python从入门到精通(二十二):python文件操作之Excel全攻略(基于pandas)
Python处理表格数据
- 1.表格的基础知识
- 1.1 xls与xlsx格式详解
- 1.2 表格内部结构的认识
- 2.表格的基础操作
- 2.1 认识表格的基本库
- 2.1.1 csv内置的标准库
- 2.1.2 xlrd 和 xlwt
- 2.1.3 openpyxl
- 2.1.4 pandas
- 2.2 安装和环境配置
- 2.3 xlrd 和 xlwt
- 2.3.1 库的说明
- 2.3.2 安装xlrd库
- 2.3.3 导入模块
- 2.3.4 深入使用
- 2.4 Pandas
- 2.4.1 简介
- 2.4.2 安装pandas
- 2.4.3 导入pandas
- 2.4.3 pandas Series数据结构
- 2.4.3.1 Series的作用和参数
- 2.4.3.2 创建一个空Series对象
- 2.4.3.3 创建一个简单的Series对象
- 2.4.3.4 根据索引值读取数据
- 2.4.3.5 手动设定索引值
- 2.4.3.7 手动设置索引并取值
- 2.4.3.8 使用key/value创建Series
- 2.4.4 pandas DataFrame数据结构
- 2.4.4.1使用ndarrays和字典创建DF
- 2.4.5 Pandas读取写入CSV
- 2.4.5.1 read_csv读取CSV文件
- 2.4.5.2 to_csv写入csv文件
- 2.4.5.3 数据处理
- 2.4.6 Pandas读取写入Execl
- 2.4.6.1 Pandas数据查看
- 2.4.6.1.1 head()
- 2.4.6.1.2 tail()
- 2.4.6.1.3 info()
- 2.4.6.1.4 set_option 指定查看行数
- 2.4.6.1.5 shape 行列数
- 2.4.6.1.6 dtypes 变量类型
- 2.4.6.1.7 describe 统计
- 2.4.6.2 Pandas数据选择
- 2.4.6.2.1 index 行名称或者行索引
- 2.4.6.2.2 columns 查找列名称
- 2.4.6.2.3 values查找表的值
- 2.4.6.2.4 df["A"] 查找某一列
- 2.4.6.2.5 df[['A','B']] 查找多个列
- 2.4.6.2.6 sample 随机选取几行
- 2.4.6.2.7 df[x:x]指定连续选择多行
- 2.4.6.2.8 loc 根据行列名称定位查找
- 2.4.6.2.9 iloc 根据索引定位查找
- 2.4.6.2.10 布尔值索引
- 2.4.6.3 Pandas数据修改
- 2.4.6.3.1 list修改列名
- 2.4.6.3.2 rename修改列名
- 2.4.6.3.3 set_index修改索引
- 2.4.6.3.4 按列修改值
- 2.4.6.3.5 切片操作
- 2.4.6.3.5 条件设置
- 2.4.6.3.5 按列修改类型
- 2.4.6.4 Pandas数据增加
- 2.4.6.4.1 使用 loc按行增加
- 2.4.6.4.1 使用 loc按列增加
- 2.4.6.3 Pandas数据拼接
- 2.4.6.3 Pandas数据删除
- 2.4.6.3.1 删除空值数据
- 2.4.6.3.2 删除格式错误数据
- 2.4.6.3.3 删除错误数据
- 2.4.6.3.4 删除重复数据
- 2.4.6.4 Pandas数据排序
- 2.4.6.5 Pandas数据过滤
- 2.4.6.6 Pandas数据分组
- 2.4.6.7 Pandas数据合并
- 2.4.6.8 Pandas时间序列处理
- 2.4.6.9 Pandas数据可视化
1.表格的基础知识
如果我们要使用python来处理表格,首先我们需要了解怎么表格的每个部分对应的python应该怎么操作
1.1 xls与xlsx格式详解
- 历史演变:xls是Excel 2003及之前版本的默认格式,采用BIFF8二进制格式存储
- xlsx格式特点:基于XML的开放格式(OOXML标准),采用ZIP压缩技术
兼容性对比:
- Excel 2007+ 支持读写两种格式
- Excel 2013+ 默认保存为xlsx
- 其他办公软件兼容性差异
文件结构差异:
- xls最大限制:65536行×256列
- xlsx最大支持:1048576行×16384列
打开方式:
- xls是excel2003及以前版本所生成的文件格式
- xlsx是excel2007及以后版本所生成的文件格式
(excel 2007之后版本可以打开上述两种格式,但是excel2013只能打开xls格式)
1.2 表格内部结构的认识
- 一个Excel电子表格文档称为一个工作簿
- 一个工作簿保存在一个扩展名为.xlsx的文件中
- 一个工作簿可以包含多个表
- 用户当前查看的表(或关闭Excel前最后查看的表)称为活动表
- 在特定行和列的方格称为单元格、格子

2.表格的基础操作
2.1 认识表格的基本库
2.1.1 csv内置的标准库
- 简介:csv 是 Python 内置的标准库,专门用于处理 CSV(逗号分隔值)文件。CSV
文件是一种简单的文本文件,数据以逗号分隔不同字段,常用于数据交换和存储。 - 优点:无需额外安装,使用简单,适合处理简单的 CSV 文件读写操作。
- 缺点:功能相对单一,只能进行基本的读写操作,缺乏数据处理和分析功能。
- 示例代码 - 读取 CSV 文件
import csvwith open('example.csv', 'r', newline='') as file:reader = csv.reader(file)for row in reader:print(row)
2.1.2 xlrd 和 xlwt
- 简介:xlrd 用于读取 Excel 文件(主要支持 .xls 格式),xlwt 用于写入 Excel 文件(仅支持 .xls
格式)。这两个库在早期 Python 处理 Excel 文件时非常常用,但由于 .xls 格式的局限性,现在逐渐被 openpyxl
取代。 - 优点:简单易用,对于处理旧版本的 Excel 文件有一定的优势。
- 缺点:仅支持 .xls 格式,不支持 Excel 2010 及以上版本的 .xlsx 格式,功能相对有限。
import xlrd# 打开 Excel 文件
workbook = xlrd.open_workbook('example.xls')# 获取指定工作表,这里以获取第一个工作表为例
sheet = workbook.sheet_by_index(0)# 获取工作表的行数和列数
rows, columns = sheet.nrows, sheet.ncols# 遍历每一行
for row in range(rows):# 用于存储当前行的数据row_data = []# 遍历当前行的每一列for col in range(columns):# 获取当前单元格的值cell_value = sheet.cell_value(row, col)row_data.append(cell_value)print(row_data)
import xlwt# 创建一个新的工作簿
workbook = xlwt.Workbook()# 创建一个工作表
sheet = workbook.add_sheet('Sheet1')# 定义要写入的数据
data = [['Name', 'Age', 'City'],['Alice', 25, 'New York'],['Bob', 30, 'Los Angeles']
]# 遍历数据列表
for row_index, row in enumerate(data):# 遍历当前行的数据for col_index, value in enumerate(row):# 在指定单元格写入数据sheet.write(row_index, col_index, value)# 保存工作簿到文件
workbook.save('output.xls')
2.1.3 openpyxl
- 简介:openpyxl 是一个用于读写 Excel 2010 及以上版本文件(.xlsx、.xlsm 等)的库。它可以直接操作 Excel
文件的单元格、工作表、图表等元素。 - 优点:能够精确控制 Excel 文件的各种元素,如单元格样式、合并单元格、设置公式等,适合需要对 Excel 文件进行复杂格式设置的场景。
- 缺点:主要专注于 Excel 文件的操作,对于其他格式的表格数据支持有限,且在数据处理和分析方面不如 pandas 强大。
from openpyxl import load_workbookworkbook = load_workbook('example.xlsx')
sheet = workbook.active
for row in sheet.iter_rows(values_only=True):print(row)
2.1.4 pandas
- 简介:pandas 是一个强大的数据处理和分析库,提供了 DataFrame 和 Series
两种主要的数据结构,非常适合处理表格数据。它支持多种文件格式的读写,包括 CSV、Excel、SQL 数据库等。 - 优点:功能全面,涵盖了数据读取、清洗、转换、分析、可视化等多个方面,提供了丰富的方法和函数,能够高效地处理大规模数据。
- 缺点:学习曲线相对较陡,对于初学者来说可能需要花费一些时间来掌握其复杂的 API。
import pandas as pddf = pd.read_csv('example.csv')
average_age = df['Age'].mean()
print(f"Average age: {average_age}")
2.2 安装和环境配置
安装必要库
pip install pandas openpyxl xlrd xlsxwriter sqlite3
2.3 xlrd 和 xlwt
2.3.1 库的说明
什么是xlrd模块
- python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写exce的库。
为什么用xlrd模块
- 在UI自动化或者接口自动化中数据维护是一个核心,所以此模块非常实用。xlrd模块可以用于读取Excel的数据,速度非常快,推荐使用!
2.3.2 安装xlrd库
1.如果安装慢或者安装失败,可以指定安装源安装

2.百度搜索安装源
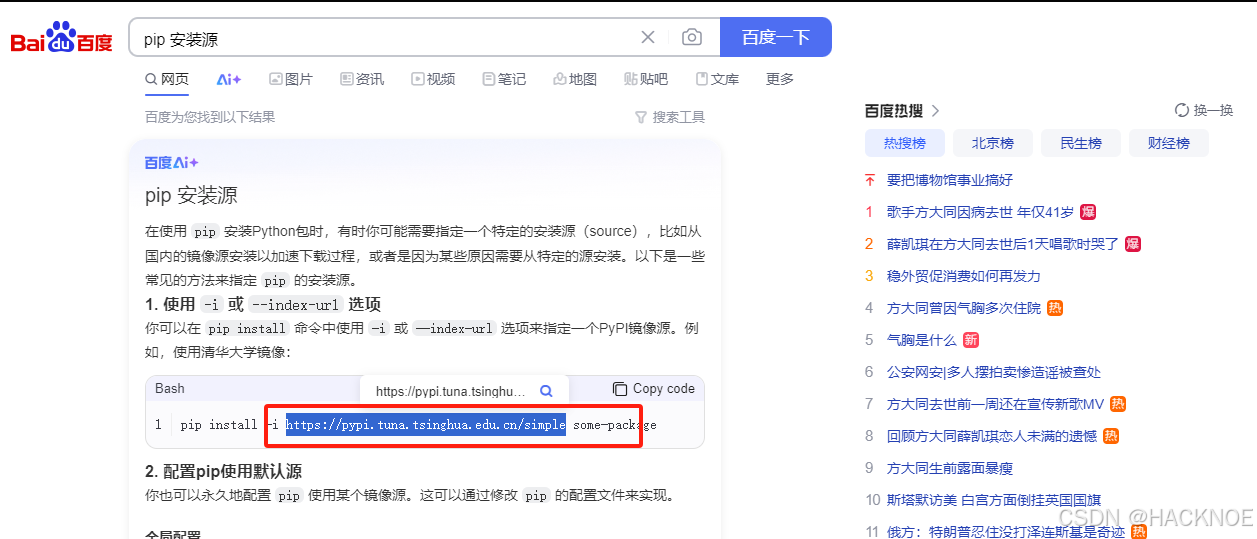
3.命令行下指定安装源安装

2.3.3 导入模块
import xlrd
2.3.4 深入使用
1.打开execl文件读取数据
data = xlrd.open_workbook("1.xls")
2.获取book中的工作表
#方法一
table = data.sheets()[0]
#方法二
table = data.sheet_by_index(0)
#方法三
table = data.sheet_by_name("sheet1")
3.返回book中的所有表
names = data.sheet_names()
4.检查sheet是否导入完毕
data.sheet_loaded(sheet_name or index)
5.获取sheet中的行数
2.4 Pandas
2.4.1 简介
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
官方网站:https://pandas.pydata.org/
官方文档:https://pandas.pydata.org/pandas-docs/stable/
2.4.2 安装pandas
pip安装pandas
pip install pandas
2.4.3 导入pandas
导入pandas并查看相应版本 as 是给pandas起一个简称,方便我们使用
import pandas as pd
pandas._version_
2.4.3 pandas Series数据结构
2.4.3.1 Series的作用和参数
Pandas Series 类似表格中的一个列(column),类似于一维数组,由一组数据值(value)和一组标签组成,其中标签与数据值之间是一一对应的关系。Series 可以保存任何数据类型。Series 由索引(index)和列组成,函数如下:
pandas.Series(data,index,dtype,name,copy)
参数说明如下所示:
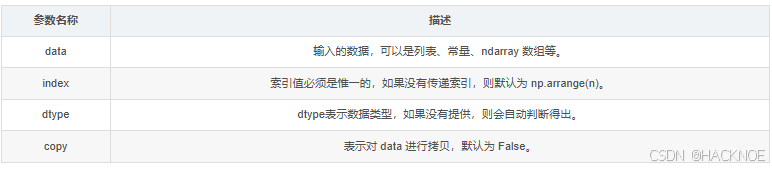
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从0开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
2.4.3.2 创建一个空Series对象
import pandas as pd
# print(pandas.__version__)series1 = pd.Series()
print(series1)
2.4.3.3 创建一个简单的Series对象
import pandas as pd
# print(pandas.__version__)a = [1,2,3]
series2 = pd.Series(a)
print(series2)
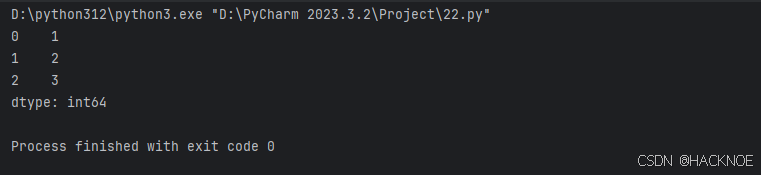
2.4.3.4 根据索引值读取数据
从上图可知,如果没有指定索引,索引值就从0开始,我们可以根据索引值读取数据:
import pandas as pd
# print(pandas.__version__)a = [1,2,3]
series2 = pd.Series(a)
print(series2[1])

