Hadoop、Hive、Spark的关系
Part1:Hadoop、Hive、Spark关系概览
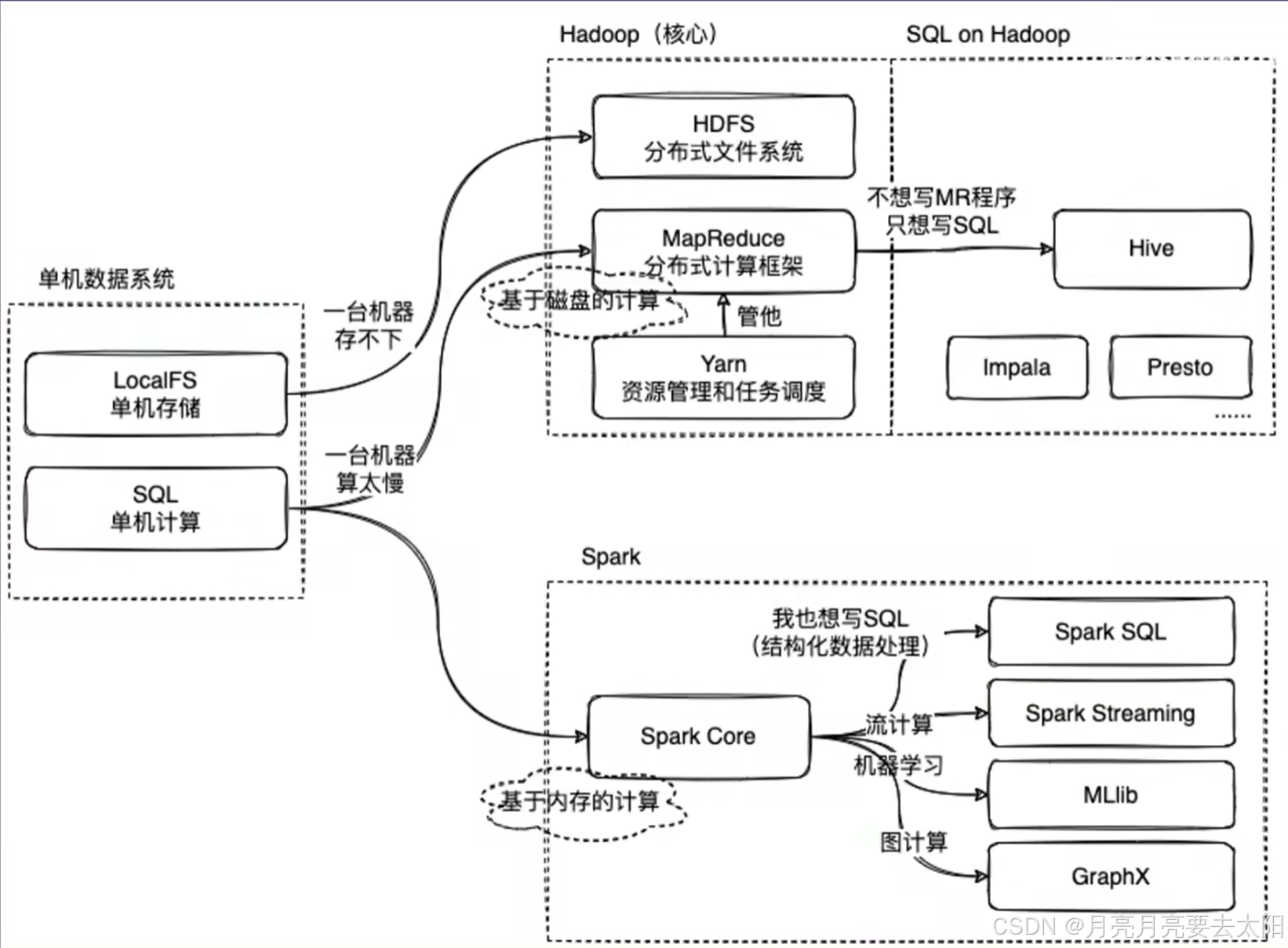
1、MapReduce on Hadoop 和spark都是数据计算框架,一般认为spark的速度比MR快2-3倍。
2、mapreduce是数据计算的过程,map将一个任务分成多个小任务,reduce的部分将结果汇总之后返回。
3、HIve中有metastore存储结构化信息,还有执行引擎将sql翻译成mapreduce,再把加工结果返回给用户。
Part2:十道Hadoop相关的题目
一、Hadoop生态系统简介:请简要描述Hadoop的核心组件及其作用。
Hadoop是一个开源的分布式计算框架,专门用于存储和处理大规模数据集(通常从TB到PB级别)。Hadoop的核心思想是分布式存储和分布式计算,通过将数据和计算任务分散到多个节点上,实现高性能和高容错性。
其核心组件包括HDFS、mapreduce、TARN.
(1)HDFS(Hadoop Distributed File System)
- 作用:HDFS是Hadoop的分布式文件系统,用于存储海量数据。
- 特点:
- 数据被分割成多个块(默认128MB或256MB),并分布存储在不同的节点上。
- 具有高容错性,数据会自动复制多份(默认3份)存储在不同的节点上。
- 关键角色:
- NameNode:管理文件系统的元数据(如文件目录结构、块的位置等)。
- DataNode:存储实际的数据块。
(2)MapReduce
- 作用:MapReduce是Hadoop的分布式计算框架(the same with Hadoop),用于处理大规模数据集。
- 工作原理:
- Map阶段:将输入数据分割成小块,并行处理并生成中间结果(键值对)。
- Reduce阶段:对Map阶段的中间结果进行汇总和计算,生成最终结果。
- 特点:
- 适合批处理任务,但不适合实时计算(因为mapreduce的机制)。
(3)YARN(Yet Another Resource Negotiator)
- 作用:YARN是Hadoop的资源管理系统,负责集群资源的调度和任务管理。
- 特点:
- 将资源管理和任务调度分离,支持多种计算框架(如MapReduce、Spark等)。
- 提高了集群的利用率和灵活性。
二、Hadoop的工作流程
1. 数据存储:
数据被上传到HDFS,分割成多个块并分布存储在不同的DataNode,NameNode记录文件的元数据和块的位置信息。
2. 数据处理:
用户提交一个MapReduce任务:YARN负责分配资源,启动Map任务和Reduce任务,Map任务读取HDFS上的数据,生成中间结果,Reduce任务对中间结果进行汇总,生成最终结果并写回HDFS。
三、HDFS:解释HDFS的架构,说明NameNode和DataNode的作用。
HDFS是Hadoop的核心组件,存储和管理大规模数据,具有高容错性和高吞吐量的特点。其架构采用主从模式,主要包括以下组件:
1. NameNode(主节点)
作用:
元数据管理:存储文件系统的元数据,如文件名、目录结构、文件块位置等。
协调客户端访问:处理客户端的读写请求,并协调DataNode的操作。
特点:
单点故障:NameNode是单点,故障会导致整个系统不可用。Hadoop 2.0通过备用NameNode解决这一问题。
内存存储:元数据存储在内存中,以加快访问速度。
2. DataNode(从节点)
作用:
数据存储:实际存储文件数据,文件被分割成多个块(默认128MB),并在多个DataNode上复制(默认3份)以实现容错。
数据块管理:负责数据块的创建、删除和复制,并定期向NameNode报告状态。
特点:
分布式存储:数据块分布在多个DataNode上,提供高吞吐量和容错性。
本地存储:数据块存储在本地文件系统中。
3. Secondary NameNode(辅助NameNode)
作用:
辅助NameNode:定期合并NameNode的编辑日志和镜像文件,减少NameNode的启动时间。
非备用NameNode:它不是NameNode的备用节点,不能直接接管NameNode的工作。
总结
NameNode:负责管理元数据和协调客户端访问,是HDFS的核心。
DataNode:负责实际数据存储和块管理,分布在多个节点上以提供高吞吐量和容错性。
Secondary NameNode:辅助NameNode进行元数据管理,但不提供故障切换功能。
四、HDFS的工作流程
1. 文件写入:
客户端向NameNode请求写入文件;NameNode分配DataNode并返回其列表;客户端将数据写入第一个DataNode,该节点再将数据复制到其他DataNode。
2. 文件读取:
客户端向NameNode请求读取文件;NameNode返回存储该文件块的DataNode列表;客户端直接从DataNode读取数据。
3. 容错与复制:
每个数据块默认复制3份,存储在不同DataNode上;如果某个DataNode失效,NameNode会检测到并将数据块复制到其他节点。
五、MapReduce:描述其工作流程,并解释Mapper和Reducer作用。
MapReduce是一种用于大规模数据处理的编程模型,由Google提出,主要用于分布式计算。它将任务分解为两个主要阶段:Map和Reduce。
工作流程
1. 输入分片(Input Splitting):
