视觉Transformer(DETR)
文章目录
- DETR总体流程
- DETR 中 transformer 结构
- encoder
- decoder
- Obeject Query
- HEAD
- FFN
- LOSS
- 正负样本分配
- 简单的demo
- 不足之处
DETR 是首次将 Transformer结构首次应用到视觉 目标检测中,实现 端到端的目标检测。
传统目标检测路线(yolo代表),大都是:
1、经过卷积模块生成多尺度特征图。
2、特征图上对预置的anchor框进行分类和回归任务。
3、对预测的冗余结果进行NMS处理。
以上流程看起里比较繁琐,为此如果能省去人为干预的预置anchor和后端的NMS,实现端到端,简化整体流程则是一件美妙的事情,DETR就是干这事的。
DETR总体流程
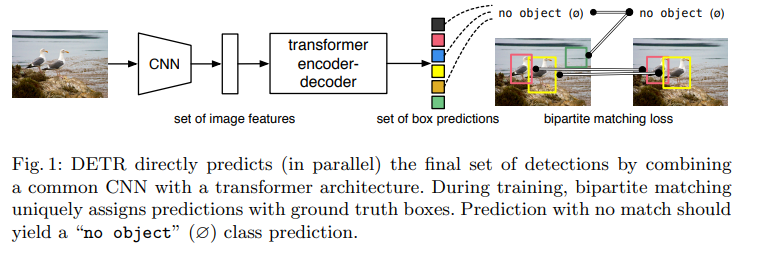
DETR总体流程如上:
1、图像经过CNN backbone 提取特征图。
2、特征展平送到Transformer结构网络中。有关Transformer介绍参考:Transformer理解
3、通过query object和匈牙利匹配的方式进行loss计算。
DETR 中 transformer 结构
对于经典Transformer 这里就不重复介绍。自注意公式为:
O = s o f t m a x ( Q ∗ K T / d k ) ∗ V O = softmax(Q* K^T / \sqrt{d_k}) * V O=softmax(Q∗KT/dk)∗V
当图像经过CNN backbone 卷积后生成的特征图,假设特征图大小为:H * W * C, 把特征展平为 (HW) * C, 就得到L=HW个特征点。把每个特征点当做一个词x,作为Transformer的输入,就等同于自然语言处理的Transformer。
 可以看到,经过self-attention 结构,所有的特征点之间都会计算自注意力权重。计算量则为 O ( H ∗ W ∗ C ) 2 ) O(H*W*C)^2) O(H∗W∗C)2)
可以看到,经过self-attention 结构,所有的特征点之间都会计算自注意力权重。计算量则为 O ( H ∗ W ∗ C ) 2 ) O(H*W*C)^2) O(H∗W∗C)2)
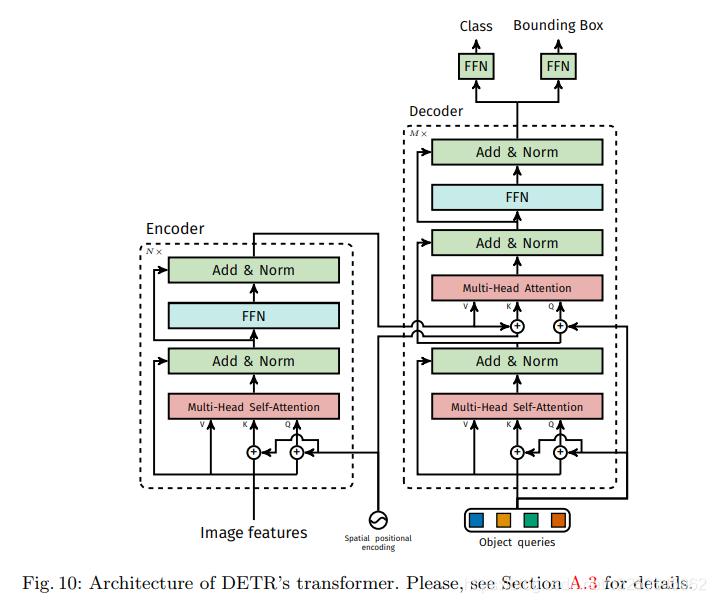
从结构上看,positional encoding在原本的transformer中是直接与input embeding相加,但是在DETR中,是加在特征的Q和K上。
在输出的分支上,DETR利用FFN引出了两个分支,一个做分类,一个做BBox的回归。
encoder
EncoderLayer由四个部分组成:多头注意力机制模块、Add & Norm模块、前向传播模块,一共有6层。
CNN backbone 输出特征图展平 : (B,L ,hidden_dim),B为batchsize, L = H*W 特征图大小,hidden_dim特征向量维度。
进入encoder 需要三个输入:
(1)、输入向量X (图像特征):shape=(B,L ,hidden_dim)
(2)、位置编码:shape=(B,L ,hidden_dim)
(3)、mask:shape=(B,L )
进入encoder:
1、将X分成三份,一份直接作为V值向量,其余两份与位置编码向量直接相加,分别作为K(键向量),Q(查询向量)。
2、将KVQ输入多头注意力模块,输出一个src1,shape=(B,L ,hidden_dim)
3、与原src直接相加短接;
4、进行第1次LN (层一化);
5、linear,Relu激活,dropout,linear还原维度,dropout,再与输入短接。
6、进行第2次LN (层一化);
7、进入下一个encoder。
8、N(N=6)个encoder 堆叠后输出。encoder 结束。
对于层归一化解释:
 层归一化(LN) 与批归一化(BN)区别:
层归一化(LN) 与批归一化(BN)区别:
BN : 在同一通道上对所有batch 做归一化,目的是让这个通道的数据分布均衡。
LN: 在同一batch上对所有通道做归一化,让网络更快、更稳定地收敛。
decoder
decoder 的结构和encoder 相似。在结构上decoder比encoder多一个多头注意力机制和Add & Norm,目的是对query embedding 和 query pos 进行学习。
decoder 的每一层输入除了上一层输出外,还要单独重新加入query pos 和 encoder 的positional encoding。