2.4.3.5 手动设定索引值
import pandas as pd
# print(pandas.__version__)a = [1,2,3]
series2 = pd.Series(a,index=('x','y','z'))
print(series2)
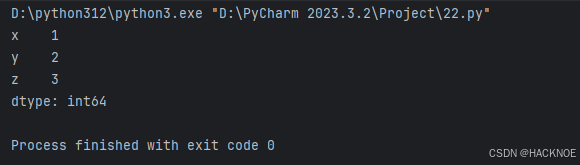
2.4.3.7 手动设置索引并取值
import pandas as pd
# print(pandas.__version__)a = [1,2,3]
series2 = pd.Series(a,index=('x','y','z'))
print(series2["x"])
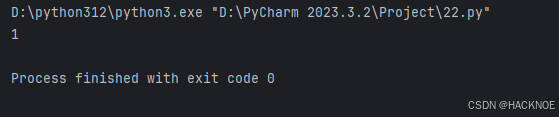
2.4.3.8 使用key/value创建Series
字典的 key 变成了索引值
import pandas as pd
# print(pandas.__version__)a = {1:"xsad",2:"dsadas",3:"sdasds"}
series2 = pd.Series(a)
print(series2)
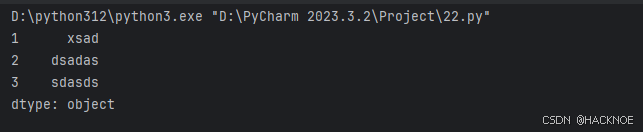
如果我们只需要字典中的一部分数据,只需要指定需要数据的索引即可,如下实例:
import pandas as pd
# print(pandas.__version__)a = {1:"xsad",2:"dsadas",3:"sdasds"}
series2 = pd.Series(a,index=[1,2])
print(series2)
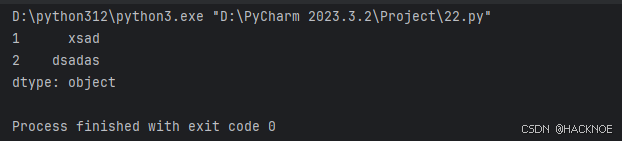
设置series的name
import pandas as pd
# print(pandas.__version__)a = {1:"xsad",2:"dsadas",3:"sdasds"}
series2 = pd.Series(a,name="lucky-series-test")
print(series2)
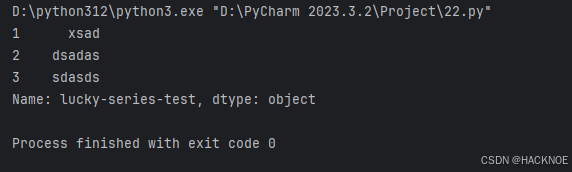
2.4.4 pandas DataFrame数据结构
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series组成的字典(共同用一个索引)。
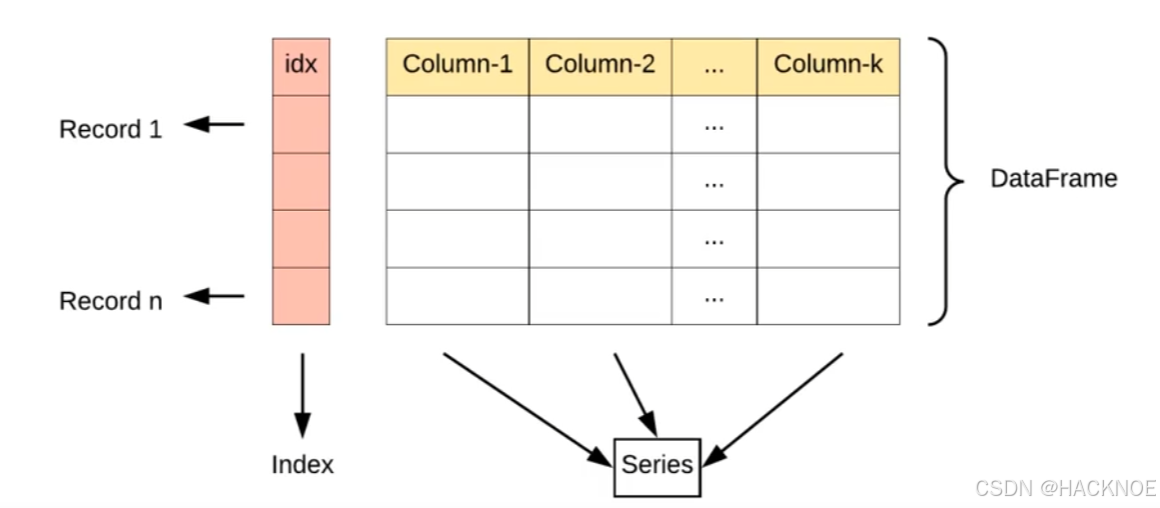
DataFrame 其实是从 Series 的基础上演变而来,就是多个Series组成的字典
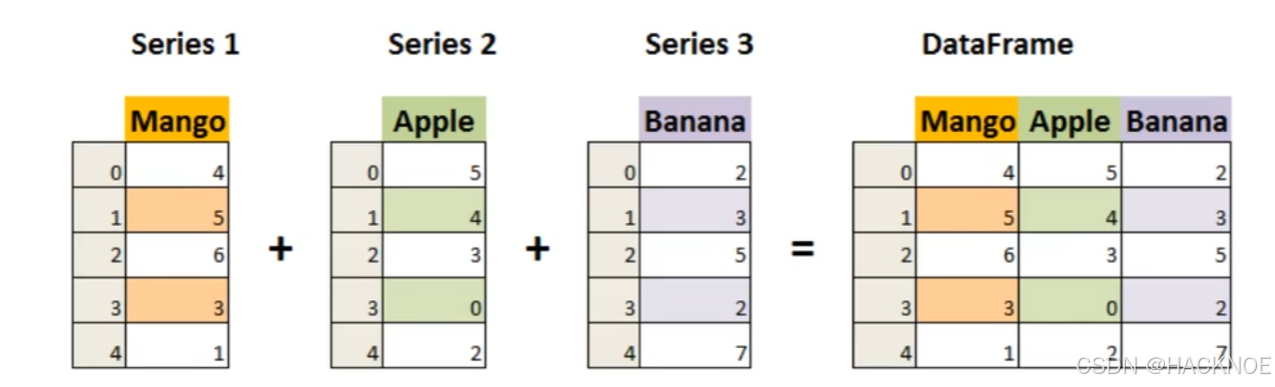
行标签(index),又有列标签(columns)
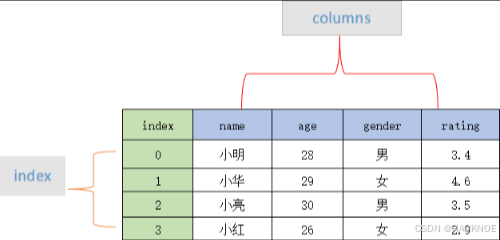
标签和现实表格的对应关系
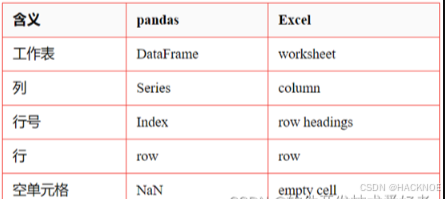
DataFrame 构造方法如下:
pandas.DataFrame( data,index,columns,dtype,copy)
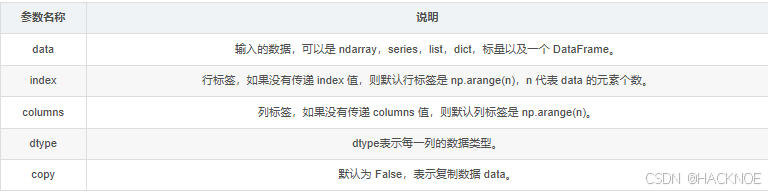
- data:一组数据(ndarray,series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签
- columns:列标签,默认为 Rangelndex(0,1,2,…,n)。
- dtype:数据类型。
- copy:拷贝数据,默认为False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组
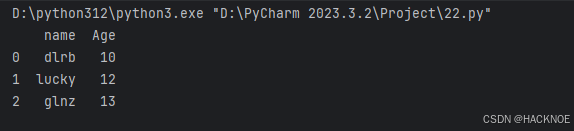
import pandas as pd
# print(pandas.__version__)data =[['dlrb',10],['lucky',12],['glnz',13]]
df = pd.DataFrame(data,columns=['name','Age'])
print(df)
2.4.4.1使用ndarrays和字典创建DF
以下实例使用 ndarrays 创建,ndarray的长度必须相同,如果传递了 index,则索引的长度应等于数组的长度。如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
ndarray(N 维数组)是一个快速且灵活的数据集容器。
以下实例-使用 ndarrays 创建
import pandas as pd
# print(pandas.__version__)data ={'Name':['elrb','lucky','glnz'],'Age':[10,12,13]}
df = pd.DataFrame(data)
print(df)
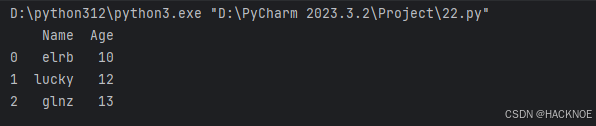
从以上输出结果可以知道, DataFrame 数据类型一个表格,包含rows(行)和columns(列):
还可以使用字典(key/value),其中字典的 key 为列名
实例-使用字典创建
import pandas as pd
# print(pandas.__version__)data = [{'a':1,'b':2,'c':3,'d':4,'e':5},{'a':1,'b':2,'c':3,'d':4,'e':5},{'a':1,'b':2,'c':3,'d':4,'e':5},{'a':1,'b':2,'c':3,'d':4,'e':5},{'a':1,'b':2,'c':3,'d':4,'e':5}]
df = pd.DataFrame(data)
print(df)
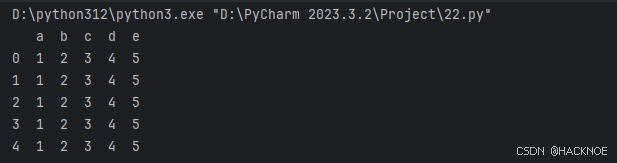
Pandas 可以使用loc属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
import pandas as pd
# print(pandas.__version__)data ={"calories":[420,380,390],"duration":[50,40,45]
}
df = pd.DataFrame(data)
print(df.loc[0])
print(df.loc[1])
注意:返回结果其实就是一个 Pandas Series 数据。
返回多行数据,也可以返回多行数据,使用[[…]]格式,…为各行的索引,以逗号隔开:
import pandas as pd
# print(pandas.__version__)data ={"calories":[420,380,390],"duration":[50,40,45]
}
df = pd.DataFrame(data)
print(df.loc[[0,1]])
返回某行数据
import pandas as pd
# print(pandas.__version__)data ={"calories":[420,380,390],"duration":[50,40,45]
}
df = pd.DataFrame(data,index=['day1','day2','day3'])
print(df)
print(df.loc['day1'])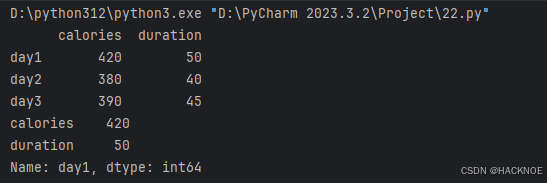
2.4.5 Pandas读取写入CSV
CSV(Iomma-Separated Values,逗号分隔值,有时也称为CSV字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
Pandas 可以很方便的处理 CSV 文件 本文以 nba.csv为例
2.4.5.1 read_csv读取CSV文件
import pandas as pddata = pd.read_csv('2.csv')
print(data.to_string())
to_string()用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面5行和未尾5行,中间部分以…代替。
2.4.5.2 to_csv写入csv文件
import pandas as pddata = pd.read_csv('2.csv')
data.to_csv('test.csv')
print(data.to_string())
注意: 在写入csv文件会默认将索引写入如果不需要索引 则需添加参数进行处理
data.to_csv('test.csv',index=False)
2.4.5.3 数据处理
1.head()
head( n)方法用于读取前面的n行,如果不填参数n,默认返回 5 行。
实例-读取前面10行
import pandas as pddata = pd.read_csv('2.csv')
print(data.head(10))
2.tail()
tail( n)方法用于读取尾部的n行,如果不填参数n,默认返回 5 行,空行各个字段的值返回 NaN,
实例-读取未尾10 行
import pandas as pddata = pd.read_csv('2.csv')
print(data.tail(10))
3.info()
info()方法返回表格的一些基本信息
import pandas as pddata = pd.read_csv('2.csv')
print(data.info())
2.4.6 Pandas读取写入Execl
Pandas提供了非常强大的功能操作Excel,是数据分析领域处理Excel文档的重要工具
Pandas方法
- 读取Excel
df= pd.read excel()
- 写入Excel
df.to excel()
常用参数
- index:是否写入索引默认为True
- header :是否写入表头 默认True
- sheet_name:写入哪个sheet页 默认sheet1
- startrow 写入Excel数据开始行 默认0行
- startcol 写入Excel数据开始列 默认0列
import pandas as pd# 读取Excel 去除表头 使用默认生成表头
df = pd.read_excel('1.xlsx',header=None)
print(df.to_string())# 写入Excel 去除表头header=None和索引index=False
df.to_excel('1.xlsx',index=False,header=False)
注意
当前在读取Excel以后会默认把第一行作为表头,这样在写入的时候会自带格式,为了防止这个问题出现,所以需要再读取和写入的时候给定参数,下面所有数据操作都以这个表为对象
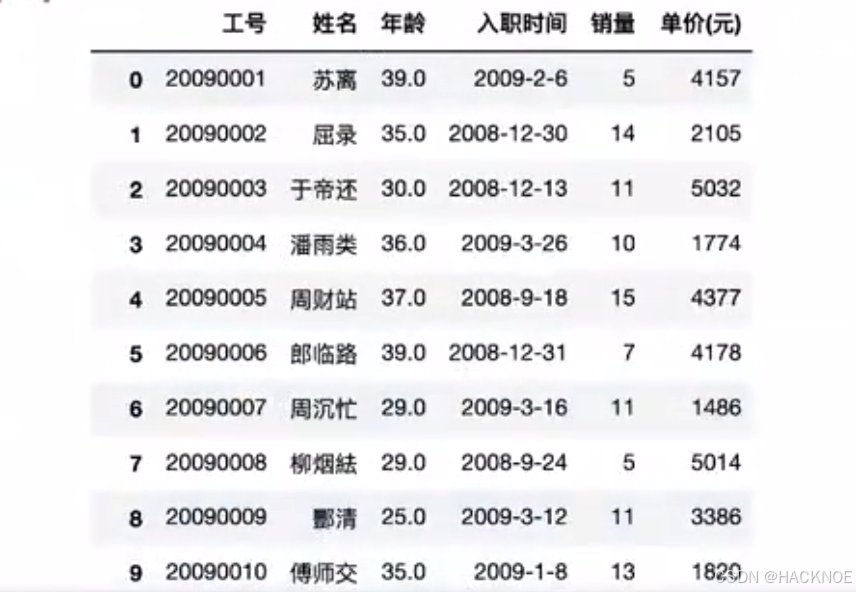
2.4.6.1 Pandas数据查看
上面处理csv的所有方法在这里可以同样去使用,这里就不在过多赘述~
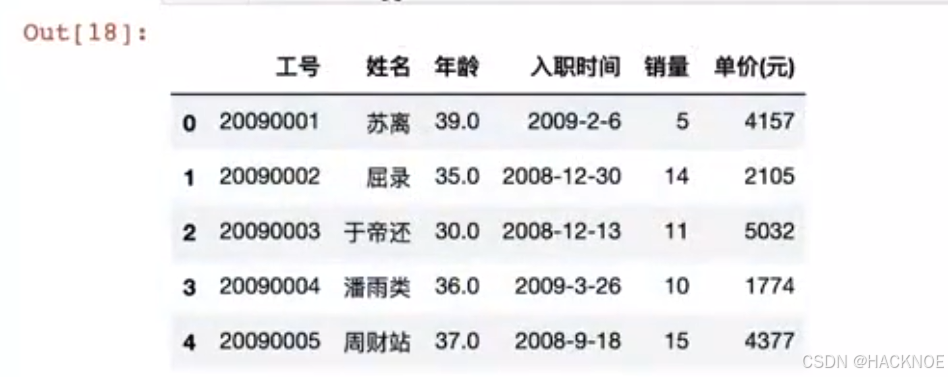
2.4.6.1.1 head()
head( n)方法用于读取前面的n行,如果不填参数n,默认返回 5 行。
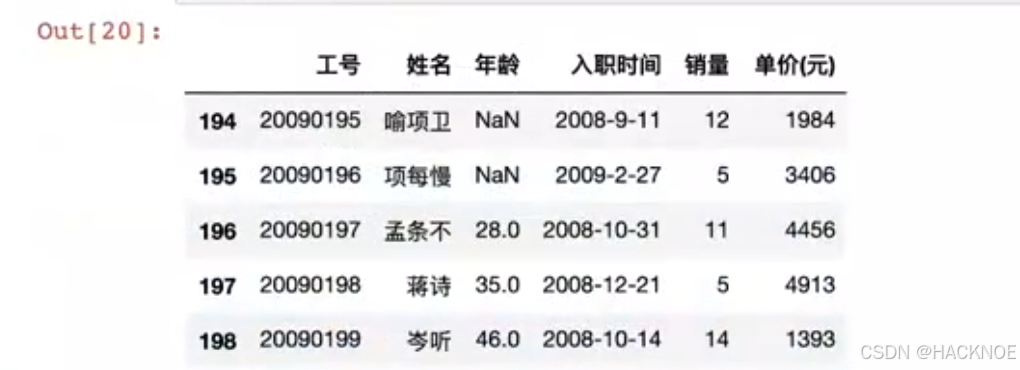
2.4.6.1.2 tail()
tail( n)方法用于读取尾部的n行,如果不填参数n,默认返回 5 行,空行各个字段的值返回 NaN,
实例-读取未尾10 行
2.4.6.1.3 info()
info()方法返回表格的一些基本信息
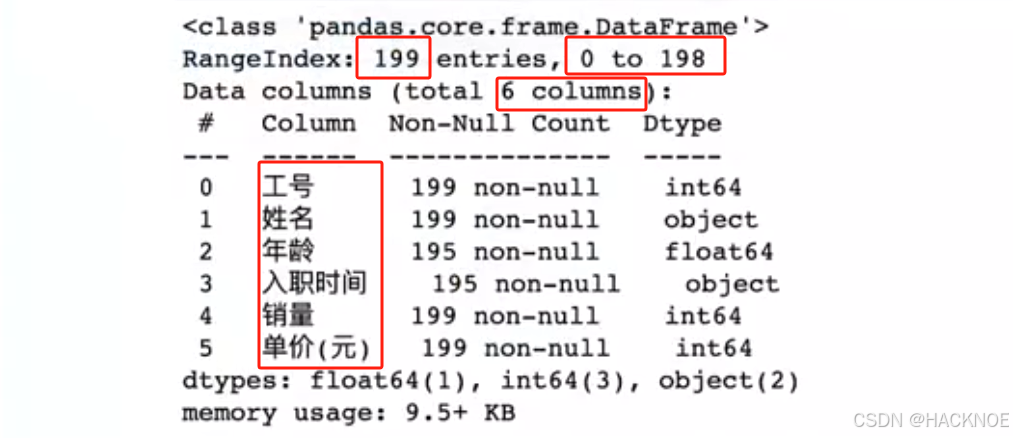
import pandas as pd# 读取Excel 去除表头 使用默认生成表头
df = pd.read_excel('1.xlsx',header=None)
# print(data.to_string())
print(df.head())
print(df.head(10))
print(df.tail())
print(df.tail(10))
print(df.info())# 写入Excel 去除表头和索引
df.to_excel('1.xlsx',index=False,header=False)
2.4.6.1.4 set_option 指定查看行数
df= pd.set option('max rows',200) # 可查看200行
2.4.6.1.5 shape 行列数
df.shape #DataFrame的行列数 199行 6列