输入数据被划分为多个分片(splits),每个分片由一个Mapper处理。
2. Map阶段:
每个Mapper处理一个输入分片,生成键值对(key-value pairs)作为中间结果。
3. Shuffle和Sort:
系统将Mapper输出的中间结果按键分组并排序,确保相同键的值被送到同一个Reducer。
4. Reduce阶段:
Reducer接收分组后的中间结果,进行汇总处理,生成最终输出。
5. 输出:
Reducer的输出写入存储系统,如HDFS。
Mapper的作用:
数据处理:Mapper读取输入分片,逐条处理并生成键值对。
并行处理:多个Mapper可以同时处理不同分片,提升效率。
中间结果生成:Mapper的输出是中间结果,供Reducer进一步处理。
Reducer的作用
数据汇总:Reducer对Mapper输出的中间结果进行汇总。
聚合计算:Reducer执行如求和、计数等聚合操作。
生成最终结果:Reducer的输出是最终结果,通常存储在分布式文件系统中。
示例:假设统计文本中单词的出现次数
1. Map阶段:每个Mapper读取一部分文本,生成形如`(word, 1)`的键值对。
2. Shuffle和Sort:系统将相同单词的键值对分组,如`("hello", [1, 1, 1])`。
3. Reduce阶段:Reducer对每个单词的计数求和,生成`("hello", 3)`。
4. 输出:最终结果写入文件,如`hello 3`。
总结
Mapper:负责数据的分片处理和中间结果的生成。
Reducer:负责中间结果的汇总和最终结果的生成。
六、MapReduce中,数据是如何进行分区和排序的?解释Partitioner和Combiner的作用。
在MapReduce中,数据的分区和排序的步骤主要由Partitioner和Combiner来完成。
数据分区(Partitioning)
Partitioner的作用
数据分配:Partitioner负责将Mapper输出的键值对分配到不同的Reducer。它通过哈希函数对键进行计算,决定数据应发送到哪个Reducer。
负载均衡:合理的分区策略可以确保各Reducer的负载均衡,避免某些Reducer过载。
分区过程:
1. Mapper输出:Mapper生成键值对后,Partitioner根据键的哈希值决定其所属分区。
2.分区数量:分区数量通常等于Reducer的数量。
3. 数据发送:每个分区的数据被发送到对应的Reducer。
默认Partitioner
HashPartitioner:MapReduce默认使用哈希分区器,通过`hash(key) % numReduceTasks`计算分区。
数据排序(Sorting)
排序过程
1. Mapper端排序:Mapper输出的键值对在发送到Reducer之前,会在本地进行排序。
2. Reducer端排序:Reducer在接收到所有Mapper的数据后,会再次进行全局排序,确保相同键的值按顺序处理。
排序机制
按键排序:MapReduce框架默认按键进行排序,确保Reducer处理时键是有序的。
自定义排序:可以通过实现`WritableComparable`接口自定义排序逻辑。
示例:假设统计文本中单词的出现次数:
1. Map阶段:
Mapper生成键值对,如`("hello", 1)`。
2. Combiner阶段:
Combiner对Mapper的输出进行局部聚合,如将`("hello", [1, 1, 1])`合并为`("hello", 3)`。
3. Partitioner阶段:
Partitioner根据键的哈希值决定数据发送到哪个Reducer。
4. Sort阶段:
数据在发送到Reducer之前进行排序,确保相同键的值按顺序处理。
5. Reduce阶段:
Reducer对接收到的数据进行最终聚合,生成`("hello", 3)`。
总结:
Partitioner:负责将Mapper输出的键值对分配到不同的Reducer,确保负载均衡。
Combiner:在Mapper端进行局部聚合,减少数据传输量,优化性能。
七、YARN在Hadoop中的作用,及其与MapReduce的关系
YARN是Hadoop 2.0引入的核心组件,用于资源管理和作业调度。它的主要作用是解耦资源管理和数据处理逻辑,使得MapReduce只需专注于数据处理,同时支持其他计算框架。
YARN的架构
YARN主要由以下几个组件组成:
1. ResourceManager (RM):全局资源管理+启动ApplicationMaster。
2. NodeManager (NM):节点资源管理+向ResourceManager报告资源使用情况和任务状态。
3. ApplicationMaster (AM):
- 作业管理:每个应用程序都有一个ApplicationMaster,负责与ResourceManager协商资源,与NodeManager协作执行任务。
- 任务调度:ApplicationMaster负责将任务调度到合适的容器中执行。
4. Container:理解为资源的封装,任务在Container中执行,由NodeManager监控。
YARN与MapReduce的关系:
1. 解耦资源管理和作业调度:
- 在Hadoop 1.0中,MapReduce既负责资源管理又负责作业调度,导致扩展性和灵活性受限。
- YARN将资源管理和作业调度解耦,使得MapReduce只需专注于数据处理逻辑。
2. MapReduce作为YARN的一个应用程序:
- 在YARN架构下,MapReduce作为一个应用程序运行,由ApplicationMaster负责作业的管理和任务调度。
- MapReduce的ResourceManager和JobTracker功能被YARN的ResourceManager和ApplicationMaster取代。
3. 支持多计算框架:
YARN不仅支持MapReduce,还支持其他计算框架如Spark、Flink等,使得Hadoop成为一个通用的数据处理平台。
示例:一个MapReduce作业
用户提交MapReduce作业到YARN的ResourceManager,ResourceManager为该作业分配资源,并启动一个ApplicationMaster,ApplicationMaster与ResourceManager协商资源,将Map和Reduce任务调度到各个NodeManager的Container中执行,NodeManager监控任务的执行情况,并向ApplicationMaster报告状,ApplicationMaster在作业完成后,向ResourceManager注销并释放资源。
八、Hadoop MapReduce和Apache Spark都是大数据处理框架,请简要说明它们的主要区别。
1. 数据处理模型
Hadoop MapReduce:批处理,适合静态数据;数据处理分为Map和Reduce两个阶段,中间结果需要写入磁盘。
Apache Spark:支持批处理、流处理、交互式查询和机器学习等多种数据处理模式;利用内存进行计算,减少磁盘I/O,显著提高性能。
2. 性能
Hadoop MapReduce:磁盘I/O性能相对较低,适合高延迟的批处理作业。
Apache Spark:内存计算+低延迟。
3. 易用性
Hadoop MapReduce:编程模型相对复杂+API限制(API较为底层,开发效率较低)
Apache Spark:高级API(Spark提供了丰富的高级API(如Scala、Java、Python、R),易于使用。)+开发效率高。
4. 生态系统
Hadoop MapReduce:MapReduce是Hadoop生态系统的一部分,依赖HDFS进行数据存储,
Hadoop生态系统成熟稳定,适合大规模批处理。
Apache Spark: Spark有自己的生态系统(独立),支持多种数据源(如HDFS、S3、Cassandra)。+丰富库:Spark提供了丰富的库(如Spark SQL、Spark Streaming、MLlib、GraphX),支持多种数据处理需求。
总结:
Hadoop MapReduce:适合大规模批处理和高容错性需求的场景,但性能较低,编程复杂。
Apache Spark:适合实时数据处理、迭代计算和多种数据处理模式,性能高,易于使用。
九、在配置Hadoop集群时的关键配置参数
1. dfs.replication:
◦ 作用:指定HDFS中每个数据块的副本数量。
◦ 解释:默认值为3,表示每个数据块会在集群中存储3个副本。增加副本数可以提高数据的可靠性和容错性,但也会增加存储开销。
2.mapreduce.tasktracker.map.tasks.maximum和 mapreduce.tasktracker.reduce.tasks.maximum:
◦ 作用:分别指定每个NodeManager上可以同时运行的Map任务和Reduce任务的最大数量。
◦ 解释:这些参数影响集群的并发处理能力。合理设置这些参数可以优化资源利用率和作业执行效率。
3. yarn.scheduler.maximum-allocation-mb:
◦ 作用:指定YARN可以为每个容器分配的最大内存量。
◦ 解释:这个参数决定了单个任务可以使用的最大内存资源。合理设置可以防止单个任务占用过多资源,影响其他任务的执行。
十、数据本地性优化:在Hadoop中,数据本地性(Data Locality)是什么?为什么它对性能优化至关重要?
**数据本地性(Data Locality)**是指计算任务在数据所在的节点上执行,尽量减少数据的网络传输。
• 重要性:
◦ 减少网络开销:数据本地性可以减少数据在网络中的传输,降低网络带宽的消耗。
◦ 提高性能:本地数据处理速度远快于通过网络传输数据后再处理,显著提高作业的执行效率。
◦ 负载均衡:数据本地性有助于均衡集群中各节点的负载,避免某些节点过载。
十一、Hadoop故障处理:在Hadoop集群中,如果某个DataNode宕机,系统会如何处理?NameNode在这个过程中扮演了什么角色?
1. 检测故障:
◦ NameNode通过心跳机制检测到DataNode宕机。
2. 副本复制:
◦ NameNode会检查宕机DataNode上存储的数据块,发现副本数量不足时,会启动副本复制过程,将数据块复制到其他健康的DataNode上。
3. 更新元数据:
◦ NameNode更新元数据信息,记录新的数据块副本位置。
NameNode的角色:
• 元数据管理:NameNode负责管理文件系统的元数据,包括文件到数据块的映射和数据块的位置信息。
• 故障检测与恢复:NameNode通过心跳机制检测DataNode的状态,并在DataNode宕机时协调数据块的复制和恢复。
十二、Hadoop应用场景
应用场景:日志分析
• 场景描述:大型互联网公司每天生成大量的日志数据,需要对这些日志进行分析,以提取用户行为、系统性能等信息。(大规模数据处理+成本效益+高容错性+批处理)
相关文章:

Hadoop、Hive、Spark的关系
Part1:Hadoop、Hive、Spark关系概览 1、MapReduce on Hadoop 和spark都是数据计算框架,一般认为spark的速度比MR快2-3倍。 2、mapreduce是数据计算的过程,map将一个任务分成多个小任务,reduce的部分将结果汇总之后返回。 3、HIv…...

OneM2M:全球性的物联网标准-可应用于物联网中
OneM2M 是一个全球性的物联网(IoT)标准,旨在为物联网设备和服务提供统一的框架和接口,以实现设备之间的互操作性、数据共享和服务集成。OneM2M 由多个国际标准化组织(如 ETSI、TIA、TTC、ARIB 等)共同制定,目标是解决物联网领域的碎片化问题,提供一个通用的标准,支持跨…...
)
C++类和对象入门(三)
目录 前言 一、初始化列表 1.1定义 1.2 格式和语法 1.3与在函数内初始化的区别 1.4使用初始化列表的必要性 1.5成员变量默认值的使用(C11) 1.6初始化的先后顺序 1.7初始化列表的总结 二、类型转换 2.1内置类型转化成类类型 2.2类类型之间的相…...

Ubuntu 下 Docker 企业级运维指南:核心命令与最佳实践深度解析20250309
Ubuntu 下 Docker 企业级运维指南:核心命令与最佳实践深度解析 在当今的数字化时代,Docker 已成为企业应用部署和运维的基石。其轻量级、高效且灵活的容器化技术,为企业带来了前所未有的敏捷性和可扩展性。然而,随着容器化应用的…...

