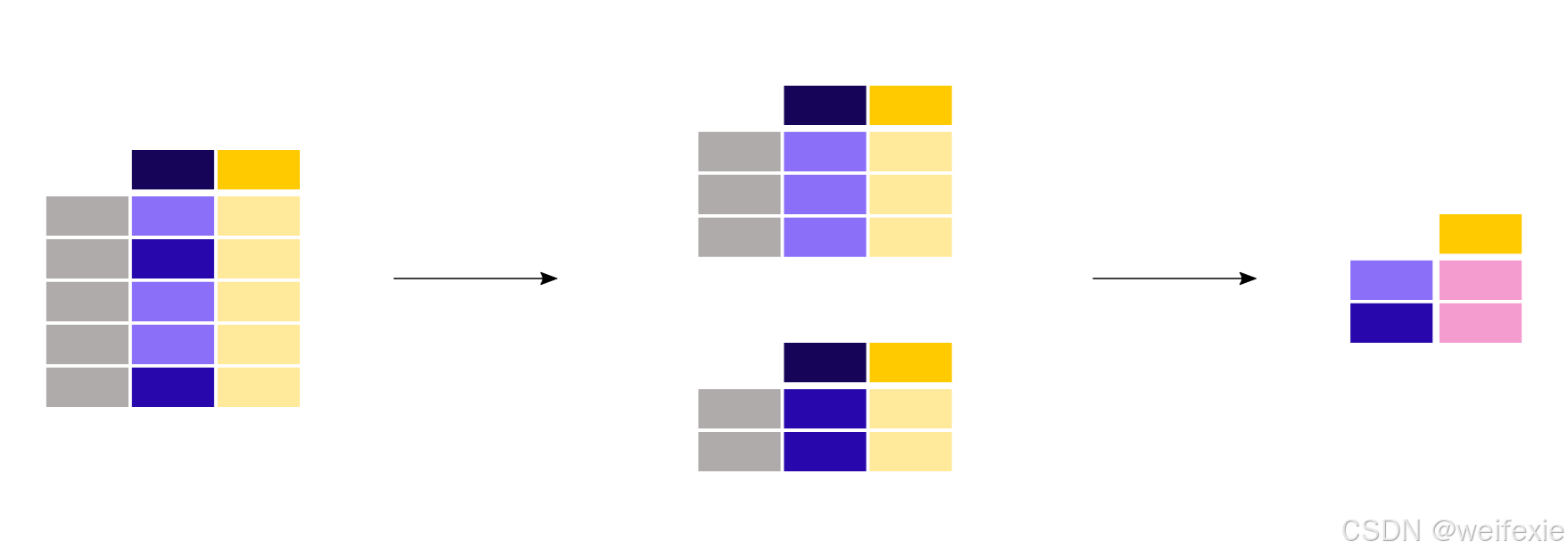
男乘客和女乘客的平均年龄是多少?
In [8]: titanic[[“Sex”, “Age”]].groupby(“Sex”).mean()
Out[8]:
Age
Sex
female 27.915709
male 30.726645
由于我们对每个性别平均年龄感兴趣,首先对这两列进行子集选择:titanic[[“Sex”, “Age”]]。接下来, groupby() 方法应用于 Sex 列,以每个类别分组。计算并返回每种性别的平均年龄。
计算某一列(例如 Sex 列中的男性/女性)中每个类别的某个统计值(例如 平均年龄)是一种常见的模式。使用 groupby 方法来支持这种操作。这符合更一般的 split-apply-combine 模式:
- 拆分 数据到不同的组
- 应用函数到每个组独立地
- 合并结果到一个数据结构中
pandas 中通常会将应用和合并步骤一起完成。
在上一个示例中,我们显式地选择了 2 列。如果不这样做,mean 方法将被应用于包含数值列的每一列,通过传递numeric_only=True:
In [9]: titanic.groupby(“Sex”).mean(numeric_only=True)
Out[9]:
PassengerId Survived Pclass … SibSp Parch Fare
Sex …
female 431.028662 0.742038 2.159236 … 0.694268 0.649682 44.479818
male 454.147314 0.188908 2.389948 … 0.429809 0.235702 25.523893
[2 rows x 7 columns]
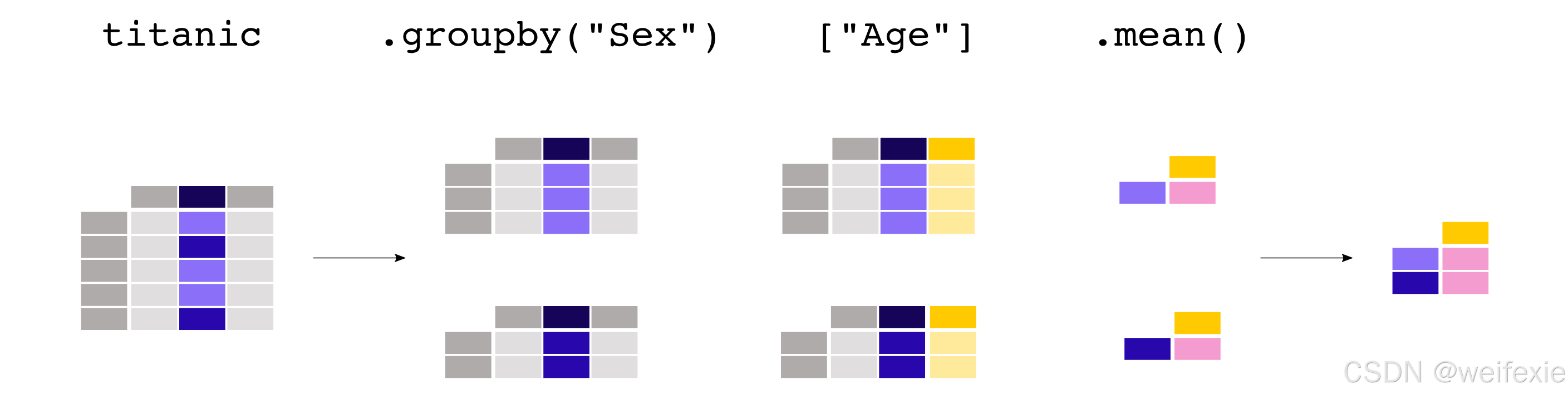
对于Pclass 列求平均值并没有太多意义。如果我们只对每个性别的平均年龄感兴趣,可以在分组数据上支持列的选择(使用通常的矩形括号[]):
In [10]: titanic.groupby(“Sex”)[“Age”].mean()
Out[10]:
Sex
female 27.915709
male 30.726645
Name: Age, dtype: float64
注意:
Pclass 列包含数值数据,但实际上代表 3 个类别(或因素),分别标记为“1”、“2”和“3”。对这些数据进行统计分析并没有太多意义。因此,pandas 提供了Categorical 数据类型来处理这种情况: 数据类型。有关详细信息,请参阅用户指南 分类数据部分。
每种性别和舱位等级组合的平均票务费用是多少?
In [11]: titanic.groupby([“Sex”, “Pclass”])[“Fare”].mean()
Out[11]:
Sex Pclass
female 1 106.125798
2 21.970121
3 16.118810
male 1 67.226127
2 19.741782
3 12.661633
Name: Fare, dtype: float64
多个列可以同时进行分组。将列名以列表的形式传递给groupby()方法。
按类别计算记录数#
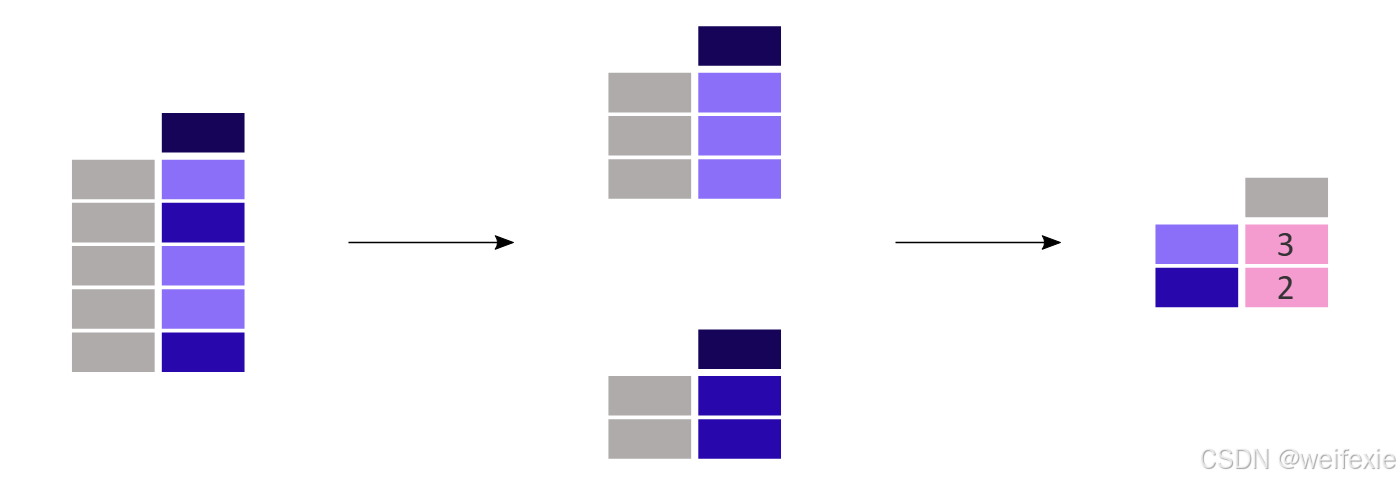
每个舱位等级的乘客数量是多少?
In [12]: titanic[“Pclass”].value_counts()
Out[12]:
Pclass
3 491
1 216
2 184
Name: count, dtype: int64
value_counts() 方法计算列中每个类别记录的数量。
这个函数是一个快捷方式,实际上它是一个按组分组的操作,再加上对每个组内记录数量的计数:
In [13]: titanic.groupby(“Pclass”)[“Pclass”].count()
Out[13]:
Pclass
1 216
2 184
3 491
Name: Pclass, dtype: int64
注意:
两者都可以与size和count结合使用 groupby。其中,size包括NaN值,仅提供行数(表格的大小),而count则不包括缺失值。在value_counts方法中,使用dropna参数来包含或排除NaN值。
NOTE:
mean()
median()
agg()
groupby()
value_counts()
size()
count()
如何重塑表格的布局#
排序表格行
根据乘客的年龄对泰坦尼克号数据进行排序。
In [6]: titanic.sort_values(by=“Age”).head()
Out[6]:
PassengerId Survived Pclass … Fare Cabin Embarked
803 804 1 3 … 8.5167 NaN C
755 756 1 2 … 14.5000 NaN S
644 645 1 3 … 19.2583 NaN C
469 470 1 3 … 19.2583 NaN C
78 79 1 2 … 29.0000 NaN S
[5 rows x 12 columns]