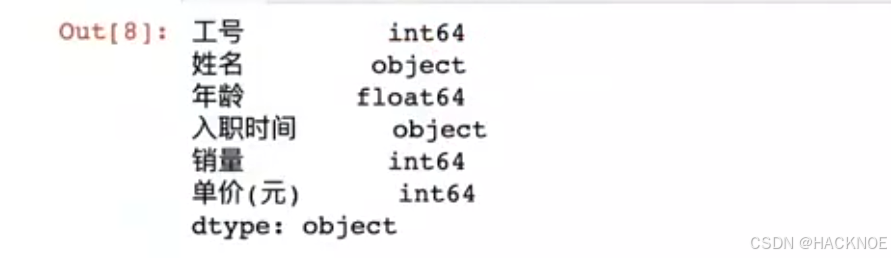
2.4.6.1.6 dtypes 变量类型
df.dtypes
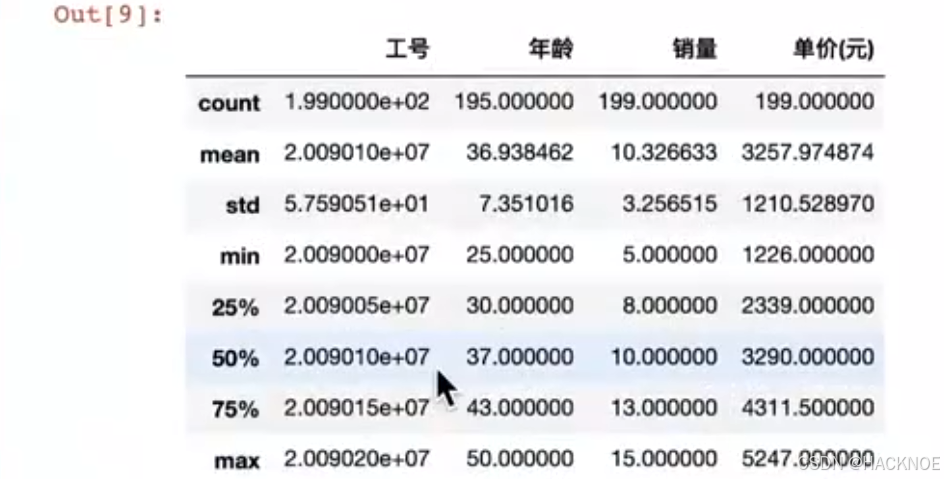
2.4.6.1.7 describe 统计
df.describe()
2.4.6.2 Pandas数据选择
2.4.6.2.1 index 行名称或者行索引
df.index
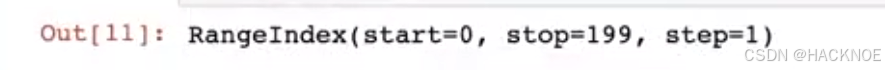
2.4.6.2.2 columns 查找列名称
df.columns

2.4.6.2.3 values查找表的值
df.values

2.4.6.2.4 df[“A”] 查找某一列
df['姓名'] #查找出姓名这一列

2.4.6.2.5 df[[‘A’,‘B’]] 查找多个列
df[['姓名','年龄']]
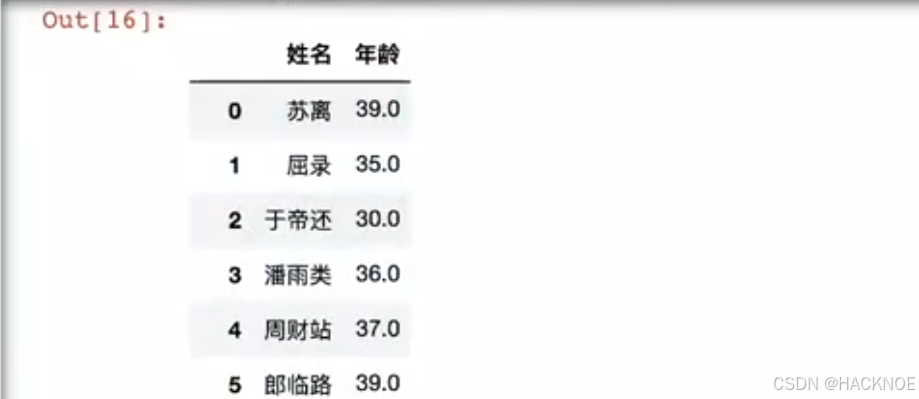
2.4.6.2.6 sample 随机选取几行
df.sample(5) #随机选5行
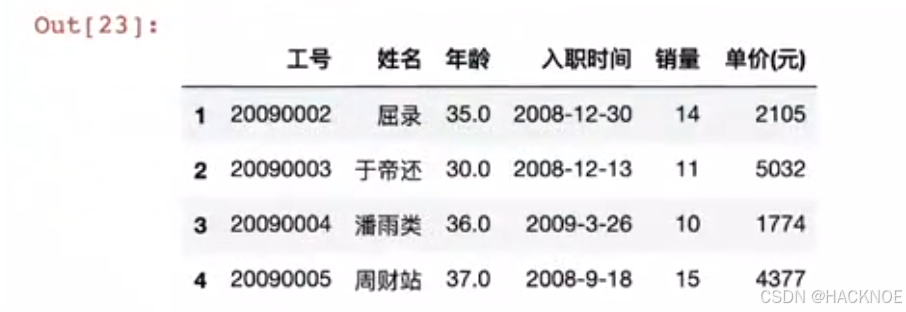
2.4.6.2.7 df[x:x]指定连续选择多行
df[1:5] #
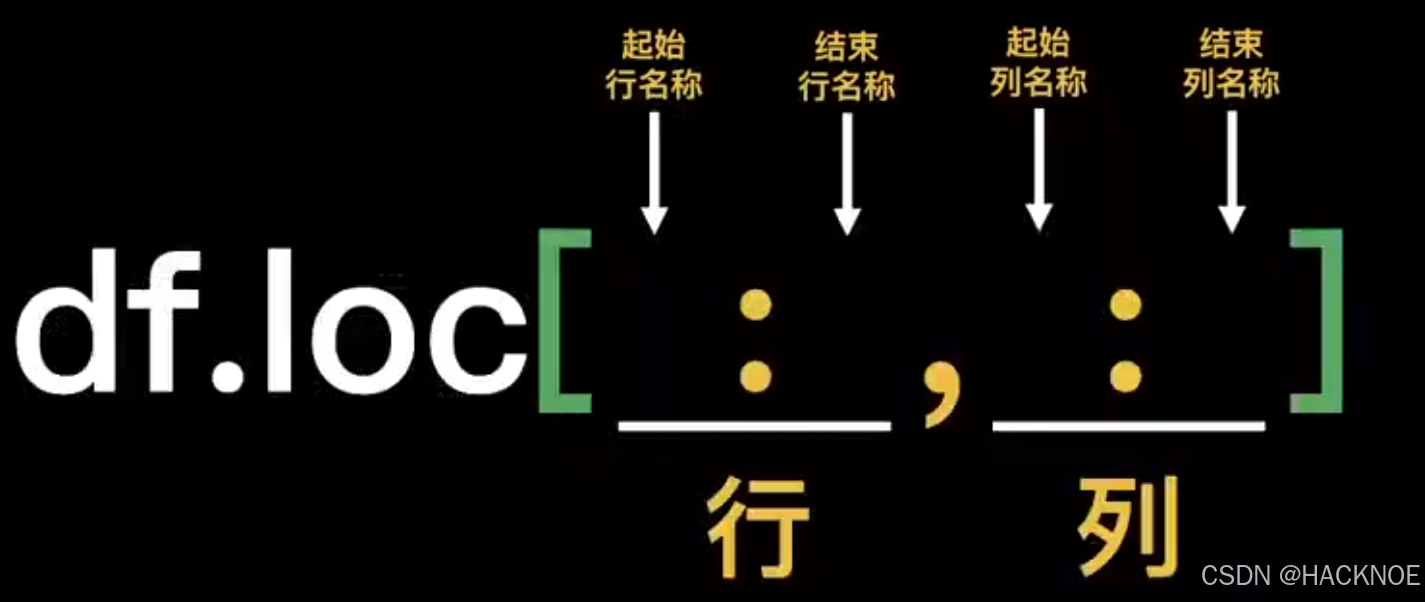
2.4.6.2.8 loc 根据行列名称定位查找
格式:
df.loc[ :,:]
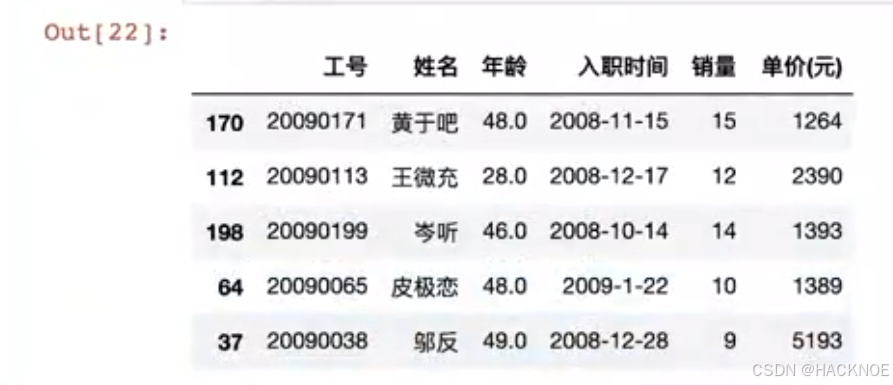
按图取出如下数据:
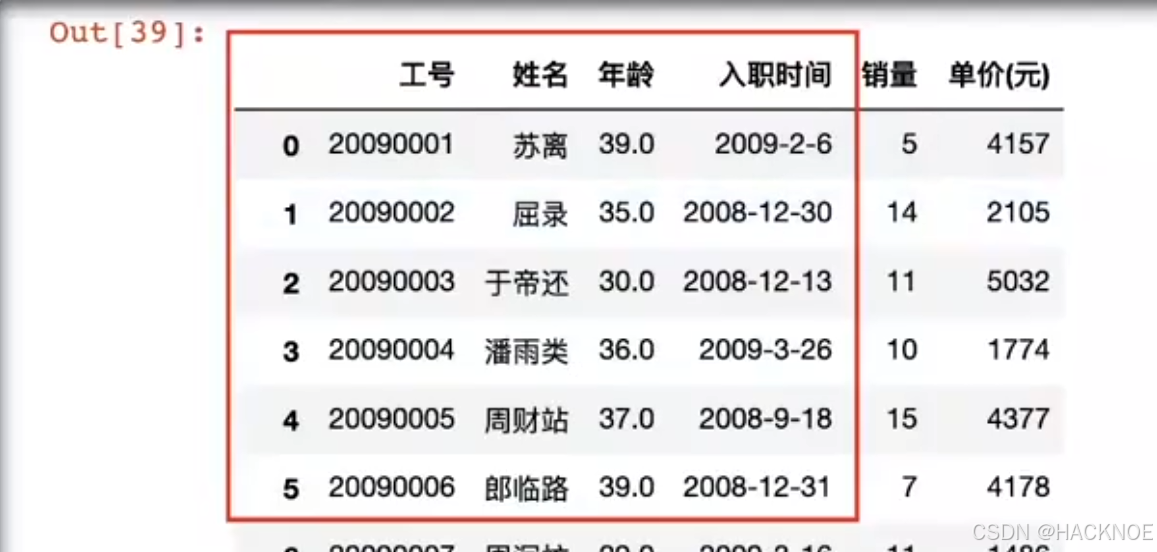
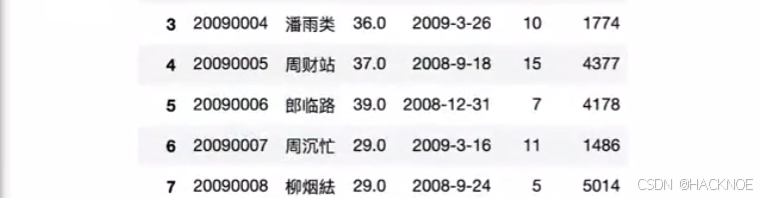
df.loc[0:5,'工号':'入职时间']
1.取一列,指定行
df.loc[0:9,'工号']
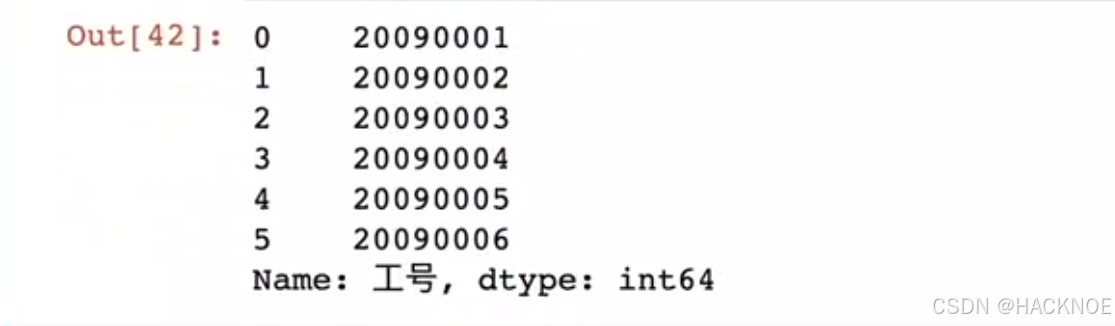
2.取一列,全部行,相当于取 series
df.loc[:,'工号']
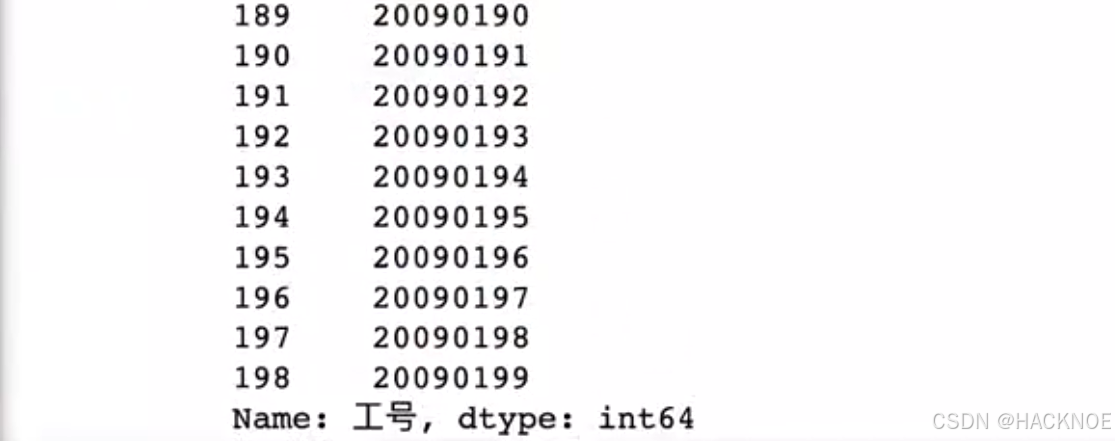
3.取一行,指定连线列
df.loc[9,'工号':'入职时间']

