SparkStreaming之03:容错、语义、整合kafka、Exactly-Once、ScalikeJDBC
SparkStreaming进阶
- 一 、要点
- :star:4.1 SparkStreaming容错
- 4.1.1 SparkStreaming运行流程
- 4.1.2 如果Executor失败?
- :star:4.1.3 如果Driver失败?
- 4.1.4 数据丢失如何处理
- :star:4.1.5 当一个task很慢容错
- :star:4.2 SparkSreaming语义
- 4.3 SparkStreaming与Kafka整合
- 4.3.1 方式一:Receiver-based Approach(不推荐使用)
- :star: 4.3.2 方式二: Direct Approach (No Receivers)
- 4.3.3 SparkStreaming与Kafka-0-8整合
- 4.3.4 SparkStreaming与Kafka-0-10整合
- 4.3.5 解决SparkStreaming与Kafka0.8版本整合数据不丢失方案
- :star::star2:4.4 SparkStreaming应用程序如何保证Exactly-Once
- 二 、扩展-ScalikeJDBC(5分钟)
- 1、什么是ScalikeJDBC
- 2、IDEA项目中导入相关库
- 3、数据库操作
- 3.1 数据库连接配置信息
- 3.2 加载数据配置信息
- 3.3 查询数据库并封装数据
- 3.4 插入数据
一 、要点
⭐️4.1 SparkStreaming容错
4.1.1 SparkStreaming运行流程
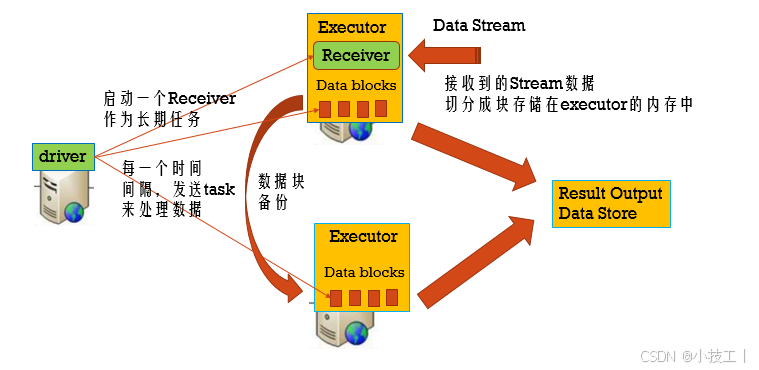
4.1.2 如果Executor失败?
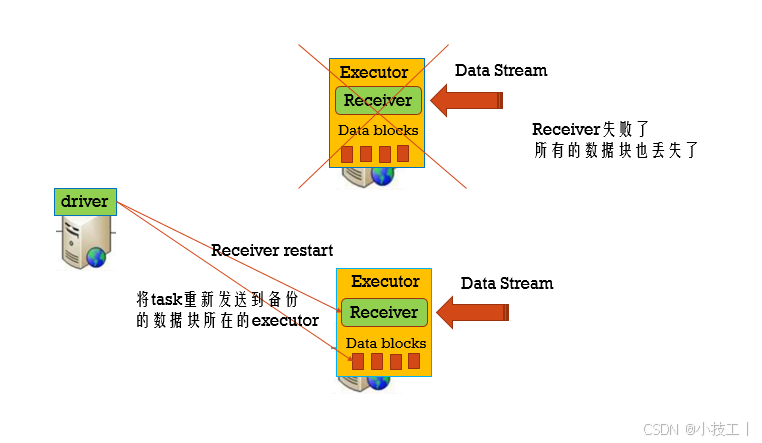
⭐️Tasks和Receiver自动的重启,不需要做任何的配置
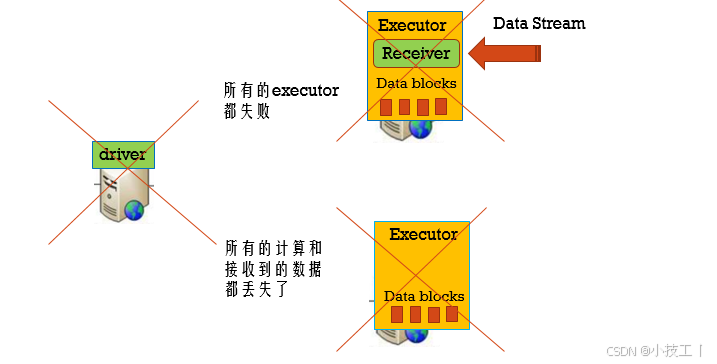
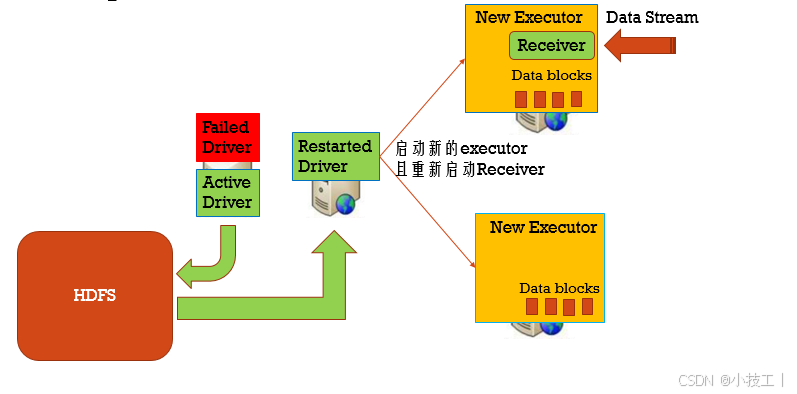
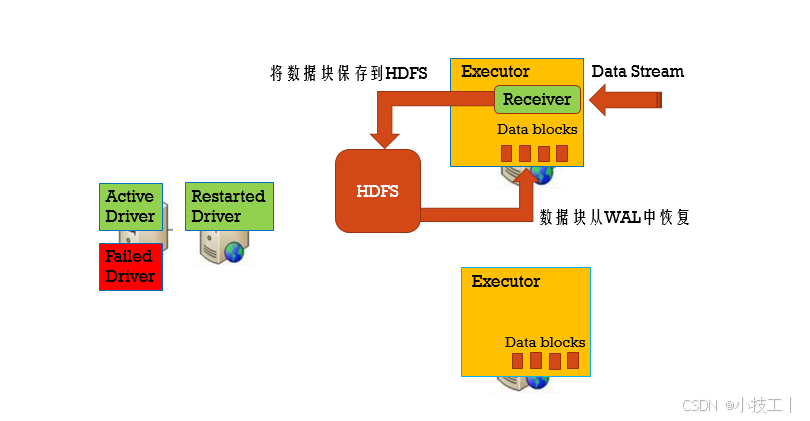
⭐️4.1.3 如果Driver失败?
利用checkpoint机制应对driver的异常;
1、在资源调度环境中启动driver重启机制;2、代码中设置checkpoint目录存到hdfs;
用checkpoint机制恢复失败的Driver
定期的将Driver信息写入到HDFS中。
步骤一:设置自动重启Driver程序
Standalone:
在spark-submit中增加以下两个参数:
–deploy-mode cluster
–supervise
Yarn:
在spark-submit中增加以下参数:
–deploy-mode cluster
在yarn配置中设置yarn.resourcemanager.am.max-attemps
Mesos:
Marathon 可以重启 Mesos应用
步骤二:设置HDFS的checkpoint目录
streamingContext.setCheckpoint(hdfsDirectory)
步骤三:代码实现
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {val ssc = new StreamingContext(...) // new contextval lines = ssc.socketTextStream(...) // create DStreams...ssc.checkpoint(checkpointDirectory) // set checkpoint directoryssc
}// Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)// Do additional setup on context that needs to be done,
// irrespective of whether it is being started or restarted
context. ...// Start the context
context.start()
context.awaitTermination()
4.1.4 数据丢失如何处理
利用WAL把数据写入到HDFS中
1、代码中设置checkpoint目录;2、spark开启WAL预写日志;
3、启动reliable receiver,完成wal预写才算完成消费;4、StorageLevel.MEMORY_AND_DISK_SER可以取消备份
步骤一:设置checkpoint目录
streamingContext.setCheckpoint(hdfsDirectory)
步骤二:开启WAL日志(Write Ahead Log 预写日志)
sparkConf.set(“spark.streaming.receiver.writeAheadLog.enable”, “true”)
步骤三:需要reliable receiver
当数据写完了WAL后,才告诉数据源数据已经消费,对于没有告诉数据源的数据,可以从数据源中重新消费数据
步骤四:取消备份
使用StorageLevel.MEMORY_AND_DISK_SER来存储数据源,不需要后缀为2的策略了,因为HDFS已经是多副本了。
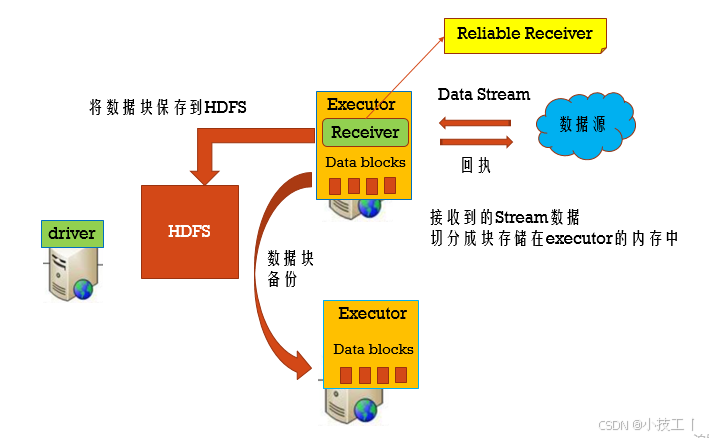
Reliable Receiver : 当数据接收到,并且已经备份存储后,再发送回执给数据源