所以decoder 的输入包括:
query embedding 也就是 object query: shape=(B,num_queries ,hidden_dim)
query pos: shape=(B, num_queries,hidden_dim)
encoder的输出 : shape=(B,L ,hidden_dim)
encoder pos:shape=(B,L ,hidden_dim)
Obeject Query
什么是Obeject Query ?positional encodings是对feature的编码,类似,Obeject Query就相当对anchor 的编码,而且是一个可学习的。好比目标检测中的anchor, 只不过它的位置和大小都不是固定的,是一个学习的参数。训练初始化时是随机参数,但模型训练结束后,Obeject Query参数也就固定下来。
Obeject Query的具体表现形式是query embeding,在源代码中,这是一个torch.nn.Embedding的对象,官方介绍:一个保存了固定字典和大小的简单查找表。
进入 decoder:
1、类似encoder 的 X输入, query embedding(第一次输入是query embeding,第二次是上一层的输出out) 分为3份,其中两份与 query pos 相加得到Q, K;
2、将Q,K,V 送入第一个multihead attention 模块,得到第一个多头输出,shape = (B,num_queries ,hidden_dim)
3、将第一个多头输出进行dropout后与out相加,然后经过第一个LN输出,记为 O。
4、 将O 与query pos 相加作为第二个multihead 的Q, encoder 输出与 encoder pos 相加作为K,encoder 输出做为V。第二个多头与encoder 一模一样。得到输出作为下一个decoder 的query embedding。
5、重复N(N=6)次得到decoder 输出,shape=(B, num_queries,hidden_dim)
6、将output堆叠成一个(B, N, num_queries,hidden_dim)的向量后输出
HEAD
FFN
就是两个全连接层,分别进行分类和bbox坐标的回归。
分类全连接:(B, N, num_queries,hidden_dim) -> (B, N, num_queries,num_classs)
回归全连接:(B, N, num_queries,hidden_dim) -> (B, N, num_queries,4)
LOSS
分类loss:CEloss(交叉熵损失);
回归loss:包括预测框与GT的中心点和宽高的L1 loss以及GIoU loss
正负样本分配
匈牙利匹配:简单暴力。
预测出来的100个框与ground truth做二分类匹配,按照最小权重原则,没有匹配上的款当做背景负样本处理。
简单的demo
class DETRdemo(nn.Module):"""Demo DETR implementation.Demo implementation of DETR in minimal number of lines, with thefollowing differences wrt DETR in the paper:* learned positional encoding (instead of sine)* positional encoding is passed at input (instead of attention)* fc bbox predictor (instead of MLP)The model achieves ~40 AP on COCO val5k and runs at ~28 FPS on Tesla V100.Only batch size 1 supported."""def __init__(self, num_classes, hidden_dim=256, nheads=8,num_encoder_layers=6, num_decoder_layers=6):super().__init__()# create ResNet-50 backboneself.backbone = resnet50() #backbone选择的是resnet50del self.backbone.fc #去掉resnet50的全连接层# create conversion layerself.conv = nn.Conv2d(2048, hidden_dim, 1) #1*1卷积进行降维,形成hidden_dim个channel的特征向量# create a default PyTorch transformerself.