4.取一行,指定不连续列
df.loc[9,['工号','入职时间']]

2.4.6.2.9 iloc 根据索引定位查找
格式:
df.iloc[:,:]
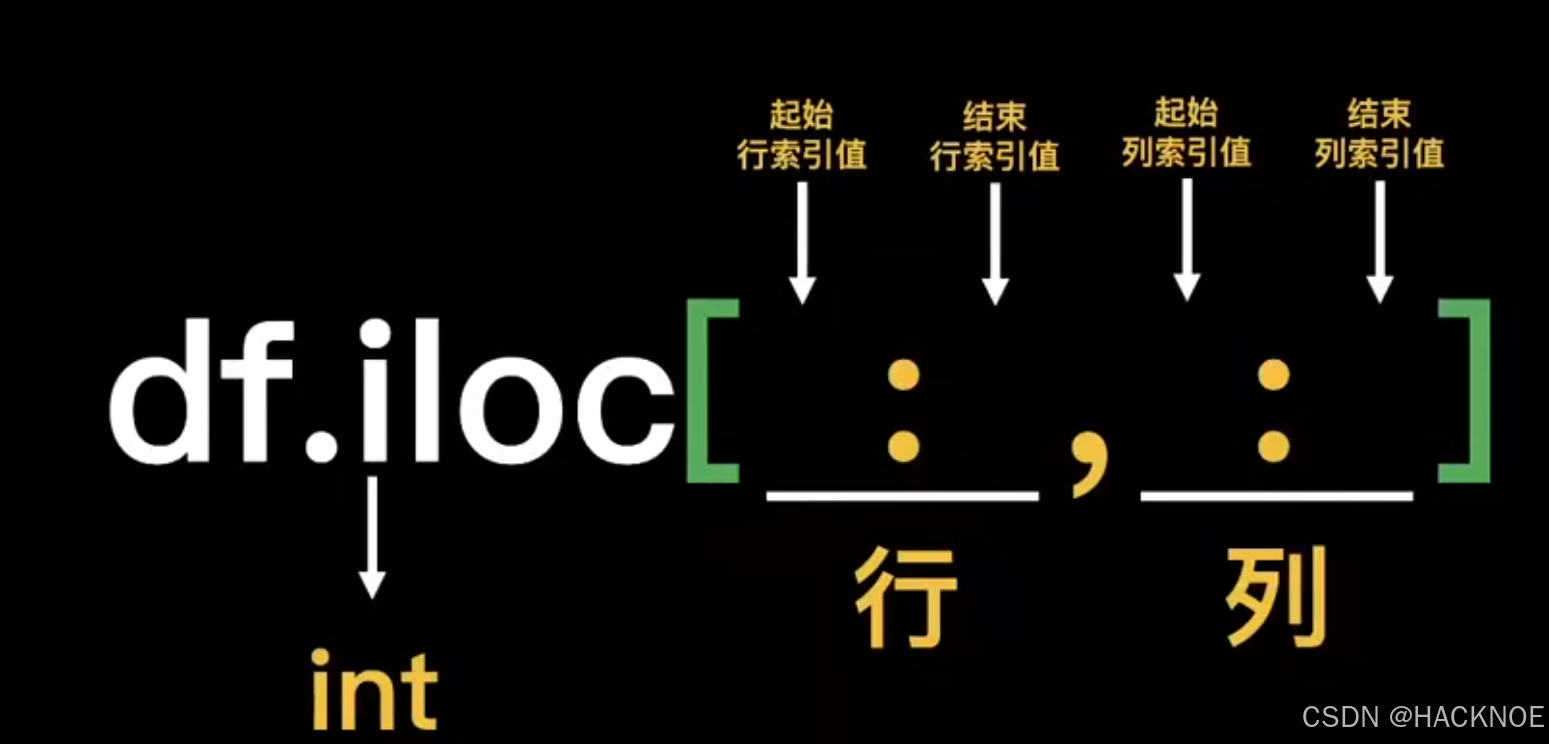
按照图中取出所需数据:
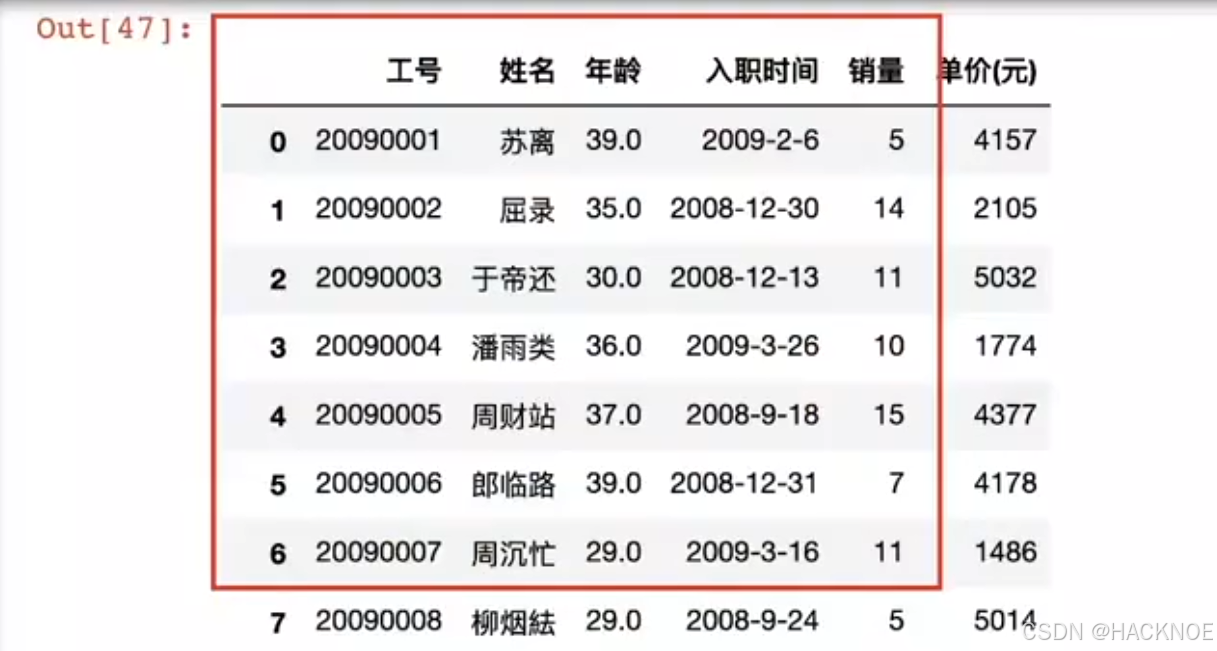
df.iloc[0:7,0:5] #包左不包右,省略顶到头
1.取一列,指定行
df.iloc[0:4,1]

2.取一列,全部行,相当于取 series
df.iloc[:,1]

3.取一行,指定连续列
df.iloc[4,1:6]

4.取一行,指定不连续列
df.iloc[5,[1,6]] #报错 取这样的数据用标签取而不是索引
5.取一行,全部列
df.iloc[46,:]

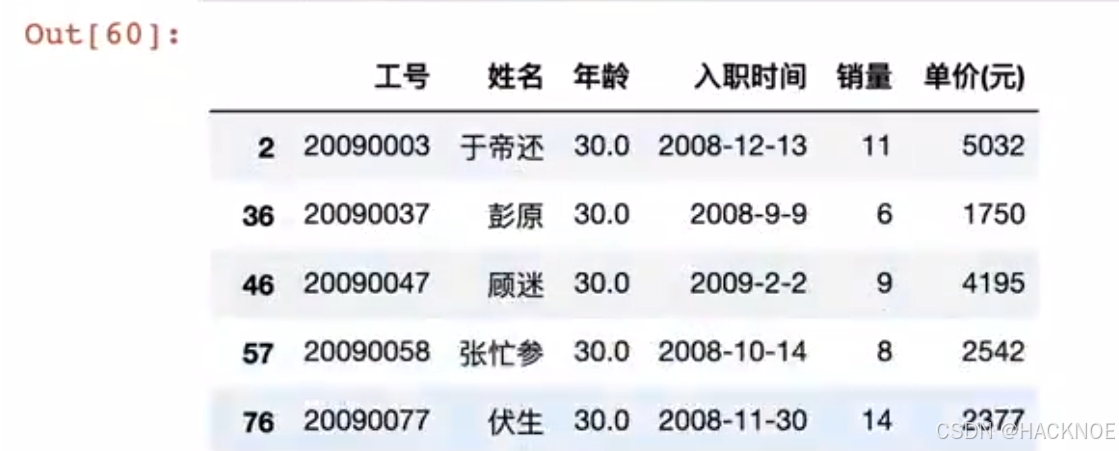
2.4.6.2.10 布尔值索引
最后我们可以采用判断指令(Boolean indexing)进行选择,我们可以约束某项条件然后选择出当前所有数据
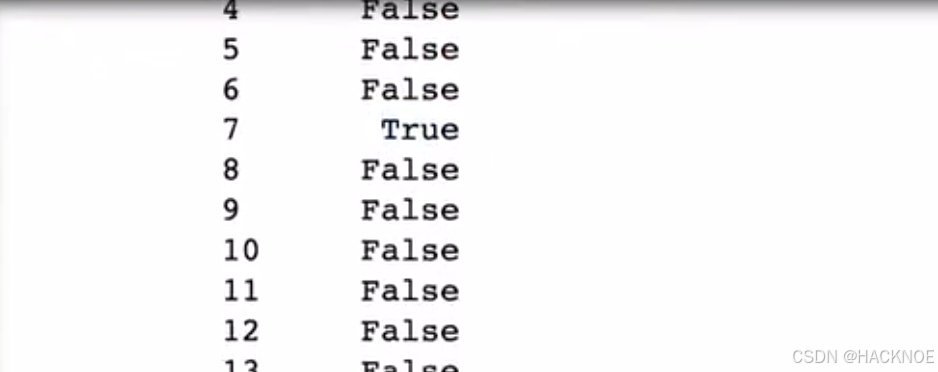
df['年龄'] == 30