Unreliable Receiver : 不发送回执给数据源
🌟WAL
WAL使用在文件系统和数据库中用于数据操作的持久性,先把数据写到一个持久化的日志中,然后对数据做操作,如果操作过程中系统挂了,恢复的时候可以重新读取日志文件再次进行操作。
对于像kafka和flume这些使用接收器来接收数据的数据源。接收器作为一个长时间的任务运行在executor中,负责从数据源接收数据,如果数据源支持的话,向数据源确认接收到数据,然后把数据存储在executor的内存中,然后driver在exector上运行任务处理这些数据。
如果wal启用了,所有接收到的数据会保存到一个日志文件中去(HDFS), 这样保存接收数据的持久性,此外,如果只有在数据 写入到log中之后接收器才向数据源确认,这样drive重启后那些保存在内存中但是没有写入到log中的数据将会重新发送,这两点保证的数据的无丢失。
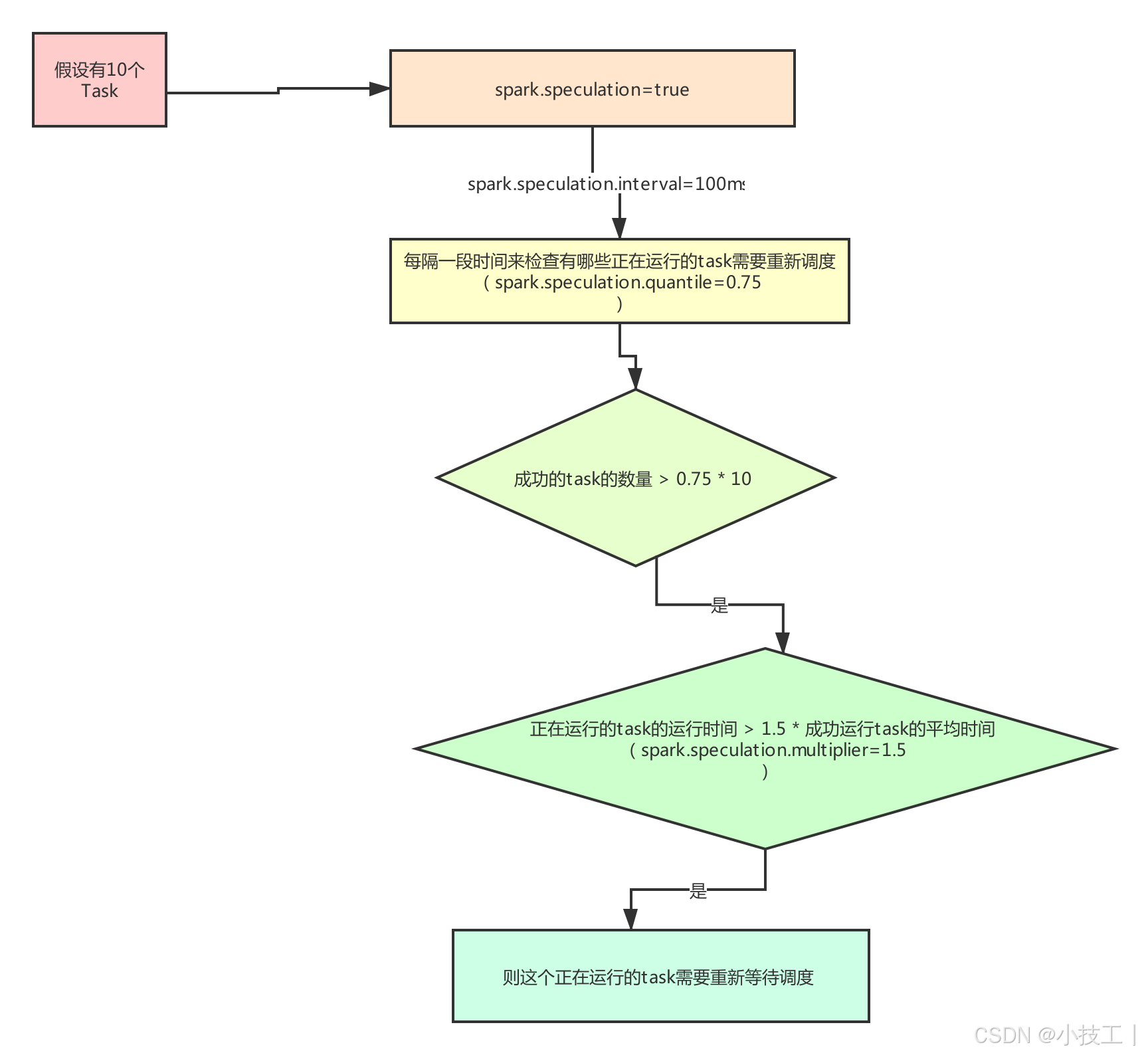
⭐️4.1.5 当一个task很慢容错
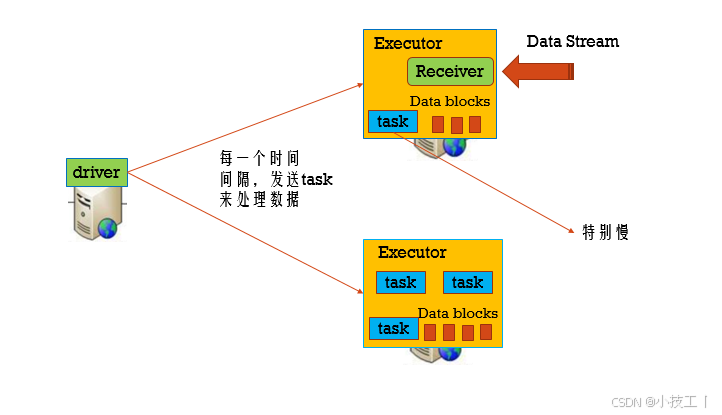
开启推测机制:
spark.speculation=true,每隔一段时间来检查有哪些正在运行的task需要重新调度(spark.speculation.interval=100ms),
假设总的task有10个,成功的task的数量 > 0.75 * 10(spark.speculation.quantile=0.75),
正在运行的task的运行时间 > 1.5 * 成功运行task的平均时间(spark.speculation.multiplier=1.5),
则这个正在运行的task需要重新等待调度。
⭐️4.2 SparkSreaming语义
有三种语义:
1、At most once 一条记录要么被处理一次,要么没有被处理
2、At least once 一条记录可能被处理一次或者多次,可能会重复处理
3、Exactly once 一条记录只被处理一次
4.3 SparkStreaming与Kafka整合
SparkStreaming整合Kafka官方文档
4.3.1 方式一:Receiver-based Approach(不推荐使用)
此方法使用Receiver接收数据。Receiver是使用Kafka高级消费者API实现的。与所有接收器一样,从Kafka通过Receiver接收的数据存储在Spark执行器中,然后由Spark Streaming启动的作业处理数据。但是,在默认配置下,此方法可能会在失败时丢失数据(请参阅接收器可靠性。为确保零数据丢失,必须在Spark Streaming中另外启用Write Ahead Logs(在Spark 1.2中引入)。这将同步保存所有收到的Kafka将数据写入分布式文件系统(例如HDFS)上的预写日志,以便在发生故障时可以恢复所有数据,但是性能不好。
pom.xml文件添加如下:
groupId = org.apache.sparkartifactId = spark-streaming-kafka-0-8_2.11version = 2.3.3
核心代码:
import org.apache.spark.streaming.kafka._val kafkaStream = KafkaUtils.createStream(streamingContext,[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
⭐️ 4.3.2 方式二: Direct Approach (No Receivers)
这种新的不基于Receiver的直接方式,是在Spark 1.3中引入的,从而能够确保更加健壮的机制。替代掉使用Receiver来接收数据后,这种方式会周期性地查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
这种方式有如下优点:
1、简化并行读取:如果要读取多个partition,不需要创建多个输入DStream然后对它们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDD partition之间,有一个一对一的映射关系。
2、高性能:如果要保证零数据丢失,在基于receiver的方式中,需要开启WAL机制。这种方式其实效率低下,因为数据实际上被复制了两份,Kafka自己本身就有高可靠的机制,会对数据复制一份,而这里又会复制一份到WAL中。而基于direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,那么就可以通过Kafka的副本进行恢复。
3、一次且仅一次的事务机制:
基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。
4、降低资源。
Direct不需要Receivers,其申请的Executors全部参与到计算任务中;而Receiver-based则需要专门的Receivers来读取Kafka数据且不参与计算。因此相同的资源申请,Direct 能够支持更大的业务。
5、降低内存。
Receiver-based的Receiver与其他Exectuor是异步的,并持续不断接收数据,对于小业务量的场景还好,如果遇到大业务量时,需要提高Receiver的内存,但是参与计算的Executor并无需那么多的内存。而Direct 因为没有Receiver,而是在计算时读取数据,然后直接计算,所以对内存的要求很低。实际应用中我们可以把原先的10G降至现在的2-4G左右。
6、鲁棒性更好。
