第TR3周:Pytorch复现Transformer
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
Transformer通过自注意力机制,改变了序列建模的方式,成为AI领域的基础架构
编码器:理解输入,提取上下文特征。
解码器:基于编码特征,按顺序生成输出。
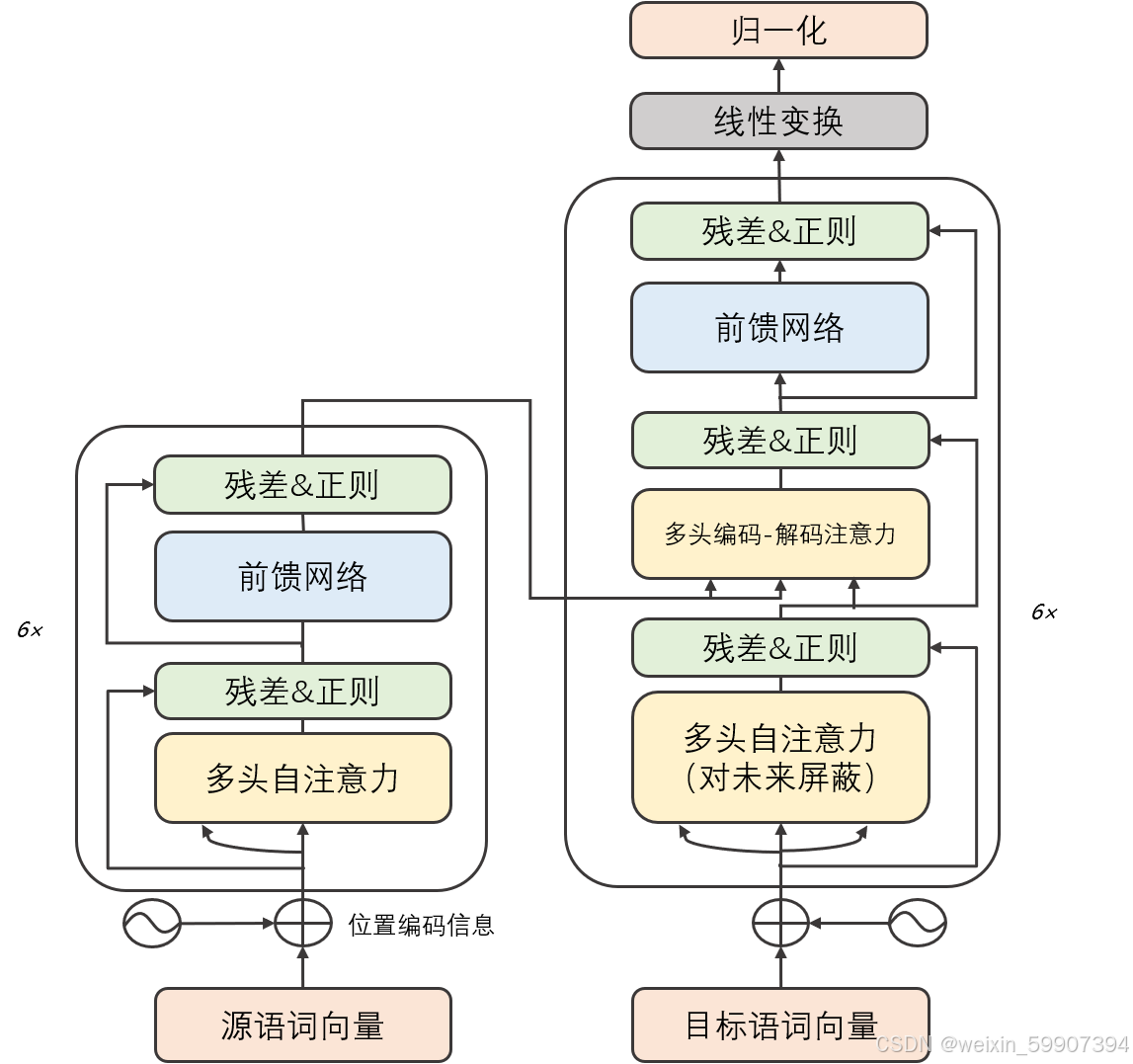
1.多头注意力机制
import math
import torch
import torch.nn as nndevice=torch.device('cuda' if torch.cuda.is_available() else 'cpu')class MultiHeadAttention(nn.Module):# n_heads:多头注意力的数量# hid_dim:每个词输出的向量维度def __init__(self,hid_dim,n_heads):super(MultiHeadAttention,self).__init__()self.hid_dim=hid_dimself.n_heads=n_heads#强制hid_dim必须整除 hassert hid_dim % n_heads == 0#定义W_q矩阵ceself.w_q=nn.Linear(hid_dim,hid_dim)#定义W_k矩阵self.w_k=nn.Linear(hid_dim,hid_dim)#定义W_v矩阵self.w_v=nn.Linear(hid_dim,hid_dim)self.fc =nn.Linear(hid_dim,hid_dim)#缩放self.scale=torch.sqrt(torch.FloatTensor([hid_dim//n_heads]))def forward(self,query,key,value,mask=None):#Q,K,V的在句子这长度这一个维度的数值可以不一样,可以一样#K:[64,10,300],假设batch_size为64,有10个词,每个词的Query向量是300维bsz=query.shape[0]Q =self.w_q(query)K =self.w_k(key)V =self.w_v(value)#这里把K Q V 矩阵拆分为多组注意力#最后一维就是是用self.hid_dim // self.n_heads 来得到的,表示每组注意力的向量长度,每个head的向量长度是:300/6=50#64表示batch size,6表示有6组注意力,10表示有10词,50表示每组注意力的词的向量长度#K: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 -> [64,6,10,50]#转置是为了把注意力的数量6放在前面,把10和50放在后面,方便下面计算Q=Q.view(bsz,-1,self.n_heads,self.hid_dim//self.n_heads).permute(0,2,1,3)K=K.view(bsz,-1,self.n_heads,self.hid_dim//self.n_heads).permute(0,2,1,3)V=V.view(bsz,-1,self.n_heads,self.hid_dim//self.n_heads).permute(0,2,1,3)#Q乘以K的转置,除以scale#[64,6,12,50]*[64,6,50,10]=[64,6,12,10]#attention:[64,6,12,10]attention=torch.matmul(Q,K.permute(0,1,3,2)) / self.scale#如果mask不为空,那么就把mask为0的位置的attention分数设置为-1e10,这里用‘0’来指示哪些位置的词向量不能被attention到,比如padding位置if mask is not None:attention=attention.masked_fill(mask==0,-1e10)#第二步:计算上一步结果的softmax,再经过dropout,得到attention#注意,这里是对最后一维做softmax,也就是在输入序列的维度做softmax#attention: [64,6,12,10]attention=torch.softmax(attention,dim=-1)#第三步,attention结果与V相乘,得到多头注意力的结果#[64,6,12,10] * [64,6,10,50] =[64,6,12,50]# x: [64,6,12,50]x=torch.matmul(attention,V)#因为query有12个词,所以把12放在前面,把50和6放在后面,方便下面拼接多组的结果#x: [64,6,12,50] 转置 -> [64,12,6,50]x=x.permute(0,2,1,3).contiguous()#这里的矩阵转换就是:把多头注意力的结果拼接起来#最后结果就是[64,12,300]# x:[64,12,6,50] -> [64,12,300]x=x.view(bsz,-1,self.n_heads*(self.hid_dim//self.n_heads))x=self.fc(x)return x