df[df['年龄'] == 30]
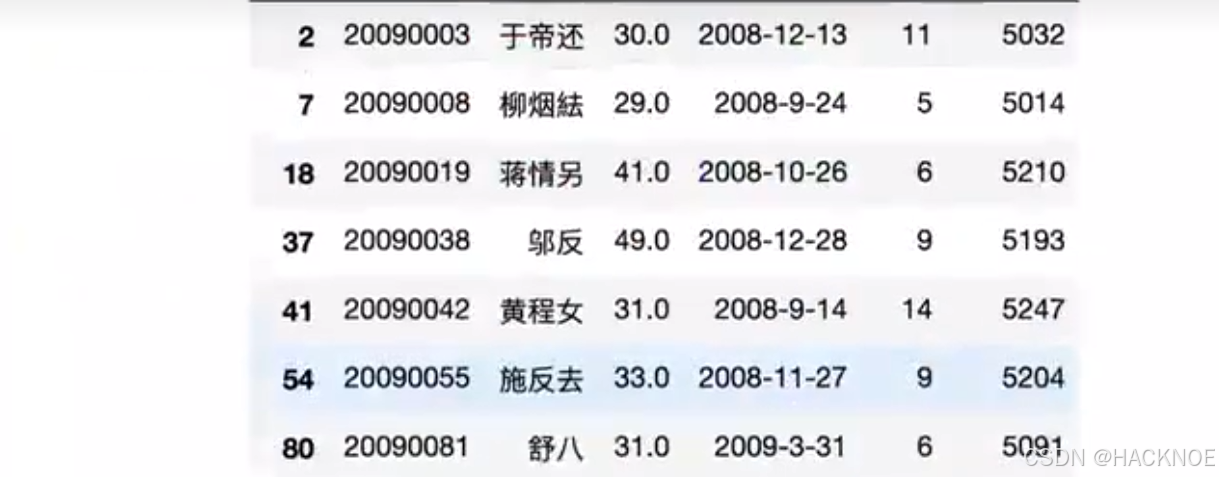
df['单价(元)'] > 5000
df[df['单价(元)'] > 5000]
2.4.6.3 Pandas数据修改
2.4.6.3.1 list修改列名
df.columns = ['num','name','age','time','sale' ,'price']
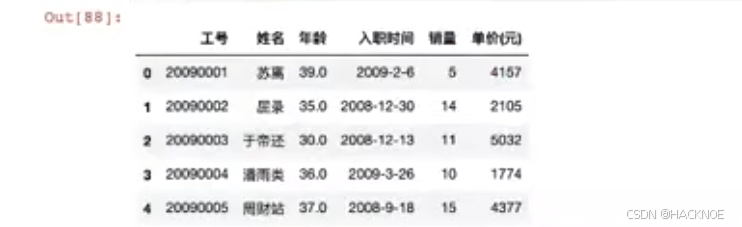
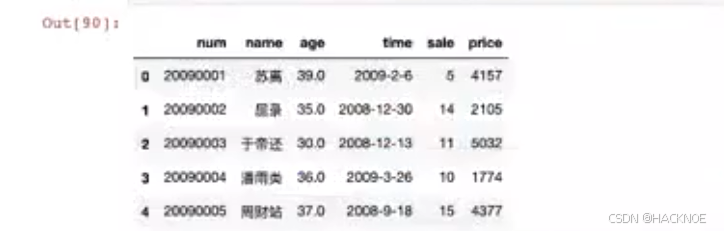
2.4.6.3.2 rename修改列名
df.rename(columns={'num'='工号','name'='姓名','age'='年龄','time'='入职时间','sale'='销量','price'='单价(元)'},inplace=True) #把英文名称改回汉字
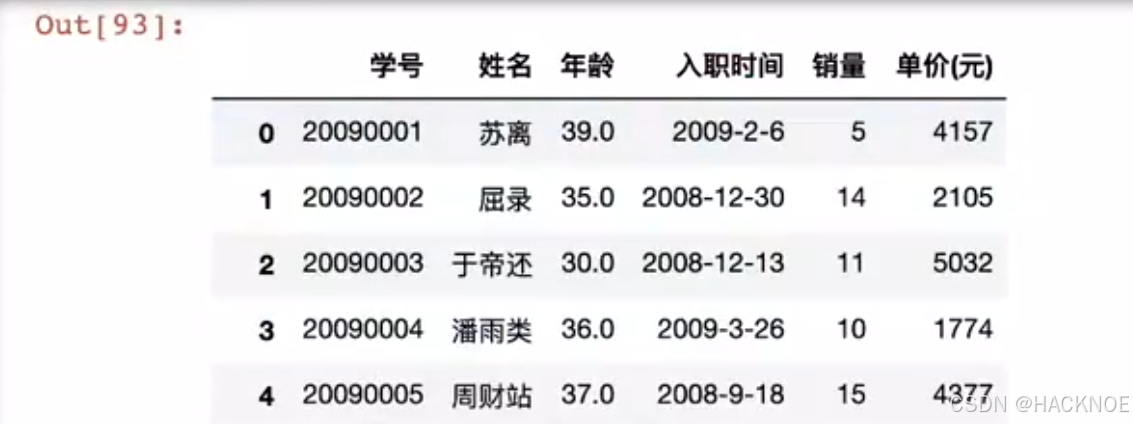
2.4.6.3.3 set_index修改索引
df.set_index('工号') #工号成了索引
df.set_index('工号',inplace=True) #工号成了索引
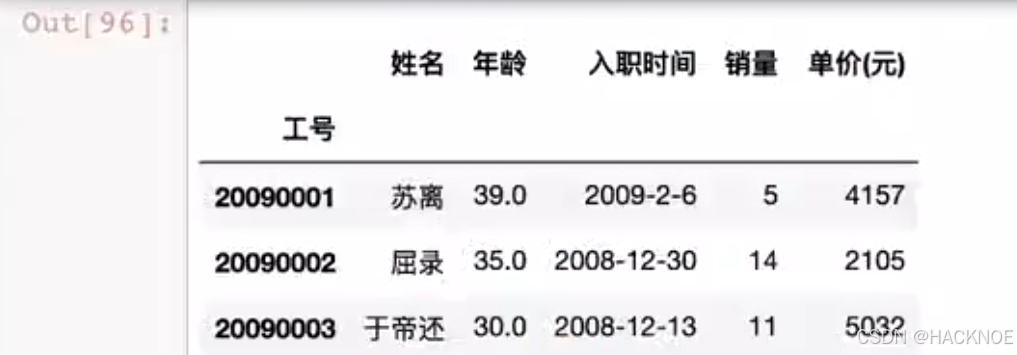
df.reset_index(inplace=True) # 取消刚才的赋值操作
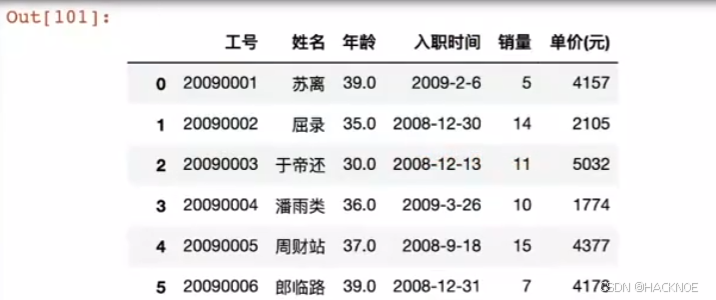
多次reset ,drop就是舍弃丢掉,当你想重新设置index的时候,就可以用到
df.reset_index(inplace=True,drop=True) # 取消刚才的赋值操作
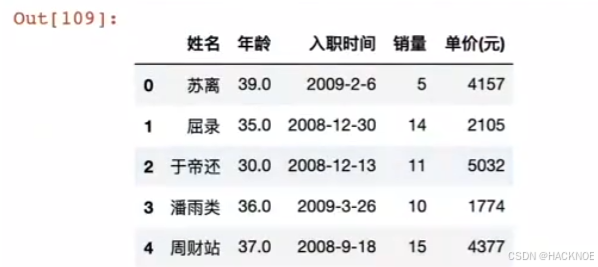
2.4.6.3.4 按列修改值
df['姓名'] + ['_同学'] #字符串列可以直接加上字符串,对整列进行操作

在原表修改
df['姓名'] = df['姓名'] + ['_同学']
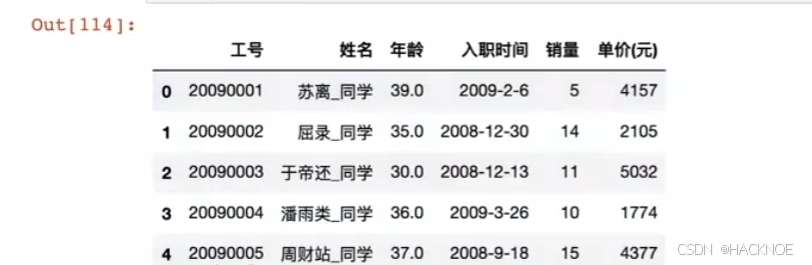
2.4.6.3.5 切片操作
字符串操作:长度
df['姓名'].str.len()

字符串操作:切分 split()
df['姓名'].str.split('_',expand=True)[0]

将姓名_同学切分后重新赋值
df['姓名'] = df['姓名'].str.split('',expand=True)[0]
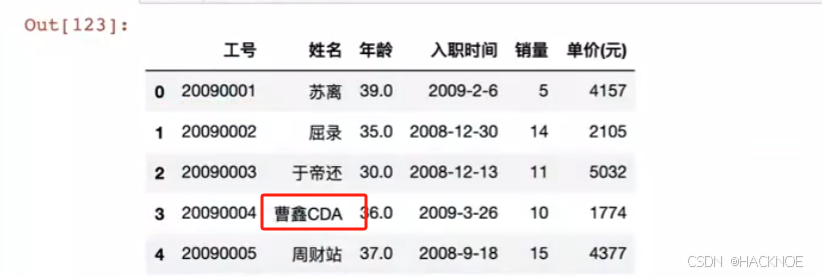
#用 loc 标签来选取修改
df.loc[3,'姓名']='曹鑫CDA'
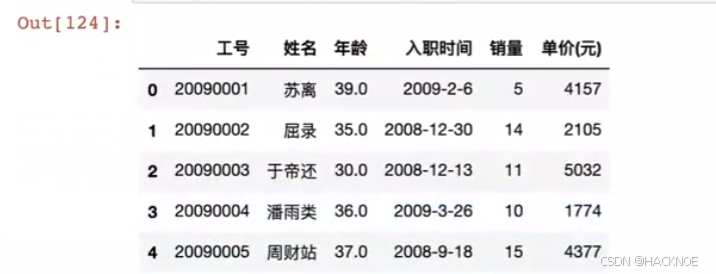
#用iloc 索引来选取修改
df.iloc[3,1]='潘雨类'
2.4.6.3.5 条件设置
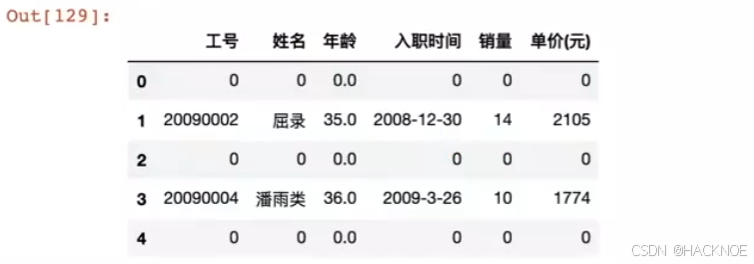
如果现在的判断条件是这样,我们想要更改B中的数,而更改的位置是取决于A的,对于A大于4的位置.更改B在相应位
df['单价(元)'] > 4000