Receiver-based方法需要Receivers来异步持续不断的读取数据,因此遇到网络、存储负载等因素,导致实时任务出现堆积,但Receivers却还在持续读取数据,此种情况很容易导致计算崩溃。Direct 则没有这种顾虑,其Driver在触发batch 计算任务时,才会读取数据并计算。队列出现堆积并不会引起程序的失败。
4.3.3 SparkStreaming与Kafka-0-8整合
支持0.8版本,或者更高的版本
pom.xml文件添加内容如下:
groupId = org.apache.sparkartifactId = spark-streaming-kafka-0-8_2.11version = 2.3.3
代码演示:
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}object KafkaDirec08 {def main(args: Array[String]): Unit = {//步骤一:初始化程序入口val sparkConf = new SparkConf().setMaster("local[2]").setAppName("StreamingKafkaApp02")val ssc = new StreamingContext(sparkConf, Seconds(10))val kafkaParams = Map[String, String]("metadata.broker.list"->"ruozehadoop000:9092","group.id" -> "testflink")val topics = "ruoze_kafka_streaming".split(",").toSet//步骤二:获取数据源val lines = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topics)//步骤三:业务代码处理lines.map(_._2).flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).print()ssc.start()ssc.awaitTermination()ssc.stop()}}
要想保证数据不丢失,最简单的就是靠checkpoint的机制,但是checkpoint机制有个特点,入代码升级了,checkpoint机制就失效了。所以如果想实现数据不丢失,那么就需要自己管理offset。
4.3.4 SparkStreaming与Kafka-0-10整合
支持0.10版本,或者更高的版本
pom.xml文件添加内容如下:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.11</artifactId><version>${spark.version}</version></dependency>
代码演示:
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010._object KafkaDirect010 {def main(args: Array[String]): Unit = {//步骤一:获取配置信息val conf = new SparkConf().setAppName("sparkstreamingoffset").setMaster("local[5]")conf.set("spark.streaming.kafka.maxRatePerPartition", "5")conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");val ssc = new StreamingContext(conf,Seconds(5))val brokers = "xxx:9092"val topics = "xx_openothers"val groupId = "xxx_consumer" //注意,这个也就是我们的消费者的名字val topicsSet = topics.split(",").toSetval kafkaParams = Map[String, Object]("bootstrap.servers" -> brokers,"group.id" -> groupId,"fetch.message.max.bytes" -> "209715200","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"enable.auto.commit" -> "false")//步骤二:获取数据源val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))stream.foreachRDD( rdd =>{//步骤三:业务逻辑处理val newRDD: RDD[String] = rdd.map(_.value())newRDD.foreach( line =>{println(line)})//步骤四:提交偏移量信息,把偏移量信息添加到kafka里val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRangesstream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)})ssc.start()ssc.awaitTermination()ssc.stop()}}高版本的方案,天然的就保证了数据不丢失了。
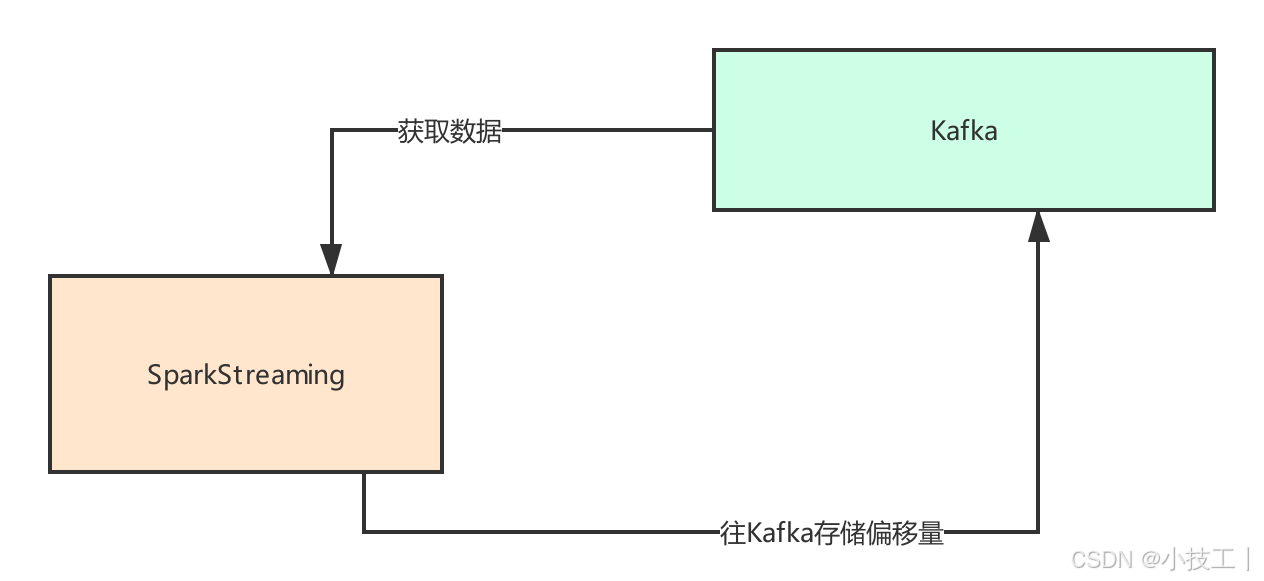
4.3.5 解决SparkStreaming与Kafka0.8版本整合数据不丢失方案
方案设计如下:

代码一:
偏移量存入Zookeeper
/*** 自己管理offset*/
class KafkaManager(val kafkaParams: Map[String, String]) extends Serializable {private val kc = new KafkaCluster(kafkaParams)/*** 创建数据流*/def createDirectStream[K: ClassTag, V: ClassTag, KD <: Decoder[K]: ClassTag, VD <: Decoder[V]: ClassTag](ssc: StreamingContext,kafkaParams: Map[String, String],topics: Set[String]): InputDStream[(K, V)] = {val groupId = kafkaParams.get("group.id").get// 在zookeeper上读取offsets前先根据实际情况更新offsetssetOrUpdateOffsets(topics, groupId)//从zookeeper上读取offset开始消费messageval messages = {val partitionsE = kc.getPartitions(topics)if (partitionsE.isLeft)throw new SparkException(s"get kafka partition failed: ${partitionsE.left.get}")val partitions = partitionsE.right.getval consumerOffsetsE = kc.getConsumerOffsets(groupId, partitions)if (consumerOffsetsE.isLeft)throw new SparkException(s"get kafka consumer offsets failed: ${consumerOffsetsE.left.get}")val consumerOffsets = consumerOffsetsE.right.getKafkaUtils.createDirectStream[K, V, KD, VD, (K, V)](ssc, kafkaParams, consumerOffsets, (mmd: MessageAndMetadata[K, V]) => (mmd.key, mmd.message))}messages}def createDirectStream[K, V, KD <: Decoder[K], VD <: Decoder[V]](jssc: JavaStreamingContext,keyClass: Class[K],valueClass: Class[V],keyDecoderClass: Class[KD],valueDecoderClass: Class[VD],kafkaParams: JMap[String, String],topics: JSet[String]): JavaPairInputDStream[K, V] = {implicit val keyCmt: ClassTag[K] = ClassTag(keyClass)implicit val valueCmt: ClassTag[V] = ClassTag(valueClass)implicit val keyDecoderCmt: ClassTag[KD] = ClassTag(keyDecoderClass)implicit val valueDecoderCmt: ClassTag[VD] = ClassTag(valueDecoderClass)createDirectStream[K, V, KD, VD](jssc.ssc, Map(kafkaParams.asScala.toSeq: _*),Set(topics.asScala.toSeq: _*));}/*** 创建数据流前,根据实际消费情况更新消费offsets* @param topics* @param groupId*/private def setOrUpdateOffsets(topics: Set[String], groupId: String): Unit = {topics.foreach(topic => {var hasConsumed = trueval partitionsE = kc.getPartitions(Set(topic))if (partitionsE.isLeft)throw new SparkException(s"get kafka partition failed: ${partitionsE.left.get}")val partitions = partitionsE.right.getval consumerOffsetsE = kc.getConsumerOffsets(groupId, partitions)if (consumerOffsetsE.isLeft) hasConsumed = falseif (hasConsumed) {// 消费过/*** 如果streaming程序执行的时候出现kafka.common.OffsetOutOfRangeException,* 说明zk上保存的offsets已经过时了,即kafka的定时清理策略已经将包含该offsets的文件删除。* 针对这种情况,只要判断一下zk上的consumerOffsets和earliestLeaderOffsets的大小,* 如果consumerOffsets比earliestLeaderOffsets还小的话,说明consumerOffsets已过时,* 这时把consumerOffsets更新为earliestLeaderOffsets*/val earliestLeaderOffsetsE = kc.getEarliestLeaderOffsets(partitions)if (earliestLeaderOffsetsE.isLeft)throw new SparkException(s"get earliest leader offsets failed: ${earliestLeaderOffsetsE.left.get}")val earliestLeaderOffsets = earliestLeaderOffsetsE.right.getval consumerOffsets = consumerOffsetsE.right.get// 可能只是存在部分分区consumerOffsets过时,所以只更新过时分区的consumerOffsets为earliestLeaderOffsetsvar offsets: Map[TopicAndPartition, Long] = Map()consumerOffsets.foreach({ case(tp, n) =>val earliestLeaderOffset = earliestLeaderOffsets(tp).offsetif (n < earliestLeaderOffset) {println("consumer group:" + groupId + ",topic:" + tp.topic + ",partition:" + tp.partition +" offsets已经过时,更新为" + earliestLeaderOffset)offsets += (tp -> earliestLeaderOffset)}})if (!offsets.isEmpty) {kc.setConsumerOffsets(groupId, offsets)}} else {// 没有消费过val reset = kafkaParams.get("auto.offset.reset").map(_.toLowerCase)var leaderOffsets: Map[TopicAndPartition, LeaderOffset] = nullif (reset == Some("smallest")) {val leaderOffsetsE = kc.getEarliestLeaderOffsets(partitions)if (leaderOffsetsE.isLeft)throw new SparkException(s"get earliest leader offsets failed: ${leaderOffsetsE.left.get}")leaderOffsets = leaderOffsetsE.right.get} else {val leaderOffsetsE = kc.getLatestLeaderOffsets(partitions)if (leaderOffsetsE.isLeft)throw new SparkException(s"get latest leader offsets failed: ${leaderOffsetsE.left.get}")leaderOffsets = leaderOffsetsE.right.get}val offsets = leaderOffsets.map {case (tp, offset) => (tp, offset.offset)}kc.setConsumerOffsets(groupId, offsets)}})}/*** 更新zookeeper上的消费offsets* @param rdd*/def updateZKOffsets[K,V](rdd: RDD[(K, V)]) : Unit = {val groupId = kafkaParams.get("group.id").getval offsetsList = rdd.asInstanceOf[HasOffsetRanges].offsetRangesfor (offsets <- offsetsList) {val topicAndPartition = TopicAndPartition(offsets.topic, offsets.partition)val o = kc.setConsumerOffsets(groupId, Map((topicAndPartition, offsets.untilOffset)))if (o.isLeft) {println(s"Error updating the offset to Kafka cluster: ${o.left.get}")}}}}
代码二:
这个类的目的是为了让API支持多语言
import scala.Tuple2;public class TypeHelper {@SuppressWarnings("unchecked")public static <K, V> scala.collection.immutable.Map<K, V> toScalaImmutableMap(java.util.Map<K, V> javaMap) {final java.util.List<Tuple2<K, V>> list = new java.util.ArrayList<>(javaMap.size());for (final java.util.Map.Entry<K, V> entry : javaMap.entrySet()) {list.add(Tuple2.apply(entry.getKey(), entry.getValue()));}final scala.collection.Seq<Tuple2<K, V>> seq = scala.collection.JavaConverters.asScalaBufferConverter(list).asScala().toSeq();return (scala.collection.immutable.Map<K, V>) scala.collection.immutable.Map$.MODULE$.apply(seq);}
}代码三:
设置监听器,目的是为了让RD开发更方便。
import kafka.common.TopicAndPartition;
import org.apache.spark.streaming.kafka.KafkaCluster;
import org.apache.spark.streaming.kafka.OffsetRange;
import org.apache.spark.streaming.scheduler.*;
import scala.Option;
import scala.collection.JavaConversions;
import scala.collection.immutable.List;import java.util.HashMap;
import java.util.Map;public class MyListener implements StreamingListener {private KafkaCluster kc;public scala.collection.immutable.Map<String, String> kafkaParams;public MyListener(scala.collection.immutable.Map<String, String> kafkaParams){this.kafkaParams=kafkaParams;kc = new KafkaCluster(kafkaParams);}// @Override
// public void onStreamingStarted(StreamingListenerStreamingStarted streamingStarted) {
//
// }@Overridepublic void onReceiverStarted(StreamingListenerReceiverStarted receiverStarted) {}@Overridepublic void onReceiverError(StreamingListenerReceiverError receiverError) {}@Overridepublic void onReceiverStopped(StreamingListenerReceiverStopped receiverStopped) {}@Overridepublic void onBatchSubmitted(StreamingListenerBatchSubmitted batchSubmitted) {}@Overridepublic void onBatchStarted(StreamingListenerBatchStarted batchStarted) {}/*** 批次完成时调用的方法* @param batchCompleted*/@Overridepublic void onBatchCompleted(StreamingListenerBatchCompleted batchCompleted) {//如果本批次里面有任务失败了,那么就终止偏移量提交scala.collection.immutable.Map<Object, OutputOperationInfo> opsMap = batchCompleted.batchInfo().outputOperationInfos();Map<Object, OutputOperationInfo> javaOpsMap = JavaConversions.mapAsJavaMap(opsMap);for (Map.Entry<Object, OutputOperationInfo> entry : javaOpsMap.entrySet()) {//failureReason不等于None(是scala中的None),说明有异常,不保存offsetif (!"None".equalsIgnoreCase(entry.getValue().failureReason().toString())) {return;}}long batchTime = batchCompleted.batchInfo().batchTime().milliseconds();/*** topic,分区,偏移量*/Map<String, Map<Integer, Long>> offset = getOffset(batchCompleted);for (Map.Entry<String, Map<Integer, Long>> entry : offset.entrySet()) {String topic = entry.getKey();Map<Integer, Long> paritionToOffset = entry.getValue();//我只需要这儿把偏移信息放入到zookeeper就可以了。for(Map.Entry<Integer,Long> p2o : paritionToOffset.entrySet()){Map<TopicAndPartition, Object> map = new HashMap<TopicAndPartition, Object>();TopicAndPartition topicAndPartition =new TopicAndPartition(topic,p2o.getKey());map.put(topicAndPartition,p2o.getValue());scala.collection.immutable.Map<TopicAndPartition, Object>topicAndPartitionObjectMap = TypeHelper.toScalaImmutableMap(map);kc.setConsumerOffsets(kafkaParams.get("group.id").get(), topicAndPartitionObjectMap);}}}@Overridepublic void onOutputOperationStarted(StreamingListenerOutputOperationStarted outputOperationStarted) {}@Overridepublic void onOutputOperationCompleted(StreamingListenerOutputOperationCompleted outputOperationCompleted) {}private Map<String, Map<Integer, Long>> getOffset(StreamingListenerBatchCompleted batchCompleted) {Map<String, Map<Integer, Long>> map = new HashMap<>();scala.collection.immutable.Map<Object, StreamInputInfo> inputInfoMap =batchCompleted.batchInfo().streamIdToInputInfo();Map<Object, StreamInputInfo> infos = JavaConversions.mapAsJavaMap(inputInfoMap);infos.forEach((k, v) -> {Option<Object> optOffsets = v.metadata().get("offsets");if (!optOffsets.isEmpty()) {Object objOffsets = optOffsets.get();if (List.class.isAssignableFrom(objOffsets.getClass())) {List<OffsetRange> scalaRanges = (List<OffsetRange>) objOffsets;Iterable<OffsetRange> ranges = JavaConversions.asJavaIterable(scalaRanges);for (OffsetRange range : ranges) {if (!map.containsKey(range.topic())) {map.put(range.topic(), new HashMap<>());}map.get(range.topic()).put(range.partition(), range.untilOffset());}}}});return map;}}⭐️🌟4.4 SparkStreaming应用程序如何保证Exactly-Once
一个流式计算如果想要保证Exactly-Once,那么首先要对这三个点有有要求:
(1)Source支持Replay。
(2)流计算引擎本身处理能保证Exactly-Once。
(3)Sink支持幂等或事务更新
也就是说如果要想让一个SparkSreaming的程序保证Exactly-Once,那么从如下三个角度出发:
(1)接收数据:从Source中接收数据。
(2)转换数据:用DStream和RDD算子转换。(SparkStreaming内部天然保证Exactly-Once)
(3)储存数据:将结果保存至外部系统。
如果SparkStreaming程序需要实现Exactly-Once语义,那么每一个步骤都要保证Exactly-Once。
案例演示:
pom.xml添加内容如下:
<dependency><groupId>org.scalikejdbc</groupId><artifactId>scalikejdbc_2.11</artifactId><version>3.1.0</version></dependency><!-- https://mvnrepository.com/artifact/org.scalikejdbc/scalikejdbc-config --><dependency><groupId>org.scalikejdbc</groupId><artifactId>scalikejdbc-config_2.11</artifactId><version>3.1.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.39</version></dependency>
