Redis主从复制
目录
点单问题
启动多个redis服务器
配置主从结构
查看主从结构信息
断开主从结构
修改主从结构
主从复制的拓扑结构
主从复制的基本流程
全量复制和部分复制
全量复制的流程
部分复制的流程
实时复制的流程
主从复制总结
主从复制是基于分布式系统进行讨论的,毕竟redis主要是在分布式系统中起到作用。
点单问题
单点问题是服务器涉及到的非常关键的问题,如果某个服务器程序,只有一个节点,意思就是说我只搞一个物理服务器,来部署这个服务器程序,会有如下问题:
1.可用性问题,如果这个机器挂了(内存不够了,硬盘不够了,网线断了,机房失火),意味着服务就中断了。
2.性能/支持的并发量也是比较有限的,主机的硬件资源是有限的,如果消耗的资源总量超过主机的硬件资源,可能导致主机出现异常情况。
引入分布式系统,主要也就是为了解决上述的单点问题。
在分布式系统中,往往希望有多个服务器来部署redis服务,从而构成一个redis集群,就可以让这个集群给整个分布式系统中提供更稳定更高效的数据存储功能。
在分布式系统中,存在以下几种redis的部署方式:
1.主从模式
若干个redis节点中,有的是主节点,有的是从节点,假设有三个物理服务器(可以称为3个节点),分别启动了一个redis-server进程,此时就可以把其中的一个节点,作为"主节点",另外两个节点作为"从节点",从节点要听主节点的,从节点的数据要和主节点保持一致。本来,在主节点上保存一分数据,引入从节点后,就要把主节点上的数据复制出来,放到从节点中,后续,主节点这边对于数据有任何修改,都会把这样的修改给同步到从节点上,从节点就是主节点的副本。
如果改了从节点的数据,是否是把从节点的数据往主节点上同步呢?redis主从模式中,从节点上的数据不允许修改,从节点只能读取数据,你要改从节点数据,只能把主节点数据改了,再把主节点数据同步给从节点。
主从模式解决性能问题
由于从节点的数据都是时刻和主节点保持一致的,因此其它的客户端从从节点这里读取数据,和从主节点这里读取数据没有区别,既然是一样的,那客户端读取数据的时候就可以随便挑一个节点给客户端提供读取数据的服务,节点数量多了,硬件资源也就多了,支持总的并发量也就高了。
主从模式解决可用性问题
之前只是单个redis服务器节点,此时这个机器挂了,整个redis就挂了,主从结构的这些redis机器不太可能"同时挂了",这概率是非常低的。
如果是挂掉了某个从节点,没啥影响,此时继续从主节点或者其他从节点读取数据,得到的效果完全相同。
如果是挂掉了主节点呢?还是有一定影响的,从节点只能读取数据,如果需要写数据,就没得写了,虽然可用性提高了,但还没到非常理想的程度。那可以搞多个主节点吗?不行,一山不能容二虎,如果存在两个主节点,相互之间如何同步数据?到底是听谁的呢?
主从模式,主要是针对"读操作",进行高并发和可用性的提高,而写操作的话,无论是可用性还是并发,都非常依赖主节点,主节点又不能搞多个,那怎么办呢?没关系,针对这样的情况后续还有很多解决方案。
这里提一嘴,实际业务场景中,读操作比写操作更频繁。
启动多个redis服务器
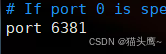
配置redis主从结构,首先需要启动多个redis服务器,正常来说,每个redis服务器程序应该在一个单独的主机上才是分布式,但是,我们光用一个主机也可以搭建主从结构,我们可以在一个云服务器主机上,运行多个redis-server进程,但是要保证多个redis-server的端口是不一样的,默认的端口号是6379,此时新启动的redis-server就不能再使用6379了,而必须使用其他端口号。
那如何去指定redis-server的端口?
可以直接在配置文件中设置端口。
也可以在启动程序的时候,通过命令行来制定端口号 --port。
此处我们采取配置文件的方式来设置不同的端口号,从而启动多个服务器。
第一步:在当前目录下创建一个文件夹,文件夹的名字叫啥都行,这里我们就叫做redis-config
![]()
第二步:进入文件夹,将 /etc/redis/redis.conf拷贝到当前文件夹
由于此处我们是设置一个主节点,两个从节点,因此我们只需要拷贝两份.conf文件即可,下面我们拷贝的两份.conf文件分别是slave1.conf 和 slave2.conf

第三步:
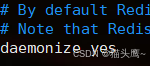
修改新增的两个配置文件中的port和daemonize
slave1.conf
![]()
daemonize:是否可以让redis-server在后台进程的方式运行
![]()
slave2.conf
配置好之后,使用 redis-server slave1.conf 和 redis-server slave2.conf 启动服务器。

此时我们登录端口号为6379和6380的redis客户端,redis-cli默认的端口号就是6379,如果要启动端口号为6380的服务器,此时redis-cli -p 6380即可。
6379客户端将key设置为111,6380客户端是获取不到的,6380客户端将key设置为222,6379客户端获取到的还是111,说明这两个客户端还是各自为政的,没半毛钱关系。

这几个节点并没有构成主从结构,而是各自为政,要想成为主从结构,还需要配置。
配置主从结构
可以以命令行的方式配置,但是命令行的方式需要每次启动时都需要加入,因此我们采取修改配置文件一劳永逸的方式。
此处我们以6379为主节点,6380和6381为从节点。
此处我们需要在从节点配置文件的末尾加上 slaveof选项,后面跟上主节点的ip地址和端口号。
就是我们创建的slave1.conf和slave2.conf。
修改slave1.conf
![]()
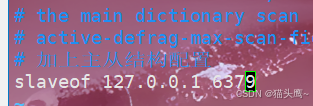
修改slave2.conf![]()
![]()
修改完毕之后需要重启redis服务器,配置文件才能生效,接下来我们重启一下服务器。
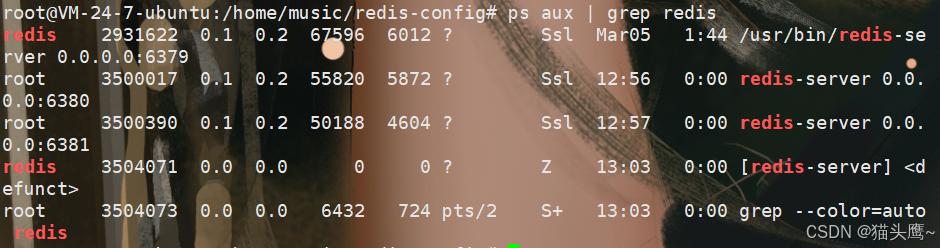
此处我们直接用kill -9干掉这两个服务器 。
使用ps aux | grep redis查到端口号后用kill命令干掉即可。