Tensorflow 2.0 GPU的使用与限制使用率及虚拟多GPU
Tensorflow 2.0 GPU的使用与限制使用率及虚拟多GPU 1. 获得当前主机上特定运算设备的列表2. 设置当前程序可见的设备范围3. 显存的使用4. 单GPU模拟多GPU环境 先插入一行简单代码,以下复制即可用来设置GPU使用率: import tensorflow as tf import numpy…...

【PyCharm】Python和PyCharm的相互关系和使用联动介绍
李升伟 整理 Python 是一种广泛使用的编程语言,而 PyCharm 是 JetBrains 开发的专门用于 Python 开发的集成开发环境(IDE)。以下是它们的相互关系和使用联动的介绍: 1. Python 和 PyCharm 的关系 Python:一种解释型、…...

动态规划:多重背包
本题力扣上没有原题,大家可以去卡码网第56题 (opens new window)去练习,题意是一样的。 56. 携带矿石资源(第八期模拟笔试) 题目描述 你是一名宇航员,即将前往一个遥远的行星。在这个行星上,有许多不同类…...

AI编程: 一个案例对比CPU和GPU在深度学习方面的性能差异
背景 字节跳动正式发布中国首个AI原生集成开发环境工具(AI IDE)——AI编程工具Trae国内版。 该工具模型搭载doubao-1.5-pro,支持切换满血版DeepSeek R1&V3, 可以帮助各阶段开发者与AI流畅协作,更快、更高质量地完…...

TensorFlow 的基本概念和使用场景
TensorFlow 是一个由 Google 开发的开源深度学习框架,用于构建和训练机器学习模型。它的基本概念包括以下几点: 张量(Tensor):在 TensorFlow 中,数据以张量的形式表示,张量可以是多维数组&#…...

gRPC学习笔记
微服务 一旦某个服务器宕机,会引起整个应用不可用,隔离性差 只能整体应用进行伸缩,浪费资源,可伸缩性差 代码耦合在一起,可维护性差 微服务架构:解决了单体架构的弊端 可以按照服务进行单独扩容 各个…...

Linux常见指令
Linux常见指令 1、ls指令2、pwd命令3、cd指令4、touch指令5、mkdir指令6、rmdir指令和rm指令7、man指令8、cp指令9、mv指令10、cat指令11、重定向12、more指令13、less指令14、head指令15、tail指令16、管道17、时间相关指令18、cal指令19、find指令20、grep指令21、zip/unzip指…...