想根据舱位等级和年龄降序对泰坦尼克号数据进行排序
In [7]: titanic.sort_values(by=[‘Pclass’, ‘Age’], ascending=False).head()
Out[7]:
PassengerId Survived Pclass … Fare Cabin Embarked
851 852 0 3 … 7.7750 NaN S
116 117 0 3 … 7.7500 NaN Q
280 281 0 3 … 7.7500 NaN Q
483 484 1 3 … 9.5875 NaN S
326 327 0 3 … 6.2375 NaN S
[5 rows x 12 columns]
使用 DataFrame.sort_values(),表格中的行将根据定义的列进行排序。索引将遵循行顺序。
长格式到宽格式的表格转换#
让我们使用空气质量数据集的一个小子集。我们只关注 (NO_2) 数据,并且只使用每个位置的前两个测量值(即每个组的头)。这个数据子集将被称为no2_subset。
# filter for no2 data only
In [8]: no2 = air_quality[air_quality[“parameter”] == “no2”]
# use 2 measurements (head) for each location (groupby)
In [9]: no2_subset = no2.sort_index().groupby([“location”]).head(2)
In [10]: no2_subset
Out[10]:
city country … value unit
date.utc …
2019-04-09 01:00:00+00:00 Antwerpen BE … 22.5 µg/m³
2019-04-09 01:00:00+00:00 Paris FR … 24.4 µg/m³
2019-04-09 02:00:00+00:00 London GB … 67.0 µg/m³
2019-04-09 02:00:00+00:00 Antwerpen BE … 53.5 µg/m³
2019-04-09 02:00:00+00:00 Paris FR … 27.4 µg/m³
2019-04-09 03:00:00+00:00 London GB … 67.0 µg/m³
[6 rows x 6 columns]
关于上两行命令的解释
no2 = air_quality[air_quality[“parameter”] == “no2”]
no2_subset = no2.sort_index().groupby([“location”]).head(2)
第一行解释:
功能:从原始 DataFrame air_quality 中筛选出 parameter 列为 “no2”(二氧化氮)的所有数据。
操作细节:
air_quality[“parameter”] == “no2” 生成一个布尔型 Series(True/False 标记符合条件的行)。
通过布尔索引 air_quality[布尔条件],仅保留 True 的行。
结果:no2 是一个新 DataFrame,仅包含二氧化氮的监测数据。
第二行解释:
步骤分解:按索引排序
no2.sort_index():对 no2 的索引(通常是时间戳或其他有序标签)进行升序排序,确保数据按顺序处理。
按监测位置分组
.groupby([“location”]):根据 location 列的值将数据分组,每个组包含同一监测位置的所有记录。
取每组前两条记录
.head(2):在每个分组中,保留排序后的前两行数据。
结果:no2_subset 是一个新 DataFrame,包含每个监测位置(location)的前两条二氧化氮记录(按索引顺序)。
linux交互界面上try的结果
>>> air_quality[air_quality["parameter"] == "no2"].sort_index().groupby(["location"])
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x27a8750>
>>> air_quality[air_quality["parameter"] == "no2"].sort_index().groupby(["location"]).head()city country location parameter value unit
date.utc
2019-04-09 01:00:00+00:00 Antwerpen BE BETR801 no2 22.5 µg/m³
2019-04-09 01:00:00+00:00 Paris FR FR04014 no2 24.4 µg/m³
2019-04-09 02:00:00+00:00 London GB London Westminster no2 67.0 µg/m³
2019-04-09 02:00:00+00:00 Antwerpen BE BETR801 no2 53.5 µg/m³