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers) #transformer模块# prediction heads, one extra class for predicting non-empty slots# note that in baseline DETR linear_bbox layer is 3-layer MLPself.linear_class = nn.Linear(hidden_dim, num_classes + 1) #分为两个分支,一个分支预测类别(为什么加1呢,因为对与背景,实际上给了一个$的类别)self.linear_bbox = nn.Linear(hidden_dim, 4) #预测bbox# output positional encodings (object queries)self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))# spatial positional encodings# note that in baseline DETR we use sine positional encodingsself.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))def forward(self, inputs):# propagate inputs through ResNet-50 up to avg-pool layerx = self.backbone.conv1(inputs)x = self.backbone.bn1(x)x = self.backbone.relu(x)x = self.backbone.maxpool(x)x = self.backbone.layer1(x)x = self.backbone.layer2(x)x = self.backbone.layer3(x)x = self.backbone.layer4(x)# convert from 2048 to 256 feature planes for the transformerh = self.conv(x)# construct positional encodingsH, W = h.shape[-2:]pos = torch.cat([self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),], dim=-1).flatten(0, 1).unsqueeze(1)# propagate through the transformerh = self.transformer(pos + 0.1 * h.flatten(2).permute(2, 0, 1),self.query_pos.unsqueeze(1)).transpose(0, 1)# finally project transformer outputs to class labels and bounding boxesreturn {'pred_logits': self.linear_class(h), 'pred_boxes': self.linear_bbox(h).sigmoid()}不足之处
1、DETR 在检测大目标方面效果很好,但是对于小目标检测的效果不是很理想。
2、由于DETR在 HW特征图上做自注意力,当输入图像很大时,计算量很大, 为 ( H W ) 2 (HW)^2 (HW)2,因此训练和推理非常消耗时间。
deformable DETR 就是要解决以上的问题。
相关文章:
视觉Transformer(DETR)
文章目录 DETR总体流程DETR 中 transformer 结构encoderdecoderObeject Query HEADFFNLOSS正负样本分配 简单的demo不足之处 DETR 是首次将 Transformer结构首次应用到视觉 目标检测中,实现 端到端的目标检测。 传统目标检测路线(yolo代表)…...
)
Linux下学【MySQL】中如何实现:多表查询(配sql+实操图+案例巩固 通俗易懂版~)
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 本章是MySQL篇中,非常实用性的篇章,相信在实际工作中对于表的查询,很多时候会涉及多表的查询,在多表查询…...