Vue3、vue学习笔记
<!-- Vue3 --> 1、Vue项目搭建 npm init vuelatest cd 文件目录 npm i npm run dev // npm run _ 这个在package.json中查看scripts /* vue_study\.vscode可删 // vue_study\src\components也可删除(基本语法,不使用组件) */ // vue_study\.vscode\lau…...
)
用OpenCV写个视频播放器可还行?(C++版)
引言 提到OpenCV,大家首先想到的可能是图像处理、目标检测,但你是否想过——用OpenCV实现一个带进度条、倍速播放、暂停功能的视频播放器?本文将通过一个实战项目,带你深入掌握OpenCV的视频处理能力,并解锁以下功能&a…...

clion+arm-cm3+MSYS-mingw +jlink配置用于嵌入式开发
0.前言 正文可以跳过这段 初识clion,应该是2015年首次发布的时候, 那会还是大三,被一则推介广告吸引到,当时还在用vs studio,但是就喜欢鼓捣新工具,然后下载安装试用了clion,但是当时对cmake规…...

物联网-IoTivity:开源的物联网框架
IoTivity 是一个开源的物联网(IoT)框架,旨在为物联网设备提供互操作性、安全性和可扩展性。它由 Open Connectivity Foundation (OCF) 主导开发,遵循 OCF 的标准,致力于实现设备之间的无缝连接和通信。IoTivity 提供了一个统一的框架,支持设备发现、数据交换、设备管理和…...

Acrobat DC v25.001 最新专业版已破,像word一样编辑PDF!
在数字化时代,PDF文件以其稳定性和通用性成为了文档交流和存储的热门选择。无论是阅读、编辑、转换还是转曲,大家对PDF文件的操作需求日益增加。因此,一款出色的PDF处理软件不仅要满足多样化的需求,还要通过简洁的界面和强大的功能…...

【c++】模板进阶
在前面我们学习了模板的基础用法【c】 模板初阶-CSDN博客初步认识了函数模板和类模板,接下来让我们看看模板还有哪些进阶的应用。 非类型模板参数 之前我们用到的模板全都使用了类型参数 类型参数:表示某种数据类型(如 int、double、自定义…...

IntelliJ IDEA 2021版创建springboot项目的五种方式
第一种方式,通过https://start.spring.io作为spring Initializr的url来创建项目。 第二种方式,通过https://start.spring.io官网来直接创建springboot项目压缩包,然后导入至我们的idea中。 点击generate后,即可生成压缩包…...
、Bartlett方法(周期图)(Python))
数字信号处理之信号功率谱计算welch方法(分段加窗平均周期图)、Bartlett方法(周期图)(Python)
welch方法原理说明 welch方法[1]通过将数据划分为重叠的段,计算每个段的进行修改(加窗)后的周期图,然后对所有段的周期图求和进行平均,得到最终的功率谱密度。 Python和Matlab中均存在welch函数。welch函数通过配置noverlap为0,可…...

【面试】Java 基础
基础 1、Java 中几种基本数据类型什么,各自占用多少字节2、基本数据同包装类的区别3、Java 基本类型的参数传递和引用类型的参数传递有啥区别4、隐式类型转换和显式类型转换5、switch 语句表达式结果的类型6、数组的扩容方式7、面向对象三大特征8、静态变量和成员变…...
)
【工具使用】IDEA 社区版如何创建 Spring Boot 项目(详细教程)
IDEA 社区版如何创建 Spring Boot 项目(详细教程) Spring Boot 以其简洁、高效的特性,成为 Java 开发的主流框架之一。虽然 IntelliJ IDEA 专业版提供了Spring Boot 项目向导,但 社区版(Community Edition)…...

CTFHub-FastCGI协议/Redis协议
将木马进行base64编码 <?php eval($_GET[cmd]);?> 打开kali虚拟机,使用虚拟机中Gopherus-master工具 Gopherus-master工具安装 git clone https://github.com/tarunkant/Gopherus.git 进入工具目录 cd Gopherus 使用工具 python2 "位置" --expl…...

【Python字符串】\n是什么?它与raw字符串、多行字符串的运用有什么关系?
李升伟 整理 在Python中,\n 是换行符,用于在字符串中表示新的一行。当你在字符串中使用 \n 时,Python 会在该位置插入一个换行符,使得输出在 \n 处换行。 1. 普通字符串中的 \n 在普通字符串中,\n 会被解释为换行符…...