使用kill -9 停止redis-server的方式,是基于之前通过redis-server [配置文件]命令的方式搭配的。
如果是使用service redis-server start 这种方式启动的,就必须使用service redis-server stop来进行停止,如果使用kill -9的方式停止,kill掉之后,redis-server进程能自动启动,这是因为redis服务器针对这种情况进行了处理,被杀掉之后服务器快速重启,尽可能的降低服务器挂掉的损失。
接下来重新启动这两个服务器即可。
此时这两个节点就可以同步了,当主节点设置key时,从节点就可以获取到。

那么从节点可以修改数据吗?
当从节点要修改数据时,就会直接报错。

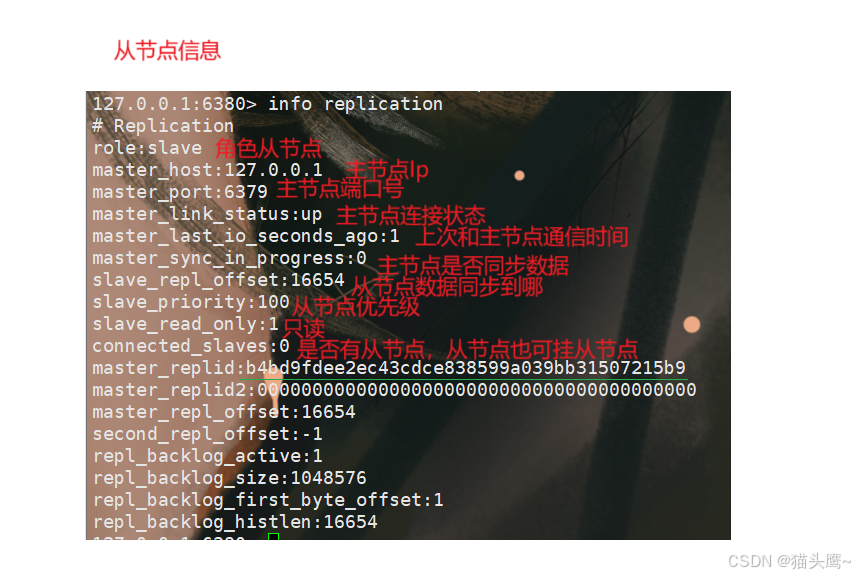
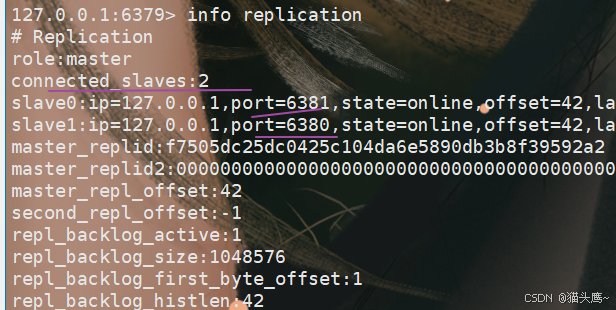
查看主从结构信息
info replication命令可以查看节点信息。
主节点信息:

从节点信息:
断开主从结构
slaveof no one命令:这个命令可以断开主从复制关系。
从节点断开主从关系之后,它就恢复自由身了,不再属于其它节点了,但里面之前同步的数据,是不会抛弃的,但之后主节点的数据它就无法同步了。
6380断开主从关系,此时6380就不再是6379的从节点了。
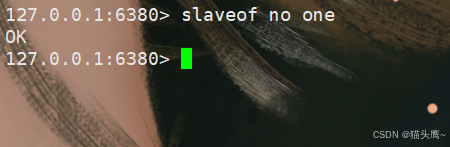
我们看6379的信息,可以看到它的从节点个数少了一个。
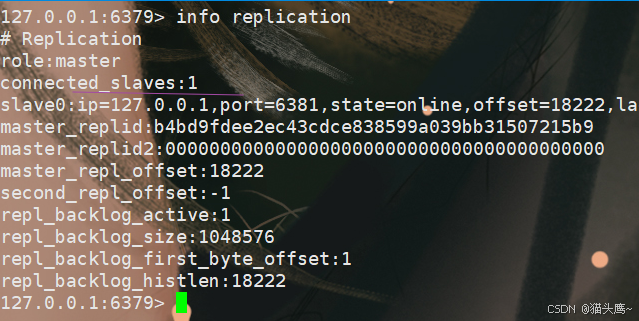
此时6379的数据,6380就不会同步了。
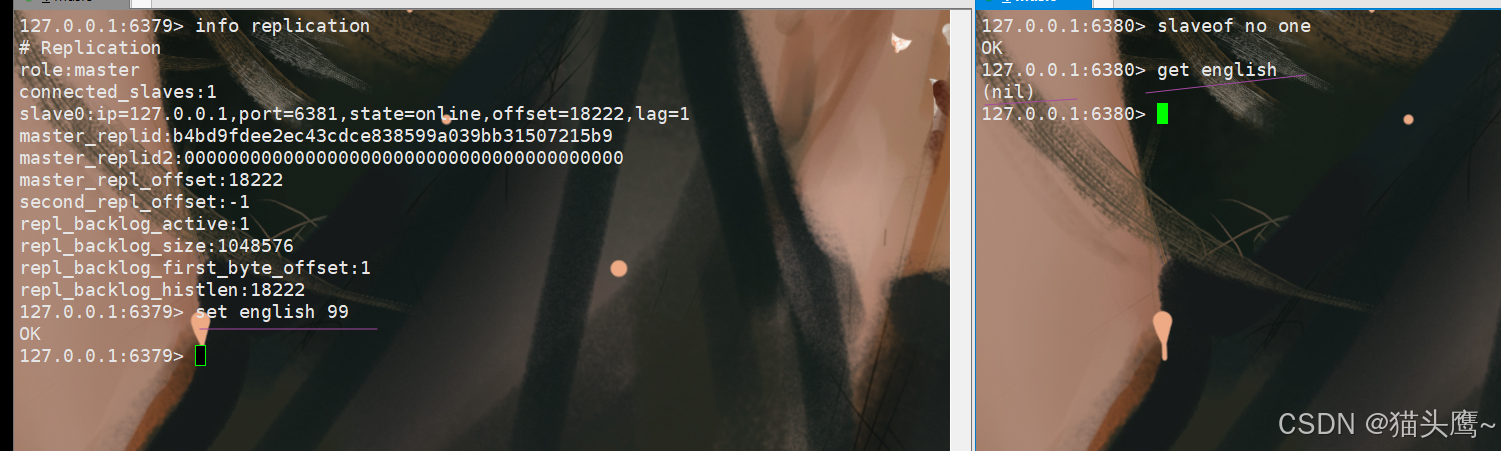
修改主从结构
6380如果要想认6381为主节点呢?此处我们在6380的客户端输入slaveof ip port即可。