2019-04-09 02:00:00+00:00 Paris FR FR04014 no2 27.4 µg/m³
2019-04-09 03:00:00+00:00 Antwerpen BE BETR801 no2 54.5 µg/m³
2019-04-09 03:00:00+00:00 London GB London Westminster no2 67.0 µg/m³
2019-04-09 03:00:00+00:00 Paris FR FR04014 no2 34.2 µg/m³
2019-04-09 04:00:00+00:00 Antwerpen BE BETR801 no2 34.5 µg/m³
2019-04-09 04:00:00+00:00 Paris FR FR04014 no2 48.5 µg/m³
2019-04-09 04:00:00+00:00 London GB London Westminster no2 41.0 µg/m³
2019-04-09 05:00:00+00:00 Paris FR FR04014 no2 59.5 µg/m³
2019-04-09 05:00:00+00:00 Antwerpen BE BETR801 no2 46.5 µg/m³
2019-04-09 05:00:00+00:00 London GB London Westminster no2 41.0 µg/m³
2019-04-09 06:00:00+00:00 London GB London Westminster no2 41.0 µg/m³
>>> air_quality[air_quality["parameter"] == "no2"].sort_index().groupby(["location"]).head(2)city country location parameter value unit
date.utc
2019-04-09 01:00:00+00:00 Antwerpen BE BETR801 no2 22.5 µg/m³
2019-04-09 01:00:00+00:00 Paris FR FR04014 no2 24.4 µg/m³
2019-04-09 02:00:00+00:00 London GB London Westminster no2 67.0 µg/m³
2019-04-09 02:00:00+00:00 Antwerpen BE BETR801 no2 53.5 µg/m³
2019-04-09 02:00:00+00:00 Paris FR FR04014 no2 27.4 µg/m³
2019-04-09 03:00:00+00:00 London GB London Westminster no2 67.0 µg/m³
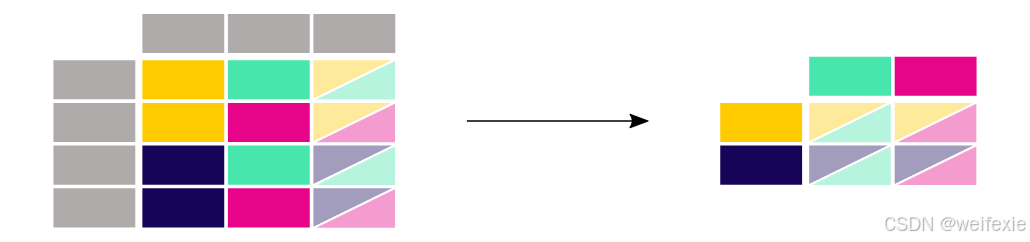
三个站点的值作为单独的列并排显示,如上图
In [11]: no2_subset.pivot(columns=“location”, values=“value”)
Out[11]:
location BETR801 FR04014 London Westminster
date.utc
2019-04-09 01:00:00+00:00 22.5 24.4 NaN
2019-04-09 02:00:00+00:00 53.5 27.4 67.0
2019-04-09 03:00:00+00:00 NaN NaN 67.0
pivot() 函数完全是数据重塑:每个索引/列组合只需要一个值。
解释上.pivot()函数
代码逐行解析:no2_subset.pivot(columns=“location”, values=“value”)
功能说明
此代码将 no2_subset 数据从 长格式(long format)转换为 宽格式(wide format),目的是以监测点(location)为列名,展示不同位置的二氧化氮浓度值(value)。类似于Excel中的数据透视表。它会根据指定的索引、列和值来重新排列数据。但在这个例子中,用户没有指定index参数,所以需要确认默认情况下如何处理。
输入数据结构 (no2_subset)
假设原始数据示例:
datetime location parameter value
2023-01-01 08:00 Paris no2 25
2023-01-01 09:00 Paris no2 30
2023-01-01 08:00 London no2 18
2023-01-01 09:00 London no2 20
代码执行过程
pivot(columns=“location”, values=“value”)
columns="location":将 location 列的唯一值(如 “Paris”、“London”)转换为新列名。
values="value":用 value 列的实际数值填充新列。
隐式索引:默认使用原始数据的索引(通常是时间戳 datetime)作为新表的行索引。
输出结果示例
datetime Paris London
2023-01-01 08:00 25 18
2023-01-01 09:00 30 20