【Office-Word】如何自动生成中英文目录
1.目录介绍 Word这个自动生成目录非常强大,涉及的功能很琐碎,想要完美的生成目录不仅仅是只会目录这么简单,前后涉及到的大纲级别、目标样式和域代码等操作是比较头疼的。 下面就一步一步开始介绍 2.多级标题级别编号设置 目录想要设置好…...

低代码平台的后端架构设计与核心技术解析
引言:低代码如何颠覆传统后端开发? 在传统开发模式下,一个简单用户管理系统的后端开发需要: 3天数据库设计5天REST API开发2天权限模块对接50个易出错的代码文件 而现代低代码平台通过可视化建模自动化生成,可将开发…...

【微信小程序】每日心情笔记
个人团队的比赛项目,仅供学习交流使用 一、项目基本介绍 1. 项目简介 一款基于微信小程序的轻量化笔记工具,旨在帮助用户通过记录每日心情和事件,更好地管理情绪和生活。用户可以根据日期和心情分类(如开心、平静、难过等&#…...

【leetcode hot 100 73】矩阵置零
解法一:(使用两个标记变量)用矩阵的第一行和第一列代替方法一中的两个标记数组(col、row[ ]:第几列、行出现0),以达到 O(1) 的额外空间。 这样会导致原数组的第一行和第一列被修改,…...

【Linux】自定协议和序列化与反序列化
目录 一、序列化与反序列化概念 二、自定协议实现一个加法网络计算器 (一)TCP如何保证接收方的接收到数据是完整性呢? (二)自定义协议 (三)自定义协议的实现 1、基础类 2、序列化与反序列…...
:高效处理复杂任务的智能架构,DeepSeek性能出色的秘诀)
混合专家模型(MoE):高效处理复杂任务的智能架构,DeepSeek性能出色的秘诀
混合专家模型 1. 什么是混合专家模型 混合专家模型(Mixture of Experts,简称 MoE) 是一种先进的神经网络架构,旨在通过整合多个 专门化的子模型(或称为“专家”) 的预测来提升整体模型性能。其核心思想是…...

使用 Spring Boot 实现前后端分离的海康威视 SDK 视频监控
使用 Spring Boot 实现前后端分离的海康威视 SDK 视频监控系统,可以分为以下几个步骤: 1. 系统架构设计 前端:使用 Vue.js、React 或 Angular 等前端框架实现用户界面。后端:使用 Spring Boot 提供 RESTful API,负责与…...

C++ 内存序在多线程中的使用
目录 一、内存顺序 二、 指令重排在多线程中的问题 2.1 问题与原因 2.2 解决方案 三、六种内存序 3.1 memory_order_relaxed 3.2 memory_order_consume 3.3 memory_order_acquire 3.4 memory_order_release 3.5 memory_order_acq_rel 3.6 memory_order_seq_cst 一、…...

【MySQL】表的操作
文章目录 👉表的操作👈创建表查看表修改表删除表 👉表的操作👈 创建表 create tabletable_name (field1 datatype,field2 datatype,field3 datatype ) character set 字符集 collate 校验规则 engine 存储引擎;说明:…...

【Flink银行反欺诈系统设计方案】3.欺诈的7种场景和架构方案、核心表设计
【Flink银行反欺诈系统设计方案】3.欺诈的7种场景和架构方案、核心表设计 1. **欺诈场景分类与案例说明**1.1 **大额交易欺诈**1.2 **异地交易欺诈**1.3 **高频交易欺诈**1.4 **异常时间交易欺诈**1.5 **账户行为异常**1.6 **设备指纹异常**1.7 **交易金额突变** 2. **普适性软…...
)
DeepSeek-R1本机部署(VLLM+OpenWebUI)
本文搭建环境 系统:Ubuntu 22.04.4 LTS Python版本:Python 3.10 显卡:RTX 4090D 一、DeepSeek-R1-14b原始模型和q8量化模型 1.从modelscope下载模型 官方原始模型:https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Di…...

计算机网络软考
1.物理层 1.两个主机之间发送数据的过程 自上而下的封装数据,自下而上的解封装数据,实现数据的传输 2.数据、信号、码元 码元就是数字通信里用来表示信息的基本信号单元。比如在二进制中,用高电平代表 “1”、低电平代表 “0”,…...

vscode 查看3d
目录 1. vscode-3d-preview obj查看ok 2. vscode-obj-viewer 没找到这个插件: 3. 3D Viewer for Vscode 查看obj失败 1. vscode-3d-preview obj查看ok 可以查看obj 显示过程:开始是绿屏,过了1到2秒,后来就正常看了。 2. vsc…...