此时的结构就成下图这样了,现在6379是6381的主节点,6381会同步6379的数据,此时6381是6380的主节点,6380会同步6381的数据,也就是说6380也是会同步6379的数据,可以认为6380是6379的从节点,但是6379的info信息里的从节点数量不会增加,只会记录与它直接相连的从节点数量。
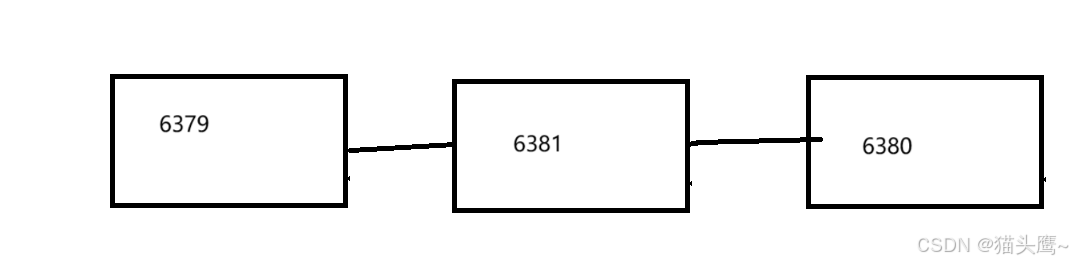
此时我们在6379设置key,6380也是可以看到的。
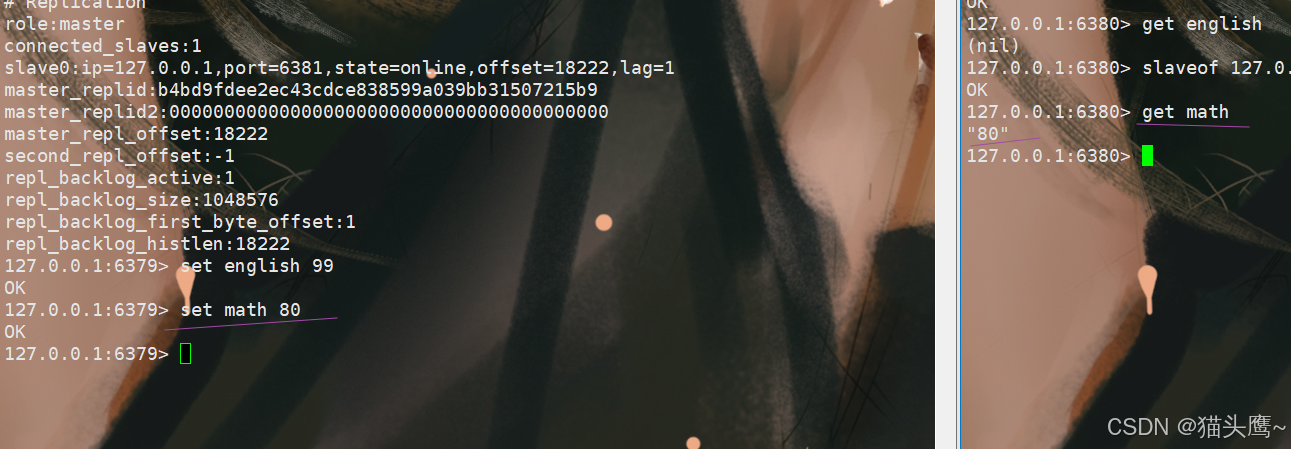 此时我们看看6379的节点信息,我们发现6379作为主节点,但它的从节点只有一个,因为6380是通过6381间接的同步了6379的数据。
此时我们看看6379的节点信息,我们发现6379作为主节点,但它的从节点只有一个,因为6380是通过6381间接的同步了6379的数据。
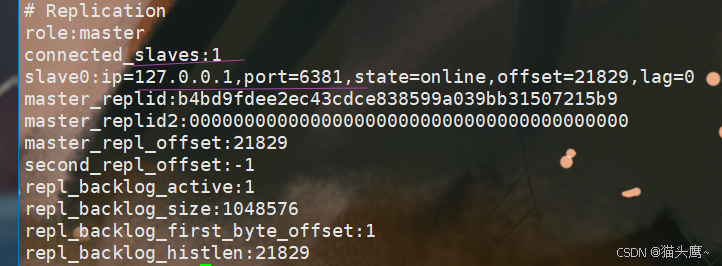
我们来看6381的节点信息,我们可以看到6381既有主节点又有从节点。
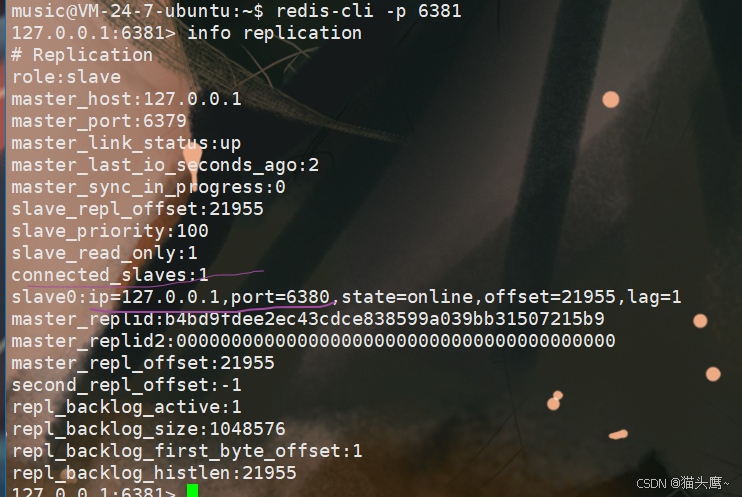
6381虽然是6380的主节点,但是它是不能写数据的,只能读数据 ,因为它也是6379的从节点。

这里使用使用slave命令的方式修改主从关系只是临时的,如果服务器重启,还是会恢复到配置文件上设置的主从结构,实际上命令行更改主从结构也不太建议,一般我们把配置文件上的主从结构配置好之后就不会发生变动了。
此时我们把3个服务器重启,然后看看6379主节点的从节点数量是不是两个,可以看到,服务器重启后,主从结构就会恢复成配置文件里的结构。
主从复制的拓扑结构
拓扑结构就是若干个节点之间,按照什么样的方式来进行组织连接。
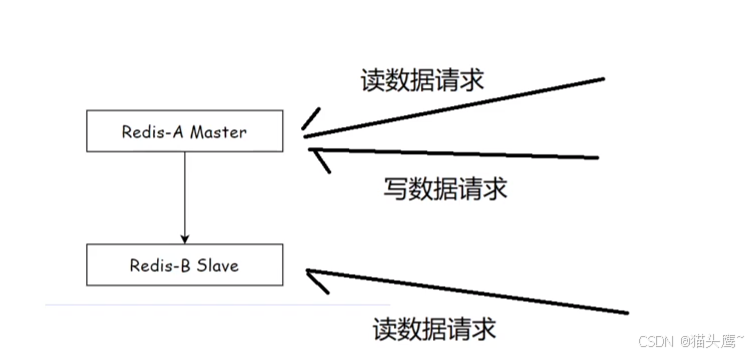
一主一从
一主一从是一个主节点和一个从节点,当读数据请求来的时候,主节点或者从节点处理都可以,当写数据请求来的时候,只能让主节点来写数据,然后把数据通过网络同步给从节点。
如果写的数据太多,此时也会给主节点造成一些压力,此时我们可以通过关闭主节点的aof,只在从节点开启aof,但是这种设定有一个严重的缺陷,一但主节点挂了,不能让主节点自动重启,如果自动重启,此时没有aof文件,主节点之前的数据就全没了,然后从节点会同步主节点,此时从节点的数据也没了,这咋能行。
解决的方法就是让主节点重启的时候先把从节点的aof文件同步过来,在重新启动。
一主多从——层状结构
实际开发中,读的请求远远大于写的,因此一个从节点是远远不够的,就引入了一个主节点多个从节点的模式,当主节点的数据发生变化时,会把主节点的数据同步给所有的从节点,当读请求数据来的时候,交给任何一个节点处理就可以。
但是一主多从有个问题,就是当写数据来时,此时主节点要把写的数据同步给所有的从节点,如果有100个从节点,同步一条数据,就需要传输100次,数据同步是需要通过网络的,此时就需要主节点有很大的网络带宽。