2.前馈传播
class Feedforward(nn.Module):def __init__(self,d_model,d_ff,dropout=0.1):super(Feedforward,self).__init__()#两层线性映射和激活函数self.linear1=nn.Linear(d_model,d_ff)self.dropout=nn.Dropout(dropout)self.linear2=nn.Linear(d_ff,d_model)def forward(self,x):x=torch.nn.functional.relu(self.linear1(x))x=self.dropout(x)x=self.linear2(x)return x
3.位置编码
class PositionalEncoding(nn.Module):"实现位置编码"def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)# 初始化Shape为(max_len, d_model)的PE (positional encoding)pe = torch.zeros(max_len, d_model).to(device)# 初始化一个tensor [[0, 1, 2, 3, ...]]position = torch.arange(0, max_len).unsqueeze(1)# 这里就是sin和cos括号中的内容,通过e和ln进行了变换div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term) # 计算PE(pos, 2i)pe[:, 1::2] = torch.cos(position * div_term) # 计算PE(pos, 2i+1)pe = pe.unsqueeze(0) # 为了方便计算,在最外面在unsqueeze出一个batch# 如果一个参数不参与梯度下降,但又希望保存model的时候将其保存下来# 这个时候就可以用register_bufferself.register_buffer("pe", pe)def forward(self, x):"""x 为embedding后的inputs,例如(1,7, 128),batch size为1,7个单词,单词维度为128"""# 将x和positional encoding相加。x = x + self.pe[:, :x.size(1)].requires_grad_(False)return self.dropout(x)
4.编码层
class EncoderLayer(nn.Module):def __init__(self,d_model,n_heads,d_ff,dropout=0.1):super(EncoderLayer,self).__init__()#编码器层包含自注意机制和前馈神经网络self.self_attn=MultiHeadAttention(d_model,n_heads)self.feedforward=Feedforward(d_model,d_ff,dropout)self.norm1=nn.LayerNorm(d_model)self.norm2=nn.LayerNorm(d_model)self.dropout=nn.Dropout(dropout)def forward(self,x,mask):#自注意力机制atten_output=self.self_attn(x,x,x,mask)x=x+self.dropout(atten_output)x=self.norm1(x)#前馈神经网络ff_output=self.feedforward(x)x=x+self.dropout(ff_output)x=self.norm2(x)return x
5.解码层
class DecoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super(DecoderLayer, self).__init__()# 解码器层包含自注意力机制、编码器-解码器注意力机制和前馈神经网络self.self_attn = MultiHeadAttention(d_model, n_heads)self.enc_attn = MultiHeadAttention(d_model, n_heads)self.feedforward = Feedforward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_output, self_mask, context_mask):# 自注意力机制attn_output = self.self_attn(x, x, x, self_mask)x = x + self.dropout(attn_output)x = self.norm1(x)# 编码器-解码器注意力机制attn_output = self.enc_attn(x, enc_output, enc_output, context_mask)x = x + self.dropout(attn_output)x = self.norm2(x)# 前馈神经网络ff_output = self.feedforward(x)x = x + self.dropout(ff_output)x = self.norm3(x)return x
6.Transformer模型构建
class Transformer(nn.Module):def __init__(self, vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout=0.1):super(Transformer, self).__init__()# Transformer 模型包含词嵌入、位置编码、编码器和解码器self.embedding = nn.Embedding(vocab_size, d_model)self.positional_encoding = PositionalEncoding(d_model)self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_encoder_layers)])self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_decoder_layers)])self.fc_out = nn.Linear(d_model, vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, src, trg, src_mask, trg_mask):# 词嵌入和位置编码src = self.embedding(src)src = self.positional_encoding(src)trg = self.embedding(trg)trg = self.positional_encoding(trg)# 编码器for layer in self.encoder_layers:src = layer(src, src_mask)# 解码器for layer in self.decoder_layers:trg = layer(trg, src, trg_mask, src_mask)# 输出层output = self.fc_out(trg)return output
vocab_size = 10000
d_model = 128
n_heads = 8
n_encoder_layers = 6
n_decoder_layers = 6
d_ff = 2048
dropout = 0.1device = torch.device('cpu')transformer_model = Transformer(vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout)# 定义输入
src = torch.randint(0, vocab_size, (32, 10)) # 源语言句子
trg = torch.randint(0, vocab_size, (32, 20)) # 目标语言句子
src_mask = (src != 0).unsqueeze(1).unsqueeze(2) # 掩码,用于屏蔽填充的位置
trg_mask = (trg != 0).unsqueeze(1).unsqueeze(2) # 掩码,用于屏蔽填充的位置# 模型前向传播
output = transformer_model(src, trg, src_mask, trg_mask)
print(output.shape)
![]()
相关文章:
第TR3周:Pytorch复现Transformer
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 Transformer通过自注意力机制,改变了序列建模的方式,成为AI领域的基础架构 编码器:理解输入,提取上下文特征…...