由于 pandas 内置支持多列的绘图(参见绘图教程),从长格式转换为宽格式表格使我们能够同时绘制不同时间序列:
In [12]: no2.head()
Out[12]:
city country location parameter value unit
date.utc
2019-06-21 00:00:00+00:00 Paris FR FR04014 no2 20.0 µg/m³
2019-06-20 23:00:00+00:00 Paris FR FR04014 no2 21.8 µg/m³
2019-06-20 22:00:00+00:00 Paris FR FR04014 no2 26.5 µg/m³
2019-06-20 21:00:00+00:00 Paris FR FR04014 no2 24.9 µg/m³
2019-06-20 20:00:00+00:00 Paris FR FR04014 no2 21.4 µg/m³
In [13]: no2.pivot(columns=“location”, values=“value”).plot()
Out[13]: <Axes: xlabel=‘date.utc’>
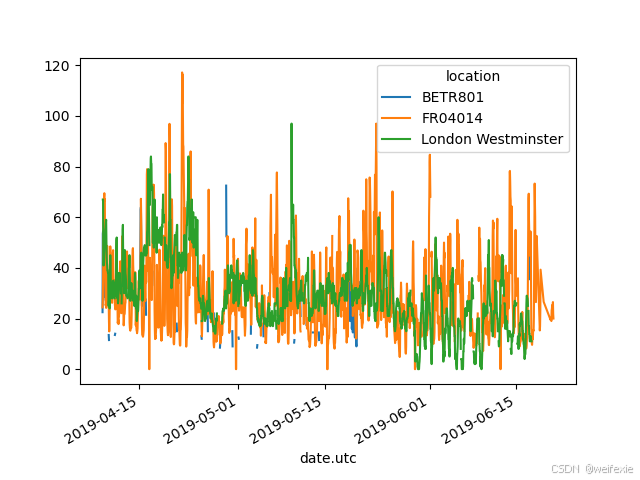
注意:当 index 参数未定义时,将使用现有的索引(行标签)。
透视表 #
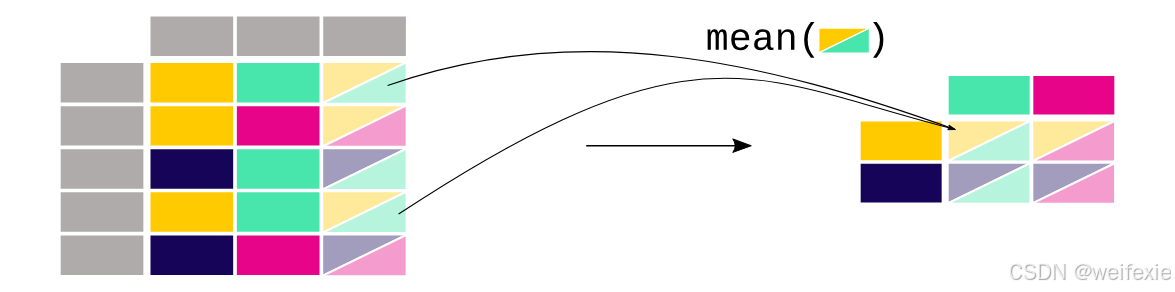
以表格形式获取每个站点的 (NO_2) 和 (PM_{2.5}) 的平均浓度
In [14]: air_quality.pivot_table(
…: values=“value”, index=“location”, columns=“parameter”, aggfunc=“mean”
…: )
…:
Out[14]:
parameter no2 pm25
location
BETR801 26.950920 23.169492
FR04014 29.374284 NaN
London Westminster 29.740050 13.443568
在 pivot() 的情况下,数据仅被重新排列。当需要聚合多个值(在这种特定情况下,是不同时间步长的值)时,可以使用 pivot_table() ,并提供一个聚合函数(例如均值),说明如何将这些值结合起来。
透视表是电子表格软件中一个熟知的概念。当需要每个变量的行/列边缘(子总计)时,将 margins 参数设置为 True :
In [15]: air_quality.pivot_table(
…: values=“value”,
…: index=“location”,
…: columns=“parameter”,
…: aggfunc=“mean”,
…: margins=True,
…: )
…:
Out[15]:
parameter no2 pm25 All
location
BETR801 26.950920 23.169492 24.982353
FR04014 29.374284 NaN 29.374284
London Westminster 29.740050 13.443568 21.491708
All 29.430316 14.386849 24.222743
好奇的话, pivot_table() 确实直接关联着 groupby() 。同样的结果也可以通过按 parameter 和 location 分组得出:
air_quality.groupby([“parameter”, “location”])[[“value”]].mean()
可得到
air_quality.groupby([“parameter”, “location”])[[“value”]].mean()
value
parameter location
no2 BETR801 26.950920
FR04014 29.374284
London Westminster 29.740050
pm25 BETR801 23.169492
London Westminster 13.443568
宽格式到长格式 #
从上一节中创建的宽格式表格再次开始,我们向 DataFrame 添加一个新的索引 reset_index() 。
In [16]: no2_pivoted = no2.pivot(columns=“location”, values=“value”).reset_index()
In [17]: no2_pivoted.head()
Out[17]:
location date.utc BETR801 FR04014 London Westminster
0 2019-04-09 01:00:00+00:00 22.5 24.4 NaN
1 2019-04-09 02:00:00+00:00 53.5 27.4 67.0
2 2019-04-09 03:00:00+00:00 54.5 34.2 67.0
3 2019-04-09 04:00:00+00:00 34.5 48.5 41.0
4 2019-04-09 05:00:00+00:00 46.5 59.5 41.0