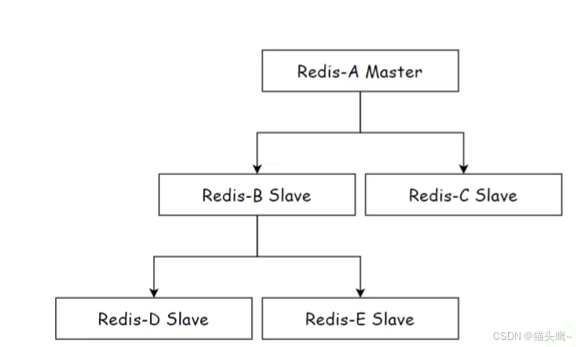
一主多从——树形结构
当读数据来时,请求任何一个节点都可以,当写数据来时,主节点只需要将数据同步给它下面的几个从节点,然后由它的从节点在依次次向下传递,此时主节点就不需要那么高的网络带宽了。
但是它的问题在于,一旦数据进行修改了,同步的延时是比刚才更长的,要同步数据到D,要先到达B才能到达D,同步是层数越多,时间就越长,这样就可以能导致数据不太一致,可能数据同步还没到D,此时又A又有写的数据过来了,此时A和D是数据就会暂时不一致。
如果我们更关注网络带宽,使用树形结构就行,如果我们更关注同步的延时,采用层状结构即可。
主从复制的基本流程
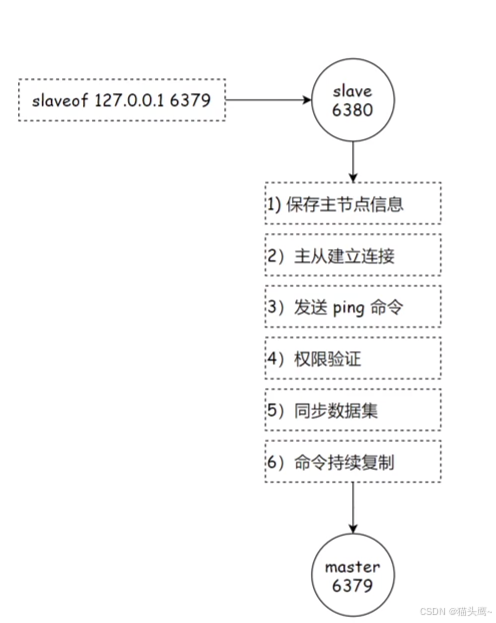
现在有6379节点和6380节点,这两个节点刚开始都是独立的,此时6380客户端执行了slaveof 127.0.0.1 6379,意味着6380要成为6379的从节点,那这个过程是怎样的呢?
第一步:6380会保存主节点的信息(ip地址和端口号)。要同步信息,当然需要知道主节点ip地址和端口号呀,不然怎么网络通信。
第二步:主从节点建立连接。这个建立连接就是TCP三次握手,为了验证通信双方是否能正确读写数据。
第三步:发送ping命令。ping命令就相当于验证我的数据是否能发给你。
第四步:验证权限。如果redis主节点开启了密码,就会触发权限验证,从节点会把自己保存的密码发送给主节点,看看密码是否匹配,如果匹配在进行后续数据同步,不匹配,那还玩啥呢。
第五步:同步数据集。刚建立主从关系的时候,从节点会把主节点上的所有数据一下子全都给同步过来。
第六步:命令持续复制。当之后主节点又有写数据的时候,从节点就会持续的把主节点新增的数据同步过来。
全量复制和部分复制
redis提供了psync命令,完成数据同步的过程,这个命令不需要手动执行,redis服务器会在建立好主从同步关系之后,自动执行psync,是从节点执行psync,从节点从主节点这边拉取数据。
psync:语法
psync replicationid offset
虽然我们不会手敲这个命令,但是如果明白这个命令的参数是啥意思,也就知道同步的过程了。
replication:这个单词其实就是复制的意思,id就是身份标识的含义,这个id是主节点启动的时候生成的,同一个主节点每次重启生成的replicationid都是不同的,当主节点和从节点建立好复制关系,从节点就会从主节点这边获取到replicationid,从节点通过这个id就知道自己的数据是从哪个主节点获取。我们通过info relication就可以获取到replicationid具体的值。
可是为啥有两个呢?replid和replid2,说是两个其实是一个,一般情况下这个replid2是用不上的,啥时候会用上?假设有一个主节点a,还有一个从节点b,接下来,a会生成replid,b会获取到replid,如果a和b通信过程中出现了一些网络抖动,b可能会认为a挂了,这个时候b就会自己成为自己的主节点,它也就会给自己生成一个replid,但是它也会记得之前旧的replid,怎么记?就是通过replid2,目的是为了有朝一日再回到之前主节点的怀抱,后续网络稳定了,通过replid2重新成为a的从节点。
offset:偏移量。主节点和从节点上都会维护这样一个偏移量(整数),主节点的偏移量,主节点上会收到很多修改操作的命令,此时每个命令都要占据几个字节,主节点会把这些修改命令,每个命令的字节数进行累加。从节点的偏移量,就描述了,现在从节点这里数据同步到哪里了。
如果发现两个机器的replication id和offset也一样,就可以认为这两个redis机器上存储的数据就是完全一样的。
psync这里可以从主节点获取全量数据,也可以获取一部分数据。
全量复制
如果offset写作-1,就是获取全量数据。获取所有数据虽然是最稳妥的,但是效率是比较低的。
什么时候进行全量复制?
1.首次和主节点进行数据同步
2.主节点不方便进行部分复制的时候
部分复制
如果offset写为具体的正整数,则是从当前偏移量位置来进行获取。如果从节点之前已经从主节点复制过一部分数据了,就只需要把新的之前没复制过的数据复制过来即可。
并不是从节点要哪一部分,主节点就一定给哪部分,主节点会自行判定方便不方便,如果不方便就会给全量数据。
什么时候进行部分复制?
从节点之前已经从主节点上复制过数据了,因为网络抖动或者从节点重启了,从节点需要重新从主节点这边同步数据,此时看看能不能只同步一小部分数据(大部分数据都一致)。
全量复制的流程
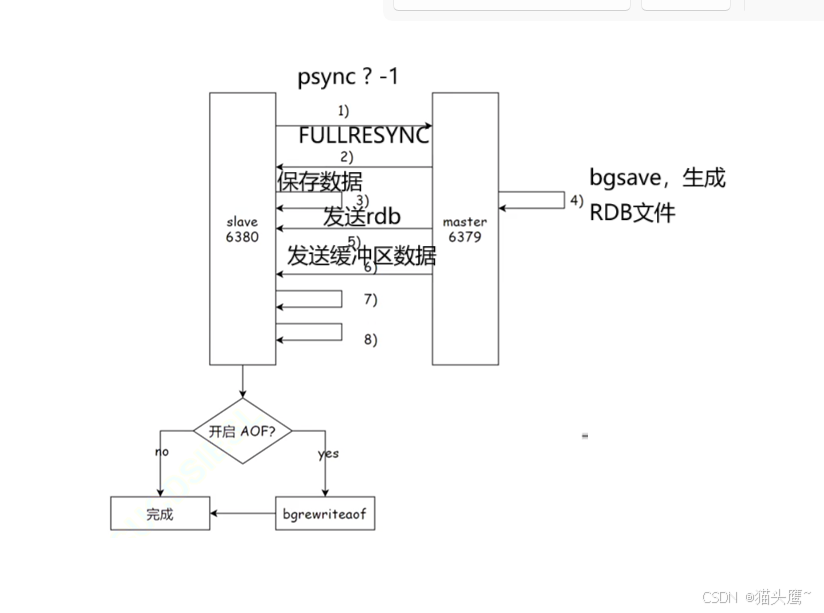
(1)从节点给主节点发送psync命令给主节点进行数据同步,由于是第一次进行复制,从节点并没有主节点运行的id和复制偏移,因此运行id给?,复制偏移给-1。
(2)主节点收到从节点发来的psync命令后,知道了要进行全量复制,主节点会回复FULLRESYNC(表示接下来要进行全量复制)并把自己的ip和端口等信息发送给从节点。
(3)从节点收到主节点的信息后,将ip和端口号进行保存。
(4)主节点执行bgsave进行RDB文件的持久化。
(5)主节点把持久化的RDB文件发送给从节点,从节点将RDB文件保存到硬盘。
这里为啥要把RDB文件发给从节点,发AOF文件不行吗?我们知道RDB文件是二进制,而AOF是文本文件,二进制当然是比文本更节省空间。