代码:
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.slf4j.LoggerFactory
import scalikejdbc.{ConnectionPool, DB, _}
/*** SparkStreaming EOS:* Input:Kafka* Process:Spark Streaming* Output:Mysql** 保证EOS:* 1、偏移量自己管理,即enable.auto.commit=false,这里保存在Mysql中* 2、使用createDirectStream* 3、事务输出: 结果存储与Offset提交在Driver端同一Mysql事务中*/
object SparkStreamingEOSKafkaMysqlAtomic {@transient lazy val logger = LoggerFactory.getLogger(this.getClass)def main(args: Array[String]): Unit = {val topic="topic1"val group="spark_app1"//Kafka配置val kafkaParams= Map[String, Object]("bootstrap.servers" -> "node1:6667,node2:6667,node3:6667","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"auto.offset.reset" -> "latest",//latest earliest"enable.auto.commit" -> (false: java.lang.Boolean),"group.id" -> group)//在Driver端创建数据库连接池ConnectionPool.singleton("jdbc:mysql://node3:3306/bigdata", "", "")val conf = new SparkConf().setAppName(this.getClass.getSimpleName.replace("$",""))val ssc = new StreamingContext(conf,Seconds(5))//1)初次启动或重启时,从指定的Partition、Offset构建TopicPartition//2)运行过程中,每个Partition、Offset保存在内部currentOffsets = Map[TopicPartition, Long]()变量中//3)后期Kafka Topic分区动扩展,在运行过程中不能自动感知val initOffset=DB.readOnly(implicit session=>{sql"select `partition`,offset from kafka_topic_offset where topic =${topic} and `group`=${group}".map(item=> new TopicPartition(topic, item.get[Int]("partition")) -> item.get[Long]("offset")).list().apply().toMap})//CreateDirectStream//从指定的Topic、Partition、Offset开始消费val sourceDStream =KafkaUtils.createDirectStream[String,String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Assign[String,String](initOffset.keys,kafkaParams,initOffset))sourceDStream.foreachRDD(rdd=>{if (!rdd.isEmpty()){val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRangesoffsetRanges.foreach(offsetRange=>{logger.info(s"Topic: ${offsetRange.topic},Group: ${group},Partition: ${offsetRange.partition},fromOffset: ${offsetRange.fromOffset},untilOffset: ${offsetRange.untilOffset}")})//统计分析//将结果收集到Driver端val sparkSession = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()import sparkSession.implicits._val dataFrame = sparkSession.read.json(rdd.map(_.value()).toDS)dataFrame.createOrReplaceTempView("tmpTable")val result=sparkSession.sql("""|select| --每分钟| eventTimeMinute,| --每种语言| language,| -- 次数| count(1) pv,| -- 人数| count(distinct(userID)) uv|from(| select *, substr(eventTime,0,16) eventTimeMinute from tmpTable|) as tmp group by eventTimeMinute,language""".stripMargin).collect()//在Driver端存储数据、提交Offset//结果存储与Offset提交在同一事务中原子执行//这里将偏移量保存在Mysql中DB.localTx(implicit session=>{//结果存储result.foreach(row=>{sql"""insert into twitter_pv_uv (eventTimeMinute, language,pv,uv)value (${row.getAs[String]("eventTimeMinute")},${row.getAs[String]("language")},${row.getAs[Long]("pv")},${row.getAs[Long]("uv")})on duplicate key update pv=pv,uv=uv""".update.apply()})//Offset提交offsetRanges.foreach(offsetRange=>{val affectedRows = sql"""update kafka_topic_offset set offset = ${offsetRange.untilOffset}wheretopic = ${topic}and `group` = ${group}and `partition` = ${offsetRange.partition}and offset = ${offsetRange.fromOffset}""".update.apply()if (affectedRows != 1) {throw new Exception(s"""Commit Kafka Topic: ${topic} Offset Faild!""")}})})}})ssc.start()ssc.awaitTermination()}}
使用案例演示-java(单词统计):
import kafka.serializer.StringDecoder;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.*;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;import java.util.*;public class JavaWordCount {public static void main(String[] args) {SparkConf conf = new SparkConf().setAppName("test_kafka_offset_monitor").setMaster("local[4]");JavaStreamingContext ssc = new JavaStreamingContext(conf, Durations.seconds(5));String topics="xxx_arbitrationlogic"; //主题String groupId="xxx_test_consumer";//你的consumer的名字String brokers="xxx:9092";//brokersSet<String> topicsSet = new HashSet<>(Arrays.asList(topics.split(",")));Map<String, String> kafkaParams = new HashMap<>();//kafka参数kafkaParams.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);kafkaParams.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);//关键步骤一:增加监听器,批次完成时自动帮你自动提交偏移量ssc.addStreamingListener(new MyListener(TypeHelper.toScalaImmutableMap(kafkaParams)));//关键步骤二:使用数据平台提供的KafkaManager,根据偏移量获取数据// 如果你是Java代码 调用createDirectStreamfinal KafkaManager kafkaManager = new KafkaManager(TypeHelper.toScalaImmutableMap(kafkaParams));JavaPairInputDStream<String, String> myDStream = kafkaManager.createDirectStream(ssc,String.class,String.class,StringDecoder.class,StringDecoder.class,kafkaParams,topicsSet);myDStream.map(new Function<Tuple2<String,String>, String>() {@Overridepublic String call(Tuple2<String, String> tuple) throws Exception {return tuple._2;}}).flatMap(new FlatMapFunction<String, String>() {@Overridepublic Iterator<String> call(String line) throws Exception {return Arrays.asList(line.split("_")).iterator();}}).mapToPair(new PairFunction<String, String, Integer>() {@Overridepublic Tuple2<String, Integer> call(String word) throws Exception {return new Tuple2<>(word,1);}}).reduceByKey(new Function2<Integer, Integer, Integer>() {@Overridepublic Integer call(Integer a, Integer b) throws Exception {return a+b;}}).foreachRDD(new VoidFunction<JavaPairRDD<String, Integer>>() {@Overridepublic void call(JavaPairRDD<String, Integer> rdd) throws Exception {rdd.foreach(new VoidFunction<Tuple2<String, Integer>>() {@Overridepublic void call(Tuple2<String, Integer> wordCount) throws Exception {System.out.println("单词:"+ wordCount._1 + " "+ "次数:"+wordCount._2);}});}});ssc.start();try {ssc.awaitTermination();} catch (InterruptedException e) {e.printStackTrace();}ssc.stop();}}
使用案例演示-scala(单词统计):
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}object WordCount {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[3]").setAppName("test")conf.set("spark.streaming.kafka.maxRatePerPartition", "5")conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");val ssc = new StreamingContext(conf,Seconds(50))val brokers = "xxx:9092"val topics = "xxx_infologic"val groupId = "xxx_test" //注意,这个也就是我们的消费者的名字val topicsSet = topics.split(",").toSetval kafkaParams = Map[String, String]("metadata.broker.list" -> brokers,"group.id" -> groupId,"client.id" -> "test")//关键步骤一:设置监听器,帮我们完成偏移量的提交ssc.addStreamingListener(new MyListener(kafkaParams));//关键步骤二: 创建对象,然后通过这个对象获取到上次的偏移量,然后获取到数据流val km = new KafkaManager(kafkaParams)val messages = km.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)//完成你的业务逻辑即可messages.map(_._2).foreachRDD( rdd =>{rdd.foreach( line =>{print(line)print("-============================================")})})ssc.start()ssc.awaitTermination()ssc.stop()}}
二 、扩展-ScalikeJDBC(5分钟)
1、什么是ScalikeJDBC
ScalikeJDBC是一款给Scala开发者使用的简洁DB访问类库,它是基于SQL的,使用者只需要关注SQL逻辑的编写,所有的数据库操作都交给ScalikeJDBC。这个类库内置包含了JDBC API,并且给用户提供了简单易用并且非常灵活的API。并且,QueryDSL(通用查询查询框架)使你的代码类型安全的并且可重复使用。我们可以在生产环境大胆地使用这款DB访问类库。
2、IDEA项目中导入相关库
<!-- https://mvnrepository.com/artifact/org.scalikejdbc/scalikejdbc -->
<dependency><groupId>org.scalikejdbc</groupId><artifactId>scalikejdbc_2.11</artifactId><version>3.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scalikejdbc/scalikejdbc-config -->
<dependency><groupId>org.scalikejdbc</groupId><artifactId>scalikejdbc-config_2.11</artifactId><version>3.1.0</version>
</dependency>
<!-- mysql " mysql-connector-java -->
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version>
</dependency>
3、数据库操作
3.1 数据库连接配置信息
在IDEA的resources文件夹下创建application.conf:
#mysql的连接配置信息
db.default.driver="com.mysql.jdbc.Driver"
db.default.url="jdbc:mysql://localhost:3306/spark"
db.default.user="root"
db.default.password="123456"
scalikeJDBC默认加载default配置
或者使用自定义配置:
#mysql的连接配置信息
db.fred.driver="com.mysql.jdbc.Driver"
db.fred.url="jdbc:mysql://localhost:3306/spark"
db.fred.user="root"
db.fred.password="123456"
3.2 加载数据配置信息
//默认加载default配置信息
DBs.setup()
//加载自定义的fred配置信息
DBs.setup('fred)
3.3 查询数据库并封装数据
//配置mysql
DBs.setup()//查询数据并返回单个列,并将列数据封装到集合中
val list = DB.readOnly({implicit session =>SQL("select content from post").map(rs => rs.string("content")).list().apply()
})
for(s <- list){println(s)
}
case class Users(id:String, name:String, nickName:String)/*** 查询数据库,并将数据封装成对象,并返回一个集合*/
//配置mysql
DBs.setup('fred)//查询数据并返回单个列,并将列数据封装到集合中
val users = NamedDB('fred).readOnly({implicit session =>SQL("select * from users").map(rs =>Users(rs.string("id"), rs.string("name"),rs.string("nickName"))).list().apply()
})
for (u <- users){println(u)
}
3.4 插入数据
3.4.1 AutoCommit
/*** 插入数据,使用AutoCommit* @return*/
val insertResult = DB.autoCommit({implicit session =>SQL("insert into users(name, nickName) values(?,?)").bind("test01", "test01").update().apply()
})
println(insertResult)
3.4.2 插入返回主键标识
/*** 插入数据,并返回主键* @return*/
val id = DB.localTx({implicit session =>SQL("insert into users(name, nickName, sex) values(?,?,?)").bind("test", "000", "male").updateAndReturnGeneratedKey("nickName").apply()
})
println(id)
3.4.3 事务插入
/*** 使用事务插入数据库* @return*/
val tx = DB.localTx({implicit session =>SQL("insert into users(name, nickName, sex) values(?,?,?)").bind("test", "haha", "male").update().apply()//下一行会报错,用于测试var s = 1 / 0 SQL("insert into users(name, nickName, sex) values(?,?,?)").bind("test01", "haha01", "male01").update().apply()
})
println(s"tx = ${tx}")
3.4.4 更新数据
/*** 更新数据* @return*/
DB.localTx({implicit session =>SQL("update users set nickName = ?").bind("xiaoming").update().apply()
})
相关文章:

SparkStreaming之03:容错、语义、整合kafka、Exactly-Once、ScalikeJDBC
SparkStreaming进阶 一 、要点:star:4.1 SparkStreaming容错4.1.1 SparkStreaming运行流程4.1.2 如果Executor失败?:star:4.1.3 如果Driver失败?4.1.4 数据丢失如何处理:star:4.1.5 当一个task很慢容错 :star:4.2 SparkSreaming语义4.3 SparkStreaming与…...

让单链表不再云里雾里
一日不见,如三月兮!接下来与我一起创建单链表吧! 目录 单链表的结构: 创建单链表: 增加结点: 插入结点: 删除结点: 打印单链表: 单链表查找: 单链表…...
——Ubuntu Server环境下载安装图形化界面、英伟达显卡驱动、Cuda、cudnn、conda的深度学习环境)
Linux系统管理(十八)——Ubuntu Server环境下载安装图形化界面、英伟达显卡驱动、Cuda、cudnn、conda的深度学习环境
安装ubuntu系统 镜像源地址:https://ubuntu.com/download/server 安装镜像是最好联网,这样不需要自己配置网络地址,会自动生成动态地址 配置镜像源 在装系统时最好设置好镜像源地址 清华镜像源:https://mirrors.tuna.tsinghua.…...