将所有空气质量测量值收集到单个列中(长格式),如上图
In [18]: no_2 = no2_pivoted.melt(id_vars=“date.utc”)
In [19]: no_2.head()
Out[19]:
date.utc location value
0 2019-04-09 01:00:00+00:00 BETR801 22.5
1 2019-04-09 02:00:00+00:00 BETR801 53.5
2 2019-04-09 03:00:00+00:00 BETR801 54.5
3 2019-04-09 04:00:00+00:00 BETR801 34.5
4 2019-04-09 05:00:00+00:00 BETR801 46.5
pandas.melt() 方法将数据表从宽格式转换为长格式。列标题将作为新创建列中的变量名。
解决方案是简要说明如何应用 pandas.melt() 。该方法会将未在 id_vars 中提到的所有列合并成两列:一列是列标题名称,一列是对应的值。后者默认命名为 value 。
传递给 pandas.melt() 的参数可以更详细地定义:
In [20]: no_2 = no2_pivoted.melt(
…: id_vars=“date.utc”,
…: value_vars=[“BETR801”, “FR04014”, “London Westminster”],
…: value_name=“NO_2”,
…: var_name=“id_location”,
…: )
…:
In [21]: no_2.head()
Out[21]:
date.utc id_location NO_2
0 2019-04-09 01:00:00+00:00 BETR801 22.5
1 2019-04-09 02:00:00+00:00 BETR801 53.5
2 2019-04-09 03:00:00+00:00 BETR801 54.5
3 2019-04-09 04:00:00+00:00 BETR801 34.5
4 2019-04-09 05:00:00+00:00 BETR801 46.5
额外的参数具有以下效果:
- value_vars 指定要熔合在一起的列
- value_name 为 values 列提供自定义列名,而不是默认列名 value
- var_name 为收集的列头名称提供一个自定义列名。否则,它将使用索引名称或默认值 variable 。
因此, value_name 和 var_name 这两个参数只是用户定义的两个生成列的名称。要熔化的列由 id_vars 和 value_vars 定义。
NOTE:
sort_values()
pivot()
pivot_table()
reset_index()
pandas.melt()
如何从多个表格中合并数据#
连接对象#
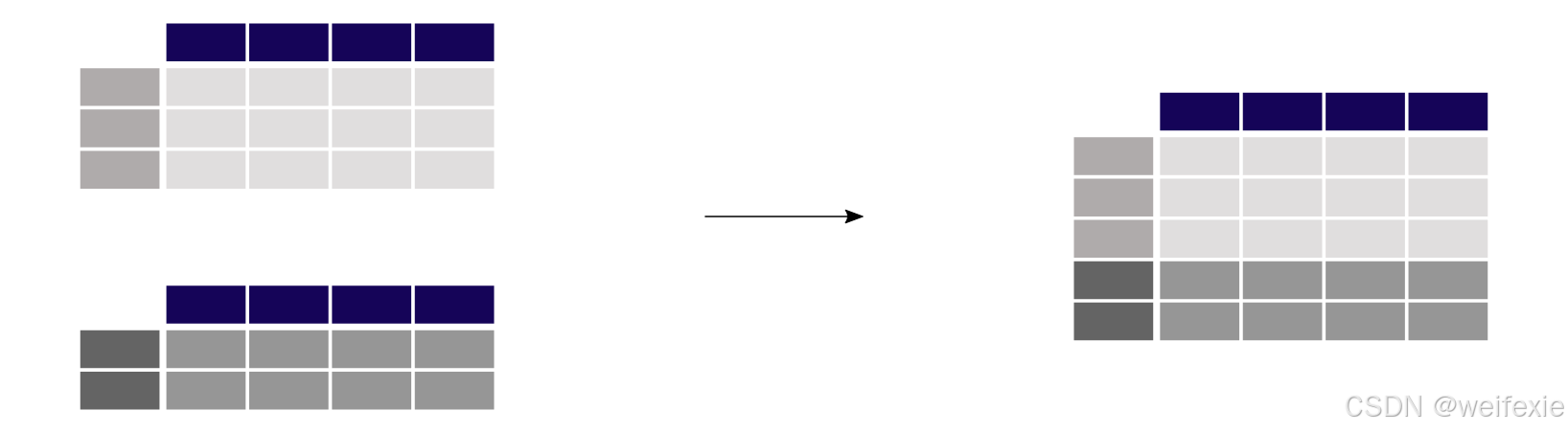
将两个具有类似结构的表格 (NO_2) 和 (PM_{25}) 的测量值合并到一个表格中
In [8]: air_quality = pd.concat([air_quality_pm25, air_quality_no2], axis=0)
In [9]: air_quality.head()
Out[9]:
date.utc location parameter value
0 2019-06-18 06:00:00+00:00 BETR801 pm25 18.0
1 2019-06-17 08:00:00+00:00 BETR801 pm25 6.5
2 2019-06-17 07:00:00+00:00 BETR801 pm25 18.5
3 2019-06-17 06:00:00+00:00 BETR801 pm25 16.0
4 2019-06-17 05:00:00+00:00 BETR801 pm25 7.5
concat() 函数执行沿一个轴(行或列)的多个表格的连接操作。
默认情况下,连接是沿着轴 0 进行的,因此结果表将输入表的行合并在一起。我们可以通过检查原始表和连接后的表的形状来验证此操作:
In [10]: print('Shape of the air_quality_pm25 table: ', air_quality_pm25.shape)
Shape of the air_quality_pm25 table: (1110, 4)
In [11]: print('Shape of the air_quality_no2 table: ', air_quality_no2.shape)
Shape of the air_quality_no2 table: (2068, 4)
In [12]: print('Shape of the resulting air_quality table: ', air_quality.shape)
Shape of the resulting air_quality table: (3178, 4)
相关文章:

python pandas模块
python pandas模块 终于也到介绍pandas的时候了,python中用于处理data的一个lib 从wiki中找到的关于pandas的介绍,如下, Original author(s) Wes McKinney Developer(s) Community Initial release 11 January 2008; 17 years ago [citatio…...

系统部署【信创名录】及其查询地址
一、信创类型 (一)服务器: 1.华为云 2.腾讯云 3.阿里云 (二)中央处理器(CPU): 1.海思,鲲鹏920服务器 (三)中间件 1.人大金仓 ࿰…...

docker-compose部署MongoDB分片集群
前言 MongoDB 使用 keyFile 进行 节点间身份验证,我们需要先创建一个 keyFile 并确保所有副本集的节点使用相同的 keyFile。 openssl rand -base64 756 > mongo-keyfile chmod 400 mongo-keyfiledocker-compose部署分片集群 无密码方式 # docker-compose-mongodb.yml s…...

博奥龙Nanoantibody系列IP专用抗体
货号名称BDAA0260 HRP-Nanoantibody anti Mouse for IP BDAA0261 AbBox Fluor 680-Nanoantibody anti Mouse for IP BDAA0262 AbBox Fluor 800-Nanoantibody anti Mouse for IP ——无轻/重链干扰,更高亲和力和特异性 01Nanoantibody系列抗体 是利用噬菌体展示纳…...

CTFshow 【WEB入门】信息搜集 【VIP限免】 web1-web17
CTFshow 【 WEB入门】、【VIP限免】 web1 ----源码泄露 首先第一步,看源代码 web2----前台JS绕过 简单点击查看不了源代码,可以强制查看 比如 Ctrl Shift ICtrl U或者在url前加一个view-source: view-source:http://79999ca1-7403-46da-b25b-7ba9…...

css 知识点整理
1.css 层叠样式表 中的 inherit、initial、unset 关键字适用属性类型行为逻辑典型场景inherit所有属性强制继承父级值统一子元素样式initial所有属性重置为规范初始值清除自定义或继承样式unset所有属性自动判断继承或重置简化全局样式重置或覆盖 2. sass 常用语法 2.1、变量…...

02.Kubernetes 集群部署
Kubernetes 集群部署 Kubernetes 相关端口 1. Kubernetes 集群组件运行模式 独立组件模式 除 Add-ons 以外,各关键组件以二进制方式部署于节点上,并运行于守护进程;各 Add-ons 以 Pod 形式运行 静态 Pod 模式 控制平面各组件以静态 Pod …...
原理与应用)
支持向量机(SVM)原理与应用
背景 支持向量机(Support Vector Machine, SVM)是一种经典的监督学习算法,广泛应用于分类和回归问题。SVM以其强大的数学基础和优异的性能在机器学习领域占据了重要地位。本文将详细介绍SVM的原理、核函数的作用以及如何在Python中使用SVM解决…...

【文献阅读】SPRec:用自我博弈打破大语言模型推荐的“同质化”困境
📜研究背景 在如今的信息洪流中,推荐系统已经成为了我们生活中的“贴心小助手”,无论是看电影、听音乐还是购物,推荐系统都在努力为我们提供个性化的内容。但这些看似贴心的推荐背后,其实隐藏着一个严重的问题——同质…...
?)
【WRF模拟】如何查看 WPS 的输入静态地理数据(二进制格式)?
查看 WPS 的输入静态地理数据方法总结 方法 1:使用 gdal_translate 将二进制数据转换为 GeoTIFFgdal_translate 工具概述使用 gdal_translate 将二进制数据转换为 GeoTIFF方法 2:使用 ncdump 查看 geo_em.dXX.nc方法 3:使用 Python xarray + matplotlib 可视化 geo_em.dXX.n…...
进行知识蒸馏)
介绍如何使用RDDM(残差噪声双扩散模型)进行知识蒸馏
下面为你详细介绍如何使用RDDM(残差噪声双扩散模型)进行知识蒸馏,从而实现学生RDDM模型的一步去噪。这里假定你已经有了RDDM模型,并且使用PyTorch深度学习框架。 整体思路 数据准备:加载训练数据并进行必要的预处理。…...

【lf中的git实战】
1)开发分支 develop 2)各种功能分支 author/feature_func 3)release分支 4)合并author/feature_func到develop author/feature_func 到 develop时: cd develop git merge --squash author/feature_func 5)develop合并到author/feature_func时: cd author/feature_func g…...

Java实现Consul/Nacos根据GPU型号、显存余量执行负载均衡
Java实现Consul/Nacos根据GPU型号、显存余量执行负载均衡 步骤一:服务端获取GPU元数据 1. 添加依赖 在pom.xml中引入Apache Commons Exec用于执行命令: <dependency><groupId>org.apache.commons</groupId><artifactId>comm…...

编译支持 RKmpp 和 RGA 的 ffmpeg 源码
一、前言 RK3588 支持VPU硬件解码,需要rkmpp进行调用;支持2D图像加速,需要 RGA 进行调用。 这两个库均能通过 ffmpeg-rockchip 进行间接调用,编译时需要开启对应的功能。 二、依赖安装 编译ffmpeg前需要编译 rkmpp 和 RGA…...
)
布隆过滤器(Bloom Filter)
布隆过滤器是一种概率型数据结构,用于快速判断一个元素是否可能在集合中存在。它的核心特点是: 节省空间:相比哈希表,布隆过滤器占用的存储空间非常小。高效查询:查询时间复杂度为 (O(k)),其中 (k) 是哈希…...