df[df['单价(元)'] > 4000] = 0
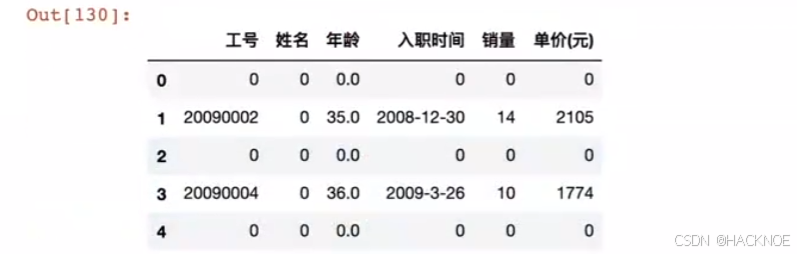
df.loc[df['年龄']>30,'姓名'] = 0 #年龄>30的姓名改为0
2.4.6.3.5 按列修改类型
#一列一列的处理,str,float,int
df['工号'] = df['工号'].astype('str')
df .dtypes
#一列一列的处理,时间
df['入职时间']= pd.to_datetime(df['入职时间'])
df .dtypes
2.4.6.4 Pandas数据增加
2.4.6.4.1 使用 loc按行增加
df.loc[199]=[1,1,1,1,1,1]
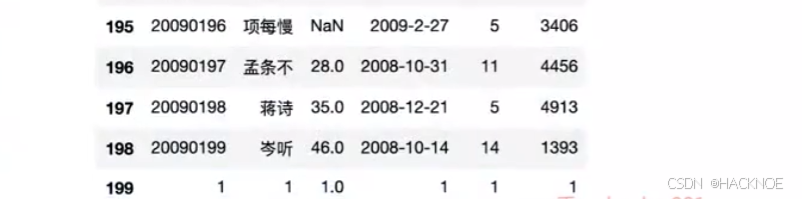
2.4.6.4.1 使用 loc按列增加
在原始上面改还是新建一列呢?
df['新姓名'] = df['姓名'〕+ ' 同学'
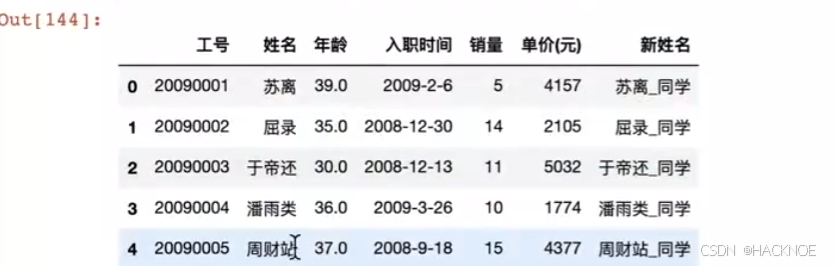
2.4.6.3 Pandas数据拼接
dfl = df.loc[0:5,:]
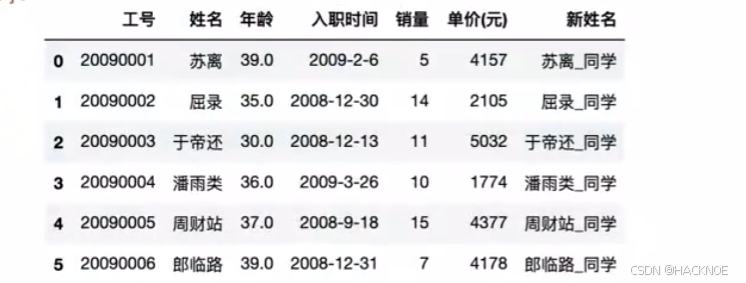
df2 =df.loc[4:10,:]
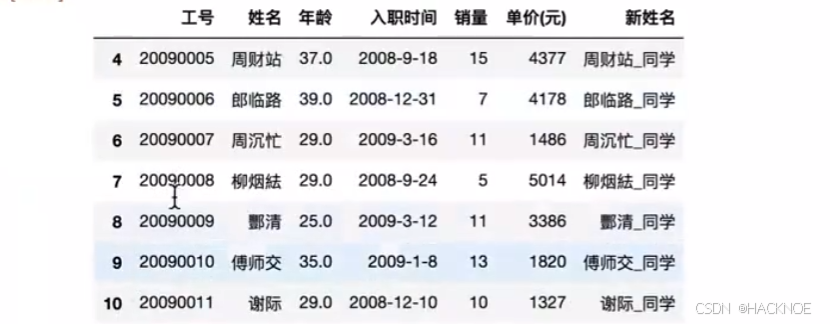
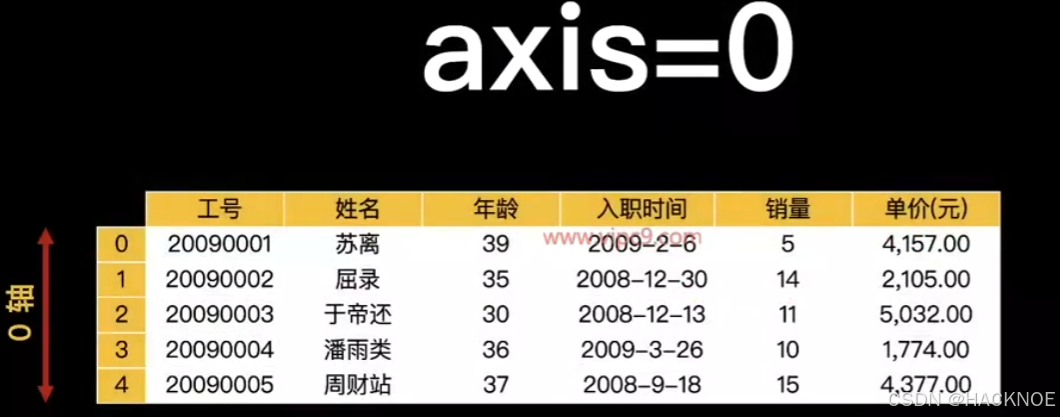
pd.concat([dfl,df2],axis=0) #axis=0 上下拼接 删除 0-5 4-10
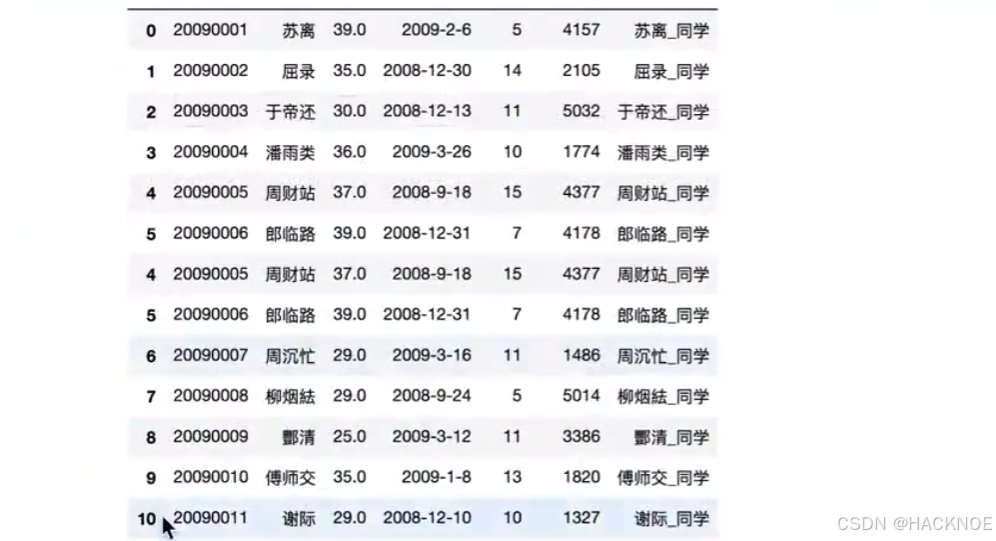
pd.concat([dfl,df2],axis=0,ignore_index=True ) #ignore_index重新生成index,拼接的index是乱的
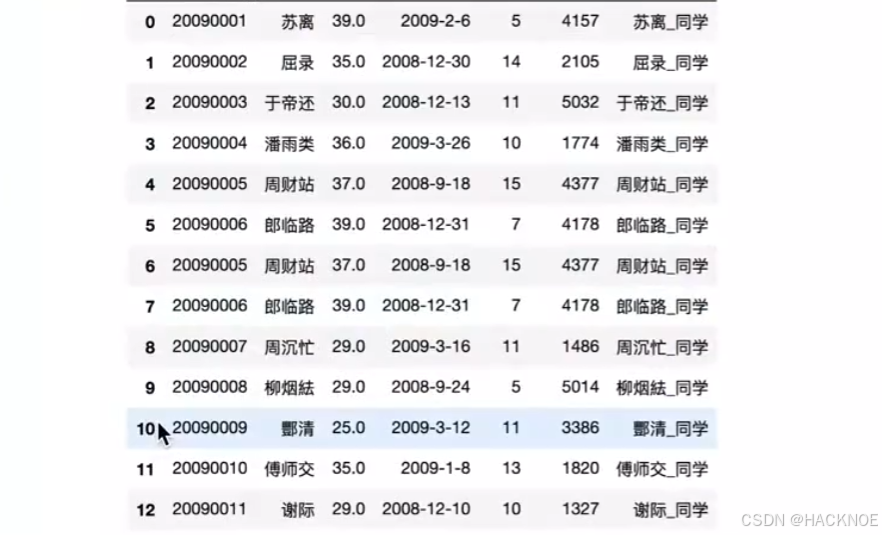
df4 =pd.concat([dfl,df2],axis=1) #axis=1 横向拼接
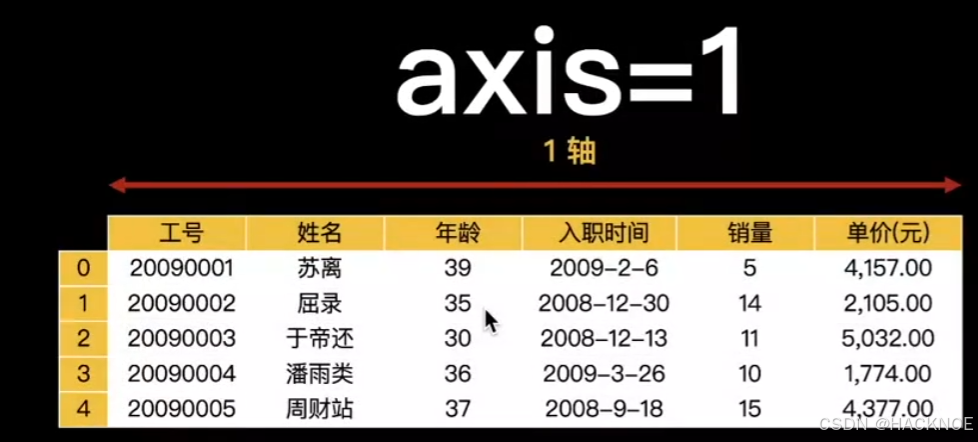
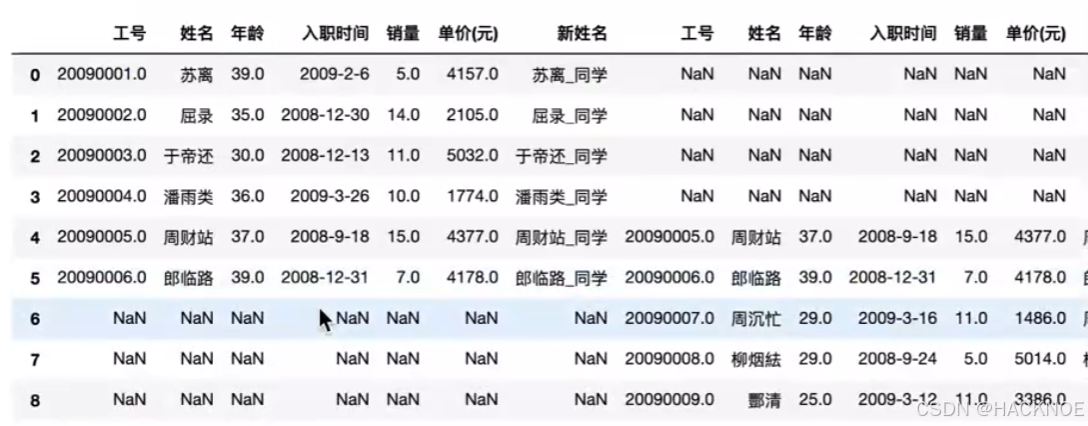
2.4.6.3 Pandas数据删除
数据清洗是对一些没有用的数据进行处理的过程,很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理
在这个教程中,我们将利用 Pandas包来进行数据清洗。
请观察下面表格
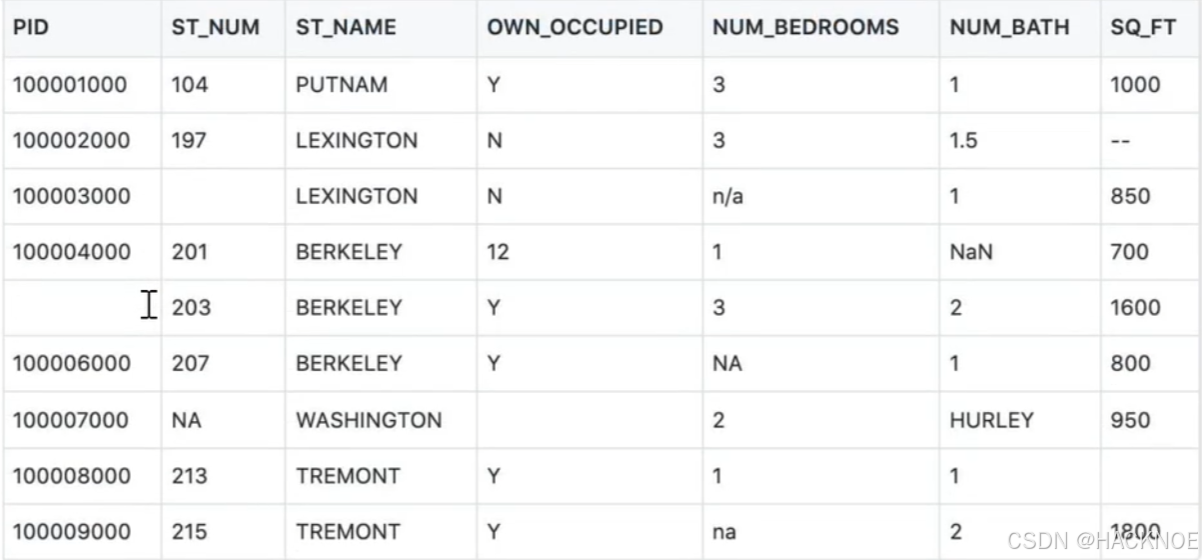
表包含了四种空数据
- n/a
- NA
- na
- - -
2.4.6.3.1 删除空值数据
如果我们要删除包含空字段的行,可以使用 dropna()方法语法格式如下:
DataFrame.dropna(axis=0,how='any',thresh=None,subset=None,inplace=False)
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1表示逢空值去掉整列。
- how:默认为’any’如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how=‘all’ 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据
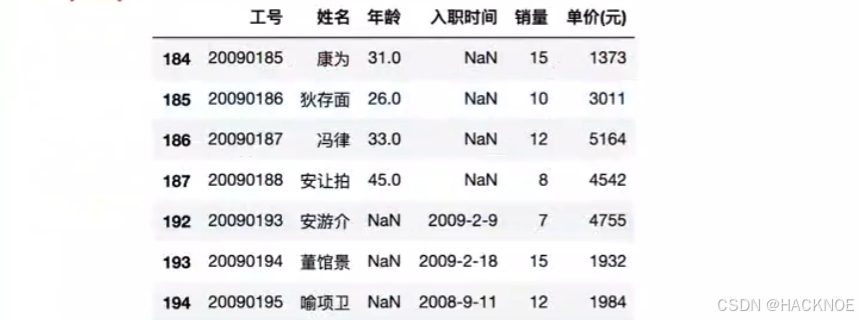
我们可以通过 isnull()判断各个单元格是否为空
df['年龄'].isnull()

df[df['年龄'].isnull()] #取出空值的行
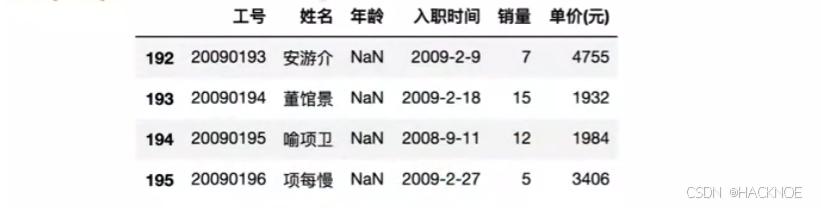
df[df['年龄'].isnu1l()| df['入职时间'].isnu11()]
以上例子中我们看到 Pandas 把 n/a 和 NA 当作空数据,na 不是空数据,不符合我们要求,我们可以指定空数据类型:
import pandas as pdmissing_values =['n/a","na',"--"]
df = pd.read_csv('property-data.csv',na_values = missing_values)
print(df['NUM_BRDROOMS'])
print(df['NUM_BRDROOMS'].isnull())
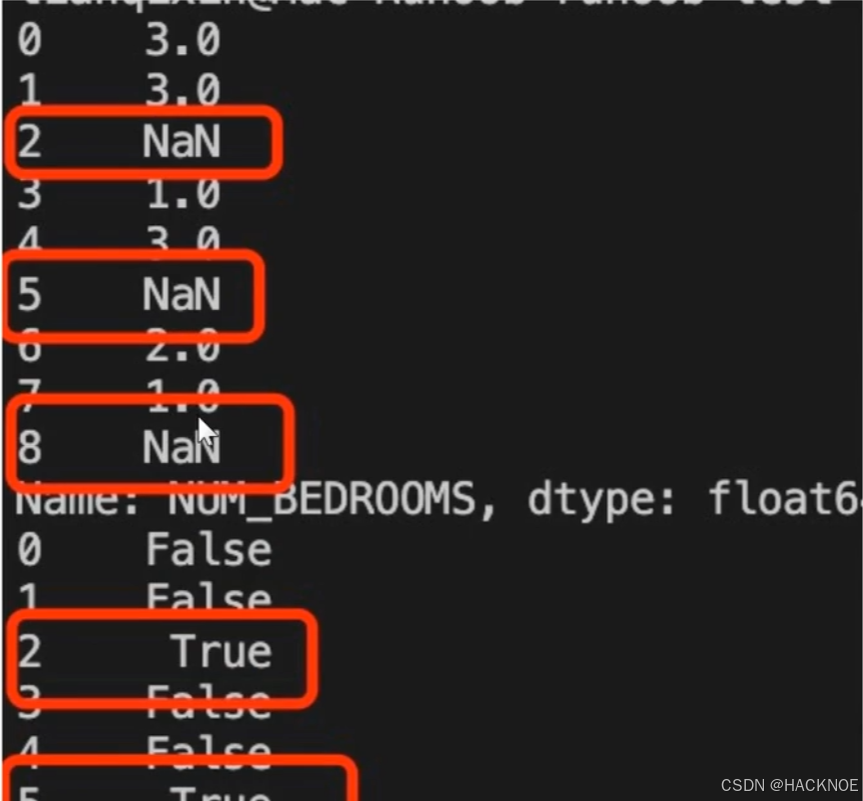
接下来的实例演示了删除包含空数据的行
df.dropna(axis=1,how='any')
'any':只要存在NaN 就 drop 掉:'al1'必须全部是 NaN 才 drop
import pandas as pddf = pd.read_csv('property-data.csv')
new_df = df.dropna()
print(new_df.to_string())