深度学习的隐身术:详解 PyTorch nn.Dropout
前言 你是否遇到过这样的情况?训练时模型表现得像个学霸,准确率高得离谱,可一到测试集就原形毕露,像是考试作弊被抓包的学生,成绩一落千丈。这种现象叫过拟合,你的模型可能只是死记硬背了训练数据,并没有真正理解其中的模式。 别慌!解决过拟合的方法之一就是Dropout,…...

vscode工作区看不清光标
案例分析: 有的时候当我们把vscode的背景色设置成黑色或者默认黑色时 "workbench.colorTheme": "Visual Studio Dark"这时鼠标指针在非停留状态(指针移动时就看不清),需要改下系统的鼠标指针设置,而不是vscode的光标设置…...

2025-03-04 学习记录--C/C++-PTA 习题5-4 使用函数求素数和
合抱之木,生于毫末;九层之台,起于累土;千里之行,始于足下。💪🏻 一、题目描述 ⭐️ 二、代码(C语言)⭐️ #include <stdio.h>// 函数声明:判断一个数是…...
)
Open3D 学习指南 (持续学习)
本章仅为个人学习整理。 Open3D: https://www.open3d.org/ Github repo: https://github.com/isl-org/Open3D 1. 概述 Open3D 是一个开源库,旨在为 3D 数据处理提供高效且易用的工具。它由 Intel 开发和维护,支持多种 3D 数据处理任务,如…...

端口安全测试全方位指南:风险、流程与防护策略
在数字化时代,网络安全至关重要,而端口安全作为网络防护的前沿阵地,稍有疏忽就可能为恶意攻击者打开入侵的大门。以下为您详细阐述端口安全测试的全面流程、核心风险点、应对策略及防护建议。 一、测试前的周密筹备 (一…...

3dsmax烘焙光照贴图然后在unity中使用
效果预览 看不清[完蛋!] 实现步骤 使用 软件 软体名称地址photoshophttps://www.adobe.com/products/photoshop.htmlunity3Dhttps://unity.com/3dsmaxhttps://www.autodesk.com.cn/products/3ds-max/free-trialpacker-iohttps://www.uv-packer.com/HDR 贴图地址…...

GCN从理论到实践——基于PyTorch的图卷积网络层实现
Hi,大家好,我是半亩花海。图卷积网络(Graph Convolutional Network, GCN)是一种处理图结构数据的深度学习模型。它通过聚合邻居节点的信息来更新每个节点的特征表示,广泛应用于社交网络分析、推荐系统和生物信息学等领…...

Ollama存在安全风险的情况通报及解决方案
据清华大学网络空间测绘联合研究中心分析,开源跨平台大模型工具Ollama默认配置存在未授权访问与模型窃取等安全隐患。鉴于目前DeepSeek等大模型的研究部署和应用非常广泛,多数用户使用Ollama私有化部署且未修改默认配置,存在数据泄露、算力盗…...

大模型在高血压预测及围手术期管理中的应用研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的 1.3 国内外研究现状 二、大模型预测高血压的原理与方法 2.1 常用大模型介绍 2.2 数据收集与预处理 2.3 模型训练与验证 三、术前风险预测与手术方案制定 3.1 术前风险因素分析 3.2 大模型预测术前风险的方法与结果 …...

网络安全rt是什么意思
1.什么时EDR :完全不同以往的端点被防护思路,而是通过云端威胁情报,机器学习,异常行为分析,攻击指示器等方式,主动发现来自外部或内部的安全威胁 。并进行自动化的阻止,取证,补救和溯源从而有效…...
)
数据结构篇—栈(stack)
一、引入 在数学史上有这样一个经典问题——汉诺塔问题。 通过动图演示我们发现每一个圆片的运动是什么样的呢? 我们发现,第一个放入的最大圆片将位于整个塔的最底端。所以若想将最大圆片拿出来,就得将压在它身上的所有圆片先按顺序取出才能将…...
)
python3.13安装教程【2025】python3.13超详细图文教程(包含安装包)
文章目录 前言一、python3.13安装包下载二、Python 3.13安装步骤三、Python3.13验证 前言 本教程将为你详细介绍 Python 3.13 python3.13安装教程,帮助你顺利搭建起 Python 3.13 开发环境,快速投身于 Python 编程的精彩实践中。 一、python3.13安装包下…...

动态内存分配
动态内存分配 1. malloc1.1函数原型1.2参数1.3特点1.4注意事项 2.calloc2.1函数原型2.2参数2.3特点2.4注意事项 3.realloc3.1函数原型3.2参数3.3特点3.4注意事项 4.free4.1 函数原型4.2参数4.3特点 结语 在 C 语言中,主要使用标准库函数 <stdlib.h> 中的几个函…...

物联网设备数据割裂难题:基于OAuth2.0的分布式用户画像系统设计!格行代理是不是套路?2025有什么比较好的副业?低成本的创业好项目有哪些?
一、行业基本面:双赛道增长逻辑验证 1.1 随身WiFi市场:场景红利与技术博弈 移动办公、户外直播等场景推动随身WiFi需求持续增长,格行核心的三网切换技术(移动/联通/电信自动择优)有效解决单一运营商信号覆盖盲区问题&…...

17.10 LangSmith Evaluation 深度实战:构建智能评估体系驱动大模型进化
LangSmith Evaluation 深度实战:构建智能评估体系驱动大模型进化 关键词:LangSmith 评估体系, 大模型质量评估, 自动化评测流水线, 多维度指标分析, 生产环境模型监控 1. 评估体系设计哲学 LangSmith Evaluation 采用 规则评估+模型评估+人工反馈 三位一体的评估框架: #me…...

Gravitino SparkConnector 实现原理
Gravitino SparkConnector 实现原理 本文参考了官网介绍,想看官方解析请参考 官网地址 本文仅仅介绍原理 文章目录 Gravitino SparkConnector 实现原理背景知识-Spark Plugin 介绍(1) **插件加载**(2) **DriverPlugin 初始化**(3) **ExecutorPlugin 初始化**(4) *…...

前端开发好用的AI工具介绍
以下是前端开发中提升效率的 AI 工具 推荐,涵盖代码生成、UI设计、调试优化等场景: 一、代码生成与辅助工具 工具名称特点适用场景GitHub Copilot基于 OpenAI,智能代码补全(支持 JS/TS/React/Vue)快速生成代码片段、函…...

Linux的用户与权限--第二天
认知root用户(超级管理员) root用户用于最大的系统操作权限 普通用户的权限,一般在HOME目录内部不受限制 su与exit命令 su命令: su [-] 用户名 -符号是可选的,表示切换用户后加载环境变量 参数为用户名,…...
详解)
COUNT(CASE WHEN ... THEN ... END)详解
在 SQL 查询中,COUNT(CASE WHEN ... THEN ... END) 是一种常见的用法,用于统计满足特定条件的记录数。具体例子: # sexType 2表示女生 COUNT(CASE WHEN h_employee.sexType 2 THEN 1 END) AS 女员工人数解释 CASE WHEN ... THEN ... END&a…...
——FFmpeg源码中,对H.264的各种RTP有效载荷结构的解析)
音视频入门基础:RTP专题(14)——FFmpeg源码中,对H.264的各种RTP有效载荷结构的解析
一、引言 由《音视频入门基础:RTP专题(10)——FFmpeg源码中,解析RTP header的实现》可以知道,FFmpeg源码的rtp_parse_packet_internal函数的前半部分实现了解析某个RTP packet的RTP header的功能。而在解析完RTP head…...

FPGA——4位全加器及3-8译码器的实现
文章目录 一、全加器1、Verilog实现四位全加器2、下载测试 二、3-8译码器1、Verilog实现3-8译码器2、7段数码管显示3-8译码器 三、总结四、参考资料 一、全加器 全加器的定义: 全加器英语名称为full-adder,是用门电路实现两个二进制数相加并求出和的组合…...

软考中级-数据库-3.4 数据结构-图
图的定义 一个图G(Graph)是由两个集合:V和E所组成的,V是有限的非空顶点(Vertex)集合,E是用顶点表示的边(Edge)集合,图G的顶点集和边集分别记为V(G)和E(G),而将图G记作G(V,E)。可以看出,一个顶点集合与连接这…...

软考中级-数据库-3.3 数据结构-树
定义:树是n(n>=0)个结点的有限集合。当n=0时称为空树。在任一非空树中,有且仅有一个称为根的结点:其余结点可分为m(m>=0)个互不相交的有限集T1,T2,T3...,Tm…,其中每个集合又都是一棵树,并且称为根结点的子树。 树的相关概念 1、双亲、孩子和兄弟: 2、结点的度:一个结…...

Win11被背刺,官方泄露免费激活方法
AI已经成为科技圈的主旋律了,在PC圈的龙头微软也不例外。 但最近喜欢背刺用户、极力推崇AI的微软被自家产品背刺了一把。 罪魁祸首就是Microsoft Copilot,如果向Microsoft Copilot提问,是否可以帮忙提供激活Windows11的脚本。 Copilot会立马…...