51c视觉~3D~合集2
我自己的原文哦~ https://blog.51cto.com/whaosoft/13422809 #中科大统一内外参估计和3DGS训练 这下真的不用相机标定了? 同时优化相机的内外参和无序图像数据 在给定一组来自3D场景的图像及其相应的相机内参和外参的情况下,3D高斯喷溅ÿ…...

dify在腾讯云服务器上部署
Dify 是一个开源的 LLM 应用开发平台。提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等能力,轻松构建和运营生成式 AI 原生应用,比 LangChain 更易用。 首先到dify官方网站上有详细介绍 https://docs.dify.ai/zh-hans/getting-started/ins…...

Redis——缓存穿透、击穿、雪崩
缓存穿透 什么是缓存穿透 缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库…...

Java 并发编程:synchronized 与 Lock 的区别
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 Java 并发编程:synchronized 与 Lock 的深度对比 在 Java 多线程编程中,同步机制是保证线程安全的核心手段。synchronized 关键字和 …...

12组复古暖色调旅行电影摄影照片调色Lightroom预设 12 Warm Vintage Film Lightroom Presets
使用这 12 种暖色复古胶片 Lightroom 预设来转换您的照片,旨在将经典胶片的永恒精髓带入您的数字编辑中。每个预设都经过精心制作,以唤起丰富的色彩、微妙的颗粒和怀旧的色调。 这些预设非常适合寻求复古魅力和现代精度融合的摄影师,将毫不费…...

WebSocket:实现实时通信的利器
在现代Web应用中,实时通信变得越来越重要。无论是聊天应用、在线游戏,还是实时数据推送,传统的HTTP请求-响应模式已经无法满足需求。WebSocket作为一种全双工通信协议,应运而生,成为实现实时通信的利器。本文将深入探讨…...

小谈java内存马
基础知识 (代码功底不好,就找ai优化了一下) Java内存马是一种利用Java虚拟机(JVM)动态特性(如类加载机制、反射技术等)在内存中注入恶意代码的攻击手段。它不需要在磁盘上写入文件,…...

wordpress自定the_category的输出结构
通过WordPress的过滤器the_category来自定义输出内容。方法很简单,但是很实用。以下是一个示例代码: function custom_the_category($thelist, $separator , $parents ) {// 获取当前文章的所有分类$categories get_the_category();if (empty($categ…...

Flink深入浅出之01:应用场景、基本架构、部署模式
Flink 1️⃣ 一 、知识要点 📖 1. Flink简介 Apache Flink — Stateful Computations over Data StreamsApache Flink 是一个分布式大数据处理引擎,可对有界数据流和无界数据流进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以…...
)
react脚手架(creat-react-app)
安装 react脚手架 React官方提供的脚手架工程Create React App:https://github.com/facebook/create-react-app npm install create-react-app -g 全局安装 create-react-app my-react (my-react为项目名称,可以自定义) cd my-react 启动项目:…...
)
TypeError: Cannot set properties of undefined (setting ‘xxx‘)
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》 🍚 蓝桥云课签约作者、…...
)
使用Node.js从零搭建DeepSeek本地部署(Express框架、Ollama)
目录 1.安装Node.js和npm2.初始化项目3.安装Ollama4.下载DeepSeek模型5.创建Node.js服务器6.运行服务器7.Web UI对话-Chrome插件-Page Assist 1.安装Node.js和npm 首先确保我们机器上已经安装了Node.js和npm。如果未安装,可以通过以下链接下载并安装适合我们操作系…...

考网络安全工程师证要什么条件才能考?
在当今数字化时代,网络安全问题日益凸显,网络安全工程师成为了一个备受瞩目的职业。许多有志于投身这一行业的学子或职场人士,都希望通过考取网络安全工程师证书来提升自己的专业素养和竞争力。那么,考网络安全工程师证需要具备哪…...

【情境领导者】评估情境——准备度水平
本系列是看了《情境领导者》一书,结合自己工作的实践经验所做的学习笔记。 在文章【情境领导者】评估情境——什么是准备度-CSDN博客我们提到准备度是由能力和意愿两部分组成的。 准备度水平 而我们要怎么去评估准备度呢?准备度水平是指人们在每项工作中…...