注意:默认情况下,dropna()方法返回一个新的DataFrame,不会修改源数据。
如果你要修改源数据 DataFrame,可以使用 inplace =True 参数:
import pandas as pddf = pd.read_csv('property-data.csv')
df.dropna(inplace=True)
print(df.to_string())
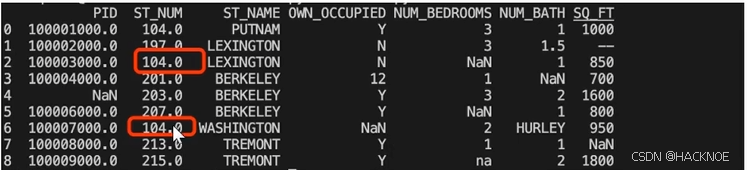
我们也可以移除指定列有空值的行:移除 ST NUM 列中字段值为空的行
import pandas as pddf = pd.read_csv('property-data.csv')
df.dropna(subset=['ST NUM'],inplace=True)
print(df.to_string())
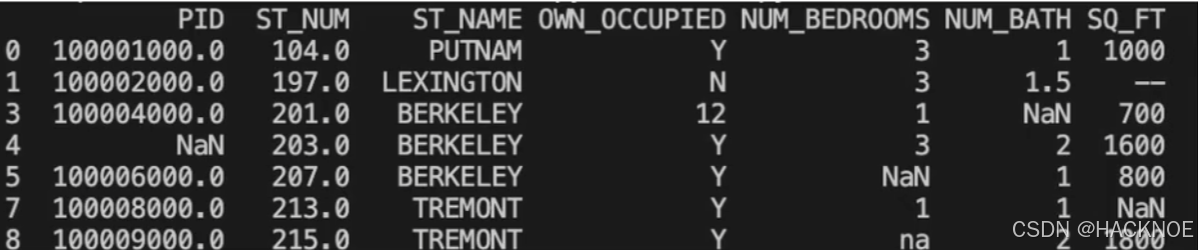
我们也可以 filna() 方法来替换一些空字段,使用 12345 替换空字段
import pandas as pddf = pd.read_csv('property-data.csv')
df.fillna(12345,inplace =True)
print(df.to_string())
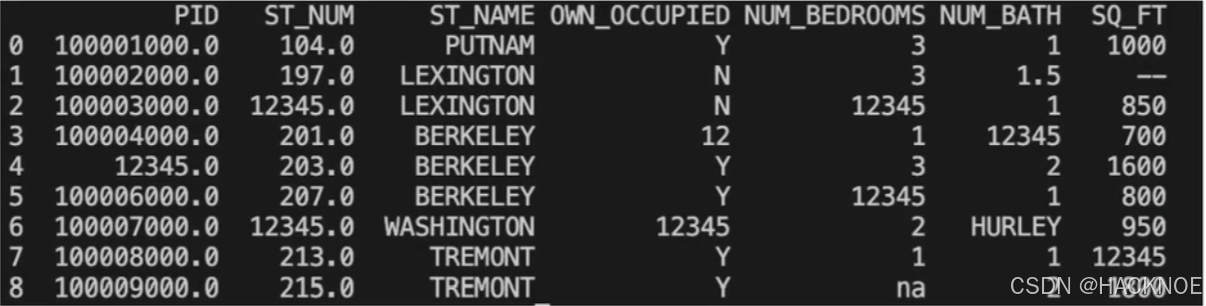
我们也可以指定某一个列来替换数据,使用 12345 替换 PID 为空数据:
import pandas as pddf = pd.read_csv('property-data.csv')
df['PID'].fillna(12345,inplace = True)
print(df.to_string())
替换空单元格的常用方法是计算列的均值、中位数值或众数。
Pandas使用 mean()、median()和 mode()方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数)
使用 mean()方法计算列的均值并替换空单元格
import pandas as pddf = pd.read_csv('property-data.csv')
x= df["ST NUM"].mean()
df["ST NUM"].fillna(x,inplace = True)
print(df.to_string())
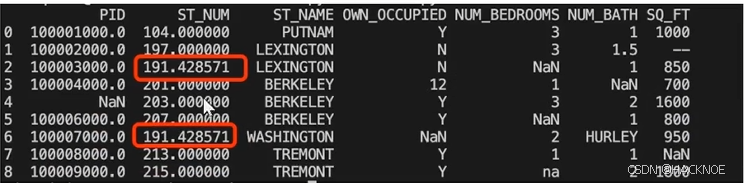
使用 median()方法计算列的中位数并替换空单元格
import pandas as pddf = pd.read_csv('property-data.csv')
x= df["ST NUM"].median()
df["ST NUM"].fillna(x,inplace = True)
print(df.to_string())
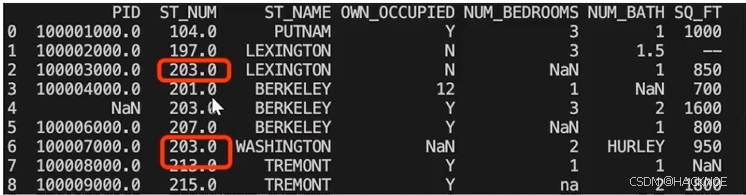
使用 mode()方法计算列的众数并替换空单元格
import pandas as pddf = pd.read_csv('property-data.csv')
x= df["ST NUM"].mode()
df["ST NUM"].fillna(x,inplace = True)
print(df.to_string())
2.4.6.3.2 删除格式错误数据
数据格式错误的单元格会使数据分析变得困难,甚至不可能,我们可以通过包含空单元格的行,或者将列中的所有单元格转换为相同格式的数据。
以下实例会格式化日期
import pandas as pd#第三个日期格式错误
data ={"Date":['2020/12/01','2020/12/02','2020/12/26'],"duration":[50,40,45]
}df = pd.DataFrame(data,index=["day1","day2","day3"])
df["Date"] = pd.to_datetime(df["Date"])
print(df)
2.4.6.3.3 删除错误数据
数据错误也是很常见的情况,我们可以对错误的数据进行替换或移除。
以下实例会替换错误年龄的数据
import pandas as pdperson = {
"name":['dlrb','lucky','Iglnz'],"age":[50,40,12345]# 12345 年龄数据是错误的
}df = pd.DataFrame(person)
print(df)
df.loc[2,'age']=30 # 修改数据
print(df.to_string())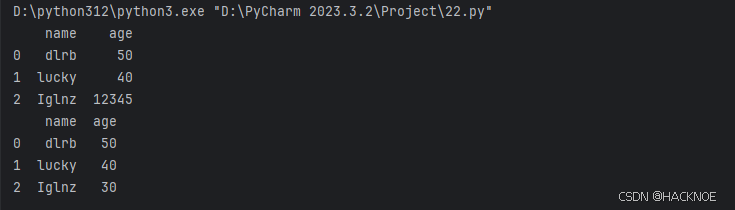
也可以设置条件语句:
将 age 大于 120 的设置为 120:
import pandas as pdperson = {
"name":['dlrb','lucky','Iglnz'],"age":[50,40,12345]# 12345 年龄数据是错误的
}df = pd.DataFrame(person)
print(df)
for i in df.index:if df.loc[i,'age'] > 120 :df.loc[i,'age'] = 120print(df.to_string())
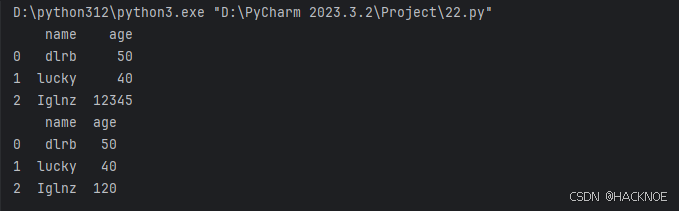
将 age 大于 120 的删除:
import pandas as pdperson = {
"name":['dlrb','lucky','Iglnz'],"age":[50,40,12345]# 12345 年龄数据是错误的
}df = pd.DataFrame(person)
print(df)
for i in df.index:if df.loc[i,'age'] > 120 :df.drop(i,inplace=True)print(df.to_string())
2.4.6.3.4 删除重复数据
如果我们要清洗重复数据,可以使用 duplicated()和drop_duplicates()方法。
如果对应的数据是重复的,duplicated()会返回 True,否则返回 False。
import pandas as pdperson ={"name":['dlrb','lucky','lucky','glnz'],"age":[50,0,40,23]
}
df = pd.DataFrame(person)
print(df)
print(df.duplicated())
df.drop duplicates()
print(df)
df.drop duplicates() #快速删除重复数据

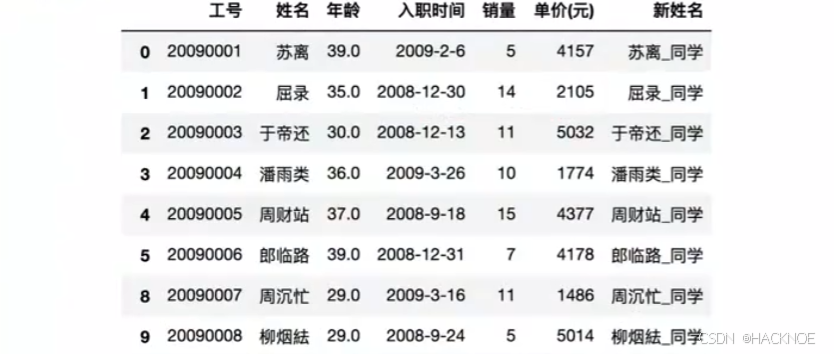
按列删除
df.drop(labels='工号',axis=1)
按行删除
df.drop(labels=1,axis=0)
2.4.6.4 Pandas数据排序
df.sort_values(by=['入职时间'],ascepding = 1) # by参数指定按照什么进行排 acsending参数指定是顺序还是逆序,1顺序,0逆序
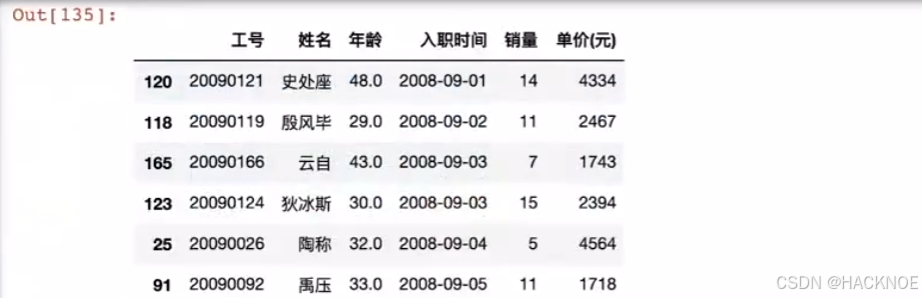
df.sort _values(by=['入职时间','销量','年龄'],ascending=[1,1,1])
2.4.6.5 Pandas数据过滤
2.4.6.6 Pandas数据分组
2.4.6.7 Pandas数据合并
2.4.6.8 Pandas时间序列处理
2.4.6.9 Pandas数据可视化
相关文章:
:python文件操作之Excel全攻略(基于pandas))
python从入门到精通(二十二):python文件操作之Excel全攻略(基于pandas)
Python处理表格数据 1.表格的基础知识1.1 xls与xlsx格式详解1.2 表格内部结构的认识 2.表格的基础操作2.1 认识表格的基本库2.1.1 csv内置的标准库2.1.2 xlrd 和 xlwt2.1.3 openpyxl2.1.4 pandas 2.2 安装和环境配置2.3 xlrd 和 xlwt2.3.1 库的说明2.3.2 安装xlrd库2.3.3 导入模…...

html常用标签
文章说明 本文旨在总结 HTML 中常见的标签,并提供简洁的解释,方便大家快速查找和复习。我们假设读者已经具备一定的 HTML 基础知识。本文将持续更新和完善,欢迎大家参与续写和补充 一、 HTML 标签 整个网页从 <html> 开始到 </html…...

ROS分布式部署通信
目录 一、概念 二、设置 ROS 分布式网络 1. 环境要求 2. 主机(Master)设置 3. 从机(节点设备)设置 4. 测试是否正常通信 三、进阶启动多从机节点(launch)。 一、概念 ROS 分布式通信用于在多台计算机…...

.Net 6 上传文件接口 文件大小报错整体配置
/// <summary>/// 上传文件/// </summary>/// <param name"file"></param>/// <returns></returns>[HttpPost("UploadifyFile")][RequestSizeLimit(2000 * 1024 * 1024)] // 设置最大请求体大小为 100MBpublic async …...

12.【线性代数】——图和网络
十二 图和网络(线性代数的应用) 图 g r a p h { n o d e s , e d g e s } graph\{nodes, edges\} graph{nodes,edges}1.关联矩阵2. A A A矩阵的零空间,求解 A x 0 Ax0 Ax0 电势3. A T A^T AT矩阵的零空间,电流总结电流图结论 …...

游戏引擎学习第145天
仓库:https://gitee.com/mrxiao_com/2d_game_3 今天的计划 目前,我们正在完成遗留的工作。当时我们已经将声音混合器(sound mixer)集成到了 SIMD 中,但由于一个小插曲,没有及时完成循环内部的部分。这个小插曲主要是…...
命令详解:zip)
Linux(Centos 7.6)命令详解:zip
1.命令作用 打包和压缩(存档)文件(package and compress (archive) files);该程序用于打包一组文件进行分发;存档文件;通过临时压缩未使用的文件或目录来节省磁盘空间;且压缩文件可以在Linux、Windows 和 macOS中轻松提取。 2.命…...