第十天-字符串:编程世界的文本基石
在编程的广阔领域中,字符串是极为重要的数据类型,它就像一座桥梁,连接着人类的自然语言和计算机能够理解与处理的数字信息。下面,让我们深入探索字符串的世界。 一、字符串简介 字符串是由零个或多个字符组成的有序序列ÿ…...

CentOS7 安装Redis 6.2.6 详细教程
本文主要介绍CentOS7系统下安装Redis6.2.6的详细教程。 1.安装依赖 redis是基于C语言开发,因此想要在服务器上运行redis需要验证是否安装了gcc,没有安装gcc则需先安装 查看是否安装gcc gcc -v如果没有安装gcc,则通过如下命令安装 yum in…...

VsCode使用
vscode前端vue项目启动:Vue项目的创建启动及注意事项-CSDN博客 vscode使用教程:史上最全vscode配置使用教程 - 夏天的思考 - 博客园 vscode如何从git拉取代码:vscode如何从git拉取代码 • Worktile社区...

mac上最好的Python开发环境之Anaconda+Pycharm
文章目录 一、前言 1. Anaconda介绍2. Pycharm介绍 编码协助项目代码导航代码分析Python重构支持Django框架集成版本控制 二、下载Anaconda和Pycharm 1. 下载Anaconda2. 下载Pycharm 三、安装Anaconda和Pycharm 1. 安装Anaconda2. 安装Pycharm 一、前言 1. Anaconda介绍 …...

防火墙旁挂组网双机热备负载均衡
一,二层交换网络: 使用MSTPVRRP组网形式 VLAN 2--->SW3为主,SW4 作为备份 VLAN 3--->SW4为主,SW3 作为备份 MSTP 设计 --->SW3 、 4 、 5 运行 实例 1 : VLAN 2 实例 2 : VLAN 3 SW3 是实例 1 的主根,实…...
——数据管理)
Docker 学习(三)——数据管理
容器中的管理数据主要有两种方式: 数据卷 (Data Volumes): 容器内数据直接映射到本地主机环境; 数据 卷容器( Data Volume Containers): 使用特定容器维护数据卷 1.数据卷 数据卷…...

中间件专栏之MySQL篇——MySQL缓存策略
本文所说的MySQL缓存策略与前文提到的buffer pool不同,那是MySQL内部自己实现的,本问所讲的缓存策略是使用另一个中间件redis来缓存MySQL中的热点数据。 一、为什么需要MySQL缓存方案 缓存用户定义的热点数据,用户可以直接从缓存中获取热点…...
_196. 删除重复的电子邮箱)
高频 SQL 50 题(基础版)_196. 删除重复的电子邮箱
高频 SQL 50 题(基础版)_196. 删除重复的电子邮箱 思路 思路 DELETE p1 FROM Person p1,Person p2 WHEREp1.Email p2.Email AND p1.Id > p2.Id...

github进不去,一直显示错误
1、进入网址Dns检测|Dns查询 - 站长工具 2、复制检测出来的任意一个ip 3、打开电脑的文件夹:C:\Windows\System32\drivers\etc 下的hosts文件下复制这个ip地址 20.205.243.166 4、winr 打开cmd,输入ipconfig/flushdns ipconfig/flushdns出现这个就可以…...

MWC 2025|美格智能发布基于高通®X85 5G调制解调器及射频的新一代5G-A通信模组SRM819W
3月3日,在MWC 2025世界移动通信大会上,美格智能正式推出基于高通X85调制解调器及射频的新一代5G-A通信模组SRM819W,集5G-A、毫米波、AI加持的网络优化等最前沿的通信技术,成为行业首批搭载高通X85的5G通信模组产品,将助…...

【零基础到精通Java合集】第十集:List集合框架
课程标题:List集合框架(15分钟) 目标:掌握List接口核心实现类(ArrayList/LinkedList)的使用与场景选择,熟练操作有序集合 0-1分钟:List概念引入 以“购物清单”类比List特性:元素有序(添加顺序)、可重复、支持索引访问。说明List是Java集合框架中最常用的数据结构…...

《今日-AI-编程-人工智能日报》
一、AI行业动态 荣耀发布“荣耀阿尔法战略” 荣耀在“2025世界移动通信大会”上宣布,将从智能手机制造商转型为全球领先的AI终端生态公司,并计划未来五年投入100亿美元建设AI设备生态。荣耀展示了基于GUI的个人移动AI智能体,并推出多款AI终端…...

在 MyBatis 中,若数据库字段名与 SQL 保留字冲突解决办法
在 MyBatis 中,若数据库字段名与 SQL 保留字冲突,可通过以下方法解决: 目录 一、使用转义符号包裹字段名二、通过别名映射三、借助 MyBatis-Plus 注解四、全局配置策略(辅助方案)最佳实践与注意事项 一、使用转义符号…...
:MOS管的全面解析与实际应用)
从基础到实践(十):MOS管的全面解析与实际应用
MOS管(金属-氧化物半导体场效应晶体管)是现代电子技术的基石,凭借高输入阻抗、低功耗和易集成特性,成为数字电路、电源管理和信号处理的核心元件。从微处理器到新能源汽车电驱系统,其高效开关与放大功能支撑了计算机、…...

电源测试系统有哪些可以利用AI工具的科技??
AI技术的发展对电源模块测试系统的影响是深远的,不仅协助系统提升了测试效率和精度,还推动了测试方法的创新和智能化。那么在电源测试系统中哪些模块可以利用AI工具实现自动化测试? 1. 自动化测试与效率提升 智能测试流程优化 AI算法可以自动优化测试…...

RabbitMQ 最新版:安装、配置 与Java 接入详细教程
目录 一、RabbitMQ 简介二、RabbitMQ 的安装1. 安装 Erlang下载 Erlang安装 Erlang2. 安装 RabbitMQ下载 RabbitMQ安装 RabbitMQ3. 配置环境变量4. 启用管理插件三、RabbitMQ 的配置1. 创建用户和设置权限2. 配置文件四、Java 接入 RabbitMQ1. 添加依赖2. 创建连接3. 创建通道4…...

股市现期驱动因子
在股票投资中,我们把驱动股市收益的基本元素称为基本因素: 例如资产负债、现金流量 从短期来看,股市的上涨和下跌基于市场情绪,它更依赖于投资者的期望,投它涨的人多,它就涨。从长期来看,股市…...

物联网中的气象监测设备具备顶级功能
物联网中的气象监测设备具备顶级功能时,通常集成GPS、数据上报和预警系统,以确保精准监测和及时响应。以下是这些功能的详细说明: 1. GPS定位 精准定位:GPS模块提供设备的精确地理位置,确保数据与具体位置关联&#…...

算法1-4 凌乱的yyy / 线段覆盖
题目描述 现在各大 oj 上有 n 个比赛,每个比赛的开始、结束的时间点是知道的。 yyy 认为,参加越多的比赛,noip 就能考的越好(假的)。 所以,他想知道他最多能参加几个比赛。 由于 yyy 是蒟蒻,…...

gn学习存档
以下答案均由deepseek提供,仅作学习存档。 1. 举例说明action和action_foreach区别 场景设定 假设需要处理一组文件: 输入文件:src/data/file1.txt, src/data/file2.txt, src/data/file3.txt处理逻辑:将每个 .txt 文件转换为 …...
)
SQL注入练习场:PHPStudy+SQLI-LABS靶场搭建教程(零基础友好版)
注意:文中涉及演示均为模拟测试,切勿用于真实环境,任何未授权测试都是违法行为! 一、环境准备 下载PHPStudy 官网下载地址:https://www.xp.cn/php-study(选择Windows版) 安装时建议选择自定…...

python学习笔记——Thread常用方法
Thread对象中的一些方法: 以前说过多线程,用到threading模块中的Thread对象,其中的start和run方法比较熟悉了,start()是重载了Thread对象中的run方法,其实作用还是,当执行这个start…...

2024年数学SCI2区TOP:雪雁算法SGA,深度解析+性能实测
目录 1.摘要2.算法原理3.结果展示4.参考文献5.代码获取 1.摘要 本文提出了一种雪雁算法(SGA),该算法借鉴了雪鹅的迁徙行为,并模拟了其迁徙过程中常见的“人字形”和“直线”飞行模式。 2.算法原理 雪雁以其卓越的长途迁徙能力和…...