(6)主节点进行bgsave持久化的时候,是需要时间的,把RDB文件通过网络交给从节点也是需要时间的,在这两段时间里很有可能又出现了大量的修改创建操作,此时主节点会将这期间写或修改的数据写入到缓冲区中,等从节点保存完RDB文件之后,主节点再把自己缓冲区中的数据发送给从节点。
(7)从节点把自己原有的数据清空。
(8)从节点加载RDB文件,从而与主节点数据保持一致。
(9)如果从节点加载RDB完成之后,并且开启了AOF持久化功能,它会进行bgrewrite操作,得到最新的AOF文件。
如果从节点已经开启了AOF,在上述加载的过程中,从节点会产生大量的AOF日志,由于当前收到的是大批量的数据,此时产生的AOF日志,整体来说,可能会存在一定的冗余信息,因此针对AOF日志进行整理,也是很有必要的。
主节点使用bgsave命令生成一个RDB文件,然后通过网络发送给从节点,从节点收到之后,再读取RDB文件同步数据。这里为啥主节点不直接把数据通过网络发送给从节点呢?这样就省去了生成RDB文件的时间以及读取硬盘的时间,这样不是更好吗?的确,这样的传输方式就是"无硬盘模式",可以提高整体传输的效率,但是,虽然引入了无硬盘模式,但仍然整个操作是比较重量,比较耗时的,因为网络传输是没法省的,相比于网络传输来说,读写硬盘只是小头,虽然能提升效率,但是不明显。
部分复制的流程
从节点要从主节点这里进行全量复制,开销是很大的,有些时候,从节点本身已经持有了主节点的绝大部分数据,这个时候,就不太需要进行全量复制了,比如出现网络抖动,主节点最近修改的数据可能就无法及时同步过来了,更严重的,从节点已经感知不到主节点了,从节点可能会升级成主节点。
网络抖动,一般都是"暂时的",过一会就恢复了,此时就可以让从节点和主节点重新建立联系,当从节点和主节点重新建立连接之后,就需要进行数据的同步。
如何同步呢?发送psync,此时的psync就带有具体的replid和offset,主节点就要根据psync的参数进行判定,当前这次是按照全量复制合适还是部分复制合适。
部分复制的流程分为如下六步:
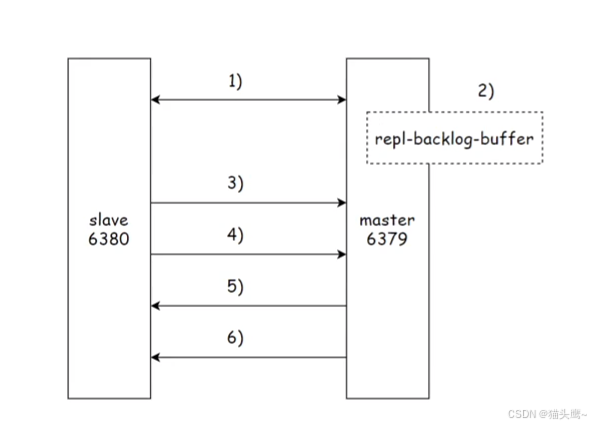
(1) 当主节点和从节点之间出现网络中断时,如果超过了超时时间,主节点会认为从节点故障并终止复制的连接。
(2)断开连接之后,主节点仍然会接受请求,此时因为主从节点断开这些新的请求都无法交给从节点,因此会先把这些数据放到积压缓冲区中。info replication可以看到积压缓冲区信息。
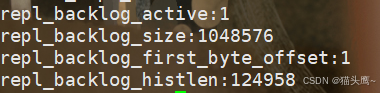
积压缓冲区就是一个内存中的简单队列,上面这些信息就是在描述队列的信息。
(3)当主从节点网络恢复之后,从节点会再次连上主节点。
(4)从节点会将之前保存的replicationId和复制偏移量作为psync的参数发送给主节点,请求进行部分复制。
(5)主节点收到psync请求后,会看从节点发来的replicationId是否和自己的一致,如果一样,说明该节点之前就是我的从节点,如果不是,说明它之前不是我的从节点,此时直接进行全量复制,一样之后再看复制的偏移量,是否在自己积压缓冲区的范围内,如果在范围内,直接进行部分复制,把最近这段时间的数据复制过去即可,如果已经超出积压缓冲区的范围,直接进行全量复制。
积压缓冲区的大小是有限的,只会记录最近一段时间修改的数据,随着时间的推移,就会把之前旧的数据逐渐覆盖掉。
(6)主节点将需要从节点同步的数据发送给从节点,最终完成一致性。
实时复制的流程
全量复制:从节点刚连上主节点之后,进行初始化工作。
部分复制:全量复制的特殊情况,优化手段,目的和全量复制一样。
实时复制:从节点已经和主节点同步好了数据,从节点这一时刻已经和主节点数据一致了,但是之后,主节点这边会源源不断的收到新的修改数据的请求,主节点上的数据就会随之改变,这些数据也需要能够同步给从节点。
从节点和主节点之间会建立TCP的长连接,主节点把自己收到的修改数据的请求,通过上述连接,发送给从节点,从节点再根据这些修改请求,修改内存中的数据,但是发送给从节点这个过程也是需要时间的,正常来说,这个延时是比较短的,但如果是多级从节点的树形结构,并且从节点有很多层,这个延时就比较长了。在进行实时复制的时候,需要保证连接处于可用状态,此时需要心跳包机制。
心跳包机制:
主节点这边默认10秒给从节点发送一个ping命令,从节点收到就返回一个pong,如果超过60秒,从节点还没返回pong,说明从节点出了点问题。从节点这边每隔1秒就给主节点发起一个特定的请求,就会上报当前从节点复制数据的进度。通过这两个机制,就可以随时获取主节点和从节点的工作状态。
主从复制总结
主从复制解决的问题:单点问题
1.单个redis节点,可用性不高。
2.单个redis节点,性能有限。
主从复制的特点:
1.复制分为全量复制、部分复制、实时复制。
2.redis通过复制功能实现主节点的多个副本。
3.复制支持多种拓扑结构,可以在适当的场景选择合适的拓扑结构。
4.主节点用来写,从节点用来读,这样做可以降低主节点的访问压力。
5.主从节点之间通过心跳机制保证主从节点通信正常和数据一致性。
主从复制配置的过程:
1.主节点配置不需要改动
2.从节点在配置文件中加入 slaveof主节点ip主节点端口的形式即可。
主从复制的缺点:
1.从机多了,复制数据的延时非常明显。
2.主节点挂了,从节点就迷茫了,虽然能够提供读操作,但是从节点不能自动的升级成为主节点,它只能成为自己的主节点,不能替换原有主节点对应的角色,此时,就需要程序员/运维手动恢复主节点。
为了解决这个问题就需要引入Redis哨兵,自动的对挂了的主节点进行替换。
相关文章:

Redis主从复制
目录 点单问题 启动多个redis服务器 配置主从结构 查看主从结构信息 断开主从结构 修改主从结构 主从复制的拓扑结构 主从复制的基本流程 全量复制和部分复制 全量复制的流程 部分复制的流程 实时复制的流程 主从复制总结 主从复制是基于分布式系统进行讨论的&am…...

玩转python:掌握Python数据结构之栈Stack
栈(Stack)是计算机科学中一种非常基础且重要的数据结构。它的特点是后进先出(LIFO,Last In First Out),就像我们生活中叠盘子一样,最后放上去的盘子总是最先被拿走。本文将用通俗易懂的语言和丰…...

电脑如何拦截端口号,实现阻断访问?
如果你弟弟喜欢玩游戏,你可以查询该应用占用的端口,结合以下方法即可阻断端口号,让弟弟好好学习,天天向上! 拦截端口可以通过防火墙和路由器进行拦截 ,以下是常用方法: 方法 1:使用…...
)
DeepSeek 医疗大模型微调实战讨论版(第一部分)
DeepSeek医疗大模型微调实战指南第一部分 DeepSeek 作为一款具有独特优势的大模型,在医疗领域展现出了巨大的应用潜力。它采用了先进的混合专家架构(MoE),能够根据输入数据的特性选择性激活部分专家,避免了不必要的计算,极大地提高了计算效率和模型精度 。这种架构使得 …...

Apache Httpd 多后缀解析
目录 1.原因 2.环境 3.复现 4.防御 1.Apache Httpd 多后缀解析原因 Apache HTTP Server 在处理文件请求时,通常会根据文件的后缀来确定如何处理该文件。例如,.php文件会被交给 PHP 解释器处理,而.html文件则直接作为静态文件返回。 然而…...

2025年03月07日Github流行趋势
项目名称:ai-hedge-fund 项目地址url:https://github.com/virattt/ai-hedge-fund项目语言:Python历史star数:12788今日star数:975项目维护者:virattt, seungwonme, KittatamSaisaard, andorsk, arsaboo项目…...
:自动拉取、打包、部署)
Jenkins在Windows上的使用(二):自动拉取、打包、部署
(一)Jenkins全局配置 访问部署好的Jenkins服务器网址localhost:8080,完成默认插件的安装后,接下来将使用SSH登录远程主机以实现自动化部署。 1. 配置插件 选择dashboard->Manage Jenkins->plugins 安装下面两个插件 …...
4)
【JavaEE】-- 多线程(初阶)4
文章目录 8.多线程案例8.1 单例模式8.1.1 饿汉模式8.1.2 懒汉模式 8.2 阻塞队列8.2.1 什么是阻塞队列8.2.2 生产者消费者模型8.2.3 标准库中的阻塞队列8.2.4 阻塞队列的应用场景8.2.4.1 消息队列 8.2.5 异步操作8.2.5 自定义实现阻塞队列8.2.6 阻塞队列--生产者消费者模型 8.3 …...

测试直播postman+Jenkins所学
接口自动化 什么是接口?本质上就是一个url,用于提供数据。后台程序提供一种数据地址,接口的数据一般是从数据库中查出来的。 postman自动化实操: 一般来说公司会给接口文档,如果没有,通过拦截,…...

5人3小时复刻Manus?开源OpenManus项目全解剖,我的DeepSeek股票报告这样诞生
大家好,我是大 F,深耕AI算法十余年,互联网大厂技术岗。分享AI算法干货、技术心得。 更多文章可关注《大模型理论和实战》、《DeepSeek技术解析和实战》,一起探索技术的无限可能! OpenManus是什么 1. 项目背景 OpenManus 是由 MetaGPT 核心团队仅用 3 小时复刻而成的开源…...
)
【javaEE】多线程(基础)
1.❤️❤️前言~🥳🎉🎉🎉 Hello, Hello~ 亲爱的朋友们👋👋,这里是E绵绵呀✍️✍️。 如果你喜欢这篇文章,请别吝啬你的点赞❤️❤️和收藏📖📖。如果你对我的…...