Linux 配置静态 IP
一、简介 在 Linux CentOS 系统中默认动态分配 IP 地址,每次启动虚拟机服务都是不一样的 IP,因此要配置静态 IP 地址避免每次都发生变化,下面将介绍配置静态 IP 的详细步骤。 首先先理解一下动态 IP 和静态 IP 的概念: 动态 IP…...

git lfs使用方法指南【在github保存100M以上大文件】
为了在 GitHub 仓库中存储超过 100MB 的大文件并避免推送失败,使用 Git LFS(Large File Storage) 是最佳解决方案。以下是详细步骤: 一、安装 Git LFS 下载并安装 Git LFS: 访问 Git LFS 官网 下载对应系统的安装包。或…...

【Linux】初识线程
目录 一、什么是线程: 重定义线程和进程: 执行流: Linux中线程的实现方案: 二、再谈进程地址空间 三、小结: 1、概念: 2、进程与线程的关系: 3、线程优点: 4、线程…...

【Linux学习笔记】Linux基本指令分析和权限的概念
【Linux学习笔记】Linux基本指令分析和权限的概念 🔥个人主页:大白的编程日记 🔥专栏:Linux学习笔记 文章目录 【Linux学习笔记】Linux基本指令分析和权限的概念前言一. 指令的分析1.1 alias 指令1.2 grep 指令1.3 zip/unzip 指…...

uniapp登录用户名在其他页面都能响应
使用全局变量 1、在APP.vue中定义一个全局变量,然后在需要的地方引用它; <script>export default {onLaunch: function() {console.log(App Launch)this.globalData { userInfo: {} };},onShow: function() {console.log(App Show)},onHide: fu…...
:使用 AT 命令)
ESP8266 入门(第 2 部分):使用 AT 命令
使用 AT 命令对 WiFi 收发器ESP8266编程 本教程是上一个教程 ESP8266 入门(第 1 部分)的延续。因此,简单回顾一下,在之前的教程中,我们介绍了 ESP 模块,并学习了一些基础知识。我们还使用 FTDI 串行适配器模块制作了一个开发板,该模块可以很容易地用于使用 AT 命令和 A…...

介绍一下Qt 中的QSizePolicy 布局策略
在 Qt 中,QSizePolicy 类用于描述一个控件在布局中如何分配空间,它定义了控件在水平和垂直方向上对空间的需求和响应策略。以下是对 QSizePolicy 策略的详细介绍: 基本概念 QSizePolicy 包含两个主要的属性:Policy(策…...

从ETL到数仓分层:大数据处理的“金字塔”构建之道
在当今数据驱动的时代,大数据处理已成为企业决策和业务优化的核心。而ETL(Extract, Transform, Load)作为数据处理的基石,其背后的数仓分层理念更是决定了数据处理的效率与质量。本文将深入探讨ETL工作中的数仓分层理念࿰…...

springBoot集成声明式和编程式事务的方式
一、声明式事务 前提集成了mybatisplus插件 1、pom依赖 <dependencies><!-- MyBatis-Plus 启动器 --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.3.4&l…...

前端实现版本更新自动检测✅
🤖 作者简介:水煮白菜王,一位资深前端劝退师 👻 👀 文章专栏: 前端专栏 ,记录一下平时在博客写作中,总结出的一些开发技巧和知识归纳总结✍。 感谢支持💕💕&a…...

Python零基础学习第三天:函数与数据结构
一、函数基础 函数是什么? 想象你每天都要重复做同一件事,比如泡咖啡。函数就像你写好的泡咖啡步骤说明书,每次需要时直接按步骤执行,不用重新想流程。 # 定义泡咖啡的函数 def make_coffee(sugar1): # 默认加1勺糖 print("…...

深入了解Linux —— 调试程序
前言 我们已经学习了linux下许多的工具,vim、gcc、make/makefile等; 已经能够在linux写代码,并且进行编译运行,让程序在linux下跑起来。 但是,如果我们在写代码的时候遇见了错误;但是我们并不知道错误在哪&…...

解决VScode 连接不上问题
问题 :VScode 连接不上 解决方案: 1、手动杀死VS Code服务器进程,然后重新尝试登录 打开xshell ,远程连接服务器 ,查看vscode的进程 ,然后全部杀掉 [cxqiZwz9fjj2ssnshikw14avaZ ~]$ ps ajx | grep vsc…...