23年以后版本pycharm找不到conda可执行文件解决办法
这个问题很痛苦,折磨了我半天。 就是链接远程服务器的时候 就一直以为这三个都要配置 就这个conda环境这里怎么都找不到服务器的虚拟环境的python可执行文件,非常痛苦。 后面查找了资料,找了好久,才发现,原来只需要配…...
技术介绍)
AGI(Artificial General Intelligence,通用人工智能)技术介绍
文章目录 **AGI的关键特点**1. **泛化能力**:2. **自主性和适应性**:3. **自我意识与推理**: **与当前AI的区别****AGI的挑战**1. **技术难点**:2. **伦理与安全**:3. **资源与算力**: **AGI的实现路径**- …...

createrepo centos通过nginx搭建本地源
yum update 先安装一个nginx。 安装Nginx yum install gcc gcc-c pcre pcre-devel openssl openssl-devel libtool zlib zlib-devel -y cd /usr/local/src wget http://nginx.org/download/nginx-1.22.0.tar.gz tar -zxvf nginx-1.22.0.tar.gz cd nginx-1.22.0 ./configu…...

279.完全平方数
279.完全平方数 力扣题目链接(opens new window) 给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, ...)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。 给你一个整数 n ,返回和为 n 的完全平方数的 最少数…...
)
Dify部署踩坑指南(Windows+Mac)
组件说明 Dify踩坑及解决方案 ⚠️ 除了修改镜像版本,nginx端口不要直接修改docker-compose.yaml !!!!!!! 1、更换镜像版本 这个文件是由.env自动生成的,在.env配置 …...

备赛蓝桥杯之第十五届职业院校组省赛第六题:简易JSX解析器
提示:本篇文章仅仅是作者自己目前在备赛蓝桥杯中,自己学习与刷题的学习笔记,写的不好,欢迎大家批评与建议 由于个别题目代码量与题目量偏大,请大家自己去蓝桥杯官网【连接高校和企业 - 蓝桥云课】去寻找原题࿰…...

深入解析ECDSA与RSA公钥算法:原理、对比及AWS最佳实践
一、公钥加密算法概述 在HTTPS通信和数字证书领域,ECDSA(椭圆曲线数字签名算法)和RSA(Rivest-Shamir-Adleman)是最主流的两种非对称加密算法。它们共同构成了现代网络安全的基础,但设计理念和技术实现存在显著差异。 © ivwdcwso (ID: u012172506) 二、RSA算法详解…...

单例设计模式---懒汉式--线程安全和不安全、枚举类
单例设计模式—懒汉式–线程安全和不安全 优点 资源利用率高:只有在真正需要使用单例实例时才进行创建,避免了在应用启动时就占用不必要的资源。 缺点 线程安全问题:在多线程环境下,如果多个线程同时调用获取实例的方法ÿ…...

c++: 容器vector
文章目录 介绍initializer_list与string的不同底层总代码 介绍 C 中的 vector 是一种序列容器,它允许你在运行时动态地插入和删除元素。 vector 是基于数组的数据结构,但它可以自动管理内存,这意味着你不需要手动分配和释放内存。 与 C 数组相…...

肖恩的n次根
1.肖恩的n次根 - 蓝桥云课 问题描述 喜欢研究数学问题的肖恩注意到,在编程语言中通常内置函数只有开平方根和开立方根,但是肖思想知道开高次方根(大于3次方称为高次方),应该怎么做。请你设计一个程序来帮帮肖恩。 输…...
)
Java直通车系列15【Spring MVC】(ModelAndView 使用)
目录 1. ModelAndView 概述 2. ModelAndView 的主要属性和方法 主要属性 主要方法 3. 场景示例 示例 1:简单的 ModelAndView 使用 示例 2:使用 ModelAndView 处理列表数据 示例 3:使用 ModelAndView 处理异常情况 1. ModelAndView 概…...
)
LeetCode和为k的字数组(560题)
题目展示 给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。 子数组是数组中元素的连续非空序列。 示例 1: 输入:nums [1,1,1], k 2 输出:2示例 2: 输入:nums …...

消息队列为什么会有消费组的概念,什么作用,以订单系统为例说明
消息队列中的消费组(Consumer Group)概念是为了实现消息的并行处理和负载均衡。在分布式系统中,消费组允许多个消费者实例共同消费同一个主题(Topic)中的消息,从而提高消息处理的速度和系统的吞吐量。 消费…...

数据结构--AVL树
一、二叉搜索树(Binary Search Tree, BST) 基本性质 对于树中的每个节点,其左子树中的所有节点值均小于该节点值。其右子树中的所有节点值均大于该节点值。左右子树也分别是二叉搜索树。 极端场景 在极端情况下,如插入节点顺序…...

OpenManus 的提示词
OpenManus 的提示词 引言英文提示词的详细内容工具集的详细说明中文翻译的详细内容GitHub 仓库信息背景分析总结 引言 OpenManus 是一个全能 AI 助手,旨在通过多种工具高效地完成用户提出的各种任务,包括编程、信息检索、文件处理和网页浏览等。其系统提…...

达梦数据库在Linux,信创云 安装,备份,还原
(一)系统环境检查 1操作系统:确认使用的是国产麒麟操作系统,检查系统版本是否兼容达梦数据库 V8。可以通过以下命令查看系统版本: cat /etc/os-release 2硬件资源:确保服务器具备足够的硬件资源࿰…...

怎么使用Sam Helper修改手机屏幕分辨率,使得游戏视野变广?
1.准备Shizuku 和Sam Helper软件 2.打开设置,找到关于本机,连续点击版本号五次打开开发者选项 3.找到开发者选项,打开USB调试和无线调试 4.返回桌面,我们接着打开shizuku,点击配对,这里打开开发者选项,找…...

Unity DOTS 从入门到精通之 创建实体
文章目录 前言安装 DOTS 包创建实体1.手动创建空实体(适用于运行时动态创建)2.克隆 预制体(主线程同步操作)3.克隆 预制体(兼容Job System)4.通过 GameObject 转换(Baker方式) 其他E…...
、本部门数据权限、本部门及以下数据权限、仅本人数据权限)
【OA角色数据权限】自定数据权限(自定义部门)、本部门数据权限、本部门及以下数据权限、仅本人数据权限
文章目录 引言I 表设计部门表设计角色表设计II 数据过滤处理注解参数说明数据权限使用数据过滤处理切面 DataScopeAspectQuery 基类知识扩展引言 I 表设计 部门表设计 部门表采用部门路径反应祖先层级关系(包含自己部门的ID) 查询用户所在的本部门及其对应的下级部门:采用…...
:注册账号及下载工具(250308))
记录小白使用 Cursor 开发第一个微信小程序(一):注册账号及下载工具(250308)
文章目录 记录小白使用 Cursor 开发第一个微信小程序(一):注册账号及下载工具(250308)一、微信小程序注册摘要1.1 注册流程要点 二、小程序发布流程三、下载工具 记录小白使用 Cursor 开发第一个微信小程序(…...

STM32旋转编码器驱动详解:方向判断、卡死处理与代码分析 | 零基础入门STM32第四十八步
主题内容教学目的/扩展视频旋转编码器电路原理,跳线设置,结构分析。驱动程序与调用。熟悉电路和驱动程序。 师从洋桃电子,杜洋老师 📑文章目录 一、旋转编码器原理与驱动结构1.1 旋转编码器工作原理1.2 驱动程序结构 二、方向判断…...

海思Hi3516DV00移植yolov5-7.0的模型转化流程说明
一、YOLOv5 YOLOv5作为单阶段检测框架的集大成者,凭借其卓越的实时性、高精度和易用性,已成为工业界实际部署的首选方案。yolov5的最新版本是7.0,该版本是官方最后更新的一个版本。yolov5-7.0 工程化实现卓越:基于PyTorch框架构…...
)
C++ string类(前)
目录 一、前言 二、正文 1.1什么是string类 1.2为什么学习string类 1.3string使用注意 1.4 string 类常用接口说明 1.4.1string类对象的常见构造 1.4.2string类对象的容量操作 1.4.3 string 类对象的访问以及遍历操作 1.4.4 string 类对象的修改操作 三、结言 一、前…...

MySQL---INSERT语句、UPDATE语句、DELETE语句
目录 INSERT语句-插入 1.格式 2.操作 UPDATE语句-修改 1.格式 2.操作 DELETE语句-删除 1.格式 2.操作 INSERT语句-插入 1.格式 格式: insert into 表名 values (value1,value2,.....) 1. value后的内容:与表字段匹配的数据,如果字段为主键&…...

vuejs 模板语法、条件渲染、v-for、事件处理、表单输入绑定
创建vue项目之后我们就可以开始写代码了,我们的代码一般都会写在src目录-components目录-HelloWord.vue文件内。 我们之前写的HTML文件的结构是HTML代码可以集成或者连接外部的css/js文件。 我们通过vue建立的项目,它的结构是在一个vue文件内集成了HTML…...

Mysql中的常用函数
1、datediff(date1,date2) date1减去date2,返回两个日期之间的天数。 SELECT DATEDIFF(2008-11-30,2008-11-29) AS DiffDate -- 返回1 SELECT DATEDIFF(2008-11-29,2008-11-30) AS DiffDate -- 返回-1 2、char_length(s) 返回字符串 s 的字符数 3、round(x,d)…...
)
使用JMeter(组件详细介绍+使用方式及步骤)
JSON操作符 在我们使用请求时,经常会遇到JSON格式的请求体,所以在介绍组件之前我会将介绍部分操作符,在进行操作时是很重要的 Operator Description $ 表示根元素 当前元素 * 通配符,所有节点 .. 选择所有符合条件的节点 .name 子元素,name是子元素名称 [start:e…...

【大模型聊天】实时交互技术选型
在Python开发中,实现RAG问答或大模型聊天功能无需强制使用WebSocket,技术选型需结合实时性需求与交互场景。以下是技术分析及示例: 技术方案对比 技术适用场景优缺点WebSocket双向高频交互(如实时对话)优点࿱…...

计算机网络:计算机网络的概念
1.计算机网络:由若干个结点和链接这些的链路组成。 2.集线器(Hub):可以把多个结点连接起来,组成一个计算机网络。 不能避免数据冲突的情况 3.交换机(Switch):可以把多个结点连接起来&#x…...

Trae:引领未来的 AI 编程新时代
目录 Trae:引领未来的 AI 编程新时代 更快、更好、更准确的 AI IDE 无缝协作,AI 赋能开发者 Builder 模式:从 0 到 1 的智能助力 深度上下文理解,精准满足开发需求 实时代码补全,极致提升开发效率 智能 AI 协作…...

Vue _总结
文章目录 一 Vue介绍1 什么是Vue.js2 MVVM二 第一个例子1 引入vue2 html中用法3 创建vue实例对象三 Vue基本语法1 v-text2 v-bind3 v-on4 v-model5 v-if6 v-for7 计算属性8 组件化全局注册本地注册9 生命周期10 员工程序使用vue.js重构list.htmladd.htmlupdate.html四 使用vue-…...

Refreshtoken 前端 安全 前端安全方面
网络安全 前端不需要过硬的网络安全方面的知识,但是能够了解大多数的网络安全,并且可以进行简单的防御前两三个是需要的 介绍一下常见的安全问题,解决方式,和小的Demo,希望大家喜欢 网络安全汇总 XSSCSRF点击劫持SQL注入OS注入请求劫持DDOS 在我看来,前端可以了解并且防御前…...

基于深度学习的医学图像分割算法研究——结合MRI/CT图像的肿瘤区域自动分割与三维重建
针对课题《基于深度学习的医学图像分割算法研究——结合MRI/CT图像的肿瘤区域自动分割与三维重建》,以下是详细的研究框架与技术实现方案: 1. 核心研究要点 主要目标:构建端到端的深度学习模型,实现MRI/CT肿瘤区域的精准分割,并通过三维可视化支持临床诊断。核心挑战: 医…...

企业如何选择研发项目进度管理软件?盘点15款实用工具
这篇文章介绍了以下工具: 1. PingCode; 2. Worktile; 3. 腾讯 TAPD; 4. 华为 DevCloud; 5. 亿方云; 6. 阿里云效; 7. CODING 码云; 8. 明道云; 9. 进度猫; 10. 轻流等。 …...

【2024_CUMCM】图论模型
基本概念 注:以下叙述大多是自话,夹杂多数不专业表述 点集、边集 图论中图是由点和边组成的 G(V,E) V--点集 E--边集 权 G(V,E,W) W--权 一般都有权,构成赋权图 赋权图 在图中每条边都赋予一个非负实数权重的图,就是给每一条…...

Unity UGUI下优化需要射线检测类的UI元素的一种方式
直接上脚本 - 原理探究 先看MaskableGraphic 可以看到继承了Graphic,继续深入 在构造函数中找到了useLegacyMeshGeneration 而useLegacyMeshGeneration用来判断是否使用旧的网格生成系统,这里我们使用新的 在这个方法中,Graphic默认通过…...

unity3d 背景是桌面3d数字人,前面是web的表单
是可以实现的,但涉及多个技术栈的结合,包括 Unity3D、Web 技术(HTML、JavaScript)、以及可能的 WebGL 或 WebRTC 技术。大致有以下几种实现方案: 方案 1:Unity 作为独立应用(桌面端࿰…...

一周热点-Claude 3.7 Sonnet-在响应和思考模型之间切换
Anthropic 最近发布了 Claude 3.7 Sonnet,这是一款具有混合推理能力的模型,允许用户在即时响应和扩展思考模式之间切换,以适应不同类型的任务需求。以下是关于 Claude 3.7 Sonnet 的详细介绍: 1 混合推理模式 标准模式:快速生成响应,适合日常对话和简单任务,能在短时间内…...

【大模型安全】安全解决方案
【大模型安全】安全解决方案 1.技术层面2.数据层面数据收集阶段训练阶段模型推理阶段 1.技术层面 在使用大语言模型时,通常有几种选择:一种是采用封装好的大语言模型SaaS云服务;另一种是在公有云上部署自有的大语言模型,并通过权…...

Clion快捷键、修改字体
文章目录 一、Clion快捷键1.撤销:crtl Z2.重做:crtl shift Z3.删除该行:crtl Y4.多行后退:选中多行 Tab5.多行缩进:选中多行 shift Tab 二、修改注释的斜体 一、Clion快捷键 1.撤销:crtl Z 2.重做…...

软件工程笔记下
从程序到软件☆ 章节 知识点 概论☆ 软件的定义,特点,生存周期。软件工程的概论。软件危机。 1.☆软件:软件程序数据文档 (1)软件:是指在计算机系统的支持下,能够完成特定功能与性能的包括…...

探索DeepSeek:牛仔技术的未来在哪里?
引言 在当今快速发展的科技世界中,DeepSeek作为一种前沿技术,正逐渐改变我们对信息搜索和数据处理的认知。本文将深入探讨DeepSeek技术的核心优势、应用场景以及未来发展趋势,带您全面了解这一技术的魅力所在。 一、DeepSeek技术简介 1.1 什…...

Wireshark抓包标准化流程
1. 软件安装与验证 安装路径规范 按企业要求部署至指定目录: xxxx/xxxx/xxxx/xxxx验证安装完整性: 检查是否勾选 Install TShark(默认已选)确认安装后生成 Wireshark.exe 和 tshark.exe 可执行文件 权限配置 右键点击安装目录下…...