一套企业级智能制造云MES系统源码, vue-element-plus-admin+springboot
MES应该是继ERP之后制造企业信息化最热门的管理软件,它适应产品个性化与敏捷化制造需求,满足生产过程精益管理而产生和发展起来的信息系统。 作为企业实现数字化与智能化的核心支撑技术与重要组成部分,MES在帮助制造企业走向数字化、智能化等…...

蓝桥杯备考:动态规划线性dp之传球游戏
按照动态规划的做题顺序 step1:定义状态表示 f[i][j] 表示 第i次传递给了第j号时一共有多少种方案 step2: 推到状压公式 step3:初始化 step4:最终结果实际上就是f[m][1] #include <iostream> #include <cstring> using namespace std;const int N …...

网络编程 day05
网络编程 day05 12. SQL 数据库概念常用数据库MySQL与SQLite的区别 SQL基础SQL语句使用基本语句的使用—命令行操作sqlite3系统命令sqlite命令 sqlite3编程—函数接口 13. setsockopt:设置套接字属性 12. SQL 数据库 概念 数据库是“按照数据结构来组织、存储和管理…...

Excel中COUNTIF用法解析
COUNTIF 是 Excel 中一个非常实用的函数,用于统计满足某个条件的单元格数量。它的基本语法如下: 基本语法 COUNTIF(范围, 条件) 范围:需要统计的单元格区域,例如 A1:A10 或整列 A:A。 条件:用于判断哪些单元格需要被…...

使用XShell连接RHEL9并配置yum阿里源
目录 1.先在终端查看本地IP 2.打开XShell进行连接 方法一: 方法二: 3.关闭防火墙及SElinux 4.更改主机名为node2 5.修改YUM源为阿里源(将系统中国外的yum文件换成国内的阿里镜像文件) 1.找到本机的yum配置文件 2.删除原有…...

FPGA时序约束的几种方法
一,时钟约束 时钟约束是最基本的一个约束,因为FPGA工具是不知道你要跑多高的频率的,你必要要告诉工具你要跑的时钟频率。时钟约束也就是经常看到的Fmax,因为Fmax是针对“最差劲路径”,也就是说,如果该“最差劲路径”得到好成绩,那些不是最差劲的路径的成绩当然比…...

C# 在Excel中插入和操作切片器-详解
目录 使用工具 C# 在Excel中插入切片器 插入切片器到透视表 插入切片器到表格 C# 在Excel中修改切片器 C# 删除Excel中的切片器 切片器(Slicer)是Excel中的一个强大工具,它提供了直观且交互式的方式来过滤数据。通过切片器,…...

新编大学应用英语综合教程3 U校园全套参考答案
获取全套答案: 链接:https://pan.quark.cn/s/abaa0338724e...

Kubernetes中的 iptables 规则介绍
#作者:邓伟 文章目录 一、Kubernetes 网络模型概述二、iptables 基础知识三、Kubernetes 中的 iptables 应用四、查看和调试 iptables 规则五、总结 在 Kubernetes 集群中,iptables 是一个核心组件, 用于实现服务发现和网络策略。iptables 通…...

操作系统 2.2-多进程总体实现
多个进程使用CPU的图像 如何使用CPU呢? 通过让程序执行起来来使用CPU。 如何充分利用CPU呢? 通过启动多个程序,交替执行来充分利用CPU。 启动了的程序就是进程,所以是多个进程推进 操作系统需要记录这些进程,并按照…...

基于SeaShips数据集的yolov8训练教程
之前已经试过在yolov3和faster-rcnn上训练SeaShips数据集,本次在yolov8上进行训练。 yolov8的训练有两种方式,一种是在mmdetection框架下下载mmyolo运行,另一种是直接采用ultralytics。本文两种方法都会介绍。 目录 一、mmyolo 1.1 创建环…...

【时间序列聚类】从数据中发现隐藏的模式
在大数据时代,时间序列数据无处不在。无论是股票市场的价格波动、天气的变化趋势,还是用户的点击行为,这些数据都随着时间推移而产生。然而,面对海量的时间序列数据,我们如何从中提取有价值的信息?答案之一…...