HTML第三节
一.初识CSS 1.CSS定义 A.内部样式表 B.外部样式表 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title&g…...

爬虫去重:数据采集时如何进行去重,及去重优化策略
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 1. 去重的核心思路2. 常见的去重方法2.1 基于集合(Set)的去重2.2 基于布隆过滤器(Bloom Filter)的去重2.3 基于数据库的去重2.4 基于文件存储的去重2.5 基于 Redis 的去重3. 去重的优化策略3.1 URL 规范化3.2 分片去…...

IDEA集成DeepSeek,通过离线安装解决无法安装Proxy AI插件问题
文章目录 引言一、安装Proxy AI1.1 在线安装Proxy AI1.2 离线安装Proxy AI 二、Proxy AI中配置DeepSeek2.1 配置本地部署的DeepSeek(Ollama方式)2.2 通过第三方服务商提供的API进行配置 三、效果测试 引言 许多开发者尝试通过安装Proxy AI等插件将AI能力…...
)
【电子基础】运算放大器应用笔记(持续更新)
目录 运放应用1: 运放基础知识同相比例运算放大器计算放大倍数 电压比较器 运放应用2:500W调压器同相比例运算放大器计算放大倍数计算平衡电阻 积分电路 运放应用3:逆变电焊机电压跟随器积分电路 加油站1. 为什么比例运算放大电路要加平衡电阻…...

计算机网络核心知识点:信道容量、OSI模型与调制技术详解
目录 一、信道容量与调制技术 奈奎斯特定理(无噪声环境) 核心公式: 参数说明: 应用场景: 香农定理(有噪声环境) 核心公式: 参数说明: 应用场景: 奈奎…...

AI赋能企业协作4-NL2Sql技术路线
1.1 对话即服务的一点思考 在数智化转型的过程中,基于即时通信(IM)的协作平台正悄然成为企业智能化转型的“新基建”。协作平台天然具备高频交互、实时协同和场景化落地的特性,仿佛是为对话式AI量身定制的试验场——员工在熟悉的聊…...
)
如何用FFmpeg高效拉流(避坑指南)
FFmpeg作为音视频处理领域的“瑞士军刀”,其拉流功能在直播、监控、流媒体分析等场景中应用广泛。本文从实战角度出发,系统梳理FFmpeg拉流的核心工具链、协议适配技巧及高频踩坑点,助你快速掌握流媒体处理核心技能! 一、FFmpeg拉流工具链全解析 核心工具 ffplay:快速验证…...

面试基础--MySQL SQL 优化深度解析
MySQL SQL 优化深度解析:EXPLAIN、索引优化与分库分表实践 引言 在互联网大厂的高并发场景下,数据库的性能优化是至关重要的。MySQL 作为最流行的关系型数据库之一,SQL 查询的性能直接影响了系统的响应时间和吞吐量。本文将深入探讨 MySQL …...

WebRTC简介
WebRTC简介 WebRTC(Web Real-Time Communication)是一种支持浏览器之间进行实时音视频通信和数据传输的开放标准和技术。它由Google发起,现已成为W3C和IETF的标准。WebRTC允许开发者在不依赖第三方插件或软件的情况下,直接在网页…...

清北deepseek8本手册
“清北手册”通常是“清华大学和北京大学推出的DeepSeek手册”的简写。近期,随着AI技术的迅速发展,清北两高校陆续发布多本自家的DeepSeek学习手册,助力普通人学习进阶。 清华大学的DeepSeek手册已推出5册,内容丰富全面࿰…...
下载)
前后分离文件上传案例,前端HTML,后端Net6开发的webapi(完整源代码)下载
文件上传功能在项目开发中非常实用,本案例前端用HTML页面的form表单实现,后端用Net6实现。 前后分离文件上传案例,前端HTML,后端Net6(完整源代码) 下载链接https://download.csdn.net/download/luckyext/9…...

6.过拟合处理:确保模型泛化能力的实践指南——大模型开发深度学习理论基础
在深度学习开发中,过拟合是一个常见且具有挑战性的问题。当模型在训练集上表现优秀,但在测试集或新数据上性能大幅下降时,就说明模型“记住”了训练数据中的噪声而非学习到泛化规律。本文将从实际开发角度系统讲解如何应对过拟合,…...