0.大模型开发知识点需求综述
文章目录 一、机器学习与深度学习基础二、自然语言处理(NLP)基础三、大模型架构四、训练优化技术五、数据处理与预处理六、分布式训练与并行化策略七、微调方法与参数高效微调八、训练框架、工具与自动化流程九、评估与部署十、前沿技术与未来趋势 已更新…...

WHAT - 前端阻塞场景梳理
目录 前言场景梳理1. JavaScript 执行阻塞主线程场景优化思路具体代码示例1. 长时间运行的同步 JavaScript 代码2. 过多的主线程任务(如频繁的 setTimeout/setInterval)3. 未优化的第三方库或框架初始化逻辑总结 2. 样式计算与布局(Layout&am…...

微前端框架 Qiankun 的应用及问题分析
一、Qiankun 的核心应用场景与优势 多技术栈共存与灵活集成 Qiankun 支持主应用与子应用使用不同技术栈(如 Vue、React、Angular 等),通过 HTML Entry 方式接入子应用,无需深度改造子应用即可实现集成,降低了技术迁移成…...

bash: uwsgi: 未找到命令
针对你提出的“bash: uwsgi: command not found”问题,以下是一些可能的解决方案,请按照步骤逐一排查: 1、检查uwsgi命令是否正确: 确保你输入的命令是uwsgi,而不是uWSGI或其他变体。 2、确认uwsgi是否已安装&…...

HAL库,配置adc基本流程
1. 初始化阶段---cubemx (1) GPIO初始化 函数:HAL_GPIO_Init() 作用:配置ADC引脚为模拟输入模式。 代码示例: // 使能GPIOA时钟 __HAL_RCC_GPIOA_CLK_ENABLE();// 配置PA1为模拟输入 GPIO_InitTypeDef GPIO_InitStruct {0}; GPIO_InitStr…...
Project窗口文件夹锁定器)
【Unity】 HTFramework框架(六十一)Project窗口文件夹锁定器
更新日期:2025年3月7日。 Github源码:[点我获取源码] Gitee源码:[点我获取源码] 索引 Project窗口文件夹锁定器框架文件夹锁定自定义文件夹锁定限制条件 Project窗口文件夹锁定器 在Project窗口中,文件夹锁定器能够为任何文件夹加…...

网络安全技术整体架构 一个中心三重防护
网络安全技术整体架构:一个中心三重防护 在信息技术飞速发展的今天,网络安全的重要性日益凸显。为了保护信息系统不受各种安全威胁的侵害,网络安全技术整体架构应运而生。本文将详细介绍“一个中心三重防护”的概念,并结合代码示…...

《AJAX:前端异步交互的魔法指南》
什么是AJAX AJAX(Asynchronous JavaScript and XML,异步 JavaScript 和 XML) 是一种用于创建异步网页应用的技术,允许网页在不重新加载整个页面的情况下,与服务器交换数据并局部更新页面内容。尽管名称中包含 XML&…...

Elasticsearch 2025/3/7
高性能分布式搜索引擎。 数据库模糊搜索比较慢,但用搜索引擎快多了。 下面是一些搜索引擎排名 Lucene是一个Java语言的搜索引擎类库(一个工具包),apache公司的顶级项目。 优势:易扩展、高性能(基于倒排索引…...
LLM论文笔记 19: On Limitations of the Transformer Architecture
Arxiv日期:2024.2.26机构:Columbia University / Google 关键词 Transformer架构幻觉问题数学谜题 核心结论 1. Transformer 无法可靠地计算函数组合问题 2. Transformer 的计算能力受限于信息瓶颈 3. CoT 可以减少 Transformer 计算错误的概率&#x…...

那年周五放学
2025年3月7日,周五,天气晴,脑子一瞬间闪过02-05年中学期间某个周五下午,17:00即将放学的场景,那种激动,那种说不上的欣喜感,放学后,先走一段316国道,再走一段襄渝铁路&am…...
)
002-SpringCloud-OpenFeign(远程调用)
SpringCloud-OpenFeign 1.引入依赖2.编写一个远程调用接口3.测试 1.引入依赖 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId> </dependency><dependencyManageme…...

SAP 顾问的五年职业规划
SAP 顾问的职业发展受到技术进步、企业需求变化和全球经济环境的影响,因此制定长远规划充满挑战。面对 SAP 产品路线图的不确定性,如向 S/4HANA 和 Business Technology Platform (BTP) 的转变,顾问必须具备灵活性,以保持竞争力和…...

Pandas使用stack和pivot实现数据透视
Pandas的stack和pivot实现数据透视 经过统计得到多维度指标数据非常常见的统计场景,指定多个维度,计算聚合后的指标 案例:统计得到“电影评分数据集”,每个月份的每个分数被评分多少次:(月份,分…...

图像生成-ICCV2019-SinGAN: Learning a Generative Model from a Single Natural Image
图像生成-ICCV2019-SinGAN: Learning a Generative Model from a Single Natural Image 文章目录 图像生成-ICCV2019-SinGAN: Learning a Generative Model from a Single Natural Image主要创新点模型架构图生成器生成器源码 判别器判别器源码 损失函数需要源码讲解的私信我 S…...

c++ 操作符重载详解与示例
c 操作符重载详解与示例 操作符重载详解一、基本规则二、必须作为成员函数重载的运算符1. 赋值运算符 2. 下标运算符 []3. 函数调用运算符 ()4. 成员访问运算符 ->5. 转型运算符 三、通常作为非成员函数重载的运算符1. 算术运算符 2. 输入/输出运算符 << >> 四、…...

在Spring Boot项目中分层架构
常见的分层架构包括以下几层: 1. Domain 层(领域层) 作用:领域层是业务逻辑的核心,包含与业务相关的实体类、枚举、值对象等。它是对业务领域的抽象,通常与数据库表结构直接映射。 主要组件: 实体类(Entity):与数据库表对应的Java类,通常使用JPA或MyBatis等ORM框架…...
文件上传分析)
upload-labs详解(1-12)文件上传分析
目录 uploa-labs-main upload-labs-main第一关 前端防御 绕过前端防御 禁用js Burpsuite抓包改包 upload-labs-main第二关 上传测试 错误类型 upload-labs-env upload-labs-env第三关 上传测试 查看源码 解决方法 重命名,上传 upload-labs-env第四关…...

无人机应用探索:玻纤增强复合材料的疲劳性能研究
随着无人机技术的快速发展,轻量化已成为其结构设计的核心需求。玻纤增强复合材料凭借高强度、低密度和优异的耐环境性能,成为无人机机身、旋翼支架等关键部件的理想选择。然而,无人机在服役过程中需应对复杂多变的环境:高空飞行时…...
)
计算机毕业设计Python+DeepSeek-R1大模型空气质量预测分析(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...
)
【渗透测试】基于时间的盲注(Time-Based Blind SQL Injection)
发生ERROR日志告警 查看系统日志如下: java.lang.IllegalArgumentException: Illegal character in query at index 203: https://api.weixin.qq.com/sns/jscode2session?access_token90_Vap5zo5UTJS4jbuvneMkyS1LHwHAgrofaX8bnIfW8EHXA71IRZwsqzJam9bo1m3zRcSrb…...