在线研讨会 | 加速游戏和AI应用,全面认识Imagination DXTP GPU
近日,Imagination宣布推出 Imagination DXTP GPU IP,该产品重新定义了智能手机和其他功耗受限设备的图形和计算加速。它专为高效的效率而设计,能够提供运行AI、游戏和用户界面体验所需的性能,确保这些体验可以全天候流畅且持续地运…...

百度SEO关键词布局从堆砌到场景化的转型指南
百度SEO关键词布局:从“堆砌”到“场景化”的转型指南 引言 在搜索引擎优化(SEO)领域,关键词布局一直是核心策略之一。然而,随着搜索引擎算法的不断升级和用户需求的多样化,传统的“关键词堆砌”策略已经…...

数据库基础练习1
目录 1.创建数据库和表 2.插入数据 创建一个数据库,在数据库种创建一张叫heros的表,在表中插入几个四大名著的角色: 1.创建数据库和表 #创建表 CREATE DATABASE db_test;#查看创建的数据库 show databases; #使用db_test数据库 USE db_te…...

UVC for USBCamera in Android
基于UVC 协议,完成USBCamera 开发 文章目录 一、目的:二、USBCamera 技术实现方案难点 三、误区:四、基础补充、资源参考架构图了解Camera相关专栏零散知识了解部分相机源码参考,学习API使用,梳理流程,偏应…...

C++学习之路,从0到精通的征途:入门基础
目录 一.C的第一个程序 二.命名空间 1.namespace的价值 2.命名空间的定义 3.命名空间使用 三.C的输入与输出 1.<iostream> 2.流 3.std(standard) 四.缺省参数 1.缺省参数的定义 2.全缺省/半缺省 3.声明与定义 五.函数重载 1.参数个数不同 2.参数类型不…...

RSA-OAEP填充方案与定时攻击防护
目录 RSA-OAEP填充方案与定时攻击防护一、前言二、RSA 与 OAEP 填充方案概述2.1 RSA 加密算法基础2.2 OAEP 填充方案的引入2.3 数学公式推导 三、定时攻击原理与防护策略3.1 定时攻击的基本原理3.2 防护定时攻击的策略 四、基于 Python 的 RSA-OAEP 与定时攻击防护实现五、完整…...

探索高性能AI识别和边缘计算 | NVIDIA Jetson Orin Nano 8GB 开发套件测评总结
# NVIDIA Jetson Orin Nano 8GB测评:当边缘计算遇上"性能暴徒",树莓派看了想转行 引言:比咖啡机还小的"AI超算",却让开发者集体沸腾 2025年的某个深夜,程序员老王盯着工位上巴掌大的NVIDIA Jets…...

Seata
Seata是一款开源的分布式事务解决方案,由阿里巴巴发起并维护,旨在帮助应用程序管理和协调分布式事务。以下是对Seata的详细介绍: 一、概述 Seata致力于提供高性能和简单易用的分布式事务服务,它为用户提供了AT、TCC、SAGA和XA等…...

STM32之Unix时间戳
时间戳按秒计时,可转换成年月日时分。32有符号存储时间戳,2的32次/2-1到2038年,STM32是2的32次方-1,到2106年溢出。所有时区共用一个时间戳秒计数器,在伦敦和北京都是0,不同经度加上小时即可。...

告别手动复制粘贴:可定时自动备份的实用软件解析
软件介绍 此前不少小伙伴都在找备份工具,其实复制文件用fastcopy就可以,但它需要手动操作。 今天介绍的简易备份工具则能实现定时备份。 这款软件有个小问题,当源目录和目标目录路径太长时,【立即备份】按钮可能会超出软件界面范…...

Django下防御Race Condition
目录 漏洞原因 环境搭建 复现 A.无锁无事务时的竞争攻击 B.无锁有事务时的竞争攻击 防御 A.悲观锁加事务防御 B.乐观锁加事务防御 总结 漏洞原因 Race Condition 发生在多个执行实体(如线程、进程)同时访问共享资源时,由于执行顺序…...
:文件操作和目录管理难度分级练习题)
python从入门到精通(二十三):文件操作和目录管理难度分级练习题
文件操作和目录管理 文件操作基础难度1. 简单文件写入2. 简单文件读取3. 追加内容到文件 中级难度4. 逐行读取文件并统计行数5. 读取文件并提取特定信息6. 复制文件内容到新文件 高级难度7. 处理二进制文件8. 批量文件处理9. 日志文件分析 参考答案示例1. 简单文件写入2. 简单文…...