行式数据库与列式数据库区别
列式数据库(Columnar Database)和行式数据库(Row-based Database)是两种不同的数据存储和检索方式,它们在数据组织、存储结构和适用场景上有显著区别。以下是对两者的详细对比: 1. 数据存储方式 行式数据库…...
)
如何将本地已有的仓库上传到gitee (使用UGit)
1、登录Gitee。 2、点击个人头像旁边的加号,选择新建仓库: 3、填写仓库相关信息 4、复制Gitee仓库的地址 5、绑定我们的本地仓库与远程仓库 6、将本地仓库发布(推送)到远程仓库: 注意到此处报错ÿ…...

FIWARE:开源的物联网平台,支持设备虚拟化和数据管理
FIWARE 是一个开源的物联网(IoT)平台,旨在为物联网应用提供强大的数据管理和设备虚拟化功能。FIWARE 提供了一系列通用的 API 和组件,支持设备管理、数据采集、数据处理、数据共享和安全通信等功能,使得开发者能够快速构建和扩展物联网解决方案。以下是 FIWARE 的核心功能…...
—— RV指令集)
RISC-V汇编学习(三)—— RV指令集
有了前两节对于RISC-V汇编、寄存器、汇编语法等的认识,本节开始介绍RISC-V指令集和伪指令。 前面说了RISC-V的模块化特点,是以RV32I为作为ISA的核心模块,其他都是要基于此为基础,可以这样认为:RISC-V ISA 基本整数指…...

【Linux】冯诺依曼体系与操作系统理解
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:Linux 目录 前言 一、冯诺依曼体系结构 二、操作系统 1. 操作系统的概念 2. 操作系统存在的意义 3. 操作系统的管理方式 4. 补充:理解系统调用…...

Android15使用FFmpeg解码并播放MP4视频完整示例
效果: 1.编译FFmpeg库: 下载FFmpeg-kit的源码并编译生成安装平台库 2.复制生成的FFmpeg库so文件与包含目录到自己的Android下 如果没有prebuiltLibs目录,创建一个,然后复制 包含目录只复制arm64-v8a下...
——RTP封装音频时,音频的有效载荷结构)
音视频入门基础:RTP专题(16)——RTP封装音频时,音频的有效载荷结构
一、引言 《RFC 3640》和《RFC 6416》分别定义了两种对MPEG-4流的RTP封包方式,这两个文档都可以从RFC官网下载: RFC Editor 本文主要对《RFC 3640》中的音频打包方式进行简介。《RFC 3640》总共有43页,本文下面所说的“页数”是指在pdf阅读…...

3.3.2 Proteus第一个仿真图
文章目录 文章介绍0 效果图1 新建“点灯”项目2 添加元器件3 元器件布局接线4 补充 文章介绍 本文介绍:使用Proteus仿真软件画第一个仿真图 0 效果图 1 新建“点灯”项目 修改项目名称和路径,之后一直点“下一步”直到完成 2 添加元器件 点击元…...

MySQL创建数据库和表,插入四大名著中的人物
一、登录数据库并创建数据库db_ck 二、创建表t_hero 表属性包括(id,name,nickname,age,gender,address,weapon,types) mysql> create table t_hero(-> id int,-…...

matlab和FPGA联合仿真时读写.txt文件数据的方法
在FPGA开发过程中,往往需要将MATLAB生成的数据作为原始激励灌入FPGA进行仿真。为了验证FPGA计算是否正确,又需要将FPGA计算结果导入MATLAB绘图与MATLAB计算结果对比。 下面是MATLAB“写.txt”、“读.txt”,Verilog“读.txt”、“写.txt”的代…...

C++修炼之路:初识C++
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路! 我的博客:<但凡. 我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》 欢迎点赞,关注! 引言 …...

ACE协议学习1
在多核系统或复杂SoC(System on Chip)中,不同处理器核心或IP(Intellectual Property)模块之间需要保持数据的一致性。常用的是ACE协议or CHI。 先对ACE协议进行学习 ACE协议(Advanced Microcontroller Bu…...
)
通俗易懂的介绍LLM大模型技术常用专业名词(通用版)
1. 神经网络 (Neural Network) 解释: 一种模拟人脑神经元结构的计算模型,用于处理复杂的数据模式。 示例: 图像识别中的卷积神经网络(CNN)。 2. 深度学习 (Deep Learning) 解释: 基于多层神经网络的机器学习方法,能够自动提取数…...

深度学习环境安装
Anaconda 3.0 下载地址 Download Success | Anaconda CUDA 下载地址 cuda_12.4.0 https://developer.nvidia.com/cuda-12-4-0-download-archive?target_osWindows&target_archx86_64&target_version11&target_typeexe_local pytorch 下载地址 (2…...