学习threejs,Animation、Core、CustomBlendingEquation、Renderer常量汇总
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️Animation常量汇总1.1.1 循…...
:分组查询、连接查询 有小例子)
2、数据库的基础学习(中):分组查询、连接查询 有小例子
二、分组函数 功能:用作统计使用,又称为聚合函数或者统计函数或组函数 1、分类: sum 求和、avg 平均值、max最大值、min 最小值、count 计算个数 2、参数支持哪些类型 Sum\avg 一般处理数值型数据 max、min 可以数值型也可以字符型…...

Ubuntu搭建最简单WEB服务器
安装apache2 sudo apt install apache2 检查状态 $ sudo systemctl status apache2 ● apache2.service - The Apache HTTP ServerLoaded: loaded (/lib/systemd/system/apache2.service; enabled; vendor prese>Active: active (running) since Thu 2025-03-06 09:51:10…...

如何学习编程?
如何学习编程? 笔记来源:How To Study Programming The Lazy Way 声明:该博客内容来自链接,仅作为学习参考 写在前面的话: 大多数人关注的是编程语言本身,而不是解决问题和逻辑思维。不要试图记住语言本身…...
实现对比度保留去色(Contrast Preserving Decolorization)的函数decolor())
OpenCV计算摄影学(14)实现对比度保留去色(Contrast Preserving Decolorization)的函数decolor()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将彩色图像转换为灰度图像。它是数字印刷、风格化的黑白照片渲染,以及许多单通道图像处理应用中的基本工具。 cv::decolor 是 OpenCV…...
Deployment)
K8s 1.27.1 实战系列(七)Deployment
一、Deployment介绍 Deployment负责创建和更新应用程序的实例,使Pod拥有多副本,自愈,扩缩容等能力。创建Deployment后,Kubernetes Master 将应用程序实例调度到集群中的各个节点上。如果托管实例的节点关闭或被删除,Deployment控制器会将该实例替换为群集中另一个节点上的…...

Python第十五课:机器学习入门 | 从猜想到预测
🎯 本节目标 理解机器学习两大核心范式(监督/无监督学习)掌握特征工程的核心方法论实现经典算法:线性回归与K-Means聚类开发实战项目:房价预测模型理解模型评估与调优基础 一、机器学习核心概念(学生与老师…...
)
python 程序一次启动有两个进程的问题(flask)
0. 背景 写了一个使用 flask 作为服务框架的程序,发现每次启动程序的时候,使用 ps 都能观察到两个 python 进程。 此外,这个程序占用了 GPU 资源,我发现有两个 python 进程,分别占用了完全相同的 GPU 显存 1. 原因 …...

使用jcodec库,访问网络视频提取封面图片上传至oss
注释部分为FFmpeg(确实方便但依赖太大,不想用) package com.zuodou.upload;import com.aliyun.oss.OSS; import com.aliyun.oss.model.ObjectMetadata; import com.aliyun.oss.model.PutObjectRequest; import com.zuodou.oss.OssProperties;…...

MyBatis-Plus 与 Spring Boot 的最佳实践
在现代 Java 开发中,MyBatis-Plus 和 Spring Boot 的结合已经成为了一种非常流行的技术栈。MyBatis-Plus 是 MyBatis 的增强工具,提供了许多便捷的功能,而 Spring Boot 则简化了 Spring 应用的开发流程。本文将探讨如何将 MyBatis-Plus 与 Spring Boot 进行整合,并分享一些…...

python-51-使用最广泛的数据验证库Pydantic
文章目录 1 Pydantic2 models2.1 基本模型应用2.1.1 实例化2.1.2 访问属性2.1.3 修改属性2.2 嵌套模型【Optional】3 Fields3.1 Field()函数3.2 带注释的模式Annotated3.3 默认值3.3.1 default参数3.3.2 default_factory3.4 字段别名3.5 数字约束3.6 字符串约束3.7 严格模式4 A…...
)
Linux - 网络基础(应用层,传输层)
一、应用层 1)发送接收流程 1. 发送文件 write 函数发送数据到 TCP 套接字时,内容不一定会立即通过网络发送出去。这是因为网络通信涉及多个层次的缓冲和处理,TCP 是一个面向连接的协议,它需要进行一定的排队、确认和重传等处理…...

ADB、Appium 和 大模型融合开展移动端自动化测试
将 ADB、Appium 和 大模型(如 GPT、LLM) 结合,可以显著提升移动端自动化测试的智能化水平和效率。以下是具体的实现思路和应用场景: 1. 核心组件的作用 ADB(Android Debug Bridge): 用于与 Android 设备通信,执行设备操作(如安装应用、获取日志、截图等)。Appium: 用…...

【Pandas】pandas Series unstack
Pandas2.2 Series Computations descriptive stats 方法描述Series.argsort([axis, kind, order, stable])用于返回 Series 中元素排序后的索引位置的方法Series.argmin([axis, skipna])用于返回 Series 中最小值索引位置的方法Series.argmax([axis, skipna])用于返回 Series…...

rv1126交叉编译opencv+ffmpeg+x264
文章目录 🌕交叉编译x264🌙创建build_x264.sh(放在下载的x264目录下)🌙编译过程🌙查看编译后的so文件是否是arm版的 🌕下载编译ffmpeg🌙下载ffmpeg🌙创建编译脚本🌙创建ffmpeg编译路…...

【C++】ImGui:VSCode下的无依赖轻量GUI开发
本教程将手把手带您用纯原生方式构建ImGui应用,无需CMake/第三方库。您将全程明了自己每个操作的意义,特别适合首次接触GUI开发的新手。 环境配置 安装VSCode 作用:轻量级代码编辑器,提供智能提示操作: 官网下载安装…...

BUU44 [BJDCTF2020]ZJCTF,不过如此1 [php://filter][正则表达式get输入数据][捕获组反向引用][php中单双引号]
题目: 我仿佛见到了一位故人。。。也难怪,题目就是ZJCTF 按要求提交/?textdata://,I have a dream&filenext.php后: ......不太行,好像得用filephp://filter/convert.base64-encode/resourcenext.php 耶?那 f…...

Jetpack Compose — 入门实践
一、项目中使用 Jetpack Compose 从此节开始,为方便起见,如无特殊说明,Compose 均指代 Jetpack Compose。 开发工具: Android Studio 1.1 创建支持 Compose 新应用 新版 Android Studio 默认创建新项目即为 Compose 项目。 注意:在 Language 下拉菜单中,Kotlin 是唯一可…...