六十天前端强化训练之第一天到第七天——综合案例:响应式个人博客项目
欢迎来到编程星辰海的博客讲解 目录 前言回顾 HTML5与CSS3基础 一、知识讲解 1. 项目架构设计(语义化HTML) 2. 响应式布局系统(Flex Grid) 3. 样式优先级与组件化设计 4. 完整响应式工作流 二、核心代码示例 完整HTML结…...

java数据结构_再谈String_10
目录 字符串常量池 1. 创建对象的思考 2. 字符串常量池(StringTable) 3. 再谈String对象创建 字符串常量池 1. 创建对象的思考 下面两种创建String对象的方式相同吗? public static void main(String[] args) {String s1 "hello&…...

MCP:重塑AI与数据交互的新标准
MCP:重塑AI与数据交互的新标准 前言 在人工智能领域,大型语言模型(LLM)的应用日益广泛,但其与外部数据源和工具的集成却一直面临复杂性和碎片化的挑战。 Anthropic提出的MCP(Model Context Protocol&…...

Cursor+Claude3.7实现从原型到app开发
最近在X上看到了一些人在用Claude 3.7 Sonnet生成 app原型图的尝试,受到启发,发现这么先生成不同界面的原型图再让Cursor基于原型图开发app会是很好的尝试。尤其是,你也可以不两步直接生成,而是在过程中更可视化地思考你要生产的原…...

洛谷P1334
题目如下 思路: 每次选择最短的两块木板进行合并,直到只剩下一块木板。使用最小堆(优先队列)来实现这一过程。使用最小堆: 将所有木板的长度放入最小堆(优先队列) 每次从堆中取出两块最短的木…...

使用wifi连接手机adb进行调试|不使用数据线adb调试手机|找应用错误日志和操作日志
手机在开发者选项里要开启无线调试 在手机设置中查看WiFi的IP地址 设置 -> WLAN -> 已连接的WiFi -> IP地址 使用手机的IP地址连接 adb connect 192.168.1.12:xxxxx 检查连接状态 adb devices 断开特定设备 adb disconnect 192.168.x.x:xxxxx 断开所有设备 …...
的核心原理)
大语言模型中温度参数(Temperature)的核心原理
大语言模型中温度参数(Temperature)的核心原理是通过调整模型输出的概率分布,控制生成结果的随机性和多样性。以下是其原理的详细说明: 一、定义与核心作用 温度参数是生成式模型(如GPT系列)中的一个超参数…...

【AIGC】通义万相 2.1 与蓝耘智算:共绘 AIGC 未来绚丽蓝图
一、引言 在人工智能技术迅猛发展的今天,AIGC(生成式人工智能内容生成)领域正以惊人的速度改变着我们的生活和工作方式。从艺术创作到影视制作,从广告设计到智能客服,AIGC 技术的应用越来越广泛。通义万相 2.1 作为一…...

在Ubuntu上搭建Samba服务,实现与windows之间的文件共享
1.安装samba 首先切换为root账户,就是带#符号的表示当前登录的是root超级用户; su - 如果忘记密码,就输入以下命令修改密码 sudo passwd root 再切换为超级用户 然后进行更新软件列表 sudo apt update sudo apt install samba安装 whe…...

Labview培训案例3: 输出正弦波并采集显示
本案例介绍如何从板卡(USB6008)的模拟量输出端口输出一个正弦波,然后模拟量输入模块进行采样,然后显示到vi画面的‘波形图’中。 详细代码在:Labview课程3:正弦波输出&采集数据&显示资源-CSDN文库 …...

使用 Deepseek + kimi 快速生成PPT
前言 最近看到好多文章和视频都在说,使用 Deepseek 和 kimi 能快速生成精美的 ppt,毕竟那都是别人说的,只有自己尝试一次才知道结果。 具体操作 第一步:访问 deepseek 我们访问 deepseek ,把我们想要输入的内容告诉…...