2025-03-10 学习记录--C/C++-C语言 易错点 大总结
C语言 易错点 大总结 一、strlen(strs) 使用错误 ⭐️ 若strs 是一个指针数组(const char* strs[]),则不可用strlen(strs) 计算 strs 的长度,因为 strlen 是用于计算 字符串 的长度,而不是数组的长度。 解决方法 &…...

康谋应用 | 基于多传感器融合的海洋数据采集系统
在海洋监测领域,基于无人艇能够实现高效、实时、自动化的海洋数据采集,从而为海洋环境保护、资源开发等提供有力支持。其中,无人艇的控制算法训练往往需要大量高质量的数据支持。然而,海洋数据采集也面临数据噪声和误差、数据融合…...
请求处理)
SpringMVC (二)请求处理
目录 章节简介 一 请求处理(初级) eg:请求头 二 请求处理(进阶) eg:请求体 三 获取请求头 四 获取Cookie 五 级联封装 六 使用RequestBoby封装JSON对象 七 文件的上传 八 获取整个请求 HttpEntity 九 原生请求 Spring…...

数据结构——单链表list
前言:大家好😍,本文主要介绍数据结构——单链表 目录 一、单链表 二、使用步骤 1.结构体定义 2.初始化 3.插入 3.1 头插 3.2 尾插 3.3 按位置插 四.删除 4.1头删 4.2 尾删 4.3 按位置删 4.4按值删 五 统计有效值个数 六 销毁…...

课程《Deep Learning Specialization》
在coursera上,Deep Learning Specialization 课程内容如下图所示: Week2 assignment, Logistic Regression....

低版本 Linux 系统通过二进制方式升级部署高版本 Docker
一、背景: 在一些 Linux 系统中,由于系统自带的软件源版本较低,或者因网络、权限等限制无法直接通过源文件来升级到最新版本的 Docker。这种情况下,采用二进制方式升级部署高版本 Docker 就成为一种有效的解决方案。下面将详…...

线索二叉树构造及遍历算法
线索二叉树构造以及遍历算法 线索二叉树(中序遍历版)构造线索二叉树构造双向线索链表遍历中序线索二叉树 线索二叉树(中序遍历版) 中序遍历找到对应结点的前驱(土方法) #mermaid-svg-eunGO5d2GhjLxCn5 {fo…...

3. 自定义类型****
目录 1. 内存对齐(必考) 如何计算? 为什么要内存对齐? 2. 联合 2.1 联合的定义 2.2 联合的特点 1. 内存对齐(必考) 结构体内存对齐是一个特别热门的考点。 如何计算? 第一个成员在与结构…...
深度解析:构建高可用分布式缓存系统的核心机制)
Redis Sentinel (哨兵模式)深度解析:构建高可用分布式缓存系统的核心机制
一、传统主从复制的痛点 在分布式系统架构中,Redis 作为高性能缓存和数据存储解决方案,其可用性直接关系到整个系统的稳定性。传统的主从复制架构虽然实现了数据冗余,但在面临节点故障时仍存在明显缺陷: 手动故障转移…...

deepseek本地部署
deepseek本地部署 哈喽,兄弟们!大家可以想象一下,如果有一个超级聪明的人机大脑,能帮你解答任何问题,从复杂的数学难题到编程代码,再到那些让你头疼的写作任务,它都能轻松搞定。这不是科幻电影里的场景,而是DeepSeek带来的现实奇迹!DeepSeek,这个名字听起来就充满了…...

责任链模式的C++实现示例
核心思想 责任链模式是一种行为设计模式,允许多个对象都有机会处理请求,从而避免请求的发送者与接收者之间的耦合。请求沿着处理链传递,直到某个对象处理它为止。 解决的问题 解耦请求发送者与处理者:请求的发送者无需知道具…...

【蓝桥杯python研究生组备赛】003 贪心
题目1 股票买卖 给定一个长度为 N 的数组,数组中的第 i 个数字表示一个给定股票在第 i 天的价格。 设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。 注意:你不能同时参与多笔交易&…...

Banana Pi 与瑞萨电子携手共同推动开源创新:BPI-AI2N
2025年3月11日, Banana Pi 开源硬件平台很高兴宣布,与全球知名半导体解决方案供应商瑞萨电子(Renesas Electronics)正式达成技术合作关系。此次合作标志着双方将在开源技术、嵌入式系统和物联网等领域展开深度合作,为全…...

【算法工具】HDL: 基于摘要统计数据的高维连锁不平衡分析软件
## 前言 在基因组研究中,连锁不平衡(Linkage Disequilibrium, LD)分析是理解遗传变异之间关联的关键步骤。然而,当面对高维数据时,传统分析方法往往面临巨大计算挑战。今天为大家介绍一款强大的工具——HDL (High-Dimensional Linkage diseq…...

虚拟展览馆小程序:数字艺术与文化展示的新形式探索
虚拟展览馆小程序:数字艺术与文化展示的新形式探索 一、传统展览的痛点:物理空间的局限与数字化的必然 在传统的艺术与文化展览中,观众往往需要跨越地理距离、排队数小时才能进入展馆,而许多珍贵展品因保护需求无法长期展出。数据显示,全球90%以上的博物馆藏品常年沉睡于…...

docker 搭建alpine下nginx1.26/mysql8.0/php7.4环境
docker 搭建alpine下nginx1.26/mysql8.0/php7.4环境 docker-compose.yml services:mysql-8.0:container_name: mysql-8.0image: mysql:8.0restart: always#ports:#- "3306:3306"volumes:- ./etc/mysql/conf.d/mysql.cnf:/etc/mysql/conf.d/mysql.cnf:ro- ./var/log…...
)
java项目之基于ssm的在线学习系统(源码+文档)
项目简介 在线学习系统实现了以下功能: 该系统可以实现论坛管理,通知信息管理,学生管理,回答管理,教师管理,教案管理,公告信息管理,作业管理等功能。 💕💕作…...

macOS 安装配置 iTerm2 记录
都说 macOS 里替换终端最好的就是 iTerm2 ,这玩意儿还是开源的,所以就也根风学习一下,但全是英文的挺麻烦,所以这里记录一下自己的设置,以最简单的安装及设置为主,想要更酷炫、更好看的还请自己百度吧&…...
)
矩阵分析-浅要理解(深度学习方向)
梯度分析与最优化 在深度学习的任务中,我们所期望的是训练一个神经网络,使得预测结果与真实标签之间的误差最小化,这可以近似看作是一个提供梯度下降等优化找到全局最优解的凸优化问题。 奇异值分解 在信息工程领域,对数据处理的…...