揭开AI-OPS 的神秘面纱 第二讲-技术架构与选型分析 -- 数据采集层技术架构与组件选型分析
基于上一讲预设的架构图,深入讨论各个组件所涉及的技术架构、原理以及选型策略。我将逐层、逐组件地展开分析,并侧重于使用数据指标进行技术选型的对比。 我们从 数据采集层 开始,进行最细粒度的组件分析和技术选型比对。 数据采集层技术架构…...

jupyter配置多个核心
CMD输入 先创建虚拟环境 "D:\Program Files\Python37\python.exe" -m venv myenv激活虚拟环境 myenv\Scripts\activate"D:\Program Files\Python37\python.exe" -m pip install ipykernel "D:\Program Files\Python37\python.exe" -m ipykern…...

如何优化FFmpeg拉流性能及避坑指南
FFmpeg作为流媒体处理的核心工具,其拉流性能直接影响直播/点播体验。本文从协议优化、硬件加速、网络策略三大维度切入,结合实战案例与高频踩坑点,助你突破性能瓶颈! 一、性能优化进阶:从协议到硬件的全链路调优 协议选…...

机器学习:线性回归,梯度下降,多元线性回归
线性回归模型 (Linear Regression Model) 梯度下降算法 (Gradient Descent Algorithm) 的数学公式 多元线性回归(Multiple Linear Regression)...

笔记五:C语言编译链接
Faye:孤独让我们与我们所爱的人相处的每个瞬间都无比珍贵,让我们的回忆价值千金。它还驱使你去寻找那些你在我身边找不到的东西。 ---------《寻找天堂》 目录 一、编译和链接的介绍 1.1 程序的翻译环境和执行环境 1.1.1 翻译环境 1.1.2 运行环境 …...

SpringUI:打造高质量Web交互设计的首选元件库
SpringUI作为一个专为Web设计与开发领域打造的高质量交互元件库,确实为设计师和开发者提供了极大的便利。以下是对SpringUI及其提供的各类元件的详细解读和一些建议: SpringUI概述 SpringUI集合了一系列预制的、高质量的交互组件,旨在帮助设…...
 教程)
LeetCode - 神经网络的 反向传播(Sigmoid + MSE) 教程
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/146085177 使用 Python + Numpy,设计带有 Sigmoid 激活函数 的神经网络,实现反向传播以更新神经元的权重和偏置。函数输入:特征向量(Input)、真实标签(Label)、初始…...

Elastic如何获取当前系统时间
文章目录 1. 使用 _ingest.timestamp 在 Ingest Pipeline 中获取当前时间2. 使用 Painless Script 获取当前时间3. 使用 now 关键字在查询中获取当前时间4. 使用 date 类型字段的默认值5. 使用 Kibana 的 Dev Tools 查看当前时间6. 使用 date 聚合获取当前时间7. 使用 Elastics…...
)
腾讯云对象存储服务(COS)
腾讯云对象存储服务(COS) 安全、可扩展、低成本的云存储解决方案 腾讯云 对象存储服务(COS,Cloud Object Storage) 是一种高可靠、高性能、可扩展的云存储服务,专为海量非结构化数据(如图片、…...

力扣35.搜索插入位置-二分查找
class Solution:def searchInsert(self, nums: List[int], target: int) -> int:# 初始化左右指针left, right 0, len(nums) - 1# 当左指针小于等于右指针时,继续循环while left < right:# 计算中间位置mid (left right) // 2# 如果中间元素等于目标值&…...

SSLScan实战指南:全面检测SSL/TLS安全配置
SSLScan是一款开源的SSL/TLS安全扫描工具,用于检测服务器的加密协议、支持的加密套件、证书信息以及潜在的安全漏洞。本指南将详细介绍如何安装、使用SSLScan,并结合实战案例帮助您全面评估服务器的安全性。 一、SSLScan简介 功能特性: 检测支持的SSL/TLS协议版本(如TLS 1.…...