图解MOE大模型的7个核心问题并探讨DeepSeekMoE的专家机制创新
原文地址:https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts #mermaid-svg-FU7YUSIfuXO6EVHa {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-FU7YUSIfuXO6EVHa .error-icon{fill…...

青训营:简易分布式爬虫
一、项目介绍 该项目是一个简易分布式爬虫系统,以分布式思想为基础,通过多节点协作的方式,将大规模的网页抓取任务分解,从而高效、快速地获取网络数据 。 项目地址:https://github.com/yanchengsi/distributed_crawle…...
)
Scala(Array,List,Set,Map,Tuple,字符串 使用的简单介绍)
目录 Array 不可变数组 ArrayBuffer可变数组 List 不可变列表 ListBuffer 可变列表 Set 集合(可变不可变) Map映射(可变不可变)(键值对) Tuple 元组 字符串 Array 不可变数组 // Array 数组// scala 中的数组下标是()// scala 中的数组是值…...

fmql之Linux WDT
正点原子第52章。 基础知识 正点原子教程 fmql-dts 代码 APP代码(不需要编写驱动代码) static int dw_wdt_drv_probe(struct platform_device *pdev) {struct device *dev &pdev->dev;struct watchdog_device *wdd;struct dw_wdt *dw_wdt; …...

IntelliJ IDEA集成MarsCode AI
IntelliJ IDEA集成MarsCode AI IDEA中安装插件 安装完毕之后登录自己的账号 点击链接,注册账号 https://www.marscode.cn/events/s/i5DRGqqo/ 可以选择不同的模型...

python-leetcode-打家劫舍 III
337. 打家劫舍 III - 力扣(LeetCode) 这个问题可以通过动态规划解决。可以通过递归的方式来解决每个房子的最大偷窃金额,递归过程中,我们会记录每个房子是否偷或不偷时能够获得的最大金额。 思路: 对于每个房子,我们有两种选择: 偷这个房子,那么它的直接相邻(父亲和孩…...

数据结构——队列
1. 概念与结构 队列(Queue)是一种先进先出(FIFO, First In First Out)的数据结构,即最先被插入队列的数据会最先被删除。队列广泛应用于计算机科学中,特别是在任务调度、缓冲区管理、网络数据传输等领域。…...

GaussianCity:实时生成城市级数字孪生基底的技术突破
在空间智能领域,如何高效、大规模地生成高质量的3D城市模型一直是一个重大挑战。传统方法如NeRF和3D高斯溅射技术(3D-GS)在效率和规模上存在显著瓶颈。GaussianCity通过创新性的技术方案,成功突破了这些限制,为城市级数字孪生的构建提供了全新路径。 一、核心创新:突破传…...

【AGI】智谱开源2025:一场AI技术民主化的革命正在到来
智谱开源2025:一场AI技术民主化的革命正在到来 引言:开源,一场技术平权的革命一、CogView4:中文AI生成的里程碑1. 破解汉字生成的“AI魔咒”2. 开源协议与生态赋能 二、AutoGLM:人机交互的范式跃迁1. 自然语言驱动的跨…...

【算法学习之路】5.贪心算法
贪心算法 前言一.什么是贪心算法二.例题1.合并果子2.跳跳!3. 老鼠和奶酪 前言 我会将一些常用的算法以及对应的题单给写完,形成一套完整的算法体系,以及大量的各个难度的题目,目前算法也写了几篇,题单正在更新…...

C++11中的右值引用和完美转发
C11中的右值引用和完美转发 右值引用 右值引用是 C11 引入的一种新的引用类型,用 && 表示。它主要用于区分左值和右值,并且可以实现移动语义,避免不必要的深拷贝,提高程序的性能。左值通常是可以取地址的表达式…...

Leetcode 1477. 找两个和为目标值且不重叠的子数组 前缀和+DP
原题链接: Leetcode 1477. 找两个和为目标值且不重叠的子数组 class Solution { public:int minSumOfLengths(vector<int>& arr, int target) {int narr.size();int sum0;int maxnINT_MAX;vector<int> dp(n,maxn);//dp[i]表示以索引i之前的满足要求…...