Odoo 18 中的自动字段和预留字段
Odoo 18 中的自动字段和预留字段 作为一个开源平台,Odoo 的价值在于其使用和开发的灵活性、可扩展性和经济性。虽然 Odoo 本身主要用 Python 和 JavaScript 编写,但其作为开源 ERP 系统的价值超越了特定编程语言的范畴,为各行各业的企业提供了…...

【操作系统安全】任务1:操作系统部署
目录 一、VMware Workstation Pro 17 部署 二、VMware Workstation 联网方式 三、VMware 虚拟机安装流程 四、操作系统介绍 五、Kali 操作系统安装 六、Windows 系统安装 七、Windows 系统网络配置 八、Linux 网络配置 CSDN 原创主页:不羁https://blog.csd…...

Linux:自动化构建-make/Makefile
1.背景 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作…...

maven wrapper的使用
写在前面 考虑这样的场景,张三创建了一个maven项目使用了3.9版本,当李四下载下来去开发配置的却是3.6版本,此时李四就不得不再去配置一个3.9版本的maven,为了解决这个问题,maven引入了maven wrapper的机制(…...

DB-GPT-0.7版本win11安装,最新版本,安装方式变更了
之前两天折腾要死,只因为安装了旧版本问题太多,现在安装最新版本 快速开始_V0.7.0 语雀 DB-GPT 0.7.0 部署教程 - yyhhyys blog DB-GPT 0.7.0 与 DeepSeek 集成使用指南 - yyhhyys blog 首先代码结构换了,python包管理工作也换了…...

树莓集团落子海南,如何重构数字产业生态体系
树莓集团在海南的布局,是其整体商业战略中的关键一环。这背后,是对政策机遇、产业协同、以及区域优势的深度考量。 政策机遇 海南自贸港建设带来前所未有的政策红利,包括贸易、投资、资金等方面的自由便利。树莓集团紧抓这一机遇࿰…...

Spring Boot 项目部署启动异常问题分析与解决:主类缺失与依赖冲突的分析
Spring Boot 项目部署启动异常问题分析与解决 在近期的 Spring Boot 项目部署工作中,遭遇了一起典型的启动异常状况。经过多维度的深入排查以及细致的调试,最终确定问题的根源在于打包插件配置与依赖管理的综合影响。以下将详细阐述整个问题的分析过程以及对应的解决办法。 …...
——进程通信)
共享内存(System V)——进程通信
个人主页:敲上瘾-CSDN博客 进程通信: 匿名管道:进程池的制作(linux进程间通信,匿名管道... ...)-CSDN博客命名管道:命名管道——进程间通信-CSDN博客 目录 一、共享内存的原理 二、信道的建立 …...

考研数学非数竞赛复习之Stolz定理求解数列极限
在非数类大学生数学竞赛中,Stolz定理作为一种强大的工具,经常被用来解决和式数列极限的问题,也被誉为离散版的’洛必达’方法,它提供了一种简洁而有效的方法,使得原本复杂繁琐的极限计算过程变得直观明了。本文&#x…...

12 DHCP的内容和HTTP的改良
一、回顾 计算机分配相关身份 网络号、主机号 网络号内的主机识别 局部网通信网关 不同网络的通信DNS服务器 域名解析 因特网通信 二、DHCP协议 建议学习前看这个视频,14分钟,所有的知识点都有,很容易理解 1、理解 DHCP 的全称是 Dynam…...

多光谱相机数据采集过程中常见仪器
1.BF1515多光谱相机 2.VIX-N220推扫式可见光近红外高光谱相机 覆盖光谱范围:400-1000nm; 光谱分辨率:2nm; 设备配套软件:VIX-N220、XuanDo(用于调节相机推扫速度); 镜头调节所需材料:黑色条…...

【调研】olmOCR解析PDF
测试用例: olmOCR GOT-OCR 将最底下没有文字的部分,可能是样式解析出重复 olmOCR GOT-OCR 无重复 重复 速度上,olmOCR效果更快 效果上,olmOCR解析得到的内容排版更加清晰整齐,而且对于6份GOT-OCR有重复的测…...

蓝桥杯随笔练——二分模板
答案 #include <bits/stdc.h> //洛谷2249 using namespace std;const int N 1e610; int n,m; int a[N];int Array_Search(int a[],int len,int x) {int L 0,R len1;while(L1 < R){int mid (RL) >> 1;if(a[mid] < x ) L mid;else R mid;}if(a[R] x) r…...

【Golang】第三弹----运算符
笔上得来终觉浅,绝知此事要躬行 🔥 个人主页:星云爱编程 🔥 所属专栏:Golang 🌷追光的人,终会万丈光芒 🎉欢迎大家点赞👍评论📝收藏⭐文章 一、运算符介绍 运算符是一…...

MongoDB 聚合管道速成教程
一、引言 MongoDB 的聚合管道(Aggregation Pipeline)是一种强大的数据处理工具,它允许你对文档进行一系列的操作,如过滤、转换、分组和聚合等。聚合管道由多个管道组成,每个管道对输入的文档进行特定的处理࿰…...

「JavaScript深入」二进制数据处理详解「Blob、File、FileReader、ArrayBuffer、Typed Arrays、DataView」
二进制数据处理详解 1. Blob(Binary Large Object)Blob 的特性创建 BlobBlob 主要方法Blob 的应用 2. FileFile 对象的属性获取 File 对象 3. FileReader创建 FileReader主要方法主要事件文件上传与读取内容示例文件分块读取示例 4. ArrayBuffer 与 Type…...